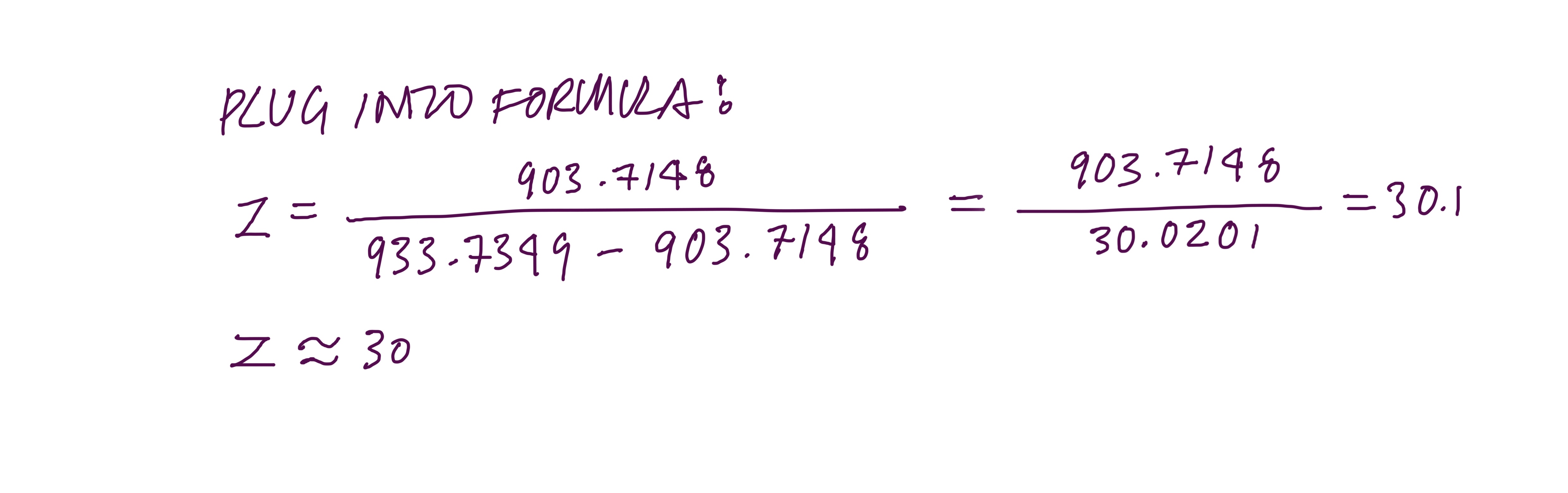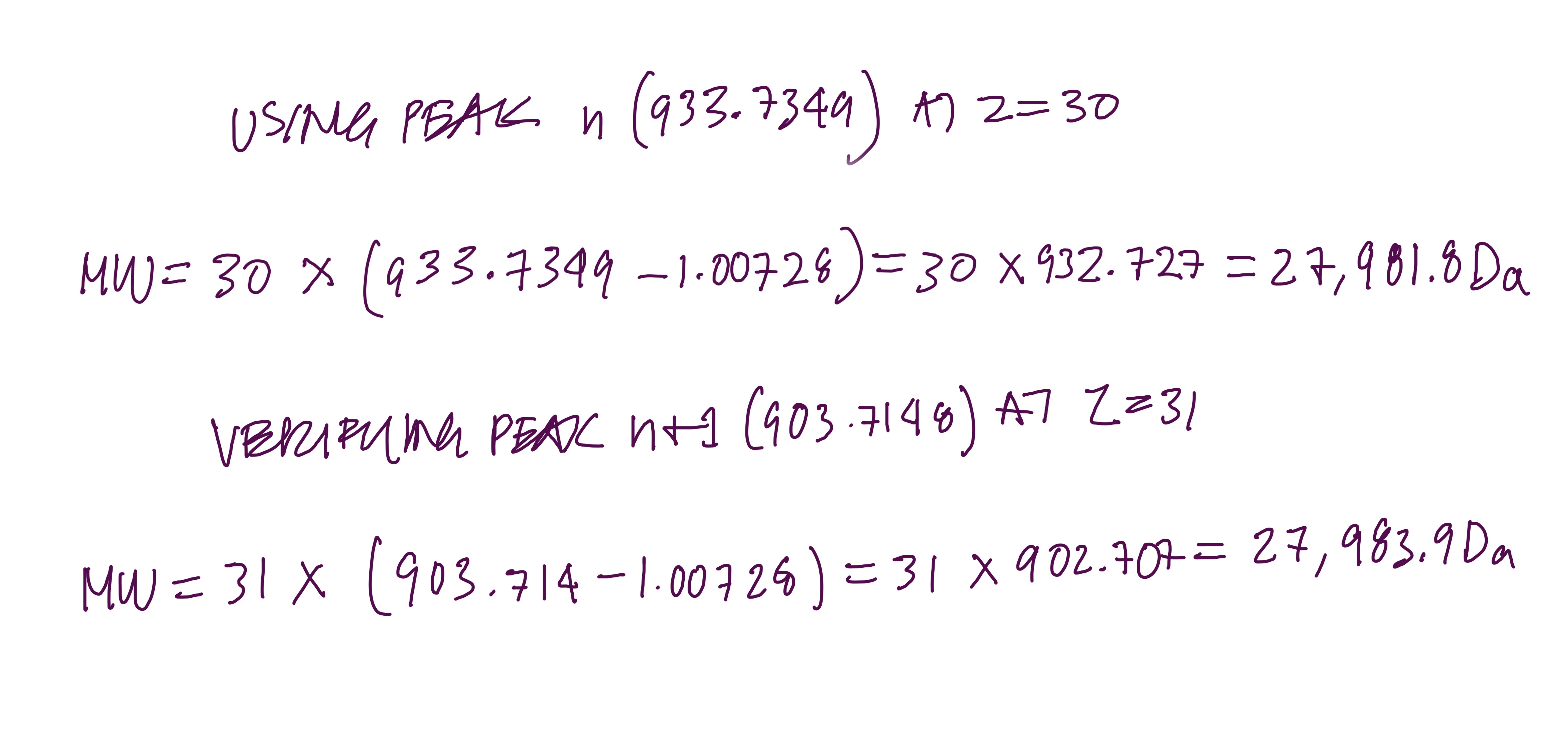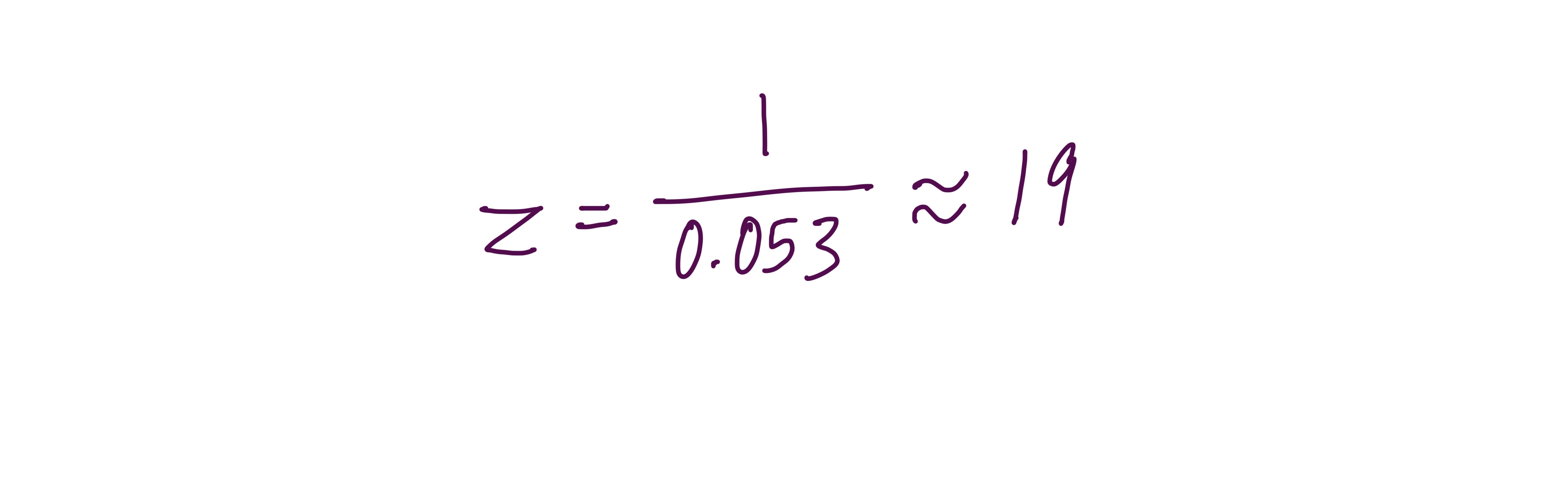IDEA
Through art, design, biology, and apparel, I am interested in exploring how wearers can become more attuned to their identity by expressing their unique microbial genomes and ecosystems that make up their bodies through a bio-engineered second-skin-like textile. This project explores clothing as a custom, an expression, and a living interface that evolves with the body, offering an alternative to the rapid cycles of novelty and replacement characteristic of fashion today. The garment becomes a second skin that is not consumed or discarded, but lived with, every day, shifting gradually and meaningfully over time (National Institutes of Health).
Week 10 — Advanced Imaging & Measurement Technology Final Project Measurments What I will measure
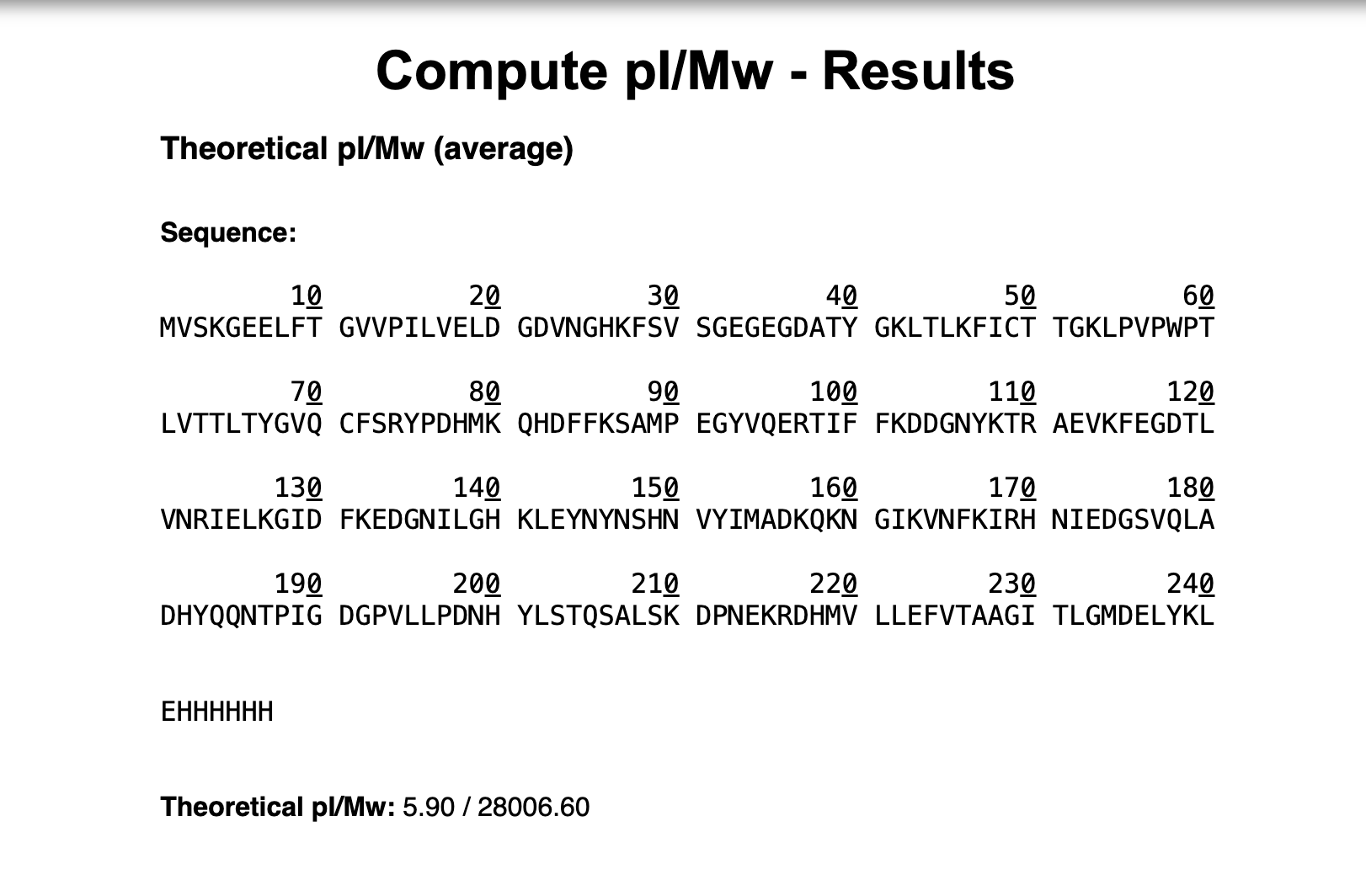
The mass of my fusion protein CsgA-hCRY2-DrBphP to confirm it was made at the correct size of approximately 156.7 kDa.
The amino acid sequence of each domain to confirm no errors were introduced during DNA synthesis or expression.
Part 1: Benchling & In-silico Gel Art
https://benchling.com/s/seq-B1mFk0Oh2ZF9coVeqBMH?m=slm-ySVijsqZThHxK3Qq6kwq
Part 2: Gel Art - Restriction Digests and Gel Electrophoresis
I am interested in the protein Reflectin. This protein is common in Cephalopods and is responsible for their structural colour as their skin changes with the environment. I am interested in the potential applications of Reflectin in smart materials/textiles. Reflectins’ optical properties can be reversibly engineered to change colour under different conditions. There is one study in which Reflecin was used in this way in a thin film substrate, and responsive to hydration or dehydration of the material.
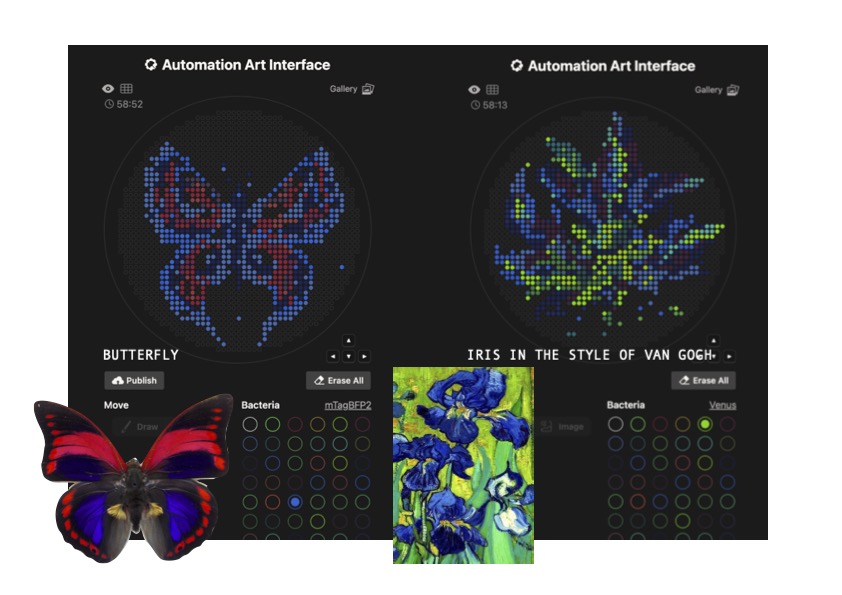
OPENTRON GEL ART Figure 1
I tried creating a butterfly using the OpenTron drawing tool, with 4 different colours, dark blue, light blue, red and purple, which are some of the available colours in Lifefabs.
I also tried to create an Iris in the style of Van Gogh. As this is a more fluid and asymmetrical design, it would be harder to achieve, given the complexity of the multiple colours in organic scaddered shades, rather than in small units. Moreover, the dots and spaces are quite compact, which would make it harder to achieve a clean result.
(American Chemical Society, 2023)
Protein Design Google Collab
Part A. Conceptual Questions Answer any NINE of the following questions from Shuguang Zhang: (i.e. you can select two to skip)
Why do humans eat beef but do not become a cow, eat fish but do not become fish? Even though some may like to say you are what you eat, this really isn’t the case when it comes to eating an organism. Even though we consume its parts and convert protein into energy we are transforming energy into energy that we can use. One may argue we embody that organism to a degree, but we dont fully transform into that being. Your cells follow a genetic blueprint, and while other DNA enters your body, you do not absorb its genome, nor does it integrate into yours.
Week 5 HW: Protein Design Part II (Carnaroli et al.,2025)
PART A: SOD1 Binder Peptide Design (From Pranam) Superoxide dismutase 1 (SOD1) is a cytosolic antioxidant enzyme that converts superoxide radicals into hydrogen peroxide and oxygen. In its native state, it forms a stable homodimer and binds copper and zinc.
DNA ASSEMBLY Answer these questions about the protocol in this week’s lab:
What are some components in the Phusion High-Fidelity PCR Master Mix and what is their purpose?
The Phusion High-Fidelity PCR Master Mix is a pre-mix solution used to amplify DNA during PCR. There are a few components that make the master mix efficient and accurate.
ASSIGNMENT PART 1: Intracellular Artificial Neural Networks (IANNs) IANN ADVANTAGES VS GENETIC CIRCUITS
Intracellular Artificial Neural Networks, are genetic circuits designed with the same framework as neural networks taking from the most intelligent systems of communication that exist in our inner worlds. In traditional genetic circuits the outpus are boolean ON(1)OFF(0), however IAANs have outputs with continous analog, rather 0.2,0.5,0.75,1… The advantages of Iann vs genetic circuit logic, is the complexity of the analogue captured, combining many inputs as well as nonlinear relationships, and thus work better with biological systems with gradual changes and growth (Nilsson et al., 2022).
General Homework Questions 1. Explain the main advantages of cell-free protein synthesis over traditional in vivo methods, specifically in terms of flexibility and control over experimental variables. Name at least two cases where cell-free expression is more beneficial than cell production.
The first advantage of cell-free protein synthesis (CFPS) over traditional in vivo methods is that it avoids the ethical concerns associated with modifying living cells; CFPS uses cellular machinery such as ribosomes and enzymes. The second advantage of CFPS is the time and cost. CFPS takes around 1-2 hours while cell-based expressions, such as in E. coli, take around a few days to a week, depending on the expression. Third, there is increased biosafety and controllability with CFPS. CFPS are more controllable and programmable. Unlike using living cells which can escape into the environment and potentially cause harm depending on the organism. Lastly
Subsections of Homework
Week 1 HW: Principles and Practices
IDEA
Through art, design, biology, and apparel, I am interested in exploring how wearers can become more attuned to their identity by expressing their unique microbial genomes and ecosystems that make up their bodies through a bio-engineered second-skin-like textile. This project explores clothing as a custom, an expression, and a living interface that evolves with the body, offering an alternative to the rapid cycles of novelty and replacement characteristic of fashion today. The garment becomes a second skin that is not consumed or discarded, but lived with, every day, shifting gradually and meaningfully over time (National Institutes of Health).
I am drawn to the skin microbiome as a dynamic and richly complex ecosystem that continuously evolves in response to environmental stimuli, material contact, and everyday life. The skin absorbs and interacts with everything it encounters—from air and surfaces to residues such as microplastics—while remaining in constant dialogue with its own microflora. I envision a bespoke “second skin” generated through the bioengineering of an individual’s genomic profile and cutaneous microbiome, translated into algorithmically encoded, chromatically responsive pattern systems.
This work is inspired by Neri Oxman’s approach to material ecology, particularly her use of modularity, gradience, and unity to integrate biological processes directly into design (Marvin, J.). In this project, patterns within the material are speculated to evolve gradually as the wearer’s skin ecosystem undergoes microbial succession in response to environmental exposure, climate, and daily interaction. Bioengineered, non-pathogenic microbial consortia or biologically derived, metabolically active materials are embedded within the textile architecture, functioning as living intermediaries between the body and its environment. These systems respond to localized changes in the skin’s microenvironment, such as pH, moisture, temperature, and biochemical flux, through controlled shifts in pigmentation, pattern density, and material morphology (Atallah, C.).
Rather than interpreting or evaluating bodily states, the garment becomes a living material archive, reflecting a healthy, dynamic relationship among the wearer, their microbial ecosystem, and the world they move through. In this way, fashion becomes a site of ongoing exchange and evolution, replacing short-term satisfaction with a deeply personal, evolving form of embodiment.
In a previous exploratory project, “SECOND-SKIN”, I sampled and analysed skin-associated microbial communities from distinct anatomical regions, observing that different areas of the body host unique microbial ecologies. This work focused on translating the otherwise invisible microbiome of the human body into an expressive, artistic language.
In this project, I extend this inquiry by proposing a modular design and material system that reflects the evolution of an individual’s skin microbiome over time. The textile functions as a responsive biological interface or living biologically active material that registers changes in microbial composition, metabolic activity, or by-products present on the skin’s surface. These shifts are translated into gradual changes in colour, texture, or pattern, allowing the textile to act as a temporal record of the wearer’s ever-evolving microbial life.
Project “SECOND-SKIN” 2020
GOVERNANCE POLICY GOALS:
GOAL 1: Prevent Harm and Ensure Safety
Because this textile directly interfaces with the body and incorporates living or biologically active components, governance must prioritise physical, biological, and environmental safety throughout design, experimentation, and use.
Sub Goal 1: Biological Safety
Ensure the safety of the wearer’s skin and microbiome by regulating the use of non-pathogenic organisms, fully contained or controlled living systems, and biocompatible materials. Prevent adverse skin reactions and unintended microbial transfer during use, experimentation, and prolonged wear.
Sub Goal 2: Prevent Environmental Contamination
Establish controlled experimental conditions, follow appropriate laboratory protocols, and ensure safe containment, deactivation, or disposal of biological components at the end of the material’s lifecycle to prevent unintended environmental release.
Sub Goal 3:Clarification and Communication
Clearly communicate the material’s biological components, symbiotic role, and limitations to users and research participants. Avoid misclassification of the textile as a diagnostic, therapeutic, or medical technology by framing it explicitly as an expressive, cultural, and experiential material system.
GOAL 2: Protecting Autonomy, Consent and User Agency
Working with microbiome-derived data and living materials raises ethical concerns related to bodily autonomy, consent, and ownership of biological information.
Sub Goal 1: Informed Consent
Users should clearly understand what biological information is being used (e.g. abstracted microbiome composition), how it is translated into material form, and what is not being measured or inferred. Consent should be explicit, ongoing, and revisitable as the material evolves.
Sub Goal 2: Time, Control and Lifecycle Awareness
Ensure users understand the material’s temporal nature, how it may evolve, change, or age and provide clear mechanisms for disengagement, pausing, or material retirement. Users should be informed about how environmental exposure may influence material behaviour.
Sub Goal 3: Protect Biological Data and Privacy
While microbiome data may be used to generate initial material patterns, governance should ensure abstraction, anonymisation, and minimisation of biological data. Prevent misuse, re-identification, or unintended interpretation of microbiome information during research, development, or documentation.
GOAL 3: Design Collaboration and Material Interface
This project treats biological systems not as tools, but as collaborators in material expression.
Sub Goal 1: Encourage Interpretive Ambiguity
Frame material expression in a way that remains open and personal, avoiding fixed meanings or biological judgments. Patterns, colors, and textures should be experienced as aesthetic and reflective rather than explanatory, allowing wearers to form their own understanding over time.
Sub Goal 2: Fostering Long Term Embodied Relationships
Encourage design approaches that support lasting engagement with the garment. The material should evolve gradually with the wearer and their environment, promoting attachment, care, and continuity rather than novelty or performance monitoring.
Sub Goal 3: Respecting Living Organisms and Collaborators
Ensure that biological organisms involved in the design process are treated as collaborators rather than passive tools. This includes designing with respect for uncertainty, emergence, and biological behavior, and valuing learning and responsiveness over control.
GOAL 4: Diversity and Social Value
Sub Goal 1: Avoid Biological Hierarchies
Design the system to celebrate microbial diversity and variation rather than framing certain biological compositions as superior, healthier, or more desirable.
Sub Goal 2: Inclusive and Contextual Design
Account for diverse bodies, skin types, climates, cultures, and environmental contexts. Recognise that microbiomes vary widely and meaningfully across individuals and environments.
Sub Goal 3: Innovation and Long-Term Social and Cultural Value
Promote designs that cultivate appreciation for inner biological diversity and interdependence with the environment, positioning fashion as a medium for ecological awareness and long-term reflection rather than critique or correction of the body.
GOVERNANCE ACTIONS AND EVALUATION
Governance Action 1: Abstraction and Use of Microbiome Data
Purpose:
Currently, biological data, especially DNA, is often treated as a source for identity and diagnosis. This governance action proposes using microbiome data solely to reflect and generate material patterns for a “custom skin design,” rather than as a health monitor. The goal of the design is to enable personalisation of wearables to complement identity through one’s personal microflora without reinforcing medicalised interpretations of the body’s health states over time (Nuffield Council on Bioethics).
Design:
Through a design lens, this would require that microbiome data is reduced to high-level non-identifying parameters and indicators, before translating material forms, textures and colours. Academic researchers and designers would document this abstraction process through an ethical review, and institutions or collaborators would approve projects only with clear boundaries between the user and their biological content being used to drive material changes and custom patterns.
Assumptions:
This approach assumes that abstraction can preserve the richness of biological variation without revealing sensitive or identifying information. It also assumes users can connect with such a textile and material without it immediately reflecting some information related to the state of their health and microflora. There is also an assumption that the material will not be contaminated by other genetic material upon exposure, thereby triggering changes in its material codes.
Risk of Failure and Success:
This governance action can fail if the abstraction is not clearly communicated to viewers, and if viewers view the material as a marker revealing biological truths subject only and specifically to their genetic skin material. If successful, the material will invite an understanding of one’s microbiome, and one will feel connected to the material through their identity reflected in their own personal ‘second skin’ with encoded patterns.
Governance Action 2: Consent and Awareness Over Time
Purpose:
As this textile is designed to reflect, react and evolve with one’s microflora over time, consent needs to surpass time rather than a one-time agreement. This governance action aims to ensure that users are always informed and in control of their own genetic material as it interacts, changes, and reveals patterns of their skin over time (Nuffield Council on Bioethics).
Design:
Users should be clearly informed about how the material of their genomic and microbial makeup is used and how it may change over time. They should also be informed of the factors related to those changes like triggers in the environment, temperature, ph, and even their diets. Users should understand consent as ongoing, with the opportunity for disengagement over time in relation to material evolution.
Assumption:
This assumes that users are engaging with the material over time and are interested in transparency through evolution rather than at a first-time basis in a finished product or object. It also assumes the designer understands most possible changes, allowing them to clearly communicate material changes with users. It also assumes most users will reflect similar patterns without understanding all potential microbiome reflections in a material, and that changes to material patterns are limited by encoded engineered material.
Risk of Failure and Success
The action’s failure is indicated if the user feels overwhelmed by their personal information and biological data and disengages with their custom skin. If successful, the material is always engaging and evolving, inspiring surprise, wonder, and a sense of a “custom” look, without the need for other satisfactory components, as in “fast fashion”.
Governance Action 3: Design for Long-Term Biological Relationship rather than one-time use / Rapid Consumption
Purpose:
Fashion systems today value speed, novelty, and constant replacement, encouraging users to constantly change and seek satisfaction. This governance action proposes an alternative model in which biointeractive textiles are designed to evolve slowly with the wearer and form a long, healthy, symbiotic relationship, rather than providing short-term satisfaction. The purpose of this textile is to form a personalised system rooted in biological time, where changes are driven by the constant dialogue between the body’s microbiome and its environment.
Design:
This requires the design to be bioengineered to reflect data from the microbiome first as a template for a custom DNA fingerprint, and then as a gradual system that transforms over use and time. This enables the user to grow a deeper relationship with the material over time. This reflects the design philosophy of patina, where ageing with the material becomes more valuable than a static material or object. Cultural institutions, as well as Art and Design communities and academic institutions, could support this design approach and change the language and cultural dialogue in how materials are approached. Evaluating success through longevity, attachment, and stewardship should be the leading criteria when designing responsibly, rather than focusing on scalability.
Assumptions:
This assumes that wearers have the ability to care for slower forms of engagement over time rather than shift from one-time use excitement and satisfaction. It also assumes that the fashion system can function on individual personalised systems rather than consumable production cycles and that biological change over time can be experienced as meaningful rather than unpredictable and inconvenient.
Risks of Failure and Success:
Failure could be seen where users could expect instant personalisation and are impatient with gradual changes over time. There is also the risk of market pressures reintroducing fast fashion logic and trying to accelerate production in biological processes that take time and are not scalable. If successful, the approach is culturally accepted and appreciated through a patina philosophy of design lens. The approach also challenges existing fashion paradigms and shifts into a niche that longs for custom-fitting products targeting individuals’ ecosystems rather than the masses.
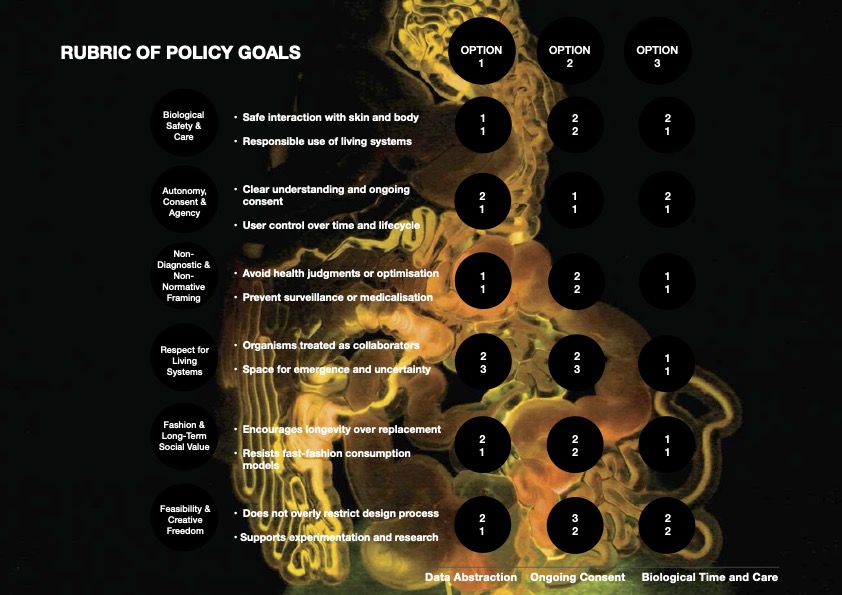
PRIORITIZED GOVERNANCE OPTIONS, TRADE-OFFS AND RECOMMENDATIONS
Drawing on the rubric, I would prioritise Option 3: Designing for a Long-Term Biological Relationship (Biological Time and Care), supported by Option 1: Abstraction First Use of Microbiome Data (Abstraction Data) and Option 2: Ongoing Consent and Lifecycle Transparency as essential safeguards (Ongoing Consent). Option 3 emerges as the strongest core strategy because it most directly supports the project’s fashion-specific and cultural goals: encouraging longevity over replacement, resisting fast-fashion consumption models, and framing the garment as a living system that gains meaning through time and use. By embedding biological time and co-evolution into the design, this option aligns with respect for living systems and positions fashion as a practice of care and stewardship rather than optimisation or novelty.
However, Option 3 alone would be insufficient without the protections offered by Options 1 and 2. Option 1 is critical in preventing health judgments, biological hierarchies, or genetic determinism by ensuring that microbiome data is abstracted before use and never interpreted diagnostically. Option 2 complements this by protecting user agency over time, recognising that consent must remain ongoing as the material evolves and as the relationship between wearer and garment deepens.
The primary trade-off in prioritising Option 3 is feasibility and scalability. Designing garments that evolve slowly and unpredictably may challenge existing fashion production models and limit immediate commercial adoption. There is also uncertainty around how users will respond to gradual biological change rather than instant personalisation. Nevertheless, these limitations are consistent with the project’s intent to change how we approach design as a living and growing system rather than a mass-market solution.
One key ethical concern is the risk of biological over-interpretation, particularly how easily biological data, especially DNA, can be read as defining identity, health, or value. Even when design intent is non-diagnostic, audiences may project meaning onto biological materials, raising concerns around determinism and surveillance.
Another concern involves time and consent. Working with living or evolving materials challenges traditional notions of informed consent, which are often treated as one-time agreements. This raises questions about how users remain informed and empowered as materials evolve over time.
Finally, the project highlights tensions between care and control in the design of living systems. Treating organisms as collaborators rather than tools requires accepting uncertainty and resisting extractive design instincts, an ethical shift that challenges dominant engineering and fashion paradigms as well as approaches to design.
To address these concerns, the governance actions proposed, particularly abstraction-first data use and ongoing consent, serve as mechanisms to limit overreach, preserve user agency, and maintain ethical boundaries around interpretation. Additionally, clearly framing bio-interactive textiles as cultural and expressive systems rather than medical or wellness technologies helps protect both users and designers from unintended misuse or misclassification.
This project aims to redefine textile paradigms by reframing how we understand and engage with what we wear. By connecting wearers to their own living micro-universe and genetic codes, the garment invites a deeper appreciation of both who they are and how they are evolving. Through daily use, the material develops its own patina, not through wear alone but through biological change, encouraging an ongoing relationship with the textile. In doing so, the project fosters care and respect for the body as a dynamic system, and for the microbial worlds that support our skin’s rich ecosystem and for the environments that continuously shape it.
REFERENCES:
Atallah, C., El Abiad, A., El Abiad, M., Nakad, M. and Assaf, J.C. (2025) ‘Bioengineered Skin Microbiome: The Next Frontier in Personalized Cosmetics’, Cosmetics, 12(5), p. 205. doi: 10.3390/cosmetics12050205.
The mass of my fusion protein CsgA-hCRY2-DrBphP to confirm it was made at the correct size of approximately 156.7 kDa.
The amino acid sequence of each domain to confirm no errors were introduced during DNA synthesis or expression.
Weather the FAD cofactor is loaded inside hCRY2, since this is essential for the quantum sensing mechanism to work.
Whether hCRY2 responds to electromagnetic fields through the radical pair mechanism.
If DrBphP switches correctly between its red (660 nm) and far-red (740 nm) states and whether this switching is modulated by hCRY2.
Whether the curli fiber mat self-assembles correctly from the secreted fusion protein.
How I will perform these measurements
I will measure the mass of the intact protein using intact LC-MS. The protein is detected as multiple charge states and the adjacent charge state method gives me the true molecular weight, which I compare to my theoretical value of 156,669.69 Da as a ppm error — the same method used in this course for eGFP.
Confirm the sequence of each domain by digesting the protein with trypsin and running the resulting peptide fragments through LC-MS. The mass and fragmentation pattern of each peptide confirms all three domains are present and correct with no mutations, exactly as done in Waters Part III.
I will confirm FAD loading by measuring UV-Vis absorbance at 370–450 nm and fluorescence at 520 nm. I will supplement FAD at 25 µM during expression because UniProt states only a minority of hCRY2 molecules contain it naturally.
I will confirm the radical pair mechanism by illuminating the protein with blue light and measuring the FADH• radical signal at 580 nm. I then place it inside a Helmholtz coil at 0–500 µT to test whether the signal changes under a magnetic field, modelled directly on Xu et al. (2021, Nature).
I will confirm DrBphP photoswitching by tracking absorbance at 660 nm and 740 nm under alternating red and far-red light, checking whether the switching rate changes when hCRY2 receives an electromagnetic input.
I will confirm curli fiber self-assembly using Congo Red staining, which detects amyloid fiber formation by shifting absorbance to approximately 540 nm.
Technologies I will use
Intact LC-MS is my primary technology for confirming the molecular weight of the full fusion protein using the adjacent charge state method — the same approach used in this course on eGFP.
Tryptic peptide mapping by LC-MS/MS confirms the sequence of every domain by digesting the protein with trypsin and fragmenting each peptide in the mass spectrometer to give percentage amino acid coverage of the full construct.
UV-Vis spectroscopy is the central technology for confirming hCRY2 quantum sensing — tracking FAD loading, FADH• radical formation, and DrBphP photoswitching all through light absorbance measurements, modelled on Xu et al. (2021).
Helmholtz coil provides the controlled electromagnetic field to directly test whether hCRY2 responds to EM fields by measuring field-dependent changes in the FADH• radical signal.
SDS-PAGE gel electrophoresis is a quick first check after expression to confirm the protein is approximately the right size before moving to more detailed measurements.
Congo Red staining confirms curli fiber self-assembly by detecting amyloid fiber formation colorimetrically.
Benchling, AlphaFold, and IDT Codon Optimization were used in Aim 1 for all computational measurements — molecular weight, reading frame, active site geometry, and codon efficiency — forming the theoretical baseline that all Aim 2 experiments test against.
Waters Part I — Molecular Weight
Theoretical Molecular Weight = 28,006.60 Da
Adjacent Charge State Calculations:
2.1 : Find z using the formula
Peaks chosen:
Peak n = 933.7349
Peak n+1 = 903.7148
)
So peak n has charge state z = 30 and peak n+1 has charge state z = 31
2.2 : Calculate MW
)
Both give the same answer, measured MW ≈ 27,982 Da ≈ 28.0 kDa
2.3 : Calculate Accuracy
)
This is a very accurate measurement, with less than 0.1% error.
Can you observe the charge state of the zoomed-in peak?
)
Yes, you can; the charge state is z = 19.
In the zoomed inset of Figure 1, the isotope peaks are spaced approximately 0.053 m/z apart. The spacing between isotope peaks always equals 1/z, so:
You can tell because, at 30,000 resolution, the instrument can barely resolve the individual isotope peaks in this m/z range, which is why the zoom is needed. Without it, the peaks blur together, and you cannot measure the spacing. The zoom reveals the fine-scale isotope structure that indicates the charge state.
Homework: Waters Part IV — Oligomers
Finding Oligomers
7FU Decamer 10 × 340 kDa = 3,400 kDa = 3.4 MDa - Located at the 3.4 MDa peak on Figure 7
8FU Didecamer 20 × 400 kDa = 8,000 kDa = 8.0 MDa - Located at the 8.33 MDa peak on Figure 7 - (tallest peak)
8FU 3-Decamer 30 × 400 kDa = 12,000 kDa = 12.0 MDa - Located at the 12.67 MDa peak on Figure 7
8FU 4-Decamer 40 × 400 kDa = 16,000 kDa = 16.0 MDa - Not clearly visible on Figure 7 - (too low abundance to detect under these conditions)
Week 11 HW: Bioproduction & Cloud Labs
Week 11 : Bioproduction & Cloud Labs
Part A: The 1,536 Pixel Artwork Canvas | Collective Artwork
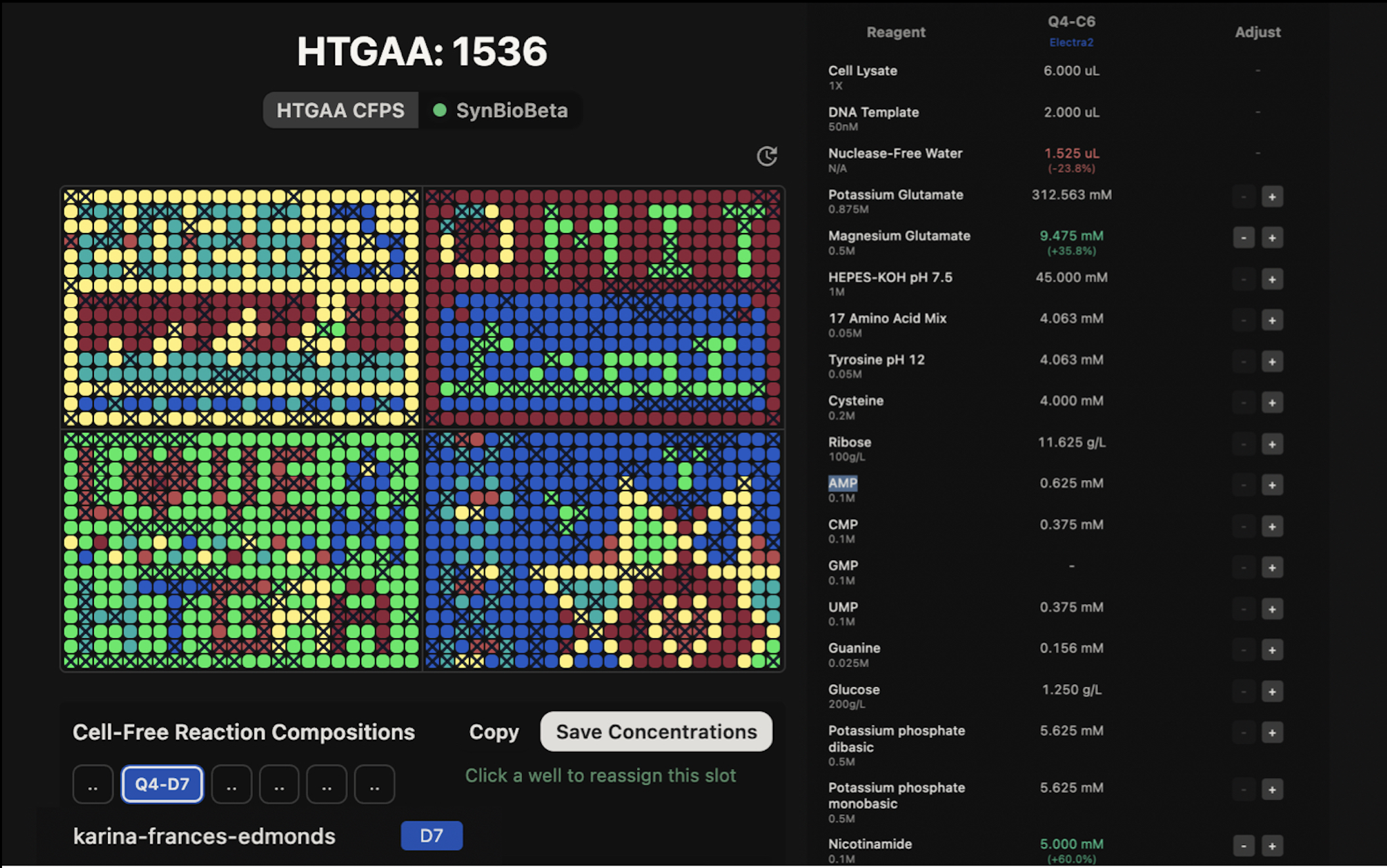
I found the Collective Cloud Artwork really interesting, I liked the idea of collaborating not just on art but on biology simultaneously, like each person contributing one ingredient to a shared recipe, or a single cell within a larger organism. There are so many cool potential applications for this kind of collective experiment. I personally appreciated the concept of each person adding only one well, since it reduces individual control and makes the outcome more spontaneous and truly collaborative. The fact that every student’s composition is slightly different also means the artwork doubles as a large-scale reagent optimisation experiment, when the fluorescence data comes back, correlating pixel brightness with each person’s reagent choices could reveal genuinely useful design rules for cell-free systems.
I contributed to the cell-free fluorescent protein artwork by composing a custom reagent supplement for well Q4-C6, assigned to the Electra2 far-red fluorescent protein. My composition doubled both Glucose (1.25 → 2.5 g/L) and Nicotinamide (3.125 → 6.25 mM) relative to the baseline 20-hour NMP-Ribose master mix, targeting sustained NAD⁺ regeneration through two independent metabolic routes over the full 36-hour incubation.
Future Improvements
Giving students more than 2 µL of supplement volume, or allowing adjustments to more reagents, would widen the hypothesis space and make the resulting dataset more statistically powerful. Perhaps there could also be an AI assistant that could give feedback in real time based on the reagent trials. Perhaps the student can have freedom with the flourescent choice, giving more of an artistic exploration.
Roles
E. coli Lysate BL21(DE3) Star
Provides the complete cellular machinery for gene expression: ribosomes, translation factors, tRNA synthetases, chaperones, and T7 RNA polymerase for transcription of the DNA template.
Potassium Glutamate - 312.6 mM
Maintains physiological ionic strength and stabilizes ribosome structure; acts as a compatible solute mimicking the intracellular environment of E. coli.
HEPES-KOH pH 7.5 - 45 mM
Buffers the reaction at pH 7.5, the optimal pH for ribosome activity and most translation factors.
Magnesium Glutamate - 7.0 mM
Mg²⁺ is essential for ribosome assembly, peptidyl-transferase activity, and stabilizing RNA secondary structures throughout transcription and translation.
Potassium phosphate dibasic + monobasic - 5.6 mM each
Provides inorganic phosphate as a secondary pH buffer and phosphate donor for NMP-to-NTP phosphorylation reactions.
Ribose - 11.625 g/L (~77.4 mM)
The pentose sugar backbone for nucleotide synthesis; lysate kinases convert ribose into phosphorylated intermediates that regenerate NTPs from NMPs sustainably over long incubations.
Glucose - 1.25 g/L (baseline) → 2.5 g/L (our supplement)
Feeds glycolysis to actively regenerate ATP and NAD⁺ via GAPDH, providing a second independent energy source alongside the NMP-ribose recycling system.
AMP - 0.625 mM | CMP · 0.375 mM | UMP · 0.375 mM
Nucleoside monophosphates that are phosphorylated by lysate kinases to their active triphosphate forms for RNA synthesis and energy metabolism.
GMP - 0 µM
Absent because GTP is instead generated from free guanine via the purine salvage pathway — a cheaper and more stable alternative.
Guanine - 0.156 mM
Salvaged by HGPRT in the lysate and converted to GMP, then phosphorylated to GTP, making it available for transcription without adding GMP directly.
17 Amino Acid Mix - 4.063 mM
Supplies all standard amino acids except tyrosine and cysteine, providing the building blocks for polypeptide synthesis.
Tyrosine pH 12 - 4.063 mM
Added separately at high pH because tyrosine is nearly insoluble at neutral pH; dissolved at pH 12 to maintain concentration without precipitating.
Cysteine - 4.000 mM
Added separately because cysteine oxidizes rapidly and can form unwanted disulfide crosslinks if premixed; also critical for proper beta-barrel folding in many fluorescent proteins.
Nicotinamide - 3.125 mM (baseline) → 6.25 mM (our supplement)
Inhibits NADase activity in the lysate to preserve NAD⁺ levels needed for energy metabolism; we double this to maximize NAD⁺ protection over the full 36-hour incubation.
Nuclease-Free Water (backfill)
Brings the master mix to final reaction volume; RNase/DNase-free to prevent degradation of the DNA template and mRNA transcripts.
Bonus
Although GMP is absent, the lysate contains the purine salvage enzyme HGPRT, which attaches free guanine to PRPP to form GMP on demand. GMP is then sequentially phosphorylated to GTP by nucleoside kinases already present in the lysate, making free guanine a cheaper and more stable way to supply GTP for transcription without adding it directly.
Part B : 1H PEP-NTP VS 20H NMP-Ribose Differences
The 1-hour system gives the reaction everything needed for the reaction to occur. All four building blocks for RNA (NTPs) plus fast energy sources, thus proteins are made quickly however the reaction burns out within an hour. The 20-hour system instead provides simpler ingredients that the lysate’s own enzymes slowly convert into NTPs as needed, like a slow-release fuel, keeping the reaction running sustainably for much longer. It’s also a cleaner, simpler recipe, fewer additives, and only includes the essentials.
Property targeted: Sustained translational activity and NAD⁺ homeostasis over 36 hours
Hypothesis: The hypothesis is that doubling both Glucose (1.25 → 2.5 g/L) and Nicotinamide (3.125 → 6.25 mM) will maximise Electra2 fluorescence over a 36-hour cell-free incubation by sustaining NAD⁺ availability through two independent metabolic routes. Nicotinamide inhibits NADase in the lysate, slowing passive NAD⁺ degradation, while elevated Glucose feeds glycolysis to actively regenerate NAD⁺ via GAPDH, together maintaining the redox balance required for continuous NTP recycling from NMPs. Because Electra2 is a slow-maturing far-red protein whose chromophore cyclisation occurs late in the incubation, sustained translational activity over the full 36 hours is more critical than for fast-maturing proteins like sfGFP, making long-term energy regeneration the primary bottleneck to address. This dual-pathway strategy is the most distinctive approach to solving it.
Part D:
Building a Cloud Lab
I was not successful in the optional assignment, but I genuinely enjoyed exploring the models across their different view frames and layouts. What I find fascinating is how biology is increasingly becoming a designable, digital medium, and as someone who works at the intersection of design, biology and technology, that feels deeply relevant to my own practice. The more we digitise and standardise these systems, the more I believe knowledge can be shared universally, making science less siloed and more collectively accessible.
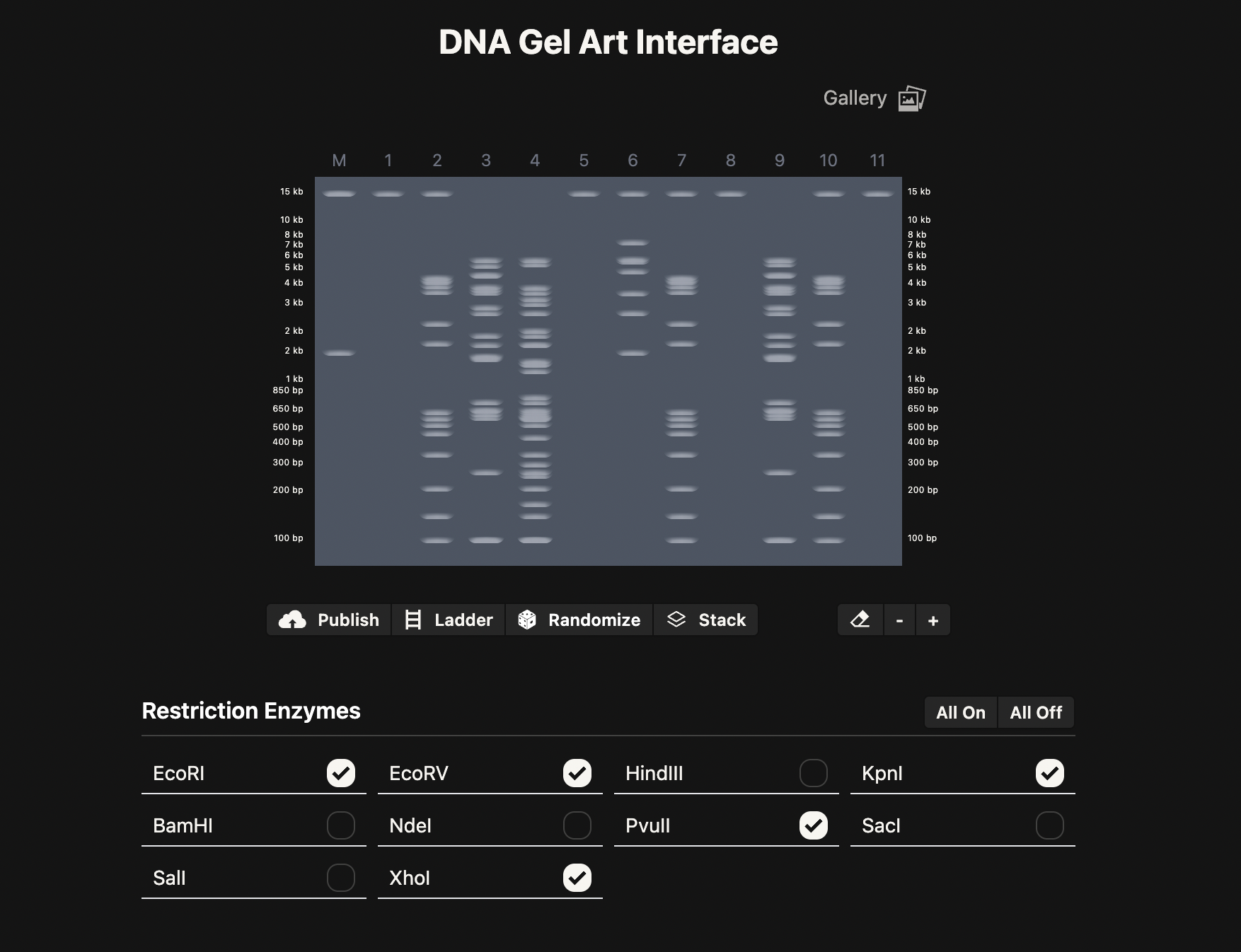
Part 2: Gel Art - Restriction Digests and Gel Electrophoresis
I am interested in the protein Reflectin. This protein is common in Cephalopods and is responsible for their structural colour as their skin changes with the environment. I am interested in the potential applications of Reflectin in smart materials/textiles. Reflectins’ optical properties can be reversibly engineered to change colour under different conditions. There is one study in which Reflecin was used in this way in a thin film substrate, and responsive to hydration or dehydration of the material.
3.2. Reverse Translate: Protein (amino acid) sequence to DNA (nucleotide) sequence.
reverse translation of tr|Q6WDN6|Q6WDN6_EUPSC Reflectin 3a OS=Euprymna scolopes OX=6613 PE=4 SV=1 to a 864 base sequence of most likely codons.
atgaaccgctatatgaaccgctttcgcaacttttatggcaacatgtgccgcaaccgcaac
cgcggcatgatggaaccgatgagccgcatgaccatggattttcagggccgctatatggat
agccagggccgcatggtggatccgcgctattatgattattatggccgctataacgattat
gatcgctattatggccgcagcatgtttaactatggctggatgatggatggcgatcgctat
aaccgctataaccgctggatggattatccggaacgctatatggatatgagcggctatcag
atggatatgtatggccgctggatggatatgcagggccgccattgcaacccgtatagccag
tggatgatgtataactataaccgccatggctattatccgaactatagctatggccgccat
atgttttatccggaacgctggatggatatgagcaactatagcatggatatgtatggccgc
tatatggatcgctggggccgctattgcaacccgttttatcattattataaccattggaac
cgcagcggcaacaacccgggctattatagctattattatatgtattatccggaacgctat
tttgatatgagcaactggcagatggatatgcagggccgctggatggatatgcagggccgc
tattgcagcccgtattggtataactggtatggccgccagatgtattatccgtatcagaac
tattattggtatggccgctgggattatccgggcatggattatagcaactggcagatggat
atgcagggccgctggatggatatgcagggccgctatatggatccgtggtggatgaacgat
agctattataacaactattataac
3.3. Codon optimization.
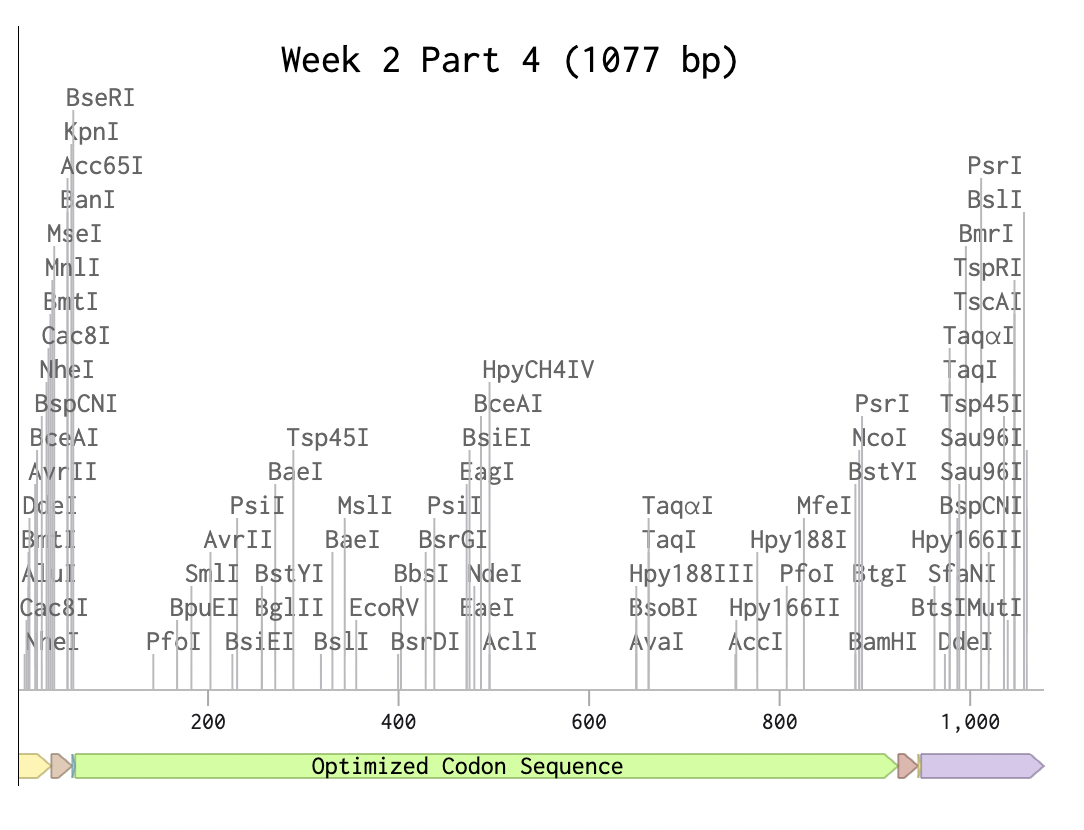
Optimized Codon Sequence
Using Yeast (Pichia Pastoris)
While E-Coli is a great organism to use for simple codon optimization, in this case with the codon optimization for Reflectin 3a Protein, Yeast ‘Pichia Pastoris’, is a better choice for a more complex fold and protein like Reflectin a more sufisticated and complex eukaryotic protein.
Reflectin, as a protein, has many potential applications, especially in textiles. Once the yeast has harvested the reflectin protein with optimised codons for yeast Pichia Pastoris, the reflectin protein can be purified and used as a structural colour material in textiles, with multiple different gradients. Relfectin could also be engineered to be expressed in cells with biological signals. In the same way that reflectin is used in cephalopods to express a change in environment in response to stimuli, Reflectin can be engineered into a material that responds to its environment. Reflectin also has electrical and dialectic properties which could be used for bioelectronic systems and technologies. There is increasing research on the future of bioelectronics, including deriving electrical signals from biological organisms and engineered systems in which they are embedded and used to power systems. In the case of Reflectin, it can be incorporated into a bioconductive system, for example, EMG, and respond to one’s own muscular electrical pulses, changing depending on one’s skin conductivity,(Cai.T). Skin conductivity can also reflect one’s neurological system, thereby revealing one’s internal worlds and expressing emotions such as excitement and adrenaline.
(i) What DNA would you want to sequence (e.g., read) and why? This could be DNA related to human health (e.g. genes related to disease research), environmental monitoring (e.g., sewage waste water, biodiversity analysis), and beyond (e.g. DNA data storage, biobank).
I would like to sequence the ‘16S rRNA gene’. This DNA is found in the skin microbiome and serves as a diversity metric for the bacteria in our skin’s gut and more! As we are all made of a diverse ecosystem of bacteria, I would love to further extract one’s metrics from this DNA, which serves as a ‘bacterial barcode’; it is also a cheap and efficient DNA to work with. Additionally, instead of sequencing a single DNA sample, I can sequence all microbial DNA in a single sample. This makes 16S a very efficient DNA. With its diverse micropalette, I would love to explore its potential for applications in materials that reflect one’s unique microflora.
(ii) In lecture, a variety of sequencing technologies were mentioned. What technology or technologies would you use to perform sequencing on your DNA and why?
To perform the DNA edit of the 16S rRNA gene, I would choose the Illumina next-generation sequencing technology as 16S regions are short (250-500bp), and Illumina gives high accuracy, as well as allowing a multiplexity of samples. For more comprehensive functional analysis through whole metagenomic sequencing sampling, I would pick the Oxford Nanopore for long sequencing for long reads to improve genome assembly and detect structural variations. Together, these technologies can provide a functional analysis of the DNA and its microbial species.
Also answer the following questions:
Is your method first-, second- or third-generation or other? How so?
What is your input? How do you prepare your input (e.g. fragmentation, adapter ligation, PCR)? List the essential steps.
What are the essential steps of your chosen sequencing technology, how does it decode the bases of your DNA sample (base calling)?
What is the output of your chosen sequencing technology?
Illumina sequencing is a second-generation ’next-generation’ sequencing technology. It is considered second-generation due to a few factors. Firstly, it performs massively parallel sequencing, where DNA fragments are sequenced simultaneously; it also relies on sequencing by synthesis of clonal amplification. This is unlike technologies like Sanger, which sequence one fragment at a time, and require PCR amplification.
The preparation steps begin with collecting microbial DNA from skin swabs. Next, total microbial DNA is extracted through cell lysis and purification. The 16S rRNA hypervariable regions are then amplified using PCR with region-specific primers. In a subsequent indexing PCR step, Illumina adapters and sample-specific barcodes are added to both ends of the amplicons to enable multiplexing and flow cell binding. The amplified libraries are purified to remove primer dimers and unwanted fragments, quantified, normalised, and pooled. The final product is an adapter-ligated DNA library ready for cluster generation and sequencing on an Illumina platform.
Illumina decodes DNA through ‘sequencing by synthesis’. Flourecently labeled nucelotideswith reversible terminators are incorporated one base at a time. Fluorescent imaging then detects each nucleotide. The software then converts the visible fluorescent signals into base calls (A, C, T, G). The output is millions of sequence reads stored as FASTQ files, including all nucleotide sequences and quality scores for each base.
5.3 DNA Edit(i) What DNA would you want to edit and why? In class, George shared a variety of ways to edit the genes and genomes of humans and other organisms. Such DNA editing technologies have profound implications for human health, development, and even human longevity and human augmentation. DNA editing is also already commonly leveraged for flora and fauna, for example in nature conservation efforts, (animal/plant restoration, de-extinction), or in agriculture (e.g. plant breeding, nitrogen fixation). What kinds of edits might you want to make to DNA (e.g., human genomes and beyond) and why?
Based on the DNA sequencing of 16S, and identifying the microuniverse, microflora and diverse rich ecosystems of one’s skin, I would edit specific pigment biosynthesis in microbial genes to produce select pigments, creating chromatic responses in a textile. I would insert promoters responsive to environmental factors such as pH, humidity, or metabolite concentration. The engineered microbes could then produce pigment in dynamic gradiations according to the wearer and their environment. This design interface approach leverages gene editing as a translational medium for expressing microworlds as a visual living and smart material.
(ii) What technology or technologies would you use to perform these DNA edits and why?
Also answer the following questions:
To perform this gene edit, the use of a CRISPR-Cas9 system would be needed for pigment biosynthesis. Crispr Cas9 can offer precise base pair editing of promoter regions, tuning expression without breaking the double strand. Editing machinery into bacterial cells could be achieved via electroporation or conjugative plasmids. Inducing pigment production responsive to the environment, synthetic gene circuits would be engineered through inducible promoters or quorum-sensing systems. PCR sequences would also need to be validated edited strains before integrating into a bioresponsive textile system.
How does your technology of choice edit DNA? What are the essential steps?
What preparation do you need to do (e.g. design steps) and what is the input (e.g. DNA template, enzymes, plasmids, primers, guides, cells) for the editing?
Cas9 is an RNA-guided endonuclease which induces a double-strand break at a target DNA sequence chosen by the complementary guide RNA and recircularized PM site. The Cas9 enzyme then cuts the DNA in the target site. The cell then repairs the cut, and DNA sequences can be changed during the repair by disrupting the gene or inserting a new sequence with a provided repair template. For the editting process I would first need to design an RNA reciprocale with the target gene and ensure a PAM site is close to the target. The input would contain a plasmid including the CAS9, guide RNA, bacterial cells and the repair template. The process would first include the plasmid construction, introducing the plasmid into cells, CRISPR cutting the DNA, and lastly selecting the successful edits of the cell.
What are the limitations of your editing methods (if any) in terms of efficiency or precision?
One limitation of CRISPR-Cas9 editing tools is the potential for off-target effects, in which the guide RNA partially binds to unintended genomic regions, leading to unintended DNA cuts. Also, as this technology requires a PAM site near the target site, it limits the locations that can be edited. The cell’s DNA repair mechanisms can also reduce efficiency, as homology-directed repair may often be unpredictable and can require screening of multiple clones. Efficiency can also be reduced by the delivery of CRISPR components into bacterial cells, especially in non-model organisms. Lastly, viability may be reduced by continuous double-strand breakage, which can be toxic to cells and thus reduce viability.
RESOURCES:
Cai, T., Han, K., Yang, P., Zhu, Z., Jiang, M., Huang, Y., Xie, C. (2019) Reconstruction of dynamic and reversible color change using reflectin protein. Scientific Reports, 9, 5201. Available at: https://www.nature.com/articles/s41598-019-41638-8
USE OF AI
“Polish/Edit this paragraph to my conceptual idea”
Week 3 HW: Lab Automation
OPENTRON GEL ART
Figure 1
I tried creating a butterfly using the OpenTron drawing tool, with 4 different colours, dark blue, light blue, red and purple, which are some of the available colours in Lifefabs.
I also tried to create an Iris in the style of Van Gogh. As this is a more fluid and asymmetrical design, it would be harder to achieve, given the complexity of the multiple colours in organic scaddered shades, rather than in small units. Moreover, the dots and spaces are quite compact, which would make it harder to achieve a clean result.
After a few attempts on Google Collab and speaking back and forth with Google Gemini, I was finally able to get my Iris. For some reason, however, the Iris came out multi-coloured (Figure 2), and there are way more colours than originally used in my Ginkgo drawing board. Not sure if it’s because I added all these colours to the working space below as seen in (Figure 1).
Figure 2 “Colourful Iris”
This was my first attempt at getting my Iris.
Figure 3
After many attempts (Figure 3), I was finally able to get my Iris. Although it’s not in the colours I used and made it with on Ginkgo, I made sure to prioritise getting them in the colours of Lifefabs, for the Opentron printing. It is also good practice as an artist in a real lab setting to work with the mediums available.
Maximising the scientific resources available is important as an artist in this space, and the beauty of cross-disciplinary work, where beauty is found even when an artist doesn’t have an unlimited colour palette. With this in mind, I wanted to maximise on the colours given to us by Lifefabs, so I also coded a butterfly inspired by the “Prepona Praeneste” from Peru, and the “Papilio Ulysses” butterfly from Indonesia, which I found to better resemble the colours for this exercise with its blue and red pink hues(Figure 4).
“Prepona Praeneste” butterfly
Figure 4
POST-LAB QUESTIONS
The publication Semiautomated Production of Cell-Free Biosensors, published by the American Chemical Society (ACS Publications), explores the assembly of cell-free biosensors through liquid handling robotics versus manual methods commonly used in lab-scale development. The process is a combination where, “both manual and semiautomated reaction assembly approaches using the Opentrons OT-2 liquid handling platform on two different cell-free gene expression assay systems that constitutively produce colourimetric (LacZ) or fluorescent (GFP) signals,(Brown).” The designed protocols demonstrate that they perform close to expected detection outcomes in a more controlled environment (Brown).
In my final project, I intend to use automated fabrication tools to create 3d printed templates, moulds, and matrices within the fabric, as well automating the liquid handling in the textile. Through automation, I will construct a textile embedded with patterned cavities designed to host distinct bacterial-sensing environments. The fabric’s automated structure serves as the fixed framework, while the bacteria and their metabolic activity constitute the variable component. As microbial signals interact with each cavity, dynamic changes in colour and pattern emerge, allowing the fabric to visually reflect microbial activity and ecological variation across its surface.
To do this, the following steps are needed.
1. Opentron OT-2 liquid handling and 3d Printed textile:
First, I need to design the 3D mould for the hydrogel fabric textile, which will consist of a cavity matrix that will host the cell-free biosensors. I also need to 3d print a holder to lay the textile flat and dispense to OT-2 coordinates.
2. Bioprinting hydrogel:
Next, I need to print the hydrogel containing the pattern cavities designed and corresponding to the OT-2 dispense coordinates. This can be done by bioprinting or mould casting the hydrogel into shape/texture.
3. Opentrol OT-2 despensing:
The Opentron OT-2 will despense the DNA mixture and CFE into the bioprinted hydrogel cavities and coordinates. This will ensure accurate volume, distribution, and reproducibility across various textile matrices.
4. Sealing of textile hydrogel:
The textile hydrogel will be sealed with a semipermeable layer that allows skin metabolites to permeate into the cavities and activate cell-free biosensors to reveal patterns.
Horland, R., Lindner, G., Wagner, I., Atac, B., Hoffmann, S., Gruchow, M., Sonntag, F., Klotzbach, U.,
Lauster, R. & Marx, U., 2011. Human hair follicle equivalents in vitro for transplantation and chip-based substance testing.
BMC Proceedings, 5(Suppl 8), p.O7.https://pmc.ncbi.nlm.nih.gov/articles/PMC3284944/?utm_
Answer any NINE of the following questions from Shuguang Zhang: (i.e. you can select two to skip)
Why do humans eat beef but do not become a cow, eat fish but do not become fish?
Even though some may like to say you are what you eat, this really isn’t the case when it comes to eating an organism. Even though we consume its parts and convert protein into energy we are transforming energy into energy that we can use. One may argue we embody that organism to a degree, but we dont fully transform into that being. Your cells follow a genetic blueprint, and while other DNA enters your body, you do not absorb its genome, nor does it integrate into yours.
Why are there only 20 natural amino acids?
Although the genetic code contains 64 possible codons, evolution stabilized around 20 canonical amino acids. This was not due to a strict numerical limitation, but because these 20 provide an optimal balance of chemical diversity, stability, and functional efficiency. Biochemical availability on early Earth also played a crucial role, early life utilized the amino acids that were most readily synthesized under prebiotic conditions. Mathematical analyses of the canonical set suggest that the 20 amino acids achieve a near-optimal coverage of chemical property space, maximizing structural and catalytic versatility while minimizing redundancy. Furthermore, the structure of the genetic code itself is organized in a way that reduces the impact of mutations: codons that differ by a single nucleotide often encode amino acids with similar physicochemical properties, thereby limiting potential damage to protein structure and function.
Can you make other non-natural amino acids? Design some new amino acids.
Yes, and we already have. Scientists have even been able to genetically engineer organisms to expand the genetic code beyond the 20, by introducing new codons.() Some of the amino acids that have been synthesised include fluorescent amino acids, for example, to help scientists localise proteins in a cell and observe their interactions, improving observation.
Where did amino acids come from before enzymes that make them, and before life started?
Amino acids can form spontaneously under prebiotic conditions through chemistry. Scientists have simulated Earth’s atmosphere using simple gases and found that amino acids can form through life’s basic chemistry.
If you make an α-helix using D-amino acids, what handedness (right or left) would you expect?
If you make an α-helix using D-amino acids, you would expect a left-handed twist, because the molecular building blocks themselves are mirrored. D-amino acids have the opposite chirality of the natural L-forms, so their backbone geometry favors a left-handed helix rather than a right-handed one.
Can you discover additional helices in proteins?
Yes research continues to identify unsual or distrorted helical geometries. Scienttists have also designe helices from non antural amino acids, or even alternate hydrogen bonding patterns.
Why are most molecular helices right-handed?
Most moleculart helices are right handed beacuse of chirality. The presence of molecular assymetry in L- amino acids determening helix twist direction, favouring a right handed direction. While left handed helices are possible, they are rare. An example of a left handed helices is a D helices, which its molecular building block is most stable and corresponds to a left hand.
Why do β-sheets tend to aggregate?
β-sheets tend to aggregate because their extended structure exposes backbone hydrogen bond donors and acceptors, allowing strands from different proteins to easily form intermolecular hydrogen bonds. Their flat geometry also enables tight stacking into stable, repetitive “cross-β” structures, making aggregation energetically favorable.
What is the driving force for β-sheet aggregation?
Backbone hydrogen bonds form between neighbouring β strands, satisfying exposed N-H and C=O groups. Hydrophobic chains pack together and repel water, thus loweing the systems free energy and agregates state is more stable than partially unfolded state.
Why do many amyloid diseases form β-sheets?
Because the β-sheet structure is the most stable form in which misfolded proteins can agregate and be reorganized, creating a strong cross β structure.
Can you use amyloid β-sheets as materials?
Amyloid β-sheets are one of the strongest and most stable protein structures in nature, making them greatly appealing in material architecture. Some of the properties that arise and be applied in material science include, tensile strength, chemical stability, self assembly in asolutions, heat resistance, and mechanical stiffness. Examples where nature uses the intelligent structure present in β-sheet scaffolidng is in silk fibroin and curli fibers in bacterial biofilms. Common applications of Amyloid β-sheets are hydrogels, drug delivery, nanofibres, tissue scafolidng, bioprinting, and even in conductive biofilms.
Design a β-sheet motif that forms a well-ordered structure.
Part B: Protein Analysis and Visualization**
I will continue to explore reflectins and their biomechanical properties as they respond to stimuli and can serve as a beautiful template for material engineering and especially in applications such as smart textiles.
The most frequent amino acid is Tyrosine with 58 in the sequence of 288 total residues.
(Use of AI, asking chat gpt to tell me how many of each amino acid in that sequence.)
Using UniProt BLAST with default parameters against UniProtKB, 5 significant sequence homologs were identified.
Reflectin belongs to the reflectin protein family including various types.
There is no refletcin 3a protein structure solved, and can be classifies as IDP- intrinsically dissordered protein.
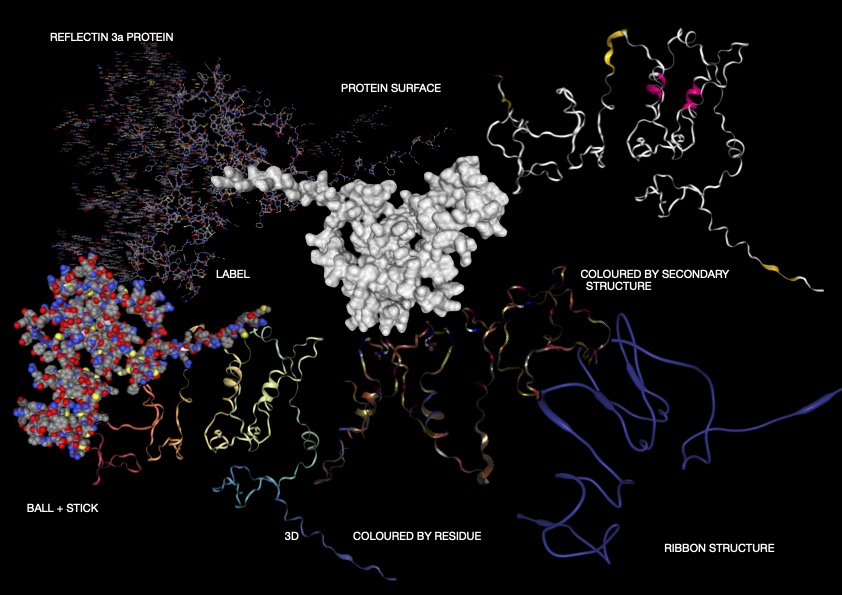
REFLECTIN 3A STRUCTURE:
Figure 1
ANALYSIS:
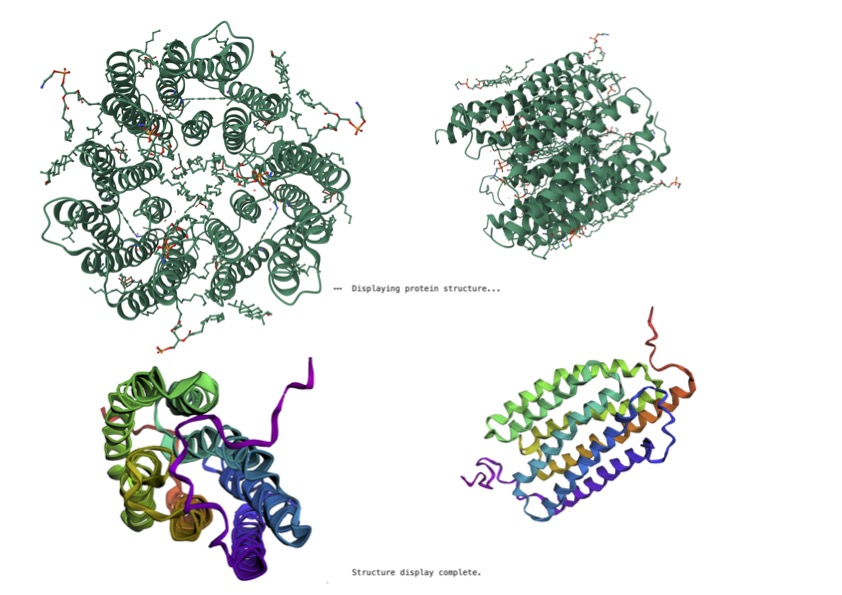
As shown above (Figure 1), I visualised the Reflectin 3a protein in various forms. In the representation coloured by secondary structure, Reflectin appears to contain a mixture of structural elements, with some helical regions present alongside a larger proportion of flexible coil segments. The distribution of hydrophobic and hydrophilic residues appears relatively balanced; however, rather than forming a tightly packed globular structure with clear segregation, the residues are arranged in a more dispersed manner. While it may appear that hydrophobic residues are positioned toward the exterior and hydrophilic residues toward the interior, this organisation is not as clearly defined as in fully folded proteins, reflecting a less stable structural arrangement. Additionally, small cavities or regions resembling binding pockets can be observed, though these are likely transient and not rigidly maintained.
Overall, the 3D visualizations of Reflectin 3a reveal a predominantly extended and flexible structure with limited stable secondary elements, indicating that the protein is largely intrinsically disordered. The dominance of coil regions and absence of a compact globular core suggest that Reflectin does not adopt a fixed conformation but instead remains structurally dynamic. This flexibility, combined with its linear sequence organization and lack of rigid folding, supports its known function as a responsive biomaterial. Reflectin likely undergoes environmentally triggered conformational and assembly changes, enabling tunable optical properties such as those observed in cephalopod coloration.
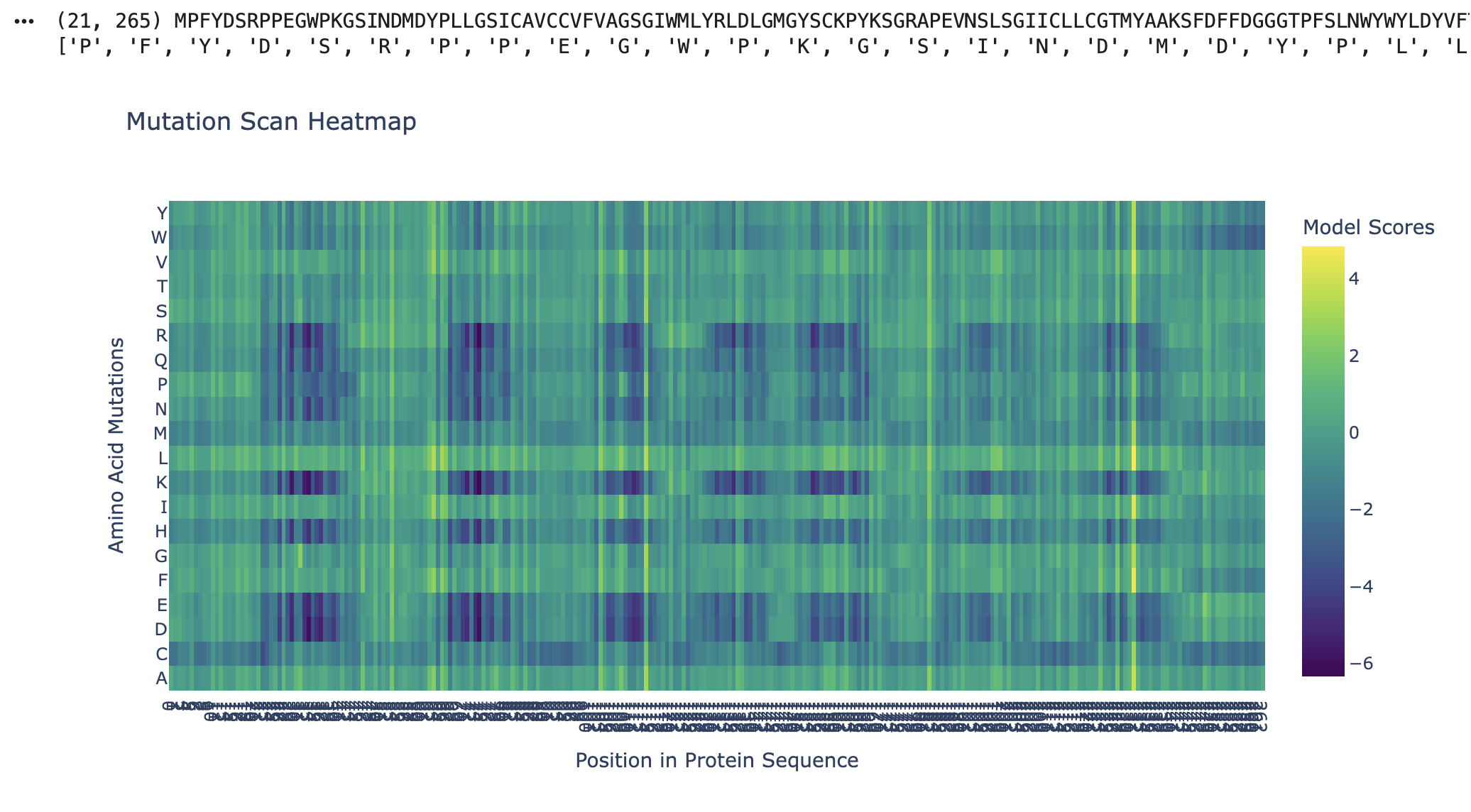
As seen in the mutation scan for Kalium Channelrhodopsin 1, many amino acids show dark purple bands. The protein likely resists mutation at these positions due to their functional roles, where mutations would destabilise the protein or its folding. Some of the functions of the residues in Kalium Channelrhodopsin 1 include retinal binding pockets, ion conduction pathways, and transmembrane helix packing residues. Rows (D, E, K, and R) correspond to the disruptive residues in hydrophobic regions, and since Kalium Channelrhodopsin 1 is a membrane protein, its helices are embedded in the membrane. Kalium Channelrhodopsin 1 is an evolutionary constraint, and this graph shows its intolerance to mutations due to its key roles relying on structure, such as retinal binding and ion conduction (RCSB PDB).
Latent Space Visual
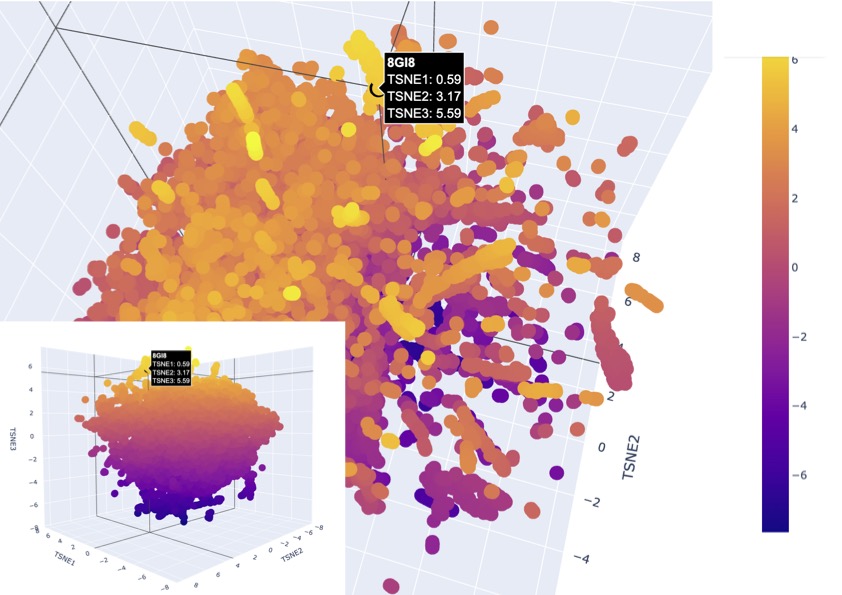
Figure 3
After many attempts, I finally found the protein. Some key errors in the code were missing the addition of:
#color it differently
fig_3d.add_scatter3d(
x=[my_point[“TSNE1”]],
y=[my_point[“TSNE2”]],
z=[my_point[“TSNE3”]],
marker=dict(
size=10, # Choose the dot size
color=“Black” # Choose a color
),
text=[“8GI8”],
hovertemplate="%{text} TSNE1: %{x:.2f} TSNE2: %{y:.2f} TSNE3: %{z:.2f}"
)
,before the protein synthesis, which specifically coloured the protein I was looking for.
The latent space visualisation shows that the protein is embedded within a dense cluster of neighbouring points rather than appearing as an outlier in a distinct class. This indicates that the protein shares strong similarity with a broader family of proteins in the dataset, suggesting conserved structural and functional features, as there are also no clear boundaries around the point. Additionally, the high density of surrounding points suggests that this region of the latent space corresponds to a well-represented and evolutionarily conserved protein family. Given that channelrhodopsins are membrane proteins with characteristic alpha-helical structures, the clustering supports that the model has correctly captured these features and placed the protein among structurally similar transmembrane proteins, existing as a larger family.
ESM Protein Fold
Figure 4
Kalium Channelrhodopsin VS ESM Predicted Fold Protein
The ESM-predicted structure represents the protein as a single subunit, whereas the reference structure appears oligomeric, consisting of multiple interacting chains. This indicates that the model captures the fold of an individual protein chain but does not fully reproduce the higher-order quaternary structure of the native assembly. In addition, the reference structure is more compact and ordered, with clearer symmetry and well-defined alpha-helical regions. The prediction successfully captures the overall secondary structure, particularly the alpha-helical architecture, but shows reduced accuracy in loop placement and local packing. These differences suggest that while the model is effective at predicting the general fold and topology of the protein, it is less precise in reconstructing flexible regions and inter-subunit interactions, which are important for full structural and functional accuracy.
After many attempts, I finally got an inverse sequence. The inverse protein design results show that the model can generate a significantly different amino acid sequence (sequence recovery ~32%) while maintaining compatibility with the original protein structure. This suggests that the overall fold of the protein is robust to sequence variation and that multiple sequences can encode the same structural architecture. Notably, the designed sequence retains a high proportion of hydrophobic residues, consistent with the protein’s transmembrane nature, indicating that the model preserves key biophysical constraints required for membrane insertion. The improved score of the designed sequence further suggests that it is a stable alternative to the original sequence, highlighting the ability of inverse design methods to explore diverse sequence solutions for a given structural fold.
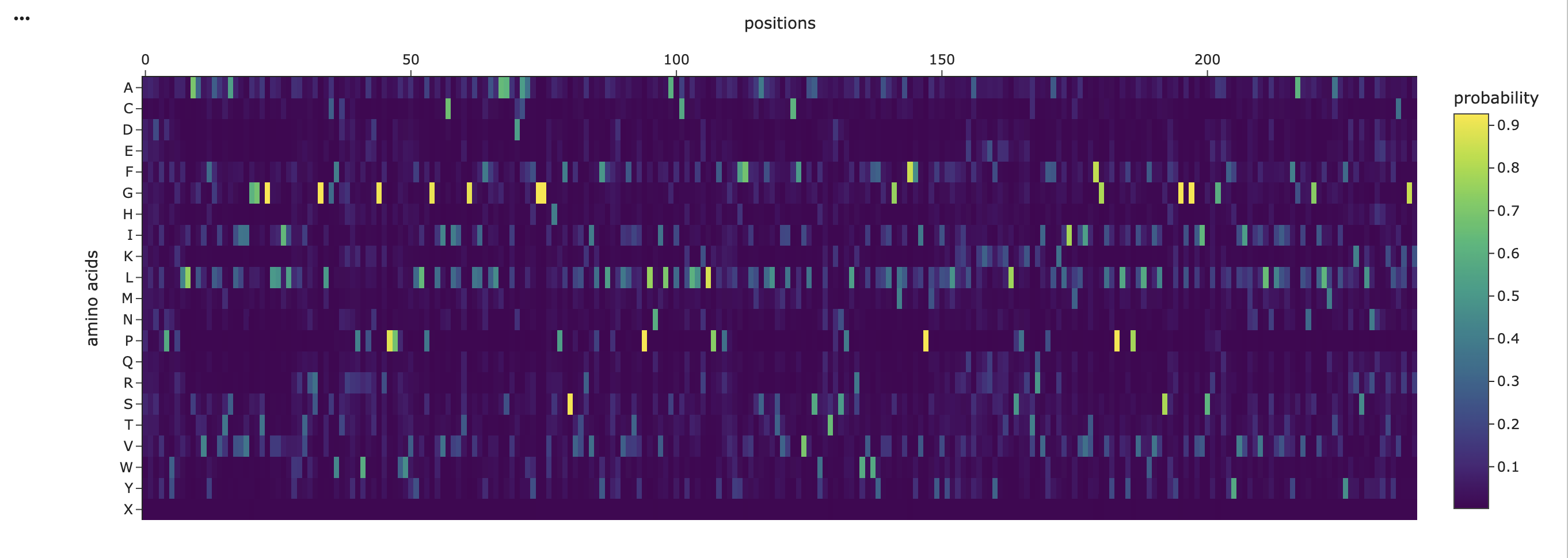
Amino acid Probabilities
Figure 5
The amino acid probability heatmap shows that most positions in the protein exhibit a strong preference for a single amino acid, indicated by sharp high-probability peaks. This suggests that many residues are structurally or functionally constrained, which is important for maintaining the protein’s fold. In contrast, some of the positions display more distributed probabilities across multiple amino acids, indicating regions of greater flexibility that may tolerate mutation. Hydrophobic residues such as leucine (L), isoleucine (I), and valine (V) are highly present across many positions, and are consistent with the transmembrane nature of the protein. Overall, the probability distribution highlights a balance between conserved structural regions and more flexible positions, which can guide rational mutation design.
RCSB PDB (2023) 8GI8: Kalium channelrhodopsin 1 from Hyphochytrium catenoides (HcKCR1) embedded in peptidisc. Available at: https://www.rcsb.org/structure/8GI8 (Accessed: 29 March 2026).
USE OF AI
“Help me analyze this output from collab and take me step by step on what is happening and why, take me step by step”
“Why is the prediction of a 3d fold so different from one from PDB? What is happening?”
“Edit this paragraph analysis”
Week 5 HW: Protein Design Part II
Week 5 HW: Protein Design Part II
(Carnaroli et al.,2025)
PART A: SOD1 Binder Peptide Design (From Pranam)
Superoxide dismutase 1 (SOD1) is a cytosolic antioxidant enzyme that converts superoxide radicals into hydrogen peroxide and oxygen. In its native state, it forms a stable homodimer and binds copper and zinc.
Mutations in SOD1 cause familial Amyotrophic Lateral Sclerosis (ALS). Among them, the A4V mutation (Alanine → Valine at residue 4) leads to one of the most aggressive forms of the disease. The mutation subtly destabilizes the N-terminus, perturbs folding energetics, and promotes toxic aggregation.
Your challenge:
Design short peptides that bind mutant SOD1.
Then decide which ones are worth advancing toward therapy.
You will use three models developed in our lab:
PepMLM: target sequence-conditioned peptide generation via masked language modeling
PeptiVerse: therapeutic property prediction
moPPIt: motif-specific multi-objective peptide design using Multi-Objective Guided Discrete Flow Matching (MOG-DFM)
SEQUENCE OF SOD1 Protein with A4V MUTATION
PART 1: Generate Binders with PepMLM
PepMLM Sequences:
PART 2: Evaluate Binders with AlphaFold3
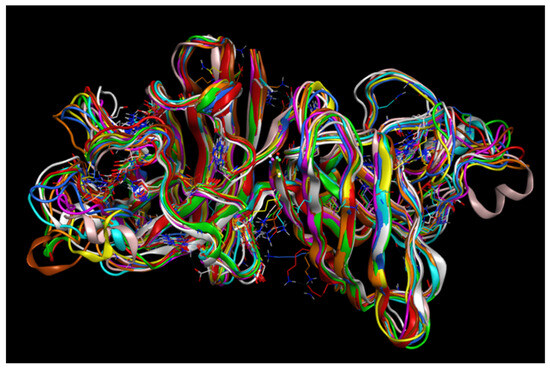
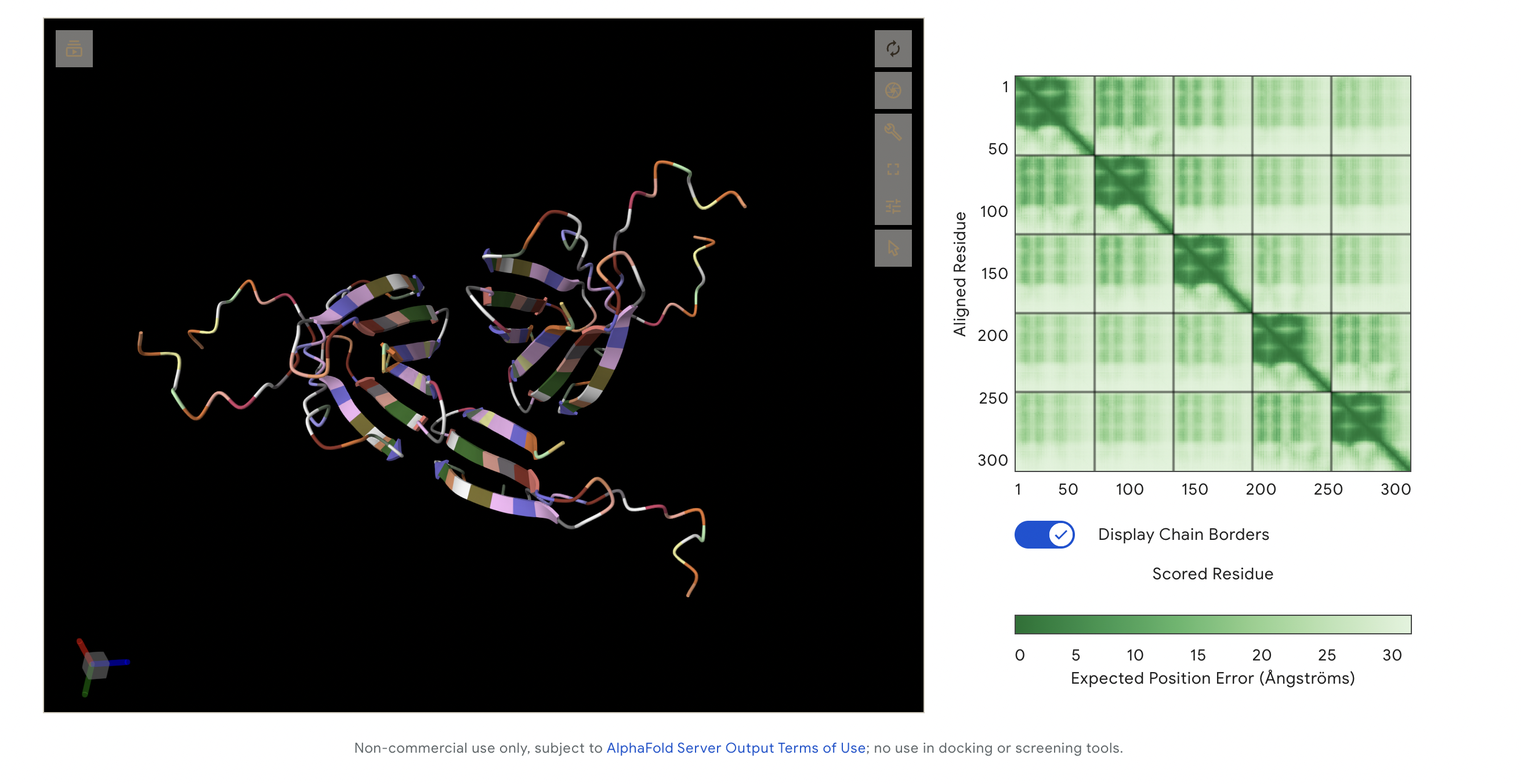
Alphafold outcome:
This image captures all peptides in one visualisation as I was meant to add them all together on alphafold. This made it hard to read, but I like the visualisation outcome, as it looks like a single protein made up of 3 large segments. The following are each of the peptide variants individually.
Part 3: Evaluate Properties of Generated Peptides in the PeptiVerse
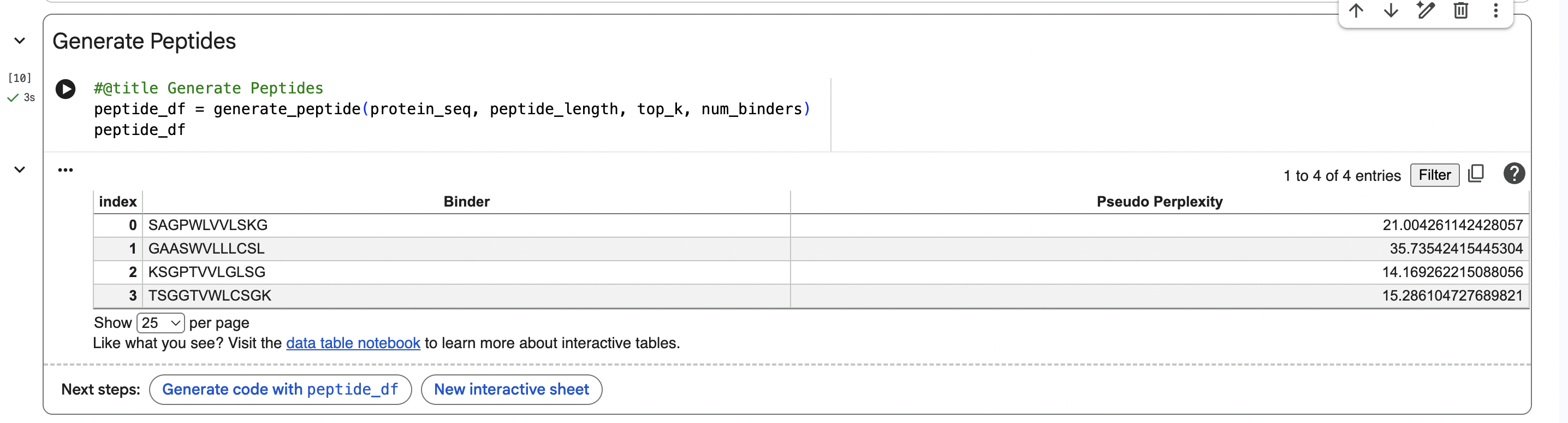
Figure 1
Peptide 1: SAGPWLVVLSKG
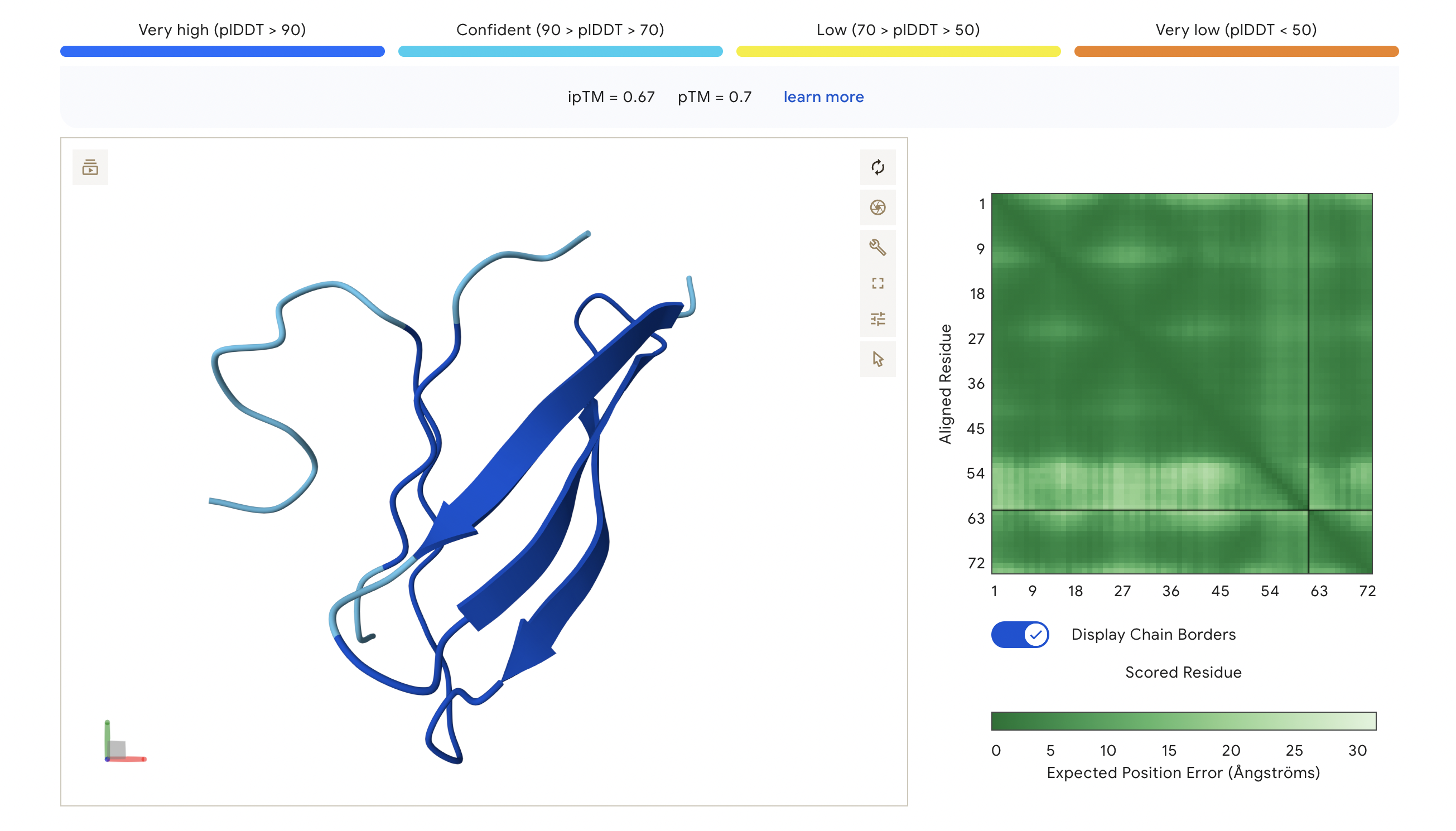
The ipTM score of this peptide is 0.67. This is the highest ipTM of all the peptides, indicading the most confident interaction between the peptide and A4V mutation. As seen in (Figure 1), the peptide seems to bind at the surface of the β-barrel but tucked stretching from one end of the protein chain to the other.
Figure 2
Peptide 2: GAASWVLLLCSL
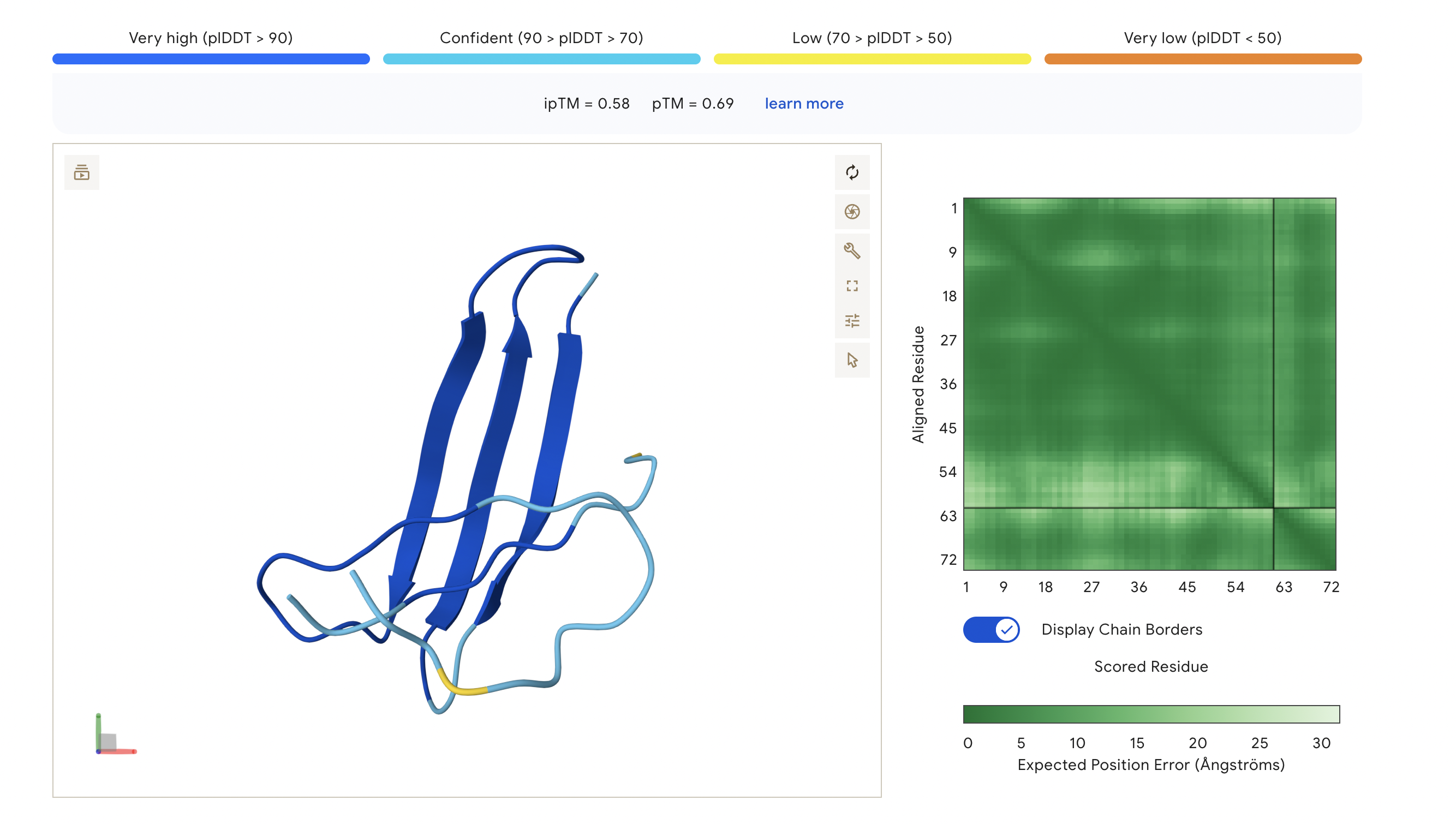
The ipTM score of this peptide is 0.58 which is the second most confident, a moderately stable interaction. The peptide is also at the surface and more tucked in near the C terminus, stabalizing a different interaction rather than the mutation located at the 4th amino acid position of the protein sequence.
Figure 3
Peptide 3: KSGPTVVLGLSG
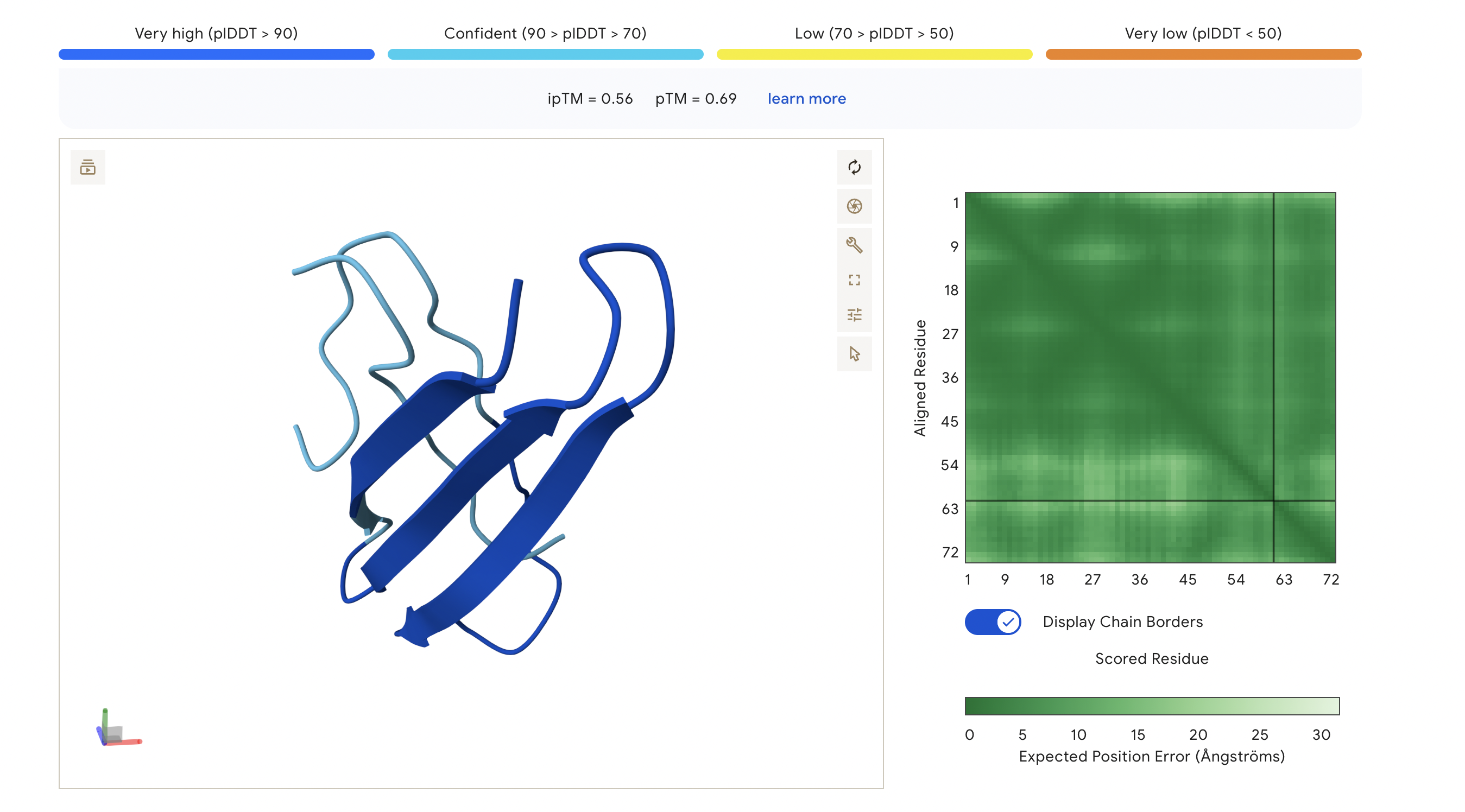
The ipTM score for this peptide is 0.56 which is the third most confident interaction. Even though it’s lower than the peptide 2 in (Figure 2), this peptide shows a more structural and stable composition, indicated by the blue colours in the regions, compared to the other, with some more unstable yellow regions. The peptide is also tucked and surfacing near the C terminus.
Figure 4
Peptide 4: TSGGTWLCSGK
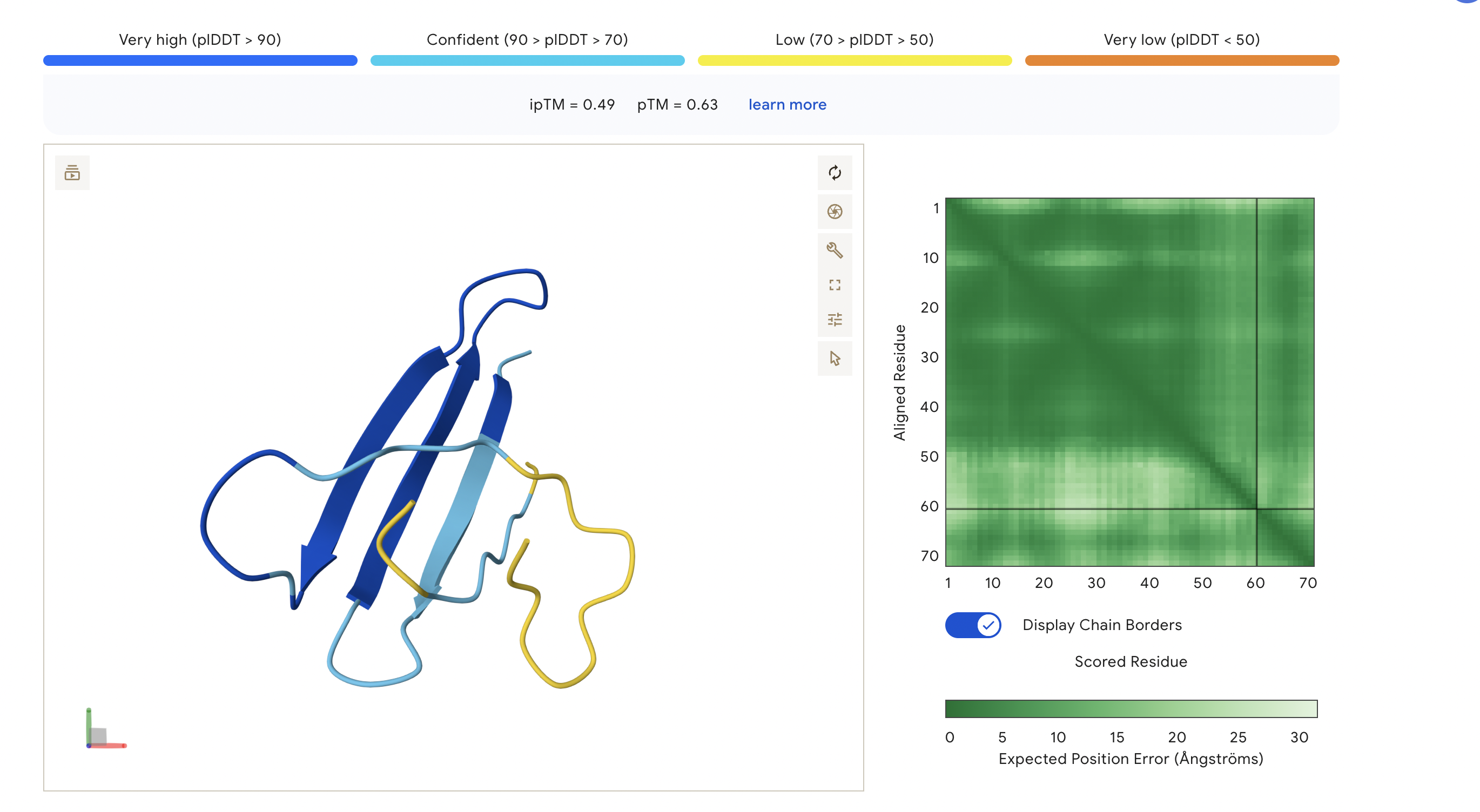
The ipTM score for this peptide is 0.49 and is the second least confident. The peptide seems to stretch tucked from the N terminus to the C terminus, which has low structural stability.
Figure 5
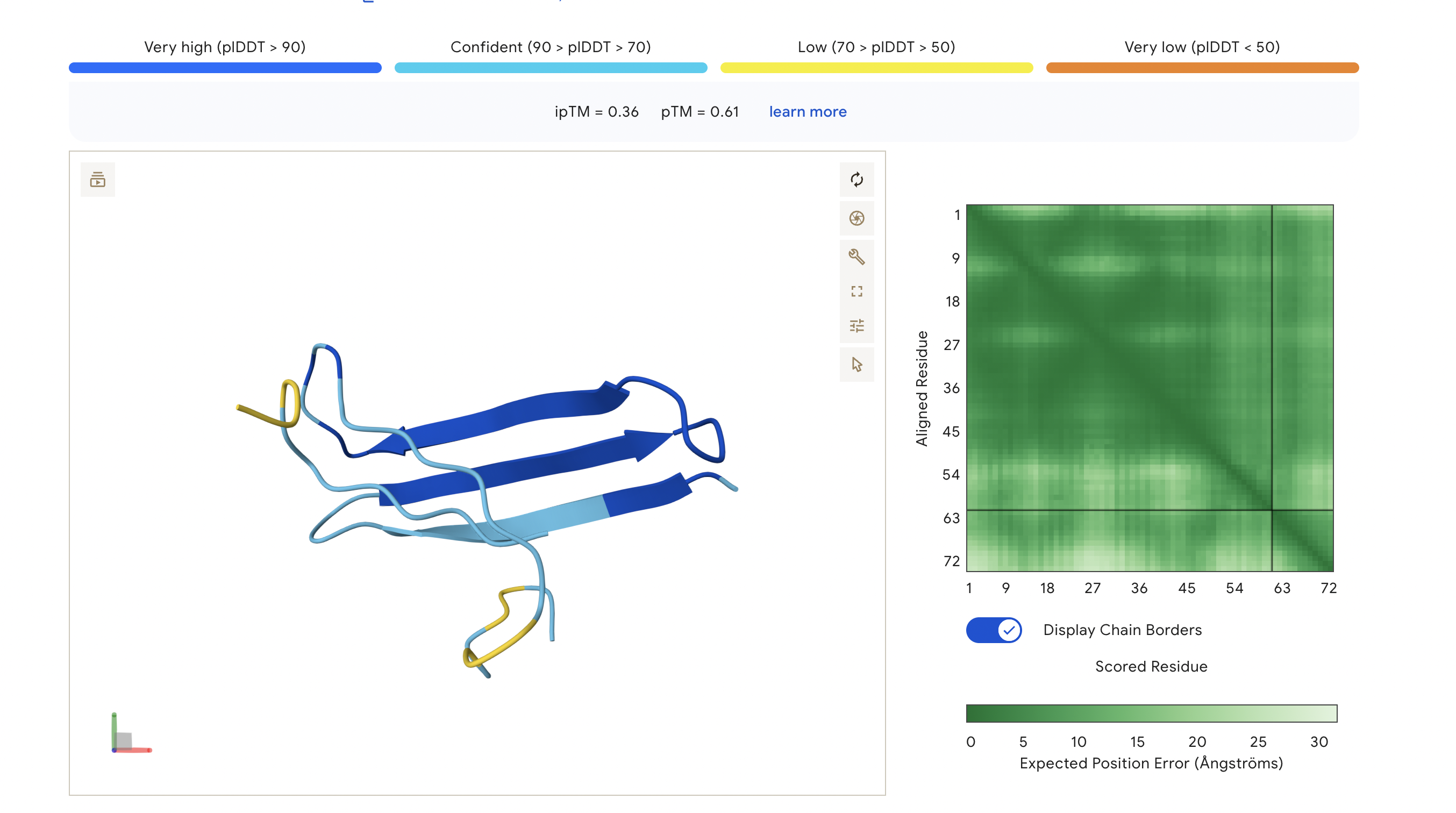
Peptide 5: FLYRWLPSRRGG
The ipTM score for this peptide is 0.36, and is the least confident bind. The peptide is surfacing near the C terminus, and shows little structural stability, whereas the β-barrel is structurally confident.
Analysis
While ipTM often reflects how well the peptide fits structurally, it doesn’t always guarantee stronger binding affinity. In the analysis, peptide 4 had a lower ipTM score (0.49), indicating a less stable structural fit. Yet, it showed the highest predicted binding affinity (7.063), suggesting it forms key interactions despite imperfect alignment. This highlights that structural confidence and binding predictions can diverge. In choosing a peptide to advance, one can balance both structural fit and therapeutic properties. Peptide 4 stands out as a strong candidate due to its higher affinity, making it worth advancing despite the structural uncertainty.
AGKKKEKEKKLN Final score: [0.9788, 0.9779, 0.8333]
KEKKKNTFEKKN Final score: [0.9860, 0.9842, 0.9167]
KKKKGDTKESQE Final score: [0.9886, 0.9891, 1.0000]
BEST —> WORST
KKKKGDTKESQE, KEKKKNTFEKKN, AGKKKEKEKKLN
The mmplot/moPPIt optimisation appears to have been successful, as all three candidate peptides showed clear improvements in score over the course of sampling. Among the generated sequences, KKKKGDTKESQE was the strongest overall candidate, achieving the best final multi-objective profile (0.9886, 0.9891, 1.0000). KEKKKNTFEKKN also performed very well and would be a strong secondary candidate, while AGKKKEKEKKLN was somewhat weaker due to a lower third-objective score. Overall, the results suggest successful convergence toward high-scoring peptides, though the strong lysine enrichment across all candidates may indicate limited sequence diversity.
RESOURCES
Carnaroli, M.; Deriu, M.A.; Tuszynski, J.A. Computational Search for Inhibitors of SOD1 Mutant Infectivity as Potential Therapeutics for ALS Disease. Int. J. Mol. Sci. 2025, 26, 4660. https://doi.org/10.3390/ijms26104660
USE OF AI
“Why is my protein so symmetrical? Have I done it wrong? Walk me step by step on using AlphaFold with 5 different peptides to analyze seperatley (key word)”
“Help me understand the nature of this protein and walk me through how one would approach analysis on alphafold”
“Explain to me each part of the protein and what exactly I should be looking for when analysing its structure and confidence as a successful protein peptide.”
“What am I looking for on mmplot, walk be step by step”
Week 6 HW: Genetic Circuits Part I: Assembly Technologies
DNA ASSEMBLY
Answer these questions about the protocol in this week’s lab:
What are some components in the Phusion High-Fidelity PCR Master Mix and what is their purpose?
The Phusion High-Fidelity PCR Master Mix is a pre-mix solution used to amplify DNA during PCR. There are a few components that make the master mix efficient and accurate.
Phusion High-Fidelity DNA Polymerase synthesises new DNA strands by adding new nucleotides to the primer and has very low error rates with proof-reading abilities from (3’—>5’)exonuclease. The mix also includes a reaction buffer that maintains the optimal pH, salt concentration, and ionic environment for the polymerase and stabilises it during PCR. Mg²⁺ ions, magnesium ions, also help stabilise the reaction and enable enzyme and nucleotide catalysis during DNA synthesis (Thermo Fisher Scientific).
What are some factors that determine primer annealing temperature during PCR?
The primer annealing temperature is primarily determined by the primers’ melting temperature (Tm). At least 50% of the primers need to melt at this temperature. Primers containing a high content of GC require higher melting temperatures because G-C base pairs have 3 hydrogen bonds, while A-T only have two. Longer primers also have higher melting temperatures because they have more nucleotides to denature. Salt and ion concentration also affect the annealing temperature, with higher salt concentration increasing binder stability and thus requiring a higher Tm. Lastly, primers with more complementarity have a higher Tm, whereas mismatches have weaker binding and thus don’t require a high Tm.
There are two methods from this class that create linear fragments of DNA: PCR, and restriction enzyme digests. Compare and contrast these two methods, both in terms of protocol as well as when one may be preferable to use over the other.
PCR and restriction enzyme digestion are both methods for generating linear DNA fragments, but they differ significantly in their mechanisms, protocols, and applications.
PCR (Polymerase Chain Reaction) is an amplification-based method using primers, a DNA polymerase, and thermal cycling to selectively copy specific regions of a DNA. The steps involve repeated cycles of denaturation, primer annealing, and extension, resulting in exponential amplification of the target sequence. PCR is highly specific, and primers can be designed to amplify almost any sequence. Additionally, PCR enables the introduction of mutations or additional sequences via primer design (Addgene).
In contrast, restriction enzyme digestion relies on enzymes to recognise specific short DNA sequences and cleave the DNA at or near these sites. The protocol is relatively simple, typically involving incubation of DNA with one or more restriction enzymes under appropriate buffer and temperature conditions. This method does not amplify DNA; instead, it cuts existing DNA into predictable fragments based on the locations of restriction sites (PubMed Central).
In terms of preferred methods, PCR is ideal when a specific DNA fragment needs to be amplified, when the starting DNA is limited, or when sequence modification is required. On the other hand, restriction digestion is preferable when working with larger quantities of DNA, and when precise, reproducible cutting at known sequences is needed, for example, in cloning where compatible ends are required for ligation (Addgene).
Overall, PCR offers high specificity and flexibility, while restriction digestion provides precision and simplicity when suitable recognition sites are already present.
How can you ensure that the DNA sequences that you have digested and PCR-ed will be appropriate for Gibson cloning?
To ensure that the DNA sequences that you have digested and PCR-ed will be appropriate for Gibson cloning, the fragments must have homologous ends. Gibson assembly relies on 20 - 40 base pair overlaps between adjacent DNA fragments, which enables them to anneal and be joined seamlessly.
How does the plasmid DNA enter the E. coli cells during transformation?
There are two main methods in which plasmid DNA enter E. coli cells during transformation. The first and most common method amongst labs is Heat shock, where the membrane of the cell becomes permeable by first being treated with calcium chloride (CaCl₂) and then “heat shocked” for 30-60 seconds at a temperature of 42 degrees Celsius. The DNA is then pulled into the cell and after enters a repaired and expressed plasmid gene.
The second and most efficient method is electroporation, in which cells and DNA are placed in a cuvette and a short, high-voltage pulse is applied, creating tiny pores in the membrane. The DNA then enters through these pores and then reseals.
Describe another assembly method in detail (such as Golden Gate Assembly)
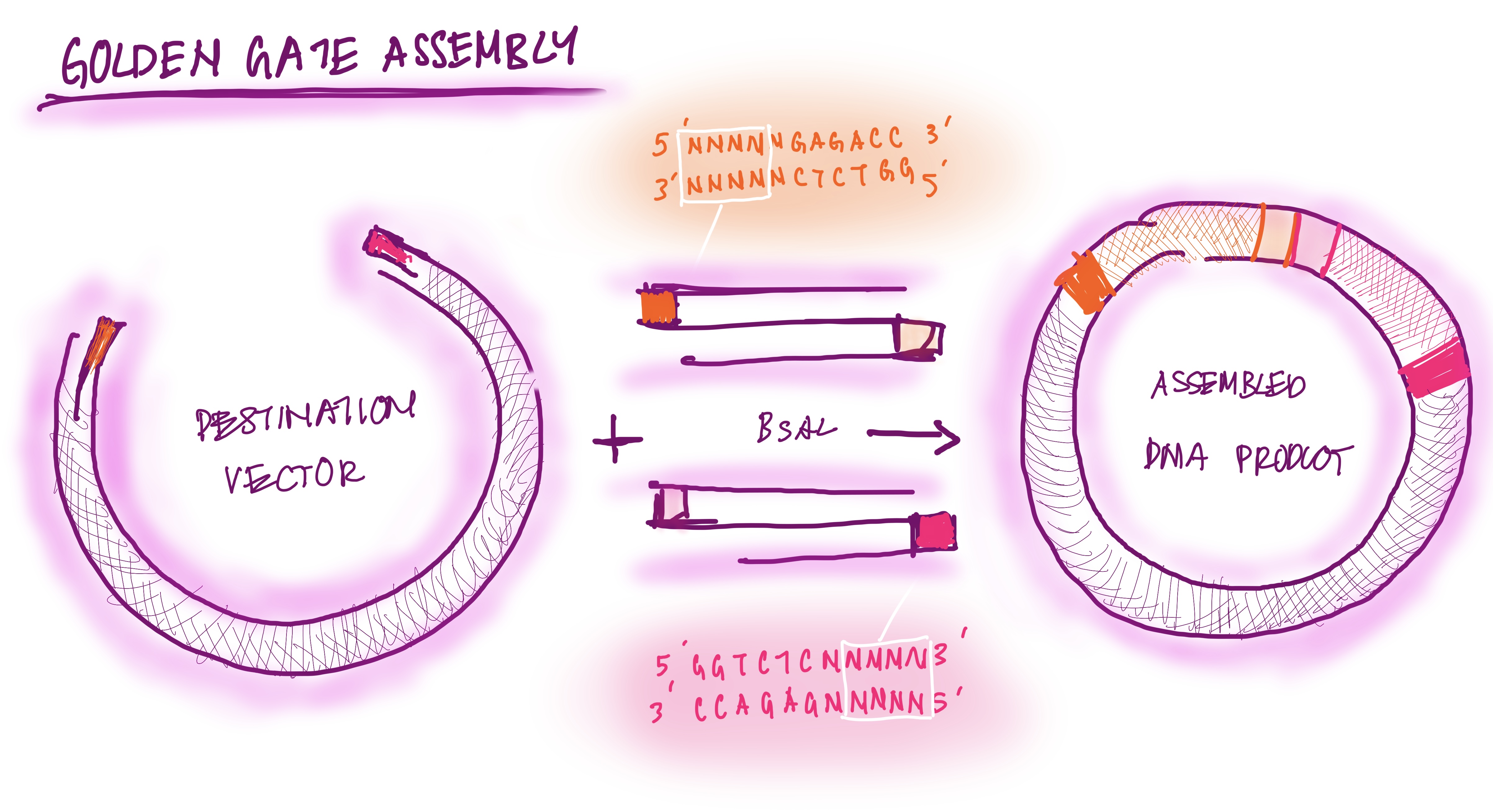
The Golden Gate assembly is a process for molecular cloning where DNA fragments are bound with ISS restriction enzymes and DNA ligase in a single seamless reaction. The first type of ISS restriction enzyme cuts the DNA outside the recognition site, creating sticky sites (overhangs). The DNA fragments are designed to have reciprocal overhangs. DNA ligase connects matching overhang ends, forming continuous DNA strands. The reaction alternates cutting and ligating. This assembly process is efficient because it can assemble multiple fragments at once and avoids waste of DNA base pairs; DNA is “scarless” (New England Biolabs).
GOLDEN GATE ASSEMBLY DIAGRAM DRAWING
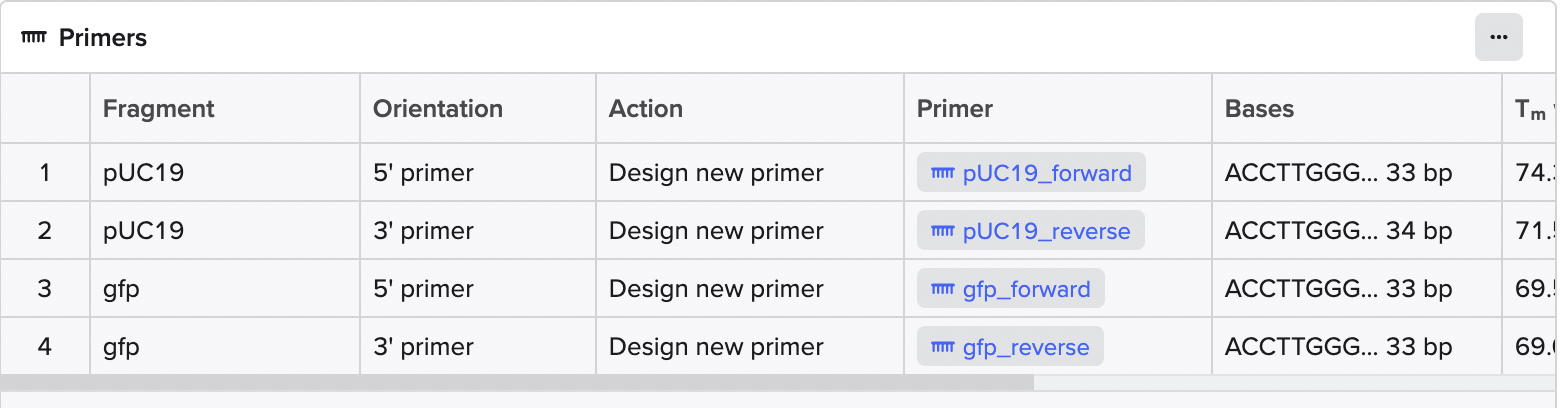
Modelling Golden Gate Assembly using Benchlink
The sequence view shows the BsaI recognition site and the designed primer overhang at the junction between pUC19 and GFP.
Golden Gate Assembly Drawing: prompt “feedback on drawing of the Golden Gate assembly”
“Edit my answer to this question”
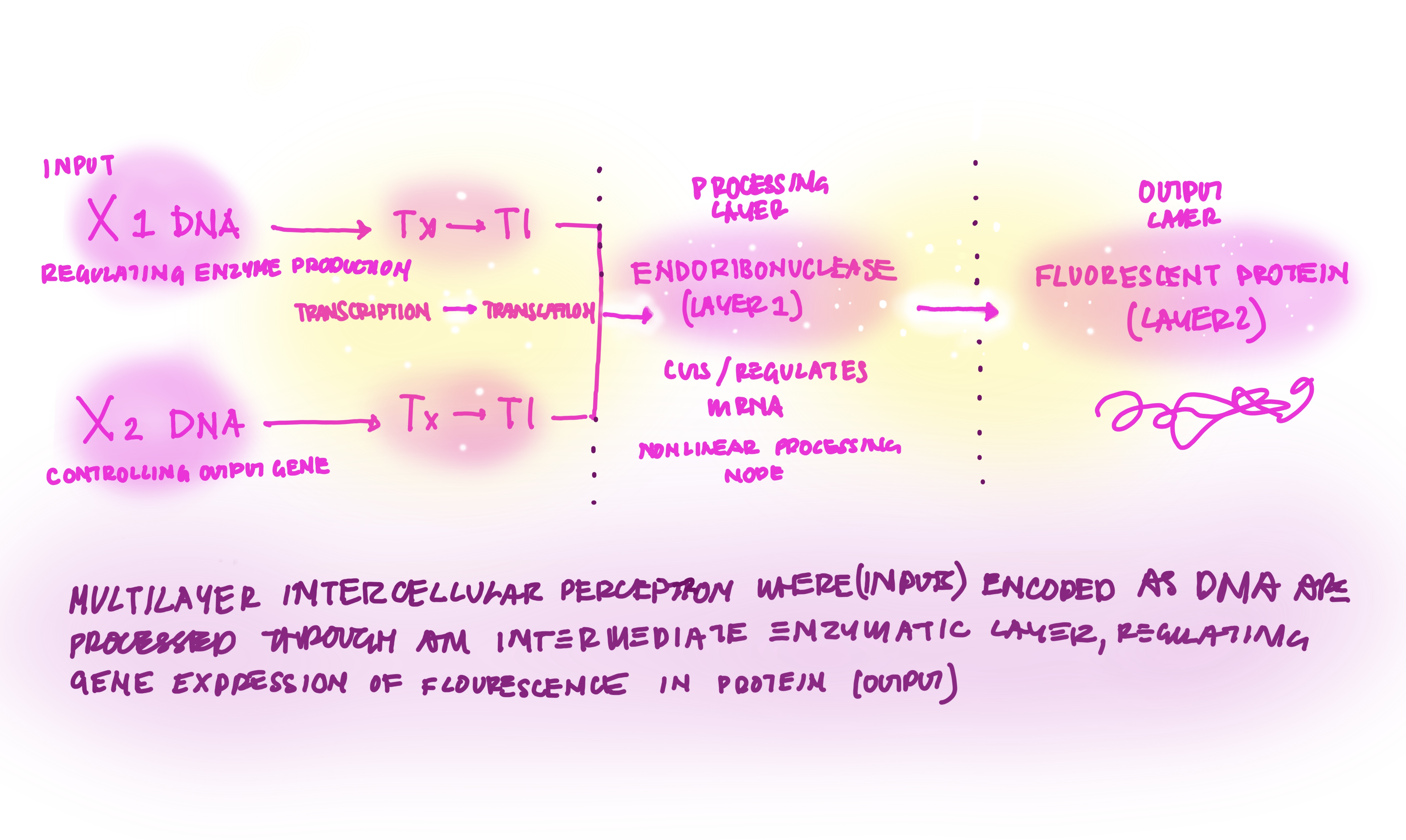
Week 7 HW: Genetic Circuits Part II: Neuromorphic Circuits
ASSIGNMENT PART 1: Intracellular Artificial Neural Networks (IANNs)
IANN ADVANTAGES VS GENETIC CIRCUITS
Intracellular Artificial Neural Networks, are genetic circuits designed with the same framework as neural networks taking from the most intelligent systems of communication that exist in our inner worlds. In traditional genetic circuits the outpus are boolean ON(1)OFF(0), however IAANs have outputs with continous analog, rather 0.2,0.5,0.75,1… The advantages of Iann vs genetic circuit logic, is the complexity of the analogue captured, combining many inputs as well as nonlinear relationships, and thus work better with biological systems with gradual changes and growth (Nilsson et al., 2022).
IANN APPLICATIONS
A common application of intracellular artificial neural networks (IANNs) is the detection of disease states within cells. For example, different fluorescent reporters can be used to represent biological signals: F1 for inflammation, F2 for metabolic activity, and F3 for pH levels. An IANN can interpret complex patterns across these inputs, such as producing a strong output when F1 is high, F2 is moderate, and F3 is low, while suppressing output when all three signals are high. This capacity to integrate and layer multiple inputs enables the system to recognise nuanced disease states, rather than relying on simple binary classifications (Nanda, 2019).
However, IANNs also have limitations. One key constraint is response time: because they rely on transcription and translation, their outputs are not instantaneous, which can hinder rapid decision-making. Additionally, biological noise presents a challenge, as gene expression levels can fluctuate, introducing variability and reducing the reliability of the system’s output (Nilsson et al., 2022).
DIAGRAM DRAWING
ASSIGNMENT PART 2: Fungal Materials
What are some examples of existing fungal materials, and what are they used for? What are their advantages and disadvantages over their traditional counterparts?
Some examples of fungal materials include mushroom leather, such as Mycoworks, which grows mycelium leather in a lab. Mycoworks applications can be seen in fashion, such as collaborations with Stella McCartney (Figure1) or even in interiors. The leather is made by first cultivating the mycelium on agricultural substrates under tightly controlled environmental conditions to form dense, interwoven sheets. Through its “Fine Mycelium” process, the growth of the fungal network is guided to create a material with structural properties similar to leather. Once the desired structure is achieved, growth is terminated, and the material is ready for tanning and finishing processes to enhance aesthetic, durability, and flexibility (MycoWorks).
What might you want to genetically engineer fungi to do and why? What are the advantages of doing synthetic biology in fungi as opposed to bacteria?
Funghi can be genetically engineered to produce stronger materials by altering the composition of the fungal cell wall. Fungal cell walls are made up of chitin, proteins, and glucans, which affect the stiffness, strength, flexibility, and permeability of the cell wall. By changing the genes involved in cell wall synthesis, one can also modify the fungal material structure and thus strength. Other genes that can be modified include growth-regulation genes, which can alter growth states, such as becoming more compact or fluffier. The fungi can also be engineered to secrete biomolecules that alter their properties, such as producing permeable coatings.
Nanda, S., Sahu, P.K. & Mishra, R.K. Inverse artificial neural network modeling for metamaterial unit cell synthesis. J Comput Electron 18, 1388–1399 (2019). https://doi.org/10.1007/s10825-019-01371-x
Nilsson, A., Peters, J.M., Meimetis, N., Bryson, B. and Lauffenburger, D.A., 2022. Artificial neural networks enable genome-scale simulations of intracellular signaling. Nature Communications, 13, p.3069. Available at: (Accessed 29 Mar. 2026).
USE OF AI
“Give me good resources delving deep into the IANNs as well as Genetic Circuits”
“Is this a good diagram? Feedback on diagram”
“What are some of the fungi material makers? Give me resources for the process of making funghi leather for example”
“Polish/Edit this paragraph”
Week 9 HW: Cell-Free Systems
General Homework Questions
1. Explain the main advantages of cell-free protein synthesis over traditional in vivo methods, specifically in terms of flexibility and control over experimental variables. Name at least two cases where cell-free expression is more beneficial than cell production.
The first advantage of cell-free protein synthesis (CFPS) over traditional in vivo methods is that it avoids the ethical concerns associated with modifying living cells; CFPS uses cellular machinery such as ribosomes and enzymes. The second advantage of CFPS is the time and cost. CFPS takes around 1-2 hours while cell-based expressions, such as in E. coli, take around a few days to a week, depending on the expression. Third, there is increased biosafety and controllability with CFPS. CFPS are more controllable and programmable. Unlike using living cells which can escape into the environment and potentially cause harm depending on the organism. Lastly
2. Describe the main components of a cell-free expression system and explain the role of each component.
Why is energy provision regeneration critical in cell-free systems? Describe a method you could use to ensure continuous ATP supply in your cell-free experiment.
A cell-free expression system contains the molecular machinery for transcription and translation containing ribosomes to build the target protein, tRNA to bring amino acids to the target site, RNA polymerase to transcribe DNA into RNA, and translation factors to elongate
a DNA template to encode the target protein. The DNA template, usually a plasmid or linear DNA, instructs the cell-free system to produce the protein. The template includes a promoter, a coding sequence, and a terminator. All 20 amino acids are also included. The energy system of the cell, such as ATP to power transcription, and GTP to power translation. Finally and most importantly, the cell-free system’s “environment” is made up of Mg²⁺, K⁺ to stabilise ribosomes and enzymes, NTPs (ATP, CTP, GTP, UTP), for mRNA synthesis, and buffers to maintain pH level, for the reactions to occur efficiently and successfully.
3. Compare prokaryotic versus eukaryotic cell-free expression systems. Choose a protein to produce in each system and explain why.
How would you design a cell-free experiment to optimize the expression of a membrane protein? Discuss the challenges and how you would address them in your setup.
To optimise a membrane protein in cell-free expression, I would first choose the lysate based on the protein type: E. coli extract for a bacterial target, and wheat germ or another eukaryotic extract for an eukaryotic target. I would then screen several membrane mimics directly in the reaction—such as mild detergents, liposomes, and nanodiscs—to promote cotranslational insertion and reduce aggregation. I would test multiple conditions for magnesium, temperature, DNA concentration, and reaction format, then compare total expression, soluble fraction, and functional activity rather than yield alone. The major challenges are aggregation, misfolding, poor membrane insertion, and low functional recovery, and these are addressed by matching the CFPS chassis to the target, providing an appropriate lipid environment during synthesis, and screening conditions systematically.
4. Imagine you observe a low yield of your target protein in a cell-free system. Describe three possible reasons for this and suggest a troubleshooting strategy for each.
The first reason for a low yield in the target protein is an imbalance in the composition as well as a lack of ATP and GTP. Cell-free systems rely on ATP, GTP, amino acids, salts, cofactors, and an appropriate magnesium and potassium balance. To troubleshoot, one uses the correct measuring tools and is exact in optimising each component especially magnessium and template concentration. One must also ensure the correct temperatures are used with measured time. One can also switch energy usages as cell free systems rely on massive amounts of ATP and GTP. One could use Creatine Phosphate or Glucose.
The second reason for a low yield is inefficient folding and aggregation. In a cell-free extract, proteins can become stuck together, forming inclusion bodies rather than functional proteins. This could be due to a higher concetration in protein. To fix this, one could supplement the mix with purified DnaK/J-GrpE or GroEL/ES complexes to assist with folding. Dropping the incubation temperature can also help. Slower translation often helps the protein find its native conformation.
The final reason for a low yield of the target protein in template degradation is also commonly known as the RNase problem. Cell-free extracts contain endogenous nucleases. DNA template or newly transcribed mRNA is digested before ribosomes can finish their run, and yield drops completely in the first 30-60 seconds, even if the system has enough energy. One can supplement the reaction with 0.5–1.0 U/μL of a recombinant RNase inhibitor. There are also methods to protect linear DNA ends from degradation by the RecBCD exonuclease, such as adding the GamS protein to PCR products. One should also ensure there is no contamination in the tools to minimise surface-bound nuclease contamination.
Homework question from Kate Adamala
Part 1
Q1. What would your synthetic cell do? What is the input and what is the output?
The synthetic cell functions as a biological electromagnetic field sensor. hCRY2 contains a FAD cofactor that, upon blue light absorption at approximately 450 nm, forms a radical pair whose singlet/triplet spin state ratio is altered by external magnetic fields. This change in spin state modulates hCRY2 repressor activity, which drives expression of a nanoLuc bioluminescence reporter. The two inputs are blue light, which initiates radical pair formation, and magnetic field strength and orientation, which modulate the radical pair spin chemistry. The output is nanoLuc luminescence, whose intensity is inversely proportional to hCRY2 repressor activity and therefore encodes the magnetic field experienced by the cell.
Q2. Could this function be realized by cell-free Tx/Tl alone, without encapsulation?
No, encapsulation is essential. In bulk solution, radical pairs are rapidly quenched by molecular oxygen and random collisions, making magnetic sensitivity impossible. Encapsulation provides an oxygen-scavenged microenvironment that extends radical pair lifetime long enough for the magnetic field to exert its effect. It also maintains the local protein concentrations and molecular crowding needed for correct spin chemistry, and provides a stable compartment to sustain the Tx/Tl machinery required for the reporter output.
Q3. Could this function be realized by a genetically modified natural cell?
In principle yes, since hCRY2 is already expressed in human cells as part of the circadian clock. However, endogenous antioxidants would quench radical pairs unpredictably, intracellular oxygen and FAD levels cannot be independently controlled, and the magnetosensing signal cannot be isolated from hCRY2’s other cellular functions. The synthetic cell provides full control over every parameter governing the radical pair mechanism, making it the more precise and tractable approach.
Q4. Describe the desired outcome of your synthetic cell operation.
The desired outcome is a population of GUVs that produce measurably different nanoLuc luminescence levels depending on the strength and orientation of an applied magnetic field, under blue light illumination. The response should be reversible upon removal of the field, and should be completely abolished when FAD is omitted or when the internal oxygen scavenging system is disabled, confirming that the output is mechanistically dependent on radical pair spin chemistry.
Part 2 — Component Design
2.1 What would the membrane be made of?
The membrane would consist of GUVs composed of DPPC at 50 mol%, DOPE at 30 mol%, and cholesterol at 20 mol%. DPPC’s saturated acyl tails and the high cholesterol content produce a low-fluidity, low-oxygen-permeability bilayer that is specifically chosen to extend the radical pair lifetime inside the vesicle by limiting oxygen ingress.
2.2 What would you encapsulate inside?
The interior would contain purified hCRY2 protein pre-loaded with FAD as the magnetosensor, free FAD at 150 µM, plasmids encoding AmCLK, AmCYC, and nanoLuc under E-box promoter control, and a mammalian cell-free extract to provide Tx/Tl machinery. An oxygen scavenging system of glucose, glucose oxidase, and catalase would protect the radical pair, while Trolox at 1 mM would stabilize its lifetime, and creatine phosphate with creatine kinase would regenerate ATP.
2.3 Which organism will the Tx/Tl system come from?
A mammalian cell-free extract from HEK293 or HeLa cells is required. A bacterial system cannot be used because the E-box promoter driving nanoLuc requires eukaryotic RNA polymerase II machinery, hCRY2 signaling depends on eukaryotic post-translational modifications such as phosphorylation by casein kinase 1 epsilon, and proper FAD incorporation requires eukaryotic chaperones. A commercially available system such as the Thermo Fisher 1-Step Human IVT kit is appropriate and is additionally well-matched to hCRY2 given its human origin.
2.4 How will your synthetic cell communicate with the environment?
No membrane channels are required. Blue light photons and the magnetic field both pass freely through the lipid bilayer and act directly on the encapsulated hCRY2-FAD complex, and nanoLuc bioluminescence is emitted as photons that pass outward through the membrane to be detected externally. The entire input/output communication of this synthetic cell is electromagnetic and requires no membrane transport proteins.
Part 3 — Experimental Details
3.1 List of all lipids and genes
The lipids required are DPPC (Avanti 850355), DOPE (Avanti 850725), and cholesterol (Sigma C8667). The genes required are hCRY2 (Gene ID 4236) as the magnetosensor, AmCLK (Gene ID 406114) and AmCYC (Gene ID 411055) as the transcriptional activators, and nanoLuc (Promega) as the reporter, all codon-optimized for mammalian expression. Key small molecules include FAD at 150 µM (Sigma F6625), glucose with glucose oxidase and catalase for oxygen scavenging, Trolox at 1 mM (Sigma 238813), and creatine phosphate with creatine kinase for ATP regeneration.
3.2 How will you measure the function?
Vesicles would be exposed to magnetic fields of 0 to 500 µT via a Helmholtz coil array while nanoLuc luminescence is recorded on a plate reader, to determine whether output scales with field strength. Field orientation would be rotated across all three axes at fixed strength to test directional sensitivity. The critical mechanistic control is the RF oscillating field test, in which a radiofrequency field applied at the Larmor frequency disrupts radical pair spin state interconversion and should abolish the magnetic response, confirming a quantum mechanical origin. FAD-minus and oxygen scavenging-minus conditions would serve as additional controls confirming cofactor and radical pair dependence respectively.
Homework question from Peter Nguyen
Freeze-Dried Cell-Free Systems in Textiles
Application Field: Textiles and Fashion
One-sentence pitch:
A garment embedded with freeze-dried cell-free biosensors that activates upon contact with the wearer’s sweat, translating electrodermal skin conductivity into a shifting visual patina on the textile surface that externalises the wearer’s neurological and emotional state in real time.
How will it work?
Freeze-dried cell-free systems remain entirely dormant when dry and reactivate upon hydration, meaning the wearer’s own sweat serves as the biological trigger without any external power or living cells required. The textile is embedded with microreactors containing freeze-dried Tx/Tl machinery programmed to respond to biomarkers present in sweat, specifically the ionic composition and conductivity changes associated with electrodermal activity, which is a direct readout of sympathetic nervous system arousal. Upon activation, the cell-free system drives expression of chromogenic enzymes or pigment-producing biosynthetic pathways, such as the violacein pathway, that physically alter the textile’s colour and patterning in proportion to the intensity of the electrodermal signal. The result is a dynamic, personalised patina that is unique to each wearer and each emotional experience, forming a wearable record of one’s inner neurological world rendered visibly on the body.
What societal challenge or market need does this address?
Mental health and emotional experience remain largely invisible and difficult to communicate, both to others and to the individual themselves. This concept addresses the growing cultural need for tools that make inner states legible and expressible, sitting at the intersection of mental health awareness, biofeedback wearables, and sustainable fashion. Unlike electronic biosensors, this system requires no battery, no screen, and no data transmission, making it radically accessible, low-cost, and free from the privacy concerns associated with digital health monitoring. It also responds to the fashion industry’s interest in programmable and living materials as an alternative to static, environmentally costly textile production.
How will you address the limitations of cell-free reactions?
The primary limitations of freeze-dried cell-free systems are their one-time activation, finite reagent supply, and sensitivity to environmental conditions. The one-time use constraint is reframed here as a design feature rather than a drawback, since each wearing produces a permanently fixed, unrepeatable patina that functions as a record of that specific emotional experience, giving the garment biographical value over time. Stability during storage and transport is addressed by the freeze-drying process itself, which has already been demonstrated to preserve cell-free system activity across months without refrigeration when embedded in paper and textile substrates. To extend functional longevity across multiple wears, microreactor chambers within the textile can be designed as replaceable or rechargeable modules, allowing the biological sensing layer to be refreshed while the garment itself is reused, addressing both sustainability and repeatability.
Homework Questions From Ally Huang
Genes in Space Mock Proposal
BioBits Cell-Free Lichen-Inspired Radiation Biosensor for Astronaut Health Monitoring
Background
Astronauts on long-duration missions are exposed to cosmic radiation approximately 200 times more intense than on Earth, generating reactive oxygen species that damage DNA and increase cancer risk. Lichen are among the only organisms demonstrated to survive direct exposure to open space, enduring vacuum, unfiltered cosmic radiation, and extreme temperature swings during ESA’s EXPOSE experiments on the ISS. Their cyanobacterial partner Nostoc has evolved highly efficient oxidative stress response systems fine-tuned for exactly these conditions. Harnessing this space-proven biological machinery as a cell-free diagnostic could provide astronauts with a lightweight, resource-minimal biosensor uniquely suited to the demands of deep space exploration.
Molecular Target
The molecular target is the OxyR oxidative stress sensor protein and its downstream KatG promoter, derived from the lichen cyanobacterial partner Nostoc, driving fluorescent reporter expression in BioBits.
How the Target Relates to the Challenge
In Nostoc, reactive oxygen species generated by radiation directly oxidise the OxyR protein, causing a conformational change that activates the KatG promoter and upregulates antioxidant defence genes. By placing a fluorescent reporter gene downstream of the KatG promoter within the BioBits cell-free system, ROS present in an astronaut’s saliva sample can activate this space-proven stress circuit, producing a fluorescent signal proportional to oxidative stress levels. Unlike the equivalent E. coli system, OxyR and KatG were shaped by evolution in an organism that genuinely survives space conditions, making this a more robust and contextually appropriate sensing circuit.
Hypothesis and Reasoning
We hypothesise that a freeze-dried BioBits cell-free system incorporating Nostoc OxyR as the sensor protein and a KatG-driven fluorescent reporter will produce a measurable, dose-dependent fluorescent signal when rehydrated with saliva samples from astronauts experiencing radiation-induced oxidative stress. We further hypothesise that the addition of usnic acid, a lichen-derived secondary metabolite with known UV-absorbing and antioxidant properties, to the freeze-dried disc formulation will improve system stability and longevity under space radiation conditions compared to a standard BioBits formulation. The reasoning is that Nostoc evolved its OxyR/KatG circuit under conditions of genuine radiation stress, making it more sensitive and robust than equivalent circuits from non-space-adapted bacteria. Usnic acid, which lichen use to shield their photosynthetic partners from radiation damage, could perform the same protective role for the cell-free machinery during storage aboard the ISS.
Experimental Plan
Saliva samples collected from astronauts at regular mission intervals would be pipetted onto freeze-dried BioBits® discs containing Nostoc OxyR protein and a KatG-GFP reporter construct, with usnic acid incorporated into the disc matrix. After 30 minutes of incubation, fluorescence would be visualised using the P51 Molecular Fluorescence Viewer. Controls would include discs rehydrated with water alone as a negative control, discs rehydrated with defined hydrogen peroxide solution as a positive ROS control, and discs formulated without usnic acid to quantify its protective contribution to system stability. Ground-based saliva from non-irradiated individuals would serve as baseline reference.
Part A. Conceptual Questions
Answer any NINE of the following questions from Shuguang Zhang: (i.e. you can select two to skip)
Why do humans eat beef but do not become a cow, eat fish but do not become fish?
Even though some may like to say you are what you eat, this really isn’t the case when it comes to eating an organism. Even though we consume its parts and convert protein into energy we are transforming energy into energy that we can use. One may argue we embody that organism to a degree, but we dont fully transform into that being. Your cells follow a genetic blueprint, and while other DNA enters your body, you do not absorb its genome, nor does it integrate into yours.
Why are there only 20 natural amino acids?
Although the genetic code contains 64 possible codons, evolution stabilized around 20 canonical amino acids. This was not due to a strict numerical limitation, but because these 20 provide an optimal balance of chemical diversity, stability, and functional efficiency. Biochemical availability on early Earth also played a crucial role, early life utilized the amino acids that were most readily synthesized under prebiotic conditions. Mathematical analyses of the canonical set suggest that the 20 amino acids achieve a near-optimal coverage of chemical property space, maximizing structural and catalytic versatility while minimizing redundancy. Furthermore, the structure of the genetic code itself is organized in a way that reduces the impact of mutations: codons that differ by a single nucleotide often encode amino acids with similar physicochemical properties, thereby limiting potential damage to protein structure and function.
Can you make other non-natural amino acids? Design some new amino acids.
Yes, and we already have. Scientists have even been able to genetically engineer organisms to expand the genetic code beyond the 20, by introducing new codons.() Some of the amino acids that have been synthesised include fluorescent amino acids, for example, to help scientists localise proteins in a cell and observe their interactions, improving observation.
Where did amino acids come from before enzymes that make them, and before life started?
Amino acids can form spontaneously under prebiotic conditions through chemistry. Scientists have simulated Earth’s atmosphere using simple gases and found that amino acids can form through life’s basic chemistry.
If you make an α-helix using D-amino acids, what handedness (right or left) would you expect?
If you make an α-helix using D-amino acids, you would expect a left-handed twist, because the molecular building blocks themselves are mirrored. D-amino acids have the opposite chirality of the natural L-forms, so their backbone geometry favors a left-handed helix rather than a right-handed one.
Can you discover additional helices in proteins?
Yes research continues to identify unsual or distrorted helical geometries. Scienttists have also designe helices from non antural amino acids, or even alternate hydrogen bonding patterns.
Why are most molecular helices right-handed?
Most moleculart helices are right handed beacuse of chirality. The presence of molecular assymetry in L- amino acids determening helix twist direction, favouring a right handed direction. While left handed helices are possible, they are rare. An example of a left handed helices is a D helices, which its molecular building block is most stable and corresponds to a left hand.
Why do β-sheets tend to aggregate?
β-sheets tend to aggregate because their extended structure exposes backbone hydrogen bond donors and acceptors, allowing strands from different proteins to easily form intermolecular hydrogen bonds. Their flat geometry also enables tight stacking into stable, repetitive “cross-β” structures, making aggregation energetically favorable.
What is the driving force for β-sheet aggregation?
Backbone hydrogen bonds form between neighbouring β strands, satisfying exposed N-H and C=O groups. Hydrophobic chains pack together and repel water, thus loweing the systems free energy and agregates state is more stable than partially unfolded state.
Why do many amyloid diseases form β-sheets?
Because the β-sheet structure is the most stable form in which misfolded proteins can agregate and be reorganized, creating a strong cross β structure.
Can you use amyloid β-sheets as materials?
Amyloid β-sheets are one of the strongest and most stable protein structures in nature, making them greatly appealing in material architecture. Some of the properties that arise and be applied in material science include, tensile strength, chemical stability, self assembly in asolutions, heat resistance, and mechanical stiffness. Examples where nature uses the intelligent structure present in β-sheet scaffolidng is in silk fibroin and curli fibers in bacterial biofilms. Common applications of Amyloid β-sheets are hydrogels, drug delivery, nanofibres, tissue scafolidng, bioprinting, and even in conductive biofilms.
Design a β-sheet motif that forms a well-ordered structure.
Part B: Protein Analysis and Visualization
Briefly describe the protein you selected and why you selected it.
Identify the amino acid sequence of your protein.
2.1 How long is it? What is the most frequent amino acid? You can use this Colab notebook to count the frequency of amino acids.
2.2 How many protein sequence homologs are there for your protein? Hint: Use Uniprot’s BLAST tool to search for homologs.
2.3 Does your protein belong to any protein family?
Identify the structure page of your protein in RCSB
3.1 When was the structure solved? Is it a good quality structure? Good quality structure is the one with good resolution. Smaller the better (Resolution: 2.70 Å)
3.2 Are there any other molecules in the solved structure apart from protein?
3.3 Does your protein belong to any structure classification family?
Open the structure of your protein in any 3D molecule visualization software:
Visualize the protein as “cartoon”, “ribbon” and “ball and stick”.
Color the protein by secondary structure. Does it have more helices or sheets?
Color the protein by residue type. What can you tell about the distribution of hydrophobic vs hydrophilic residues?
Visualize the surface of the protein. Does it have any “holes” (aka binding pockets)?