Week 1 HW: Principles and Practices
Benchling & In-Silico Gel Art
I completed this bio lab last week at GenSpace! It was an exciting and easy-to-follow lecture. I’ll be attending Lab in-person this week, and will gather images of how the gel art turned out.




DNA Design Challenge
For my protein, I am choosing superfolder GFP (sfGFP) expressed in E. coli. This is primarily because I’m new to a science-lab environment, and my online research suggested this would be a simple, commonly-used protein that would help me learn and understand the tools and systems without the homework getting overly complicated (i.e. I don’t want to get stuck without a TA at home!).
Additionally, it sounds like superfolder GFP (sfGFP) expressed in E. coli can be used as a bio-indicator (emitting light), which may end up being helpful for my final project.
I have used Uniprot to obtain the following protein sequence:
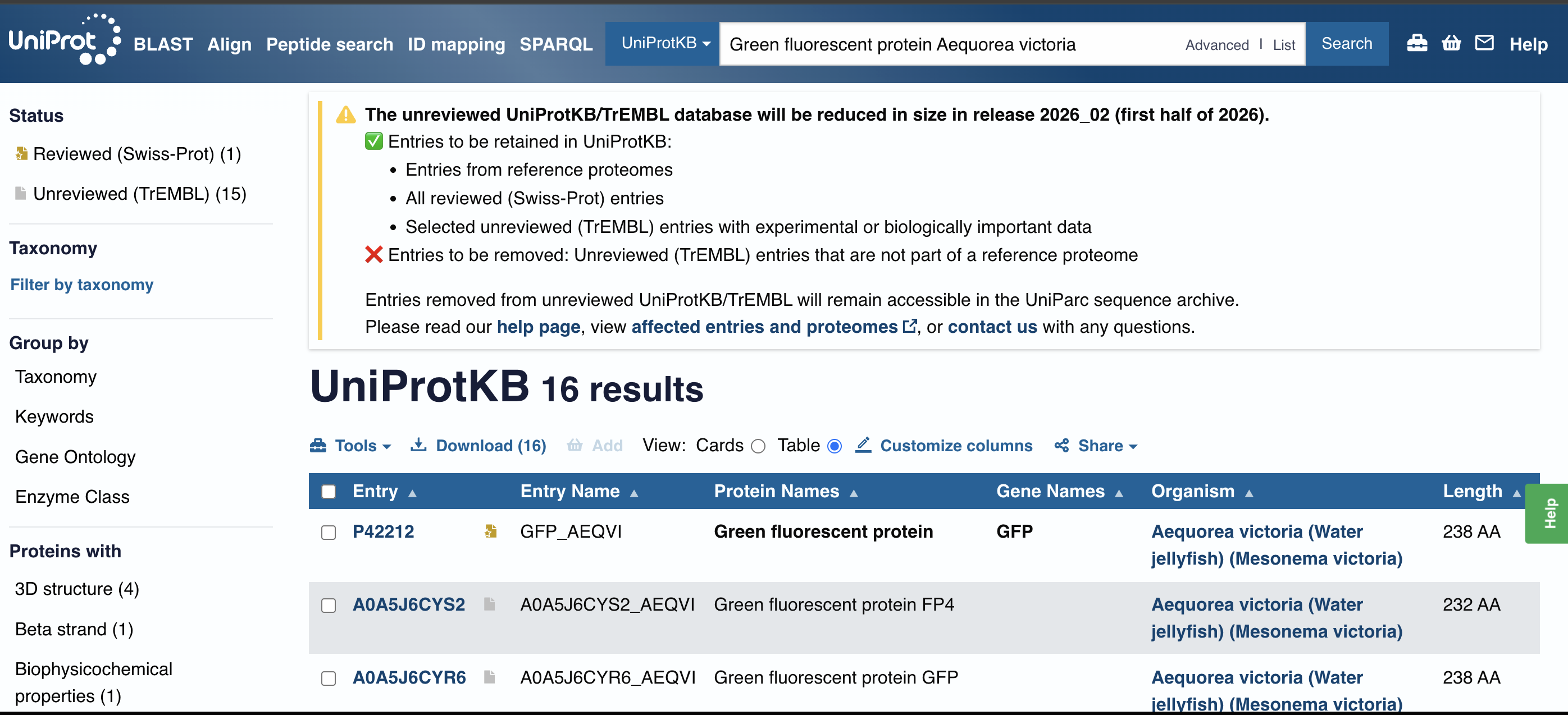
I asked ChatGPT to help me understand exactly which name to search in Uniprot to find my protein:
Taylor, B. N. (2026). Consultation with ChatGPT (OpenAI, GPT-5) to determine appropriate UniProt search term for selected protein (“Green fluorescent protein Aequorea victoria”). Personal communication, February 16, 2026.
My sequence (yay!):
sp|P42212|GFP_AEQVI Green fluorescent protein OS=Aequorea victoria OX=6100 GN=GFP PE=1 SV=1 MSKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDATYGKLTLKFICTTGKLPVPWPTL VTTFSYGVQCFSRYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGNYKTRAEVKFEGDTLV NRIELKGIDFKEDGNILGHKLEYNYNSHNVYIMADKQKNGIKVNFKIRHNIEDGSVQLAD HYQQNTPIGDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGITHGMDELYK
Reverse Translating My Sequence
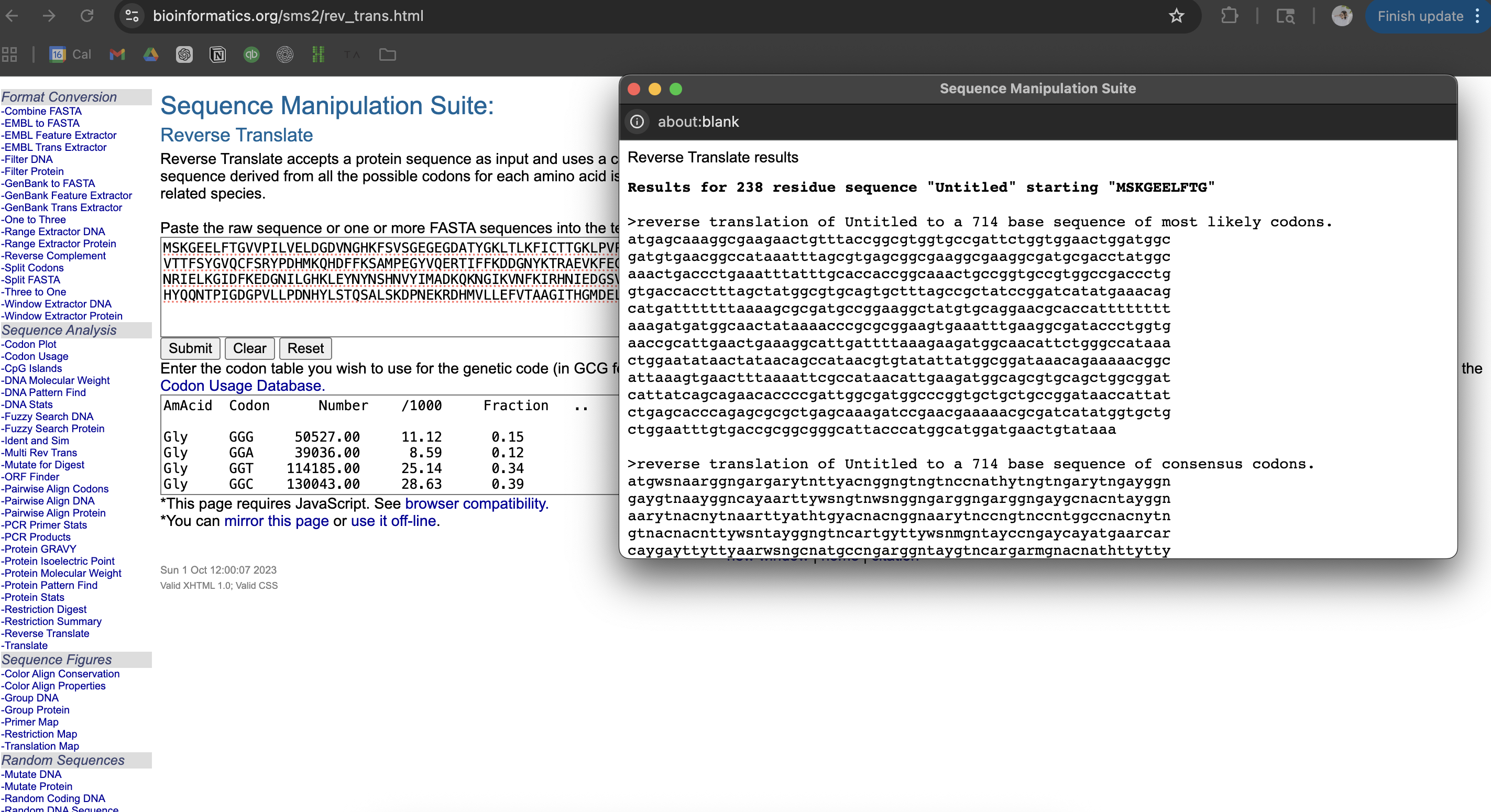
Next, I found an online reserve translation tool to reverse my protein sequence. I chose Bioinformatics. I copied and pasted my protein sequence, and hit ‘submit’ to get the following codons:
atgagcaaaggcgaagaactgtttaccggcgtggtgccgattctggtggaactggatggc gatgtgaacggccataaatttagcgtgagcggcgaaggcgaaggcgatgcgacctatggc aaactgaccctgaaatttatttgcaccaccggcaaactgccggtgccgtggccgaccctg gtgaccacctttagctatggcgtgcagtgctttagccgctatccggatcatatgaaacag catgatttttttaaaagcgcgatgccggaaggctatgtgcaggaacgcaccatttttttt aaagatgatggcaactataaaacccgcgcggaagtgaaatttgaaggcgataccctggtg aaccgcattgaactgaaaggcattgattttaaagaagatggcaacattctgggccataaa ctggaatataactataacagccataacgtgtatattatggcggataaacagaaaaacggc attaaagtgaactttaaaattcgccataacattgaagatggcagcgtgcagctggcggat cattatcagcagaacaccccgattggcgatggcccggtgctgctgccggataaccattat ctgagcacccagagcgcgctgagcaaagatccgaacgaaaaacgcgatcatatggtgctg ctggaatttgtgaccgcggcgggcattacccatggcatggatgaactgtataaa
Next, I did some online reading about codon optimization, as I wasn’t sure about the ‘why’ and didn’t recall the why from the relevant lecture. This included Google and ChatGPT research:
Taylor, B. N. (2026). Consultation with ChatGPT (OpenAI, GPT-5) regarding codon optimization rationale and host organism selection (E. coli) for GFP expression. Personal communication, February 16, 2026.
I will be using e.coli as, again, my research suggests it is simple and commonly-used, and I am optimizing for minimizing complexity while I am learning new skills.
I tried using the Twist Codon Optimization Tool, as that’s what’s referenced in the homework examples, but hit a roadblock figuring out how to input my codon sequence into the tool. I therefore pivoted to IDTDNA. I input my reverse codon ouput (and removed line breaks!), and then hit optimize:
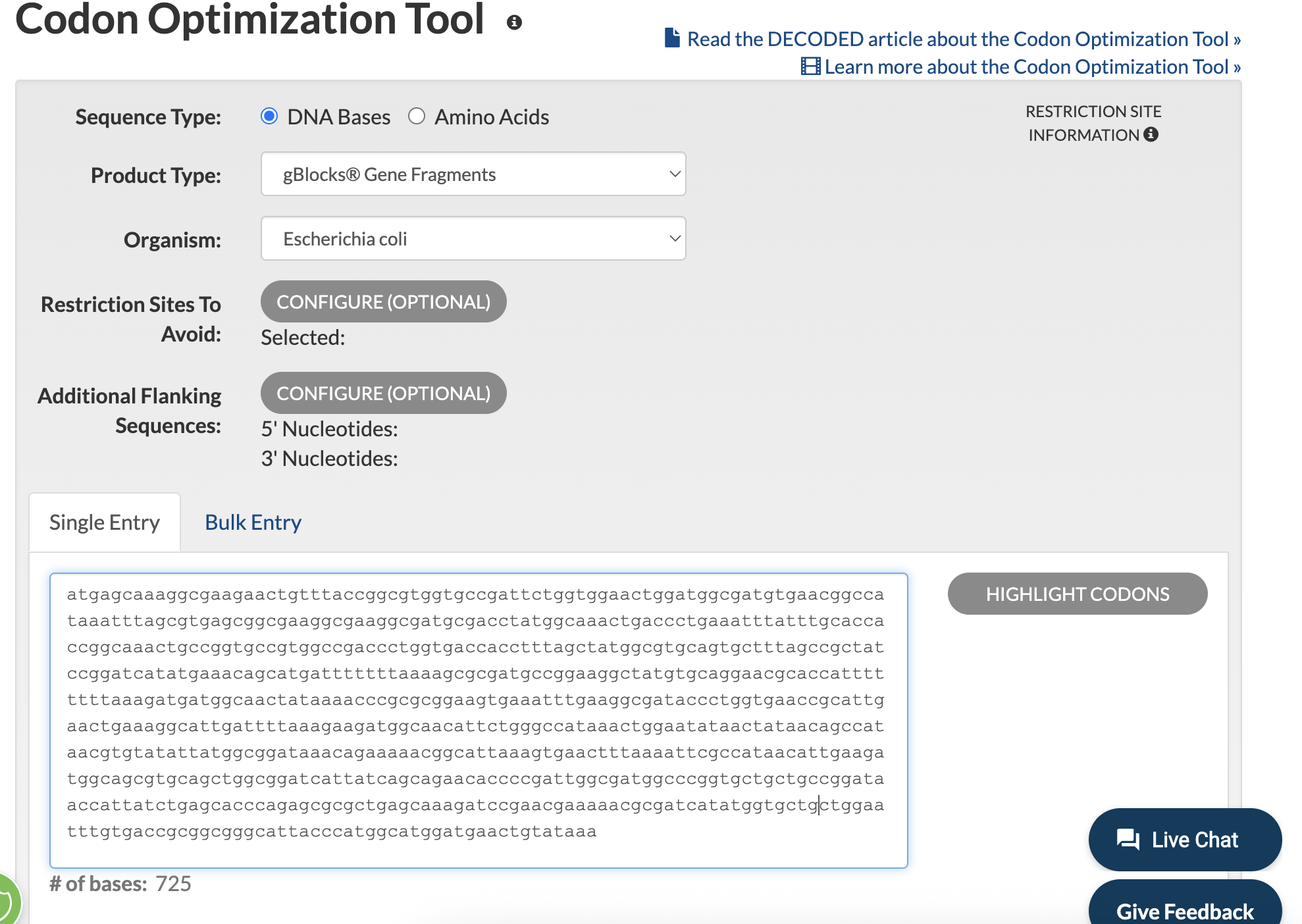
I then obtained the follow results:
ATG AGC AAG GGC GAA GAA TTG TTC ACT GGC GTT GTT CCT ATT CTG GTG GAA CTG GAT GGT GAT GTA AAC GGT CAT AAA TTT AGT GTC TCC GGA GAG GGG GAA GGC GAC GCG ACT TAC GGT AAG CTG ACC CTG AAA TTC ATT TGC ACA ACT GGC AAA TTG CCG GTT CCT TGG CCA ACC CTG GTA ACA ACA TTT TCA TAT GGT GTT CAA TGC TTT AGC CGT TAT CCT GAC CAT ATG AAA CAA CAT GAT TTT TTC AAA AGT GCG ATG CCC GAA GGT TAC GTC CAA GAA AGA ACG ATT TTC TTC AAA GAT GAC GGT AAT TAT AAA ACA CGG GCC GAA GTT AAG TTT GAA GGA GAT ACA TTA GTA AAC CGT ATT GAG CTG AAA GGC ATT GAT TTC AAG GAA GAT GGT AAT ATT CTG GGT CAC AAG TTA GAA TAT AAC TAC AAC AGC CAT AAT GTT TAT ATT ATG GCT GAT AAA CAG AAA AAC GGC ATT AAG GTA AAC TTT AAG ATC CGG CAT AAT ATT GAG GAT GGA TCA GTG CAG TTA GCT GAT CAT TAT CAA CAG AAT ACA CCT ATA GGT GAC GGG CCG GTC CTG TTG CCT GAT AAC CAT TAT CTG AGT ACC CAA TCC GCG TTG TCA AAA GAC CCG AAC GAA AAA CGT GAC CAT ATG GTT TTG TTA GAA TTT GTT ACC GCC GCT GGG ATA ACT CAT GGA ATG GAC GAA CTG TAT AAA
Plus, restriction enzyme sites found:
BclI (TGATCA) BspEI (TCCGGA) MscI (TGGCCA) NdeI (CATATG) PsiI (TTATAA) SspI (AATATT)
Once I have the optimized GFP DNA sequence, the protein can be made either inside living cells or using a cell-free system.
In a cell-dependent method, the GFP DNA would be inserted into a plasmid with a promoter and ribosome binding site. The plasmid would then be put into E. coli bacteria. Inside the bacteria, the cell’s machinery reads the DNA. First, RNA polymerase transcribes the DNA into messenger RNA (mRNA). Then, the ribosome reads the mRNA and translates it into the GFP protein using the genetic code. As the protein folds, it becomes fluorescent.
In a cell-free system, the same DNA can be added to a mixture that contains the necessary transcription and translation machinery (enzymes, ribosomes, nucleotides, amino acids). The system produces mRNA and then translates it into protein outside of a living cell. This method is useful when working conditions need to be tightly controlled.
Taylor, B. N. (2026). Consultation with ChatGPT (OpenAI, GPT-5) to clarify transcription and translation steps for GFP expression from optimized DNA. Personal communication, February 17, 2026.
Prepare a Twist DNA Synthesis Order
I opened Benchling, and entered my DNA string:
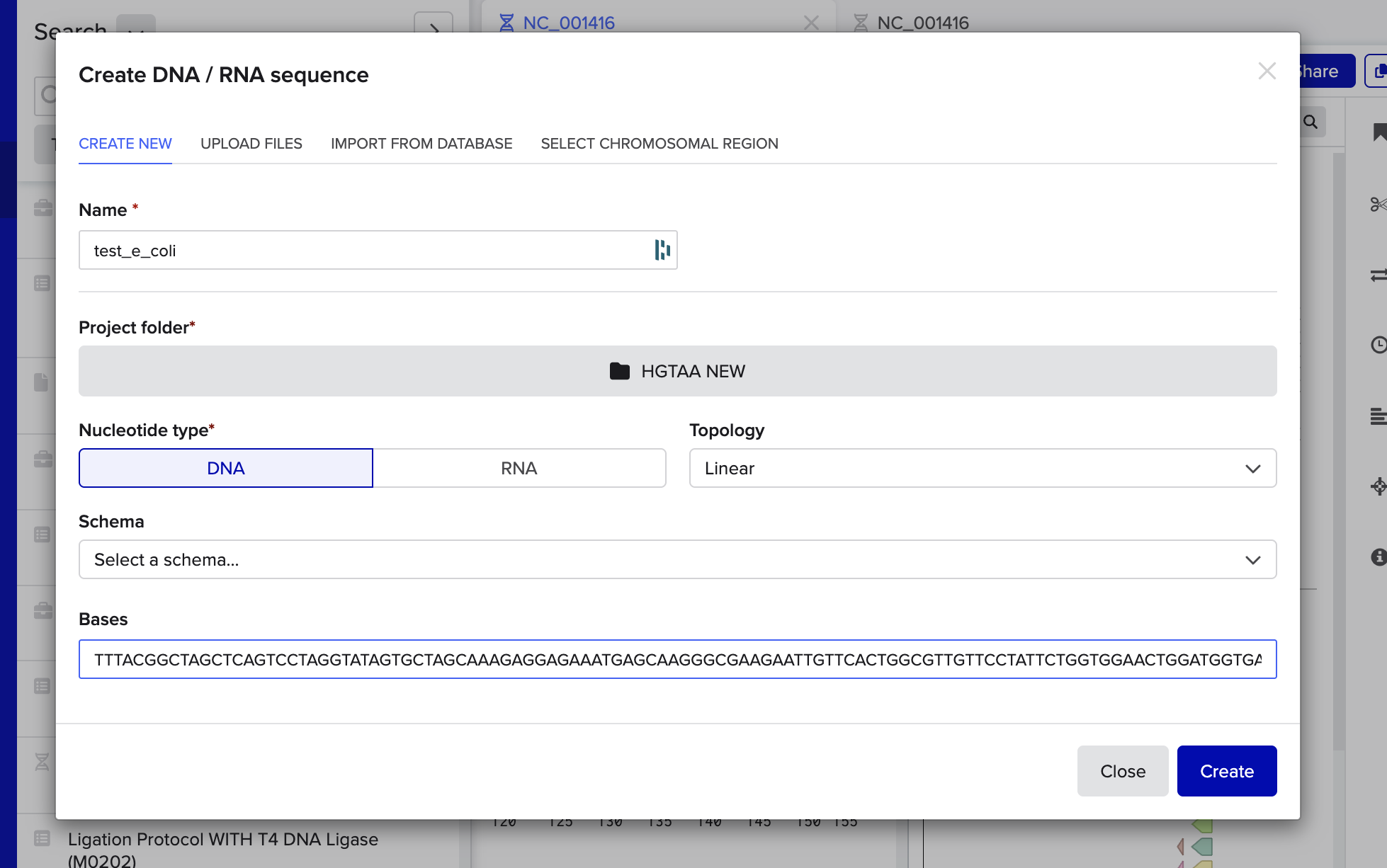
Then I began annotating:
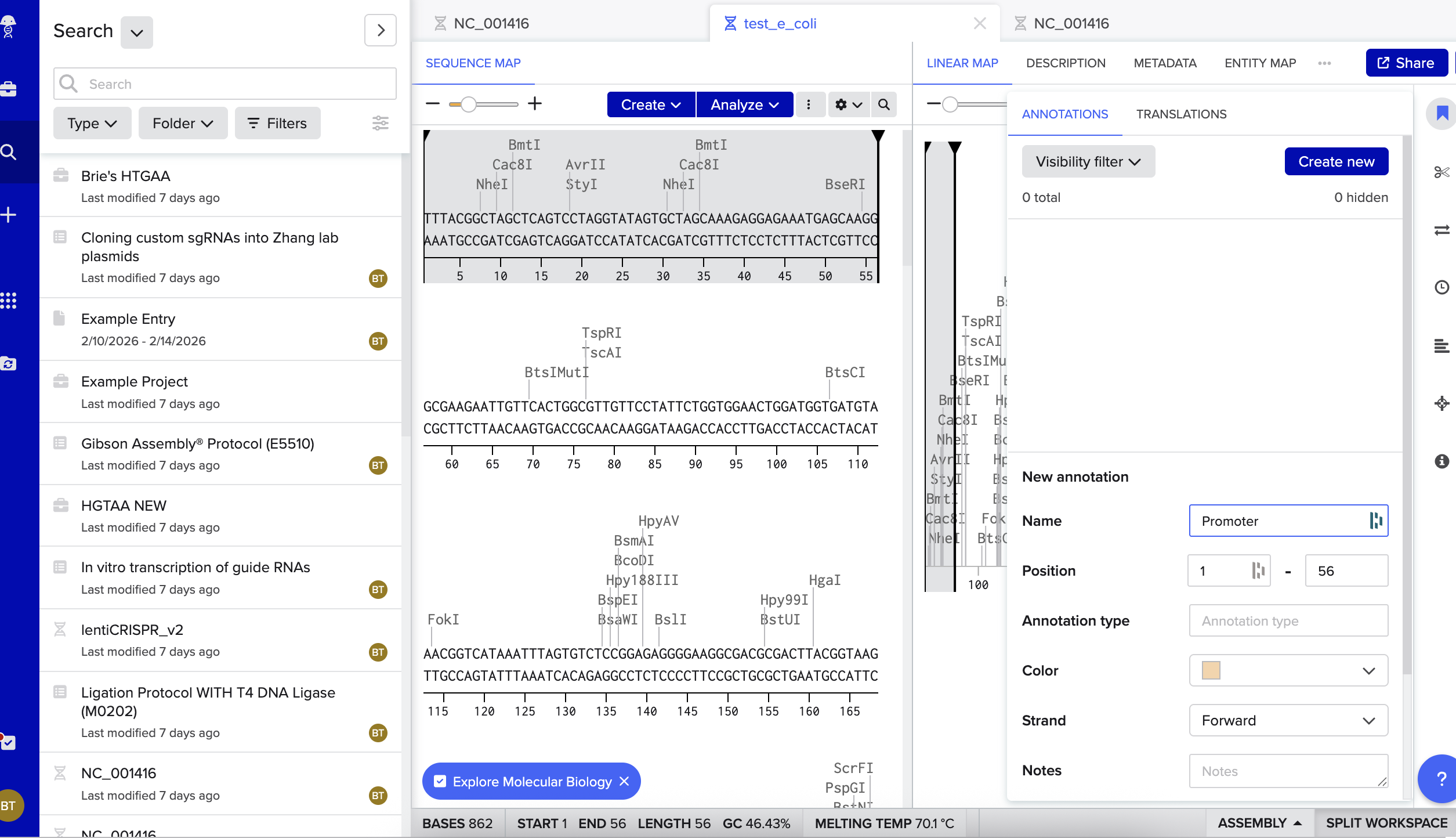
Next up, I added annotations. Oh boy. This was really hard. I may have made mistakes here. Though I tried very very hard! I mostly tried to mimic the sequence and annotations listed in the homework file, though did also ask ChatGPT for help talking me through the steps and understanding what is going on:
Taylor, B. N. (2026). Consultation with ChatGPT (OpenAI, GPT-5) for guidance on assembling and annotating a GFP expression cassette in Benchling (promoter, RBS, CDS, His tag, stop codon, terminator). Personal communication, February 17, 2026.
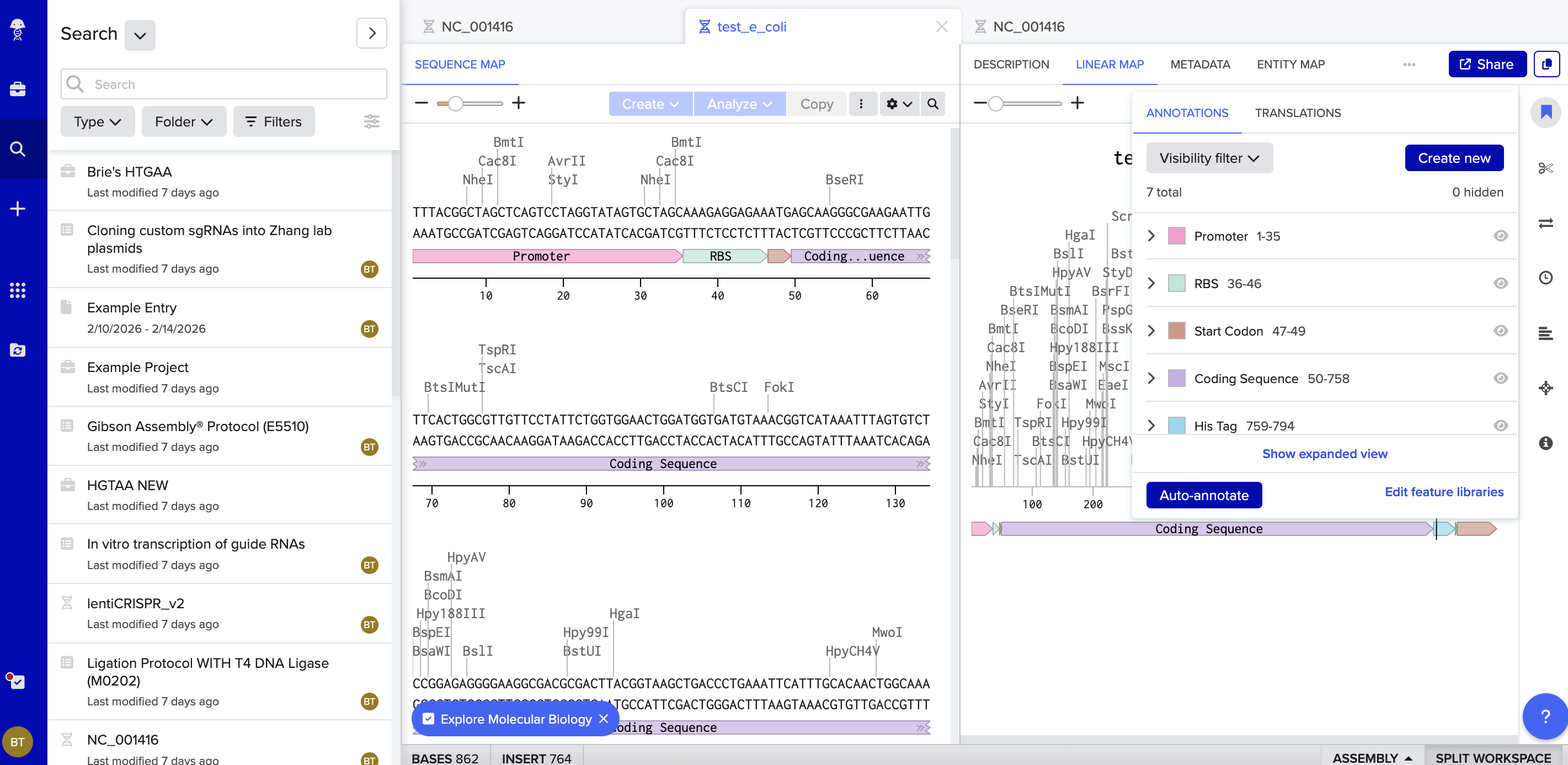
Here is the link to my linear map: https://benchling.com/s/seq-DQElyxqQGlBDYM96Iy9P?m=slm-LevVABkxM5ZzWgkQx9rv
Downloading My Sequence + Ordering on Twist
I then followed the homework instructions to download my sequence, and upload it into Benchling. Here’s the receipts!
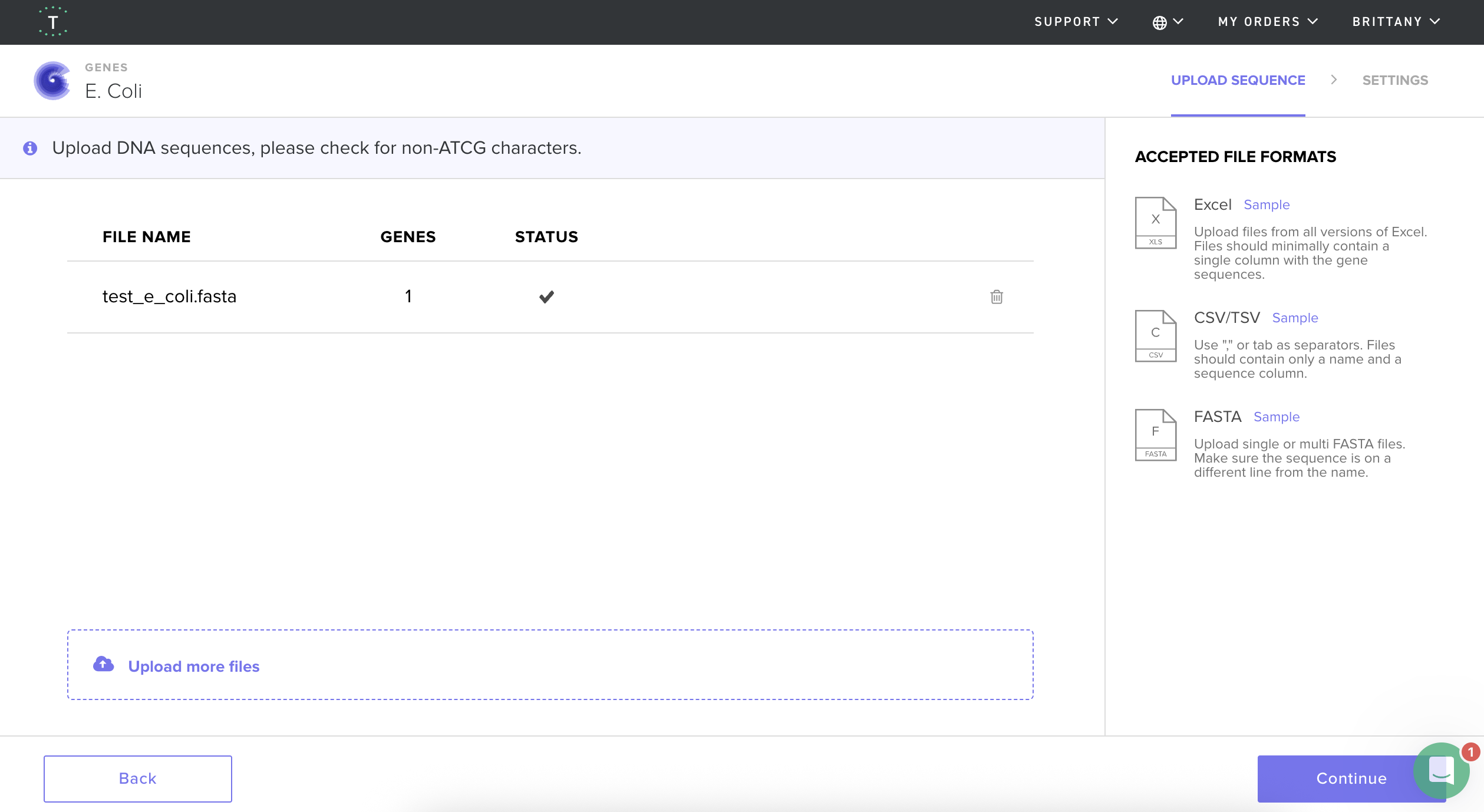
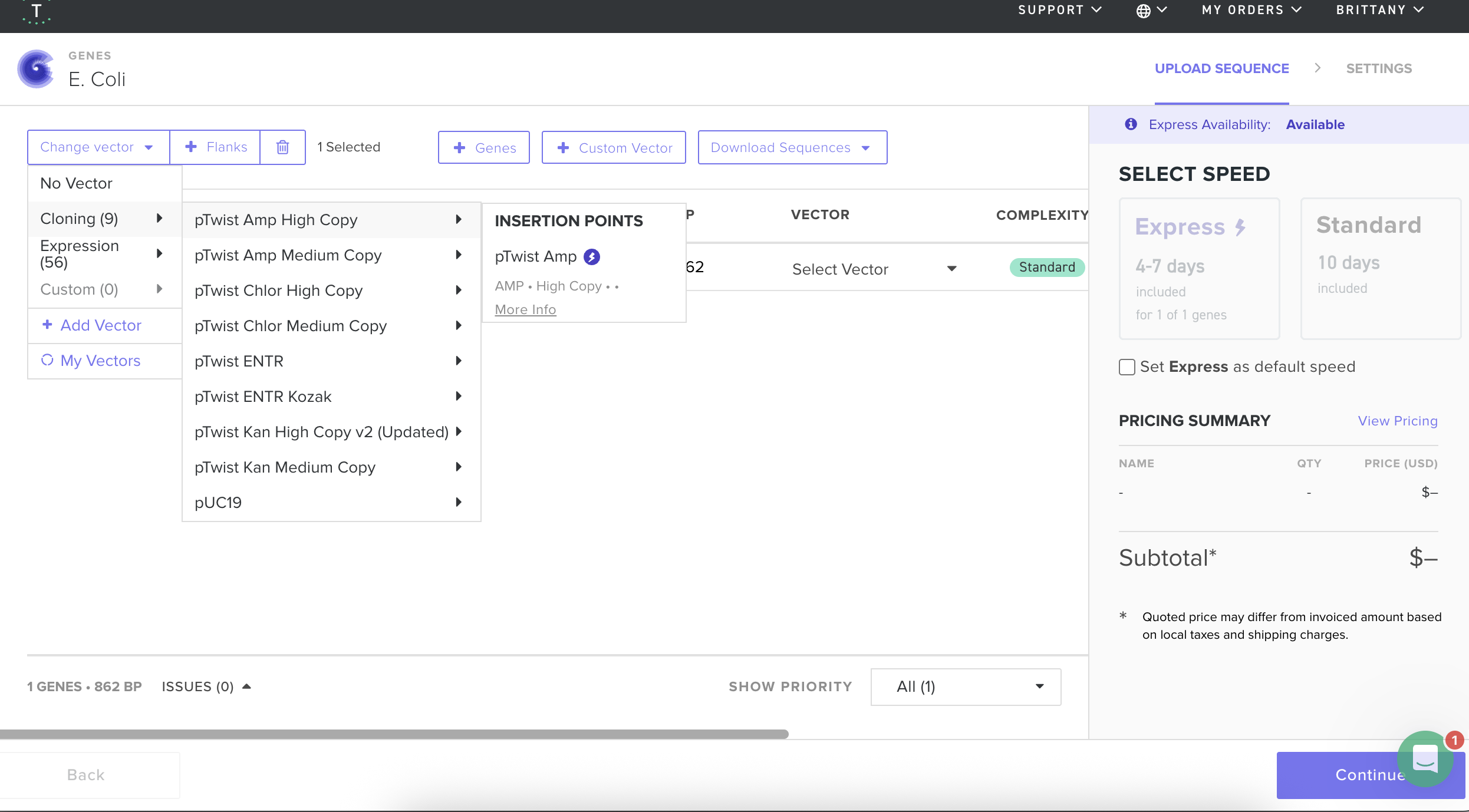
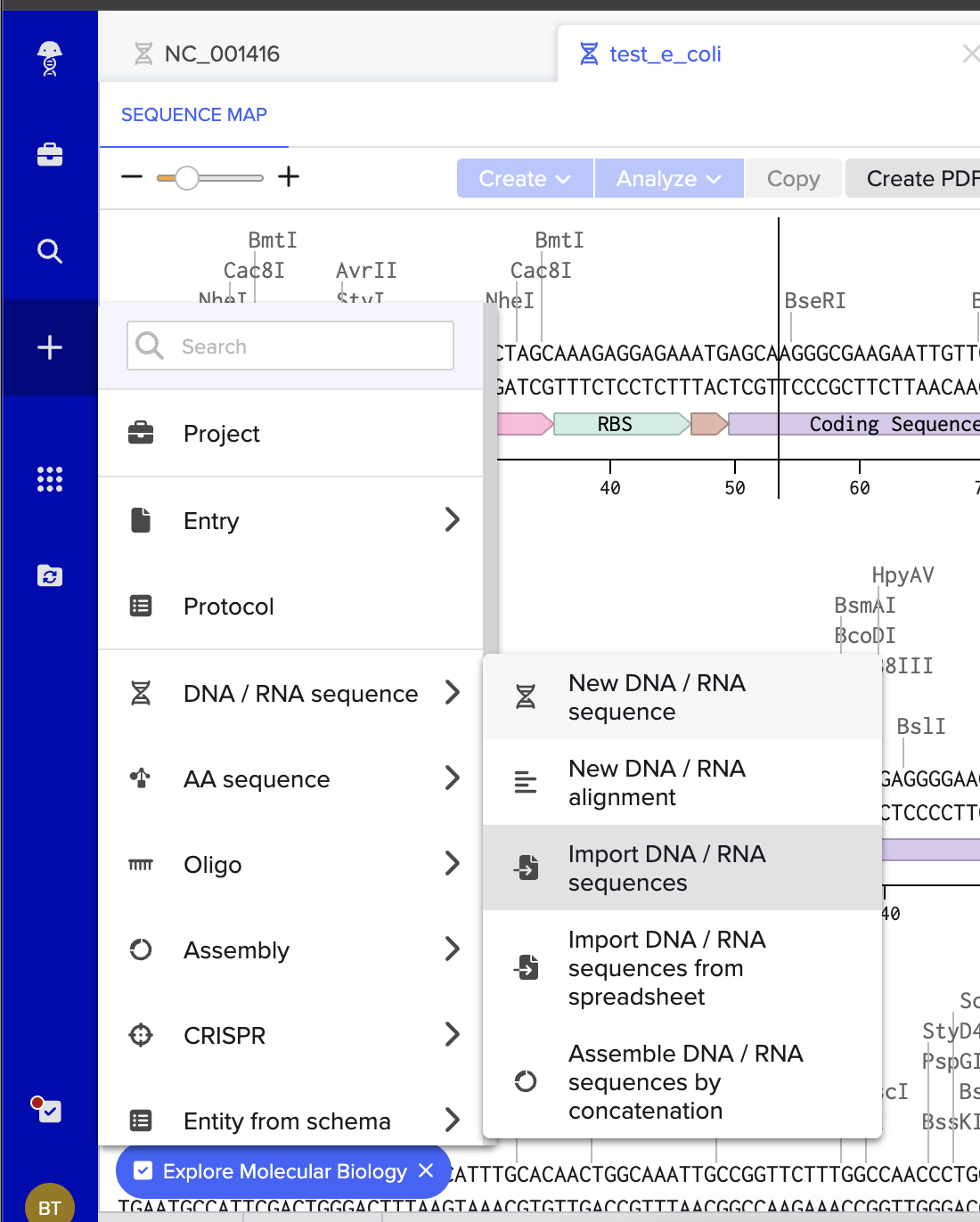
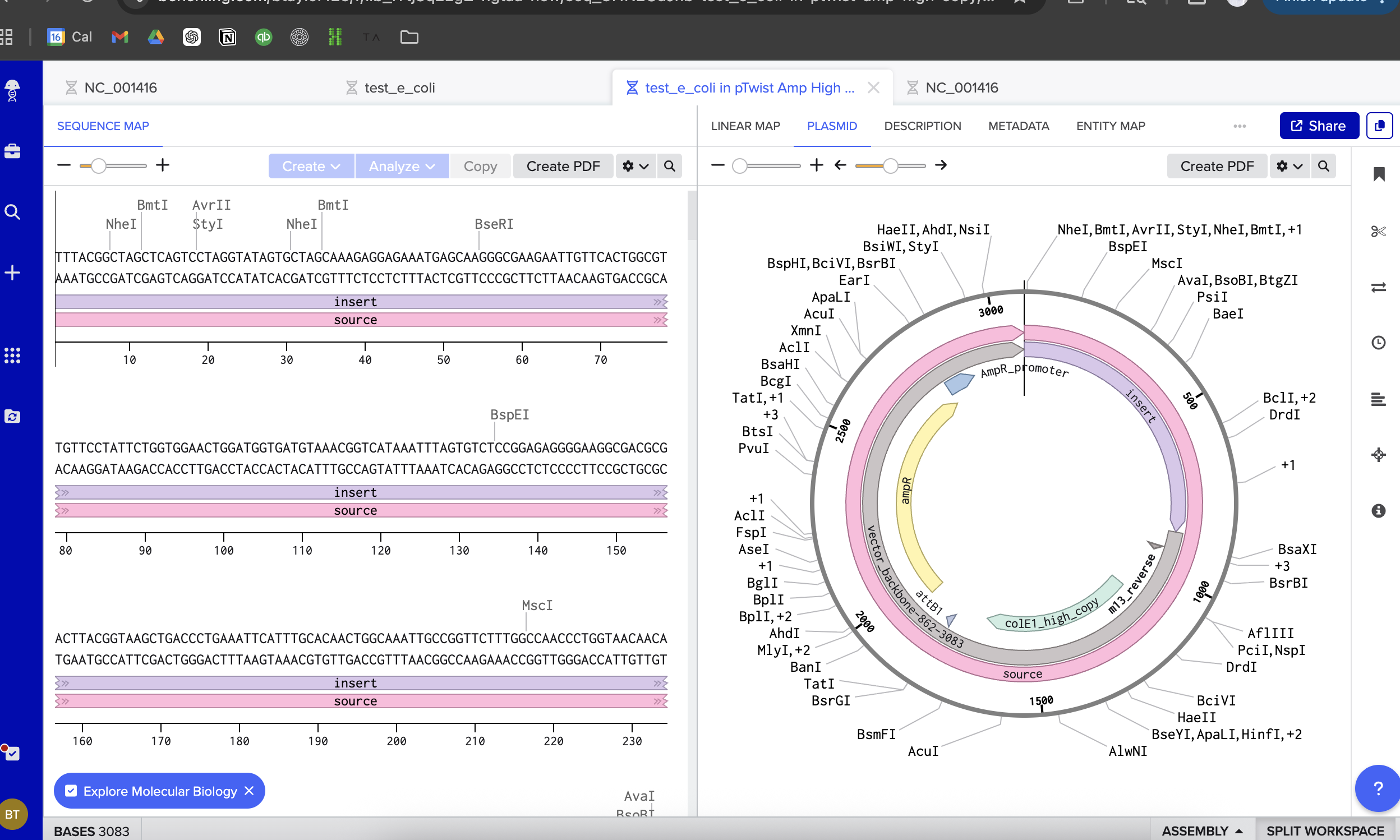
DNA Read
I would want to sequence DNA from environmental water samples, such as river or wastewater samples. This could help identify which bacteria or microorganisms are present. I’m interested in environmental systems, and sequencing environmental DNA (eDNA) could help detect pollution or biodiversity changes.
What technology would I use?
I would use Illumina sequencing. It is widely used, high accuracy, and good for sequencing many short DNA fragments at once.
This is a second-generation sequencing method.
Input: DNA extracted from a sample.
Preparation: DNA is fragmented, adapters are added, and PCR is used to amplify fragments.
During sequencing, fluorescent signals are detected as nucleotides are added one by one.
Output: Short DNA reads in digital format that can be analyzed on a computer.
Limitations: Reads are short, so assembly can be complex. It also requires lab preparation and equipment.
Taylor, B. N. (2026). Consultation with ChatGPT (OpenAI, GPT-5) to clarify sequencing, synthesis, and genome editing concepts for introductory-level coursework. Personal communication, February 17, 2026.
DNA Write
I would synthesize a GFP expression cassette for E. coli, like the one I designed. This could allow bacteria to produce a visible signal (fluorescence), which could later be adapted for sensing systems.
What technology would I use?
I would use chemical DNA synthesis (phosphoramidite synthesis) combined with gene assembly.
Short DNA fragments are chemically synthesized.
These fragments are assembled into a full gene.
The gene can then be cloned into a plasmid.
Limitations: There are size limits and cost constraints. Longer sequences require assembly steps.
Taylor, B. N. (2026). Consultation with ChatGPT (OpenAI, GPT-5) to clarify sequencing, synthesis, and genome editing concepts for introductory-level coursework. Personal communication, February 17, 2026.
DNA Edit
I would edit bacterial DNA to insert a reporter gene like GFP under control of a promoter that responds to environmental signals (for example, stress or pollution). This could allow bacteria to act as biosensors.
What technology would I use?
I would use CRISPR-Cas9.
A guide RNA is designed to match a target DNA sequence.
Cas9 cuts the DNA at that location.
A repair template can be added to insert new DNA.
Limitations: Off-target effects can happen. Efficiency is not always 100%.
Taylor, B. N. (2026). Consultation with ChatGPT (OpenAI, GPT-5) to clarify sequencing, synthesis, and genome editing concepts for introductory-level coursework. Personal communication, February 17, 2026.