Week 1 HW: Principles and Practices
Class Assignment
- First, describe a biological engineering application or tool you want to develop and why.
There is currently an urgent research focus on the biodegradation of plastics, due to the extremely long life cycle of synthetic polymers. Prior work has focused on a mix of exploring bacterial and microbial processes (e.g. anaerobic digestion) to break down plastics, and developing compositions that can be commercial compostable (e.g. for single use plastics). My personal interest is in fiber arts and sustainability, so I’d like to tackle this problem from a textile perspective. Fast fashion has exacerbated the volume of cheap, low quality clothes produced everyday. These clothes are often made with synthetic fibers and not for long term use (although the two are not necessarily interchangeable). I believe it’s incredibly important to find a way to biodegrade polyester, one of the most common synthetic polymers in fast fashion clothing.
- Next, describe one or more governance/policy goals related to ensuring that this application or tool contributes to an “ethical” future.
- Ensuring safety:
- What material/process is being used for plastic degradation? Any byproducts?
- Can we guarantee the safety of workers throughout the process?
- Can we guarantee the safety of the surrounding community?
- Upholding equity:
- Who/what affected areas will benefit the most from this application? More specifically, how can we prioritize places that need the most help (e.g. fast fashion landfills in Chile)?
- Textile and fast fashion industries in particular have historically exploited low-cost labor. How can we counter that in our mission to combat fast fashion production?
- Promoting a circular economy (avoiding greenwashing):
- How can we ensure that this solution is actually helpful? How do we avoid being just another step before the landfill?
- What is our end product and its use? What are the byproducts?
- Next, describe at least three different potential governance “actions”.
Action 1: Standardization of Process
- Purpose: A standard process, with clearly understood materials (end products, byproducts) and equipment, will better communicate the safety and efficacy of industrial facilities to the public. These exist for some products like compostable utensils but not necessarily synthetic clothing.
- Design: Research scientists and regulatory safety boards must work in conjunction to develop and validate the process.
- Assumptions: That the biodegradation process can be strictly controlled given the wide range of material types in clothing, and that biodegradation can scale up the same way industrial composting does.
- Risks of Failure & “Success”: Restriction of the process might make the success rate lower, due to the process being less efficient.
Action 2: Polyester Tracking for Success Metrics
- Purpose: Keeping tabs on where the material comes and goes, upstream and downstream, to evaluate how successful we are. Where are we getting polyester from? Where are our outputs going?
- Design: We need the cooperation of all parties for data transfer.
- Assumptions: That this data is currently already collected, and if not, that it’d be easy to start collecting. E.g. do most clothing landfills track the percentage breakdown of natural vs synthetic fibers?
- Risks of Failure & “Success”: Our process is less effective than it appears. E.g. maybe we are primarily biodegrading high-quality athleticwear. Still good, but not the impact we want.
Action 3: Community Awareness
- Purpose: Education programs about clothing and material composition can encourage more sustainable practices by the public, as well as more * engagement with our facility.
- Design: Planning events, town hall discussions, etc, as well as accepting donations of clothing.
- Assumptions: That community support hinges upon understanding of what we’re doing, and the negative impacts on the community are otherwise negligible.
- Risks of Failure & “Success”: Education programs are ineffective if the work needed is not in the hands of the community. E.g. if we cannot accept mixed-material clothing, the community cannot necessarily separate material on our behalf. That lies with clothing production facilities.
Action 4: Regulation on Composite Material Production
- Purpose: A big bottleneck in clothing recycling is the mixing of different materials (e.g. polyester fabric with cotton stitching, metal zippers, PVC coating). High-level regulations could target the production of these clothing.
- Design: Regulation through fines/taxes in local textile facilities. May be harder to regulate overseas production.
- Assumptions: That the volume of clothes produced locally is a significant enough % of clothes we take in. That these regulations are effective against overseas textile production.
- Risks of Failure & “Success”: We have to turn away a majority of clothes and are only able to focus on a niche in synthetic fibers. Could also end up constricting the companies that choose to produce locally, leading to failure.
- Next, score (from 1-3 with, 1 as the best, or n/a) each of your governance actions against your rubric of policy goals.
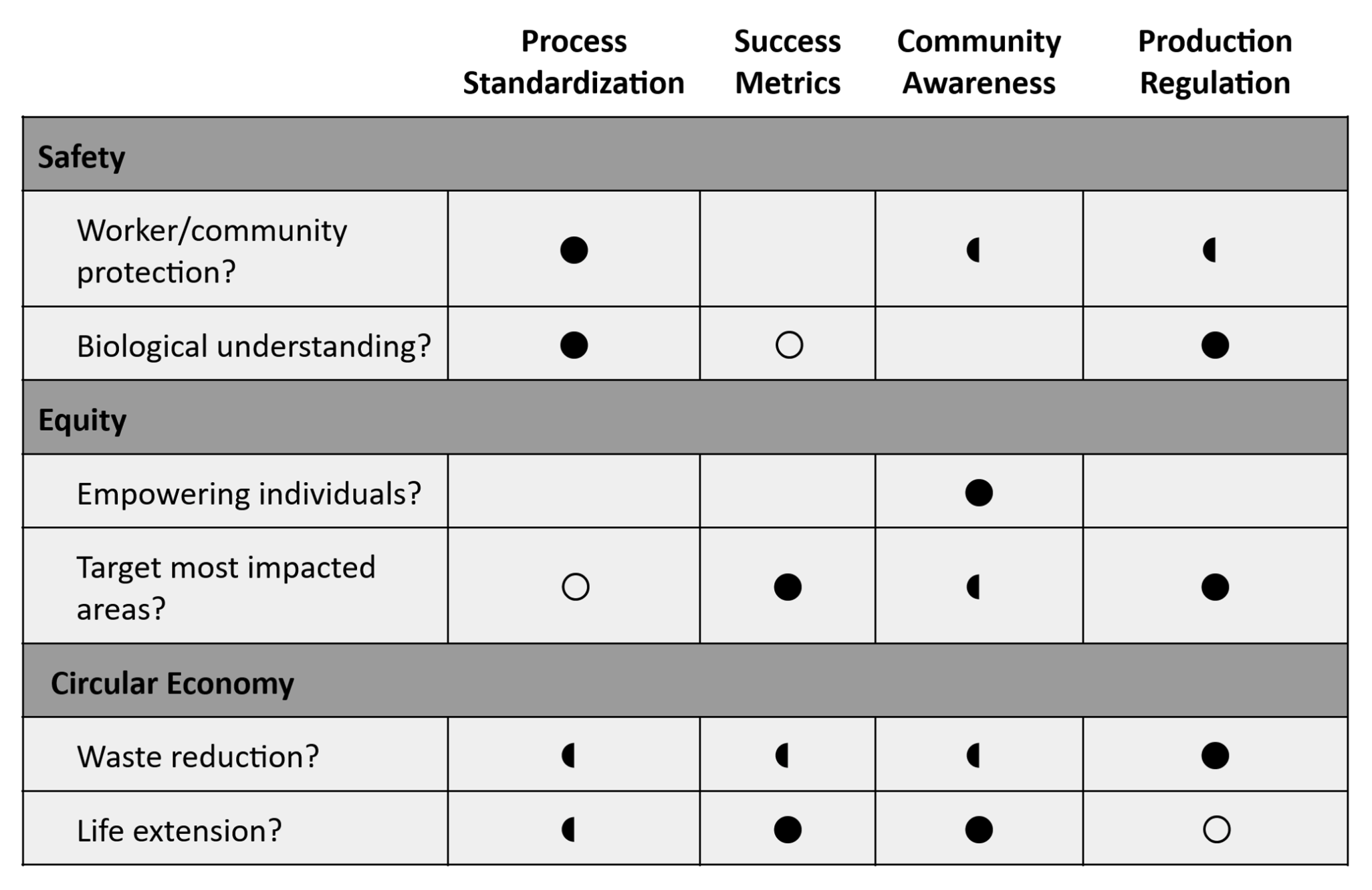
- Last, drawing upon this scoring, describe which governance option, or combination of options, you would prioritize, and why.
I’d focus on Process Standardization, as safety is the absolute first priority. Following that, between Success Metrics and Community Awareness, both have potential to contribute to a circular economy, but I’d like to prioritize Success Metrics for its potential to better target impacted areas down the line. So I’d work on a more technical level to develop more effective processes and data collection (which would likely involve academic institutions/environment-focused agencies).
- Ethical Concerns
I’m wary of how effective we’d be in a global setting, especially since my perceived impact with this depends on how well we can affect overseas institutions, where I believe most of fast fashion waste is made and accumulated.
Assignment (Week 2 Lecture Prep)
Homework Questions from Professor Jacobson
- Nature’s machinery for copying DNA is called polymerase. What is the error rate of polymerase? How does this compare to the length of the human genome. How does biology deal with that discrepancy?
The error rate for polymerase is 1:106, or 1 out of every 1,000,000 base pairs might be wrong. Meanwhile, the human genome spans billions of base pairs, with a diploid being about 6.3 Gigabase pairs (pr 3.2 Gigabase pairs for a haploid)1. However, the polymerase can go through a proofreading process where it uses exonuclease to remove the nucleotide through the entire monophosphate base2, essentially, allowing the sequence to “backspace” before continuing.
How many different ways are there to code (DNA nucleotide code) for an average human protein? In practice what are some of the reasons that all of these different codes don’t work to code for the protein of interest?
An average human protein is about 1036 bp.
Codons are sets of 3 base pairs, so this is about 345 amino acids.
However, many of these amino acids are redundant and can be expressed through multiple base pairs, with 6 being the highest number of variations (in Arginine). We can roughly calculate the amount of variations in a single amino acid through 64 codons/20 amino acids = 3.2 codon variations per amino acid.
This presents about 3.2 variations 345 amino acids, which gives my calculator an overflow error (about 10174).
So that’s clearly an excessive amount of variation for a single protein. However, organisms have developed something called “codon usage bias”, or preference for certain codons evolved over time. This can be due to the following reasons3:
- Resource use: different tRNAs recognize different codons, so less variation means more efficient tRNA production.
- Protein folding: different tRNAs for codons can translate at different rates. Codons can be deliberately chosen to have the protein fold at “fast translated” sections while waiting for the “slow translated” sections.
- Gene expression: certain codons result in stronger gene expression than others. Interestingly, this can work the other way around–codon optimization is a technique that aims to increase protein expression through swapping codons4.
Homework Questions from Dr. LeProust
- What’s the most commonly used method for oligo synthesis currently?
Oligonucleotides are defined as DNA chains with a length under 200 nucleotides5. Oligo synthesis began with solid-phase synthesis, with additional methods (phosphodiester, phosphotriester, phosphitetriester, phosphoramidite) developed up until the 1980s. Currently solid-phase synthesis using the phosphoramidite method is the most common method; the process was leveraged to implement the first automated DNA synthesizer and has since been optimized for high DNA production volume/thermal control5.
- Why is it difficult to make oligos longer than 200nt via direct synthesis?
Longer chains have reduced theoretical yield, since each additional nucleotide has an additional “elongation cycle efficiency” (think error rate) that stacks up5. This is calculated with the equation theoretical yield = elongation cycle efficiencynt. Assuming efficiency of 99%,
- nt = 100 → yield = .99100 = 0.366
- nt = 200 → yield = .99200 = 0.134
- nt = 300 → yield = .99300 = 0.049
The phosphoramidite method in particular becomes ineffective beyond 200 base pairs. As a result, more recent alternatives (e.g. enzymatic) are being explored, as research turns to using longer sequences.
- Why can’t you make a 2000bp gene via direct oligo synthesis?
If we further calculate using the above equation, the yield becomes
- bp = 2000 → yield = .992000 = 0.000000002 = ~0
or effectively zero. At such a high length, the individual “error rates” compound, leaving no chance for success. Current efforts try to improve the process, i.e. increasing the elongation cycle efficiency, or use workarounds like making batches of shorter segments to link together5.
Homework Question from George Church
- [Given slides #2 & 4 (AA:NA and NA:NA codes)] What code would you suggest for AA:AA interactions?
Not sure I’m fully understanding the question, but given there are 64 possible codons for amino acids yet only 20 amino acids, I’d create a code where all possible codons are inputted and outputted as “plaintext” and “ciphertext”, with the encryption “key” being the 20 amino acids they could be interpreted as. Something like the drawing below:
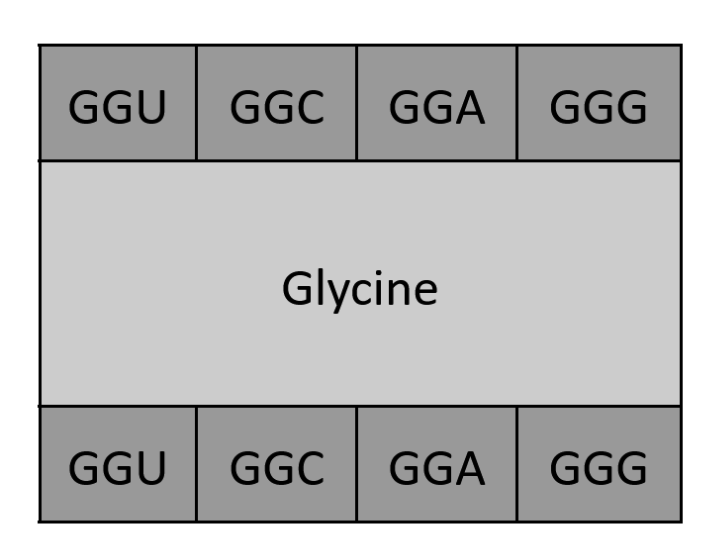 This could even be further streamlined for repeating letters:
This could even be further streamlined for repeating letters:
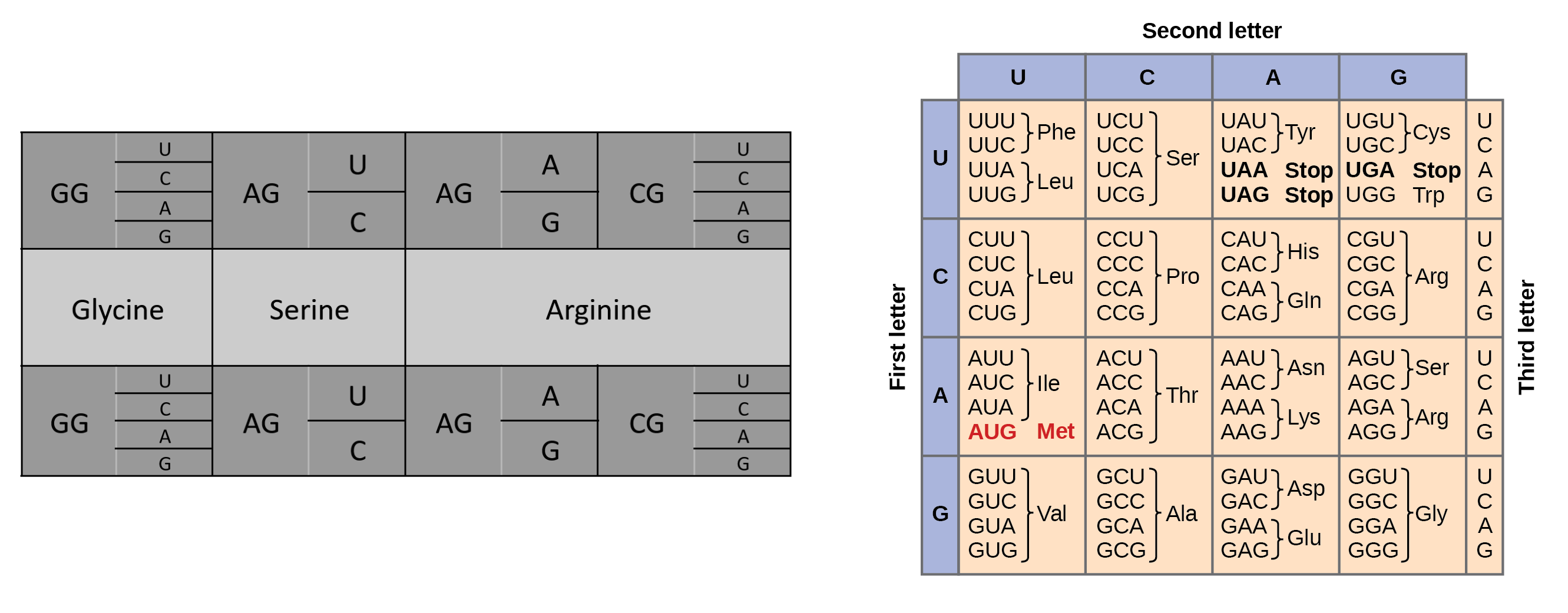 (Prof. Church’s slides and paper at [6] used for reference.)
(Prof. Church’s slides and paper at [6] used for reference.)
Citations
[1] Piovesan A, Pelleri MC, Antonaros F, Strippoli P, Caracausi M, Vitale L. On the length, weight and GC content of the human genome. BMC Res Notes. 2019 Feb 27;12(1):106. https://doi.org/10.1186/s13104-019-4137-z
[2] Hopfield, JJ. Kinetic proofreading: a new mechanism for reducing errors in biosynthetic processes requiring high specificity. Proc Natl Acad Sci USA. 1974 Oct; 71(10):4135-9. https://doi.org/10.1073/pnas.71.10.4135
[3] Ford, T. Plasmids 101: Codon usage bias. addgene Blog. 2018 Sept. https://blog.addgene.org/plasmids-101-codon-usage-bias
[4] Athey J, Alexaki A, Osipova E, Rostovtsev A, Santana-Quintero LV, Katneni U, Simonyan V, Kimchi-Sarfaty C. A new and updated resource for codon usage tables. BMC Bioinformatics. 2017 Sep 2; 18(1):391. https://doi.org/10.1186/s12859-017-1793-7
[5] Hoose, A., Vellacott, R., Storch, M. et al. DNA synthesis technologies to close the gene writing gap. Nat Rev Chem 7, 2023 Jan; 144–161. https://doi.org/10.1038/s41570-022-00456-9
[6] Acevedo-Rocha CG, Budisa N. Xenomicrobiology: a roadmap for genetic code engineering. Microb Biotechnol. 2016 Sep; 9(5):666-76. https://doi.org/10.1111/1751-7915.12398