Week 05 HW: Protein design part II

Part A: SOD1 Binder Peptide Design (From Pranam)
Part 1: Generate Binders with PepMLM
1. Begin by retrieving the human SOD1 sequence from UniProt (P00441) and introducing the A4V mutation.
2. Using the PepMLM Colab linked from the HuggingFace PepMLM-650M model card:
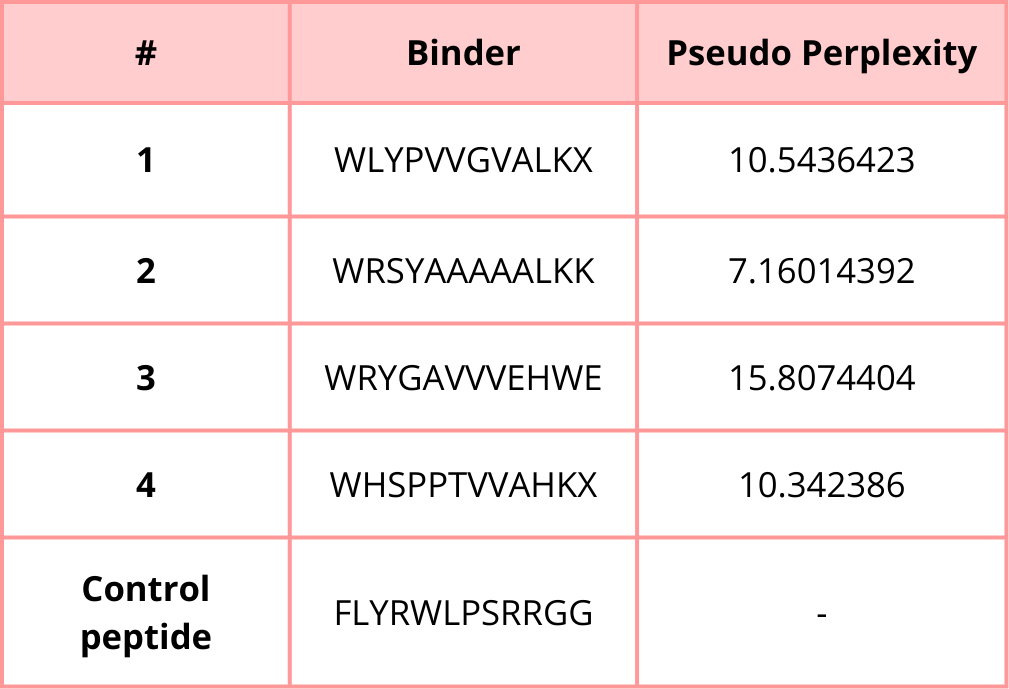
3. Generate four peptides of length 12 amino acids conditioned on the mutant SOD1 sequence.
4. To your generated list, add the known SOD1-binding peptide FLYRWLPSRRGG for comparison.
5. Record the perplexity scores that indicate PepMLM’s confidence in the binders.
Part 2: Evaluate Binders with AlphaFold3
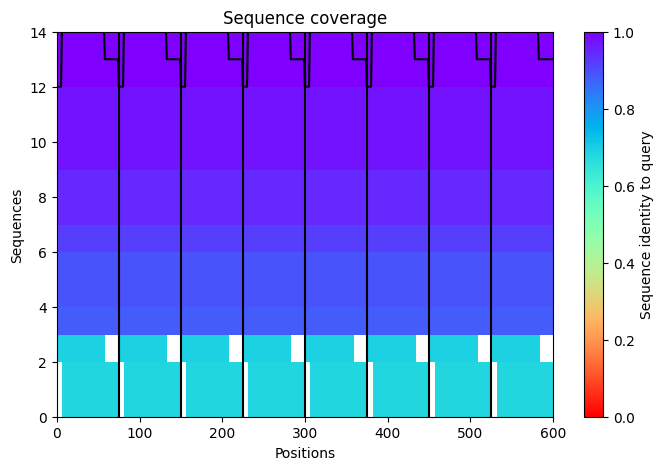
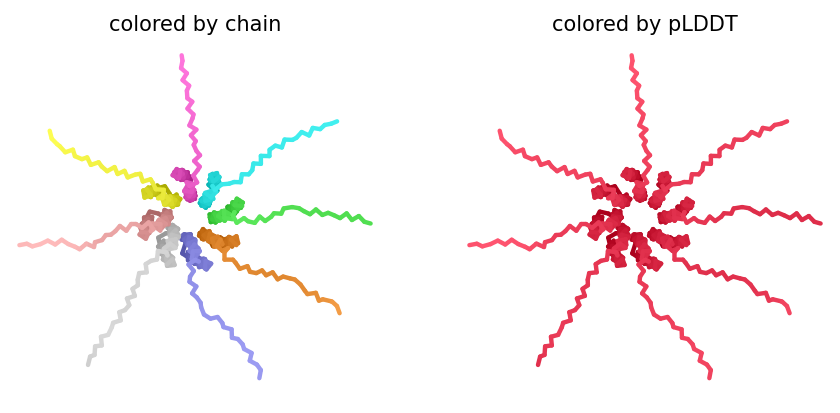
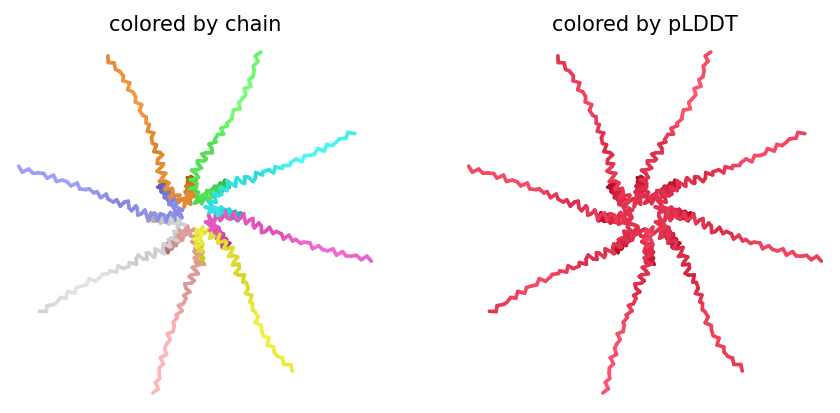
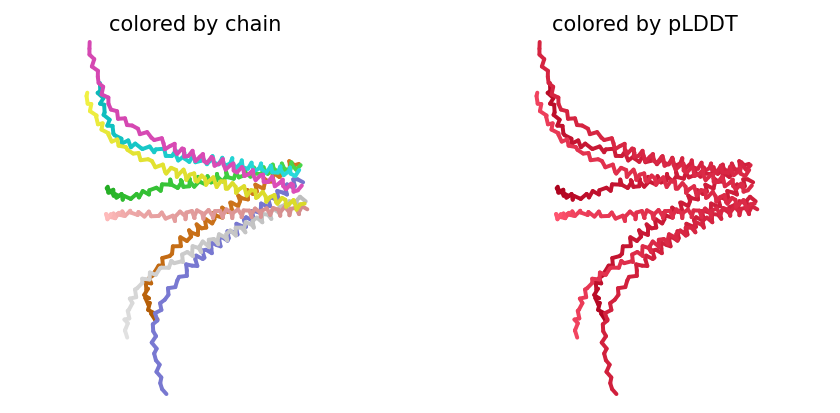
1. Navigate to the AlphaFold Server: alphafoldserver.com
2. For each peptide, submit the mutant SOD1 sequence followed by the peptide sequence as separate chains to model the protein-peptide complex.
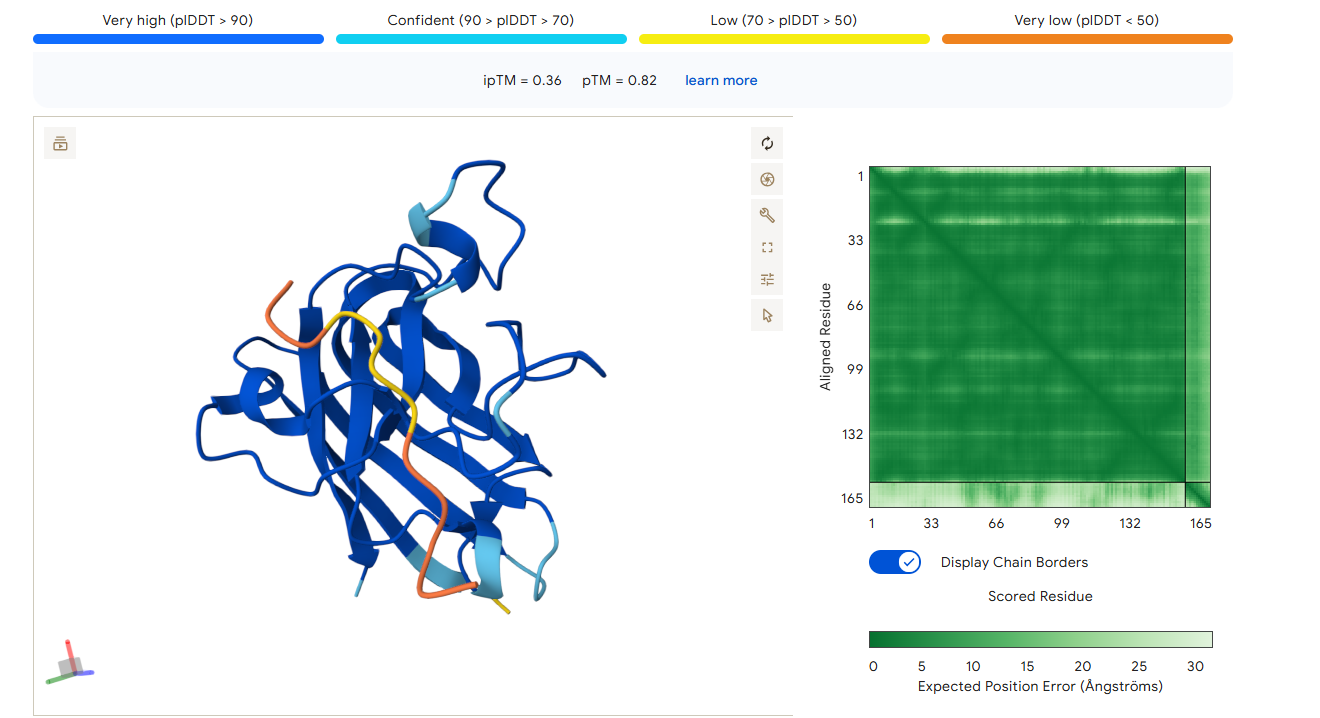
3. Record the ipTM score and briefly describe where the peptide appears to bind. Does it localize near the N-terminus where A4V sits? Does it engage the β-barrel region or approach the dimer interface? Does it appear surface-bound or partially buried?
4. In a short paragraph, describe the ipTM values you observe and whether any PepMLM-generated peptide matches or exceeds the known binder.
Peptide 1
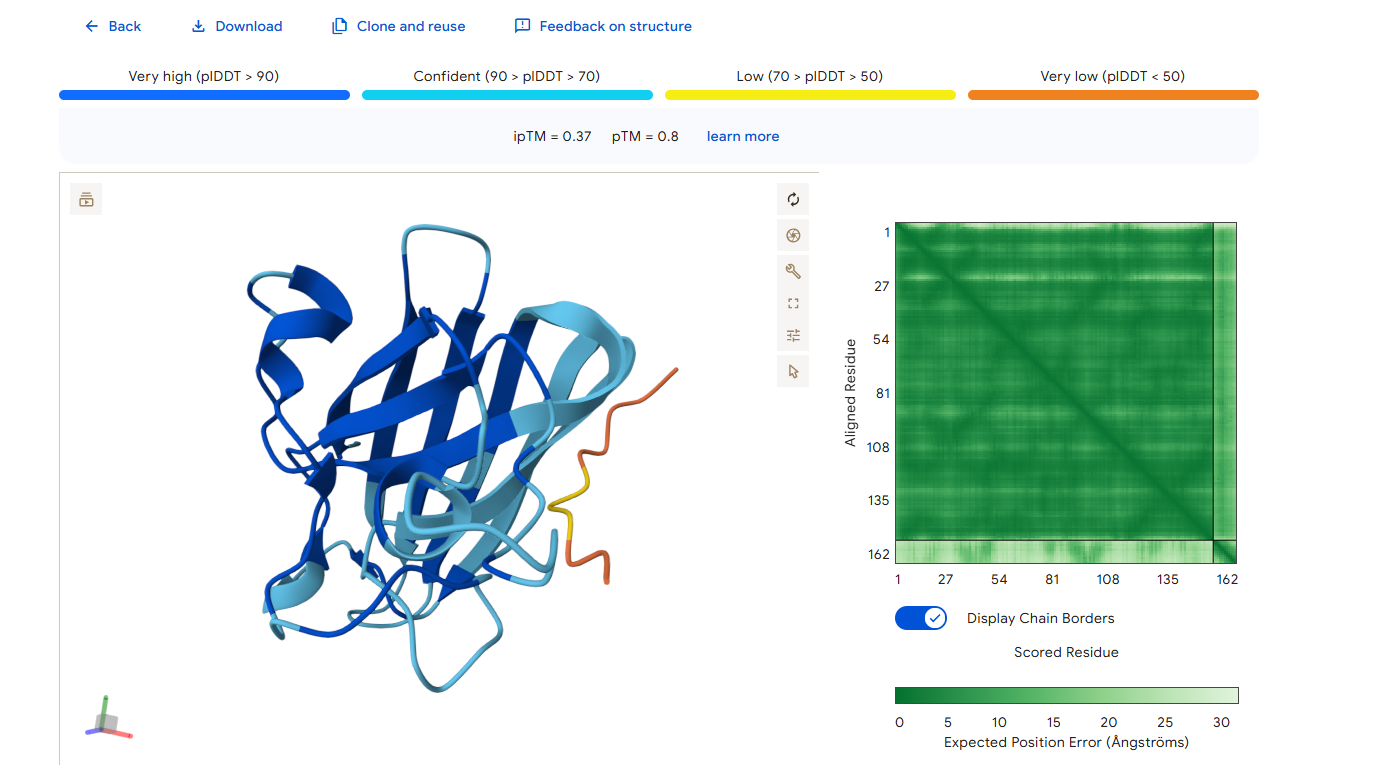
Peptide 2
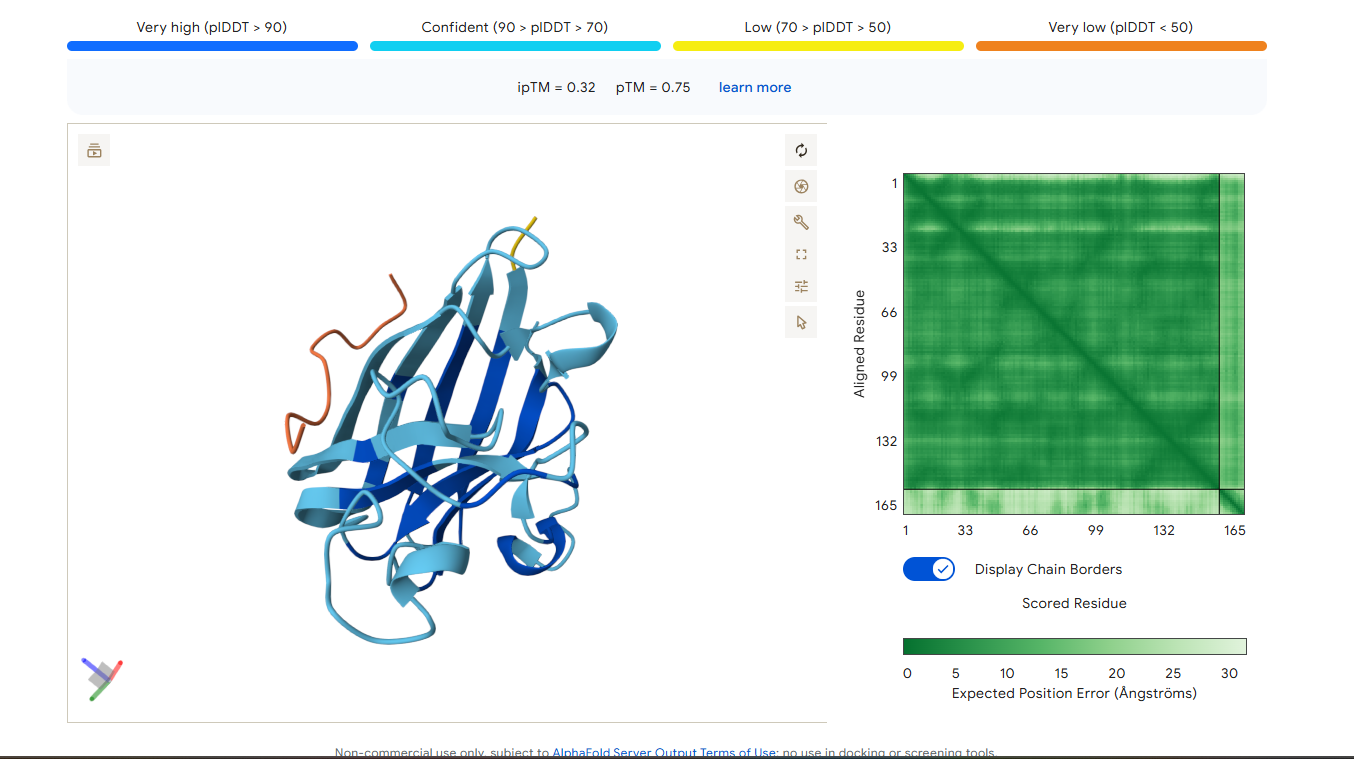
Peptide 3
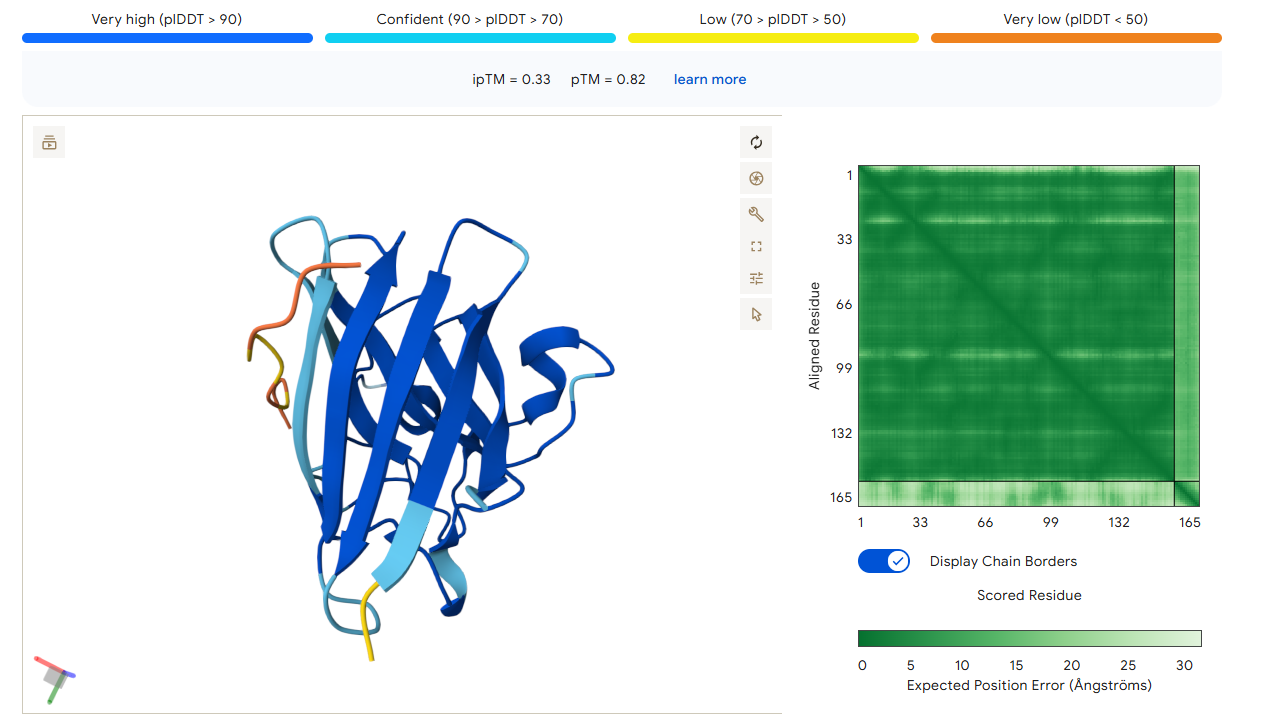
Peptide 4
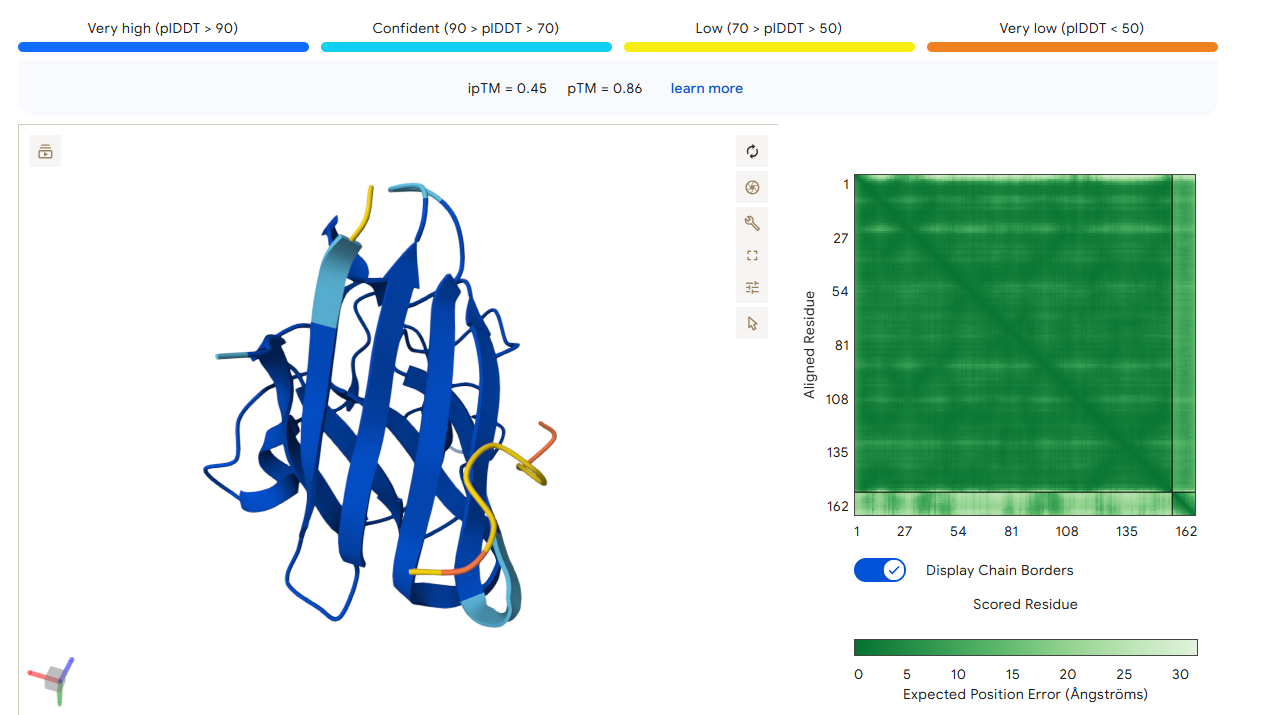
Control Peptide
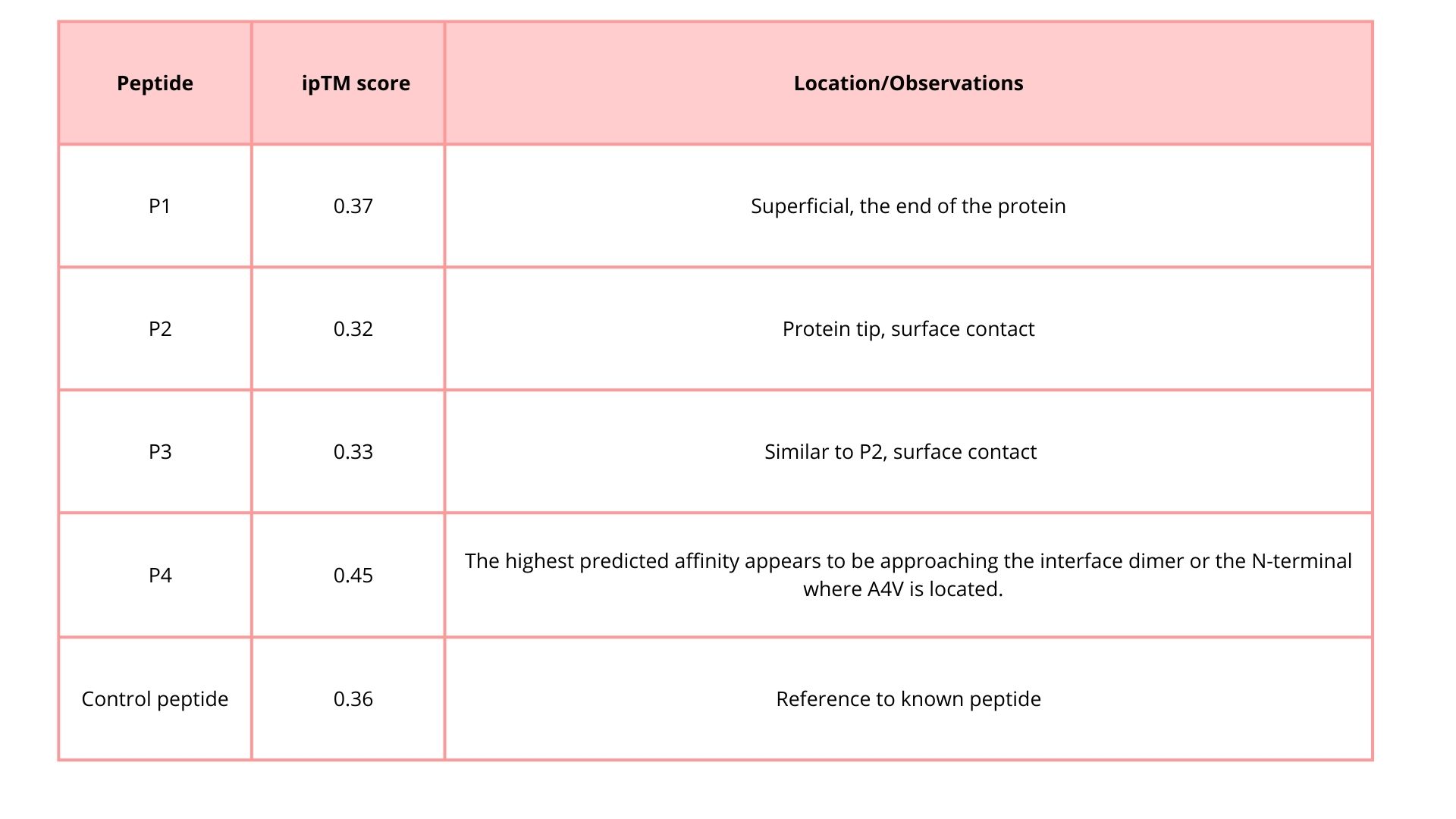
The ipTM score gives you an idea of the confidence in the interaction:
Values close to 1 → peptide binds in the predicted region.
Values close to 0 → low confidence, weak or doubtful interaction.
The ipTM score for peptide 2 is 0.32, indicating a relatively low affinity for the protein-peptide complex. Visually, the peptide is localized on the surface. This suggests that, although the peptide can bind to the protein, it is unlikely to directly influence protein stabilization.
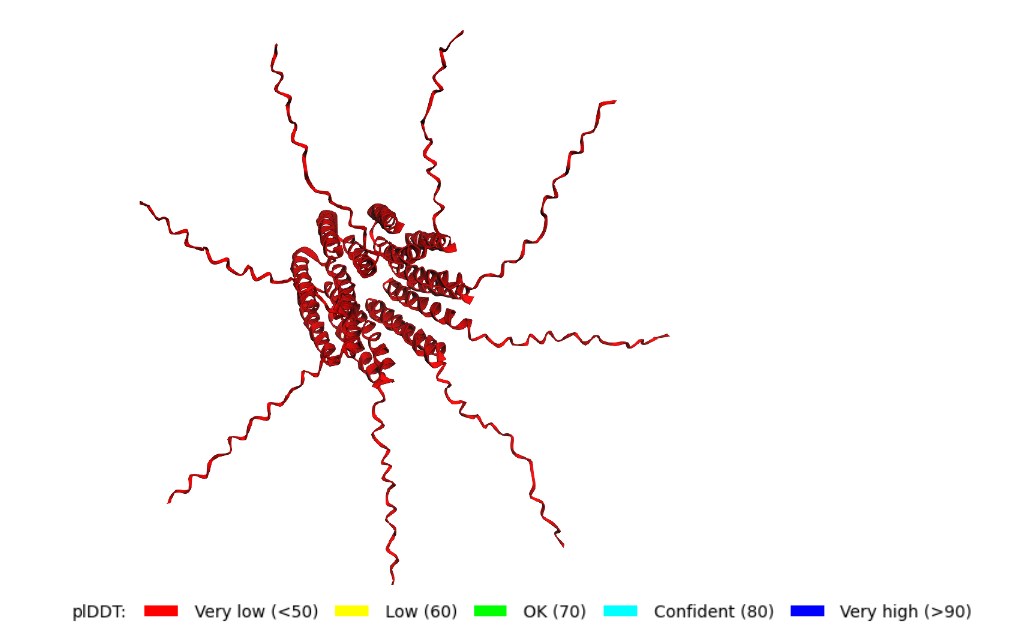
The ipTM score for peptide 3 is 0.33, indicating a relatively low affinity for the protein-peptide complex. Visually, the peptide is localized on the surface. This suggests that, although the peptide can bind to the protein, it is unlikely to directly influence protein stabilization. The ipTM score of peptide 4 is 0.45, indicating a relatively low affinity, but higher than the other peptides, for the protein-peptide complex. It binds to the N-terminus, where the A4V mutation is located, or to the interface dimer, suggesting that it could interfere with SOD1 aggregation or stability.
The ipTM score of the control peptide is 0.36, indicating a relatively low affinity for the protein-peptide complex. Visually, the peptide is localized to the surface. This suggests that, although the peptide may bind to the protein, it is unlikely to directly influence protein stabilization.
In summary, among the four peptides, peptide 4 has the highest ipTM, which may be the best option.
Part 3: Evaluate Properties of Generated Peptides in the PeptiVerse
Structural confidence alone is insufficient for therapeutic development. Using PeptiVerse, let’s evaluate the therapeutic properties of your peptide! For each PepMLM-generated peptide:
1. Paste the peptide sequence.
2. Paste the A4V mutant SOD1 sequence in the target field.
3. Check the boxes
Predicted binding affinity
Solubility
Hemolysis probability
Net charge (pH 7)
Molecular weight
Compare these predictions to what you observed structurally with AlphaFold3. In a short paragraph, describe what you see. Do peptides with higher ipTM also show stronger predicted affinity? Are any strong binders predicted to be hemolytic or poorly soluble? Which peptide best balances predicted binding and therapeutic properties?
Choose one peptide you would advance and justify your decision briefly.
Peptide 1

Peptide 2
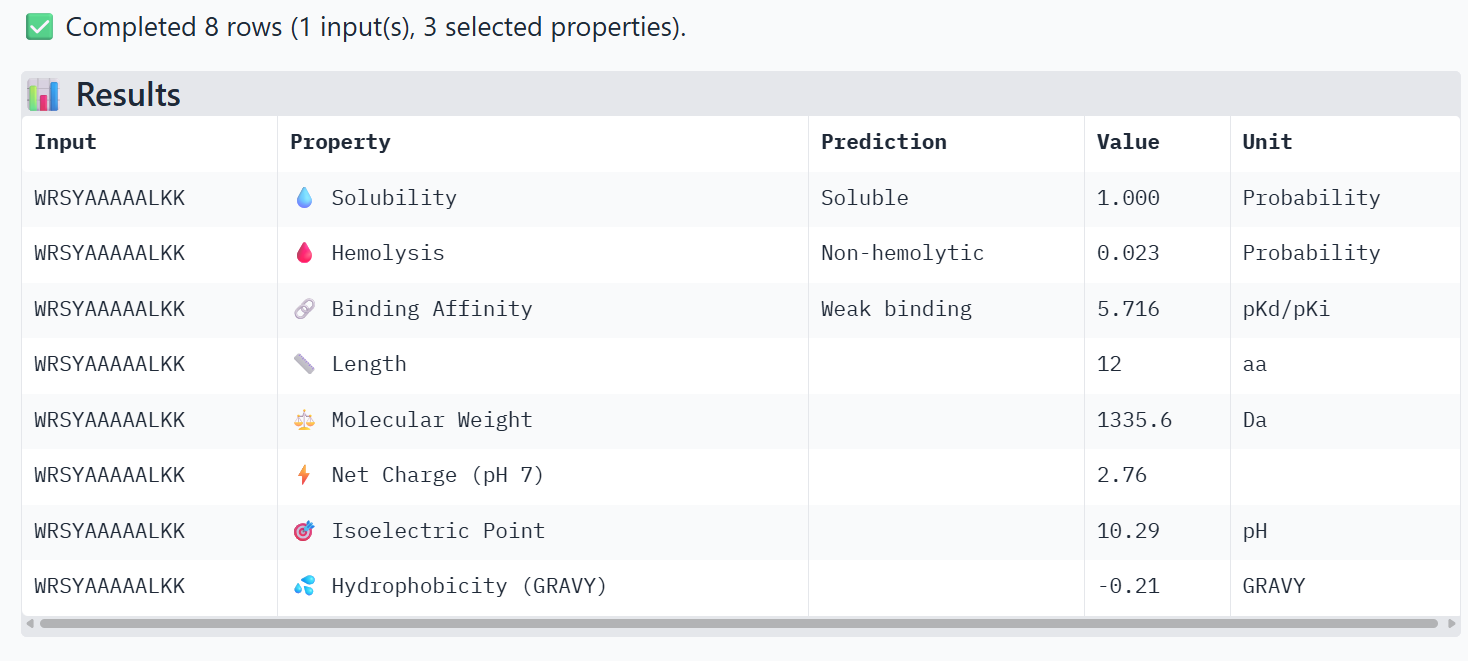
Peptide 3
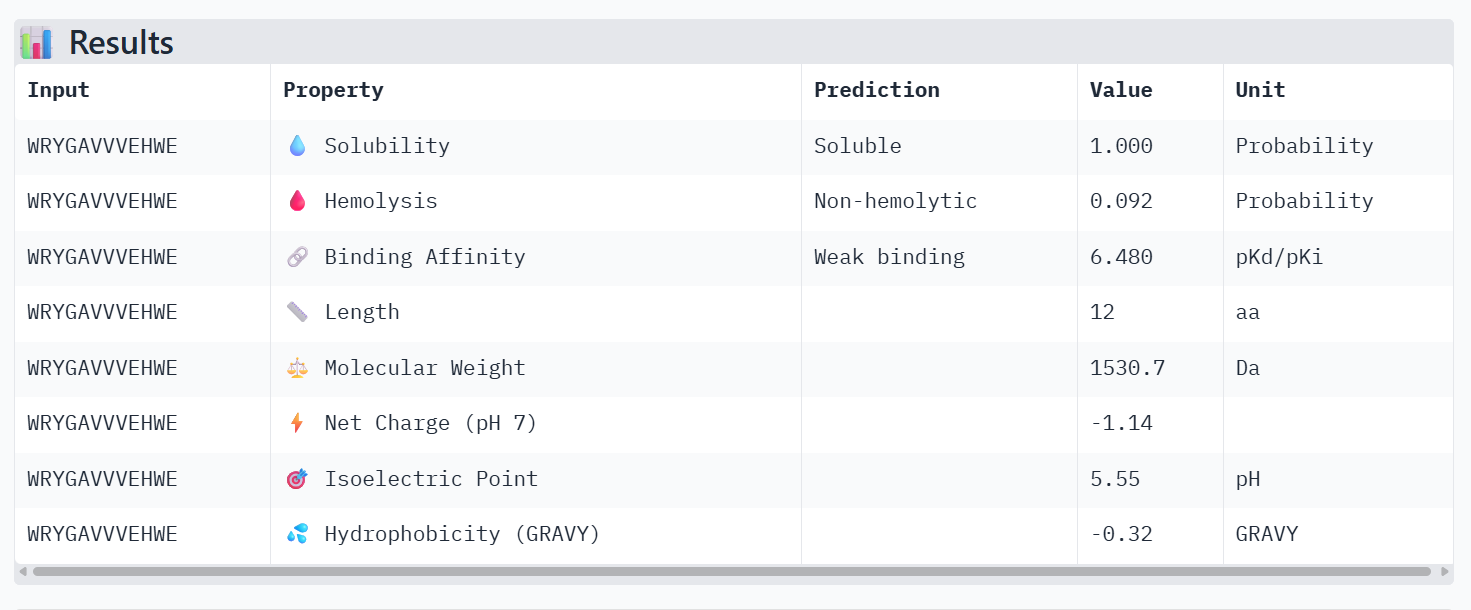
Peptide 4

Control Peptide
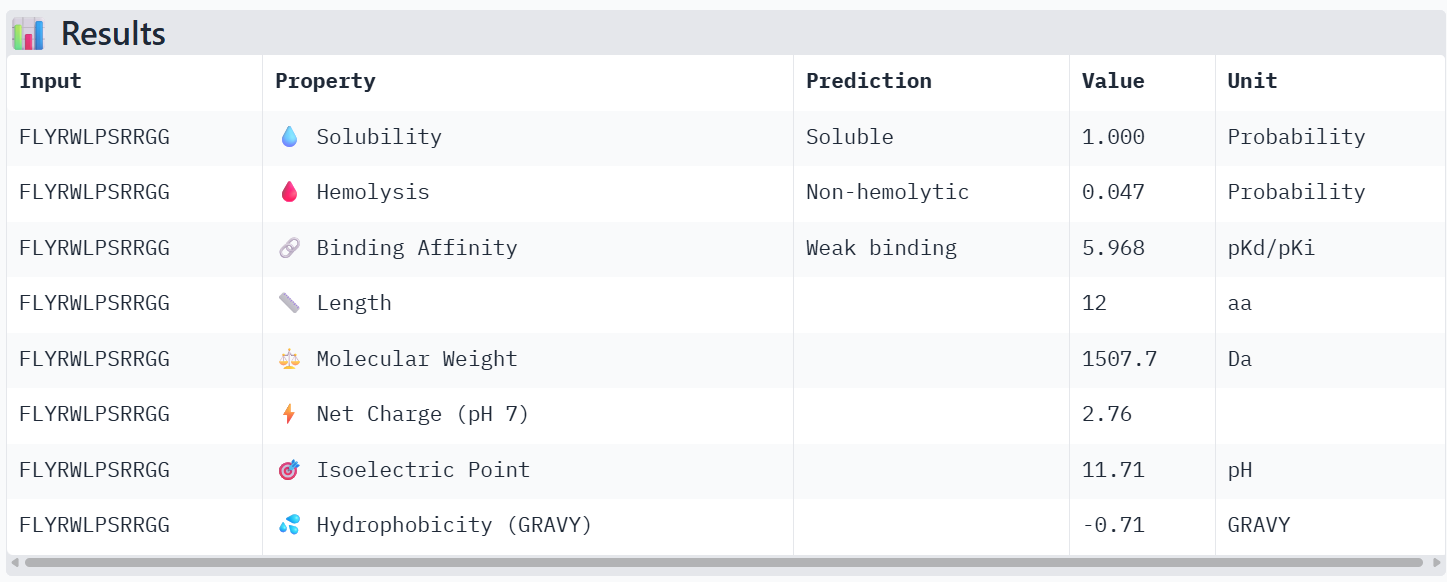
All the peptides show weak predicted binding affinity, non-hemolytic activity, and good solubility. The predicted pKd/pKi values are around ~6, which corresponds to weak to moderate binding on the logarithmic scale, where strong affinity interactions are typically associated with values ≥ 9. Peptide 4 shows slightly lower predicted binding affinity than the control peptide according to PeptiVerse, despite having the highest ipTM score in the AlphaFold structural prediction.
However, I still chose peptide 4 because, in AlphaFold, structural prediction has the best ipTM value, even though it is not the greatest. Moreover, in PeptiVerse the value is not high but either low, or it is the peptide with the lowest value of probability of hemolysis.
Part 4: Generate Optimized Peptides with moPPIt
Now, move from sampling to controlled design. moPPIt uses Multi-Objective Guided Discrete Flow Matching (MOG-DFM) to steer peptide generation toward specific residues and optimize binding and therapeutic properties simultaneously. Unlike PepMLM, which samples plausible binders conditioned on just the target sequence, moPPIt lets you choose where you want to bind and optimize multiple objectives at once.
1. Open the moPPit Colab linked from the HuggingFace moPPIt model card
2. Make a copy and switch to a GPU runtime.
3. In the notebook:
Paste your A4V mutant SOD1 sequence.
Choose specific residue indices on SOD1 that you want your peptide to bind (for example, residues near position 4, the dimer interface, or another surface patch).
Set peptide length to 12 amino acids.
Enable motif and affinity guidance (and solubility/hemolysis guidance if available). Generate peptides.
4. After generation, briefly describe how these moPPit peptides differ from your PepMLM peptides. How would you evaluate these peptides before advancing them to clinical studies?
In moPPIt, motif guidance was applied by specifying position 4 within the peptide sequence to encourage residues that may promote interaction with the target region. Additional objectives including affinity, solubility, and hemolysis were enabled to balance binding with therapeutic properties.
The peptides generated with PepMLM and moPPIt differ mainly in their design strategy and optimization objectives. PepMLM peptides are generated through sequence sampling conditioned on the target protein sequence. The model predicts plausible peptide binders but does not explicitly optimize specific therapeutic properties.
In contrast, moPPIt peptides design peptides that bind to specific residues on the target protein while simultaneously optimizing therapeutic properties. This approach produces peptides that are optimized for desirable biochemical and therapeutic characteristics.
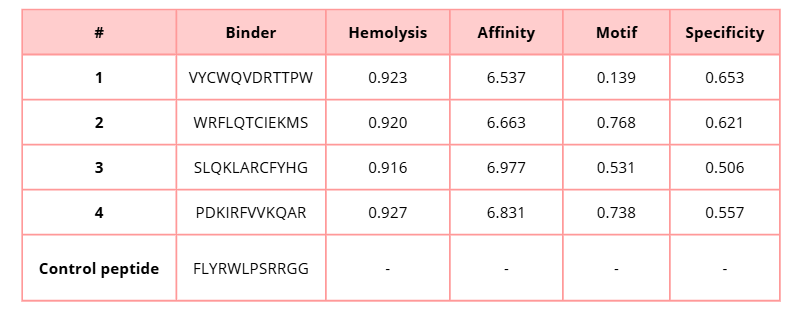
In this table, lower hemolysis values are preferable because they indicate a lower predicted risk of lysis. On the other hand, higher values for affinity, motif, and specificity are desirable, since they suggest stronger binding to the target protein, better motif compatibility, and greater binding specificity.
SLQKLARCFYHG shows the highest predicted affinity (6.977), suggesting stronger potential binding to the mutant SOD1 protein. However, PDKIRFVVKQAR presents a balanced profile with high affinity (6.831), strong motif score (0.738), and relatively good specificity (0.557), which may indicate a favorable interaction with the targeted binding site.
Similarly, WRFLQTCIEKMS also demonstrates good performance with high affinity (6.663) and the highest motif score (0.768) among the generated peptides, suggesting strong compatibility with the selected binding motif.
I would evaluate these peptides using:
- Computational validation
- In vitro binding assays
- Toxicity and hemolysis testing
Part C: Final Project: L-Protein Mutants
High-level summary: The objective of this assignment is to improve the stability and auto-folding of the lysis protein of a MS2-phage. This mechanism is key to the understanding of how phages can potentially solve antibiotic-resistance.
L-Protein Engineering | Option 1: Mutagenesis
1. Designing these mutants with good computational confidence is hard. It will show you limitations of some of the structure based models. Ultimately, you can pick various combinations of mutations and get lab results and then decide to pick the next round of mutations, but this assay will not be easy to run at scale in this class.
2. Run this notebook to generate for each position in the amino acid sequence, a “score” for what would happen to the protein if you mutated into another amino acid. It can be positive or negative for the protein. We want to identify possible mutations that are “positive” If you run this notebook - you will see a .csv file in the sidebar. You can download it and look at it in the google sheets if that’s easier
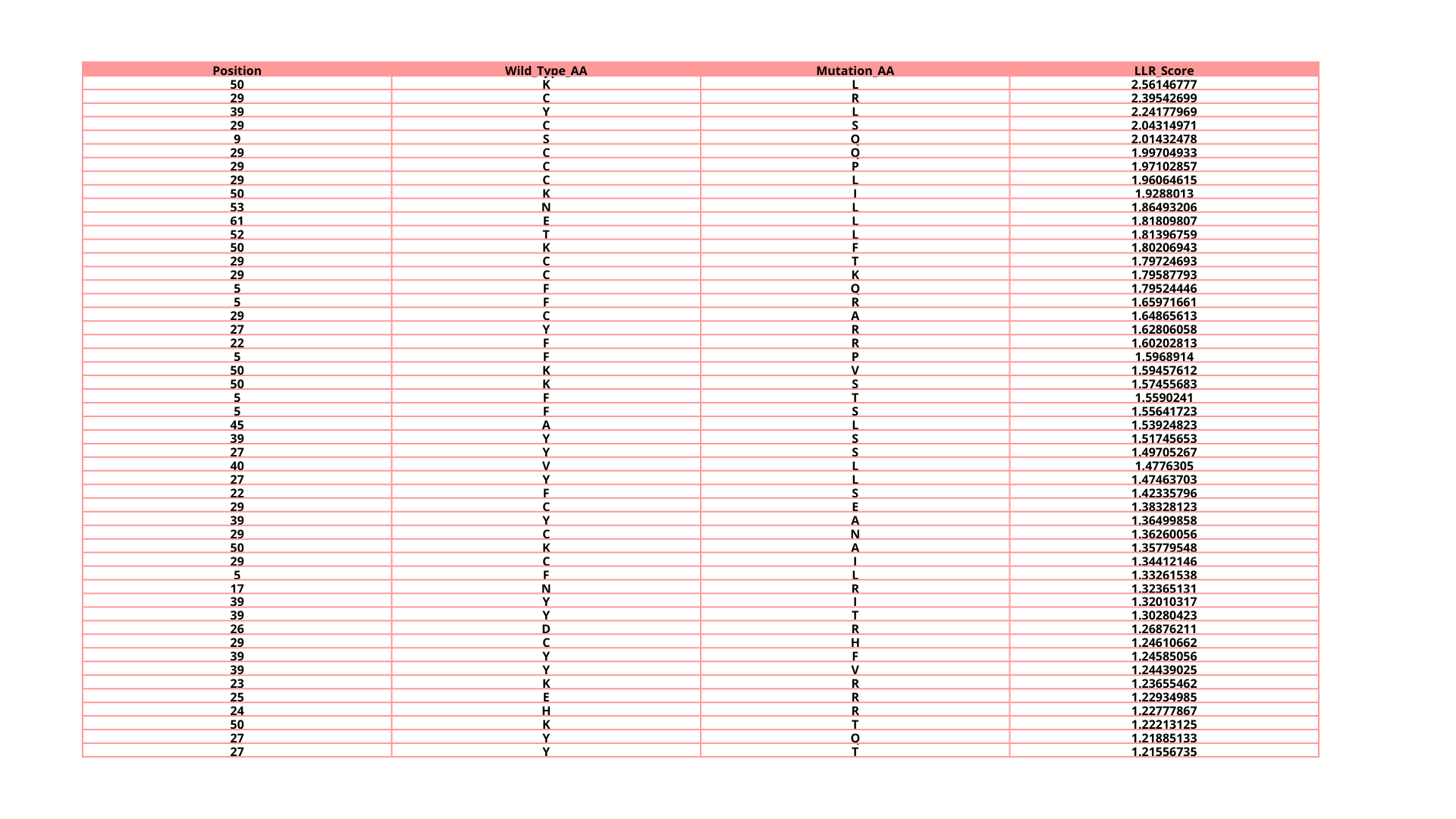
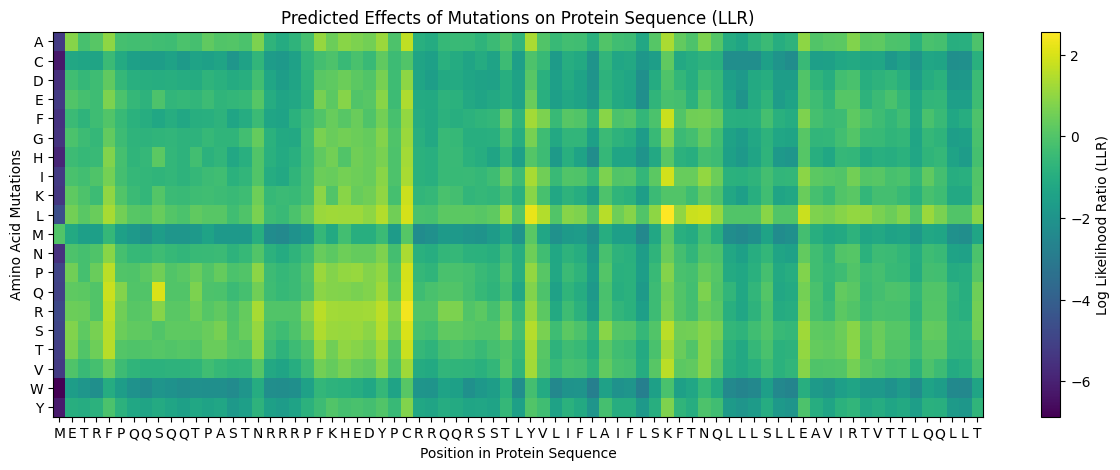
3. Use the experimental data here. This dataset contains information about mutants of the L-Protein and their effect on lysis in the lab - L-Protein Mutants
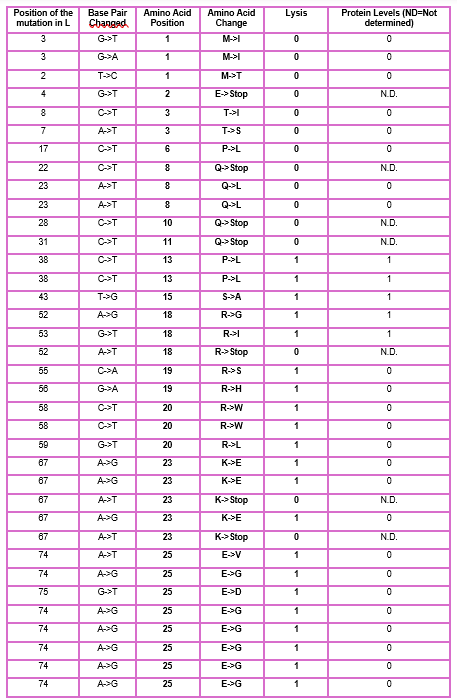
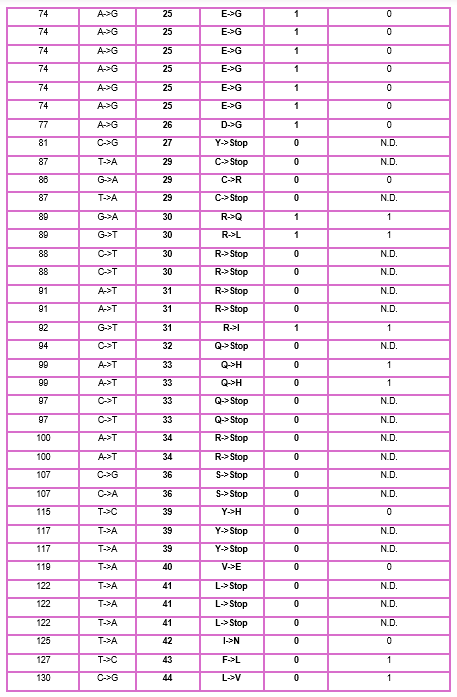
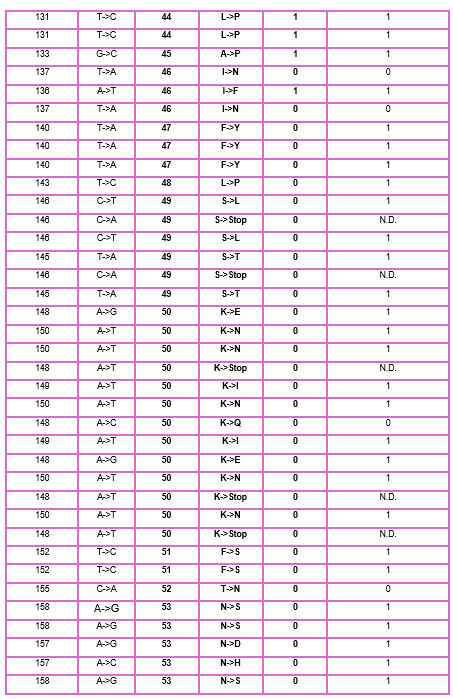
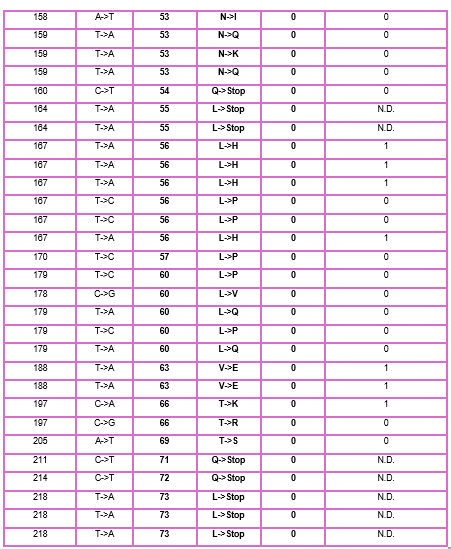
4. First check, does the experimental data correlate with the scores from the notebook in (b)? This should give you a clue on how well these language embeddings capture information about this protein sequence
When I compared the experimental data with the theoretical scores obtained from the Colab notebook, I observed that there is not a perfect correlation but there is a partial one, which means that I cannot find the same specific mutation in the experimental data; however, I found that in some positions, the change for other amino acids might be favorable to increase the Lysis protein activity indicating that the language embeddings capture some relevant structural and functional information about this protein.
5. Using information about the effect of protein mutations at these sites - both the scores and the experimental data in the drive, come up with 5 mutations for each student along with how you came up with them and why you believe they would work. 2 of the variants you submit must have mutations in the transmembrane region (refer to notes above on what amino acid positions these are) and 2 of them must be in the soluble region . Remember that you can also use the pBLAST to see which residues are conserved and not mutate them if you want to.
One easy way to generate sequence mutations could be to look for residue positions and mutations that have a positive mutational effect either in the experimental or have a positive score from step 1. And pick a combination of those mutations.
I decided to choose these mutations because they have lysis protein activity of 1 in experimental data and in the Colab notebook; their score is positive, which means that the mutations are favorable.
Transmembrane mutations (A45L and A45V): could influence the protein’s ability to insert into and form pores in the membrane.
Soluble DnaJ domain mutations (D26R, K23R, and E25R): enhance the protein’s stability or interactions without disrupting its overall structure.
These mutations were selected based on a combination of experimental evidence, computational predictions, and consideration of their location within functional regions of the protein.
6. You can utilize Af2_Multimer to generate a Multimeric Assembly; you can do this by making your query sequence as. We want to do this because - A running hypothesis for how this protein functions is that it assembles to make a perforation in the bacterial membrane.