Homework 1 Introduction Over the past few decades, we have developed increasingly sophisticated methods to sequence and understand genomes and understood the genetic basis of several diseases. There are approximately 10,000 known monogenic diseases - caused by mutations to a single gene. But out of these, very few are treatable even though we understand the mechanism. This is due to challenges with delivering genes to the right places - common vectors like AAV don’t have the capacity to store large genes, each vector has varying specificity and duration of expression and many are immunogenic.
Subsections of Homework
Week 1 HW: Principles and Practices
Homework 1
Introduction
Over the past few decades, we have developed increasingly sophisticated methods to sequence and understand genomes and understood the genetic basis of several diseases. There are approximately 10,000 known monogenic diseases - caused by mutations to a single gene. But out of these, very few are treatable even though we understand the mechanism. This is due to challenges with delivering genes to the right places - common vectors like AAV don’t have the capacity to store large genes, each vector has varying specificity and duration of expression and many are immunogenic.
Recent advances in lipid nanoparticles address many of these challenges. They were successfully used to manufacture vaccines for COVID-19 since they can carry larger cargo, don’t generate immune memory and have been proven at large scale. I want to explore applications of lipid nanoparticles to delivering other kinds of cargo and treating more monogenic diseases.
Drug development is a mature field with well-established protocols for how drugs are tested, regulated and approved by agencies such as the FDA. Any drug approved for wide use in humans must rightfully meet a high bar and this involves a lot of testing and documentation. The document submitted to the FDA for approval is known as a Common Technical Document (CTD), which can span 10s of thousands of pages covering every detail of research & manufacturing. Large drug development companies often dedicate months with teams of people to compile these documents, even with their organizational knowledge of the regulatory requirements. The situation is worse for smaller companies because CTD’s and the precise of expectations of the regulatory agency are opaque.
The action I propose here is to make this process more transparent by asking agencies to release atleast a small subset of submitted and approved CTDs, redacted as needed to make clear to all players what their decision criteria are
Does the option:
Option 1
Option 2
Option 3
Enhance Biosecurity
• By preventing incidents
• By helping respond
Foster Lab Safety
• By preventing incident
• By helping respond
Protect the environment
• By preventing incidents
• By helping respond
Other considerations
• Minimizing costs and burdens to stakeholders
• Feasibility?
• Not impede research
• Promote constructive applications
Week 2 Lecture Prep
Nature’s machinery for copying DNA is called polymerase. What is the error rate of polymerase? How does this compare to the length of the human genome. How does biology deal with that discrepancy?
DNA polymerase in humans has an error rate of about 1 in $10^{6}$ , and the human genome has about 3 billion = 3x$10^9$ base pairs of DNA. That means in each replication of DNA, we would expect 30,000 errors. However, there are also mechanisms to correct errors such as proofreading and mismatch repair. Proofreading alone fixes about 99% of these errors and mismatch repair fixes more, and this is what enables our DNA to keep replicating with high fidelity even in the presence of errors.
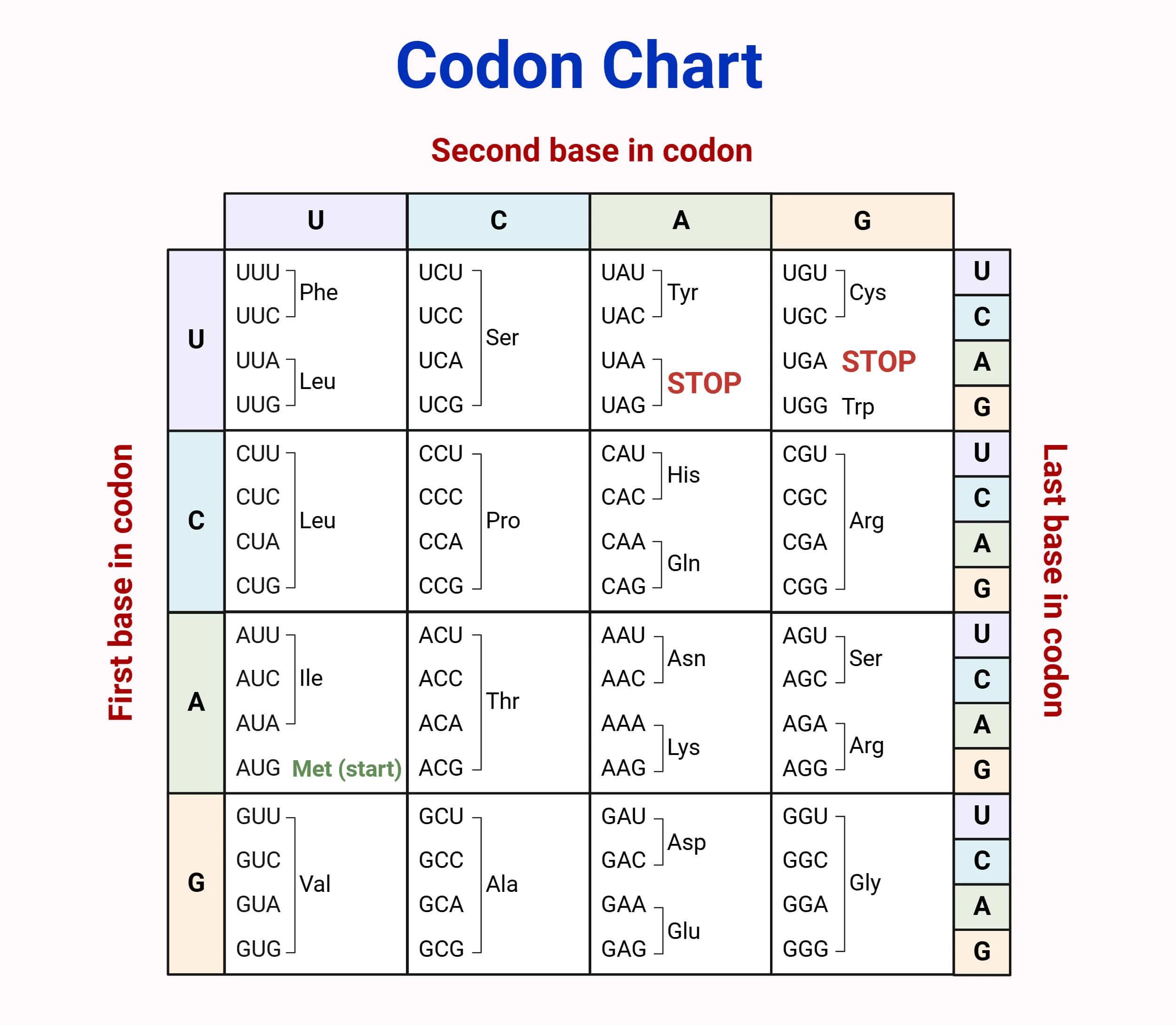
How many different ways are there to code (DNA nucleotide code) for an average human protein? In practice what are some of the reasons that all of these different codes don’t work to code for the protein of interest?
The chart shows that each of the 20 amino acids theoretically has several encodings. On average, there are $61/20 ~= 3.05$ encodings per amino acid. On average there are 476 amino acids in a human protein, meaning a massive $3.05^{476}$ possible ways to encode an average protein. However, there are practical reasons like the availability of tRNA and the the resulting mRNA structure that limits the number of codes that work.
What’s the most commonly used method for oligo synthesis currently?
The most common method today is solid-phase synthesis via the phosphoramidite method. It’s now done using automated machines that bind the nucleotides to a solid material while its being built.
Why is it difficult to make oligos longer than 200nt via direct synthesis?
The process consists of coupling steps, which is the addition of one more nucleotide to the existing strand. Each coupling step succeeds about 99% of the time, but the incomplete or incorrect oligos resulting from an error remain on the solid substrate. The rest is multiplicative error - 0.99 is great, but $0.99^{200}$ = $0.13$ = $13%$ . The error compounds with each step.
Why can’t you make a 2000bp gene via direct oligo synthesis?
It’s the same problem as above, but with 2000 steps the success rate would be $1.8e-9$ . This is why longer oligonucleotides are assembled by directly synthesizing shorter chains and then using techniques like Gibson Assembly or Golden Gate Assembly to combine them.
What are the 10 essential amino acids in all animals and how does this affect your view of the “Lysine Contingency”?
The 10 essential amino acids are arginine, histidine, methionine, isoleucine, leucine, lysine, phenylalanine, threonine, tryptophan, and valine. Since Lysine is one of them, this means that most animals cannot synthesize their own Lysine and must get it from their diet. So disabling their ability to synthesize Lysine would only make them more likely to crave a tasty human snack if they escaped.