Weeek 4 HW: Protein design - Part 1
Notes about key concepts for deeper understanding
About ESM
Key Concepts to Know:
Evolutionary Scale Model (ESM): A model that generates likelihood values for the existence of an amino acid at a specific position within a protein sequence. It is essentially a Masked Language Modeling (MLM) architecture.
Deep Mutational Scanning (DMS): A 2D map representing the probability values generated by the ESM for every possible mutation in a sequence.
Latent Space: Upon inputting a FASTA sequence, the language model adds start and end tokens, generating a high-dimensional vector (320 dimensions in the case of the recitation model). This vector classifies the protein; when projected into a 3D space, it creates a map that clusters the protein alongside others from a provided database based on functional or family similarities.
Multi-Layer Perceptron (MLP): Consist on two linear transformation with an non-linear activation (https://www.ultralytics.com/glossary/gelu-gaussian-error-linear-unit) in between.
Steps for 3D Protein Structure Prediction with ESM-2:
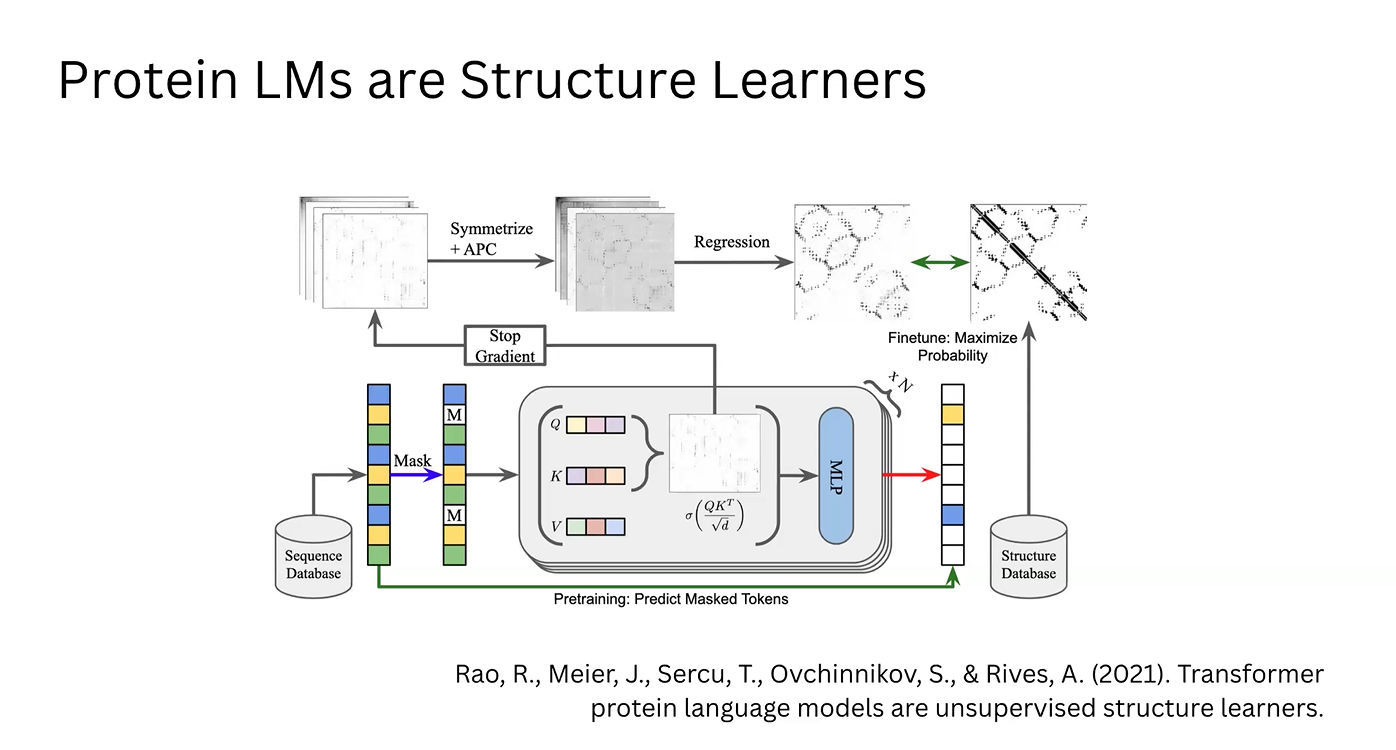
Likelihood Generation: We utilize the fundamental property of the ESM (Masked Language Modeling) to calculate amino acid probabilities based on the sequence context.
Attention Mechanism: These data points are processed as Queries (Q), Keys (K), and Values (V). This generates an Attention Matrix, where vectors for each amino acid indicate the relevance and position of other residues in the chain.
Structural Extraction (Simple ESM): The raw attention matrix is symmetrized to ensure physically plausible distances and refined using Average Product Correction (APC) to eliminate correlation noise. Through regression, a 2D contact map is obtained.
Model Optimization: This map is compared against structural databases (like the PDB) to adjust the model. This feedback loop updates the model’s weights, maximizing the log-likelihood of real-world protein structures found in nature.
Enrichment via MLP: In parallel, the correlation vectors from the attention matrix are processed by a Multi-Layer Perceptron (MLP). This generates enriched vectors that describe the physicochemical implications of the attention data.
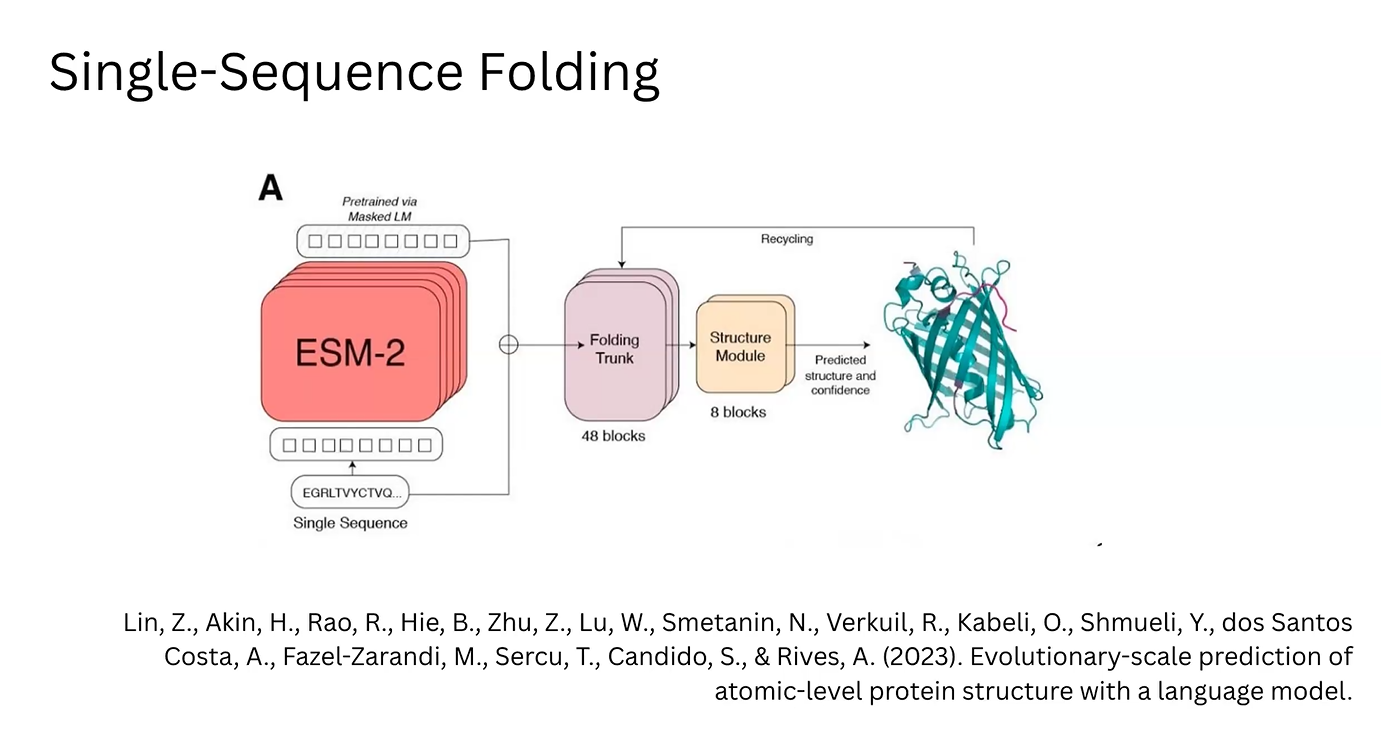
3D Prediction (ESM-2/ESMFold): In the ESM-2 architecture, these MLP-enriched vectors are fed into a “Folding Trunk” module. This module applies learned rules to predict the 3D structure, including bond angles and atomic coordinates.
About AlphaFold ans MSA
Key Concepts to Know:
- Multiple Sequence Alignments (MSA): The different dialects of the tree of life for the same protein

Basic concepts about amino acids and protein functions
Protein analysis and visualization
I selected a small transcription factor protein related to cellular reprogramming
Using ML-Based Protein Design Tools
For this part I used transcription factor Klf4 and realized a Deep mutational Scan, Latent Space Analysis, folding protein exercise, and inverse-folding protein exercise.