First, describe a biological engineering application or tool you want to develop and why. This could be inspired by an idea for your HTGAA class project and/or something for which you are already doing in your research, or something you are just curious about. Implementing alternative methods against Pathogen-Ralstonia Solanacearum Raza 4 disease in platain and banana crops with wild bacteria. The identification and extraction of metabolites from wild isolated strain with high efficiency in the inhibition of the symptoms would help to stablish new alternatives
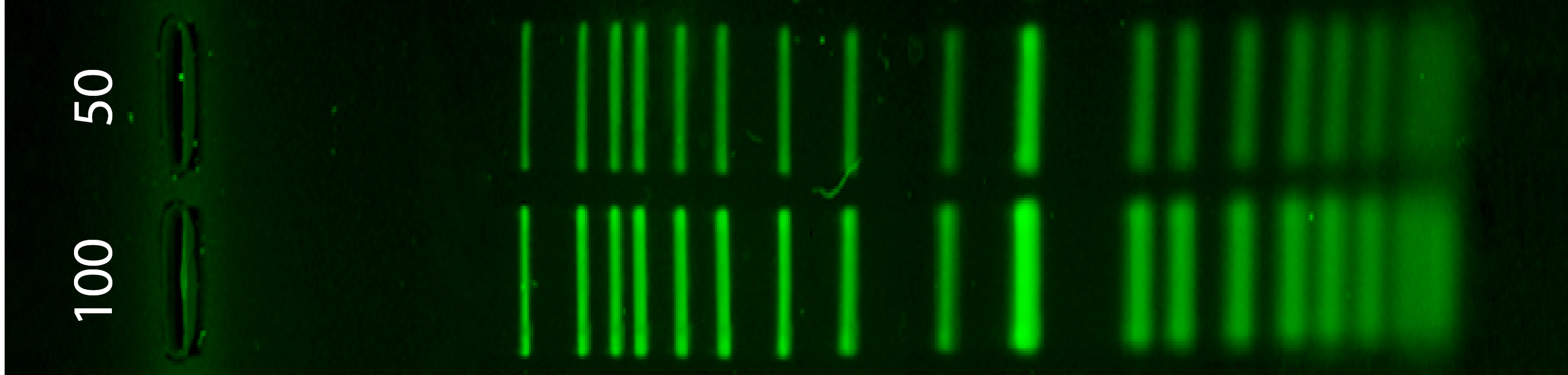
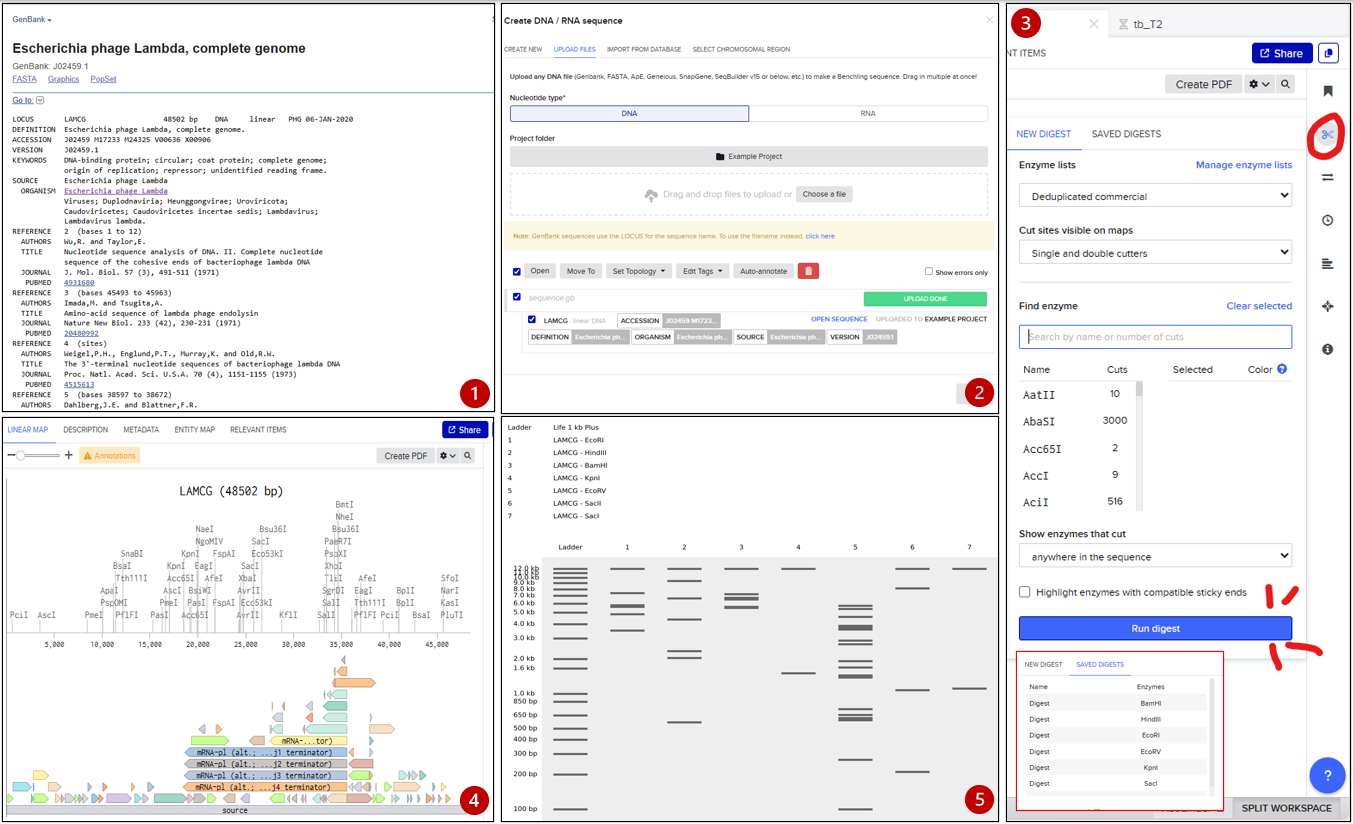
Part 1: Benchling & In-silico Gel Art 1.1 Simulation of the enzyme digestion with the following enzymes Next to the ladder (Life 1kb Plus) there are the digestion from the enzymes:
EcoRI - HindIII - BamHI - KpnI - EcoRV - SacI - SalI Search the genome “Escherichia phage Lambda” (for this I used NCBI) Download or export the complete genome as a genbank file Open Benchling and import new DNA/RNA sequence (import the .gb file and rename) Now we have a visualization of our genome. Next, go to the right side of the bar and click in digestion (the scisors symbol). Select the restriction enzimes required and run each one. Click in “run digest” and visualize the simulation. For each one, I recommend to save each process so you can consult the results anytime. Benchling Workspace: https://benchling.com/s/seq-okBuD9NENrRXJIgK3yvh?m=slm-CAeF79q6rB0gWIBLHfkl
Assignment 1: Python Script for Opentrons Artwork Task 1.1: Create a Python file to run on an Opentrons liquid handling robot.
For this asignment I used the GUI for generate the design and the coordinates. Then, with the assistance of GeminiAI, the coordinates were integrated using iterations. The pattern was divided and inserted in blocks and compilated part-by-part, until I was able to simulate the complete design and check its correct execution. For this work I used a pixel art design of the character Usagi from Chiikawa. There are also two more designs that I made as practice exercises. Also there is the link of the Usagi code for reference (Assisted with GeminiAI)
Objective: Learn basic concepts:
amino acid structure 3D protein visualization the variety of ML-based design tools Brainstorm as a group how to apply these tools to engineer a better bacteriophage (setting the stage for the final project). Part A. Conceptual Questions Answer any NINE of the following questions from Shuguang Zhang: (i.e. you can select two to skip)
Subsections of Homework
Week 1 HW: Principles and Practices
1. First, describe a biological engineering application or tool you want to develop and why. This could be inspired by an idea for your HTGAA class project and/or something for which you are already doing in your research, or something you are just curious about.
Implementing alternative methods against Pathogen-Ralstonia Solanacearum Raza 4 disease in platain and banana crops with wild bacteria. The identification and extraction of metabolites from wild isolated strain with high efficiency in the inhibition of the symptoms would help to stablish new alternatives
Ecuador is one of the main producers of Banana and platains in the world, registering an income of USD 1.528,7 M in the last year (Fronteras, 2025) . With significant importance, the spread of the MOKO disease caused by Ralstonia Solanacearum in the main crops represents a risk not only for industry but also for civilians due to the cultural use of platain in the Ecuadorian diet. However, due to its resistance and fast adaptation, the standard methods can’t offer a complete solution, involving the complete loss of the contaminated crop.
2. Next, describe one or more governance/policy goals related to ensuring that this application or tool contributes to an “ethical” future, like ensuring non-malfeasance (preventing harm). Break big goals down into two or more specific sub-goals. Below is one example framework (developed in the context of synthetic genomics) you can choose to use or adapt, or you can develop your own. The example was developed to consider policy goals of ensuring safety and security, alongside other goals, like promoting constructive uses, but you could propose other goals for example, those relating to equity or autonomy.
Main governance goal 1: Ensure biosafety and non-maleficence
To avoid harm effects to ecosystems, crops, and human health
Sub-goals:
Prevent unintended spread of wild or engineered bacterial strains into non-target ecosystems.
Ensure that extracted metabolites do not negatively affect soil microbiota, non-target plants, or human health.
Minimize the risk of horizontal gene transfer between introduced bacteria and native microbial communities.
Main governance goal 2: Promote responsible and sustainable agricultural innovation
Sub-goals:
Encourage alternatives to chemical pesticides that reduce environmental contamination.
Support long-term effectiveness of biological control methods, avoiding resistance development.
Align new biotechnological solutions with sustainable agriculture and food security goals.
Main governance goal 3: Ensure equity and accessibility for local farmersSub-goals:
Make biological control solutions affordable and accessible to small and medium-scale producers.
Avoid dependence on proprietary or highly patented technologies that exclude local communities.
Promote local participation in research, validation, and implementation.
Does the option:
Option 1
Option 2
Option 3
Enhance Biosecurity
• By preventing incidents
1
2
2
• By helping respond
1
1
1
Foster Lab Safety
• By preventing incident
1
2
n/a
• By helping respond
2
3
n/a
Protect the environment
• By preventing incidents
1
2
1
• By helping respond
2
2
1
Other considerations
• Minimizing costs and burdens to stakeholders
1
• Feasibility?
1
2
3
• Not impede research
3
2
3
• Promote constructive applications
1
2
2
Last, drawing upon this scoring, describe which governance option, or combination of options, you would prioritize, and why. Outline any trade-offs you considered as well as assumptions and uncertainties.
I consider important to take in count the first goal, because in my country we aim to seek for biosafe and sustainable alternatives, due to our policies against GMOs and to ensure the availability of this solutions not only for the industry but also for minor producers
Preparation for 2nd week: Pre-lecture assignment “DNA Read, Write, and Edit"
Homework Questions from Professor Jacobson:1. Nature’s machinery for copying DNA is called polymerase. What is the error rate of polymerase? How does this compare to the length of the human genome. How does biology deal with that discrepancy?
- The error rate of polymerase is 1:10^6. Humans genome have an aproximately lenght of 3.2Gbp and comparing with the error rate of polymerase, the quotient implies an aprox. of 3200 errors per replication (without additional fixes)
- First, it is important to understand that polymerase work in three levels. Proofreading allow polymerase detect and stops if an error (wrong base) is detected and activate the self-correction systems. Then, the post-replication checking allow to scan and seek for the restant errors and fix them (working as a double check). Finally, if any damage exists, there will be mechanisms to allow the instant repair of the DNA. So, the rate of errors (or mutations) decrease considerably.
2. How many different ways are there to code (DNA nucleotide code) for an average human protein? In practice what are some of the reasons that all of these different codes don’t work to code for the protein of interest?
- An average human proteing have around 1000 aminoacids, because of the nature of the genetic code (it degenerates), each aminoacid can be used by multiple codons. Then, in a simple way, the total number of possible result for encoding an average human protein can be expressed as the result of 3^1000.
- In the practice there are a lot of possible sequences for encoding the same protein, but aspects as the codon bias or mRNA structure can affect the translation and proper protein folding.
Homework Questions from Dr. LeProust:i. What’s the most commonly used method for oligo synthesis currently?
- The most commonly used method is Solid-phase phosphoramidite synthesis
iii. Why is it difficult to make oligos longer than 200nt via direct synthesis?
- Each nucleotide addition is not 100% efficient (~99%).
- Errors and incomplete couplings accumulate exponentially with length. It leads to many truncated and mutated products. Also,beyond ~200 nt, full-length yield and purity drop dramatically.
v. Why can’t you make a 2000bp gene via direct oligo synthesis?
- Each synthesis step is <100% efficient, so yield collapses exponentially over 2000 cycles. The accumulated error rate would introduce mutations in most molecules. Also, long chains become chemically unstable during synthesis and are built by assembling shorter oligos, not by direct synthesis.
Homework Question from George Church:1. (Choosed) What are the 10 essential amino acids in all animals and how does this affect your view of the “Lysine Contingency”?
Histidine
Isoleucine
Leucine
Lysine
Methionine
Phenylalanine
Threonine
Tryptophan
Valine
Arginine
How affects my perspective?
Lysine is primarily obtained through the diet since it cannot be synthesized by the body. Because of this, low intake or malnutrition can lead to growth problems. This implies limited access to vital resources necessary for proper development, especially in regions with poor access to adequate nutrition.
Week 2 hw: DNA, Read, Write & edit
Part 1: Benchling & In-silico Gel Art
1.1 Simulation of the enzyme digestion with the following enzymes
Next to the ladder (Life 1kb Plus) there are the digestion from the enzymes:
All material was generated an inspired by Paul Vanouse’s Latent Figure Protocol artworks and designed with https://rcdonovan.com/gel-art
Part 2: Gel Art - Restriction Digests and Gel Electrophoresis
No wet lab experience available
Part 3: DNA Design Challenge
3.1. Choose your protein!!
I choose the tdTomato, is a basic (constitutively fluorescent) orange fluorescent protein published in 2004, derived from corals (Discosoma sp.).
How it works? tbTomato absorbs light from an external source (such as blue-green light) then it re-emit it in a glowing red light. Due to the photostability that offers, it is primarily used in biomedical research as a biomarker to visualize tissues and cells inside living organisms.
Personally, I like marine biology and how many things the sea can show us, so when I heard the origin of this protein while researching candidates I knew it. Also, my favorite group are mollusks but cnidarians (like corals) are quite special for their big potential in the production of innovative metabolites.
Comparing TdTomato glow with another fluorescent protein "mCherry" with same tone expresion. Image Extracted from paper "Optimizing the Protein Fluorescence Reporting System for Somatic Embryogenesis Regeneration Screening and Visual Labeling of Functional Genes in Cotton"
Extracted from ncbi and FpBase (for reference)
AAV52169.1 tandem-dimer red fluorescent protein [synthetic construct]
MVSKGEEVIKEFMRFKVRMEGSMNGHEFEIEGEGEGRPYEGTQTAKLKVTKGGPLPFAWDILSPQFMYGS
KAYVKHPADIPDYKKLSFPEGFKWERVMNFEDGGLVTVTQDSSLQDGTLIYKVKMRGTNFPPDGPVMQKK
TMGWEASTERLYPRDGVLKGEIHQALKLKDGGHYLVEFKTIYMAKKPVQLPGYYYVDTKLDITSHNEDYT
IVEQYERSEGRHHLFLGHGTGSTGSGSSGTASSEDNNMAVIKEFMRFKVRMEGSMNGHEFEIEGEGEGRP
YEGTQTAKLKVTKGGPLPFAWDILSPQFMYGSKAYVKHPADIPDYKKLSFPEGFKWERVMNFEDGGLVTV
TQDSSLQDGTLIYKVKMRGTNFPPDGPVMQKKTMGWEASTERLYPRDGVLKGEIHQALKLKDGGHYLVEF
KTIYMAKKPVQLPGYYYVDTKLDITSHNEDYTIVEQYERSEGRHHLFLYGMDELYK
3.2. Reverse Translate: Protein (amino acid) sequence to DNA (nucleotide) sequence.
reverse translation of td_Tomato1 to a 1428 base sequence of most likely codons.
atggtgagcaaaggcgaagaagtgattaaagaatttatgcgctttaaagtgcgcatggaa
ggcagcatgaacggccatgaatttgaaattgaaggcgaaggcgaaggccgcccgtatgaa
ggcacccagaccgcgaaactgaaagtgaccaaaggcggcccgctgccgtttgcgtgggat
attctgagcccgcagtttatgtatggcagcaaagcgtatgtgaaacatccggcggatatt
ccggattataaaaaactgagctttccggaaggctttaaatgggaacgcgtgatgaacttt
gaagatggcggcctggtgaccgtgacccaggatagcagcctgcaggatggcaccctgatt
tataaagtgaaaatgcgcggcaccaactttccgccggatggcccggtgatgcagaaaaaa
accatgggctgggaagcgagcaccgaacgcctgtatccgcgcgatggcgtgctgaaaggc
gaaattcatcaggcgctgaaactgaaagatggcggccattatctggtggaatttaaaacc
atttatatggcgaaaaaaccggtgcagctgccgggctattattatgtggataccaaactg
gatattaccagccataacgaagattataccattgtggaacagtatgaacgcagcgaaggc
cgccatcatctgtttctgggccatggcaccggcagcaccggcagcggcagcagcggcacc
gcgagcagcgaagataacaacatggcggtgattaaagaatttatgcgctttaaagtgcgc
atggaaggcagcatgaacggccatgaatttgaaattgaaggcgaaggcgaaggccgcccg
tatgaaggcacccagaccgcgaaactgaaagtgaccaaaggcggcccgctgccgtttgcg
tgggatattctgagcccgcagtttatgtatggcagcaaagcgtatgtgaaacatccggcg
gatattccggattataaaaaactgagctttccggaaggctttaaatgggaacgcgtgatg
aactttgaagatggcggcctggtgaccgtgacccaggatagcagcctgcaggatggcacc
ctgatttataaagtgaaaatgcgcggcaccaactttccgccggatggcccggtgatgcag
aaaaaaaccatgggctgggaagcgagcaccgaacgcctgtatccgcgcgatggcgtgctg
aaaggcgaaattcatcaggcgctgaaactgaaagatggcggccattatctggtggaattt
aaaaccatttatatggcgaaaaaaccggtgcagctgccgggctattattatgtggatacc
aaactggatattaccagccataacgaagattataccattgtggaacagtatgaacgcagc
gaaggccgccatcatctgtttctgtatggcatggatgaactgtataaa
Translation from Aminoacid to DNA executed with https://www.bioinformatics.org/sms2/rev_trans.html
3.3 Codon Optimization
Why you need to optimize codon usage?
The expression varies in species, sometimes one specie prefers the usage of X codon instead of Y. As it was presented in the slides, it can be demonstrated in both stability of the RNA Structure and percentages of efficiency in the expression: Arginine expression in e.coli works smoothly with an CGC (22.3%) codon instead of CGG (5.4%).
Which organism have you chosen to optimize the codon sequence for and why?
For this activity I choose e. coli because is a well know bacterian model, also it is easy and simple to use in compare to other candidates I had (like zebra fishes).
Codon optimization was executed with https://www.novoprolabs.com/tools/codon-optimization
3.4. You have a sequence! Now what?
What technologies could be used to produce this protein from your DNA? You may describe either cell-dependent or cell-free methods, or both. (DeepseekAI assisted)
For this step, I would choose cell-dependent expression. I would insert the tdTomato gene into a compatible plasmid and introduce the recombinant plasmid into E. coli cells using heat shock or electroporation. Then, I would incubate them and monitor their growth until they reach an optimal density. I would induce protein expression (using IPTG, since E. coli can metabolize lactose-based inducers) and incubate again for a few hours to visualize gene expression as a red fluorescent color (meaning the protein folded correctly).
Part 5: DNA Read/Write/Edit
5.1 DNA Read
What DNA would you want to sequence (e.g., read) and why? This could be DNA related to human health (e.g. genes related to disease research), environmental monitoring (e.g., sewage waste water, biodiversity analysis), and beyond (e.g. DNA data storage, biobank).
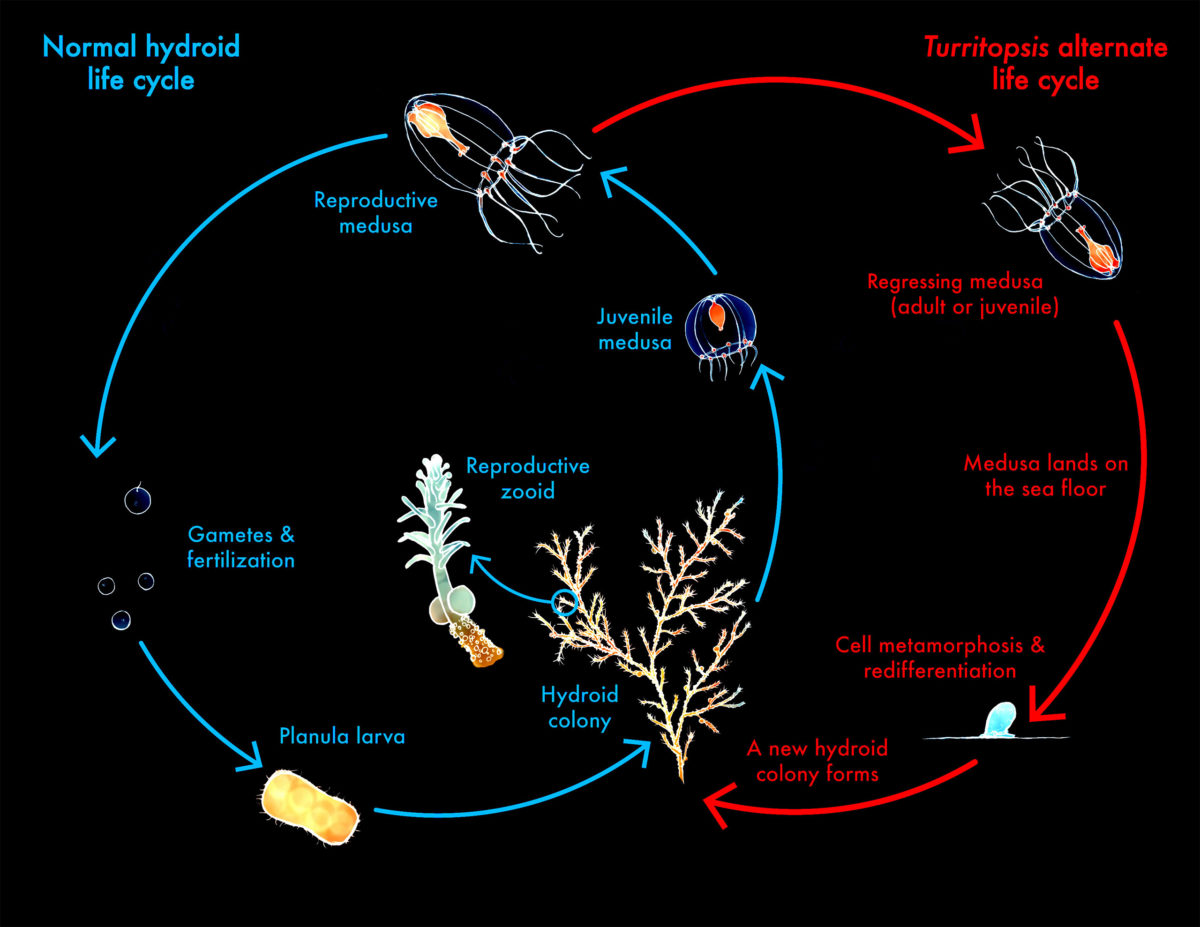
I would like to sequence the DNA of Turritopsis dohrnii. **Why?** Turritopsis dohrnii is a curious animal since it is well-known for the ability to restart its biological clock. It is the only living form that can do this with total control and without any Dna damage. Unfavorable conditions can trigger this biological regression, but it is not the common rule. This cyclical rejuvenation let T. dohrnii come back to its planula stage where it can repeat the whole juvenile and adult lifestages. In a curious way, these cnidarians biohacked their bodies in some point of history and indirectly, achieved an stable inmortality. It is important to notice how relevant T. dohrnii could be in terms of new medical insights, genomics and regeneration technologies. Understanding how their DNA works, what genes are expressing for the biological restart and measure it could be the key to achieve the next step in human evolution.
In lecture, a variety of sequencing technologies were mentioned. What technology or technologies would you use to perform sequencing on your DNA and why? Also answer the following questions:
Is your method first-, second- or third-generation or other? How so?
The method I use is second-generation. I opted for Illumina given its accessibility and low cost compared to other methods1. Furthermore, since a reference genome already exists (provided by Hasegawa et al. (2023))2, the need for de novo sequencing and assembly is reduced, compare to a process that would require a hybrid method(PacBio x Illumina as Hasegawa et al used) if we were the pioneers in the study of this specie.
What is your input? How do you prepare your input (e.g. fragmentation, adapter ligation, PCR)? List the essential steps.INPUT: For DNA extraction, only one individual of T. dohrnii would be needed. Currently, modern Illumina kits have high sensitivity and require only 1–100 ng of DNA, thus we avoid having to clone or collect more specimens. The steps for the extraction are enlisted:
1. DNA extraction: Isolate total DNA from the jellyfish tissue. (Kit illumina)
2. Tagmentation (optional): enzyme transposase fragments the DNA and adds adapters in a single step.
3. Adapter ligation (if not using tagmentation): Illumina-specific adapters are ligated to the ends of the fragments.
4. PCR enrichment: The library is amplified to add indices (barcodes) and increase the amount of DNA.
5. Normalization and pooling: The concentration is adjusted, and samples are mixed if multiple jellyfish are being sequenced simultaneously.
What are the essential steps of your chosen sequencing technology, how does it decode the bases of your DNA sample (base calling)?(Assisted with deepseekAI)
Cluster generation: Fragments bind to the flow cell and are locally amplified to form “clusters” of identical copies.
Sequencing by synthesis (SBS): Fluorescently labeled nucleotides (each base with a different color) with a reversible terminator are added. The polymerase incorporates one nucleotide per cycle.
Base Calling:
- A laser excites the fluorophores.
- A camera records the color emitted by each cluster.
- The software translates each color into a specific base (A, T, C, G) and assigns a quality score (Q-score) to each call.
Repeat: The terminator and dye are removed, and the cycle is repeated (e.g., 150 cycles for 150 bp reads).
What is the output of your chosen sequencing technology?(Assisted with deepseekAI)
The direct output of the sequencing process would be FASTQ files containing millions of short reads (e.g., 150 bp) along with their corresponding quality scores (Q-scores) for each base call. After bioinformatic analysis, these reads are aligned against the T. dohrnii reference genome provided by Hasegawa et al. (2023)2, generating BAM files that contain the mapped reads. Finally, variant calling analysis produces a VCF file (Variant Call Format) listing all genetic variants found in the sequenced sample compared to the reference genome, along with coverage statistics and sequencing quality metrics2.
5.2 DNA write
5.2.1 What DNA would you want to synthesize (e.g., write) and why?
These could be individual genes, clusters of genes or genetic circuits, whole genomes, and beyond. As described in class thus far, applications could range from therapeutics and drug discovery (e.g., mRNA vaccines and therapies) to novel biomaterials (e.g. structural proteins), to sensors (e.g., genetic circuits for sensing and responding to inflammation, environmental stimuli, etc.), to art (DNA origamis). If possible, include the specific genetic sequence(s) of what you would like to synthesize! You will have the opportunity to actually have Twist synthesize these DNA constructs! :)
I choose the lactase enzime. This because there are studies related to Food_desensitization3 where the main methodology implies the ingestion of dosis of the alergen (in this case milk), but what if we could skip this step (a process that can be uncomfortable and time-consuming) and implement the lactase enzime to decrease the ingestion of the alergen. I propose producing recombinant lactase enzyme that could be administered directly as a supplement or incorporated into dairy products, allowing individuals to digest lactose without undergoing desensitization. Specifically, I want to focus on the evolved beta-galactosidase subunit alpha from Escherichia coli K-12. This enzyme catalyzes the hydrolysis of lactose into D-glucose and D-galactose (assimilable forms).
5.2.2 What technology or technologies would you use to perform this DNA synthesis and why?
Also answer the following questions:
a. What are the essential steps of your chosen sequencing methods?
I would use oligonucleotide-based chemical synthesis (specifically, the phosphoramidite solid-phase synthesis method), which is the standard approach for custom gene synthesis offered by commercial providers like Twist Bioscience, IDT, or GenScript.
b. What are the limitations of your sequencing method (if any) in terms of speed, accuracy, scalability?
The primary limitations of chemical DNA synthesis include an inherent error rate (typically 1 error per 500-1000 bases) that necessitates careful sequence verification and potential correction rounds, especially for longer genes like the ~3kb lactase sequence.
Cost remains significant, with synthesis at $0.10-0.30 per base pair making a full-length gene $300-900 before cloning and validation.
Sequence complexity can pose challenges, as highly repetitive regions or extreme GC content may be difficult to synthesize accurately. Turnaround time is relatively slow, with standard gene synthesis taking 2-4 weeks for delivery plus additional time for cloning and verification. Size constraints also apply, as genes beyond 3-5 kb may require special assembly strategies. Finally, codon optimization, while computationally guided, involves some uncertainty since the “optimal” codon set for a given expression host cannot always be perfectly predicted and may require empirical testing of multiple variants to achieve maximum expression yields.
5.3 DNA Edit
5.3.1 What DNA would you want to edit and why?
In class, George shared a variety of ways to edit the genes and genomes of humans and other organisms. Such DNA editing technologies have profound implications for human health, development, and even human longevity and human augmentation. DNA editing is also already commonly leveraged for flora and fauna, for example in nature conservation efforts, (animal/plant restoration, de-extinction), or in agriculture (e.g. plant breeding, nitrogen fixation). What kinds of edits might you want to make to DNA (e.g., human genomes and beyond) and why?
I personally choose the genes related to the pigmentation of human iris. Since I have partial heterochromia I’ve been always curious about how this mutation occured or what were the mechanisms related to the correct pigmentation of iris that mutated the moment I was just a cell!!.
A particular region of chromosome 15 plays an important role in eye color. Within this region, there are two genes located very close together, OCA2 and HERC2. The protein produced from the OCA2 gene, known as the P protein, is involved in the maturation of melanosomes, cellular structures that produce and store melanin. Therefore, the P protein plays a crucial role in the amount and quality of melanin present in the iris. Several common variations (polymorphisms) in the OCA2 gene reduce the amount of functional P protein that is produced. Less P protein means there is less melanin present in the iris, leading to blue eyes instead of brown eyes in people with a polymorphism in this gene.4
The presence of other genes involved in pigmentation is known; however, the effects of these genes are likely combined with those of OCA2 and HERC2 to produce a continuum of eye colors in different people. My interest is to understand if its possible simulate this type of mutation, or induce it.
5.3.2 What technology or technologies would you use to perform these DNA edits and why? (Assisted with DeepseekAI)
Also answer the following questions:
i. How does your technology of choice edit DNA? What are the essential steps?ii. What preparation do you need to do (e.g. design steps) and what is the input (e.g. DNA template, enzymes, plasmids, primers, guides, cells) for the editing?iii. What are the limitations of your editing methods (if any) in terms of efficiency or precision?
To introduce or correct a mutation associated with heterochromia in the OCA2 or HERC2 genes, I would use CRISPR-Cas9 genome editing technology. This is the most suitable option due to its high precision, efficiency, and programmability.
CRISPR-Cas9 edits DNA by creating a targeted double-strand break, which the cell then repairs through natural pathways.
First, a synthetic guide RNA (gRNA) is designed with a 20-nucleotide sequence complementary to the target region in the OCA2 gene. This gRNA binds to the Cas9 protein, forming a ribonucleoprotein (RNP) complex that scans the DNA until it finds a sequence matching the gRNA adjacent to a Protospacer Adjacent Motif (PAM), which for standard Cas9 is "NGG". Once bound, Cas9 acts as molecular scissors, creating a precise double-strand break at the target site. The cell's repair machinery then determines the editing outcome: error-prone Non-Homologous End Joining (NHEJ) often introduces small insertions or deletions ideal for gene knockout, while Homology-Directed Repair (HDR) can introduce specific mutations if an exogenous donor DNA template is provided containing the desired sequence flanked by homology arm.
The preparation begins with careful in silico design: selecting a unique 20bp target sequence in the OCA2 gene adjacent to a PAM motif, and designing a donor DNA template with homology arms if precise HDR editing is desired. The required inputs include the target cells (such as melanocytes or cell lines), Cas9 (provided as plasmid DNA, mRNA, or recombinant protein), a synthetic guide RNA designed for your specific gene sequence, a donor DNA template for precise edits, and a delivery reagent like lipofection reagents or electroporation devices to introduce these components into the cells.
Despite Crispr-CAS9 potential, it has some limits. The primary precision concern is off-target effects, where guide RNAs may bind to similar genomic sequences and introduce unintended mutations, potentially disrupting tumor suppressors or oncogenes. Regarding efficiency, Homology-Directed Repair (HDR) for precise edits remains inefficient compared to the dominant error-prone Non-Homologous End Joining (NHEJ) pathway, and HDR is largely restricted to dividing cells. Additional challenges include mosaicism in multicellular organisms, risk of large structural variants like deletions or translocations, delivery hurdles for in vivo applications, and potential immunogenicity from the bacterial-derived Cas9 protein.
Hasegawa, Y., Watanabe, T., Otsuka, R., Toné, S., Kubota, S., & Hirakawa, H. (2023). Genome assembly and transcriptomic analyses of the repeatedly rejuvenating jellyfish Turritopsis dohrnii. DNA research : an international journal for rapid publication of reports on genes and genomes, 30(1), dsac047. https://doi.org/10.1093/dnares/dsac047↩︎↩︎↩︎
Piraino Sosa, Pedro, & Ojeda Soley, Giovanni. (2023). Desensibilización con alimentos. Revista alergia México, 70(4), 284-292. Epub 29 de abril de 2024.https://doi.org/10.29262/ram.v70i4.1339 ↩︎
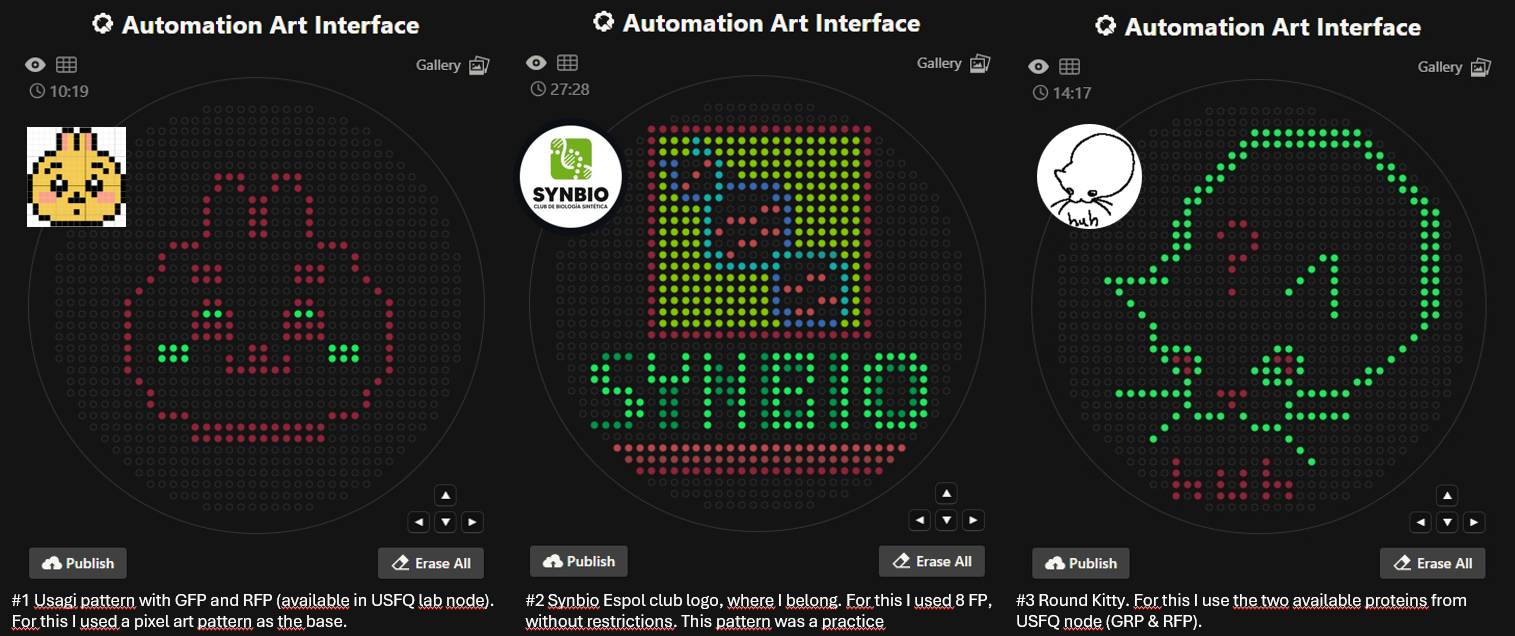
Task 1.1: Create a Python file to run on an Opentrons liquid handling robot.
For this asignment I used the GUI for generate the design and the coordinates. Then, with the assistance of GeminiAI, the coordinates were integrated using iterations. The pattern was divided and inserted in blocks and compilated part-by-part, until I was able to simulate the complete design and check its correct execution. For this work I used a pixel art design of the character Usagi from Chiikawa. There are also two more designs that I made as practice exercises.
Also there is the link of the Usagi code for reference (Assisted with GeminiAI)
In addition,there is the result inoculated by opentrons (ty to SYNBIO USFQ node!) in black agar
Assignment 2: Post-Lab Questions
One of the great parts about having an automated robot is being able to precisely mix, deposit, and run reactions without much intervention, and design and deploy experiments remotely.
Task 2.1: Find and describe a published paper that utilizes the Opentrons or an automation tool to achieve novel biological applications.
(Assisted with DeepseekAI)
This paper addresses a common problem such as manual and DNA assembly-related human errors. The authors developed AssemblyTron, an open-source Python package that acts as a bridge between DNA design software and the physical automation of the Opentrons OT-2 liquid handling robot. The biological applications are core molecular cloning tasks:
Automated PCR setup with an optimized annealing temperature gradient.
Golden Gate assembly of multi-part DNA constructs (e.g., assembling four fragments to create chromoprotein expression plasmids).
Homology-dependent assembly (like IVA and AQUA cloning) for site-directed mutagenesis and plasmid construction.
AssemblyTron automates the entire cloning workflow. Its utility was demonstrated by successfully assembling four-part chromoprotein plasmids and performing site-directed mutagenesis with efficiencies comparable to manual methods. The key achievement is creating an accessible, low-cost automation solution that reduces human error, training time, and the cost barrier for academic labs to engage in high-throughput synthetic biology.
Task 2.2: Write a description about what you intend to do with automation tools for your final project. You may include example pseudocode, Python scripts, 3D printed holders, a plan for how to use Ginkgo Nebula, and more. You may reference this week’s recitation slide deck for lab automation details.
The aim for this part is to automate the key steps required to extract metabolites from three distinct microbial consortia (complex samples). The workflow includes:
Serial dilution and plating to isolate individual bacterial strains from each consortium.
Preparation of agar plates for culturing.
Colony picking and inoculation into liquid media.
Preparation of samples for DNA extraction (for identification).
Metabolite extraction from liquid cultures. (I have few informations for this step but the manage of samples requieres automatization).
Automation will increase throughput, reduce manual errors, and allow remote execution of experiments. The project will leverage an Opentrons OT-2 for liquid handling, custom 3D‑printed adapters to stabilise agar plates during colony manipulation, and the Ginkgo Bioworks Nebula platform for cloud‑based experiment design and remote protocol execution (such as interpretation of biochemical characterization and identification).
Final Project Ideas
I developt three ideas related to the use of microorganisms. I love microbiology and how microbes can be both versatile and resilient. Some species posses interesting features that can be used for human purposes. In this case, the first slide reflects the use of possible bioproducts from wild microbes as a natural alternative of pesticides/chemicals in the treatment/prevention of bacterial MOKO disease in economy-importance crops in Ecuador (musaceae and solanaceae).
Subsections of Week 3 HW: Lab Automation
Google Collab extension
Week 4 HW: Protein Design Part I
Objective:
Learn basic concepts:
amino acid structure
3D protein visualization
the variety of ML-based design tools
Brainstorm as a group how to apply these tools to engineer a better bacteriophage (setting the stage for the final project).
Part A. Conceptual Questions
Answer any NINE of the following questions from Shuguang Zhang: (i.e. you can select two to skip)
1. Why do humans eat beef but do not become a cow, eat fish but do not become fish?
2. Why are there only 20 natural amino acids?
3. Can you make other non-natural amino acids? Design some new amino acids.
Part B: Protein Analysis and Visualization
In this part of the homework, you will be using online resources and 3D visualization software to answer questions about proteins. Pick any protein (from any organism) of your interest that has a 3D structure and answer the following questions:
Briefly describe the protein you selected and why you selected it.
Identify the amino acid sequence of your protein.
How long is it? What is the most frequent amino acid? You can use this Colab notebook to count the frequency of amino acids.
How many protein sequence homologs are there for your protein? Hint: Use Uniprot’s BLAST tool to search for homologs.
Does your protein belong to any protein family?
Identify the structure page of your protein in RCSB
When was the structure solved? Is it a good quality structure? Good quality structure is the one with good resolution. Smaller the better (Resolution: 2.70 Å)
Are there any other molecules in the solved structure apart from protein?
Does your protein belong to any structure classification family?
Open the structure of your protein in any 3D molecule visualization software:
PyMol Tutorial Here (hint: ChatGPT is good at PyMol commands)
Visualize the protein as “cartoon”, “ribbon” and “ball and stick”.
Color the protein by secondary structure. Does it have more helices or sheets?
Color the protein by residue type. What can you tell about the distribution of hydrophobic vs hydrophilic residues?
Visualize the surface of the protein. Does it have any “holes” (aka binding pockets)?
Part C. Using ML-Based Protein Design Tools
In this section, we will learn about the capabilities of modern protein AI models and test some of them in your chosen protein. We will now try multiple things in the three sections below; report each of these results in your homework writeup on your HTGAA website:
Part D. Group Brainstorm on Bacteriophage Engineering##