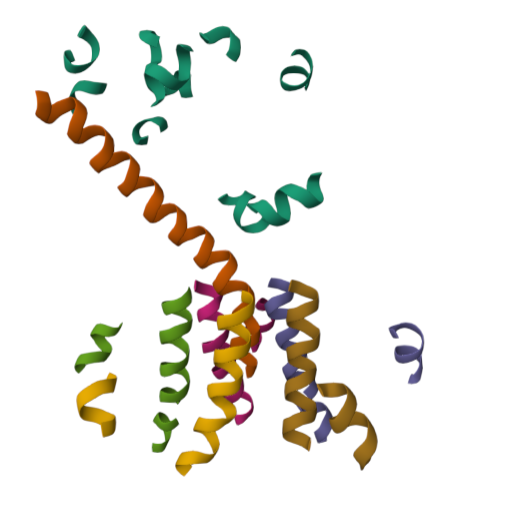My name is Marcos López, I am a final year biotechnology student at the National University of Rosario, Argentina. I work at the Institute of Molecular and Celular Biology of Rosario in plant sciences
Part A. Conceptual questions Questions from Shunguan zhang
Since meat isnt 100% protein, we have to calculate the porcentage of protein that this piece of meat has. Researching i found that is on average 22%, meaning that of those 500 g of meat, only 110 g are proteins. Then, dividing the total mass of protein (110 g) for the average molar mass of amino acids (100 g/mol) we find that there is 1.1 moles of amino acids in this piece of meat.
Question #1 During my undergraduate thesis project I developed a whole-cell bacterial biosensor for the high-sensitivity quantification of glyphosate, the most widely used herbicide globally. The project consists of an engineered strain of Agrobacterium tumefaciens as a biological chassis. The tool works by leveraging the natural phn operon (for degradation of phosphonates), regulated by the PhnF repressor and a promoter sensitive to it, which I have repurposed into a genetic circuit where the presence of glyphosate triggers the expression of a Green Fluorescent Protein (GFP). I am curious about this because glyphosate is essential for modern agriculture and its environmental accumulation and potential health risks are a growing concern. Current detection methods like HPLC-MS are expensive, centralized, and require complex sample preparation. My goal is to create a tool that allows for decentralized, low-cost environmental monitoring, enabling farmers and regulatory agencies to quantify herbicide levels directly in the field with high specificity and sensitivity.
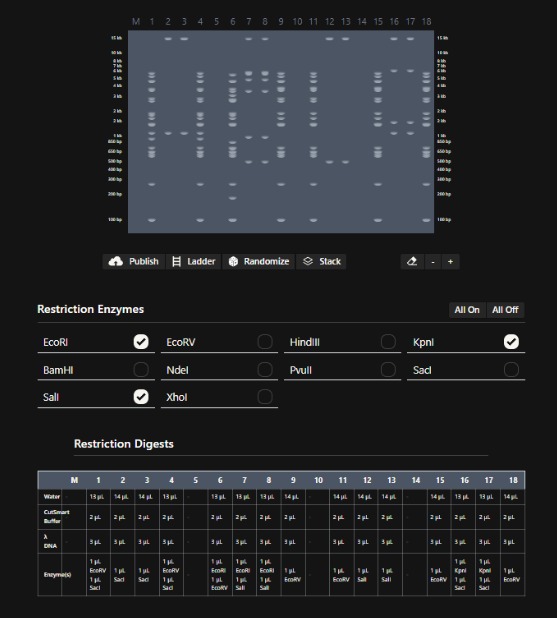
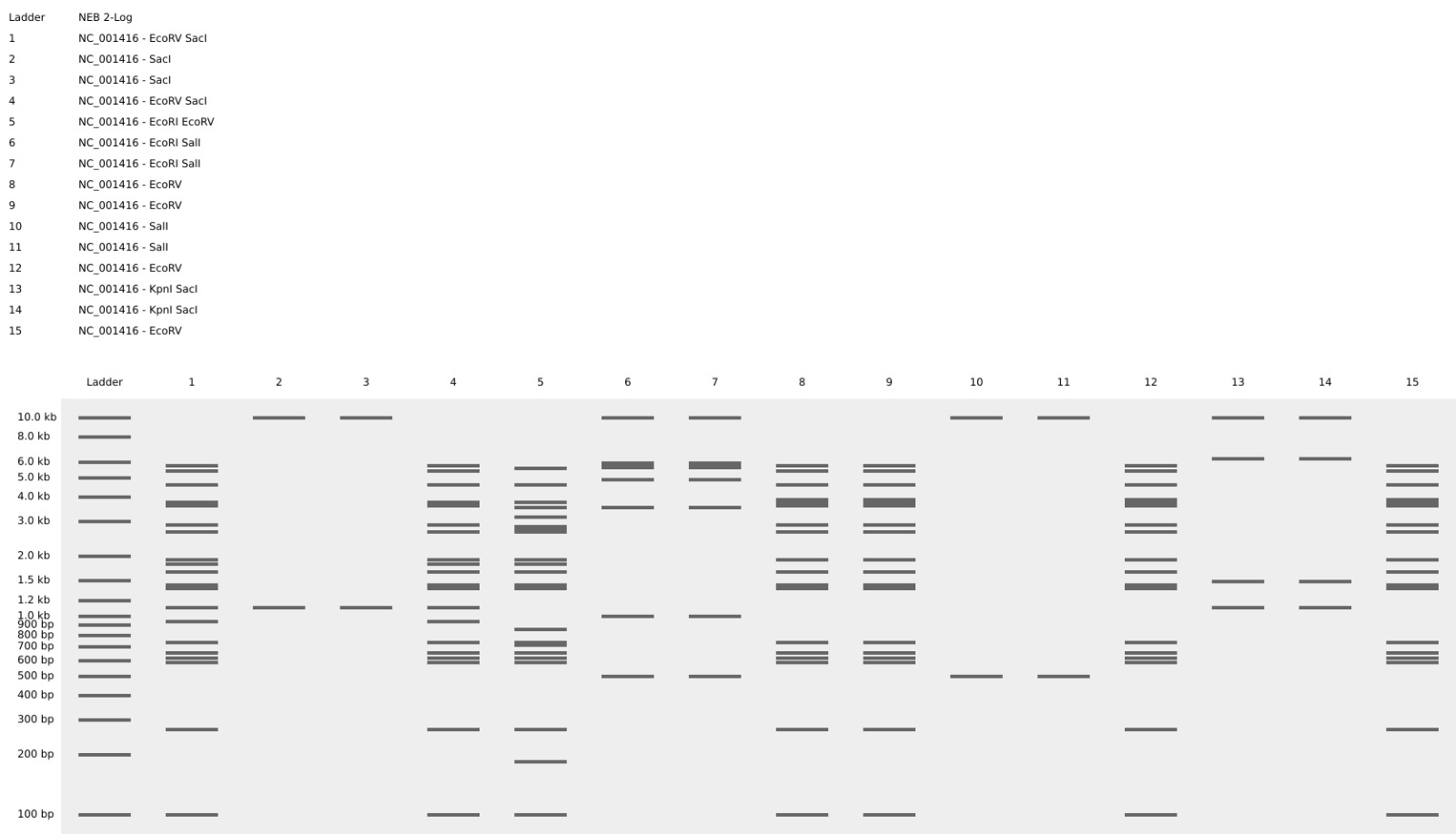
Part 1 For this part of the assignment I started playing with Ronan´s website by making random patterns with the enzymes given. Som of the electrophoresis digestion patterns of the DNA started to look like letters and I decided to make my own word.
Then, i tried to design that same pattern in benchling digestion tool, but i think it look better in Ronan´s website, because there are sapces between the gel lanes.
Python script for opentrons artwork Post lab questions Transforming microfluidics for single-cell analysis with robotics and artificial intelligenceDOI In this Review, the authors highlight the importance of single cell resolution analysis aided by robotic automated microfluidics.
The traditional method of bulk analysis averages signals across entire cell populations, maskin critical biological diversity at single cell levels. In a population of cells, there are different cell populations, due to genetic, epigenetic and environmental variations. In cancer and immunology research this is fundamental because even a small fraction of drug-resistant cells can drive disease progression and treatment failure. The process of screening diverse methods of treatment or looking for molecular markers could make a decisive impact on how we treat this diseases.
Subsections of Homework
hw #4-protein-design-part-i
Part A. Conceptual questions
Questions from Shunguan zhang
Since meat isnt 100% protein, we have to calculate the porcentage of protein that this piece of meat has. Researching i found that is on average 22%, meaning that of those 500 g of meat, only 110 g are proteins.
Then, dividing the total mass of protein (110 g) for the average molar mass of amino acids (100 g/mol) we find that there is 1.1 moles of amino acids in this piece of meat.
Then, by multiplying by avogadro´s number (6.022 x 1023) we could obtain the aproximatedly number of aminoacids in this piece, that is 6.62 x 1023 aminoacids in a 500 g piece of meat.
That is because when we eat food, we actually break down that complex matrix of cells and molecules in simple ones that we can absorb and distribute to our body, for example, we degrade the proteins in very small chains called polypeptides or even aminoacids, by doing that, the intestinal epitelium can absrob this small molecular by different molecular transport systems. Also, since the aminoacids are essentialy the same by most of living organisms the we can use them to for our proteins.
a
Yes, while mainteining the backbone of the amnioacid you can modify the R group at your will. If you want to design your own aminoacid you will have to think of the functionality that this new group brings into the mix, you will have to consider the interactions that this new functional group has with other aminoacids, you could probably predict them by understandig the caracteristics of this molecule, if it is acid, basic, polar or non polar.
I found an intresting example of a synthetic aminoacid, the adition of an azide group to a standard phenylalanine structure, with this new aminoacid you could tag proteins in vivo without killing the cell and you could see the actual interactions of this protein in real time.
It is belived that aminoacids were formed by simple molecules (like water, methane, ammonia and hydrogen) that reacted with the energy provided with electricity in the early ages of the earth. This has been experimented in the famous Stanley Miller experiment, in wich after combining this compunds found in ancient earth with a zap of electricity found a variety of aminoacids.
The chirality of the helix is dictated by the orientation fo the side chains. In a right-handed helix, the side chains point outward and away from the backbone, minimizing steric hindrance. If you tried to force L-amino acids into a left-handed helix, the side chains would bump into the backbone and the structure would be unstable. With D-amino acids, the atoms are arranged in a mirror-image configuration, the geometry is reversed. To keep those side chains pointing safely outward, the entire backbone must twist in the opposite direction, creating a left-handed spiral.
Yes, amino acid chains can twist into several distinct helical shapes depending on how tightly they pack the AA´s.
The 3(10) helix: this is the second most common helix. It is tighter and thinner than a standard alpha helix. In this one there are exactly 3 AA´s per turn, less than the standar 3.6 in alpha helixes.
the pi-helix: because of the unique ring shape of Proline forces a different geometry of the helix
This is because almost all life on earth uses L-amino acids, the right handed twists of the helixes allows the side chains to pint outward and interact with another groups of molecules, giving the proteins their functionality. If the side chains were pinting inward, there will be an esteric impediment and probably the proteins will not maintain their biological activity.
That is because in a b-like sheet the chemical groups responsible of hydrogen bonding point outward from the edges, in this way, b-sheets are designed to link up with others.
The reason amyloid diseases are defined by b-sheets is that this is the most thermofynamically stable low energy state of a protein. When a protein misfold, it falls into this lowest state of energy. Differently to alpha sheet (that rely hevily in the side chains for the interactiosn) b-sheets are held together by the protein backbone.
Part B. Analysis and visualization
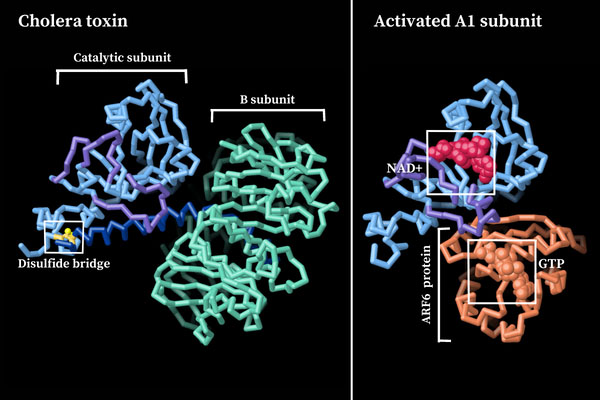
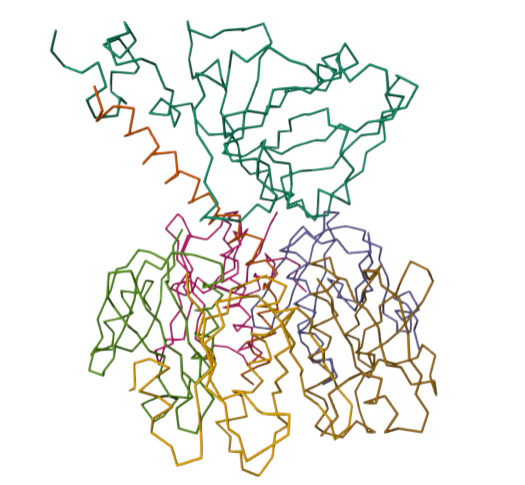
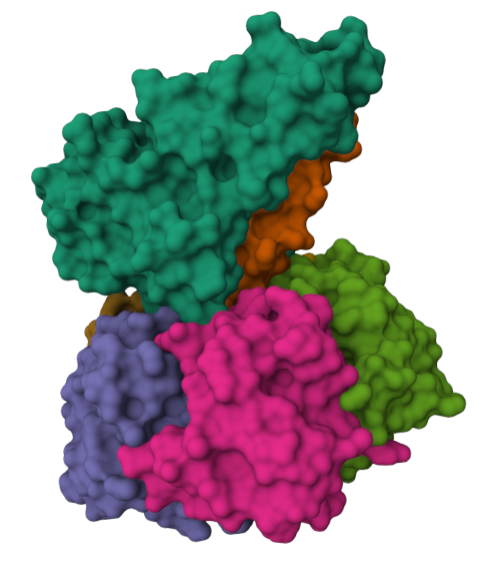
For this part of the homework i actually choose one of the repertory of “the protein of the month” on PDB. This molecule is the cholera toxin. this protein attacks intesitanl cells to cause life-threatening dehydration. It contains two sub units A (shown in blue) includes the toxic enzyme portion (A1 chain) and the linker (A2 chain), and subunit B (shown in turquoise) includes the carbohydrate-binding portion. When the toxin binds to a cell, the disulfide bridge (shown in yellow) that connects the two chains of the A subunit is then broken, releasing the toxic portion (shown in light blue) into the cell. The structure on the right (PDB entry 2a5f) shows that when the A1 chain binds to the ARF6 protein (shown in orange, with a bound GTP), the toxin’s catalytic loops (shown in yellow) undergo conformational changes and NAD+ (shown in green) binds to the active site. The activated A1 subunit can then attach an ADP group to permanently activate a G-protein.
Protein sequence
For the simplicity of this part of the assignmen i will only use the Chain A of the toxin.
Part D. Group brainstorm on bacteriophage engineering
Week 1 HW: Principles and Practices
Question #1
During my undergraduate thesis project I developed a whole-cell bacterial biosensor for the high-sensitivity quantification of glyphosate, the most widely used herbicide globally. The project consists of an engineered strain of Agrobacterium tumefaciens as a biological chassis. The tool works by leveraging the natural phn operon (for degradation of phosphonates), regulated by the PhnF repressor and a promoter sensitive to it, which I have repurposed into a genetic circuit where the presence of glyphosate triggers the expression of a Green Fluorescent Protein (GFP).
I am curious about this because glyphosate is essential for modern agriculture and its environmental accumulation and potential health risks are a growing concern. Current detection methods like HPLC-MS are expensive, centralized, and require complex sample preparation. My goal is to create a tool that allows for decentralized, low-cost environmental monitoring, enabling farmers and regulatory agencies to quantify herbicide levels directly in the field with high specificity and sensitivity.
Question #2
To ensure this biosensor contributes to an ethical future,
Goal #1: Focus on Bioavailable Quantification over Total Concentration. The aim is to shift the regulatory paradigm from measuring total chemical presence to biological impact.
Sub-goal 1a: Establish a standardized metric for bioavailable glyphosate, defining how the bacterial response correlates to actual ecological and human health risks.
Sub-goal 1b: Validate the biosensor against traditional HPLC-MS methods to demonstrate that ‘biological sensing’ provides a more accurate representation of environmental toxicity in soil and water.
Goal #2: Democratization through Open-Source Accessibility. The goal is to break the monopoly of centralized high-cost laboratories on environmental monitoring
Sub-goal 2a: Develop an Open-Source Laboratory Framework, providing free access to the genetic circuits (PhnF-based) and calibration protocols so local public health labs can replicate the sensor.
Sub-goal 2b: Reduce the cost-per-test to a fraction of an HPLC run, ensuring that low-resource communities can perform their own independent environmental audits
Goal #3: Ensuring Environmental Health Equity. This goal focuses on the right of every community to know the state of their surroundings.
Sub-goal 3a: Integrate the biosensor into Citizen Science programs, empowering rural and marginalized populations to generate their own data regarding herbicide exposure.
Sub-goal 3b: Advocate for the legal recognition of biosensor-derived data as ’early-warning’ evidence for regulatory intervention in contaminated areas.
Goal #4: Responsible Data Governance and Sovereignty. Protecting the information generated is as important as the detection itself.
Sub-goal 4a: Implement Data Anonymization and Privacy standards to ensure that small-scale farmers are not unfairly penalized or their lands devalued by the mapping of glyphosate levels.
Sub-goal 4b: Establish community-owned data repositories, preventing private corporations from harvesting environmental data for profit or surveillance.
Question #3
Action 1: Creation of a “Bioavailable Standard” Certification
Type: New Requirement / Regulatory Rule
Actor: Federal Environmental Agencies (e.g., EPA, SENASA) and Standard-Setting Organizations (ISO).
Purpose: Currently, legislation only recognizes total glyphosate concentration via HPLC. I propose a new regulatory category for “Biological Bioavailability.” This changes the legal requirement from just “how much is there” to “how much is actively affecting the microbiome and health.”
Design: Regulators must approve the Agrobacterium biosensor as a valid “pre-screening” tool. If the biosensor detects high bioavailability, it triggers a mandatory, more detailed environmental audit.
Assumptions: I am assuming that the correlation between the GFP signal in my biosensor and the toxicological impact on other species is consistent across different soil types.
Risks of Failure & Success: Failure: If the biosensor is too sensitive (false positives), it could lead to unnecessary legal bans on farming. Unintended Success: If it becomes the gold standard, it might lead to companies designing herbicides that are “invisible” to this specific bacterial strain but still toxic to other organisms.
Action 2: Open-Source “Bio-Foundry” Kits for Local Labs
Type: Financial Incentive / Technical Strategy
Actor: Academic Researchers, NGOs, and Government Science Grants.
Purpose: Instead of each lab trying to “reinvent” the sensor, we propose an open-source kit that includes the lyophilized (freeze-dried) bacteria and the standardized PhnF genetic circuits. This moves the tech from a single thesis in Rosario to any community lab in the world.
Design: Grant agencies would fund the production of these “starter kits.” Local labs “opt-in” by signing a peer-to-peer agreement to share their environmental data in a public, transparent repository.
Assumptions: I assume that local labs have the basic equipment (like a fluorometer or a simple dark box with a camera) to read the GFP signal from the bacteria.
Risks of Failure & Success: Failure: Without proper training, local labs might misinterpret results, leading to “bad data” that damages the project’s reputation. Unintended Success: If everyone uses it, the sheer volume of data could overwhelm regulatory agencies, making it impossible for them to act on every reported contamination site.
Action 3: “Community Data Shield” Protocol
Type: Policy / Rule
Actor: Lawmakers and Citizen Science Alliances.
Purpose: To prevent the data from being used against the people who collect it. I propose a legal framework that anonymizes the specific location of a “positive” glyphosate test when shared publicly, unless the community decides otherwise.
Design: The software used to upload the biosensor results must include a “privacy-by-design” layer. This would require the approval of data protection authorities to ensure it meets GDPR-like standards for biological information.
Assumptions: It assumes that the benefit of knowing a region is contaminated outweighs the risk of individual farms being identified and potentially devalued.
Risks of Failure & Success: Failure: Lack of transparency could make the data useless for holding specific polluters accountable. Unintended Success: If the data is too well-protected and anonymized, it might prevent scientists from finding the exact “source” of a contamination plume in a river or aquifer.
Question #4
Does the option:
Option 1
Option 2
Option 3
Focus on Bioavailable Quantification over Total Concentration
1
1
• By stablishing a standarized metric
1
1
• By validating the biosensor
1
1
1
Democratization through Open-Source Accessibility
2
1
2
• By developing an open source network
2
1
1
• By reducing the test cost
2
1
3
Ensures Environmental Health Equity
1
1
1
• By empowering marginalized populations
1
1
2
• By being an early warning
1
2
-
Responsible Data Governance and Sovereignty
1
1
• By implemeting data anonymization and privacy standards
2
1
• By establishing community owned data repositiories
1
1
Question #5
Final Recommendation and Prioritization Strategy
Target Audience: National Environmental Agencies (e.g., SENASA, EPA) and International Public Health Organizations (WHO/FAO).
Recommendation: Based on the scoring matrix, I prioritize a hybrid governance model that combines Open-Source “Bio-Foundry” Kits (Action 2) with the Community Data Shield (Action 3). While the formal Certification of Bioavailability (Action 1) is a critical long-term goal for regulatory science, the immediate ethical priority is to democratize environmental monitoring. By providing low-cost, open-source kits based on my Agrobacterium biosensor research, we can empower local laboratories to bypass the financial barriers of HPLC-MS. This technical decentralization must be legally protected by a “Data Shield” framework to ensure that the resulting information serves to protect public health and the environment, rather than being used for corporate surveillance or land devaluation.
Trade-offs and Justifications: The primary trade-off considered was Regulatory Authority vs. Social Accessibility. Choosing Action 1 would have provided more “legal weight” to the results, but it would have restricted the technology to high-end, expensive labs, effectively excluding the communities most affected by glyphosate use. I decided to sacrifice immediate regulatory formalization in favor of Global Equity. Another trade-off involves Data Transparency vs. Privacy. By prioritizing the “Data Shield,” we might slow down the ability of central governments to identify exact contamination sources, but we gain the essential trust of farmers and local citizens who might otherwise fear using the tool.
Assumptions and Uncertainties:
Technical Robustness (Assumption): I assume that the genetic circuits (PhnF/GFP) developed in my thesis can be successfully stabilized in a “Bio-Foundry” kit format (lyophilized) without losing the sensitivity required to measure bioavailable fractions in diverse soil types.
Community Participation (Uncertainty): It remains uncertain whether local health labs will have the baseline technical capacity (e.g., basic fluorescence detection) to implement these open-source protocols without extensive on-site training.
Legal Recognition (Uncertainty): There is an uncertainty regarding how long it will take for “Citizen Science” data to be accepted as valid evidence in environmental litigation against large-scale agrochemical misuse.
Week #2 Lecture prep’
Homework Questions from Professor Jacobson
The error rate of the DNA polymerase is 1:107. The human genome has roughly 3x109 bp without a proofreading or repair system, the polymerase would commit arround 300 mistakes during DNA replication in the human genome. Biology deals with it by having different repair systems like MMR, NER and hologous restart of the replication joint. Also the polymerase has different activities that improve the error rate.
For a human protein that has arroun 300-400 AA, we could make 10^150 different combinations. There are different ways for an organism to produce a certain protein, like codon bias, mRNA secondary structure, GC content, etc
Homework Questions from Dr. LeProust
The most common method for oligo syinthesis at the moment is phosphoramidite syntesis, made of four steps.
The difficulty lies in the yield and accumulated errors of the chemical process, by the time you reach aprox 200 nt , the yield of perfect sequences is so low that it is not practical.
Because of the low efficiency of the process, you could use Hierarchical assembly
Homework Question from George Church
The 10 essential amionacids for animals are: F, V, T, W, I, M, H, R, L and K. Regarding the lysine contingency, in reality all animals live in a natural multy contingency because they depend on all of this AA´s for the development of new proteins and they only can gather them from another sources.
week-02-hw-dna-read-write-and-edit
Part 1
For this part of the assignment I started playing with Ronan´s website by making random patterns with the enzymes given. Som of the electrophoresis digestion patterns of the DNA started to look like letters and I decided to make my own word.
Then, i tried to design that same pattern in benchling digestion tool, but i think it look better in Ronan´s website, because there are sapces between the gel lanes.
Part 3
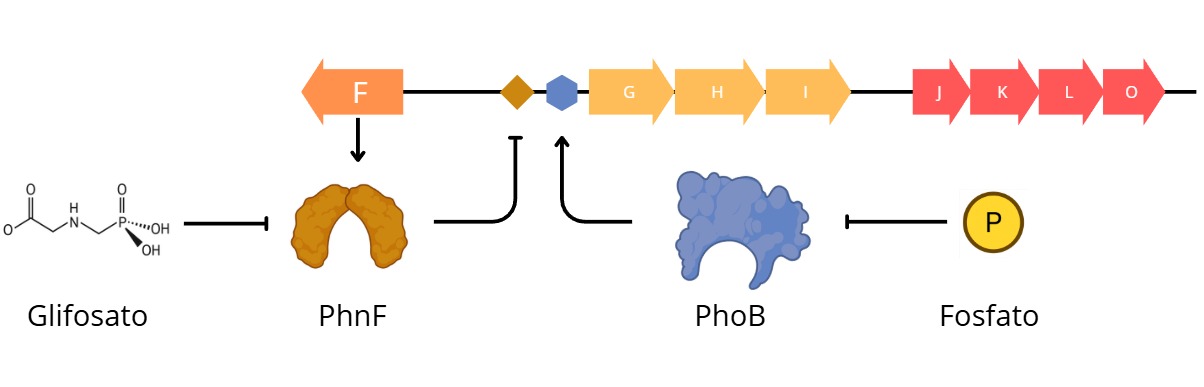
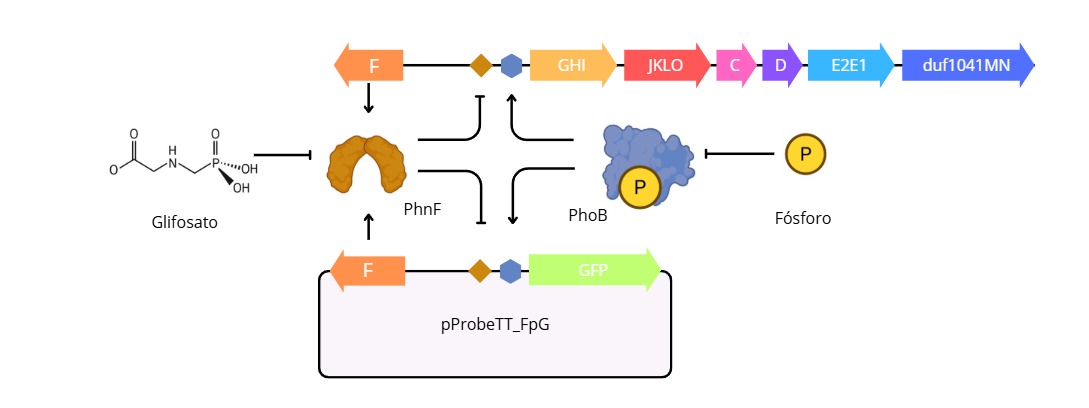
For this part I chosed a protein that I am very familiarized with. It is the transcriptional repressor PhnF from the phn operon responsible for the phosphonate degradation in bacteria. It repress the transcription of the phng gen in the absence of phosphonates, a core catalitic enzyme of the C-P lyase complex. This promoter is also regulted by the PhoB activator, so in the presence of phosphonates and the deplition of inorganic phosphorous this degradative path activates and provides the bacteria of an alternate source of phosphate
During my undergraduate thesis project, working as a research assistant at the Institute of Molecular and Celullar Biology (IBR-CONICET), I used this regulatory mechanism as a transcriptional phusion for the expression of the fluorescent protein GFP. In depletion of inorganic phosphorous and the prescent of a source of phosphonates, the promoter has an activity proportional to the amount of phosphonate in the media, then, by a non-linear regression the system can quantify the concentration or mass of gliphosate (or other phosphonates) in the media
For the expression of this protein, you could use a pET family vector in an E. coli JM109 starin, inducible by IPTG and translated by the T7 phage RNA polymerase. Then by cell lysis and protein extraction you could purificate (if you need) by adding an His x6 tag and in an Ni+2 column
Part 4
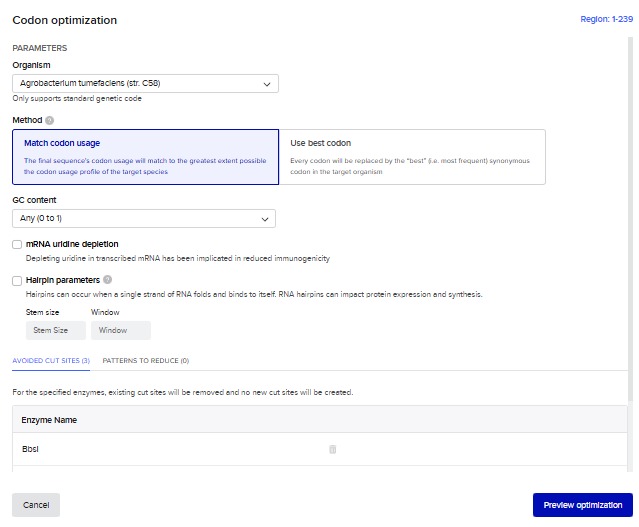
For this part I used the same sequence from part #3. I added individually every component as a DNA sequence to benchling (eg: promoter, rbs, terminator, His tag), then i edited the sequence of the codon optimized PhnF by adding this components in their respective place.
The olny part i couldnt do is adding restriction enzymes for extracting the insert later. I wanted to add EcoRI sites in the sequence but I couldnt in the Gibson assembly system in benchling.
Part 5
DNA read
What DNA would you want to sequence (e.g., read) and why?
I would like to perform genomic analysis of genetically modified crops. Last year I attended a seminar dictated by Dr. Juan Debernardi where he explained the services that they offer at the plant transformation facility in the UC-Davies. The offer a service where they transform a crop with an Agrobacterium tumefaciens strain and modify it with CrispR. The part that cautivated me the most was the develop of high efficiency CrsipR vector, for wich they performed genomic analysis for evoiding offtargeting of the crops.
In lecture, a variety of sequencing technologies were mentioned. What technology or technologies would you use to perform sequencing on your DNA and why?
I´d like to use a combination of long reads sequencing and short reads for the complete analysis of a genome. I think that this way you could have a bulk of big quality data for performing genomic analysis. For this you could use thecniques like Oxford Nanopore for the long read sequencing (Third generation) and Illumina (Second generation) for the short reads. The difference in the generations of the methods is due to the application of PCR and amplifications techniques used in Illumina where you need to use “connectors” for every individual read.
Specifically in the Illumina method you have to perform a Library preparation, involving the digestion of the DNA fragment into smaller pieces, and bind adapters to all the small molecules of DNA (arround 300 bp). Then you load the DNA into a flow cell and you amplify each single moleculle via bridge PCR to create a cluster of identical DNA strands. Then you sequence by synthesis using fluorescenctly labeled reversible termiantor nucleotides emmiting fluorescence in different wavelenghts so you can identify each base. Then yo can trasnform this fluorescent reads into short reads (about 300 bp) of DNA and assembly using a reference genome.
DNA write
What DNA would you want to synthesize (e.g., write) and why?
I´d like to synthesize an antifungical gene for its expression in wheat. By designing the DNA in silico withouth the need of a backbone of a PCR, I could optimize the codons for their expression in the wheat specific genetic code. Also I could directly add al the components necessary for the expression like a constitutive plan promoter, a secretory signal and insert it into an agrobacterium based vector.
What technology or technologies would you use to perform this DNA synthesis and why?
To implement this i would use Silicon based phosphoramidite synthesis to write the DNA molecule with a high fidelity throughput and for a low cost. Once the gene is synthesized and inserted into the wheat crop, I would use Illumina sequencing to verify the result. This assures that te gene is correctly inserted and there are no genetic complications within the genomic DNA of the crop. The limitations of this method are: the speed that requires due to the process of ligating the adapters, and the accuracy of the short reads, due to Wheat being an hexaplid there are many repetitive sequences, it could affect the quality of the short reads, in that case, there could be many alternatives for the genomic analysis of the genetically modified plant.
DNA Edit
What DNA would you want to edit and why?
I would like to edit the genomic DNA of crops to improve both its nutritional quality and yield. There are many different method for plant transformation or editing, clasically the most direct approach is to transform a plant with and Agrobacterium strain crrrying a Ti derived plasmid that insert into the plant DNA in a random place. One of the most important aspects of plant editing is the design of protocols to circumvent the GMO regultations, like inserting a CrispR vector and eliminating it with plant repoduction thanks to the poliploid caractheristics that modern crops carry. But there are different alternatives to plan editing that do not involve adding a transgene like delivering directly the enzymes for editing in protoplasts or using a viral derived vector. Editing plants to improve their nutritional quality or yield is fundamental for the
What technology or technologies would you use to perform these DNA edits and why?
To do this I could perform precision Knockouts using CRIPSR to break different genes. I also could use base editors to change a single base in a gene. The future of plant editing is bright, every year, new technologies are being developed, to modify genes without adding a transgene, also, in the developing of new techniques, old ones are not forgotten, like in random mutagenesis using gamma rays or chemical mutagens, the plant phenotipation field is developing quickly.
If i had to choose CrispR to design a knockdown experiment, first I had to get the ORF of the gene from a species specific library, then develop the guide crispr RNA, by using different genomic analysis software to mimimize the off-targeting of the editor, then decide wich Crispr-Cas system i would use, bucause it determines the PAM region, and different CAS enzymes have different functions and effectivness. Then, once the CrispR vector is designed, i would have to build and transfrom it into an Agrobacterium tumefaciens strain and transform it into the crop by floral dipping or plant regeneration, the select the transformants by antibiotic selection and generate the offspring of three or four generations. The most important limitations of a CrispR editing protocol is that it is time consuming, it can take several months to grow a fully developed crop from a graph, and somateimes it could take some several generations for the mutation to stabilize. Another aspect to consider is the natural defense mechanisms that plants have against viruses, involving the DICER protein that degrades single stranded mRNA, if you express your crispR vector in large quantities, using a constitutive vector for example, the plant would recognize the mRNA as foreign and degrade it, expanding the resistance to all the plant and evading the transation of the Cas system. Also, some crispR systems have a very low editing efficiency and even if the transgene is present, the cas system does not edit the gene, in those cases you have to develop the crispR vector all over again or chose a different Cas system.
In this Review, the authors highlight the importance of single cell resolution analysis aided by robotic automated microfluidics.
The traditional method of bulk analysis averages signals across entire cell populations, maskin critical biological diversity at single cell levels. In a population of cells, there are different cell populations, due to genetic, epigenetic and environmental variations. In cancer and immunology research this is fundamental because even a small fraction of drug-resistant cells can drive disease progression and treatment failure. The process of screening diverse methods of treatment or looking for molecular markers could make a decisive impact on how we treat this diseases.
Microfluidics enable the single cell analysis at scale. By confining cells within microchambers or tiny droplets, microfluidics systems achieve a high throughput of isolated cells, that we cand study individually and discover new sub populations improving the treatment methods or researching the disease.
Another fundamental aspect that the paper mentions is the high reliability that robotic automation achieve. Removing human variability from the mos sensitive and repetitive steps is fundamental, avoiding the need for specialized personnel or chip-to-chip variation.
Here are some quotes from the paper that I found relevant to my final proyect.
“Ctortecka et al. developed an automated platform for multiplexed single-cell proteomics using a custom-designed microfabricated chip (proteoCHIP) coupled with the high-precision robotic system cellenONE”
“By eliminating manual handling and carrier proteome dependence, the platform enabled the identification of ∼2600 proteins across 170 single cells, with high reproducibility and over 90% data completeness per run.”
In this quote, the authors show how single cell analysis could be improved by robotic automation, enabling high reproducibility in proteomics assays that could improve the throughput of sreening at the single cell level different populations.
Automation in my final project.
Sample preparation before chip loading
One of the most critical and error-prone steps is preparing the biological sample before it even reaches the microfluidic chip. Robotic liquid handlers could standardize and automate several of these upstream tasks.
Cell counting and viability assessment could be performed robotically with a consistent technique, ensuring that only samples meeting predefined quality thresholds proceed to the chip.
Reagent preparation — including buffers, lysis solutions, and barcoding reagents — could be dispensed with picoliter-to-nanoliter precision, eliminating the pipetting variability that a human operator inevitably introduces.
This matters enormously in cancer research because tumor samples from biopsies are often scarce and irreplaceable. A robot like the Opentrons OT-2, mentioned in the paper for cell migration assays, could handle these preparatory steps reliably within a sterile environment, reducing the risk of contamination and sample loss before the experiment even begins.
Droplet generation and handling
The paper highlights the RAD microfluidics approach, where a commercial Tecan Freedom EVO robot was coupled to droplet microfluidic components including generators, mergers, and sorters, creating a fully automated droplet workflow. A similar integration in the chip could control the timing and flow rates of droplet generation with grater consistency than manual syringe pump operation. Improving the uniformity of single cell encapsulation and its efficiency.
Post-isolation sample handling for Omics workflows
Once the cells are isolated, the preparation for different omics analysis is a process sensitive to errors. In the paper, the authors name a variety of examples (nanoPOTS or PiSPA) that uses robotic systems to perform nanoliter-scale cell lysis, enzymatic digestion and sample transfer with minimal loss, achieving a high rate of total proteins for proteomic analysis. Also for transcriptomic assays, some robots like proteoCHIP and cellenONE, could automate the coloading of barcoded beads of the isolated cells and perform the scRNA-seq by integrating different attachments.
Multiplexed screening of cancer subpopulations
Other point of interest is the automation of screening processes. The robotics integration tool is perfect for this job, because they can run many experimental conditions in parallel without the increase of human effort. In the review, they mention the use of a OT-2 for the screening of 172 compunds across tens of thousends of cells.
Interactomics and functional assays
For the interactomics and functional experiments, the robots could automate the timed adittion of stimuly, co culture partners or signalling molecules to the isolated cells in precise intervals
Generating data for AI-driven analysis
Most importantly, the robotic automation would allow the plataform to generate large and standarized datasets needed to train LLMs, that could be applied in every part of the process like cell clasification, data agumentation, multi omics integration and the interpetation of data.
Final project ideas
Microfluidic Lab-on-a-Chip System for Single-Cell Encapsulation in Tumor Heterogeneity Research
This project proposes the development of a droplet based microfluidic system lab-on-chip (LoC) platform designed for single cell encapsulation and isolation. The aim is to understand the intratumoral heterogeneity at the individual cell level. This approach help us to study cancer subpopulations. Coupled to diverse Omics studies could help us disentangle the dynamics of tumors.
The identification of rare tumor subpopulations (including drug-resistant and stem-like cells) is fundamental in cancer research and treatment options, because they drive disease progression and therapeutic failure. The conventional bulk analysis of tumor biopsies mask the failure of therapeutic drugs and the perseverance of important subpopulations that could . The single cell approach combined with the omics optic could give us a more complex understanding in the dynamics of the tumor development
A novel aptamer biosensor for the detection of herbicides in complex food matrices
This project proposes the development of an aptamer-based biosensor platform for the sensitive and selective detection of herbicide residues in complex food matrices.
In this project, we address a growing analytical challenge in food safety monitoring and regulatory compliance. Herbicide contamination in food products represents a critical public health concern as most widely used agrochemicals (e.g glyphosate) persist through food processing chains and remain undetected because of the analytical complexity of the matrices
The biosensing strategy is centered on the rational selection and optimization of DNA or RNA aptamers with a high binding affinity and specificity toward the target herbicide molecules. The choice for this molecule of recognition is based in the key advantages that aptamers offer over conventional antibodies, like grater chemical stability, lower production costs, easier functionalization and the capacity for in vitro selection wia systematic evolution of ligand by exponential enrichment (SELEX).
Viral vector-based Caspase delivery system for targeted apoptosis induction in solid tumors
This project proposes the design and development of a viral vector-based delivery platform engineered to selectively deliver and activate caspase proteins within solid tumor cells, exploiting the intrinsic machinery of programmed cell death to achieve targeted oncological treatment.
This delivery system addresses a fundamental limitation of conventional cancer therapies which lack tumor specificity,, inducing systemic toxicity and off target damage to healthy tissues while frequently failing to eradicate drug-resistant or apoptosis-evasive tumor subpopulation that drive recurrence and metastatic progression
Caspases are the executioner proteases of the apoptotic cascade. Tumor cells commonly evade apoptosis through the downregulation or mutation of pro-apoptotic signaling components. By directly delivering exogenous caspases (particularly effector caspases) into tumor cells via a viral vector this approach bypasses the upstream signalling failures that confer apoptotic resistance in tumor cells.