I’m Giuliana, a biologist from Ecuador. Since reading a book about Mendelian inheritance as a teenager, I became aware of the existence of genes as regulators of fenotypes. Later on, I became engrossed with red biotechnology, specially potential therapeutical applications of gene editing on human diseases. During my undergraduate studies, I had the opportunity to perform biomed research in a multi-omic oriented lab. This experience taught me that gene regulation is complex: it depends on different omic levels, and is influenced by the cell’s microenvirontment. For me, reconciling this knowledge with circuit designing has become a very engaging approach. I loved the introductory class, as I believe science moves forward when it crosses paths with other ways of thinking—and that Latin America has a lot to contribute to this conversation.
If building purpose-driven biotech with local roots resonates with you—let’s chat c:
Systemic Lupus Erythematosus (SLE) disproportionately affects women at a 9:1 female/male ratio (McDonald et al., 2015), with higher prevalence in Latin American populations compared to European ancestry groups (Ugarte-Gil et al., 2023). In Ecuador, qualitative studies document significant barriers to SLE treatment and care for women in rural and Andean Indigenous communities, where cultural mismatches with Western medicine delay diagnosis and treatment (Miles, 2011; Bautista-Valarezo et al., 2021). Current immunosuppressive therapies require frequent clinical monitoring unavailable in these settings, leading to uncontrolled disease activity and organ damage.
Part 0: Basics of Gel Electrophoresis
I reviewed this week’s lecture and recitation videos, which provide excellent foundational explanations of gel electrophoresis principles. Having hands-on experience running agarose gels in my research lab, I can confirm that all the technical considerations mentioned are crucial for successful results. One safety tip that particularly resonated with me was handling hot flasks after microwave use. In our lab, we always used heat-resistant gloves, yet we were still advised to minimize contact time with hot containers—a precaution I now understand is essential.
Python Script for Opentrons Artwork After making a copy of the collab doc into my drive, I searched for a reference image for my design. In the Designer Cells node there are two color options: red and green. So, I looked for a minimalistic design that could look good in green, my favorite color. I ended up choosing a hummingbird, as they come oftentimes to my garden to feed on the flowers’ nectar.
At the Automation Art Interface, there is the function of submitting an online image directly coping its direction, and it is suggested that its backdrop is white. The following is the selected reference image that meets the previous criteria:
Conceptual Questions How many amino acid molecules in 500 grams of meat? A typical 500-gram portion of meat contains approximately 100–125 grams of protein, depending on fat content and cut. Assuming an average amino acid molecular weight of 110 Daltons (accounting for side chain diversity beyond the 100 Da backbone), this translates to roughly 0.9–1.1 moles of amino acids. Using Avogadro’s number, this equals approximately 5.5 × 10²³ individual amino acid molecules.
Subsections of Homework
Week 1 HW: Principles and Practices
Systemic Lupus Erythematosus (SLE) disproportionately affects women at a 9:1 female/male ratio (McDonald et al., 2015), with higher prevalence in Latin American populations compared to European ancestry groups (Ugarte-Gil et al., 2023). In Ecuador, qualitative studies document significant barriers to SLE treatment and care for women in rural and Andean Indigenous communities, where cultural mismatches with Western medicine delay diagnosis and treatment (Miles, 2011; Bautista-Valarezo et al., 2021). Current immunosuppressive therapies require frequent clinical monitoring unavailable in these settings, leading to uncontrolled disease activity and organ damage.
I want to propose the design of an in vitro prototype of a synthetic mammalian gene circuit. The idea is that the circuit autonomously senses and regulates type I interferon (IFN-α) levels—a validated biomarker of poor outcomes- elevated in over 70% of systemic lupus erythematosus (SLE) adult patients (Whittall Garcia et al., 2024). When IL-10 is chronically exposed to IFN-α in vivo, it becomes part of a pro-inflammatory signaling, instead of its original anti-inflammatory function (Yuan et al., 2011). So, by detecting and regulating IFN- α levels, it will be possible to restore IL-10 anti-inflammatory properties and improve patients’ outcomes. Communities already distrust the traditional healthcare system, so maybe they would be more receptive to this approach, that for them may seem less invasive and restrictive if conducted correctly.
A primary governance goal necesary for developing the project would be to: Ensure bioethical, development of autonomous therapies for diseases affecting marginalized women.
To reach it, I consider the following subgoals:
Bioethical guided protocol and trial design: Before human trials, replicability and circuit stability should be guaranteed at least in cellular lines. Bioethics are of utmost importance when designing a biomedical protocol, even more when treating vulnerable groups (e.g. indigenous women). All research decisions are to be made taking into consideration patients’: a) direct personal gains/ benefits from the trial; b) informed consent and willingness to be involved in the trial; and c) rights and personal safety.
Culturally grounded consent: Develop dynamic consent frameworks respecting communal decision-making models in Indigenous Kichwa communities (Bautista-Valarezo et al., 2021).
Rural accessibility: Guarantee technology pathways reach women in communities >2 hours from tertiary hospitals.
Prevent therapeutic abandonment: Ensure patients receive ongoing support if circuit recalibration is needed.
Analyzing the scope of the project, derivated three ordenance actions that meet real concerns came to mind:
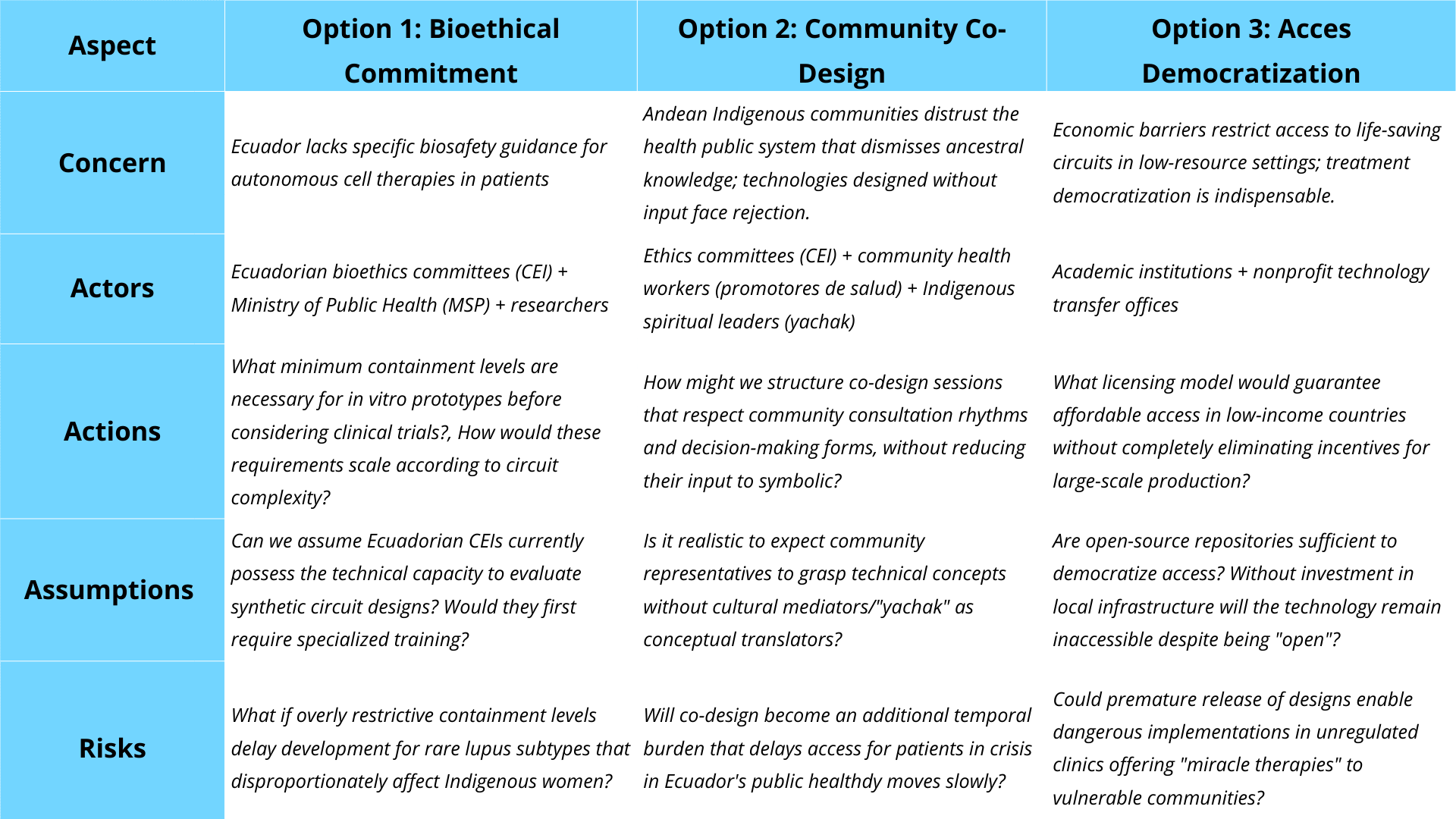
To implement the three ordenance actions, they were evaluated in function of how they follow the proposed Governance’s criterion (from 1 to 3, with 1 as the best):
Governance Criterion
Option 1: Tiered Containment
Option 2: Co-Design
Option 3: Open-Source
Bioethical trial design
• Ensures replicability
●●○ (1)
○○○ (3)
●○○ (2)
• Guarantees patient safety
●●○ (1)
●○○ (2)
○○○ (3)
Culturally-grounded consent
• Respects communal decisions
○○○ (3)
●●○ (1)
○○○ (3)
• Integrates ancestral knowledge
○○○ (3)
●●○ (1)
○○○ (3)
Rural accessibility
• Reaches remote communities
○○○ (3)
●○○ (2)
●●○ (1)
• Minimizes economic barriers
○○○ (3)
○○○ (3)
●●○ (1)
Prevent therapeutic abandonment
• Ensures ongoing support
●○○ (2)
●○○ (2)
●●○ (1)
• Guarantees long-term monitoring
●○○ (2)
○○○ (3)
○○○ (3)
Cross-cutting considerations
• Feasibility in Ecuador
●○○ (2)
●○○ (2)
○○○ (3)
• Does not impede research
●○○ (2)
○○○ (3)
●●○ (1)
• Minimizes costs
○○○ (3)
●○○ (2)
●●○ (1)
Based on the scoring framework above, I would prioritize a sequential implementation strategy: Option 1 (Bioethical Commitment) and Option 2 (Community Co-Design) as mandatory requirements during the research and early clinical phases, with Option 3 (Access Democrtization) introduced only after successful Phase II clinical validation. This sequencing addresses the fundamental trade-off between safety and accessibility—while open-source democratization (Option 3) scores highest for rural accessibility and minimizing economic barriers, its weak performance in patient safety (score 3) makes premature implementation ethically unacceptable for an autonomous therapy affecting vulnerable indigenous women. Containment requirements (Option 1) provide the non-negotiable safety foundation (scores 1,1 for replicability and patient safety), while co-design (Option 2) ensures cultural legitimacy by centering communal decision-making models (scores 1,1 for culturally-grounded consent)—a critical factor given documented Indigenous distrust of medical systems that dismiss ancestral knowledge (Bautista-Valarezo et al., 2021). The primary trade-off I acknowledge is timeline extension: mandatory co-design workshops and dual-redundant kill switch validation will delay deployment compared to a purely technical development path. However, this delay prevents two greater harms: (a) therapeutic abandonment if communities reject culturally inappropriate designs, and (b) catastrophic safety failures from insufficient containment.
My recommendation targets three audiences simultaneously: (1) locally, the Ethics Committees (CEI) of hospitals collaborating with universities’ CEI should adopt co-design requirements immediately; (2) nationally, Ecuador’s Ministry of Public Health (MSP) must develop tiered containment guidelines specific to synthetic biology therapies, preferably within a set time frame; and (3) internationally, the WHO Ethics Advisory Committee should enforce global standards recognizing that “informed consent” for autonomous therapies must accommodate communal decision-making structures in Indigenous contexts. This phased approach honors both the precautionary principle and justice: safety first, then equitable access, never the reverse.
REFLECTING ON WEEK 1,
There was a new ethical concern (for me) that emerged: The tension between the developing circuit regulated therapies for a patient, and the status quo in decision-making embedded in family/community networks that may forbid the patient access to treatment. In Ecuadorian indigenous communities, health decisions often involve extended family consultation, especially when there is a preexistent prejudice with the local public system. An autonomous circuit designed based on individualism might undermine culturally valued collective decision-making. As stated before, this requires governance actions that bring together key members first, to reach the whole community. On a more detailed note, circuit designers can reach a middle ground with the indigenous by showcasing how their system interfaces can be linked with existing social decision-making structures. For example: Could the circuit include a “real-time feedback” function to let family members know if an input (e.g. related to their traditional medical care system, or whether to activate a kill switch) could aid the patient? With this I have learned that deployment strategy is as important as technology and funding to effectively reach target communities. This exercise revealed that what we perceive as autonomy is not a universal value but culturally constructed. Ethical synthetic biology requires not just technical safety, but cultural open mindedness—designing with communities rather than for them. As future builders of biological systems, we must ask not only “Can we build this?” but “Should we build it this way, for these people, in this context?”
Homework Questions from Professor Jacobson:
Nature’s machinery for copying DNA is called polymerase. What is the error rate of polymerase? How does this compare to the length of the human genome. How does biology deal with that discrepancy?
The slides (p.8 & p.10) state that polymerase has an error rate of ~1:10⁶ (1 mistake per million base pairs) and that the human genome length has a length of 3.2 Gbp (which could be expressed as 3.2 × 10⁹ bp). Thus, in humans, each replication generates approximately 3,200 mistakes. Biology –not synthetic biology- copes with this by relying on 3’→5’ proofreading, a mechanism where polymerase detects incorrect base pairings, retires the wrong nucleotide and replaces it as needed.
How many different ways are there to code (DNA nucleotide code) for an average human protein? In practice what are some of the reasons that all of these different codes don’t work to code for the protein of interest?
According to slide 6, the average human protein length is 1036 bp. A codon (a base pair triplets) codes for one protein. Assuming that the given protein length on the slide excluded non-coding base pairs of the gene, we have: 1036/ 3= ~345 amino acids. The protein length is fixedly of ~345 amino acids, however due to codon degeneracy, more than one base pair triplet combination/codon can code for the same amino acid (e.g. both AGA and AGG code for Arg). So, with 3 codons per amino acid and 345 amino acid “slots” an average human protein can have: 3³⁴⁵ possible coding ways. In nature, a huge percentage of these coding ways are not viable, as there exists a codon usage bias, set by natural selection, to improve efficiency and precision in translation. The slides (p.39- p. 43) show that regions with a high content of GC (and AT) pairs form hairpin-like structures. These interfere with transcription/ translation as they can act as signaling regions, inducing splicing or stopping transcription/translation. Thus, maybe codon usage bias intents to keep G-C % to a minimum.
Homework Questions from Dr. LeProust:
What’s the most commonly used method for oligo synthesis currently? Why is it difficult to make oligos longer than 200nt via direct synthesis? Why can’t you make a 2000bp gene via direct oligo synthesis?
In the slides (p.11) the first automated method of oligo synthesis was, proposed by ABI (Applied Biosystems), with subsequent optimizations. However, it was mainly based on the CPG method, which in turn uses the phosphoramidite method, both designed by Caruthers (Matteucci & Caruthers, 1981). So, at its core, the most used is the phosphoramidite method.
The cycle consists of phosphoramidite-based synthesis consists of four steps repeated per nucleotide addition:
-Coupling: Phosphoramidite addition
-Capping: Blocking unreacted sites
-Oxidation: Stabilizing the bond
-Deblock: Removing the protecting group for the next cycle
The yield per cycle is determined by the coupling efficiency and the length (in bases) of the oligonucleotide by the formula:
So, even if coupling efficiency always reaches a 90.0%-99.5% range, the longer the length, the poorer the yield (Merck, 2026). This limitation is shown when applying the formula to an oligo with a length of 200 bases at 99,5%: Yield= 0.995200 ^ 200= 0.367= 36.7% The formula works as it explains that in each cycle, while 99% of the oligonucleotide chains are synthetized, the remaining 1% is truncated and starts to accumulate. Only 0.995 ^ (n cycles) of the original chains reach complete length.
Based on that logic, if a direct oligo synthesis was performed for an oligo with a 2000 bp length, the yield would not be significative (<0.001%). On the other hand, by following the multiplexed gene fragment solution proposed on the slides, the overall yield increases, making synthesis more accurate as a whole.
Homework Question from George Church:
Given slides #2 & 4 (AA:NA and NA:NA codes), what code would you suggest for AA:AA interactions?
Nucleic acid/Nucleic acid (NA:NA) code refers to the nucleotides forming determined/ fixed base pairs that will always bond with one another: “A” bonds with “T” (“U” in RNA), and “C” bonds with “G”. Based on this empirical rule, this type of code becomes a programable basepair code, allowing us to design a sequence with certainty. In the case of Amino acid/ Nucleic acid (AA:NA) code, the rule is that the ribosome can translate one stranded sequence - by reading codons, base triplets- into amino acids. Each codon codes for a specific amino acid, allowing the synthesis of bigger proteins. However, in translation, there is more than one codon that can be translated into the same amino acid (codon degeneracy).
In that line, the amino acid/ amino acid (NA: NA) code should be the set, deterministic rule that describes all amino acid interactions. Protein primary structures result from a covalent bond between the N terminus of one to the c terminus of another. Nevertheless, there is not such a thing as a generalized fixed way of interaction among amino acids, due to the presence of their variable side chains. The functional groups make the side chains unique, directly giving amino acid their properties: polarity, charge/ attraction (covalent bonds) and the ability to form hydrogen bridges. When interacting, those properties will make interactions-that cause secondary, tertiary and quaternary structures- no deterministic, but statistical and contextual.
So, the difficulty of assigning a code to amino acid interactions lies mainly in the variability introduced by the side chain. And that same variability what makes them form functional proteins. Bertozzi biorthogonal reactions occur independently without affecting the natural biochemistry/natural reactions of molecules in the cell. In them a “clic” reaction occurs between an azide and an alkyne cycle, resulting in in a new compound that is a union of both compounds, like “connecting to parts of a seatbelt” (Agard et al., 2005). Now this technology is widely used for fluorescent marking and observation of cellular processes. But maybe we could go an step further, and directly explore how modifying side chains to have azide and alkyne cycles as functional groups impact in improving predictability of secondary, tertiary and quaternary structures.
REFERENCES
Agard, N. J., Prescher, J. A., & Bertozzi, C. R. (2005). A strain-promoted [3 + 2] Azide−Alkyne cycloaddition for covalent modification of biomolecules in living systems [J. am. Chem. Soc. 2004, 126, 15046−15047]. Journal of the American Chemical Society, 127(31), 11196–11196. https://doi.org/10.1021/ja059912x
Bautista-Valarezo, E., Duque, V., Verhoeven, V., Mejia Chicaiza, J., Hendrickx, K., Maldonado-Rengel, R., & Michels, N. R. M. (2021). Perceptions of Ecuadorian indigenous healers on their relationship with the formal health care system: barriers and opportunities. BMC Complementary Medicine and Therapies, 21(1), 65. https://doi.org/10.1186/s12906-021-03234-0
Matteucci, M. D., & Caruthers, M. H. (1981). Synthesis of deoxyoligonucleotides on a polymer support. Journal of the American Chemical Society, 103(11), 3185–3191. https://doi.org/10.1021/ja00401a041
McDonald, G., Cabal, N., Vannier, A., Umiker, B., Yin, R. H., Orjalo, A. V., Jr, Johansson, H. E., Han, J.-H., & Imanishi-Kari, T. (2015). Female bias in systemic lupus erythematosus is associated with the differential expression of X-linked toll-like receptor 8. Frontiers in Immunology, 6, 457. https://doi.org/10.3389/fimmu.2015.00457
Ugarte-Gil, M. F., Fuentes-Silva, Y., Pimentel-Quiroz, V. R., Pons-Estel, G. J., Quintana, R., Pons-Estel, B. A., & Alarcón, G. S. (2022). Global excellence in rheumatology in Latin America: The case of systemic lupus erythematosus. Frontiers in Medicine, 9, 988191. https://doi.org/10.3389/fmed.2022.988191
Whittall Garcia, L. P., Gladman, D. D., Urowitz, M., Bonilla, D., Schneider, R., Touma, Z., & Wither, J. (2024). Interferon-α as a biomarker to predict renal outcomes in lupus nephritis. Lupus Science & Medicine, 11(2). https://doi.org/10.1136/lupus-2024-001347
Yuan, W., DiMartino, S. J., Redecha, P. B., Ivashkiv, L. B., & Salmon, J. E. (2011). Systemic lupus erythematosus monocytes are less responsive to interleukin-10 in the presence of immune complexes. Arthritis and Rheumatism, 63(1), 212–218. https://doi.org/10.1002/art.30083
Week 2 — DNA Read, Write, & Edit
Part 0: Basics of Gel Electrophoresis
I reviewed this week’s lecture and recitation videos, which provide excellent foundational explanations of gel electrophoresis principles. Having hands-on experience running agarose gels in my research lab, I can confirm that all the technical considerations mentioned are crucial for successful results. One safety tip that particularly resonated with me was handling hot flasks after microwave use. In our lab, we always used heat-resistant gloves, yet we were still advised to minimize contact time with hot containers—a precaution I now understand is essential.
Part 1: Benchling & In-silico Gel Art
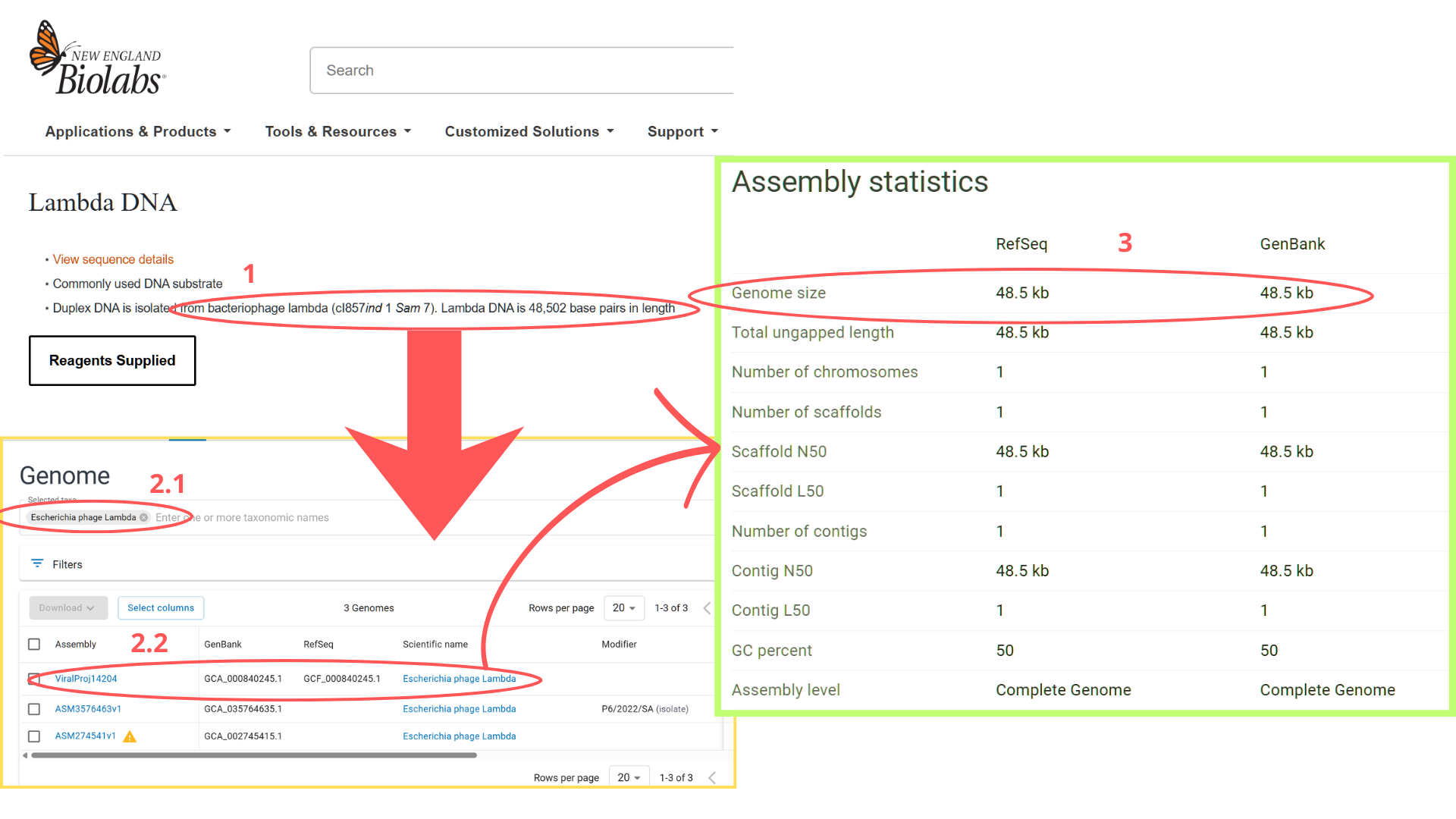
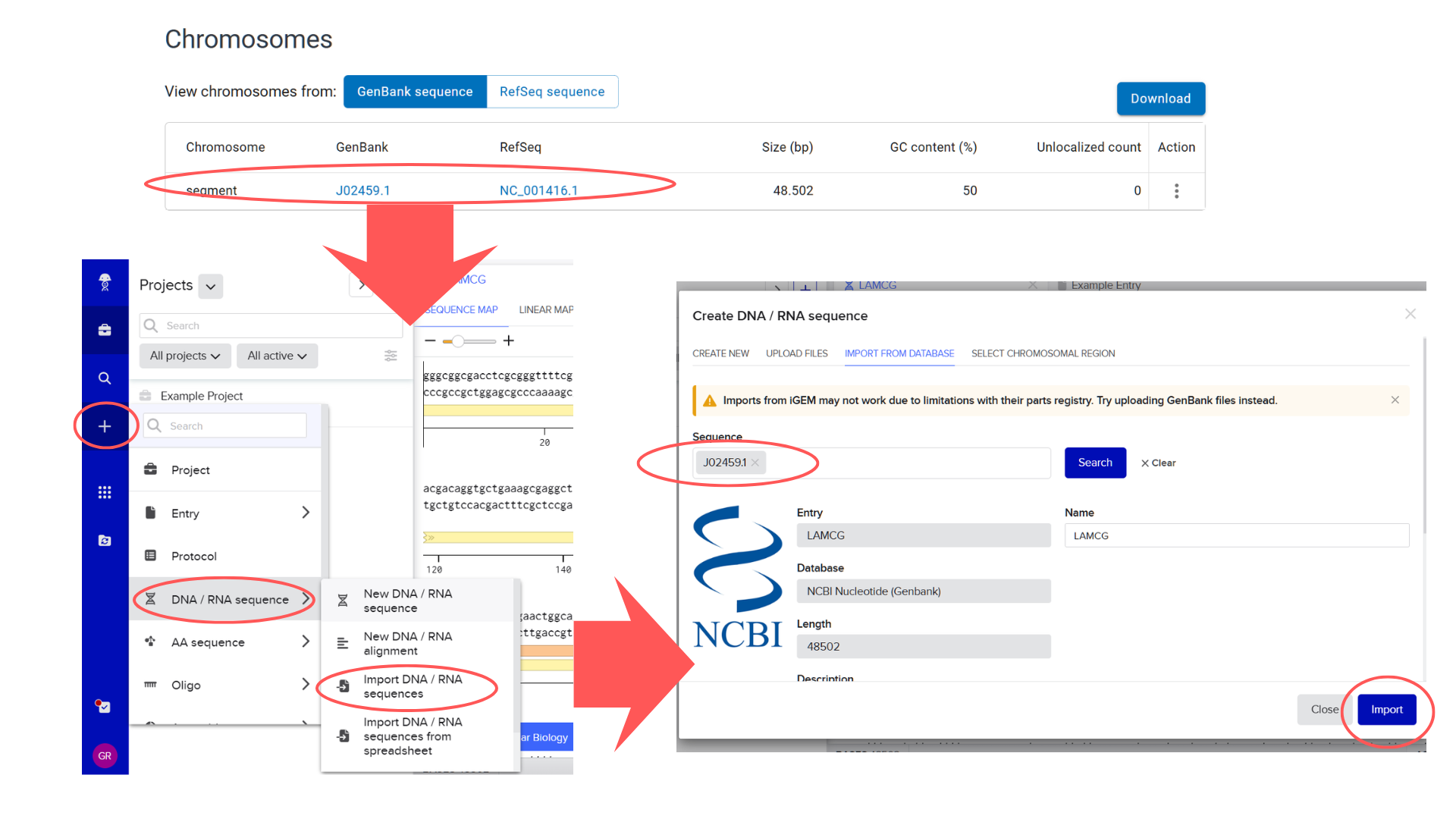
I began by locating the Lambda DNA identifier in NCBI’s Genome database. My search strategy involved the keywords “bacteriophage lambda” and the known genome length (48,502 bp). The search returned three results; I selected the first entry because its Assembly status indicated “Viral Project,” which typically signifies a complete genome sequencing effort. Upon verification, the genome size matched the expected 48.5 kb.
From this entry, I extracted the GenBank identifier (J02459.1) and directly imported the sequence into Benchling via the “DNA/RNA sequence” import function.
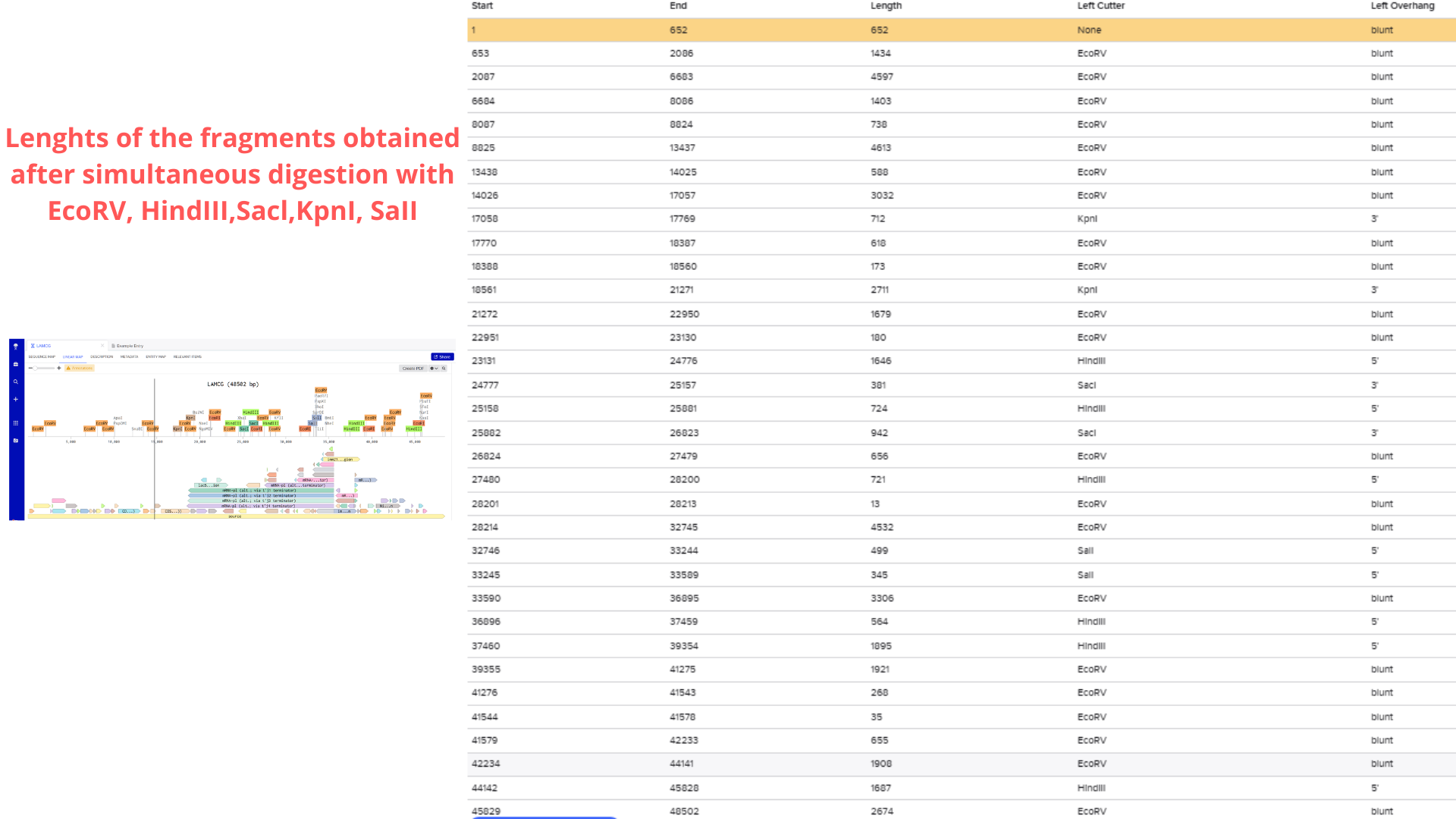
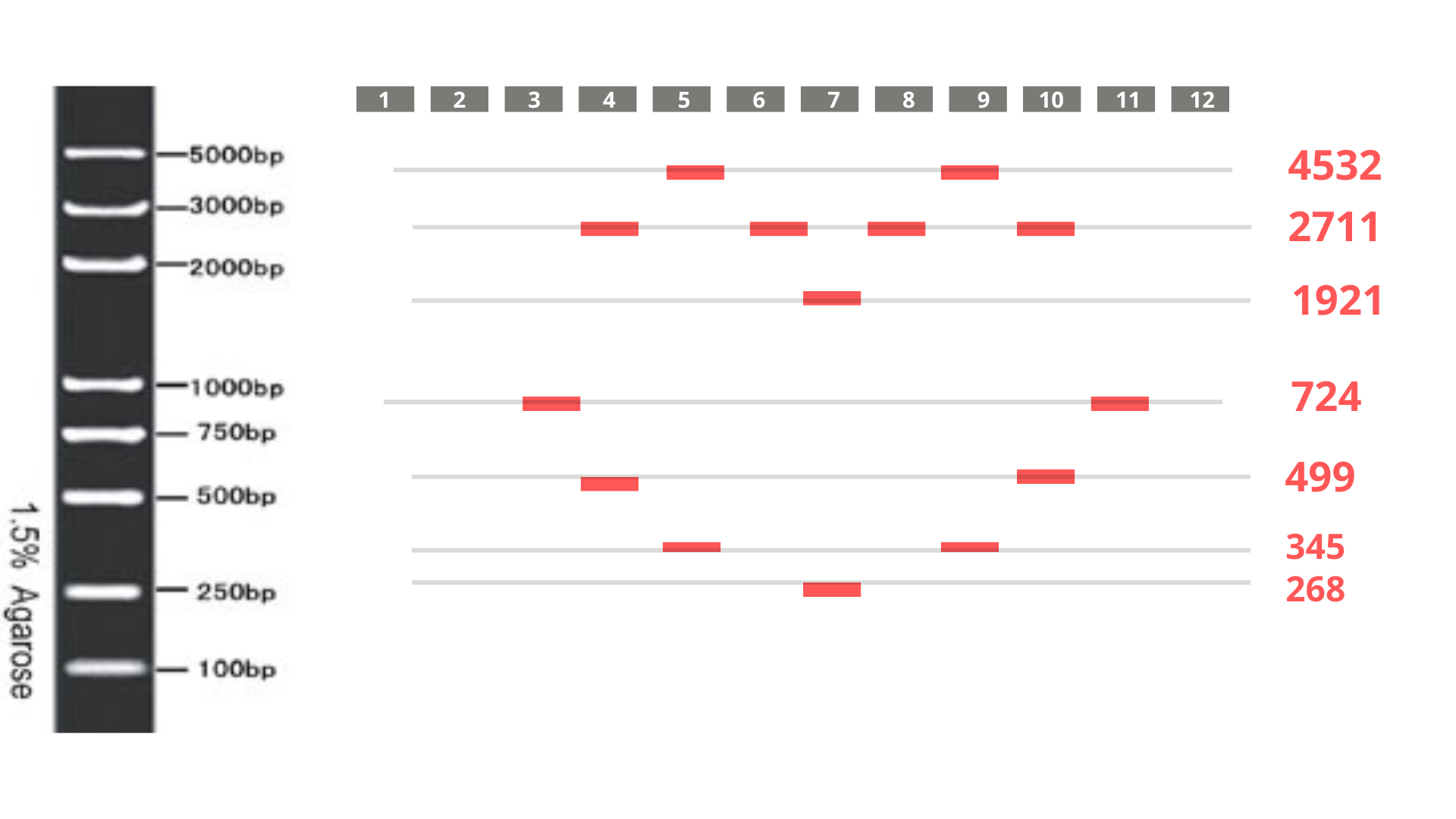
Considering the genome’s 48.5 kb size, I initially planned to use a 50 kb ladder for reference. However, after performing a test restriction digest with EcoRV, HindIII, SacI, KpnI, and SalI, Benchling’s fragment table revealed that all resulting fragments were under 5 kb.
Consequently, I switched to a 5 kb ladder (Geneon’s “DNA Ladder mix - high range”) for my gel art design. The final pattern aims to form a heart shape, as visualized below:
Part 3: DNA Design Challenge
Building on my Week 1 project, I focused on modulating IFN-α levels to reduce poor outcomes in systemic lupus erythematosus (SLE) patients. Current pharmacological approaches for severe SLE also target IFN-α inhibition (Baker et al., 2024). Literature indicates that IFN-α activation occurs through a signaling cascade initiated by Interferon Regulatory Factor 7 (IRF-7). When IRF-7 is no longer needed, the body naturally deactivates it via TRIM28, a SUMO E3 ligase with specific activity against IRF-7 (without affecting the similar IRF-3) (Liang et al., 2011). This mechanism offers a more targeted, less invasive therapeutic approach for SLE.
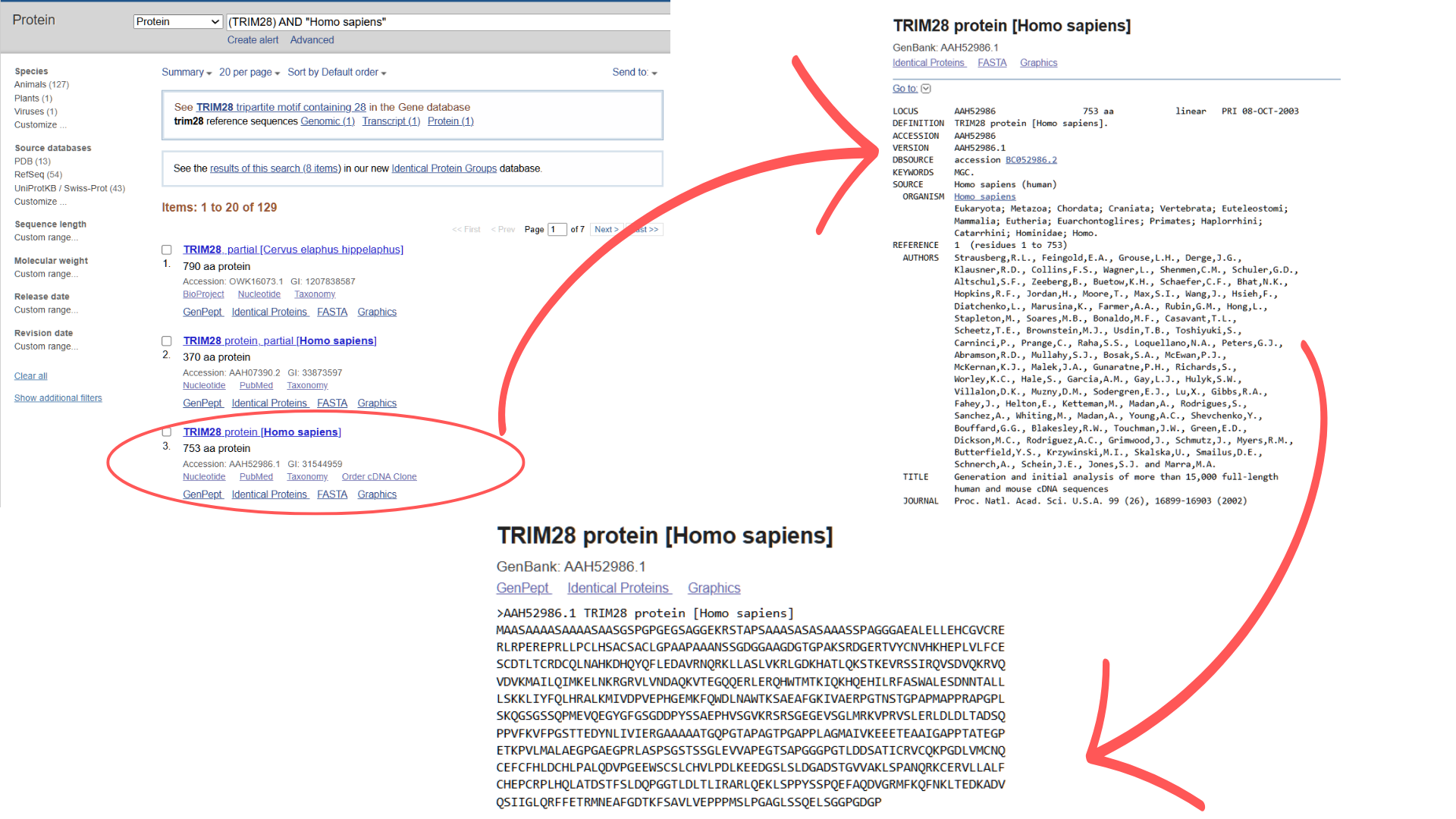
I retrieved the TRIM28 amino acid sequence from NCBI Protein using the search terms “TRIM28” and “Homo sapiens.” From the results, I selected the third hit (the first two were fragments), obtaining the complete protein sequence in FASTA format:
“>AAH52986.1 TRIM28 protein (Homo sapiens)
MAASAAAASAAAASAASGSPGPGEGSAGGEKRSTAPSAAASASASAAASSPAGGGAEALELLEHCGVCRERLRPEREPRLLPCLHSACSACLGPAAPAAANSSGDGGAAGDGTGPAKSRDGERTVYCNVHKHEPLVLFCESCDTLTCRDCQLNAHKDHQYQFLEDAVRNQRKLLASLVKRLGDKHATLQKSTKEVRSSIRQVSDVQKRVQVDVKMAILQIMKELNKRGRVLVNDAQKVTEGQQERLERQHWTMTKIQKHQEHILRFASWALESDNNTALLLSKKLIYFQLHRALKMIVDPVEPHGEMKFQWDLNAWTKSAEAFGKIVAERPGTNSTGPAPMAPPRAPGPLSKQGSGSSQPMEVQEGYGFGSGDDPYSSAEPHVSGVKRSRSGEGEVSGLMRKVPRVSLERLDLDLTADSQPPVFKVFPGSTTEDYNLIVIERGAAAAATGQPGTAPAGTPGAPPLAGMAIVKEEETEAAIGAPPTATEGPETKPVLMALAEGPGAEGPRLASPSGSTSSGLEVVAPEGTSAPGGGPGTLDDSATICRVCQKPGDLVMCNQCEFCFHLDCHLPALQDVPGEEWSCSLCHVLPDLKEEDGSLSLDGADSTGVVAKLSPANQRKCERVLLALFCHEPCRPLHQLATDSTFSLDQPGGTLDLTLIRARLQEKLSPPYSSPQEFAQDVGRMFKQFNKLTEDKADVQSIIGLQRFFETRMNEAFGDTKFSAVLVEPPPMSLPGAGLSSQELSGGPGDGP”
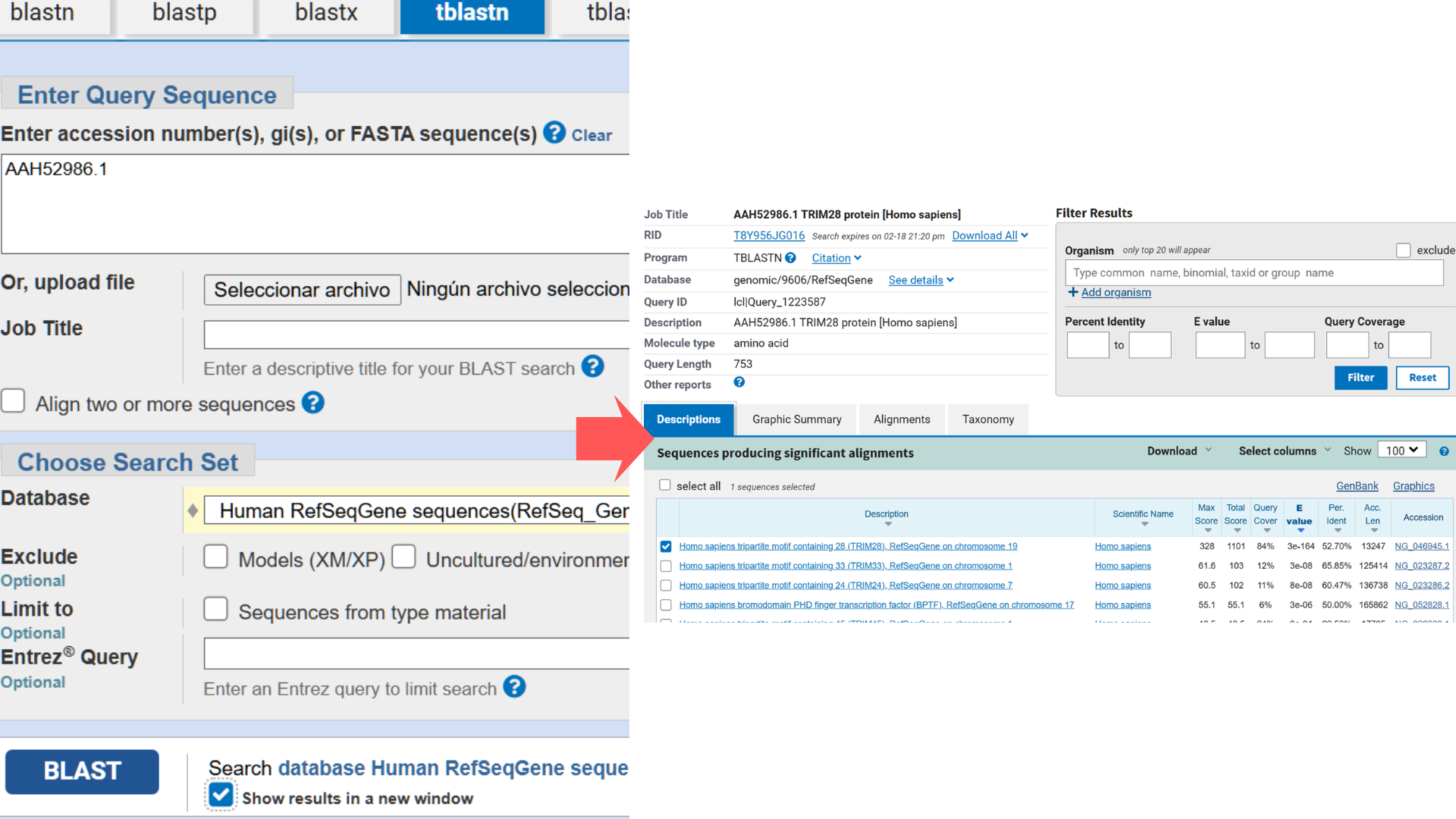
Next, I used NCBI’s “tblastn” BLAST tool to identify the corresponding nucleotide sequence. The top hit (Accession NG_046945.1) showed the highest Query Score (82%) and lowest E-value (3e-164), though the alignment revealed significant gaps between amino acid and nucleotide sequences.
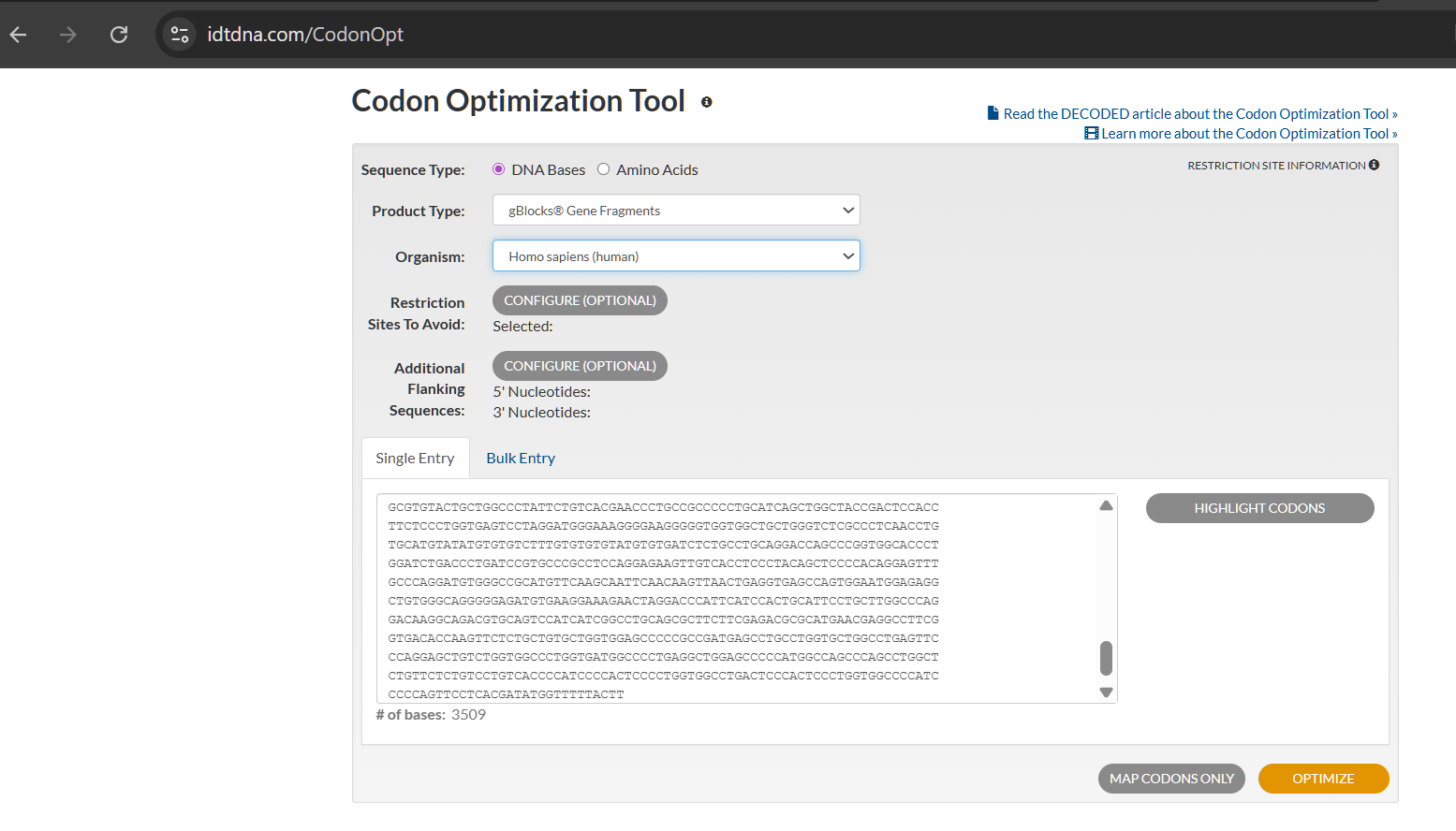
Since multiple codons can encode the same amino acid, nucleotide sequences vary across taxa even when the protein sequence remains identical. Therefore, codon optimization must align with the intended host organism. Translation efficiency depends on tRNA abundance; optimization replaces rare codons with synonymous frequent ones matching the host’s tRNA pool. For my project’s therapeutic goal, I optimized the sequence for human cells.
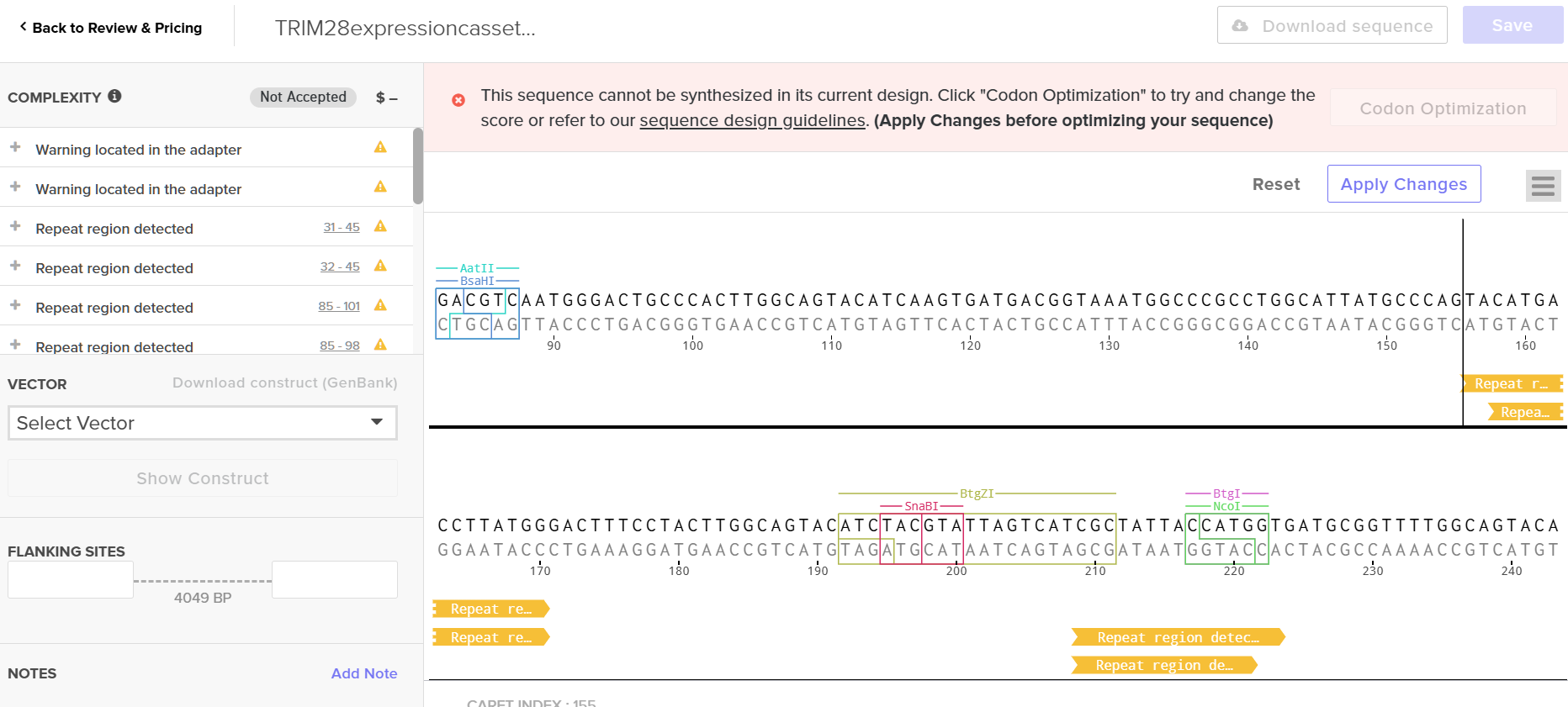
(Note: The optimization tool flagged this sequence as “high complexity,” indicating potential synthesis challenges with commercial methods.)
With the human-optimized sequence ready, the next step is transforming this digital information into a functional protein capable of immune modulation. Two feasible routes exist: cell-dependent or cell-free systems. I could use a cell-free system for initial circuit prototyping (better cost-benefit ratio) and transition to live-cell systems for actual production.
Part 4: Prepare a Twist DNA Synthesis Order
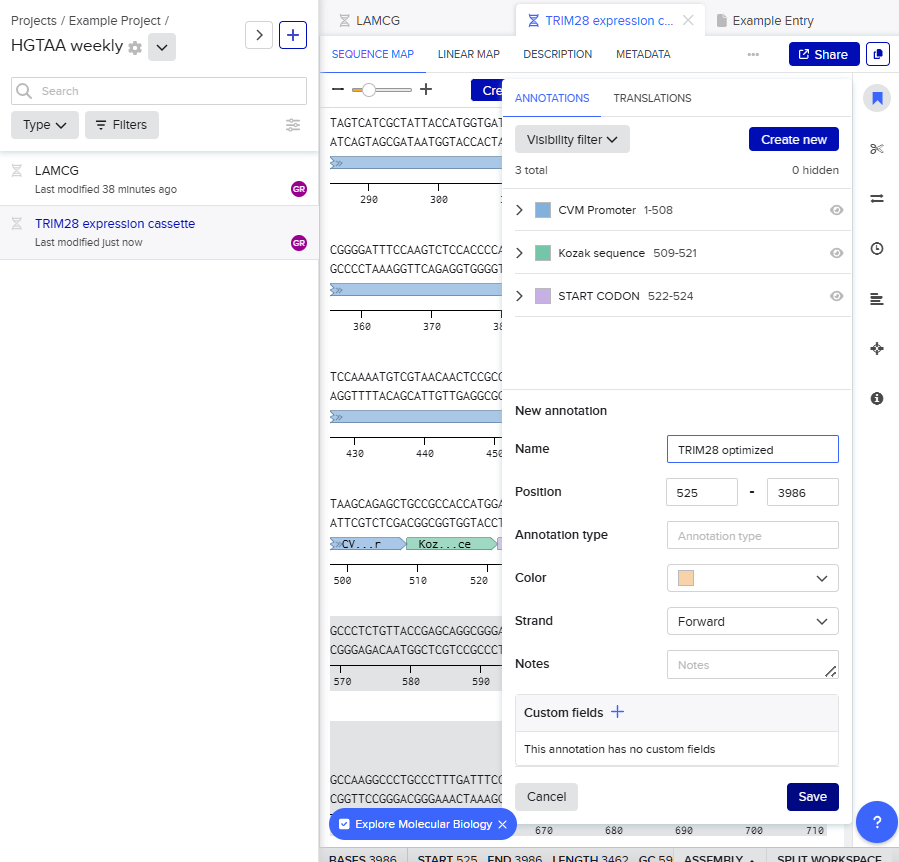
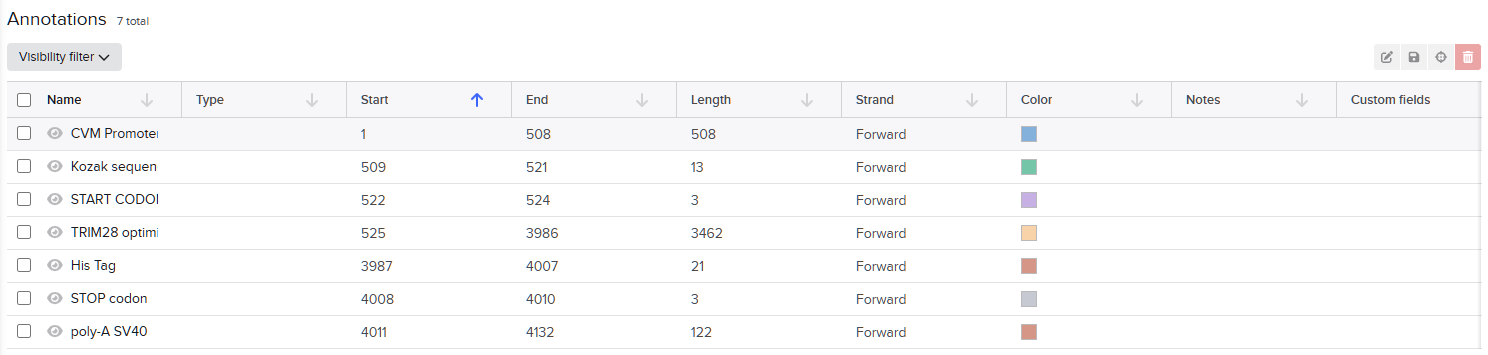
For this exercise, I designed a vector for constitutive TRIM28 expression. In the final project version, I plan to add an IFN-α sensor that inhibits TRIM28 production when concentration exceeds a specific threshold. For now, expressing TRIM28 alone in human cells requires these regulatory elements (McCarty et al., 2023): CMV promoter, Kozak sequence (5’ UTR), Start codon, Optimized TRIM28 coding sequence, His Tag, Stop codon and SV40 polyadenylation signal (3’ UTR).These elements ensure transcriptional and translational efficiency and accuracy.
In Benchling, starting from an empty file:
I sequentially assembled these components to form the cassette:
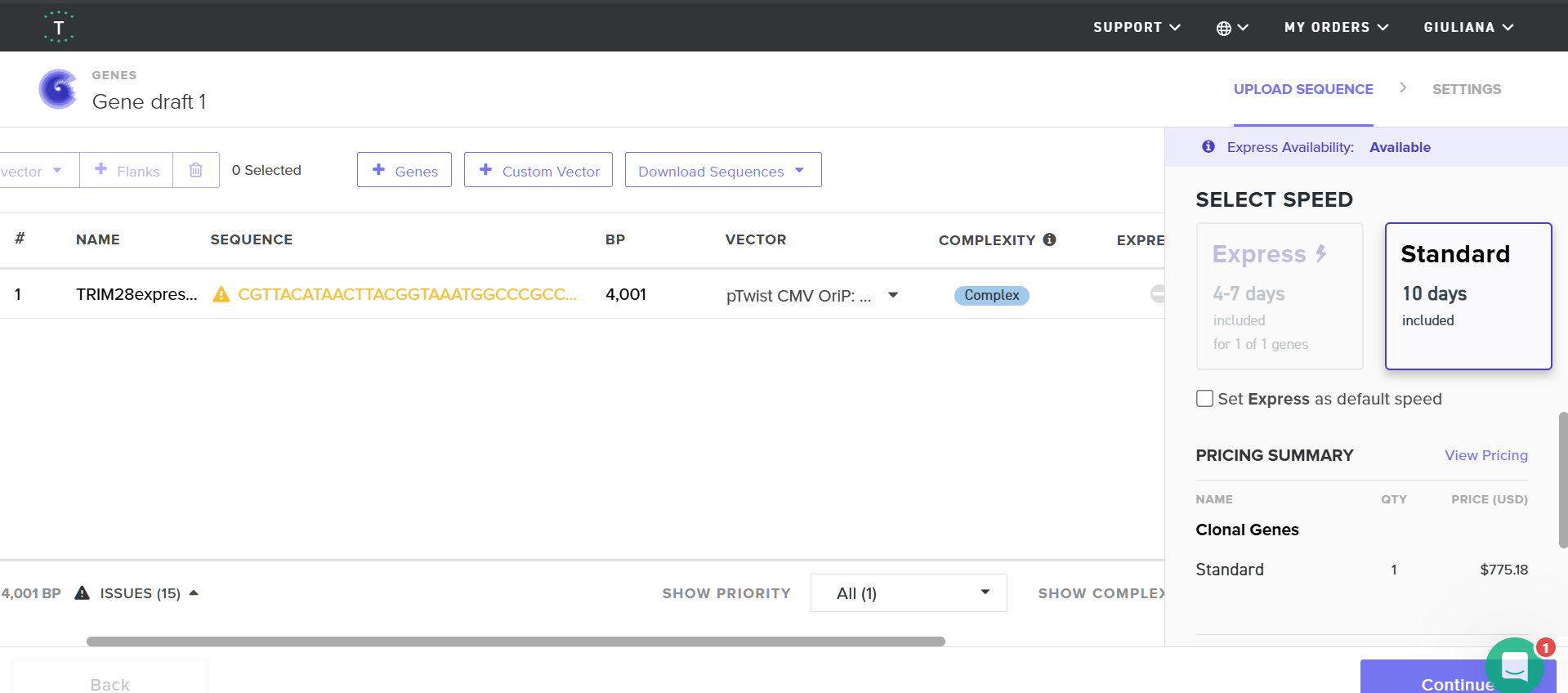
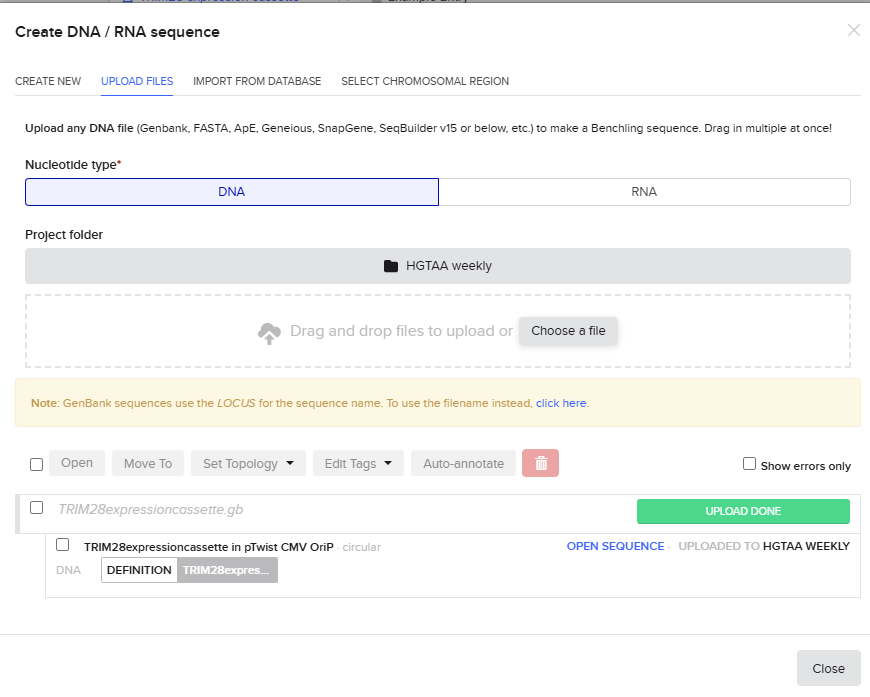
I exported the cassette as a FASTA file and uploaded it to Twist.
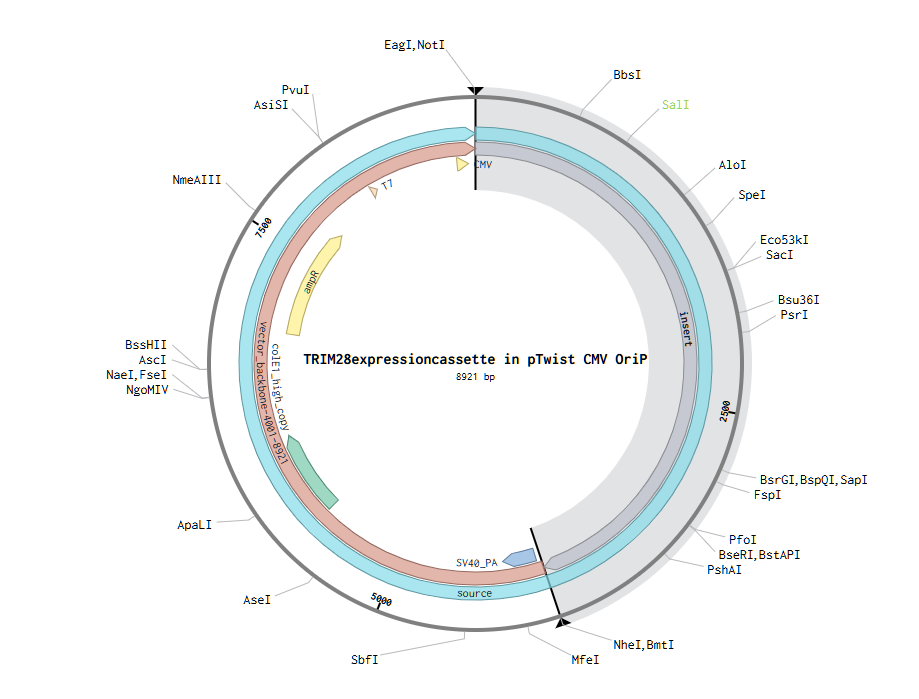
When deciding between Clonal Genes and Gene Fragments, the determining factors were: my cassette’s small size (even accounting for future sensor addition) and the practicality of working with a plasmid vector. For the backbone, I selected pTwist CMV OriP, which ensures high-level transient expression in mammalian cells, provides ampicillin resistance, and facilitates elevated protein expression.
Upon uploading, the platform flagged multiple repetitive sequence regions—consistent with the “high complexity” warning from the optimization tool. TRIM28 is an enzyme with functional domains; repetitive regions are expected. However, I’m concerned that my edits to bypass synthesis constraints may have compromised these functional domains.
Anyway, I downloaded the resulting GenBank file and re-imported it into Benchling.
The final plasmid/vector is:
Part 5: DNA Read/Write/Edit
5.1 DNA Read:
(i) What DNA would you want to sequence and why?
In my proposed lupus autoregulatory circuit project, I would sequence cell-free DNA (cfDNA) from patient plasma to detect interferon-stimulated gene (ISG) signatures that predict disease flares. cfDNA sequencing offers a minimally invasive way to aquire information aboud patients’ in-real-time situation. Elevated IFN-α family actitvity would trigger preemptive TRIM28 circuit activation before clinical symptoms manifest—transforming lupus management from reactive to predictive.
(ii) Sequencing technology choice
In my expereience Ecuador, Illumina NovaSeq is the to go technology for biomedical research (second-generation sequencing). It is second-generation sequencing (sequencing-by-synthesis with reversible terminators), and works fine when needing to balances accuracy (Q30+ scores) with scalability—critical (e.g. when screening hundreds of rural patients).
For the input (taken from the “QIAseq cfDNA All-in-One Kit Handbook”):
Extract 10 ng cfDNA from 1 mL plasma (using silica-column kits compatible with low-input Twist workflows)
Fragment to 300 bp via enzymatic shearing (avoiding sonication that degrades already-short cfDNA)
Ligate Twist Universal Adapters with unique dual indexes (UDIs) to enable multiplexing of 96 samples per lane
PCR amplify with 8 cycles (minimizing chimera formation noted in LeProust’s slides, p. 38)
Base calling mechanism: Fluorescently labeled nucleotides (A/C/G/T with distinct dyes) are incorporated sequentially. After each cycle, lasers excite the dyes and cameras capture emission wavelengths. Software converts fluorescence patterns into base calls (A=green, C=blue, G=yellow, T=red), with quality scores reflecting signal-to-noise ratios.
Output: 150 bp paired-end reads (300 bp total coverage per fragment) in FASTQ format.
5.2 DNA Write(i) What DNA would you want to synthesize and why?
I would synthesize the TRIM28 expression cassette I designed in Part 3—a 1.2 kb sequence containing CMV promoter, Kozak sequence, human-optimized TRIM28 coding sequence, His tag, and SV40 poly-A signal. This cassette represents the effector module of my lupus circuit: when IFN-α levels rise during pre-flare states, TRIM28 would be expressed to SUMOylate and deactivate IRF-7 (Liang et al., 2011), breaking the pathogenic IFN-α amplification loop without broad immunosuppression. Unlike current therapies (e.g., anifrolumab antibody injections requiring monthly clinic visits), this circuit could provide continuous, autonomous regulation—critical for patients in Chimborazo province who travel 6+ hours for care.
(ii) Synthesis technology choice
I would use Twist Bioscience’s silicon-based phosphoramidite synthesis.
In silico design: Finalize cassette in Benchling with codon optimization for human cells (avoiding rare codons like AGG that stall ribosomes)
Chip synthesis: 150-mer oligos synthesized in parallel on silicon wafer (1 million oligos/chip)
Enzymatic assembly: i would opt to join independtly synthesized oligos into a full-length cassette.
Error correction: there must be a MutS protein to bind mismatched bases for removal
As stablished, I choosed cloning as to make it easier for the vector (pTwist CMV OriP) to reach mammalian (host cells) expression.
A limitation encountered was that during my simulation (Part 4), Twist flagged my TRIM28 sequence as “high complexity” due to repetitive domains. This reflects a fundamental constraint: phosphoramidite chemistry has ~99% coupling efficiency per cycle (LeProust slides), making synthesis of long repeats error-prone. For my final project, I’d need to:
-Break repeats with synonymous codon substitutions (preserving amino acid sequence)
-Use Twist’s Ultra-complex Genes service (which is costly!!) for sequences with homopolymers >20 bp
Accept that some functional domains may require post-synthesis assembly via Golden Gate cloning
5.3 DNA Edit(i) What DNA would you want to edit and why?
My project is not about directly editing the patients DNA, as I am very concerned about incidentally damaging the patient. What I aim to do is to provide an external aid that is not as invasive as the current pharmacological guidelines. If I would given to choose what DNA to directly edit, I would be interested in modifying plants to become natural biorreactors: instead of producing their wildtype fruits (e.g. compounds required for the development of the seed), they could be edited to produce an specific compound (such as insulin for example).
References
Baker T, Sharifian H, Newcombe PJ, et al. Type I interferon blockade with anifrolumab in patients with systemic lupus erythematosus modulates key immunopathological pathways in a gene expression and proteomic analysis of two phase 3 trials. Annals of the Rheumatic Diseases. 2024;83:1018-1027.
Liang Q, Qi H, Hou F, et al. TRIM28 is a SUMO E3 ligase for IRF7. Journal of Biological Chemistry. 2011;286(37):32448-32456.
McCarty NS, Graham AE, Studena L, et al. Rapid and scalable characterization of CRISPR technologies using an E. coli cell-free transcription-translation system. Molecular Cell. 2023;83(1):1-15.
Week 3— Lab Automation
Python Script for Opentrons Artwork
After making a copy of the collab doc into my drive, I searched for a reference image for my design. In the Designer Cells node there are two color options: red and green. So, I looked for a minimalistic design that could look good in green, my favorite color. I ended up choosing a hummingbird, as they come oftentimes to my garden to feed on the flowers’ nectar. At the Automation Art Interface, there is the function of submitting an online image directly coping its direction, and it is suggested that its backdrop is white. The following is the selected reference image that meets the previous criteria:
With it i obtained this incredibly beautiful and complex design:
I tinkered manually with the dots and with the default settings (Brightness, Contrast and Saturation) to modify the original suggested design, plus I changed all the dots to the “mClover3” color as I initially intended. After that, the coordinates I obtained were:
Returning to the Google collab document, scrolling to the last celd, below the Your code comment, I copy pasted the tuple containing the coordinates. Below the pasted tuple, on the same level of indentatio, I defined the well for retrieving the green color based on the posted examples. Then, to dispense the “colorant” into the precise coordinate it was needed, I started with the following lines of code:
pipette_20ul.pick_up_tip()# to make the robot pick up a pipette tip to start dispensingpipette_20ul.aspirate(len(mclover3_points)*1.2,location_of_color('Green'))# to pick up enough volume of the “colorant” for all the coordinates’ dots.forx,yinmclover3_points:adjusted_location=center_location.move(types.Point(x=x,y=y))# to let the robot correctly identify the placement of the coordinatesdispense_and_detach(pipette_20ul,1,adjusted_location)# to dispense 1µL per dotpipette_20ul.drop_tip()# to drop the tip at the end of the task
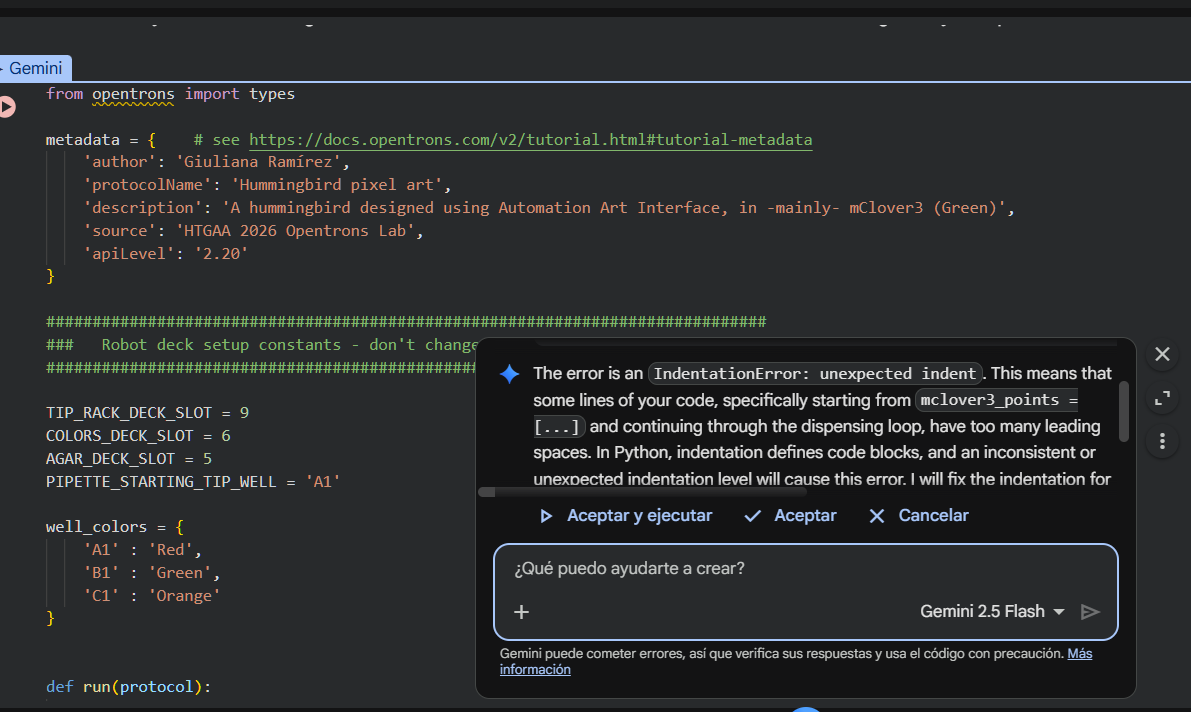
I selected Run all and after the run, an error message popped up: I was calling pipette_20ul.pick_up_tip(), which didn’t exist. The run stopped there, and I accepted the help of the Gemini assistant to understand where the mistake lay:
Gemini observed that I had an indentation error when pasting the tuple with my coordinates, due which I had called for pipette_20ul.pick_up_tip() outside of def run(protocol). From that point on, I got the indentation for my code wrong.
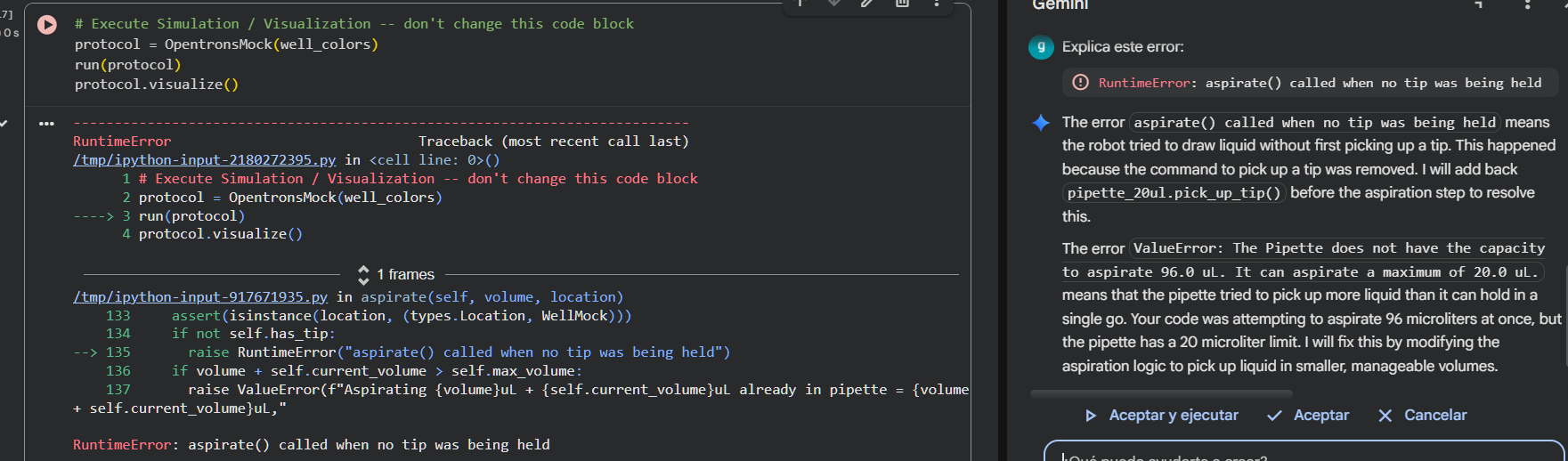
I corrected this by using tab at the start of every code line, and clicked on Run all again. However, for the second time an error message popped up:
Gemini summed up the mistake in that I had coded pipette_20ul.aspirate(len(mclover3_points) * 1.2, location_of_color('Green')) forgetting that the robot was using 20 ul tips. With the current line of code, I was taking 90 ul at the start of the task, which was physically impossible.
Gemini suggested the next edit to correct the mistake while guaranteeing that the robot would not run out of “colorant”:
# Aspirate more liquid every 20 dispenses (or when starting) to avoid exceeding pipette capacityfori,(x,y)inenumerate(mclover3_points):# Aspirate more liquid every 20 dispenses (or when starting) to avoid exceeding pipette capacityifi%20==0:# Calculate the volume to aspirate: either 20uL (max for p20) or less if fewer than 20 points remainvolume_to_aspirate=min(20,len(mclover3_points)-i)ifvolume_to_aspirate>0:# Only aspirate if there's something to aspiratepipette_20ul.aspirate(volume_to_aspirate,green_well)
I hit the Run all option again and this time the code ran smoothly, and I could visualize my final design:
How AI aided me?: I am familiar with Python coding (but not with the Opentron API libraries). Gemini helped me to understand the logic/algorithm behind the coding. And this AI also became proofreader, noticing details that I missed but that directly affected my run.
Post-Lab
Finding a published paper that utilizes Opentrons or an automation tool to achieve novel biological applications:
Taken from the paper by (Wainaina & Taherzadeh, 2023)
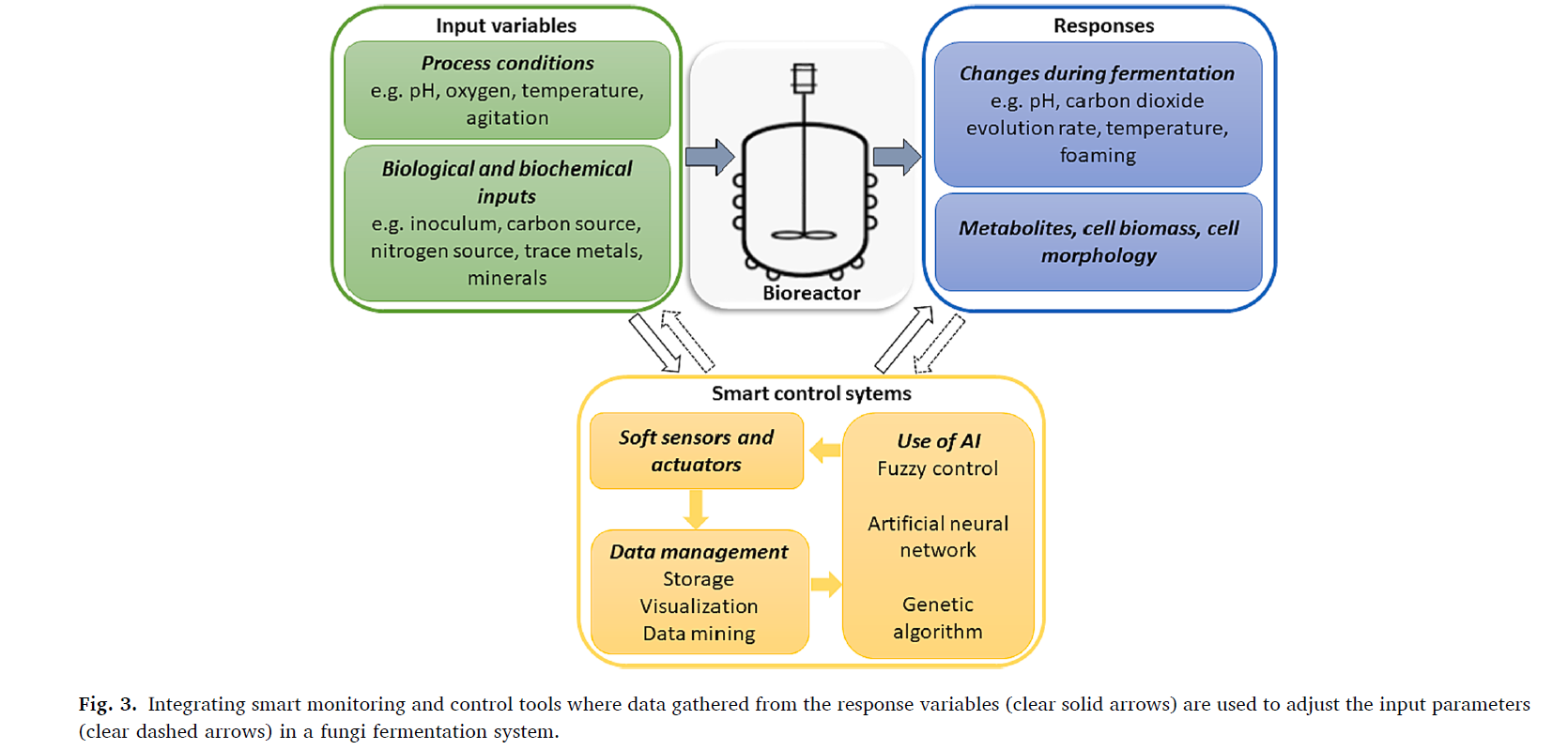
On their subchapter 3.4, they present the concept of the smart bioreactor in the context of filamentous fungi. The authors propose that such bioreactors should integrate the existing infrastructure of a bioreactor with the concept of a hierarchical structure control system (HSCS). HSCS is a “set of devices and software organized in a tiered manner” where “the layers on the higher levels are designed to perceive theoretical models and execute planning while the lower ones perform local tasks…”(Wainaina & Taherzadeh, 2023). The authors explain that automated sensors could help detect fermentation rate and related parameters, so researchers could monitor the bioreactor progress and make adjustments in real-time. This grabbed my attention, being the first time that I associated automation with bioreactors. HSCS prototyping could be a door to upscaling bioreactor production on low funded startups.
Intended automation tools usage in my final project:
During Week 2, when I designed my TRIM28 expression cassette in Twist, the platform flagged my sequence as “high complexity” due to repetitive sequence parts (which I presume are part of the RBCC region’s domains). I have heard before that this is a common challenge when working with natural enzyme sequences that contain tandem repeats. This technical barrier directly impacts my goal of developing an autoregulatory circuit for lupus patients with a poor initial prognosis. I had to manually delete several high repetition regions for Twist being able to accept my order, and I wondered how this change could alter the original functionality of the enzyme. I also started to question the opposite: how much I could simplify the sequence and have the resulting protein performing its original function. A further simplified sequence would be cheaper and faster to sequence, optimizing at least one step of the process needed to reach my project´s goal.
So, I thought that I can use Opentron to make a trial in this regard:
I could order 3 to -5 variants of my TRIM28 construct, each with more high repetition sites manually deleted. However, to each construct I would add a ubiquitination sensor (Qin et al., 2022; Choi et al., 2019).
In the presence of TRIM28 and IRF7 ubiquitination should occur as part of IRF7 degradation process. I could gauge which construct is working by measuring the ubiquitination rate. Ubiquitination occurs naturally in the cells, so a control group of cells (without the construct expressing continuously TRIM28) should be added to the well, to have a contrast that can showcase the “extra” ubiquitination activity in the transfected cells. Literature suggests that after a cell culture is transfected, analysis should start after 24- 48 hours (only then cells could be harvested) (Qin et al., 2022).
I would use the Opentron robot to automate the process of adding each different construct to a well in a well plate containing mammalian cell lines. After robot preparation, cells would be manually transferred to a standard CO₂ incubator — a hybrid workflow that reduces human error in small-volume transfers. After the incubation period, the well plate would return to the Opentron robot to trypsinize cells for 2 purposes: 1) make a subculture; 2) Perform a fluorescence test.
The cell subcultures of each cell group would be used to perform a western blot to determine the presence and relative abundance of TRIM28. The Opentron website mentions that the western blotting process could be automated , so this part could be left to the robot to increase throughput.
There is also a link in the Opentron website about Fluorescence-Activated Cell Sorting (FACS) Sample Prep , however, in this protocol the robot adds staining fluorescent antibodies, which is not needed or wanted for my current design. If this step could be omitted, and some other steps edited to enhance coherence within steps, then the fluorescence assay could be automated too. If not, then after cell trypsinization the cell culture remaining in the well plate could be manually taken to the fluorescence microscopy equipment.
References:
Choi, YS., Bollinger, S.A., Prada, L.F. et al. High-affinity free ubiquitin sensors for quantifying ubiquitin homeostasis and deubiquitination. Nat Methods 16, 771–777 (2019). https://doi.org/10.1038/s41592-019-0469-9
Qin, W., Steinek, C., Kolobynina, K., Forné, I., Imhof, A., Cardoso, M. C., & Leonhardt, H. (2022). Probing protein ubiquitination in live cells. Nucleic acids research, 50(21), e125. https://doi.org/10.1093/nar/gkac805
Wainaina, S., & Taherzadeh, M. J. (2023). Automation and artificial intelligence in filamentous fungi-based bioprocesses: A review. Bioresource Technology, 369(128421), 128421. https://doi.org/10.1016/j.biortech.2022.128421
Week 4— Protein Design Part 1
Conceptual Questions
How many amino acid molecules in 500 grams of meat?
A typical 500-gram portion of meat contains approximately 100–125 grams of protein, depending on fat content and cut. Assuming an average amino acid molecular weight of 110 Daltons (accounting for side chain diversity beyond the 100 Da backbone), this translates to roughly 0.9–1.1 moles of amino acids. Using Avogadro’s number, this equals approximately 5.5 × 10²³ individual amino acid molecules.
Why do humans eat beef but do not become cows?
We consume foreign proteins that don’t have the capability of acting as “blueprints”, but as raw materials. Digestive proteases in the stomach and small intestine hydrolyze dietary proteins into individual amino acids and small peptides, which then are repurposed to meet our metabolic needs. These universal monomers enter our metabolic pool and are reassembled according to instructions encoded in our own DNA—not the cow’s genome. Eating beef provides building blocks; our genome provides the architectural plan.
Why are there only 20 natural amino acids?
The “standard 20” represents an evolutionary optimization between functional diversity and translational fidelity—a balance George Church highlighted in his Week 2 slides when asking, “What is the right balance between codon code redundancy and diversity?” These 20 amino acids span sufficient chemical space (hydrophobic, hydrophilic, charged, aromatic) to construct functional proteins while maintaining error tolerance through codon degeneracy. I suppose that adding more amino acids would require additional biological machinery to take care of “production” mistakes, increasing genomic burden without proportional functional gain.
Can you make non-natural amino acids? Design examples.
Yes—hundreds of non-standard amino acids (NSAAs) have been chemically synthesized and site-specifically incorporated into proteins using engineered translation systems. Church’s slides illustrate NSAAs with orthogonal chemistries like ketone-bearing or azobenzyl side chains that enable bioorthogonal reactions impossible with natural amino acids. For my lupus circuit project, I would design two NSAAs with therapeutic relevance:
(1) a photocaged cysteine derivative where a nitrobenzyl group blocks the thiol until UV exposure—allowing light-triggered activation of TRIM28’s catalytic domain during disease flares;
(2) a dansyl-lysine variant with environment-sensitive fluorescence that reports local hydrophobicity changes when TRIM28 engages IRF-7, serving as a real-time conformational sensor.
Where did amino acids come from before enzymes and life?
Amino acids seemed to be produced by abiotic synthesis pathways operating on early Earth. The Miller-Urey experiments demonstrated that lightning discharges through reducing atmospheres (CH₄, NH₃, H₂O, H₂) generate glycine, alanine, and other proteinogenic amino acids. Hydrothermal vent systems provide mineral catalysts (iron-sulfur surfaces) that facilitate reactions between aldehydes, hydrogen cyanide, and ammonia forming α-amino nitriles that hydrolyze to amino acids.
α-helix handedness with D-amino acids?
A polypeptide composed exclusively of D-amino acids forms a left-handed α-helix—the mirror image of the right-handed helix formed by natural L-amino acids. This inversion occurs because backbone dihedral angles (φ, ψ) that produce right-handed coiling in L-polymers generate left-handed coiling when monomer chirality flips.
Why are most molecular helices right-handed?
Right-handed helicity predominates due to stereochemical constraints imposed by L-amino acid chirality and evolutionary fixation. In α-helices, the right-handed conformation minimizes steric clashes between side chains and backbone carbonyl groups for L-amino acids; left-handed helices require energetically unfavorable φ/ψ angles except for glycine (which lacks a side chain). Once homochirality (L-amino acids, D-sugars) became established in early life, right-handed helices dominated through evolutionary selection—systems built on consistent chirality function more reliably.
Why do β-sheets tend to aggregate?
β-sheets aggregate because their edge strands present unsatisfied hydrogen bonding potential—backbone amide (H-donor) and carbonyl (H-acceptor) groups at sheet termini seek partners, creating ends that recruit additional β-strands. This drive combines with the hydrophobic effect: many amyloidogenic sequences have alternating hydrophobic/hydrophilic residues that, when strands align in-register, allow hydrophobic side chains to interdigitate into a dry “steric zipper” interface excluding water.
Can you use amyloid β-sheets as materials?
Yes—amyloid β-sheets’ exceptional mechanical properties (tensile strength rivaling steel per weight) and self-assembly under mild conditions make them promising sustainable biomaterials. Bacterial curli fibers—functional amyloids produced by E. coli—have been engineered for conductive biofilms and tissue engineering scaffolds. For my Ecuador-focused work, I see particular promise in adapting these principles for low-resource settings: amyloid-based hydrogels could stabilize vaccines during transport to rural Chimborazo communities without refrigeration, leveraging the same stability that makes pathological amyloids resistant to degradation. However, ethical governance is essential: material applications must avoid normalizing amyloid formation in therapeutic contexts where aggregation causes disease.
Protein Analysis and Visualization
Since the week when I had to consider alternative ideas for my final project, I have found it interesting to revisit the concept of applying fungal degradation to textiles with a high percentage of petroleum-derived materials. Therefore, I want to select an enzyme capable of degrading PAHs. The lignolytic enzymes from white-rot basidiomycete fungi are capable of oxidizing and degrading persistent molecules (with aromatic rings) (Moses, 2024).
From among this group of enzymes, I selected laccase, which can metabolize petroleum-derived dyes present in wastewater from industrial textile production processes into melanin (a non-toxic product) (Upadhyay et al., 2016; Tesfaye et al., 2025).
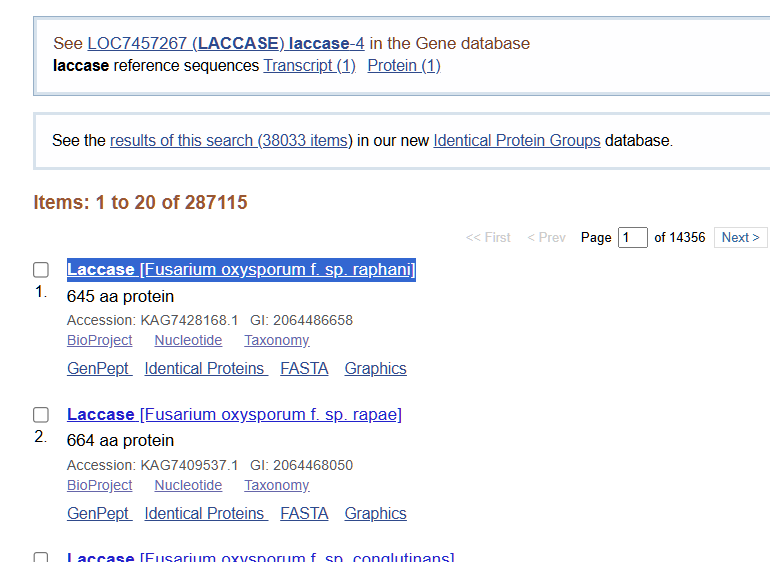
I am not certain which fungi have laccase available in NCBI, so my preliminary search is very general:
From the options available to choose from, I selected the first complete laccase enzyme option (from Fusarium oxysporum f. sp. Raphani), with GenBank ID: KAG7428168.1
The amino acid sequence of my selected protein is:
“>KAG7428168.1 Laccase Fusarium oxysporum f. sp. raphani
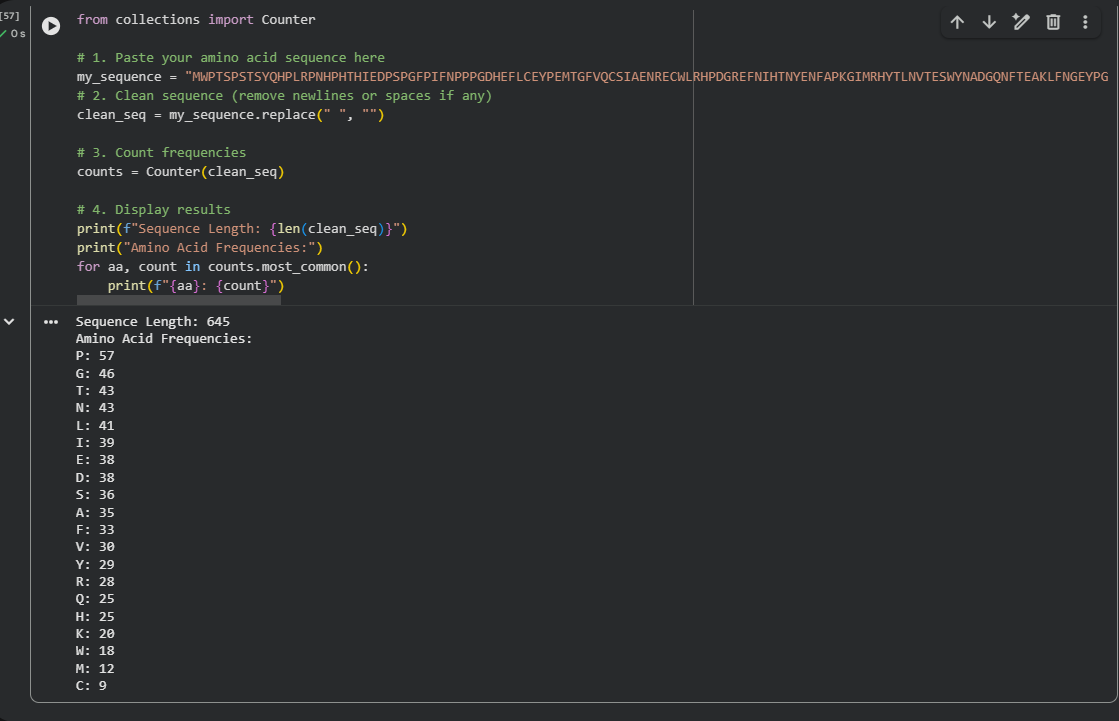
According to NCBI information, the protein length is 645 aa.
When using the Collab notebook, the result for the most frequent amino acid count was Proline, with a frequency of 57.
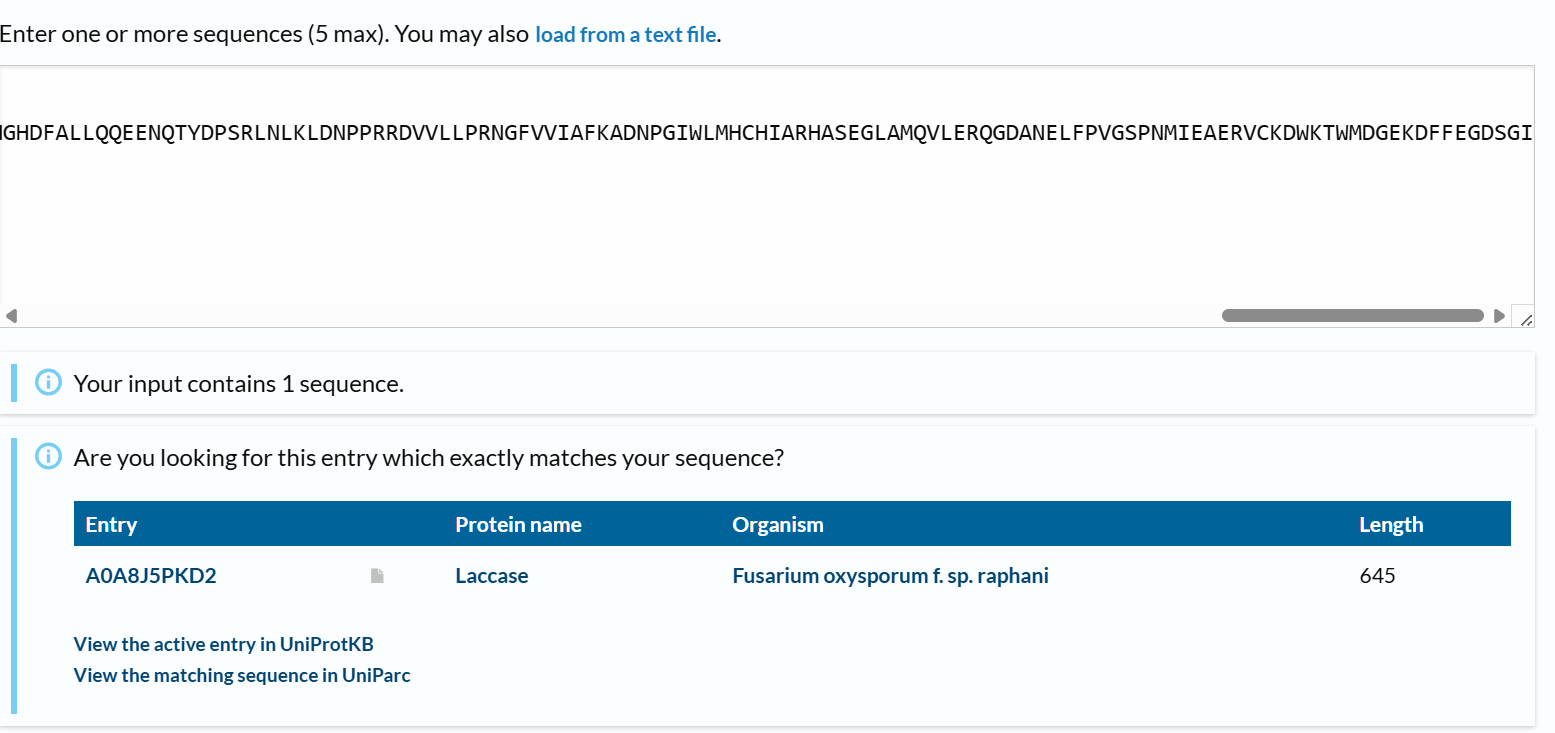
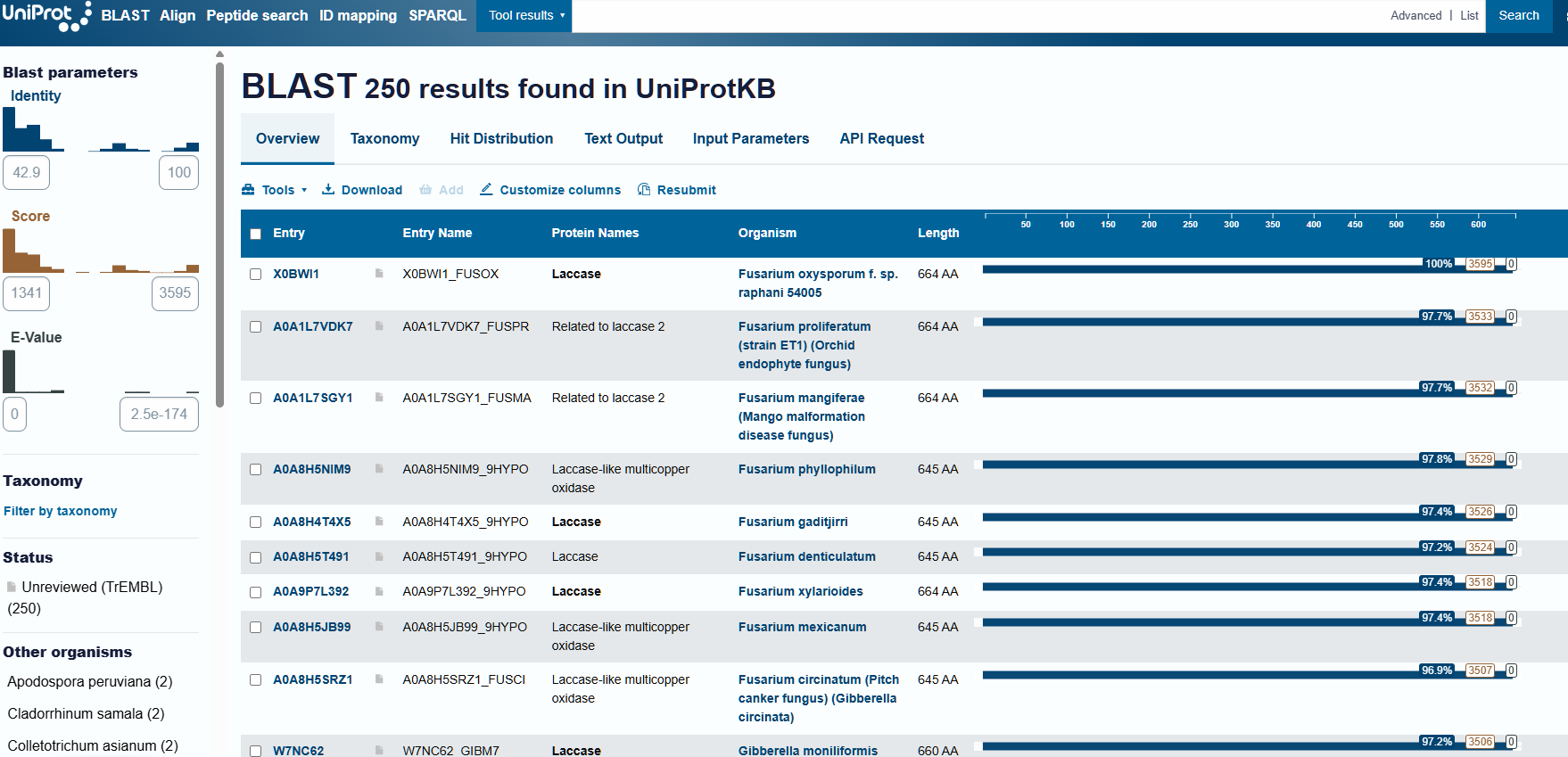
After using the homologue search in UniProt with the sequence in FASTA format, I obtained 250 results that were either laccases or laccase-like in other organisms:
To find the family to which my protein belongs, I resorted to searching for conserved domains, present among the NCBI information options. In this way, I identified that laccase can be classified within the multicopper oxidases (ArchID 12990618).
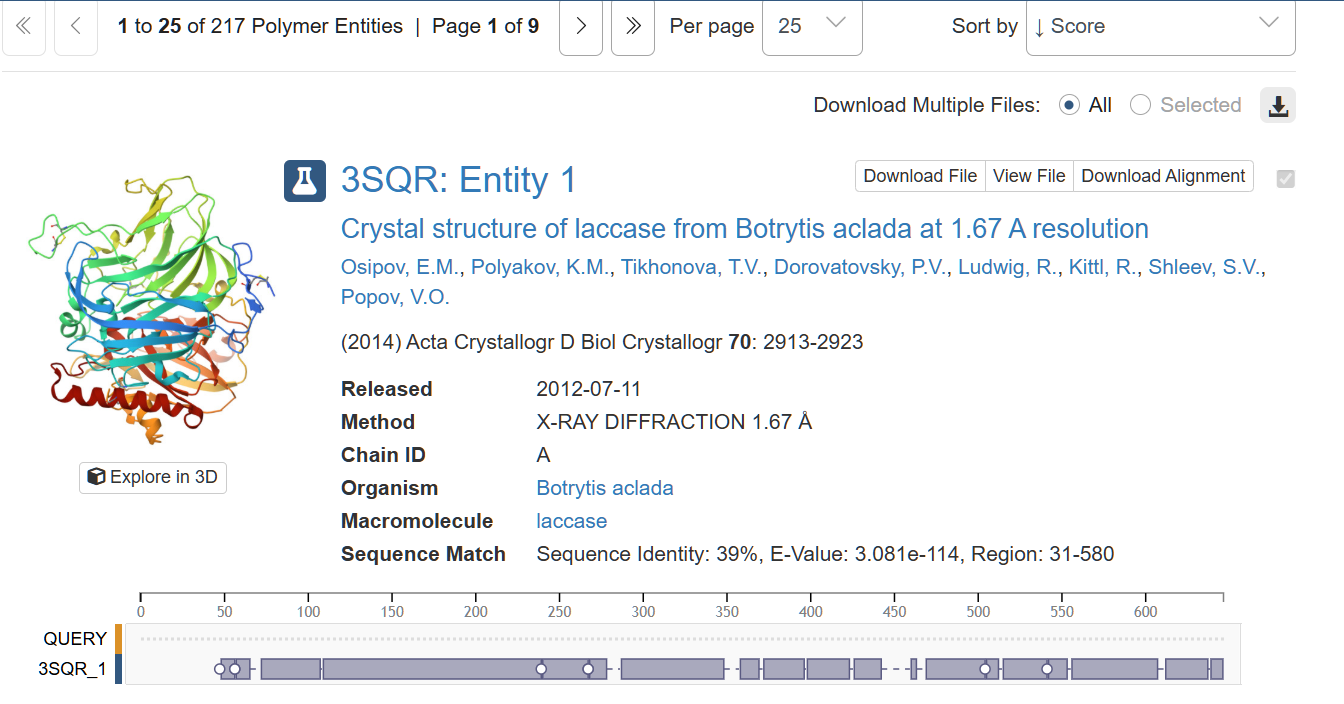
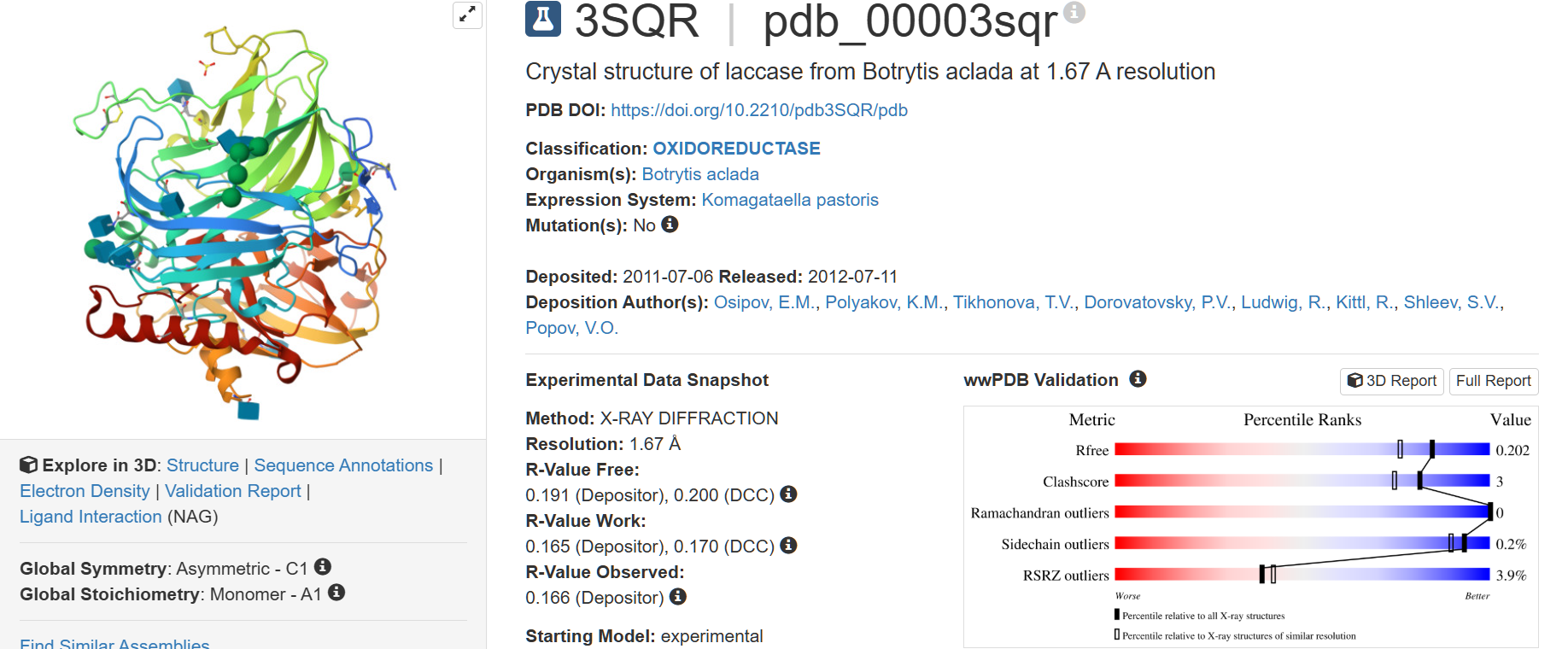
When searching for the page corresponding to my protein’s structure, the first result was the one with the highest percentage of sequence identity (39%), and the E-value is very small (3.081e-114), which is a good starting point. Therefore, I selected that structure, with PDB ID 3SQR to continue with the subsequent steps of this section.
The structure was deposited on 2011-07-06 and solved on 2012-07-11. It has a resolution of 1.67 Å, being the lowest resolution among laccase structures with a sequence identity greater than 35%.
There aren’t any other molecules in the solved structure apart from the laccase protein chain. However, there are 3 ligands of interest for the structure:
NAG (2-acetamido-2-deoxy-beta-D-glucopyranose)
MAN (alpha-D-mannopyranose)
SO4 (sulfate ion).
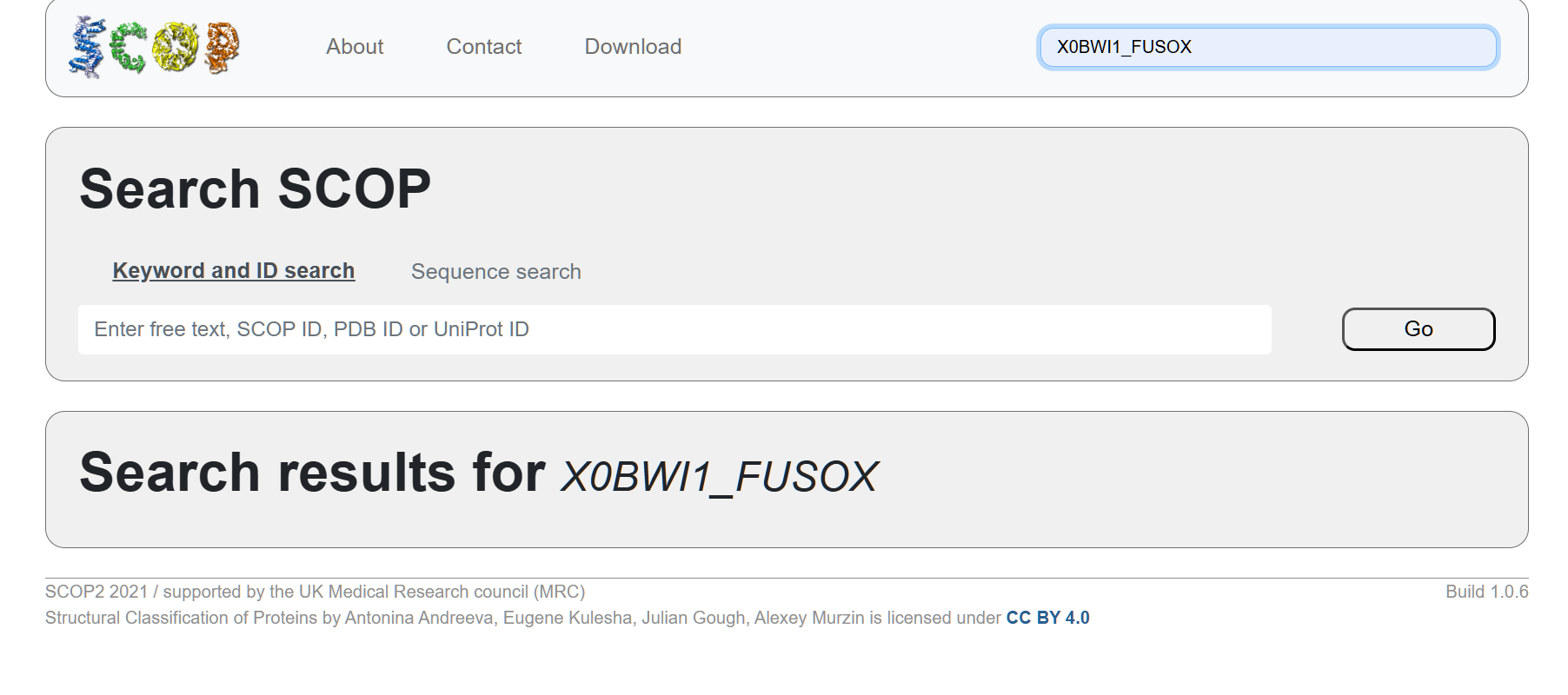
When using SCOP to search for the structure classification family of laccase (using its NCBI protein ID) there were no search results. However, literature says that laccases are under the multicopper oxidase (MCO) superfamily (Kim et al., 2024).
To visualize the 3D structure of my selected protein (laccase), I downloaded the ChimeraX software, as it is highly recommended to beginners at protein structure visualization for being intuitive.
Once installed, I went to the File tab and clicked on the option File → Fetch by ID. I selected PDB as the database for the search and then wrote the ID of the sequence I chose in PDB: 3SQR and clicked Fetch.
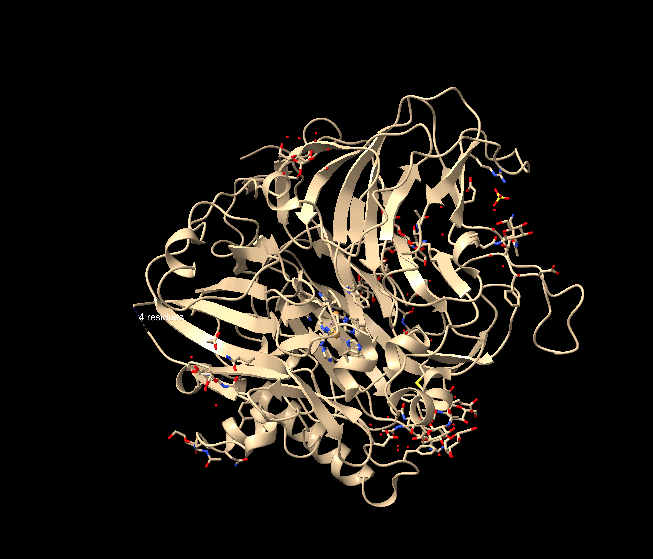
Upon loading the structure, I was able to visualize it as follows:
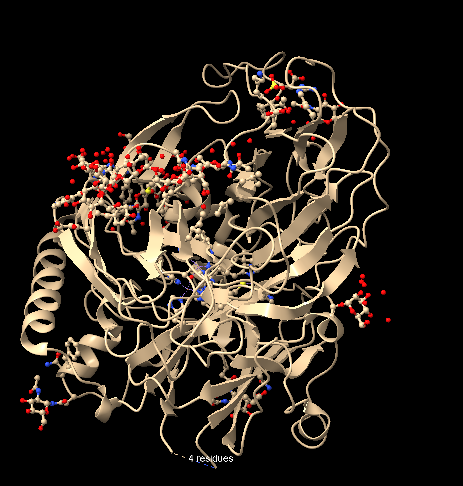
To visualize the protein as cartoon, I entered the command cartoon directly. The structure is visualized as follows, although I feel there is no major change compared to how it appeared previously:
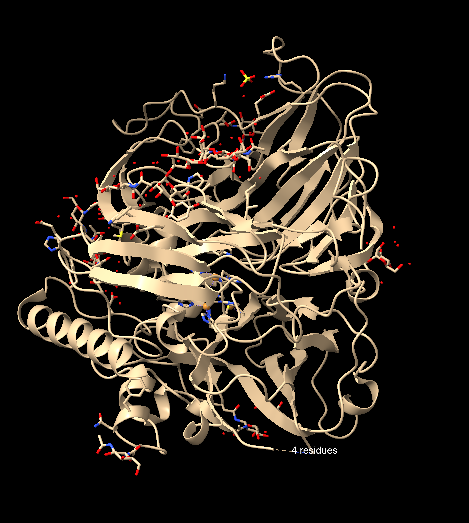
Rather, when using the command hide cartoon, a change in visualization is perceived, as the ribbon segments of the structure disappear:
To visualize the structure as a ribbon, I entered the command ribbon, and the structure appeared as follows, again:
To visualize the structure as ball and stick, I entered the command ball and stick, and the structure appeared as follows, allowing visualization of the atoms/bonds of the structure (with balls proportional to atomic VDW radii):
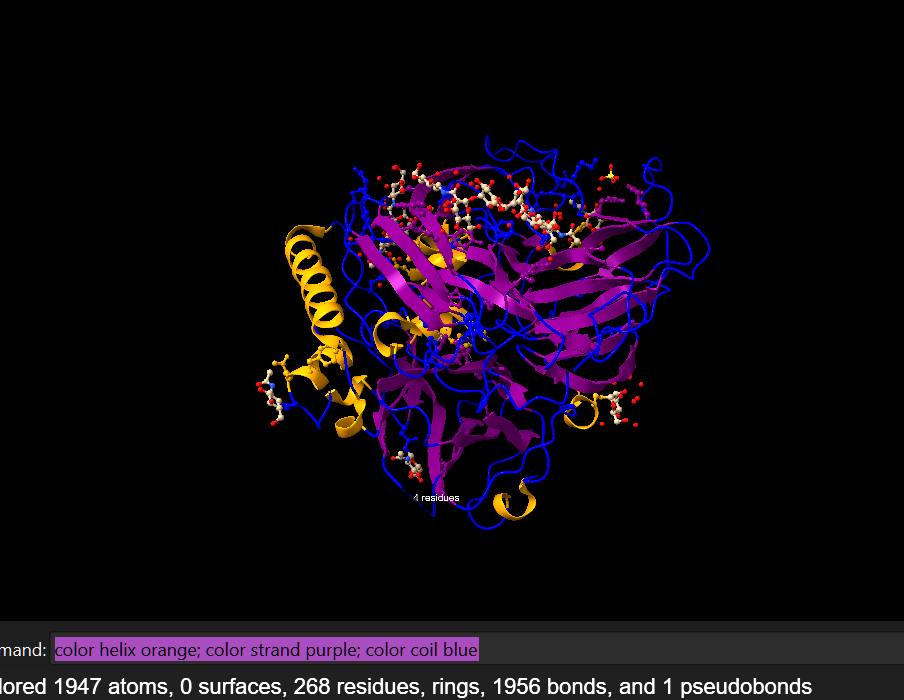
To color the protein according to its secondary structures, I employed the following command line: color helix orange; color strand purple; color coil blue.
It can be visualized that it has more helices (10) than sheets (3) if we go by the number of each, but that the sheets constitute a larger percentage of the protein than the helices.There is also a high percentage of coils:
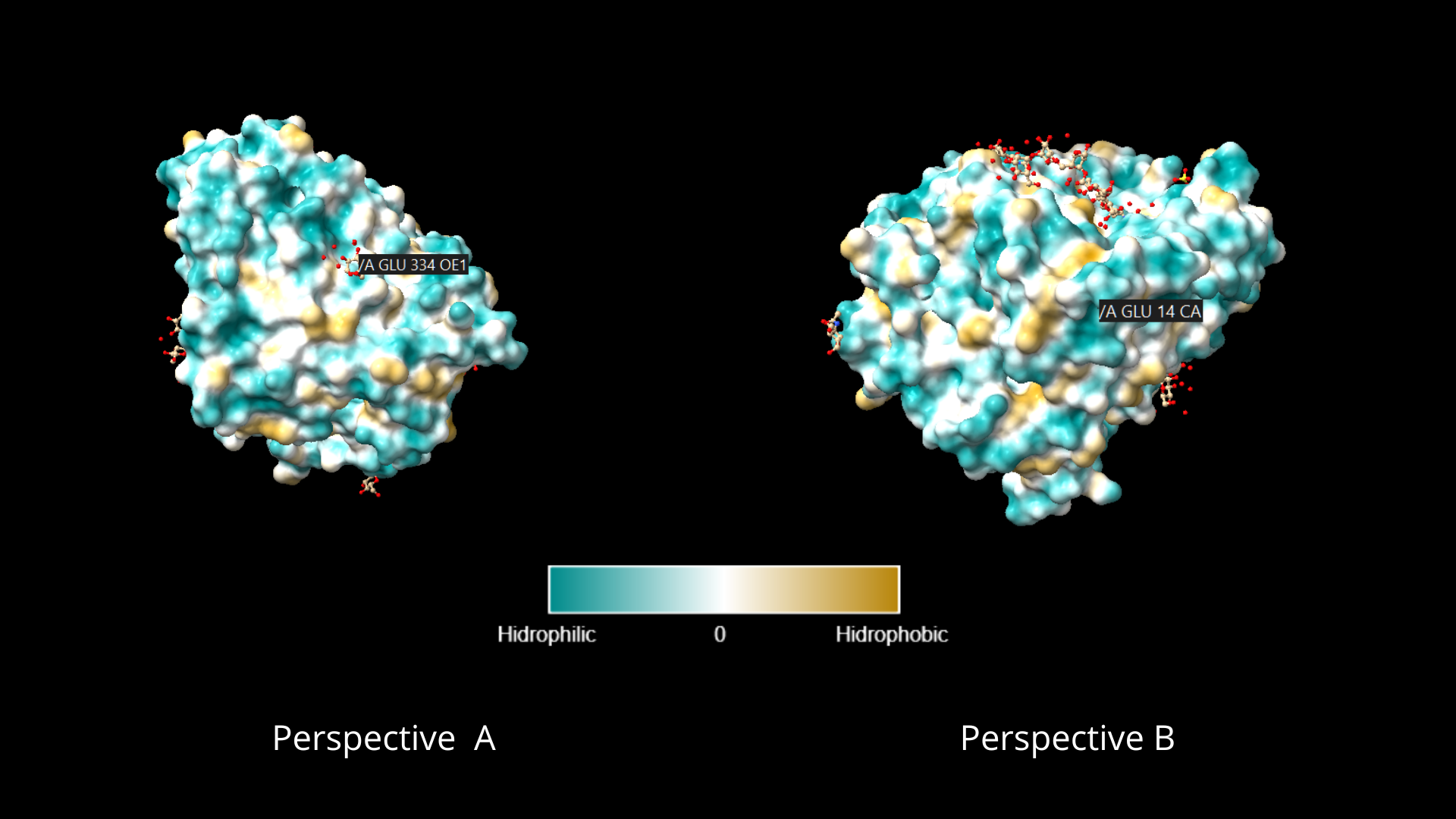
To color the protein according to its residue types, I went to the toolbar, in the Molecule Display tab, and clicked on the hydrophobic option, within the Coloring section. As can be appreciated, the distribution of hydrophilic residues occupies a larger percentage of the protein, and in the case of lipophilic residues, they appear to be usually surrounded by hydrophilic residues:
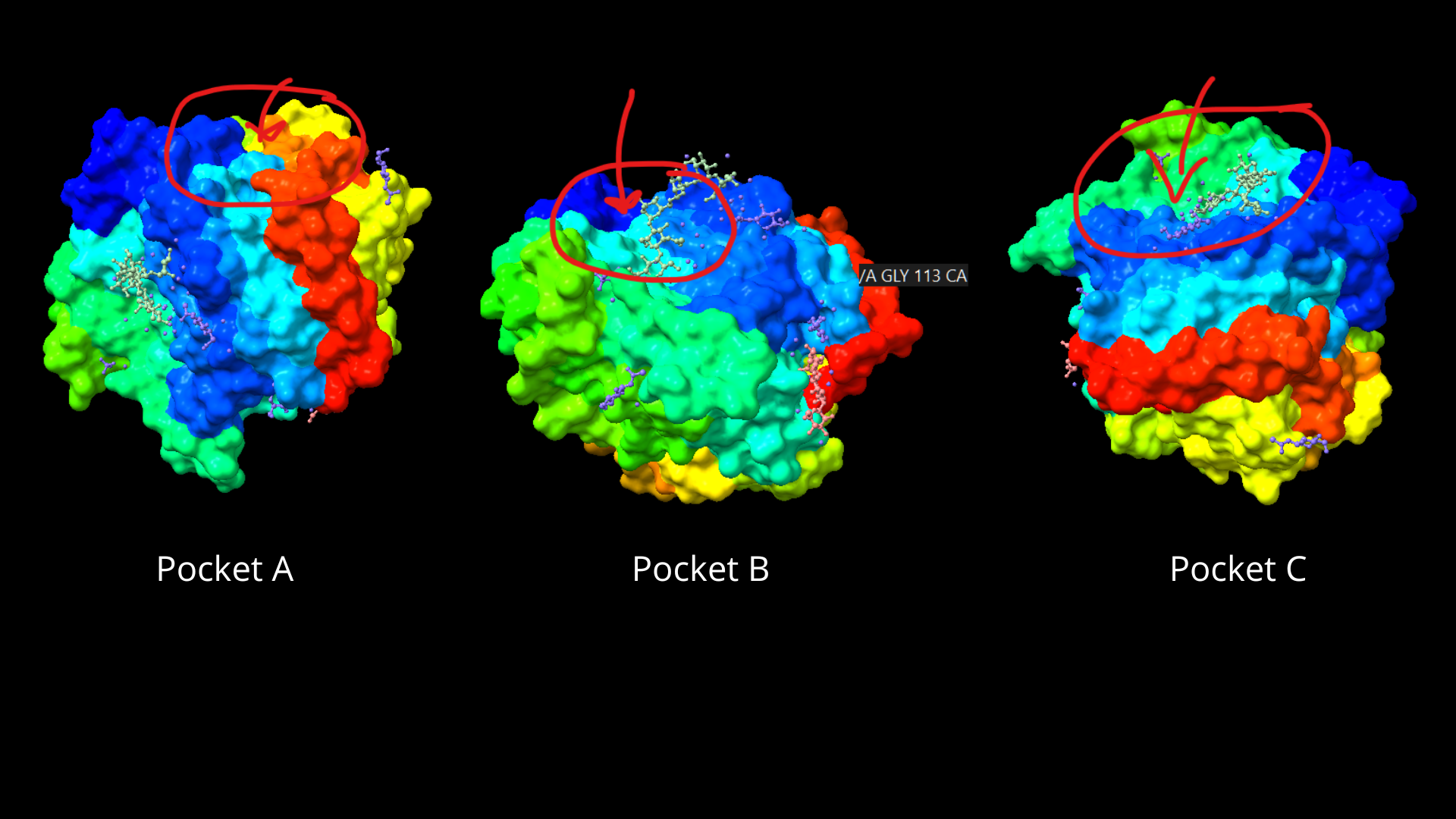
When visualizing the protein surface, some “gaps” can be identified that could be binding pockets:
Using ML-Based Protein Design Tools
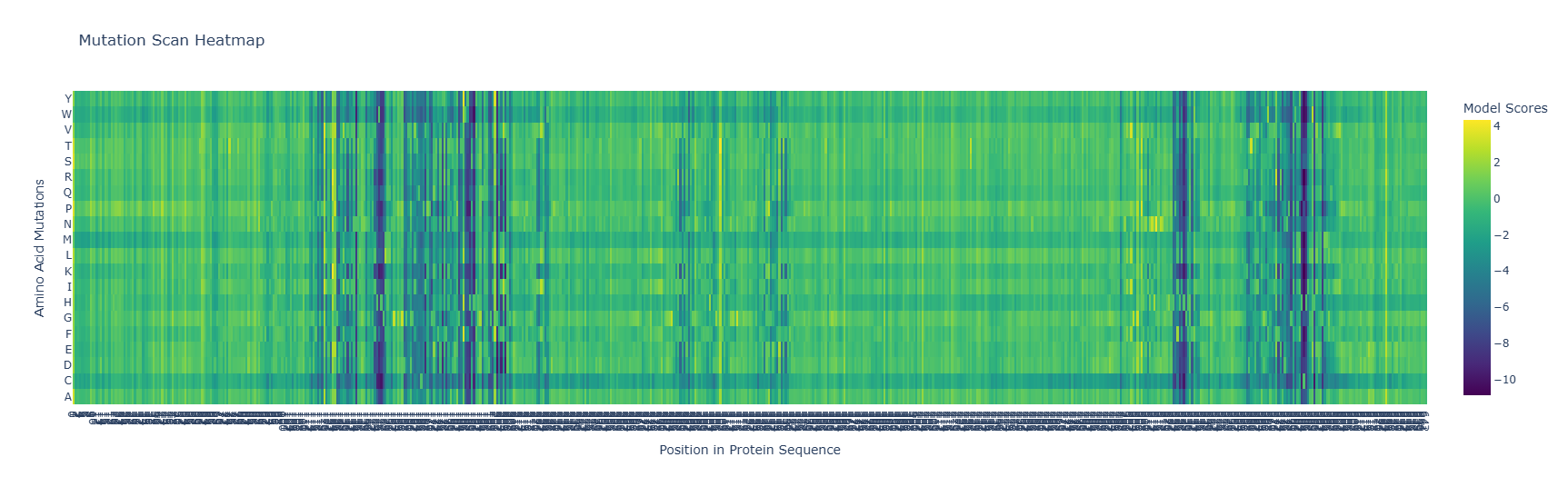
To begin this section, I made a copy of the provided Google Collab file. Then I advanced to the cell Mutation Scans, where I changed the default amino acid sequence for the laccase sequence from NCBI. Then I ran all the code and obtained the following heatmap:
The X-axis represents the position in the protein along the amino acid chain that makes up the laccase, and the Y-axis has the 20 possible amino acids. In this way, what is visualized in the heatmap are the probabilities that a specific amino acid is conserved at a position. The color itself indicates whether a mutation in a specific part of the sequence is stable/probable in the protein: if it tends toward yellow/green, the mutation is stable. If it tends toward blue, that mutation is detrimental to the protein.
As can be appreciated, for most of the sequence the heatmap shows a color leaning toward green/yellow. Only in three regions (vertical bands) is there a markedly blue coloration.
Proceeding, I searched for the cell Latent Space Analysis and there I searched for the code line protein_sequence_strings = [str(record.seq).upper() for record in sequences]. After this, I added the following code lines to add my protein to the list of sequences retrieved by the program:
my_protein="METRFPQQSQQTPASTNRRRPFKHEDYPCRRQQRSSTLYVLIFLAIFLSKFTNQLLLSLLEAVIRTVTTLQQLLT"# My aa sequenceprotein_sequence_strings.append(my_protein)# To add my protein sequence to the list
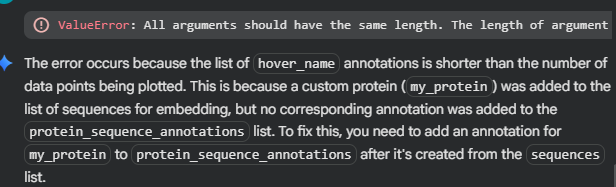
However when I clicked Run, there was an error:
It seems that by adding my sequence into the list, I unwittingly made another part of the code fail, as protein_sequence_strings seems to be paired with another list, the one containing the embeddings values.
I felt lost trying to identifying where in the code should I add another value to equiparate the embedding list’s n, so I accepted the help of the IA assistant. Here is the description of what it had done:
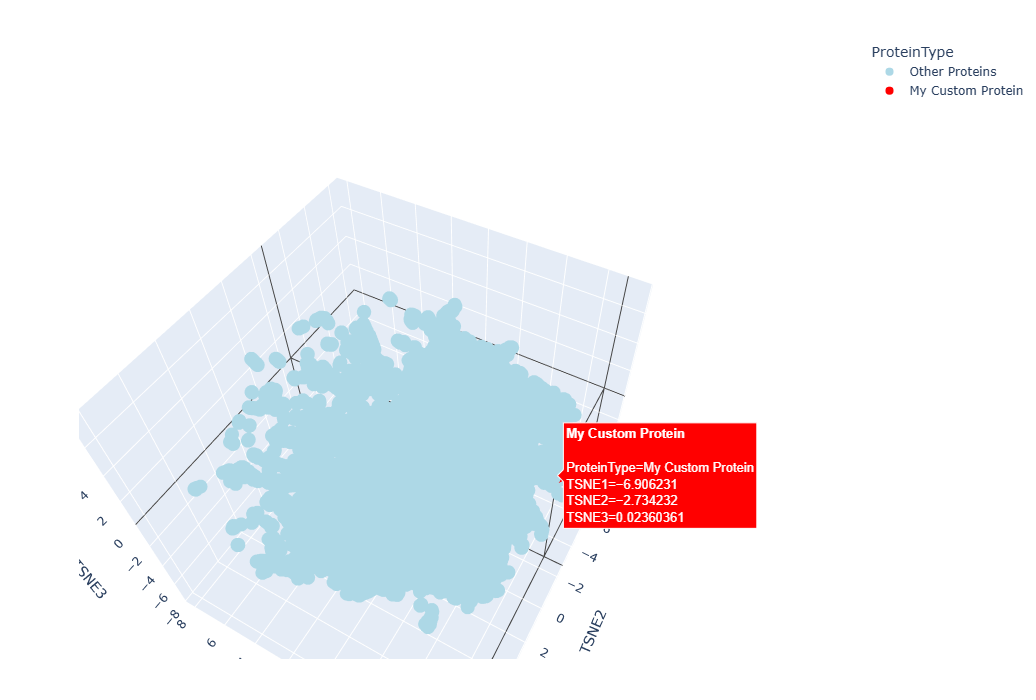
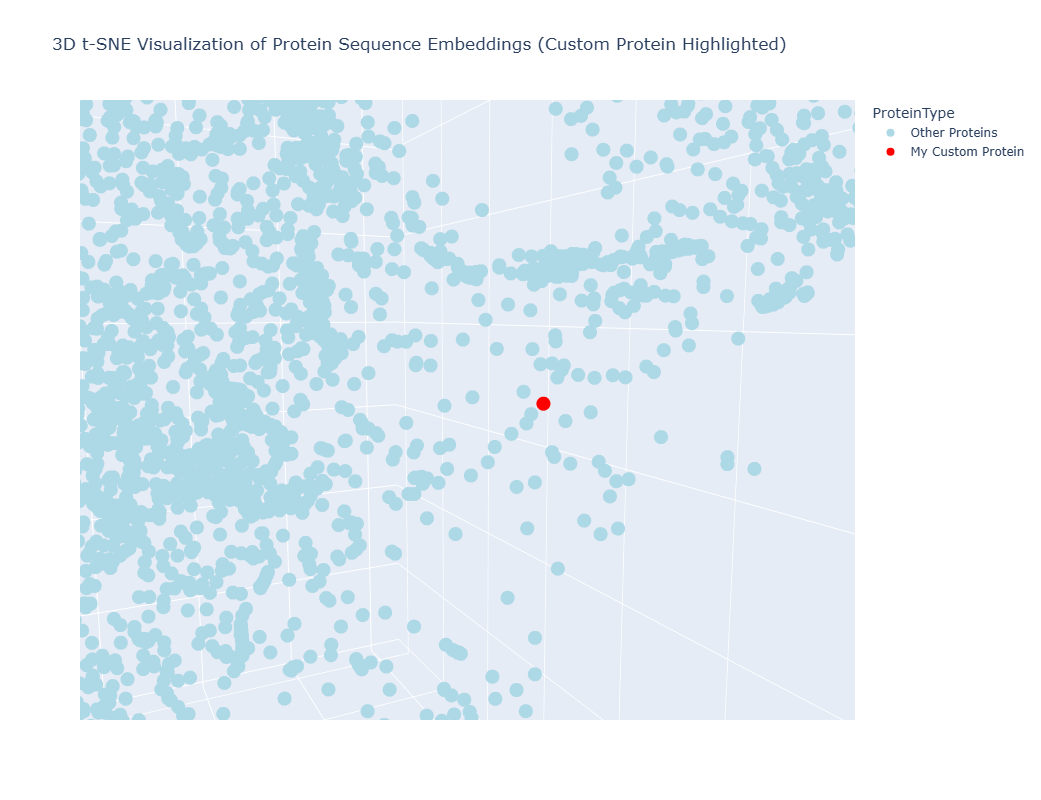
It worked, a 3D interctive graphic was timely generated, however I couldn´t locate my protein amongst the others, as they formed a tightly united cluster. I spend at least 10 minutes searching for my protein using the Hover feature of my mouse to no avail, so I asked Gemini for help to make my protein stan out in the graphic:
The resulting 3D graphic was:
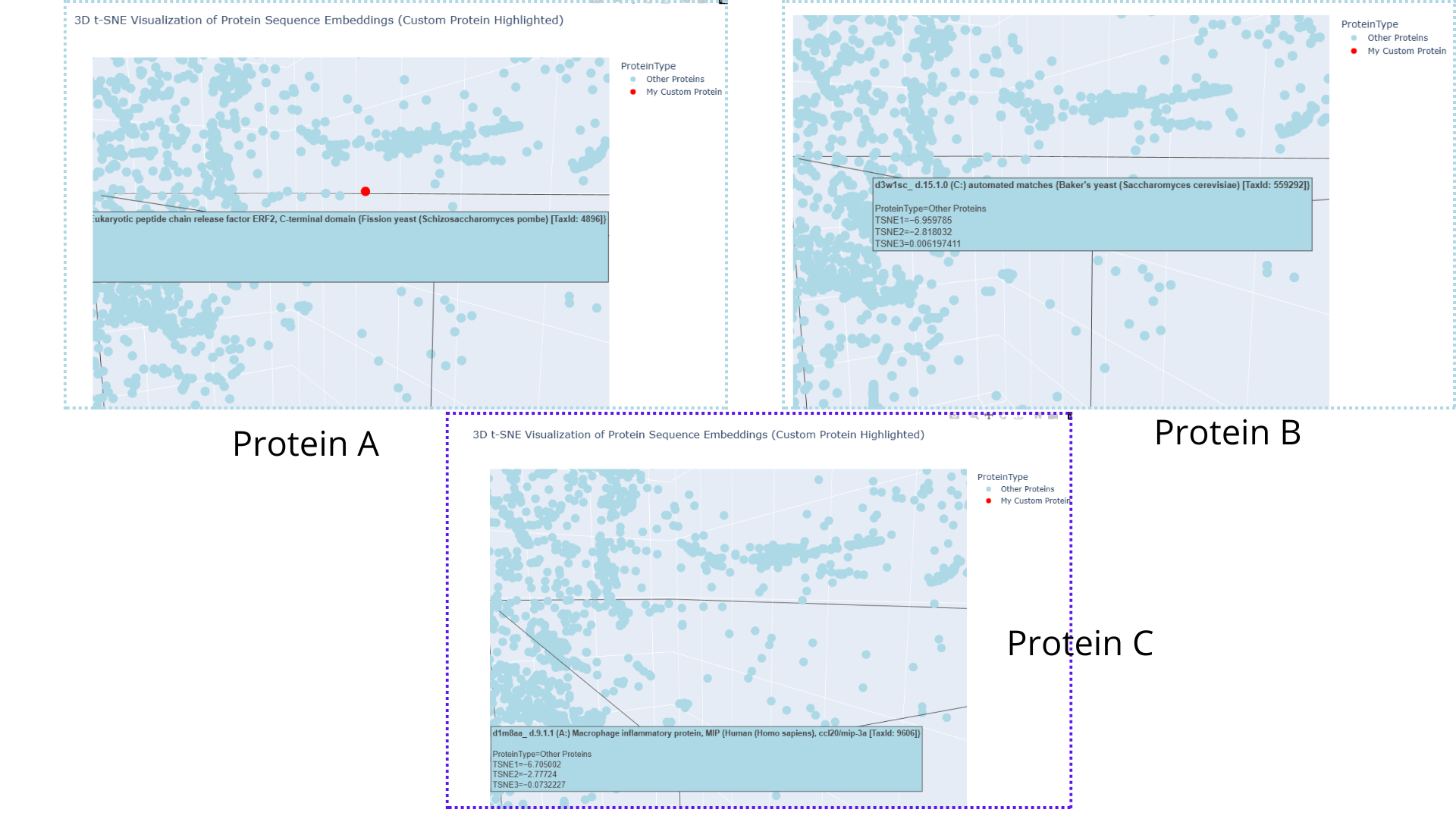
By zooming, rotaing and paning, I was able to identify three points “points” (a.k.a proteins) that were in close proximity to my laccase sequence:
This means that the model suggests that the four proteins share evolutionary traits. This could be somewhat plausible in the case of the protein belonging to Saccaromyces cereviacea, as my laccase belongs to a fungus. It seems likely that the evolutionary trait they share is characteristic of the Multicopper oxidases. This would also explain why, overall, there are so many proteins belonging to other fungi, bacteria and plants. However, in the case of the human protein (and in the case of other animals too), the shared evolutionary traits/function seems likely to be due to evolutionary convergence rather than sharing a common ancestor or being part of the same protein family.
For the next part, I scrolled to the Protein Folding with ESMFold celd. To compare how the protein’s structure changes due to mutations, first I entered the original aa sequence of my protein:
“>KAG7428168.1 Laccase Fusarium oxysporum f. sp. raphani
MWPTSPSTSYQHPLRPNHPHTHIEDPSPGFPIFNPPPGDHEFLCEYPEMTGFVQCSIAENRECWLRHPDGREFNIHTNYENFAPKGIMRHYTLNVTESWYNADGQNFTEAKLFNGEYPGPWLEACWGDTFNITVINSMKRNGTSIHWHGIRQNQTMDMDGVNGITQCPIAPGDSFSYIFNTTQYGTSWYHSHYSVQYADGLQGPITIHGPQSAPYDATKRPLLMTDWSHESAFRLLFPGSQFSNKTILLNGAGNVSHYGYTPTLPVPDNYELYFNKTPTDKPSRPKRYLLRLINTSFDSTLVFSIDNHWLQIVTSDFVPIEPYFNTSVLIGIGQRYNVIVEANPLAGDVNEIPEDGNFWIRTWVADACGIAPGGDGYEKTGILRYNHTDKALPSSQPWVNISKACSDETYTSLRPKIPWYIGPAANAQAADQTGERFNVTFDPNAKNTPEFQEEYPVATFGLQRPGQNFRPLQINYSDPVMFHLDEPRDTYPPKWVVIPEDYTEKEWVYFVLTIEGISARTGAHPIHLHGHDFALLQQEENQTYDPSRLNLKLDNPPRRDVVLLPRNGFVVIAFKADNPGIWLMHCHIARHASEGLAMQVLERQGDANELFPVGSPNMIEAERVCKDWKTWMDGEKDFFEGDSGI”
However I had run out of GPU usage, so I will complete this part later on, waiting for regain my GPU.
Until then , here is what I´m planning to do concerning this part:
Save the image of the resulting structure from the original sequence
Enter an edited version of the original aa sequence where I substituted some aa with their neighbors just to see how the estructure could be affected
Finally, enter a version of the original aa sequence where I deleted 5 random fragments (of 3-4 amino acids each)
Compare each structure to ascertain if the general position of secondary structures is retained (as the original) or if does change. The plddt for each version describes the model’s confidence, >70 being a good confidence. If the plddt drops drastically or the overall structure of the protein looses shape and becomes like an sphere-like glob, then the protein is not resilient to the made mutations.
For the next part, what I would do is:
I will scroll to the Inverse Folding with ProteinMPNN celd, search for pdb='5MBA' , then change 5MBA to the PDB code of laccase, 3SQR
This celd will generate and print a sequence that I will copy to paste in the sequence variable in the ESMFold celd from the previous part. Then I will RunESMFold.
Finally I will compare the new resulting structure (designed sequence) with the original structure. If they are visually similar, it means ProteinMPNN successfully designed a sequence that folds like the original.
Proposal on Bacteriophage Engineering
After reviewing the literature, I propose to address two computationally viable objectives:
Disrupt the interaction with DnaJ to accelerate lysis (medium priority)
Based on the proposed readings, the following implications for design can be considered:
Key Finding
Source
Implication for Design
The basic N-terminal domain (aa 1-36) is dispensable for lysis
Chamakura et al., 2017
Can be modified without losing function
Lodj mutants (without N domain) cause lysis ~20 min earlier
Chamakura et al., 2017
Disrupting DnaJ accelerates lysis
MS2-L forms oligomers of 10+ monomers in membranes
Mezhyrova et al., 2023
Stability depends on oligomerization
LS motif (Leu48-Ser49) is completely conserved
Chamakura et al., 2017
Must NOT be mutated
DnaJ interacts with the N-terminal domain
Chamakura et al., 2017
Target for disruption
So, what can we modify without breaking function?
N-terminal domain: Lodj mutants eliminate it and function better
Non-conserved residues: Alignment shows variability at specific positions
Net charge: Reducing basicity may decrease DnaJ dependency
However, there are several limitations:
Membrane Proteins Are Difficult to Model: Structural predictions may not reflect behavior in native membranes, so it will be more feasible to prioritize mutations in the N-terminal soluble domain (more computationally accessible).
There is limited Data on Phage-Bacteria Interactions: BOTH (Chamakura et al., 2017) and (Mezhyrova et al., 2023) - verify that theThe cellular target of MS2-L remains unknown. We cannot design mutations that improve interaction if information on the target is missing. Due to that, we have to focus on Focus on known objectives (DnaJ, oligomerization) instead of the final target.
Experimental Validation is Required: Even if a model works perfectly at the in silico level, computationally designed mutants may not work in vivo. To surpass this limitation, we could select multiple candidates to increase the probability of success.
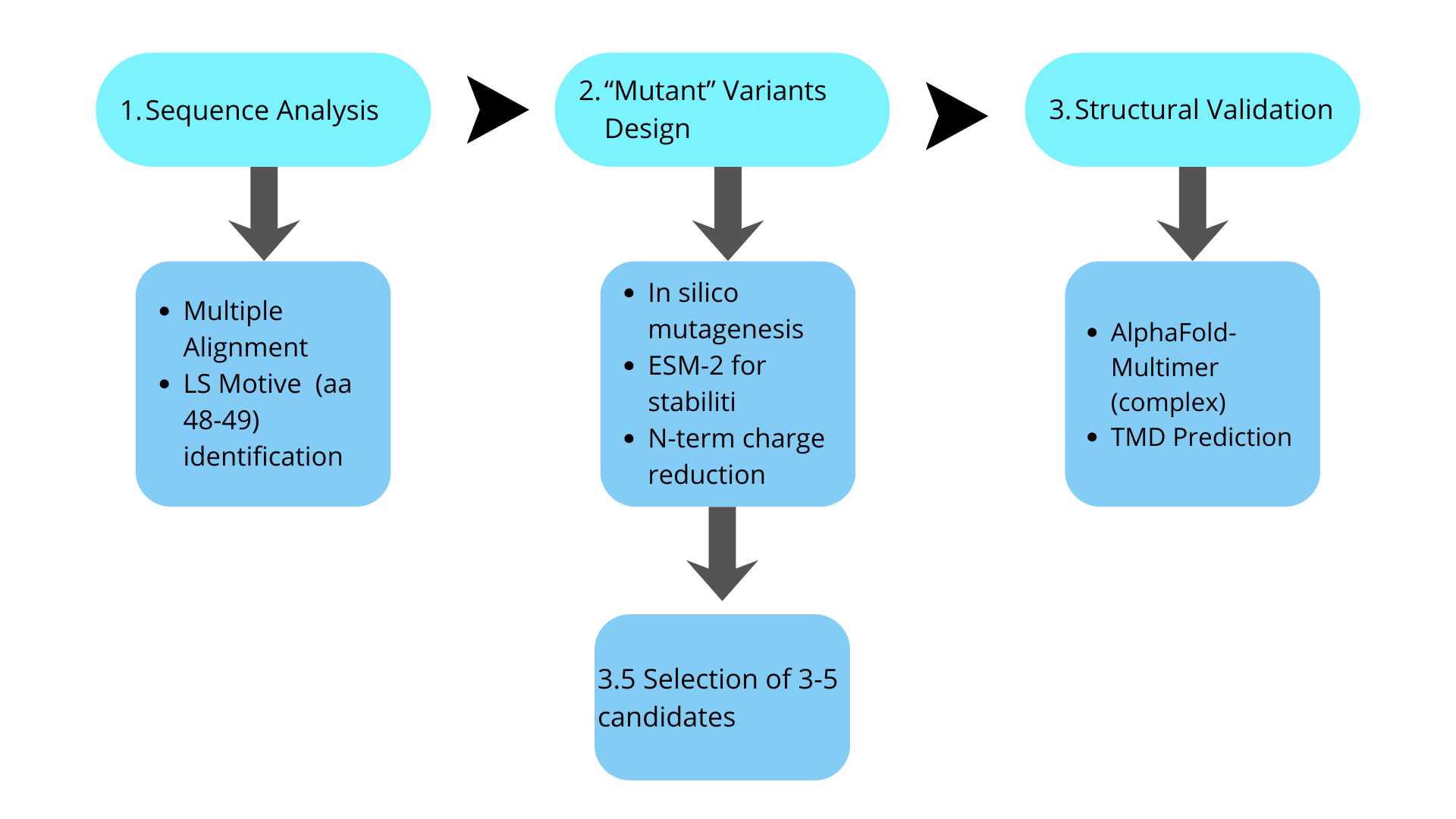
Considering the previous context, the tools to be used would be:
Tool
Purpose
ESM-2 / ProtBERT
Predict mutation effects on stability
AlphaFold-Multimer
Model MS2-L + DnaJ complex
TMHMM / Phobius
Predict transmembrane domain
ConSurf
Identify conserved residues
And the proposed pipeline (as an initial algorithm outline) would be:
References
Kim, J.-H., Park, Y.-J., & Jang, M.-J. (2024). Identification of laccase family of Auricularia auricula-judae and structural prediction using alphafold. -International Journal of Molecular Sciences, 25(21), 11784. https://doi.org/10.3390/ijms252111784
Moses, I. O. (2024). Oyster mushroom in bioremediation: A review of its potential and applications. Journal of Multidisciplinary Science: MIKAILALSYS, 3(1), 61–70. https://doi.org/10.58578/mikailalsys.v3i1.4362
Tesfaye, E. L., Bogale, F. M., & Aragaw, T. A. (2025). Biodegradation of polycyclic aromatic hydrocarbons: The role of ligninolytic enzymes and advances of biosensors for in-situ monitoring. Emerging Contaminants, 11(1), 100424. https://doi.org/10.1016/j.emcon.2024.100424
Upadhyay, S., Xu, X., Lowry, D., Jackson, J. C., Roberson, R. W., & Lin, X. (2016). Subcellular compartmentalization and trafficking of the biosynthetic machinery for fungal melanin. Cell Reports, 14(11), 2511–2518. https://doi.org/10.1016/j.celrep.2016.02.059






{kind=link}