Week 13 Review: AI, SynBio, and Scaling Health Innovation with ARPA-H
Week 13 — AI, SynBio, and Scaling Health Innovation (ARPA-H)
Why most synthetic-biology breakthroughs never become products — and what observability of the lab bench can do about it
At a glance. Modern synthetic biology has a discovery surplus and a scaling deficit. We can engineer cells to make almost anything; we cannot reliably get those protocols to run in a second lab, a contract manufacturer, or a robot without burning a year on tech transfer.
This week’s guest lecture — from Renee Wegrzyn, inaugural director of ARPA-H — re-framed the problem as a data problem: scientific papers publish the optimised recipe (the numerator) and hide the failed attempts, magic-hands tricks, and tacit knowledge (the denominator) that actually got the result. Her startup, Transfyr, is building the sensor stack — cameras, voice, agents — that captures the denominator.
The lesson generalises far beyond her lab: it is the same problem that holds back engineered living materials, mRNA scale-up, cloud labs, and most of the ARPA-H portfolio.
| Course | HTGAA Spring 2026 |
| Lecture | Renee Wegrzyn (Apr 28, 2026), introduced by David S. Kong |
| Author | Fiona Connolly (Committed Listener BioPunk) |
Spine of the chapter. §1 the numerator/denominator framework · §2 the Magic Hands case · §3 the observability stack · §4 specialise the layers · §5 what observability does not solve · §6 failure modes · §7 back to ELMs.
A note on the topic vs content
The HTGAA syllabus was set as engineered living materials (ELMs) — designing, programming, and fabricating materials whose structural matrix is grown and maintained by living cells: self-healing bacterial concrete, programmable curli-fiber biofilms, responsive hydrogels with engineered microbes inside. The field is real, fast-moving, and worth knowing. The Nguyen et al. 2018 Advanced Materials review is the right place to start for the framework; the Wiktor & Jonkers 2011 Cement and Concrete Composites paper is the canonical primary source for self-healing bacterial concrete (encapsulated Bacillus pseudofirmus / B. cohnii spores plus calcium lactate, precipitating limestone into cracks); and the 2024 Manjula-Basavanna et al. Nature Communications paper from the Joshi group is the current state of the art on curli-fiber compostable plastics produced directly from cultured bacterial biomass.
The guest lecture, however, deliberately went sideways. Wegrzyn told the class up front she was not going to talk about engineered biology, and took time to discuss the structural reason that breakthroughs in that field and many other take a decade or more to reach the world. The remainder of this guide is built around her lecture as it is a universal issue in biotech, (and the ELM literature is already well covered elsewhere as noted in §7 at the end.
Reproducibility matters
Discovery, in synthetic biology, is no longer the rate-limiting step. The bottleneck has moved downstream — into the handoffs. Per Wegrzyn’s reported experience as a Ginkgo Bioworks executive, an acquired company’s science typically took 12–18 months to reproduce inside the new organisation. Her contacts at contract development and manufacturing organisations (CDMOs) reported tech-transfer projects running over time or over budget on roughly 80% of incoming work — a figure presented in the lecture as one operator’s observation, not as a published industry survey. The first CDC COVID-19 diagnostic test failed on distribution because the protocol could not survive the journey out of its originating lab, costing the United States roughly a month of testing capacity at the start of the pandemic.
The same gap operates inside academia: the seminal Nature survey by Monya Baker (2016) reported that >70% of researchers had tried and failed to reproduce another lab’s experiments, and >50% had failed to reproduce their own. The downstream consequence — increasingly hard to ignore as foundation models begin to design drugs — is that AI-for-science is being trained on the cleaned-up summary of work that did succeed. The training corpus has a giant hole where reality lives.
ARPA-H itself sits inside this argument. The Advanced Research Projects Agency for Health was created by Congress in 2022, modelled deliberately on DARPA’s program-manager-driven structure: a small set of doer-PMs each chasing a specific high-risk goal, with built-in attrition across multiple competing teams. Across Wegrzyn’s tenure (Oct 2022 – Feb 2025) she managed the standing-up of the agency and what she described as a ~$4 billion portfolio. The implicit promise of the model is that breakthroughs will be funded and scaled. The argument of this lecture is that the second half of that promise is not yet possible at the speed and reliability the model requires.
If synthetic biology is going to scale into health innovation — into ELMs in buildings, into cell and gene therapies in hospitals, into engineered probiotics in supermarkets — this is the gap that has to close.
§1. Numerator science vs. denominator science

Wegrzyn’s organising frame for the lecture:
| What it is | Who sees it | What AI is trained on | |
|---|---|---|---|
| Numerator | The optimised protocol that worked. The five-page paper. The clean figure. | Everyone | Almost exclusively this |
| Denominator | Every failed attempt, every troubleshooting decision, the senior postdoc’s unwritten tricks, the reagent batch swap that fixed it. | The originating lab, sometimes only one person in it | Almost none |
flowchart TD
A[Everything that happens at the bench<br/>1000s of micro-decisions, failed runs, tacit fixes] --> B[What gets written in the lab notebook<br/>~10% of the actual execution]
B --> C[What survives into the protocol section<br/>~1% of the original work]
C --> D[What gets published in the paper<br/>The optimised numerator]
D --> E[What reaches AI training data<br/>The numerator, cleaned and abstracted]
style A fill:#1f2937,stroke:#60a5fa,color:#fff
style B fill:#374151,stroke:#60a5fa,color:#fff
style C fill:#4b5563,stroke:#60a5fa,color:#fff
style D fill:#6b7280,stroke:#60a5fa,color:#fff
style E fill:#9ca3af,stroke:#60a5fa,color:#000A Nature or Science paper is, by construction, a summary of the numerator. It does not include the failed buffers, the misread gels, the protocol variants the lab quietly retired, or the technique adjustment a single grad student made and never mentioned because it felt too obvious. Wegrzyn estimated that as a graduate student and postdoc, roughly half her own time went into troubleshooting — and almost none of that information ever left her lab notebook, because the lab notebook itself is a notoriously lossy capture device.
This matters in two distinct ways. First, it is why protocol handoffs fail: the receiving lab is rebuilding from the numerator, missing the denominator information that would have told them what actually matters. Second, it is why models trained on the literature inherit the same blind spot. An AI scientist that has read every paper on RNA-seq has read zero observations of how RNA-seq is done.
Key point. Reproducibility is not a problem of bad faith or carelessness. It is a data-collection problem. The information needed to reproduce a result is generated during the experiment and then thrown away.
§2. The Magic Hands case
The lecture’s most useful single anecdote — and, to date, the most thoroughly documented public case study of the denominator problem — was a story about an RNA-sequencing protocol at a frontier academic lab. Two operators were given the same written protocol. One — a senior scientist universally referred to as “Magic Hands” because everyone in the lab agreed her results were better — reliably finished the six-hour protocol in about four hours, with roughly 25% better yield. She was also the lab’s official protocol trainer.
Transfyr’s sensor stack went in to watch what was actually happening.
The protocol step in question read “mix gently by pipetting.” Neither operator pipetted; both decided silently that pipetting took too long. The first operator vortexed the sealed plate. Magic Hands did something nobody on the team had ever seen and that she had never thought to mention or teach: she slammed the sealed plate against the lab bench. Asked to explain afterwards, she said vortexing aspirated sample up onto the seal where it was lost; slamming the plate against the bench mixed the contents and simultaneously brought any aspirated volume back to the bottom of the well. The PI of the lab had no idea this is what she was doing.
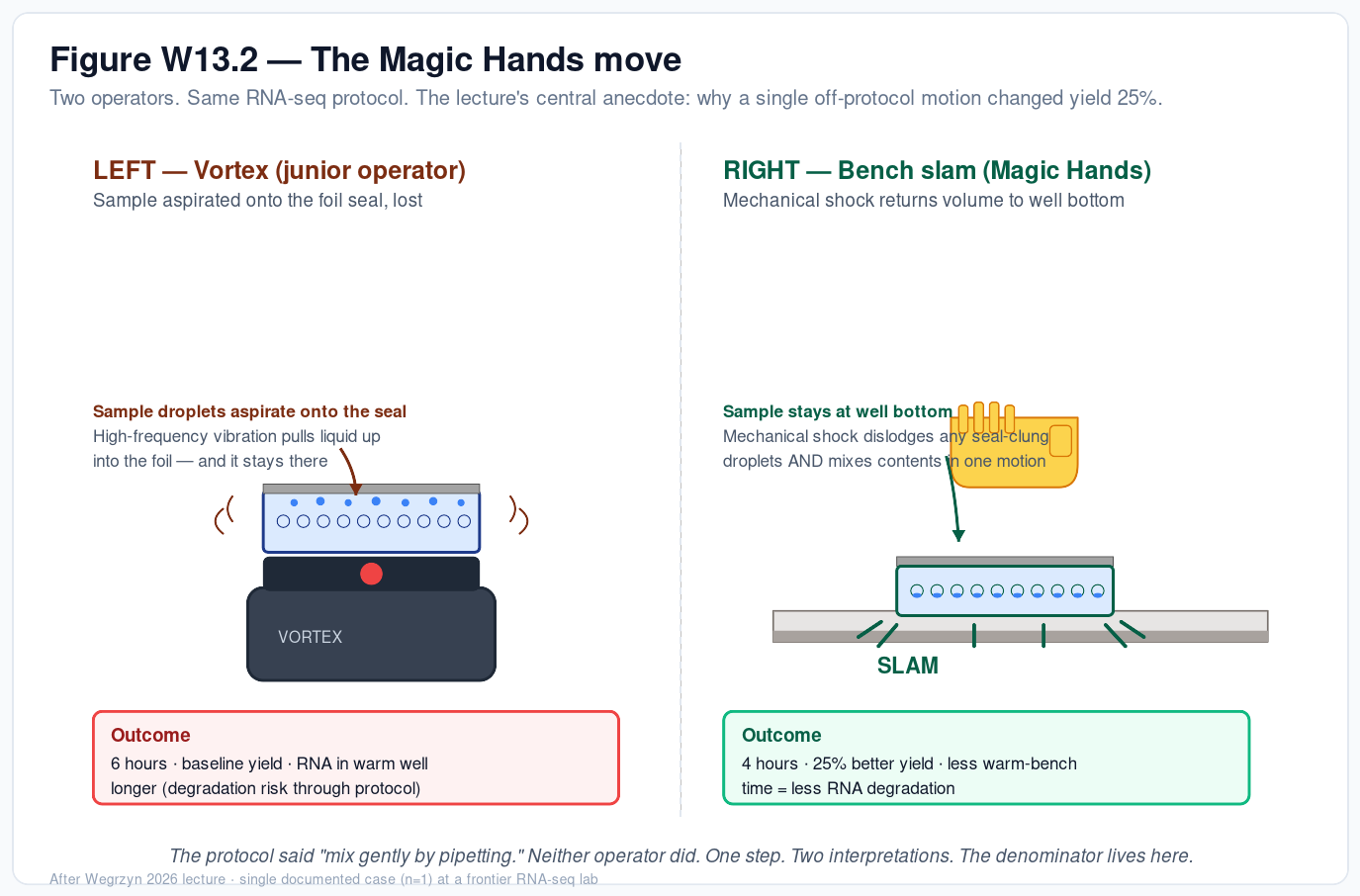
The four-hour-versus-six-hour gap was not the slam alone. She had also, off-protocol, pre-labelled all 52 tubes at the start instead of stopping to label them throughout — a fifteen-minute saving every time the protocol called for a labelling step. RNA is unstable at room temperature, and the longer warm exposure is a plausible contributor to the yield gap; the lecture stopped short of a clean causal decomposition.
The takeaway. The most consequential information in this protocol — the slam, the pre-labelling — was nowhere in the written record. It existed only in one person’s hands, and it was only retrievable because a camera was watching. Every protocol you have ever run almost certainly has some version of this hidden inside it.
This is one well-documented case, not a meta-analysis. The broader question — how often tacit-knowledge gaps are causally responsible for yield differences between operators, and what fraction of lab-to-lab irreproducibility is fixable by observability alone — is still open. The lecture did not say whether the originating lab subsequently adopted Magic Hands’s slam method or simply continued to depend on her.
A second observation from the same study deserves attention. When Magic Hands was teaching a junior, she performed the protocol exactly as written. She demonstrated the official numerator. The slam, the pre-labelling, the entire denominator — none of it transferred. She is the most generous expert in the lab, and the knowledge that made her the expert did not propagate.
§3. The observability thesis- multi angle views needed
The thesis of Transfyr is that science needs the same observability infrastructure that sport, autonomous driving, and aviation already have. The architecture is straightforward; the novelty is deploying it at scale over real wet-lab work.
The sensor stack deployed at Transfyr’s testbed at The Engine at MIT:
- Top-down camera over the bench (the spatial layout of reagents and consumables)
- Side-view camera (what is happening to the reagents — pipette tips, tube transfers, volumes)
- Egocentric camera worn by the scientist (eye-line view; this turns out to be the most important channel, because it tells the model what the scientist considered worth looking at — the meniscus, the colour change, the bubble)
- Microphones, with the scientist encouraged to narrate steps lightly (“this is reagent X, batch Y, step 3”). Verbal scaffolding gives the models anchors to align the visual stream against.
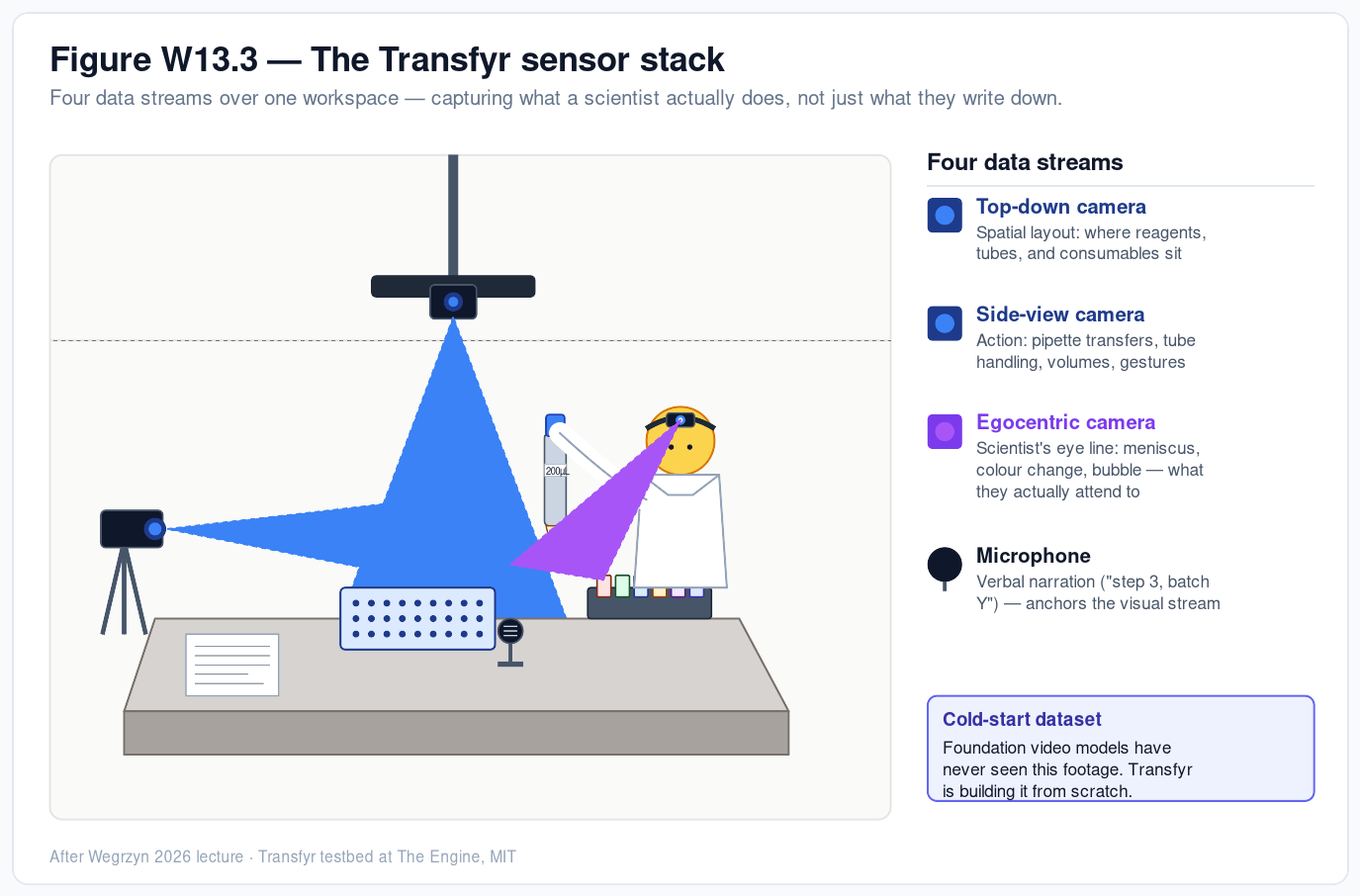
The data this produces is, as Wegrzyn put it, completely out of distribution. Foundation video models have seen billions of hours of TikTok, sports, and dashboard-cam footage, and essentially zero hours of someone pipetting into a 96-well plate. Transfyr is currently sitting on what is likely the largest existing dataset of this type — not because it is enormous, but because no one else is collecting any of it.
Waymo analogy. When Google launched its autonomous vehicle programme, it did not upload Google Maps to a car and hope. It put highly sensorised cars onto real streets, accumulated millions of miles of footage including failure modes — emergency vehicles, roundabouts, animals crossing — and trained on those failure modes. The DARPA Autonomous Vehicle Challenges of the mid-2000s provided the warm-start dataset for the entire field. By Waymo’s own published safety data, on the geofenced routes they currently operate, their per-mile incident rates compare favourably with human-driven baselines. Science has had no equivalent dataset and no equivalent warm start. It is, as Wegrzyn phrased it, a cold-start problem.
How this fits alongside existing infrastructure
Biotech is not infrastructure-free. A fair reader will ask: but we already have electronic lab notebooks (ELN), laboratory information management systems (LIMS), protocols.io, Benchling, and the cloud-lab vendors — what does an observability stack add? The honest answer is that each of those layers solves a different piece:
| Layer | What it captures | What it does not capture |
|---|---|---|
| ELN / LIMS (Benchling, LabArchives, …) | What the scientist chooses to write down; sample provenance and metadata | What the scientist actually did but did not write |
| protocols.io / shared protocols | A standardised written exchange format | Execution-time variance from the written text |
| Cloud labs (Strateos, Emerald Cloud Lab, Ginkgo) | The exact robotic execution, because the same robot runs every protocol | Everything that doesn’t fit current cloud-lab automation; most academic and frontier work |
| Observability (Transfyr’s bet) | Ground-truth video, audio, and gaze of human execution at the bench | Strategic experimental design; clinical-trial-grade documentation |
Transfyr is not a replacement for any of these — it is the layer underneath that generates the ground truth that ELN/LIMS/protocols.io/cloud labs currently lack. The four layers are complements, not substitutes.
What observability immediately buys
| Capability | What it looks like in practice |
|---|---|
| Instant replay | “Did I pipette into that well or not?” Roll the tape ten seconds back instead of throwing the sample out and starting over. |
| Protocol calibration across operators | Watch 10 scientists perform the same step. Find the steps where their behaviour varies, then check whether that variance correlates with results. The steps that vary and matter get re-specified. |
| Strike-zone analysis | Plot operator outcomes (e.g., yields, replicate concordance) and identify the cluster of operators who land “in the zone.” Then look at what those operators do that the others do not. |
| Real-time coaching | Long-term goal: the agent notices you reaching for buffer 3 when the protocol says buffer 2, and stops you. Or you ask, “I just added double the volume — is this recoverable?” and the agent gives a model-grounded answer. |
| Machine-readable protocols for robots | A human pipettes a 96-well plate in ~5 minutes. A robotic arm doing the same plates serially can put 30 minutes between the first and last well — long enough to change the experiment. Capturing the human timing first lets the robot’s protocol be written knowing what the human result depended on. |
§4. Specialise the layers: the MOSIS analogy
The deeper structural argument of the lecture was that biology in 2026 is roughly where silicon chips were before the DARPA MOSIS programme (Metal Oxide Semiconductor Implementation Service). Before MOSIS, designing a chip largely required access to a fab; the number of organisations in the world that could ideate new circuits was therefore tiny. MOSIS deliberately separated design from manufacturing, and the ecosystem reorganised itself: TSMC and similar foundries specialised in manufacturing, and the rest of the world was free to specialise in design.
(The full story is more gradual — Mead–Conway design rules in the late 1970s, the rise of standard-cell libraries, and the early Asian foundry ecosystem all preceded MOSIS — but MOSIS is the cleanest single reference point for the structural shift.)
Biology has been stuck in the pre-MOSIS vertical-integration mode. A small biotech company is expected to discover the molecule, do the preclinical study, run the clinical trial, set up GMP manufacturing, and only then hand off to pharma — by which point the moment is gone and the timeline has eaten years. The fix, Wegrzyn argued, is to specialise the layers: design here, build there, test elsewhere, manufacture at scale somewhere else again. The fix only works if the handoffs are robust, which is precisely where observability becomes load-bearing. You cannot industrialise a layer you cannot precisely describe.
Two precedents she leaned on
DARPA Living Foundries: 1000 Molecules — Wegrzyn’s own program, launched 2010. Designed to produce ~1,000 defence-relevant molecules using engineered biology; eventually delivered over 1,630 molecules and materials. The arc convinced the U.S. Department of Defense to fund BioMADE, the bioindustrial-manufacturing institute that today operates at football-stadium scale. The proof-of-concept came first; the infrastructure followed.
Cultivarium — a non-profit Focused Research Organisation (FRO) building the tooling to cultivate and genetically modify currently-unculturable and non-model organisms. The implicit thesis: make a thousand molecules in a thousand chassis, not a thousand molecules in two. As Wegrzyn put it, trying to make every molecule in E. coli or yeast is “like trying to get a goat to lay eggs” — possible, but the wrong chassis for many products. Cultivarium and similar FROs are an attempt to specialise the chassis layer the way MOSIS specialised the manufacturing layer.
§5. What observability does not solve
A reader leaving this chapter thinking that capturing the bench will solve scaling has gone too far. Observability addresses the protocol-knowledge layer. It is upstream of, and necessary but not sufficient for, the regulatory layer that defines clinical and commercial scaling.
The journey from a research-grade bench protocol to a clinical-grade manufacturing protocol typically requires: documented analytical methods (ICH Q2 validation); process characterisation studies (ICH Q11, Q14); comparability studies for any process change (ICH Q5E); sterility, endotoxin, mycoplasma, and adventitious-agent testing; audited supplier qualification for every consumable and reagent; and continuous environmental monitoring of the manufacturing suite. A robust bench protocol with perfect observability does not become a clinical product without surviving that translation. Knowing exactly what the scientist did is the first step toward a process that can be GMP-validated — it makes the regulatory work tractable rather than guesswork — but it does not replace any of it. The lecture did not engage this layer; this guide should, briefly, because it is where most real-world scaling actually breaks.
§6. Failure modes of observability itself
Observability is not a free upgrade. Several failure modes came up directly in the lecture and Q&A:
| Failure mode | Mechanism | Mitigation |
|---|---|---|
| Hypervigilance / management overreach | The person writing the cheque is the manager; the person using the tool is the scientist. The capability can be deployed either way — as performance review (chilling, paternalistic, ultimately self-defeating) or as scientist-owned coaching infrastructure. | Insist scientists be in the deployment conversation; refuse customers who want it deployed for surveillance. Wegrzyn flagged that not every vendor will hold this line. |
| Observer effect | When Magic Hands was filmed training a junior, she performed the protocol by the book — slam excluded. The same subject, watched passively over time, slid back to her real technique. | Sensor stack must become ambient enough that scientists stop noticing it. Otherwise the captured data is performance theatre. |
| Model hallucination on idle frames | During 15-minute incubation steps when nothing scientific is happening, current vision-language models will keep narrating something — sometimes the operator’s notebook doodles (“fashionable dress with great haircut”). | SME-adjudicated labelling in the near term; longer term, models trained to know when there is no scientific signal in the frame. |
| Cloud-lab / robotic translation gaps | Robots execute a protocol written for a human; unintended consequences are not always documented. A serial plate-pipetting deck silently introduces tens of minutes of differential incubation between the first and last well. The robot did exactly what it was told. The result still moves. | Capture human timing as ground truth before writing the robot protocol. Specify temporal constraints explicitly. |
| Lab rituals and superstition | Affirmations to thermal cyclers, lullabies to THP-1 cells, snack breaks during Western blot washes. Most are harmless; a few are real (subtle timing or thermal effects nobody has measured). | Identify which rituals correlate with results and which do not. Don’t reflexively debunk; leave harmless lore alone. |
Engineering takeaway. Adopt observability with the people doing the work, not over them. Build it to surface tacit knowledge and accelerate learning, not to grade individuals. The technology is value-neutral; the deployment is not.
§7. Returning to engineered living materials
The cleanest test case for the lecture’s whole argument is, in fact, the orginally billed topic of this week, ELMs.
A self-healing concrete batch (Jonkers, TU Delft) only behaves correctly if the Bacillus spore preparation, the calcium-lactate carrier, and the mixing-and-curing protocol all reproduce exactly between the originating lab and the precast facility. A curli-fiber biofilm material (Joshi lab, Northeastern; Manjula-Basavanna 2024) only behaves correctly if the E. coli culture conditions, the induction timing, and the post-processing all reproduce between the originating lab and whatever facility makes the compostable plastic at industrial volumes.
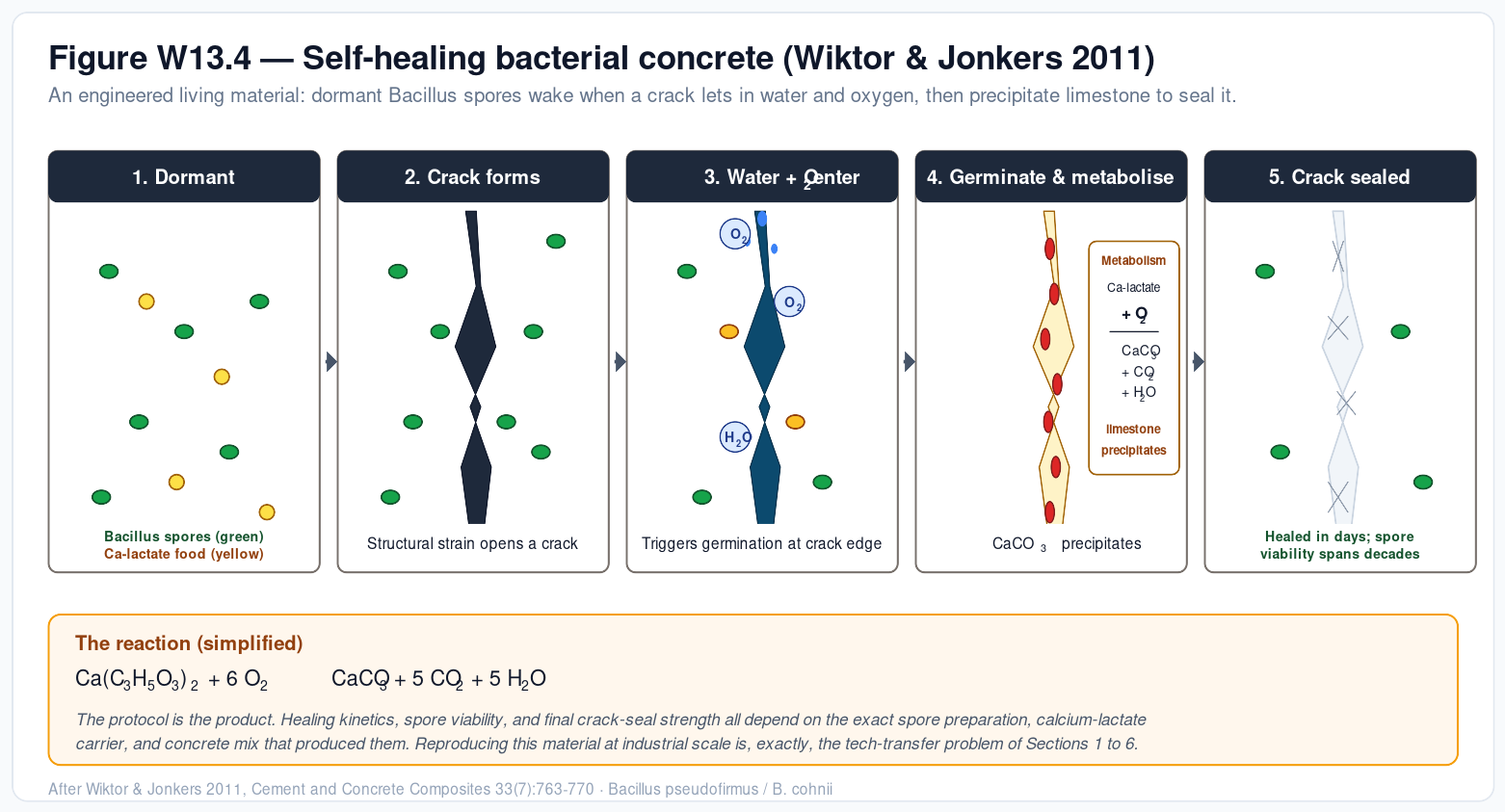
In both cases, the protocol is the product. The mechanism is straightforward: a living material is inseparable from the conditions that produced it. The chassis cell line, the induction timing, the temperature and shear during processing — these don’t just make the material, they are imprinted in the material’s mechanical properties, its self-healing kinetics, its response to environmental stimulus. A purely chemical product has a structural formula that fully describes it; an engineered living material does not.
Engineered living materials are therefore an extreme version of the general scaling problem. They cannot be specified by composition and geometry. They have to be specified by a process, and that process has to survive the journey from the academic bench to the factory floor and (eventually) back to the academic bench when something needs debugging. Without a Transfyr-style observability layer — or an equivalent solution to the same problem — the next decade of ELM breakthroughs lands in the same 12-to-18-month tech-transfer purgatory as everything else has.
The synthetic biology is hard. The scaling is harder. The week’s two halves are the same problem.
Recommended reading
Nguyen P. Q., Courchesne N. M. D., Duraj-Thatte A., Praveschotinunt P., Joshi N. S. (2018). Engineered Living Materials: Prospects and Challenges for Using Biological Systems to Direct the Assembly of Smart Materials. Advanced Materials 30(19):1704847. DOI: 10.1002/adma.201704847. Read it for: the conceptual framework of ELMs before any specific system.
Wiktor V., Jonkers H. M. (2011). Quantification of Crack-Healing in Novel Bacteria-Based Self-Healing Concrete. Cement and Concrete Composites 33(7):763–770. DOI: 10.1016/j.cemconcomp.2011.03.012. Read it for: the canonical primary source on self-healing bacterial concrete — quantified crack closure with Bacillus pseudofirmus / B. cohnii + calcium-lactate carriers.
Baker M. (2016). 1,500 scientists lift the lid on reproducibility. Nature 533:452–454. DOI: 10.1038/533452a. Read it for: the survey data that made the reproducibility crisis undeniable. Reads as a direct empirical companion to Wegrzyn’s numerator/denominator framing.
Boiko D. A., MacKnight R., Kline B., Gomes G. (2023). Autonomous chemical research with large language models. Nature 624(7992):570–578. DOI: 10.1038/s41586-023-06792-0. Read it for: the current high-water mark of AI-driven autonomous experimentation (Coscientist). Concretises what an “agent at the bench” looks like when it can both design and execute.
Course resources
- ARPA-H institutional overview and program list: arpa-h.gov — created 2022, modelled on DARPA, currently ~$1.5B/year congressional appropriation.
- Wegrzyn — C&EN inaugural-director interview: cen.acs.org/policy/global-health/ARPA-Hs-inaugural-director-cross/101/i24
- DARPA Living Foundries program page: darpa.mil/research/programs/living-foundries
- BioMADE (bioindustrial-manufacturing institute that grew out of Living Foundries): biomade.org
- Joshi Lab (engineered living materials, Northeastern): neel-joshi.sites.northeastern.edu
- Manjula-Basavanna et al. 2024 (compostable curli-fiber ELM): 10.1038/s41467-024-53052-4
- Vannevar Bush, As We May Think, The Atlantic, July 1945 — the eighty-year-old conceptual ancestor of every “AI co-scientist,” explicitly invoked by Wegrzyn. Open-access mirror: w3.org/History/1945/vbush/vbush.shtml
- Cultivarium (non-model-organism FRO mentioned in the Q&A; founded 2021, tools for 300+ microbes including non-model fungi and archaea): cultivarium.org
- Transfyr company site (Boston, MA; founded 2025; co-founders Anna Marie Wagner [CEO] and Renee Wegrzyn [Chief Innovation Officer]): transfyr.bio
Last updated: 2026-05-26 ·