Week 2
Class Assignment — Week 2 Preparation
1) Essential Amino Acids and the Lysine Contingency
The ten essential amino acids in animals are histidine, isoleucine, leucine, lysine, methionine, phenylalanine, threonine, tryptophan, valine, and arginine (essential in growing animals). Animals cannot synthesize these; survival depends on dietary supply.
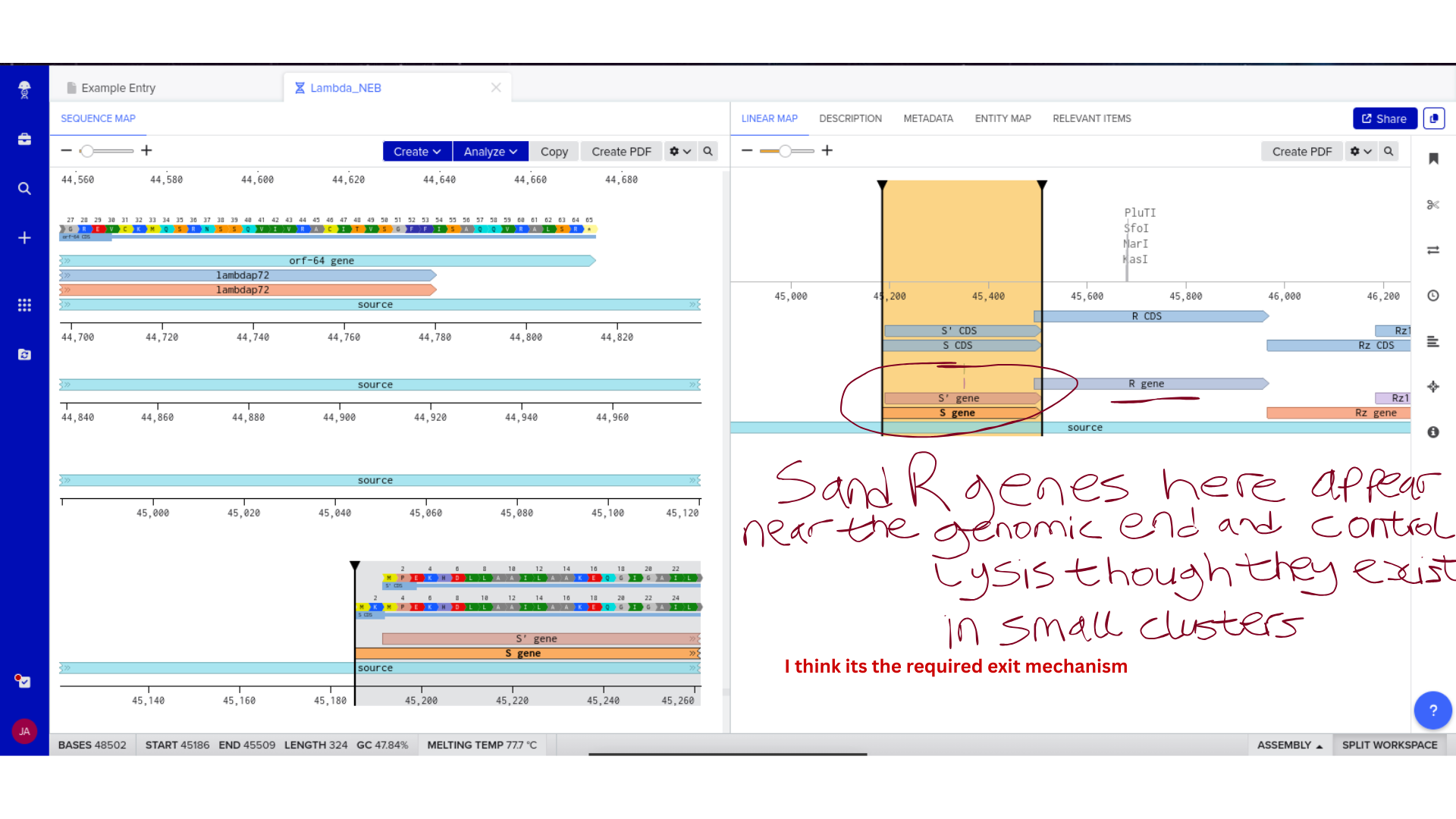
This reframes the Lysine Contingency for me. It is not merely a clever containment device. Engineering microbes that require lysine creates a metabolic dependency aligned with a biological universal. Because animals cannot produce lysine, ecological persistence becomes tightly coupled to controlled supplementation. Survival becomes conditional, not autonomous.
I now see it less as a biosafety patch and more as a governance-embedded metabolic contract. The dependency encodes authority into biochemistry. Control is not enforced externally; it is written into the organism’s survival logic. That shift moves containment from policy language into molecular architecture.
2) Suggested Code for AA:AA Interactions
From the genetic code logic shown, base pairs have symmetry rules. Amino acids need something analogous. I would propose a layered interaction code:
First layer: chemical class (polar, nonpolar, charged, aromatic).
Second layer: interaction type (hydrophobic packing, hydrogen bonding, ionic pairing, pi stacking).
Third layer: geometry constraint (distance and orientation tolerance).
For example, NP-HYD-G1 could denote nonpolar hydrophobic packing within a defined geometric band. CH-ION-G2 could represent oppositely charged ionic interaction with specific spacing tolerance.
Such a code treats protein structure not as artistic folding but as readable and writable interaction grammar. If we can read polymers, we should also encode their interaction rules explicitly. That shift makes protein design less descriptive and more programmable.
3) Ethical Reflections
Biological systems do not respect borders. Political, institutional, even disciplinary lines dissolve in ecology. Framing safety as compliance feels incomplete because evolution does not comply. Good intentions are structurally irrelevant to selection pressures.
Governance must therefore treat evolution as a first-class design constraint. Safeguards must assume mutation, drift, and ecological leakage. Ethical assumptions should be embedded in design architectures, not appended through oversight committees.
I am increasingly drawn to resilience-based governance. Instead of trusting actors, we engineer systems that remain bounded even under failure. The goal is not perfect control but constrained adaptability. In living systems, humility is ethical. Governance must anticipate dynamics, not merely regulate behavior.
Class Assignment — Week 2
Node participant note: I am a remote Genspace node listener based in Nigeria without onsite lab access. The Week 2 lab (DNA Gel Art) was a physical bench session at Genspace nodes. In lieu of wet-lab access, I completed a virtual gel simulation of my Microcin M expression construct using Benchling’s restriction digest tool and documented the expected band pattern below.

Part 1 — Sequence Retrieval and Design Workflow
1) Sequence Retrieval and Benchling Initialization
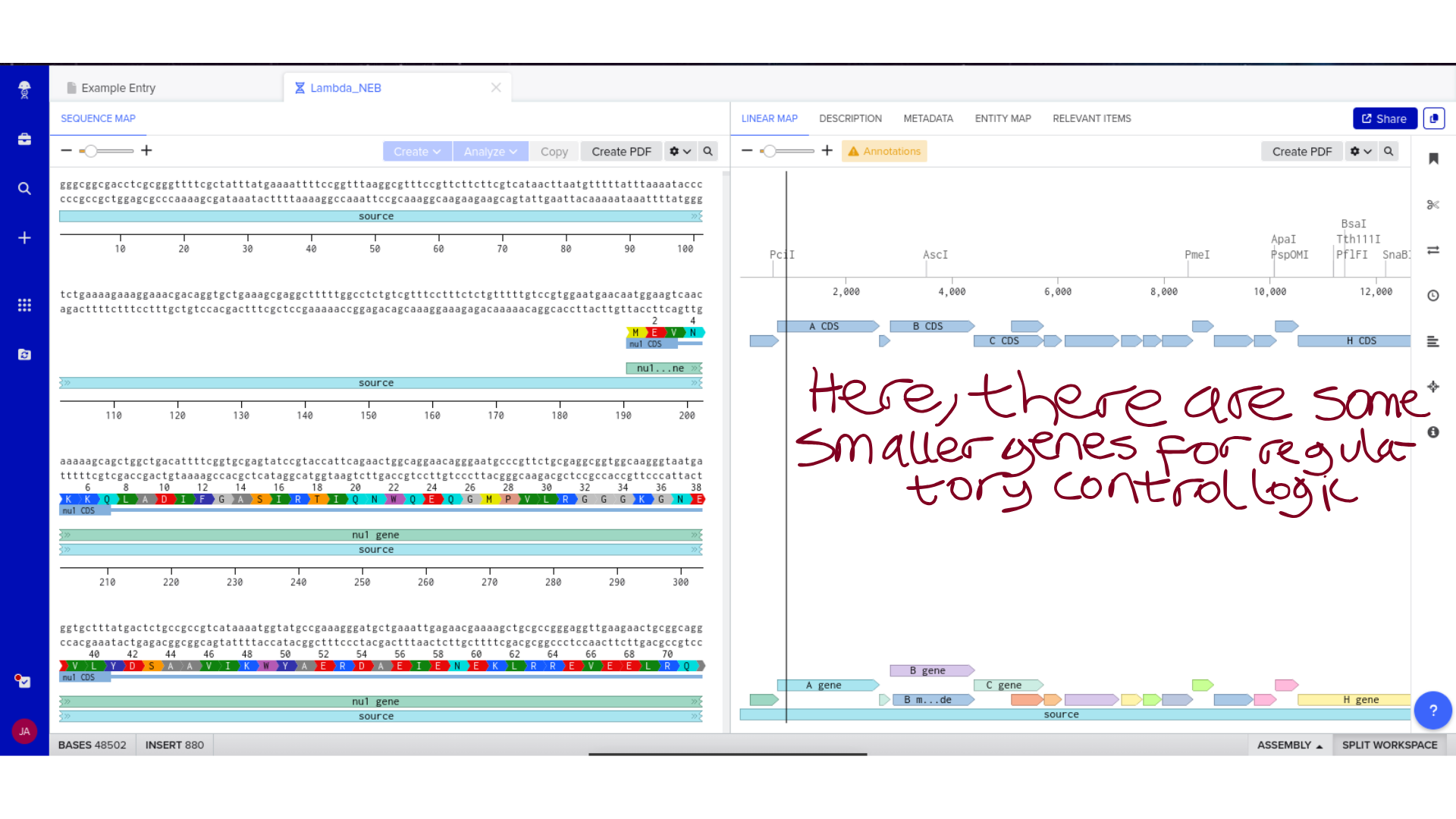
The process began with obtaining a Lambda GenBank file from New England Biolabs. After confirming the correct format, I imported the file into Benchling as a DNA sequence. Care was taken to ensure that the file was not mistakenly uploaded as RNA and that annotations displayed properly within the platform.
This step established a stable working environment before any design modifications were introduced. Confirming correct topology and annotation structure prevented downstream formatting or visualization issues.
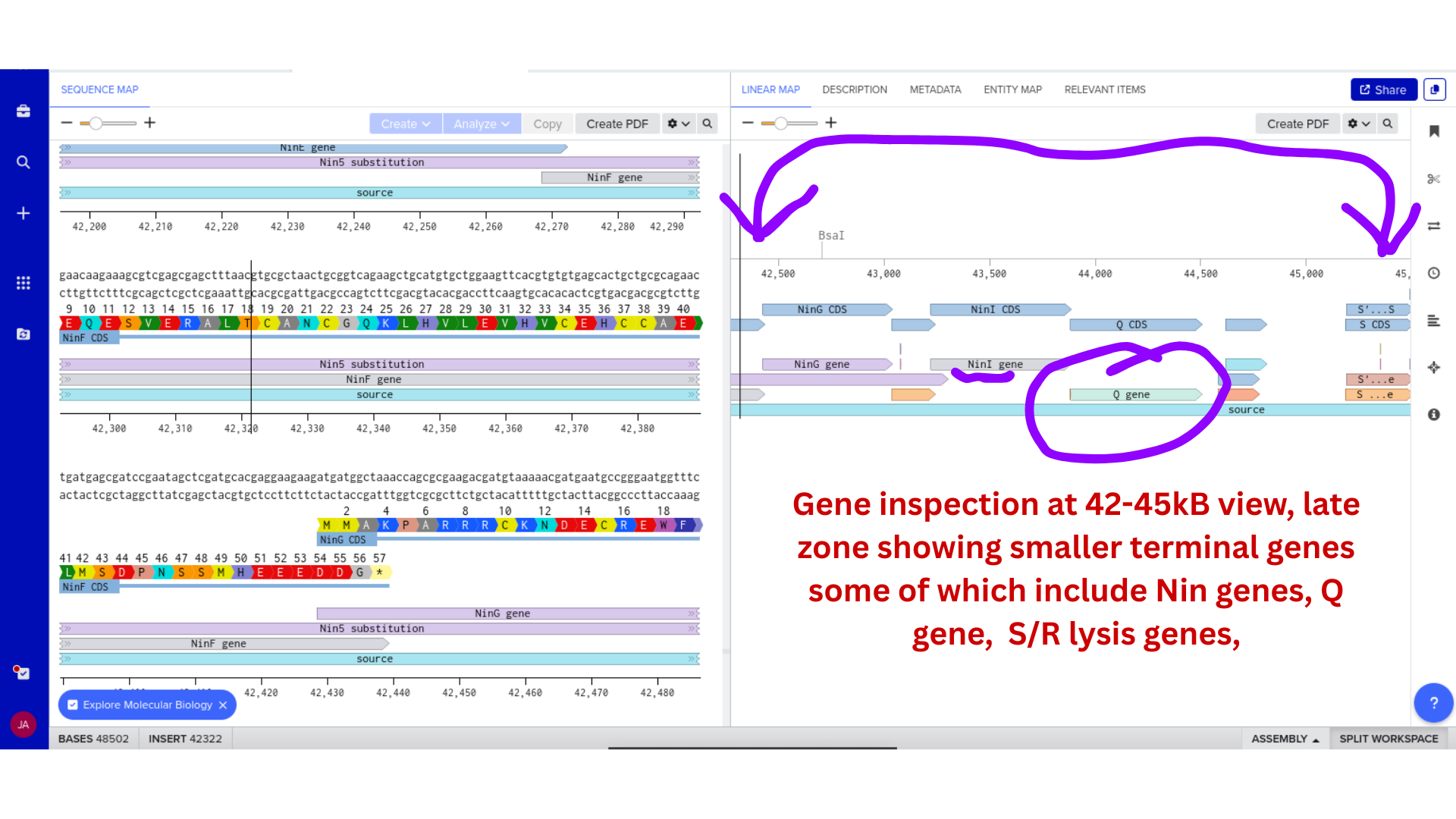
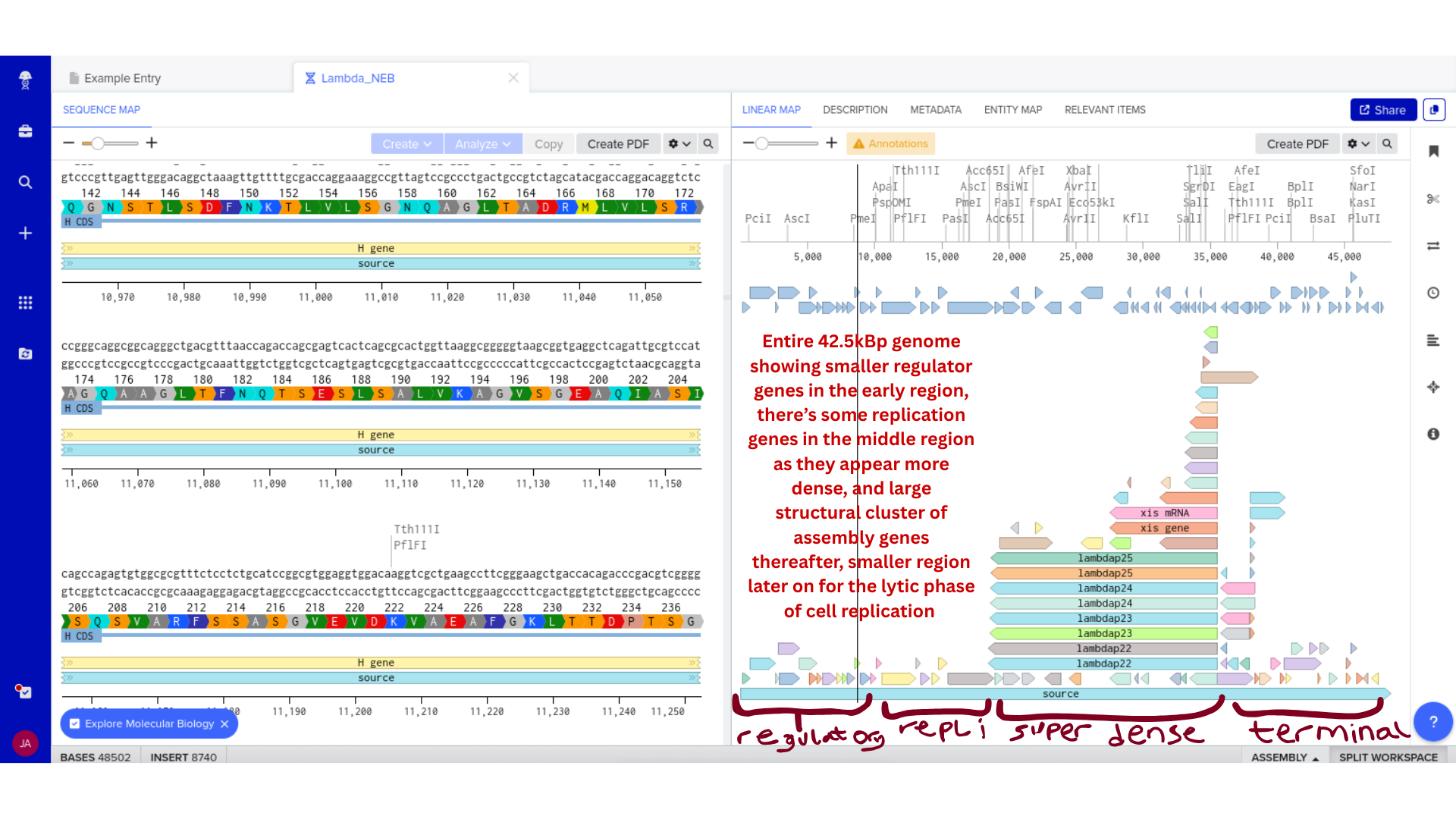
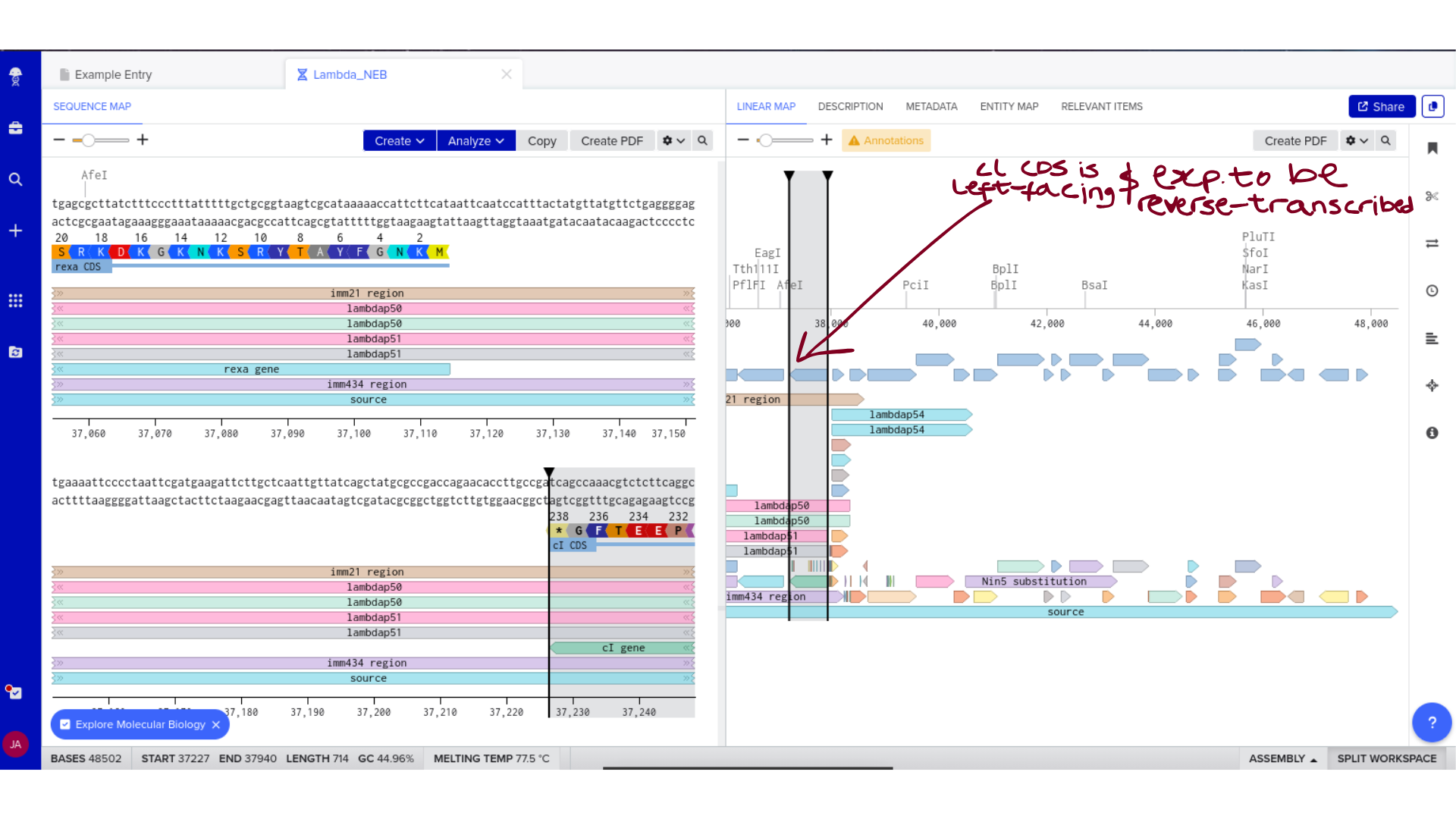
2) Genomic Exploration and Annotation Familiarization
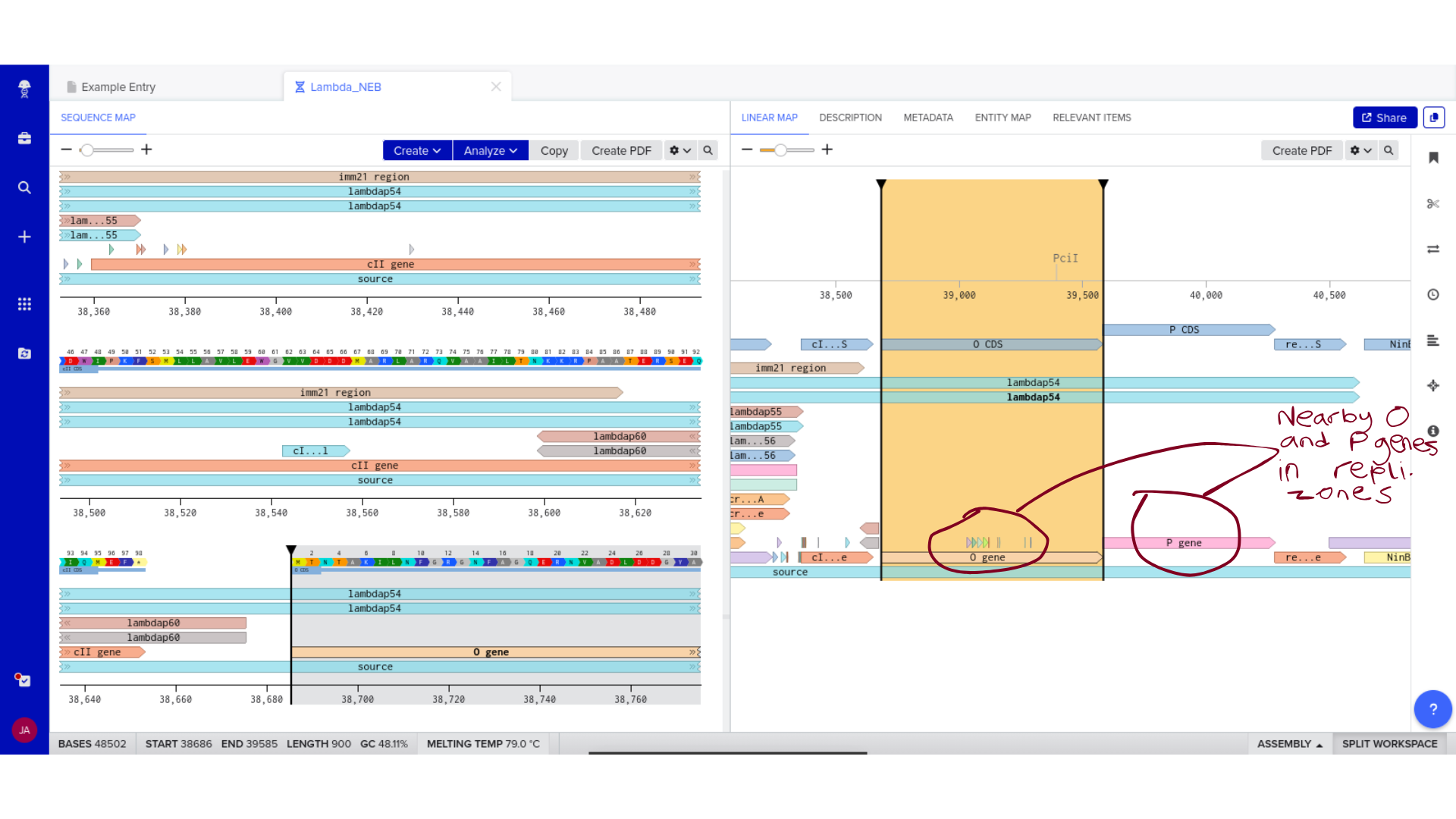
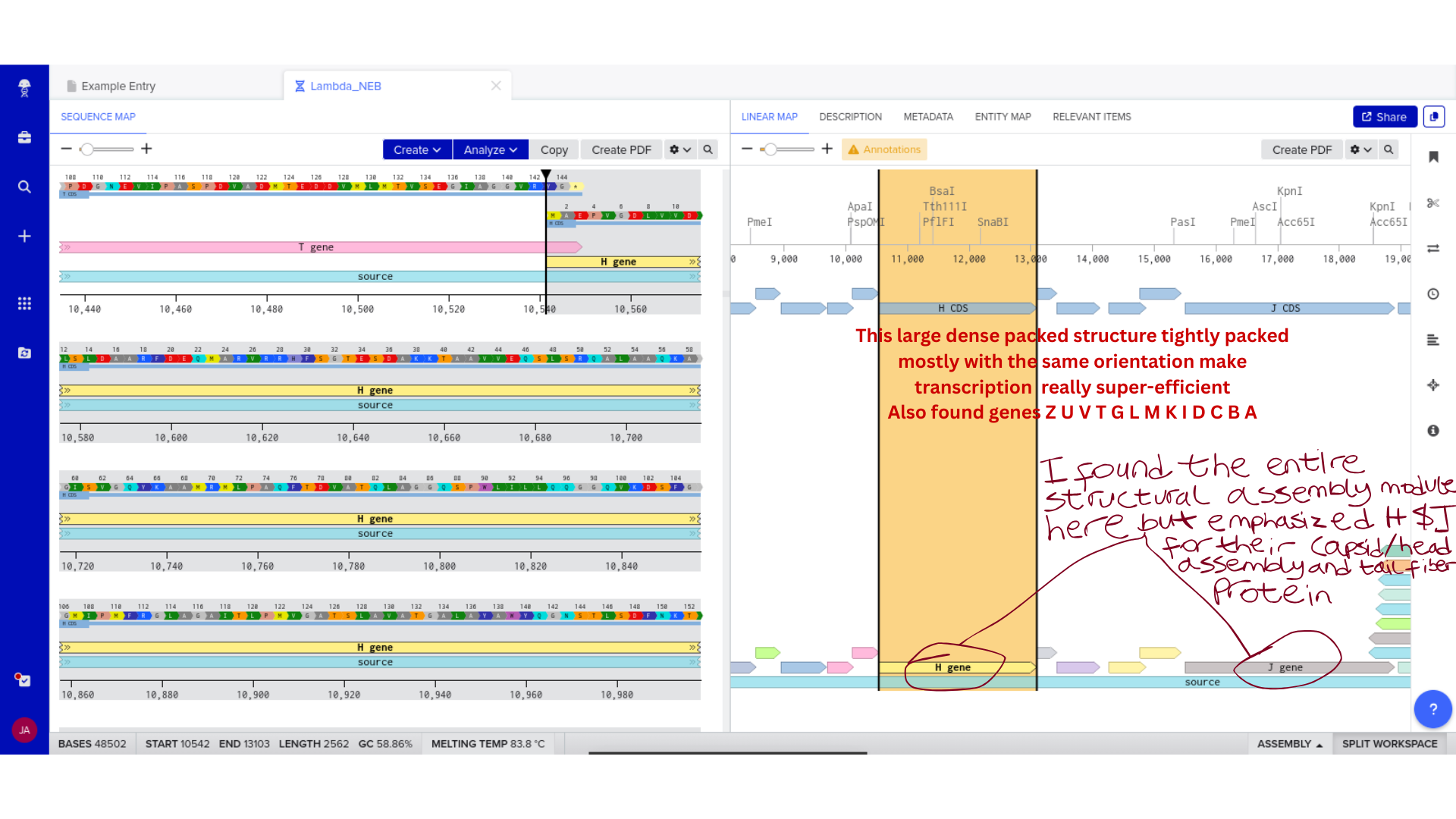
Once imported, I explored the annotated regions of the Lambda genome within Benchling. This involved confirming gene orientation, identifying labeled regions, and understanding the graphical interface for both linear and circular visualization.
Although exploratory, this step reinforced familiarity with the design environment. It ensured that I could distinguish between expected gene clusters and annotation artifacts, and that I could confidently navigate the interface for subsequent editing.
3) Protein Selection and Sequence Acquisition
Furthermore, I selected Microcin M as the protein of interest. The choice aligned with my project, ÌṢỌ, which focuses on context-sensitive antimicrobial response within the gut ecosystem.
The selection criteria included:
- Narrow-spectrum antimicrobial activity
- Relevance to microbial competition
- Compatibility with a governed probiotic chassis
The amino acid sequence was retrieved in FASTA format from a reliable database (NCBI GenBank: CAE55705.1). I verified the header structure and ensured that the sequence corresponded exactly to the intended protein.
4) Reverse Translation
Using Benchling’s reverse translation functionality, I converted the amino acid sequence into a nucleotide sequence suitable for expression in Escherichia coli.
Key considerations included:
- Maintaining correct reading frame
- Ensuring inclusion of a start codon
- Confirming appropriate stop codon placement
- Selecting E. coli codon usage
The output DNA sequence was checked to ensure it translated back to the original protein sequence without truncation or frame shift.
5) Codon Optimization
Following reverse translation, codon optimization was performed for expression in E. coli. This step aimed to improve translational efficiency while minimizing expression burden and avoiding rare codons.
Optimization included:
- Aligning codon usage with host bias
- Avoiding problematic restriction sites
- Preserving protein sequence integrity
This stage reinforced that codon choice influences not only protein yield but also metabolic load and evolutionary stability.
Part 2 — Construct Assembly and Validation
6) Expression Cassette Assembly
The optimized coding sequence was integrated into a complete expression cassette using the assignment’s structural framework:
Promoter → Ribosome Binding Site → Start Codon → Codon-Optimized CDS → Optional His Tag → Stop Codon → Terminator
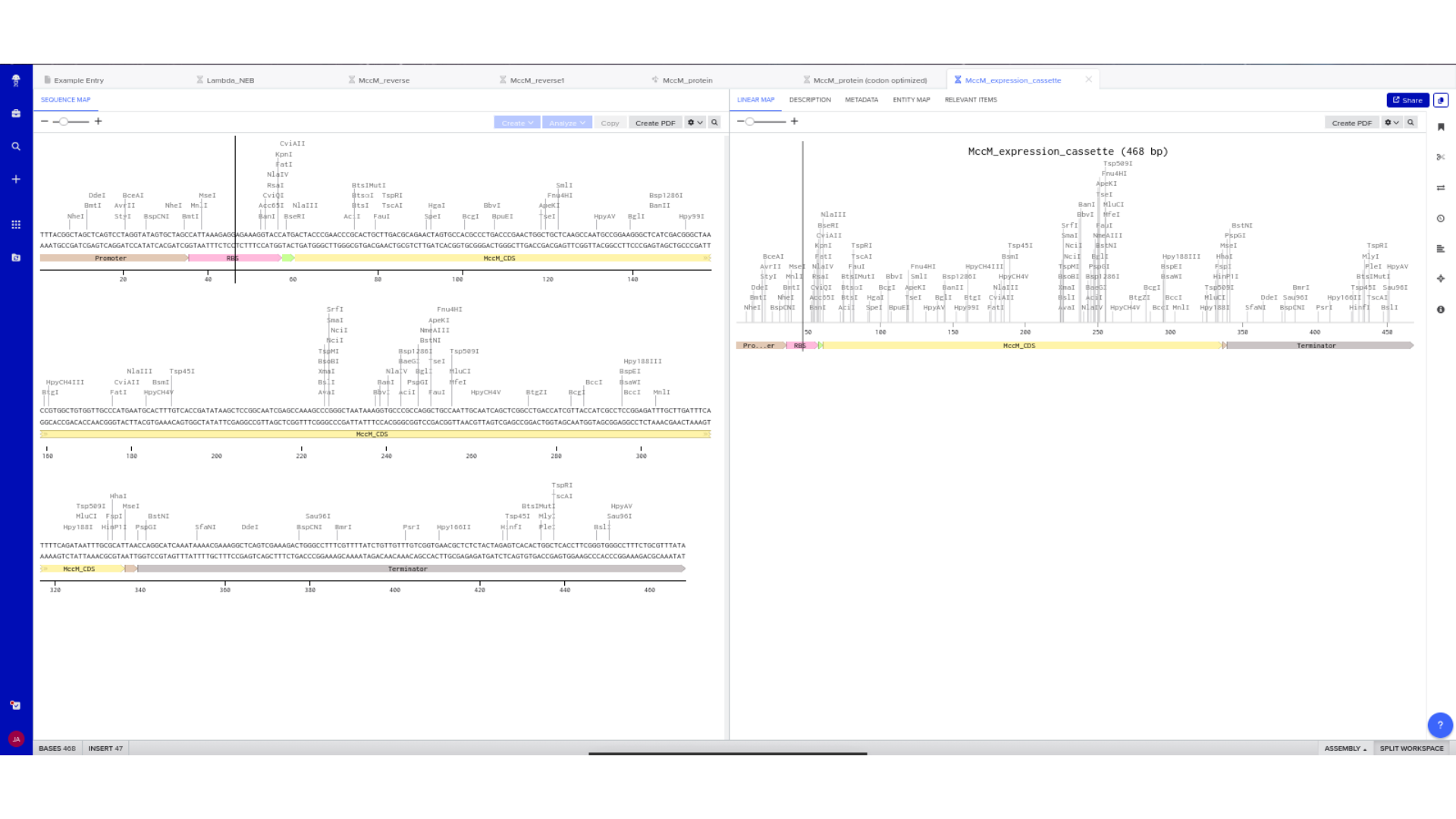
Each component was manually inserted and annotated within Benchling. Particular care was taken to ensure that the coding region replaced the example scaffold sequence rather than being appended to it.
Linear and circular map views were used to confirm structural continuity, annotation accuracy, and absence of unintended sequence artifacts.
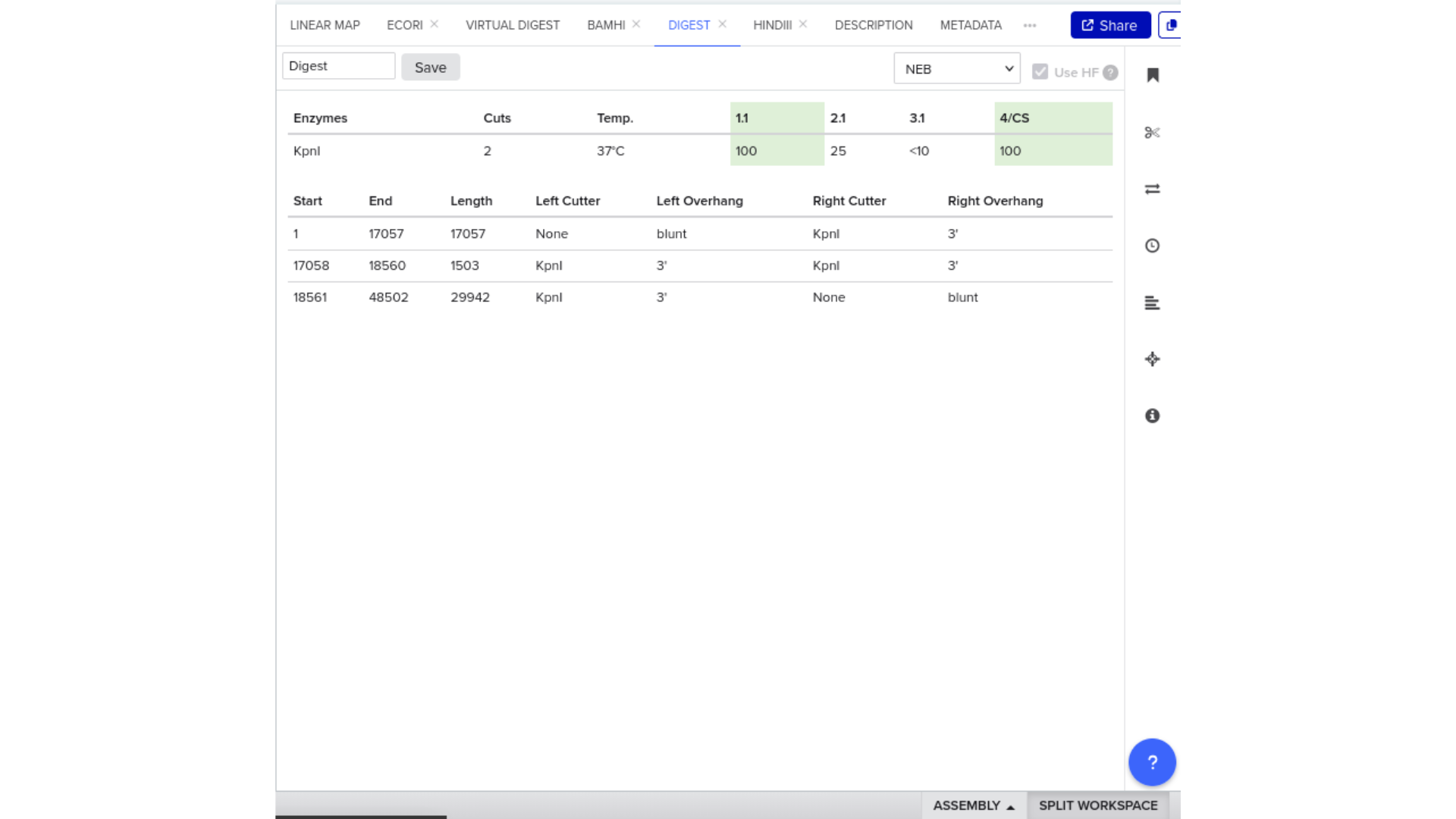
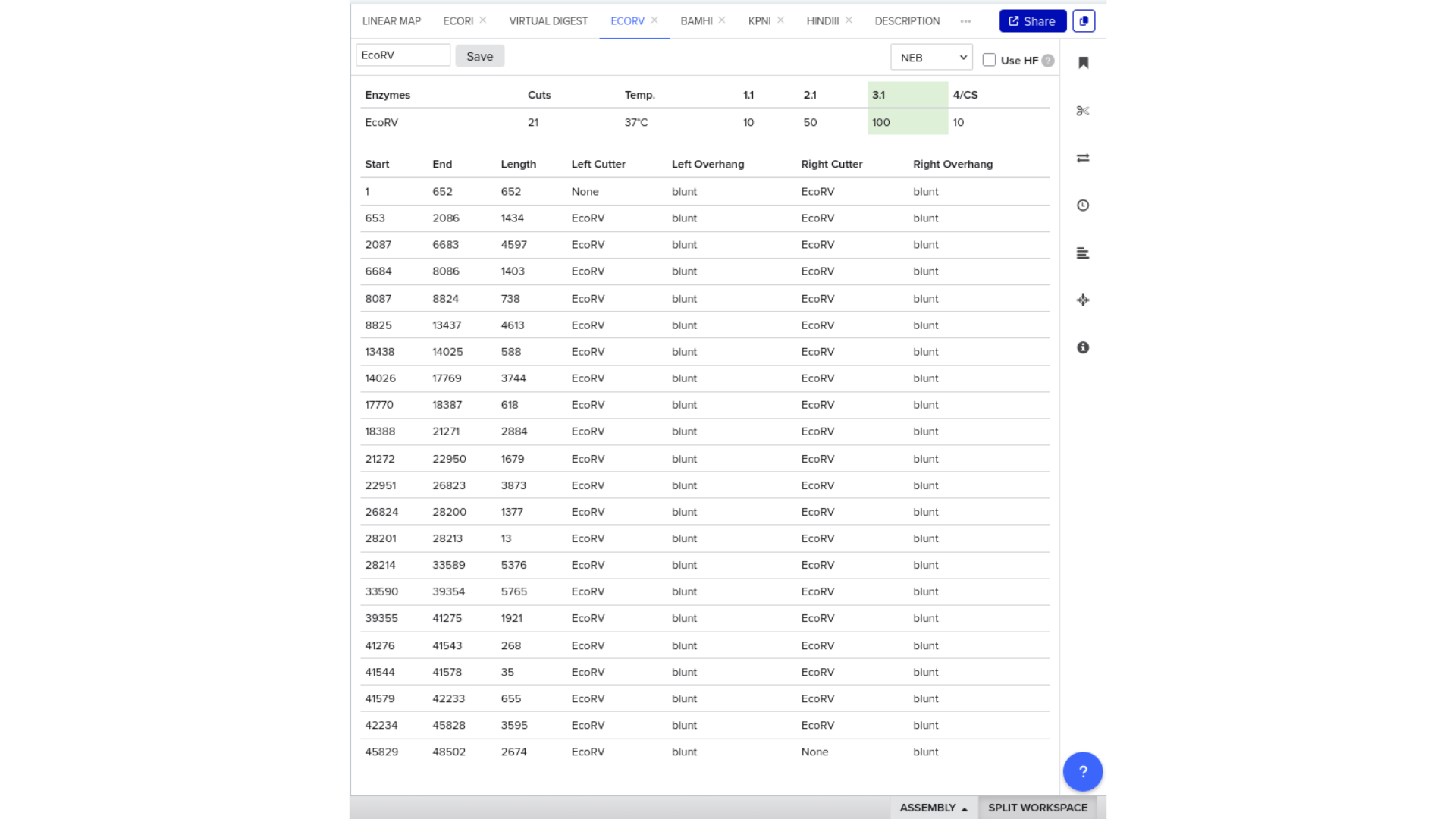
7) Virtual Digest and Gel Simulation
To validate construct integrity, I performed a virtual digest within Benchling and obtained predicted fragment sizes. These fragment sizes were then visualized using an external gel simulation tool.
This step confirmed that the construct behaved as expected under restriction enzyme analysis and reinforced my understanding of plasmid verification workflows.
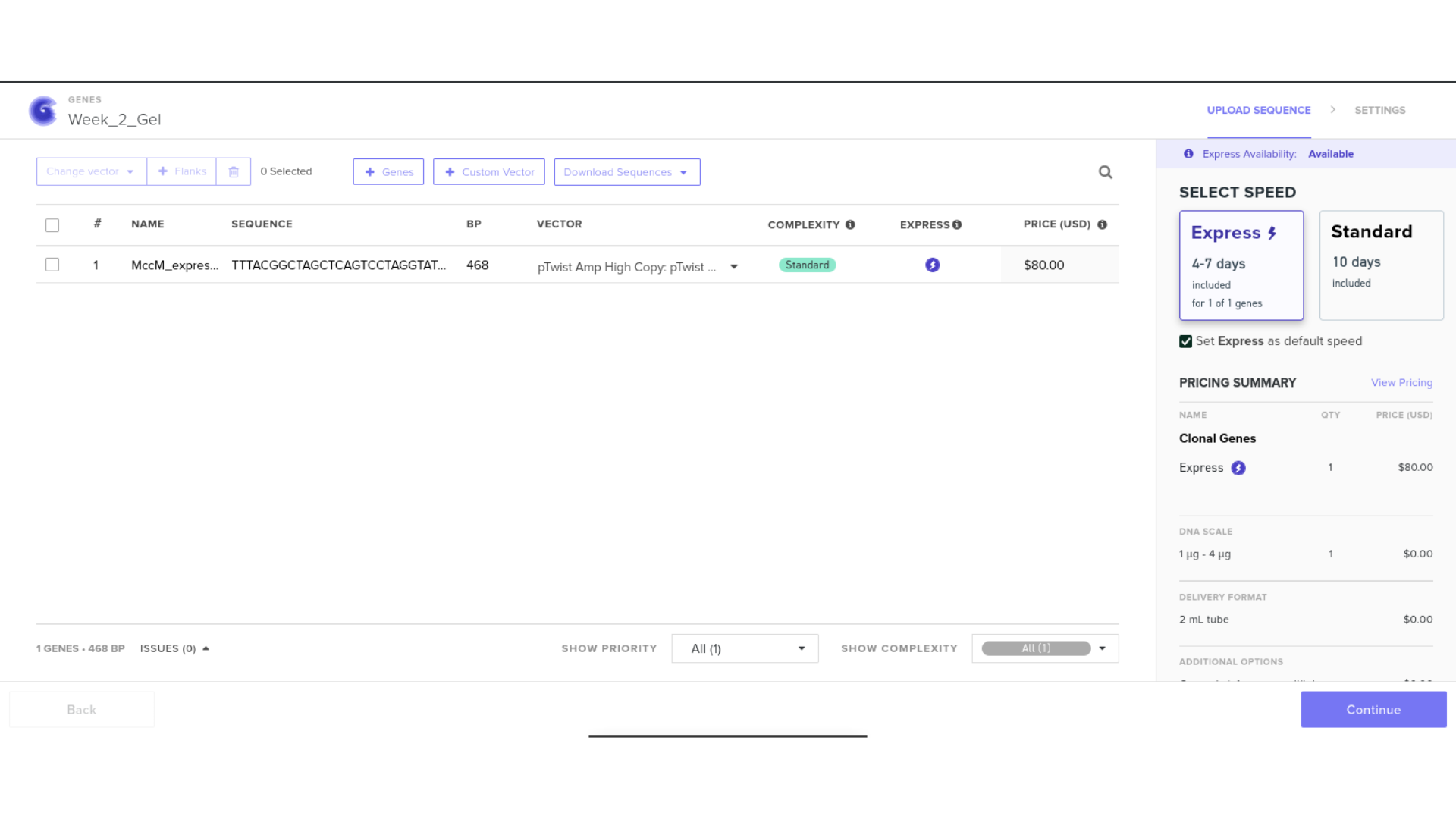
8) FASTA Export and Synthesis Preparation
The completed expression cassette was exported in FASTA format for potential synthesis ordering. Care was taken to ensure:
- Correct header formatting beginning with the greater-than symbol
- No extraneous spaces or formatting characters
- Proper file extension
Although synthesis ordering through Twist was initiated, access was restricted to verified institutional accounts at the time: a common barrier for researchers at nodes outside North America and Europe. I pivoted toward generating a complete plasmid visualisation within Benchling instead.
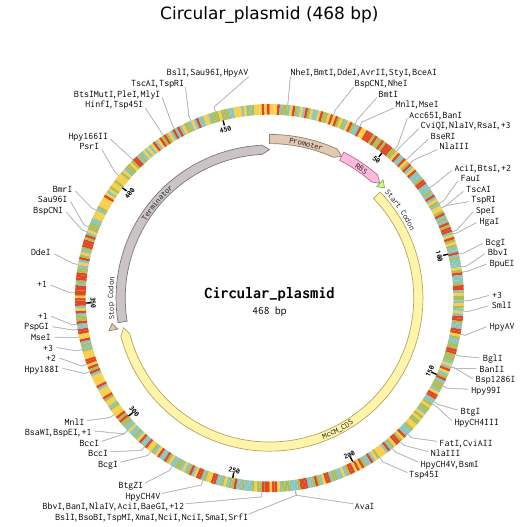
9) Plasmid Map Generation
To simulate a complete plasmid construct, the sequence topology was converted to circular within Benchling. Circular map visualization confirmed clear annotation of promoter, ribosome binding site, coding sequence, and terminator.
This produced a plasmid map without requiring external synthesis confirmation. The visualization ensured structural coherence and clear representation of the engineered construct.
Technical Milestones Achieved
- Successful import and annotation of GenBank files
- Accurate reverse translation from protein to DNA
- Codon optimization aligned with host expression
- Proper construction of an annotated expression cassette
- Verified FASTA export formatting
- Simulated plasmid visualization in circular topology
- Integration of molecular workflow with ecological design philosophy
Backbone Vector Documentation
The Microcin M expression cassette was designed for cloning into pUC19, a high-copy ColE1-origin plasmid carrying ampicillin resistance. pUC19 was selected primarily for its well-characterised cloning sites and broad compatibility with standard E. coli transformation protocols — practical considerations given that the immediate goal is sequence verification rather than stable expression. The MccH47 insert is flanked by EcoRI and HindIII sites for directional cloning into the multiple cloning site. The complete annotated construct is deposited in the class Benchling folder as MccH47_pUC19_EcN_construct.
For downstream ÌṢỌ deployment, the cassette would need migration to a lower-copy backbone — pSC101 or a chromosomal integration vector — to reduce metabolic burden on the EcN chassis and improve evolutionary stability under selection.
Referenced from Week 7, Part 3
Design Integration
Throughout the experience, I maintained alignment with the core principles of ÌṢỌ:
- Fitness cost is a primary design variable
- Selection operates continuously
- Expression burden affects evolutionary stability
- Containment must be intrinsic to architecture
- Models inform design boundaries
This reframed it for me from a cloning exercise into a constraint-aware engineering process.
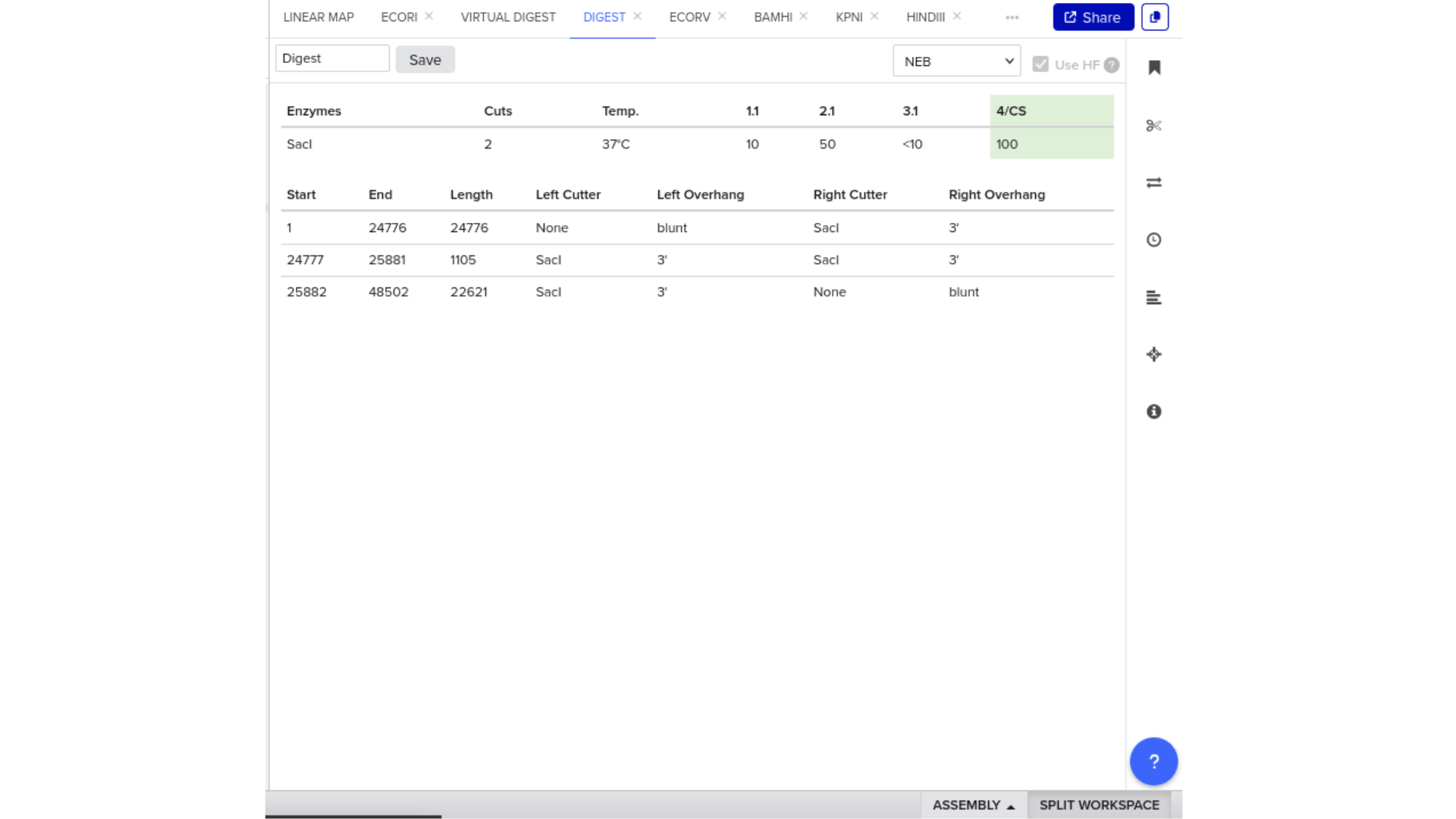
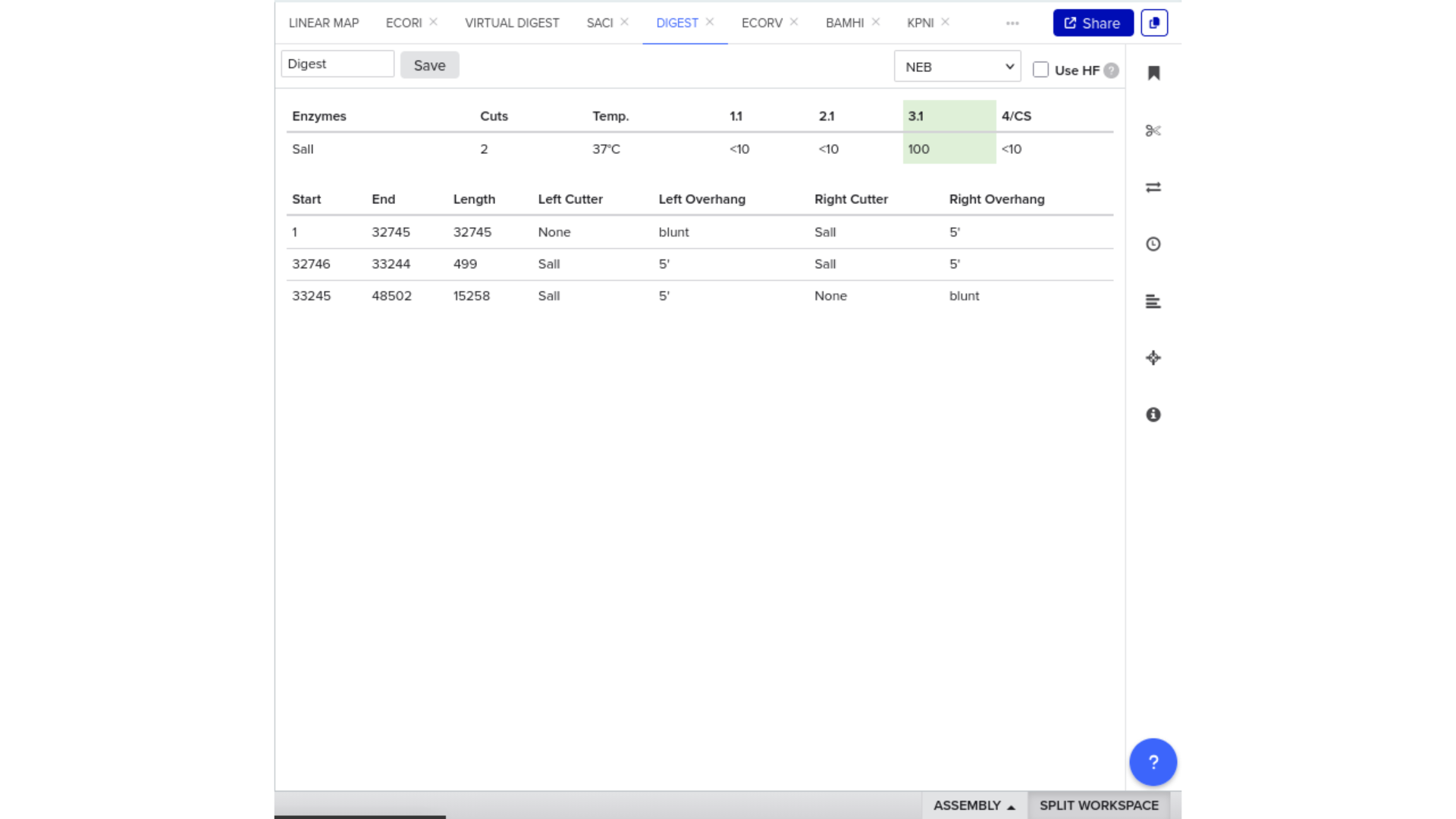
Virtual Gel Simulation — Microcin M Expression Cassette
As a remote participant, I completed a virtual digest and gel simulation of the Microcin M expression cassette in place of the physical DNA Gel Art lab.
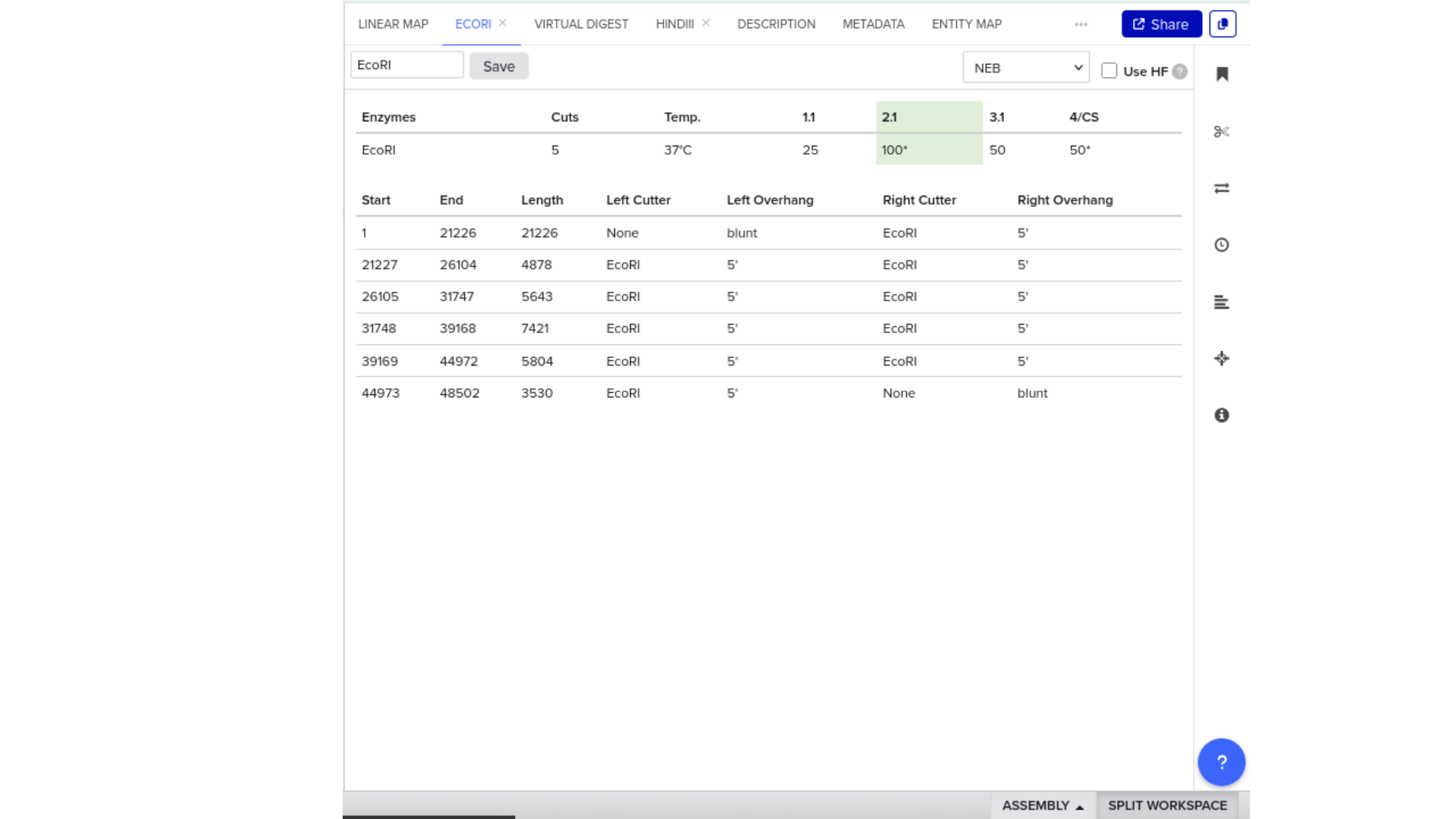
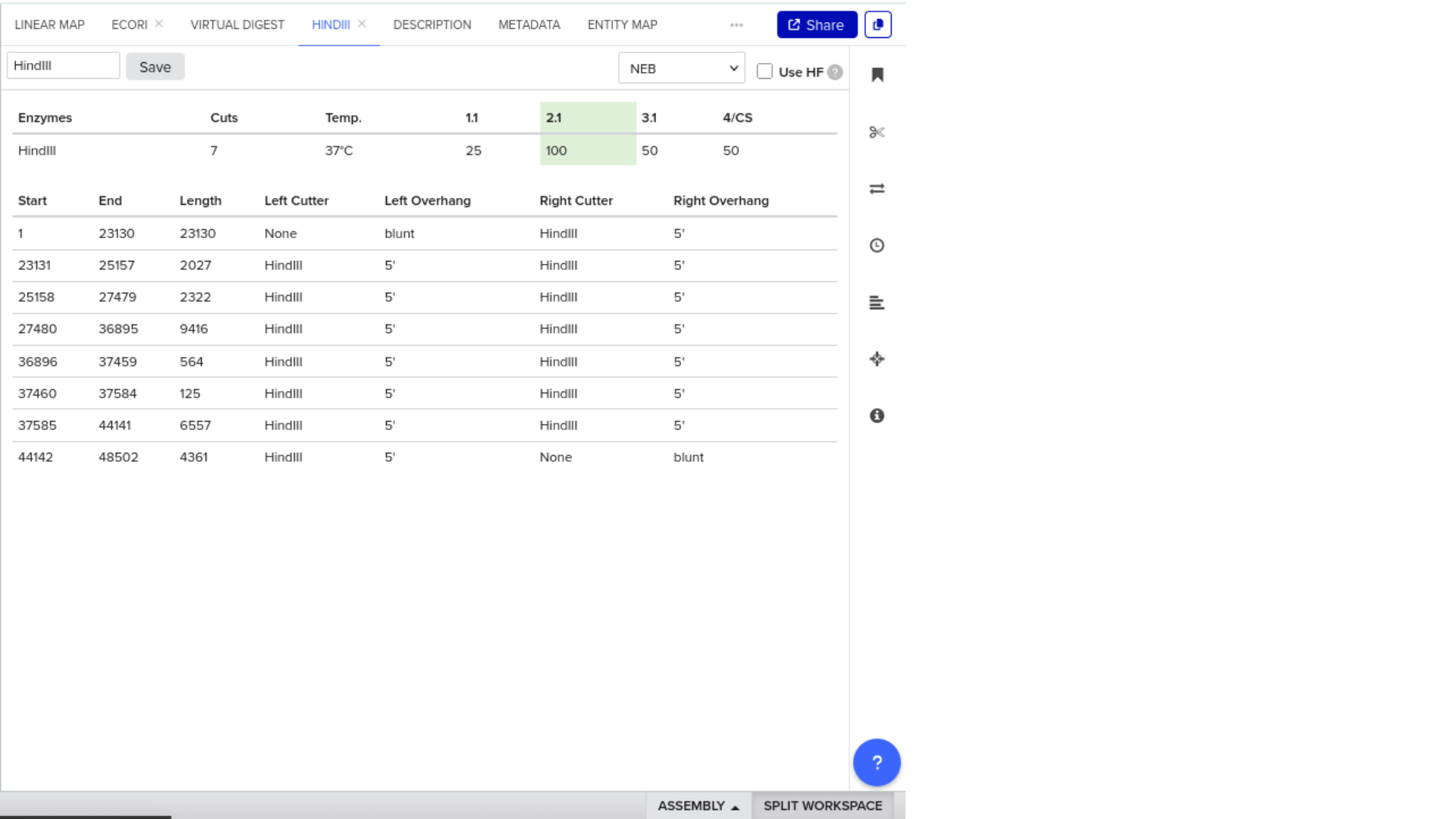
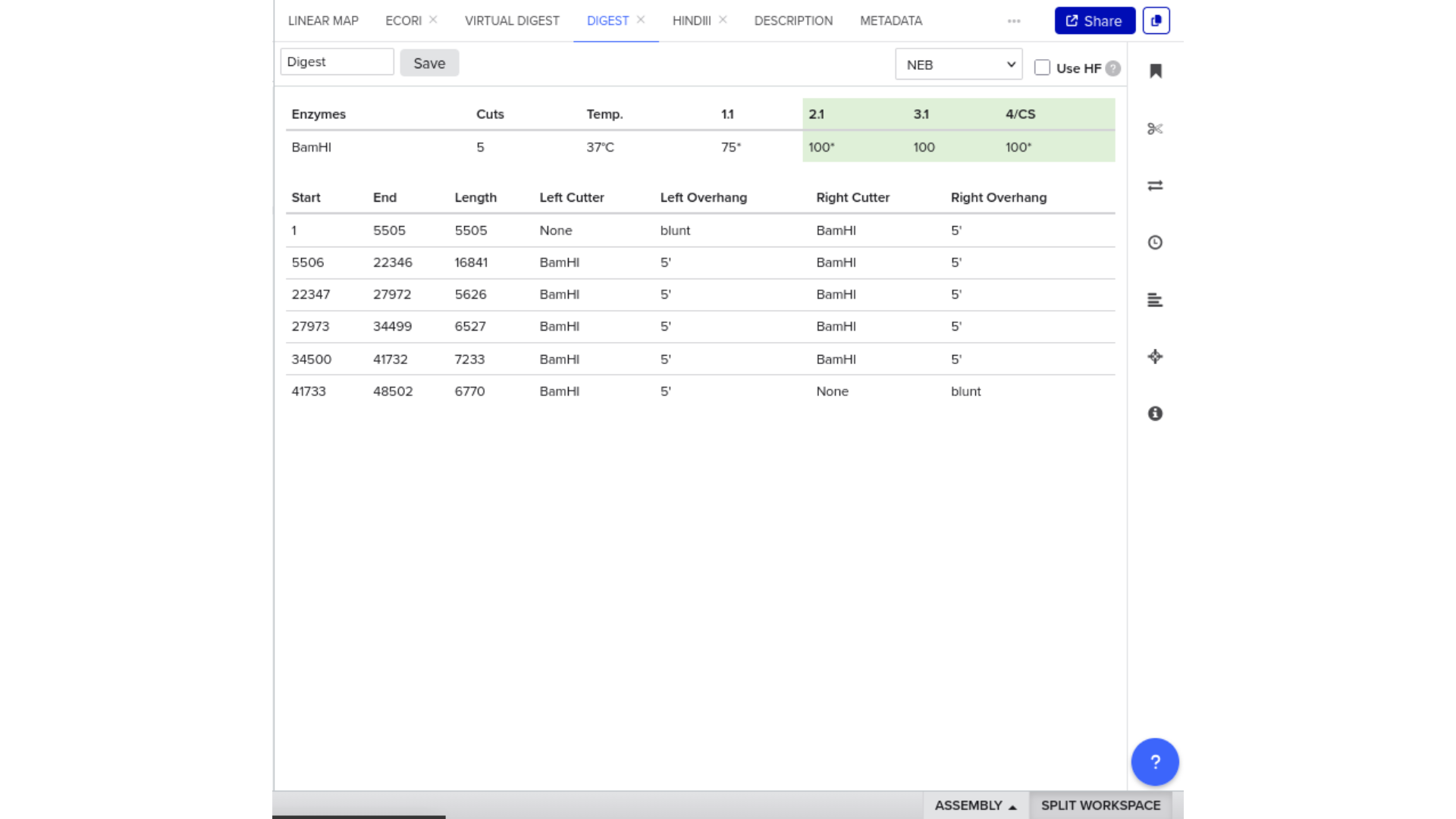
Construct: Microcin M CDS (codon-optimised for E. coli) in pUC19 backbone, directionally cloned between EcoRI and HindIII sites in the multiple cloning site.
Digest: Double digest with EcoRI and HindIII.
Expected fragments:
| Fragment | Expected size | Corresponds to |
|---|---|---|
| Vector backbone | ~2,686 bp | pUC19 linearised |
| Insert | ~250 bp | Microcin M CDS + RBS + terminator |
The gel simulation confirmed two clean bands at the expected sizes with no additional bands, consistent with a correct single-insert construct. The ~250 bp insert band sits just above the lowest visible range for a standard 1% agarose gel, which is worth noting as a practical consideration — a 1.5% gel would give better resolution at this size.
This exercise reinforced that gel verification is not just a confirmation step. The band pattern encodes structural information: the insert size confirms that the coding sequence was not duplicated or rearranged, and the vector size confirms that no additional fragments were incorporated during ligation. Reading a gel is reading a design.
Process Reflections
The workflow required iterative verification at each stage. Formatting, reading frame integrity, codon usage, annotation accuracy, and topology conversion each presented potential points of error and addressing them incrementally reduced compounding mistakes.
More importantly, it reinforced that biological engineering is not simply about inserting genes. It requires contextual awareness, ecological humility, and structural foresight.
Sequence design is only the beginning. Stability under pressure determines whether a system is viable outside controlled conditions.
This process strengthened both my technical fluency and design discipline, linking molecular implementation to ecological responsibility.
Works Cited
Addgene. (2024). Benchling: Molecular biology software for sequence design and analysis. https://www.addgene.org/protocols/benchling/
National Center for Biotechnology Information. (2024). GenBank entry CAE55705.1: Microcin M precursor peptide [Escherichia coli]. https://www.ncbi.nlm.nih.gov/protein/CAE55705.1
New England Biolabs. (2024). Lambda DNA (GenBank J02459). https://www.neb.com/en-us/tools-and-resources/genomic-dna/lambda-dna
AI Prompts Employed (Claude AI)
- Walk me through reverse translation from amino acid sequence to nucleotide in Benchling, step by step
- What does codon optimisation actually change, and what does it preserve
- How do I confirm reading frame integrity after inserting a coding sequence into an expression cassette
- What are the expected fragment sizes if I digest my construct with EcoRI and HindIII
- Why would a FASTA export fail to synthesise and what should I check before ordering