My Homework What’s the most commonly used method for oligo synthesis currently? The phosphoramidite method using solid-phase synthesis is the most commonly used approach for oligonucleotide (oligo) synthesis today. This method builds oligos in the 3’ to 5’ direction on solid supports like controlled pore glass (CPG) or polystyrene, allowing automation and high efficiency. It involves four key steps per cycle: detritylation to expose the 5’-OH, coupling with activated phosphoramidite monomers, capping unreacted sites, and oxidation to stabilize phosphite triesters into phosphates. Commercial synthesizers make it scalable from small research batches to large therapeutic production.
My Homework Prompt in Perplexity : Can you identify the ten essential amino acids in animals, and explain how this relates to your understanding of the “Lysine Contingency”?
What are the 10 essential amino acids in all animals and how does this affect your view of the “Lysine Contingency”?
There are nine universally essential amino acids for all animals, including lysine, which they must obtain from their diet since they cannot synthesize them. The “Lysine Contingency” from Jurassic Park is scientifically implausible because lysine is abundant in nature. All animals, including humans, require nine essential amino acids—histidine, isoleucine, leucine, lysine, methionine, phenylalanine, threonine, tryptophan, and valine that their bodies cannot synthesize and must obtain from food sources like meat, plants, or prey. While some species need a tenth like arginine, these nine are universal across animals for protein building and vital functions. The “Lysine Contingency” in Jurassic Park portrayed dinosaurs genetically engineered to lack lysine synthesis as a failsafe, meant to kill them by withholding the nutrient, but this is scientifically flawed since lysine is already an essential amino acid for all animals, abundantly available in nature from sources like soybeans, grains, and animal tissues. Dinosaurs could easily survive by eating wild plants or animals, rendering the contingency useless and highlighting poor genetic engineering logic in the story. This doesn’t change my view of it as entertaining but implausible fiction, real biotech safeguards would need novel dependencies, not mimicking natural nutritional limits.
My Homework Nature’s machinery for copying DNA is called polymerase. What is the error rate of polymerase? How does this compare to the length of the human genome. How does biology deal with that discrepancy? DNA polymerase, the enzyme that copies DNA, makes a mistake roughly once every 10⁴ to 10⁵ nucleotides synthesized, which sounds small but would lead to about 300,000 errors per round of human‑genome replication (about 3 billion bases) if left unchecked. Biology solves this by stacking multiple layers of quality control: the polymerase active site is selective for correct base pairs, the enzyme can proofread its own work by removing mispaired bases (3′→5′ exonuclease activity), and after replication specialized mismatch repair proteins scan and fix errors, bringing the effective mutation rate down to about 1 per 10⁷ to 10⁹ bases per cycle, which keeps the overall mutation load low enough for the organism to function reliably.
From Genes to Neurons : CRISPR as a Breakthrough for Ischemic Stroke
Describe a biological engineering application or tool you want to develop and why? Stroke, or cerebrovascular accident (CVA), is a leading cause of mortality and morbidity in my country, Indonesia. Compared to other Southeast Asian countries, Indonesia has the highest age- and sex-standardized mortality rate and the greatest loss of disability-adjusted life years. Reducing stroke incidence is key to lowering stroke-related disability. This condition is generally classified as either ischemic—caused by arterial blockage from thrombi, emboli, or hemorrhagic, due to intracranial bleeding. Ischemic stroke, the most common type, often stems from atherosclerosis or thromboembolism. Given these issues, I want to learn more about the problem and what solutions we can develop through biological engineering. Despite advances in acute management, current therapeutic options remain limited, highlighting the need for innovative strategies. In this context, CRISPR genome-editing technology has emerged as a promising biological engineering approach, offering the potential to modulate genes involved in inflammation, neuroprotection, and vascular repair, thereby opening new avenues for ischemic stroke research and therapy.
Part 1: Benchling & In-silico Gel Art step 01 : I have already made my benchling account step 02 : copy lambda_NEB sequence and import the sequence in my benchling Part 3: DNA Design Challenge my protein data from –> https://www.uniprot.org 498 AA | EC=3.2.1.1 | Full=1,4-alpha-D-glucan glucanohydrolase A | amyA | Aspergillus awamori (Black koji mold) | UniProtKB:P0C1B3
Python Script for Opentrons Artwork Actually I really struggle with python :( , I’ll try very soon. This picture below is my trial for generate an artistic design from https://opentrons-art.rcdonovan.com/
I make this design without picture This one with picture preference desc : 0,75 uL
Part A : Conseptual Questions Questions from Shuguang Zhang: (i.e. you can select two to skip)
How many molecules of amino acids do you take with a piece of 500 grams of meat? (on average an amino acid is ~100 Daltons)
Why do humans eat beef but do not become a cow, eat fish but do not become fish? Because DNA determines what organism you are, not the food you eat. When we eat meat, proteins are broken down into amino acids and then cells use those amino acids to build human proteins, based on the instructions in our human DNA.
Part A : SOD1 Binder Peptide Design Part 1: Generate Binders with PepMLM
Part 2: Evaluate Binders with AlphaFold3
Part 3: Evaluate Properties of Generated Peptides in the PeptiVerse
Part 4: Generate Optimized Peptides with moPPIt
Part C: Final Project: L-Protein Mutants L-Protein and DnaJ Sequence Lysis Protein Sequence (UniProtKB ID: https://www.uniprot.org/uniprotkb/P03609/entry)
DNA ASSEMBLY What are some components in the Phusion High-Fidelity PCR Master Mix and what is their purpose? High-Fidelity DNA Polymerases are important for applications in which the DNA sequence needs to be correct after amplification. Phusion High-Fidelity DNA Polymerase offers both high fidelity and robust performance, and thus can be used for all PCR applications. Its unique structure, a novel Pyrococcus-like enzyme fused with a processivity-enhancing domain, increases fidelity and speed. Phusion DNA Polymerase is an ideal choice for cloning and can be used for long or difficult amplicons. With an error rate >50-fold lower than that of Taq DNA Polymerase and 6-fold lower than that of Pyrococcus furiosus DNA Polymerase, Phusion is one of the most accurate thermostable polymerase available. Phusion DNA Polymerase possesses 5´→ 3´ polymerase activity, 3´→ 5´ exonuclease activity and will generate blunt-ended products. Phusion High-Fidelity PCR Master Mix with HF Buffer is a 2X master mix consisting of Phusion DNA Polymerase, deoxynucleotides and reaction buffer that has been optimized and includes MgCl2. All that is required is the addition of template, primers and water. Phusion High-Fidelity PCR Master Mix is a 2X concentrated, ready-to-use solution containing Phusion DNA Polymerase, optimized reaction buffer (HF or GC), MgCl2, and dNTPs. It provides high-fidelity, high-speed, and robust amplification, designed for blunt-end cloning. Only template DNA, primers, and water are needed for reaction setup.
Subsections of Homework
Pre-HW Week 2 From Dr. LeProust
My Homework
What’s the most commonly used method for oligo synthesis currently?
The phosphoramidite method using solid-phase synthesis is the most commonly used approach for oligonucleotide (oligo) synthesis today. This method builds oligos in the 3’ to 5’ direction on solid supports like controlled pore glass (CPG) or polystyrene, allowing automation and high efficiency. It involves four key steps per cycle: detritylation to expose the 5’-OH, coupling with activated phosphoramidite monomers, capping unreacted sites, and oxidation to stabilize phosphite triesters into phosphates. Commercial synthesizers make it scalable from small research batches to large therapeutic production.
Why is it difficult to make oligos longer than 200nt via direct synthesis?
Direct chemical synthesis of oligonucleotides longer than 200 nucleotides (nt) is challenging due to cumulative inefficiencies and side reactions in the phosphoramidite method.
Why can’t you make a 2000bp gene via direct oligo synthesis?
Direct chemical synthesis cannot produce a reliable 2000 bp gene due to exponential error accumulation and physical limitations in the phosphoramidite process. Direct chemical synthesis can’t make a reliable 2000 bp gene because each added nucleotide has only ~99% success rate. Multiplying that over 2000 steps gives almost zero full-length product. Plus, reagents can’t reach the growing chain well on solid supports, causing more errors and junk.
Pre-HW Week 2 From George Church
My Homework
Prompt in Perplexity : Can you identify the ten essential amino acids in animals, and explain how this relates to your understanding of the “Lysine Contingency”?
What are the 10 essential amino acids in all animals and how does this affect your view of the “Lysine Contingency”?
There are nine universally essential amino acids for all animals, including lysine, which they must obtain from their diet since they cannot synthesize them. The “Lysine Contingency” from Jurassic Park is scientifically implausible because lysine is abundant in nature. All animals, including humans, require nine essential amino acids—histidine, isoleucine, leucine, lysine, methionine, phenylalanine, threonine, tryptophan, and valine that their bodies cannot synthesize and must obtain from food sources like meat, plants, or prey. While some species need a tenth like arginine, these nine are universal across animals for protein building and vital functions. The “Lysine Contingency” in Jurassic Park portrayed dinosaurs genetically engineered to lack lysine synthesis as a failsafe, meant to kill them by withholding the nutrient, but this is scientifically flawed since lysine is already an essential amino acid for all animals, abundantly available in nature from sources like soybeans, grains, and animal tissues. Dinosaurs could easily survive by eating wild plants or animals, rendering the contingency useless and highlighting poor genetic engineering logic in the story. This doesn’t change my view of it as entertaining but implausible fiction, real biotech safeguards would need novel dependencies, not mimicking natural nutritional limits.
Pre-HW Week 2 From Professor Jacobson
My Homework
Nature’s machinery for copying DNA is called polymerase. What is the error rate of polymerase? How does this compare to the length of the human genome. How does biology deal with that discrepancy?
DNA polymerase, the enzyme that copies DNA, makes a mistake roughly once every 10⁴ to 10⁵ nucleotides synthesized, which sounds small but would lead to about 300,000 errors per round of human‑genome replication (about 3 billion bases) if left unchecked. Biology solves this by stacking multiple layers of quality control: the polymerase active site is selective for correct base pairs, the enzyme can proofread its own work by removing mispaired bases (3′→5′ exonuclease activity), and after replication specialized mismatch repair proteins scan and fix errors, bringing the effective mutation rate down to about 1 per 10⁷ to 10⁹ bases per cycle, which keeps the overall mutation load low enough for the organism to function reliably.
How many different ways are there to code (DNA nucleotide code) for an average human protein? In practice what are some of the reasons that all of these different codes don’t work to code for the protein of interest?
An “average” human protein is roughly 300–400 amino acids long, and each amino acid is encoded by a DNA codon of 3 nucleotides, since the genetic code is degenerate (most amino acids have multiple codons), there are immensely many different DNA sequences that could encode the same amino‑acid sequence for such a protein on the order of many trillions or more of distinct nucleotide codes just for one average length protein. In practice, not all of these DNA variants actually work well because some change regulatory features (such as promoter or splice‑site signals), others introduce mRNA‑structure shifts that affect translation efficiency or trigger nonsense‑mediated decay, and still others create cryptic signals (like premature stop codons, frameshifts, or toxic repeat‑expansion‑like sequences) that either kill the protein’s function, destabilize the mRNA, or make the encoded protein harmful to the cell.
Week 1 HW: Principles and Practices
From Genes to Neurons : CRISPR as a Breakthrough for Ischemic Stroke
Describe a biological engineering application or tool you want to develop and why?
Stroke, or cerebrovascular accident (CVA), is a leading cause of mortality and morbidity in my country, Indonesia. Compared to other Southeast Asian countries, Indonesia has the highest age- and sex-standardized mortality rate and the greatest loss of disability-adjusted life years. Reducing stroke incidence is key to lowering stroke-related disability. This condition is generally classified as either ischemic—caused by arterial blockage from thrombi, emboli, or hemorrhagic, due to intracranial bleeding. Ischemic stroke, the most common type, often stems from atherosclerosis or thromboembolism. Given these issues, I want to learn more about the problem and what solutions we can develop through biological engineering. Despite advances in acute management, current therapeutic options remain limited, highlighting the need for innovative strategies. In this context, CRISPR genome-editing technology has emerged as a promising biological engineering approach, offering the potential to modulate genes involved in inflammation, neuroprotection, and vascular repair, thereby opening new avenues for ischemic stroke research and therapy.
Describe one or more governance/policy goals related to ensuring that this application or tool contributes to an “ethical” future, like ensuring non-malfeasance (preventing harm). Break big goals down into two or more specific sub-goals.
A primary governance goal is to ensure non-malfeasance by preventing unintended harm from CRISPR applications in ischemic stroke therapy, such as off-target genetic edits or exacerbation of inflammation. Mandate preclinical trials with multi-generational follow-up to verify no adverse effects on edited genes, restricting use to well-characterized targets prevalent in healthy populations. Besides that, establish regulatory for ongoing risk reassessment, prohibiting germline editing until credible data confirm safety and barring enhancements beyond disease prevention.
Describe at least three different potential governance “actions” by considering the four aspects below (Purpose, Design, Assumptions, Risks of Failure & “Success”).
Establish Multidisciplinary Oversight Committees
The purpose to ensure ethical oversight of CRISPR applications in stroke therapy by balancing innovation with bioethics principles like non-maleficence and justice. Form committees with clinicians, geneticists, ethicists, policymakers, and patients to review protocols, informed consent, and long-term follow-ups before clinical trials.
Risks of Failure -> Oversight committees may slow down research due to bureaucratic delays, suffer from unequal influence among members, or lack up-to-date technical expertise in CRISPR. If their decisions are not enforceable, the committees may have little real impact beyond symbolic approval.
Success -> This action succeeds if it ensures ethical, transparent, and inclusive decision-making for CRISPR stroke therapies, strengthens patient safety and informed consent, and builds public trust while still allowing responsible scientific innovation.
Implement Transparent Global Reporting Standards
The purpose to promote equity and prevent misuse by mandating open data on CRISPR stroke trials, aligning with frameworks like WHO’s genome editing guidelines. This governance require public registries for trial data, adverse events, and equity metrics, audited by independent bodies like NExTRAC (Novel and Exceptional Technology and Research Advisory Committee) equivalents. International cooperation overcomes data-sharing barriers digital platforms ensure accessibility.
Risks of Failure -> Data suppression by proprietary interests; overload of unverified info eroding trust.
Success -> Accelerated learning from global trials, reducing disparities in stroke therapy access.
Mandate Risk-Based Preclinical Testing Protocols
The purpose is to prevent harm from off-target edits or unforeseen effects in ischemic stroke gene therapies by enforcing rigorous safety validation. This governance require multi-generational animal studies, off-target analysis, and delivery system testing (e.g., nanoparticles for brain access), with phased human trials tied to milestones. Besides that, current lab tech accurately predicts human outcomes; funding supports extended testing timelines.
Risks of Failure -> High costs exclude smaller researchers; false negatives allow subtle long-term harms.
Success -> Proven safety data enabling equitable regulatory approval in high-burden areas like Indonesia.
Score (from 1-3 with, 1 as the best, or n/a) each of your governance actions against your rubric of policy goals.
Establish Multidisciplinary Oversight Committees (A)
Implement Transparent Global Reporting Standards (B)
Mandate Risk-Based Preclinical Testing Protocols (C)
Does the option:
Option 1 (A)
Option 2 (B)
Option 3 (C)
Enhance Biosecurity
• By preventing incidents
1
1
1
• By helping respond
2
2
2
Foster Lab Safety
• By preventing incident
1
1
1
• By helping respond
2
2
2
Protect the environment
• By preventing incidents
2
1
3
• By helping respond
2
2
2
Other considerations
• Minimizing costs and burdens to stakeholders
3
2
1
• Feasibility?
2
1
1
• Not impede research
3
1
1
• Promote constructive applications
2
1
2
• Patient safety and clinical risk
1
1
3
• Ethical acceptability
1
2
3
• Scientific effectiveness
2
1
2
• Equity and access
2
1
3
• Long term sustainability
2
1
3
Drawing upon this scoring, describe which governance option, or combination of options, you would prioritize, and why. Outline any trade-offs you considered as well as assumptions and uncertainties.
Drawing on the scoring across safety, feasibility, and responsible innovation criteria, I would prioritize a combination of Option 2 and Option 1. This hybrid approach best balances patient safety, ethical responsibility, and scientific progress in the development of CRISPR based therapies for stroke. The main trade-off in prioritizing this combined approach is speed versus safety. Centralized oversight may slow research timelines and increase administrative burdens for researchers and institutions. However, these costs are justified by the high clinical risks associated with CRISPR, including off-target effects, long-term genomic consequences, and unequal access if therapies are commercialized too quickly. In contrast, a minimally regulated, market-driven approach was not prioritized due to its poor performance in patient safety, ethical acceptability, and equity.
JOURNAL SOURCE :
Adityasiwi, G.L., Budiono, I., Zainafree, I., Cahyati, W.H. 2025.Stroke in Indonesia: An epidemiological overview. Physical Therapy Journal of Indonesia 6(1): 70-73. DOI: 10.51559/ptji.v6i1.274
Alavian F. & Ghasemi S. CRISPR-Based Therapy for Ischemic Stroke: A Narrative Review. Cell Mol Neurobiol (2026). https://doi.org/10.1007/s10571-025-01662-x
Yang Y, Zhu H, Xiong T, Li S. Inflammatory Biomarkers in Ischemic Stroke: Mechanisms, Clinical Applications, and Future Directions. Neurosurgical Subspecialties. 2025;1(4):188-196. doi: 10.14218/NSSS.2025.00029.
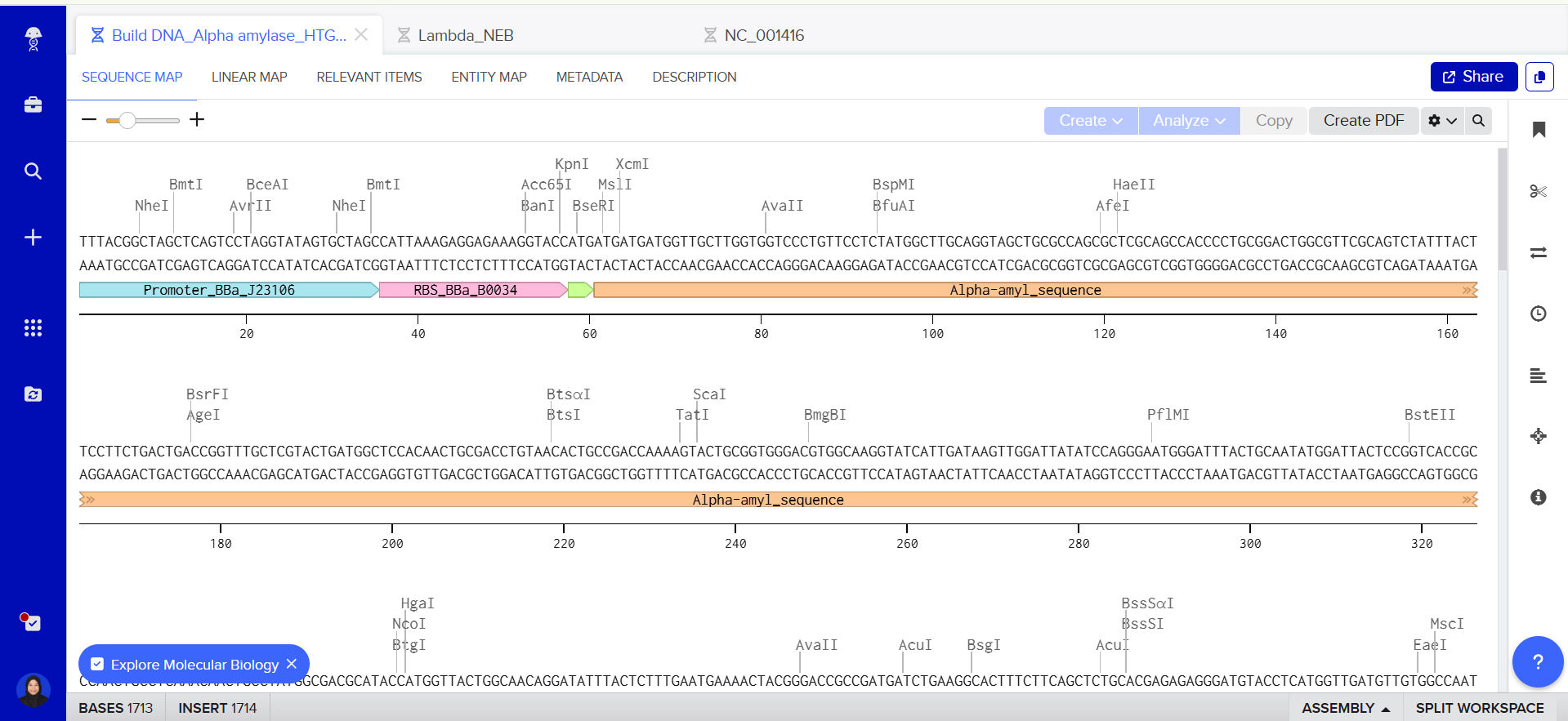
step 01 : I have already made my benchling account
step 02 : copy lambda_NEB sequence and import the sequence in my benchling
Part 3: DNA Design Challenge
my protein data from –> https://www.uniprot.org
498 AA | EC=3.2.1.1 | Full=1,4-alpha-D-glucan glucanohydrolase A | amyA | Aspergillus awamori (Black koji mold) | UniProtKB:P0C1B3
ATG ATG ATG GTT GCT TGG TGG TCC CTG TTC CTC TAT GGC TTG CAG GTA GCT GCG CCA GCG CTC GCA GCC ACC CCT GCG GAC TGG CGT TCG CAG TCT ATT TAC TTC CTT CTG ACT GAC CGG TTT GCT CGT ACT GAT GGC TCC ACA ACT GCG ACC TGT AAC ACT GCC GAC CAA AAG TAC TGC GGT GGG ACG TGG CAA GGT ATC ATT GAT AAG TTG GAT TAT ATC CAG GGA ATG GGA TTT ACT GCA ATA TGG ATT ACT CCG GTC ACC GCC CAA CTG CCT CAA ACA ACT GCC TAT GGC GAC GCA TAC CAT GGT TAC TGG CAA CAG GAT ATT TAC TCT TTG AAT GAA AAC TAC GGG ACC GCC GAT GAT CTG AAG GCA CTT TCT TCA GCT CTG CAC GAG AGA GGG ATG TAC CTC ATG GTT GAT GTT GTG GCC AAT CAC ATG GGT TAC GAC GGC GCC GGT TCG TCC GTC GAT TAC TCG GTC TTC AAG CCC TTC TCT AGT CAA GAC TAT TTC CAC CCC TTC TGC TTC ATT CAA AAC TAT GAG GAT CAG ACA CAA GTC GAA GAC TGC TGG CTT GGC GAC AAC ACC GTT TCA TTG CCT GAC CTT GAC ACG ACT AAA GAT GTA GTG AAG AAC GAG TGG TAT GAT TGG GTC GGC TCT CTG GTC TCT AAC TAT AGT ATC GAT GGT CTT CGG ATT GAT ACG GTG AAA CAC GTT CAG AAG GAC TTC TGG CCT GGT TAT AAC AAG GCA GCT GGC GTT TAC TGC ATC GGC GAA GTG CTC GAT GGA GAC CCC GCC TAT ACC TGC CCC TAT CAG AAC GTC ATG GAC GGG GTA CTC AAT TAC CCG ATA TAC TAC CCG TTG CTC AAC GCT TTC AAA TCG ACG TCC GGC TCC ATG GAC GAT CTT TAC AAT ATG ATA AAC ACA GTT AAG TCG GAT TGC CCA GAC TCA ACT CTG CTG GGG ACT TTC GTG GAG AAC CAT GAC AAC CCT CGC TTC GCT TCG TAC ACA AAC GAC ATC GCA CTG GCG AAA AAT GTC GCT GCC TTT ATC ATC CTC AAT GAC GGA ATC CCT ATT ATC TAC GCA GGC CAG GAA CAG CAT TAT GCC GGG GGC AAC GAC CCC GCT AAC AGG GAA GCT ACA TGG TTG TCA GGC TAT CCT ACT GAT AGC GAA CTC TAT AAA CTT ATC GCT TCT CGT AAC GCA ATC CGG AAC TAC GCT ATA TCT AAA GAT ACC GGG TTC GTT ACC TAT AAA AAT TGG CCC ATC TAT AAG GAT GAT ACA ACA ATC CCA ATG CGC AAA GGT ACA GAC GGT AGC CAG ATT GTG ACC ATT TTG TCC AAC AAA GGT GCA TCG GGC GAC TCG TAC ACC CTT AGT TTG AGT GGA GCA GGG TAC ACC GCC GGA CAG CAA CTG ACT GAG GTG ATC GGA TGC ACC ACC GTG ACC GTT GGA TCA GAT GGT AAC GTC CCA GTT CCT ATG GCT GGG GGA CTG CCC CGA GTT CTT TAT CCA ACA GAA AAG CTC GCT GGC TCC AAG ATT TGT TAT GGT TAA
Alpha-amylase can be produced from DNA using recombinant DNA technology in either living cells (cell-dependent systems) or cell-free protein synthesis systems. In a cell-dependent method, the gene encoding alpha-amylase is first isolated—often from organisms such as Aspergillus species—and amplified using PCR. The gene is then inserted into a plasmid vector containing regulatory elements like a promoter, ribosome binding site, and terminator. This recombinant plasmid is introduced into a host organism such as Escherichia coli, Bacillus subtilis, or yeast. Once inside the host cell, the gene is expressed when the promoter is activated. The cells are grown in culture, often in a bioreactor, where they produce the alpha-amylase protein. The enzyme can then be harvested and purified. Alternatively, in a cell-free system, the DNA template is added directly into a reaction mixture containing ribosomes, enzymes, nucleotides, amino acids, and energy sources extracted from cells. In this system, transcription and translation occur in vitro without the need for living cells, allowing rapid protein production.
At the molecular level, the DNA sequence encoding alpha-amylase is first transcribed into messenger RNA (mRNA) by RNA polymerase. The enzyme binds to the promoter region of the gene, unwinds the DNA, and synthesizes a complementary mRNA strand using base-pairing rules. Once transcription is complete, the mRNA molecule is used as a template for translation. During translation, a ribosome binds to the mRNA and reads its nucleotide sequence in groups of three bases called codons. Each codon corresponds to a specific amino acid, which is delivered by transfer RNA (tRNA). The ribosome links these amino acids together through peptide bonds, forming a growing polypeptide chain. When a stop codon is reached, translation ends and the newly synthesized polypeptide is released. The chain then folds into its functional three-dimensional structure, forming active alpha-amylase.
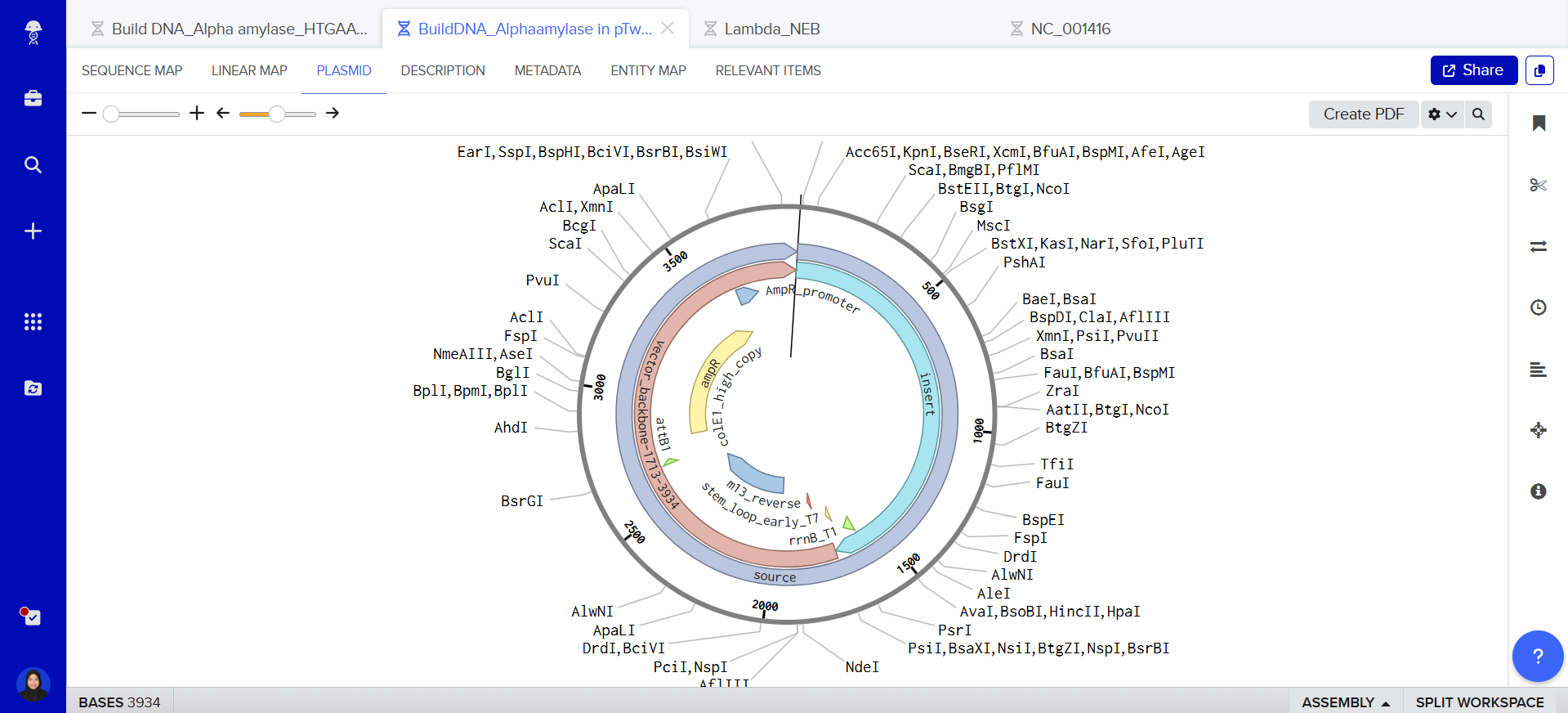
Part 4: Prepare a Twist DNA Synthesis Order
I have already made my twist and benchling account, and then I build my DNA insert sequence to benchling.
This is my plasmid, I just built with my expression cassette included! <3
Part 5: DNA Read/Write/Edit
DNA READ
(i) What DNA would you want to sequence (e.g., read) and why?
(ii) In lecture, a variety of sequencing technologies were mentioned. What technology or technologies would you use to perform sequencing on your DNA and why?
DNA WRITE
(i) What DNA would you want to synthesize (e.g., write) and why?
(ii) What technology or technologies would you use to perform this DNA synthesis and why? Also answer the following questions:
What are the essential steps of your chosen sequencing methods?
What are the limitations of your sequencing method (if any) in terms of speed, accuracy, scalability?
DNA EDIT
(i) What DNA would you want to edit and why?
(ii) What technology or technologies would you use to perform these DNA edits and why?
Week 3 HW: Lab Automation
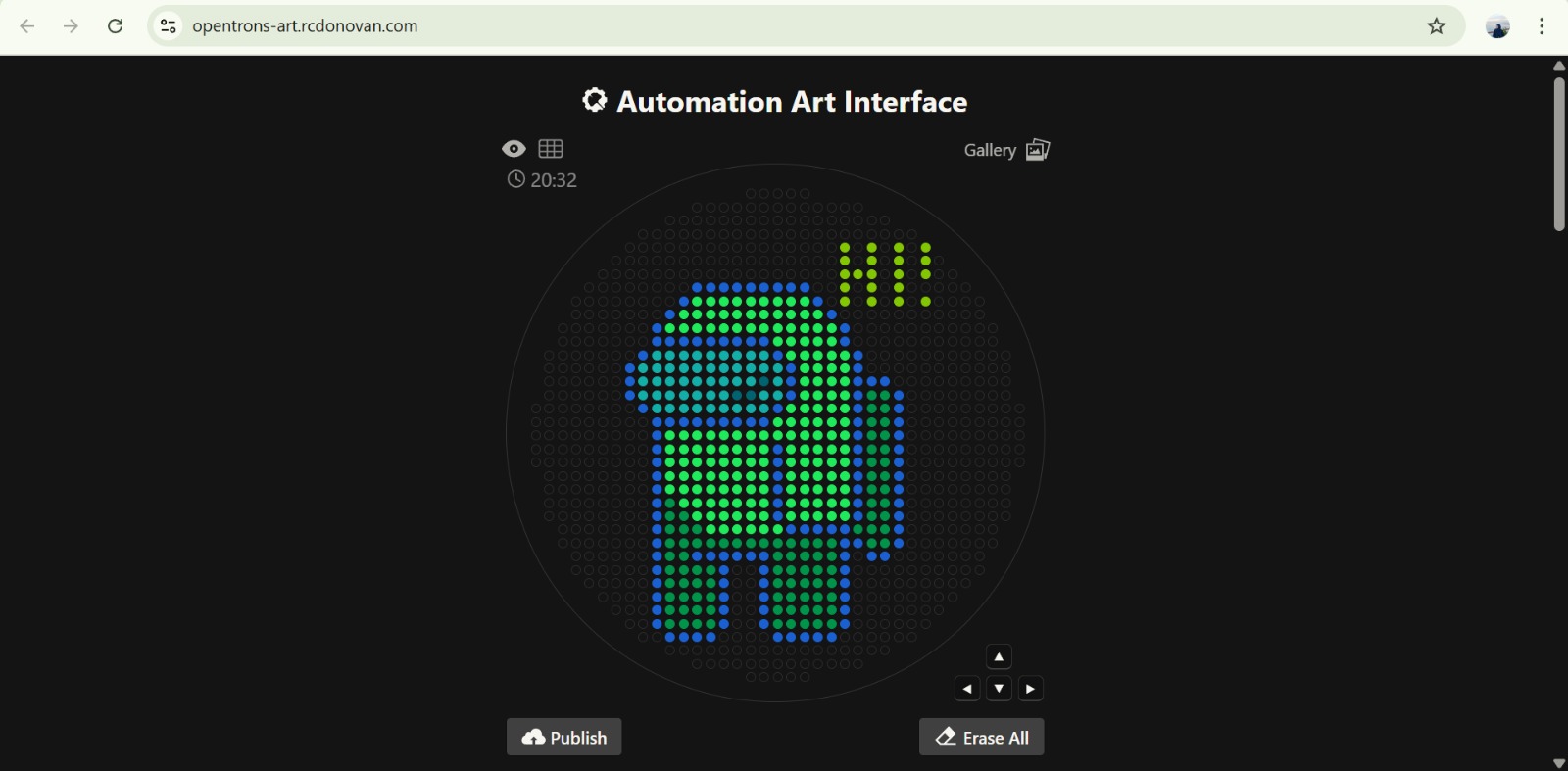
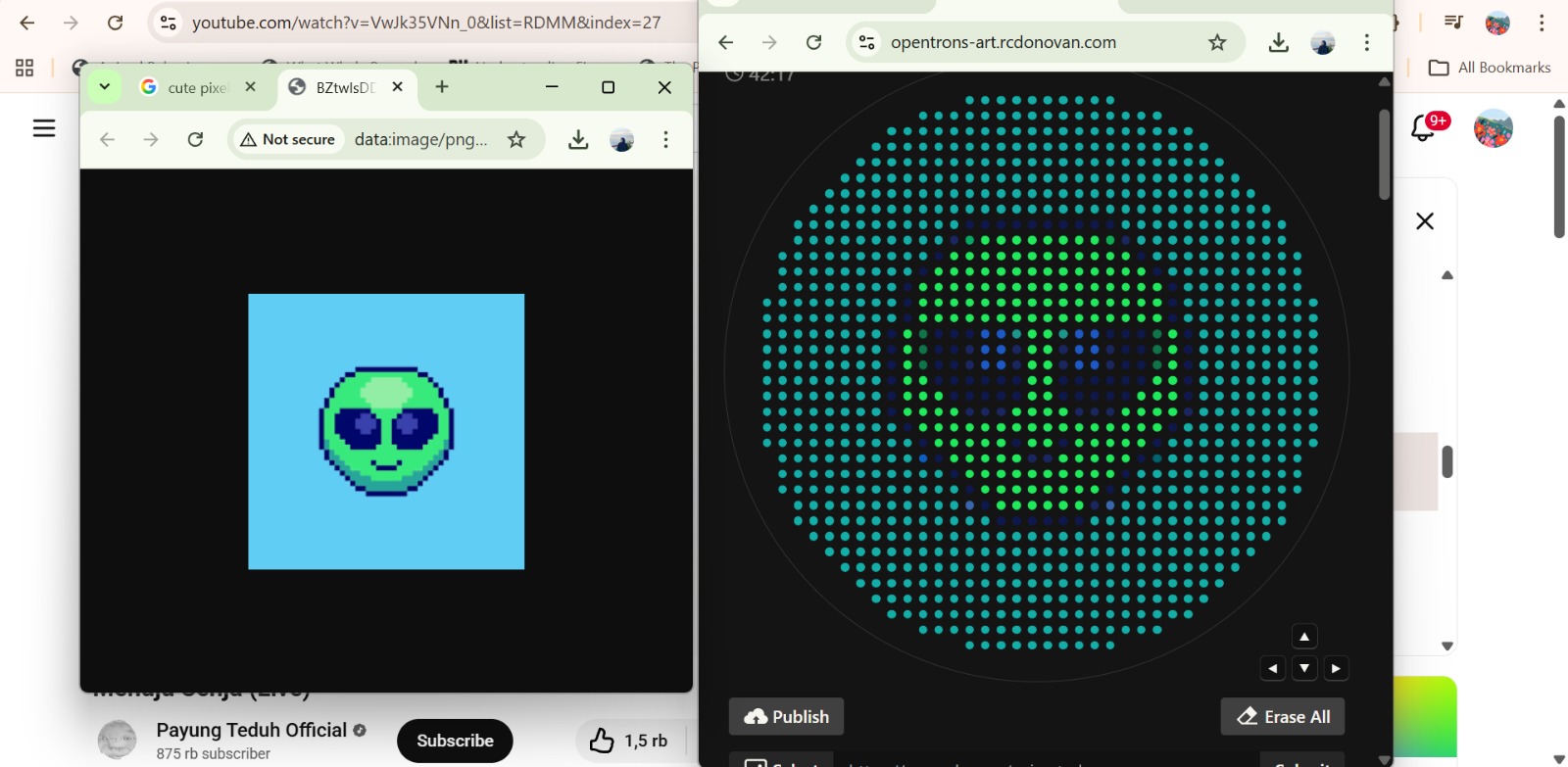
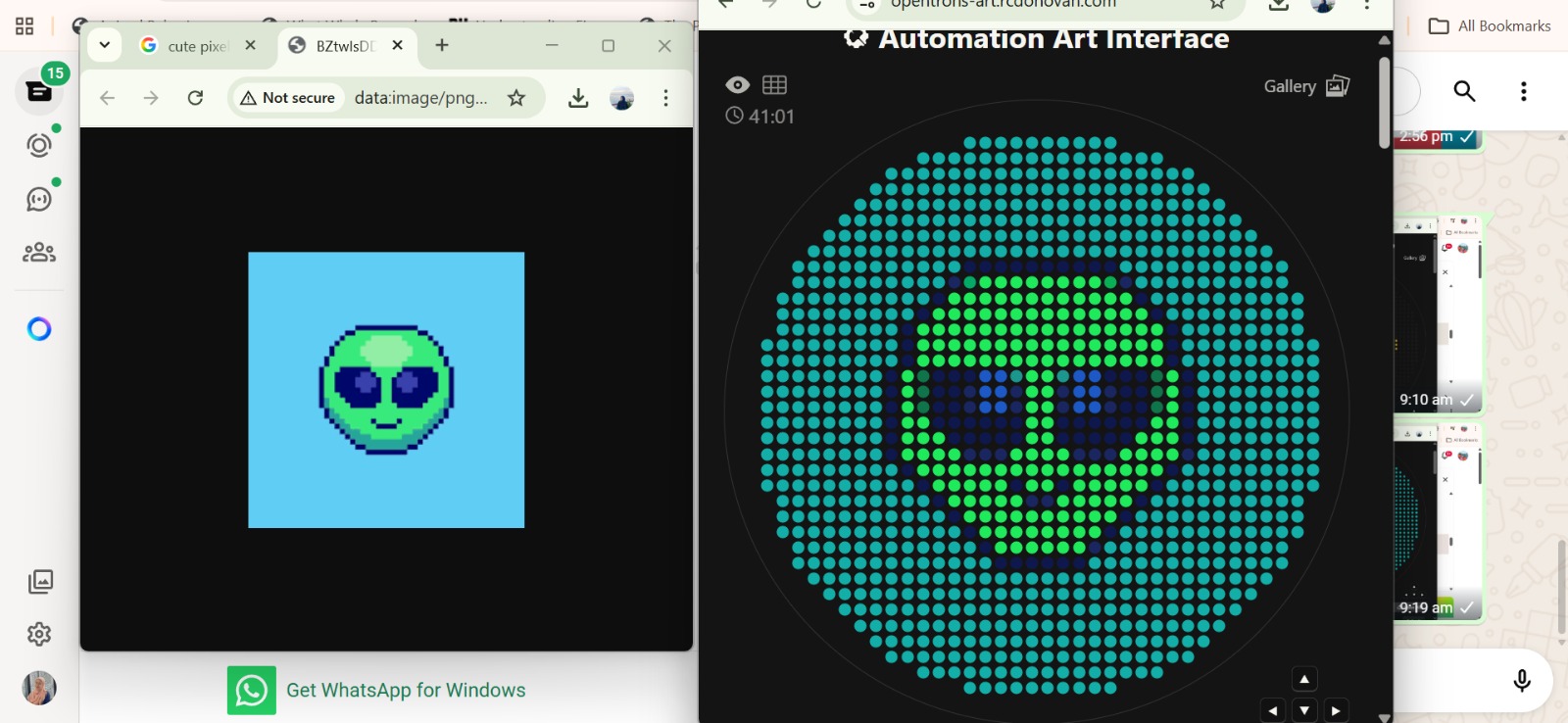
Python Script for Opentrons Artwork
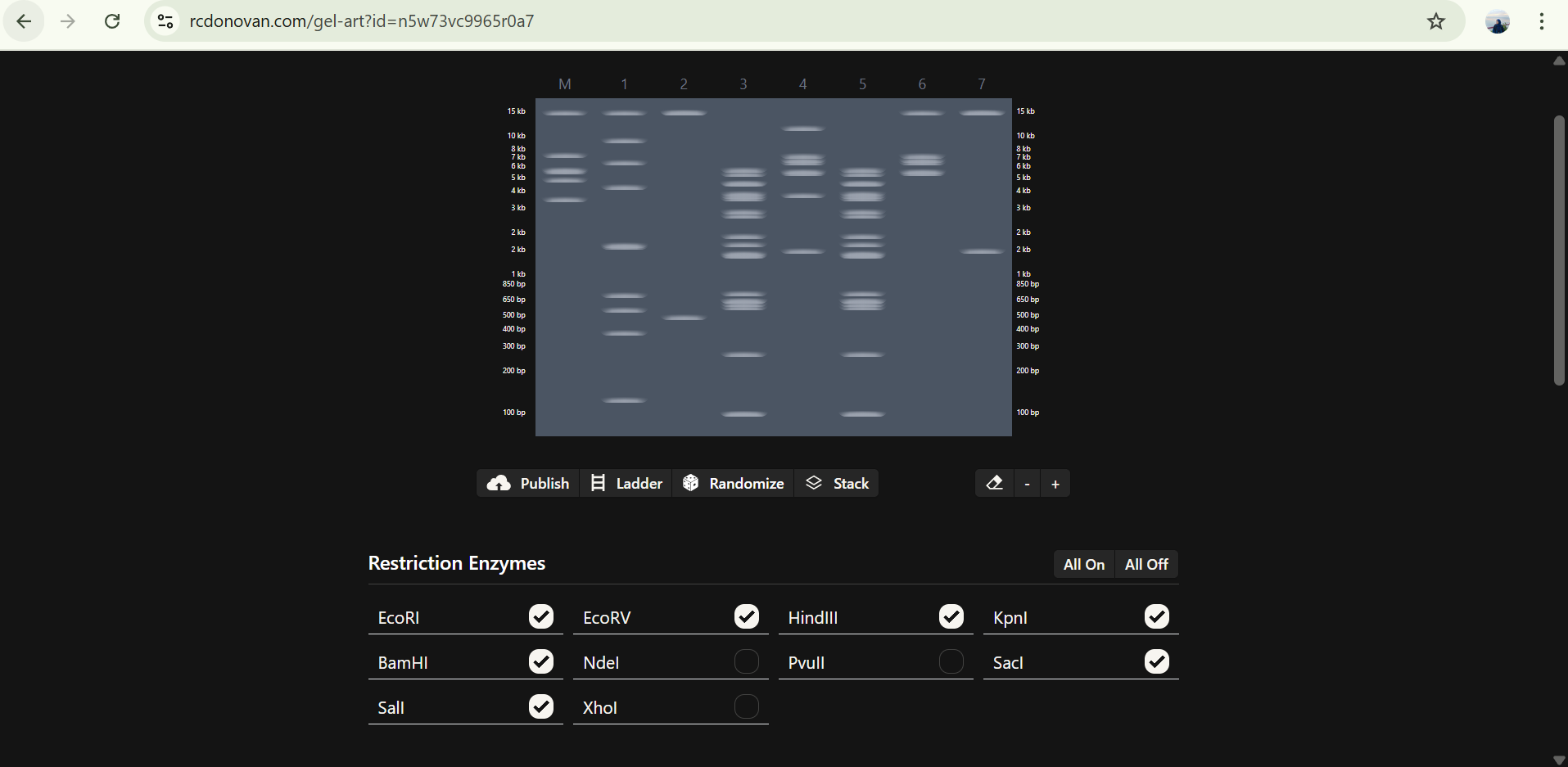
Actually I really struggle with python :( , I’ll try very soon. This picture below is my trial for generate an artistic design from https://opentrons-art.rcdonovan.com/
I make this design without picture
This one with picture preference
desc : 0,75 uL
desc : 1,5 uL
Post-Lab Questions
Boucher St-Amour, V.-T.; Tomar, V.; Belzile, F. High-Throughput DNA Extraction Using Robotic Automation (RoboCTAB) for Large-Scale Genotyping. Plants 2025, 14, 2263. https://doi.org/10.3390/plants14152263
Final Project Ideas
Structural Modeling and Molecular Docking Analysis of Cas9–DNA Interactions Targeting Stroke-Associated Genes
Computational Design and Off-Target Analysis of CRISPR-Cas9 Guide RNAs for Stroke-Associated Genes
Cloning of Glucoamylase Encoding Gene from Aspergillus niger for Maltooligosaccharide Production
Week 4 HW: Protein Design Part 1
Part A : Conseptual Questions
Questions from Shuguang Zhang: (i.e. you can select two to skip)
How many molecules of amino acids do you take with a piece of 500 grams of meat? (on average an amino acid is ~100 Daltons)
Why do humans eat beef but do not become a cow, eat fish but do not become fish?
Because DNA determines what organism you are, not the food you eat. When we eat meat, proteins are broken down into amino acids and then cells use those amino acids to build human proteins, based on the instructions in our human DNA.
Why are there only 20 natural amino acids?
Evolution “settled” on 20 because:
They provide enough chemical diversity (acidic, basic, hydrophobic, etc.) to build all the proteins needed for life.
Adding more would require more complex machinery (tRNA, enzymes) without big advantages.
Some organisms have a 21st (selenocysteine) or 22nd (pyrrolysine), but 20 is the standard set used by almost all life.
Can you make other non-natural amino acids? Design some new amino acids.
Where did amino acids come from before enzymes that make them, and before life started?
Amino acids formed abiotically (without life) on early Earth.
Miller–Urey experiment (1953) showed that sparking a mixture of simple gases (methane, ammonia, hydrogen, water vapor) produces amino acids.
So they likely formed in:
Volcanic vents
Lightning strikes in early atmosphere
Outer space (found in meteorites)
If you make an α-helix using D-amino acids, what handedness (right or left) would you expect?
Left-handed. Natural proteins use L-amino acids, which form right-handed α-helices. D-amino acids are mirror images, so they form left-handed α-helices.
Can you discover additional helices in proteins?
Yes! Besides the α-helix, there are:
3₁₀-helix (tighter, 3 amino acids per turn)
π-helix (wider, 4.4 amino acids per turn)
Polyproline helix (type I and II, no H-bonds inside helix)
Scientists still find new variations, especially in designed peptides.
Why are most molecular helices right-handed?
Most molecular helices, such as alpha-helices in proteins and B-DNA, are right-handed because this conformation is more energetically stable and structurally favorable. This preference arises because L-amino acids (in proteins) and D-sugars (in DNA) fit together more efficiently in a right-handed twist, minimizing steric hindrance and maximizing stabilizing hydrogen bonds. Another answer :
In a left-handed helix with L-amino acids, side chains bump into the backbone.
So evolution selected for right-handed α-helices in proteins.
DNA helices are right-handed (B-DNA) due to sugar-phosphate backbone geometry and base stacking.
Why do β-sheets tend to aggregate?
What is the driving force for β-sheet aggregation?
Driving forces:
Hydrogen bonding between backbone N-H and C=O groups of different strands.
Hydrophobic interactions between side chains.
Van der Waals packing.
β-strands have “sticky” edges that can pair with other strands, leading to aggregation, especially if the protein misfolds.
Why do many amyloid diseases form β-sheets?
Can you use amyloid β-sheets as materials?
In diseases like Alzheimer’s, proteins misfold into cross-β structure—long, stacked β-sheets that are very stable and insoluble, forming plaques. Yes! Amyloid fibers are super strong. Researchers use them for:
Nanowires (coated with metal)
Hydrogels for tissue engineering
Biosensors
Drug delivery
Design a β-sheet motif that forms a well-ordered structure.
Part B: Protein Analysis and Visualization
Week 5 HW: Protein Design Part 2
Part A : SOD1 Binder Peptide Design
Part 1: Generate Binders with PepMLM
Part 2: Evaluate Binders with AlphaFold3
Part 3: Evaluate Properties of Generated Peptides in the PeptiVerse
Note: Lysis protein contains a soluble N-terminal domain followed by a transmembrane protein (blue/last 35 residues). Transmembrane protein affects the lysis activity. The soluble domain (green) is the domain responsible for interaction with DnaJ.
Week 6 HW: Genetic Circuits Part 1 : Assembly Technologies
DNA ASSEMBLY
What are some components in the Phusion High-Fidelity PCR Master Mix and what is their purpose?
High-Fidelity DNA Polymerases are important for applications in which the DNA sequence needs to be correct after amplification.
Phusion High-Fidelity DNA Polymerase offers both high fidelity and robust performance, and thus can be used for all PCR applications.
Its unique structure, a novel Pyrococcus-like enzyme fused with a processivity-enhancing domain, increases fidelity and speed. Phusion DNA Polymerase is an ideal choice for cloning and can be used for long or difficult amplicons.
With an error rate >50-fold lower than that of Taq DNA Polymerase and 6-fold lower than that of Pyrococcus furiosus DNA Polymerase,
Phusion is one of the most accurate thermostable polymerase available. Phusion DNA Polymerase possesses 5´→ 3´ polymerase activity, 3´→ 5´ exonuclease activity and will generate blunt-ended products.
Phusion High-Fidelity PCR Master Mix with HF Buffer is a 2X master mix consisting of Phusion DNA Polymerase, deoxynucleotides and reaction buffer that has been optimized and includes MgCl2. All that is required is the addition of template, primers and water.
Phusion High-Fidelity PCR Master Mix is a 2X concentrated, ready-to-use solution containing Phusion DNA Polymerase, optimized reaction buffer (HF or GC), MgCl2, and dNTPs. It provides high-fidelity, high-speed, and robust amplification, designed for blunt-end cloning. Only template DNA, primers, and water are needed for reaction setup.
Function :
Phusion DNA Polymerase :
Optimized reaction buffer (HF or GC) :
MgCl2 :
dNTPs :
What are some factors that determine primer annealing temperature during PCR?
Primary factors that determine the optimal primer annealing temperature :
Primer Melting Temperature
Primer Length
GC Content
Salt Concentration Mg2+ and Monovalent Cations
Primer Concentration
Primer-Dimer and Hairpin Formation
Mismatches with the Template
Note : If you’re doing electrophoresis and the result is smear or no band, is likely too high annealing temperature (try lowering it). If the results is multiple bands (Non-specific), is likely too low annealing temperature (try raising it).
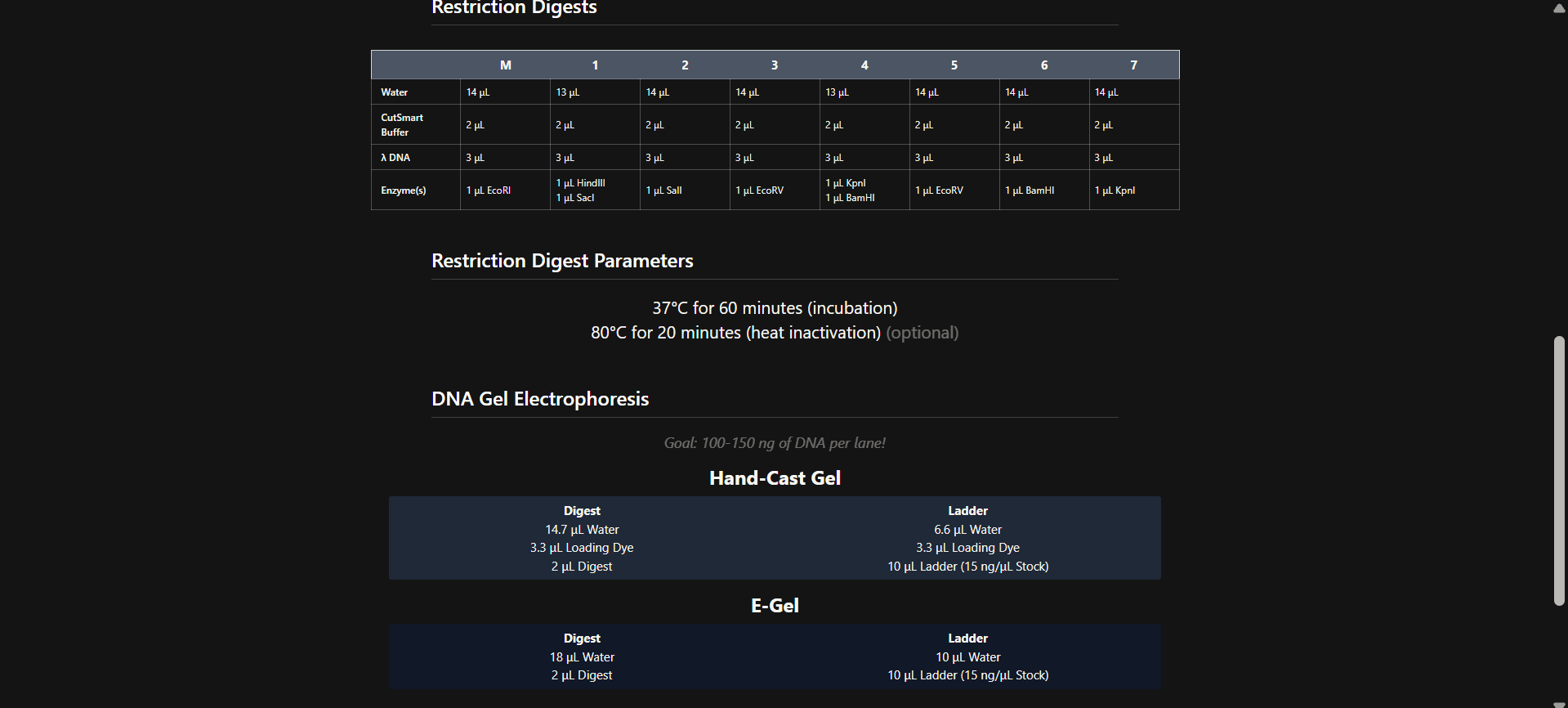
There are two methods from this class that create linear fragments of DNA: PCR, and restriction enzyme digests. Compare and contrast these two methods, both in terms of protocol as well as when one may be preferable to use over the other.
How can you ensure that the DNA sequences that you have digested and PCR-ed will be appropriate for Gibson cloning?
How does the plasmid DNA enter the E. coli cells during transformation?
Describe another assembly method in detail (such as Golden Gate Assembly)
Explain the other method in 5 - 7 sentences plus diagrams (either handmade or online).
Model this assembly method with Benchling or Asimov Kernel!