First, describe a biological engineering application or tool you want to develop and why. This could be inspired by an idea for your HTGAA class project and/or something for which you are already doing in your research, or something you are just curious about.
This project focuses on developing a wearable biosensor patch designed to detect early signs of muscle stress and overload in athletes. The patch would be worn on the skin over active muscle groups and would monitor biochemical markers present in sweat or interstitial fluid, such as lactate, pH changes, or inflammation-related molecules.
Python Script for Opentrons Artwork Generate an artistic design using the GUI at opentrons-art.rcdonovan.com. Here is my design with opentrons-art.rcdonovan.com.
opentrons-art.rcdonovan.com/?id=l061355i5d3bc5n
Using the coordinates from the GUI, follow the instructions in the HTGAA26 Opentrons Colab to write your own Python script which draws your design using the Opentrons. Here is my script from Google Colab:
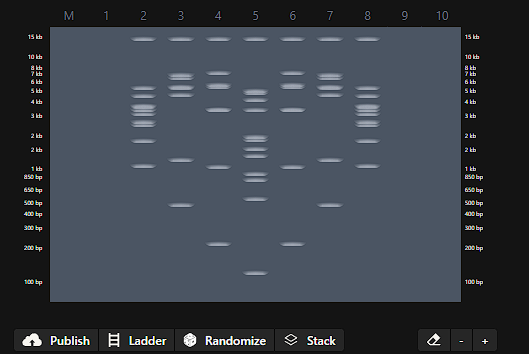
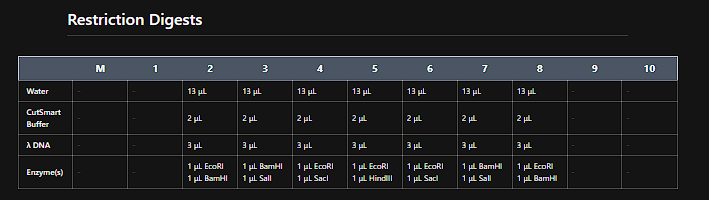
Part 1: Benchling & In-silico Gel Art I created an account in benchling and before playing with the digestion tool, I looked up Ronan’s website to get inspired by his designs, at the end I saw a pattern to make a heart.
I use the following enzymes:
Then I went to benchilng and do the same pattern, but seems that the fragment of aprox. 100 pb is not shown in the virtual digestion.
Subsections of Homework
Week 1 HW: Principles and Practices
First, describe a biological engineering application or tool you want to develop and why. This could be inspired by an idea for your HTGAA class project and/or something for which you are already doing in your research, or something you are just curious about.
This project focuses on developing a wearable biosensor patch designed to detect early signs of muscle stress and overload in athletes. The patch would be worn on the skin over active muscle groups and would monitor biochemical markers present in sweat or interstitial fluid, such as lactate, pH changes, or inflammation-related molecules.
Wearable biosensors for monitoring physiological biomarkers during exercise are an active and rapidly growing area of research. In particular, lactate and pH levels in sweat have been shown to correlate with exercise intensity and muscle fatigue, making them useful indicators of muscle stress (Yang et al., 2024; Shen et al., 2022). Recent studies have demonstrated flexible, skin-mounted patches capable of continuously measuring these biomarkers during physical activity (Xuan et al., 2021).
The sensing mechanism of the proposed patch would rely on using genetic circuits embedded in a cell-free system rather than living engineered organisms. Cell-free biosensors are increasingly recognized as a safe and flexible platform for biological sensing, as they eliminate risks associated with replication or environmental release while maintaining high sensitivity (Zhang et al., 2020; Wang & Lu, 2022). Similar approaches have already been demonstrated in wearable materials embedded with synthetic biology sensors, supporting the feasibility of this design strategy (Nguyen et al., 2021). These biological components would be integrated into a soft, biocompatible, and potentially biodegradable material suitable for prolonged skin contact.
Many muscle injuries occur because physiological stress accumulates before pain or visible symptoms appear. The motivation for this application is rooted in injury prevention. Current diagnostic methods are often invasive, expensive, or retrospective. A non-invasive, real-time monitoring tool could help athletes and clinicians make better training and recovery decisions, supporting long-term health and performance.
Next, describe one or more governance/policy goals related to ensuring that this application or tool contributes to an “ethical” future, like ensuring non-malfeasance (preventing harm). Break big goals down into two or more specific sub-goals. Below is one example framework (developed in the context of synthetic genomics) you can choose to use or adapt, or you can develop your own. The example was developed to consider policy goals of ensuring safety and security, alongside other goals, like promoting constructive uses, but you could propose other goals for example, those relating to equity or autonomy.
The main governance goal is to ensure that this technology contributes to an ethical and beneficial future, prioritizing athlete health, safety, and autonomy while minimizing biological, environmental, and social risks.
Biosecurity: By relying on cell-free synthetic biology systems, the patch avoids the use of living genetically modified organisms, significantly reducing biosecurity concerns. Clear system behavior and visible outputs allow potential malfunctions to be identified quickly.
Environmental friendly: The use of sealed biological components and biodegradable materials limits environmental exposure. Safe disposal procedures reduce the risk of environmental contamination.
Next, describe at least three different potential governance “actions” by considering the four aspects below (Purpose, Design, Assumptions, Risks of Failure & “Success”). Try to outline a mix of actions (e.g. a new requirement/rule, incentive, or technical strategy) pursued by different “actors” (e.g. academic researchers, companies, federal regulators, law enforcement, etc). Draw upon your existing knowledge and a little additional digging, and feel free to use analogies to other domains (e.g. 3D printing, drones, financial systems, etc.).
1. Governance ActionActors: Academic researchers and biotechnology developers
Purpose: This action focuses on reducing risk directly through technical design rather than relying solely on external regulation.
Design: The biosensor patch would use non-replicating, cell-free biological components, physically sealed within the biomaterial.
Assumptions: This approach assumes that technical safeguards would reduce risk and that developers are willing to prioritize safety even when it increases development costs.
Risk of failure and success: Higher costs could limit accessibility, and strong safety-by-design approaches could lead to overconfidence and reduced oversight.
2. Governance ActionActors: Sports federations (Sports minister)
Purpose: This option aims to prevent misuse of the technology, such as coercive monitoring or excessive performance pressure.
Design: Guidelines would restrict use to health and injury prevention, require informed consent.
Assumptions: It assumes that institutions will enforce these guidelines and that athletes are able to provide meaningful consent.
Risk of failure and success: Enforcement may vary across organizations and countries, and guidelines may lag behind technological developments or the person in charge of the regulatory agency.
3. Governance ActionActors: Universities, public funding agencies
Purpose: Encourage constructive and equitable applications of the technology.
Design: Public funding and institutional support could be tied to safety standards, open technical approaches, and affordability, helping extend benefits beyond elite sports contexts.
Assumptions: Incentives influence research priorities and promote socially beneficial outcomes.
Risk of failure and success: Increased administrative requirements may reduce private-sector participation.
Next, score (from 1-3 with, 1 as the best, or n/a) each of your governance actions against your rubric of policy goals. The following is one framework but feel free to make your own:
Does the option:
Option 1
Option 2
Option 3
Enhance Biosecurity
• By preventing incidents
1
2
2
• By helping respond
1
2
2
Foster Lab Safety
• By preventing incident
1
2
2
• By helping respond
Protect the environment
• By preventing incidents
1
2
2
• By helping respond
Other considerations
• Minimizing costs and burdens to stakeholders
2
3
2
• Feasibility?
1
2
2
• Not impede research
1
2
1
• Promote constructive applications
1
1
1
Last, drawing upon this scoring, describe which governance option, or combination of options, you would prioritize, and why. Outline any trade-offs you considered as well as assumptions and uncertainties.
Based on the table above, the most effective governance approach combines option 1 with option 3. But it would be useful to use the ethical guidelines from option 2 to support the idea.
Integrating security into the technology reduces biological and environmental risks before deployment, while incentive-based strategies promote accessibility and socially beneficial uses. Ethical guidelines protect its misuse.
References
Nguyen, P. Q., Soenksen, L. R., Donghia, N. M., Angenent-Mari, N. M., de Puig, H., Huang, A., Lee, R., Slomovic, S., Galbersanini, T., Lansberry, G., Sallum, H. M., Zhao, E. M., Niemi, J. B., & Collins, J. J. (2021). Wearable materials with embedded synthetic biology sensors for biomolecule detection. Nature biotechnology, 39(11), 1366–1374. https://doi.org/10.1038/s41587-021-00950-3
Shen, Y., Liu, C., He, H., Zhang, M., Wang, H., Ji, K., Wei, L., Mao, X., Sun, R., & Zhou, F. (2022). Recent Advances in Wearable Biosensors for Non-Invasive Detection of Human Lactate. Biosensors, 12(12), 1164. https://doi.org/10.3390/bios12121164
Wang, T., & Lu, Y. (2022). Advances, Challenges and Future Trends of Cell-Free Transcription-Translation Biosensors. Biosensors, 12(5), 318. https://doi.org/10.3390/bios12050318
Xuan, X., Pérez-Ràfols, C., Chen, C., Cuartero, M. and Crespo, G. (2021). Lactate biosensing for reliable on-body sweat analysis. ACS Sensors. 6 (7), 2763-277. DOI: 10.1021/acssensors.1c01009
Yang, G., Hong, J., & Park, S. B. (2024). Wearable device for continuous sweat lactate monitoring in sports: a narrative review. Frontiers in physiology, 15, 1376801. https://doi.org/10.3389/fphys.2024.1376801
Zhang, L., Guo, W., & Lu, Y. (2020). Advances in Cell-Free Biosensors: Principle, Mechanism, and Applications. Biotechnology journal, 15(9), e2000187. https://doi.org/10.1002/biot.202000187
Week 2 Lecture Prep
Homework Questions from Professor Jacobson: 1. Nature’s machinery for copying DNA is called polymerase. What is the error rate of polymerase? How does this compare to the length of the human genome. How does biology deal with that discrepancy?
DNA polymerase with proofreading has an error rate of about 10⁻⁶ mistake per base pairs copied. Comparing to the size of the human genome, which is roughly 3.2 billion base pairs long, at that error rate, thousands of mistakes would be introduced every time a human genome is replicated. This discrepancy is solved by its proofreading 3’ – 5’ activity that removes misincorporated bases as replication occurs, and any remaining errors are further corrected by post-replication DNA repair systems such as mismatch repair.
2. How many different ways are there to code (DNA nucleotide code) for an average human protein? In practice what are some of the reasons that all of these different codes don’t work to code for the protein of interest?
An average human protein is encoded by about 1,036 base pairs, and because most amino acids are specified by multiple synonymous codons, the same protein sequence can be written in an huge number of different nucleotide combinations. In practice, however, only a small fraction of these sequences work well in living cells, and each organism have preferred codons in order to produce a successful protein. Many synonymous DNA sequences form problematic secondary structures, especially those with extreme GC content, which can interfere with transcription and translation. Others use rare codons that slow translation, or accidentally introduce regulatory signals that disrupt expression. As a result, although the genetic code is highly redundant in theory, biological and physical constraints drastically limit which DNA sequences can successfully produce a functional protein.
Homework Questions from Dr. LeProust: 1. What’s the most commonly used method for oligo synthesis currently?
The most commonly used method is solid-phase phosphoramidite synthesis. DNA is built one nucleotide at a time on a solid support through repeated chemical cycles.
2. Why is it difficult to make oligos longer than 200nt via direct synthesis?
Each step in chemical DNA synthesis has a small chance of error. As the oligo gets longer, these small errors add up, leading to lots of truncated or incorrect sequences. Beyond ~200 nucleotides, the yield and accuracy of full-length oligos drop sharply, and purification becomes much harder
3. Why can’t you make a 2000bp gene via direct oligo synthesis?
A 2000 bp gene would require thousands of chemical synthesis steps, which would result in extremely low yields and very high error rates. Because of this, long genes are not made directly. Instead, they are assembled from shorter, synthesized oligos or fragments using enzymatic methods, followed by sequence verification
Homework Question from George Church: 1. What are the 10 essential amino acids in all animals and how does this affect your view of the “Lysine Contingency”?
The 10 essential amino acids in animals are His, Ile, Leu, Lys, Met, Phe, Thr, Trp, Val, and Arg (often conditionally essential). Lysine’s strict essentiality and central role in protein–DNA interactions support the idea of a real “lysine contingency,” where growth and regulation are limited by lysine availability.
Week 3 Lab Automation
Python Script for Opentrons Artwork
Generate an artistic design using the GUI at opentrons-art.rcdonovan.com.
Here is my design with opentrons-art.rcdonovan.com.
opentrons-art.rcdonovan.com/?id=l061355i5d3bc5n
Using the coordinates from the GUI, follow the instructions in the HTGAA26 Opentrons Colab to write your own Python script which draws your design using the Opentrons.
I used chat gpt to help me coding the script to produce my design.
Post-Lab Questions
Find and describe a published paper that utilizes the Opentrons or an automation tool to achieve novel biological applications.
The paper I found is: AssemblyTron: flexible automation of DNA assembly with Opentrons OT-2 lab robots.
What is this paper about?
This paper presents an open-soruce Python package that integrates j5 DNA design outputs with the Opentrons OT-2 to automate DNA assembly workflows. The system performs optimized PCR, Golden Gate, and homology-based assemblies with minimal human intervention. AssemblyTron reduces human error in the Build step of the Design–Build–Test–Learn (DBTL) cycle. The authors demonstrate comparable fidelity and transformation efficiency to manual cloning. This work makes automated molecular cloning more accessible and affordable for academic laboratories.
Write a description about what you intend to do with automation tools for your final project. You may include example pseudocode, Python scripts, 3D printed holders, a plan for how to use Ginkgo Nebula, and more. You may reference this week’s recitation slide deck for lab automation details.
While your description/project idea doesn’t need to be set in stone, we would like to see core details of what you would automate. This is due at the start of lecture and does not need to be tested on the Opentrons yet.
I would like to design and optimize a synthetic transcriptional biosensor that detects inglammatory biomakers, another idea was using as well a biosensor as a patch to detects muscle stress, both using cell free gene circuit. For either idea automation is necessary to enable high-throughput DNA assembly, standardized reaction set up, reproducible cell free expression assays, and measurment of circuit performance.
Week 4 Protein Design Part I
Week 2 DNA Read, Write, & Edit
Part 1: Benchling & In-silico Gel Art
I created an account in benchling and before playing with the digestion tool, I looked up Ronan’s website to get inspired by his designs, at the end I saw a pattern to make a heart.
I use the following enzymes:
Then I went to benchilng and do the same pattern, but seems that the fragment of aprox. 100 pb is not shown in the virtual digestion.
Part 3: DNA Design Challenge
In recitation, we discussed that you will pick a protein for your homework that you find interesting. Which protein have you chosen and why?
I chose p53 because I like its role in live (Tumor suppression, apoptosis). I remember well this protein from my classes of molecular biology and recombinant DNA. Also I love its nickname “guardian of the genome”.
Once a nucleotide sequence of your protein is determined, you need to codon optimize your sequence. You may, once again, utilize google for a “codon optimization tool”. In your own words, describe why you need to optimize codon usage. Which organism have you chosen to optimize the codon sequence for and why?
I know the genetic code is degenerated, so there are multiple codons combinations that can encode the same amino acid. But here is the trick, each organism has their own preferences for codons combinations, so for example if I want to express a human protein in a bacteria but its sequence is for the human and not for the bacteria, then the expression of the protein would not be as effective as if the sequence is encoded for that bacteria. The optimization of the codons for each organism improves mostly in translation efficiency.
I chose E. coli K-12, because it is widely used for recombinant protein expression (it grows quickly, it is inexpensive, non-pathogenic, stable and reduced genome)
p53 DNA sequence with Codon-Optimization for E. coli K-12
What technologies could be used to produce this protein from your DNA? Describe in your words the DNA sequence can be transcribed and translated into your protein. You may describe either cell-dependent or cell-free methods, or both.
I know cell dependent method, basically insert the optimized sequence into a plasmid (expression vector), transform the bacteria (introduce this plasmid in E. coli cells) and then culture the bacteria in a medium with an antibiotic to only get my transform bacteria.
3.5. [Optional] How does it work in nature/biological systems?
Describe how a single gene codes for multiple proteins at the transcriptional level.
This is all thanks to the alternative splicing, wich can produce multiple proteins by including o exluding diferent exons of the gen to produce the mRNA.
So from the same gene, it can be produce multiple isoforms of the protein.
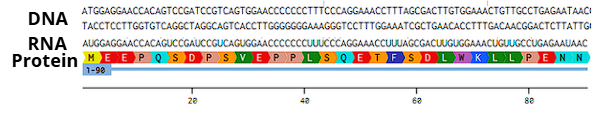
Try aligning the DNA sequence, the transcribed RNA, and also the resulting translated Protein!!! See example below.
Part 4: Prepare a Twist DNA Synthesis Order
4.1. Create a Twist account and a Benchling account
(i) What DNA would you want to sequence (e.g., read) and why? This could be DNA related to human health (e.g. genes related to disease research), environmental monitoring (e.g., sewage waste water, biodiversity analysis), and beyond (e.g. DNA data storage, biobank).
Since 2025 I’ve been working with rare genetic diseases, so probably I would choose a Cystic fibrosis or PKU (Phenylketonuria). I remembered the first time when i analyze a WES for a patient and the suspense of finding a pathogenic mutation or not.
(ii) In lecture, a variety of sequencing technologies were mentioned. What technology or technologies would you use to perform sequencing on your DNA and why?
Also answer the following questions:
We work with Illumina sequencing, wich is short-read and high accuracy, this technology is ideal for our work, because we need high accuracy in order to detect mutations.
Is your method first-, second- or third-generation or other? How so?
Illumina is a second generation (short reads, sequencing by synthesis)
What is your input? How do you prepare your input (e.g. fragmentation, adapter ligation, PCR)? List the essential steps.
The input is the patient’s extracted DNA. We send it to companies to do the sequencing, but what happens is that they prepare the libraries (add the adapters, barcodes) with the samples and then sequence it.
What are the essential steps of your chosen sequencing technology, how does it decode the bases of your DNA sample (base calling)?
Adapters+DNA binds to the flow cell, then occurs these bridges amplification, wich creates clusters. After that fluorescently labeled reversible terminator nucleotides are added. Then is data collecion where imaging detects incorporated base. And finally, fluorophore is removed, let the next cycle start. The base calling is by de fluorescense color, each base has an specific color.
What is the output of your chosen sequencing technology?
Fastq files that contains the sequence reads plus the quality score of the sequencing.
5.2 DNA Write
(i) What DNA would you want to synthesize (e.g., write) and why? These could be individual genes, clusters of genes or genetic circuits, whole genomes, and beyond. As described in class thus far, applications could range from therapeutics and drug discovery (e.g., mRNA vaccines and therapies) to novel biomaterials (e.g. structural proteins), to sensors (e.g., genetic circuits for sensing and responding to inflammation, environmental stimuli, etc.), to art (DNA origamis). If possible, include the specific genetic sequence(s) of what you would like to synthesize! You will have the opportunity to actually have Twist synthesize these DNA constructs! :)
I would like to synthesize a CRISPR-based genetic construct designed to selectively eliminate antibiotic-resistant bacteria by targeting resistance genes. I think it is a would project to work on and also would be good for the war against antimicrobial resistance.
(ii) What technology or technologies would you use to perform this DNA synthesis and why?
I would use Gibson Assembly, because allows joining of multiple DNA fragments in one reaction.
Also answer the following questions:
What are the essential steps of your chosen sequencing methods?
The fargment desing, DNA fragment amplification, Gibson Assembly reaction, transformation of the plasmid into a competent bacteria, verify the trasnformation in the bacteria by PCR.
What are the limitations of your sequencing method (if any) in terms of speed, accuracy, scalability?
There can be a lot of problems with the design, also the size of the constructs (if it is very large the efficiency decreases)
5.3 DNA Edit
(i) What DNA would you want to edit and why? In class, George shared a variety of ways to edit the genes and genomes of humans and other organisms. Such DNA editing technologies have profound implications for human health, development, and even human longevity and human augmentation. DNA editing is also already commonly leveraged for flora and fauna, for example in nature conservation efforts, (animal/plant restoration, de-extinction), or in agriculture (e.g. plant breeding, nitrogen fixation). What kinds of edits might you want to make to DNA (e.g., human genomes and beyond) and why?
I would focus on human somatic editing in order to correct mutations, in this case for PKU, I would like to edit PAH gene.
(ii) What technology or technologies would you use to perform these DNA edits and why?
Also answer the following questions:
Base editing, I think is more effective than CRISPR-Cas9, and in this disease that usually pathogenic mutations are SNPs.
How does your technology of choice edit DNA? What are the essential steps?
I would use a Cytosine Base Editor (like pin-point). It basically change a cystosine for a uracil, and then after the DNA is repaired this U will be read as T.
The essential steps are:
a. gRNA directs Cas9 to the target DNA
b. Cas9 bind to the DNA and modifies the base (using a deaminase enzyme)
c. Cellular DNA repair machinery resolves the mismatch and the change becomes permanent.
What preparation do you need to do (e.g. design steps) and what is the input (e.g. DNA template, enzymes, plasmids, primers, guides, cells) for the editing?
First of all, indetify the SNP or mutation, then desing the gRNA for the position of the mutation.
The inputs would be the Base editor, gRNA, a delivery vehicle as LNPs, and then work ex vivo with patient stem cells.
What are the limitations of your editing methods (if any) in terms of efficiency or precision?
Base editing is limited by the conversion that it has, like C to T or A to G. Also the off target deamination or breaks, usually because the interaction between the gRNA and the DNA is not perfectly specific.