Week 2 HW: Read, write and Edit
Part 1: Benchling & In-silico Gel Art
I began by signing into my Benchling account and creating a new folder called HTGAA-read, write, and edit I then added a new sequence that is the Lambda_NEB fasta sequence On the right-hand side, I used the icon that looks like scissors to enter the different restriction enzymes and then viewed the different digestion sites on the virtual digest tab. Below is the image from the virtual digest for the different enzymes.

Part 3: DNA Design Challenge
3.1. Choose your protein
Through a literature search using pubmed I searched for papers that have explored naturally occurring peptides that have antimicrobial activity towards both Gram-positive and Gram-negative bacteria. Staphylococcus aureus (Gram-positive), Escherichia coli (Gram-negative), and Streptococcus uberis (Gram-positive) are the most common mastitis-causing bacteria in dairy farming.
Pituitary adenylate cyclase-activating polypeptide (PACAP) is a naturally occurring cationic peptide known for its strong immunosuppressive and cell-protective effects. It belongs to the secretin, growth hormone-releasing hormone (GHRH), and vasoactive intestinal peptide (VIP) family, and exhibits significant anti-inflammatory and cytoprotective capabilities. While PACAP is most concentrated in the brain, it is also present in notable amounts in other tissues, such as the thymus, spleen, lymph nodes, and duodenal mucosa (Vaudry et al., 2009). Despite its therapeutic potential, the use of PACAP as a pharmaceutical agent is hindered by its extremely short half-life in the bloodstream after systemic delivery, largely due to rapid degradation—particularly by the enzyme DPP IV, which targets the peptide’s amino terminus through exopeptidase activity (Green et al., 2006). PACAP occurs in two bioactive forms, both amidated, consisting of either 38 or 27 amino acids.
Producing PACAP synthetically is crucial for scalability, uniformity, and ethical reasons(Starr et al., 2018). Since the peptide is primarily found in sensitive tissues like the brain and immune organs, extracting it from natural sources is neither feasible nor appropriate for widespread agricultural applications. Instead, recombinant methods using engineered microorganisms enable large-scale, cost-efficient production through fermentation, ensuring consistent quality and purity.
The UniProt Sequence
sp|Q29W19|PACA_BOVIN Pituitary adenylate cyclase-activating polypeptide OS=Bos taurus OX=9913 GN=ADCYAP1 PE=2 SV=1 MTMCSGARLALLVYGILMHSSVYGSPAASGLRFPGIRPENEVYDEDGNPQQDFYDSESLG VGSPASALRDAYALYYPAEERDVAHGILNKAYRKVLDQPSARRSPADAHGQGLGWDPGGS ADDDSEPLSKRHSDGIFTDSYSRYRKQMAVKKYLAAVLGKRYKQRVKNKGRRIPYL
REFERENCES
Green, B. D., Irwin, N., & Flatt, P. R. (2006). Pituitary adenylate cyclase-activating peptide (PACAP): Assessment of dipeptidyl peptidase IV degradation, insulin-releasing activity and antidiabetic potential. Peptides, 27(6), 1349–1358. https://doi.org/10.1016/j.peptides.2005.11.010
Starr, C. G., Maderdrut, J. L., He, J., Coy, D. H., & Wimley, W. C. (2018). Pituitary adenylate cyclase-activating polypeptide is a potent broad-spectrum antimicrobial peptide: Structure-activity relationships. Peptides, 104, 35–40. https://doi.org/10.1016/j.peptides.2018.04.006
Vaudry, D., Falluel-Morel, A., Bourgault, S., Basille, M., Burel, D., Wurtz, O., Fournier, A., Chow, B. K. C., Hashimoto, H., Galas, L., & Vaudry, H. (2009). Pituitary Adenylate Cyclase-Activating Polypeptide and Its Receptors: 20 Years after the Discovery. Pharmacological Reviews, 61(3), 283–357. https://doi.org/10.1124/pr.109.001370
3.2. Reverse Translate: Protein (amino acid) sequence to DNA (nucleotide) sequence
I used the “Reverse Translate” tool of the Sequence Manipulation Suite to get the nucleotide sequence. And confirmed that the sequence was accurate using the NCBI BlastX to confirm that it is accurate.
atgaccatgtgcagcggcgcgcgcctggcgctgctggtgtatggcattctgatgcatagc agcgtgtatggcagcccggcggcgagcggcctgcgctttccgggcattcgcccggaaaac gaagtgtatgatgaagatggcaacccgcagcaggatttttatgatagcgaaagcctgggc gtgggcagcccggcgagcgcgctgcgcgatgcgtatgcgctgtattatccggcggaagaa cgcgatgtggcgcatggcattctgaacaaagcgtatcgcaaagtgctggatcagccgagc gcgcgccgcagcccggcggatgcgcatggccagggcctgggctgggatccgggcggcagc gcggatgatgatagcgaaccgctgagcaaacgccatagcgatggcatttttaccgatagc tatagccgctatcgcaaacagatggcggtgaaaaaatatctggcggcggtgctgggcaaa cgctataaacagcgcgtgaaaaacaaaggccgccgcattccgtatctg
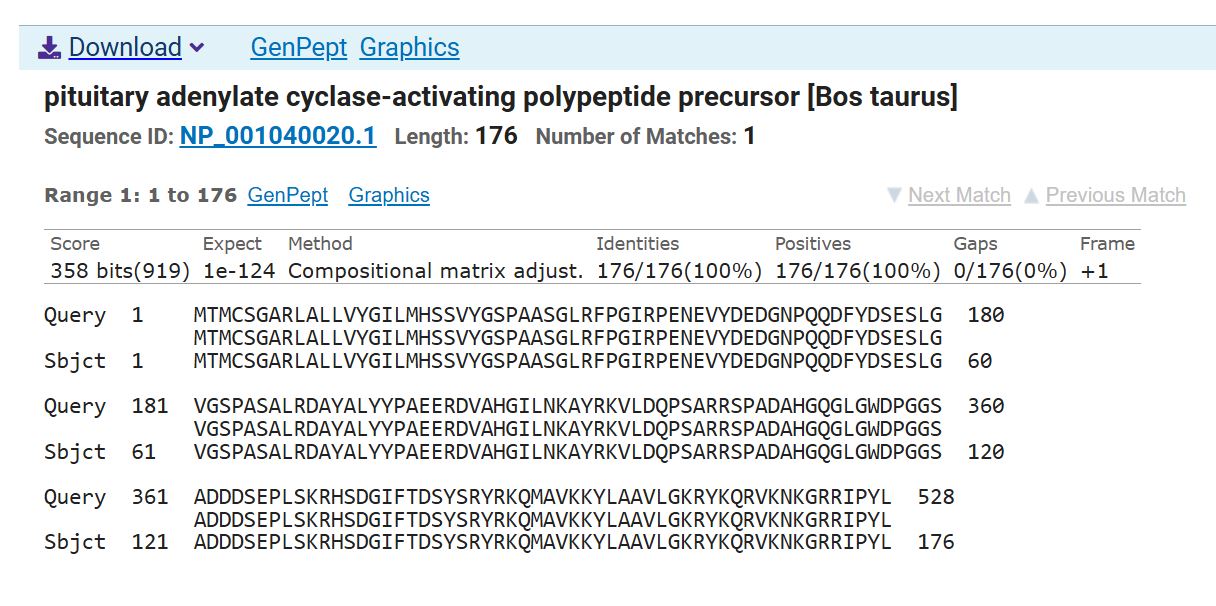 Screenshot of the BlastX results confirming accurate reverse translation
Screenshot of the BlastX results confirming accurate reverse translation
3.3. Codon optimization
Codon optimization is essential because, while several DNA codons can code for the same amino acid, different species show distinct preferences in codon usage. Expressing the bovine PACAP sequence directly in a microbial host without adjustment could lead to poor translation efficiency and, consequently, low protein output. To support economical, large-scale production, the gene sequence was adapted for use in Escherichia coli, a widely adopted system for recombinant protein expression. By aligning codon usage with the host’s natural preferences, translation becomes more efficient, protein yields improve, and overall production costs decrease, enabling viable industrial synthesis of the antimicrobial peptide.
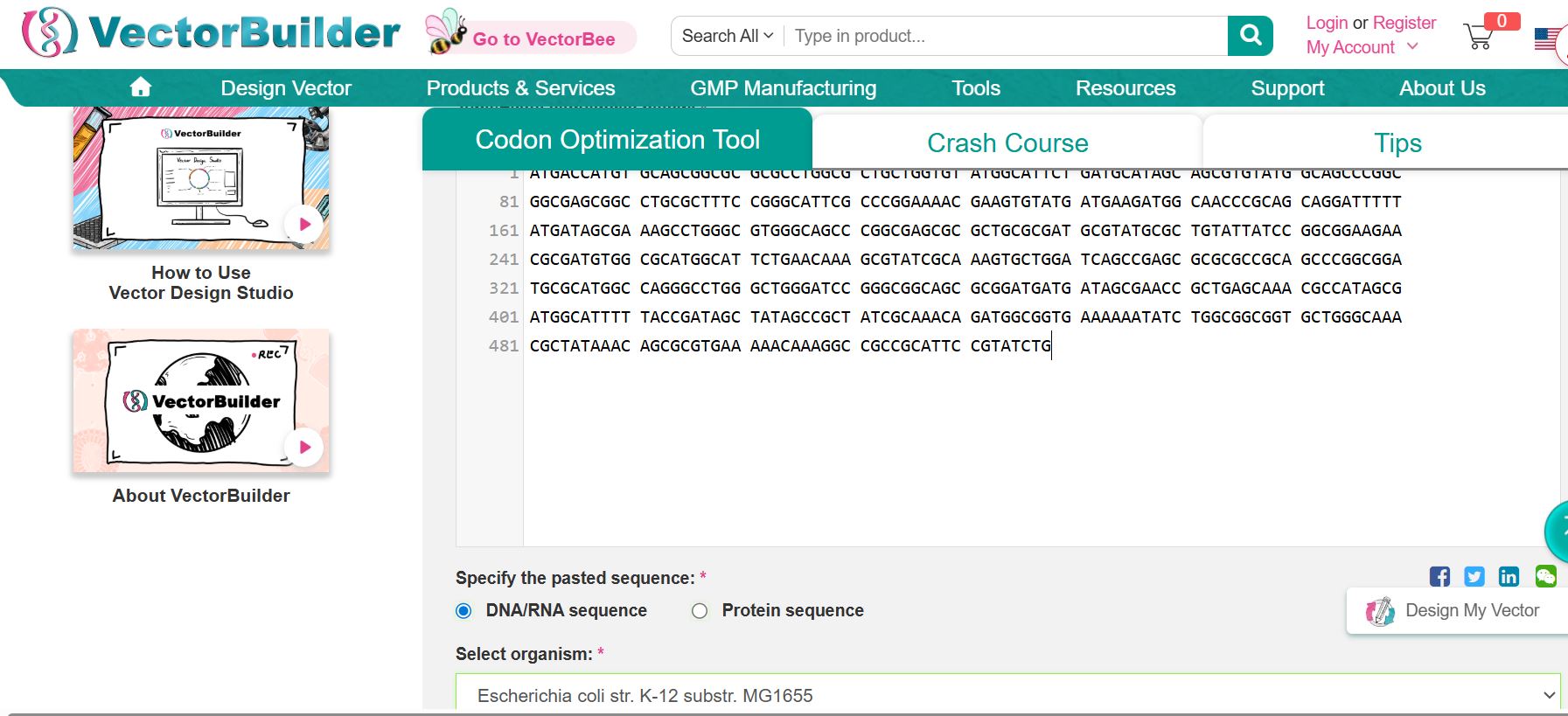 Codon optimization using VectorBuilder
Codon optimization using VectorBuilder
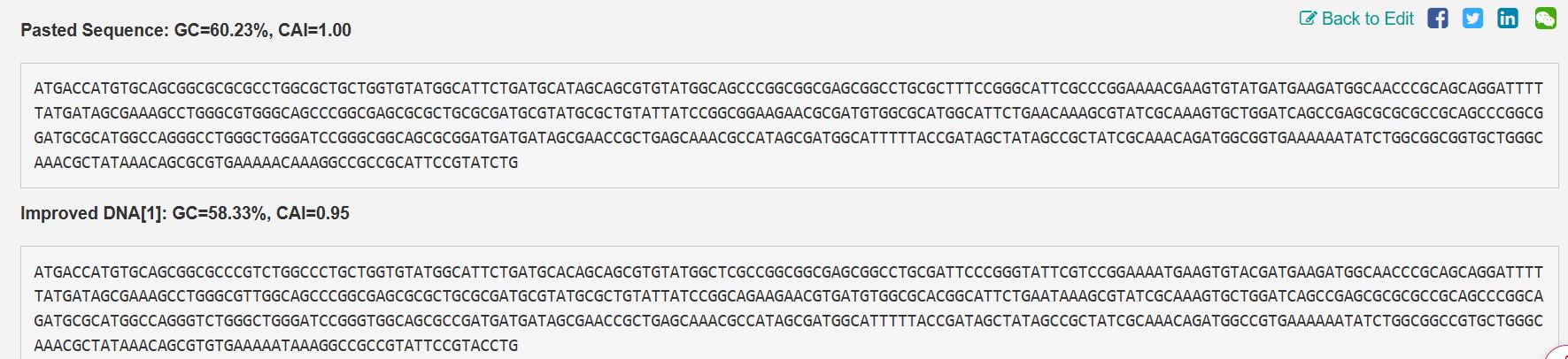 Improved sequences from VectorBuilder
Improved sequences from VectorBuilder
The following is the improved DNA sequence post-codon optimization ATGACCATGTGCAGCGGCGCCCGTCTGGCCCTGCTGGTGTATGGCATTCTGATGCACAGCAGCGTGTATGGCTCGCCGGCGGCGAGCGGCCTGCGATTCCCGGGTATTCGTCCGGAAAATGAAGTGTACGATGAAGATGGCAACCCGCAGCAGGATTTTTATGATAGCGAAAGCCTGGGCGTTGGCAGCCCGGCGAGCGCGCTGCGCGATGCGTATGCGCTGTATTATCCGGCAGAAGAACGTGATGTGGCGCACGGCATTCTGAATAAAGCGTATCGCAAAGTGCTGGATCAGCCGAGCGCGCGCCGCAGCCCGGCAGATGCGCATGGCCAGGGTCTGGGCTGGGATCCGGGTGGCAGCGCCGATGATGATAGCGAACCGCTGAGCAAACGCCATAGCGATGGCATTTTTACCGATAGCTATAGCCGCTATC
3.4. You have a sequence! Now what?
Once the codon-optimized DNA sequence for PACAP is available, it needs to be integrated into a biological system capable of transcribing the DNA into mRNA and subsequently translating that mRNA into the PACAP protein. Given the objective of producing PACAP as an affordable antimicrobial peptide for managing mastitis, a cell-based production system using E. coli fermentation is the most suitable choice. This approach offers high protein output, low manufacturing costs, scalability for industrial use, and practical potential for commercial application. The PACAP gene would first be incorporated into an expression vector, typically a plasmid, which is then delivered into Escherichia coli cells. Within the bacterial host, RNA polymerase recognizes the promoter region and initiates transcription of the PACAP gene into mRNA. Ribosomes then attach to the mRNA and begin translation, synthesizing the PACAP peptide with the help of tRNAs that correspond to the optimized codons. As the bacteria grow and divide, they generate substantial quantities of the peptide, which can later be harvested and purified.
Part 4: Prepare a Twist DNA Synthesis Order
4.2. Build Your DNA Insert Sequence
Following the instructions from the homework, I manually inserted the following sequences sequentially into the bases section
Promoter (e.g. BBa_J23106): TTTACGGCTAGCTCAGTCCTAGGTATAGTGCTAGC RBS (e.g. BBa_B0034 with spacers for optimal expression): CATTAAAGAGGAGAAAGGTACC Coding Sequence (The codon optimized sequence already had a start codon so I did not put two start codons) 7x His Tag (Let’s add a 7×His tag at the C-terminus of the protein to enable protein purification from E. coli): CATCACCATCACCATCATCAC Stop Codon: TAA Terminator (e.g. BBa_B0015): CCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCTACTAGAGTCACACTGGCTCACCTTCGGGTGGGCCTTTCTGCGTTTATA
Here is the link to the annotated sequence: https://benchling.com/s/seq-7dMM0y6i3bzKtgtg4ARN?m=slm-ovXPs57Txzw1F9ZhxeXZ
Below are the screenshots from the various steps during the annotation process.
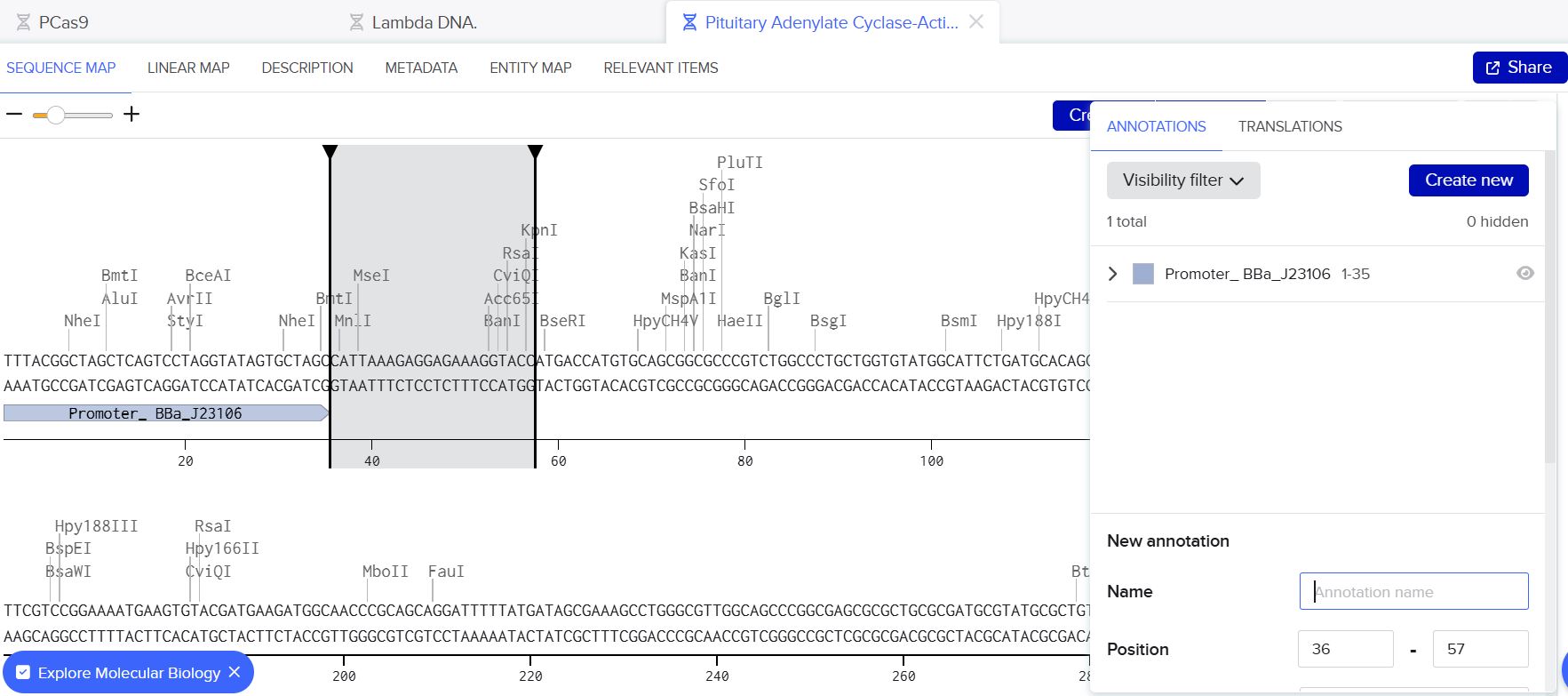 Annotation window
Annotation window
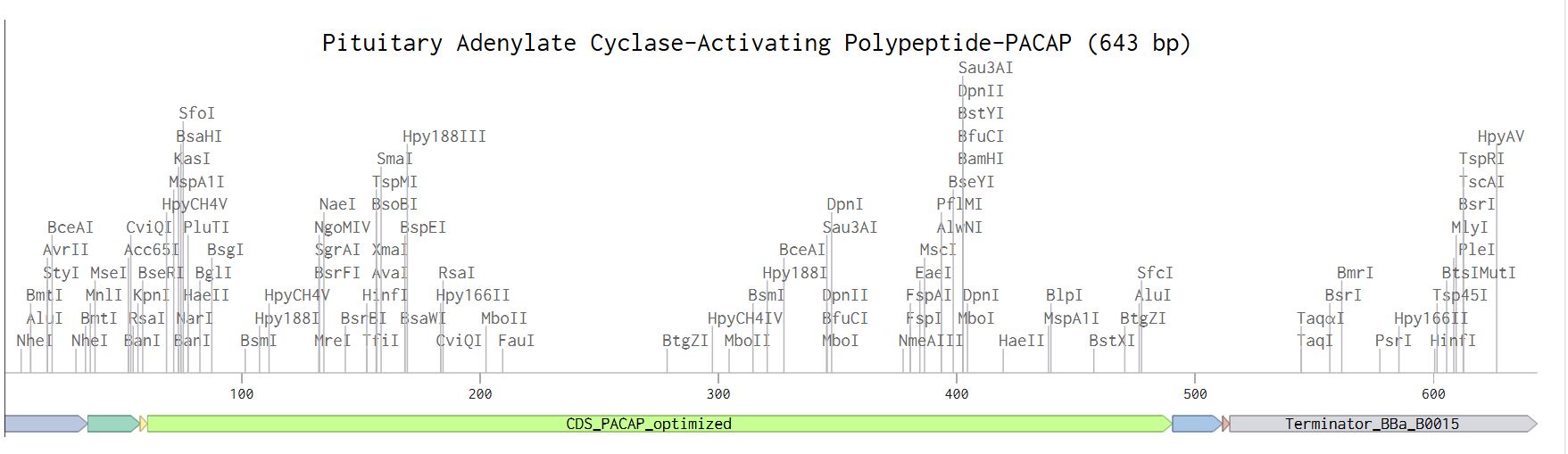 Linear map of the annotated sequence.
Linear map of the annotated sequence.
Twist Workflow
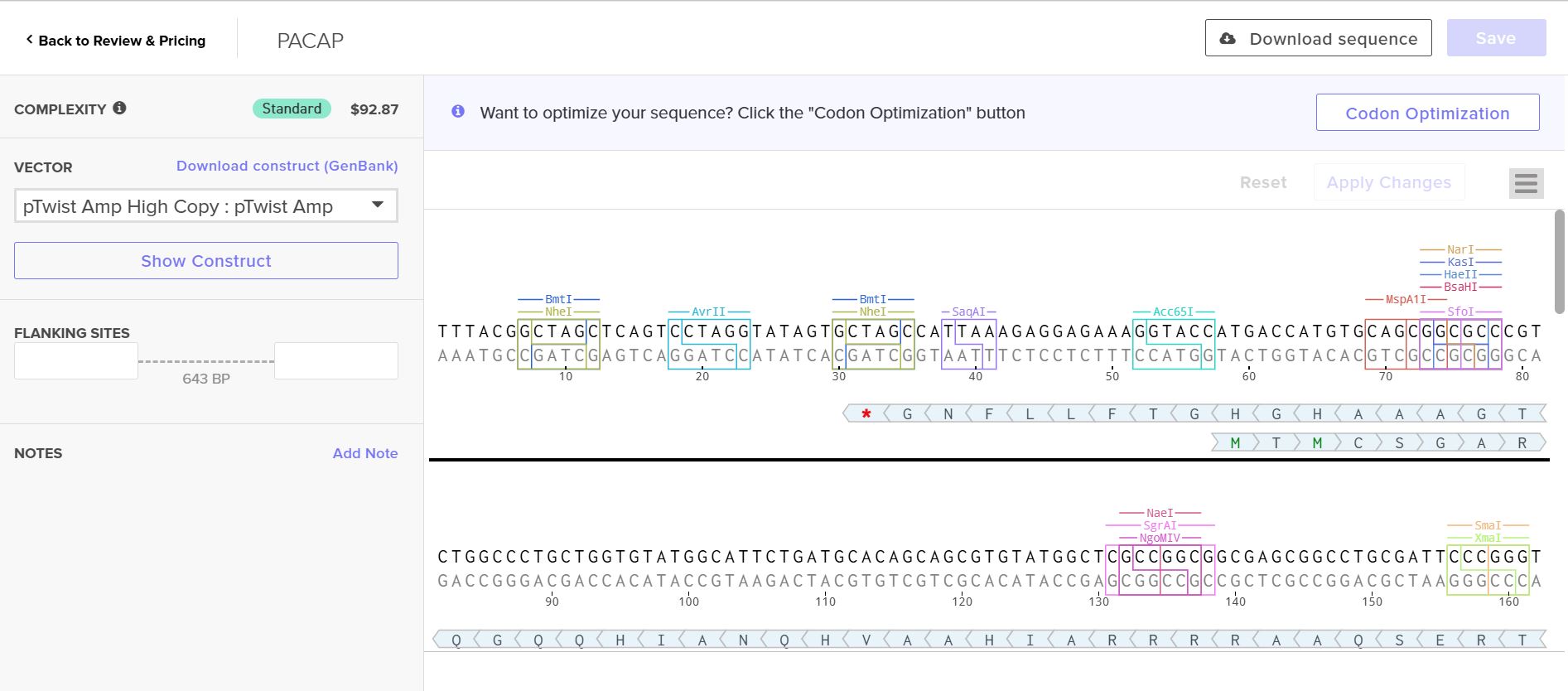
Construct- Twist
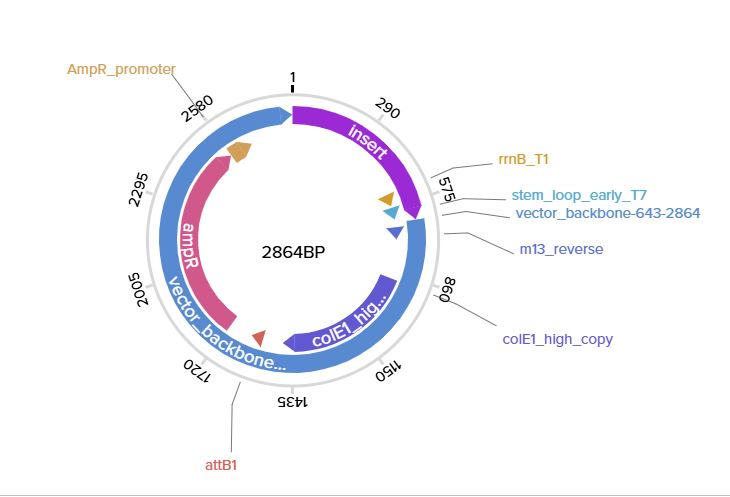
Plasmid with expression cassette - Benchling
Part 5: DNA Read/Write/Edit
5.1 DNA Read
(i) What DNA would you want to sequence (e.g., read) and why?
In the context of mastitis control and epidemiological surveillance, I would sequence metagenomic DNA extracted from milk, teat swabs, and environmental samples collected from dairy farms with and without biosecurity measures. Sequencing this DNA would allow identification of the dominant mastitis-causing bacteria circulating within these farms and enable detection of antibiotic resistance genes present in the microbial populations. This information would provide real-world insight into pathogen prevalence and resistance patterns, which would directly inform the rational design and optimisation of my PACAP-based antimicrobial peptide to ensure it is effective against the most relevant and resistant strains. In addition, I would sequence my final PACAP expression construct to confirm sequence accuracy and ensure that no mutations were introduced during cloning or synthesis.
(ii) In lecture, a variety of sequencing technologies were mentioned. What technology or technologies would you use to perform sequencing on your DNA and why?
For metagenomic analysis of dairy farm samples, I would use shotgun next-generation sequencing (NGS), specifically a short-read platform such as Illumina sequencing. This method is classified as a second-generation sequencing technology.
The input for this method would be total DNA extracted from milk, teat swabs, or environmental samples collected from dairy farms. After extraction, the DNA must be prepared into a sequencing library. (Usually, there is a step by step protocal shared on how to prepare the libraries, including pulling and how to send them for sequencing)
The output of this sequencing technology is a large dataset of short DNA reads in FASTQ format, which includes both the nucleotide sequence and associated quality scores for each base. These reads can then be assembled or mapped against reference databases to identify bacterial species present in the samples and detect antibiotic resistance genes.
5.2 DNA Write
(i) What DNA would you want to synthesize (e.g., write) and why?
I would synthesise a codon-optimised version of the PACAP-27 gene designed for efficient expression in Escherichia coli. The sequence would be optimised to match the preferred codon usage of the host organism in order to maximise protein yield. Additionally, based on insights gained from metagenomic surveillance data, I may incorporate rational modifications to improve antimicrobial activity, stability, or resistance to proteolytic degradation. Synthesising the gene rather than amplifying it from a natural source allows full control over sequence design and ensures the construct is tailored specifically to the pathogens identified in dairy farm environments.
(ii) What technology or technologies would you use to perform this DNA synthesis and why?
I would use commercial chemical DNA synthesis technology, which relies on phosphoramidite chemistry to generate short oligonucleotides that are enzymatically assembled into full-length genes. This method allows precise sequence customisation, incorporation of optimised codons, and removal of unwanted restriction sites. It is reliable, accurate, and particularly suitable for small genes such as PACAP, making it an efficient approach for generating a ready-to-clone expression construct.
5.3 DNA Edit
(i) What DNA would you want to edit and why?
I would edit the PACAP gene sequence to enhance its antimicrobial properties while maintaining safety and specificity. Edits may include amino acid substitutions that increase cationic charge, improve membrane disruption, or enhance activity against Gram-negative bacteria and biofilm-forming strains identified in the metagenomic analysis. These modifications would be guided by epidemiological data to ensure the peptide is effective against the most prevalent mastitis pathogens. I may also edit regulatory elements within the expression vector to optimise protein yield or secretion efficiency.
(ii) What technology or technologies would you use to perform these DNA edits and why?
To introduce precise amino acid substitutions into the PACAP gene, I would use site-directed mutagenesis, as it enables targeted and controlled sequence modifications without altering the rest of the construct. Site-directed mutagenesis would be sufficient to generate improved peptide variants informed by metagenomic surveillance data.