Week 02 HW
HW.1: Benchling & In-silico Gel Art
- Make a free account at benchling.com, Import the Lambda DNA.
- Simulate Restriction Enzyme Digestion with the following Enzymes: EcoRI HindIII BamHI KpnI EcoRV SacI SalI
- Create a pattern/image in the style of Paul Vanouse’s Latent Figure Protocol artworks.
Benchling screenshots.
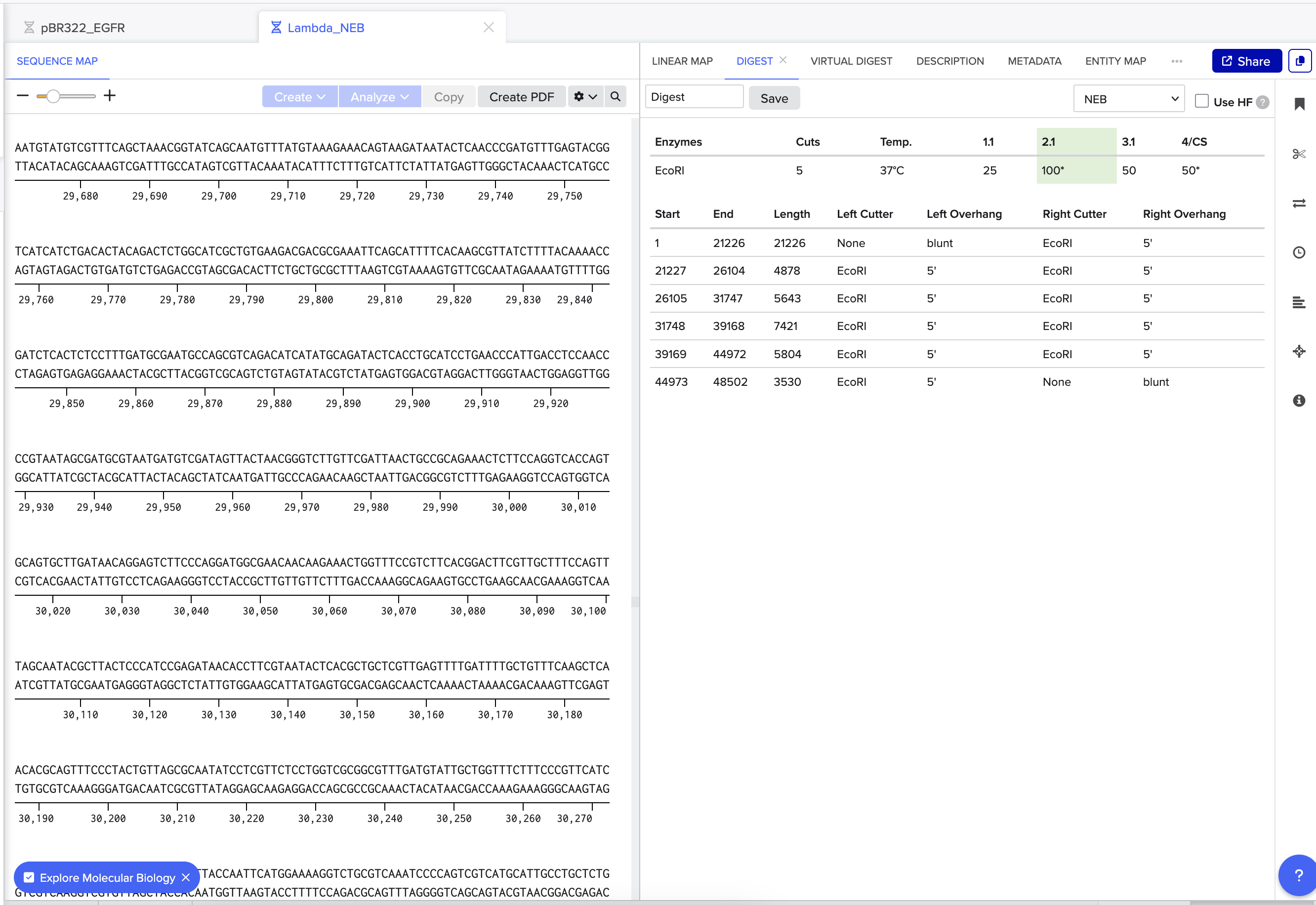
Experimental design for Gel art.
HW.2: Gel Art - Restriction Digests and Gel Electrophoresis
In the wet-lab perform the lab experiment you designed in Part 1 and outlined in this week’s lab protocol “Gel Art: Restriction Digests and Gel Electrophoresis”.
N/A - no access to BioClub Tokyo Lab.
HW.3: DNA Design Challenge
3.1. Choose your protein.
In recitation, we discussed that you will pick a protein for your homework that you find interesting. Which protein have you chosen and why? Using one of the tools described in recitation (NCBI, UniProt, google), obtain the protein sequence for the protein you chose.
Miraculin - https://rest.uniprot.org/uniprotkb/P13087.fasta https://rest.uniprot.org/uniprotkb/P13087.txt
3.2. Reverse Translate: Protein (amino acid) sequence to DNA (nucleotide) sequence.
Using https://www.bioinformatics.org/sms2/rev_trans.html:
3.3. Codon optimization.
Describe why you need to optimize codon usage. Which organism have you chosen to optimize the codon sequence for and why?
Proteins are translated from mRNA by tRNA’s. The tRNA’s “pair” with codons from the mRNA. A codon is a 3-base sequence which is then mapped onto a single amino acid. As we covered last week, there are 64 different codons (permutations of a string of 3 nuceleotide bases) which map down to only 20 amino acids. The degeneracy means we can swap out parts of the DNA/mRNA to express the same amino acids aka proteins. Why would we do this? Because mRNA codons are translated into amino acids by the available tRNA in the organism. Each tRNA matches a codon (or several synonymous codons, see wobble pairing at 3rd base). There is not a uniform concentration of tRNA for all codons. So some mRNA codons will translate more efficiently than others, because there is more tRNA.
To restate:
- DNA encodes triplet codons.
- mRNA is transcribed from DNA.
- Ribosomes read mRNA in triplets.
- tRNAs carrying amino acids base-pair with codons (binding with the tRNA’s complementary anticodon)
- Translation rate is approximately proportional to local charged tRNA abundance and ribosomal processivity.
Multiple codons encode the same amino acid, yet different organisms use these synonymous codons at different frequencies (codon usage bias). If a gene from organism A is expressed in organism B without modification, the codon distribution may not match the tRNA pool of B.
You need to optimize codon usage in order to achieve (good) yields from your biomanufacturing process.
I choose Escherichia coli (E. coli) as the target host for optimization:
- Takes less time
- Cell division is faster
- Well established protocols to isolate plasmid
- Each cell has single chromosome
- Single circular plasmid
- Each replicated cell has exact copy of DNA
- Easy method
3.4. You have a sequence! Now what?
What technologies could be used to produce this protein from your DNA? Describe in your words how the DNA sequence can be transcribed and translated into your protein. You may describe either cell-dependent or cell-free methods, or both.
Recombinant expression in a host organism like E. Coli.
- Clone the coding sequence into an expression vector (a plasmid).
- Promoter - T7 under lac control: binds the RNA polymerase
- Ribosome binding site - Shine–Dalgarno AGGAGG: recruits ribosome
- Coding sequence - see Miraculin DNA sequence above.
- Terminator - hairpin-forming sequence: stops transcription
- Antibiotic resistance gene - ampR: for selection of culture
- Transform into E. Coli (transform the plasmid into host cells.)
- Bacteria are given a heat shock.
- Colonies grow.
- Pick colonies.
- Plate on ampicillin → only plasmid-containing cells survive.
- Inoculate the liquid cultures (by introducing single colonies)
- Induce expression (e.g., add IPTG if T7/lac system).
- T7 RNA polymerase binds promoter
- DNA is transcribed into mRNA
- Ribosome binds RBS on mRNA.
- tRNA translates into protein, stop at terminator.
- tRNAs decode codons
- Amino acids polymerize into polypeptide
- Harvest. Cells are lysed. Protein is purified.
- Lyse cells (sonication or chemical lysis).
- Purify protein (e.g., His-tag + Ni-NTA affinity column).
Apparently E. coli is possible but non-ideal for a cysteine-rich, glycosylated plant secreted protein like miraculin.
3.5. [Optional] How does it work in nature/biological systems?
Describe how a single gene codes for multiple proteins at the transcriptional level. Try aligning the DNA sequence, the transcribed RNA, and also the resulting translated Protein!!! See example below.
HW.4: Twist DNA Synthesis Order
Steps to build a plasmid:
- Import DNA into Benchling.
- Add promoter, RBS, start/stop codons, 7x His Tag, and terminator
- Export .fasta and import into Twist.
- Order Twist clonal gene, using pTwist Amp High Copy vector.
- Export .gb (genbank) file for plasmid.
- Import plasmid .gb file into Benchling, open Info>Toplogy and set Circular.
HW.5: DNA Read/Write/Edit
DNA Read
(i) What DNA would you want to sequence (e.g., read) and why? This could be DNA related to human health (e.g. genes related to disease research), environmental monitoring (e.g., sewage waste water, biodiversity analysis), and beyond (e.g. DNA data storage, biobank).
No idea. Possibly my basil plant.
(ii) In lecture, a variety of sequencing technologies were mentioned. What technology or technologies would you use to perform sequencing on your DNA and why?
I would use long-read sequencing (1–100+ kb). Even though it is more expensive, it would provide greater accuracy.
The way that DNA sequencing works currenly is by taking DNA, lysing it, and then reassembling fragments based on probabilistic approaches. The “read length” refers to how large these fragments are in terms of base pairs. A fragment of length = 1 bp would be near useless, since there is no way to “place” it probabilistically within the greater genome. A fragment of length = 150bp map well because apparently the human genome is largely non-repetitive at that scale.
Short-read sequencing is a read of 50–600 bp. Long-read sequencing is 1-100 kb.
Technologies:
- Polymerase-based sequencing
- Enzymatic digest sequencing
- Nanopore sequencing
- DNA microarrays
DNA Write
(i) What DNA would you want to synthesize (e.g., write) and why?
I have no idea.
(ii) What technology or technologies would you use to perform this DNA synthesis and why?
- Recombinant DNA synthesis
- Oligonucleotide synthesis - can make complex motifs, extremely large DNA molecules (1kbp+)
DNA Edit
(i) What DNA would you want to edit and why?
I have no idea. Potentially plant DNA. I don’t know anything about what DNA plants have. I would like to figure out how to increase the growth speed, change the bark texture. Or even doing experiments on yeast. Perhaps I could figure out the enzymes/proteins and what DNA/genes code for it, and then edit that.
(ii) What technology or technologies would you use to perform these DNA edits and why?
CRISPR-Cas9