First, describe a biological engineering application or tool you want to develop and why. Engineered bacteriophage as a delivery vector or indicator. Factors such as selective host range, ability to integrate, infection of drug-resistant bacteria, reproducibility, and more would make them a versatile tool.
Next, describe one or more governance/policy goals related to ensuring that this application or tool contributes to an “ethical” future, like ensuring non-malfeasance (preventing harm). Break big goals down into two or more specific sub-goals. (slightly edited from example framework)
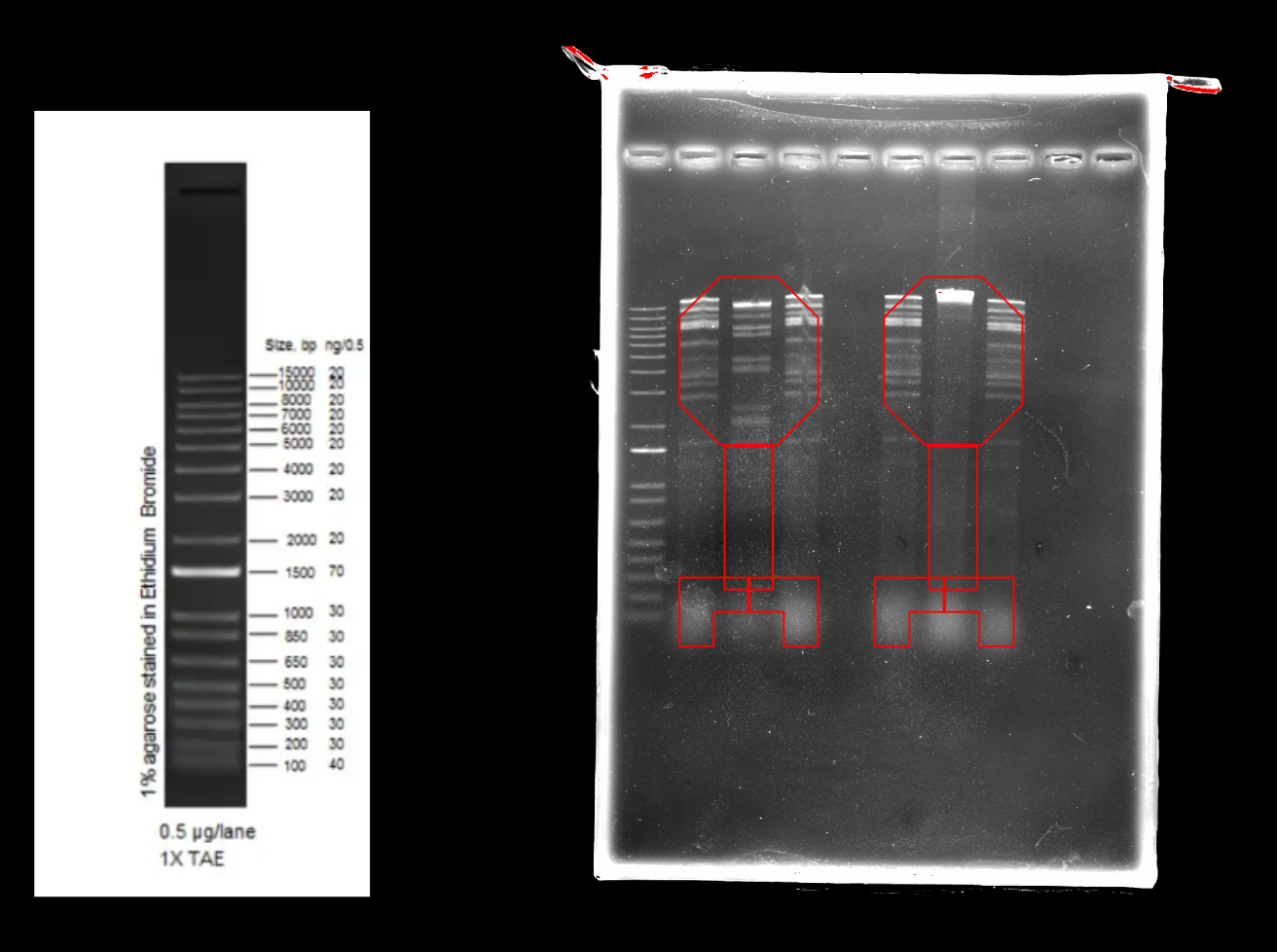
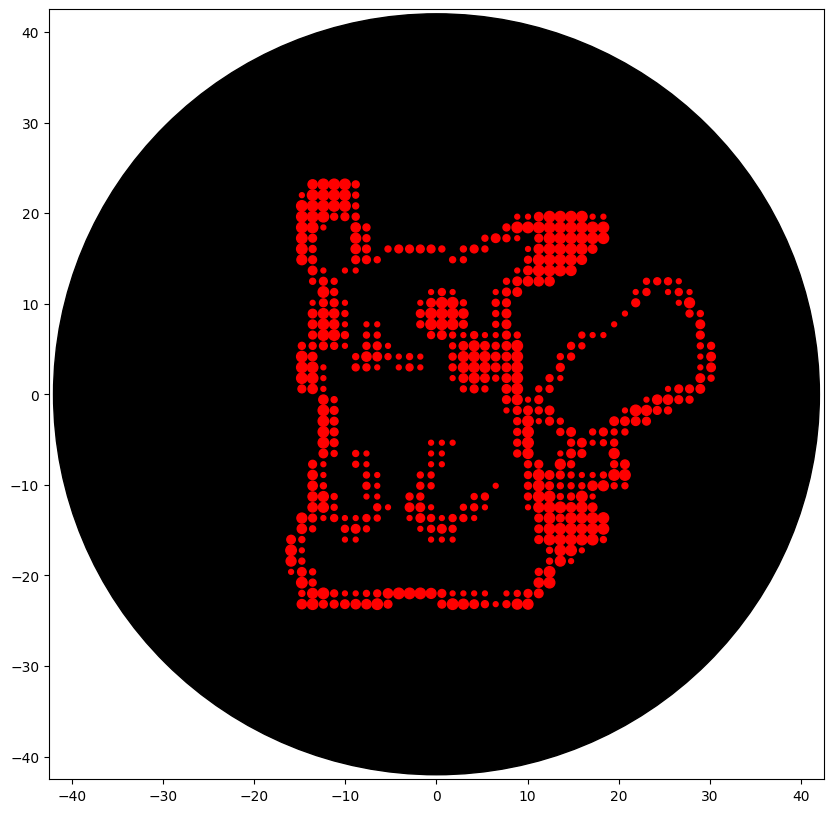
Part 1: Benchling & In-silico Gel Art My node (W&M) is using one of our phages’(Kampy) DNA for the Gel Art
DNA - https://phagesdb.org/phages/Kampy/ Our lab’s restriction enzymes: AfIII Age1 AluI ApaI BamHI-HF BbsI BsaI-HF BglI BstXI DpnI Eco0109I Eco47III EcoICRI EcoRI-HF EcoRV HindIII I-SceI KpnI NotI-HF PspAI PstI-HF SpaI-HF XbaI XhoI Part 2: Gel Art - Restriction Digests and Gel Electrophoresis Our design
Python Script for Opentrons Artwork Designs Using the GUI at opentrons-art.rcdonovan.com
Using custom design tools (trying out stippling, different dot sizes)
Python Files What the different dot design looks like after programming so far (still need to scale a bit)
Part A. Conceptual Questions How many molecules of amino acids do you take with a piece of 500 grams of meat? (on average an amino acid is ~100 Daltons) Meat is about 25% protein so 500 grams of meat is about 125 grams of protein. 100 Daltons is equivalent to 100 grams/mol so it is about 1.25 moles amino acids. Multiplying this by avogadro’s number, 6.022x1023, we get about 7.5275x1024 molecules of amino acids for a 500 gram piece of meat.
Assignment Part 1: Intracellular Artificial Neural Networks (IANNs) What advantages do IANNs have over traditional genetic circuits, whose input/output behaviors are Boolean functions? IANNs allow for the detection of more gradient cellular signals and multiple signals being taken into account at once, which results in more nuanced outputs (not based on a single on/off like in traditional circuits).
Subsections of Homework
Week 1 HW: Principles and Practices
First, describe a biological engineering application or tool you want to develop and why.
Engineered bacteriophage as a delivery vector or indicator. Factors such as selective host range, ability to integrate, infection of drug-resistant bacteria, reproducibility, and more would make them a versatile tool.
Next, describe one or more governance/policy goals related to ensuring that this application or tool contributes to an “ethical” future, like ensuring non-malfeasance (preventing harm). Break big goals down into two or more specific sub-goals.
(slightly edited from example framework)
Enhance Biosecurity
• By preventing incidents
• By helping respond
Foster Lab Safety
• By preventing incidents
• By helping respond
Protect the environment
• By preventing incidents
• By helping respond
Ensure Equitable Use
• Regulation
• Education
Next, describe at least three different potential governance “actions” by considering the four aspects below (Purpose, Design, Assumptions, Risks of Failure & “Success”).
Considering actors like researchers, industry/corporations, governments and health organizations, manufacturers, and users/general public.
Goals include:
• Education (best practices, use, risks, etc.)
• Guidelines (patenting, manufacturing, use cases, who can buy, development, etc.)
Next, score (from 1-3 with, 1 as the best, or n/a) each of your governance actions against your rubric of policy goals:
Does the option:
Education
Guidelines
Monitoring
Enhance Biosecurity
• By preventing incidents
2
1
3
• By helping respond
3
2
1
Foster Lab Safety
• By preventing incident
1
2
n/a
• By helping respond
n/a
2
1
Protect the environment
• By preventing incidents
2
1
n/a
• By helping respond
3
2
1
Ensure Equitable Use
• By preventing incidents
2
1
n/a
• By helping respond
3
1
2
Last, drawing upon this scoring, describe which governance option, or combination of options, you would prioritize, and why. Outline any trade-offs you considered as well as assumptions and uncertainties.
I would prioritize guidelines for industry and manufacturing actors, education for the general public/users and for researchers, and monitoring by governments and health agencies. Preventative measures (guidelines/education) are important to preventing misuse, unequal use, or dangerous impacts, while monitoring and having response plans are important for responding to problems. There needs to be a balance of governance for all actors, with most of my three categories being utilized for each group in different ways.
Reflecting on what you learned and did in class this week, outline any ethical concerns that arose, especially any that were new to you. Then propose any governance actions you think might be appropriate to address those issues.
Ethical concerns surround the use and possible misuse of synthetic biology. Governance actions in a lot of emerging areas are seen on the research side and health agency sides, but I believe that as use becomes broader, it will be important to have regulation for industry and education for the general public (for example, a lot of people have never heard of phage therapy).
Assignment (Week 2 Lecture Prep)
Homework Questions from Professor Jacobson:
Nature’s machinery for copying DNA is called polymerase. What is the error rate of polymerase? How does this compare to the
length of the human genome. How does biology deal with that discrepancy?
Error rate is 1:10^(6) while the human genome is about 3.2 Gbp. Biology deals with this through error checks and correction methods, including proof reading, redundancy, and cell self-destruction.
How many different ways are there to code (DNA nucleotide code) for an average human protein? In practice what are some of the
reasons that all of these different codes don’t work to code for the protein of interest?
There are many different ways to code for the same protein due to multiple codons leading to the same amino acid (redundancy). In practice, all of those different codes don’t work or aren’t seen creating the protein due to base pair and tRNA bias in different organisms.
Homework Questions from Dr. LeProust:
What’s the most commonly used method for oligo synthesis currently?
Solid-phase oligonucleotide synthesis using phosphoramidite chemistry.
Why is it difficult to make oligos longer than 200nt via direct synthesis?
Due to the accumulation of small errors.
Why can’t you make a 2000bp gene via direct oligo synthesis?
It is difficult to make oligos longer than 200nt via direct synthesis due to error accumulation.
Homework Question from George Church:
[Using Google & Prof. Church’s slide #4] What are the 10 essential amino acids in all animals
and how does this affect your view of the “Lysine Contingency”?
The 10 essential amino acids are Arginine, Histidine, Isoleucine, Leucine, Lysine, Methionine, Phenylalanine, Threonine, Tryptophan, and Valine. This is interesting for the “Lysine Contingency” since animals cannot synthesize any of these essential amino acids (in high enough quantities), so they have to get them through their diet. Making dinosaurs reliant on external Lysine is just making them like any normal animal.
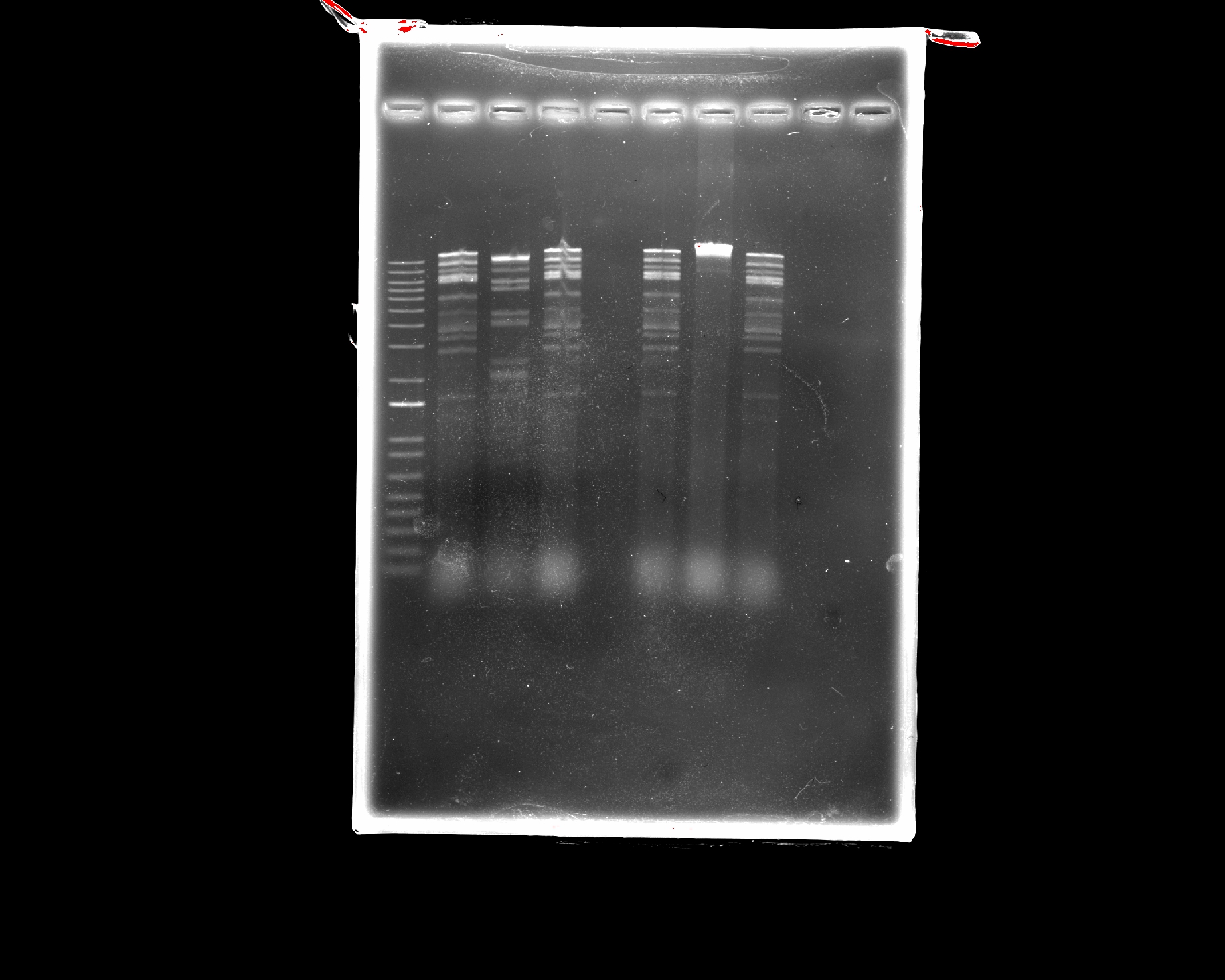
Part 2: Gel Art - Restriction Digests and Gel Electrophoresis
Our design
Our gel results
Part 3: DNA Design Challenge
3.1. Choose your protein.
I chose Antirepressor protein ant from Salmonella phage P22 since my lab is interested in antirepressors in bacteriophage and how they induce phage.
>sp|P03037|RANT_BPP22 Antirepressor protein ant OS=Salmonella phage P22 OX=10754 GN=ant PE=1 SV=1 MNSIAILEAVNTSYVPFNGQHVLTAMVAGVAYVAMKPVVDNIGLSWSSQVQKLLKMKDKFNYVDIDMVAGDMKKRLMGCIPLKKLNGWLFSINPEKVRADIRDKLIKYQEECFTVLYDYWTKGKAENPRKKTSVDERTPLRDAVNMLVSKKHLMYPEAYAMIHQRFNVESIEELEASQIPLAVEYIHRVVLEGEFIGKQEKKTNDLSAKEANSLVWLWDYANRSQALFRELYPAMRQIQSNYSGKCYDYGHEFSYIIGIARDVLINHTRDVDINEPDGPTNLSAWMRLKDKELPPSLHRY
3.2. Reverse Translate: Protein (amino acid) sequence to DNA (nucleotide) sequence.
Ant protein DNA sequence with Codon-Optimization ATGATGAATTCTATTGCTATTTTAGAAGCTGTTAATACTTCTTATGTTCCTTTTAATGGTCAACATGTTTTAACTGCTATGGTTGCTGGTGTTGCTTATGTTGCTATGAAACCTGTTGTTGATAATATTGGTTTATCTTGGTCTTCTCAAGTTCAAAAATTATTAAAAATGAAAGATAAATTTAATTATGTTGATATTGATATGGTTGCTGGTGATATGAAAAAACGTTTAATGGGTTGTATTCCTTTAAAAAAATTAAATGGTTGGTTATTTTCTATTAATCCTGAAAAAGTTCGTGCTGATATTCGTGATAAATTAATTAAATATCAAGAAGAATGTTTTACTGTTTTATATGATTATTGGACTAAAGGTAAAGCTGAAAATCCTCGTAAAAAAACTTCTGTTGATGAACGTACTCCTTTACGTGATGCTGTTAATATGTTAGTTTCTAAAAAACATTTAATGTATCCTGAAGCTTATGCTATGATTCATCAACGTTTTAATGTTGAATCTATTGAAGAATTAGAAGCTTCTCAAATTCCTTTAGCTGTTGAATATATTCATCGTGTTGTTTTAGAAGGTGAATTTATTGGTAAACAAGAAAAAAAAACTAATGATTTATCTGCTAAAGAAGCTAATTCTTTAGTTTGGTTATGGGATTATGCTAATCGTTCTCAAGCTTTATTTCGTGAATTATATCCTGCTATGCGTCAAATTCAATCTAATTATTCTGGTAAATGTTATGATTATGGTCATGAATTTTCTTATATTATTGGTATTGCTCGTGATGTTTTAATTAATCATACTCGTGATGTTGATATTAATGAACCTGATGGTCCTACTAATTTATCTGCTTGGATGCGTTTAAAAGATAAAGAATTACCTCCTTCTTTACATCGTTATTAA
3.3. Codon optimization.
Different organisms have different bias to certain tRNA which makes them quicker as translating certain codons. Therefore to make the most proteins the quickest, you need to optimize for the organism that will be producing the protein (is being engineered to make it). I have optimized for Salmonella typhimurium (LT2) since it is the only option I found in benchling from the Salmonella genus (which the phage infects).
Ant protein DNA sequence with Codon-Optimization ATGATGAACAGCATCGCGATTTTGGAGGCCGTGAATACGTCGTATGTCCCGTTTAATGGCCAGCATGTCCTGACCGCAATGGTAGCGGGCGTCGCATATGTGGCGATGAAGCCGGTTGTTGATAATATCGGTCTTAGTTGGTCGTCCCAGGTCCAAAAACTTCTGAAAATGAAAGATAAGTTCAACTATGTTGATATCGACATGGTTGCGGGCGATATGAAAAAAAGACTGATGGGCTGCATTCCGCTGAAGAAATTGAACGGGTGGCTCTTCTCCATAAATCCCGAAAAAGTACGAGCGGATATTCGTGACAAGCTGATCAAATATCAGGAAGAGTGCTTTACAGTACTTTACGACTATTGGACGAAAGGAAAAGCCGAGAACCCGCGTAAAAAAACGTCTGTGGACGAACGGACCCCGTTACGCGATGCGGTTAACATGCTCGTGAGCAAAAAACACCTGATGTACCCGGAAGCTTATGCTATGATCCATCAGCGCTTTAACGTGGAATCAATCGAGGAACTGGAAGCCTCGCAAATTCCATTAGCCGTCGAATACATTCACCGCGTGGTGCTCGAAGGTGAGTTTATTGGCAAACAGGAAAAGAAGACCAATGATTTGTCCGCAAAAGAGGCCAACAGCCTGGTGTGGCTATGGGACTACGCCAATCGCAGCCAGGCTCTGTTTCGTGAACTGTACCCGGCGATGCGTCAGATTCAAAGCAATTATAGCGGAAAATGTTATGATTATGGCCATGAATTCTCTTATATCATTGGGATCGCGCGTGACGTATTAATTAATCATACCCGCGATGTCGATATAAACGAACCTGACGGTCCAACTAACCTGAGTGCGTGGATGCGGCTGAAAGATAAAGAGCTGCCTCCCTCACTGCACCGCTACTAA
3.4. You have a sequence! Now what?
The DNA can be transcribed and translated into the protein by inserting it into a plasmid which is put into the host (bacteria) through methods like chemical transformation or electroporation (which interupt the stability of the cell membrane), and then the host starts expressing it like it would for one of its own proteins.
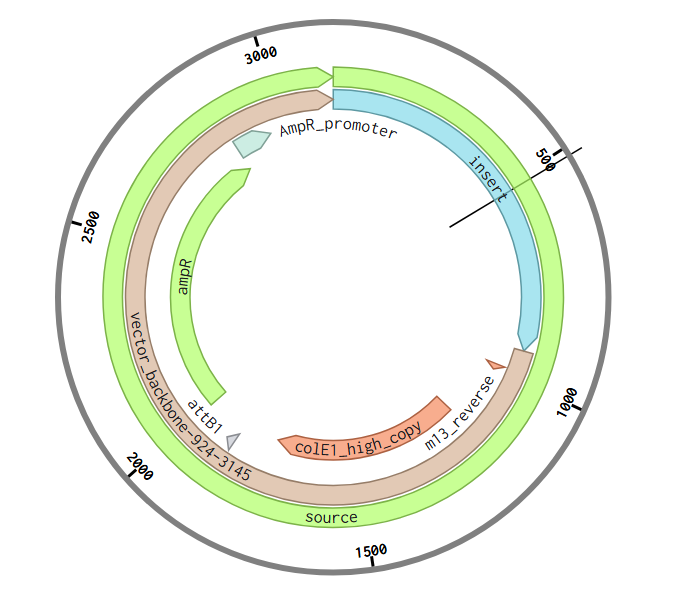
Part 4: Prepare a Twist DNA Synthesis Order
Benchling annotation
Plasmid
Part 5: DNA Read/Write/Edit
5.1 DNA Read
(i) What DNA would you want to sequence (e.g., read) and why?
I am interested in sequencing bacteriophage and environmental samples. Bacteriophage are becoming a possibility for drug resistant bacteria treatments, and they can be a vector in bio engineering. Their prevalence in the environment and interactions with bacteria also make it interesting to study metagenomic samples with and without phage.
(ii) In lecture, a variety of sequencing technologies were mentioned. What technology or technologies would you use to perform sequencing on your DNA and why?\
In the past, we have used illumina (NGS) and plasmidsaurus (nanopore) for phage. Plasmidsaurus is quicker and less expensive but has had variable results. Metagenomics also uses NGS and sometimes nanopore (can be more portable for lab work).
NGS is second-gen, nanopore is third-gen.
Input is the library which is fragmented extracted DNA which has gone through end repair, a-tailing, and adapter ligation, also possibly pcr if the target sequence needs to be amplified.
Illumina works by isothermically amplifying the fragments, fragment strands binding to oligos on one end, polymerase creating the reverse strands of the fragments, and then bridge amplification repeating over and over for all the fragments. The reverse strands are discarded and then the forward strands are sequenced through fluorescently tagged nucleotides being added one by one, with the signals being read for each added base and associated with the length.
The output of illumina is millions or more of short reads. The output for plasmidsaurus is long reads or whole plasmid.
5.2 DNA Write
(i) What DNA would you want to synthesize (e.g., write) and why?
I think that DNA encoded sensors are interesting. With a background in computing, I can see a lot of places where similar principals would apply and biological sensors could be useful (e.g. water testing, health testing, soil testing, working with hardware to give timelines, etc.).
(ii) What technology or technologies would you use to perform this DNA synthesis and why?\
Enzymatic DNA Synthesis would be good to use since it is more sustainable (and better for longer single strands), but it would be likely easier to start with phosphoramidite method synthesis which is industry standard and more cost-effective (for now).
The essential steps of the phosphoramidite method for oligonucleotide synthesis are
Deprotection (acid removes protecting group to expose hydroxyl group)
Coupling (nucleoside phosphoramidite is activated and added to hydroxyl group)
Capping (unreacted hydroxyl groups are “capped” to prevent further nucleotide addition)
Oxidation/Sulfurization (phosphite triester linkage is converted into stable pentavalent phosphotriester bond)
Limitations of the phosphoramidite method include length (only 100-200bp possible) and having way less sustainability (toxic organic waste is generated).
5.3 DNA Edit
(i) What DNA would you want to edit and why?
I think more can be done for flora, especially in the accessibility of parts (such as seeds) with edits. I think that in human medicine, preventatives and sensors are interesting. My aunt was diagnosed with stage 4 liver cancer in December with no prior warning. It would be great to have better ways to detect and understand silent conditions.
(ii) What technology or technologies would you use to perform these DNA edits and why?\
CRISPR Cas12a can be useful for biosensors, and bacterium mediated transfer and engineered phage (through plasmid transformation) are of interest for targeting plants.
CRISPR Cas12a processes its own precursor (unlike cas9) into crRNA which combines with the enzyme to form ribonucleoprotein (RNP) complexes. The complex recognizes and binds to a specific Protospacer Adjacent Motif (PAM) site, then breaks both strands (forms sticky ends) and starts breaking down ssDNA close by.
Preperation includes selecting the target sequence downstream of a PAM and designing the crRNA.
Limitations include requiring a specific PAM and lower efficiency than cas9 in some mammalian cells
Using custom design tools (trying out stippling, different dot sizes)
Python Files
What the different dot design looks like after programming so far (still need to scale a bit)
AI Usage documentation
I utilized Claude Opus 4.6 to help program a web app to assign values (light-dark as 0-8) to pixels of an image so that it could be represented in different dot sizes or clustering on a petri dish. I also used the model to help scale my programming and cordinates to the proper plate size. Claude models work well for general programming related tasks, but sometimes struggle with nailing down details (e.g. it worked out the logic for pixel calculations very well, but struggled to fix the display attributes and relative sizing)
The paper by Dufour et al. presents and evaluates using liquid handling robots for high-throughput phage susceptibility testing. This is important since as bacteriophage are used more for phage therapy and other applications, single phage and cocktail testing is used to determine the best phage for the particular target, but can be very time consuming to test manually. The method with the liquid handling robot was found to have lower variance and very similar mean results to the manual assays.
Final Project Lab Automation
For my final independent project I would like to use the Opentron T2 to run a large range of phage susceptibility tests, similar to my choosen paper. For my more computational project ideas this could be used to validate phage-host range results or possibly be done in the future with the edited phage designs, and for my phage sensor idea this would be done with the transformed bacteria to gather the luminance-titer results.
Final Project Ideas
Week 4 HW: Protein Design Part I
Part A. Conceptual Questions
How many molecules of amino acids do you take with a piece of 500 grams of meat? (on average an amino acid is ~100 Daltons)
Meat is about 25% protein so 500 grams of meat is about 125 grams of protein. 100 Daltons is equivalent to 100 grams/mol so it is about 1.25 moles amino acids. Multiplying this by avogadro’s number, 6.022x1023, we get about 7.5275x1024 molecules of amino acids for a 500 gram piece of meat.
Why do humans eat beef but do not become a cow, eat fish but do not become fish?
We digest what we eat, breaking it down into components to use in our cells (such as amino acids to make new proteins).
Why are there only 20 natural amino acids?
They fufill a range of roles well (polar, charged, neutral, different sizes), they were based on the elements avalible, and the evolutionary outcome was set at some point as everything down the line started using the same basic building blocks.
Can you make other non-natural amino acids? Design some new amino acids.
Yes, some examples of uses are for tagging proteins or making bio engineering solutions only work in environments where the non-canonical amino-acid is provided.
Where did amino acids come from before enzymes that make them, and before life started?
They might have come from space on meteorites, or been created through interactions of elements around hydrothermal vents.
If you make an α-helix using D-amino acids, what handedness (right or left) would you expect?
D-amino acids form a left handed helix (mirror to the normal right handed helix with L-amino acids).
Why are most molecular helices right-handed?
The right-handed helix is more stable, and there is no steric hindrance between the side chains in that cofirmation.
Why do β-sheets tend to aggregate?
What is the driving force for β-sheet aggregation?
Their edges are prone to binding together (due to unsatisfied hydrogen bonds).
Why do many amyloid diseases form β-sheets?
Can you use amyloid β-sheets as materials?
Amyloid diseases include Alzheimer’s and Parkinson’s. Protein misfolding causes the structures to form to stablize, making them hard to break apart. Yes, there are bio engineering applications in things like material for bio fabrics.
Part B: Protein Analysis and Visualization
Briefly describe the protein you selected and why you selected it.
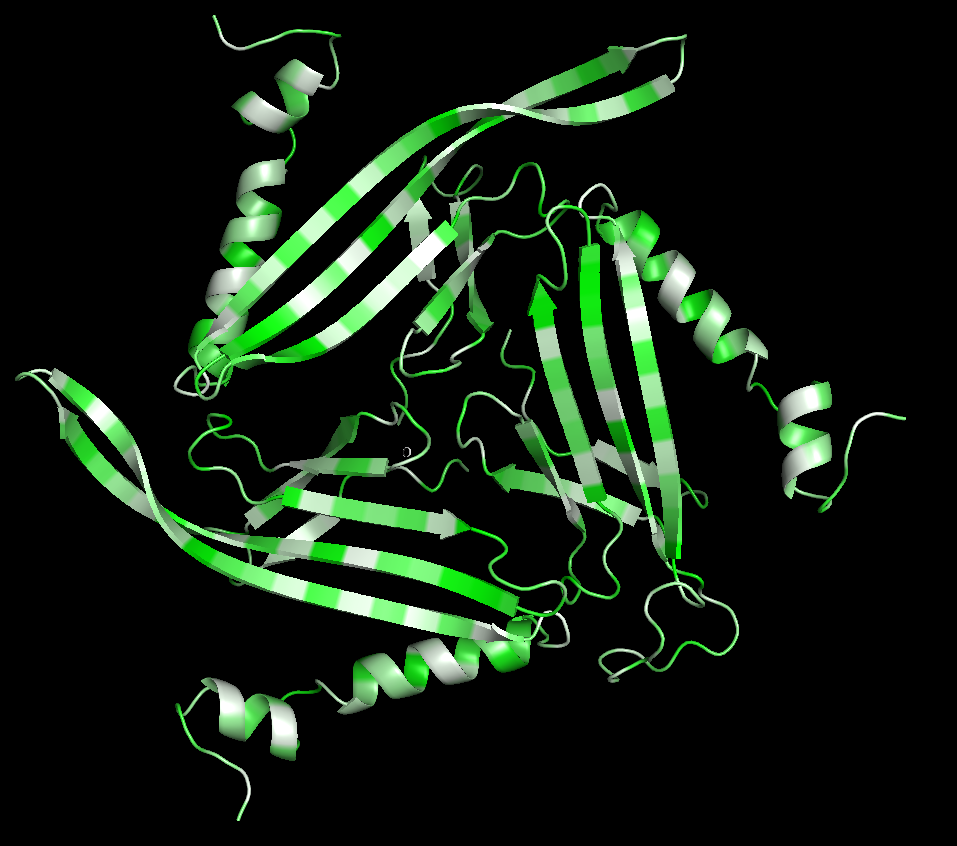
I choose pdb_00002ms2 which is the MS2 coat protein since that is the bacteriophage we are focusing on for the group final project.
Identify the amino acid sequence of your protein.
How long is it? What is the most frequent amino acid?
It is only 127 amino acids long and the most frequent amino acid is Alanine.
How many protein sequence homologs are there for your protein?
There are 12 blast hits, most of which are other coat/capsid proteins.
Does your protein belong to any protein family?
It belongs to the Leviviricetes capsid protein family.
Identify the structure page of your protein in RCSB
When was the structure solved? Is it a good quality structure?
The structure was released in 1995. The resolution is 2.80 Å which is considered good.
Are there any other molecules in the solved structure apart from protein?
No, the coat protein is the only solved structure.
A few homologs are identified under superfamily RNA bacteriophage capsid protein, domain 2BU1 A.
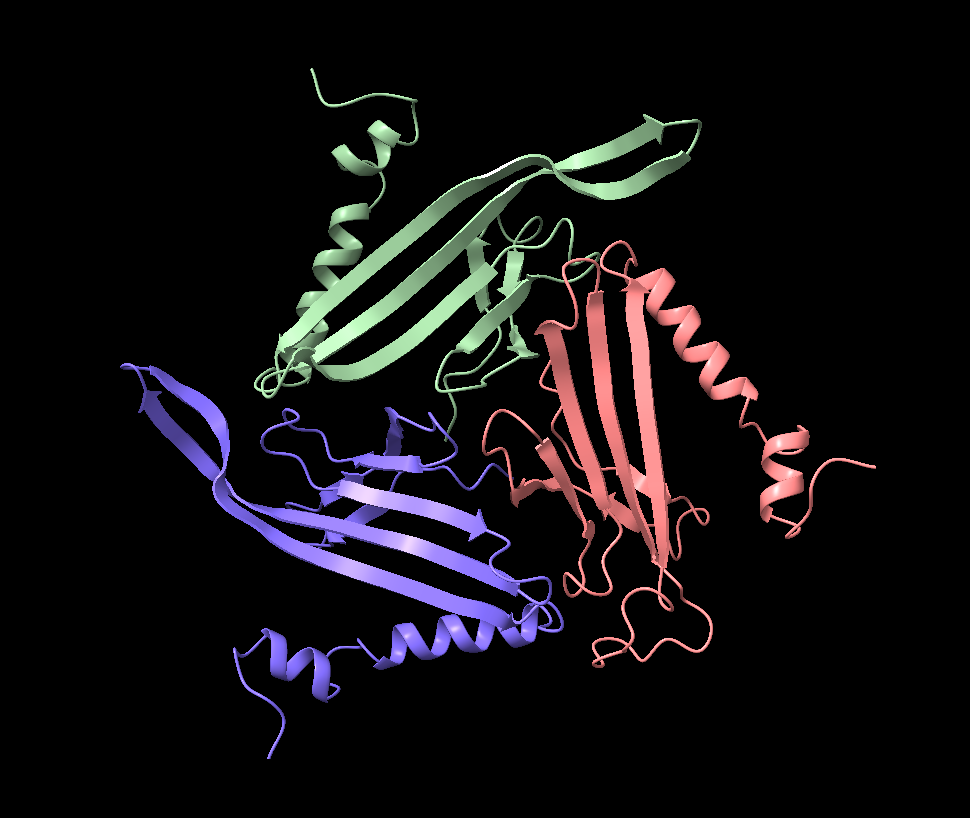
Open the structure of your protein in any 3D molecule visualization software:
Visualization in ChimeraX:
Visualization in Pymol:
Cartoon
Ribbon
Ball and Stick
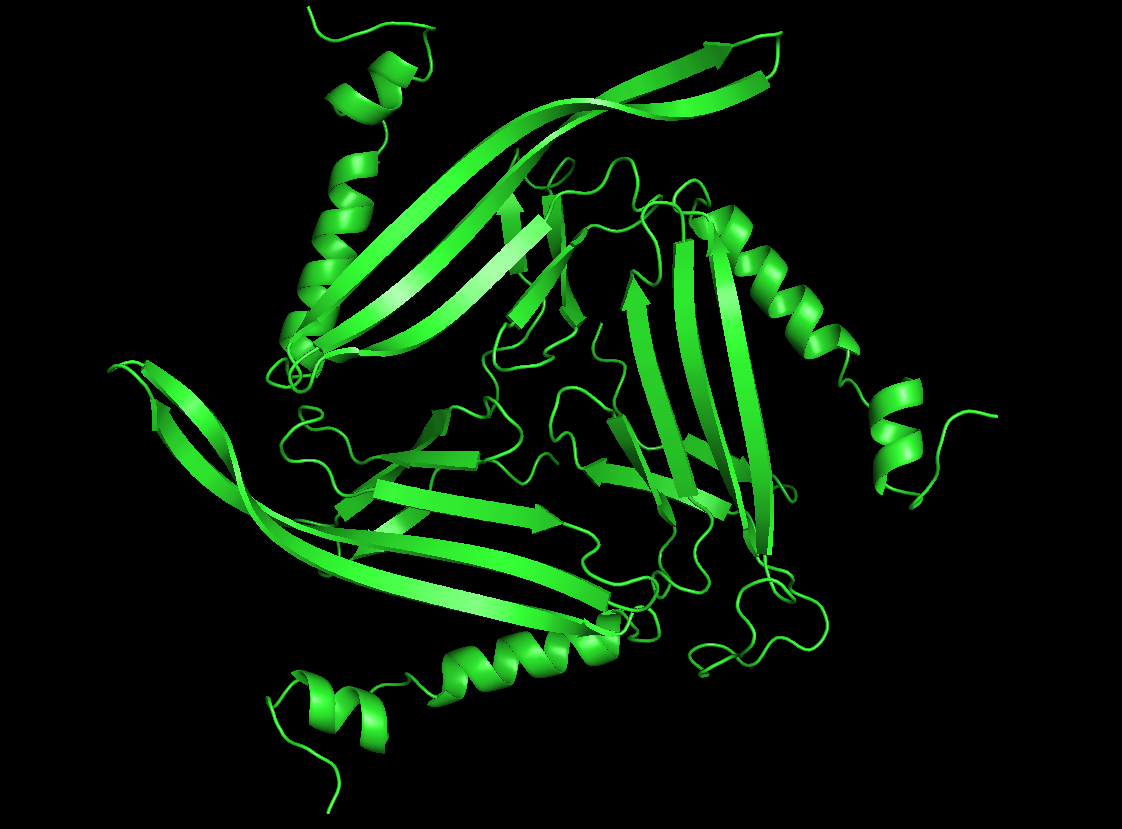
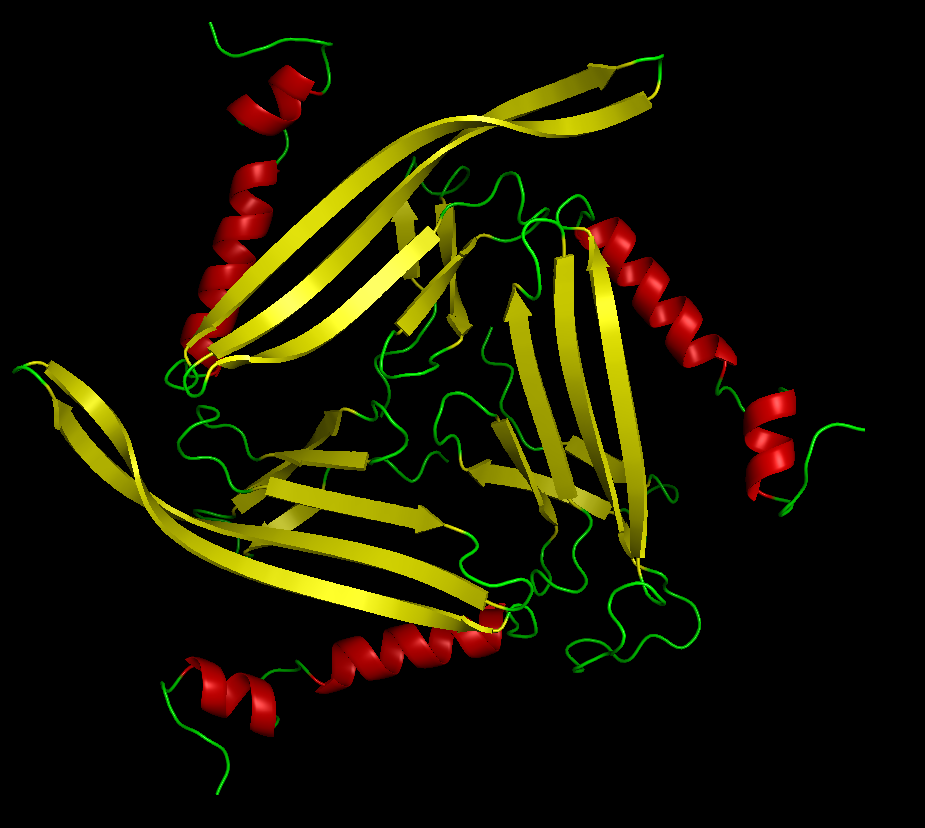
Colored by secondary structure
It has more sheets, with 3 sections with very similar structures of sheets, helices, and loops.
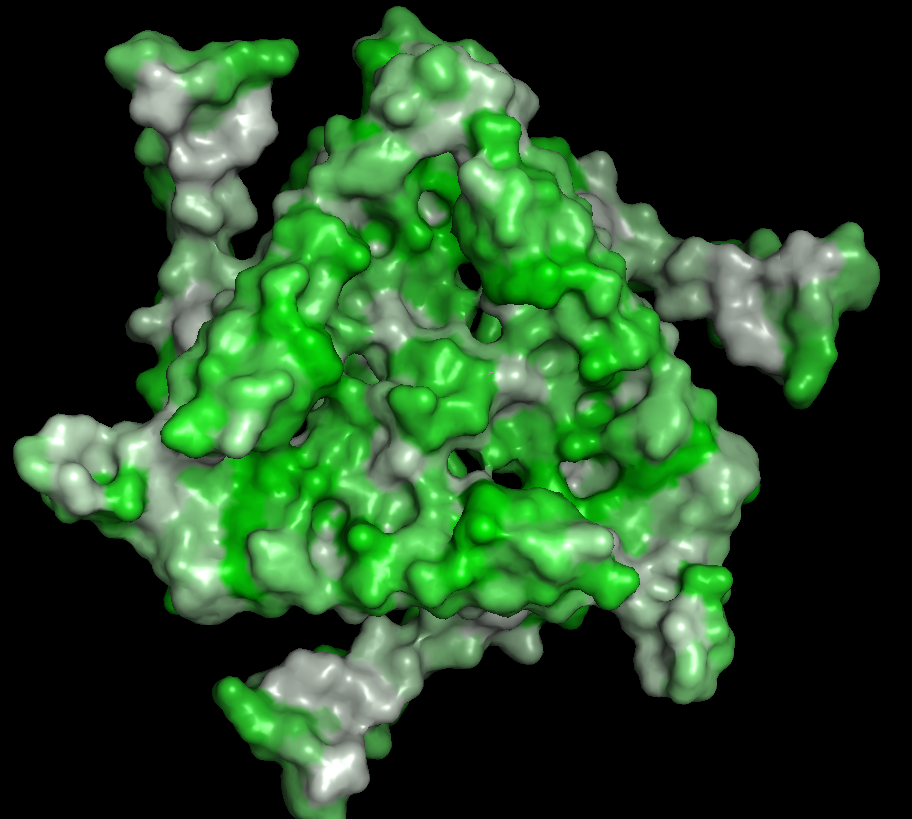
Colored by Residue Type
(all residues)
(residue types, specific)
(residue types, hydrophobic/hydrophilic)
There are mostly polar/nonpolar residues. The hydrophobic and hydrophilic residues are evenly distributed throughout the protein.
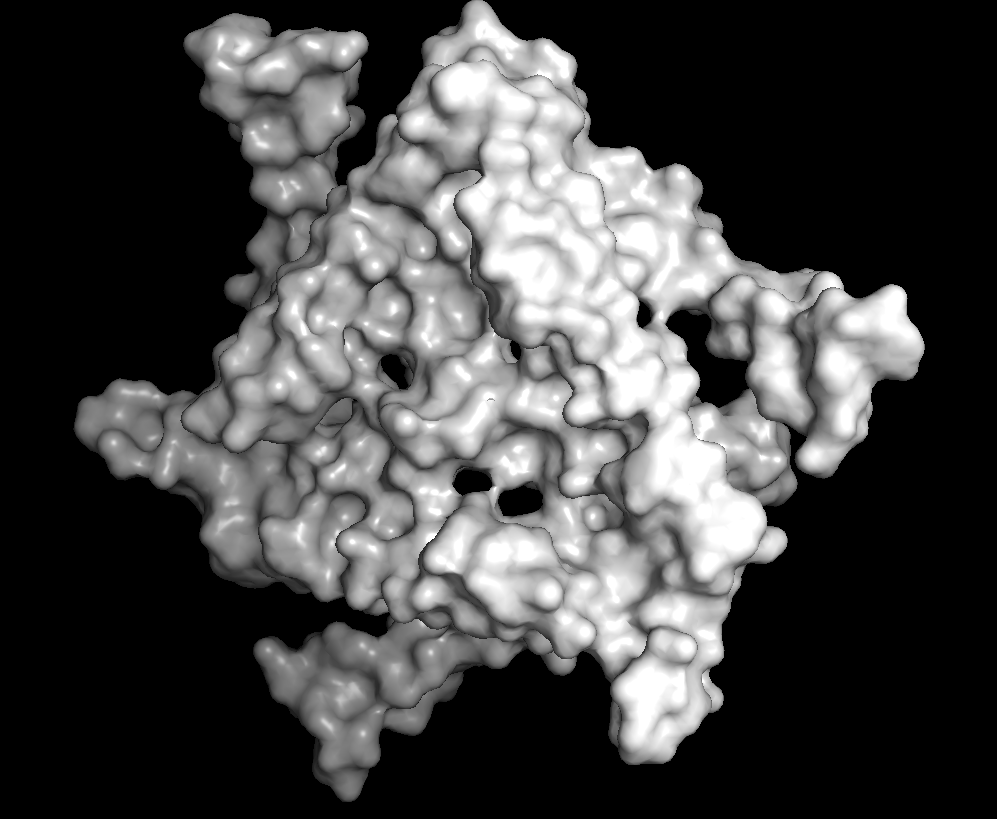
Surface
There are many holes and structural pockets for things to bind.
Part C. Using ML-Based Protein Design Tools
C1. Protein Language Modeling
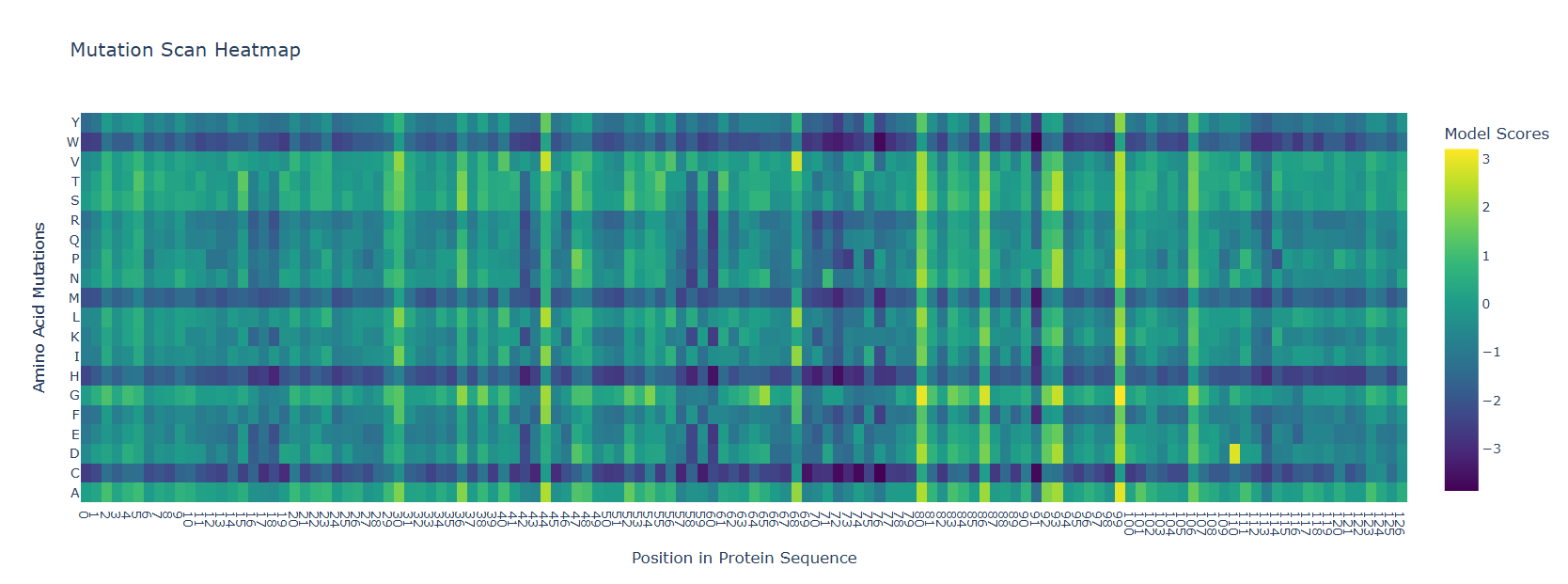
Deep Mutational Scans
Use ESM2 to generate an unsupervised deep mutational scan of your protein based on language model likelihoods.
Can you explain any particular pattern? (choose a residue and a mutation that stands out)
(Bonus) Find sequences for which we have experimental scans, and compare the prediction of the language model to experiment.
Latent Space Analysis
Use the provided sequence dataset to embed proteins in reduced dimensionality.
Analyze the different formed neighborhoods: do they approximate similar proteins?
Place your protein in the resulting map and explain its position and similarity to its neighbors.
C2. Protein Folding
Folding a protein
Fold your protein with ESMFold. Do the predicted coordinates match your original structure?
Try changing the sequence, first try some mutations, then large segments. Is your protein structure resilient to mutations?
C3. Protein Generation
Inverse-Folding a protein: Let’s now use the backbone of your chosen PDB to propose sequence candidates via ProteinMPNN
Analyze the predicted sequence probabilities and compare the predicted sequence vs the original one.
Input this sequence into ESMFold and compare the predicted structure to your original.
Part D. Group Brainstorm on Bacteriophage Engineering
Choose one or two main goals from the list that you think you can address computationally (e.g., “We’ll try to stabilize the lysis protein,” or “We’ll attempt to disrupt its interaction with E. coli DnaJ.”).
Write a 1-page proposal (bullet points or short paragraphs) describing:
Which tools/approaches from recitation you propose using (e.g., “Use Protein Language Models to do in silico mutagenesis, then AlphaFold-Multimer to check complexes.”).
Why do you think those tools might help solve your chosen sub-problem?
Name one or two potential pitfalls (e.g., “We lack enough training data on phage–bacteria interactions.”).
Week 6 HW: Genetic Circuts Part I: Assembly Technologies
Week 7 HW: Genetic Circuts Part II: Neuromorphic Circuts
Assignment Part 1: Intracellular Artificial Neural Networks (IANNs)
What advantages do IANNs have over traditional genetic circuits, whose input/output behaviors are Boolean functions?
IANNs allow for the detection of more gradient cellular signals and multiple signals being taken into account at once, which results in more nuanced outputs (not based on a single on/off like in traditional circuits).
Describe a useful application for an IANN; include a detailed description of input/output behavior, as well as any limitations an IANN might face to achieve your goal.
Insulin/glucose detection and response might be a useful applictaion for an IANN. In those with diabetes, fluctuations are not binary and must be managed in both directions. An IANN could work better than a traditional genetic circuit to detect high/low levels of glucose and insulin and produce a proportional response. This is similar to the natural function of the pancreas. Limitations include the black box nature of IANNs, the risks of circuit failure, and immune responses.
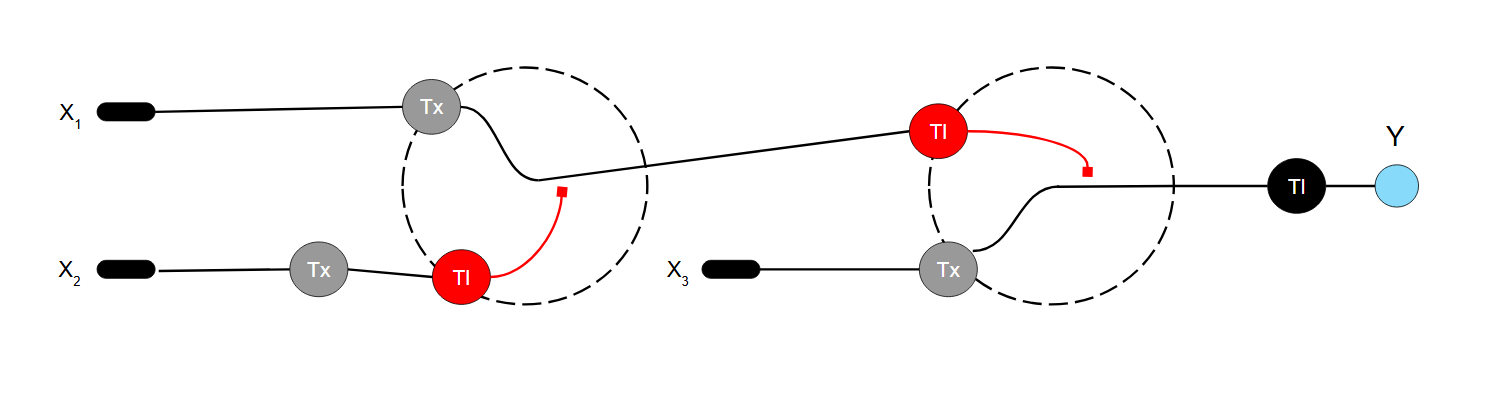
Below is a diagram for an intracellular multilayer perceptron where layer 1 outputs an endoribonuclease that regulates a fluorescent protein output in layer 2. The X1 input is DNA encoding for the Csy4 endoribonuclease, the X2 input is DNA encoding for a protein that down regulates the Csy4 endoribonuclease mRNA, and the X3 input is DNA encoding for a fluorescent protein output whose mRNA is regulated by Csy4. Tx: transcription; Tl: translation.
Assignment Part 2: Fungal Materials
What are some examples of existing fungal materials and what are they used for? What are their advantages and disadvantages over traditional counterparts?
Fungal materials include mycelium which is used for packaging, insulation, and construction material. They are more sustainable than their traditional counterparts, but require growing time and have lower durability (sensitivity to moisture, less mechanical strength).
What might you want to genetically engineer fungi to do and why? What are the advantages of doing synthetic biology in fungi as opposed to bacteria?
Fungi would be a good possibility for a chassis for breaking down environmental toxins since they have enzymes that break down a lot of chemical structures and can be more resilent than bacteria in certain environments. As Eukaryotes, fungi can fold proteins with post-translational modifications, which gives them more synthetic biology possibilities.