Week 2 — DNA Read, Write, & Edit

This week explores the read–write–edit toolkit: sequencing and synthesis workflows, restriction digests and gel electrophoresis, and early genome-editing frameworks.
Lecture (Tues, Feb 10)
Recitation (Wed, Feb 11)
DNA Gel, restriction enzymes, Benchling intro, Twist intro
(▶️Recording |
💻Slides)
Ice Kiattisewee
Lab (Thurs-Fri, Feb 12 - 13)
Homework — DUE BY FEB 17 2PM MIT TIME
Questions?
MIT / Harvard students: htgaa2026-TAs@media.mit.edu
Global students: htgaa2026-globalTAs@media.mit.edu
Need help with webpages? Editing/Publishing Category
Documentation
Make sure to document every step of the in-silico and lab experiments. Make sketches, screenshots, notes, drawings… anything that helps you - and others - understand the experiment.
Your documentation should help you - and others - to understand the topic. Don’t be afraid to add things that don’t work. Show your failures - and how you overcame them. Your Documentation should be a description of the amazing journey you are on!
Part 0: Basics of Gel Electrophoresis
Assignees for this section
| MIT/Harvard students | Required |
| Committed Listeners | Required |
Attend or watch all lecture and recitation videos. Optionally watch bootcamp.
Part 1: Benchling & In-silico Gel Art
Assignees for this section
| MIT/Harvard students | Required |
| Committed Listeners | Required |
See this week’s lab protocol “Gel Art: Restriction Digests and Gel Electrophoresis” for details. Overview:
- Make a free account at benchling.com
- Import the Lambda DNA.
- Simulate Restriction Enzyme Digestion with the following Enzymes:
- EcoRI
- HindIII
- BamHI
- KpnI
- EcoRV
- SacI
- SalI
- Create a pattern/image in the style of Paul Vanouse’s Latent Figure Protocol artworks.
- You might find Ronan’s website a helpful tool for quickly iterating on designs!
Part 2: Gel Art - Restriction Digests and Gel Electrophoresis
Assignees for this section
| MIT/Harvard students | Required |
| Committed Listeners | Optional (for those with Lab access) |
In the wet-lab perform the lab experiment you designed in Part 1 and outlined in this week’s lab protocol “Gel Art: Restriction Digests and Gel Electrophoresis”.
Part 3: DNA Design Challenge
Assignees for this section
| MIT/Harvard students | Required |
| Committed Listeners | Required |
3.1. Choose your protein.
In recitation, we discussed that you will pick a protein for your homework that you find interesting. Which protein have you chosen and why? Using one of the tools described in recitation (NCBI, UniProt, google), obtain the protein sequence for the protein you chose.
[Example from our group homework, you may notice the particular format — The example below came from UniProt]
>sp|P03609|LYS_BPMS2 Lysis protein OS=Escherichia phage MS2 OX=12022 PE=2 SV=1 METRFPQQSQQTPASTNRRRPFKHEDYPCRRQQRSSTLYVLIFLAIFLSKFTNQLLLSLL EAVIRTVTTLQQLLT
3.2. Reverse Translate: Protein (amino acid) sequence to DNA (nucleotide) sequence.
The Central Dogma discussed in class and recitation describes the process in which DNA sequence becomes transcribed and translated into protein. The Central Dogma gives us the framework to work backwards from a given protein sequence and infer the DNA sequence that the protein is derived from. Using one of the tools discussed in class, NCBI or online tools (google “reverse translation tools”), determine the nucleotide sequence that corresponds to the protein sequence you chose above.
[Example: Get to the original sequence of phage MS2 L-protein from its genome phage MS2 genome - Nucleotide - NCBI]
Lysis protein DNA sequence
atggaaacccgattccctcagcaatcgcagcaaactccggcatctactaatagacgccggccattcaaacatgaggattacccatgtcgaagacaacaaagaagttcaactctttatgtattgatcttcctcgcgatctttctctcgaaatttaccaatcaattgcttctgtcgctactggaagcggtgatccgcacagtgacgactttacagcaattgcttacttaa
3.3. Codon optimization.
Once a nucleotide sequence of your protein is determined, you need to codon optimize your sequence. You may, once again, utilize google for a “codon optimization tool”. In your own words, describe why you need to optimize codon usage. Which organism have you chosen to optimize the codon sequence for and why?
[Example from Codon Optimization Tool | Twist Bioscience while avoiding Type IIs enzyme recognition sites BsaI, BsmBI, and BbsI]
Lysis protein DNA sequence with Codon-Optimization
ATGGAAACCCGCTTTCCGCAGCAGAGCCAGCAGACCCCGGCGAGCACCAACCGCCGCCGCCCGTTCAAACATGAAGATTATCCGTGCCGTCGTCAGCAGCGCAGCAGCACCCTGTATGTGCTGATTTTTCTGGCGATTTTTCTGAGCAAATTCACCAACCAGCTGCTGCTGAGCCTGCTGGAAGCGGTGATTCGCACAGTGACGACCCTGCAGCAGCTGCTGACCTAA
3.4. You have a sequence! Now what?
What technologies could be used to produce this protein from your DNA? Describe in your words the DNA sequence can be transcribed and translated into your protein. You may describe either cell-dependent or cell-free methods, or both.
3.5. [Optional] How does it work in nature/biological systems?
- Describe how a single gene codes for multiple proteins at the transcriptional level.
- Try aligning the DNA sequence, the transcribed RNA, and also the resulting translated Protein!!! See example below.
[Example shows the biomolecular flow in central dogma from DNA to RNA to Protein] Special note that all “T” were transcribed into “U” and that the 3-nt codon represents 1-AA.
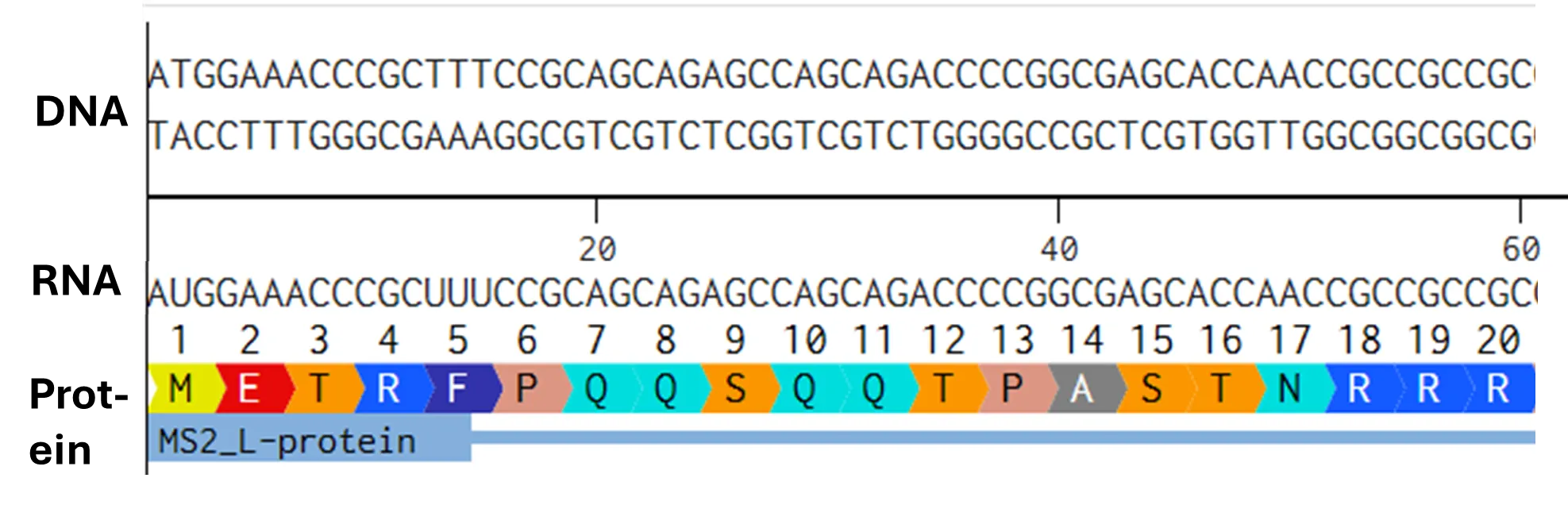
Rearranged snapshot of MS2 L-protein information flow from DNA to RNA to Protein. Captured from Ice’s Benchling and stitched together in a ppt
Part 4: Prepare a Twist DNA Synthesis Order
Assignees for this section
| MIT/Harvard students | Required |
| Committed Listeners | Required |
This is a practice exercise, not necessarily your real Twist order!
4.1. Create a Twist account and a Benchling account
click through for Twist signup
click through for Benchling signup
4.2. Build Your DNA Insert Sequence
For example, let’s make a sequence that will make E. coli glow fluorescent green under UV light by constitutively (always) expressing sfGFP (a green fluorescent protein):
In Benchling, select New DNA/RNA sequence
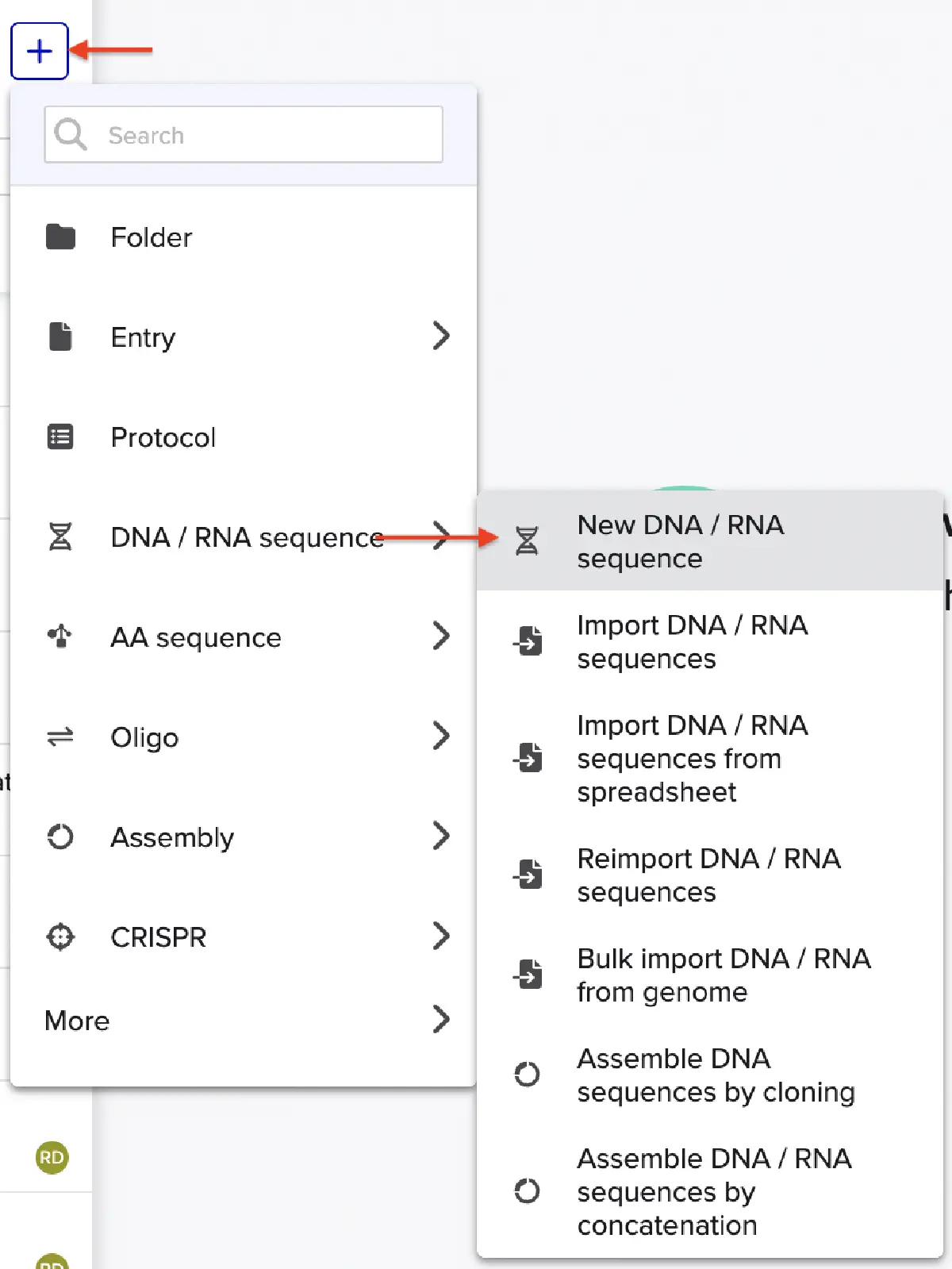
Give your insert sequence a name and select DNA with a Linear topology (this is a linear sequence that will be inserted into a circular backbone vector of our choosing).
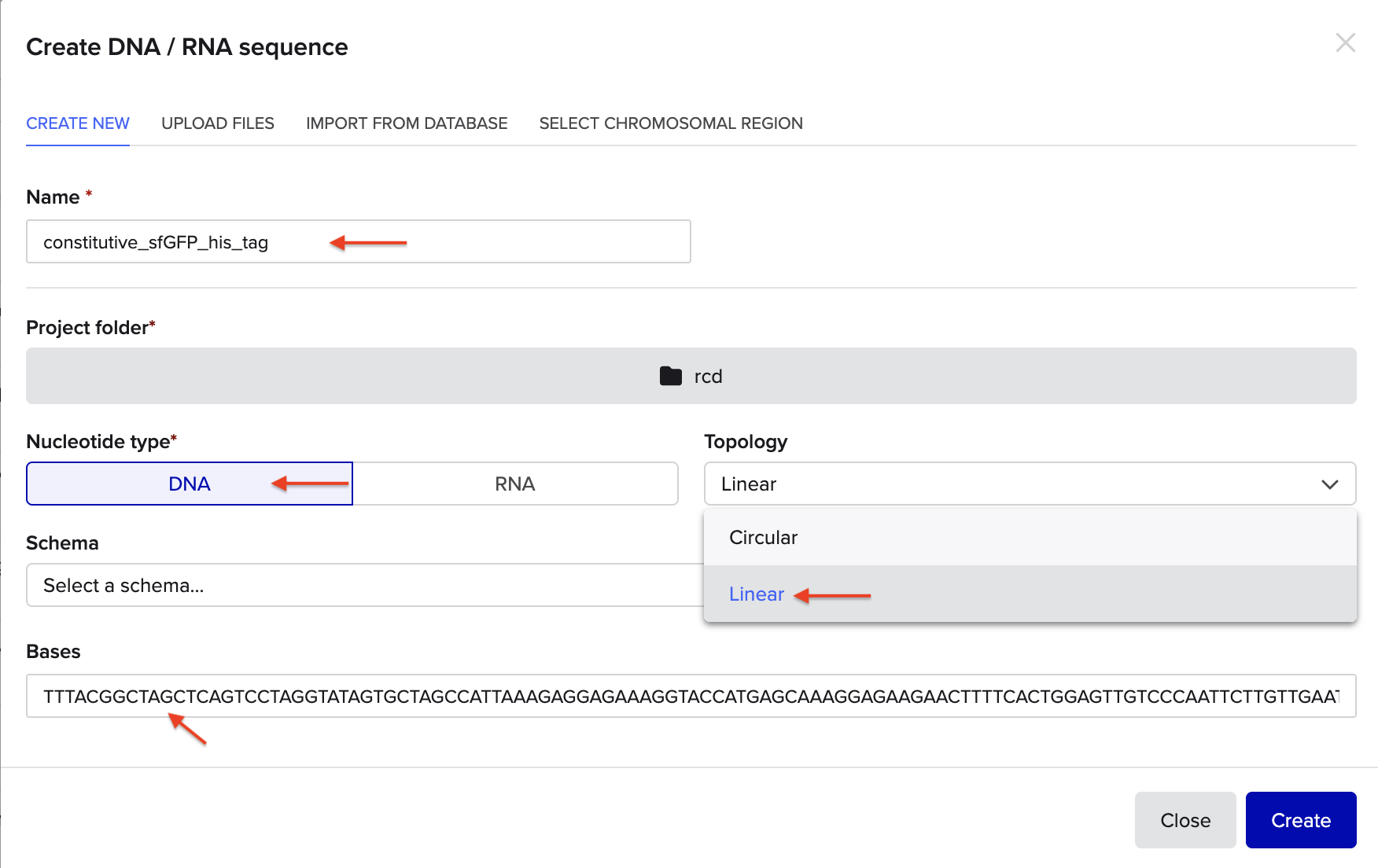
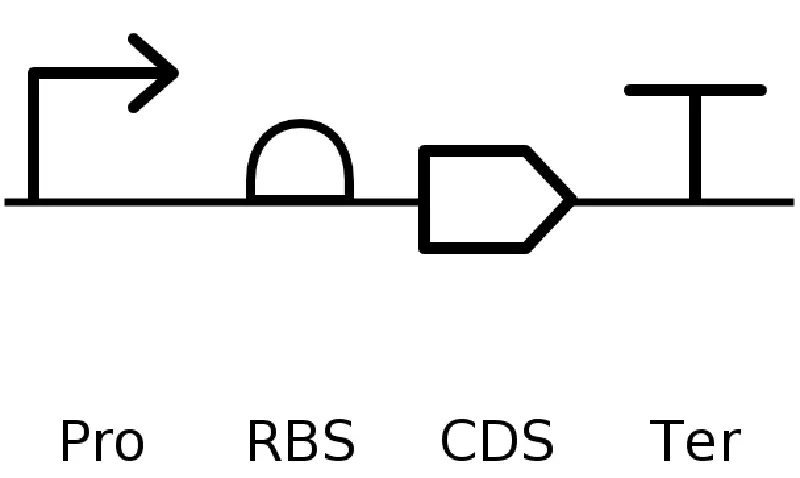
Go through each piece of the given DNA sequences highlighted below (Promoter, RBS, Start Codon, Coding Sequence, His Tag, Stop Codon, Terminator) and paste the sequences into the Benchling file one after the other (replacing the coding sequence with your codon optimized DNA sequence of interest!). Each time you add a new piece of the sequence, make sure to annotate by right clicking over the sequence and creating an annotation that describes what each piece (e.g., Promoter, RBS, etc.) is (see image below).
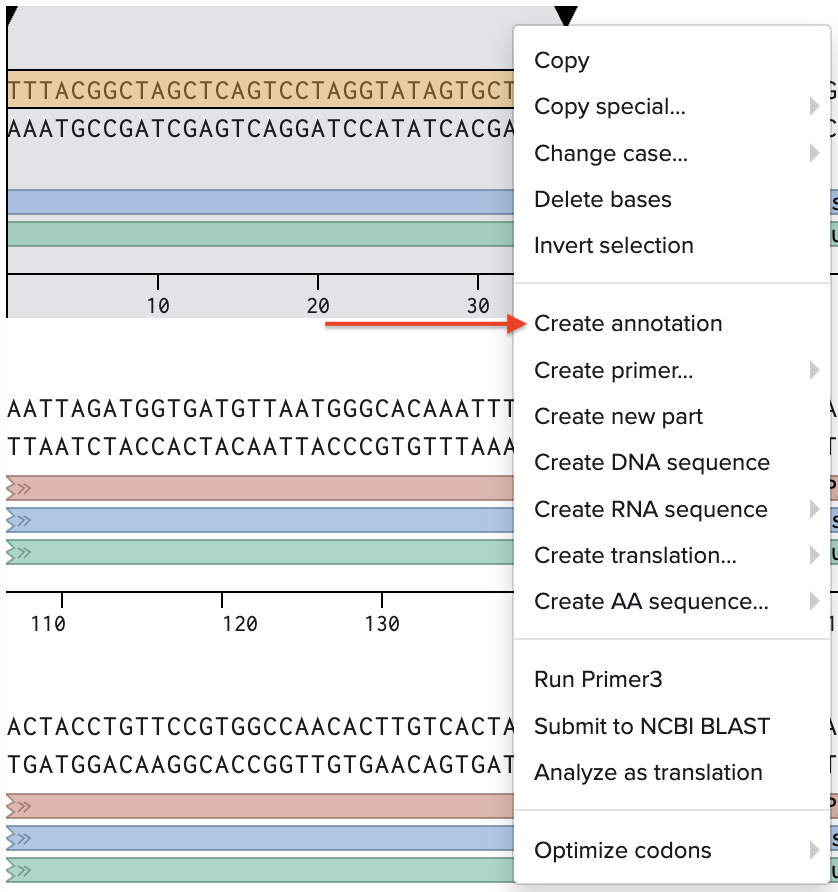
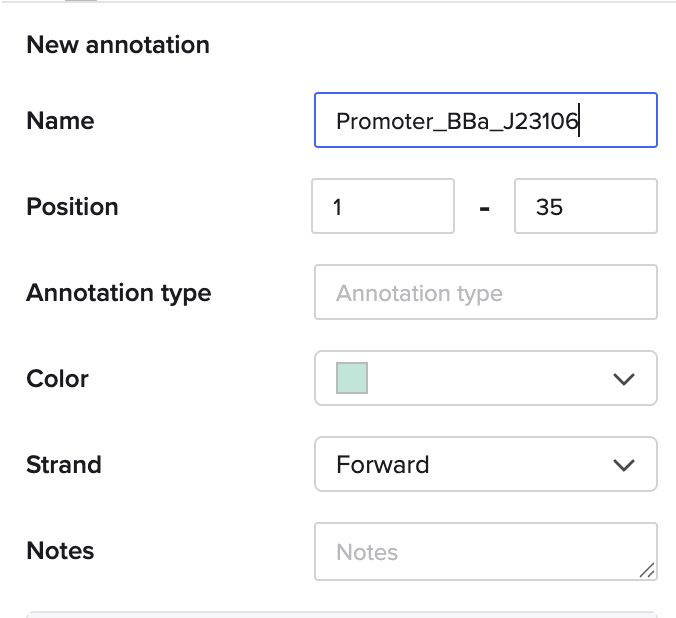
- Promoter (e.g. BBa_J23106):
TTTACGGCTAGCTCAGTCCTAGGTATAGTGCTAGC - RBS (e.g. BBa_B0034 with spacers for optimal expression):
CATTAAAGAGGAGAAAGGTACC - Start Codon:
ATG - Coding Sequence (your codon optimized DNA for a protein of interest, sfGFP for example):
AGCAAAGGAGAAGAACTTTTCACTGGAGTTGTCCCAATTCTTGTTGAATTAGATGGTGATGTTAATGGGCACAAATTTTCTGTCCGTGGAGAGGGTGAAGGTGATGCTACAAACGGAAAACTCACCCTTAAATTTATTTGCACTACTGGAAAACTACCTGTTCCGTGGCCAACACTTGTCACTACTCTGACCTATGGTGTTCAATGCTTTTCCCGTTATCCGGATCACATGAAACGGCATGACTTTTTCAAGAGTGCCATGCCCGAAGGTTATGTACAGGAACGCACTATATCTTTCAAAGATGACGGGACCTACAAGACGCGTGCTGAAGTCAAGTTTGAAGGTGATACCCTTGTTAATCGTATCGAGTTAAAGGGTATTGATTTTAAAGAAGATGGAAACATTCTTGGACACAAACTCGAGTACAACTTTAACTCACACAATGTATACATCACGGCAGACAAACAAAAGAATGGAATCAAAGCTAACTTCAAAATTCGCCACAACGTTGAAGATGGTTCCGTTCAACTAGCAGACCATTATCAACAAAATACTCCAATTGGCGATGGCCCTGTCCTTTTACCAGACAACCATTACCTGTCGACACAATCTGTCCTTTCGAAAGATCCCAACGAAAAGCGTGACCACATGGTCCTTCTTGAGTTTGTAACTGCTGCTGGGATTACACATGGCATGGATGAGCTCTACAAA - 7x His Tag (Let’s add a 7×His tag at the C-terminus of the protein to enable protein purification from E. coli):
CATCACCATCACCATCATCAC - Stop Codon:
TAA - Terminator (e.g. BBa_B0015):
CCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCTACTAGAGTCACACTGGCTCACCTTCGGGTGGGCCTTTCTGCGTTTATA
Once you’ve completed this, click on Linear Map to preview the entire sequence. If you intend to have a TA review a sequence in the future, this is a good way to verify that all sections are annotated!

This is not required for this exercise, but to share your design with others, please ensure that link sharing is turned on!
 (Optional) Share your final sequence link with a TA for review!
(Optional) Share your final sequence link with a TA for review!
This insert sequence you built is commonly referred to as an expression cassette in molecular biology (a sequence you can drop into any vector and it’ll perform its function). Go ahead and download the FASTA file for the sequence you made.
It’s helpful to visualize DNA designs using SBOL Canvas (Synthetic Biology Open Language) to convey your designs. Here’s an example of what you just annotated in Benchling:
4.3. On Twist, Select The “Genes” Option

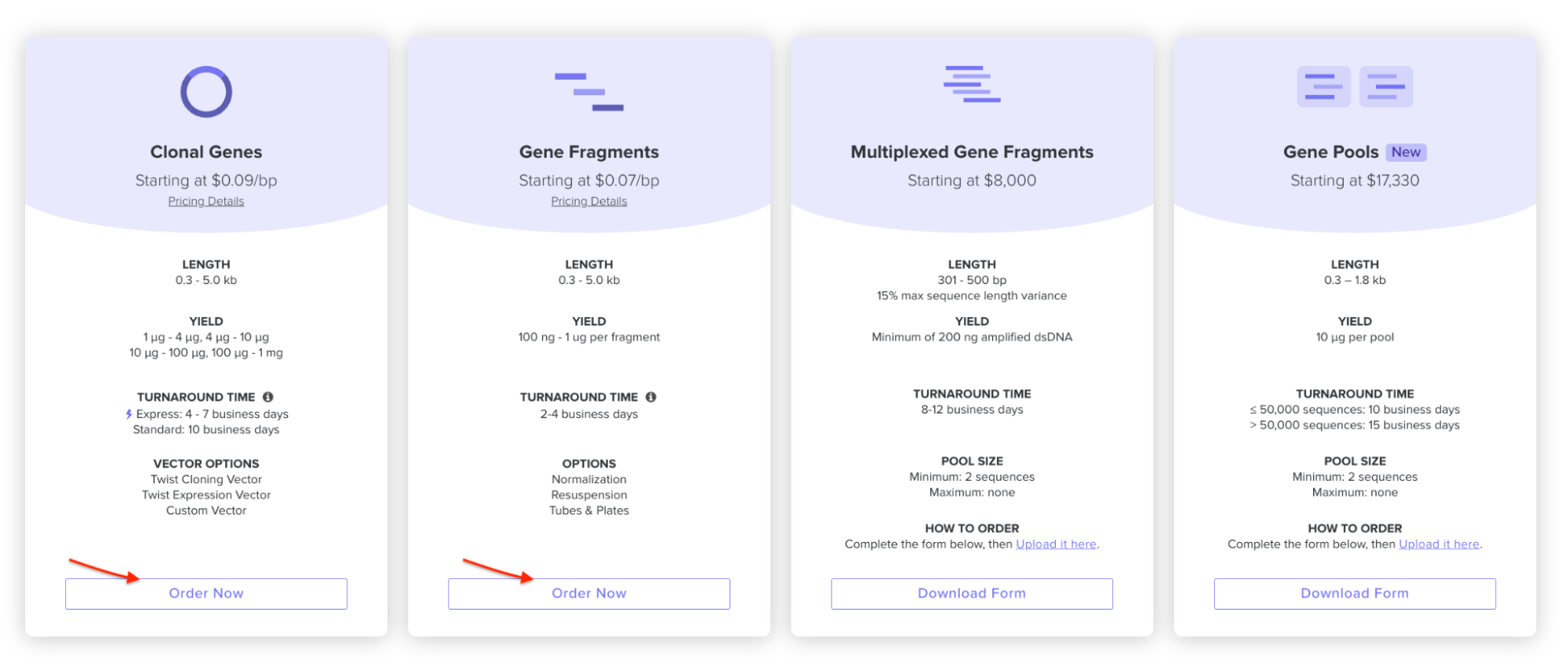
4.4. Select “Clonal Genes” option
For this demonstration, we’ll choose Clonal Genes. You’ll select clonal genes or gene fragments depending on your final project.
Historically, HTGAA projects using clonal genes (circular DNA) have reached experimental results 1-2 weeks quicker because they can be transformed directly into E. coli without additional assembly.
Gene fragments (linear DNA) offer greater design flexibility but typically require an assembly or cloning step prior to transformation. An advantage is If designed with the appropriate exonuclease protection, gene fragments can be used directly in cell-free expression.
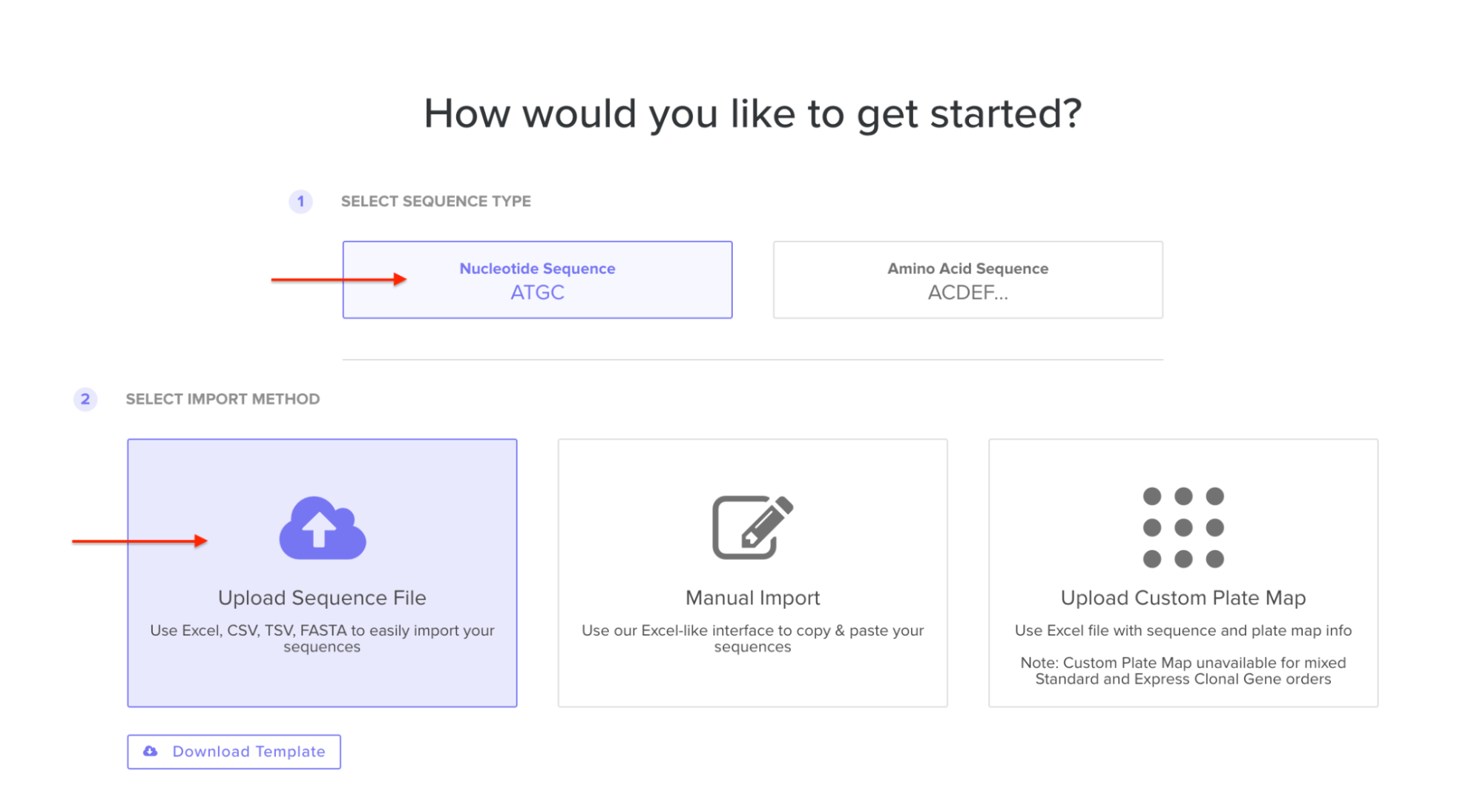
4.5. Import your sequence
You just took an amino acid sequence of interest and converted it into DNA, codon optimized it, and built an expression cassette around it! Choose the Nucleotide Sequence option and Upload Sequence File to upload your FASTA file.
4.6. Choose Your Vector
Since we’re ordering a clonal gene, you will need to refer to Twist’s Vector Catalog to choose your circular backbone. You can think of this as taking your linear expression cassette for your protein of interest, and completing the rest of the circle!
The backbone confers many special properties like antibiotic resistance, an origin of replication, and more. Discuss with your node to decide on appropriate antibiotic options. At MIT/Harvard, you can use Ampicillin, Chloramphenicol, or Kanamycin resistance.
Twist vectors do not contain restriction sites near the insert fragment, so make sure to flank your design with cut sites if you are intending to extract this DNA insert fragment later.
For this demonstration, choose a Twist cloning vectors like pTwist Amp High Copy.


Click into your sequence and select download construct (GenBank) to get the full plasmid sequence:
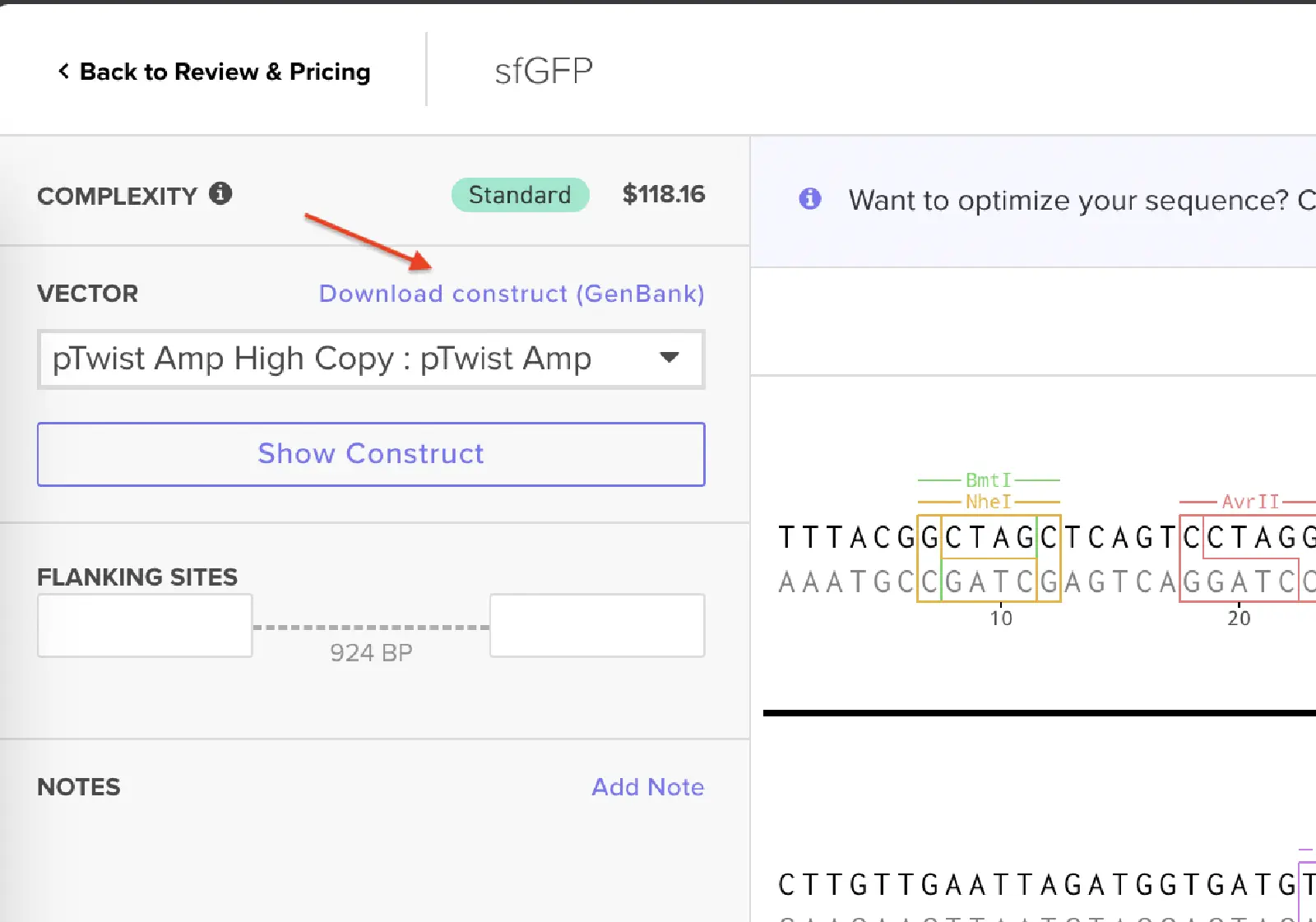
Go back to your Benchling account. Inside of a folder, click the import DNA/RNA sequence button and upload the GenBank file you just downloaded.


This is the plasmid you just built with your expression cassette included. Congratulations on building your first plasmid!
Important
For your final projects, remember to include:
- Fully annotated Benchling insert fragment
- Desired Twist cloning vector
Part 5: DNA Read/Write/Edit
Assignees for this section
| MIT/Harvard students | Required |
| Committed Listeners | Required |
5.1 DNA Read
(i) What DNA would you want to sequence (e.g., read) and why? This could be DNA related to human health (e.g. genes related to disease research), environmental monitoring (e.g., sewage waste water, biodiversity analysis), and beyond (e.g. DNA data storage, biobank).
![DNA-based digital data storage technology. Source: Archives in DNA: Workshop Exploring Implications of an Emerging Bio-Digital Technology through Design Fiction - Scientific Figure on ResearchGate. Available from: https://www.researchgate.net/figure/DNA-based-digital-data-storage-technology_fig1_353128454 [accessed 11 Feb 2025]](/2026a/course-pages/weeks/week-02/image4.png)
DNA-based digital data storage technology. Source: Archives in DNA: Workshop Exploring Implications of an Emerging Bio-Digital Technology through Design Fiction - Scientific Figure on ResearchGate. Available from: https://www.researchgate.net/figure/DNA-based-digital-data-storage-technology_fig1_353128454 [accessed 11 Feb 2025]
(ii) In lecture, a variety of sequencing technologies were mentioned. What technology or technologies would you use to perform sequencing on your DNA and why?
Also answer the following questions:
- Is your method first-, second- or third-generation or other? How so?
- What is your input? How do you prepare your input (e.g. fragmentation, adapter ligation, PCR)? List the essential steps.
- What are the essential steps of your chosen sequencing technology, how does it decode the bases of your DNA sample (base calling)?
- What is the output of your chosen sequencing technology?
5.2 DNA Write
(i) What DNA would you want to synthesize (e.g., write) and why? These could be individual genes, clusters of genes or genetic circuits, whole genomes, and beyond. As described in class thus far, applications could range from therapeutics and drug discovery (e.g., mRNA vaccines and therapies) to novel biomaterials (e.g. structural proteins), to sensors (e.g., genetic circuits for sensing and responding to inflammation, environmental stimuli, etc.), to art (DNA origamis). If possible, include the specific genetic sequence(s) of what you would like to synthesize! You will have the opportunity to actually have Twist synthesize these DNA constructs! :)
See some famous examples of DNA design
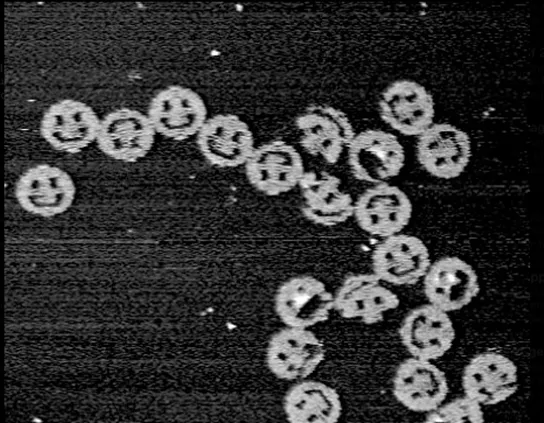
DNA origami by Paul W. K. Rothemund, California Institute of Technology, 2004. 100 nanometers in diameter.
(ii) What technology or technologies would you use to perform this DNA synthesis and why?
Also answer the following questions:
- What are the essential steps of your chosen sequencing methods?
- What are the limitations of your sequencing method (if any) in terms of speed, accuracy, scalability?
5.3 DNA Edit
(i) What DNA would you want to edit and why? In class, George shared a variety of ways to edit the genes and genomes of humans and other organisms. Such DNA editing technologies have profound implications for human health, development, and even human longevity and human augmentation. DNA editing is also already commonly leveraged for flora and fauna, for example in nature conservation efforts, (animal/plant restoration, de-extinction), or in agriculture (e.g. plant breeding, nitrogen fixation). What kinds of edits might you want to make to DNA (e.g., human genomes and beyond) and why?

Colossal Biosciences Inc., a biotechnology company using genetic engineering to de-extinct various historic animals such as the woolly mammoth, dodo, and dire wolf.
(ii) What technology or technologies would you use to perform these DNA edits and why?
Also answer the following questions:
- How does your technology of choice edit DNA? What are the essential steps?
- What preparation do you need to do (e.g. design steps) and what is the input (e.g. DNA template, enzymes, plasmids, primers, guides, cells) for the editing?
- What are the limitations of your editing methods (if any) in terms of efficiency or precision?