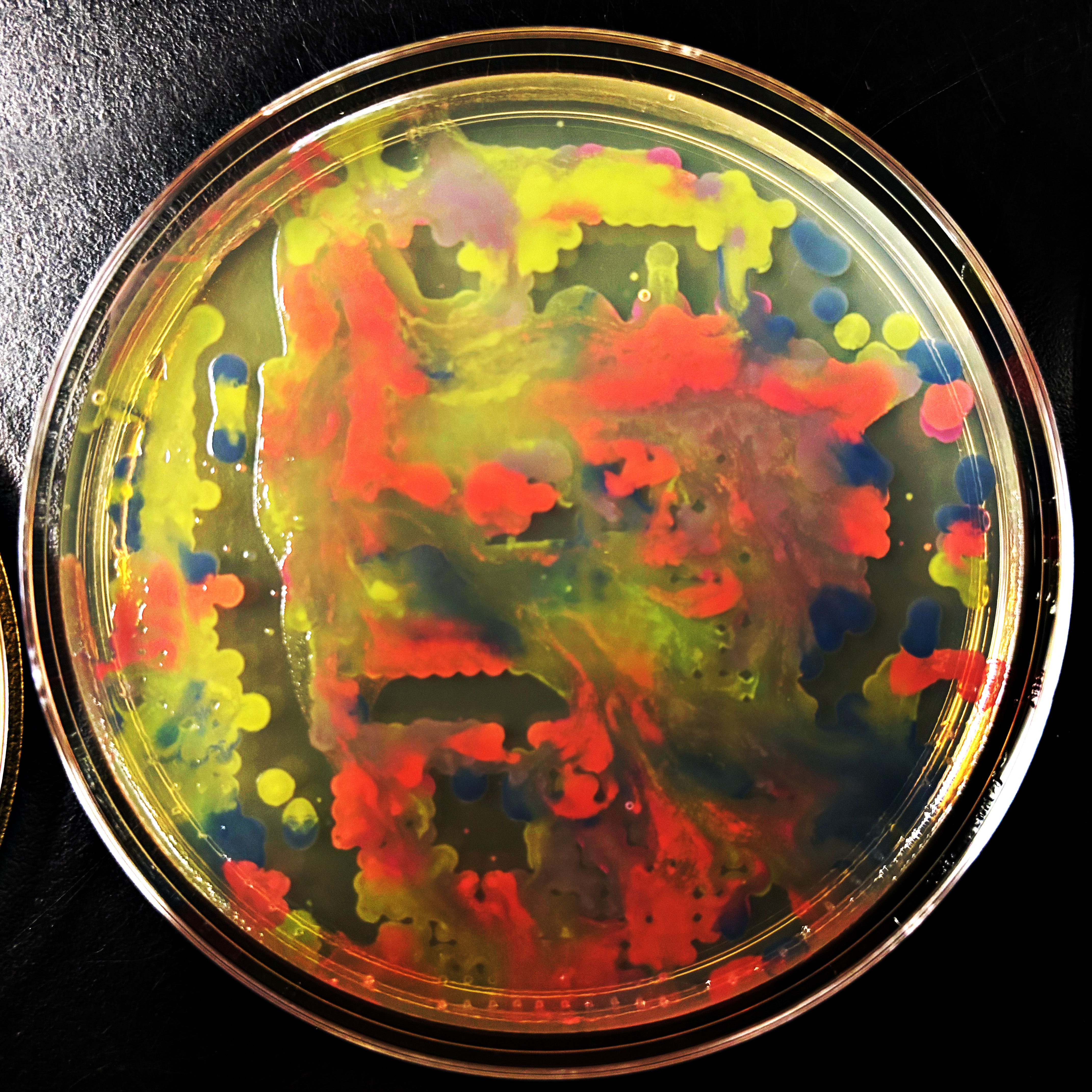
SCOBY DNA Steganography A biological engineering application or tool that I want to develop is a system for biomaterials for artist books that contains the book contents in its DNA. Above is an example of a a previous project of mine, where I was making masks out of SCOBYs, Symbiotic Cultures Of Bacteria and Yeast. A next level project might be to use SCOBY to create pages of artist books, where the the content of the pages (illustrations, text, relief sculptures, etc.) is also written into the DNA of the yeasts and/or bacteria that makes up the SCOBY. The reasons I am interested in this, and believe others will be interested as well, is primarily twofold: 1) I am interested in this as an unusual form of artwork that “grows on you” on multiple levels (such as genetic level, personal level, cultural(!) level, etc.) and 2) I am interested in this as a form of storytelling and story distrubution that can replicate itself, where the DNA creates new copies as the yeast reproduces, then thise new copies are used to create new copies of books.
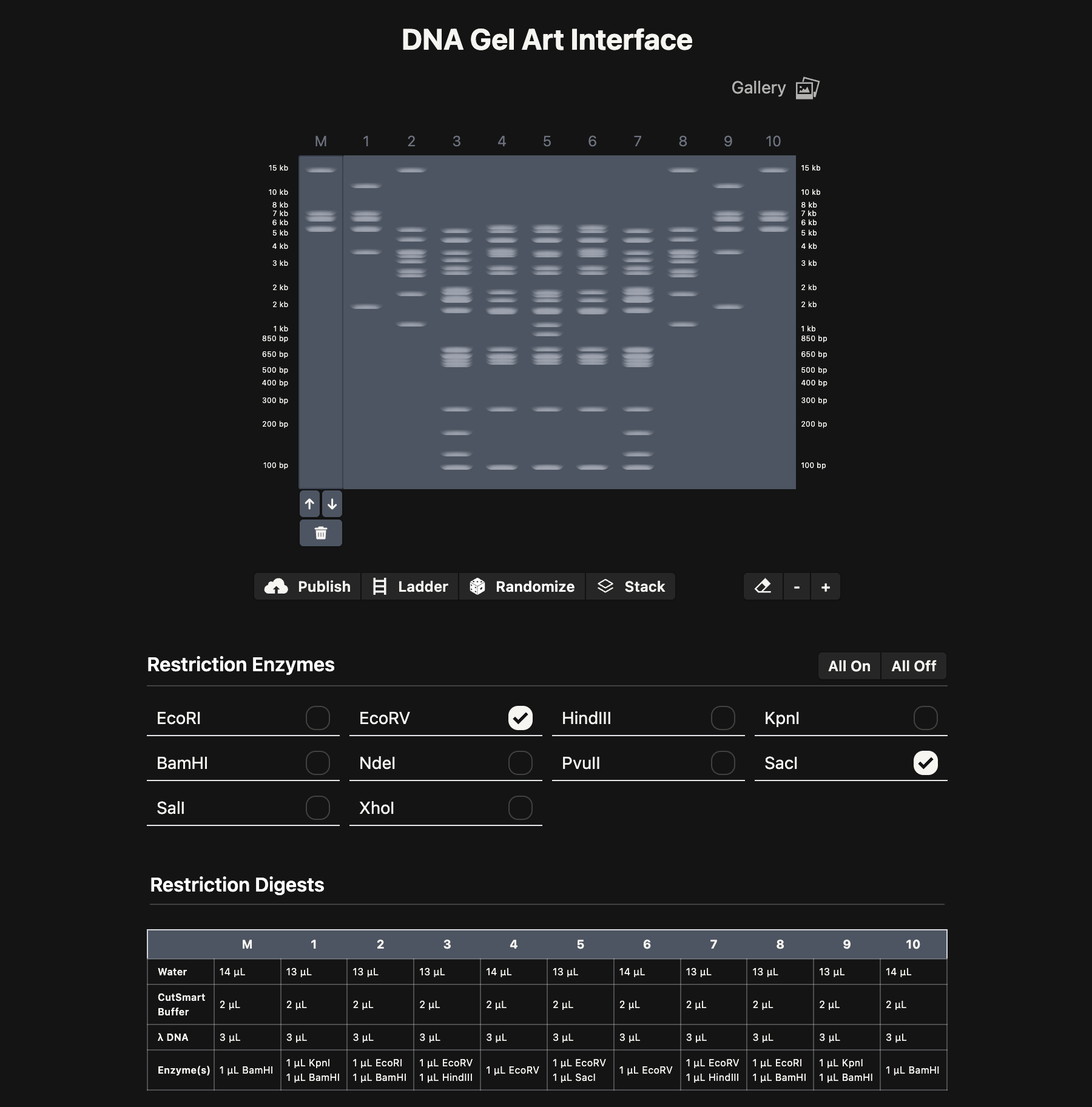
Part 1: Benchling & In-silico Gel Art Above is maybe my favorite Gel Electrophoresis design I created. I was trying to make monster faces, so hopefully this looks sort of like a skull with horns! I made this with the “DNA Gel Art Interface” website created by Ronan at https://rcdonovan.com/gel-art
Part 1: Generate an artistic design NOTE: Some of my newer and hopefully maybe better images are toward the end!
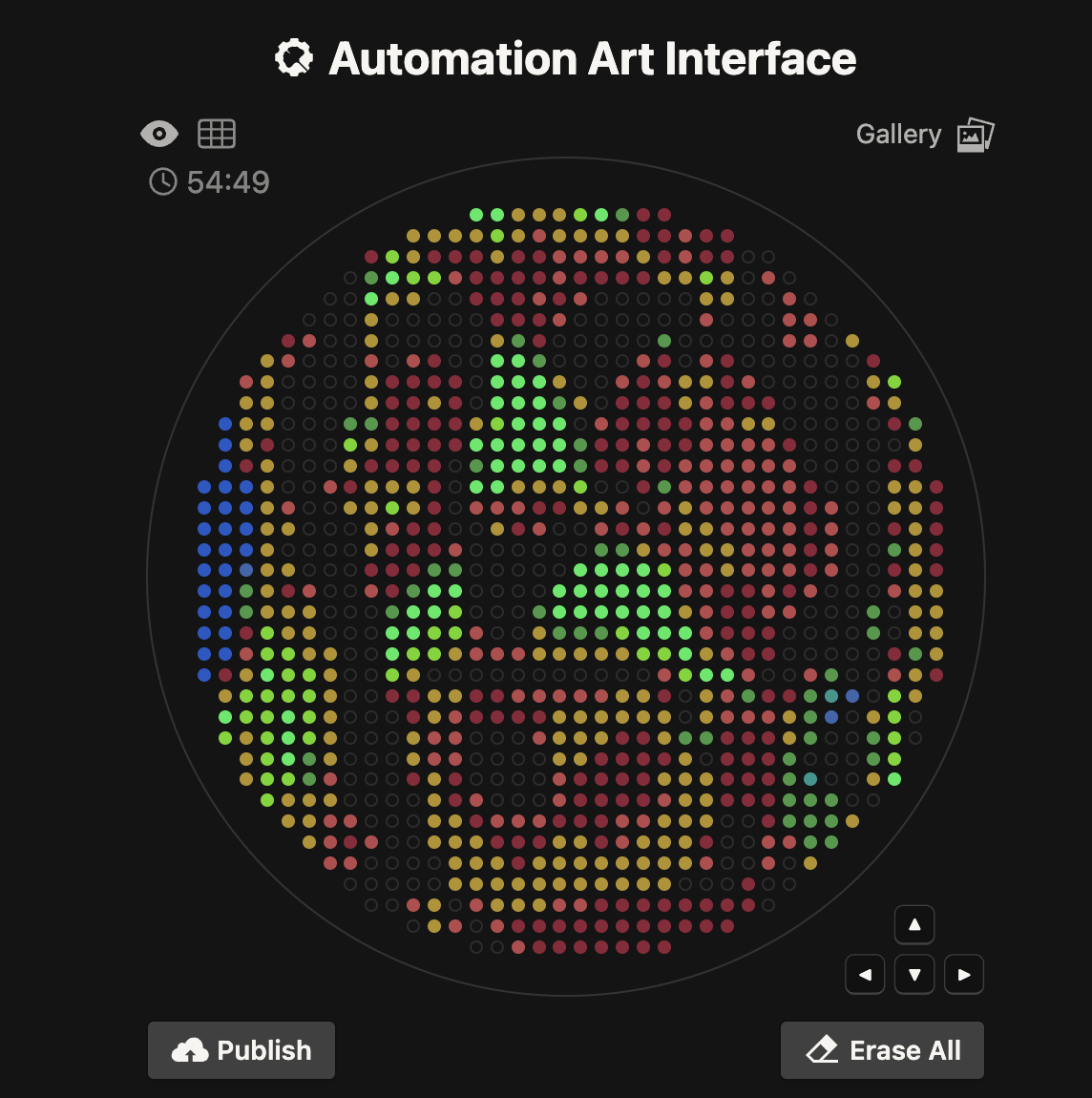
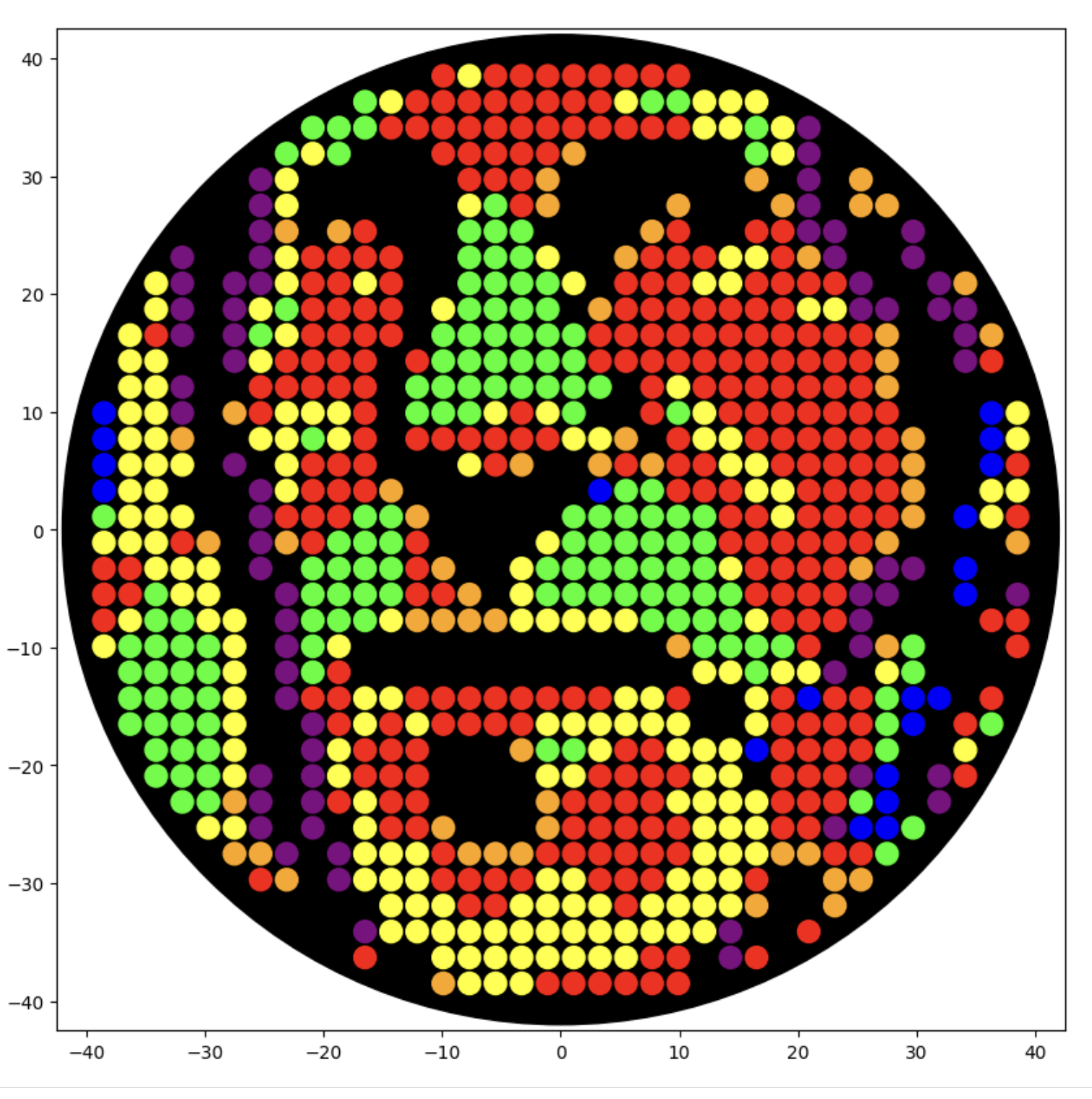
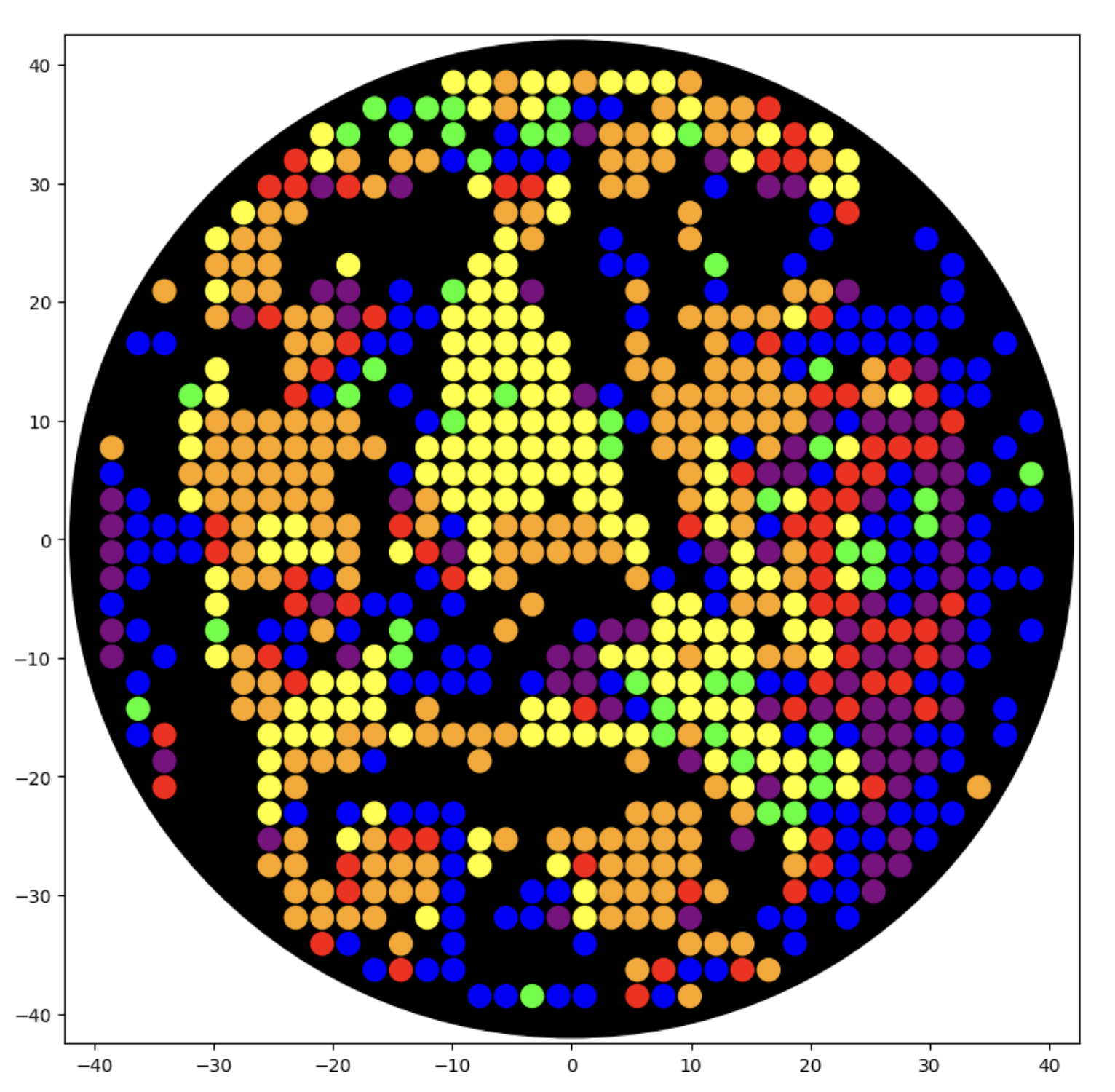
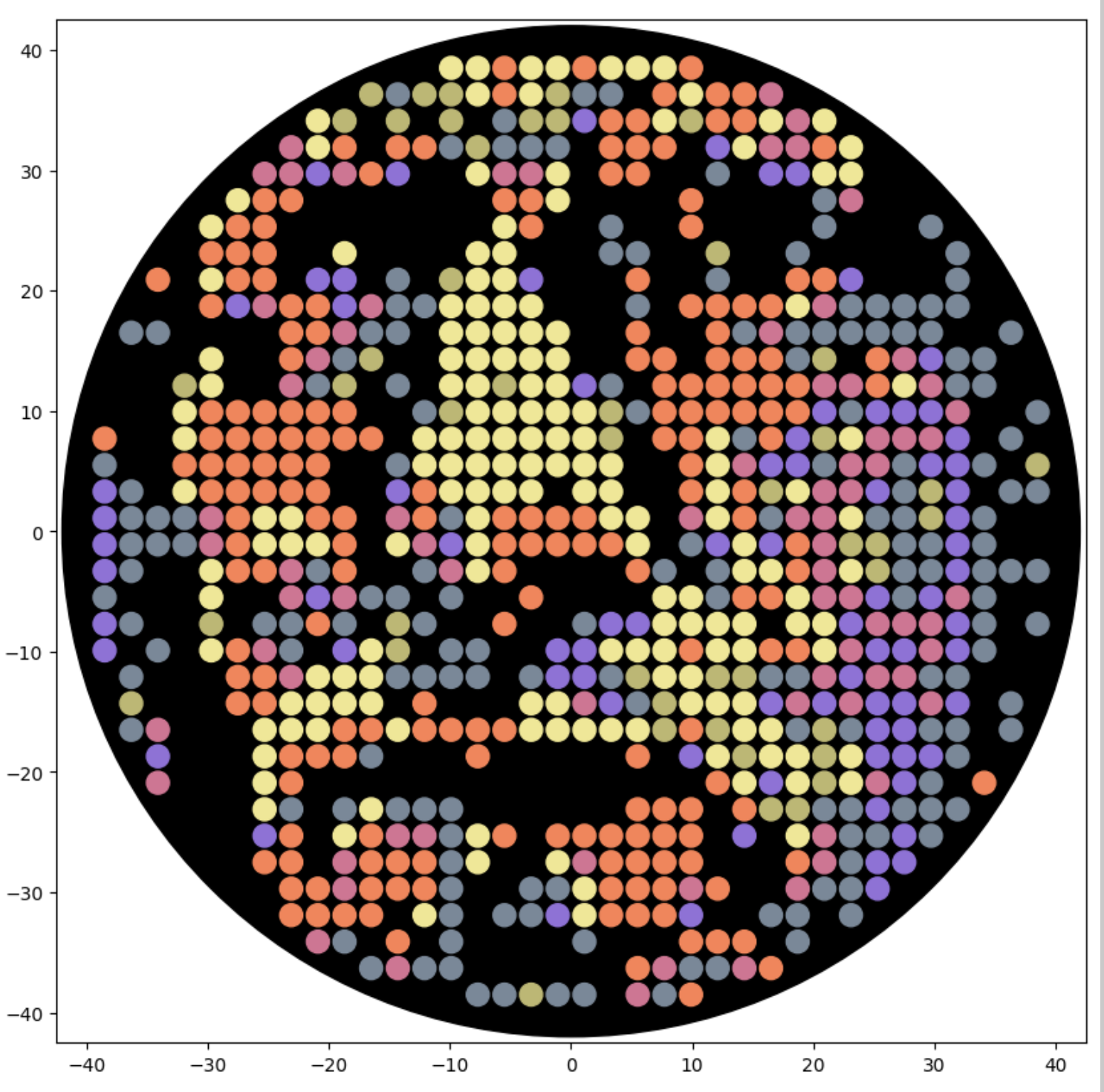
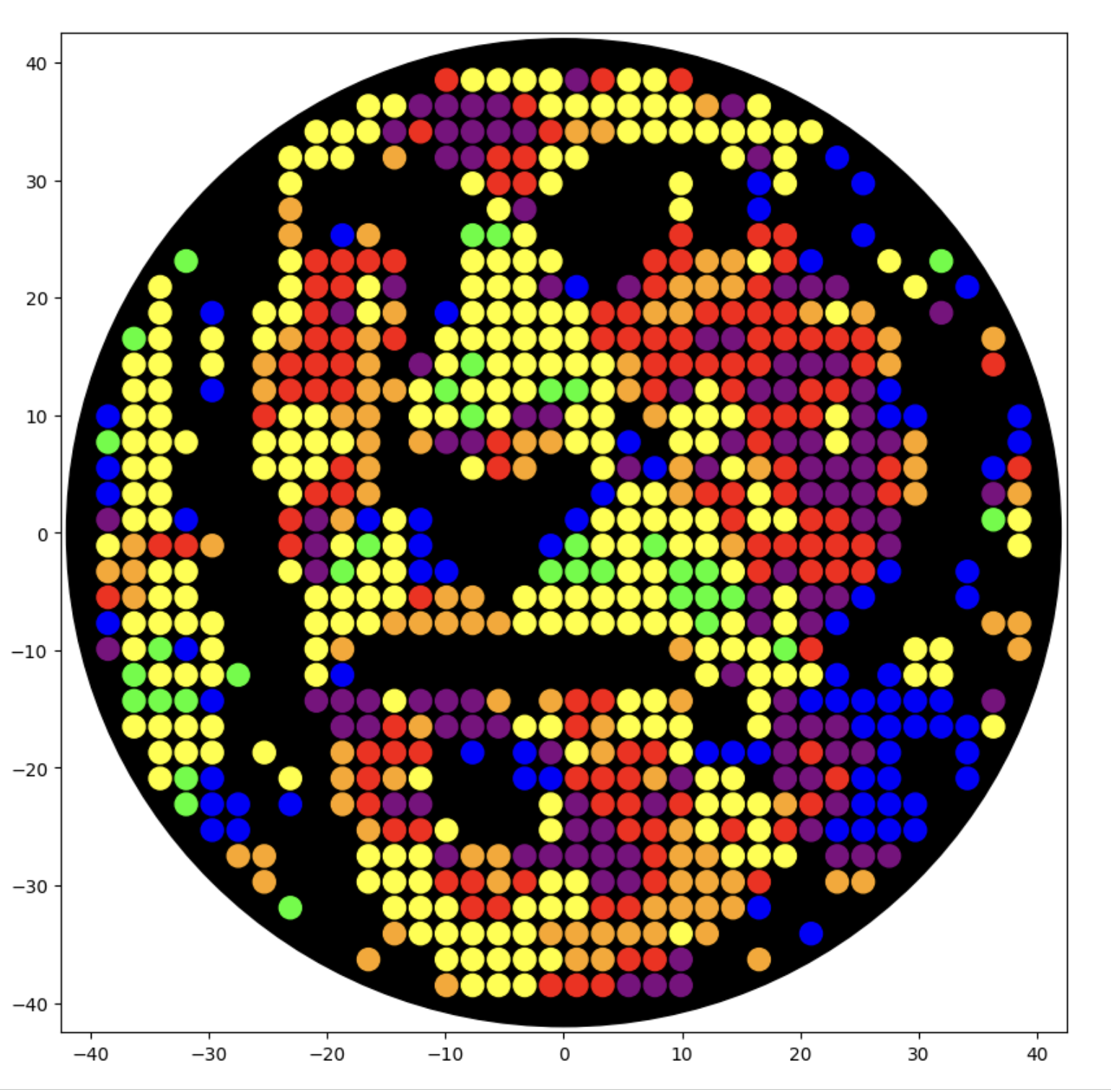
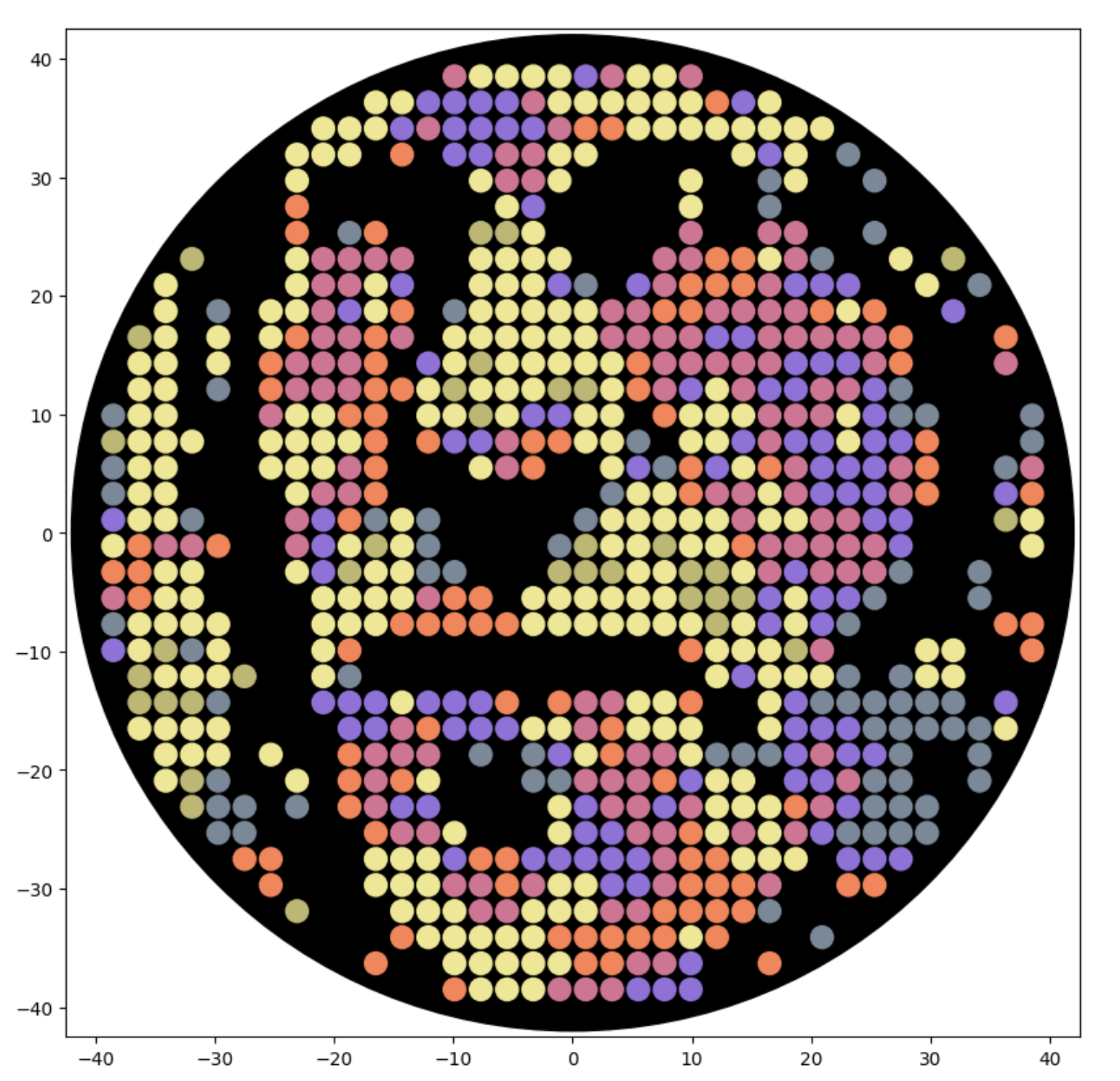
I generated the above artistic design – a self portrait – using the GUI at opentrons-art.rcdonovan.com – NOTE: BUGSS Lab has colors: orange, green, yellow, purple, red, blue
A below is me working on simulating that, redrawing and recoloring little bit in the Google Colab notebok with the six colors at BUGSS Lab. Thanks to Amanda and everyone for helping hack up that code.
Part A. Conceptual Questions 1. How many molecules of amino acids do you take with a piece of 500 grams of meat? (on average an amino acid is ~100 Daltons)
Meat is about 20% protein, so that is 100 g of protein. There are 6.022e+23 Daltons per gram, so for 100 grams that is 6.022e+25 Daltons. Then if there are 100 Daltons in an average amino acid, we’re back to 6.022e+23 molecules of amino acids.
Part A: SOD1 Binder Peptide Design (From Pranam) Part 1: Generate Binders with PepMLM https://www.uniprot.org/uniprotkb/P00441/entry#sequences
“Generate four peptides of length 12 amino acids conditioned on the mutant SOD1 sequence.” I did this step several times. Here are two examples of my generating four peptides:
Assignment: DNA Assembly 1. What are some components in the Phusion High-Fidelity PCR Master Mix and what is their purpose? From New England Biolabs “Phusion High-Fidelity PCR Master Mix with HF Buffer is a 2X master mix consisting of Phusion DNA Polymerase, deoxynucleotides and reaction buffer that has been optimized and includes MgCl2. All that is required is the addition of template, primers and water.”
Assignment Part 1: Intracellular Artificial Neural Networks (IANNs) What advantages do IANNs have over traditional genetic circuits, whose input/output behaviors are Boolean functions?
Traditional genetic circuits are binary digital on/off. IANNs can be more analog, with greater ranges, which is shown in the blue gradient diagrams in the neuromorphic wizard.
Describe a useful application for an IANN; include a detailed description of input/output behavior, as well as any limitations an IANN might face to achieve your goal.
#General homework questions
Explain the main advantages of cell-free protein synthesis over traditional in vivo methods, specifically in terms of flexibility and control over experimental variables. Name at least two cases where cell-free expression is more beneficial than cell production.
From “A User’s Guide to Cell-Free Protein Synthesis,” https://pmc.ncbi.nlm.nih.gov/articles/PMC6481089/
Two advantages would be 1) “elimination of reliance on living cells,”" so we don’t hve to wait for the living organism’s growth cycle an maintain their living conditions, and 2) “the ability to focus all system energy on production of the protein of interest.” Two cases where cell-free systems have benfits over in vivo methods include 1) “The production of functional antibodies and antibody fragments in vitro using CFPS has the potential to allow for simplification of the antibody production process for more rapid manufacturing,” and 2) “Metalloproteins … are difficult to produce in vivo … have the potential to enable renewable hydrogen fuel and other important biotechnological advancements.”
Homework: Final Project Please identify at least one (ideally many) aspect(s) of your project that you will measure. It could be the mass or sequence of a protein, the presence, absence, or quantity of a biomarker, etc.
Please describe all of the elements you would like to measure, and furthermore describe how you will perform these measurements.
Part A: The 1,536 Pixel Artwork Canvas | Collective Artwork I contributed a few early pixels to the HTGAA global artwork experiment at https://rcdonovan.com/1536
I will say that they were largely decorative, incremental changes because I was working when the wait time between each person’s changes was one minute, so I wasn’t able to make any really drastic changes. I was mostly just trying to add some additional variety and visual interest to what other collaborators had already drawn.
Subsections of Homework
Week 1 HW: Principles and Practices
SCOBY DNA Steganography
A biological engineering application or tool that I want to develop is a system for biomaterials for artist books that contains the book contents in its DNA. Above is an example of a a previous project of mine, where I was making masks out of SCOBYs, Symbiotic Cultures Of Bacteria and Yeast. A next level project might be to use SCOBY to create pages of artist books, where the the content of the pages (illustrations, text, relief sculptures, etc.) is also written into the DNA of the yeasts and/or bacteria that makes up the SCOBY. The reasons I am interested in this, and believe others will be interested as well, is primarily twofold: 1) I am interested in this as an unusual form of artwork that “grows on you” on multiple levels (such as genetic level, personal level, cultural(!) level, etc.) and 2) I am interested in this as a form of storytelling and story distrubution that can replicate itself, where the DNA creates new copies as the yeast reproduces, then thise new copies are used to create new copies of books.
The chose the mask example above because these might be sort of like Lovecraftian grimoires, sell books with monstrous faces on them, as I am thinking of suffucuenty advanced technologies being indistinguishable from magic, computer coded and genetic codes as forms of magic, etc. This is also based on “steganography,” the practice of embedding hidden coded information within another object. The term “steganography” dates back to the “Steganographia” from 1499, whcih is a book of cryptography disguised as a book of magic.
I could also possibly drink the brewed kombucha to let the DNA into my own body’s systems, and possibly sell the drink to others during art events, where people coul ddrink the kombucha that makes the SCOBYs that make the pages of the books …
Governance goals and actions
My main governance/policy goals are to make sure that this biomaterial system is safe for artists like myself when they are creating the materials, and also to make sure they are safe for viewers and collectors of the artist books. I will name these goals as the standard goals provided in class, 1) Enhance Biosecurity, 2) Foster Lab Safety, 3) Protect the environment, and 4) Other considerations.
My three different potential governance “actions” are 1) Develop guide for safe SCOBY DNA Steganography creation for artists, 2) Provide screening and training of potential collecting institutions so they can safely handle and preserve the books, and 3) Register any kombucha drink manufacturing facility with the FDA, and adhere to FDA regulations related to creating and selling drinks.
Scoring from 1-3 with 1 as the best, 3 as the worst:
Does the option:
Develop guide for safe SCOBY DNA Steganography creation for artists
Provide screening and training of potential collecting institutions so they can safely handle and preserve the books
Register any kombucha drink manufacturing facility with FDA, adhere to FDA regulations
Enhance Biosecurity
• By preventing incidents
1
2
1
• By helping respond
2
2
1
Foster Lab Safety
• By preventing incident
1
3
1
• By helping respond
2
3
1
Protect the environment
• By preventing incidents
1
1
1
• By helping respond
2
2
1
Other considerations
• Minimizing costs and burdens to stakeholders
3
1
2
• Feasibility?
1
3
2
• Not impede research
1
2
2
• Promote constructive applications
1
3
2
Based upon this scoring, I think the governance option I would prioritize is “Develop guide for safe SCOBY DNA Steganography creation for artists.” This is not only an effective option for creating lab safety for artists, and protecting the environment and others in it, it is also a governance option that I know would be highly feasible as I would be th eprimary artist to use it. If this project scales up and includes othwrs drinking the kombucha used to make the SCOBYS, then FDA registration and following FDA regualtiosn woudl be required and highly beneficial.
Refelctning on this project proposal and new ethical concerns that I am thinking about, I would say that the combination of this as a lab safety project, an art preservation project, and a potential food safety project. I would say that those are areas that I have previously thought of individually, and am now thinking of them all together on the same project for the first time. I am also now thinking about whether this also introduces other governance/policy, perhaps related to shipping, storage, etc.
Nature’s machinery for copying DNA is called polymerase. What is the error rate of polymerase? How does this compare to the length of the human genome? How does biology deal with that discrepancy?
The error rate of polymerase is 1:106. The human genome length is roughly 3 x 109 base pairs. The error rate is lower because of MutS Repair System in Error Correcting Gene Synthesis (slides 14 and 15).
How many different ways are there to code (DNA nucleotide code) for an average human protein? In practice what are some of the reasons that all of these different codes don’t work to code for the protein of interest?
Google AI Overview says: “An average human protein (~500 amino acids) can be encoded by a practically astronomical number of different DNA sequences, potentially exceeding (10^{100}) combinations, due to codon redundancy where 61 triplets encode 20 amino acids. However, only a few of these codes are functionally efficient or viable in vivo due to factors like codon usage bias, mRNA stability, and proper folding.”
What’s the most commonly used method for oligo synthesis currently?
Solid phase synthesis
Why is it difficult to make oligos longer than 200nt via direct synthesis?
Google AI Overview says: “Making oligonucleotides (oligos) longer than 200 nucleotides (nt) via direct chemical synthesis is difficult primarily because of exponentially decreasing yields caused by imperfect coupling efficiency and the accumulation of errors. "
Why can’t you make a 2000bp gene via direct oligo synthesis?
Google AI Overview says: “A 2000bp gene cannot be produced via direct (single-pass) chemical oligonucleotide synthesis because the efficiency of the coupling reaction drops significantly, leading to low yields of full-length product and high rates of sequence errors (insertions/deletions). "
Using Google & Prof. Church’s slide #4 What are the 10 essential amino acids in all animals and how does this affect your view of the “Lysine Contingency”?
Google AI Overview says: “The 10 essential amino acids that all animals must obtain from their diet (as they cannot synthesize them in sufficient quantities) are phenylalanine, valine, threonine, tryptophan, isoleucine, methionine, histidine, arginine, leucine, and lysine. This reality makes the “Lysine Contingency” from Jurassic Park scientifically flawed, as all vertebrates, including engineered dinosaurs, would already be unable to synthesize lysine, rendering the engineered deficiency redundant.”
Week 2 HW: DNA Read, Write, & Edit
Part 1: Benchling & In-silico Gel Art
Above is maybe my favorite Gel Electrophoresis design I created. I was trying to make monster faces, so hopefully this looks sort of like a skull with horns! I made this with the “DNA Gel Art Interface” website created by Ronan at https://rcdonovan.com/gel-art
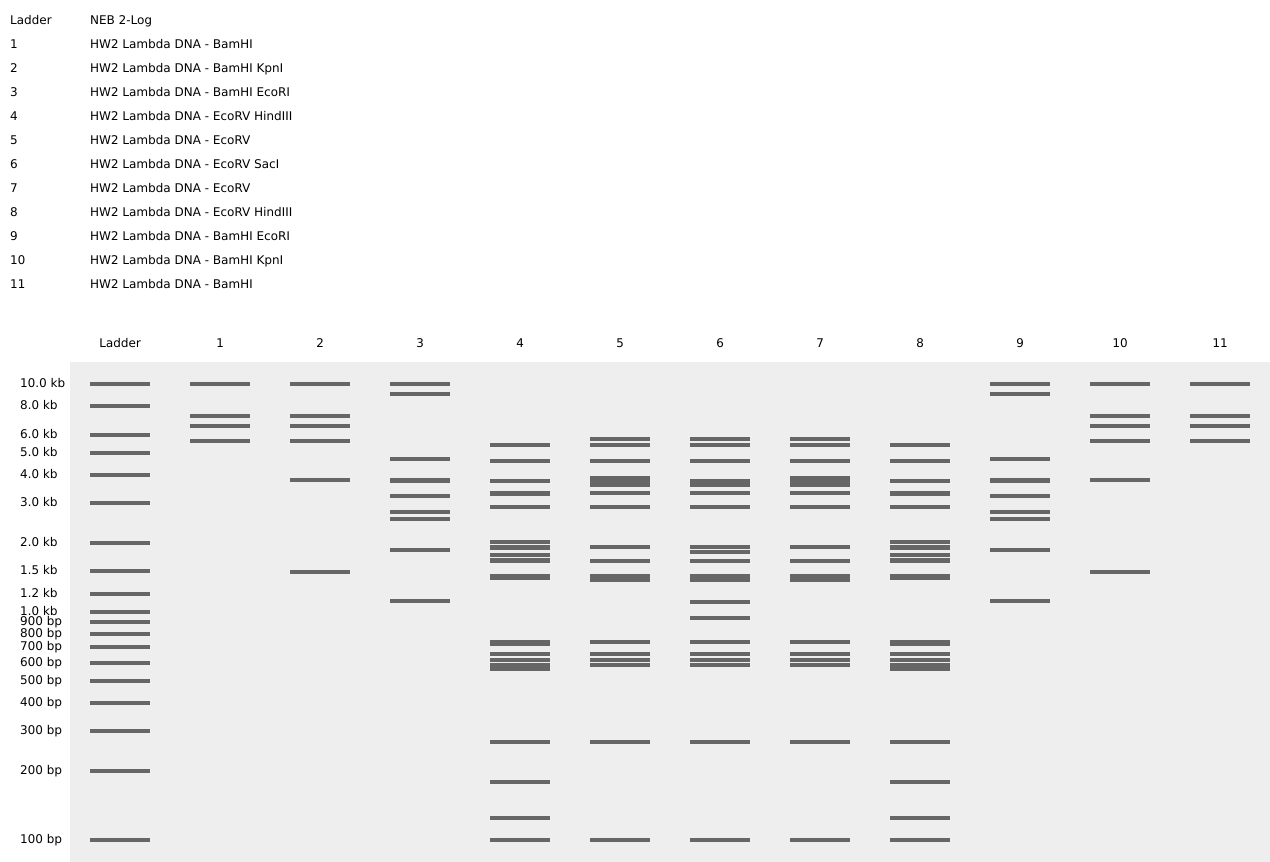
And below is a screenshot of some of my work in Benchling with the Lambda DNA from https://raw.githubusercontent.com/htgaa/htgaa2023/main/02_gel-art/Lambda_NEB.fasta and restriction enzymes, with the “NEB 2-log” ladder selected in the Virtual Digest tab, and with multiple Digests appearing in the same Virtual Digest, which I reorderdd by dragging the tabs around. These are the same restriction enzymes used in the horned skull drawing at the top of the page.
Part 2: Gel Art - Restriction Digests and Gel Electrophoresis
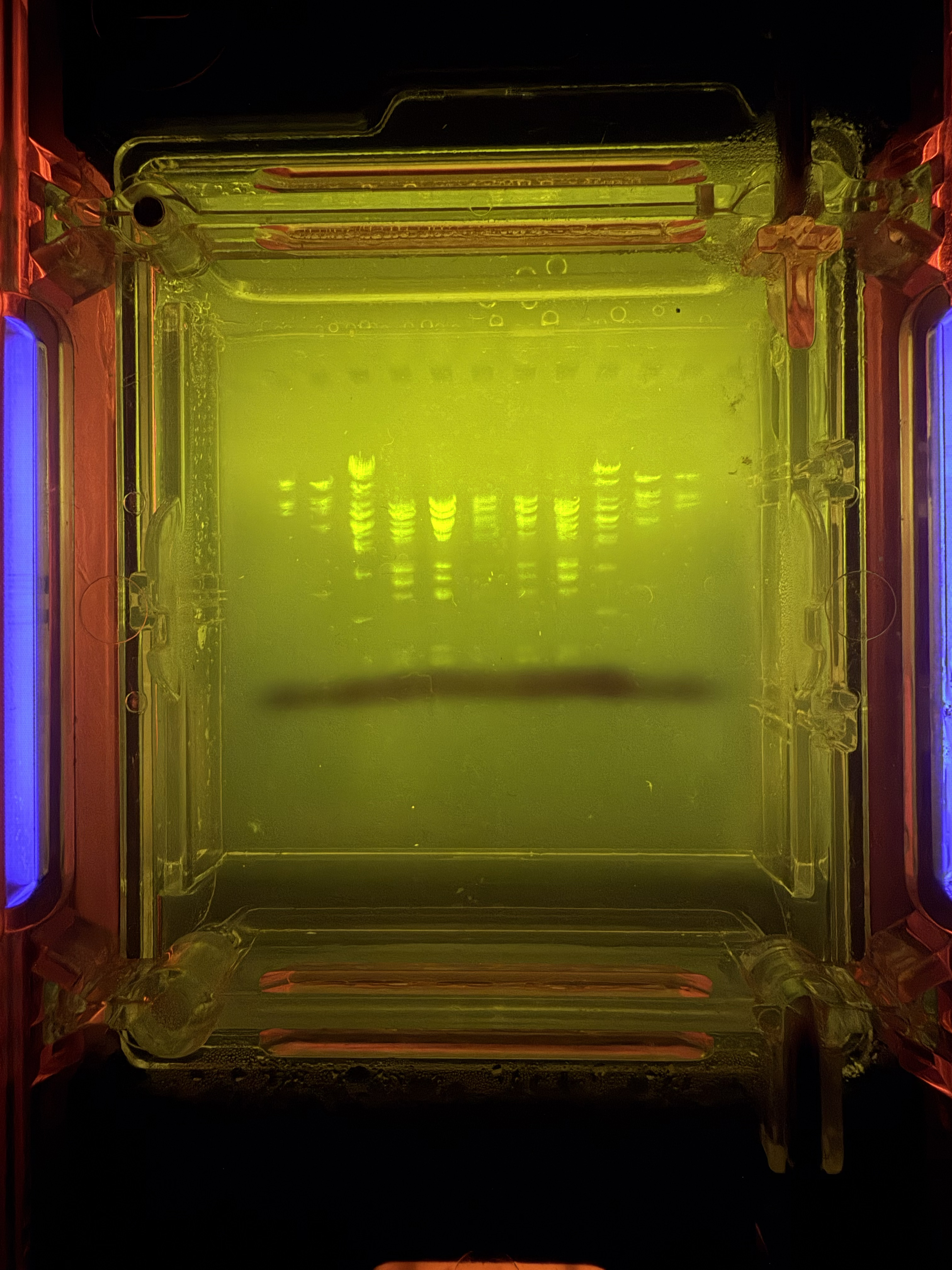
Below is my DNA gel electrophoresis art looking pretty good after about 45 minutes. This was done at the BUGSS Lab (Baltimore UnderGround Sceince Space) on Sunday, Feb 15. Thanks to Amanda and Joel and everyone else!
Part 3: DNA Design Challenge
Will do in lab on Sunday? Or on my own on Monday?
Part 4: Prepare a Twist DNA Synthesis Order
I created my account, still need to prepare my order …
Week 3 HW: Lab Automation
Part 1: Generate an artistic design
NOTE: Some of my newer and hopefully maybe better images are toward the end!
I generated the above artistic design – a self portrait – using the GUI at opentrons-art.rcdonovan.com – NOTE: BUGSS Lab has colors: orange, green, yellow, purple, red, blue
A below is me working on simulating that, redrawing and recoloring little bit in the Google Colab notebok with the six colors at BUGSS Lab. Thanks to Amanda and everyone for helping hack up that code.
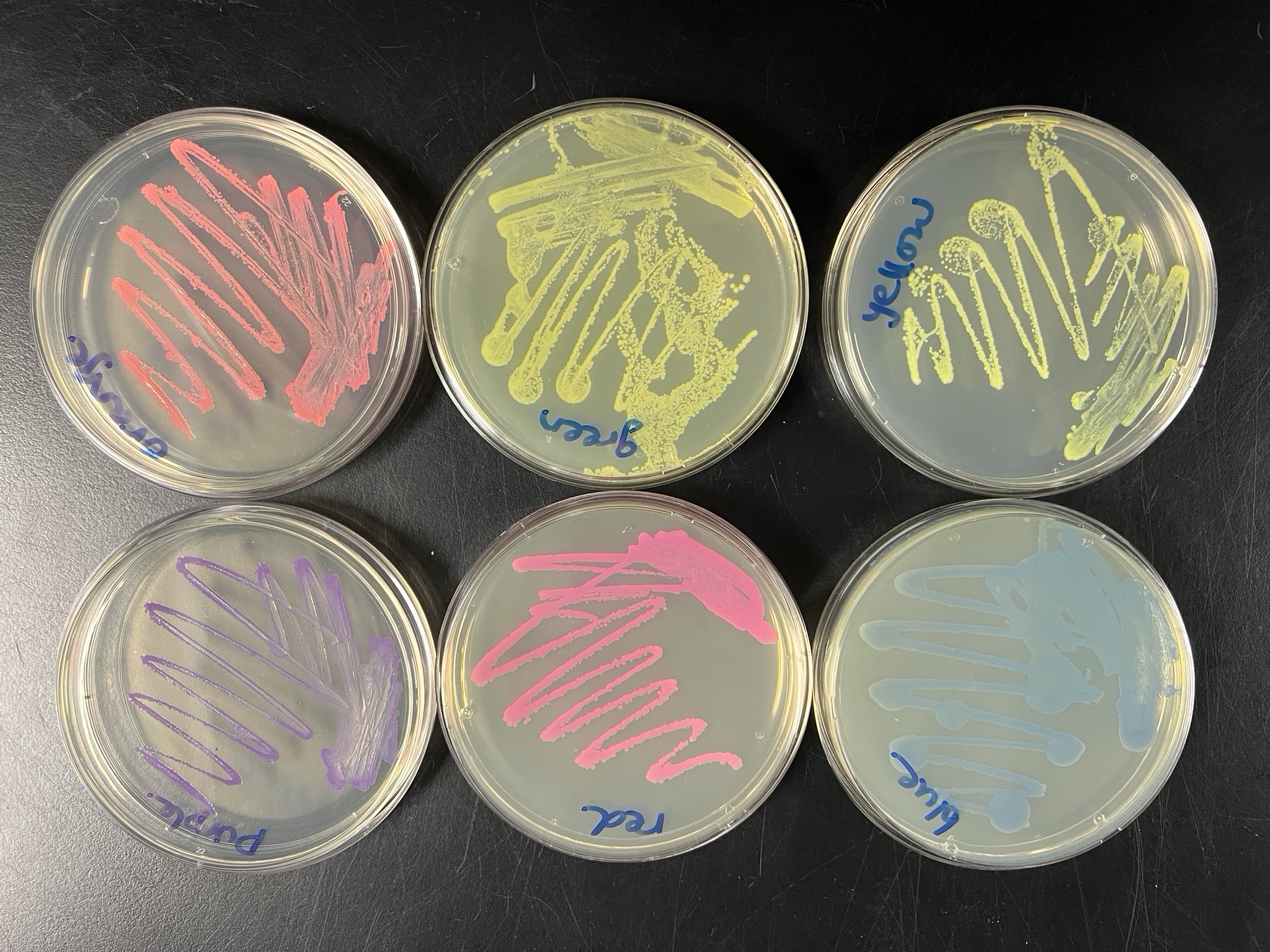
And below this is the photo of the six colors at BUGSS Lab:
And then below this is my self-portrait trying to get closer to those colors:
And below this is me working in the google colab notebook to make symmetrical multicolor designs. This is me drawing directly with google colab python code, rather than importing code from Ronan’s website.
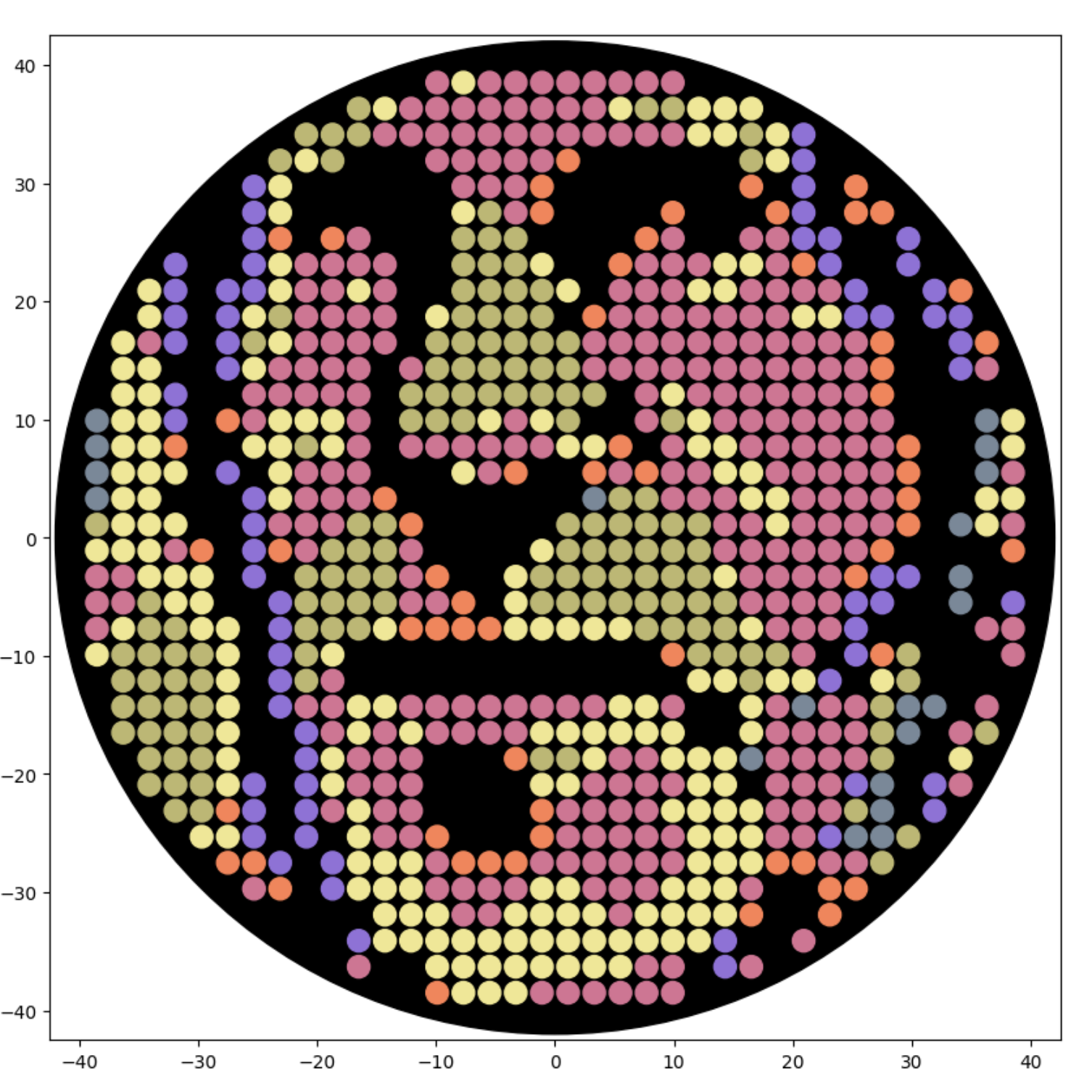
Updated Feb 21: Here is a new self-portrait, closer up, with less flat areas of color, in a screenshot from the Google Colab notebok:
Also updated Feb 21: Here is that same new self-portrait, trying to simulate the six colors at BUGSS Lab:
OK! Last set of uopdates before lab! Here is myabe my best, trying to hit the sweet spot of everything I did so far. Her eon Ronan’s site:
That with saturated colors in the google colab:
And finally that trying to simulate colors in the photo from BUGSS Lab:
And, update March 9! Here is a photo our awesome TA Joel Tyson took, who said “messing with the opentrons a little. Here are some runs I tried with Eric’s design w 0.2ul drops. I also put a pause between drops to see if it helps dry it.” Thanks, Joel!
Week 4 HW: Protein Design Part I
Part A. Conceptual Questions
1. How many molecules of amino acids do you take with a piece of 500 grams of meat? (on average an amino acid is ~100 Daltons)
Meat is about 20% protein, so that is 100 g of protein. There are 6.022e+23 Daltons per gram, so for 100 grams that is 6.022e+25 Daltons. Then if there are 100 Daltons in an average amino acid, we’re back to 6.022e+23 molecules of amino acids.
2. Why do humans eat beef but do not become a cow, eat fish but do not become fish?
Because or food prepartion and digestive systems have broken the cow (and cow DNA), the cow DNA does not mix with human DNA to produce new cells, and our immune systems fight DNA other than our own.
To be continued … ??? … Will finish later …
Part B: Protein Analysis and Visualization
1. Briefly describe the protein you selected and why you selected it.
I chose the protein “Oxidoreductase cns1” from Cordyceps militaris (strain CM01) (Caterpillar fungus). (https://www.uniprot.org/uniprotkb/G3JF08/entry) I chose it because I am interested in parastic fungi and because it is “part of the gene cluster that mediates the biosynthesis of cordycepin (COR)” and “Cordycepin has antitumor, antibacterial, antifungal, antivirus, and immune regulation properties.”
2. Identify the amino acid sequence of your protein.
XP_006669647.1 oxidoreductase domain-containing protein [Cordyceps militaris CM01]
MAMNENAYPTTFPSFERENHRDALRQPFDPAFRRTWSNGVALRQLVDFARPTVANHTMSYALIEYCLSRL
PMQHLERLGQLKIPVELHAAPFQYLQKHHRACGFDWVERFVWRTHDLHKPYNFLRPELLLAQESGSQRIV
ALLTIMPGEDYIRHYASILEVAQHDGAISSHHGPIRCVLYPHLTQSMMAWTGLTELSLSVEPGDILILGF
VAELLPRFASLVPTARVIGRQDAQYYGLVRLELRPGLVFSLIGAKYSYWGNLGGRVVRELAARRPRAICY
IAKQGTLLSPGDIHRTIYSPTRYCVFDKGQACWHGDDHSALPINPLSSRFPTFDRGLHVSTPTIVEQDVD
FRTQVEAHGASSVDNELAQMARALTDVHEENPSMERVQLLPLMFITDYLRRPEELGMTVPFDLTSRNETV
HRNKELFLARSAHLVLEAFNVIERPKAIIVGTGYGVKTILPALQRRGVEVVGLCGGRDRAKTEAAGNKHG
IPCIDVSLAEVQATHGANLLFVASPHDKHAALVQEALDLGGFDIVCEKPLALDMATMRHFANQSQGSSQL
RLMNHPLRFYPPLIQLKAASKEPSNILAIDIQYLTRRLSKLTHWSAGFSKAAGGGMMLAMATHFLDLIEW
LTSSSLTPASVQDMSTSNSIGPLPTEDAGATKTPDVESAFQMNGCCGLSTKYSVDCDGAADTELFSVTLR
LDNEHELRFIQRKGSPVLLEQRLPGREWLPLKVHWEQRVREGSPWQISFQYFAEELVEAICMGTRSAFAD
KATGFSDYARQVGVFGSKVGIA
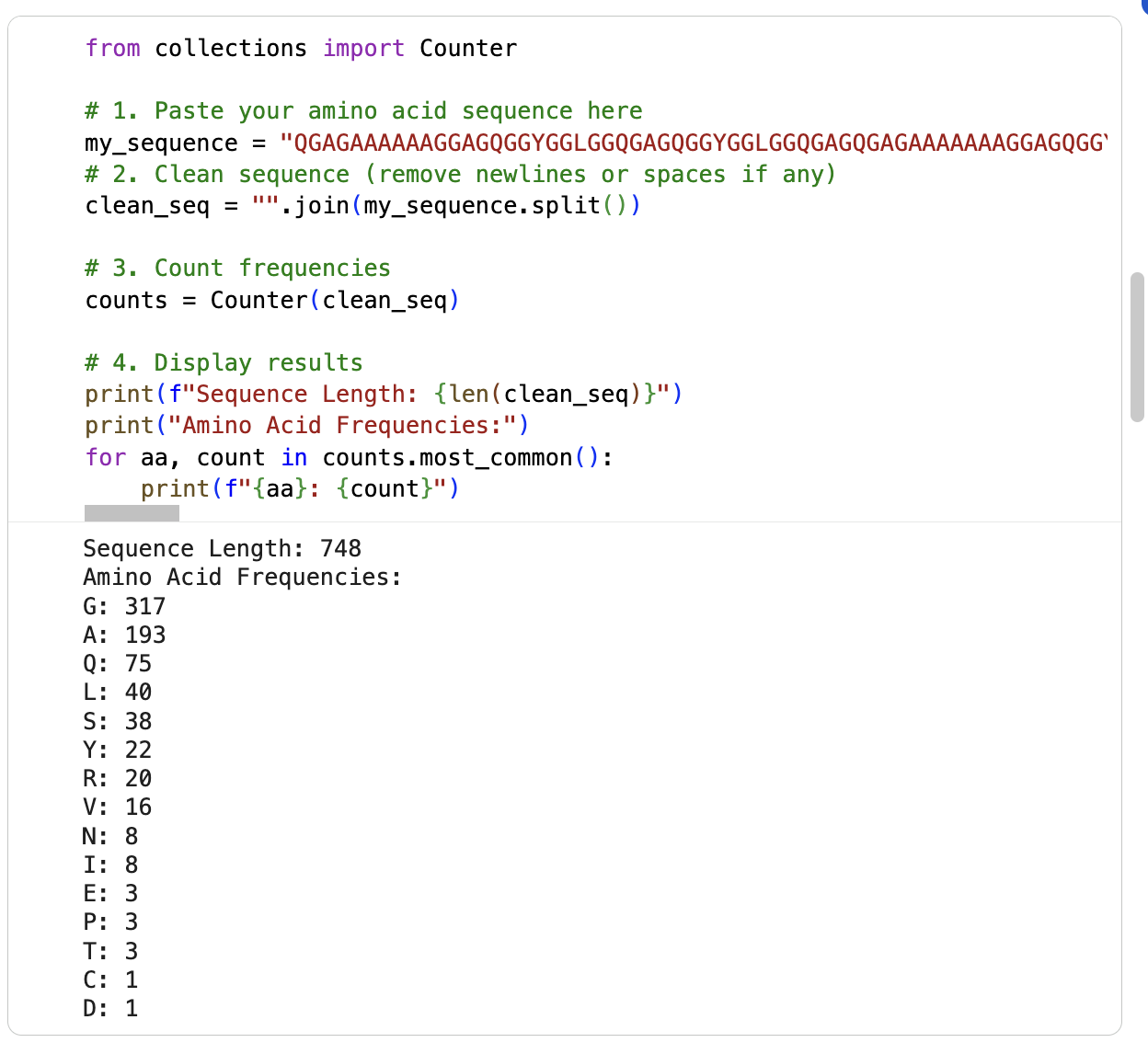
I am running the google collab notebook to count the frequency of amino acids (had some errors) … it says the sequence length is 748 and the most frequent amino acid is glycine (317) followd by alanine (193). See below:
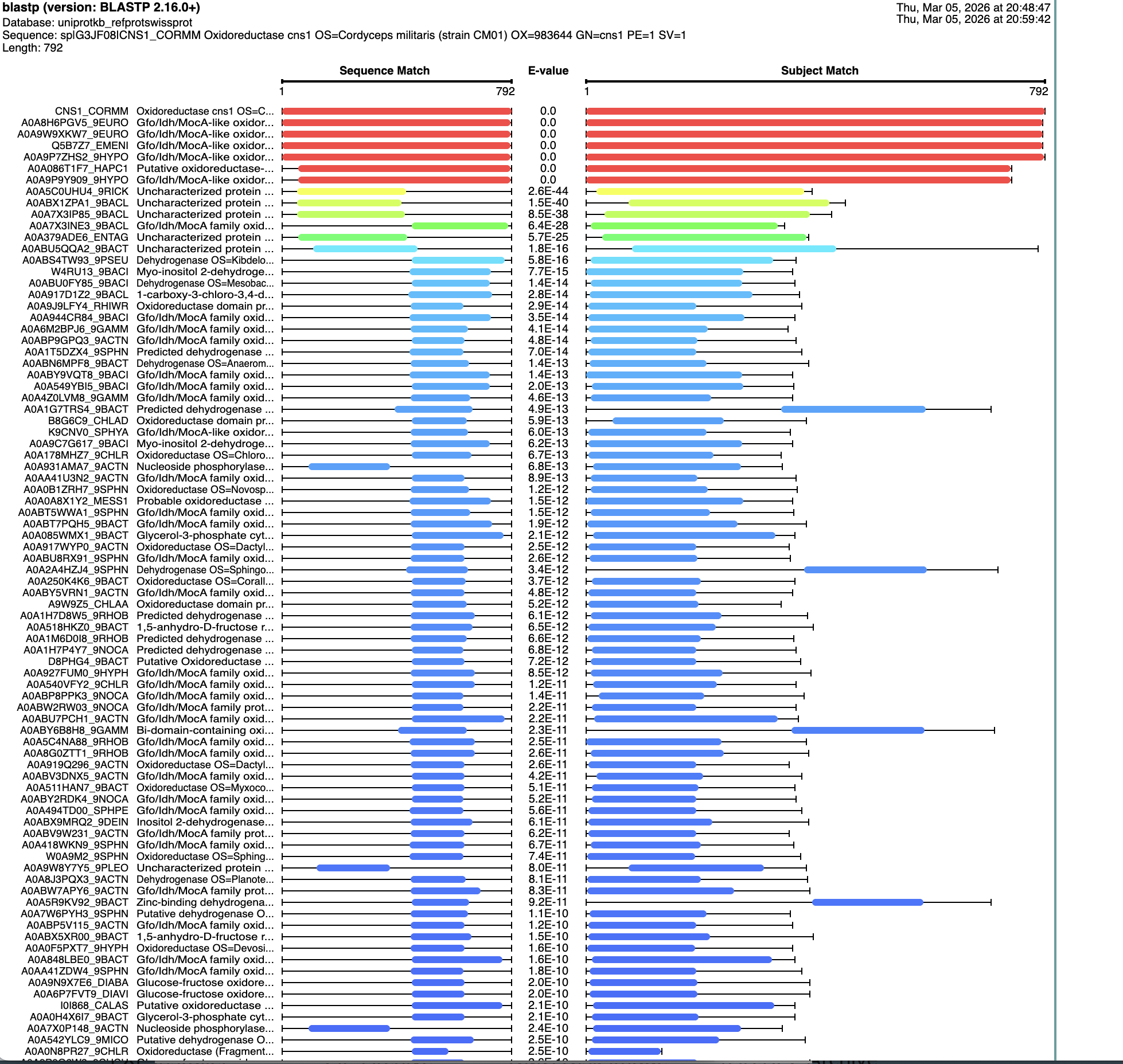
I ran a search for homologs on BLAST. There are six that are in the red, that have an E value of about 0. See below:
3. Identify the structure page of your protein in RCSB.
I dod not find the “Oxidoreductase cns1” from Cordyceps militaris (strain CM01) (Caterpillar fungus)” in RCSB. I did find “Crystal Structure of endo-beta-N-acetylglucosaminidase from Cordyceps militaris D154N/E156Q mutant in complex with fucosyl-N-acetylglucosamine” at https://www.rcsb.org/structure/6KPN
I don’t see a solved date. It was Deposited: 2019-08-15. I don’t see it listed as part of any structure classification family at https://www.ebi.ac.uk/pdbe/scop/
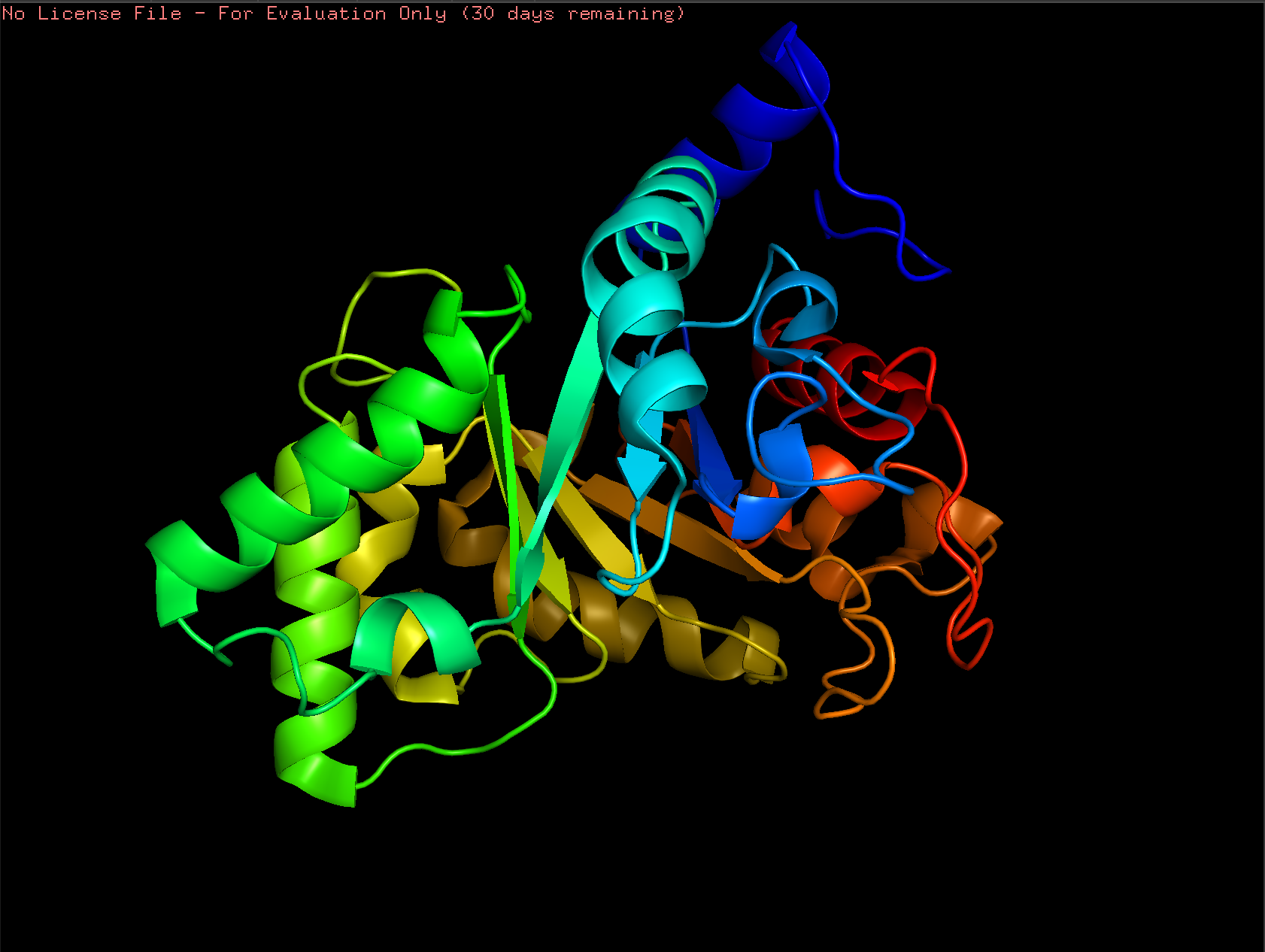
4. Open the structure of your protein in any 3D molecule visualization software
Cartoon:
Ribbon:
Ball and Stick:
To Do:
Color the protein by secondary structure. Does it have more helices or sheets?
Color the protein by residue type. What can you tell about the distribution of hydrophobic vs hydrophilic residues?
Visualize the surface of the protein. Does it have any “holes” (aka binding pockets)?
Part C1. Using ML-Based Protein Design Tools: Protein Language Modeling
To do: Can you explain any particular pattern? (choose a residue and a mutation that stands out) and (Bonus) Find sequences for which we have experimental scans, and compare the prediction of the language model to experiment.
2. Latent Space Analysis
To do: Use the provided sequence dataset to embed proteins in reduced dimensionality. Analyze the different formed neighborhoods: do they approximate similar proteins? Place your protein in the resulting map and explain its position and similarity to its neighbors.
Part C2. Using ML-Based Protein Design Tools: Protein Folding
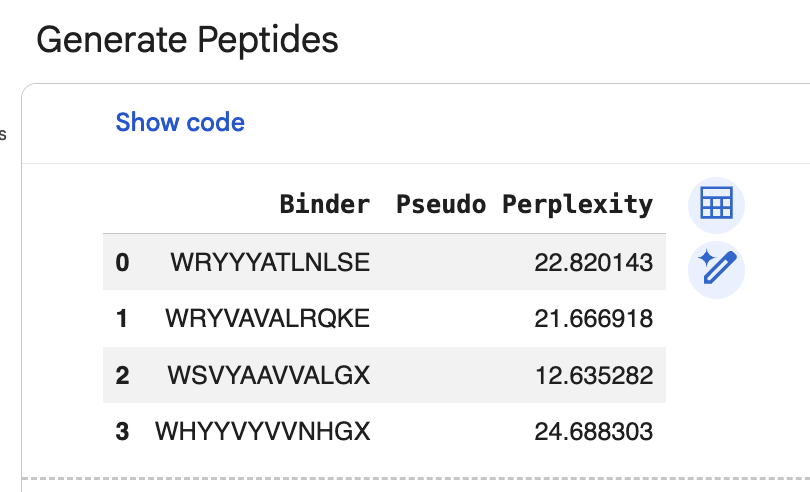
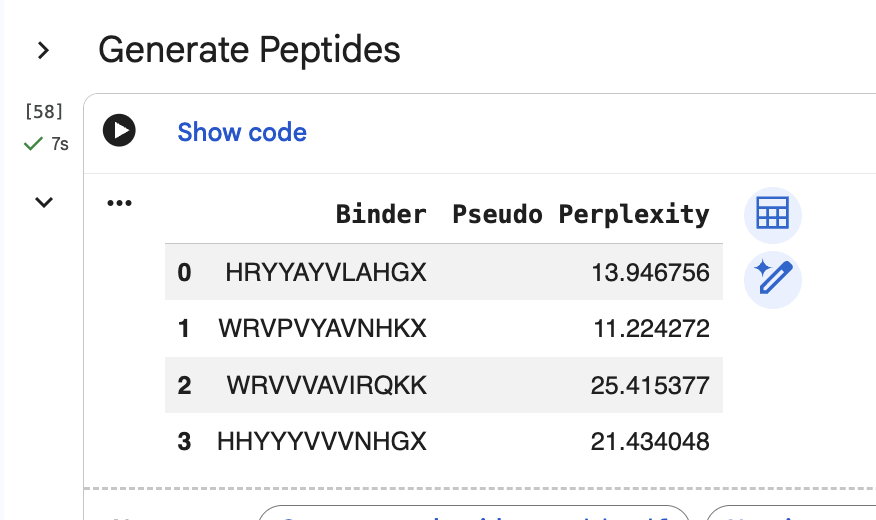
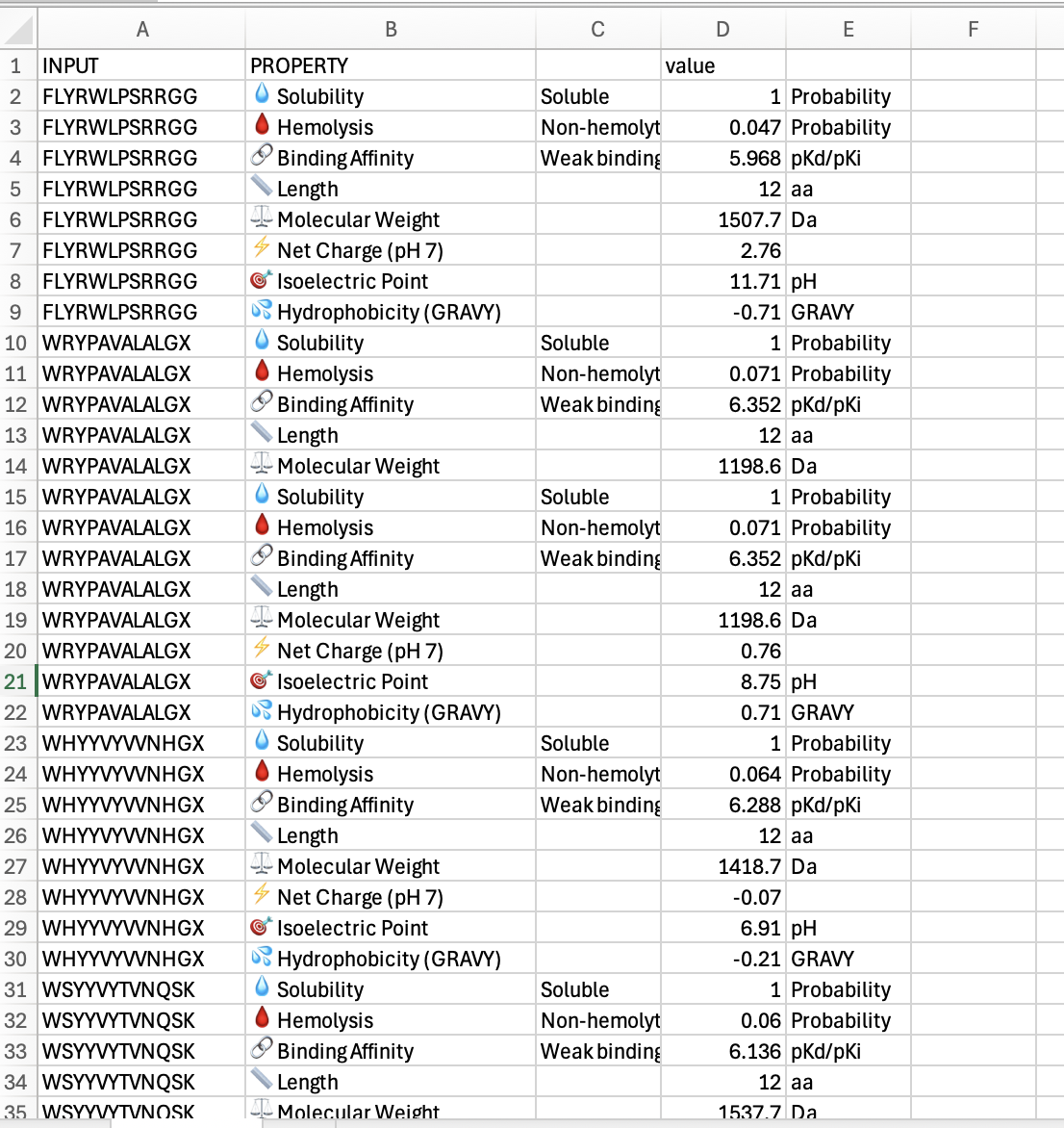
“Generate four peptides of length 12 amino acids conditioned on the mutant SOD1 sequence.” I did this step several times. Here are two examples of my generating four peptides:
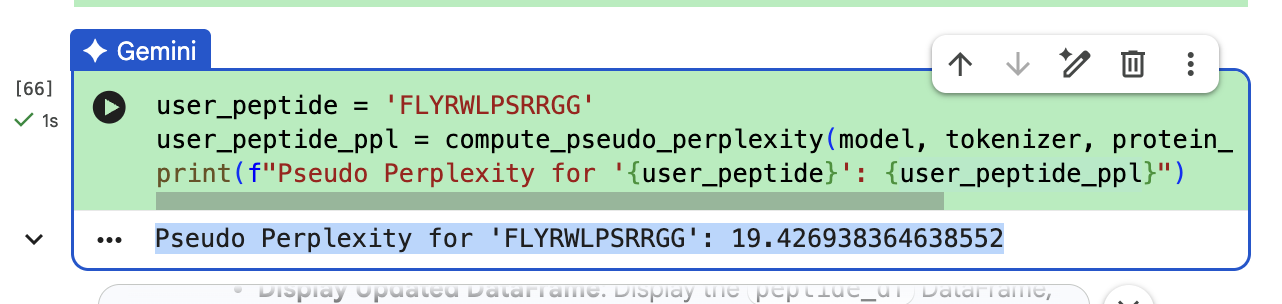
“To your generated list, add the known SOD1-binding peptide FLYRWLPSRRGG for comparison.”
“Record the perplexity scores that indicate PepMLM’s confidence in the binders.” These can be seen in the above screenshiots, and I have also recorded them in an excel spreadsheet.
Part 2: Evaluate Binders with AlphaFold3
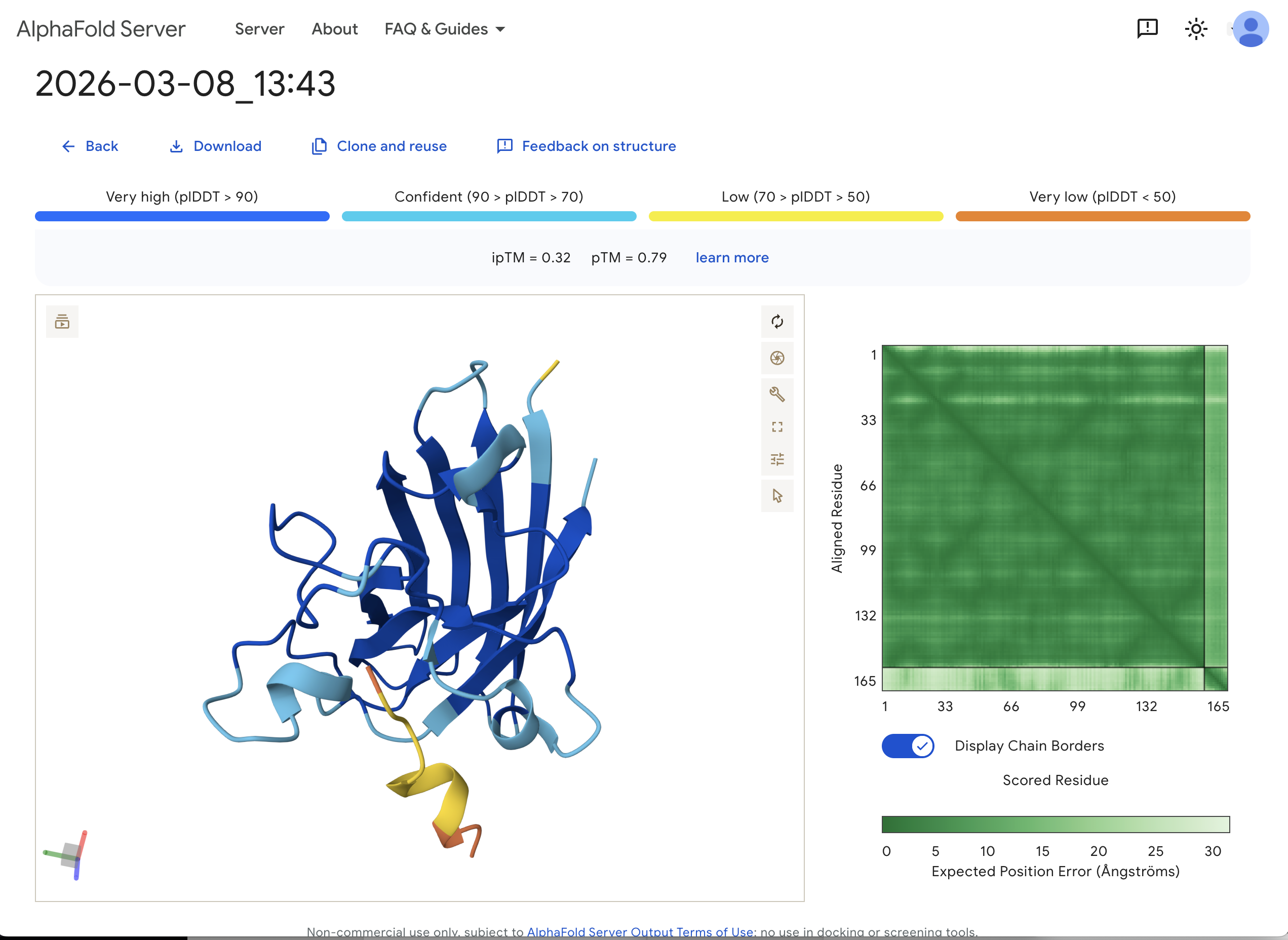
“Navigate to the AlphaFold Server: alphafoldserver.com For each peptide, submit the mutant SOD1 sequence followed by the peptide sequence as separate chains to model the protein-peptide complex.” This is one example:
“Record the ipTM score and briefly describe where the peptide appears to bind. Does it localize near the N-terminus where A4V sits? Does it engage the β-barrel region or approach the dimer interface? Does it appear surface-bound or partially buried?”
In teh one above, I’d say probably surface bound, and closer to the β-barrel region than to the N-terminus.
“In a short paragraph, describe the ipTM values you observe and whether any PepMLM-generated peptide matches or exceeds the known binder.”
The ipTM value I got for the known binder was 0.31. The peptides I generated ranged from 0.28 to 0.43 in ipTM values. My understanding is that higher ipTM values show more confidence in the prediction. I hade a few that were slightly higher than the knonw binder, like WRYPAVALALGX at 0.38 and my highest at 0.43 was WHYYVYVVNHGX.
Part 3: Evaluate Properties of Generated Peptides in the PeptiVerse
Below is a screenshot of part of my spreadsheet of results of my work in Peptiverse:
“Compare these predictions to what you observed structurally with AlphaFold3. In a short paragraph, describe what you see. Do peptides with higher ipTM also show stronger predicted affinity? Are any strong binders predicted to be hemolytic or poorly soluble? Which peptide best balances predicted binding and therapeutic properties? Choose one peptide you would advance and justify your decision briefly.”
The few peptides I tested did not show much difference. They each were soluble, and each had weak binding affinity. The widest diferences I saw were in hydrophobicity, where i had some positives and some ngatives. The one that was closest to zero was at -0.21 which was WHYYVYWNHGX. Of these, that might eb the one that I would advance. I would probbaly go back and look for ones that had more binding affinity.
Part 4: Generate Optimized Peptides with moPPIt
I am rerunning this … ran on Sunday but did not save my results …
Some results of my rerun:
Result
Hemolysis
Solubility
Affinity
Motif
STKLHTKIKCQC
0.9697153624147177
0.8333333134651184
6.467465877532959
0.7173478007316589
SVTKKETQKRFA
0.9688531029969454
0.75
5.76106595993042
0.7000954747200012
GSAEMTCKKQRK
0.9745583962649107
0.8333333134651184
6.006259441375732
0.6160933375358582
“briefly describe how these moPPit peptides differ from your PepMLM peptides. How would you evaluate these peptides before advancing them to clinical studies?”
These seem to be getting different results by using different strategies. For advancing to trials, I would probably test a few of the best results found from each system.
Part B: BRD4 Drug Discovery Platform Tutorial (Gabriele)
(optional, might get to later)
Part C: Final Project: L-Protein Mutants
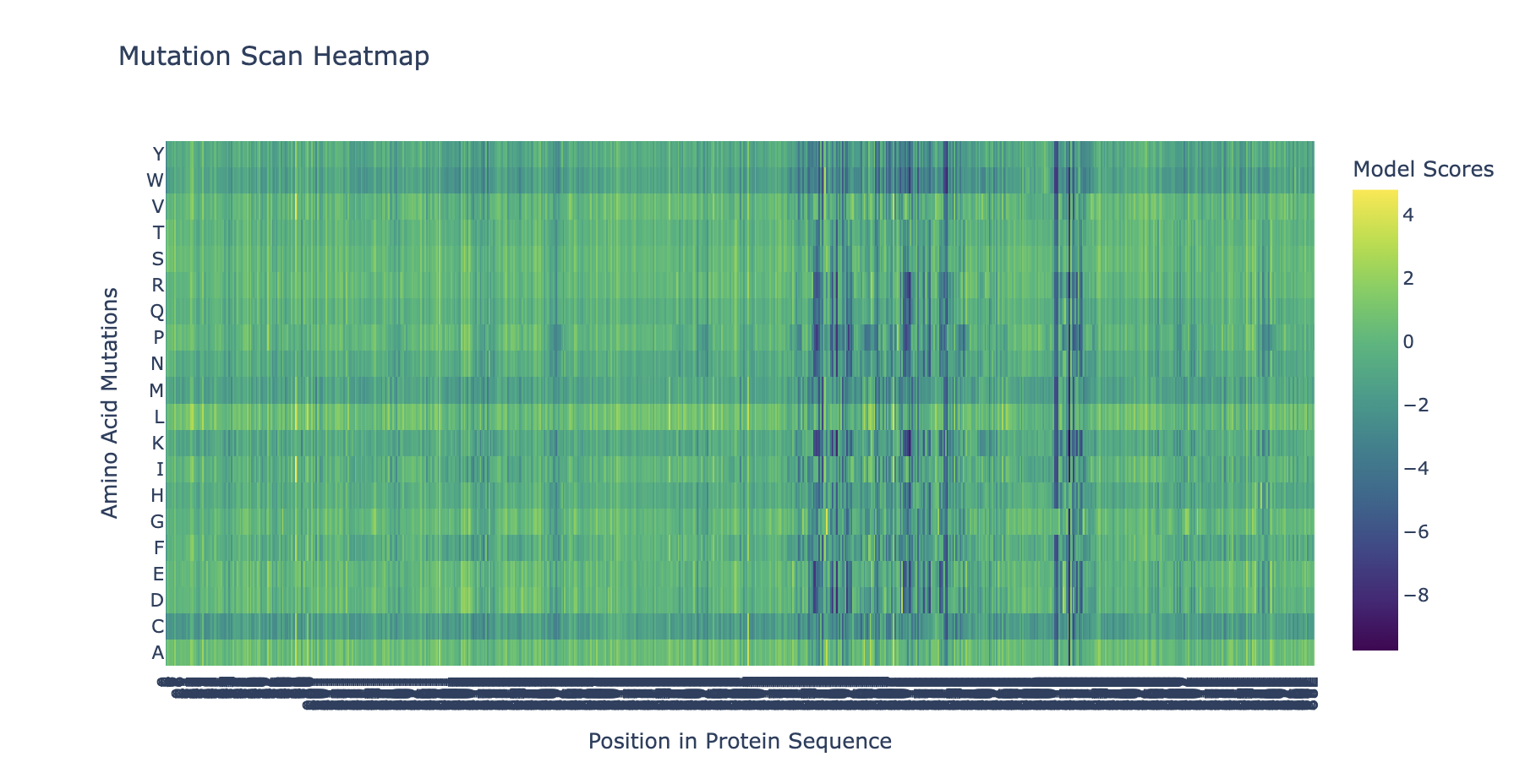
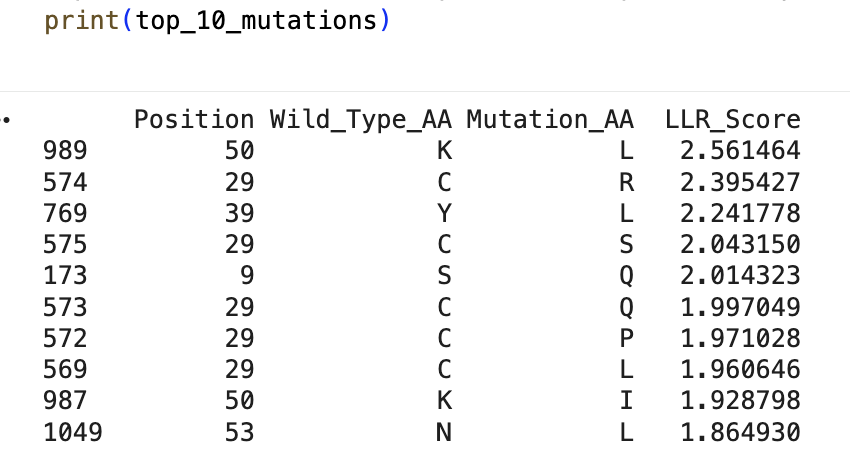
“Run this notebook to generate for each position in the amino acid sequence, a “score” for what would happen to the protein if you mutated into another amino acid”:
“does the experimental data correlate with the scores from the notebook”?
… I don’t think so … might’ve done something off … or maybe these are just different systems with different results …
Week 6 HW: Genetic Circuits Part I
Assignment: DNA Assembly
1. What are some components in the Phusion High-Fidelity PCR Master Mix and what is their purpose?
From New England Biolabs “Phusion High-Fidelity PCR Master Mix with HF Buffer is a 2X master mix consisting of Phusion DNA Polymerase, deoxynucleotides and reaction buffer that has been optimized and includes MgCl2. All that is required is the addition of template, primers and water.”
2. What are some factors that determine primer annealing temperature during PCR?
From ThermoFisher Scientific “The annealing temperature is determined by calculating the melting temperature (Tm) of the selected primers for PCR amplification. A general rule of thumb is to begin with an annealing temperature 3–5°C lower than the lowest Tm of the primers … One important consideration in Tm calculation is the use of PCR additives, co-solvents, and modified nucleotides. The presence of these reagents lowers the Tm of the primer-template complex.”
3. There are two methods from this class that create linear fragments of DNA: PCR, and restriction enzyme digests. Compare and contrast these two methods, both in terms of protocol as well as when one may be preferable to use over the other.
PCR is used to make many copies of a section of DNA. Restriction enzyme digests cut the DNA at specific points, and do not make multiple copies.
4. How can you ensure that the DNA sequences that you have digested and PCR-ed will be appropriate for Gibson cloning?
5. How does the plasmid DNA enter the E. coli cells during transformation?
6. Describe another assembly method in detail (such as Golden Gate Assembly)
7. Explain the other method in 5 - 7 sentences plus diagrams (either handmade or online).
8. Model this assembly method with Benchling or Asimov Kernel!
Assignment: Asimov Kernel
1. Create a Repository for your work
I created a repository called “Millikin Constructs HTGAA BUGSS HW06”
2. Create a blank Notebook entry to document the homework and save it to that Repository
I created a notebook called “HW06 Documentation Notebook”
3. Explore the devices in the Bacterial Demos Repo to understand how the parts work together by running the Simulator on various examples, following the instructions for the simulator found in the “Info” panel (click the “i” icon on the right to open the Info panel)
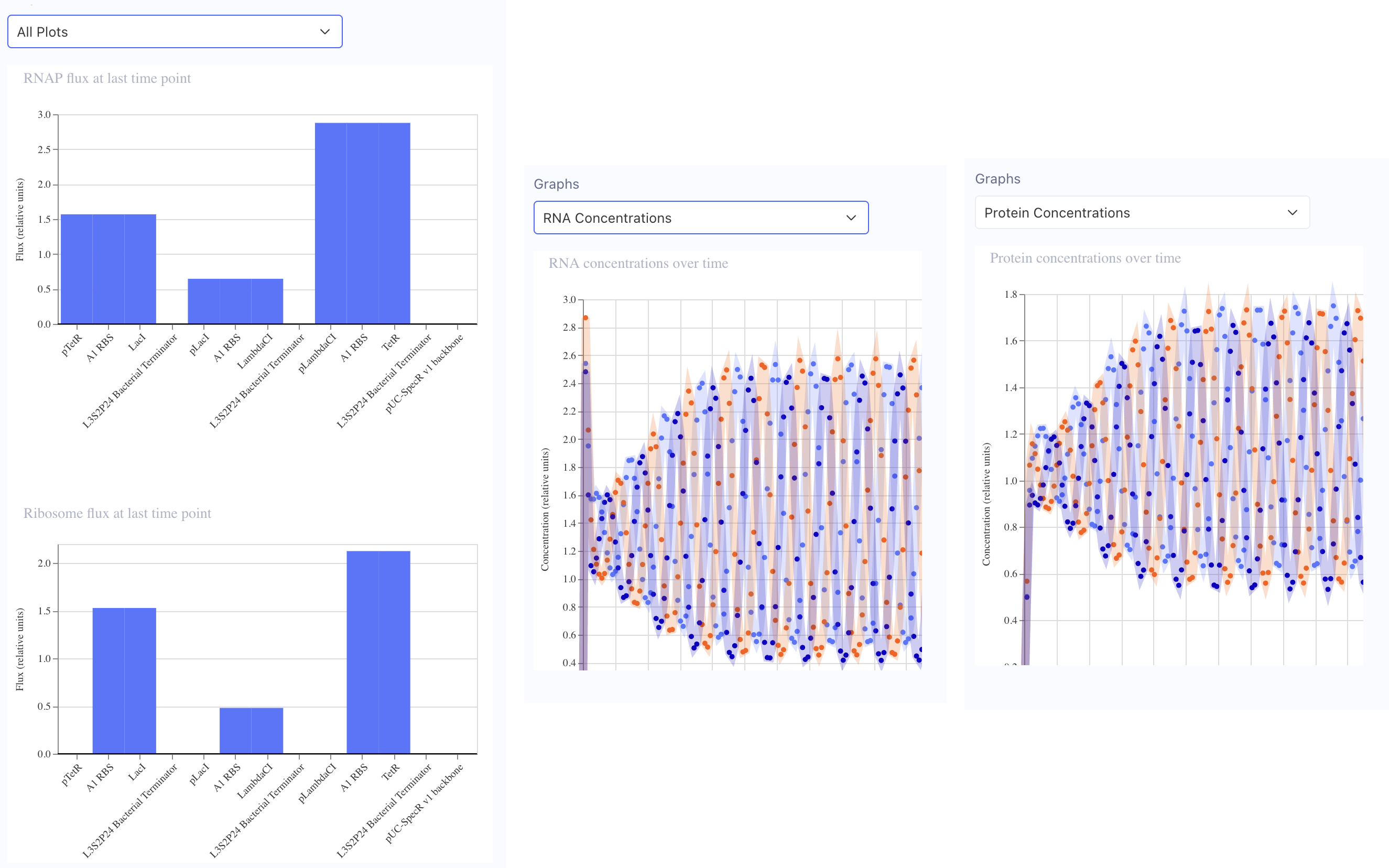
In the “Bacterial demos” repository, the “info” for the Reprissilator lists “Simulation parameters: Chassis: E. coli Duration: 24 hours Timestep: 10 minutes Transfection: Transient transfection.” I clicked the “Sim” button on the right, entered those parameters (only had to change duration) and then simulated at 10:14 AM 3/31/26. These are the graphs of my results:
4. Create a blank Construct and save it to your Repository
Recreate the Repressilator in that empty Construct by using parts from the Characterized Bacterial Parts repository. Search the parts using the Search function in the right menu.Drag and drop the parts into the Construct. Confirm it works as expected by running the Simulator (“play” button) and compare your results with the Repressilator Construct found in the Bacterial Demos repository. Document all of this work in your Notebook entry - you can copy the glyph image and the simulator graphs, and paste them into your Notebook*
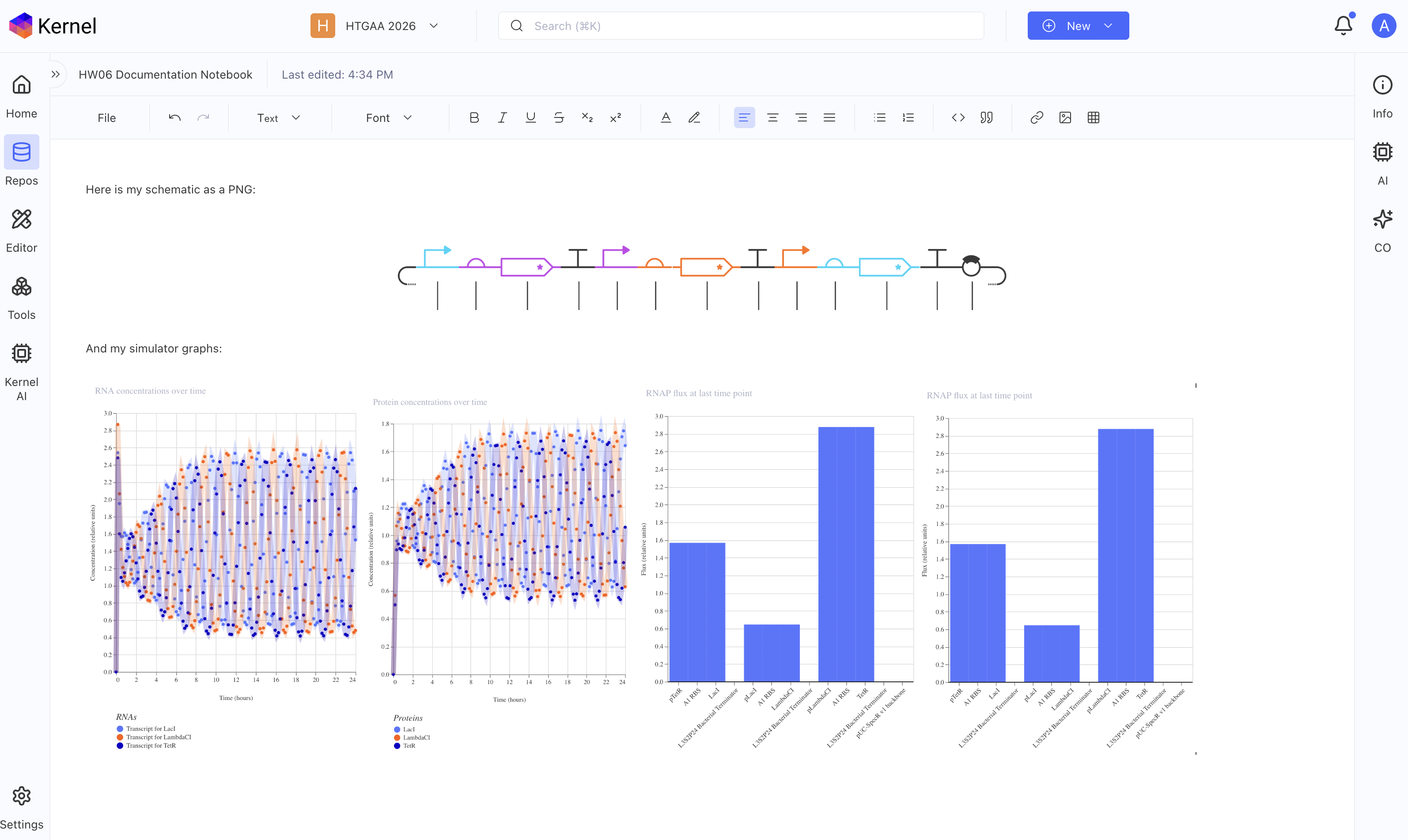
Yes! I did all of the above, below should be a screenshot of my notebook with my glyph image and simulator graphs from my recreated repressilator.
5. Build three of your own Constructs using the parts in the Characterized Bacterials Parts Repo
Explain in the Notebook Entry how you think each of the Constructs should function
Run the simulator and share your results in the Notebook Entry
If the results don’t match your expectations, speculate on why and see if you can adjust the simulator settings to get the expected outcome
Week 7 HW: Genetic Circuits Part II: Neuromorphic Circuits
Assignment Part 1: Intracellular Artificial Neural Networks (IANNs)
What advantages do IANNs have over traditional genetic circuits, whose input/output behaviors are Boolean functions?
Traditional genetic circuits are binary digital on/off. IANNs can be more analog, with greater ranges, which is shown in the blue gradient diagrams in the neuromorphic wizard.
Describe a useful application for an IANN; include a detailed description of input/output behavior, as well as any limitations an IANN might face to achieve your goal.
My memory of examples described in class involved cancer fighting Intracellular Artificial Neural Networks, which could take multiple inputs of different biological signs of cancer, give them different weights, and then could output either just a biosignal that suspected cancer has been detected, or maybe as outpur release a biological chemotherapy. Current limitations include that these are currently fairly difficult to design and test, which is why systes like the neuromorphic wizard are being developed to model them in simulation and predict their behavior.
Below is a diagram depicting an intracellular single-layer perceptron where the X1 input is DNA encoding for the Csy4 endoribonuclease and the X2 input is DNA encoding for a fluorescent protein output whose mRNA is regulated by Csy4. Tx: transcription; Tl: translation. Draw a diagram for an intracellular multilayer perceptron where layer 1 outputs an endoribonuclease that regulates a fluorescent protein output in layer 2.
Assignment Part 2: Fungal Materials
What are some examples of existing fungal materials and what are they used for? What are their advantages and disadvantages over traditional counterparts?
One example of fungal materials is objects made from mycelium, which can be grown into pretty much any shape you can make a form for, much like tradiitional casting. We saw several examples of mycelium projects including acoustic tile, packing material, insulation, and bricks. Yeast is also a fungus, so materials made from SCOBY (Symbiotic Culture Of Bacteria and Yeast) are also in part fungal materials. We saw images of several SCOBY fashion projects in recitation.
I have used fungal mycelium and SCOBYs in previous projects. Below is an image showing, on the left, a sculptural mask made of mycelium and mushrooms, and on the right is a sheet of SCOBY leather with embedded venus flytrap leaves.
What might you want to genetically engineer fungi to do and why? What are the advantages of doing synthetic biology in fungi as opposed to bacteria?
For biomaterials, genetically engineered fungi could maybe grow mycelium faster, or maybe spend less energy on fruiting and spore production and more energy on creating mycelium. A natural or agricultural fungus that has been bred and selected for creating large fruit and for reproducing well might actually be less useful for biomaterials than a fungus that has been genetically engineered for faster and stronger mycelium.
Assignment Part 3: First DNA Twist Order
Thinking about this …
Week 9 HW: Cell Free Systems
#General homework questions
Explain the main advantages of cell-free protein synthesis over traditional in vivo methods, specifically in terms of flexibility and control over experimental variables. Name at least two cases where cell-free expression is more beneficial than cell production.
Two advantages would be 1) “elimination of reliance on living cells,”" so we don’t hve to wait for the living organism’s growth cycle an maintain their living conditions, and 2) “the ability to focus all system energy on production of the protein of interest.” Two cases where cell-free systems have benfits over in vivo methods include 1) “The production of functional antibodies and antibody fragments in vitro using CFPS has the potential to allow for simplification of the antibody production process for more rapid manufacturing,” and 2) “Metalloproteins … are difficult to produce in vivo … have the potential to enable renewable hydrogen fuel and other important biotechnological advancements.”
Describe the main components of a cell-free expression system and explain the role of each component.
“In CFPS, a solution containing all the cellular machinery needed to direct protein synthesis (e.g., ribosomes, tRNAs, enzymes, cofactors, amino acids, etc.) is used to transcribe and translate a supplied nucleic acid template (e.g., plasmid DNA, linear DNA or mRNA).”
Why is energy provision regeneration critical in cell-free systems? Describe a method you could use to ensure continuous ATP supply in your cell-free experiment.
“Supplying energy for cell-free protein synthesis reactions is one of the biggest challenges to the success of these systems. Oftentimes, short reaction duration is attributed to an unstable energy source. "
Compare prokaryotic versus eukaryotic cell-free expression systems. Choose a protein to produce in each system and explain why.
How would you design a cell-free experiment to optimize the expression of a membrane protein? Discuss the challenges and how you would address them in your setup.
Imagine you observe a low yield of your target protein in a cell-free system. Describe three possible reasons for this and suggest a troubleshooting strategy for each.
Week 10 HW: Imaging and Measurement
Homework: Final Project
Please identify at least one (ideally many) aspect(s) of your project that you will measure. It could be the mass or sequence of a protein, the presence, absence, or quantity of a biomarker, etc.
Please describe all of the elements you would like to measure, and furthermore describe how you will perform these measurements.
What are the technologies you will use (e.g., gel electrophoresis, DNA sequencing, mass spectrometry, etc.)? Describe in detail.
Homework: Waters Part I — Molecular Weight
Based on the predicted amino acid sequence of eGFP (see below) and any known modifications, what is the calculated molecular weight? You can use an online calculator like the one at https://web.expasy.org/compute_pi/
Note (from meeting) that GFP loses weight (a water, and two hydrogen?) when it folds, so you have to subtract 20 daltons from what expasy reports …
Week 11 HW: Bioproduction & Cloud Labs
Part A: The 1,536 Pixel Artwork Canvas | Collective Artwork
I will say that they were largely decorative, incremental changes because I was working when the wait time between each person’s changes was one minute, so I wasn’t able to make any really drastic changes. I was mostly just trying to add some additional variety and visual interest to what other collaborators had already drawn.
The final artwork has changed so much since my early contributions, which is of course fine and cool, but maybe a future experimental version of this project could make it so there was always at least one or more pixels from each participant.
Part B: Cell-Free Protein Synthesis | Cell-Free Reagents
Looking at each omponent’s role is in the cell-free reaction:
E. coli Lysate
BL21 (DE3) Star Lysate (includes T7 RNA Polymerase): has a T7 RNA polymerase gene, which means that it can express proteins with the T7 promoter upstream in its genes
Salts/Buffer
Potassium Glutamate: helps recreate the cell’s native ionic environment by supplying potassium ions that stabilize ribosomes and enhance efficient protein synthesis
HEPES-KOH pH 7.5: maintains a stable pH, ensuring optimal activity of enzymes involved in transcription and translation in the cell-free reaction.
Magnesium Glutamate: Supplies Mg²⁺ ions, which are essential cofactors for ribosomes, RNA polymerase, and other enzymes, directly enabling transcription and translation.
Potassium phosphate monobasic: Acts as part of a phosphate buffer system and contributes to maintaining pH and ionic strength in the reaction.
Potassium phosphate dibasic: Pairs with the monobasic form to establish the buffering equilibrium that stabilizes the reaction pH.
Energy / Nucleotide System
Ribose: Serves as a precursor for nucleotide regeneration pathways, supporting sustained synthesis of ATP and other nucleotides in the reaction.
Glucose: Acts as an energy source that can be metabolized (in extract-based systems) to regenerate ATP and maintain reaction longevity.
AMP: Functions as a nucleotide precursor that can be phosphorylated to regenerate ATP, helping sustain the reaction’s energy supply.
CMP: Serves as a precursor for CTP synthesis, supporting continued RNA transcription.
GMP: Acts as a precursor for GTP, which is required for both RNA synthesis and translation processes.
UMP: Serves as a precursor for UTP, enabling ongoing RNA transcription.
Guanine: Functions as a nucleobase precursor that can be converted into GMP and subsequently GTP for transcription and translation.
Translation Mix (Amino Acids)
17 Amino Acid Mix: Provides the bulk of the amino acids required for protein synthesis during translation, excluding those supplied separately for stability or solubility reasons.
Tyrosine: Supplies tyrosine as a protein building block, often added separately due to its limited solubility in concentrated amino acid mixes.
Cysteine: Provides cysteine for protein synthesis and proper folding, typically added separately because of its reactivity and instability in solution.
Additives
Nicotinamide: Acts as a precursor to NAD⁺/NADH, supporting metabolic and redox reactions that help sustain energy regeneration in extract-based systems.
Backfill
Nuclease Free Water: Serves as a solvent to dissolve components and maintain reaction volume while preventing degradation of nucleic acids.
Part C: Planning the Global Experiment | Cell-Free Master Mix Design
For the 6 fluorescent proteins we used for our collaborative painting, here are biophysical or functional property of each protein that affects expression or readout in cell-free systems. (Such as maturation time, acid sensitivity, folding, oxygen dependence, etc)
sfGFP: Superfolder GFP is engineered for robust folding, allowing efficient fluorescence even under suboptimal conditions in cell-free systems.
mRFP1: This red fluorescent protein has relatively slow maturation, which can delay the appearance of fluorescence after protein synthesis.
mKO2: mKO2 has fast maturation but is somewhat sensitive to acidic conditions, which can reduce fluorescence intensity if pH is not well controlled.
mTurquoise2: This cyan fluorescent protein has high quantum yield and brightness but requires proper folding to achieve full fluorescence efficiency.
mScarlet-I: mScarlet-I combines high brightness with rapid maturation, improving signal output in cell-free systems compared to older red fluorescent proteins.
Electra2: Electra2 is a flavin-binding fluorescent protein that depends on oxygen-independent chromophore formation but requires flavin cofactors, which can influence fluorescence based on cofactor availability.
My hypothesis for how adjusting one or more reagents in the cell-free mastermix could improve a specific biophysical or functional property you identified above, in order to maximize fluorescence over a 36-hour incubation is:
For mScarlet-I, I think increasing potassium glutamate and magnesium glutamate will enhance fluorescence by improving folding and translation. This might allow for better/faster maturation of the fluorescent protein. And maybe more Ribose or Glucose just for more energy.
On the 1536 artwork at https://rcdonovan.com/1536 I was able to “customize the cell-free reagent composition of wells of your choosing … up to 8 wells”
OK, I wanted to do one of each color. And only change two reagents for each one, so as not to be adjusting too many variables at once. So this si what I did:
sfGFP: I raised Magnesium Glutamate for same reasons above. And, I raised Glucose for more energy. This was in Q4-P24, lower right, last pixel of the whole thimg!
mRFP1: I raised Magnesium Glutamate for same reasons above. And, I raised Glucose for more energy. This was in Q3-O22, end of the A in HTGAA
mKO2: I raised Magnesium Glutamate for same reasons above. And, I raised Glucose for more energy. This was in Q1-A1, upper left, first pixel of the whole thing!
mTurquoise2: I raised Magnesium Glutamate for same reasons above. And, I raised Glucose for more energy. This was in Q4-C4, the first crossing of the DNA double helix.
mScarlet-I: I raised Magnesium Glutamate for reasons above. And, I raised Glucose for more energy. This was in Q3-B6, in the heart in “LOVE”
Electra2: I raised Magnesium Glutamate for reasons above. Let’s mix things up: I raised Nicotinamide to hopefully help with flavin metabolism. This was in Q1-D23, the second peak of the M in the Meida Lab logo.
Part D: Build-A-Cloud-Lab | (optional) Bonus Assignment
I used the simulation tool at https://racs.rcdonovan.com/ to create the cloud lab pictured below out of the Ginkgo Reconfigurable Automation Carts. It is pretty rough! Just testing things out.