Biological engineering application or tool you want to develop and why. Functional thyroid hormone biosensing Thyroid hormones play a central role in human physiology. The thyroid gland produces thyroxine (T4; 3,3′,5,5′-tetraiodo-L-thyronine) and triiodothyronine (T3; 3,3′,5-triiodo-L-thyronine), of which T3 is the biologically active form. T3 regulates energy homeostasis, metabolism, growth, and normal development by controlling transcriptional programs across multiple tissues. Disruptions in thyroid hormone signaling therefore can cause severe consequences. For people with thyroid-related disorders is neccesary then to monitore their hormone levels frequently and “play” with the doses until they obtain a precise amount that doesnt trigger any negative effects.
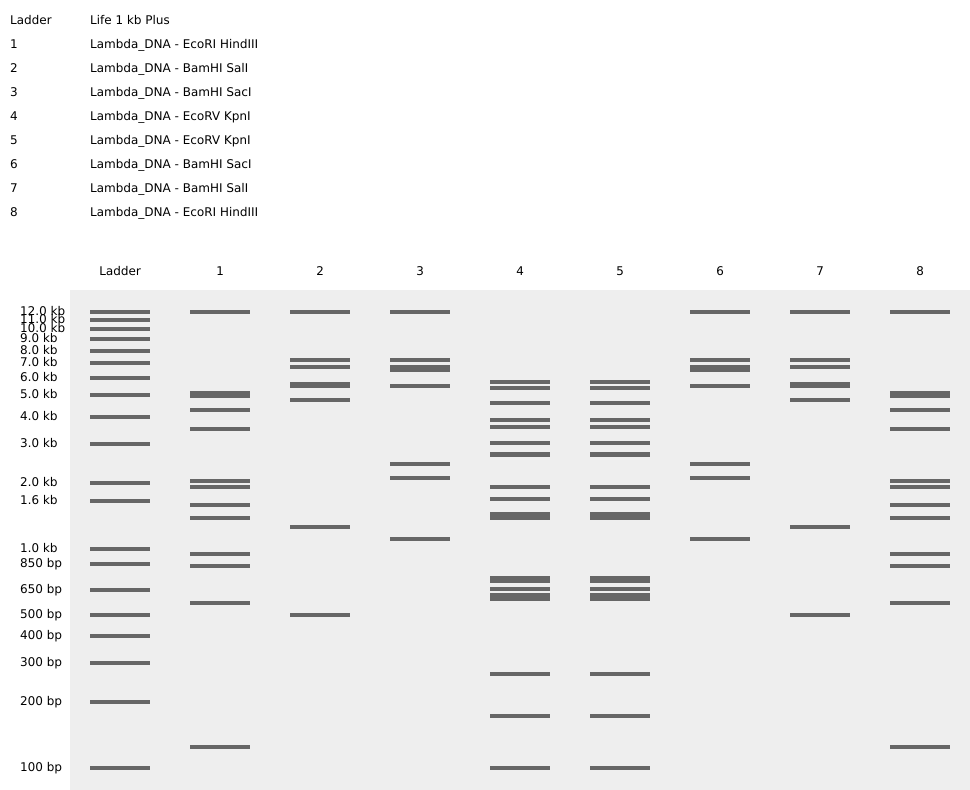
Part 1: Benchling & In-silico Gel Art Rectriction enzymes used:
EcoRI HindIII BamHI KpnI EcoRV SacI SalI I create a pattern that simulates angel feathers in benchling. I use the tool https://rcdonovan.com/gel-art to guide me c:
Part 3: DNA Design Challenge 3.1. Choose your protein = Ferrochelatase Recently I have been reading about therapeutics that target mitochondria. Specifically in the paper of Corson Lab they mention about this protein that when is inhibited causes mitochondrial dysfunction and this is benefitial for anti-angiogenesis purposes in retinal pathologies.
Python Script for Opentrons For this assignment, we were expected to create an artwork using OpenTrons. I decided to draw an artistic eye with my name on the bottom. The desgin was created through the GUI page and was edited appropriately to run on Google Colab.
The final design, after passing through the simulator, looks like this!
Part A. Conceptual Questions Question from Shuguang Zhang: Question 1 How many molecules of amino acids do you take with a piece of 500 grams of meat? (on average an amino acid is ~100 Daltons)
Subsections of Homework
Week 1 HW: Principles and Practices
Biological engineering application or tool you want to develop and why.
Functional thyroid hormone biosensing
Thyroid hormones play a central role in human physiology. The thyroid gland produces thyroxine (T4; 3,3′,5,5′-tetraiodo-L-thyronine) and triiodothyronine (T3; 3,3′,5-triiodo-L-thyronine), of which T3 is the biologically active form. T3 regulates energy homeostasis, metabolism, growth, and normal development by controlling transcriptional programs across multiple tissues. Disruptions in thyroid hormone signaling therefore can cause severe consequences. For people with thyroid-related disorders is neccesary then to monitore their hormone levels frequently and “play” with the doses until they obtain a precise amount that doesnt trigger any negative effects.
Specifically, I focused on this problem because I personally know some people that have thyroid-related disorders and have change form hiper to hypothyrodism due to unprecise doses and long waiting time before their next medical appointment. This is very dangerous overall for people in vulnerable communities that have even less opprotunities to go to medical appointments due to financial or time problems.
To address this challenge, I propose the development of an at-home biosensing platform capable of frequently monitoring thyroid hormone activity.
The envisioned system would allow individuals to collect small capillary blood samples at home and transmit hormone-related data to a mobile application. These data collected daily or weekly can create a personalized database of their hormone levels over time and relating this with their mood and other health symptoms, it will be able with time to predicted efficiently the change in their doses and alert when they have an abnormal level and need urgent in person medical attention.
To do this, rather than creating just an immunodiagnostic assay that measures free circulating T3, my approach centers on capturing functional thyroid hormone signaling. Specifically, the platform would rely on a sealed, single-use biosensing cartridge containing engineered eukaryotic cells, specifically modified yeast, designed to act as living biosensors. I decided to go with this approach because free circulating T3 in blood is not always a synonim of active hormones, because sometimes T3 has problems or delays in passing the cell membrane and then binding to the thyroid hormone receptor (TR) to regulate trasncription. With the yeast in the biosensor I can test both conditions to be fulfilled.
As a result, at the circuit level, the engineered yeast would constitutively express a synthetic TR. In another module, it will be a thyroid-response-element (TRE)–regulated promoter next to a reporter gene. In this way the synthetic TR will be the one regulating the expression of the reporter gene and only with the action of the T3 this signal will change. The signal could be colorimetric and can reflect different levels from low, normal to high fucnitonal T3 siganling. The succesful biosensor will be an example of precise and personalized medicine thanks to synthetic biology.
Governance/policy goals related to ensuring that this application or tool contributes to an “ethical” future
a. Biosecurity and biosafety (preventing harm)
Ensure the engineered yeast biosensor does not pose risks to the operator, surrounding community, or environment.
Sub-goals:
Containment and non-proliferation
Environmentally safe disposal
b. Accessibility, equity, and health justice
Ensure the technology is accessible to everyone, especially the underrepresented communities for whom this biosensor is primarily intended. Guarantee these communities are treated with respect and can use the technology effectively and safely.
Sub-goals:
Affordability and scalability
Health literacy and inclusive communication
c. Ethical data governance and responsible AI use
Protect patient privacy and ensure that machine learning does not completely replace clinical judgment, which could lead to harmful consequences.
Sub-goals:
User consent and data protection
Responsible decision support
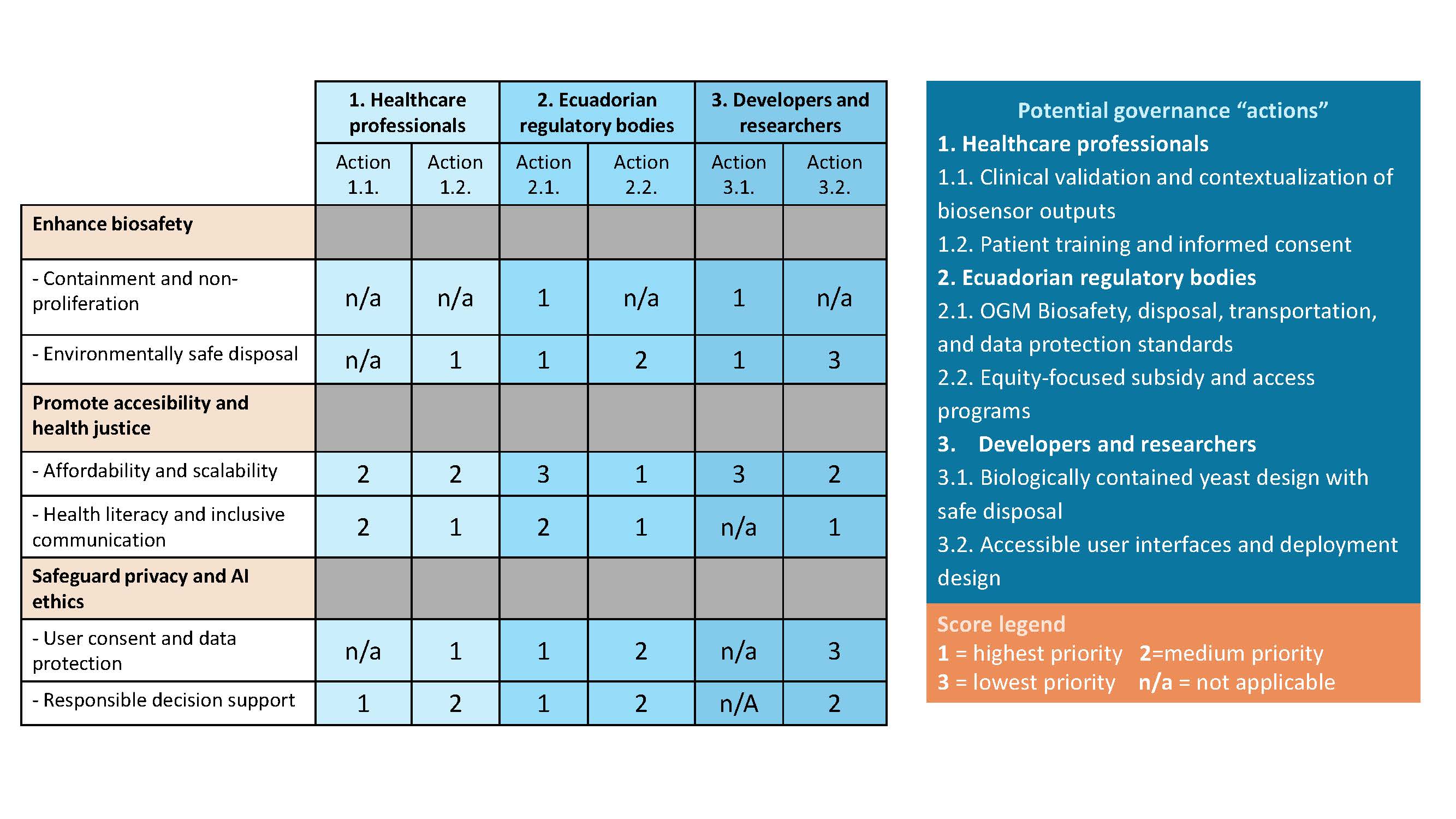
Describe at least three different potential governance “actions”
Healthcare professionals
Action 1: Clinical validation and contextualization of biosensor outputs
Healthcare professionals should validate the patient’s biosensor results by integrating them with patient-reported symptoms such as energy levels and then approve any dose changes. Also they should always be aware to refer patients to in-person care when abnormal patterns are detected.
Purpose:
Ensure remote monitoring supports good patient care and ML models do not produce medical risks.
Design:
Biosensor outputs are reviewed alongside symptom reports, with predefined thresholds that trigger clinical alerts.
Assumptions:
Clinicians have the time to review the patients’ results and will take them seriously in any part of the planet. Patients report symptoms honestly and consistently.
Risks
Failure: Incorrect interpretation or delayed referral could lead to inappropriate dose adjustments or other complications.
“Success”: Over-reliance on remote monitoring that make patients disminih their routine clinical evaluations for other health problems.
Action 2: Patient training and informed consent
Obtain and maintain informed consent from all the patients by clearly explaining how the technology works, its limitations, and how medical data will be used and protected.
Purpose:
Empower patients to safely use the technology while ensuring autonomy and ethical data use.
Design:
In-person or video-based training on finger blood sampling, cartridge use, safe disposal, and data-sharing practices, with follow-up verification of understanding like tests.
Assumptions:
Clinicians will give clear and easy explanations without discrimination and always verifying multiple times that the patients understood.
Risks:
Failure: Patients doesnt understand and refuse to use the device due to fear or complexity.
“Success”: They understand how to follow these practices but in their homes they do not have all the facilities to achieve it, such as safe disposal.
Ecuadorian regulatory bodies
Action 1: Biosafety, disposal, and data protection standards
Establish and enforce regulations addressing biosafety, transport, disposal of GMO-based cartridges, and data protection specific to ML-driven biosensors.
Purpose:
Update existing regulatory frameworks to responsibly enable new biotechnologies and AI technologies.
Design:
National guidelines and protocols to use, transport and dispose this biosensors. Anonymization standards and limits on third-party data sharing.
Assumptions:
Regulations will be supported and enforced consistently across all the Ecuadorian regions.
Risks:
Failure: Lack of regulatory adaptation may force illegal use of the technology. This is dangerous without regulations.
“Success”: Overly rigid regulations could delay implementation or limit scalability.
Action 2: Equity-focused subsidy and access programs
Implement subsidies and distribution programs to ensure affordability and prevent exclusion of low-income or rural populations.
Purpose:
Prevent the technology from becoming accessible only to high-income users.
Design:
Price controls, public subsidies, and partnerships with rural clinics.
Assumptions:
Government will have the budget to give these subsidies and there will not be corruption.
Risks:
Failure: Without subsidies, access remains limited to middle and high socioeconomic groups.
“Success”: Cost reduction pressures could compromise safety or quality controls. Also subsidies can create fake technology.
Design yeast biosensors that are non-reproducible and biologically contained, aligned with international GMO biosafety guidelines.
Purpose:
Enable safe and inocuous at-home use without risking environmental release and negative effects.
Design:
Intrinsic safeguards in the engineered yeast such as kill switches. Dedicated disposal containers that fully inactivate the cells.
Assumptions:
Containment mechanisms remain stable and do not interfere with sensing accuracy.
Risks:
Failure: Environmental release could occur, the biomass released can interfere with food chains.
“Success”: Excessive containment may reduce biosensor reliability.
Action 2: Accessible user interfaces and deployment design
Develop interfaces and devices easy to use and in different languages. Be useful for people that can not read.
Purpose:
Ensure effective use across diverse cultural and educational contexts.
Design:
Pictographic instructions, community workers’ guidance, multilingual support.
Assumptions:
Users have basic access to smartphones to use the app.
Risks:
Failure: People doesnt understand the device so communities decide to not use it.
“Success”: Extensive customization increases costs and limits scalability.
Score (from 1-3 with, 1 as the best, or n/a) each of your governance actions against your rubric of policy goals.
Describe which governance option, or combination of options, you would prioritize, and why.
Based on the scoring matrix, I would prioritize Action 2.1 (Ecuadorian biosafety, disposal, and data protection standards), Action 3.1 (biologically contained yeast design), and Action 1.2 (patient training and informed consent). Together, these actions have the highest direct impact on biosafety, accessability, and responsible data use, which are particularly important due to
Ecuador’s biodiversity
Biosensor’s focus on underserved communities
Actions 2.1 and 3.1 reduce biosafety risks prioritizing the user and environment protections thanks to clear regulations and smart design.
Additionally, action 1.2 is essential because as this device is supposed to be used at-home, is important to make sure understand how to proper use it and always get informed consent.
Prioritizing this combination however may result in higher costs, this trade-off is justified to prevent environmental harm, maintain public trust, ensure safe and effective use by marginalized populations.
Audience: Ecuadorian regulatory bodies, local research institutions, and community health centers.
Reflection:
Based on what I learned in class, together with what I researched for this assignment about governance, a new ethical concern for me was the successful application of AI ethics to all these emerging technologies. I realized that these new developments are not going to stop, as was clearly stated in class, and that all we can do is “trust”. However for countries like Ecuador where our own data is not secured, as the constitution doesnt have clear guidelines and punishments for data protection, it is more than necessary to change and improve the laws so communities and their data is safe.
Week 2 Lecture Prep
Homework Questions from Professor Jacobson:
1. Nature’s machinery for copying DNA is called polymerase. What is the error rate of polymerase? How does this compare to the length of the human genome. How does biology deal with that discrepancy?
Error Rate of Polymerase = 1:10^6
Length of the human genome = approximately 3.2 billion base pairs
Comparison:
If the human genome were a book with 3.2 billion letters, and the polymerase made 1 error per million letters, you would find approximately 3,200 typos per replication scattered throughout the entire book.
Biological strategy to deal with this:
Built-in error correction mechanisms:
3’-5’ proofreading exonuclease
5’-3’ error-correcting exonuclease
Other error correction mechanisms:
MutS Repair System - Employed by bacteria
2. How many different ways are there to code (DNA nucleotide code) for an average human protein? In practice what are some of the reasons that all of these different codes don’t work to code for the protein of interest?
Number of different DNA codes:
• Average human protein: 1,036 bp (~345 amino acids)
• Due to the degeneracy of the genetic code (most amino acids are encoded by 2-6 different codons), there are an a lot of different DNA sequences that could encode the same protein
For a 345 amino acid protein, if we assume an average of ~3 synonymous codons per amino acid, there would be roughly 3³⁴⁵ ≈ 10¹⁶⁵ different possible DNA sequences encoding the same protein sequence.
Why all these codes don’t work in practice:
a. Secondary structure formation (GC content issues)
GC content affects secondary structure
b. RNA cleavage sites
Certain sequence motifs make the mRNA unstable
c. Codon usage bias
Different organisms prefer different synonymous codons
d. Repeats and homopolymers
Sequences like “TTTTTTTTTT” or “GGGGGGGGGG” (shown in assembly examples) cause problems
e. Base pairing energies
Homework Questions from Dr. LeProust:
1. What’s the most commonly used method for oligo synthesis currently?
The phosphoramidite method is the most commonly used approach. This was developed by Caruthers in 1981.
2. Why is it difficult to make oligos longer than 200nt via direct synthesis?
Concerns about “truncation products” and maintaining “full-length” material. Although, Twist has pushed boundaries by demonstrating direct synthesis of 700-mers, which they describe as a breakthrough.
3. Why can’t you make a 2000bp gene via direct oligo synthesis?
Because the stepwise synthesis chemistry becomes too error-prone at such lengths. Instead, genes are made through assembly of shorter oligonucleotides (Ilumina).
Homework Question from George Church
1. What are the 10 essential amino acids in all animals and how does this affect your view of the “Lysine Contingency”?
The 10 essential amino acids are: Histidine, Isoleucine, Leucine, Lysine, Methionine, Phenylalanine, Threonine, Tryptophan, Valine, and Arginine.
This make me understand that the “Lysine contingency” stablished in Jurassic Park is not a good containment method.
Why the “Lysine Contingency” fails for me
Carnivorous dinosaurs would get lysine from eating other animals (all animal tissues contain lysine)
Herbivorous dinosaurs could get lysine from legumes and other lysine-rich plants
Lysine is already in the food chain everywhere
Lysine is not the only aminoacid we cannot create.
So there’s no real contingency. The dinosaurs would just eat normally and get lysine like every other animal does.
For real biocontainment, you need dependency on something that doesn’t exist in nature at all.
2. What code would you suggest for AA:AA interactions?
Existing codes:
• NA:NA → Watson-Crick base pairing (A-T, G-C)
• NA:AA → Genetic code (codons → amino acids)
• AA:NA → TALE code (slide shows 2 AA recognize 1 DNA bp)
For AA:AA, the simplest code would be:
Charge complementarity: (+) ↔ (−)
Positive (K, R, H) pairs with Negative (D, E)
Hydrophobic complementarity: Nonpolar ↔ Nonpolar
(L, I, V, F, W, A) cluster together
Polar complementarity: H-bond donors ↔ H-bond acceptors
(S, T, N, Q, Y) form H-bond networks
3. Given the one paragraph abstracts for these real 2026 grant programs sketch a response to one of them or device one of your own.
Sketch Response to BioStabilization Systems (BoSS) Program
The BoSS program seeks to eliminate the cold chain for biologics by achieving room-temperature stability.
I propose engineering biologic-producing cells with protective genes from extremophile organisms that naturally survive extreme heat.
Specifically, inserting heat-shock proteins from Thermus aquaticus (hot springs bacteria), trehalose biosynthesis pathways from tardigrades, and compatible solutes from halophilic bacteria would protect therapeutic cells and proteins from heat-induced degradation.
References
Baluta, S., Romaniec, M., Halicka-Stępień, K., Alicka, M., Pieła, A., Pala, K., & Cabaj, J. (2023). A novel strategy for selective thyroid hormone determination based on an electrochemical biosensor with graphene nanocomposite. Sensors, 23(2), 602.
Eskandar, K. (2026). Artificial intelligence and synthetic biology: biosecurity risks, dual-use concerns, and governance pathways. AI and Ethics, 6(1), 66.
Shahid, M. A., Ashraf, M. A., & Sharma, S. (2018). Physiology, thyroid hormone.
Note on AI assistance: Claude.ai was used to improve the clarity and organization of English writing based on ideas and concepts already developed by the student.
Week 2 HW: DNA READ WRITE AND EDIT
Part 1: Benchling & In-silico Gel Art
Rectriction enzymes used:
EcoRI
HindIII
BamHI
KpnI
EcoRV
SacI
SalI
I create a pattern that simulates angel feathers in benchling.
I use the tool https://rcdonovan.com/gel-art to guide me c:
Part 3: DNA Design Challenge
3.1. Choose your protein = Ferrochelatase
Recently I have been reading about therapeutics that target mitochondria. Specifically in the paper of Corson Lab they mention about this protein that when is inhibited causes mitochondrial dysfunction and this is benefitial for anti-angiogenesis purposes in retinal pathologies.
Using Online tools: bioinformatic.com I determined the nucleotide sequence that correponds to Ferrochelatase.
atgcgcagcctgggcgcgaacatggcggcggcgctgcgcgcggcgggcgtgctgctgcgc gatccgctggcgagcagcagctggcgcgtgtgccagccgtggcgctggaaaagcggcgcg gcggcggcggcggtgaccaccgaaaccgcgcagcatgcgcagggcgcgaaaccgcaggtg cagccgcagaaacgcaaaccgaaaaccggcattctgatgctgaacatgggcggcccggaa accctgggcgatgtgcatgattttctgctgcgcctgtttctggatcgcgatctgatgacc ctgccgattcagaacaaactggcgccgtttattgcgaaacgccgcaccccgaaaattcag gaacagtatcgccgcattggcggcggcagcccgattaaaatttggaccagcaaacagggc gaaggcatggtgaaactgctggatgaactgagcccgaacaccgcgccgcataaatattat attggctttcgctatgtgcatccgctgaccgaagaagcgattgaagaaatggaacgcgat ggcctggaacgcgcgattgcgtttacccagtatccgcagtatagctgcagcaccaccggc agcagcctgaacgcgatttatcgctattataaccaggtgggccgcaaaccgaccatgaaa tggagcaccattgatcgctggccgacccatcatctgctgattcagtgctttgcggatcat attctgaaagaactggatcattttccgctggaaaaacgcagcgaagtggtgattctgttt agcgcgcatagcctgccgatgagcgtggtgaaccgcggcgatccgtatccgcaggaagtg agcgcgaccgtgcagaaagtgatggaacgcctggaatattgcaacccgtatcgcctggtg tggcagagcaaagtgggcccgatgccgtggctgggcccgcagaccgatgaaagcattaaa ggcctgtgcgaacgcggccgcaaaaacattctgctggtgccgattgcgtttaccagcgat catattgaaaccctgtatgaactggatattgaatatagccaggtgctggcgaaagaatgc ggcgtggaaaacattcgccgcgcggaaagcctgaacggcaacccgctgtttagcaaagcg ctggcggatctggtgcatagccatattcagagcaacgaactgtgcagcaaacagctgacc ctgagctgcccgctgtgcgtgaacccggtgtgccgcgaaaccaaaagcttttttaccagc cagcagctg
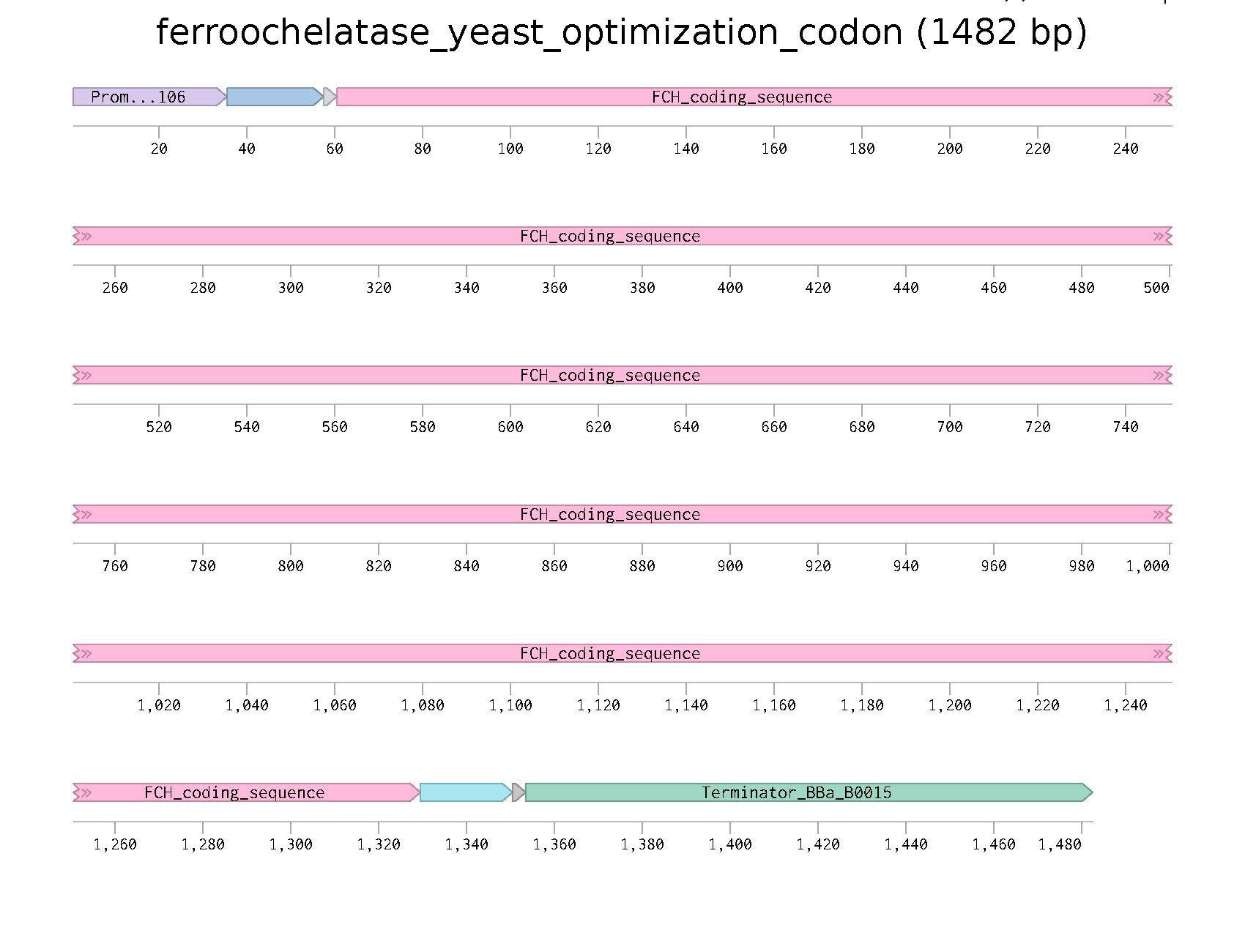
3.3. Codon optimization
Codon optimization is essential because of the degeneracy of the genetic code. Since there are multiple ways to get to some amino acids, different organisms use different codons for this purpose to translate more efficiently in their context. So, if we do not do codon optimization before a synthetic biologic application, the organism will double its efforts trying to read a code it is not familiar with.
Rather than produce this protein in mass, I want to study it without using animal models to extract it. For that reason, I would express it in yeast (Saccharomyces cerevisiae), as it is a eukaryotic model that allows better 3D structure formation compared to E. coli, and post-translational changes in protein, while it is also reproducible and cheap.
For this reason, using online tools:IDT i got the follow codon optimization.
ATG CGT AGT CTA GGT GCT AAC ATG GCA GCA GCA TTG CGT GCG GCA GGG GTG TTG TTG AGA GAT CCA CTG GCC TCC AGC AGT TGG CGT GTT TGT CAG CCG TGG AGA TGG AAA TCA GGA GCA GCA GCC GCA GCG GTT ACA ACG GAA ACT GCT CAA CAT GCA CAA GGC GCC AAG CCT CAG GTT CAG CCT CAA AAA AGA AAG CCT AAA ACA GGG ATT CTG ATG TTA AAC ATG GGT GGA CCT GAA ACC TTG GGA GAC GTC CAT GAT TTC TTA TTA AGA TTA TTT TTG GAC AGG GAT CTT ATG ACC TTA CCC ATT CAA AAT AAA CTG GCC CCT TTT ATT GCC AAA AGG AGA ACT CCG AAA ATT CAG GAA CAA TAT CGT AGG ATT GGC GGC GGA TCT CCC ATT AAG ATT TGG ACT AGC AAA CAA GGA GAG GGA ATG GTT AAG TTG CTA GAC GAG TTG TCT CCA AAT ACT GCA CCC CAC AAA TAC TAT ATT GGT TTT AGG TAT GTT CAT CCA CTA ACT GAA GAA GCT ATA GAA GAA ATG GAA AGG GAC GGC TTG GAG AGA GCT ATA GCC TTT ACT CAA TAC CCA CAA TAC TCC TGT TCT ACA ACA GGT TCT TCC CTT AAT GCT ATT TAT AGA TAC TAC AAT CAA GTT GGT AGA AAG CCT ACG ATG AAA TGG TCA ACG ATT GAC AGA TGG CCC ACC CAT CAT TTA TTG ATA CAA TGT TTT GCT GAT CAC ATT TTA AAG GAA CTT GAT CAC TTT CCT CTA GAG AAA AGA TCA GAA GTG GTA ATA TTA TTC TCA GCA CAT TCT TTA CCA ATG TCA GTA GTG AAT AGA GGA GAT CCC TAT CCT CAA GAA GTC TCT GCG ACT GTT CAA AAG GTT ATG GAA AGG CTA GAG TAC TGT AAC CCT TAT AGG CTT GTC TGG CAA AGC AAA GTA GGA CCA ATG CCA TGG TTG GGT CCA CAG ACT GAT GAA TCC ATA AAG GGT TTG TGT GAA AGA GGT AGA AAA AAT ATT TTG TTA GTA CCG ATC GCA TTT ACC TCA GAC CAT ATT GAA ACC CTT TAC GAA TTG GAT ATT GAA TAC TCT CAA GTT CTA GCG AAA GAA TGC GGT GTT GAA AAC ATA AGA CGT GCT GAA TCC TTG AAT GGT AAT CCC CTG TTT AGT AAG GCT TTA GCG GAT TTG GTG CAC TCC CAT ATA CAG TCC AAT GAG CTG TGC TCA AAA CAA TTA ACC CTA AGC TGT CCT TTG TGC GTA AAT CCT GTG TGT CGT GAA ACC AAG TCT TTC TTC ACA TCT CAA CAA CTA
3.4. Technologies to produce this protein : Cell-dependent method in yeast
1. Clone the gene
I have to insert the codon-optimized DNA into a yeast expression vector: a plasmid. This plasmid must have an appropiate promoter and a selectable marker as an antibiotic resistance gene. Also I would put an affinity tag to purifiy it later easily.
To do this I can use technologies as PCR or Gibson assembly.
2. Transform the cells
I introduce thr plasmid into the yeast cells through electroporation (creating pores in cells thanks to a a pulse of electricity)
3. Selecciont of transformed yeast
I make use of the selectable marker to allow only the transform yeast to grow
4. Transcription and translation
Yeast will transcribe the DNA into mRNA and then translate it
5. Harvest and purify the protein
I break (lyse) the yeast cells when the biomass increased, and then purify the protein through affinity chromatography thanks to the affinity tag.
(i) What DNA would you want to sequence (e.g., read) and why?
Mitochondrial DNA from tardigrades, I am curious if the protecting proteins for DNA in radiation come from this source.
(ii) In lecture, a variety of sequencing technologies were mentioned. What technology or technologies would you use to perform sequencing on your DNA and why?
I would use Illumina sequencing due to the fidelity of this short fragment sequencing platform.
Is your method first-, second- or third-generation or other? How so?
My method is second generation because it allows sequencing in parallel huge genomes, but it uses short fragments, so it is second.
What is your input? How do you prepare your input (e.g. fragmentation, adapter ligation, PCR)? List the essential steps.
My input would be extracted DNA from tardigrades. I would prepare it through DNA extraction kits.
What are the essential steps of your chosen sequencing technology, how does it decode the bases of your DNA sample (base calling)?
The essential steps of my technology are basically to create these clusters of amplification where they read multiple parts/fragments of DNA, and thanks to fluorescent signals all this is recorded.
What is the output of your chosen sequencing technology?
The output will be the fluorescent signals that can be translated into DNA sequences, a process called “Base calling”, and at the end I get a FASTQ document that also tells me the quality of sequencing.
5.2 DNA Write
(i) What DNA would you want to synthesize (e.g., write) and why?
I recently read about DNA origami scaffolds used for delivery of epitopes as a form of new HIV vaccine. I would love to synthesize it because it prevents any off-target immune system effect in complex diseases.
(ii) What technology or technologies would you use to perform this DNA synthesis and why?
Method: phosphoramidite chemistry. It is the most common method used, very standard and optimized.
What are the essential steps of your chosen sequencing methods?
It is basically chemical synthesis, through the cycle: Deblocking, Coupling, Capping, and Oxidation; it adds one nucleotide at a time.
What are the limitations of your method?
It is not 100% efficient. For long scaffolds, it should be synthesized in truncated fragments and then joined together. Environmentally, it is not as friendly as it requires a lot of organic solvents. So it would not be good for scaling up, which is essential for vaccines.
5.1 DNA Edit
(i) What DNA would you want to edit and why?
I would love to edit genetic risk factors so people are less prone to develop some diseases. For example, the allele APOE4 is known for its predisposition to cause Alzheimer, a serious neurodegenerative disease which has no definitive cure yet. So I would propose to edit the DNA from gametes to avoid people having this predisposition.
(ii) What technology or technologies would you use to perform these DNA edits and why?
It has to be very precise, so I would use CRISPR-CAS9, as it nowadays is one of the more precise ways of editing DNA.
How does your technology of choice edit DNA? What are the essential steps?
Basically it is made of two parts: a protein CAS9 that can cut the DNA and a guide RNA that specifically guides you to the place where it has to be cut. If you also insert a template DNA, the cell can use this to repair the cut DNA and do a precise modification.
What preparation do you need to do (e.g. design steps) and what is the input (e.g. DNA template, enzymes, plasmids, primers, guides, cells) for the editing?
I would design a guide RNA that specifically targets APOE4 and a DNA template with the APOE2 sequence for repair. The inputs include the guide RNA, Cas9 protein, the repair template, and the cells to be edited: gametes. Additional reagents like buffers may also be needed.
What are the limitations of your editing methods (if any) in terms of efficiency or precision?
CRISPR-CAS9 may have off-target effects if the guide RNA is not perfectly specific. It is somewhat “aggressive” because it breaks the DNA double strand, so efficiency and precision can vary depending on the cell type and delivery method. Previous trials in murine cells may not reveal all secondary effects. Finally, editing in gametes raises a lot of ethical issues that must be considered.
Week 3 HW: Lab Automation
Python Script for Opentrons
For this assignment, we were expected to create an artwork using OpenTrons. I decided to draw an artistic eye with my name on the bottom. The desgin was created through the GUI page and was edited appropriately to run on Google Colab.
The final design, after passing through the simulator, looks like this!
Find and describe a published paper that utilizes the Opentrons or an automation tool to achieve novel biological applications.
Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) is responsible for the most recent pandemic that agitated the world. Its highly contagious nature created the necessity for frequent and efficient diagnostic testing. The standard test used nasopharyngeal swabs processed by RT-qPCR. However, this method relies on specialized equipment and trained medical personnel, resulting in relatively high costs.
To address this problem, the paper proposes a strategy using a saliva-based test combined with automation to reduce costs when testing large-scale groups, such as universities.
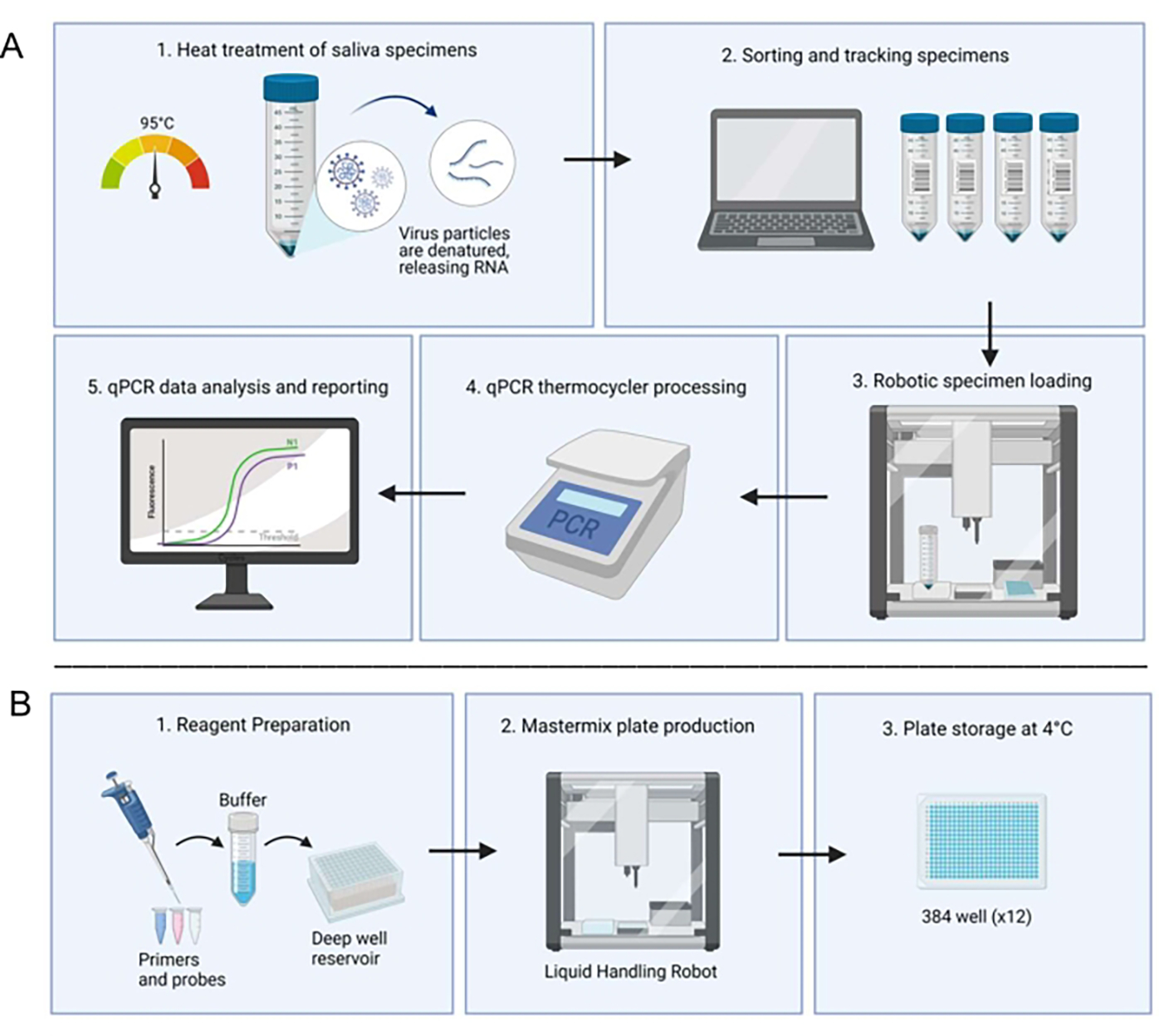
Figure 1. Laboratory workflow utilizing the saliva-based RT-qPCR diagnostic system.
Before starting the procedure, the Opentrons liquid-handling robot is used to prepare a master mix and distribute it into the wells. The protocol (Figure 1) begins with the collection of saliva samples, which can be performed by each individual without the need for specialized personnel. The recollected samples are then heat-treated at 95°C for 30 minutes. Next, the liquid-handling robot loads the samples into duplicate wells, which already have the master mix, and then they are processed in a qPCR thermocycler. The results are generated by an automated computer system and verified by a technician. If any result is unclear, the sample is rerun. It is also important to note that the technician manually loads the control samples. Through this automation process, the overall processing time is reduced.
A significant result from this paper is that the new strategy achieved 90% sensitivity and 98.9% specificity. Additionally, results from three participants did not initially agree between saliva and nasopharyngeal samples. The saliva tests were positive, and when these individuals were retested two days later, the results remained positive, which may suggest earlier detection using this method. In conclusion, the variation between automated and manual saliva sample processing was not statistically significant. Therefore, the use of automation, which reduces processing time compared to clinical laboratories, is very useful for large-scale surveillance and research.
Question 2
Write a description about what you intend to do with automation tools for your final project. You may include example pseudocode, Python scripts, 3D printed holders, a plan for how to use Ginkgo Nebula, and more. You may reference this week’s recitation slide deck for lab automation details.
Concise Automation-Focused Description
For my final project, I want to develop an optimized, yeast-based functional thyroid hormone (T3) biosensor. I will integrate automation tools throughout the workflow to enable reproducibility, scalability, and systematic circuit optimization. The 4-step plan is as follows:
Step 1: Automated DNA Assembly
A small combinatorial library of genetic circuits will be designed, incorporating variants of Thyroid Response Elements (TREs), diverse promoter strengths, and alternative reporter genes such as GFP and luciferase. An automated liquid handler, Opentrons specifically, will be employed to execute automated plasmid assembly reactions, prepare transformation mixes, and transformed yeast in a 96-well format.
Step 2: Automated Strain Screening
Following transformation, the robot will inoculate yeast colonies into 96-well plates, standardize culture volumes, and normalize cell density through optical density (OD) adjustments. Experimental replicates will then be prepared.
To ensure biosensor sensitivity, we will use the liquid handler to generate serial dilutions of T3. After which, precise hormone concentrations will be dispensed across the wells, and synchronized treatments will be initiated to ensure the generation of reproducible dose-response curves.
Step 4: High-Throughput Readout
We can do fluorescence measurements using a plate reader. If available, we can integrate with a cloud laboratory platform (e.g., Ginkgo Nebula) to centralize our data, perform remote execution of standardized protocols, or quickly iterate design-build-test-learn cycles.
Final Project Ideas
References
Ham, R. E., Smothers, A. R., King, K. L., Napolitano, J. M., Swann, T. J., Pekarek, L. G., Blenner, M. A., & Dean, D. (2022). Efficient SARS-CoV-2 Quantitative Reverse Transcriptase PCR Saliva Diagnostic Strategy utilizing Open-Source Pipetting Robots. Journal of visualized experiments : JoVE, (180), 10.3791/63395. https://doi.org/10.3791/63395
Week 4 HW: Protein Design Part 1
Part A. Conceptual Questions
Question from Shuguang Zhang:
Question 1
How many molecules of amino acids do you take with a piece of 500 grams of meat? (on average an amino acid is ~100 Daltons)
According to the European Commission (2021), if we are talking about beef, meat has a protein percentage of 16.9%.
Therefore, in 500 grams of beef, we can find 84,5 grams of protein.
Considering the transformation 1 Dalton = 1 g/mol and that proteins are just chains of amino acids, we can get that in these 84,5 grams of protein there are 0,845 moles of amino acids (84.5 grams of amino acids * (1 mol / 100 grams of amino acids)).
Finally using the conversion 1 mol = 6.022 × 1023 molecules, we obtain that in this piece there are 5.09 × 1023 molecules of aminoacids.
Question 2
Why do humans eat beef but do not become a cow, eat fish but do not become fish?
Humans do not become cows when eating beef or fish when eating fish because food is broken down into its basic molecules during digestion.
Additionally, food does not have any transformative effect on our DNA. Our cells synthesize proteins based on our own genetic information, stored in our DNA and expressed through RNA. Therefore, although we use nutrients derived from other organisms, the instructions that determine who we are, come exclusively from our own genome.
Question 3
Why are there only 20 natural amino acids?
There is still no clear answer to this; however, many scientists hypothesize that it is due to natural selection. The 20 natural amino acids likely emerged because of the conditions of early Earth: its chemical composition, biochemical processes, and the functional utility these amino acids provided for primitive metabolisms. There are additional ideas in this area, but there is still much to investigate.
Question 4
Can you make other non-natural amino acids? Design some new amino acids.
Yes. To design these we can first expand the genetic code using 4-base codons (example CCCG). Then we have to perform chemical loading of theses aa in tRNAs.
Question 5
Where did amino acids come from before enzymes that make them, and before life started?
Before enzymes and life existed, amino acids most likely originated from prebiotic synthesis on early Earth. Experiments such as the Miller–Urey experiment, which replicated primitive environmental conditions, demonstrated that amino acids can be synthesized from simple molecules like methane, ammonia, and water under those conditions.
Additionally, it is believed that amino acids could also have formed through other prebiotic pathways, such as the Strecker synthesis (the reaction of aldehydes with ammonia and hydrogen cyanide) and salt-induced peptide formation.
Finally, extraterrestrial delivery is also considered a possible source, as amino acids have been found in certain meteorites.
Question 6
If you make an α-helix using D-amino acids, what handedness (right or left) would you expect?
As α-helix using L-amino acids are right-handed, I will expect that if we use D-amino acids these helices would be left-handed.
In the literature, I found that homochiral decapeptides with D-aminoacids do form left-handed an α-helices.
Question 7
Why are most molecular helices right-handed?
Because overall they are formed from L-amino acids that inherently produce right-handed.
Additionally, these helices have greater thermodynamics and kinetic stability and can play critical functional or specific roles.
Question 8
Why do β-sheets tend to aggregate? What is the driving force for β-sheet aggregation?
There is a combination of factors that promotes this aggregation, which encompasses thermodynamic factors, such as entropy changes, as well as amino acid sequence and solvent conditions.
The main driving force overall is hydrophobic interactions. The hydrophobic faces of β-sheets tend to associate with each other in order to reduce their exposure to the surrounding solvent. This reduction in solvent exposure stabilizes the aggregated structure.
Question 9
Why do many amyloid diseases form β-sheets? Can you use amyloid β-sheets as materials?
Many amyloid diseases involve the formation of β-sheets because β-sheet structures are highly stable. This stability promotes aggregation, leading to fibril formation and protein misfolding.
Yes, β-sheets can be used as materials. They are employed in biomaterials such as hydrogels due to their favorable properties, including good biocompatibility, strong mechanical strength, and more.
Part B. Protein Analysis and Visualization
1. Briefly describe the protein you selected and why you selected it.
I select the protein: Human Ferrochelatase
Recently I have been reading about therapeutics that target mitochondria. Specifically in the paper of Corson Lab they mention about this protein that when is inhibited causes mitochondrial dysfunction and this is benefitial for anti-angiogenesis purposes in retinal pathologies. So I choose it because im interested in its therapeutic applications.
2. Identify the amino acid sequence of your protein
I found 250 coincidences, these are basically are the analogues of ferrochelatase in other species. The ones with a higher coincidence, are from closely related species such as gorillas, chimpanzees and more.
Does your protein belong to any protein family?
Yes, it belong to the ferrochelatase family.
3. Identify the structure page of your protein in RCSB
When was the structure solved? Is it a good quality structure? Good quality structure is the one with good resolution. Smaller the better (Resolution: 2.70 Å)
The crystal structure of human ferrochelatase was solved in 2001 and released on June 22, 2001. The structure was published by Wu et al. in Nature Structural Biology.
It was determined using X-ray diffraction, with a resolution of 2.0 Å (high quality).
Are there any other molecules in the solved structure apart from protein?
Yes, besides the protein chains, there are additional molecules listed as CHD, FES, and O.
FES → Iron–sulfur cluster (2Fe–2S cluster). Important for structural stability and possibly regulation.
CHD → A ligand molecule bound in the structure. Porphyrin-related compound (a heme precursor or analog bound in the active site).
O (often shown as O or HOH) → Oxygen atoms from water molecules. These are crystallographic water molecules resolved in the X-ray structure.
Does your protein belong to any structure classification family?
Using the CATCH classification system (class, architecture, topology, homology). I found that this protein does belong to some classification families. Here you can see my findings: https://www.cathdb.info/search/by_text?q=P22830
Specifically I found that it is assigned to the CATH superfamilies 3.40.50.140 and 3.40.50.1400. Which means: Class 3 (α/β proteins), with a 3-layer (αβα) sandwich architecture and Rossman fold topology.
There are some other families as well.
4. Open the structure of your protein in any 3D molecule visualization software:
Visualize the protein as “cartoon”, “ribbon” and “ball and stick”.
I use Pymol for the visualization purposes.
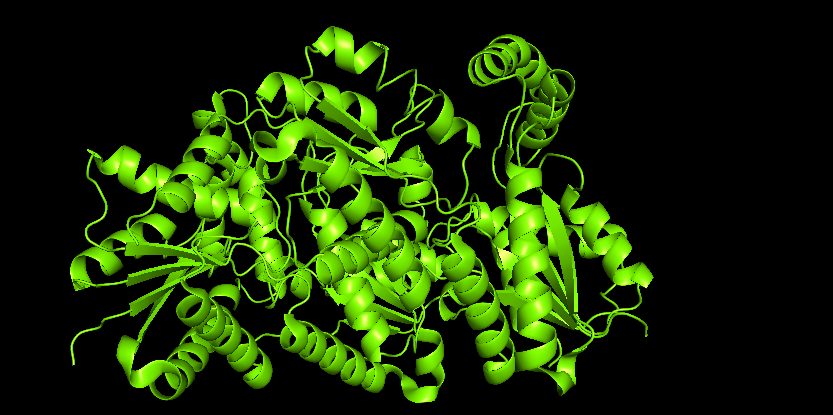
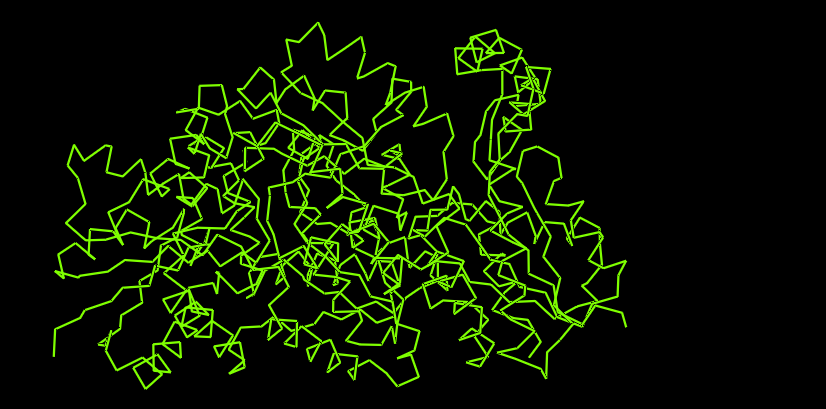
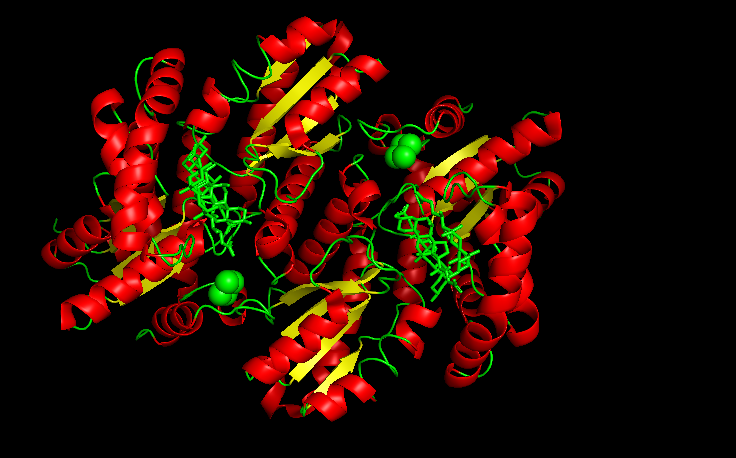
Figure 1. Cartoon
Figure 2. Ribbon
Figure 3. Ball and stick
Color the protein by secondary structure. Does it have more helices or sheets?
It is color by the legend: red helices, yellow sheets and green loops and others. Visually it appears that it has more red (helices).
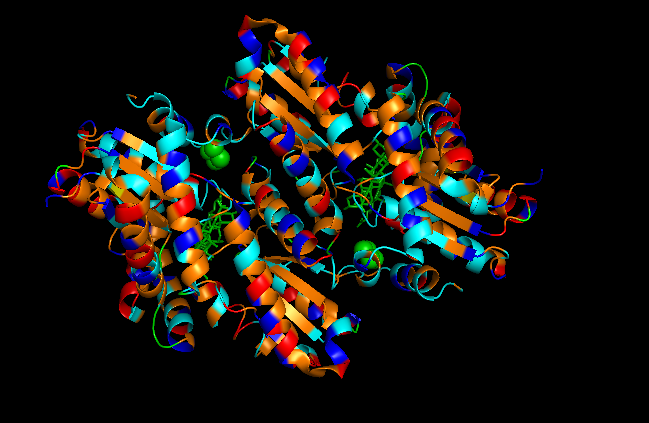
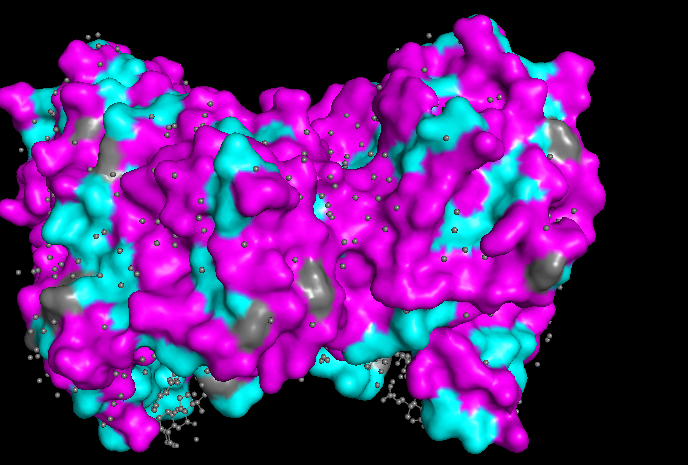
Color the protein by residue type. What can you tell about the distribution of hydrophobic vs hydrophilic residues?
First I color following this legend:
Hydrophobic residues
ALA, VAL, LEU, ILE, MET, PHE, TRP, PRO (colored orange)
Polar uncharged residues
SER, THR, ASN, GLN, TYR, CYS (colored cyan)
Negatively charged residues
ASP, GLU (colored red)
Positively charged residues
LYS, ARG, HIS (colored blue)
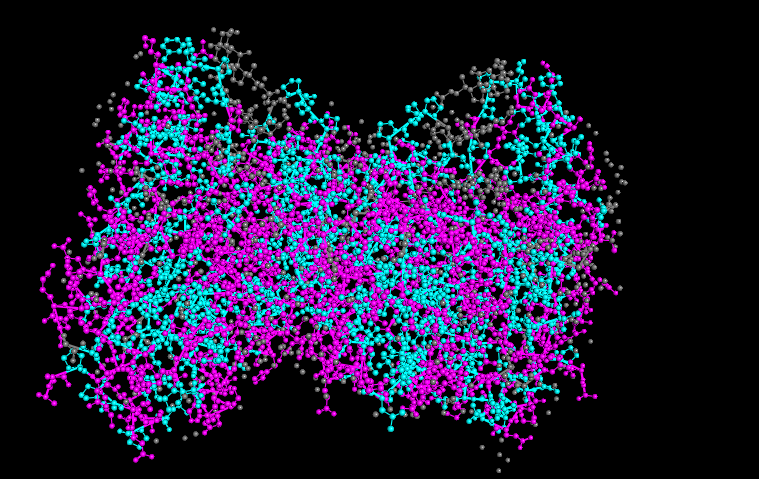
To understand the distribution of hydrophobic vs hydrophilic residues, then I color following this legend:
Hydrophobic residues
ALA, VAL, LEU, ILE, MET, PHE, TRP, PRO (colored cyan)
It seems like the hydrophobic residues are not fully just in the core of the protein, like it is common in some proteins. This is because it is associated with the inner mitochondrial membrane, allowing partial interaction with the lipid environment.
Watching the surface of the protein, we can see more magenta (hydrophilic) which is common but also some cyan (hydrophobic)
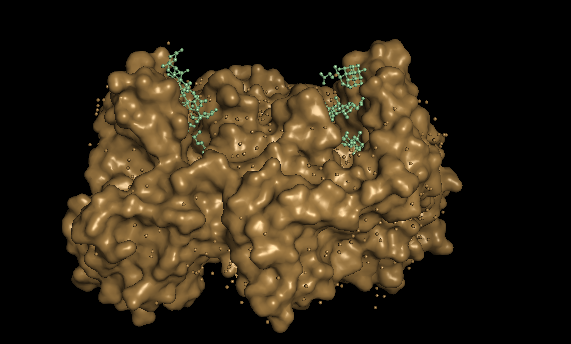
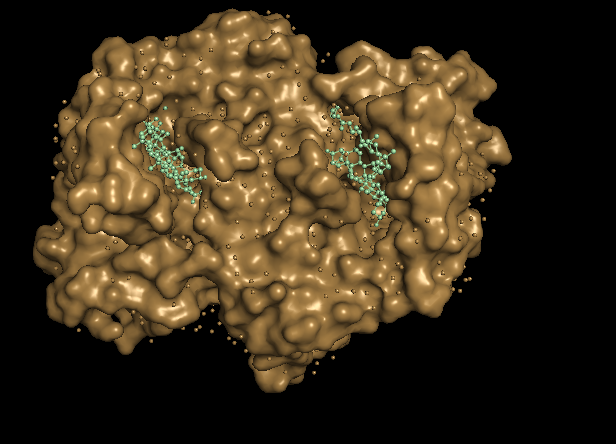
Visualize the surface of the protein. Does it have any “holes” (aka binding pockets)?
With this 2 disctint views of the protein we can see clearly 2 huge pockets.
The ferrochelatase is a homodimer, so in each chain it has a binding pocket.
Part C. Using ML-based Protein Design Tools
Copy the HTGAA_ProteinDesign2026.ipynb notebook and set up a colab instance with GPU.
Choose your favorite protein from the PDB.
We will now try multiple things in the three sections below:
C1. Protein Language Modeling
Deep Mutational Scans
a. Use ESM2 to generate an unsupervised deep mutational scan of your protein based on language model likelihoods.
b. Can you explain any particular pattern? (choose a residue and a mutation that stands out)
c. (Bonus) Find sequences for which we have experimental scans, and compare the prediction of the language model to experiment.
Latent Space Analysis
a. Use the provided sequence dataset to embed proteins in reduced dimensionality.
b. Analyze the different formed neighborhoods: do they approximate similar proteins?
c. Place your protein in the resulting map and explain its position and similarity to its neighbors.
C2. Protein folding
Folding a protein
a. Fold your protein with ESMFold. Do the predicted coordinates match your original structure?
b. Try changing the sequence, first try some mutations, then large segments. Is your protein structure resilient to mutations?
C3. Protein Generation
Inverse-Folding a protein
Let’s now use the backbone of your chosen PDB to propose sequence candidates via ProteinMPNN
a. Analyze the predicted sequence probabilities and compare the predicted sequence vs the original one.
b. Input this sequence into ESMFold and compare the predicted structure to your original.
Part D. Group Brainstorm on Bacteriophage Engineering
Main goal chosen to address computationally
We’ll try to slightly delay the timing for lysis, so the virion assembly improved and we get higher titers.
One page proposal
Link for the detailed brainstorm, plan and references:
Fernández, A. (2005). What factor drives the fibrillogenic association of β-sheets?. FEBS letters, 579(29), 6635-6640.
Jurkowski, M., Kogut, M., Sappati, S., & Czub, J. (2024). Why are left-handed G-quadruplexes scarce?. The Journal of Physical Chemistry Letters, 15(11), 3142-3148.
Li, C., Qin, R., Liu, R., Miao, S., & Yang, P. (2018). Functional amyloid materials at surfaces/interfaces. Biomaterials science, 6(3), 462-472.
Pascal, R., & Boiteau, L. (2007). Origins of Life: Emergence of Amino Acids. Wiley Encyclopedia of Chemical Biology, 1-7.
Philip, G. K., & Freeland, S. J. (2011). Did evolution select a nonrandom “alphabet” of amino acids?. Astrobiology, 11(3), 235-240.
Shepherd, N. E., Hoang, H. N., Abbenante, G., & Fairlie, D. P. (2009). Left-and right-handed alpha-helical turns in homo-and hetero-chiral helical scaffolds. Journal of the American Chemical Society, 131(43), 15877-15886.
Sisido, M., Ninomiya, K., Ohtsuki, T., & Hohsaka, T. (2005). Four-base codon/anticodon strategy and non-enzymatic aminoacylation for protein engineering with non-natural amino acids. Methods, 36(3), 270-278.