Week 4 HW: Protein Design Part I
Week 4 — Protein Design Part I
This week focuses on how sequence, structure, and energetics can be modeled and manipulated to create or optimize proteins with specified functions.
Part A. Conceptual Questions
Answer any NINE of the following questions from Shuguang Zhang: (i.e. you can select two to skip)
How many molecules of amino acids do you take with a piece of 500 grams of meat? (on average an amino acid is ~100 Daltons)
Meat contains at around 26g of protein per 100g of meat, so, in 500g of meat, this would be 26 g x 5 = 130g of protein
Average aminoacid would be ~100 g per mol, so 130g / (100g/mol) = 1.3 mol of aminoacids
Mole = 6.02 x 1023, so 1.3 x Mole = 7.8x1023
So, 7.8x10^23
Why do humans eat beef but do not become a cow, eat fish but do not become fish?
Because there is no horizontal gene transfer, or at least an effective one
Why are there only 20 natural amino acids?
I’d like to think that it is because that is as optimal life gets
Can you make other non-natural amino acids? Design some new amino acids.
Where did amino acids come from before enzymes that make them, and before life started?
The primordial soup!
If you make an α-helix using D-amino acids, what handedness (right or left) would you expect?
Left-handedness
Can you discover additional helices in proteins?
Yes
Why are most molecular helices right-handed?
Almost all aminoacids are L-aminoacids, which means they’re gonna be right-handed helices as that is as optimal as it gets for energy.
Why do β-sheets tend to aggregate?
What is the driving force for β-sheet aggregation?
Because of their hydrogen bonds, their structure sets them up for said hydrogen bombs. I believe this happens in Alzheimer’s?
Why do many amyloid diseases form β-sheets?
Can you use amyloid β-sheets as materials?
Proteins that aren’t folded properly tend be these β-sheets, and so aggregation happens, and amyloid-β peptides instead of doing their functino, they aggregate.
Design a β-sheet motif that forms a well-ordered structure.
Part B. Protein Analysis and Visualization
In this part of the homework, you will be using online resources and 3D visualization software to answer questions about proteins. Pick any protein (from any organism) of your interest that has a 3D structure and answer the following questions:
Briefly describe the protein you selected and why you selected it.
Luciferase. I think it’s just a neat protein with a neat name, has a neat function too, which is, emiting light!
Identify the amino acid sequence of your protein.
1LCI_1|Chain A|LUCIFERASE|Photinus pyralis (7054) MEDAKNIKKGPAPFYPLEDGTAGEQLHKAMKRYALVPGTIAFTDAHIEVNITYAEYFEMSVRLAEAMKRYGLNTNHRIVVCSENSLQFFMPVLGALFIGVAVAPANDIYNERELLNSMNISQPTVVFVSKKGLQKILNVQKKLPIIQKIIIMDSKTDYQGFQSMYTFVTSHLPPGFNEYDFVPESFDRDKTIALIMNSSGSTGLPKGVALPHRTACVRFSHARDPIFGNQIIPDTAILSVVPFHHGFGMFTTLGYLICGFRVVLMYRFEEELFLRSLQDYKIQSALLVPTLFSFFAKSTLIDKYDLSNLHEIASGGAPLSKEVGEAVAKRFHLPGIRQGYGLTETTSAILITPEGDDKPGAVGKVVPFFEAKVVDLDTGKTLGVNQRGELCVRGPMIMSGYVNNPEATNALIDKDGWLHSGDIAYWDEDEHFFIVDRLKSLIKYKGYQVAPAELESILLQHPNIFDAGVAGLPDDDAGELPAAVVVLEHGKTMTEKEIVDYVASQVTTAKKLRGGVVFVDEVPKGLTGKLDARKIREILIKAKKGGKSKL
How long is it? What is the most frequent amino acid? You can use this Colab notebook to count the frequency of amino acids.
550 aminoacids long.
Most frequent: L (52 times)
How many protein sequence homologs are there for your protein? Hint: Use Uniprot’s BLAST tool to search for homologs.
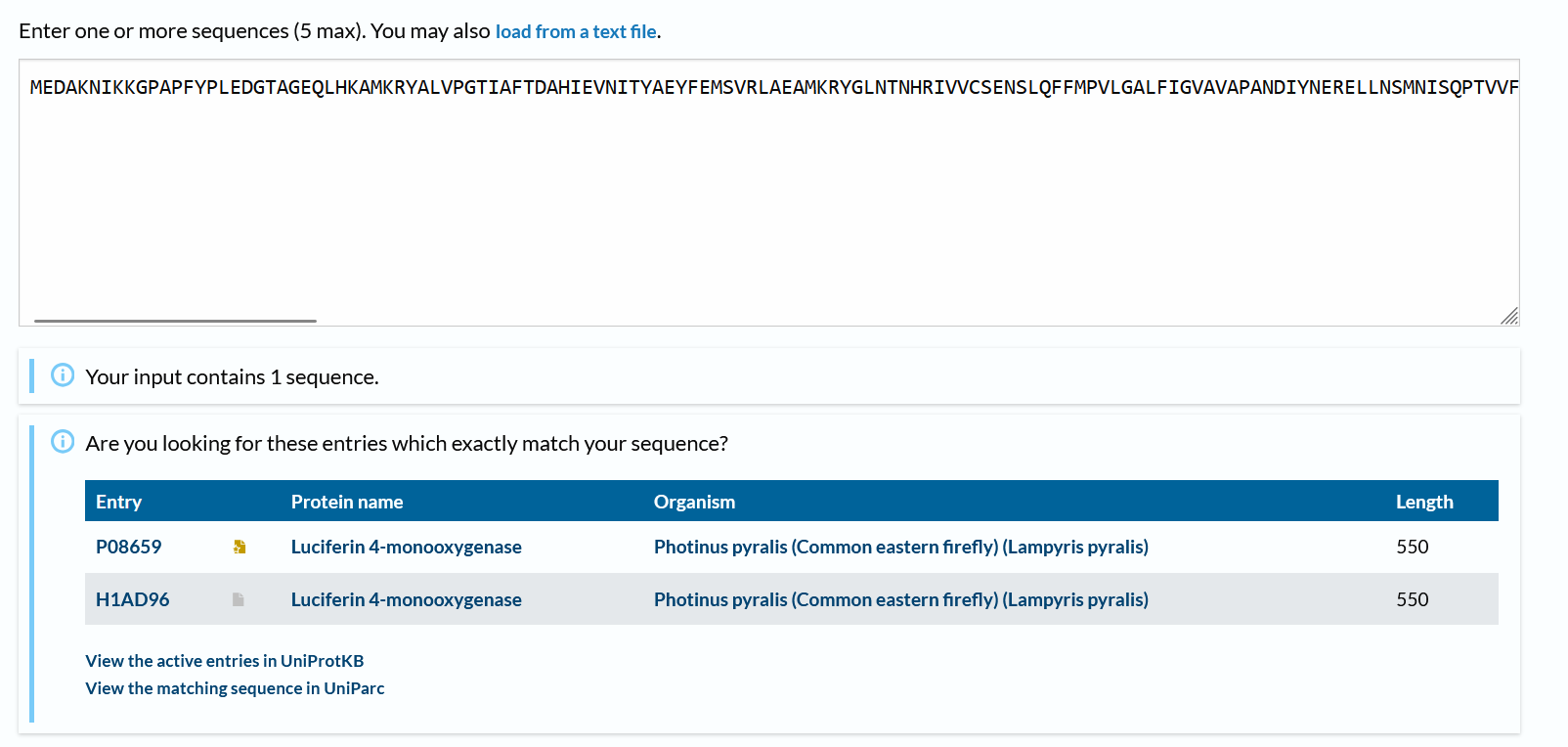
There are 2 more!
Does your protein belong to any protein family?
I believe the most correct family would be “oxidative enzymes that produce bioluminescence”.
Identify the structure page of your protein in RCSB
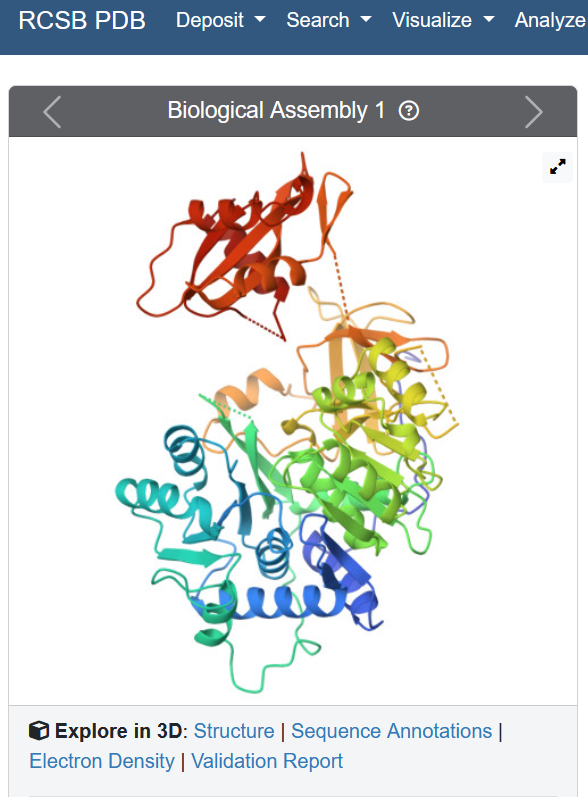
When was the structure solved? Is it a good quality structure? Good quality structure is the one with good resolution. Smaller the better (Resolution: 2.70 Å)
Well, the resolution is 2.00 Å, so yes!
Are there any other molecules in the solved structure apart from protein?
“Unique protein chains: 1”, so no
Does your protein belong to any structure classification family?
I believe oxidoreductases
Open the structure of your protein in any 3D molecule visualization software:
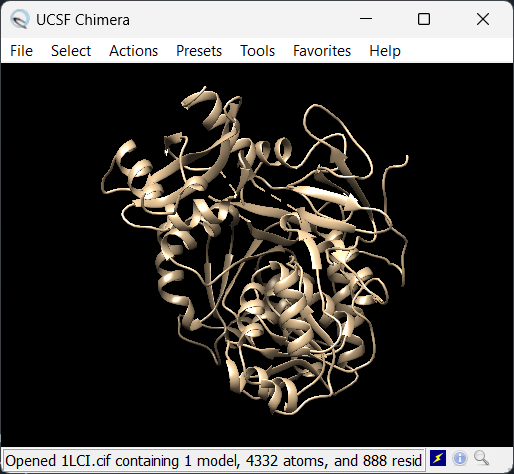
The chosen software is Chimera
PyMol Tutorial Here (hint: ChatGPT is good at PyMol commands)
Visualize the protein as “cartoon”, “ribbon” and “ball and stick”.
Nothing seems to happen for “ball and stick” and seemingly there’s no option for cartoon. This happens when only “ribbon” is colored differently:
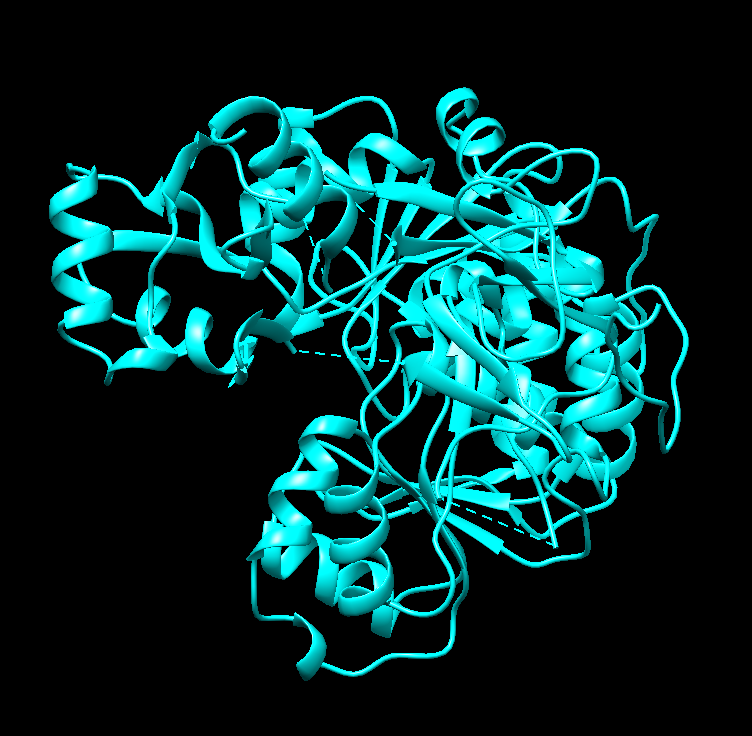
Color the protein by secondary structure. Does it have more helices or sheets?
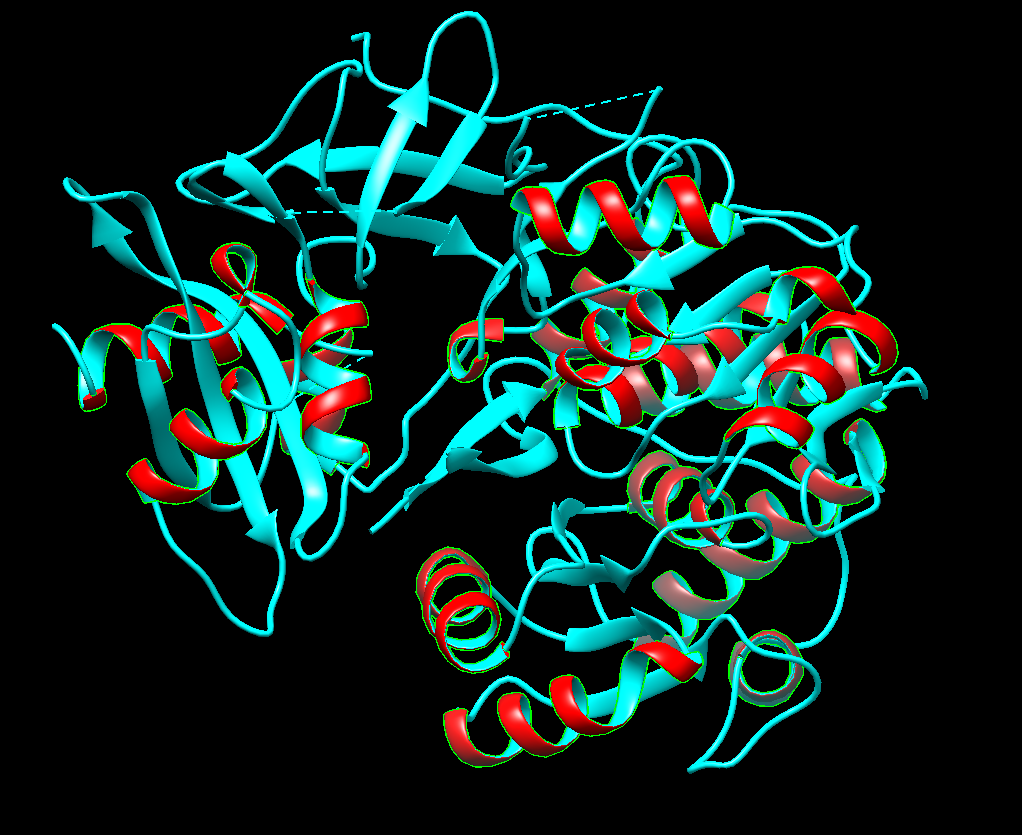
Right now I’m selecting helices (the red ones). There seems to be more sheets
Color the protein by residue type. What can you tell about the distribution of hydrophobic vs hydrophilic residues?
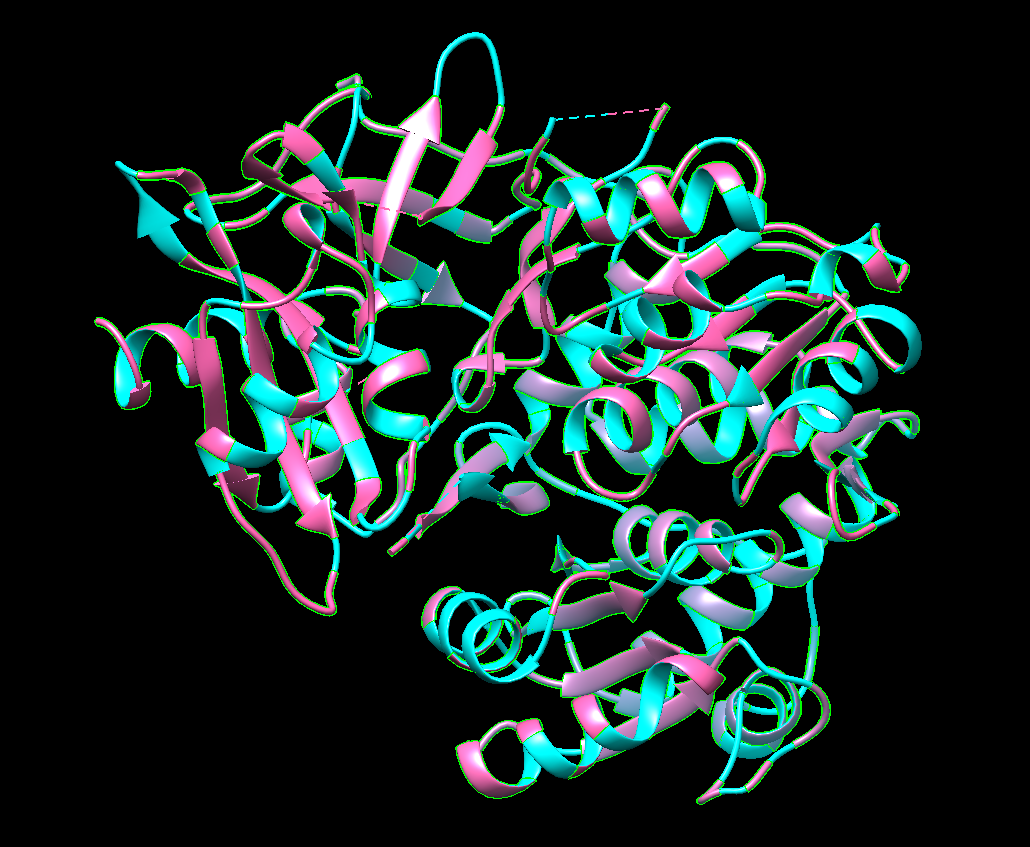
Right now I’m selecting hydrophobic regions (the pink ones). There seems to be quite a tie
Visualize the surface of the protein. Does it have any “holes” (aka binding pockets)?
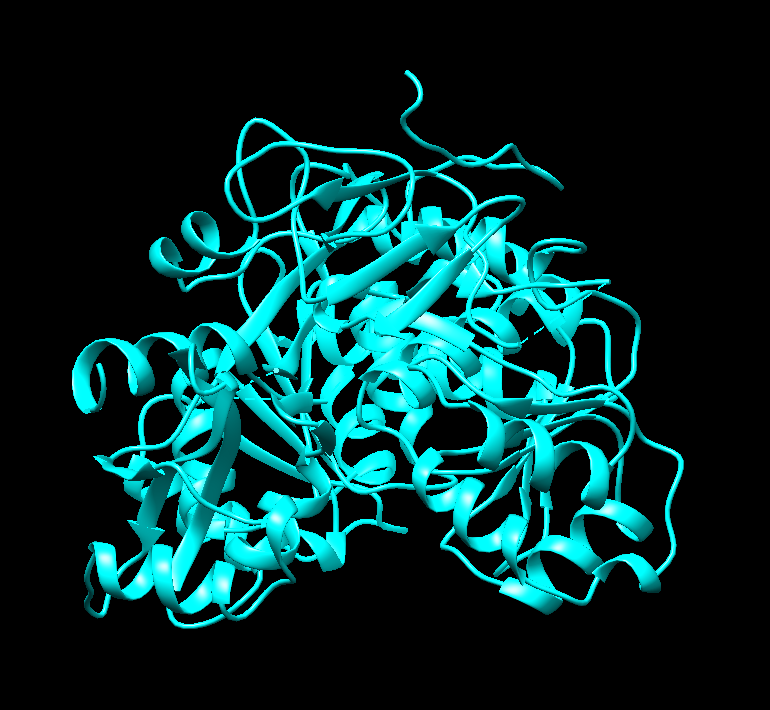
It does! I think that’s what I’m seeing.
Part C. Using ML-Based Protein Design Tools
In this section, we will learn about the capabilities of modern protein AI models and test some of them in your chosen protein.
Copy the HTGAA_ProteinDesign2026.ipynb notebook and set up a colab instance with GPU.
Choose your favorite protein from the PDB.
We will now try multiple things in the three sections below; report each of these results in your homework writeup on your HTGAA website:
C1. Protein Language Modeling
Deep Mutational Scans
Use ESM2 to generate an unsupervised deep mutational scan of your protein based on language model likelihoods. Can you explain any particular pattern? (choose a residue and a mutation that stands out) (Bonus) Find sequences for which we have experimental scans, and compare the prediction of the language model to experiment.
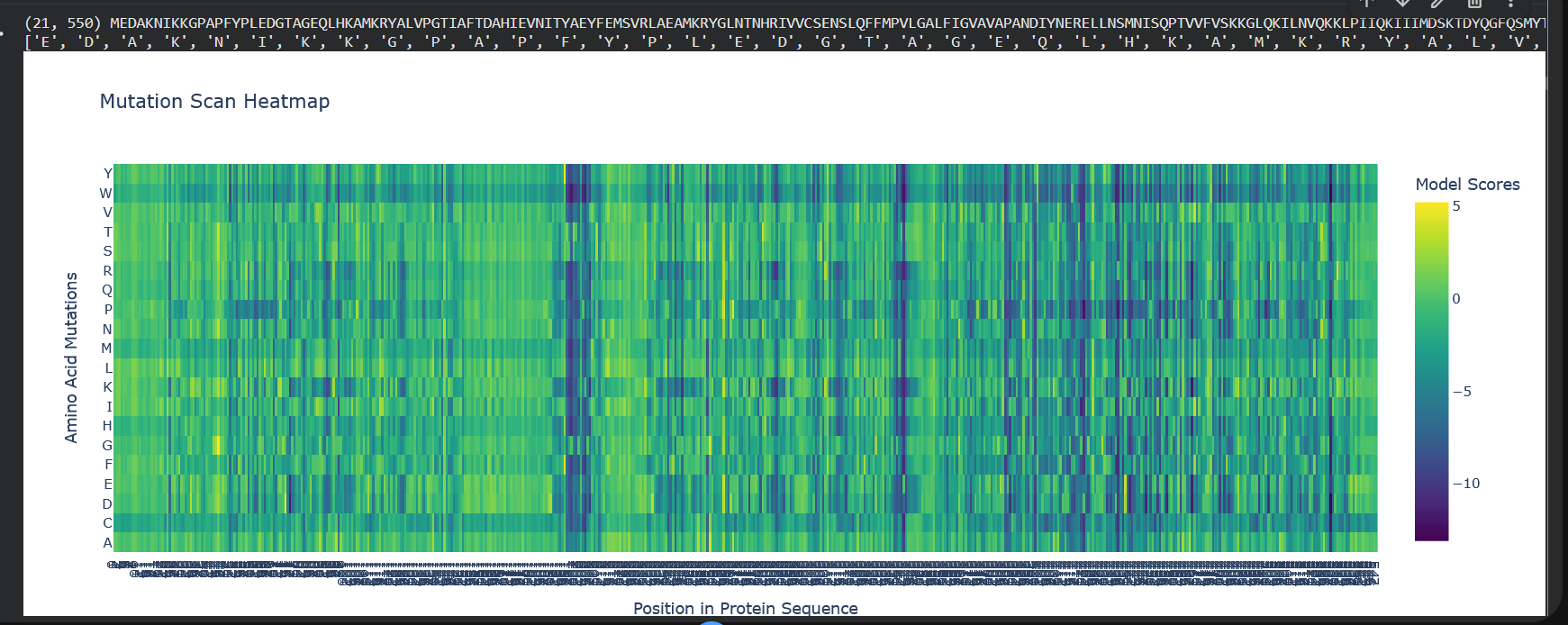
So W stands out a lot here, which is tryptophan, the color blue indicates that mutations are not well tolerated. And also notably, from position 197 to 207 there’s a lot of dark blue, so it means that this region’s quite conserved.
Latent Space Analysis
Use the provided sequence dataset to embed proteins in reduced dimensionality. Analyze the different formed neighborhoods: do they approximate similar proteins? Place your protein in the resulting map and explain its position and similarity to its neighbors.
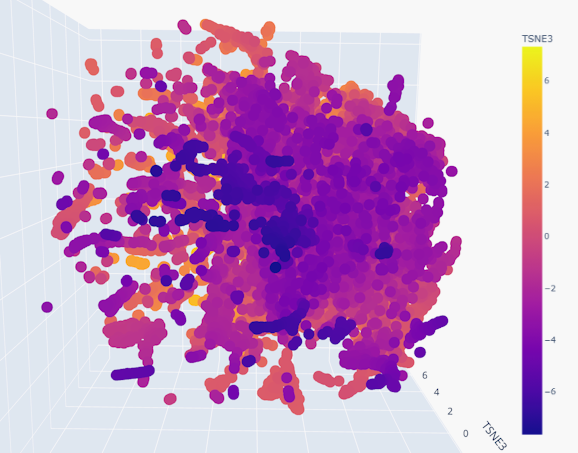
Indeed, the neighborhoods do appear to group similar proteins together, given the smoothness of the gradient
C2. Protein Folding
Folding a protein
Fold your protein with ESMFold. Do the predicted coordinates match your original structure?
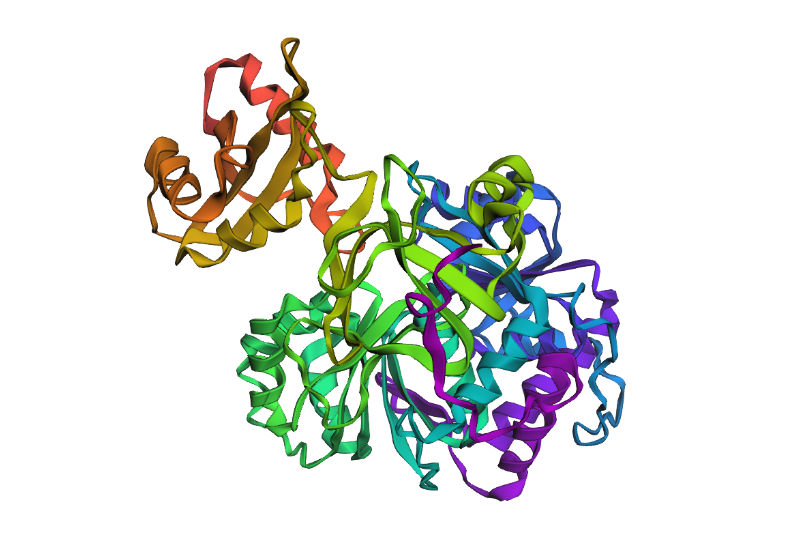
Yes! It really does! This is the predicted ESMFold
FAnd this is the original one!
Try changing the sequence, first try some mutations, then large segments. Is your protein structure resilient to mutations?
For the most part, it is resilient
C3. Protein Generation
Inverse-Folding a protein: Let’s now use the backbone of your chosen PDB to propose sequence candidates via ProteinMPNN
Analyze the predicted sequence probabilities and compare the predicted sequence vs the original one.
Input this sequence into ESMFold and compare the predicted structure to your original.
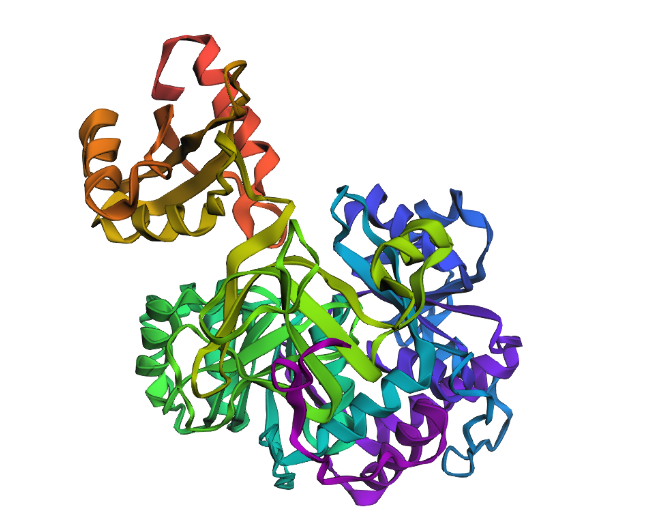 Very very similar
Very very similar