I am a Mexican biochemical engineer 🧪 with experience in phytopathogenic fungi 🍄 and plant tissue culture 🌿.
I am looking to learn strategies to promote the use of synthetic biology 🧬 in fungi for therapeutic 💊, food 🧀, and bioremediation 🏭 applications to address the problems facing my country.
Let me present my project idea 💡 which integrates synthetic biology into the management of filamentous fungi for waste utilization 🪣 through proactive governance, promotion of health and wealth; governed by principles of justice and ecological management 🌳.
Hello again! This time, I will present my progress in editing a DNA sequence with the help of bioinformatics tools in in silico conditions (since I was unable to replicate it in a laboratory 😿).
Fungal Biorefinery for Sargassum and Henequen Valorization into Antimicrobials
On the Yucatan Peninsula, various problems associated with coastal pollution have been reported due to sargassum wash-ups that affect fishing production and local tourism. Likewise, henequen-producing areas generate a considerable amount of waste that could be exploited through biotechnological processes 2.
Important
My goal is to design and implement a synthetic biology-based fungal platform using genetically modified filamentous fungi from the region (e.g., Geastrum triplex, Pleurotus djamor) to convert two problematic waste streams in the region—sargassum algae and henequen bagasse—into high-value medicinal compounds (terpenoid precursors or antibiotics) and antimicrobial proteins.
This integrated biorefinery approach aims to address waste-related environmental crises, reduce dependence on imported pharmaceuticals, and create a circular bioeconomy model in the Yucatan Peninsula.
Objective 1: Ensure equitable distribution of benefits and local capacity building.
Prevent biopiracy and ensure that economic and knowledge benefits remain within local Mayan communities.
a) Legal Frameworks for Resource Sovereignty:
Establish clear agreements that define sargassum as a “biological resource” under state sovereignty before recognized institutions (SEMARNAT), with protocols for access and benefit sharing aligned with the Nagoya Protocol.
b) Technology Transfer & Workforce Development:
Create mandatory partnerships between national and international biotech companies, as well as universities and federal research centers (UADY, CECIHTI, SIIDETEY), including joint ownership of intellectual property and training programs in genetic engineering and bioreactor operation.
c) Community-Led Monitoring Committee:
Form a permanent oversight committee composed of representatives from coastal communities, henequen ejidos, and bioethicists (CONBIOÉTICA) to review project direction, benefit sharing, and environmental impact.
Objective 2: Implement responsible governance regarding environmental release and containment.
Mitigate ecological risks from genetically modified fungi and ensure that the project improves local ecosystems rather than disrupting them.
a) Strict physical and biological containment standards:
Require the exclusive use of genetically modified strains with multiple self-destruct switches. The aim is to have genetic safety measures such as genetic microfactories in place to prevent environmental damage.
b) Environmental monitoring based on the precautionary principle:
Establish an environmental DNA monitoring network before and after implementation to track any possible leaks and impacts on the native ecosystem.
c) Transparent communication of risks and benefits:
Develop risk assessment control panels aimed at the public, departments dedicated to constant updating, and detailing the effectiveness of the strategies developed.
Potential governance actions
1. Establish a Yucatán Bioeconomy Regulatory Sandbox
Regulations on GMOs in Mexico are restrictive and not adapted to genetically modified environmental applications.
That is why I would like to propose the creation of a temporary, legally recognized “Biological Containment Unit” in designated areas (e.g., the Progreso Industrial Park or the Yucatan Science and Technology Park [PCTY]) where suitable facilities allow for pilot-scale testing of genetically modified fungi under close supervision.
It should be led by the Ministry of the Environment (SEMARNAT) with CONABIO, CIBIOGEM, and the Yucatán government.
The necessary investment can be provided by interested public institutions (e.g., the Yucatan Ministry of Science, Humanities, Technology, and Innovation [Secihti], the Scientific Research Center of Yucatán [CICY], CINVESTAV) in collaboration with biotechnology venture capital firms (e.g., GridX, Zentynel Frontier Investments) for the installation and maintenance of activities.
Regulators are expected to be willing to adopt adaptive governance models, with 100% effective containment protocols at the pilot scale and positive public opinion managed through transparency.
The aim is to prevent possible regulatory paralysis or suspension of the testing space before it begins due to mistrust in the public reaction.
2. Launch a “Community Biorefinery” Co-Ownership Model
Waste recovery projects often extract resources without returning profits or control to local collectors/workers.
This proposal is to develop a cooperative ownership structure in which companies specializing in sargassum collection and henequen producers hold shares in the establishment of the biorefinery, participating in its management alongside cooperatives, the Agency for the Development of Yucatán (ADY), private investors, and environmental engineers from the area.
The initial capital will come from impact funds, supplemented by support from the Yucatán Ministry of Sustainable Development (SDS), with cooperative assemblies overseeing important decisions.
It is expected that the cooperatives will have the organizational capacity to participate, that social trust will be generated, and that the return value of potential products will be compelling enough to generate meaningful participation.
There is a risk that in the future the cooperatives will be marginalized in technical decisions, which would lead to conflicts and disruption of the supply chain. Another scenario suggests that commercialization could lead to overexploitation of sargassum or the diversion of henequen from traditional artisans, causing cultural erosion.
3. Create an Open-Source Fungal Toolkit for Safe Engineering
Advanced synthetic biology tools (e.g., CRISPR vectors, biocontainment modules) are patented and expensive.
Given the lack of organization of genetic data on fungi in the region, I would like to propose the establishment and development of an open-source repository of standardized genetic components (BioBricks) through a recognition and optimization program for filamentous fungi, freely accessible to all partner institutions and the interested scientific community.
The initiative will be carried out in collaboration between public universities (CINVESTAV, UADY, TECNM, UNAM) and private universities (Anáhuac Mayab, Marist University, Modelo University), with technical contributions from international synthetic biology institutes (e.g., Ginkgo Bioworks), funded by Secihti and philanthropic organizations (corporate foundations such as Carlos Slim, Harp Helú, and Gonzalo Río Arronte).
Access will be public through a locally hosted digital platform with material transfer agreements that require bioinformatics security and benefit-sharing principles.
It is expected that the necessary open-source tools will be available to reduce barriers for local actors, as well as the implementation of infrastructure to maintain databases; compliance with intellectual property standards for partners, communities, and institutions will be monitored responsibly.
There is concern about the lack of resources and technical protocols for this proposal, resulting in a functionally inferior tool or one with vulnerabilities to the data entrusted to it. The worst-case scenario is that the platform will not be accessible, or that it will lack oversight tools, allowing for the design of risky or unethical experiments.
4. Implement an Independent, Transparent Bio-Impact and Benefit Audit System
Impact assessments are conducted privately, on a one-off basis, by experts hired by the companies themselves. Often, the results are not shared in full with the public or are manipulated.
I would like to suggest the creation of a permanent, independent group responsible for conducting ongoing public oversight of the actual safety of biotechnology projects within the state, in order to provide public transparency regarding the actions and resources used in this and future projects, as well as the benefits to the community.
The office responsible for auditing should include partners from the fields of science, technology, and the environment, experts in social issues, and community representatives, with support from national and international organizations. The section should have certifications, a simple public website for accessing reports, and mixed financing between public grants and income generated by specialized services for the rest of the associations.
The aim is for the company to be transparent with auditors, providing complete data and full access to facilities. Similarly, there is public interest in the publication of progress and the consistency of actions to be taken with the objectives set.
There is a risk that audit reports will be completed but then dismissed by politicians or businesspeople; that the tests will not detect a risk or social harm, creating a false sense of security; that the audit process becomes so strict and slow that it paralyzes the project’s ability to adapt and improve, stifling innovation; or that the data is used by opponents to create misleading scandals and unfairly damage the project’s reputation.
Does the option:
Option 1
Option 2
Option 3
Option 4
Enhance Biosecurity
• By preventing incidents
2
n/a
1
2
• By helping respond
2
n/a
3
1
Foster Lab Safety
• By preventing incident
1
n/a
2
3
• By helping respond
2
n/a
3
3
Protect the environment
• By preventing incidents
1
3
3
2
• By helping respond
1
3
n/a
2
Other considerations
• Correct a frame of reference in the state/country
2
1
3
1
• Feasibility?
2
3
1
3
• Not impede research
2
1
2
3
• Encourage social engagement
n/a
1
2
3
What is the best proposal?
Taking into account the facilities, the material, economic, and legal resources, as well as the experience gained in other experimental lines related to the handling of genetically modified organisms, I propose to begin with the creation of the “Biological Containment Unit” as part of the start of the economic regulatory sandbox aimed at providing a safe space where, in the future, the design and implementation of experiments and pilot tests with genetically modified fungi can be planned.
In turn, I would seek to complement the technological facilities in access to genomic databases and “biobricks” through agreements with solid and recognized institutions (for example, the European GMO Initiative for a Unified Database System [EUginius], the iGEM Foundation, The National Center for Biotechnology Information [NCBI]) for the collection, experimental management, and storage of genomic data necessary to process in silico trials that support the transition to in vitro experiments.
The proposal is intended for review by Secihti, the Directorate of Innovation and Smart Government of the City Council of Mérida, Yucatán, the Global Biotech Revolution (GBR), the iGEM Foundation, the International Gene Synthesis Consortium (IBBIS), and any other organization interested in biotechnological advances involving filamentous fungi.
Remarks
During this exercise, I continue to wonder how modifying more complex fungi will really impact industry and daily life. I am concerned that the appropriate management of species and genetic data will not be achieved in the future, which in popular culture could refer to failures such as in the video game “The Last of Us.”
I have reflected that these types of projects can be a watershed in the safe management of local resources, as long as there is trust with ethnic groups, productive groups, associations, business groups, and non-profit organizations. I would like the technological transition, bioethical, and legal frameworks to develop strategies to update and adapt to possible issues that may arise during the design of projects in this category.
Week 1 HW: Assignment (Week 2 Lecture Prep)
Homework Questions from Professor Jacobson:
Nature’s machinery for copying DNA is called polymerase. What is the error rate of polymerase? How does this compare to the length of the human genome. How does biology deal with that discrepancy?
Human DNA polymerase has a common error rate of one error per 106 bp inserted.
If the human genome has a length of ~3.2 x 109 bp, approximately 3,200 errors are expected within the entire genome.
This does not take into account that the cell has polymerases capable of correcting these errors during replication through a proofreading system, followed by mismatch repair (MMR), base excision repair (BER), and nucleotide excision repair (NER).
How many different ways are there to code (DNA nucleotide code) for an average human protein? In practice what are some of the reasons that all of these different codes don’t work to code for the protein of interest?
Given that a protein generated by the human body has an average of 1036 base pairs, when organized by codons, it can be translated into a protein of 345 amino acids; remembering that the genetic code is degenerate (the same amino acid can be encoded by more than one codon) and that there are 61 known codons that encode an amino acid (not counting 3 stop codons), and the complexion for the total number of different ways to arrange N codons of Q different aminoacids is given by:
When we want a code to express a protein of interest, not all of the above combinations will work, as they depend on processes during translation such as the stability of the messenger RNA strand, whether it forms secondary structures, the presence of signals or regulatory elements; the availability of ribosomes and tRNA, as well as the speed of recognition of the start codon and the Kozak sequence (for eukaryotic cells).
Homework Questions from Dr. LeProust:
What’s the most commonly used method for oligo synthesis currently?
According to the presentation, I understand that the standard method is solid-phase oligonucleotide synthesis using phosphoramidites in a four-step sequence: phosphoramidite coupling, capping of unreacted sites, oxidation, and deblocking.
However, specialized equipment has now been developed, such as the High-throughput oligo synthesizer (Oligator) by Illumina, Inkjet-based DNA microarray by Agilent and Electrochemical-based microarray by CombiMatrix.
Why is it difficult to make oligos longer than 200nt via direct synthesis?
The main difficulty lies in the imperfect coupling efficiency in each cycle. Efficiency per step is typically over 99%, however, losses accumulate exponentially with length as each cycle introduces impurities and the stability of the support degrades with prolonged cycles.
Why can’t you make a 2000bp gene via direct oligo synthesis?
A linear gene of 2000 bp cannot be manufactured directly and continuously due to the possibility of pairing errors or mutations in the sequence.
Furthermore, even if it could be done in a single step, it would be a very costly process.
Instead, assembly in Precision Oligo Pools is proposed to improve the signal-to-noise ratio, reduce the burden of oversampling, and increase the representation of the full length.
Homework Questions from George Church:
What are the 10 essential amino acids in all animals and how does this affect your view of the “Lysine Contingency”?
There are nine essential amino acids (those that cannot be synthesized de novo and must be obtained from the diet), which are:
The contingency of lysine analyzed from the perspective of metabolism is only a means of regulating the growth of an organism that depends on this amino acid for survival. With synthetic biology, in theory, this limitation can be overcome by implementing genes that encode the enzymes of the metabolic pathway for synthesis, thereby implementing a strategy to overcome this need, which could also be replicated for the rest of the essential amino acids.
Anara AI was used, configured with the GPT OSS rationing model. The AI was fed three articles on biosafety policies and an email address about bioethics and ethnic communities’ access to bioinformatics data. It was instructed to generate multiple proposals for governance actions aimed at making the use of synthetic biology in Mexico equitable, taking into account the country’s significant legal limitations and technological backwardness. I adapted the ideas to the context of Yucatán and the objective of my project proposal. ↩︎
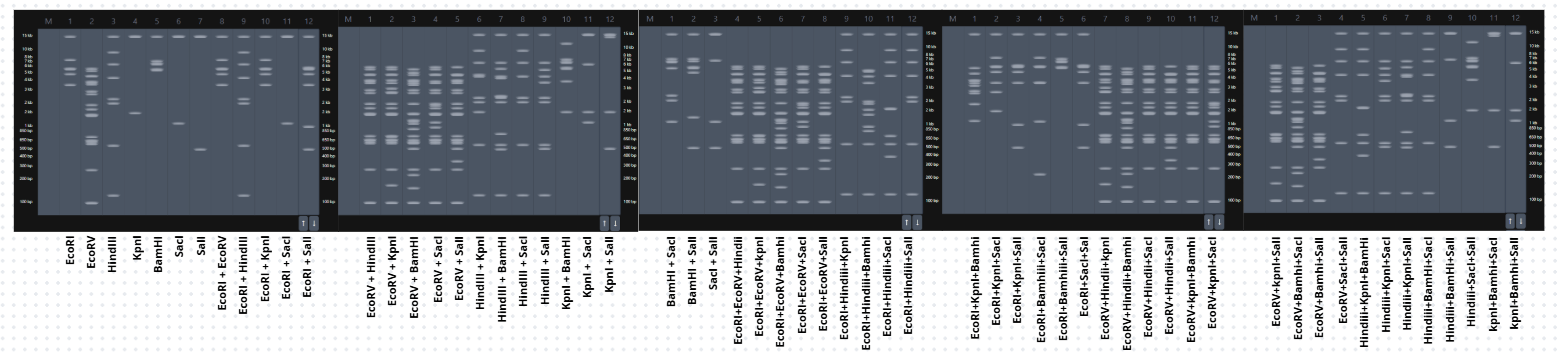
To begin my journey into understanding DNA, I made a “Gel Art” using restriction enzymes to create a beautiful image by cutting the Lambda sequence.
Gel Art
A technique that uses gel electrophoresis not for analytical purposes, but for artistic ones. Pigments or colored biomolecules are separated in an electric field to create abstract, controlled visual patterns and designs 1.
Restriction enzymes
They are “molecular scissors” (proteins) that cut DNA at specific sequences. They are fundamental tools in genetic engineering for isolating genes, recombining DNA, and analyzing samples 2.
Spoiler 😶🌫️
Here I´m gonna set my objective or the most important thing that I do during the HW.
Well, to do that, I created a Benchling account, joined the HTGAA group, created a folder with my name, and imported my sequences there.
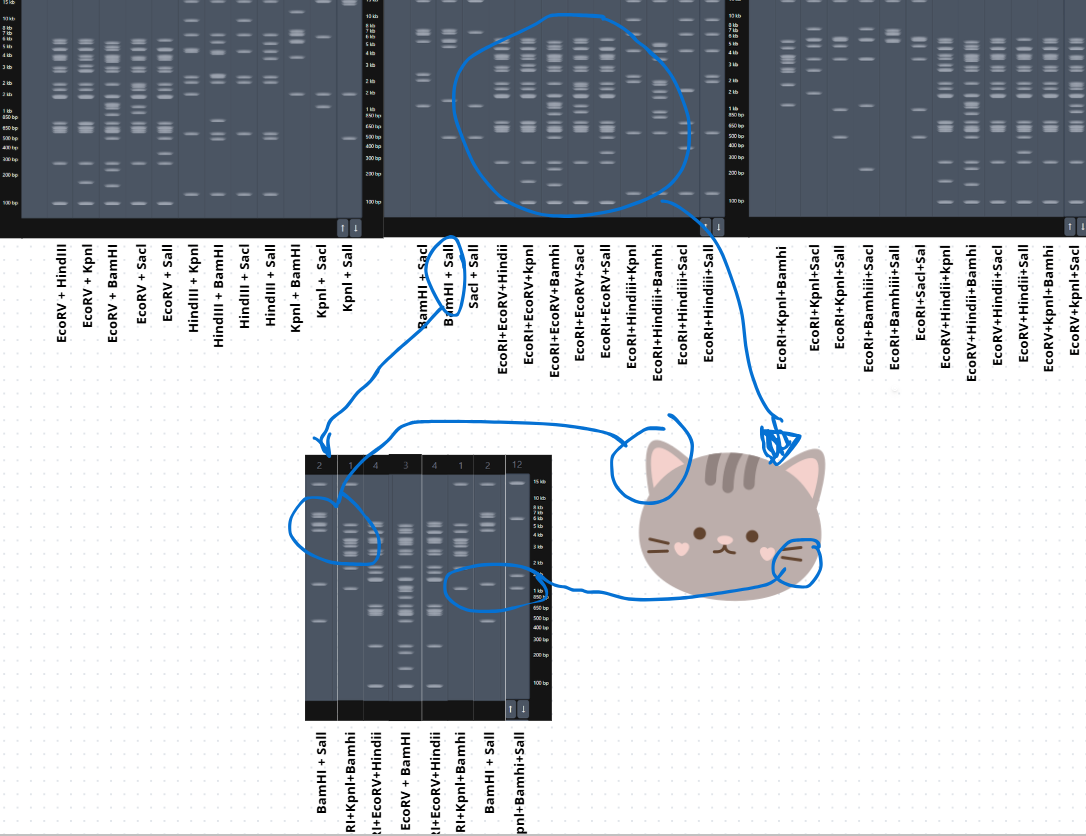
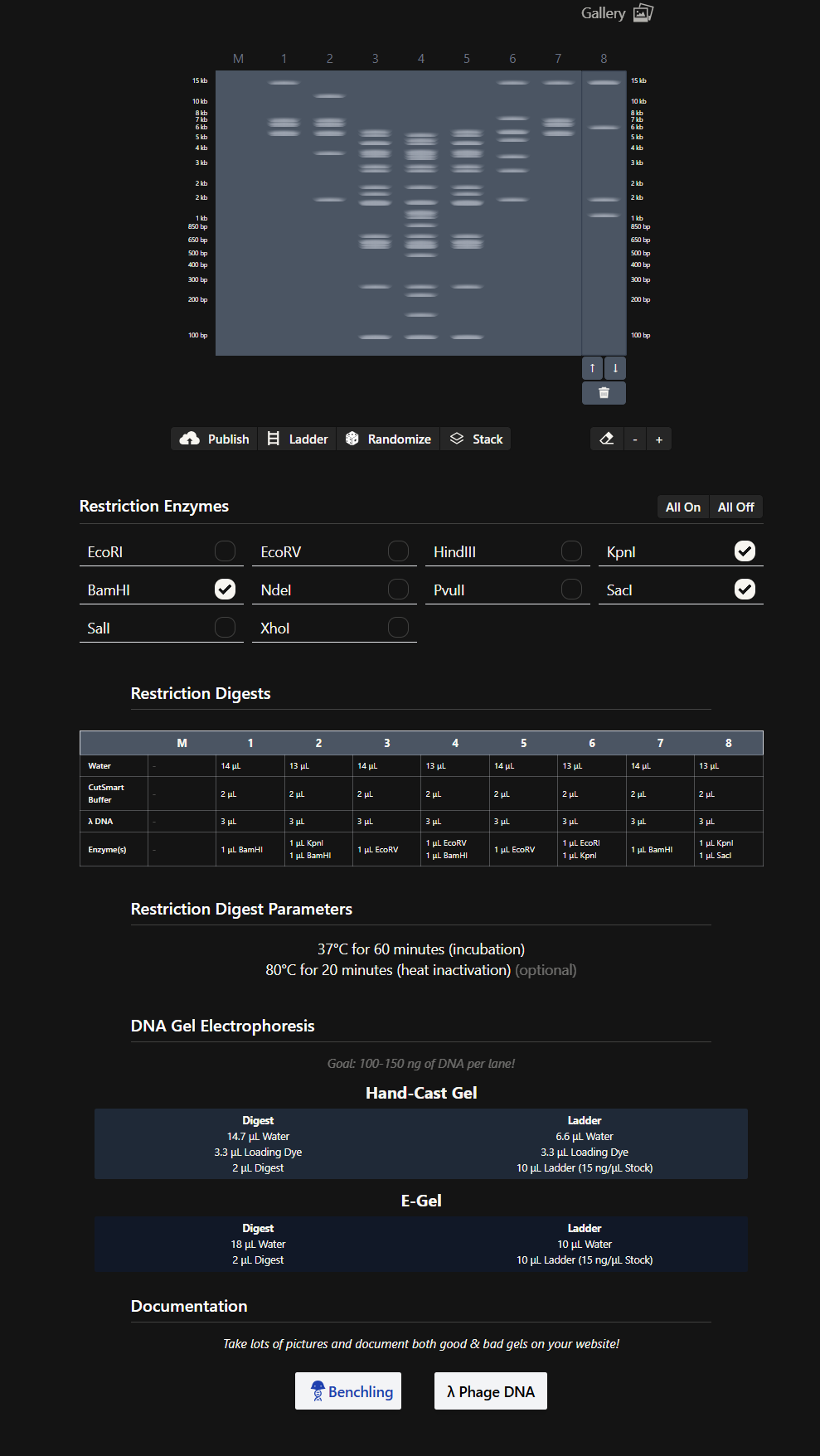
Then, on my own, I started making combinations of the digests in the DNA Gel Art Interface on Ronan’s website.
In this part, I spent some time iterating to get an idea of what figure to create.
After trying several combinations, I came up with this design for a cat’s face. 😸
Then I performed the digestion in Benchling, and this was the result.
🧬 DNA Design Challenge
For this exercise, I chose the FIP-gts protein, an immunomodulatory protein identified in the Ganoderma tsugae fungus. I selected this protein after several searches on Google Scholar, Perplexity AI, and the Crow tool on the Edison platform.3
This protein caught my attention because it has therapeutic potential as an immunomodulatory, anticancer, and antiallergic agent. I feel that its antiallergic properties could be very useful, as many people I know suffer from problems caused by environmental and food allergies.
🟩 With the help of NCBI4, I searched for the sequence of the FIP-gts protein, but it did not appear as such. Reviewing other articles, I found the accession to the homologous protein, Ling zhi-85 (Lz-8, accession number AAA33350).
Its amino acid sequence in FASTA format is:
>AAA33350.1 immunomodulatory protein [Ganoderma lucidum]MSDTALIFRLAWDVKKLSFDYTPNWGRGNPNNFIDTVTFPKVLTDKAYTYRVAVSGRNLGVKPSYAVESDGSQKVNFLEYNSGYGIADTNTIQVFVVDPDTNNDFIIAQWN
Following the central dogma of molecular biology:
---
title: Central dogma of Molecular Biology
---
graph LR;
A[DNA] -->|Replication| A
A -->|Transcription| B[RNA]
B -->|Translation| C[Protein]
The dogma does not state that reverse translation can be done conventionally, even with the help of online bioinformatics tools, I performed reverse translation with the help of ProteinIQ and obtained the following sequence:
>AAA33350.1 immunomodulatory protein [Ganoderma lucidum]ATGAGCGATACCGCCTTGATTTTCCGCTTGGCTTGGGATGTGAAGAAACTATCATTTGATTATACGCCAAACTGGGGGAGGGGTAACCCTAATAATTTTATCGACACTGTGACATTTCCAAAGGTACTCACTGATAAAGCTTACACTTATCGGGTCGCCGTTTCTGGACGTAACCTCGGCGTCAAGCCTAGCTACGCCGTGGAATCCGATGGTTCTCAAAAGGTGAACTTTCTTGAATATAACAGCGGATATGGCATCGCAGACACGAATACCATACAAGTGTTTGTAGTCGACCCGGATACCAACAATGATTTCATCATCGCACAATGGAAT
Out of curiosity, I compared it with its original genetic sequence:
>M58032.1 Ganoderma lucidum immunomodulatory protein (LZ-8) gene, complete cdsAAGTGGCATTATATCACCTTCGGATATCGCCATCCATAACCAACGTCTCAACCCCGAGATGGACGTCATCTGGAGGTAACGACCAAGGCGGTCTTCCGGCAACTGTGGTCTCGAAGACGTGAGGCGTTTACAAGGTTGGACATCTCGGGGCAATTCTGCCAAACTCGCAAGGAGAATGTACCGTCCTATCACCTGCAGTGGTCAGCAGGGGTTGCATCCAGGTCCACCTGCGGTGCAATTCGGTTCCCTGTGGCTTGCAGGGCCTCGCACGTCGTATGCACCCTGGTTTACATCATCGTGAAACGGCGCTCCGGTTGCCGTATAAAAGGACGGCAAAGGCGGCCAGTGGACTTCAGCACCTGCTCTTGTACCCACTTCTAGTAAGTCGCATACCACCTCTCCTGACAGCGACAGGTTCACTGACTAGTTCATAGTCCACAGCTCTTTGCCTTACAATCAAGGTTTGCCGACACCCTCTTTGAGCCCTCCCCCTTCAATAACCCCCTAACTTCTGCCCCGCAGCATCATGTCCGACACTGCCTTGATCTTCAGGCTCGCCTGGGACGTGAAGAAGCTCTCGTTCGACTACACCCCGAACTGGGGCCGCGGCAACCCCAACAACTTCATCGACACTGTCACCTTCCCGAAAGTCTTGACCGACAAGGCGTACACGTACCGCGTCGCCGTCTCCGGACGGAACCTCGGCGTGAAACCCTCGTACGCGGTCGAGAGCGACGGCTCGCAGAAGGTCAACTTCCTCGAGTACAACTCCGGGTATGGCATAGCGGACACGAACACGATCCAGGTGTTCGTTGTCGACCCCGACACCAACAACGACTTCATCATCGCCCAGTGGAACTAGGAGGAGGCAGTGACTGACCCCTGGCGGTCTAATCTGCGGGCCACTGTGGGGGAGGGGCATCGCCCATCAGCTTCCTTGTCTCATAATCATGCCCGTGTAACAATTGTAAATCGACCTTGTTGTACCATGCATCCAGCTTTTGTGGTGTGCCGTCTTATGTTTGGTTG
For this optimization, I used a model optimized for Komagataella phaffii (recognized as Pichia pastoris) because I believe that for the first tests it would be good to apply it to a closely compatible model, such as a yeast with high expression capacity that resembles the eukaryotic model of other fungi but with faster growth and productivity under controlled conditions.
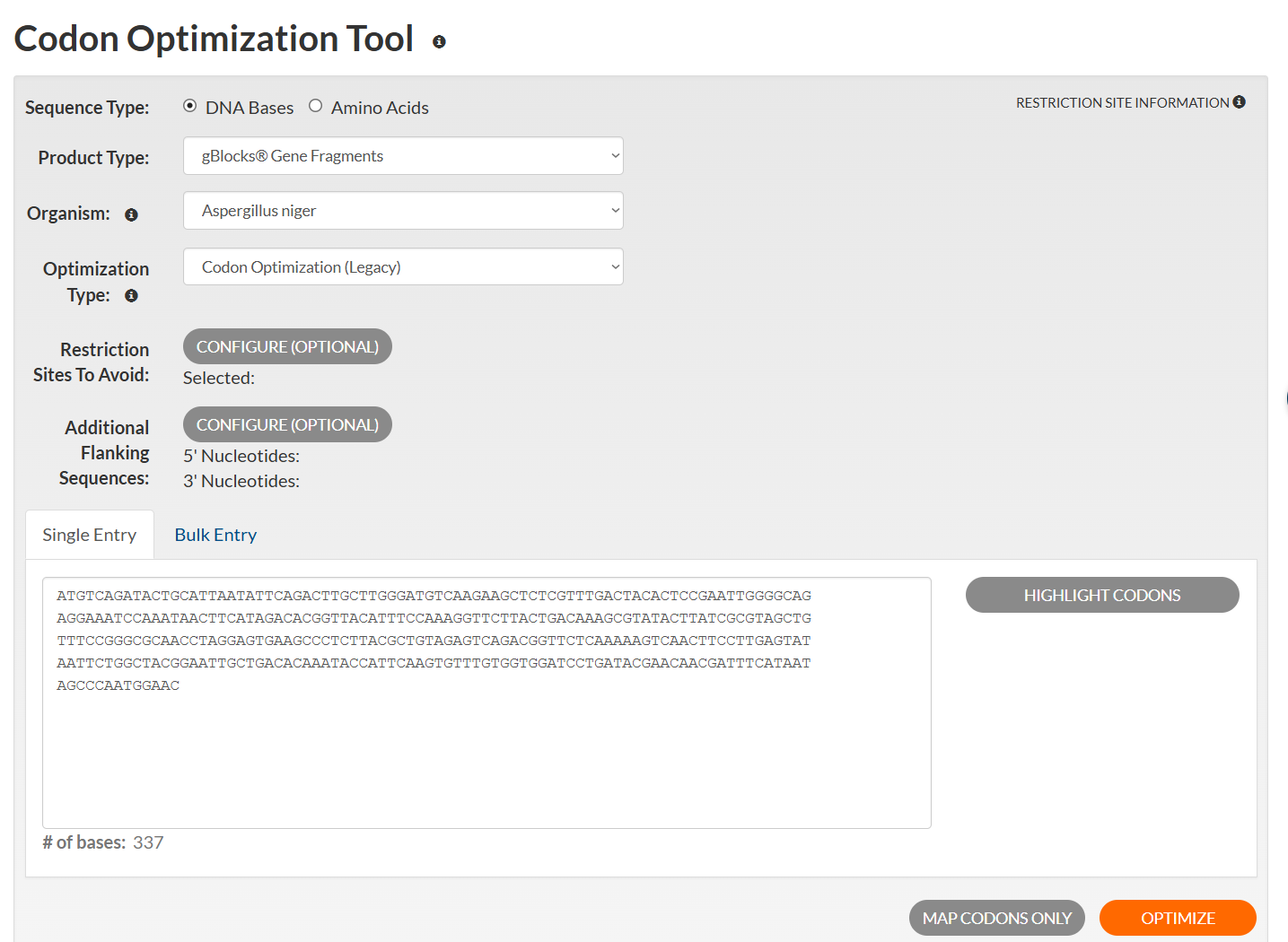
🟦 The next part of the exercise involves optimizing the codon of the nucleotide sequence using an online tool. In this case, I chose the Codon Optimization Tool from Integrated DNA Technologies.
Optimized sequenceAAG TGG CAT TAC ATC ACC TTC GGA TAC AGA CAT CCA TAA CCT ACC AGT CAG CCA CGT GAT GGA AGA CAT CTG GAG GTG ACC ACC AAG GCT GTC TTT CGT CAG CTA TGG TCC AGG CGT CGT GAA GCC TTC ACC AGA CTT GAT ATT TCT GGA CAA TTT TGT CAA ACG AGG AAG GAA AAT GTG CCC TCA TAC CAT TTG CAG TGG TCC GCT GGT GTT GCT TCC AGA TCT ACT TGT GGC GCT ATT AGA TTT CCT GTG GCC TGT AGA GCT TCC CAT GTG GTT TGT ACT TTA GTT TAC ATC ATT GTT AAA AGG AGA AGT GGA TGT CGT ATT AAG GGA AGG CAG AGA AGA CCA GTC GAT TTT TCA ACG TGT TCA TGT ACC CAT TTT TAA TGA GTG GCA TAC CAC CTG AGT TAG CAA CGT CAA GTG CAT TAA TTG GTT CAT AGT CCA CAG CTA TTT GCC TTA CAA TCT AGA TTT GCT GAT ACA CTG TTT GAA CCA AGT CCA TTC AAT AAT CCC CTT ACC TCT GCT CCT CAA CAC CAT GTT AGA CAC TGT TTG GAT TTA CAA GCT CGT TTA GGA CGT GAG GAG GCA TTG GTG AGA TTG CAC CCA GAA CTA GGT CCT AGA CAG CCC CAA CAA CTT CAT AGA CAC TGC CAT TTA CCA GAA AGT TTA GAT AGA CAA GGT GTG CAT GTG CCA AGG AGA AGA TTG CGT ACT GAG CCA AGA AGA GAA ACT TTG GTT AGA GGT AGA GAG AGA AGA TTA GCA GAG GGT CAG TTG CCA AGG GTG CAA TTA CGT GTT TGG CAT TCT GGA CAT GAA CAT GAT CCA GGT GTA AGA TGT AGG CCA AGA CAT CAA CAA AGG TTG CAC CAT AGA CCA GTA GAA CTG GGT GGA GGC TCA GAT TAG CCT CTG GCA GTC TAG TCT GCT GGA CAC TGT GGA GGC GGA GCT TCA CCA ATT TCT TTT TTG GTG AGT TAA AGT TGT CCA TGT AAT AAT TGT AAG TCT ACC TTG CTT TAT CAC GCT TCC TCC TTT TGC GGA GTT CCT TCT TAT GTC TGG TTG
To generate this protein, I believe that the most appropriate approach is to modify the Pichia pastoris yeast by inserting an expression vector using a strong promoter coupled to my optimized gene.
I believe this is the most feasible approach, considering this organism’s ability to accept the plasmid, integrate it into its transcriptional machinery, and generate multiple transcripts induced by a selective culture condition.
The transcripts may undergo transcriptional modifications, be recognized by ribosomes, and be translated efficiently. I hope that the capabilities of P. pastoris will allow the necessary post-translational modifications to be made in order to fold the protein correctly, package it, and excrete it into the medium.
How does it work in nature/biological systems?
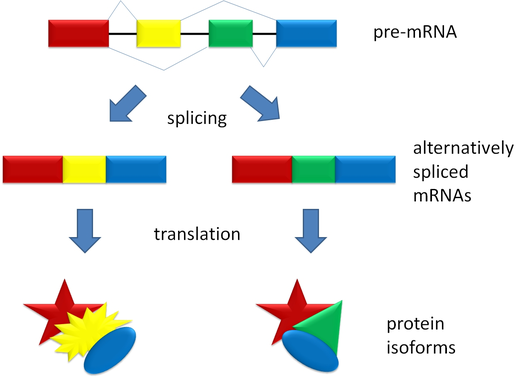
During post-transcriptional processes, there is a stage known as Alternative Splicing, which is a process that occurs after the removal of introns from the messenger RNA sequence, where the translatable fragments (exons) can be rearranged or omitted to form the final transcript. In this process, the order of the sequences can give rise to different forms of the same peptide, known as isoforms.
These isoforms can have different folding, activity, and efficiency depending on the arrangement, which can respond to different circumstances depending on the conditions of the cell.
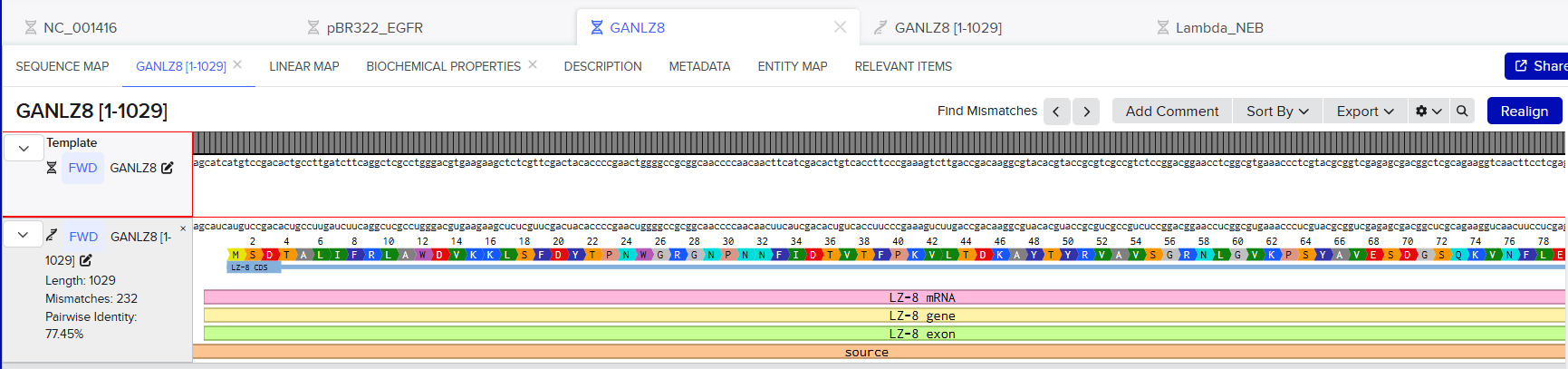
I performed this alignment using Benchling’s alignment tool. First, I generated a copy of the RNA-transcribed sequence, and then I aligned it, including the amino acid and protein markers.
🪢 Twist DNA Synthesis Order
In this part, I built my vector with the following sequences:
In this part of the activity, I should be working on the Twist Bioscience platform.
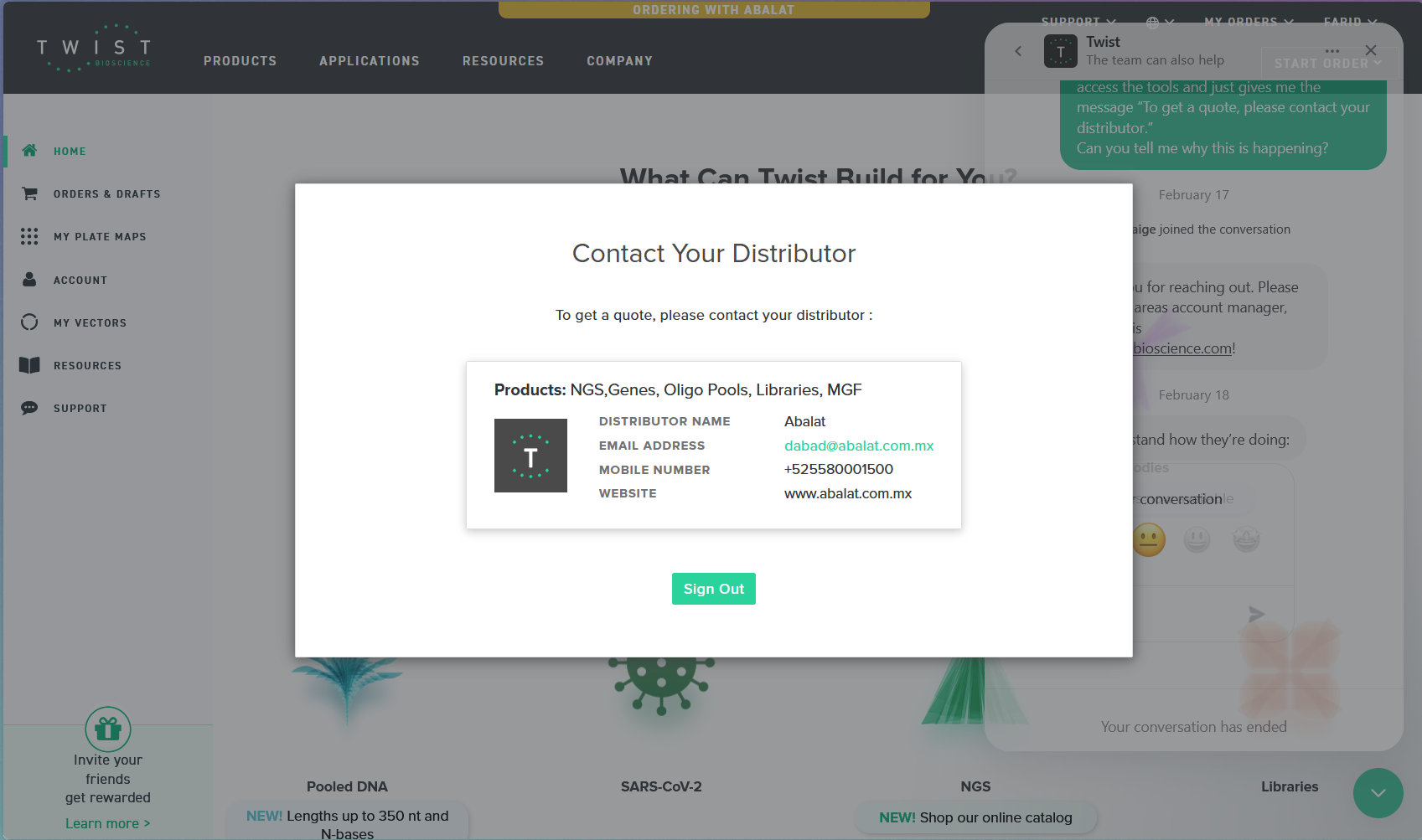
Unfortunately, after creating my account, the platform did not allow me to create my vector 😿 due to restrictions in my geographical area, which prevents me from accessing the tools as shown in the following image.
📝 DNA Read/Write/Edit
👓 Read
What DNA would you want to sequence (e.g., read) and why?
From my project to this exercise, I have focused on obtaining information on fungal genes with potential therapeutic functionality as a way to generate drugs or solutions based on secondary metabolites that stimulate the human defense system and inhibit the growth of pathogenic organisms since there are many fungi that I believe conceal their incredible machinery for combating other microorganisms or even controlling conditions such as cancerous tumors or viral infections.
What technology or technologies would you use to perform sequencing on your DNA and why?
Currently, two generations of technology are available: Illumina sequencing (2nd generation) can be used to obtain complete reference genomes or perform gene expression studies (RNA-seq) with good accuracy, high throughput, and low cost. There are also third-generation technologies such as Pacific Biosciences (PacBio) and MinION from Oxford Nanopore Technologies (ONT); both produce readings of tens of thousands of bases, ideal for resolving complex genomic structures and obtaining high-quality assemblies that reach the level of a complete chromosome . I can combine these technologies to ensure high accuracy for in-depth studies of fungal diversity in complex samples (metabarcoding).
What is your input? How do you prepare your input (e.g. fragmentation, adapter ligation, PCR)?
To sequence the DNA of my fungi, high molecular weight DNA is mechanically fragmented to obtain the desired size: for Illumina, short fragments of 200-500 bp are sought using ultrasound; while for PacBio or ONT, long fragments (>10 kb) are required using a device such as Covaris g-TUBEs, which allows for extensive reads that resolve complex regions of the fungal genome. Next, the ends of the fragments are repaired and an adenine tail is added to facilitate the ligation of specific adapters to each platform. In addition, if the amount of DNA is limited, PCR amplification is performed to generate a sufficient library for sequencing.
What are the essential steps of your chosen sequencing technology, how does it decode the bases of your DNA sample (base calling)?
The essential steps of PacBio begin with the preparation of an SMRTbell library, where hairpin adapters are ligated to DNA fragments to create a circular template. This is immobilized in a Zero-Mode Waveguide (ZMW) with a DNA polymerase. To decode the bases, the polymerase incorporates nucleotides carrying a fluorophore attached to the phosphate group. Upon incorporation, the fluorophore is cleaved and detected in real time, identifying the specific base.
What is the output of your chosen sequencing technology?
PacBio produces long reads (10-25 kb) with high accuracy. The result is sequence data in HiFi (High Fidelity) format with >99.9% accuracy, ideal for assembling complete genomes and resolving complex regions.
What DNA would you want to synthesize (e.g., write) and why?
I would like to synthesize expression vectors containing sequences that encode the production of antimicrobial and antiviral compounds or peptides (such as the immunomodulatory protein LZ-8).
What technology or technologies would you use to perform this DNA synthesis and why?
As reviewed during the course, I would use high-throughput chemical synthesis on chip platforms such as the model offered by Twist Bioscience (provided they allow me access to their platform) due to its scalability and low cost. In the case of long fragments or complex sequences, enzymatic synthesis with TdT is ideal, as I have read that it operates under mild conditions and generates high-fidelity DNA without toxic solvents.
What are the essential steps of your chosen sequencing methods?
Chemical synthesis on a chip involves the synthesis of oligonucleotides on a silicon platform with thousands of nanocavities, using phosphoramidite chemistry in miniaturized reaction volumes (100 nL). while enzymatic synthesis with TdT involves iterative cycles where a directed evolution-modified terminal deoxynucleotidyl transferase (TdT) adds nucleotides blocked with 3’-phosphate groups, followed by gentle enzymatic unblocking.
What are the limitations of your sequencing method (if any) in terms of speed, accuracy, scalability?
The limitations of the chemical method are its dependence on toxic organic solvents and a drop in yield for fragments >1,800 bp, although it offers high scalability (9,600 genes per chip) and reduced cost (~10 cents/base). Performing the same analysis as the enzymatic method reveals that there is residual sequence bias and lower commercial maturity, although this is offset by greater speed (90 sec/cycle), coupling efficiency >99%, an environmentally friendly aqueous process, and ultra-long reads.
It might be possible to edit genes associated with fungal pathogen effectors to see how they affect virulence and pathogenicity.
What technology or technologies would you use to perform these DNA edits and why?
I’m considering implementing the CRISPR/Cas9 system, as it is the most efficient and versatile model for genetic editing in filamentous fungi. Recent studies show that CRISPR achieves recombination frequencies five times higher than traditional methods such as transformation mediated by other microorganisms such as Agrobacterium. Its superiority lies in its ability to generate specific cuts guided by a guide RNA, allowing everything from simple gene disruptions to multiple edits and gene regulation, significantly accelerating the functional exploration of genes in these genetically complex organisms.
How does your technology of choice edit DNA? What are the essential steps?
According to what I have read, CRISPR/Cas9 edits by generating double-strand breaks (DSBs) in DNA at a precise location determined by the guide RNA (sgRNA). The Cas9 endonuclease, guided by the sgRNA, recognizes a PAM sequence (5′-NGG-3′) and cuts both strands, producing blunt ends. Subsequently, the cellular repair machinery acts: either through NHEJ (non-homologous end joining), which introduces insertions/deletions that inactivate the gene, or through homologous repair (HR), which incorporates a donor DNA template to introduce precise modifications such as insertions or substitutions.
What preparation do you need to do (e.g. design steps) and what is the input (e.g. DNA template, enzymes, plasmids, primers, guides, cells) for the editing?
Employing this technology requires a bioinformatic design of the guide RNA (sgRNA) complementary to the genomic target, as well as the construction of the vector with Cas9 and sgRNA, or preparation of the Cas9-sgRNA ribonucleoprotein complex (RNP). In the case of HR editing, a DNA donor template with homology arms (500-2000 bp flanking the region to be modified) and a selectable marker such as hygromycin are required. In addition, the Cas9 enzyme, ARNg, restriction enzymes, high-fidelity polymerases, and transformation reagents such as PEG and protoplast buffers are required.
What are the limitations of your editing methods (if any) in terms of efficiency or precision?
The main limitation is multinucleation and heterokaryosis in filamentous fungi, considering that cells contain multiple nuclei, and unedited nuclei persist during regeneration, making it difficult to obtain stable homokaryotic strains. Off-target effects also persist, where NgRNA recognizes unwanted similar sequences, although Cpf1 (Cas12a) shows a lower incidence than Cas9.