Jessica Wu — HTGAA Spring 2026

About me
Engineer
Engineer
There is currently an urgent research focus on the biodegradation of plastics, due to the extremely long life cycle of synthetic polymers. Prior work has focused on a mix of exploring bacterial and microbial processes (e.g. anaerobic digestion) to break down plastics, and developing compositions that can be commercial compostable (e.g. for single use plastics). My personal interest is in fiber arts and sustainability, so I’d like to tackle this problem from a textile perspective. Fast fashion has exacerbated the volume of cheap, low quality clothes produced everyday. These clothes are often made with synthetic fibers and not for long term use (although the two are not necessarily interchangeable). I believe it’s incredibly important to find a way to biodegrade polyester, one of the most common synthetic polymers in fast fashion clothing.
Action 1: Standardization of Process
Action 2: Polyester Tracking for Success Metrics
Action 3: Community Awareness
Action 4: Regulation on Composite Material Production
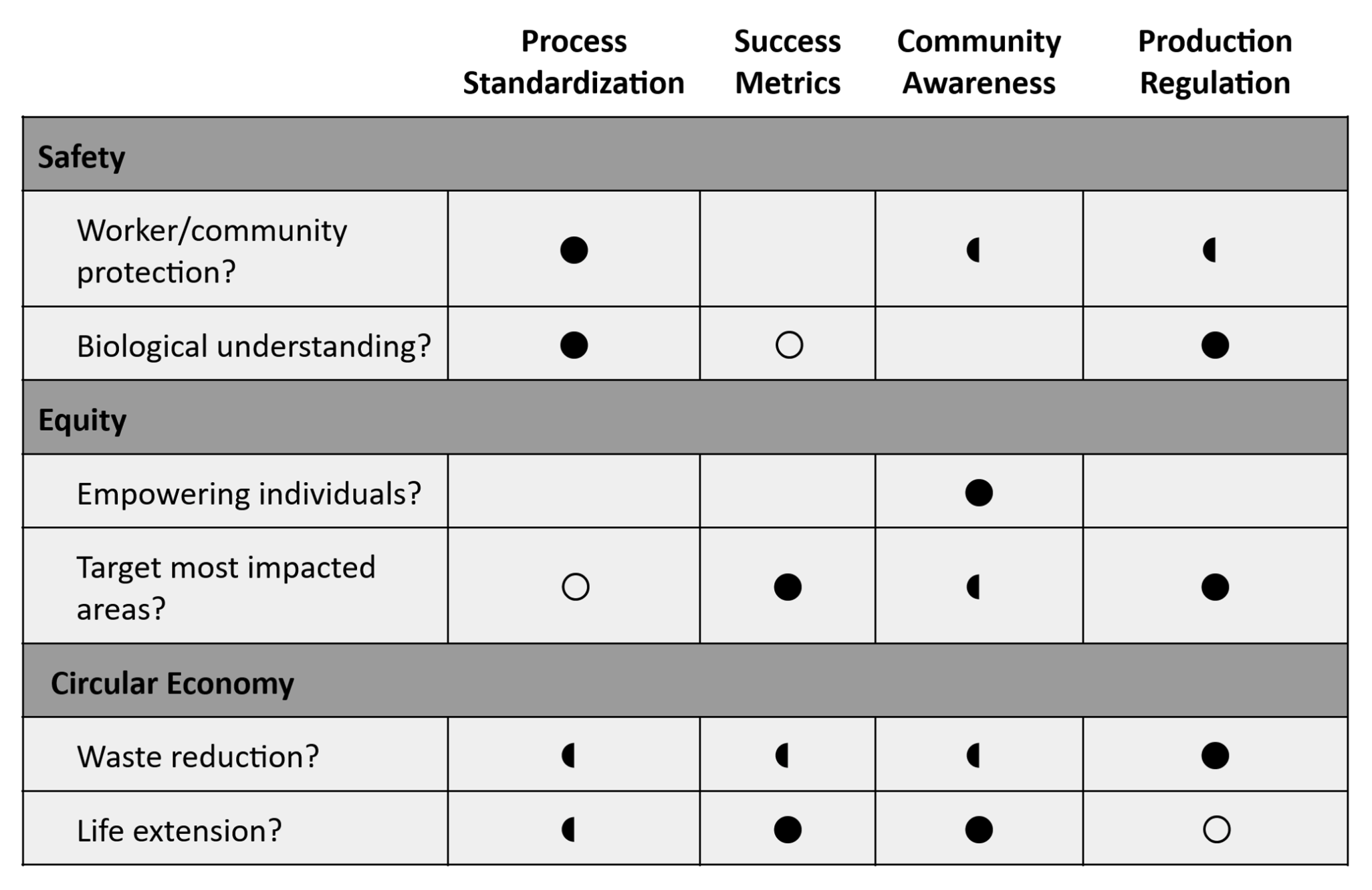
I’d focus on Process Standardization, as safety is the absolute first priority. Following that, between Success Metrics and Community Awareness, both have potential to contribute to a circular economy, but I’d like to prioritize Success Metrics for its potential to better target impacted areas down the line. So I’d work on a more technical level to develop more effective processes and data collection (which would likely involve academic institutions/environment-focused agencies).
I’m wary of how effective we’d be in a global setting, especially since my perceived impact with this depends on how well we can affect overseas institutions, where I believe most of fast fashion waste is made and accumulated.
The error rate for polymerase is 1:106, or 1 out of every 1,000,000 base pairs might be wrong. Meanwhile, the human genome spans billions of base pairs, with a diploid being about 6.3 Gigabase pairs (pr 3.2 Gigabase pairs for a haploid)1. However, the polymerase can go through a proofreading process where it uses exonuclease to remove the nucleotide through the entire monophosphate base2, essentially, allowing the sequence to “backspace” before continuing.
How many different ways are there to code (DNA nucleotide code) for an average human protein? In practice what are some of the reasons that all of these different codes don’t work to code for the protein of interest?
An average human protein is about 1036 bp.
Codons are sets of 3 base pairs, so this is about 345 amino acids.
However, many of these amino acids are redundant and can be expressed through multiple base pairs, with 6 being the highest number of variations (in Arginine). We can roughly calculate the amount of variations in a single amino acid through 64 codons/20 amino acids = 3.2 codon variations per amino acid.
This presents about 3.2 variations 345 amino acids, which gives my calculator an overflow error (about 10174).
So that’s clearly an excessive amount of variation for a single protein. However, organisms have developed something called “codon usage bias”, or preference for certain codons evolved over time. This can be due to the following reasons3:
Oligonucleotides are defined as DNA chains with a length under 200 nucleotides5. Oligo synthesis began with solid-phase synthesis, with additional methods (phosphodiester, phosphotriester, phosphitetriester, phosphoramidite) developed up until the 1980s. Currently solid-phase synthesis using the phosphoramidite method is the most common method; the process was leveraged to implement the first automated DNA synthesizer and has since been optimized for high DNA production volume/thermal control5.
Longer chains have reduced theoretical yield, since each additional nucleotide has an additional “elongation cycle efficiency” (think error rate) that stacks up5. This is calculated with the equation theoretical yield = elongation cycle efficiencynt. Assuming efficiency of 99%,
The phosphoramidite method in particular becomes ineffective beyond 200 base pairs. As a result, more recent alternatives (e.g. enzymatic) are being explored, as research turns to using longer sequences.
If we further calculate using the above equation, the yield becomes
or effectively zero. At such a high length, the individual “error rates” compound, leaving no chance for success. Current efforts try to improve the process, i.e. increasing the elongation cycle efficiency, or use workarounds like making batches of shorter segments to link together5.
Not sure I’m fully understanding the question, but given there are 64 possible codons for amino acids yet only 20 amino acids, I’d create a code where all possible codons are inputted and outputted as “plaintext” and “ciphertext”, with the encryption “key” being the 20 amino acids they could be interpreted as. Something like the drawing below:
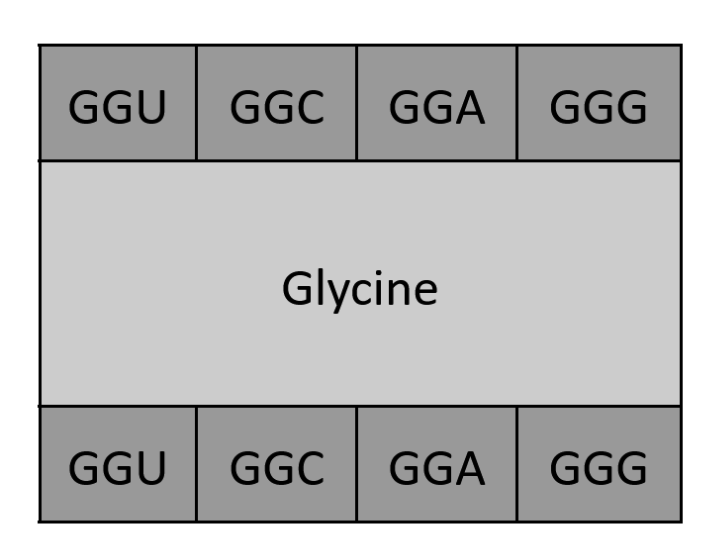 This could even be further streamlined for repeating letters:
This could even be further streamlined for repeating letters:
 (Prof. Church’s slides and paper at [6] used for reference.)
(Prof. Church’s slides and paper at [6] used for reference.)
[1] Piovesan A, Pelleri MC, Antonaros F, Strippoli P, Caracausi M, Vitale L. On the length, weight and GC content of the human genome. BMC Res Notes. 2019 Feb 27;12(1):106. https://doi.org/10.1186/s13104-019-4137-z
[2] Hopfield, JJ. Kinetic proofreading: a new mechanism for reducing errors in biosynthetic processes requiring high specificity. Proc Natl Acad Sci USA. 1974 Oct; 71(10):4135-9. https://doi.org/10.1073/pnas.71.10.4135
[3] Ford, T. Plasmids 101: Codon usage bias. addgene Blog. 2018 Sept. https://blog.addgene.org/plasmids-101-codon-usage-bias
[4] Athey J, Alexaki A, Osipova E, Rostovtsev A, Santana-Quintero LV, Katneni U, Simonyan V, Kimchi-Sarfaty C. A new and updated resource for codon usage tables. BMC Bioinformatics. 2017 Sep 2; 18(1):391. https://doi.org/10.1186/s12859-017-1793-7
[5] Hoose, A., Vellacott, R., Storch, M. et al. DNA synthesis technologies to close the gene writing gap. Nat Rev Chem 7, 2023 Jan; 144–161. https://doi.org/10.1038/s41570-022-00456-9
[6] Acevedo-Rocha CG, Budisa N. Xenomicrobiology: a roadmap for genetic code engineering. Microb Biotechnol. 2016 Sep; 9(5):666-76. https://doi.org/10.1111/1751-7915.12398
| Attempt | Result | Description |
|---|---|---|
| 1 | 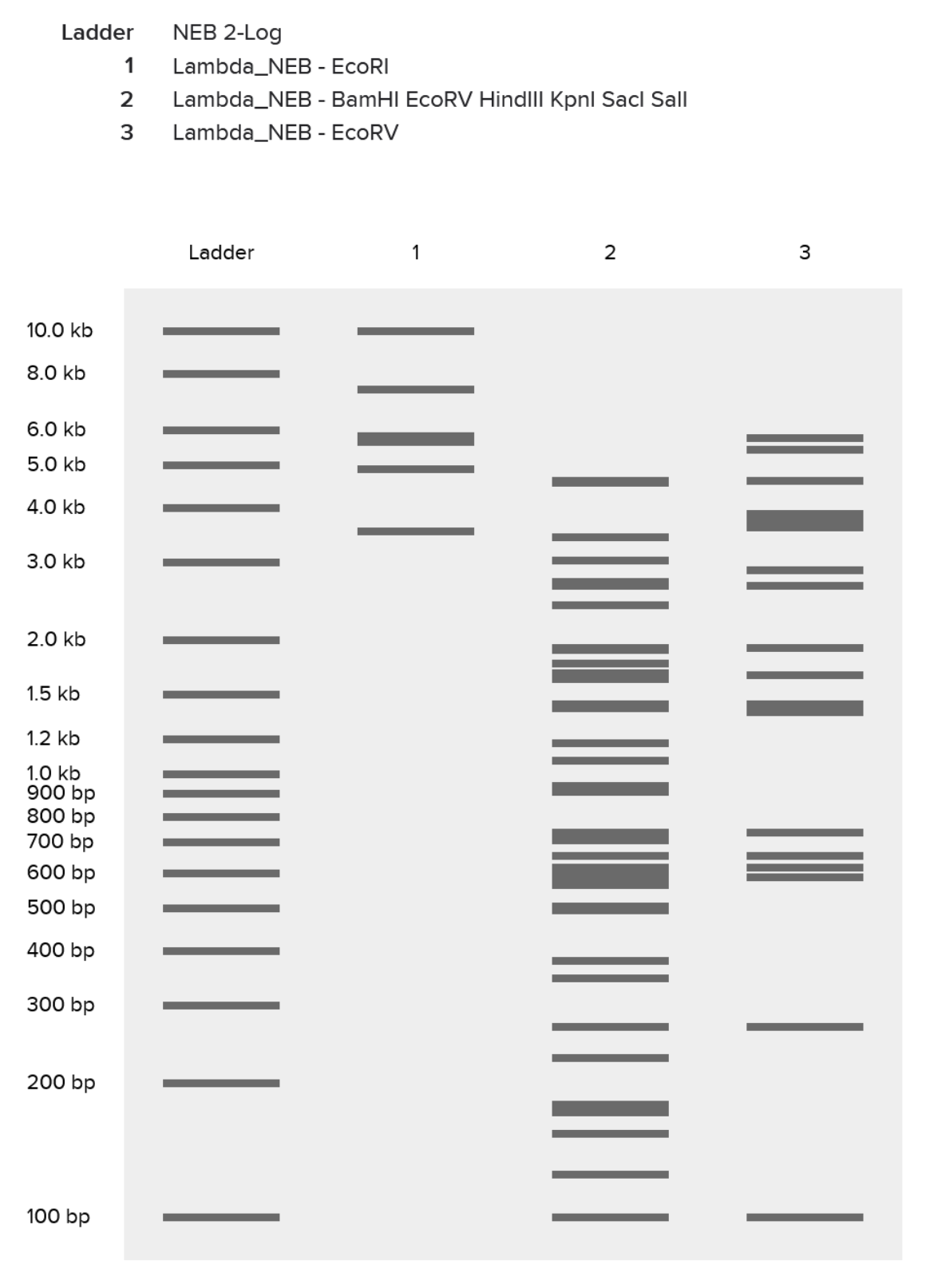
| Had an initial mess-up where I tried to “speedrun” the process and ended up with a ladder packed with the effects of multiple restriction enzymes. |
| 2 | 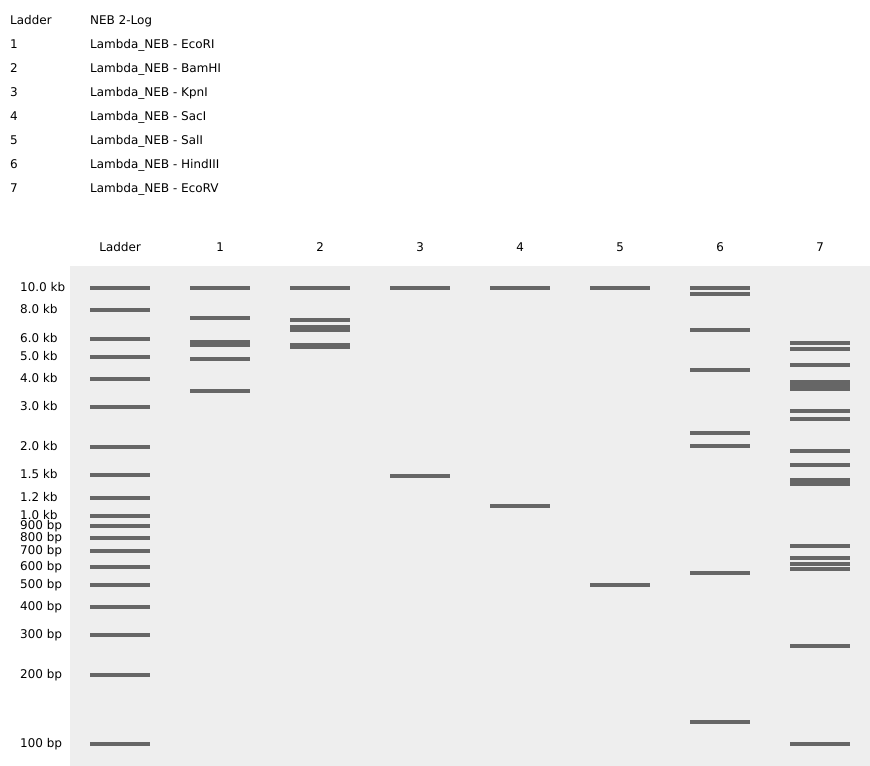
| Finally got success with all of the listed enzymes, separately. |
| 3 | 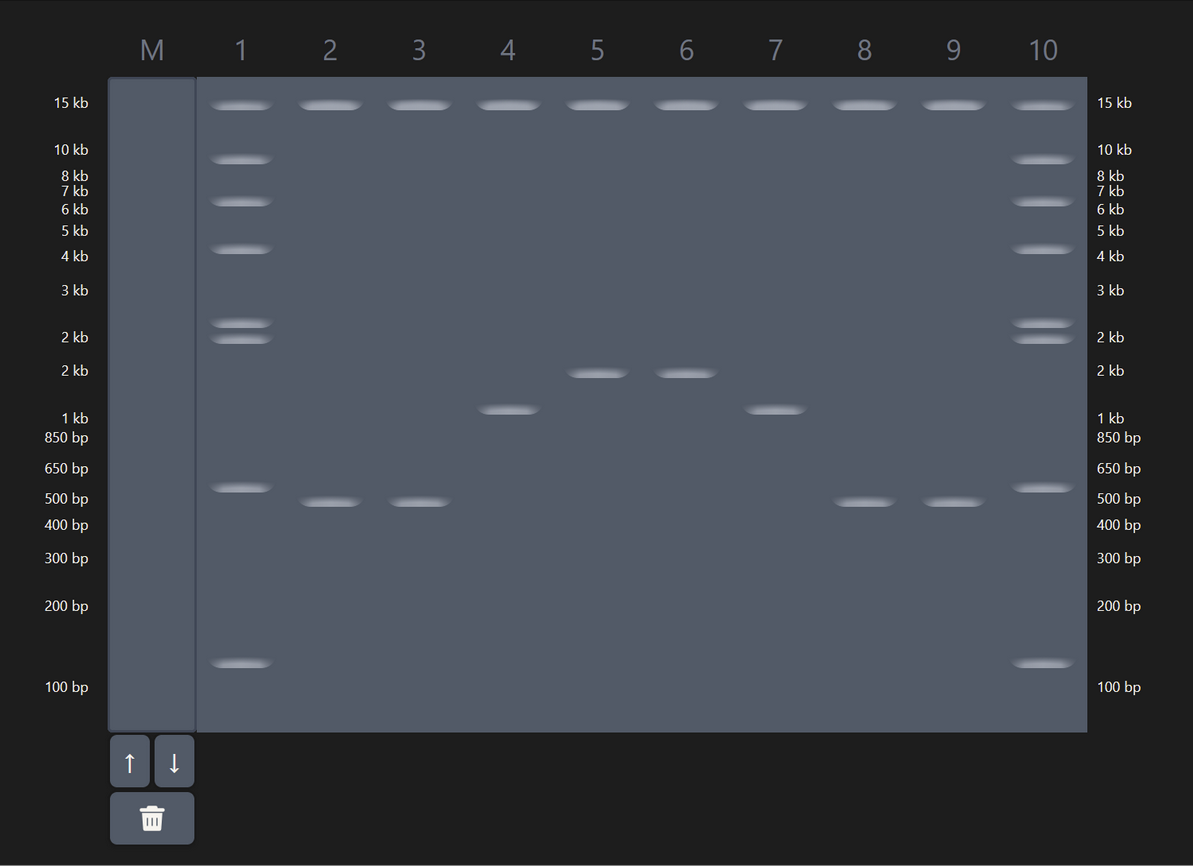
| Some experimentation on Ronan’s website got me this pattern that sort of looks like a pair of pants. In hindsight I should’ve definitely explored results from a combination of enzymes (e.g. EcoRI and HindIII together), which would’ve given me a bigger range of visual results. |
| 4 | 
| Replicated “sort-of pants” on Benchling, and my final result. |
3.1. Choose your protein.
I recently read about snake venom and how its majority composition of proteins/enzymes make it (theoretically) edible, since it can be digested in the stomach. That was a pretty fun fact. For this assignment, I picked irditoxin, a three-finger toxin that is selectively neurotoxic towards birds and lizards (but not mammals).
I found two subunits on UniProt and went with A.
3.2. Reverse Translate: Protein (amino acid) sequence to DNA (nucleotide) sequence.
I located irditoxin subunit A in the European Nucleotide Archive, with the following DNA sequence:
3.3. Codon optimization.
Codon optimization can be useful in controlling gene expression within a sequence (both increasing and decreasing it). It can also make mRNA production more efficient and impact translation speed, which can in turn affect things like folding speed (fast-translated sequences fold while waiting for slow-translated sequences).
I tried out IDT’s Codon Optimization Tool. IDT recognized a couple different stop and start codons, so I picked the sequence between the first codon (ATG, a start) and the first stop codon (TGA at position 330). The sequence was optimized for E.coli to go for a standard, well understood, commonly used organism.
Shortened old sequence:
Optimized sequence:
Another mess-up: IDT denied the optimized sequence due to its complexity, which means this sequence isn’t currently manufacturable and needs to be further redesigned. Seems some of my enzyme recognition sites weren’t ideal.
3.4. You have a sequence! Now what? What technologies could be used to produce this protein from your DNA? Describe in your words the DNA sequence can be transcribed and translated into your protein. You may describe either cell-dependent or cell-free methods, or both.
As we’re working with a neurotoxin, and not for high-volume production, I’d probably turn to a cell-free method.
4.1-2. Create a Twist account and a Benchling account, Build Your DNA Insert Sequence
From the downloaded FASTA file:
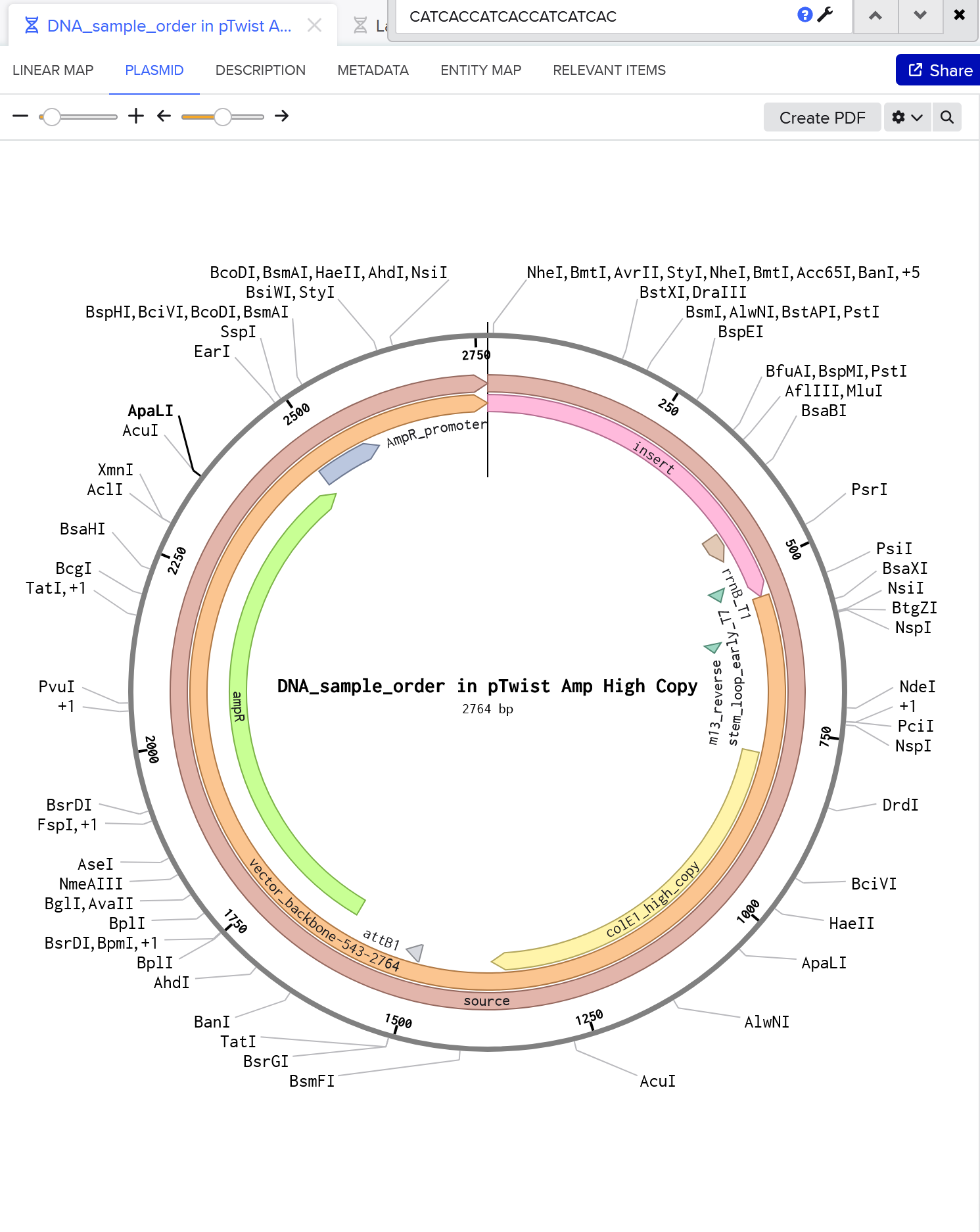
My expression casset can be accessed here.
4.3-6. Select The “Genes” Option, “Clonal Genes”, Import your sequence, and Choose Your Vector
Here’s my plasmid. She’s beautiful!
I think bioindicators are an interesting group of organisms, and sequencing them could help us isolate genes that react to surroundings and get used for a more standardized, widespread environment monitoring tool. E.g. microalgae can detect wide range of water quality issues, from heavy metals to nanoparticles, yet “only a few species have been fully sequenced without any gaps”1.
I’d likely use a NGS method to handle the sequencing of the entire genome, and of the multiple species that we come across at that. So potentially something like PacBio, which is third-generation. Both the sample used and the library need to be prepared, with the sample needing to be purified and the DNA needing to be fragmented to length and end-capped. The DNA is decoded through a polymerase that runs along the sequence. As it interacts with each nucleotide, it emits light, which is recorded live and appended onto the current sequence. The end result is a straightforward sequence of DNA nucleotides, given in a file that can be read on any notepad app.
I’m continuously interested in biomaterials as an alternative to things like plastic. There’s been a lot of work on getting plastic that is biodegradable, and I’m wondering if there’s a way to go about it from the opposite direction, like fortifying kombucha leather to last longer.
Solid-phase synthesis using the phosphoramidite method seems to be the go-to method, so I’d stick with that. The steps are coupling the base with phosphoramidite, capping unreacted sites, oxidating the phosphate, deblocking, and then repeating as needed. The limitation to this process is that it decreases in efficiency past a certain number of bp (~200 as discussed last week) so could potentially be difficult as the needed sequence becomes longer.
This feels like a touchy subject in line with our ethical considerations from last week. The responsibility of human genome sequencing seems enormous, so I’ll consider other organisms. I’m thinking of how filter feeders play an important role in the water ecosystem, essentially “purifying” the water. Could something like that be intentionally edited into plants (or other microorganisms) to boost its “purifying” effect on the air?
I’m unsure of this part as I’m not too familiar with the work needed to introduce this behavior into land organisms. I believe CRISPR-Cas9 is also a go-to for gene editing, so would probably be a popular approach regardless. The process begins with a guide RNA finding the target sequence in the DNA, at which Cas-9 “cleaves” the segment. Then either new DNA can be added (replacing the segment), or the DNA strands repair (deleting the segment). For preparation, the appropriate guide RNA needs to be sourced. A limitation of CRISPR-Cas9 is in its effectiveness; it has the potential to insert DNA incorrectly, which can lead to mutations when applied to human genome sequencing.
[1] Evangelia Stavridou, Lefkothea Karapetsi, Georgia Maria Nteve, Georgia Tsintzou, Marianna Chatzikonstantinou, Meropi Tsaousi, Angel Martinez, Pablo Flores, Marián Merino, Luka Dobrovic, José Luis Mullor, Stefan Martens, Leonardo Cerasino, Nico Salmaso, Maslin Osathanunkul, Nikolaos E. Labrou, Panagiotis Madesis, Landscape of microalgae omics and metabolic engineering research for strain improvement: An overview, Aquaculture, Volume 587, 2024, https://doi.org/10.1016/j.aquaculture.2024.740803.
I used https://ginkgoartworks.com/ to draw a mushroom and imported the program into Colab. Since the bacteria names don’t register as RGB colors, I had to “color-correct” well_colors to get the visualization to show up (but I assume both versions will work as long as the PCR tubes are physically in order).
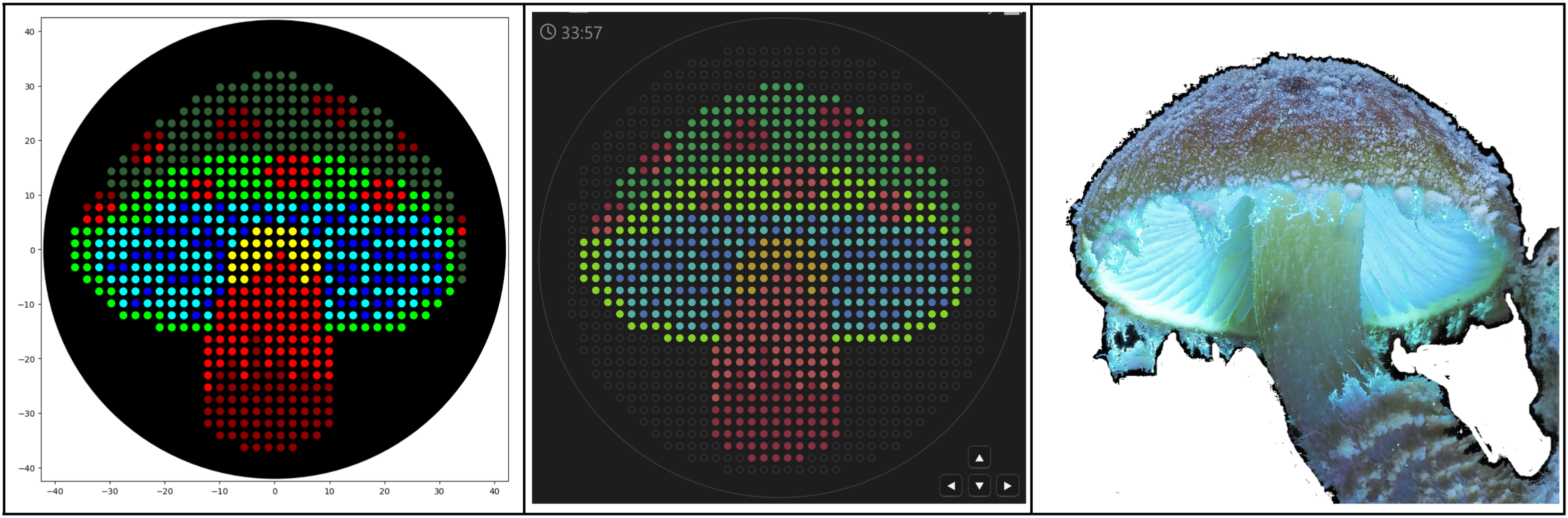
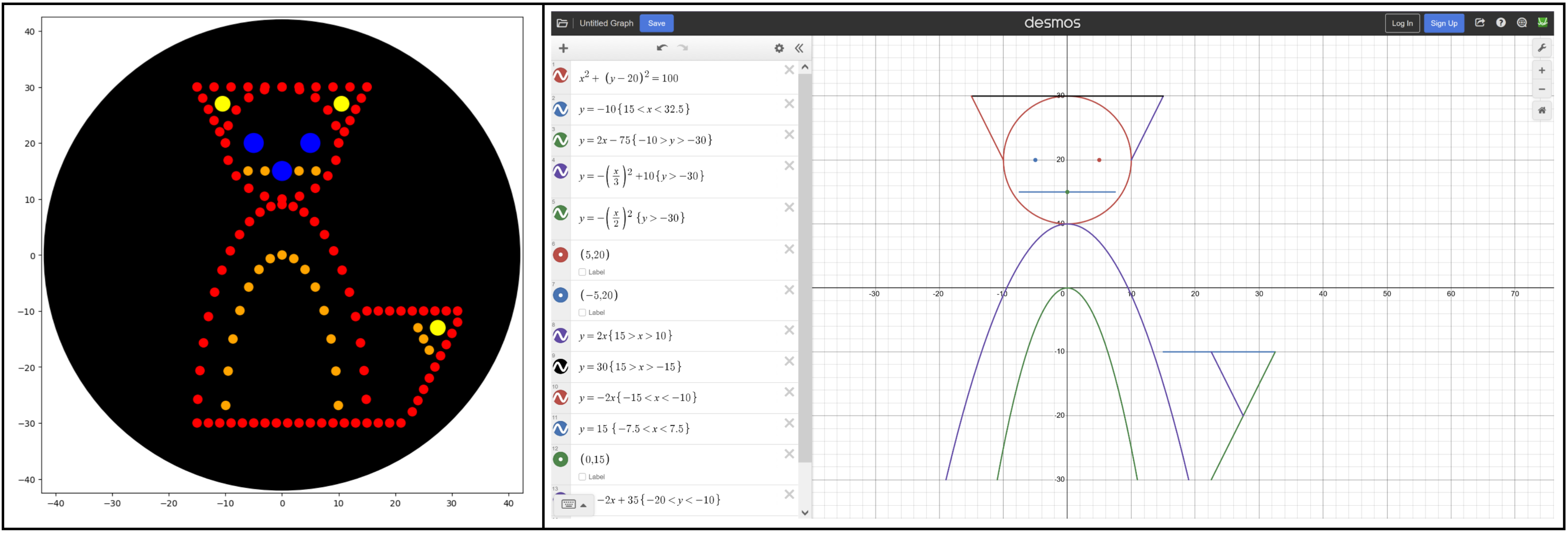
I tried to play around with math functions to create a new design, like the Mathematical Heart sample. I drew up a cute fox in Desmos graphing calculator using the following functions, making sure to scale them to the 40 mm limit. Transferring that to Colab was a bit more difficult, and I had to play around with the functions, ranges, and dispense volume to find something that looked good.
Some notes from the process:
draw() function (like the Mathematical Heart).pipette_20ul.current_volume) and is handled all at once in the draw() function.Colab link for both projects here, including the color-corrected version for the mushroom.
I designed some artwork for the 1536-well plates on the Nebula, which were made during the Saturday 2-6 pm Cloud Lab session. The first one was a firefly squid, inspired by bioluminescent photos I’ve seen of them underwater. Link to gallery image here.
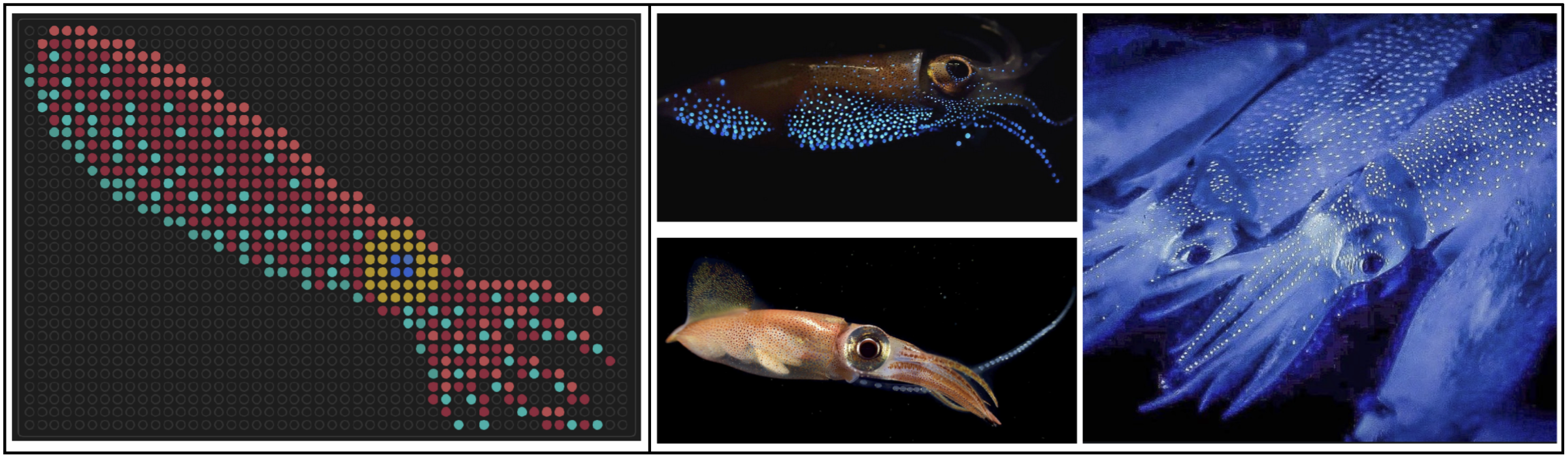

I also made a second one resembling the Chinese jianzhi for Lunar New Year. I experimented with two color sets, to see how bacteria with similar coloring would contrast against each other. Link to gallery images here and here.


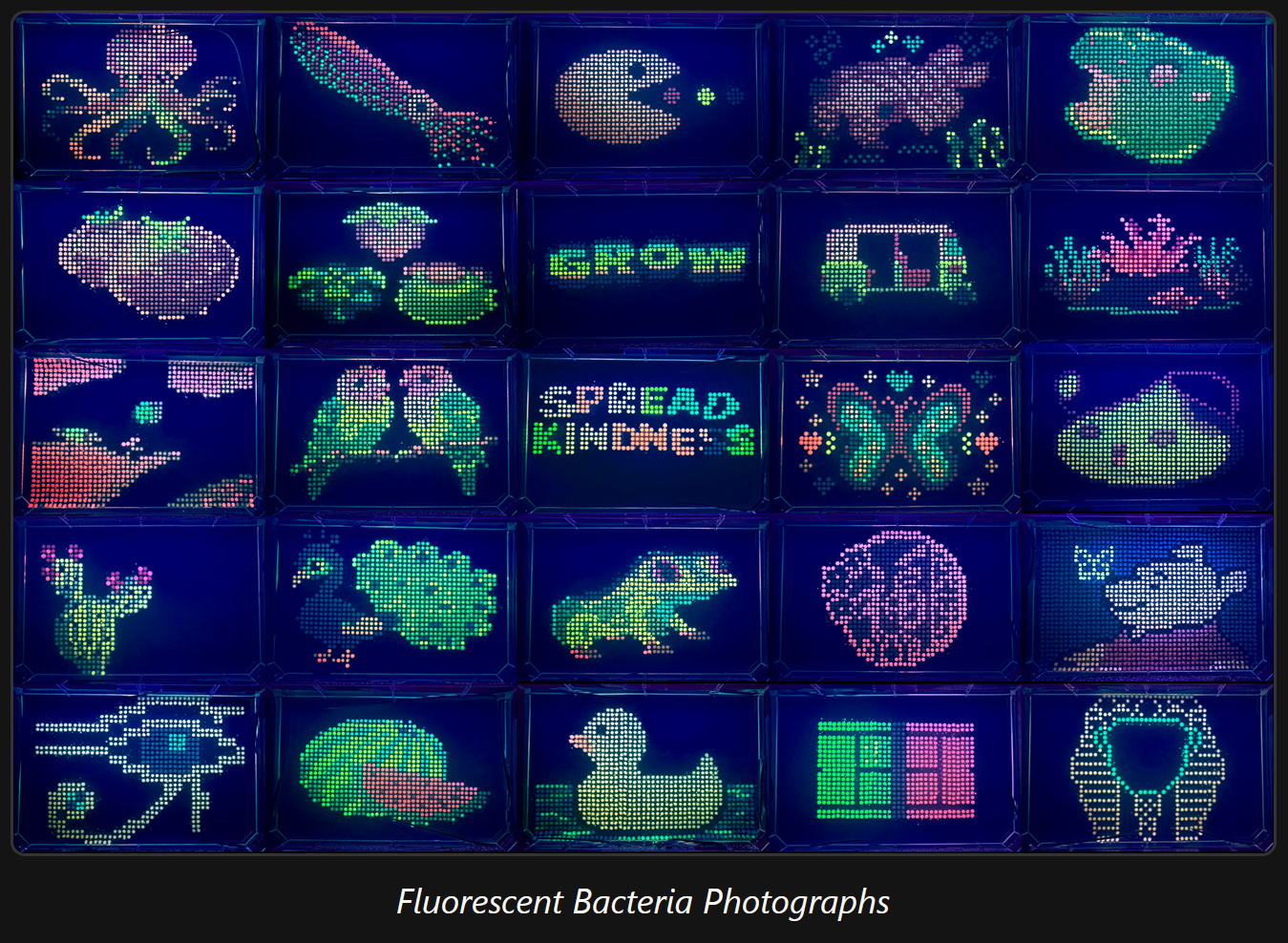
Here’s all the fluorescent artwork from that session!
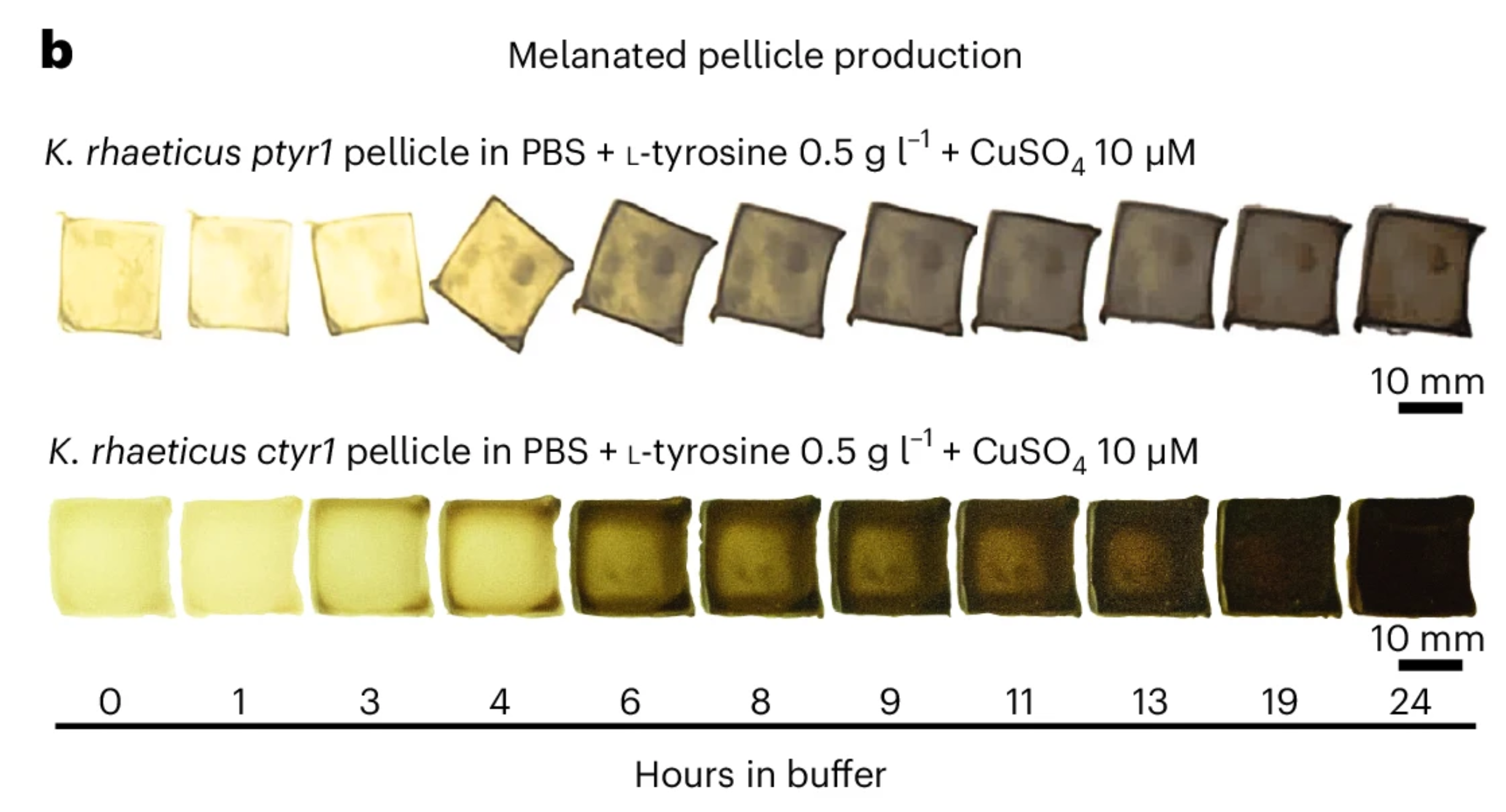
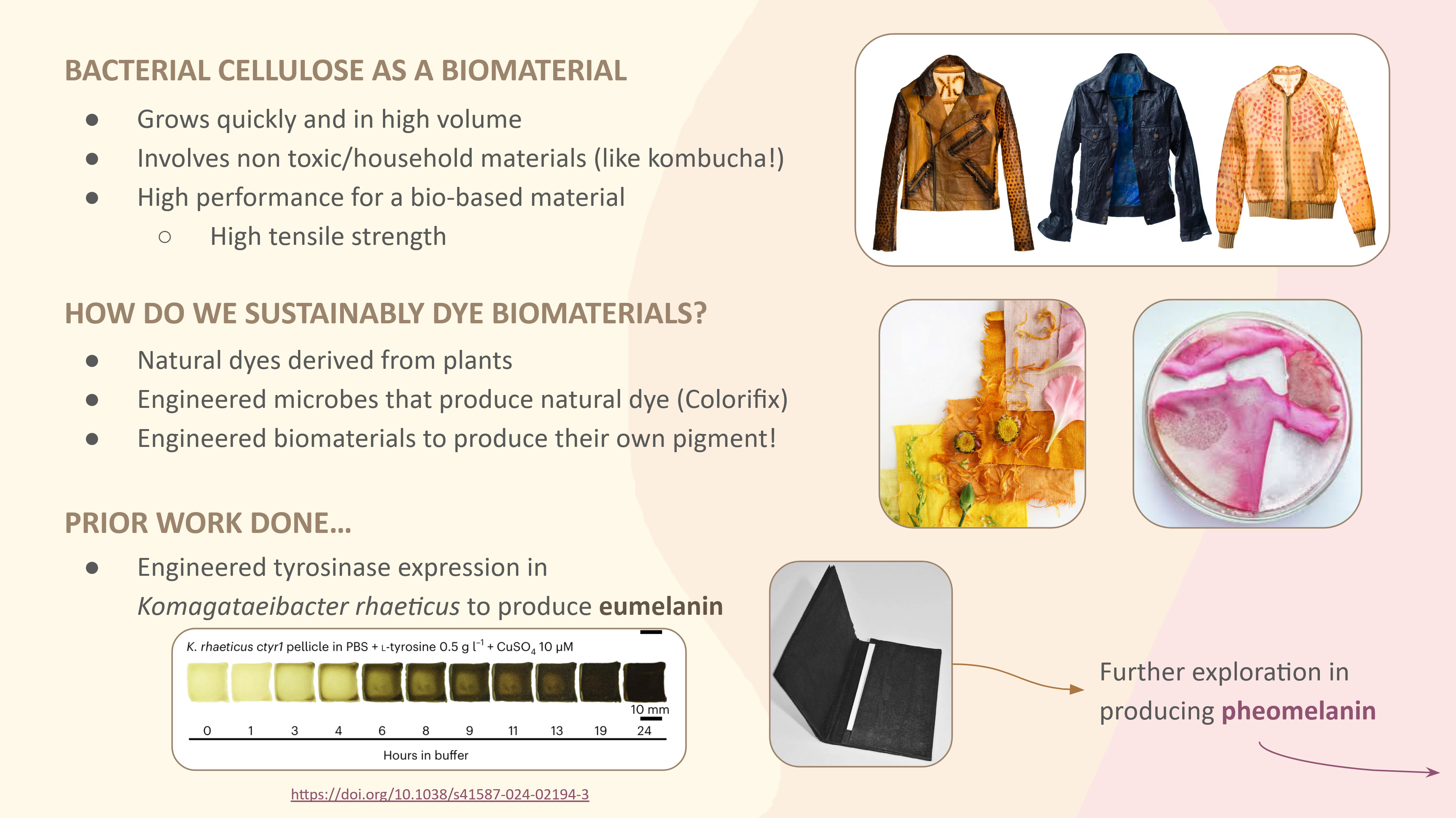
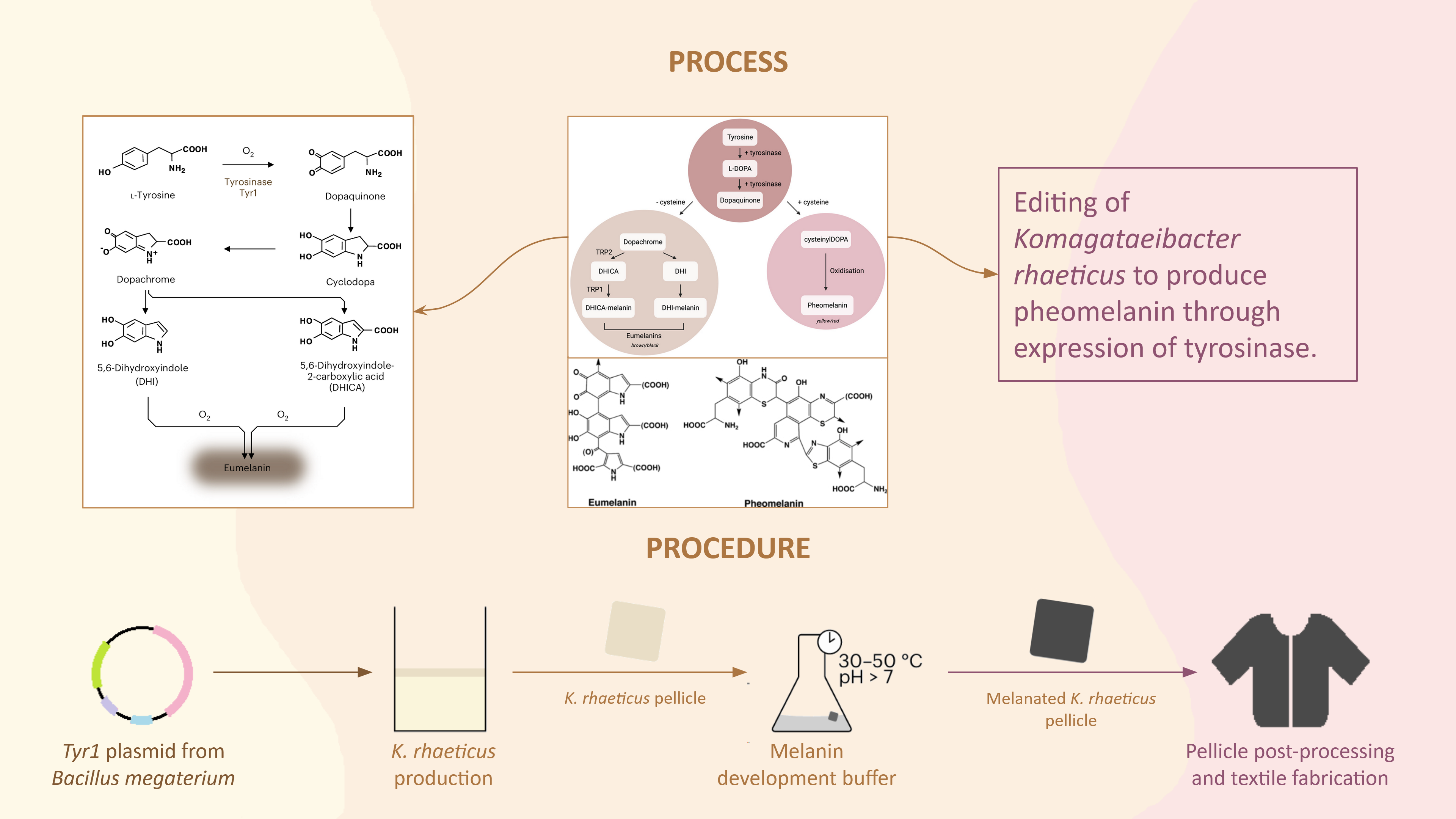
This paper explores “dyeing” bacterial cellulose, a bioplastic alternative to leather, which I found pretty interesting. Instead of applying an independent biodegradable dye, the researchers engineered Komagataeibacter rhaeticus to develop eumelanin (dark melanin), which gives a range of shades seen in the photo above. Opentrons is used in the production of the eumelanin development buffer, in which the K. rhaeticus pellicle is incubated to “dye” itself. The robot mixes the buffer, cells, and supernatant within a reaction plate while maintaining a constant low temperature to prevent initial eumelanin growth.
Walker, K.T., Li, I.S., Keane, J. et al. Self-pigmenting textiles grown from cellulose-producing bacteria with engineered tyrosinase expression. Nat Biotechnol 43, 345–354 (2025). https://doi.org/10.1038/s41587-024-02194-3
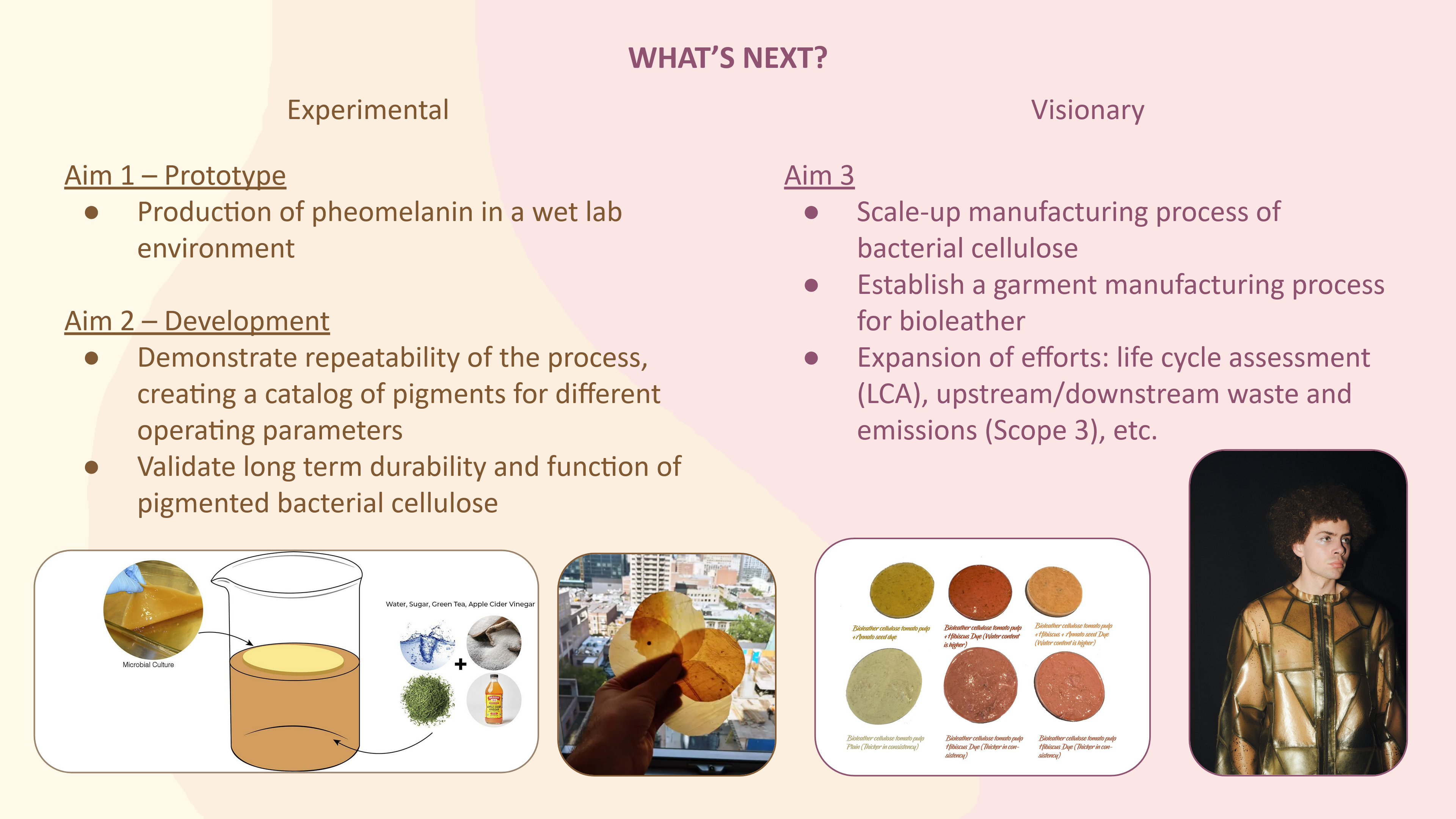
More research is needed on my part for this, but I’d like to explore scaling up or going in depth with the range of results for my project (e.g. if self-pigmenting, then trials to develop swatches of colors). This would require a lot of samples, and liquid handlers like the Opentrons would be necessary for producing all the samples indentically.
My slides for the ideas below can be seen here.
Coloring Bioplastic/Biotextiles (with an art-focused approach)
Self-pigmenting Bacterial Cellulose: Building on the above paper, further development with dyed bacterial cellulose using pheomelanin instead of eumelanin for a different color range. Likely this is already being explored, so as an ambitious goal Komagataeibacter rhaeticus could be edited to express both pheomelanin and eumelanin, allowing you a 2D range of colors.
Structural Color on Textiles as Biopigment: Naturally occuring structural color is tied to the genome, so we could intentionally induce colors as a natural, biodegradable dyes for textiles. This paper highlights a bacteria that naturally form to output structural color, and this paper explores gene knockout to change the color expressed by one of the bacterias Flavobacterium IR1. A potential project could explore different colors on these bacteria, or find a way to introduce the bacteria to textiles without affecting its formation.
Environmental Sensors (Algae biosensors?)
Polyester Biodegradation
Integration with Byproduct Biodegradation: Ideonella sakaiensis is a bacteria that can break down PET plastic through a two step process involving PETase and MHETase enzymes. The end products include carbon dioxide, water, and methane, which in itself a pollutant. Methane itself is a subject of research, with methanotrophs being a type of bacteria that metabolize methane. I’m wondering if the bacteria used for breaking down plastic can be somehow integrated with the added function of breaking down methane through gene engineering.
Polyester-Eating Enzymes: This is a less familiar topic for me, but current work on enzyme degradation focuses on improving the performance of natural enzymes, e.g. its thermostability, pH control, etc. Since there’s such a wide range of work being done, I’m sure there’s some further testing that could be done on an underfocused bacteria/performance metric/modification method.
Answer any NINE of the following questions from Shuguang Zhang:
The Dalton is an atomic mass unit that converts from mass using Avogadro’s number. So 500 grams = 500 * 6.022 * 1023 Daltons / 100 Daltons/amino acid = 5 * 6.022 * 1023 amino acids = 3.011 * 1024 amino acids.
Our bodies don’t interact with the meat that way. It’s a matter of absorbing the energy and nutrients from the cells, not carrying the cells over to reuse them. The protein also goes through our stomach and digestive track, which is a process more intended to break down what we eat and extract from it.
The natural amino acids are determined by codons, which are determined by three nucleotides (of which can be adenine, uracil, guanine, cytosine). This gives 4 x 4 x 4 = 64 total codons, but redundancy among codons produces only 20 unique amino acids. More is definitely possible, but 20 seems to encapsulate all the amino acids we need.
Natural amino acids come from the range of nucleotides across 3 spaces, 4 * 4 * 4 = 64. We can design new amino acids in a variety of ways, one notable way being reversing the chirality (from L-amino acids to D-amino acids), which could sort of be applied to any amino acid in existence for a “new” design.
The 1953 experiment making “Primordial Soup” proved that amino acids (and other organic compounds) could come from natural reactions under ideal conditions with inorganic compounds (methane, ammonia, and hydrogen). It seems like there’s a couple of different ways organic compounds could be created abiotically.
If the helices are usually right handed, then this one will be left handed (opposite to what is normal).
Additional helices can always form in new proteins, though I don’t think you can “introduce” new helices to a protein whose folding pattern is known. But since new proteins are made all the time, yes, there will frequently be helices in their shapes, which can be figured out through protein modeling/prediction.
Not exactly sure why it became this way, but it definitely stays this way for ease of transcription and translation. One type of chirality tends to be dominant so that all templates and future proteins/molecules can be identical and interact with each other. Otherwise, left- and right- handed molecules have the exact same properties, but being able to piece together requires the same handedness.
Initially, you have multiple β-strands that can arrange laterally. These strands can sort of reach left and right and “link arms” with neighboring strands through strong hydrogen bonds. The repeated structure in each strand allows for repeated patterning.
β-sheets stem from a presence of strands in the protein with hydrogen backbones, so I’m guessing amyloid diseases often have that chemical makeup. Then it’ll tend to form the sheets just because it’s a very stable configuration.
Motifs appear to be ways to arrange the strands laterally against each other. This is easy to do in concept but might not reflect motifs that can occur naturally. I’m imagining a potential concept where you take a sheet and fold two ends to make a cylinder–that’s the current beta barrel design. If you imagine a long, rectangular sheet, though, there’s a way to fold it to make sort of a ribbon (like alpha helices’ shape). I wonder if it’s possible to get to that shape with very long but few beta strands.
I picked crystallin, which is a protein in the eye responsible for the movement of your iris as you focus. It’s notably transparent, being part of the eye lens, and water-soluble, which was a callback to our lecture. I picked the protein because I was interested in how cataracts were formed.
The specific protein I went with for the following questions is P02511, or Alpha-crystallin B (in humans).
The AA sequence from UnitProt is
sp|P02511|CRYAB_HUMAN Alpha-crystallin B chain OS=Homo sapiens OX=9606 GN=CRYAB PE=1 SV=2 MDIAIHHPWIRRPFFPFHSPSRLFDQFFGEHLLESDLFPTSTSLSPFYLRPPSFLRAPSW FDTGLSEMRLEKDRFSVNLDVKHFSPEELKVKVLGDVIEVHGKHEERQDEHGFISREFHR KYRIPADVDPLTITSSLSSDGVLTVNGPRKQVSGPERTIPITREEKPAVTAAPKK
Using the Colab notebook, the protein is 175 amino acids long with the most common amino acid being P (and appearing 17 times).
According to UniProt, it’s part of the small heat shock protein (HSP20) family, along with all other Alpha-crystallin B proteins. However, according to the Transporter Classification Database, it’s part of the α-Crystallin Chaperone (CryA) family (where other Alpha-crystallin B proteins don’t appear).
Homology refers to protein sequences that likely have a common ancestor (identified through having similarities in sequence/structure?). Using the BLAST software gives 250 results for similar proteins, with results primarily appearing to be Alpha-crystallin B in different animals.
This step was particularly difficult for me, as I didn’t always understand how to get to the answer based on what I had on the screen.
The structure seems to be initially solved in 2009 but has increased members up until 2025. Some particularly high resolution structures were identified in 2012 and 2014 through X-ray diffraction, with a resolution of 1.0 - 1.5 Å.
I’m not entirely sure how to identify this…at least visually, I didn’t identify any other components that that seemed to stick out as an entirely different molecule.
Using the Structural Classification website, it belongs to the “Alpha crystallin-like” family, further within the “Hsp20 chaperone-like” family.
I chose to use PyMol to open my structure, getting the structure below.
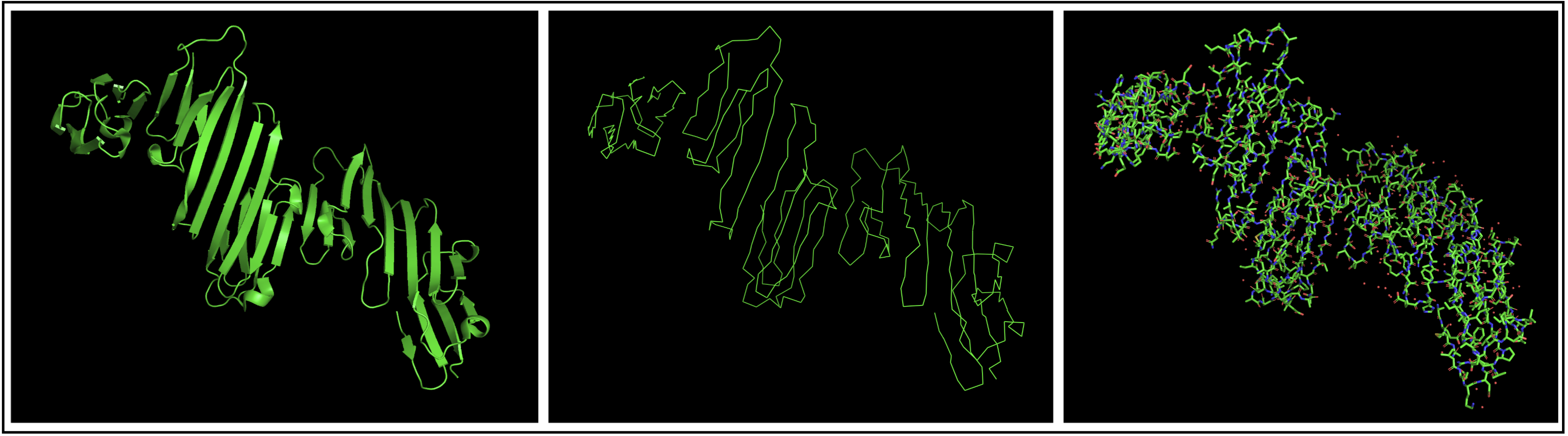
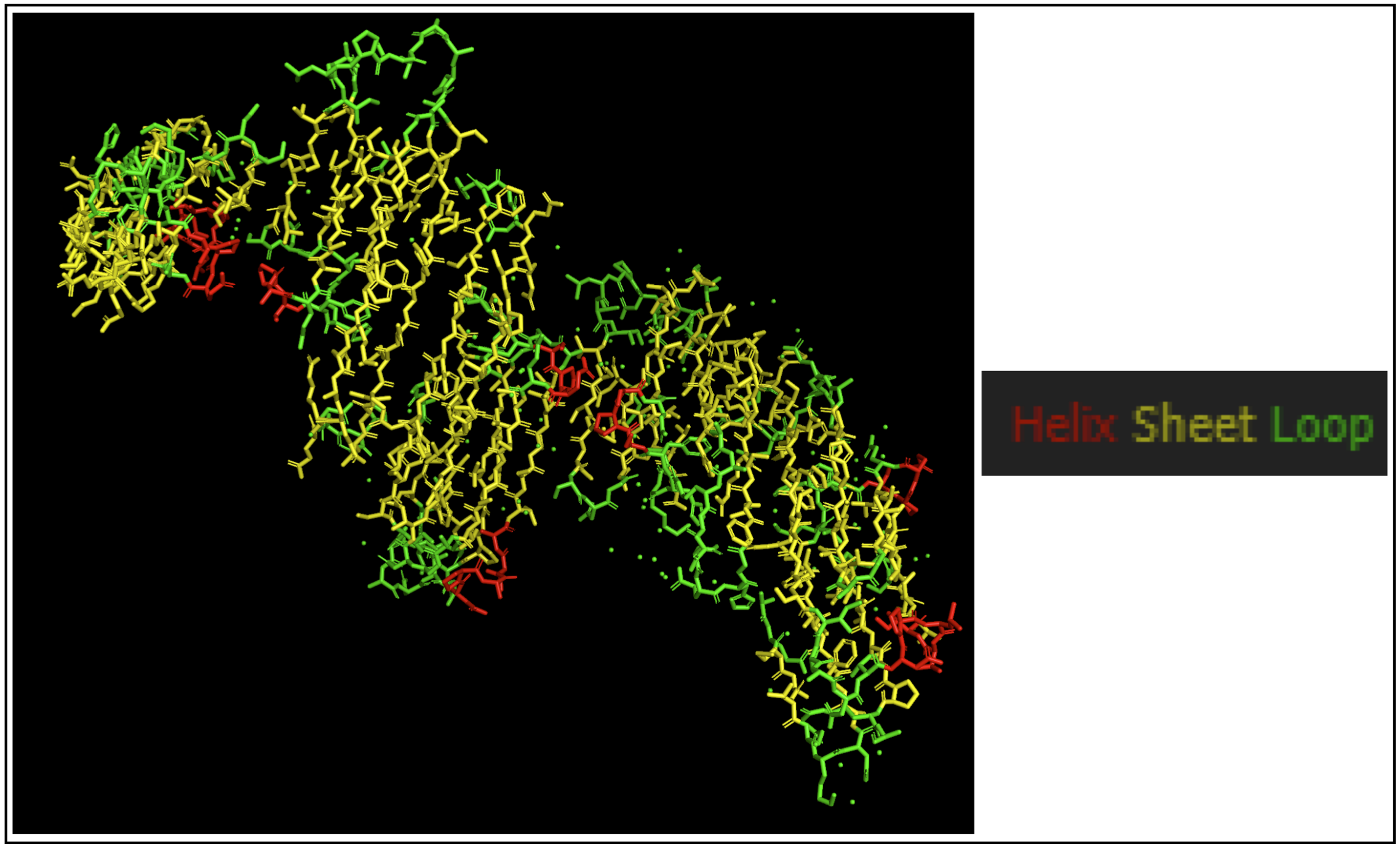
The protein seems to mostly be composed of sheets with some helices.
I colored hydrophobic residues in red and hydrophillic residues in green.
select hydrophobic, resn Gly resn Ala resn Val resn Leu resn Ile resn Pro resn Phe resn Met resn Trpselect hydrophillic, resn Ser resn Thr resn Asn resn Gln resn Cys resn Gly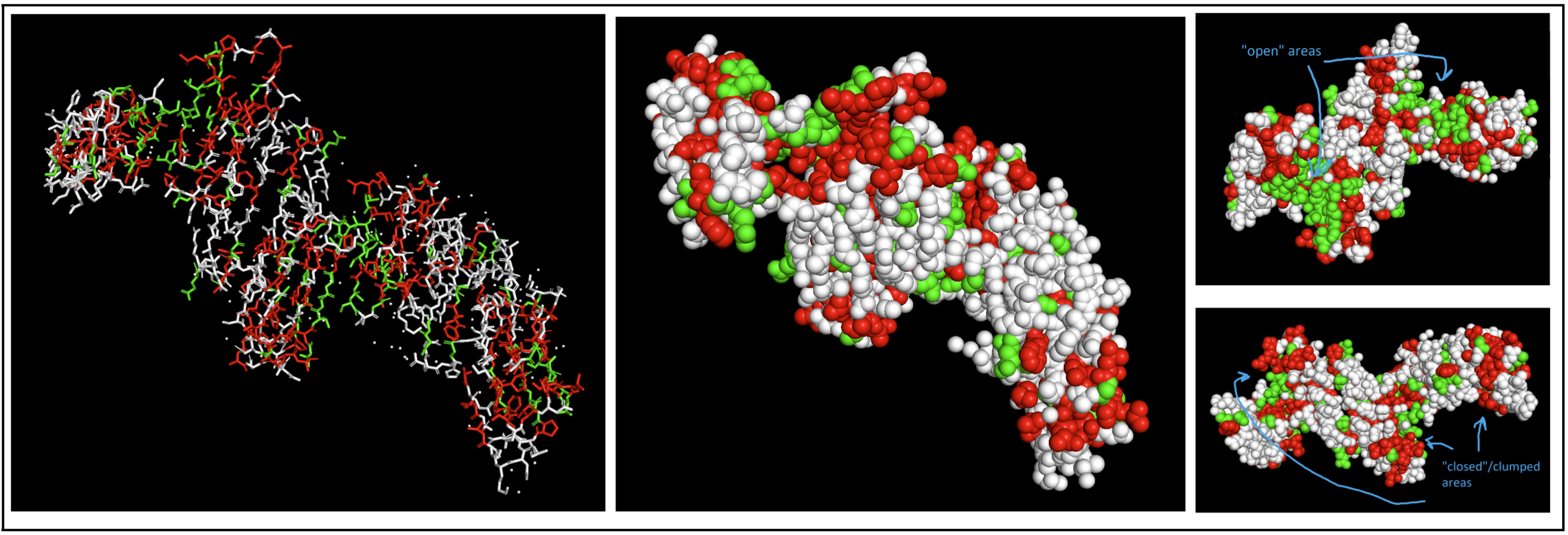 I had to switch to a spheres visualization to better see how molecules were interacting. It was a little hard for me to see a significant pattern, but I do feel like the hydrophilic residues have more “open” facing areas, whereas the hydrophobic residues were more clumped (both together and with neighboring residues).
I had to switch to a spheres visualization to better see how molecules were interacting. It was a little hard for me to see a significant pattern, but I do feel like the hydrophilic residues have more “open” facing areas, whereas the hydrophobic residues were more clumped (both together and with neighboring residues).
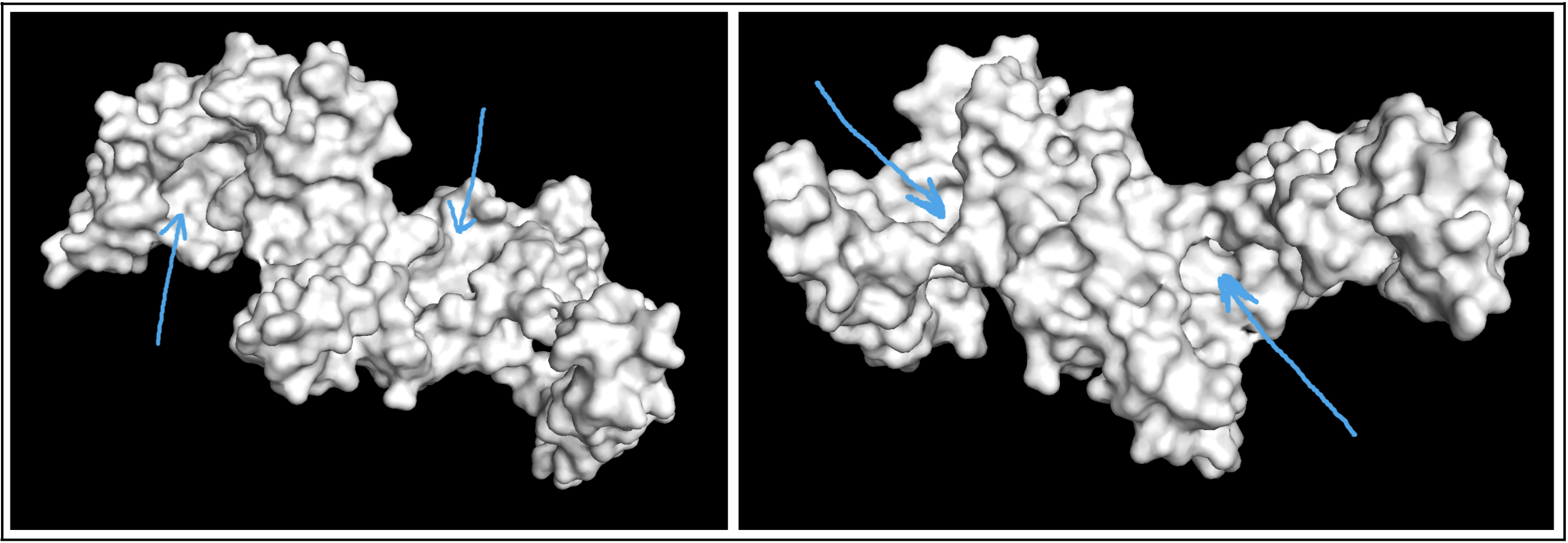
Visualizing the protein as a surface was really helpful! I could easily find a couple areas that could be binding pockets. It’s a little difficult to show it accurately in a photo, but I indicated potential areas below:
In this section, we will learn about the capabilities of modern protein AI models and test some of them in your chosen protein.
I had to pivot here as I originally chose vicilin from lentil beans (Lens culinaris), which was a type of globulin storage protein. It has a rather long sequence (shown below) and as a result made reading some results pretty challenging. I ended up switching back to crystallin from Part B.
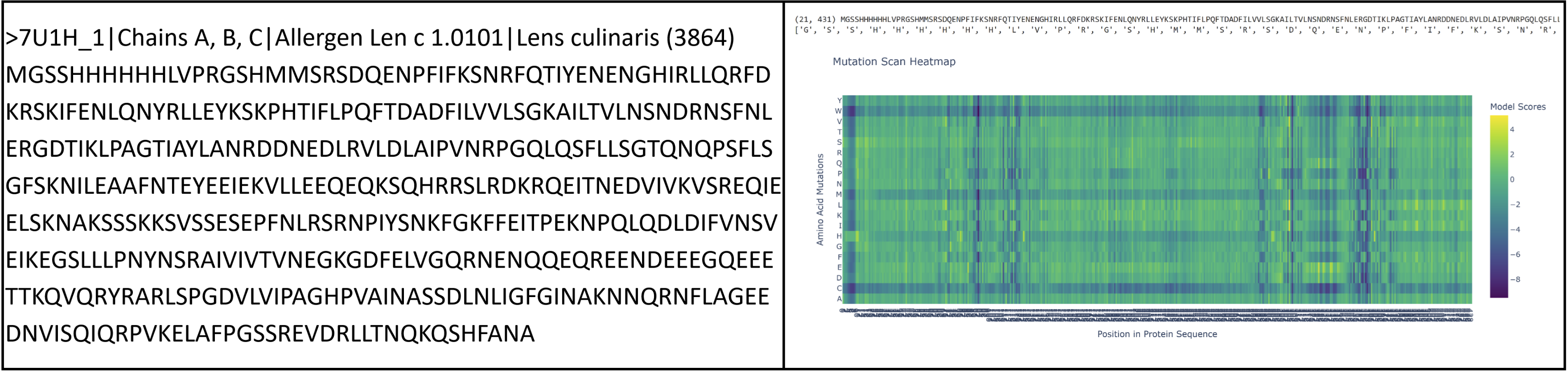
sp|P02511|CRYAB_HUMAN Alpha-crystallin B chain OS=Homo sapiens OX=9606 GN=CRYAB PE=1 SV=2 MDIAIHHPWIRRPFFPFHSPSRLFDQFFGEHLLESDLFPTSTSLSPFYLRPPSFLRAPSW FDTGLSEMRLEKDRFSVNLDVKHFSPEELKVKVLGDVIEVHGKHEERQDEHGFISREFHR KYRIPADVDPLTITSSLSSDGVLTVNGPRKQVSGPERTIPITREEKPAVTAAPKK
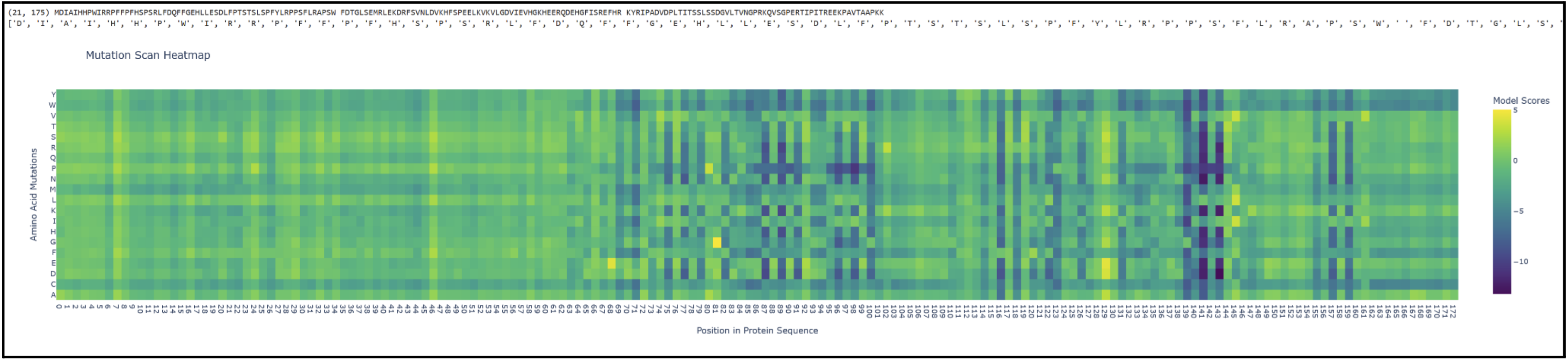
Proteins in the latter ⅔ of the sequence, particularly 87 (L), 89 (V), 96 (I), 98 (V), 139 (G), 141 (L), and 143 (V), seem subject to severely detrimental mutations (looking at the dark blue streaks). This indicates to me that Leucine and Valine are rather important residues that should avoid mutation. Meanwhile, the first ⅓ of the sequence seems pretty tolerant to any changes. Notably, protein 129 seems like it can be mutated with mostly beneficial outcomes.
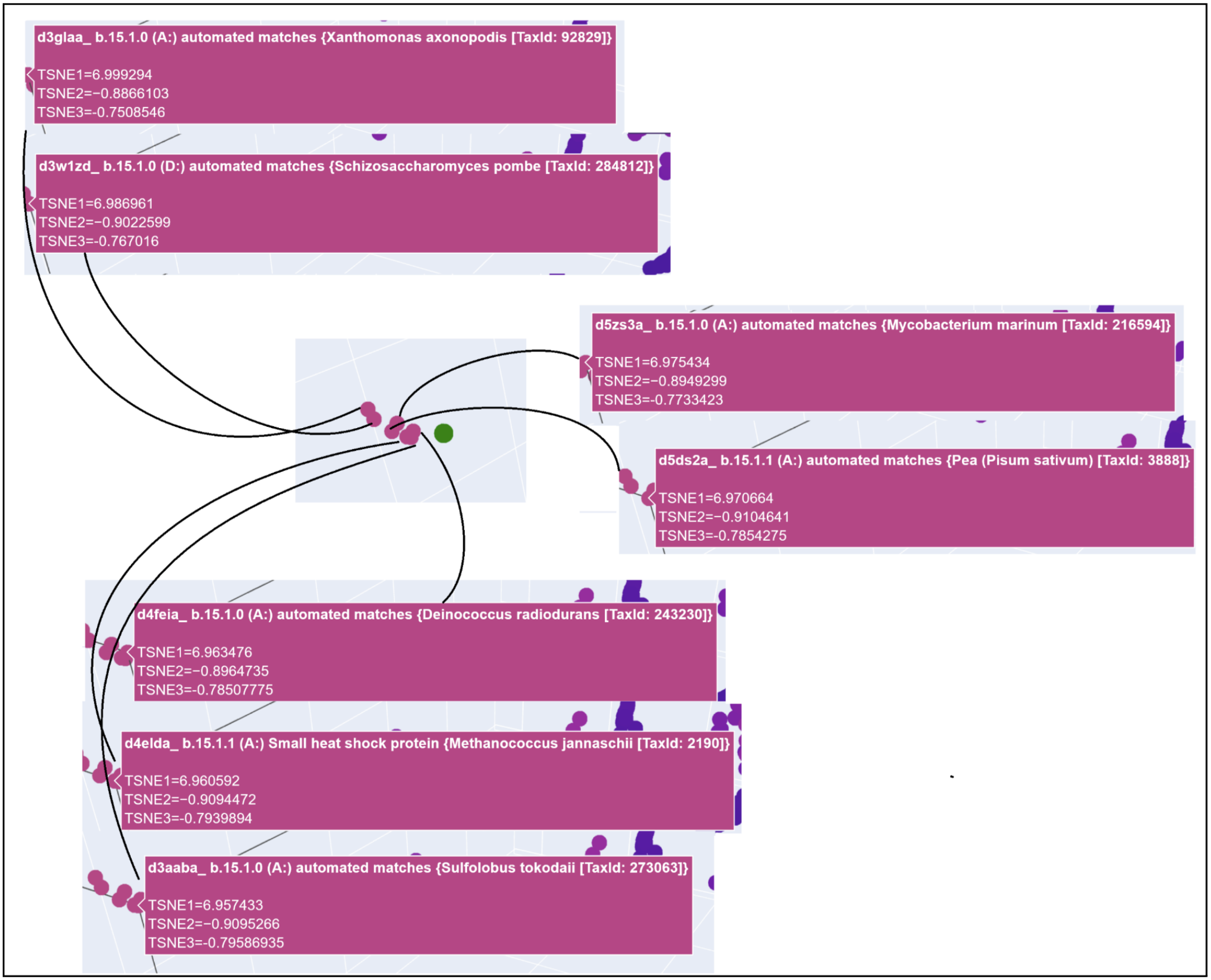
3D t-SNE Visualization (done with Plotly) in the Colab.
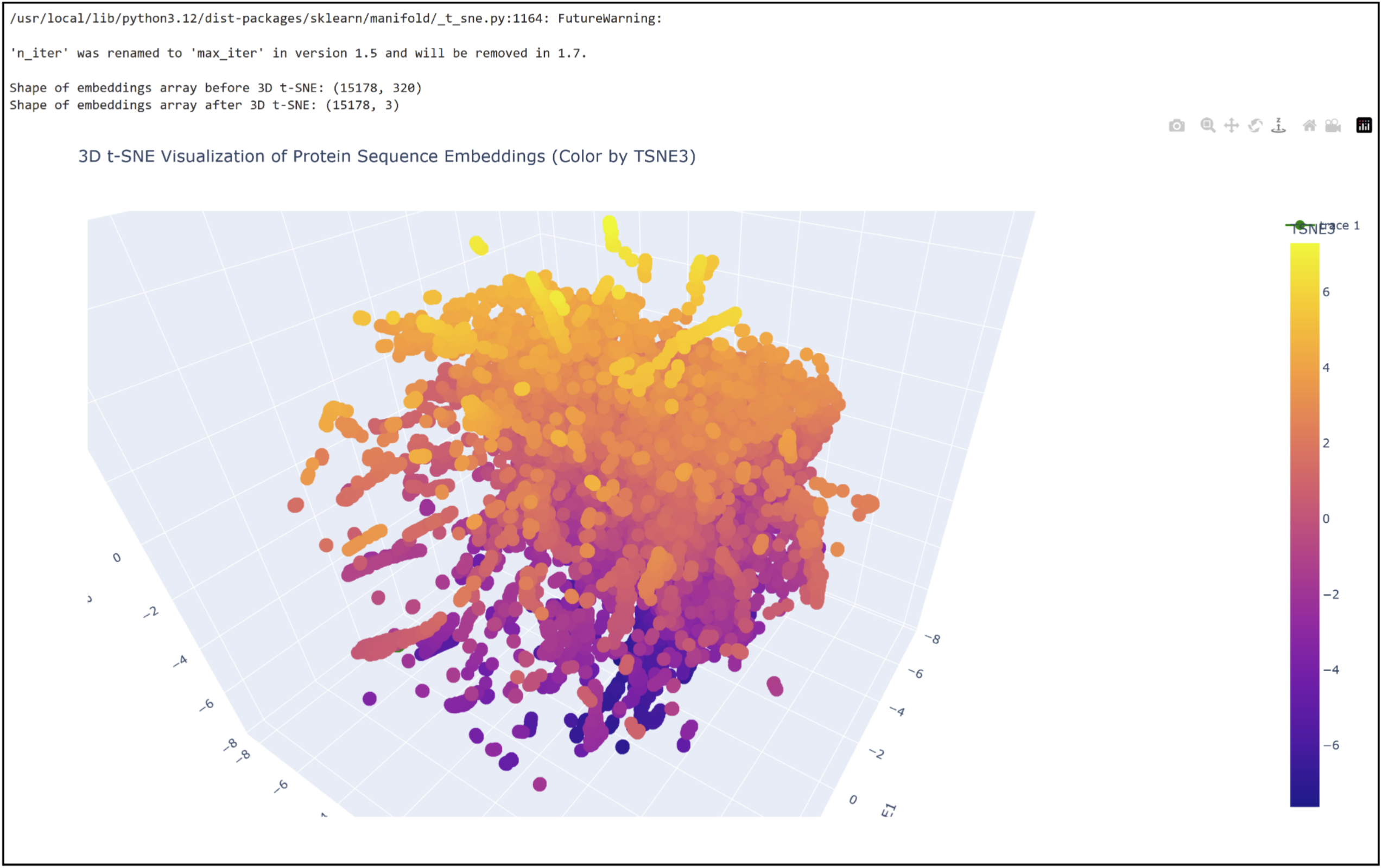 Shoutout to Nourelden Rihan for his helpful guide on the forum! I was able to plot my protein pretty easily thanks to him.
Shoutout to Nourelden Rihan for his helpful guide on the forum! I was able to plot my protein pretty easily thanks to him.
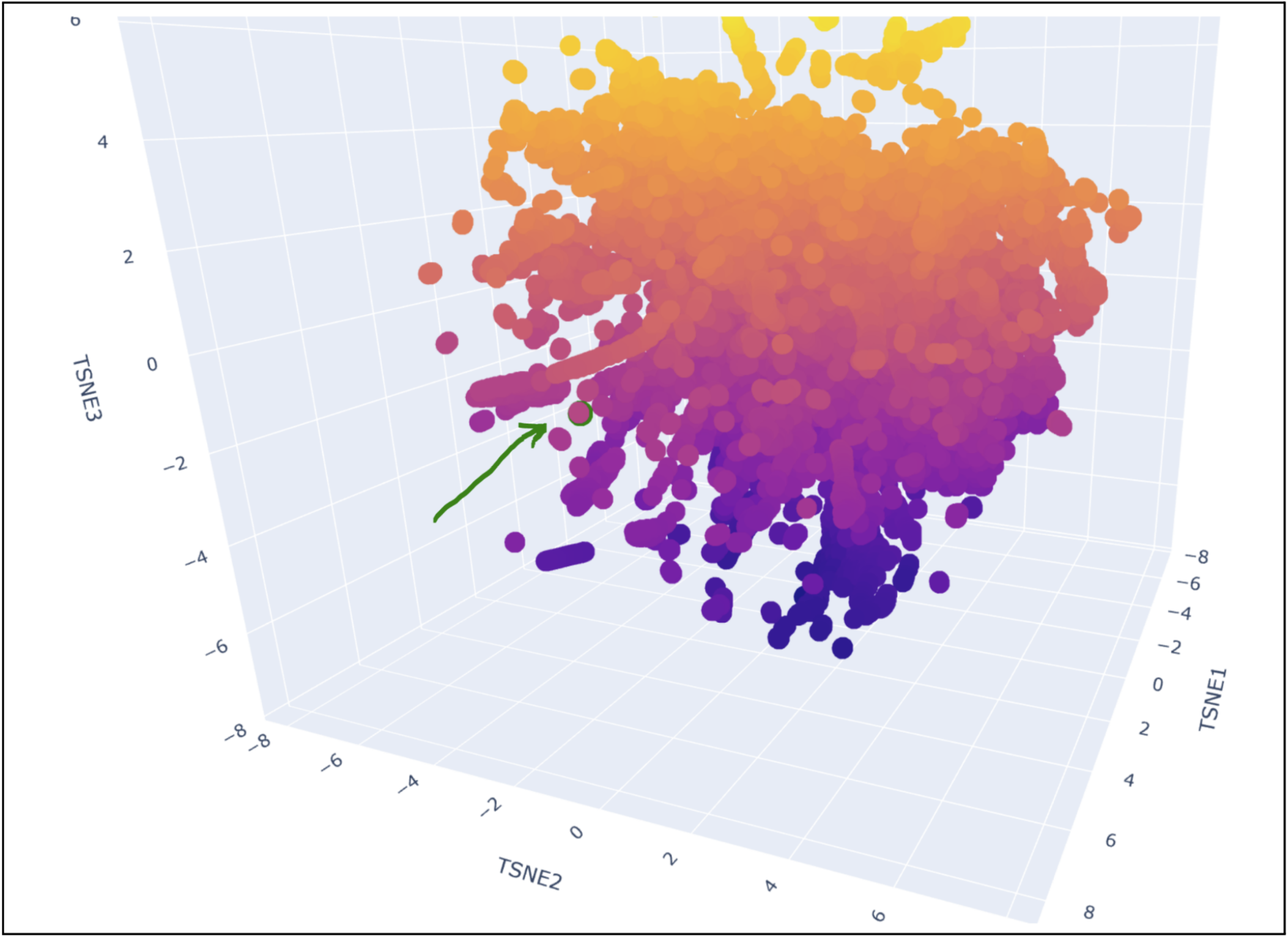 My protein was pretty close to a cluster of other proteins, seen in the photo below.
My protein was pretty close to a cluster of other proteins, seen in the photo below.
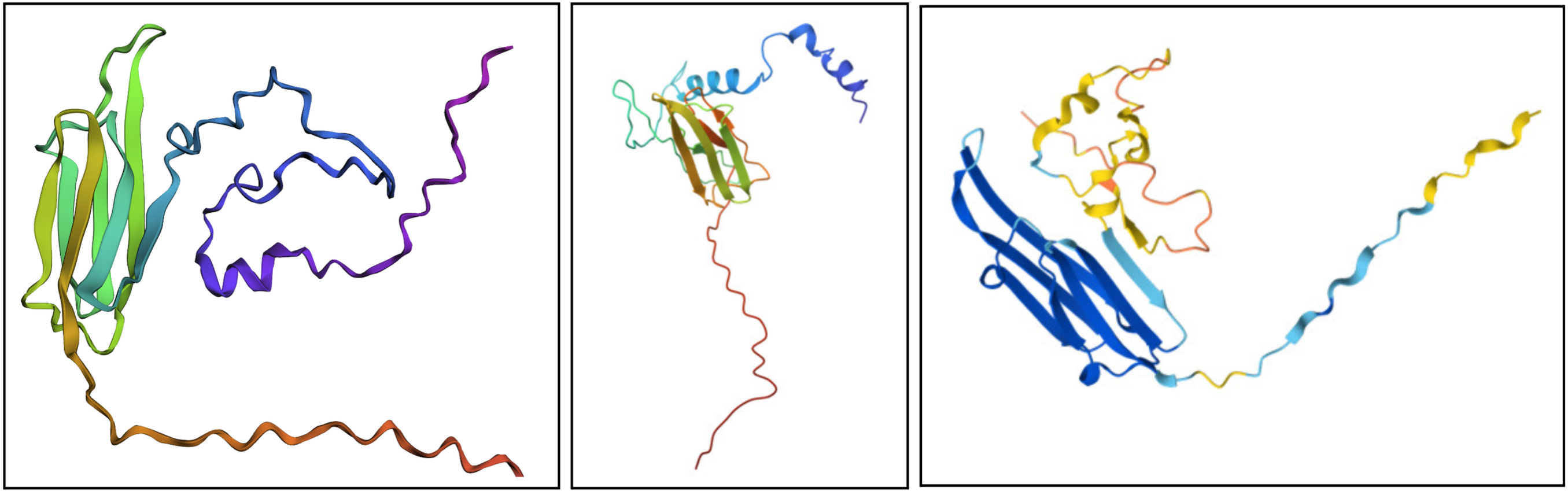
I would say it looks pretty similar. On the left is the ESMFold result, the middle is a structure derived experimentally (on PDB), and on the right is a structure derived computationally (on PDB). You can see ESMFold has a similar sheet structure with the other two, but the placement of the loops (especially the bottom one) is identical to the right structure (both theoretical) while not necessarily resembling how the structure looks in the middle photo.
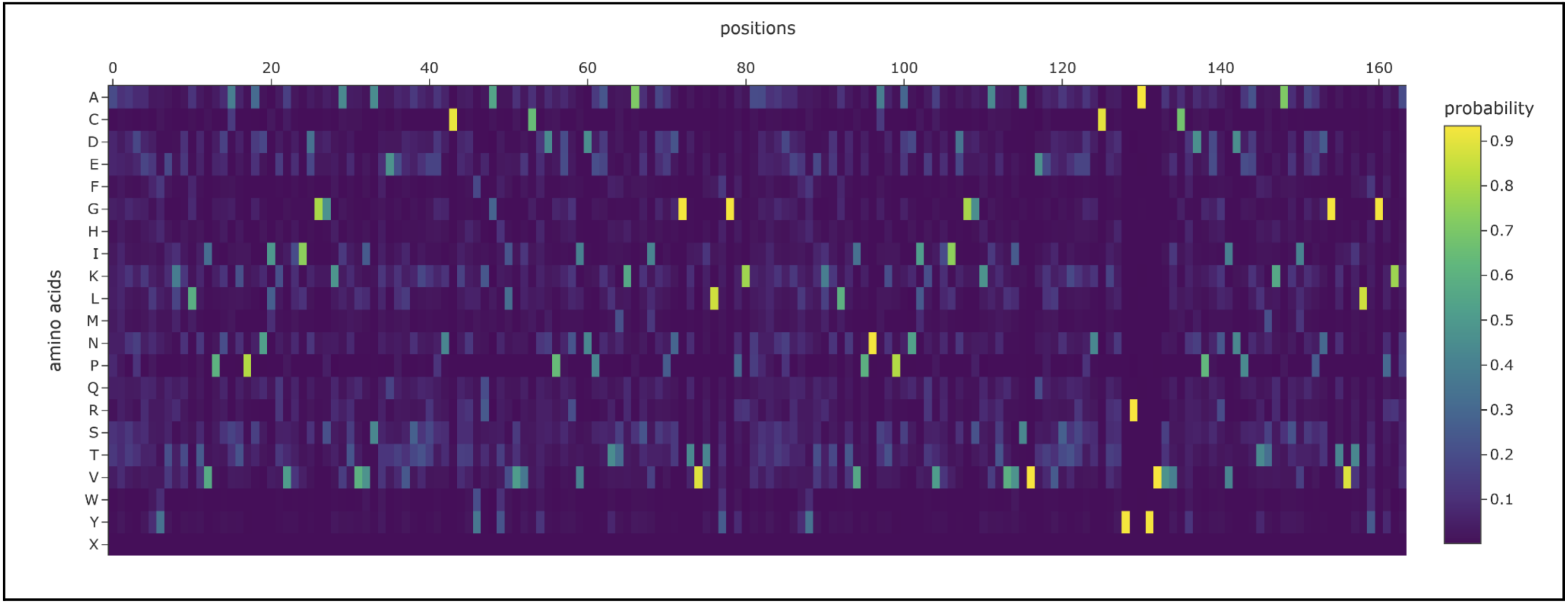
It seems somewhat resiliant to mutations but not entirely. It’s possible to lose its shape with enough fiddling.
Inverse-Folding a protein: Let’s now use the backbone of your chosen PDB to propose sequence candidates via ProteinMPNN
This part was pretty confusing to me, as the file I’d been referring to earlier (a 175 long sequence for Alpha-crystallin B, called P02511) wasn’t available on PDB. I ended up having to source 2N0K (pdb_00002n0k), a member within P02511 that ultimately had the same sequence, despite other members having different sequences.
I prompted the Colab to design for chain A and B. Both had a length of 82 AA (164 total) and had the following potential amino acid variations.
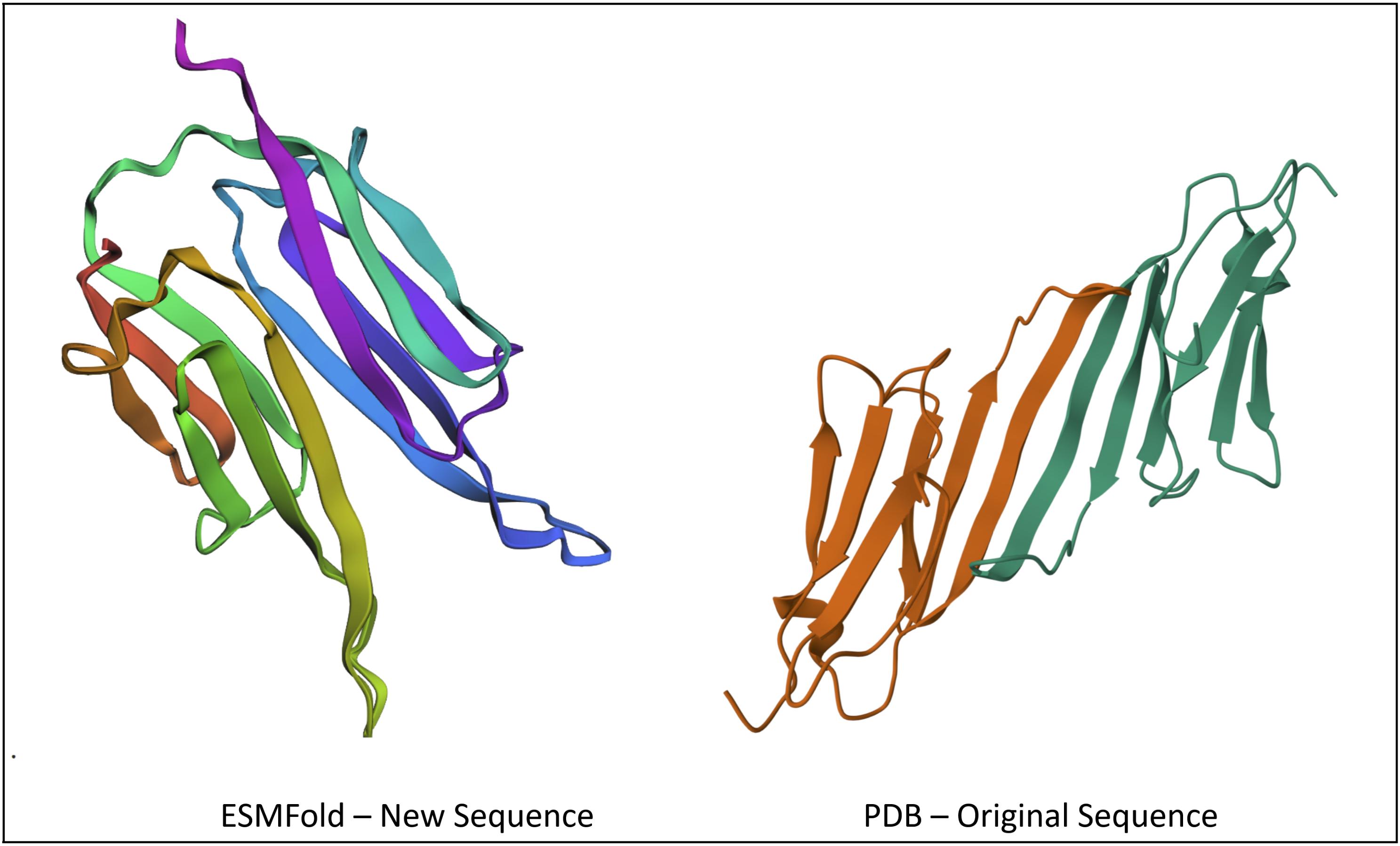
 The new sequence ended up being
The new sequence ended up being
PATPEERTIELKVPNAKPENIEVIIDGGRITVKAKELVEKRENCDYYKGYLVECDDPERVDPETMKAEIDEDGTVTIYGPGAPATPEERTIELKVPNAKPENIEVIIDGGRITVKAKELVEKRENCDYYKGYLVECDDPERVDPETMKAEIDEDGTVTIYGPGA
After plugging into ESMFold, I got a structure that looks pretty similar to the original, at least in the way the sheets fold on each other.
Our proposal (and research notes) for this assignment can be accessed here.
P00441 can be found on the UnitProt site here. It has the following sequence:
sp|P00441|SODC_HUMAN Superoxide dismutase [Cu-Zn] OS=Homo sapiens OX=9606 GN=SOD1 PE=1 SV=2 MATKAVCVLKGDGPVQGIINFEQKESNGPVKVWGSIKGLTEGLHGFHVHEFGDNTAGCTS AGPHFNPLSRKHGGPKDEERHVGDLGNVTADKDGVADVSIEDSVISLSGDHCIIGRTLVV HEKADDLGKGGNEESTKTGNAGSRLACGVIGIAQ
And I’ll swap MATKA → MATKV to get MATKVVCVLKGDGPVQGIINFEQKESNGPVKVWGSIKGLTEGLHGFHVHEFGDNTAGCTS AGPHFNPLSRKHGGPKDEERHVGDLGNVTADKDGVADVSIEDSVISLSGDHCIIGRTLVV HEKADDLGKGGNEESTKTGNAGSRLACGVIGIAQ
See table below.
See table below.
See table below.
| Binder | Pseudo Perplexity |
|---|---|
| WHYGAVAAAHKE | 7.5475612006564115 |
| WRYGATGARHKE | 11.178195011097767 |
| WRYPVAALELWK | 21.190836127543506 |
| WRYPAVVLRLKE | 13.790132945872145 |
| FLYRWLPSRRGG (control) |
| Binder | ipTM Score | Binding Spot |
|---|---|---|
| WHYGAVAAAHKE | 0.31 | Not near N-terminus, engages with β-barrel region. Surface-bound. |
| WRYGATGARHKE | 0.33 | Not near N-terminus, potentially engages with β-barrel region. Surface-bound. |
| WRYPVAALELWK | 0.21 | Not near N-terminus, potentially engages with β-barrel region. Surface-bound. |
| WRYPAVVLRLKE | 0.3 | Somewhat near N-terminus, does not engage with β-barrel region. Surface-bound. |
| FLYRWLPSRRGG (control) | 0.36 | On the complete opposite side of the N-terminus, with the β-barrel in between. Surface-bound. |
None of the ipTM values (max 0.33) exceed the known binder (0.36). However, all of the values are poor (< 0.6), which indicates the predictions might not be accurate. Some of the peptides do appear to bind better in their visualizations than the known (e.g. the first one WHYGAVAAAHKE and its interactions with the β-barrel).
Using PeptiVerse, let’s evaluate the therapeutic properties of your peptide! For each PepMLM-generated peptide:
| Binder | Predicted binding affinity (pKd/pKi) | Solubility (%) | Hemolysis probability (%) | Net charge (pH 7) | Molecular weight (Da) |
|---|---|---|---|---|---|
| WHYGAVAAAHKE | Weak binding, 5.893 | Soluble, 1.000 | Non-hemolytic, 0.024 | -0.06 | 1339.5 |
| WRYGATGARHKE | Weak binding, 6.087 | Soluble, 1.000 | Non-hemolytic, 0.028 | 1.85 | 1431.6 |
| WRYPVAALELWK | Weak binding, 6.446 | Soluble, 0.982 | Non-hemolytic, 0.061 | 0.76 | 1531.8 |
| WRYPAVVLRLKE | Weak binding, 6.506 | Soluble, 0.816 | Non-hemolytic, 0.050 | 1.77 | 1529.8 |
| FLYRWLPSRRGG (control) | Weak binding, 6.361 | Soluble, 0.608 | Non-hemolytic, 0.047 | 2.76 | 1507.7 |
Compare these predictions to what you observed structurally with AlphaFold3. In a short paragraph, describe what you see.
Actually, the extreme outlier is WRYPVAALELWK with an ipTM of 0.21, but it doesn’t vary as drastically with its other properties. It’s generally in the middle of the pack with binding affinity, solubility, and charge. One notable difference is its hemolysis probability is a bit higher, but not by much–still enough to be non-hemolytic.
The best performing two, WRYGATGARHKE with 0.33 and the control with 0.36, have solubilities on either extreme and very low to somewhat low hemolysis probability. They do have higher than average net charge, though–maybe that’s something that can be leveraged.
Choose one peptide you would advance and justify your decision briefly.
I don’t have an obvious contender, but WRYGATGARHKE is just behind the control in ipTM and is quite different in properties, so it’d be worth optimizing that to see if there’s a new direction that could produce good peptides.
I used the following inputs for generation:
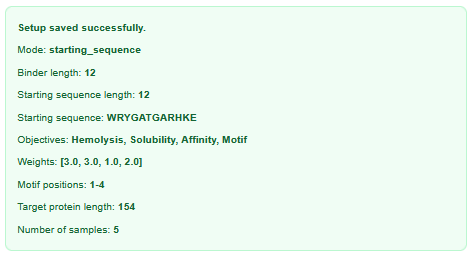
| Binder | Predicted binding affinity (pKd/pKi) | Solubility (%) | Hemolysis probability (%) | ipTM |
|---|---|---|---|---|
| CTAGSTVGVGVW | 6.7832 | 0.9996 | 0.0618 | 0.36 |
| ASATFEPPPVCH | 5.8068 | 1 | 0.0223 | 0.39 |
| VSEKYCVQFGKT | 6.2623 | 1 | 0.0405 | 0.33 |
| MSAGICNEFKQK | 5.6404 | 1 | 0.0238 | 0.55 |
| KNPCEAYCFNWV | 6.7200 | 1 | 0.0346 | 0.28 |
I’d say there’s more variety. PepMLM repeated a lot of beginning and ending amino acids in the sequence, but all these sequences look completely unique. It doesn’t reflect as much in the properties, though. For evaluating, I’d run each sequence through the same software and compare properties/ipTM to see if there’s any improvement. E.g. MSAGICNEFKQK had a huge jump in ipTM to 0.55–that’s promising!
High level summary: The objective of this assignment is to improve the stability and auto-folding of the lysis protein of a MS2-phage. This mechanism is key to the understanding of how phages can potentially solve antibiotic-resistance.
Answer these questions about the protocol in this week’s lab:
The master mix can be found here and contains “Phusion DNA Polymerase, nucleotides, and optimized reaction buffer including MgCl2”. The polymerase is an essential part of PCR, nucleotides are the base materials needed to form new DNA sequences, and reaction buffer lowers the energy needed to start the process.
The master mix can be found here and contains “Phusion DNA Polymerase, nucleotides, and optimized reaction buffer including MgCl2”. The polymerase is an essential part of PCR, nucleotides are the base materials needed to form new DNA sequences, and reaction buffer lowers the energy needed to start the process.
| Method | PCR | Restriction Enzyme |
|---|---|---|
| Throughput | High (2^n) | Low (n) |
| Protocol | Requires 3 step process of varying temperature, 1 pot reaction | Requires plasmid preparation to form recognition sites in DNA |
| Protein Involved | Primer, Polymerase | Endonuclease |
You can verify experimentally how well the DNA is assembled. Plasmids are usually built with an antibiotic resistance gene, and in the test you put an antibiotic on your plasmids to see which survives. The ones that survive should be fully assembled.
The heat shock method puts the bacteria and plasmid at a high temperature for about a minute, which “shocks” the bacteria into forming pores that the plasmid can enter through.
Describe another assembly method in detail (such as Golden Gate Assembly)
Golden Gate Assembly is also a form of molecular cloning, but uses restriction enzymes unlike Gibson Assembly. It uses recognition sites instead of overlapping sequences, and the enzymes are responsible for stripping the DNA (in place of exonuclease) and removing recognition sites to create the final construct (in place of ligase). This allows Golden Gate Assembly to accommodate multiple fragments in a one-pot reaction to create a single long strand of DNA. On the other hand, it needs more specific design and choosing of enzymes, including making sure recognition sites are unique within the sequence and do not show up accidentally.
My folder, along with the constructs and notebook documentation, can be found here.
Increased complexity in what it can process. Genetic circuits are capable of digital logic, but neural networks can fine tune connections and weights to represent a nuanced system with a set of many inputs and outputs. This is in particular in a cell’s ability to contain a “weighted summation” dependent on the situation it gets trained on.
IANNs can be used to represent complex systems in biology. An example would be cancer, as cancer cells rapidly mutate and provide continuous data. Input would be DNA, while the output would be a tag like GFP or any other form of fluorescence. IANN is good at making predictions for these systems, but has limitations like increased processing time (as with all neural networks).
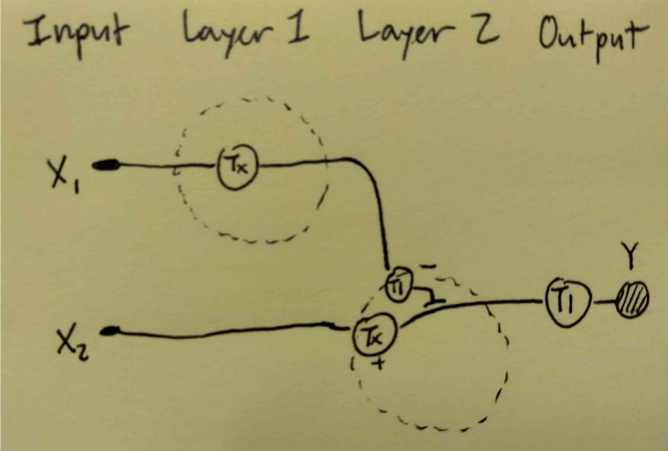
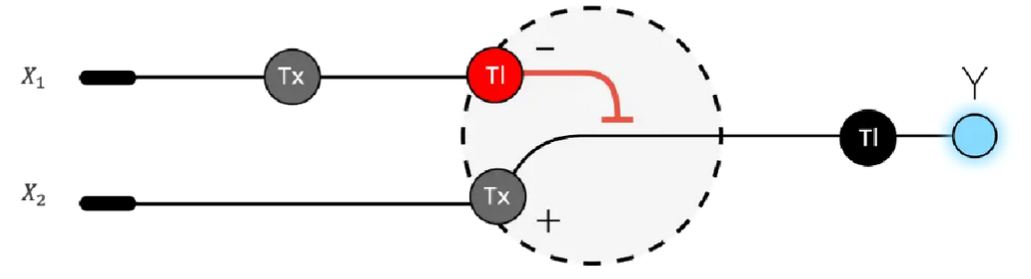 Draw a diagram for an intracellular multilayer perceptron where layer 1 outputs an endoribonuclease that regulates a fluorescent protein output in layer 2.
This diagram is neither entirely correct nor represents the multilayer perception, will be updated.
Draw a diagram for an intracellular multilayer perceptron where layer 1 outputs an endoribonuclease that regulates a fluorescent protein output in layer 2.
This diagram is neither entirely correct nor represents the multilayer perception, will be updated.
Mycelium is an example that has structural integrity. You see it in architecture concepts as a naturally grown building material. Fungi can bring a biodegradable quality to traditional materials while keeping performance.
Fungi already have natural properties that can be further optimized with genetic engineering. E.g. mycelium is fire retardant and insulatory after it’s dried, but can be engineered to be as strong as the currently used materials. You can also introduce a new aspect like color. Bacteria-produced material is currently more fragile than fungi-produced. Stuff like mycelium has inherent structure and rigidity, which occupies a different niche in material applications.
General homework questions
Cell-free systems have an advantage in “extreme” situations, while in-vivo occurs within cells that have to be kept alive. In taking the process outside of the cell, you can handle it more roughly i.e. freeze drying the system for long-distance transport, or making a system that can be kickstarted just by adding water (in remote locations). Cell-free systems also have more control because they’re synthetic, so you can determine how big the cell is and what exactly goes in it.
The components of a cell-free system are:
Energy is needed to run the reactions, and having a constant supply is crucial the longer the reaction goes. One way of continuously providing ATP is picking chemical processes that can replenish resources. This is part of why some cell-free reactions (like ribose NMP) are more efficient, because they can produce ATP which is used for both RNA synthesis and an energy source, allowing the reaction to continue for longer.
Prokaryotic cells differ from eukaryotic cells in components; notably, they lack membrane-bound organelles. For cell-free, they are the standard and are very low cost/high throughput. They’re a simple iteration of cell-free systems.
Eukaryotic cells are more complex and high cost, but can work with certain proteins and antibodies that are toxic to prokaryotic cells. All eukaryotic cells have an endoplasmic reticulum, which lets them represent functions like protein folding and post-translational modifications in cell-free systems.
I’d set it up similar to the lab process in Homework 11–with a standardized list of all components that go in (salt/buffer, enzymes, nucleotides, cofactors, etc) and vary input volume to observe how expression of the protein changes. A potential challenge could be in measuring the expression of the membrane protein (something I’m not as familiar with myself). This could be addressed by linking production of the protein to a more easily measurable protein (like GFP) to be produced as well.
Possible reasons and their solutions are
Homework question from Kate Adamala – Design an example of a useful synthetic minimal cell as follows:
My synthetic cell can be designed for medical applications, such as in drug production. The input would be the template for the molecule, e.g. inserted as a plasmid, with the output being assembly of the target drug and potentially a light indicator for success.
The process needs to be isolated, so a membrane (and therefore synthetic cell) is necessary.
It could potentially, but the process of biomanufacturing generally needs to happen in a cleanroom or at least a clean space. A synthetic cell has more understood components and a more controlled environment within itself compared to a natural cell, and the process could be better standardized.
Ideally, given a plasmid containing the sequence of the drug, they are able to produce it and a fluorescent protein.
Cell-free Tx/Tl system, plasmid/DNA encoding drug, fluorescent protein, amino acids, nucleotides, other enzymes and coenzymes TBD
Bacterial (and probably E. coli) should be fine. I’m not currently aware of any further modifications that need to occur after translation.
I would likely need membrane channel pores to allow for molecules to cross over, especially for the output proteins.
Lipids: POPC (phospholipid), cholesterol Genes: fluorescent protein (e.g. GFP), E. coli, gene for channel pores
The results should be measured in fluorescence output.
Homework question from Peter Nguyen
Freeze-dried cell-free systems can be incorporated into all kinds of materials as biological sensors or as inducible enzymes to modify the material itself or the surrounding environment. Choose one application field — Architecture, Textiles/Fashion, or Robotics — and propose an application using cell-free systems that are functionally integrated into the material. Answer each of these key questions for your proposal pitch:
I propose that cell-free biosensors for pollutants found in acid rain could be integrated into rain jackets as a concept of wearable environmental sensors.
This idea builds upon detection of acid rain through pH testing, by incorporating the response of test strips into textiles. Rain jackets are already designed for a rainy environment. If additional cell-free layers were engineered on top of the waterproof layer, similar to what was discussed in class, we could design a rain jacket that could change color in response to low pH in rainwater. This could be done by joining the cell-free system with a fluorescent protein or other colorimetric protein that operates well in low pH. The end result would be a more “live” response to the individual’s local environmental contaminants, allowing the user to constantly evaluate their surroundings while also acting as a functional article of clothing.
This is intended to be a first step in responding to local environmental injustice, giving individuals more agency to observe and detect the extent of pollution in their backyard.
One concern is the possibility of overwhelming the cell-free systems with water, since rain jackets are generally worn longterm (whenever it rains). Additionally, the jacket might be a one-time use, since the detection of acid rain once would render it ineffective for the second rainfall. This could be addressed by intentional design, allowing only a limited amount of water to reach the cell-free system (i.e. smaller access holes for water droplets) and having a swappable cell-free system layer on the jacket.
Homework question from Ally Huang
Quorum sensing is a method for bacteria to communicate on a large, colony-wide scale. This occurs through autoinducers, chemical molecules that diffuse or are transported between the cells. I think this is an interesting topic to apply to space, as testing these cells can reveal how the process of diffusion/osmosis is impacted by microgravity as well as opening a path up to explore different mediums of communication for biology in space.
Aliivibrio fischeri would be interesting as it’s a bacteria that provides bioluminescence within a squid once its population grows enough. The proteins involved are luciferase and LuxY.
Lots of prior proposals tackle the effects of microgravity, so this is sort of similar. The luciferase protein will get produced as a result of coordination across a bacteria colony. In getting to that result of fluorescence, we want to see how successfully the bacteria cells communicate with each other in microgravity.
I hypothesize that the proteins will have a faster response time and increased quorum sensing in spaceflight, as this seems to be the pattern with prior quorum sensing experiments. This might show itself in the form of fluorescence appearing much faster than it would on Earth, but might also be a false positive where fluorescence appears before cells have reached an appropriate density. This is actually a bit different than what I would have thought by intuition–I imagined that microgravity would make it harder for chemical molecules to travel across cells, which seems true, but in this case the settled molecules would be wrongfully interpreted as “positive” signals sent by other cells, resulting in a denser perceived network of cells.
The experiment is outlined below, though I’m a little skeptical of how easy it would be to implement:
For your final project:
Please identify at least one (ideally many) aspect(s) of your project that you will measure. It could be the mass or sequence of a protein, the presence, absence, or quantity of a biomarker, etc.
Please describe all of the elements you would like to measure, and furthermore describe how you will perform these measurements.
What are the technologies you will use (e.g., gel electrophoresis, DNA sequencing, mass spectrometry, etc.)? Describe in detail.
We will analyze an eGFP standard on a Waters Xevo G3 QTof MS system to determine the molecular weight of intact eGFP and observe its charge state distribution in the native and denatured (unfolded) states. The conditions for LC-MS analysis of intact protein cause it to unfold and be detected in its denatured form (due to the solvents and pH used for analysis).
Based on the predicted amino acid sequence of eGFP (see below) and any known modifications, what is the calculated molecular weight? You can use an online calculator like the one at https://web.expasy.org/compute_pi/
eGFP Sequence:
MVSKGEELFTG VVPILVELDG DVNGHKFSVS GEGEGDATYG KLTLKFICTT GKLPVPWPTL VTTLTYGVQC FSRYPDHMKQ HDFFKSAMPE GYVQERTIFF KDDGNYKTRA EVKFEGDTLV NRIELKGIDF KEDGNILGHK LEYNYNSHNV YIMADKQKNG IKVNFKIRHN IEDGSVQLAD HYQQNTPIGD GPVLLPDNHY LSTQSALSKD PNEKRDHMVL LEFVTAAGIT LGMDELYKLE HHHHHH
Note: This contains a His-purification tag (HHHHHH) and a linker (the LE before it).
Theoretical pI/Mw: 5.90 / 27875.41 (monoisotopic) Theoretical pI/Mw: 5.90 / 27857.92
Let’s take the two largest peaks on the graph, labelled at m/zn = 903.7148 and m/zn+1 = 875.4421. z = 875.4421 / (903.7148 - 875.4421) = 30.96
MW = (n * m/zn - n) = (30.96 * 903.7148 - 30.96) = 27951.85
Accuracy =|27951.85 - 27875.41| / 27875.41 = 0.002742 * 1,000,000 = 2742.545 ppm
No, I would need a second peak for the adjacent charge state approach. The second noticeable peak is not in the zoomed in photo, and I am skeptical that the small rise I see in the photo is considered a peak.
We will analyze eGFP in its native, folded state and compare it to its denatured, unfolded state on a quadrupole time-of-flight MS. We will be doing MS-only analysis (no liquid chromatography, also known as “direct infusion” experiments) on the Waters Xevo G3-QToF MS.
Based on learnings in the lab, please explain the difference between native and denatured protein conformations. For example, what happens when a protein unfolds? How is that determined with a mass spectrometer? What changes do you see in the mass spectrum between the native and denatured protein analyses (Figure 2)? Figure 2. Comparison of the mass spectra between denatured (top) and native (bottom) eGFP standard on the Waters Xevo G3 QTof MS.
Zooming into the native mass spectrum of eGFP from the Waters Xevo G3 QTof MS (see Figure 3), can you discern the charge state of the peak at ~2800 m/z? What is the charge state? How can you tell? Figure 3. Native eGFP mass spectrum from the Waters Xevo G3 Q-Tof MS. The inset is a zoomed-in view of the charge state at ~2800 $\frac{m}{z}$ on a mass spectrometer with 30,000 resolution.
MVSKGEELFTG VVPILVELDG DVNGHKFSVS GEGEGDATYG KLTLKFICTT GKLPVPWPTL VTTLTYGVQC FSRYPDHMKQ HDFFKSAMPE GYVQERTIFF KDDGNYKTRA EVKFEGDTLV NRIELKGIDF KEDGNILGHK LEYNYNSHNV YIMADKQKNG IKVNFKIRHN IEDGSVQLAD HYQQNTPIGD GPVLLPDNHY LSTQSALSKD PNEKRDHMVL LEFVTAAGIT LGMDELYKLE HHHHHH
19 peptides were generated as seen in the photo below.
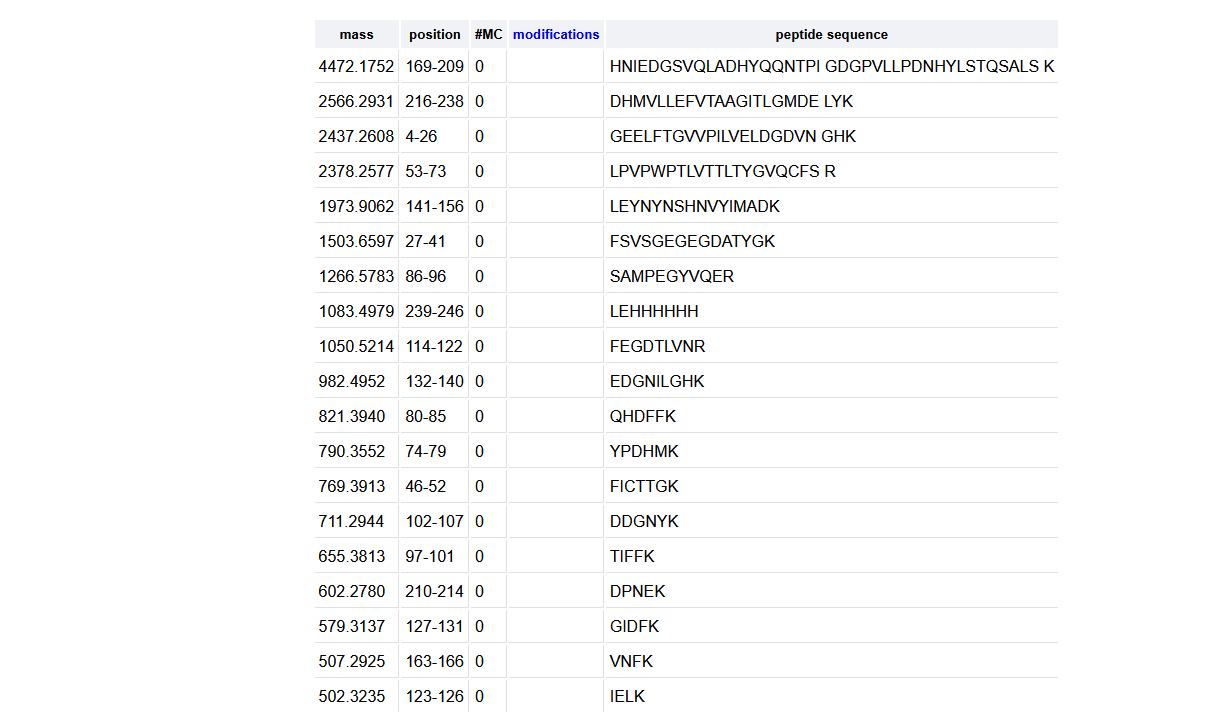
I counted 19 and used roughly 10% * 1.2e7 = 0.12e7 as a threshold (photo below).
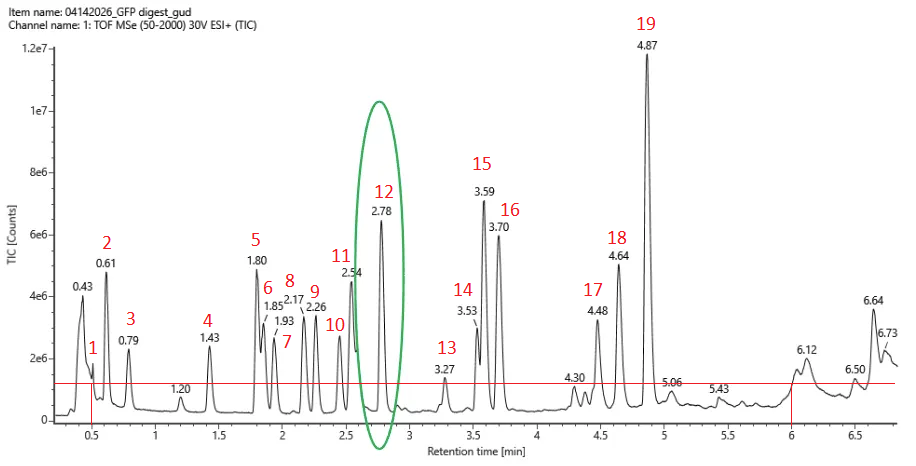
It matches exactly. I’m pleasantly surprised!
The m/z of the most abundant charge state is 525.76712, with the charge being z = 1/(Δm/z) = 1/(525.76712 - 526.25918) = 2.0322 ≈ 2
As a result, the mass is [M+H]+ = (m/z * z) - (z - 1) * H = 1051.53424 - 1.00727 = 1050.527
It’s closest to FEGDTLVNR, which has a mass of 1050.5214. AccuracyFEGDTLVNR = |1050.527 - 1050.5214| / 1050.5214 = 5.30 ppm
91.1% of my sequence is covered, not excluding peptides less than 500 Da.
We will determine Keyhole Limpet Hemocyanin (KLH)’s oligomeric states using charge detection mass spectrometry (CDMS). Identify where the following oligomeric species are on the spectrum shown below from the CDMS:
For CDMS, calculation of mass is just a function of m/z * z. So for the following:
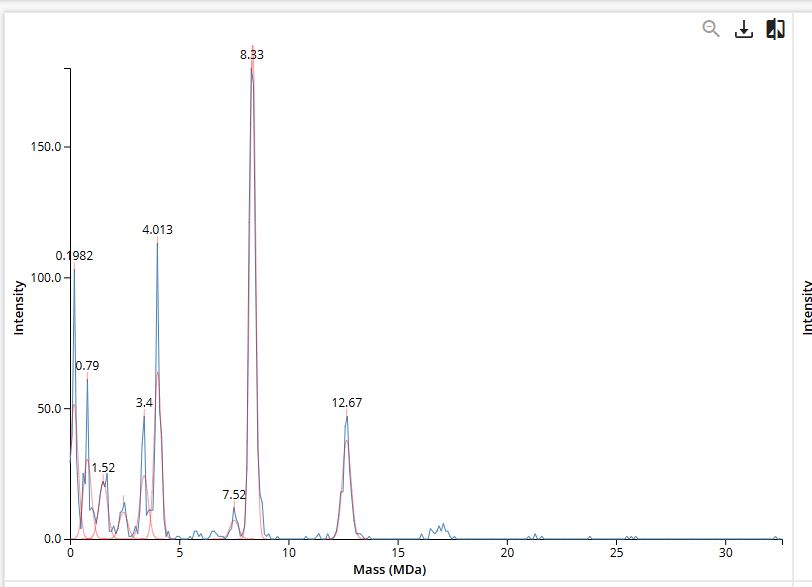
This is from data given in the homework, not lab work.
| Theoretical | Observed/measured on the Intact LC-MS | PPM Mass Error | |
|---|---|---|---|
| Molecular weight (kDa) | 27875.41 | 27951.85 | 2742.545 ppm |
My error was unusually high for observed mass.
Unfortunately, I did not get to contribute this year, but I did discuss the project with friends in the class. I really like the concept of a collaborative (and also competitive, occasionally) project with an end result that is artistic (while also leading to the lesson next week). I think the process was very lovely, with people’s ideas growing and shifting until it reaches a fully developed design. I’m not too sure if this would lose the spirit of the assignment, but coordinating within nodes or between people might better guide us towards a final design. I feel like the end result, with the four different designs on each well, was a little lucky.
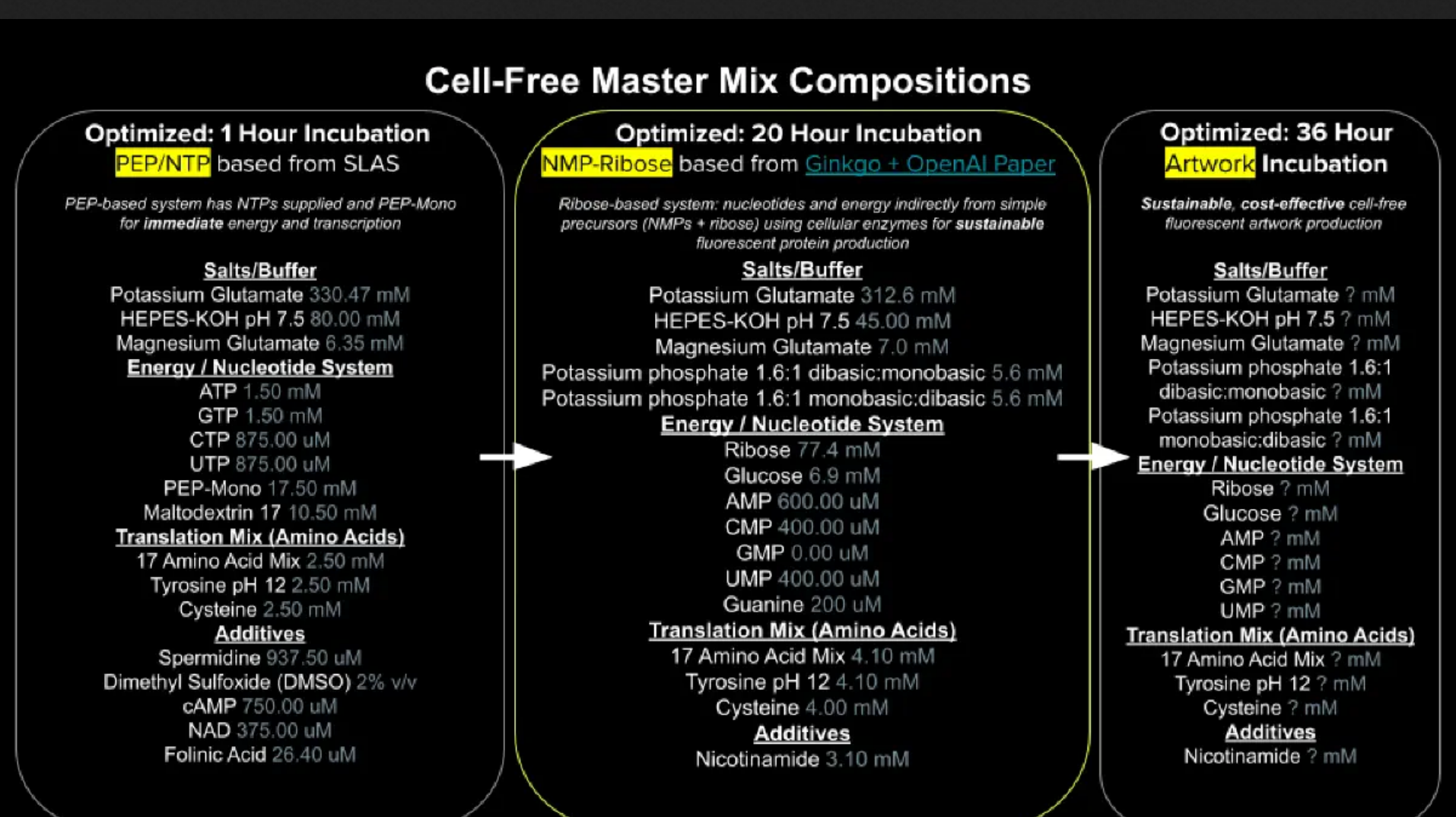
The difference lies in nucleotides. PEP-NTP has nearly ready-to-use ATP, GTP, CTP, UTP, which is the “final form” before translation. However, the process is inefficient and peters out quickly. Ribose uses AMP, GMP, CMP, UMP, which requires an additional process to convert to ATP, GTP, CTP, UTP, but the process is more sustainable and generates more energy/less byproducts for long term reacting.
Guanine is just a tertiary layer removed from GTP. Guanine would have to undergo a process to turn into GMP, and then another process to turn into GTP. Transcription would only occur after those two steps.
The amino acid sequences are shown in the HTGAA Cell-Free Benchling folder.
Most of these fluorescent proteins are less effective in acidic conditions, so we want to shift the pH in the other direction. We can adjust the concentration of salts/buffer that maintain that pH, as well as increase the concentration of potassium phosphate dibasic, which operates at a higher pH than monobasic.
So from the initial concentrations, we can adjust for mKO2, which has a pKa of 5.5. We can increase the volume of HEPES-KOH and potassium phosphate dibasic (or potentially both dibasic and monobasic if they need to be at the same volume).
Was unable to complete the lab.
The final phase of this lab will be analyzing the fluorescence data we collect to determine whether we can draw any conclusions about favorable reagent compositions for our fluorescent proteins. This will be due a week after the data is returned (date TBD!). The reaction composition for each well will be as follows:
6 μL of Lysate
10 μL of 2X Optimized Master Mix from above
2 μL of assigned fluorescent protein DNA template
2 μL of your custom reagent supplements
Total: 20 μL reaction

My single slide of my concept:

My final presentation:
Although the Group Final project did not get fully underway, students were assigned a proposal to write suggesting ideas to improve the bacteriophage MS2’s ability to kill its host bacteria E. coli. The target was to engineering its lysis protein MS2-L to better burst through E. coli, from which my team suggested increasing the stability of the protein as a first step.
Our proposal (and research notes) for this assignment can be accessed here.