Sensory Bio: HOLM 1. The Big Idea: What & Why? HOLM: Hormone-Linked Ocular Monitoring
The Why:
An often ignored and under-discussed impact of menstruation is its effect on ocular comfort and vision. Millions of women experience eye strain, blurry vision, dry eyes, and light sensitivity during different phases of their menstrual cycle. These symptoms are frequently dismissed with generic advice such as “rest your eyes,” despite being real, recurring, and disruptive.
Part 1 — Benchling and In-Silico Gel Art Objective Simulate restriction enzyme digests using lambda DNA and generate gel electrophoresis patterns. Tools Used Benchling Restriction enzyme digest simulation Lambda DNA reference sequence Restriction Enzymes EcoRI HindIII BamHI KpnI EcoRV SacI SalI XohI Part 3 — DNA Design Challenge Selected Protein Protein Name BDNF (Brain-Derived Neurotrophic Factor)
Python Script for opentron 1. Generate an artistic design using the GUI at opentrons-art.rcdonovan.com. 2. Writing the python script and results Post-lab Questions Find and describe a published paper that utilizes the Opentrons or an automation tool to achieve novel biological applications.4 Paper: Technical upgrade of an open-source liquid handler to support bacterial colony screening del Olmo Lianes et al., Frontiers in Bioengineering and Biotechnology, 2023. DOI: 10.3389/fbioe.2023.1202836
Part A: Conceptual Questions 1. How many molecules of amino acids in 500g of meat? Meat is roughly 20% protein by weight. To find the total number of molecules, we can use the following estimation:
Protein Mass: 500g × 0.20 = 100g Molar Mass: On average, an amino acid is 100 Da (which is equivalent to 100 g/mol). Moles: 100g / 100 g/mol = 1 mole Molecules: Using Avogadro’s number ($6.022 \times 10^{23}$), 500g of meat contains approximately 600 sextillion ($6 \times 10^{23}$) amino acid molecules. 2. Why don’t humans become cows or fish after eating them? When we consume protein, our digestive system does not keep the original structure intact. Instead, it breaks the long polymer chains down into individual amino acids.
Assignment 1 — DNA Assembly Questions Q1. Components of Phusion High-Fidelity PCR Master Mix Components Phusion DNA Polymerase
Thermostable, high-fidelity enzyme with proofreading activity that synthesizes new DNA strands.
Assignment Part 1: Intracellular Artificial Neural Networks (IANNs) Q1. Advantages of IANNs over traditional Boolean genetic circuits Traditional genetic circuits are limited to discrete ON/OFF outputs — they can only compute simple logic like AND, OR, NOT. IANNs go beyond this by processing continuous, graded inputs and computing weighted sums across multiple signals simultaneously, just like neurons. This means a single cell can integrate many environmental signals at once and produce nuanced, analog responses rather than just a binary switch. IANNs can also be trained — their weights (gene expression levels) can be tuned to classify complex input patterns. This makes them far more powerful for tasks like disease detection inside a cell, where multiple biomarkers need to be weighed together rather than evaluated individually.
General Homework Questions 1. Advantages of Cell-Free Protein Synthesis Over In Vivo Methods Cell-free protein synthesis (CFPS) eliminates the need to maintain viable cells, giving direct access to the reaction environment. You can tune pH, redox state, temperature, and add cofactors like chaperones or lipids directly — impossible inside a living cell.
Part I — Molecular Weight Q1 — Theoretical MW from Sequence The eGFP sequence was entered into the ExPASy Compute pI/Mw tool.
The resulting molecular weight was:
28,006.60 Da
However, eGFP undergoes autocatalytic chromophore cyclization, which removes approximately 20 Da from the protein.
Cell-Free Protein Synthesis (CFPS) CFPS recreates transcription and translation outside a living cell using a lysate supplemented with all the molecular machinery needed to produce a protein from a DNA template. No cell wall means direct control over every component.
The Lysate The BL21(DE3) Star lysate provides ribosomes, tRNAs, elongation factors — and crucially, T7 RNA Polymerase, which transcribes any gene under a T7 promoter with high speed and efficiency.
Subsections of Homework
Week 1: Principles, Ethics, & Practices
Sensory Bio: HOLM
1. The Big Idea: What & Why?
HOLM: Hormone-Linked Ocular Monitoring
The Why: An often ignored and under-discussed impact of menstruation is its effect on ocular comfort and vision. Millions of women experience eye strain, blurry vision, dry eyes, and light sensitivity during different phases of their menstrual cycle. These symptoms are frequently dismissed with generic advice such as “rest your eyes,” despite being real, recurring, and disruptive.
The goal of this project is to transform subjective visual discomfort into measurable physiological data that can support research, awareness, and future interventions.
Note: This project does not provide recommendations or medical advice. It is designed solely to generate interpretive insights.
2. Governance Goals: Keeping it Ethical
The core ethical challenge is ensuring that physiological sensing and inference empowers users without causing harm, misuse, or exclusion. The governance goals are grouped into the following categories.
Ensure User Safety and Privacy
Data Integrity and Accuracy: Physiological signals derived from sensors are inherently noisy, context-dependent, and sensitive to environmental factors (e.g., hydration, wind, lighting). Governance must require calibration standards, uncertainty quantification, and conservative interpretation thresholds to prevent misleading outputs or inappropriate self-management decisions.
Data Abstraction: Raw biological data (e.g., cortisol concentrations or inflammatory markers) should be abstracted into high-level indices before storage or sharing to minimize re-identification and secondary misuse.
Bias, Transparency, and Accountability
Algorithmic Fairness: Models must be evaluated across diverse physiological baselines and hormonal patterns to avoid bias, particularly against menstruating individuals who are often underrepresented in biomedical datasets.
Controlled Access: Access to inferred hormonal or stress states must be restricted to the user unless explicit, informed consent is provided. Employers, insurers, or institutions should not have default access.
Auditable Systems Design: Model versions, training data sources, and inference pathways should be logged to enable retrospective auditing and accountability.
Explainable Design: Outputs must be interpretable and accompanied by explanations, confidence levels, and limitations to prevent over-reliance on algorithmic authority.
3. Governance Actions: The Game Plan
Action 1: Mandatory Data Privacy & Encryption
What this does: Establishes baseline protections so sensitive physiological and inferred hormonal data cannot be misused or repurposed without consent.
How it works:
End-to-end encryption for stored and transmitted data
Data minimization using high-level indices by default
Strict opt-in consent for any data sharing
Who is involved: Device manufacturers, app developers, platform providers, and regulatory bodies.
Why it matters: Hormonal and stress-related data are socially sensitive and require strong safeguards to prevent biological surveillance.
Action 2: Explainable and Auditable ML
What this does: Reduces harm from opaque algorithmic decision-making.
How it works:
Interpretable feature-level outputs
Audit logs for model training and updates
Confidence intervals on all user-facing results
Who is involved: Researchers, ML engineers, ethics committees, journals, and funding agencies.
Why it matters: Explainability supports trust, accountability, and safe interpretation.
Action 3: Inclusive Design Incentives
What this does: Encourages systems that reflect real physiological diversity.
How it works:
Incentives for diverse testing populations
Documentation of dataset coverage and gaps
Funding and publication advantages for inclusive design
Who is involved: Funding agencies, academic institutions, standards bodies, and journals.
Why it matters: Without incentives, biosensing tools risk reinforcing existing health inequities.
Based on the scoring, a combined strategy prioritizing Action 1 (Privacy & Encryption) and Action 2 (Explainable ML) is recommended, with Action 3 (Inclusive Design) pursued in parallel as the system matures.
This balances feasibility, safety, accountability, and long-term equity.
6. Trade-Offs, Assumptions, and Uncertainties
Trade-Offs Considered
Early-Stage Scope Limitation: Initial development focuses on cisgender women with endogenous menstrual cycles, excluding trans women and individuals using exogenous hormone therapies. This is a methodological constraint to ensure model validity, with broader inclusion planned in later phases.
Risk of Over-Regulation: Excessive governance in early stages could slow exploratory research and iteration.
Key Assumptions
Users value transparency and privacy over maximum predictive accuracy.
P.S. If you notice the sensor turning bright purple during the final presentation, please hand me a coffee with Red Bull—and do not make eye contact.
Week 02: Read, Write, Edit DNA
Part 1 — Benchling and In-Silico Gel Art
Objective
Simulate restriction enzyme digests using lambda DNA and generate gel electrophoresis patterns.
Tools Used
Benchling
Restriction enzyme digest simulation
Lambda DNA reference sequence
Restriction Enzymes
EcoRI
HindIII
BamHI
KpnI
EcoRV
SacI
SalI
XohI
Part 3 — DNA Design Challenge
Selected Protein
Protein Name
BDNF (Brain-Derived Neurotrophic Factor)
Organism
Homo sapiens
Reason for Selection
I am interested in understanding how brain biology supports learning, memory, and cognition. BDNF plays an important role in synaptic plasticity and memory consolidation by helping neurons strengthen their connections during learning processes.
One particularly interesting feature is the Val66Met polymorphism, where a single nucleotide variation changes protein trafficking and influences memory formation and cognitive performance. This demonstrates how even small DNA sequence changes can produce measurable biological and behavioral effects.
(i) What DNA would you want to sequence (e.g., read) and why?
Human brain cell genomic DNA, focusing on mutated neurological disease genes to understand neurodegeneration and develop targeted therapies.
(ii) In lecture, a variety of sequencing technologies were mentioned. What technology or technologies would you use to perform sequencing on your DNA and why?
Technology: Oxford Nanopore (Third-generation)
Generation: Third-generation; reads single molecules in real time with ultra-long reads.
Input: High-molecular-weight genomic DNA from brain tissue or lab-grown neurons.
Preparation: DNA extraction, size selection, end-repair, adapter ligation — no PCR amplification needed.
Essential steps: DNA passes through a protein nanopore; ionic current changes as each base passes through.
Base calling: Electrical current disruptions are decoded by AI software into nucleotide sequences.
Output: Long FASTQ read files containing nucleotide sequences with quality scores.
Part 5.2 — DNA Write/Edit
(i) What DNA would you want to synthesize (e.g., write) and why?
Codon-optimized BDNF expression cassette for delivery into neurons to restore BDNF signaling in diseased brains.
(ii) What kinds of edits might you want to make to DNA (e.g., human genomes and beyond) and why?
Correct BDNF promoter mutations causing reduced expression in Alzheimer’s patients, and knock out disease-aggravating genes like APP.
(iii) What technology or technologies would you use to perform these DNA edits and why?
Technology: CRISPR-Cas9
How it edits: Cas9 protein guided by sgRNA cuts DNA at a precise target location.
Essential steps: Design sgRNA → deliver Cas9+sgRNA into cells → DNA cut → repair via HDR template.
Limitations: Off-target cuts possible; HDR efficiency low in non-dividing neurons; delivery into brain tissue is challenging.
Week 03: Lab Automation
Python Script for opentron
1. Generate an artistic design using the GUI at opentrons-art.rcdonovan.com.
2. Writing the python script and results
Post-lab Questions
Find and describe a published paper that utilizes the Opentrons or an automation tool to achieve novel biological applications.4
Paper: Technical upgrade of an open-source liquid handler to support bacterial colony screening
del Olmo Lianes et al., Frontiers in Bioengineering and Biotechnology, 2023.
DOI: 10.3389/fbioe.2023.1202836
What it focuses one: This paper presents COPICK, a technical solution to automate colony picking using the Opentrons OT-2. The system mounts a camera directly onto the robot to capture images of Petri dishes and automatically detect microbial colonies. The software then selects the best colonies based on criteria like size, color, and fluorescence, and executes a protocol to pick and transfer them for further analysis.
Why it’s novel:
Commercial colony pickers exist but their high price excludes small research laboratories and budget-limited institutions from high-throughput screening. COPICK democratizes this capability by turning an affordable OT-2 into a vision-guided colony picker. biorxiv
Results:
Benchmark tests on E. coli and P. putida colonies achieved a raw picking performance of 82% with 73.4% accuracy at an estimated rate of 240 colonies per hour. nih
Write a description about what you intend to do with automation tools for your final project.
What automation I would be working with is still not clear with me as I am still trying to finalize a project direction and the goals. However, as I have been planning to focus on computation first, will try to simulate stuff first virtually and then move towards validation. I would use automation tools to accelerate two key steps: transformation screening and expression optimization, after virtual simulations.
Final Project Idea
I am still not very clear about my project idea, but I have been researching about biosensors, and oxidative stress as one of my broder target ideas. The three paths that I find myslef leaning towrads are, female reproductive health: quite a recent experience with a certain effect of periods, eye strain. During, after or before periods many women experinece eye strain bad enough for them to feel irritated by their prescribed power correcters. This is one of the things that has facinated me and would like to work on.
The second path that I have been brainstroming on is oxidative stress damage to cells, majorly focusing on cromosomnal damage and genetic disformity. In my reasearch in this direction I was able to find, few gaps in how oxidative stress in cells are measured and translated into readable data. The said gap is, we use florecence to map the levels of oxidative stress, the brighter the color the more the stress. I was brainstroming towards an idea to create some type of sensor that can not just take in the levels of stress but also take in some of the important nuances. We may then use that whole to train models to predict paths and changes we never thought of.
The third path is Neurodegenration in cells, or in genral neurodegenrative dieseases. What caused neural death, how it progresses, what things incraese the speed of the said dieseas. I would most probably focus on one diseases rather than the broader perspective.
The main goal for me from any of the mentioned above project will be to compuationalize biology as much as I can. See what can be compuatationalize and what not. To come up with a more adaptable framework for these issues. I have been highly leaning towards biosensors of some type, for either of the ideas.
Week 04: Protein Design Part-1
Part A: Conceptual Questions
1. How many molecules of amino acids in 500g of meat?
Meat is roughly 20% protein by weight. To find the total number of molecules, we can use the following estimation:
Protein Mass: 500g × 0.20 = 100g
Molar Mass: On average, an amino acid is 100 Da (which is equivalent to 100 g/mol).
Moles: 100g / 100 g/mol = 1 mole
Molecules: Using Avogadro’s number ($6.022 \times 10^{23}$), 500g of meat contains approximately 600 sextillion ($6 \times 10^{23}$) amino acid molecules.
2. Why don’t humans become cows or fish after eating them?
When we consume protein, our digestive system does not keep the original structure intact. Instead, it breaks the long polymer chains down into individual amino acids.
These “bricks” are transported to our cells, where our own DNA provides the unique blueprint to reassemble them into specific human proteins. The biological identity of an organism is defined by the sequence and arrangement of these building blocks, not the raw materials themselves.
3. Why are there only 20 natural amino acids?
While many more amino acids exist in chemistry, these 20 provide sufficient chemical diversity (hydrophobicity, charge, and size) to fold into almost any functional shape required for life.
Evolution likely “settled” on this specific set early on because adding more would increase the complexity of the translation machinery (tRNAs and enzymes) without providing a significant survival advantage. It reached a point of diminishing returns.
4. Can you make non-natural amino acids?
Yes. Scientists use “expanded genetic codes” to incorporate synthetic amino acids into proteins for research and medicine.
Design Example: One could design an amino acid with a cyano-group (–CN) to act as a sensitive local probe for electric fields within a protein, or one with a photo-crosslinker that bonds to neighbors only when triggered by UV light.
5. Where did amino acids come from before life and enzymes?
Amino acids formed through abiotic synthesis (chemical processes without life).
The Miller-Urey Experiment: This famous study demonstrated that lightning-like discharges in a “primeval soup” of methane, ammonia, and hydrogen can spontaneously create amino acids.
Space: Amino acids have also been discovered on carbonaceous meteorites, suggesting that the building blocks of life can form in deep space and were delivered to Earth via impacts.
6. Handedness of an alpha-helix using D-amino acids?
Natural proteins are made of L-amino acids, which naturally twist into right-handed alpha-helices. Because D-amino acids are the mirror image of L-amino acids, the physical space (steric hindrance) between atoms is reversed. Therefore, a helix made of D-amino acids would be left-handed.
7. Why are most molecular helices right-handed?
This is due to homochirality—the fact that life uses only one “hand” (the L-form) of amino acids. In an L-amino acid chain, the geometry of the peptide bond and the positions of the side chains make the right-handed twist energetically favorable. A left-handed twist would cause the side chains to physically “clash” with the protein’s backbone.
8. Why do beta-sheets tend to aggregate?
Beta-sheets have “sticky” edges characterized by unsatisfied hydrogen bond donors and acceptors.
To reach a more stable, lower-energy state, these exposed edges seek out other strands to bond with. If they cannot find a partner within the same protein, they will bond with strands from other protein molecules, causing them to stack into large, insoluble clumps.
9. Why do amyloid diseases form beta-sheets?
Amyloid diseases (such as Alzheimer’s or Parkinson’s) occur when proteins misfold into extremely stable, “cross-beta” structures. These act like “molecular velcro,” where the sheets stack so tightly that water is completely excluded, making them very hard for the body to break down.
Materials Use: These structures are actually quite useful in engineering. They are being researched as nanofibers for tissue scaffolding or as ultra-strong adhesives because they are incredibly resistant to heat and chemical degradation.
Part B: Protein Analysis and Visualization
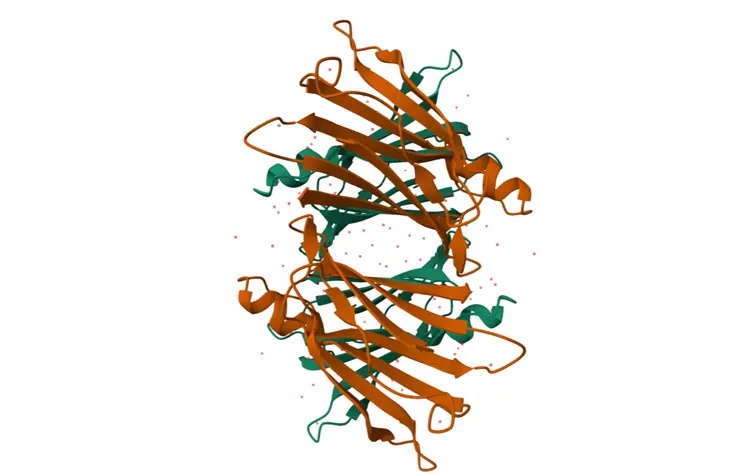
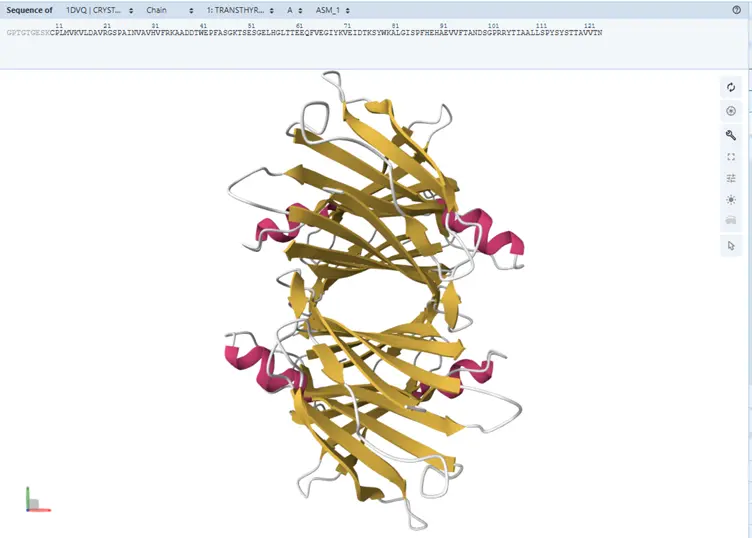
Selected Protein: Transthyretin (TTR) (P02766)
Gene: TTR
Organism: Homo sapiens
1. Briefly describe the protein you selected and why you selected it.
It is a homotetrameric transport protein produced mainly in the liver and choroid plexus of the brain. It carries thyroid hormone (thyroxine/T4) and retinol-binding protein through the bloodstream and cerebrospinal fluid.
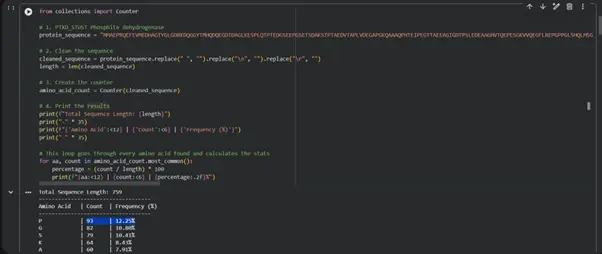
2. Identify the amino acid sequence of your protein.
4. What is the most frequent amino acid in the sequence?
Most frequent: A | 15 | 10.20%
Amino Acid Frequency Analysis
5. How many protein sequence homologs are there for your protein?
UniProt BLAST returned thousands of homologous transthyretin sequences across vertebrates including mammals, birds, reptiles, and fish, showing that the protein is highly evolutionarily conserved.
6. Does your protein belong to any protein family?
It belongs to the Transthyretin/hydroxyisourate hydrolase superfamily.
7. Identify the structure page of your protein in RCSB.
This structure was deposited in 2000 and was solved in 2001, using X-ray diffraction at 2.00 Å resolution.
9. Is it a good-quality structure?
2.00 Å — excellent quality
10. Are there any other molecules in the solved structure apart from the protein itself?
Yes — thyroxine (T4) ligand in the binding pocket, plus water molecules.
11. Does your protein belong to any structural classification family?
Transthyretin (synonym: prealbumin)
Protein Visualization
12. Visualize the protein using different structural representations.
Cartoon Representation
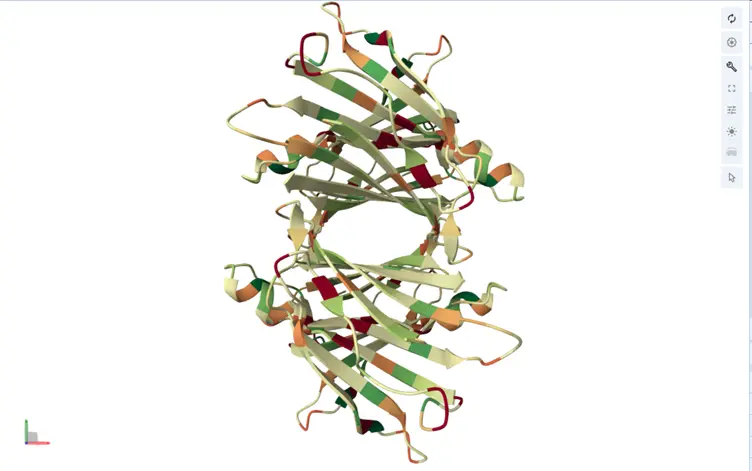
13. Color the protein by secondary structure.
The protein contains significantly more beta-sheets than alpha-helices. This is expected for transthyretin, which is a beta-sheet-rich transport protein.
14. Color the protein by residue type.
Hydrophobic residues are mainly buried inside the protein core, helping stabilize the folded structure through hydrophobic interactions. Hydrophilic residues are mostly exposed on the protein surface, where they interact with water and other molecules.
15. Visualize the molecular surface of the protein.
The structure contains visible binding pockets near the thyroxine-binding channel. These cavities are important for ligand binding and transport functionality.
Part C: Using ML-Based Protein Design Tools
C1. Protein Language Modeling
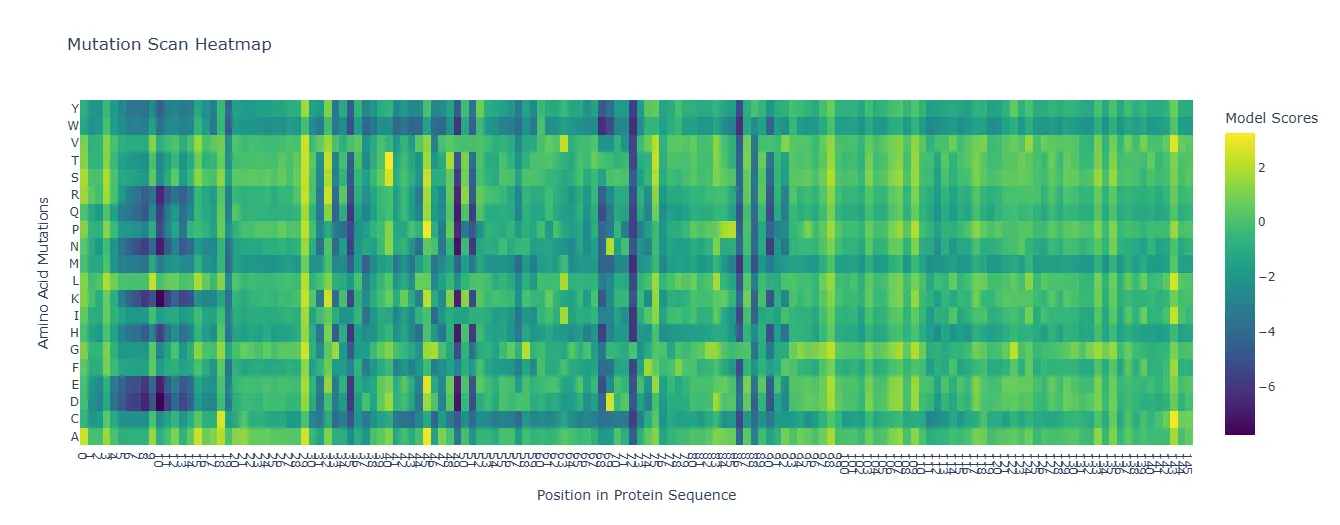
Deep Mutational Scans
The heatmap shows mutation sensitivity across sequence positions. Certain residues are highly conserved, meaning mutations at these sites strongly reduce model likelihood. Hydrophobic core residues showed especially strong intolerance to mutation.
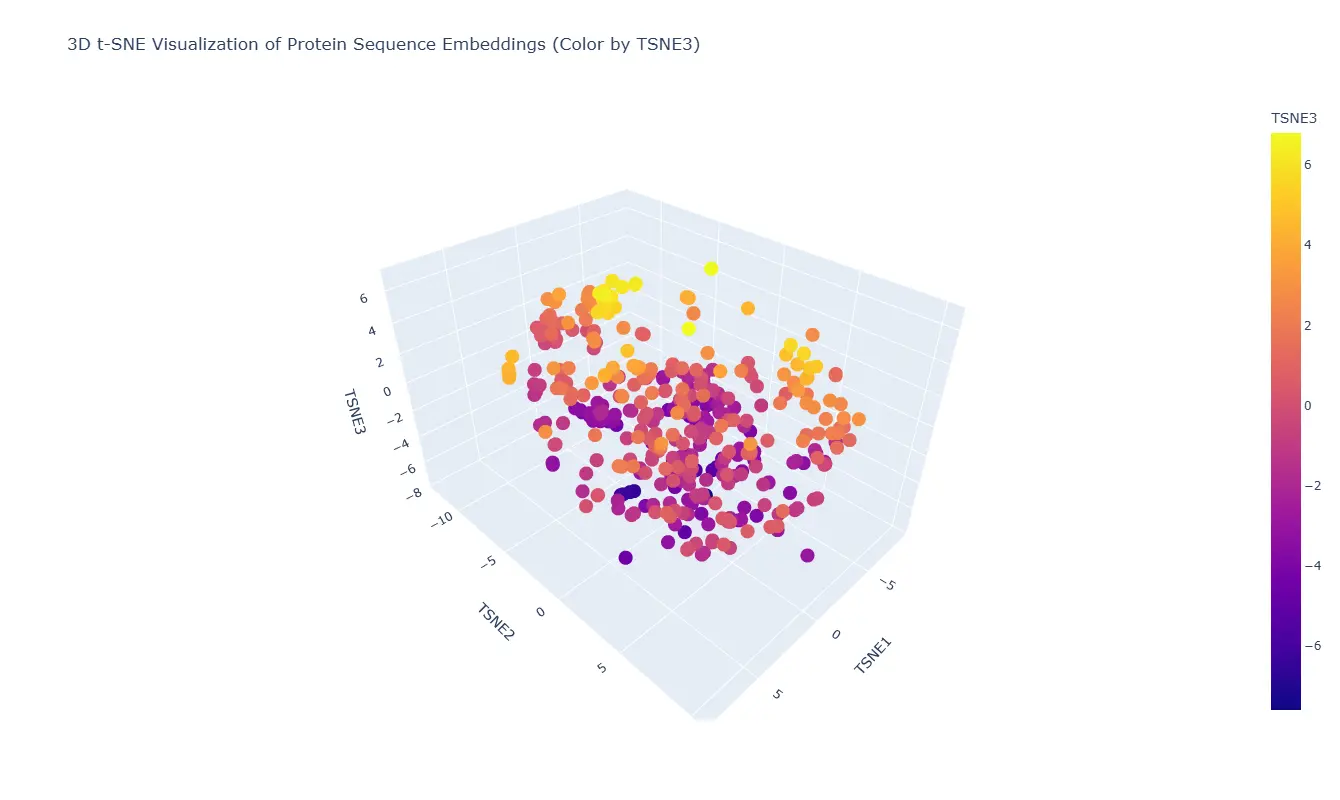
Latent Space Analysis
The embedding clusters proteins with similar sequence features close together in latent space. Transthyretin appears near proteins with similar beta-sheet-rich transport architectures.
C2. Protein Folding
Folding a Protein with ESMFold
The predicted structure generated by ESMFold closely matched the experimentally solved structure from the PDB. The overall beta-sheet-rich fold was preserved, indicating that the model successfully captured the native topology of transthyretin.
Small mutations generally did not dramatically disrupt the fold, suggesting that the protein structure is relatively resilient to conservative amino acid substitutions. However, larger sequence alterations caused visible structural deviations and reduced stability.
C3. Protein Generation
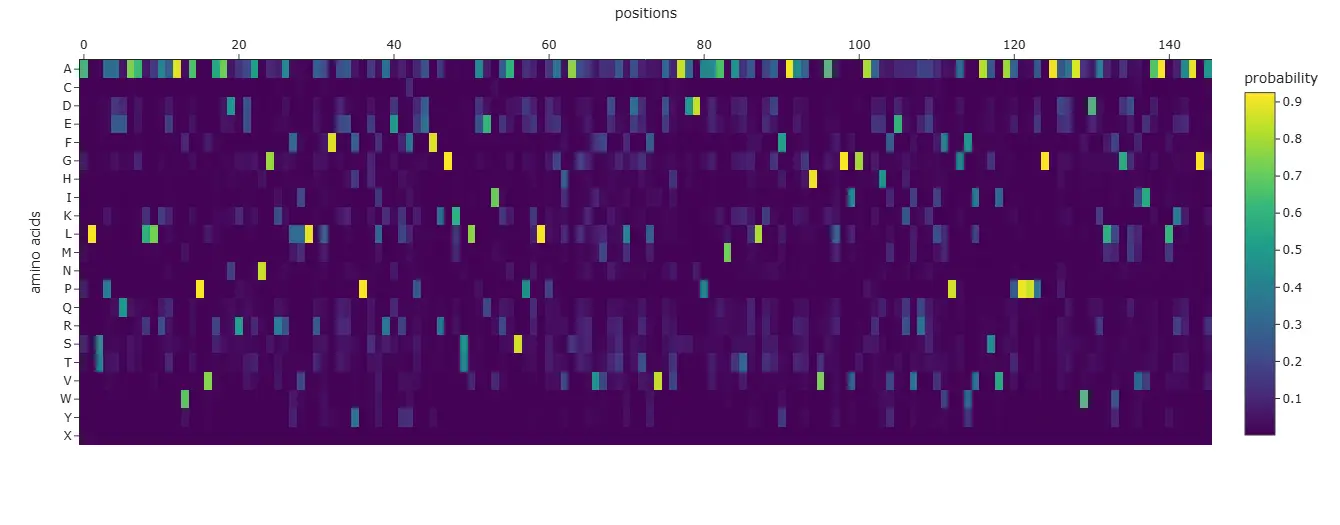
ProteinMPNN Sequence Probability Analysis
The probability map highlights which amino acids are favored at each position. Conserved residues showed high confidence scores, while flexible surface positions tolerated more variation.
The generated sequence maintained many of the important structural residues found in the original transthyretin sequence. When folded using ESMFold, the predicted structure remained highly similar to the original backbone structure.
Week 06: Genetic Circuits Part I
Assignment 1 — DNA Assembly Questions
Q1. Components of Phusion High-Fidelity PCR Master Mix
Components
Phusion DNA Polymerase Thermostable, high-fidelity enzyme with proofreading activity that synthesizes new DNA strands.
dNTPs The four nucleotide building blocks (A, T, G, and C) used to construct DNA.
Reaction Buffer Maintains optimal pH and ionic conditions. Also contains MgCl₂, an essential cofactor for polymerase activity.
Q2. Factors Determining Primer Annealing Temperature
The annealing temperature mainly depends on:
Primer length
GC content
Longer primers and primers with higher GC content generally require higher annealing temperatures because GC base pairs form three hydrogen bonds, compared to two hydrogen bonds in AT pairs.
Q3. PCR vs Restriction Enzyme Digest
Feature
PCR
Restriction Digest
Equipment
Thermocycler
Heat block / incubator
Inputs
Template DNA + primers
DNA with restriction sites + enzymes
DNA Ends Produced
Usually blunt ends
Sticky or blunt ends
Best Use Case
Amplifying or modifying DNA; adding overhangs
Removing inserts; directional cloning
Purification Required
Yes
Yes
Q4. Ensuring Fragments are Appropriate for Gibson Assembly
To ensure fragments are suitable for Gibson cloning:
Design and verify overlaps in silico using the Benchling Assembly Wizard.
Run PCR or digest products on an agarose gel to confirm expected fragment sizes.
Purify the fragments before assembly.
For maximum confidence, sequence the purified products before Gibson assembly.
Q5. How Plasmid DNA Enters E. coli During Transformation
During heat-shock transformation:
Cells are treated with CaCl₂, which helps neutralize the negative charges on DNA and the bacterial membrane.
Cells are first kept on ice and then briefly exposed to 42°C.
This sudden temperature shift temporarily creates pores in the membrane, allowing plasmid DNA to enter the cell.
Q6. Golden Gate Assembly
Golden Gate Assembly uses Type IIS restriction enzymes such as BsaI or AarI.
Key Features
These enzymes cut outside their recognition sequence.
Custom 4-base sticky ends can be designed for directional assembly.
Multiple DNA fragments can be assembled in a single reaction.
Why It Works Efficiently
Correctly assembled fragments lose the recognition sites, preventing further cutting.
Incorrect assemblies retain recognition sites and are cut again by the enzyme.
This creates a highly efficient, seamless, and scarless DNA assembly method.
Assignment 2 — Asimov Kernel
Tasks
Create a repository for your work.
Create a blank notebook entry and save it to the repository.
Explore devices in the Bacterial Demos Repository.
Run simulations using the Simulator and follow the instructions provided in the Info Panel (i icon).
Reconstruct the Repressilator construct.
Create Original constructs.
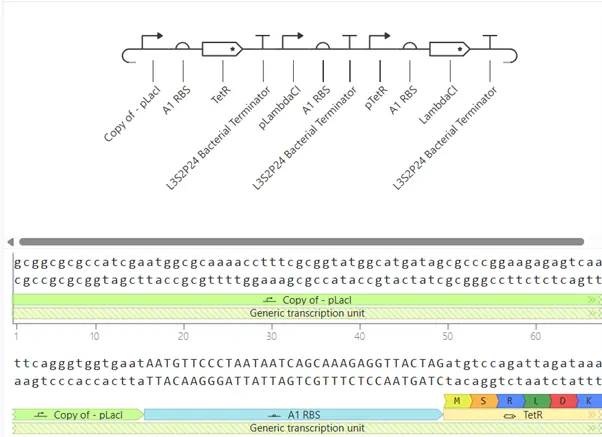
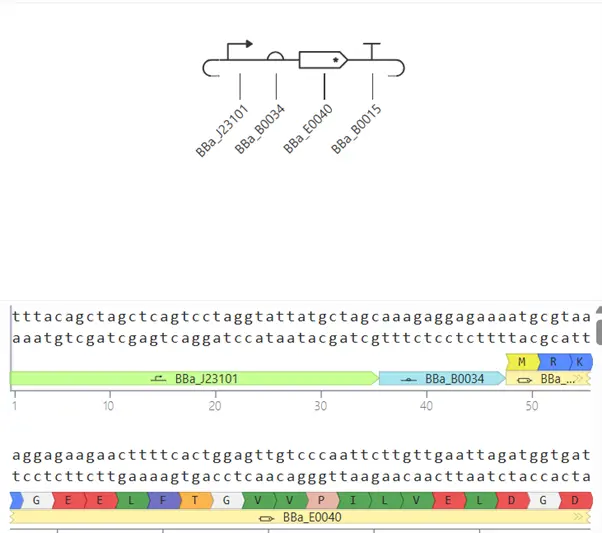
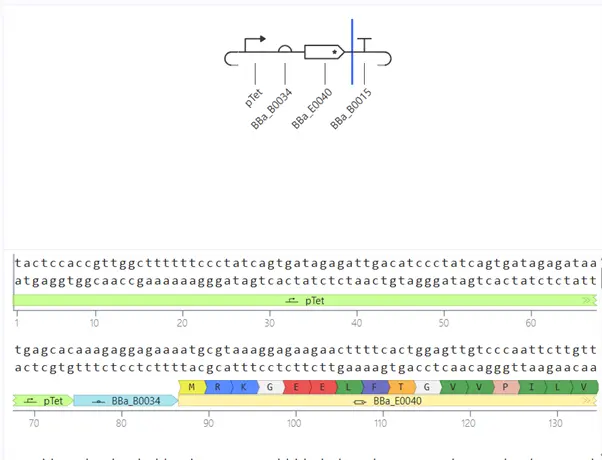
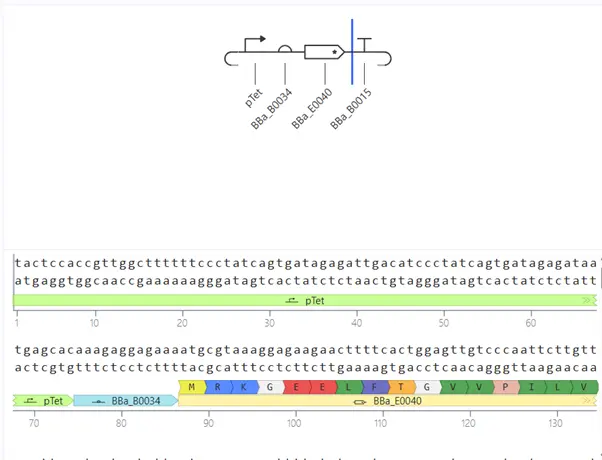
Repressilator Reconstruction
Reconstructed Circuit
Original Constructs
Construct 1 — Constitutive GFP Expression
Construct 2 — Genetic Toggle Switch
Construct 3 — TetR-Repressible Single Gene
Week 07: Genetic Circuits Part-II
Assignment Part 1: Intracellular Artificial Neural Networks (IANNs)
Q1. Advantages of IANNs over traditional Boolean genetic circuits
Traditional genetic circuits are limited to discrete ON/OFF outputs — they can only compute simple logic like AND, OR, NOT. IANNs go beyond this by processing continuous, graded inputs and computing weighted sums across multiple signals simultaneously, just like neurons. This means a single cell can integrate many environmental signals at once and produce nuanced, analog responses rather than just a binary switch. IANNs can also be trained — their weights (gene expression levels) can be tuned to classify complex input patterns. This makes them far more powerful for tasks like disease detection inside a cell, where multiple biomarkers need to be weighed together rather than evaluated individually.
Q2. Useful application for an IANN — Cancer Detection and Response
Application
An IANN engineered into immune cells (like T cells) that detects cancerous cells based on multiple surface protein markers and triggers a therapeutic response.
Input behavior
The IANN receives multiple molecular inputs simultaneously — for example, the presence of tumor antigens (e.g., HER2, PD-L1, EGFR) at varying concentrations on a target cell’s surface. Each input signal is weighted differently depending on its relevance to cancer identity.
Output behavior
If the weighted sum of inputs exceeds a threshold, the T cell activates and releases cytotoxins to kill the target cell. If the threshold is not met (i.e., a healthy cell expressing only one marker at low levels), no response is triggered.
Why IANN is better than Boolean here
A Boolean circuit might trigger on HER2 alone, which is also expressed on some healthy cells — causing toxicity. The IANN integrates all markers with learned weights, making the decision far more precise.
Limitations
Slow response time — gene expression and protein production takes hours, unlike electronic neural networks
Difficult to “retrain” weights inside a living cell once deployed
Cell-to-cell variability in gene expression can cause inconsistent behavior
Limited number of orthogonal molecular parts (RNases, promoters) available for building complex layers
Q3. Multilayer perceptron diagram description
Layer 1 (Input layer)
Input X1: DNA encoding Promoter A → Csy4 endoribonuclease (transcription Tx → translation Tl → Csy4 protein)
Input X2: DNA encoding Promoter B → a second regulatory RNA/protein (e.g., another RNase or transcription factor)
Both are weighted by their respective promoter strengths (w1, w2)
Layer 1 output: Csy4 protein concentration (and optionally a second regulator)
Layer 2 (Output layer)
Input to Layer 2: Csy4 from Layer 1 acts on the mRNA of the fluorescent protein (cleaving or stabilizing it depending on circuit design)
A second weight (w3) is applied via the RBS strength controlling translation of the fluorescent protein
Layer 2 output: Fluorescent protein expression level — a continuous analog output proportional to the combined weighted inputs from Layer 1
In plain words: X1 and X2 are transcribed and translated in Layer 1 → their protein products regulate mRNA processing in Layer 2 → fluorescent protein output is produced in proportion to the weighted sum of both inputs.
Assignment Part 2: Fungal Materials
Q1. Examples of existing fungal materials
Material
Use
Advantages
Disadvantages
Mycelium composites (e.g., Ecovative)
Packaging, insulation, building panels
Biodegradable, grown from agricultural waste, low energy production
Lower mechanical strength than plastics; sensitive to moisture
Mycelium leather (e.g., Bolt Threads’ Mylo)
Fashion, accessories
Sustainable, animal-free, tunable texture
Currently more expensive than animal leather; scaling is difficult
Fungal textiles
Clothing fibers
Renewable, compostable
Not yet widely commercially available
Chitin from fungi
Wound dressings, bioplastics
Biocompatible, antimicrobial
Extraction and processing is complex
Overall advantages over traditional materials: fully biodegradable, carbon-neutral production, grown using waste substrates, no petrochemicals. Disadvantages: currently higher cost, variable mechanical properties, limited scalability.
Q2. What to genetically engineer fungi to do, and why
I would engineer fungi to produce BDNF (Brain-Derived Neurotrophic Factor) or other neuroprotective proteins as a sustainable bioproduction platform. Fungi like Aspergillus niger or Pichia pastoris are already established as industrial protein secretion hosts.
What to engineer
Insert the codon-optimized BDNF gene under a strong inducible fungal promoter
Add a secretion signal peptide so BDNF is secreted directly into the growth medium for easy harvesting
Engineer glycosylation patterns to match human BDNF for therapeutic use
Why fungi over bacteria
Feature
Fungi
Bacteria (E. coli)
Post-translational modifications
Yes — glycosylation, folding
No — often misfolded human proteins
Protein secretion
Naturally efficient
Requires special engineering
Scale
Industrial fermentation established
Also good, but harder for complex proteins
Safety
GRAS status (generally recognized as safe)
Some strains produce endotoxins
Genome size/complexity
Can handle larger, more complex genes
Simpler but limited
Week 09: Cell-Free Systems
General Homework Questions
1. Advantages of Cell-Free Protein Synthesis Over In Vivo Methods
Cell-free protein synthesis (CFPS) eliminates the need to maintain viable cells, giving direct access to the reaction environment. You can tune pH, redox state, temperature, and add cofactors like chaperones or lipids directly — impossible inside a living cell.
Two Cases Where Cell-Free Beats In Vivo
Toxic proteins — antimicrobial peptides (e.g., magainin 2, human β-defensin-2) kill host bacteria. Cell-free has no host to protect.
Non-canonical amino acids (NCAAs) — NCAAs incorporated via amber codon suppression (TAG) and orthogonal tRNA synthetases do not need to cross a cell membrane, making CFPS the only practical route for site-specific unnatural amino acid incorporation.
2. Main Components of a Cell-Free Expression System
Encodes protein of interest (plasmid or linear PCR product)
NTPs (ATP, GTP, CTP, UTP)
Powers transcription and translation
Amino acids
Building blocks for polypeptide synthesis
Energy regeneration system
Continuously regenerates ATP (e.g., PEP + pyruvate kinase)
Salts & buffer
Mg²⁺ and K⁺ maintain ribosome activity and optimal pH
T7 RNA polymerase(if needed)
Transcribes DNA → mRNA when not present in the lysate
3. Energy Regeneration in Cell-Free Systems
ATP and GTP are consumed rapidly during translation (one ATP per amino acid activation, two GTP per elongation cycle). Without regeneration, synthesis stops within 30–60 minutes.
Method: Phosphoenolpyruvate (PEP) / Pyruvate Kinase (PK) System
Pyruvate kinase transfers the high-energy phosphate from PEP to ADP:
PEP + ADP → ATP + pyruvate
Add 10–30 mM PEP + >10 U/mL pyruvate kinase to the reaction. This is the most widely used system in E. coli-based CFPS and provides >2× higher yield than creatine phosphate alone.
4. Prokaryotic vs. Eukaryotic Cell-Free Systems
Prokaryotic (E. coli)
Eukaryotic (wheat germ / rabbit reticulocyte)
Cost
Low
High
Yield
High (mg/mL)
Moderate
PTMs
None
Glycosylation, disulfide isomerization
Speed
Fast (2–4 h)
Slower
Best for
Bacterial proteins, rapid screening
Mammalian glycoproteins, complex folds
Examples
Prokaryotic choice:Renilla luciferase — no PTMs needed, folds well in E. coli extract, widely used as a reporter in CFPS optimization.
Eukaryotic choice: Human erythropoietin (EPO) — requires N-linked glycosylation for stability and activity; only eukaryotic lysates can add these glycans correctly.
5. Optimizing Membrane Protein Expression in Cell-Free Systems
The challenge with membrane proteins in CFPS is that they are hydrophobic and aggregate in aqueous reaction mixtures. The solution is to add lipid scaffolds directly into the reaction.
Setup
Nanodiscs — Pre-assemble MSP1D1 + DMPC or POPC nanodiscs and add them directly to the CFPS reaction. Nascent membrane proteins insert co-translationally into the disc. Nanodiscs outperform detergents and liposomes for solubility.
Reduce translation rate — Use lower DNA concentration (1–5 nM) or a weaker RBS to slow elongation, giving transmembrane helices time to insert.
Detergents as alternatives — DDM or digitonin can be added above their CMC to solubilize the protein, but screen carefully because many detergents inhibit CFPS at higher concentrations.
Input: N-Acyl homoserine lactones (AHLs) secreted by biofilm-forming pathogens such as Pseudomonas aeruginosa
Output: Release of AHL lactonase (AiiA, encoded by aiiA) to degrade quorum-sensing signals and halt biofilm maturation
1b. Cell-Free Tx/Tl Alone Without Encapsulation?
No. Without encapsulation, lactonase diffuses freely into the environment with no threshold-gated release. Encapsulation couples AHL sensing to controlled output release, giving logical behavior.
1c. Could a Genetically Modified Natural Cell Do This?
Yes — E. coli can be engineered with a LuxR-responsive aiiA circuit. However, natural cells carry risks of uncontrolled replication, immune activation, and off-target effects. Synthetic cells are non-replicating and immunologically inert.
1d. Desired Outcome
Synthetic cells sense AHL above threshold → express α-hemolysin pores → release AiiA lactonase → degrade AHL → disrupt quorum sensing → biofilm bacteria become antibiotic-sensitive.
2a. Membrane Composition
POPC + cholesterol (70:30 ratio)
2b. Encapsulated Contents
PURE system (bacterial transcription/translation)
Gene: aiiA (AHL lactonase from Bacillus sp. 240B1)
Gene: hla (α-hemolysin from Staphylococcus aureus)
LuxR protein (constitutively present)
2c. Transcription/Translation System
Bacterial PURE system
AHL-LuxR signaling is bacterial, so a bacterial Tx/Tl system is the correct choice.
2d. Communication With Environment
AHL molecules passively diffuse across the membrane. Once activated, α-hemolysin forms pores in the membrane, allowing AiiA lactonase to exit and degrade extracellular AHL.
3a. Genes and Lipids
Lipids
POPC
Cholesterol
Gene 1 — aiiA
AHL lactonase from Bacillus sp. 240B1
GenBank: AF196151
Function: hydrolyzes the lactone ring of AHL molecules
Gene 2 — hla
α-hemolysin from Staphylococcus aureus
UniProt: P09616
Function: forms heptameric membrane pores
Regulator — luxR
LuxR transcriptional activator from Vibrio fischeri
UniProt: P12746
Activated by AHL and drives the lux promoter
3b. Measurement
Crystal Violet Biofilm Assay
Treat Pseudomonas aeruginosa biofilms with synthetic cells and compare against a no-AHL control.
Measure OD570 after crystal violet staining
Reduced staining indicates biofilm degradation
Secondary Assay
SYTO9/PI fluorescence microscopy to confirm bacterial sensitization and membrane integrity changes.
Peter Nguyen — Cell-Free Systems in Materials
Application: Smart Architectural Wall Panel
Pitch
A freeze-dried cell-free biosensor panel embedded into interior wall tiles changes color when indoor formaldehyde exceeds safe limits (>0.1 ppm, WHO threshold).
Mechanism
The tile contains lyophilized BioBits® pellets encoding a frmR-regulated colorimetric circuit.
Without formaldehyde → FrmR represses reporter expression
With formaldehyde → repression removed → β-galactosidase expressed
CPRG substrate changes color from yellow → blue
The user sprays water + CPRG to activate the tile. Color becomes visible within 2–4 hours.
Societal Need
Formaldehyde from furniture, flooring, and paint is a major indoor air pollutant linked to respiratory disease and cancer. Current electronic monitors cost >$100. This biosensor provides an inexpensive visual alternative.
Addressing Limitations
Stability: Lyophilized with trehalose + BSA for room-temperature storage
One-time use: Replaceable modular sensor inserts
Water activation: Prevents accidental activation from ambient humidity
Ally Huang — Mock Genes in Space Proposal
Background
Microgravity causes rapid skeletal muscle atrophy in astronauts. Pax7, a master regulator of satellite cell activation, becomes downregulated during spaceflight. Monitoring Pax7 expression in real time could help track muscle health and optimize countermeasures. Existing approaches require laboratory infrastructure unsuitable for space missions. A freeze-dried, field-deployable biosensor for Pax7 mRNA would enable portable muscle-health monitoring without refrigeration or complex equipment.
Molecular Target
Pax7 mRNA detected using a toehold switch reporter within a BioBits® cell-free reaction.
Target-Challenge Relationship
Pax7 expression is a direct indicator of muscle satellite cell activation and regenerative capacity. Microgravity suppresses mechanical loading, reducing Pax7-positive satellite cells. Measuring Pax7 mRNA abundance enables quantitative tracking of muscle regeneration status during long-duration missions.
Hypothesis
A freeze-dried BioBits® toehold switch biosensor targeting Pax7 mRNA will generate GFP fluorescence proportional to Pax7 expression levels in astronaut RNA samples, detectable using the P51 Molecular Fluorescence Viewer.
Toehold switches are programmable RNA sensors capable of recognizing nearly any target sequence. A Pax7-specific switch is incorporated into the BioBits® system so GFP translation occurs only in the presence of Pax7 transcript.
The miniPCR® device amplifies and transcribes RNA into a compatible format for the switch. This keeps the workflow entirely within the Genes in Space toolkit.
Low Pax7 → weak GFP signal
High Pax7 → strong GFP signal
Experimental Plan
Samples
Saliva or biopsy RNA from astronauts at:
T = 0 (preflight)
T = 30 days
T = 60 days
T = 90 days
Controls
Positive: synthetic Pax7 mRNA spike-in
Negative: nuclease-free water
Blank: osmolality-matched control
Procedure
Extract RNA using compact lysis kit
Use miniPCR® for RT-PCR amplification
Add amplicon to rehydrated BioBits® toehold pellet
Incubate 2 h at 37°C
Visualize fluorescence using P51 Viewer
Data
GFP fluorescence intensity serves as a proxy for Pax7 mRNA abundance. Longitudinal tracking reveals muscle health trajectory during spaceflight.
Week 10: Imaging and Measurement
Part I — Molecular Weight
Q1 — Theoretical MW from Sequence
The eGFP sequence was entered into the ExPASy Compute pI/Mw tool.
The resulting molecular weight was:
28,006.60 Da
However, eGFP undergoes autocatalytic chromophore cyclization, which removes approximately 20 Da from the protein.
Therefore:
Theoretical MW = 27,986.60 Da
Q2 — Adjacent Charge State Calculation
From Figure 1, two adjacent peaks were selected:
( m/z_n = 903.7148 )
( m/z_{n+1} = 875.4421 )
Step 1 — Determine the Charge State
$$
z = \frac{875.4421}{903.7148 - 875.4421}
$$
$$
z = \frac{875.4421}{28.2727}
$$
$$
z = 30.96 \approx 31
$$
Step 2 — Determine Molecular Weight
$$
MW = z \times \left(\frac{m}{z_n} - 1\right)
$$
This is well within the accepted threshold for confident identification.
Q7 — Sequence Coverage
From Figure 6:
88% sequence coverage
Bonus Q8 — Fragment Ion Matching
Using the Fragment Ion Calculator with:
peptide: FEGDTLVNR
singly charged ions
B and Y ions enabled
The fragmentation spectrum in Figure 5c closely matches the predicted fragments.
Most major B and Y ions align correctly. Small unmatched peaks likely represent noise or internal fragment ions.
Bonus Q9 — Did We Make eGFP?
Yes, the collected evidence strongly supports that the sample is eGFP.
Supporting evidence includes:
88% sequence coverage
peptide identifications within <10 ppm
intact molecular weight close to theoretical
The remaining unconfirmed sequence likely corresponds to peptides outside the detectable mass range.
Part IV — Oligomers
Using the subunit masses provided in Table 1:
Species
Calculation
Mass
7FU Decamer
10 × 340 kDa
3,400 kDa (3.4 MDa)
8FU Didecamer
20 × 400 kDa
8,000 kDa (8.0 MDa)
8FU 3-Decamer
30 × 400 kDa
12,000 kDa (12 MDa)
8FU 4-Decamer
40 × 400 kDa
16,000 kDa (16 MDa)
These masses correspond to the major species observed in the CDMS spectrum.
CDMS is especially useful for extremely large assemblies because it directly measures ion mass without requiring charge-state deconvolution.
Part V — Did I Make GFP?
Theoretical
Observed (Intact LC-MS)
PPM Error
Molecular Weight (Da)
27,986.60
27,984.16
87.2
Conclusion
The observed intact mass differs from the theoretical value by approximately 87 ppm, which is slightly above the ideal threshold.
However, peptide mapping provides strong supporting evidence:
88% sequence coverage
FEGDTLVNR identified within 5.3 ppm
all major peptides match predicted tryptic fragments
The small discrepancy in intact mass likely results from manual charge-state selection rather than incorrect protein identity.
Week 11: Building Genomes
Cell-Free Protein Synthesis (CFPS)
CFPS recreates transcription and translation outside a living cell using a lysate supplemented with all the molecular machinery needed to produce a protein from a DNA template. No cell wall means direct control over every component.
The Lysate
The BL21(DE3) Star lysate provides ribosomes, tRNAs, elongation factors — and crucially, T7 RNA Polymerase, which transcribes any gene under a T7 promoter with high speed and efficiency.
Salts & Buffer
Maintain the ionic environment enzymes need. HEPES-KOH keeps pH ~7.5 (neutral, like inside a cell). Mg²⁺ supports ribosome assembly and polymerase activity. K⁺ is a co-factor for many enzymes. Potassium phosphate (mono + dibasic together) provides both phosphate for energy transfer and secondary buffering.
Energy & Nucleotides
AMP, CMP, GMP, UMP are the RNA building blocks. They’re monophosphates, so they must be phosphorylated to NTPs before incorporation into RNA. Ribose and glucose fuel the metabolic pathways that do this phosphorylation. Guanine is the free base for GMP — the cell’s salvage enzymes assemble it from guanine + ribose + phosphate, which is why GMP doesn’t need to be added directly.
Two Master Mix Strategies
1-hr PEP-NTP
20-hr NMP-Ribose-Glucose
Nucleotides
NTPs (ready to use)
NMPs (must be phosphorylated)
Energy
PEP (fast, direct phosphate donor)
Glycolysis-like pathways (slow, sustained)
Trade-off
Fast but expensive
Cheap but slow
Amino Acids
All 20 amino acids must be present. Tyrosine and cysteine are added separately because tyrosine is poorly soluble and cysteine oxidizes easily — both would degrade in a bulk mix. Nicotinamide feeds NAD⁺/NADP⁺ production for redox-based energy regeneration.
Fluorescent Proteins in CFPS
The key properties that matter in a cell-free context:
sfGFP — engineered for fast, robust folding; signal appears quickly
mRFP1 — slow-maturing; delayed fluorescence signal
mKO2 — oxygen-dependent maturation; limited O₂ in tubes is a bottleneck
mTurquoise2 — high quantum yield, fast maturation; well-suited for CFPS
mScarlet-I — brighter and faster-maturing than mRFP1
Electra2 — newer, less characterized
Cloud Labs
Fully automated, remotely accessible labs where robots (liquid handlers, plate readers, incubators) execute experiments designed digitally. Key benefits: sub-microliter pipetting precision, massive parallelism (e.g. 1,536-well plates), global accessibility, and compatibility with AI-driven optimization loops.