Individual Final Project
HTGAA 2026: Individual Final Project Documentation
AI-Driven Mining of Healthcare Wastewater Metagenomes for Novel Phage-Derived Antimicrobial Peptides Against Salmonella enterica
SECTION 1: ABSTRACT
The rapid rise of antimicrobial resistance has intensified the need for new antibacterial strategies that move beyond conventional antibiotic discovery pipelines. Healthcare-associated wastewater is a particularly relevant One Health environment because it can contain clinically important bacteria, antimicrobial residues, resistance-associated genes, and diverse bacteriophages. Within this context, bacteriophages represent a valuable but underexplored source of antimicrobial molecules, including endolysin-derived peptides, membrane-active regions, and proteins associated with bacterial envelope disruption. This project aims to develop an AI-guided synthetic biology workflow to identify bacteriophage-derived antimicrobial peptide candidates from healthcare wastewater metagenomes in Andean regions and prioritize them for predicted activity against Salmonella enterica.
The central hypothesis is that healthcare-associated wastewater metagenomes harbor previously uncharacterized phage-derived peptide sequences with potential antibacterial activity against S. enterica, and that these candidates can be detected using protein language models, antimicrobial peptide classifiers, structural prediction, and synthetic DNA design. To test this hypothesis, metagenomic sequences will be processed to identify viral and phage-associated open reading frames, extract peptide candidates from relevant phage proteins, and encode these sequences using AI-based protein representation tools. Candidate peptides will then be ranked according to predicted antimicrobial activity, structural stability, novelty, and biosafety-related filters. Finally, selected candidates will be incorporated into synthetic expression construct designs suitable for future cell-free or chassis-based production. The expected outcome is a focused computational-to-design platform that transforms healthcare wastewater metagenomic data into prioritized phage-derived antimicrobial peptide candidates, contributing to future synthetic biology strategies against Salmonella enterica within a One Health framework.
SECTION 2: PROJECT AIMS
Aim 1: Experimental Aim
The first aim of this project is to identify and prioritize bacteriophage-derived antimicrobial peptide candidates from healthcare-associated wastewater metagenomic data from Andean regions, using metagenomic analysis, AI-based sequence screening, and in silico peptide–target interaction prediction against Salmonella enterica.
To achieve this aim, healthcare wastewater metagenomic sequences will be obtained from publicly available datasets, simulated inputs, or environmental sequencing data, depending on data availability. The metagenomic data will be quality-controlled, assembled into contigs, and analyzed to identify viral or bacteriophage-associated open reading frames.
Candidate phage-derived proteins or peptide regions will then be screened using antimicrobial peptide prediction tools, protein language model embeddings, and novelty-based prioritization. Selected peptide candidates will be evaluated through structural prediction and in silico interaction modeling against relevant S. enterica targets using tools such as AlphaFold-Multimer or related protein–peptide docking approaches.
Finally, at least one prioritized peptide candidate will be converted into a DNA sequence, codon-optimized, and designed as a synthetic expression construct in Benchling to connect computational discovery with synthetic biology implementation.
Relevant methods and tools may include metagenomic quality control, ORF prediction, phage sequence identification, antimicrobial peptide prediction, protein language models, latent space analysis, AlphaFold-Multimer, Benchling, codon optimization, and synthetic DNA construct design.
Aim 2: Development Aim
The second aim of this project is to experimentally produce and validate selected bacteriophage-derived antimicrobial peptide candidates for activity against Salmonella enterica using in vitro expression and infection-associated assays.
Following the computational prioritization completed in Aim 1, selected peptide sequences would be synthesized as codon-optimized DNA constructs and cloned into an appropriate expression system, such as Escherichia coli or a cell-free protein expression platform. Peptide production would be confirmed through protein-level validation methods such as SDS-PAGE, affinity-tag detection, Western blotting, or another suitable analytical approach depending on the final construct design.
The antibacterial activity of the produced peptide would then be tested against S. enterica through in vitro assays measuring bacterial viability, growth inhibition, membrane disruption, or changes in infection-related behavior. In a later stage, the peptide could be evaluated in a human cell infection model, such as HEK293 cells, comparing untreated S. enterica infection with peptide-treated conditions to determine whether the candidate reduces bacterial pathogenicity, host-cell damage, or infection-associated cytotoxicity.
This aim extends the project beyond computational prediction by testing whether the designed peptide can be produced and whether it demonstrates measurable biological activity against S. enterica.
Aim 3: Visionary Aim
The third aim of this project is to pioneer a decentralized “metagenome-to-medicine” platform in which healthcare wastewater from Andean regions is transformed into a source of AI-designed, phage-derived antimicrobial peptide therapeutics for rapid response against antimicrobial-resistant pathogens.
The long-term vision is to build an autonomous discovery pipeline capable of moving from environmental sample to therapeutic prototype through an integrated workflow of metagenomic sequencing, viral sequence mining, protein language model prediction, structural simulation, synthetic DNA design, and automated cell-free peptide production. In this model, healthcare wastewater would serve as a real-time biological sensor of local infectious disease threats and as a discovery reservoir for the phage-derived molecules needed to counter them. For Salmonella enterica, this could enable the identification of peptides that reduce pathogenicity, disrupt bacterial envelope integrity, interfere with infection-associated mechanisms, or complement existing antimicrobial strategies.
At full scale, this platform could redefine antimicrobial discovery by making it local, adaptive, programmable, and predictive. Instead of waiting years for new antibiotics to emerge through traditional pipelines, hospitals and research centers could use regional metagenomic data to design candidate antimicrobials within days or weeks. This vision would connect One Health surveillance with synthetic biology manufacturing, creating a future where antimicrobial resistance is addressed through distributed biological design infrastructure. The ultimate goal is not only to discover one peptide against S. enterica, but to establish a generalizable framework for rapidly generating pathogen-specific antimicrobial solutions from the microbial dark matter present in local environments.
SECTION 3: BACKGROUND
- Briefly summarize two peer-reviewed research citations relevant to your research
Antimicrobial resistance is one of the most urgent challenges in global health because it reduces the effectiveness of conventional antibiotics and increases the difficulty of treating bacterial infections. This problem is especially relevant in One Health environments, where human activity, clinical waste, microorganisms, antimicrobial residues, and resistance genes can interact. Healthcare-associated wastewater is a particularly important environment because it can contain antibiotic-resistant bacteria, clinically relevant antimicrobial resistance genes, pharmaceuticals, disinfectants, and viral communities. Petrovich et al. used shotgun metagenomics to study a hospital wastewater treatment system and found that antibiotic resistance genes and viruses persisted across the treatment process, supporting the idea that hospital wastewater is not only a waste stream but also a biologically informative reservoir for antimicrobial resistance surveillance (Petrovich et al., 2020)
At the next level, wastewater is also relevant because it contains bacteriophages, which are viruses that infect bacteria and are deeply connected to bacterial ecology. Strange et al. (2021) analyzed global sewage metagenomic data from 79 cities in 60 countries and showed that sewage can be used to study the distribution of bacteriophages and their relationship with bacterial communities and antimicrobial resistance genes. This supports the use of wastewater metagenomics as a practical approach to explore viral diversity at large scale.
For this project, healthcare-associated wastewater from Andean regions is therefore proposed as a focused discovery environment where bacteriophage-derived sequences may reveal new antimicrobial candidates relevant to local and global AMR challenges.
At the micro level, bacteriophages are not only important as whole viral particles; they also encode proteins and peptide regions that may have antimicrobial potential. These include endolysin-associated regions, membrane-active domains, tail-associated proteins, and other phage-derived molecular components that may interact with bacterial envelopes or infection-related structures. This is innovative because it shifts the project away from traditional whole-phage therapy and toward the discovery of modular phage-derived antimicrobial peptides that could be computationally predicted, optimized, and redesigned using synthetic biology. In this context, Salmonella enterica is used as the target pathogen because it is a clinically and food-safety-relevant bacterium, allowing the project to connect environmental discovery with a defined pathogenic outcome.
Metagenomics is essential for this project because many microbial and viral sequences in environmental samples cannot be easily recovered through culture-based methods. Instead of isolating one organism at a time, metagenomic sequencing allows the project to access the collective genetic diversity of an entire microbial community, including uncultured bacteria, bacteriophages, and unknown protein-coding sequences. Santos-Júnior et al. demonstrated that machine learning can be applied to large metagenomic and genomic datasets to predict antimicrobial peptides, generating a catalog of hundreds of thousands of non-redundant peptide candidates and experimentally validating a subset with antibacterial activity. This study directly supports the logic of this project: environmental sequence data can be transformed into prioritized antimicrobial candidates through computational prediction, AI-guided screening, and downstream synthetic biology design (Santos-Júnior et al., 2024).
Therefore, the gap addressed by this project is the lack of a focused workflow for discovering bacteriophage-derived antimicrobial peptide candidates from healthcare-associated wastewater metagenomes in Andean regions and prioritizing them against Salmonella enterica. Existing studies show that wastewater can be used for AMR and phage surveillance, and that metagenomic data can be mined for antimicrobial peptides. However, fewer approaches integrate these ideas into a single synthetic biology pipeline that moves from healthcare wastewater metagenomes to phage-derived peptide prediction, structural prioritization, and DNA construct design. This project addresses that gap by proposing an AI-guided metagenome-to-design workflow for identifying candidate phage-derived antimicrobial peptides with predicted relevance against S. enterica pathogenicity.
- Explain how your project is novel or innovative.
This project is innovative because it treats healthcare-associated wastewater from Andean regions not only as a site of microbial risk, but as a source of therapeutic design information. Rather than searching broadly for known antimicrobial genes, the project focuses on bacteriophage-derived peptide candidates that may be hidden within complex metagenomic datasets and difficult to detect through culture-dependent methods alone. The workflow is novel because it links phage sequence discovery, AI-guided peptide prioritization, structural prediction, and synthetic DNA construct design into a single pipeline. This approach expands synthetic biology beyond building with well-characterized biological parts by using environmental viral diversity as raw material for engineering new antimicrobial strategies against S. enterica.
- Explain why your project matters and what impact it could have.
This project matters because antimicrobial resistance is reducing the effectiveness of conventional treatments and creating an urgent need for alternative antimicrobial strategies. S. enterica is a relevant target because it is associated with foodborne disease, clinical infections, and increasing concerns about resistant strains, making it important for both public health and One Health surveillance. Bacteriophages are promising in this context because they naturally recognize bacteria with high specificity, which could reduce damage to beneficial microbiota compared with broad-spectrum antibiotics. However, the direct clinical use of whole phages can be limited by regulatory complexity, host-range variability, immune responses, and challenges in standardizing phage preparations. For this reason, phage-derived proteins and peptides represent an attractive alternative, because they may retain antibacterial activity while being easier to design, synthesize, optimize, and incorporate into controlled synthetic biology systems.
The impact of this project lies in creating a workflow that connects healthcare wastewater surveillance with the discovery of phage-derived antimicrobial candidates against S. enterica. By using metagenomics and AI-guided prediction, the project could help identify antimicrobial peptide candidates that would be difficult to detect through culture-based screening alone. This is especially relevant for underexplored Andean healthcare environments, where local microbial and viral diversity may contain unique biological information that has not been fully studied. If successful, the project could contribute to the development of more targeted antimicrobial strategies and support future peptide-based interventions against resistant bacterial pathogens. At a broader level, this work could help shift antimicrobial discovery from slow, generalized screening toward a more precise, predictive, and regionally informed design process.
- Describe the ethical implications associated with your project and identify relevant ethical principles (e.g., non-maleficence, beneficence, justice, or responsibility).
This project can raise several ethical considerations related to artificial intelligence, environmental metagenomics, synthetic biology, and the use of bacteriophage-derived sequences as potential antimicrobial agents. One major ethical principle involved is non-maleficence, because the discovery and engineering of antimicrobial peptides must avoid unintended biological or ecological harm. Although this project focuses on phage-derived peptides rather than whole-phage therapeutic deployment, bacteriophages themselves evolve rapidly and can interact dynamically with bacterial populations. For this reason, any laboratory work involving phage-associated genetic material must be carefully controlled to prevent unintended environmental release or uncontrolled biological propagation. Additional concerns involve responsibility and transparency in the use of AI-based predictions, since computational models may generate false positives, overestimate biological activity, or produce misleading functional interpretations if not critically validated. The principle of justice is also relevant because the project uses biodiversity-associated genetic information from underexplored Andean healthcare environments, making it important to consider equitable scientific benefit, responsible data use, and fair access to future applications derived from these biological resources.
To ensure ethical conduct, several biosafety and research responsibility measures should be implemented throughout the project. All candidate peptides identified through AI-guided prediction should undergo rigorous computational filtering and controlled experimental validation before considering any downstream application. Any laboratory manipulation involving bacteriophage-associated material should follow strict containment and decontamination procedures, including appropriate biological waste treatment, chemical inactivation of phage-containing materials, and systematic disposal protocols to reduce the risk of environmental release. Because phages can evolve rapidly, the project must ensure that all work involving phage-derived sequences is performed under controlled and traceable conditions with clearly defined containment practices. Potential unintended consequences include incorrect antimicrobial predictions, toxicity toward non-target organisms, disruption of microbial communities, or overreliance on computational models without sufficient experimental confirmation. To address these uncertainties, AI-generated predictions should be treated as probabilistic rather than definitive and complemented with structural analysis, experimental validation, and transparent reporting of limitations. Ethical alternatives include restricting early applications to laboratory-scale discovery, environmental monitoring, or controlled cell-free systems before any therapeutic consideration. Overall, the project should prioritize biosafety, transparency, scientific responsibility, and equitable public health impact while developing new antimicrobial discovery strategies.
SECTION 4: EXPERIMENTAL DESIGN, TECHNIQUES, TOOLS, AND TECHNOLOGY
Define the biological question and target pathogen
The project will focus on identifying bacteriophage-derived antimicrobial peptide candidates from healthcare-associated wastewater metagenomes and prioritizing them for predicted activity against Salmonella enterica. The expected result is a clear target framework connecting the environmental source, phage-derived peptides, and S. enterica pathogenicity.
Timeline
| Step | Methods/tools | Estimated time | Expected result |
|---|---|---|---|
| Select or obtain healthcare wastewater metagenomic data. | Metagenomic sequencing datasets will be obtained from publicly available repositories such as NCBI SRA, NMDC, MG-RAST, or ENA. If real Andean healthcare wastewater data are not available during the course, simulated or representative hospital wastewater metagenomes will be used as proof-of-concept input. | 1–2 days | A selected dataset suitable for downstream viral and peptide mining. |
| Perform quality control of raw sequencing reads. | Raw metagenomic reads will be evaluated using tools such as FastQC or MultiQC to assess read quality, GC content, adapter contamination, and sequence length distribution. Low-quality bases and adapters will be trimmed using tools such as Trimmomatic, fastp, or Cutadapt. | 1 day | A cleaned metagenomic dataset with improved read quality. |
| Assemble metagenomic reads into contigs. | Quality-controlled reads will be assembled using a metagenomic assembler such as MEGAHIT or metaSPAdes. Assembly statistics, including total assembly size, N50, contig length distribution, and number of contigs, will be evaluated using QUAST. | 1–2 days | A set of assembled contigs representing microbial and viral genetic material from the wastewater metagenome. |
| Identify viral and bacteriophage-associated contigs. | Assembled contigs will be screened for viral signatures using tools such as VirSorter2, CheckV, VIBRANT, or geNomad. Contigs predicted to be viral or bacteriophage-associated will be retained for further analysis. | 1–2 days | A curated subset of putative bacteriophage-derived contigs. |
| Predict open reading frames from phage-associated contigs. | Open reading frames will be predicted using Prodigal in metagenomic mode or another ORF prediction tool appropriate for environmental sequences. Predicted ORFs will be translated into amino acid sequences for protein-level analysis. | 1 day | A protein sequence dataset derived from putative bacteriophage contigs. |
| Annotate bacteriophage-derived proteins. | Predicted proteins will be compared against databases such as NCBI nr, PHROGs, UniProt, Pfam, or HMMER-based viral protein databases. This step will identify proteins related to endolysins, tail fibers, depolymerases, holins, virion-associated peptidoglycan hydrolases, or hypothetical phage proteins. | 2–3 days | A functional annotation table classifying candidate phage proteins. |
| Extract potential antimicrobial peptide regions. | Candidate peptide regions will be obtained either from short phage proteins or from predicted antimicrobial domains within larger phage-derived proteins. Peptide candidates will be filtered by length, charge, hydrophobicity, predicted solubility, and sequence complexity. | 1–2 days | A list of candidate bacteriophage-derived peptide sequences for AI-based screening. |
| Screen peptide candidates using antimicrobial peptide prediction tools. | Peptide sequences will be analyzed using antimicrobial peptide prediction tools such as AMPScanner, AMPlify, iAMPpred, DBAASP-associated tools, or similar models. Candidates will be ranked based on predicted antimicrobial probability. | 1–2 days | A ranked list of peptides with predicted antimicrobial activity. |
| Apply protein language model embeddings for AI-guided prioritization. | Peptide or protein sequences will be encoded using protein language models such as ESM, ProtBERT, or related embedding tools. These embeddings will be used to compare candidate sequences with known antimicrobial peptides and to detect potentially novel candidates. | 2–3 days | A numerical representation of candidates that supports clustering, novelty detection, and prioritization. |
| Perform latent space analysis. | Dimensionality reduction methods such as PCA, UMAP, or t-SNE will be used to visualize candidate peptides in relation to known antimicrobial and non-antimicrobial peptide datasets. Clustering will help identify candidates that are both antimicrobial-like and distinct from well-characterized sequences. | 1–2 days | A visual map showing candidate distribution and novelty. |
| Filter candidates for safety and feasibility. | Candidate peptides will be screened for predicted toxicity, hemolytic potential, allergenicity, and poor physicochemical properties using computational tools where available. Peptides with high predicted toxicity or poor synthesis feasibility will be deprioritized. | 1 day | A safer and more feasible shortlist of candidate peptides. |
| Select Salmonella enterica molecular targets for in silico interaction analysis. | Potential S. enterica targets may include outer membrane proteins, virulence-associated surface proteins, membrane-associated receptors, or conserved envelope-related proteins. The target selection will be based on relevance to pathogenicity, accessibility, and available structural information. | 1–2 days | A defined set of S. enterica target proteins for docking or interaction modeling. |
| Predict peptide structure. | Selected peptide candidates will be modeled using tools such as AlphaFold, ColabFold, PEP-FOLD, or related peptide structure prediction platforms. Structural outputs will be evaluated for confidence, stability, and suitability for interaction modeling. | 1–2 days | Predicted 3D structures for top peptide candidates. |
| Model peptide–target interactions. | Top peptide candidates will be tested against selected S. enterica targets using AlphaFold-Multimer, ColabFold-Multimer, or protein–peptide docking tools. Interaction outputs will be evaluated using confidence metrics, predicted interface contacts, binding orientation, and biological plausibility. | 2–4 days | Identification of peptide candidates with plausible predicted interaction with S. enterica targets. |
| Prioritize final peptide candidates. | A scoring matrix will be created to integrate antimicrobial prediction score, novelty, structural confidence, toxicity filtering, synthesis feasibility, and predicted interaction with S. enterica. The highest-ranked candidate will be selected for synthetic biology design. | 1 day | One to three final peptide candidates selected for construct design. |
| Back-translate the selected peptide into a DNA sequence. | The selected amino acid sequence will be converted into a DNA sequence and codon-optimized for the intended expression system, such as E. coli or a cell-free expression system. | 1 day | A codon-optimized DNA sequence encoding the selected antimicrobial peptide. |
| Design a synthetic expression construct in Benchling. | The construct will include a promoter, ribosome binding site, peptide coding sequence, optional affinity tag, linker if needed, terminator, and cloning or synthesis-compatible flanking regions. Benchling will be used to document the construct architecture. | 1–2 days | A complete synthetic DNA construct ready for future ordering or cloning. |
| Evaluate construct feasibility. | The designed sequence will be checked for GC content, restriction sites, repetitive regions, synthesis complexity, reading frame accuracy, and compatibility with the selected expression system. | 1 day | A validated expression-ready construct design. |
| Generate final data outputs and visualizations. | The final results will include a workflow diagram, candidate ranking table, peptide property table, latent space visualization, structural prediction images, peptide–target interaction model, and final construct map. | 2–3 days | A complete computational and design-based validation package for the final project. |
We discussed and practiced various techniques related to synthetic biology throughout the semester. Place a check next to the techniques relevant to your project.
Foundational Lab Practices
- Pipetting
- Lab Safety
- Bioethical Considerations (must check this box)
DNA Skills & Analysis
- DNA Sequencing
- DNA Editing
- DNA Construct Design
- Restriction Enzyme Digestion
- Gel Electrophoresis
- DNA Purification From Gel
- Databases (e.g., GenBank, NCBI, Ensembl, and UCSC Genome Browser)
Lab Automation
- Creating Code for Laboratory Automation
- Using Liquid Handling Robots (e.g., Opentrons)
- Designing a Twist Order
- Creating a plan to use the Autonomous lab at Ginkgo Bioworks
Protein Design
- Protein Design
- Use of Boltz or PepMLM
- Use of Asimov Kernel
- Use of Benchling
- Models and Notebooks
- Databases
Bioproduction
- Bioproduction
- Chassis Selection (e.g., DH5alpha)
- Registry of Standard Biological Parts
- Plasmid Preparation
- Bacterial Culturing
- Quality Control/Analysis
- Bacterial Processing (e.g., Centrifugation, Lysis, DNA Purification)
Cell-Free Systems
- Cell Free Reactions
- Freeze-Dried Cell Free Systems
- miniPCR Tools
- Protein Purification
Gibson Assembly
- Primer Design or Selection
- PCR Reactions
- Gibson Assembly
- Other Cloning Methods (e.g., Restriction Enzyme Digestion or Gateway Cloning)
CRISPR
- CRISPR/Cas9
- Designing Prime Editing gRNA
I would expand on DNA Construct Design and Protein Design as both are central to my final project.
For DNA construct design, I would take the prioritized phage-derived candidate, such as the CwlA-like endolysin identified from the wastewater metagenomic data, and convert its amino acid sequence into a codon-optimized DNA sequence suitable for future expression. This DNA sequence would then be incorporated into a synthetic expression cassette containing a promoter, ribosome binding site, purification tag, coding sequence, and terminator, such as pTac → RBS → 6xHis–Candidate → L3S2P24 terminator. This step connects the computational discovery phase with synthetic biology implementation by turning a predicted antimicrobial protein into a buildable genetic design.
For protein design, I would evaluate the selected candidate using bioinformatic and structural prediction tools before deciding whether it is suitable for expression and downstream testing. This would include analyzing conserved domains, physicochemical properties, predicted structure, and possible antimicrobial activity. In my project, this technique helps prioritize candidates that are not only biologically interesting but also more likely to fold properly, remain stable, and function as phage-derived antimicrobial proteins. Together, these techniques allow the project to move from metagenomic sequence discovery toward a realistic synthetic biology workflow for future anti-Salmonella enterica applications.
SECTION 5: RESULTS & QUANTITATIVE EXPECTATIONS
- You are required to validate at least one aspect of your final project aims.
I chose to validate the computational-to-design portion of my final project by identifying and prioritizing a phage-derived antimicrobial protein candidate from healthcare wastewater metagenomic data. Specifically, I validated whether quality-filtered viral contigs could be annotated to recover candidate phage proteins, confirm a biologically relevant lytic domain, and translate one selected candidate into a synthetic biology expression construct.
1.1 I began with healthcare wastewater metagenomic viral contigs obtained from the available dataset.
1.2 I used CheckV to evaluate viral contig quality and filtered the dataset to prioritize high-quality and medium-quality viral contigs.
1.3 From this quality-control step, I selected the best viral contigs for downstream annotation, reducing the analysis of low-confidence viral fragments.
1.4 I annotated the selected contigs using Pharokka, which generated GenBank and GFF outputs containing predicted viral coding sequences.
1.5 I screened the Pharokka annotation manually for candidate proteins related to bacterial lysis, especially endolysin-like proteins, and also included one hypothetical protein as an exploratory novelty candidate.
1.6 I extracted candidate information including CDS ID, contig, product annotation, predicted function, PHROG annotation, amino acid sequence, and approximate protein length.
1.7 I selected one promising candidate and analyzed its sequence using NCBI Conserved Domain Search.
1.8 The conserved domain analysis identified a CwlA superfamily domain, described as an N-acetylmuramoyl-L-alanine amidase, with an E-value of 1.07e-22.
1.9 This result supported the interpretation that the candidate may function as a phage-derived cell wall hydrolase or endolysin-like protein.
1.10 I then used AlphaFold/ColabFold to generate a predicted 3D structure of the selected candidate and evaluate whether the protein contained structured regions suitable for further analysis.
1.11 Finally, I designed a synthetic expression construct for future validation of the candidate.
1.12 The proposed construct was: pTac → RBS → 6xHis–CwlA-like candidate → L3S2P24 terminator.
1.13 This construct connects the computational discovery workflow with a synthetic biology implementation strategy for future expression and testing.
I utilized DNA construct design as the main synthetic biology technique to validate the implementation potential of my project. After selecting a CwlA-like phage endolysin candidate, I designed a modular expression cassette containing an inducible promoter, ribosome binding site, purification tag, coding sequence, and bacterial terminator. This design allows the candidate protein to be expressed in a controlled way in a future bacterial or cell-free expression system. I also used protein design and computational modeling by evaluating the candidate’s conserved domain, predicted structure, and suitability for downstream expression. Together, these techniques show how metagenomic discovery can be connected to a buildable synthetic biology design.
The main data generated in this validation include the CheckV quality-control output, Pharokka annotation results, conserved domain analysis, and AlphaFold structural prediction. CheckV allowed me to prioritize high- and medium-quality viral contigs before annotation, while Pharokka identified viral coding sequences from those contigs. The strongest candidate showed a CwlA superfamily domain with an E-value of 1.07e-22, which strongly supports its predicted role as a cell wall amidase or endolysin-like protein. This result is relevant because CwlA-like amidases are associated with peptidoglycan degradation, making the candidate biologically plausible for future anti-Salmonella enterica applications. The AlphaFold model further supported that the candidate contains structured regions, although experimental validation would still be required to confirm activity.
Figure 1. Quality control of viral contigs using CheckV.
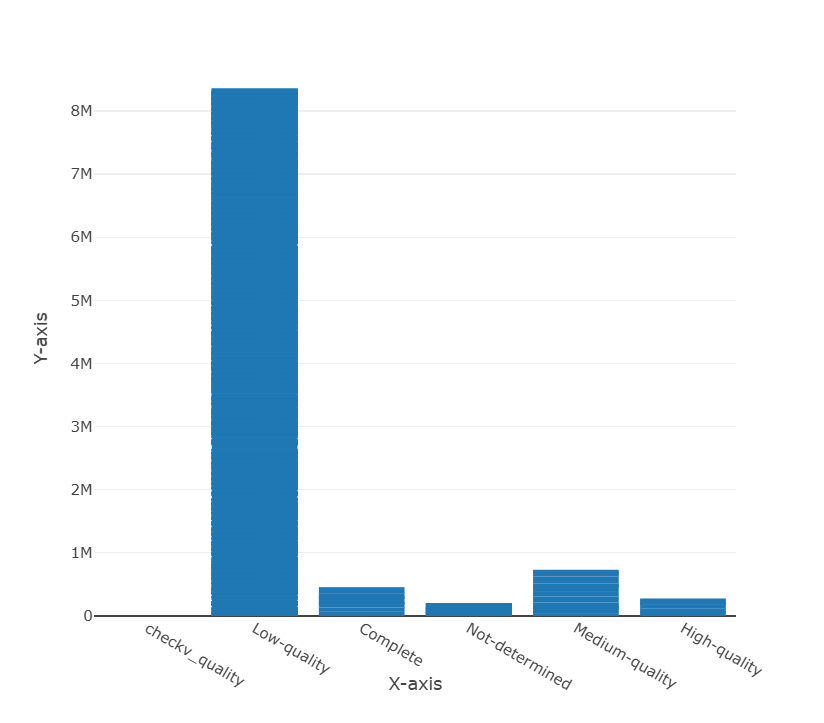
Note. Viral contigs were classified by quality category, and high- and medium-quality contigs were prioritized for downstream Pharokka annotation.
- Did you encounter any unexpected challenge(s) when performing your validation? If so, describe the challenge(s) and strategies to overcome it. If not, discuss potential problems, difficulties, limitations, and/or alternative strategies to overcome challenges in your final project. (min. 4 sentences).
During the validation, one unexpected challenge was that the viral metagenomic data contained many low-quality or fragmented contigs, which could have led to unreliable annotation and false candidate selection. To overcome this, I filtered the viral contigs using CheckV and focused only on high- and medium-quality contigs before running Pharokka. Another challenge was that Pharokka annotated many CDSs as “hypothetical protein” or “unknown function,” so I could not rely only on the initial annotation to select candidates. To address this, I used conserved domain analysis with NCBI CDD, which allowed me to identify a CwlA-like N-acetylmuramoyl-L-alanine amidase domain in one candidate and support its possible role as an endolysin-like protein.
A second limitation was that structural modeling could not fully validate antimicrobial activity. AlphaFold/ColabFold can predict whether the candidate has structured regions, but it does not experimentally prove that the protein will bind or degrade the Salmonella enterica cell wall. In addition, because the expected biological target of a CwlA-like amidase is peptidoglycan rather than a single protein receptor, protein–protein docking may not fully represent the real mechanism of action. In future work, this limitation could be addressed by combining structural prediction with molecular docking against peptidoglycan-like fragments, recombinant expression, protein purification, and antimicrobial activity assays against S. enterica.
References
Petrovich, M. L., Zilberman, A., Kaplan, A., Eliraz, G. R., Wang, Y., Langenfeld, K., Duhaime, M., Wigginton, K., Poretsky, R., Avisar, D., & Wells, G. F. (2020). Microbial and Viral Communities and Their Antibiotic Resistance Genes Throughout a Hospital Wastewater Treatment System. Frontiers In Microbiology, 11, 153. https://doi.org/10.3389/fmicb.2020.00153
Santos-Júnior, C. D., Torres, M. D., Duan, Y., Del Río, Á. R., Schmidt, T. S., Chong, H., Fullam, A., Kuhn, M., Zhu, C., Houseman, A., Somborski, J., Vines, A., Zhao, X., Bork, P., Huerta-Cepas, J., De la Fuente-Nunez, C., & Coelho, L. P. (2024). Discovery of antimicrobial peptides in the global microbiome with machine learning. Cell, 187(14), 3761-3778.e16. https://doi.org/10.1016/j.cell.2024.05.013
Strange, J. E. S., Leekitcharoenphon, P., Møller, F. D., & Aarestrup, F. M. (2021). Metagenomics analysis of bacteriophages and antimicrobial resistance from global urban sewage. Scientific Reports, 11(1), 1600. https://doi.org/10.1038/s41598-021-80990-6
Supply List and Budget
Minimum version: computational validation completed in this project
Computer or laptop (already available)
Needed for sequence handling, annotation review, and figure preparation
Estimated cost: $0 if already available
Internet access
Required to access Galaxy, NCBI, Benchling, AlphaFold/ColabFold, and databases
Estimated cost: $0–$20
Public healthcare wastewater metagenomic dataset or simulated data
Used as the input for viral contig identification and downstream annotation
Estimated cost: $0
Galaxy platform
Used for CheckV filtering, sequence processing, and Pharokka annotation
Estimated cost: $0
CheckV
Used to evaluate viral contig quality and select high- and medium-quality contigs
Estimated cost: $0
Pharokka
Used to annotate viral/phage-associated open reading frames
Estimated cost: $0
NCBI Conserved Domain Search / BLASTp
Used to identify conserved domains and compare candidates with known proteins
Estimated cost: $0
ExPASy ProtParam
Used to calculate physicochemical properties such as molecular weight, pI, and stability index
Estimated cost: $0
AlphaFold / ColabFold
Used for predicted 3D structural modeling of the selected candidate
Estimated cost: $0 if using free access
Benchling
Used to design the synthetic DNA expression construct
Estimated cost: $0 for academic/free use
Estimated minimum project cost
$0–$20, assuming public datasets and free academic bioinformatics platforms are used.
Full future experimental version
Environmental sample collection supplies
Sterile bottles, tubes, gloves, labels, coolers, sampling bags
Estimated cost: $100–$300
DNA extraction kit for wastewater or environmental samples
Needed to extract metagenomic DNA from healthcare-associated wastewater
Estimated cost: $400–$700
DNA quantification supplies
Qubit reagents, Nanodrop access, or equivalent DNA quantification tools
Estimated cost: $100–$400 if instrument access is available
Agarose gel electrophoresis supplies
Agarose, buffer, DNA stain, ladder, gel documentation access
Estimated cost: $100–$300
Metagenomic library preparation and sequencing
Shotgun metagenomic sequencing using Illumina or equivalent platform
Estimated cost: $800–$2,500+, depending on number of samples and sequencing depth
Synthetic DNA / gene fragment order
Codon-optimized DNA sequence encoding the selected candidate
Estimated cost: $150–$500 per construct
Plasmid backbone and cloning reagents
Vector, assembly reagents, competent cells, selection materials
Estimated cost: $300–$800
Protein expression supplies
Expression host or cell-free expression system, media or reaction mix, induction/control reagents
Estimated cost: $300–$1,500
Protein purification supplies
His-tag purification resin or columns, buffers, concentrators
Estimated cost: $300–$1,000
Protein analysis supplies
SDS-PAGE gels/reagents, protein ladder, staining reagents
Estimated cost: $150–$500
Antimicrobial activity validation
Only under institutional biosafety approval, using approved strains or safe surrogate organisms
Microplates, media, controls, and growth measurement access
Estimated cost: $200–$800
Biosafety and waste management supplies
PPE, disinfectants, biohazard disposal, approved containment materials
Estimated cost: $100–$500
Estimated full experimental budget
Low-cost pilot version: approximately $2,500–$5,000
More complete experimental validation: approximately $5,000–$10,000+