Assignments: Class 1 Assignment Question 1
I propose a high-throughput microscopy tool to estimate intracellular PHA accumulation from granule count and size.
Current standard quantification methods are slow, labor-intensive, and often require hazardous solvent-based extraction. By pairing PHA staining (e.g., Sudan Black B or Nile Red A) with automated imaging and machine-learning (ML) image segmentation, this approach could rapidly screen large libraries of environmental isolates and recombinant strains for high PHA producers.
Homework Part 0: Basics of Gel Electrophoresis
I have watched the Week 2 lecture and recitation on DNA read/write/edit, restriction digests, Benchling, Twist, and gel electrophoresis.
Part 1: Benchling & In-silico Gel Art
Opened Benchling and signed up. Found the Lambda sequence here and copied the sequence without the header. Pasted this sequence into Benchling through “Create” > “DNA / RNA Sequence” > “New DNA / RNA Sequence”. Then I just pasted the sequence in the “Bases” field, titled it “Lambda,” and selected the topology as “Linear.”
Python Script for Opentrons Artwork Here’s my HTGAA 2026 Opentrons Art Python Script Submission.
The artistic design I created using the GUI is available here.
I heavily used the “Example 7 Microbial Earth” by Dominika Wawrzyniak, using pixels loaded from an external resource (a CSV file hosted on my GitHub page).
I used Dominika’s well documented Notion page from HTGAA21 to understand the code and replicate it for my case. I used Gemini assistance only to debug minor typos and syntax errors, and to identify which packages to import to execute the code.
Homework: Protein Design I Part A. Conceptual Questions 1) How many molecules of amino acids do you take with a piece of 500 grams of meat? (on average an amino acid is ~100 Daltons)
~ 21% of meat is protein content (Smith et al. 2022) therefore, 500g meet contains about 105g of protein.
Part A: SOD1 Binder Peptide Design (From Pranam) Part 1: Generate Binders with PepMLM
Question 1
This is human SOD1 sequence from UniProt (P00441) removing the initial Met
ATKAVCVLKGDGPVQGIINFEQKESNGPVKVWGSIKGLTEGLHGFHVHEFGDNTAGCTSAGPHFNPLSRKHGGPKDEERHVGDLGNVTADKDGVADVSIEDSVISLSGDHCIIGRTLVVHEKADDLGKGGNEESTKTGNAGSRLACGVIGIAQ FASTA
introducing the A4V mutant associated with the most aggressive forms of the ALS disease ATKVVCVLKGDGPVQGIINFEQKESNGPVKVWGSIKGLTEGLHGFHVHEFGDNTAGCTSAGPHFNPLSRKHGGPKDEERHVGDLGNVTADKDGVADVSIEDSVISLSGDHCIIGRTLVVHEKADDLGKGGNEESTKTGNAGSRLACGVIGIAQ
Question 2 and 3
With the help of ChatGPT and Gemni, I generated 2 new cells ir order to generate four peptides of length 12 amino acids conditioned on the mutant SOD1 sequence.
Assignment: DNA Assembly Question 1: What are some components in the Phusion High-Fidelity PCR Master Mix and what is their purpose?
Phusion High-Fidelity PCR Master Mix is a 2X, ready-to-use mixture where the exact formulation is partly proprietary, but the functional components are documented in the manufacturer’s manual:
Component (Phusion 2X Master Mix) Purpose Phusion High-Fidelity DNA Polymerase DNA synthesis with high fidelity + proofreading dNTPs (dATP, dCTP, dGTP, dTTP) Building blocks for new DNA strands HF reaction buffer (salts + pH buffer) Maintains optimal pH/ionic strength for enzyme function Mg2+ (via buffer system; often MgCl2-derived) Essential polymerase cofactor Stabilizers / additives (partly proprietary) Improve enzyme stability and consistency Nuclease-free water Solvent to reach correct 2X working concentrations Reference: Thermo Fisher Phusion High–Fidelity DNA Polymerase Product Information Sheet, standard biochemistry manuals (e.g., Sambrook & Russell).
Assignment Part 1: Intracellular Artificial Neural Networks (IANNs) Question 1
Traditional genetic circuits are usually implemented in Boolean logic (ON/OFF), hand-designed as fixed logic. so representing nuanced behaviors often requires many gates, sharp thresholds, and careful tuning, which can make designs bulky and brittle. As the number of inputs grows the circuit complexity can explode combinatorially, increasing burden by stacking multiple layers and adding intermediate nodes, which increases metabolic load, failure points, and sensitivity to part-to-part variability Also, adapting to new targets or shifting biological context often means redesigning the circuit architecture, not just re-tuning parameters.
Homework Part A: General and Lecturer-Specific Questions General homework questions Exercise 1
Explain the main advantages of cell-free protein synthesis over traditional in vivo methods, specifically in terms of flexibility and control over experimental variables. Name at least two cases where cell-free expression is more beneficial than cell production.
Homework: Final Project What to measure?
I will measure visible melanin output in the material as the primary readout of the project.
I want to quantify:
Degree of darkening Spatial distribution of pigmentation Stability/Persistence of the pigmentation in the bacterial cellulose / after drying or storage These measurements are directly relevant because they indicate whether the melanin-producing system is functioning and whether the output is compatible with the intended material application.
Part A: The 1,536 Pixel Artwork Canvas | Collective Artwork I contributed 7 pixels to the global artwork experiment, helping extend a horizontal yellow line in the top-left area (see screenshot below).
At first, I was cautious and tried to understand the ongoing ideas for each section and whether there was a unifying concept. I considered introducing something new, but ultimately decided to stick with what seemed to be the area’s goal (a horizontal yellow line). For next year, it might be fun to have an in-app chat within the same domain to coordinate contributions more easily and check the current vibes.
I worked on my Final Project and prepared it for the presentation on May 13 as part of the Committed Listeners group.
Subsections of Homework
Week 1 HW: Principles and Practices
Assignments: Class 1 Assignment
Question 1
I propose a high-throughput microscopy tool to estimate intracellular PHA accumulation from granule count and size.
Current standard quantification methods are slow, labor-intensive, and often require hazardous solvent-based extraction. By pairing PHA staining (e.g., Sudan Black B or Nile Red A) with automated imaging and machine-learning (ML) image segmentation, this approach could rapidly screen large libraries of environmental isolates and recombinant strains for high PHA producers.
Future upgrades, offered as a premium beta for testing, could add a “material profile” output by predicting PHA chain-length class (SCL, MCL, or LCL) from staining/fluorescence response patterns using the lipophilic dyes. This would enable not only faster strain selection but also early-stage differentiation of polymer type, which is critical for downstream biotechnology applications.
A further upgrade could generate image-driven optimization suggestions from microscopy images. For example, if it detects a high level of extracellular debris consistent with cell lysis, or a high abundance of product granules outside the cells, it could recommend exploring strain-engineering strategies that alter cell membrane composition to increase tolerance to mechanical stress and support higher intracellular polymer accumulation as cytoplasmic granules.
Question 2
Gov / Policy Goal 1: Prevent harmful misuse
• Sub-goal 1.1 - Limit repurposability: Reduce the extent to which the tool can be used as a general-purpose and high-throughput optimization engine outside its intended PHA scope, for example by restricting supported dyes and limiting microscopy calibration parameters to validated settings.
• Sub-goal 1.2 - Increase accountability: ensure high-impact uses are traceable and that institutions have a mechanism to intervene if misuse is suspected.
Gov / Policy Goal 2: Promote safe, responsible operation and research integrity
• Sub-goal 2.1 - Standardize safe use: Require adherence to Standard Operating Procedures (SOPs) for staining, imaging, and waste handling.
• Sub-goal 2.2 - Ensure competent users: Require completion of a short training module, including lab safety + tool-specific quality control (QC) before users can access advanced features or export “final” reports.
• Sub-goal 2.3 - Maintain data quality: Require basic QC checks (controls, calibration, and logging of model version and imaging settings) to reduce false positives/negatives and prevent misinterpretations.
Gov / Policy Goal 3: Maintain access for constructive uses (equity and scientific progress)
• Sub-goal 3.1 - Preserve legitimate research utility: avoid governance mechanisms that unnecessarily slow routine PHA research and screening.
• Sub-goal 3.2 - Proportional governance: apply stricter controls only to higher-impact capabilities (e.g., advanced optimization suggestions), rather than restricting all use.
Question 3
Option 1:
General action: Norms combined with oversight mechanisms (social/regulatory governance)
Purpose: Currently, PHA quantification is typically validated through chemical extraction and analytical methods rather than standardized image-based measurement. A robust image-analysis tool like this would significantly increase throughput and expand where and how screening can be performed. If an image-analysis approach is positioned as a scalable screening tool, it should include safeguards to prevent use outside validated conditions. A responsible-use policy with “red flag” triggers would provide a proportional oversight mechanism.
Design:
• Actors: principal investigators (PIs) and laboratory personnel (primary users), microscopy core facility staff, the university biosafety office (or equivalent), and an institutional ethics/biosafety committee.
• Mechanism: implement a short pre-use declaration form and a responsible-use policy that defines “red flag” contexts (e.g., high-throughput work on unverified environmental isolates without provenance, use outside standard biosafety environments, or attempts to generalize the tool beyond PHA workflows).
• Trigger response: if a red flag is triggered, require review by the biosafety/ethics committee (or the biosafety office) and compliance with institutional requirements before experiments or tool access continue.
Assumptions:
• Users will accurately disclose the intended use and experimental context (or there will be sufficient deterrence to reduce misreporting).
• Red-flag criteria can be defined clearly enough to be actionable and consistent across labs.
• The institution has capacity to perform timely reviews without creating major delays for legitimate projects.
• Some level of auditing is feasible (e.g., metadata logs or usage reporting), which may require limited access to usage data.
Risks of failure and “success”:
• The policy becomes symbolic and is not followed; criteria are too vague to enforce; or users misreport their purpose to avoid review.
• Overly broad triggers could make oversight routine, slowing research and disproportionately burdening smaller or under-resourced labs (equity and access concerns).
Option 2:
Restrict advanced features: High-impact features require auditable access (accountability governance)
Purpose: Add accountability for higher-impact features while keeping basic screening broadly accessible.
Design:
• Actors: tool developers (academic or company), institutions adopting the tool.
• Baseline access: basic PHA screening module available for standard use.
• Advanced access (premium/beta): requires institutional opt-in (verified affiliation, training completion, and standard operating procedures adherence).
• Logging: maintain run logs with technical metadata only (model version, stain, imaging settings, quality control pass/fail, solvent/waste metadata etc).
• Incident response: provide an incident-reporting channel so access can be suspended if misuse is suspected.
Assumptions:
• Logging and gating deter misuse without driving users to ungoverned copies.
• Metadata-only logs are sufficient for accountability without compromising privacy.
• Institutions are willing to administer opt-in and training requirements.
Risks of failure and “success”:
• Users bypass controls by using modified versions or alternative tools; logging becomes incomplete.
• Reduced accessibility and higher admin burden, potentially concentrating access in well-resourced labs.
• Analogy: similar to “KYC tiers” in financial systems: more powerful capabilities require stronger verification and auditability.
Option 3:
Just for PHA: Scope capabilities through validated workflows (technical strategy / design constraint).
Purpose: General-purpose screening tools are easier to repurpose. One way to limit their repurposability is by restricting the tool to validated PHA workflows.
Design:
• Actors: tool developers and maintainers; optionally journals or core facilities that require validated workflows for reporting.
• Technical constraint: restrict supported dyes and workflows to PHA-relevant staining and analysis; lock calibration parameters to validated microscopy settings; exclude generic “optimize any phenotype” modules.
• Reporting constraint: outputs are labeled as screening support, with clear limits on claims and recommended confirmatory methods for final quantification.
• The validated workflow remains useful across common lab setups and organisms.
• Users accept constraints rather than abandoning the tool.
Risks of failure and “success”:
• Restrictions are easily removed in forks / hacks etc; scope limits become ineffective.
• Reduced scientific and commercial usefulness, including for ethically beneficial non-PHA applications; may slow innovation.
• This is analogous to 3D printers that restrict materials and firmware settings: the core function remains available, but out-of-scope production becomes harder without intentional modification.
Question 4
Does the option:
Option 1
Option 2
Option 3
Enhance Biosecurity
• By preventing incidents
2
1
3
• By helping respond
2
1
3
Foster Lab Safety
• By preventing incident
2
2
1
• By helping respond
3
1
3
Protect the environment
• By preventing incidents
2
1
2
• By helping respond
3
2
3
Other considerations
• Minimizing costs and burdens to stakeholders
2
3
1
• Feasibility?
2
2
1
• Not impede research
2
3
3
• Promote constructive applications
2
1
3
Question 5
I would prioritize Option 3 as the primary governance approach, aimed at tool developers and maintainers. Although Option 3 has the weakest overall score, I assign higher weight to practical implementability and consistent adoption, since governance mechanisms that require sustained oversight or significant administrative capacity are often applied inconsistently in real research settings. Option 3 can be implemented directly in software and routine workflows by restricting the tool to validated PHA use cases (supported dyes, locked calibration ranges, and scoped outputs). This reduces repurposability by design rather than relying on user compliance, making the default use safer and more predictable while preserving the core constructive application: scalable PHA screening.
The key trade-off is that Option 3 scores poorly on “helping respond” (biosecurity and lab safety), because it provides limited traceability and fewer mechanisms for intervention after deployment. It also narrows beneficial extensions beyond PHA, potentially limiting constructive applications in adjacent domains.
This recommendation also rests on several assumptions and uncertainties: that capability scoping meaningfully reduces repurposability in practice; that users will not widely circumvent constraints via modified versions or alternative tools; and that the validated workflow generalizes across common microscopes, organisms, and staining conditions.
Final Reflection
The main new ethical concern for me was how quickly a tool designed for a narrow, constructive purpose (PHA screening) can become a general “scale-up enabler” once it is automated and paired with machine-learning image analysis. To address this, I would recommend capability scoping by restricting the tool to validated PHA workflows (supported dyes, locked calibration ranges, and scoped outputs)
Week 2 Lecture Prep
Homework Questions from Professor Jacobson:
Question 1
High-fidelity, proofreading-proficient replicative DNA polymerases have an error rate of ≈ 10⁻⁶ during synthesis under standard conditions. The human nuclear genome is about 3.2 × 10⁹ base pairs per haploid set. If errors happened at 10⁻⁶ per base, you’d expect roughly 3.2 × 10⁹ × 10⁻⁶ ≈ 3.2 × 10³ (≈ 3,200) errors per haploid genome copy. However, in living cells, the effective replication error rate is far lower once proofreading (3′→5′ exonuclease) and post-replication repair (such as mismatch repair, MMR) are included: a commonly cited order of magnitude is ≈ 10⁻⁹ to 10⁻¹⁰ errors per base pair per replication.
Question 2
Because of codon degeneracy, the same amino-acid sequence can be encoded by many DNA coding sequences. A rough average multiplicity per amino acid is about 3.05 synonymous codons. Given an average human protein of 1036 bp and that coding DNA uses 3 bp per amino acid, 1036 bp / 3 ≈ 345 codons. So the number of different DNA coding sequences that produce the exact same protein is on the order of ≈ 10¹⁶⁷.
In practice, though, synonymous variants are not always functionally equivalent. Some synonymous changes produce transcripts with different stability and structure. For example, synonymous substitutions can lead to hairpins or repetitive motifs that increase recombination and reduce construct stability. They can also change ribosome speed patterns (which can alter co-translational folding and lead to misfolding, aggregation, or altered activity). In addition, synonymous changes can inadvertently create or disrupt regulatory sequence motifs (e.g., polyadenylation signals or splicing enhancer/silencer elements in eukaryotes).
Homework Questions from Dr. LeProust:
The gold standard for oligonucleotide synthesis is solid-phase oligonucleotide synthesis (SPOS) based on phosphoramidite chemistry (Walther et al. 2020). However, this method struggles beyond ~200 nt because every nucleotide is added through repeated chemical cycles, and small inefficiencies, truncation products, depurination, and side reactions compound with length. For the same reason, a 2000 bp gene cannot be made reliably by direct oligo synthesis. Instead, long genes are typically assembled from shorter oligos or DNA fragments, followed by error correction, cloning, and sequence verification.
Homework Question from George Church:
Question: What are the 10 essential amino acids in all animals and how does this affect your view of the “Lysine Contingency”?
Answer: The 10 essential amino acids in all animals are Arginine, Histidine, Isoleucine, Leucine, Lysine, Methionine, Phenylalanine, Threonine, Tryptophan, and Valine. Considering this, Jurassic Park’s biocontainment method is a joke, since it doesn’t create a unique dependency in animals: animals already can’t synthesize lysine. Also, as containment-by-dependency, it’s ecologically leaky because they did not consider the possibility that lysine was readily available in the environment. Lysine is available via plants and prey, so escape doesn’t remove access.
I have watched the Week 2 lecture and recitation on DNA read/write/edit, restriction digests, Benchling, Twist, and gel electrophoresis.
Part 1: Benchling & In-silico Gel Art
Opened Benchling and signed up. Found the Lambda sequence here and copied the sequence without the header. Pasted this sequence into Benchling through “Create” > “DNA / RNA Sequence” > “New DNA / RNA Sequence”. Then I just pasted the sequence in the “Bases” field, titled it “Lambda,” and selected the topology as “Linear.”
Clicked “Digest” (the scissors icon in the right menu), selected “All enzymes,” found all seven using the search tool, and clicked “Run Digest.”
This in-silico gel image uses simulated Lambda DNA restriction digest banding patterns from the required enzymes and arranges them as a visual composition inspired by Paul Vanouse’s Latent Figure Protocol.
Part 2: Gel Art - Restriction Digests and Gel Electrophoresis
I did not complete the wet-lab restriction digest and gel electrophoresis experiment. As a Committed Listener, I completed the required in-silico gel design in Benchling, but I did not have lab access for the optional wet-lab portion.
Part 3: DNA Design Challenge
3.1. Choose your protein: Poly(3-hydroxyalkanoate) polymerase subunit PhaC
I chose Polyhydroxyalkanoate synthase (PhaC) because it is involved in the catalysis of the reaction that polymerizes (R)-3-hydroxybutyryl-CoA to produce polyhydroxybutyrate (PHB), which is an important bioproduct of interest due to its plastic/polyethylene-like properties.
Biologically, PHB serves as an intracellular energy reserve material when cells grow under conditions of nutrient limitation.
Sequence of Polyhydroxyalkanoate Synthase (PhaC):
MATGKGAAASTQEGKSQPFKVTPGPFDPATWLEWSRQWQGTEGNGHAAASGIPGLDALAGVKIAPAQLGDIQQRYMKDFSALWQAMAEGKAEATGPLHDRRFAGDAWRTNLPYRFAAAFYLLNARALTELADAVEADAKTRQRIRFAISQWVDAMSPANFLATNPEAQRLLIESGGESLRAGVRNMMEDLTRGKISQTDESAFEVGRNVAVTEGAVVFENEYFQLLQYKPLTDKVHARPLLMVPPCINKYYILDLQPESSLVRHVVEQGHTVFLVSWRNPDASMAGSTWDDYIEHAAIRAIEVARDISGQDKINVLGFCVGGTIVSTALAVLAARGEHPAASVTLLTTLLDFADTGILDVFVDEGHVQLREATLGGGAGAPCALLRGLELANTFSFLRPNDLVWNYVVDNYLKGNTPVPFDLLFWNGDATNLPGPWYCWYLRHTYLQNELKVPGKLTVCGVPVDLASIDVPTYIYGSREDHIVPWTAAYASTALLANKLRFVLGASGHIAGVINPPAKNKRSHWTNDALPESPQQWLAGAIEHHGSWWPDWTAWLAGQAGAKRAAPANYGNARYRAIEPAPGRYVKAKA
Source: UniProt at https://www.uniprot.org/uniprotkb/P23608/entry#sequences
3.2. Reverse Translate: Protein (amino acid) sequence to DNA (nucleotide) sequence.
reh:H16_A1437 K03821 poly(R)-3-hydroxyalkanoate polymerase subunit PhaC EC:2.3.1.304 | (GenBank) phaC1; Poly(3-hydroxybutyrate) polymerase (N)
atggcgaccggcaaaggcgcggcagcttccacgcaggaaggcaagtcccaaccattcaaggtcacgccggggccattcgatccagccacatggctggaatggtcccgccagtggcagggcactgaaggcaacggccacgcggccgcgtccggcattccgggcctggatgcgctggcaggcgtcaagatcgcgccggcgcagctgggtgatatccagcagcgctacatgaaggacttctcagcgctgtggcaggccatggccgagggcaaggccgaggccaccggtccgctgcacgaccggcgcttcgccggcgacgcatggcgcaccaacctcccatatcgcttcgctgccgcgttctacctgctcaatgcgcgcgccttgaccgagctggccgatgccgtcgaggccgatgccaagacccgccagcgcatccgcttcgcgatctcgcaatgggtcgatgcgatgtcgcccgccaacttccttgccaccaatcccgaggcgcagcgcctgctgatcgagtcgggcggcgaatcgctgcgtgccggcgtgcgcaacatgatggaagacctgacacgcggcaagatctcgcagaccgacgagagcgcgtttgaggtcggccgcaatgtcgcggtgaccgaaggcgccgtggtcttcgagaacgagtacttccagctgttgcagtacaagccgctgaccgacaaggtgcacgcgcgcccgctgctgatggtgccgccgtgcatcaacaagtactacatcctggacctgcagccggagagctcgctggtgcgccatgtggtggagcagggacatacggtgtttctggtgtcgtggcgcaatccggacgccagcatggccggcagcacctgggacgactacatcgagcacgcggccatccgcgccatcgaagtcgcgcgcgacatcagcggccaggacaagatcaacgtgctcggcttctgcgtgggcggcaccattgtctcgaccgcgctggcggtgctggccgcgcgcggcgagcacccggccgccagcgtcacgctgctgaccacgctgctggactttgccgacacgggcatcctcgacgtctttgtcgacgagggccatgtgcagttgcgcgaggccacgctgggcggcggcgccggcgcgccgtgcgcgctgctgcgcggccttgagctggccaataccttctcgttcttgcgcccgaacgacctggtgtggaactacgtggtcgacaactacctgaagggcaacacgccggtgccgttcgacctgctgttctggaacggcgacgccaccaacctgccggggccgtggtactgctggtacctgcgccacacctacctgcagaacgagctcaaggtaccgggcaagctgaccgtgtgcggcgtgccggtggacctggccagcatcgacgtgccgacctatatctacggctcgcgcgaagaccatatcgtgccgtggaccgcggcctatgcctcgaccgcgctgctggcgaacaagctgcgcttcgtgctgggtgcgtcgggccatatcgccggtgtgatcaacccgccggccaagaacaagcgcagccactggactaacgatgcgctgccggagtcgccgcagcaatggctggccggcgccatcgagcatcacggcagctggtggccggactggaccgcatggctggccgggcaggccggcgcgaaacgcgccgcgcccgccaactatggcaatgcgcgctatcgcgcaatcgaacccgcgcctgggcgatacgtcaaagccaaggcatga
Source: KEGG at https://www.genome.jp/dbget-bin/www_bget?reh:H16_A1437
3.3. Codon optimization.
I optimized the phaC coding sequence for E. coli because it is a widely used chassis for recombinant protein expression and for rapid prototyping of metabolic engineering constructs.
I did this using the Benchling tool. I’ve selected the region of the AA sequence I wish to back translate and right clicked on the highlighted region. From the codon optimization tab:
Host: E. coli K-12
Method: Match codon usage
GC content: Medium (0.33 to 0.66) because extreme GC content can create problems. High GC can create strong secondary structures and low GC can cause instability/repeats and can make synthesis harder.
Uridine depletion: off (not relevant for bacterial expression)
Hairpin parameters: Stem size: 8 and Window 50
Restriction sites: avoid BsaI, BsmBI, BbsI (Type IIS enzymes for Golden Gate compatibility since I would have to clone phaA and phaB also, not phaC single gene in one vector)
Patterns to reduce: AAAAAA and ATATATATA
I clicked on “Optimization preview” and got this result:
3.4. You have a sequence! Now what?
PhaC alone will not produce PHB. A minimal PHB pathway typically includes PhaA (β-ketothiolase) and PhaB (acetoacetyl-CoA reductase) in addition to PhaC (PHA synthase). PhaA and PhaB convert central metabolites (via acetyl-CoA) into (R)-3-hydroxybutyryl-CoA, which is the direct substrate that PhaC polymerizes into PHB. You will also need a host capable of supplying sufficient acetyl-CoA and NADPH.
Therefore, for PHB production in E. coli, phaA, phaB, and phaC are commonly co-expressed on the same plasmid (as a single operon with one promoter and RBSs for each gene) and grown under appropriate culture conditions (e.g., carbon excess and nutrient limitation) that favor polymer accumulation.
To produce the protein from DNA, the codon-optimized phaC sequence would be placed in an expression cassette with a promoter, RBS, start codon, coding sequence, stop codon, and terminator. In a cell-dependent system such as E. coli, RNA polymerase transcribes the DNA sequence into mRNA. The ribosome binds the RBS, reads the mRNA codons, and translates them into the PhaC amino-acid chain. For PHB production rather than PhaC expression alone, phaA, phaB, and phaC should be co-expressed so the host can convert acetyl-CoA into (R)-3-hydroxybutyryl-CoA and then polymerize it into PHB.
Part 4: Prepare a Twist DNA Synthesis Order
Project: pBBR1-MSC5::phaCAB
Cell-dependent recombinant expression approach: cloning the codon-optimized phaA, phaB and phaC coding sequences into E. coli K12
The screenshot shows that my Twist account was redirected to “Contact Your Distributor” for orders through Interprise USA Corp., and another page returned an HTTP 500 server error.
Part 5: DNA Read / Write / Edit
5.1 DNA Read
I would sequence DNA used for DNA-based digital data storage because I am interested in how biological molecules can encode digital information. It would be fascinating to recover stored information from DNA as if reading an archive.
I would use Illumina sequencing, a second-generation massively parallel short-read technology, for high-accuracy base calls and reliable decoding of short oligo pools. I would also consider Oxford Nanopore sequencing, a third-generation single-molecule long-read technology, to validate longer constructs and check sequence integrity.
For Illumina, the input would be a pool of synthetic DNA oligos encoding digital data. If the oligos are already short, fragmentation may not be necessary. Library preparation would involve adapter ligation or PCR addition of adapters/indexes, followed by sequencing-by-synthesis using fluorescent reversible terminators. The output would be millions to billions of short reads in FASTQ format with per-base quality scores. The stored data would then be decoded using alignment, consensus generation, and error correction.
5.2 DNA Write
I would synthesize a PHA production cassette for E. coli K-12 containing codon-optimized phaA, phaB, and phaC. The goal would be to rapidly test/study PHB production from a designed pathway rather than cloning each gene manually from genomic DNA.
I would use commercial gene synthesis, such as Twist, because it allows designed DNA sequences to be ordered directly with defined codon usage, avoided restriction sites, and synthesis constraints. The essential steps are: design the coding sequences, codon-optimize them for E. coli, add regulatory parts such as promoter/RBSs/terminator, screen for forbidden restriction sites and problematic repeats, synthesize short oligos, assemble them into longer fragments or a full insert, clone into a plasmid, and verify the final sequence.
The main limitations are length-dependent error accumulation, synthesis difficulty from repeats or extreme GC content, turnaround time, cost for long constructs, and the need for clonal verification before experimental use.
5.3 DNA Edit
Aiming for increased expression of phaCAB and improved PHA production, I would edit E. coli metabolic and stress-tolerance genes to increase PHB yield. For example, I would target pathways that improve acetyl-CoA/NADPH supply, reduce competing carbon sinks, and increase tolerance to intracellular polymer accumulation.
For precise point mutations, I would use CRISPR base editing or prime editing because these methods can introduce targeted sequence changes without relying on double-strand breaks. For larger edits or gene insertions, I would use Cas9-assisted homologous recombination with a donor DNA template.
The design steps would include selecting the target gene, designing guide RNAs, checking off-target risk, preparing the editor plasmid or Cas9/gRNA system, designing the donor template if needed, transforming E. coli, selecting edited colonies, and confirming edits by sequencing.
Limitations include editing efficiency, PAM constraints, off-target edits, toxicity from editor expression, and the increased screening burden when multiplexing several edits.
The artistic design I created using the GUI is available here.
I heavily used the “Example 7 Microbial Earth” by Dominika Wawrzyniak, using pixels loaded from an external resource (a CSV file hosted on my GitHub page).
I used Dominika’s well documented Notion page from HTGAA21 to understand the code and replicate it for my case. I used Gemini assistance only to debug minor typos and syntax errors, and to identify which packages to import to execute the code.
Like Dominika Wawrzyniak, I planned to introduce more colors, like in the image I generated in the Automation Art Interface. However, implementing this design into code turned out to be more difficult and tedious than anticipated, so I left it as one color (red).
I submitted the Python file through the required homework submission form.
As a Committed Listener, I prepared the script and design documentation, but I did not run the protocol on a physical Opentrons robot.
Post-Lab Questions
Question 1
The paper “High-throughput experimentation for discovery of biodegradable polyesters” (Fransen et al., 2023) uses an Opentrons 1st-generation robot to automate a high-throughput biodegradation assay based on the clear-zone technique.
The researchers synthesized 642 polyesters and polycarbonates and tested their biodegradability using a clear-zone assay with Pseudomonas lemoignei. The Opentrons robot was repurposed as an automated imaging platform to capture time-lapse images of polymer degradation in 12-well plates, enabling consistent, large-scale monitoring over 13 days.
This automation allowed rapid generation of a large biodegradation dataset and supported machine learning models to predict polymer degradability from chemical structure.
Question 2
High-throughput screening of bacterial isolates for PHA production is traditionally extremely time-consuming and labor-intensive, requiring manual handling of hundreds of colonies across multiple conditions. For my final project, I plan to use an Opentrons OT-2 liquid-handling robot to automate this workflow, dramatically increasing throughput, reproducibility, and consistency compared to manual methods I used during my master’s.
Isolates will be spotted in triplicate on 60-sector plates, maintaining identical indexed positions across all plates for direct comparison. Viability will first be confirmed on LB agar, and isolates will then be inoculated onto mineral medium (MM; Ramsay et al., 1990) agar plates supplemented with individual carbon sources at 10% v/v to reach typical screening concentrations.
PHA production and bacterial growth will be assessed using a two-step staining workflow. First, Sudan Black B (0.02% in 96% ethanol, followed by ethanol washes) will identify colonies with blue coloration indicative of polymer accumulation. Second, Nile Red A incorporated into MM (0.5 μg/mL) will allow selected isolates to be ranked based on UV fluorescence (312/365 nm).
This automated setup enables rapid testing of hundreds of isolate × carbon source combinations, accelerating the discovery of strains compatible with low-cost feedstocks and efficient bioprocessing while transforming a laborious manual process into a precise, scalable screening platform.
Each “color” would correspond to a different bacterial isolate. I did not implement this in the script yet. The coordinate set is a starting layout and could be refined to achieve a more uniform, regular distribution across the plate (like in the image I drafted using the GUI available below)
Final Project Ideas
Added 3 slides with 3 ideas for an Individual Final Project in the appropriate slide deck for Commited Listeners here.
Also here’s my analoginal brainstorm
Week 4 HW: Protein Design Part 1
Homework: Protein Design I
Part A. Conceptual Questions
1) How many molecules of amino acids do you take with a piece of 500 grams of meat? (on average an amino acid is ~100 Daltons)
~ 21% of meat is protein content (Smith et al. 2022) therefore, 500g meet contains about 105g of protein.
Using the approximation of average amino acid ≈ 100 Da ≈ 100 g/mol for ~100 g protein: 100/100=1.00 mol
2) Why do humans eat beef but do not become a cow, eat fish but do not become fish?
Beef/fish supplies raw materials and energy, but it doesn’t transfer “cow/fish identity”. What we eat is digested first meaning the proteins, fats, and carbohydrates are broken down into small building blocks (amino acids, fatty acids, sugars), absorbed, and then reassembled into human molecules under human genetic and hormonal control.
3) Why are there only 20 natural amino acids?
Doig (2017) hypothesizes that the canonical set of 20 standard amino acids is best understood as an evolved “alphabet” that became fixed early because this set is sufficient and practical for building stable, soluble proteins. This set enables soluble folded structures with close-packed hydrophobic cores and ordered binding pockets, rather than being selected because each amino acid was needed for catalysis (since RNA catalysts were already effective enough). Once early life standardized a working translation system around this set, changing the alphabet would have been costly, so it became effectively locked in (“frozen”). Other references, such as Freeland et al. (2000), suggest that 20 is a good number for minimizing damage from errors (mutation/mistranslation).
4) Where did amino acids come from before enzymes that make them, and before life started?
Amino acids could plausibly have come from abiotic chemistry on early Earth. Proposed routes include cyanosulfidic protometabolism and amino-acid formation from electrical discharges in simple “primitive Earth” gas mixtures (the classic Miller experiment).
5) Can you discover additional helices in proteins?
Beyond the α-helix, proteins commonly contain 3₁₀ helices and π helices (less frequent helical variants), as well as polyproline II helices (common in Pro-rich/disordered regions) and the specialized collagen triple helix.
6) Why are most molecular helices right-handed?
Right-handed helices dominate because natural biomolecules are made from single-handed monomers, and the right-handed twist is the lowest-energy way to repeat their geometry without clashes.
7) Why do β-sheets tend to aggregate?
β-sheet aggregation buries exposed hydrophobic side chains and releases ordered water from their surfaces, which is strongly favorable, lowering enthalpy.
8) What is the driving force for β-sheet aggregation?
β-sheet aggregation is driven mainly by the hydrophobic effect and stabilized/propagated by intermolecular backbone H-bonding in the cross-β structure (often reinforced by tight steric-zipper packing).
9) Why do many amyloid diseases form β-sheets?
β-sheet architecture is an unusually generic, stable, and self-templating way for polypeptide backbones to stick together when normal folding fails. In a β-sheet, the peptide backbone forms regular hydrogen bonds. This conformation makes amyloid fibrils thermodynamically stable and hard to clear, because once a small β-sheet nucleus forms, it can seed further growth by recruiting more monomers and templating the same β-rich structure.
Part B: Protein Analysis and Visualization
Question 1
I selected poly(3-hydroxyalkanoate) depolymerase (PhaZ) because it is the key enzyme that degrades PHB, which directly controls whether a microbe accumulates bioplastic (useful for biotechnology) or breaks it down (relevant for environmental fate). phaZ inactivation is commonly discussed as a strategy to reduce PHA mobilization and increase polymer retention.
BLAST Result
Lenght: 283 aa
Most frequent amino acid: Leucine (L), 32/283 = 11.3%
250 hits
Reviewed (Swiss-Prot) homologs: 1
It belongs to the PHA depolymerase (PhaZ) family, which is part of the broader α/β-hydrolase enzyme superfamily.
Question 3
AF_AFP26495F1 - COMPUTED STRUCTURE MODEL OF POLY(3-HYDROXYALKANOATE) DEPOLYMERASE
This is not an experimentally solved structure, so there is no X-ray/EM “resolution” value. RCSB explicitly states: “There are no experimental data to verify the accuracy of this computed structure model. See Model Confidence metrics below for all regions of the polypeptide chain.” Instead, quality is reported by AlphaFold confidence. Global pLDDT: 91.95 (very high confidence overall)
RCSB lists 1 unique protein chain (monomer A1) and no ligands/non-protein entities.
Structure classification family: InterPro annotations classify it as Poly(3-hydroxyalkanoate) depolymerase (IPR011942) and an alpha/beta hydrolase fold protein (Alpha/beta hydrolase fold-1 domain, AB hydrolase superfamily).
Question 4
I opened AF-Q9R9W3-F1-model_v6 in PyMOL and visualized it in cartoon, ribbon, and ball-and-stick representations.
Colored by secondary structure, it shows a mixed α/β fold with more helices than β-sheets.
Colored by residue type, hydrophobic residues are enriched in the core (and in a few surface patches), while polar/charged residues are mostly surface-exposed, consistent with solubility.
The surface view shows clear cavities/clefts, consistent with potential binding pockets (e.g., a substrate-binding groove typical of hydrolases).
Part C. Using ML-Based Protein Design Tools
For this section, I chose PDB 6J2U as a structural reference. This entry contains a heterodimeric complex between MelC1, the tyrosinase caddy/cofactor protein, and MelC2, the tyrosinase enzyme from Streptomyces avermitilis. For my analysis, I focused on the MelC2 tyrosinase chain (6J2U_2: Represented by Chain B).
a) I used the Chain B sequence from PDB 6J2U, including the N-terminal expression tag present in the deposited sequence.
b) The vertical darker columns at certain positions are highly constrained residues where most substitutions are penalized. That usually indicates structural importance (core packing, tight turns, or residues critical for fold stability). Positions with mostly neutral colors across many substitutions are likely surface-exposed or in flexible loops, where the model predicts more tolerance.
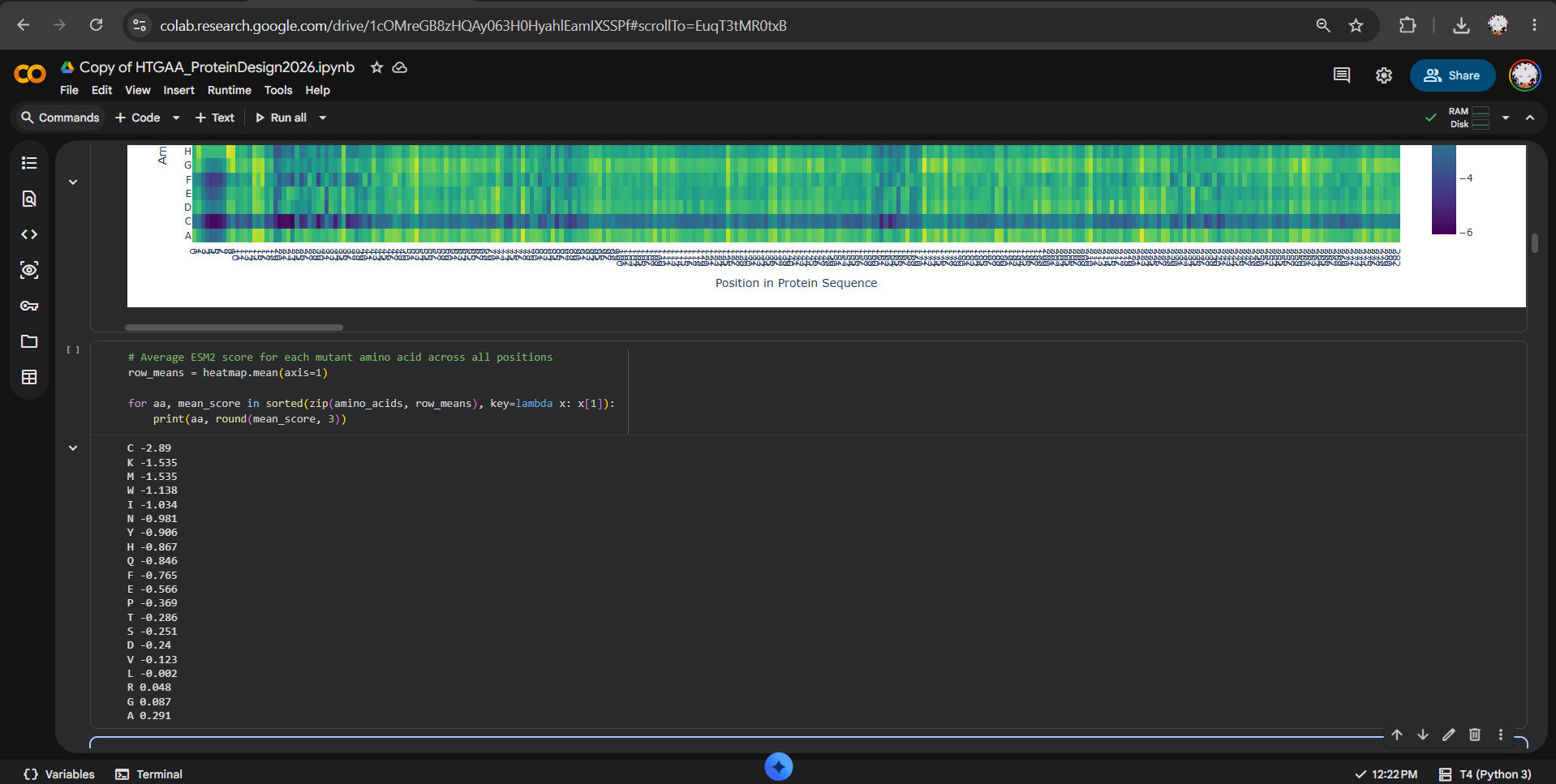
After generating the ESM2 mutational scan heatmap, I found it difficult to confidently interpret specific patterns only by visual inspection, because the plot contains many residues and mutations compressed into a dense matrix. To make the interpretation more objective, I used ChatGPT to help me write small analysis snippets to quantify the heatmap directly. I run a script to calculate the average ESM2 score for each mutant amino acid across all positions and found out that substitutions to cysteine are broadly disfavored across the MelC2 sequence.
In fact, in the heatmap, the cysteine row apparently shows many strongly negative scores, suggesting that the model predicts cysteine mutations to be poorly compatible with this protein. This makes biological sense because cysteine can introduce reactive thiol chemistry, unwanted disulfide-like interactions, or local structural constraints that may disrupt folding or stability, especially in a soluble bacterial enzyme where cysteine is not broadly used as a tolerated replacement.
Question 2
During the latent space analysis, I tried to use the provided SCOPe/Astral sequence dataset from the notebook, but I could not load it correctly in Colab. When I attempted to display sequences, I got an IndexError: list index out of range, which indicated that no sequence records had been parsed.
At first, I tested whether the issue was caused by comment lines before the first FASTA entry and tried using the fasta-pearson parser. After further debugging with Gemini/AI assistance in Colab, the issue appeared to be that the dataset URL was not returning the expected FASTA file, but HTML content instead.
I also tried opening the SCOPe/Astral page manually in the browser, but the site displayed an anti-bot verification page and did not provide access to the dataset.
Because of this, Biopython could not parse the dataset, so I was not able to generate the reduced-dimensionality map or place my protein in it.
If the dataset had loaded correctly, my workflow would have been:
Parse the SCOPe/Astral FASTA dataset.
Add the MelC2 Chain B sequence to the dataset.
Generate ESM2 embeddings for all sequences.
Reduce the embeddings using t-SNE.
Highlight MelC2 in the resulting map.
Compare MelC2 to its nearest neighbors.
a) Use the provided sequence dataset to embed proteins in reduced dimensionality I attempted to use the provided SCOPe/Astral sequence dataset, but the file could not be accessed correctly. The downloaded content was HTML rather than a valid FASTA file, so I could not generate ESM2 embeddings from the provided dataset.
b) Analyze the different formed neighborhoods: do they approximate similar proteins? Since the dataset could not be parsed, I could not generate or analyze the embedding neighborhoods directly. Conceptually, I would expect ESM2 embeddings to place proteins with related sequence-level features, domains, motifs, or families closer together, but I could not verify this with the provided dataset.
c) Place your protein in the resulting map and explain its position and similarity to its neighbors My plan was to add MelC2 tyrosinase from PDB 6J2U Chain B to the dataset before embedding, then inspect whether it clustered near related proteins such as oxidoreductases, tyrosinases, or metal-binding enzymes. Since the dataset could not be accessed correctly, I could not place MelC2 in the final map, so this remains a planned analysis rather than a completed result.
C2. Protein Folding
Question 1
I folded the MelC2 tyrosinase Chain B sequence from PDB 6J2U using ESMFold. The input sequence was 285 amino acids long. The prediction completed successfully with pTM = 0.906 and average pLDDT = 86.743, suggesting that ESMFold produced a high-confidence global fold for MelC2.
At the fold level, yes: the ESMFold prediction appears broadly consistent with the original MelC2 structure. However, I did not calculate RMSD, and the original PDB structure includes MelC2 in complex with MelC1 and metal ions, while ESMFold predicts from sequence alone. Therefore, I interpret the result as a strong qualitative fold-level match, not a precise coordinate-level comparison.
To test whether the MelC2 predicted structure is resilient to a small sequence change, I first introduced a single point mutation into the Chain B sequence.
I used the following simple Python function to generate the mutant sequence here.
I selected position 100, where the native residue is serine (S), and mutated it to cysteine (C):
I then used this S100C MelC2 mutant sequence as the input for a new ESMFold prediction, so I could compare its predicted fold and confidence scores with the native MelC2 prediction.
The S100C mutant produced almost the same ESMFold confidence scores as the native sequence.
Length: 285
ptm: 0.906
plddt: 86.874
After introducing the S100C mutation, the predicted structure still appeared compact and globular, with no obvious large-scale disruption compared to the native model. This suggests that MelC2 is structurally resilient to this single substitution at the overall fold level.
Mutant 2
I generated this 16-amino-acid segment-level mutant using a short Python script suggested by ChatGPT here. The script replaced residues 120-135 of the native MelC2 sequence with a glycine-rich segment while preserving the original protein length. I used this to test whether the predicted MelC2 fold is resilient to larger local sequence disruption.
The segment mutant produced a lower-confidence ESMFold prediction than the native and S100C sequences. The native MelC2 model had pTM = 0.906 and pLDDT = 86.743, while the segment mutant dropped to pTM = 0.865 and pLDDT = 81.386.
Visually, the predicted structure still formed a compact globular fold, so the protein did not appear completely disrupted. However, the decrease in both pTM and pLDDT suggests that replacing residues 120-135 with glycines weakened the model’s confidence in the fold.
This makes sense because a glycine-rich replacement can increase flexibility and remove side-chain interactions that may help stabilize the local structure. Still, these are structure predictions only, experimental testing would be needed to know whether catalytic activity or copper/metal-related function is preserved.
Fold still predicted, but confidence decreased, suggesting the perturbation affected structural stability more than the point mutation
C3. Protein Generation
Question 1
I used ProteinMPNN to redesign the MelC2 chain from PDB 6J2U. I set Chain B as the designed chain and kept Chain A fixed, since Chain B is MelC2 tyrosinase and Chain A is the MelC1 caddy/cofactor protein.
ProteinMPNN used 273 resolved residues from Chain B and generated a redesigned sequence with:
Native score: 1.2305
Designed score: 0.7427
Sequence recovery: 0.5751
The sequence recovery means that about 57.5% of the redesigned residues matched the native MelC2 sequence. This suggests that ProteinMPNN found a sequence predicted to fit the same backbone while changing a substantial part of the original sequence.
However, this only suggests structural compatibility. It does not prove that the redesigned protein would preserve tyrosinase activity, metal binding, or melanin production.
Question 2
I folded the ProteinMPNN-designed MelC2 sequence with ESMFold to test whether the redesigned sequence still predicts a MelC2-like structure.
Sequence
Length
pTM
pLDDT
Interpretation
Native MelC2
285 aa
0.906
86.743
High-confidence native fold prediction
ProteinMPNN design
273 aa
0.878
80.444
Still folds with good confidence, but lower than native
The ProteinMPNN-designed sequence produced pTM = 0.878 and pLDDT = 80.444. These scores are lower than the native MelC2 prediction, but still reasonably high, suggesting that the redesigned sequence remains structurally compatible with the MelC2 backbone.
Because the designed sequence had only 57.5% sequence recovery, it is substantially different from native MelC2. However, ESMFold still predicted a compact fold with good confidence. This suggests that ProteinMPNN generated a sequence that may preserve the overall structure, although this does not prove preservation of tyrosinase activity, metal binding, or melanin production.
Final Conclusions
Sequence / model
Type of test
Change introduced
Length
pTM
avg pLDDT
Result / interpretation
Native MelC2
Baseline ESMFold prediction
Original MelC2 Chain B sequence from PDB 6J2U
285 aa
0.906
86.743
High-confidence compact fold. Used as the reference for comparison.
S100C mutant
Point mutation
Serine at position 100 replaced by cysteine
285 aa
0.906
86.874
Scores were essentially unchanged compared with native MelC2. The global fold appears resilient to this single point mutation.
Segment mutant 120-135 Gly
Large local perturbation
Residues 120-135, RSLDGRVMDGPFAAST, replaced with 16 glycines
285 aa
0.865
81.386
Still predicted to fold, but with reduced confidence. This suggests the global fold is not destroyed, but the perturbation affects structural confidence/stability more than the point mutation.
ProteinMPNN-designed MelC2
Inverse-folding design + ESMFold validation
ProteinMPNN redesigned Chain B using the 6J2U backbone; sequence recovery = 0.5751
273 aa
0.878
80.444
Still predicted to fold with reasonably good confidence, despite only ~57.5% sequence recovery. Suggests the backbone can support substantial sequence variation, but function is not guaranteed.
Overall, MelC2 appears structurally robust at the global fold level. However, all of these conclusions are structural predictions. A preserved fold does not prove preserved tyrosinase activity, copper/metal binding, or melanin production. Functional validation would still require experimental testing.
Part D. Group Brainstorm on Bacteriophage Engineering
My group and I are conducting research for the group phage project. We have set up a shared Google Docs (screenshot below).
Phage reading material
We reviewed the Week 4 phage reading material and used it to focus the proposal on the MS2 L protein, especially its stability, DnaJ dependence, membrane insertion, and lysis function.
From the proposed bacteriophage engineering goals, our group focused on: Increased stability of the L protein
Our short group plan was to use computational protein design tools to identify mutations that could improve the stability of the MS2 L protein. One possible direction was to make the L protein less dependent on the bacterial chaperone DnaJ by identifying mutations that could improve folding, membrane insertion, or oligomerization.
We proposed using:
Protein language model mutational scoring
In silico mutagenesis
Experimental L-protein mutant data
Biological reasoning based on known L-protein functional regions
These tools can help prioritize mutations before experimental testing. Protein language model scores can identify substitutions that are sequence-compatible, while experimental mutant data and biological reasoning can help filter candidates based on possible effects on DnaJ dependence, membrane behavior, and lysis function.
Potential pitfalls: One pitfall is that positive LLR scores may reflect sequence plausibility, but not necessarily improved lysis function. A second pitfall is that increasing protein stability may not always improve function, because L-protein activity may require flexibility, membrane disruption, or host-factor interaction.
Pipeline schematic
MS2 L-protein sequence: mutational scoring notebook → shortlist positive-scoring substitutions → compare with experimental L-protein mutant data → map candidates to functional regions → select mutations for future experimental testing
Individual plan / contribution
My individual contribution was to select candidate MS2 L-protein mutations by combining LLR scores, experimental mutant data, and biological reasoning.
I selected two soluble-region mutants, S9Q and C29R, to probe folding and possible DnaJ dependence. I also selected three transmembrane-region mutants, A45L, T52L, and N53L, to probe membrane insertion and oligomerization.
Mutant
Region
LLR
Rationale
S9Q
Soluble / N-terminal
2.014
May affect folding or DnaJ-related surface chemistry
C29R
Soluble / N-terminal
2.395
Strong positive score; may alter chaperone-recognition surfaces
A45L
Transmembrane
1.539
May increase hydrophobic packing and membrane stability
T52L
Transmembrane
1.814
Polar-to-hydrophobic change that may improve membrane compatibility
N53L
Transmembrane
1.865
Additional transmembrane-stabilizing candidate
Use of AI assistance
I used ChatGPT as a writing and organization assistant to help structure this section and make sure the required items were clearly addressed. I reviewed, edited, and finalized the scientific content myself.
Week 5 HW: Protein Design Part 2
Part A: SOD1 Binder Peptide Design (From Pranam)
Part 1: Generate Binders with PepMLM
Question 1
This is human SOD1 sequence from UniProt (P00441) removing the initial Met
ATKAVCVLKGDGPVQGIINFEQKESNGPVKVWGSIKGLTEGLHGFHVHEFGDNTAGCTSAGPHFNPLSRKHGGPKDEERHVGDLGNVTADKDGVADVSIEDSVISLSGDHCIIGRTLVVHEKADDLGKGGNEESTKTGNAGSRLACGVIGIAQ
FASTA
introducing the A4V mutant associated with the most aggressive forms of the ALS disease
ATKVVCVLKGDGPVQGIINFEQKESNGPVKVWGSIKGLTEGLHGFHVHEFGDNTAGCTSAGPHFNPLSRKHGGPKDEERHVGDLGNVTADKDGVADVSIEDSVISLSGDHCIIGRTLVVHEKADDLGKGGNEESTKTGNAGSRLACGVIGIAQ
Question 2 and 3
With the help of ChatGPT and Gemni, I generated 2 new cells ir order to generate four peptides of length 12 amino acids conditioned on the mutant SOD1 sequence.
Interpretation: The perplexity score is PepMLM’s confidence in the peptide under its generative model. PepMLM perplexity can be interpreted this way: lower = higher confidence
PepMLM assigns higher confidence to the four generated peptides than to the known binder under this scoring scheme, with WRYGAAAVEWKE ranked best (lowest perplexity).
The known binder has higher perplexity, suggesting it is less consistent with PepMLM’s learned binder distribution for this target, even though it is experimentally reported to bind. This highlights that PepMLM perplexity is not an experimental binding score. Also, it suggests that perplexity alone is insufficient to validate binding.
As I found this really strange, I decided to find out checks I could run to see whether this was an error/artifact:
Conclusion
My generated peptides are enriched in W/V/A/Y and look like classic short hydrophobic binders. The known binder FLYRWLPSRRGG has a highly charged tail (RRGG) and a different composition pattern, which the model may assign low probability to even if it binds in reality.
At first, I mistakenly evaluated all peptides in the same run.
Then I noticed the AlphaFold Server treated that as one multi-chain complex with 6 chains total (SOD1 + 4 generated peptides + the known binder). So to compare them I would had to run 5 separate jobs.
SOD1 + HRVPVAGVEWWE: ipTM = 0.34; pTM = 0.86
Where the peptide appears to bind?
The peptide is positioned along an external surface of the SOD1 β-strand core, contacting a β-sheet edge/adjacent loop (surface-bound).
SOD1 + WSYYVTAVAHKE: ipTM = 0.22; pTM = 0.81
Where the peptide appears to bind?
The peptide shows weak localization and appears loosely associated with the protein surface, without a clearly defined contact region.
SOD1 + WRYGAAAVEWKE: ipTM = 0.41; pTM = 0.85
Where the peptide appears to bind?
The peptide is placed near a β-barrel edge/loop region on the outer surface of SOD1 (surface-bound).
SOD1 + WSVPVVAIEHGE: ipTM = 0.44; pTM = 0.86
Where the peptide appears to bind?
The peptide is positioned on a distinct surface patch on the β-barrel face/edge, appearing more localized than the others (surface-bound).
Where the peptide appears to bind?
The peptide contacts the protein surface and appears partially inserted into a shallow surface groove/cleft (partially buried relative to the others).
The observed ipTM values are uniformly low (0.22–0.44), indicating limited AlphaFold3 confidence in any specific peptide–SOD1 interface. Among the PepMLM-generated candidates, WSVPVVAIEHGE (ipTM = 0.44) and WRYGAAAVEWKE (ipTM = 0.41) score higher than the known binder FLYRWLPSRRGG (ipTM = 0.30), while HRVPVAGVEWWE (0.34) is slightly higher and WSYYVTAVAHKE (0.22) is lower. Overall, PepMLM-generated peptides match or exceed the known binder by ipTM, but the absolute scores suggest weakly supported, mostly surface-associated binding modes rather than a high-confidence complex.
Part 3: Evaluate Properties of Generated Peptides in the PeptiVerse
HRVPVAGVEWWE
WSYYVTAVAHKE
WRYGAAAVEWKE
WSVPVVAIEHGE
FLYRWLPSRRGG (control)
Across all five peptides, PeptiVerse predicts solubility = 1.000 and non-hemolytic behavior (hemolysis probabilities 0.035–0.064), so none of the candidates are flagged as poorly soluble or strongly hemolytic. Predicted binding affinities (pKd/pKi) vary and do not track ipTM: the highest-ipTM peptide (WSVPVVAIEHGE, ipTM 0.44) has the lowest predicted affinity (5.338), while WRYGAAAVEWKE has a higher predicted affinity (6.526) but slightly lower ipTM (0.41).
The known binder (FLYRWLPSRRGG) shows mid-range predicted affinity (5.962) and ipTM (0.30). Considering binding prediction plus safety-like properties, WRYGAAAVEWKE best balances the set: it has the highest predicted affinity (6.526), is predicted soluble (1.000), and has low hemolysis probability (0.047), while still achieving a relatively higher ipTM (0.41) compared to most others.
Peptide to advance: WRYGAAAVEWKE - it is predicted to be soluble, low-hemolysis, and has the strongest predicted binding affinity among the tested peptides, with moderate (though still low-confidence) structural support from AlphaFold3 (ipTM 0.41).
Part 4: Generate Optimized Peptides with moPPIt
I used the moPPIt Colab on a GPU runtime and pasted the A4V mutant SOD1 sequence (mature form without initiator Met). Here’s my collab copy.
I set binder length to 12 aa and generated a pool of candidate peptides using multi-objective guidance. I enabled affinity guidance and included solubility and hemolysis guidance to bias toward more developable peptides.
Binder (12-aa)
Solubility
Half-life
Affinity
EWWRERLRQTLI
0.5833
0.5833
6.0163
EDWLATLRAATS
0.5000
5.9279
5.7517
EEEWRQLQSQYE
0.8333
4.4313
6.8902
TEEEGVRWKRGV
0.7500
4.0548
6.4628
ELLQWILGITIE
0.4167
13.4681
6.1644
Compared to PepMLM, moPPIt produces peptides shaped by explicit objectives. PepMLM peptides were more diverse but less controlled with respect to developability properties whereas moPPIt candidates tend to show stronger biases in composition, more consistent physicochemical properties across candidates, and often a narrower “design family” reflecting the guidance constraints. On this run, the moPPIt outputs are more compositionally biased toward charged residues (E/D and R/K), consistent with explicit optimization for solubility and half-life alongside affinity. Here’s a summary interpretation of the results:
Best predicted affinity: EEEWRQLQSQYE (6.8902)
Best predicted solubility: EEEWRQLQSQYE (0.8333)
Best predicted half-life: ELLQWILGITIE (13.4681)
Most “balanced” if you prioritize binding + solubility: EEEWRQLQSQYE (top on both, but not top half-life)
Most “balanced” if you prioritize half-life strongly: ELLQWILGITIE (best half-life, but lowest solubility)
Before any clinical consideration, I would follow a staged evaluation: (1) in silico screening for interface plausibility (AlphaFold3 ipTM/PAE consistency across seeds) plus basic developability predictions (solubility, hemolysis, aggregation risk); (2) in vitro binding assays (SPR/BLI or competition ELISA), stability in serum, and cytotoxicity/hemolysis assays; (3) cell-based assays for functional effect and off-target toxicity; (4) only after robust preclinical evidence, proceed to in vivo PK/PD and safety studies. In other words, moPPIt designs are hypotheses that must be filtered by structural consistency and validated experimentally before any translational claims.
Part B: BRD4 Drug Discovery Platform Tutorial (Gabriele)
Since this was an optional part, I decided to skip for now.
Part C: Final Project: L-Protein Mutants
Phage Lysis Protein Design Challenge
L-Protein Engineering | Option 1: Mutagenesis
I ran the mutational scoring notebook to obtain per-substitution LLR scores and shortlisted mutations with positive scores.
Position
Wild_Type_AA
Mutation_AA
LLR_Score
50
K
L
2.561464
29
C
R
2.395425
39
Y
L
2.241777
29
C
S
2.043149
9
S
Q
2.014323
29
C
Q
1.997047
29
C
P
1.971026
29
C
L
1.960644
50
K
I
1.928798
53
N
L
1.864930
61
E
L
1.818097
52
T
L
1.813966
50
K
F
1.802066
29
C
T
1.797245
29
C
K
1.795876
5
F
Q
1.795244
5
F
R
1.659717
29
C
A
1.648654
27
Y
R
1.628060
22
F
R
1.602028
5
F
P
1.596888
50
K
V
1.594572
50
K
S
1.574555
5
F
T
1.559023
5
F
S
1.556416
45
A
L
1.539248
39
Y
S
1.517457
27
Y
S
1.497052
40
V
L
1.477630
27
Y
L
1.474637
I then intended to cross-check each shortlisted mutation against the experimental mutant dataset (L-Protein Mutants) to see whether the experimental lysis phenotype is directionally consistent with the LLR score.
Only 6 substitutions from my scored shortlist overlapped with the experimental table (C29R, C29S, K50I, K50S, Y27S, Y39S). In the experimental dataset, all overlapping substitutions were labeled as non-lytic (Lysis = 0) despite having positive LLR scores in the notebook. This suggests that, for MS2 L-protein, sequence-only language-model scores may not reliably capture key determinants of lysis (likely influenced by membrane insertion, oligomerization, and host-factor dependence). We therefore should treat LLR scores as a hypothesis generator, not a predictor of functional lysis.
I selected five single-point variants, including two mutations in the soluble region (positions 1–40) and three in the transmembrane region (TM) (positions 41–75), as required.
I selected five single substitutions with positive LLR scores. I enforced the assignment constraint by choosing two mutations in the soluble region (positions 1–40) and three in the transmembrane region (positions 41–75).
Here are the 5 mutants I choose:
Mutant 1 - S9Q (soluble, LLR = 2.014)
Sequence:
METRFPQQQQQTPASTNRRRPFKHEDYPCRRQQRSSTLYVLIFLAIFLSKFTNQLLLSLLEAVIRTVTTLQQLLT
Rationale: High positive score in the soluble region (putative DnaJ-interaction domain). Ser→Gln increases hydrogen-bonding potential and may alter surface chemistry without strongly destabilizing the fold.
Mutant 2 - C29R (soluble, LLR = 2.395)
Sequence:
METRFPQQSQQTPASTNRRRPFKHEDYPRRRQQRSSTLYVLIFLAIFLSKFTNQLLLSLLEAVIRTVTTLQQLLT
Rationale: One of the strongest positive-scoring substitutions in the soluble region. Adds a positive charge that could reshape chaperone-recognition or interaction surfaces.
Mutant 3 - A45L (TM, LLR = 1.539)
Sequence:
METRFPQQSQQTPASTNRRRPFKHEDYPCRRQQRSSTLYVLIFLLIFLSKFTNQLLLSLLEAVIRTVTTLQQLLT
Rationale: Hydrophobic substitution in the transmembrane segment. Ala→Leu increases hydrophobicity and may stabilize membrane helix packing/insertion and oligomer stability.
Mutant 4 - T52L (TM, LLR = 1.814)
Sequence:
METRFPQQSQQTPASTNRRRPFKHEDYPCRRQQRSSTLYVLIFLAIFLSKFLNQLLLSLLEAVIRTVTTLQQLLT
Rationale: Polar→hydrophobic change in the TM region. Thr→Leu may increase membrane compatibility and reduce local insertion/misfolding penalties.
Mutant 5 - N53L (TM, LLR = 1.865)
Sequence:
METRFPQQSQQTPASTNRRRPFKHEDYPCRRQQRSSTLYVLIFLAIFLSKFTLQLLLSLLEAVIRTVTTLQQLLT
Rationale: Polar→hydrophobic change in the TM region with a strong positive score. Selected as an additional TM-stabilizing candidate.
Week 6 HW: Genetic Circuits Part 1: Assembly Technologies
Assignment: DNA Assembly
Question 1: What are some components in the Phusion High-Fidelity PCR Master Mix and what is their purpose?
Phusion High-Fidelity PCR Master Mix is a 2X, ready-to-use mixture where the exact formulation is partly proprietary, but the functional components are documented in the manufacturer’s manual:
Component (Phusion 2X Master Mix)
Purpose
Phusion High-Fidelity DNA Polymerase
DNA synthesis with high fidelity + proofreading
dNTPs (dATP, dCTP, dGTP, dTTP)
Building blocks for new DNA strands
HF reaction buffer (salts + pH buffer)
Maintains optimal pH/ionic strength for enzyme function
Mg2+ (via buffer system; often MgCl2-derived)
Essential polymerase cofactor
Stabilizers / additives (partly proprietary)
Improve enzyme stability and consistency
Nuclease-free water
Solvent to reach correct 2X working concentrations
Higher Ta increases stringency, reduces non-specific binding
Question 3: There are two methods from this class that create linear fragments of DNA: PCR, and restriction enzyme digests. Compare and contrast these two methods, both in terms of protocol as well as when one may be preferable to use over the other.
Aspect / Decision point
PCR (amplification)
Restriction enzyme (cutting)
What it does
Amplifies a defined region between two primers
Cuts existing DNA at specific recognition sites
Input
Template DNA + primers
DNA substrate (plasmid/PCR product/genomic DNA) + restriction enzyme(s)
Key reagents
Polymerase mix, primers, dNTPs, buffer, Mg2+
Restriction enzyme(s), buffer, often BSA (enzyme-dependent)
Protocol core steps
Denature → anneal → extend (cycling)
Incubate DNA with enzyme(s) at recommended temperature/time
Sequence requirements
Need primer-binding sites flanking target
Need the enzyme recognition site(s) present in the DNA
Output fragment boundaries
Defined by primer positions (base-precise)
Defined by cut sites (exact where enzyme cleaves)
Can create new sequences?
Yes - primers can add overhangs/tags/sites
No - only cuts at existing sites (unless sites were engineered earlier)
Typical use cases
Generate a specific insert, add adapters, site-directed changes, amplify from low-abundance template
Linearize a plasmid, excise an insert, diagnostic mapping, generate compatible ends for cloning
Speed / setup
Moderate - requires optimization (Ta, primers)
Fast/simple if sites exist and enzyme conditions are known
Failure modes
Non-specific bands, primer-dimers, no amplification, PCR errors
Star activity (wrong cuts), incomplete digestion, missing sites
Fidelity / errors
Depends on polymerase; can introduce mutations
No replication - does not introduce point mutations
When preferable
When you need a specific fragment and/or to add features (overhangs, tags), or template amount is low
When the fragment is already present and flanked by useful sites; when you need clean linearization/excision without amplification
Question 4: How can you ensure that the DNA sequences that you have digested and PCR-ed will be appropriate for Gibson cloning?
Check / requirement
What to do (PCR + digest)
Why it matters for Gibson
20–40 bp overlaps at every junction
Design primers so each fragment end has 20–40 bp homology to the adjacent fragment/backbone
Gibson assembly depends on annealing of complementary overlaps
Correct orientation of overlaps
Ensure the overlap sequence matches the correct neighbor (A→B, B→C, insert→vector, etc.)
Wrong overlap = wrong assembly or no assembly
Linearized backbone
Restriction-digest the vector to a single linear band; gel-purify if needed
Gibson requires a linear backbone (no undigested circular plasmid carryover)
Remove template plasmid from PCR
If PCR was from plasmid, treat with DpnI (cuts methylated template)
Prevents parental plasmid background colonies
Clean fragment ends (no inhibitors)
Purify PCR and digest products (spin column or gel extraction)
Salts, ethanol, detergents inhibit Gibson enzymes
Correct fragment sizes
Run an agarose gel to confirm expected sizes; excise/gel-purify correct bands if mixed
Verifies you’re assembling the intended pieces
Avoid duplicate/competing overlaps
Keep overlaps unique (no repeated identical overlap sequences across multiple junctions)
Prevents mis-assembly and rearrangements
Overlap doesn’t create strong hairpins/repeats
Check overlap sequences for high secondary structure/repeats
Improves annealing and reduces drop in assembly efficiency
Balanced fragment concentrations
Quantify DNA (Nanodrop/Qubit) and use equimolar amounts; keep total DNA in recommended range
Too much/too little of one piece reduces correct assembly
No internal cuts from chosen restriction enzymes
Verify your insert/parts don’t contain the restriction sites used to linearize the vector
Prevents unintended fragmentation or loss of insert
Question 5: How does the plasmid DNA enter the E. coli cells during transformation?
The plasmid DNA enter the E. coli cells during transformation through transient permeability of the cell envelope. This can happen either via:
Electroporation: a short electric pulse creates temporary membrane pores that let DNA pass into the cytoplasm.
Chemical (heat-shock) transformation: divalent cations (e.g., Ca²⁺) reduce electrostatic repulsion between DNA and the membrane, and a brief heat shock promotes DNA uptake through temporary pores/defects.
Question 6: Describe another assembly method in detail (such as Golden Gate Assembly)
a) Explain the other method in 5 - 7 sentences plus diagrams (either handmade or online).
Golden Gate Assembly is a molecular cloning technique that allows multiple DNA fragments to be assembled simultaneously in a single reaction. It uses Type IIS restriction enzymes such as BsaI, BsmBI, or BbsI, which cut DNA outside their recognition sequence and generate custom sticky ends. We can control the order and orientation in which DNA fragments assemble by placing Type IIS restriction sites around each fragment and designing specific 4-bp overhangs that are complementary only to the intended neighboring fragment, the order and orientation of DNA assembly are precisely controlled.. During the reaction, the restriction enzyme digests the DNA fragments while T4 DNA ligase simultaneously ligates matching overhangs in the same tube, making the process efficient and rapid. Because the restriction sites are removed during assembly, the correctly assembled construct cannot be cut again, while incorrect products continue to be digested, driving the reaction toward the desired product. The reaction is typically performed in a thermocycler alternating between ~37 °C (optimal for digestion) and ~16 °C (optimal for ligation). This method is widely used in synthetic biology because it enables scarless assembly of many DNA parts, although internal Type IIS restriction sites must first be removed usually by silent mutation(s).
Golden Gate Assembly – Step-by-Step Diagram
Step 1: Design fragments with Type IIS sites
Vector: [BsaI]─────────────[BsaI]
Fragment A: [BsaI]──Part A──[BsaI]
Fragment B: [BsaI]──Part B──[BsaI]
Inward-facing BsaI sites. Overhangs are designed to match the next fragment.
Step 2: Type IIS cuts outside recognition sites
Vector: GCTT—–
Fragment A: —–AATG (overhang)
Fragment B: AATG—–GCTT (overhangs)
Recognition sites (BsaI) are removed on small excised pieces.
Step 3: Annealing of fragments
Vector —–GCTT
Fragment A GCTT—–AATG
Fragment B AATG—–CGAA
Overhangs anneal only to the correct partner. Orientation is fixed.
Step 4: Ligase seals fragments
Final construct:
Vector ── Fragment A ── Fragment B
Scarless assembly. BsaI sites are gone, so the construct is stable.
Step 5: Reaction drives correct assembly
Misassembled fragments still have exposed BsaI sites → cut again
Correct product accumulates over multiple cycles
Key Points:
Modular → promoters, RBS, genes, terminators
Multi-fragment assembly in one tube
Order & orientation controlled by 4-bp overhangs
Scarless final product
b) Model this assembly method with Benchling or a similar tool!
I imported the pBBR1MCS-5 sequence as circular DNA (pBBR1MCS-5 (raw)) and imported phaA, phaB, phaC as separate linear DNA sequences.
I checked for internal BsaI sites (GGTCTC) in all sequences: the genes have no BsaI sites, and pBBR1MCS-5 has a single BsaI site, so it is not a Golden Gate destination vector by direct digest. To model Golden Gate anyway, I created a PCR-linearized Golden Gate backbone: I duplicated the plasmid and saved a linear version (pBBR1MCS-5_GG_backbone).
On this linear backbone, I created two endpoint annotations (first ~20 bp and last ~20 bp) to represent that PCR primers would add inward-facing BsaI sites + 4 bp overhangs:
start: BsaI + Overhang OH1 (added by PCR primer)
end: BsaI + Overhang OH4 (added by PCR primer)
To simplify the Benchling model, I represented Golden Gate flanks (inward-facing BsaI sites and 4-bp overhangs) as annotations rather than explicitly adding the flanking sequences. In a real build, these flanks would be introduced via PCR primers or synthesis.
I duplicated each gene to create Golden Gate-ready parts (phaA (codon optimized) anotated, phaB (codon optimized) anotated and phaC (codon optimized) anotated) and defined the assembly overhang scheme for directional order. For each gene, I added annotations with intended Golden Gate junction overhangs:
Left end: Intended Golden Gate overhang: OH1 (conceptual)
Right end: Intended Golden Gate overhang: OH2 (conceptual)
Overhangs were not added as literal sequences, I only annotated the first/last 20 bp to indicate where BsaI-generated 4 bp overhangs would be introduced via primers/synthesis.
For a simplified Golden Gate model in Benchling, I manually constructed the final plasmid sequence by opening pBBR1MCS-5 at the MCS and concatenating the backbone with phaA–phaB–phaC in the intended order. Overhangs/Type IIS flanks were represented as annotations only.
Assignment: Asimov Kernel
Asimov Kernel notes / all material on my repo “Kanbe-Mariana-HW6”. Below are just some of the info, but please have a look at the Kernel direcly.
HW6: Asimov Kernel
Exercises 1,2:
Exercise 3:
Finding the “Bacterial Demos” public repo
I started analysing the constructs with the Repressilator.
This is the description: “This is a repressilator genetic circuit. It consists of 3 transcription units, where the CDS in each is a repressor that represses the promoter in the next transcription unit. This results in an oscillation of the concentrations of the 3 proteins.”
These 3 constructs have 3 different promoters, which generates different genetic ←→ phenotipic outputs:
J23101 Promoter: A transcription unit with a strong promoter.
J23106 Promoter: A transcription unit with a medium promoter.
Using Simulation feature, the repressillator was simulated using the following parameters:
Chassis: E. coli
Duration: 408 hours
Timestep: 60 min
Transfection: Transient transfection
These was the output:
Summary of the findings:
The simulation shows rapid initial accumulation followed by relatively stable RNA and protein concentration ranges over time, while endpoint RNAP and ribosome fluxes differ substantially among the three transcription units.
The construct driven by the J23101 (strong promoter) shows the highest activity, the J23106 (medium promoter) shows intermediate activity, and the J23117 (weak promoter) shows the lowest activity.
Exercise 4: Repressilator reconstructions
I recreated the Repressilator in the empty construct using parts from the Characterized Bacterial Parts repository.
First, I used the Search function in the right-hand menu to find the required bacterial parts. Then, I dragged and dropped the selected parts into the empty construct to assemble the circuit. The final design reproduced the three-transcription-unit repressilator architecture.
After building the construct, I used the Simulator by clicking the play button to test its behavior. I then compared the simulation output with the original Repressilator Construct available in the Bacterial Demos repository.
Repressillator Reconstruction 1
I replaced pLacI (regulated by LacI) with pTetR (regulated by TetR) in the first unit, while all other simulation parameters were kept the same. That means the input regulator of that node changed, but the overall loop structure is preserved.
The goal was to observe whether changing the promoter identity altered the resulting RNA concentrations, protein concentrations, RNAP flux, or ribosome flux compared with the original repressilator design.
Using Simulation feature, the new repressillator pTetR was simulated using the same parameters as before:
Chassis: E. coli
Duration: 408 hours
Timestep: 60 min
Transfection: Transient transfection
These was the output:
Summary of the findings:
The simulation looks the same cecause from the model’s perspective the system is still a symmetric 3-repressor cycle and each node still produces a repressor and represses the next node. So the dynamics remain qualitatively equivalent.
Repressilator Reconstruction 2:
In order to try to experiment another cyclic repression topology different from TetR → LacI → LambdaCI → TetR I’ve tried these:
Replace pLambdaCI with pLacI: to make two transcription units use the same promoter and see how that would affect the circuit’s behavior.
Replace pLacI with pLambdaCI: to test what happens when I switch which repressor controls that transcription unit.
Replace TetR CDS with LacI CDS: to see how the simulation changes when one repressor is replaced by another and the circuit has less repressor diversity.
And so I re-runned the simmulation and these were the plots:
The modified circuit converges to a steady state dominated by LambdaCI, with LacI and TetR near zero, and no oscillatory behavior observed.
Exercise 5
Construct 1
I designed this construct to test high constitutive expression using the strong J23101 promoter placed upstream of LacI, with an A1 RBS to support translation and an L3S2P24 terminator to end transcription. My rationale was to build a simple bacterial circuit with no regulatory feedback, so I would expect continuous LacI expression and relatively high, stable RNA and protein levels in the simulation.
The simulation of this first construct shows rapid initial expression followed by a stable steady state. RNA concentration increases quickly and stabilizes at approximately 0.8 relative units, while protein concentration stabilizes at approximately 0.65. RNAP and ribosome flux are constant, indicating continuous transcription and translation. This matches the expectation for a constitutive expression construct driven by the strong J23101 promoter.
Construct 2
The second construct shows significantly lower expression compared to the first. RNA concentration stabilizes at approximately 0.003 relative units and protein concentration at approximately 0.0025, both much lower than in the strong promoter construct. RNAP and ribosome flux are also reduced. The system still reaches a steady state with constant expression over time, indicating that changing the promoter strength affects the magnitude of expression but not the overall behavior.
Construct 3
For the third construct, I copied the Self-regulating Circuit from the Bacterial Demos repository into my workspace and ran the simulation without modifying its structure. This allowed me to observe the behavior of a circuit with built-in feedback regulation and compare it with the constitutive expression constructs.
The self-regulating circuit shows stable expression over time, reaching a steady state without oscillations. RNA concentration stabilizes at approximately 0.56 relative units and protein concentration at approximately 0.45. RNAP and ribosome flux are constant, indicating continuous but regulated expression. Compared to the constitutive constructs, the expression level is intermediate, reflecting the effect of feedback regulation on maintaining controlled output.
These results show that promoter strength controls expression level, while circuit structure, such as feedback regulation, influences how expression is maintained over time.
Week 7 HW: Genetic Circuits Part 2: Neuromorphic Circuits
Assignment Part 1: Intracellular Artificial Neural Networks (IANNs)
Question 1
Traditional genetic circuits are usually implemented in Boolean logic (ON/OFF), hand-designed as fixed logic. so representing nuanced behaviors often requires many gates, sharp thresholds, and careful tuning, which can make designs bulky and brittle. As the number of inputs grows the circuit complexity can explode combinatorially, increasing burden by stacking multiple layers and adding intermediate nodes, which increases metabolic load, failure points, and sensitivity to part-to-part variability Also, adapting to new targets or shifting biological context often means redesigning the circuit architecture, not just re-tuning parameters.
Intracellular Artificial Neural Networks (IANNs) are parametric and trainable: you can adjust “weights” to fit a desired behavior from data (calibration/learning), then iterate as conditions change. This is more condizent with the noisy and complex nature of biological signals. IANNs are parametric and trainable, designed to operate on analog inputs, tolerate noise through distributed computation, and approximate complex decision boundaries without enumerating every logic case. Using IANN you can adjust “weights” to fit a desired behavior from data (calibration/learning), then iterate as conditions change, which is in general a very wanted feature for biological modelling.
Question 2
A useful application for an IANN could be a multi-signal “smart probiotic” controller that decides when to express a therapeutic payload in the gut based on a noisy inflammation signature. This could be a proposed pipeline:
Sensors detect several analog inputs. These can be related to a mesurable intracellular signal (i.e. information on promoters/sensors response to nitrate/NO, tetrathionate, ROS, and low pH <-> measurable intracellular signal like transcription rate or a regulator concentration)
The IANN integrates these signals as weighted contributions and computes a graded output: a continuously tunable expression level of a payload gene (e.g., an anti-inflammatory cytokine mimic, a barrier-protective peptide, or a locally acting enzyme), plus an optional reporter for monitoring.
Instead of requiring all conditions to be “true” or “false,” like Boolerian models the IANN can implement a “risk score” that turns on strongly only when the combined pattern matches inflammation, while remaining low for benign fluctuations. In practice, you would calibrate the weights using training data from known conditions (healthy vs inflamed models) so the output tracks the probability or intensity of the target state.
Limitations / failure modes: IANNs still face real biological constraints such as sensor cross-talk and context effects. These can shift input distributions. Also, weights can drift as cells evolve, and metabolic burden can reduce growth or change the very physiology being measured. The dynamic range and noise of biological parts can compress signals, making it hard to separate “moderate” from “high” states without careful normalization and controls. Time dynamics also matter: inputs arrive on different timescales (transcription vs metabolites), so the network may need memory/filters to avoid reacting to transient spikes, which can substantially increase the complexibility of the network. Finally, safety and containment become part of the spec, thus important to define acceptance balance between error type 1 and 2 defining if you’d likely need a kill switch and strict limits on maximum output to avoid unintended activation in off-target contexts.
Question 3
Assigment Part 2: Fungal Materials
Question 1
Example 1: Mycelium composite foams (grown on agricultural waste)
Used for protective packaging, insulation panels, acoustic damping, and lightweight cores.
Advantages: renewable feedstocks, low-temperature manufacturing, biodegradable or compostable end-of-life, and tunable density via growth conditions.
Disadvantages: mechanical properties can vary batch-to-batch, moisture sensitivity unless coated, and long-term durability and standards testing can be harder than for petrofoams.
Example 2: Mycelium “leather” (mycelium-based sheets)
Used for footwear, bags, apparel, and upholstery as a leather alternative.
Advantages: avoids the animal leather supply chain, potentially lower land and chemical burden, and tunable texture and thickness.
Disadvantages: still often needs finishing steps for durability and water resistance, performance can lag high-grade leather, and cost and scale are still improving.
Example 3: Fungal biocement or mycelium-bound “bio-bricks”
Used for low-load building blocks, interior architectural elements, and decorative panels.
Advantages: low-energy fabrication, can use local waste substrates, lightweight, and potentially lower embodied carbon than fired bricks or some concretes.
Disadvantages: typically not comparable to concrete for structural strength, humidity and fire performance require careful engineering, and regulatory acceptance is slower.
Example 4: Fungal pigments and dyes (fermentation-derived)
Used for textiles, inks, coatings, and cosmetics.
Advantages: renewable production, avoids some petroleum-derived dye routes, and potentially lower toxic byproducts depending on the process.
Disadvantages: stability and colorfastness can be challenging, purification costs can be nontrivial, and some pigment pathways have safety constraints depending on the organism and compound.
Question 2
One may want to tune mycelium architecture (hyphal branching, wall composition, and crosslinking) to achieve specific strength, flexibility, porosity, and water resistance for composite materials. Another application is producing programmable functional materials by engineering fungi to secrete adhesives, hydrophobins, melanin-like coatings, or crosslinking enzymes so the final material is tougher or more water-stable without heavy post-processing.
Beyond material applications, genetically engineered fungi can be used for biosensing if we add genetic circuits that turn on a visible reporter in response to VOCs, toxins, inflammation markers, or pollutants, enabling living “sensor materials.” They can also be used for biomanufacturing high-value enzymes, small molecules, and therapeutics that benefit from eukaryotic processing or secretion, and for bioremediation by enhancing the breakdown of lignin, plastic additives, dyes, PFAS-like contaminants (where feasible), or heavy-metal binding, depending on pathway and safety constraints.
Fungi can be advantageous over bacteria because filamentous growth lets them act as a self-assembling scaffold, so the organism is both the “factory” and the “fabrication method.” They also offer eukaryotic protein processing because fungi handle disulfide bonds, folding, secretion, and many post-translational modifications better than most bacteria, which matters for secreted enzymes and complex proteins. In addition, fungi naturally secrete many enzymes, which is ideal for biomass conversion and environmental breakdown workflows. Another advantage relative to bacteria is metabolic breadth since fungi often tolerate more extreme acidic conditions and diverse feedstocks, and many are strong at producing secondary metabolites.
However, bioprocesses with engineered fungi may have practical limitations compared with bacteria, such as slower growth and iteration, more complex regulation and morphology (heterogeneity in filamentous cultures can make outputs less uniform), and genetic tools that can be trickier because strain engineering and predictable expression are often less plug-and-play than in E. coli.
Assigment Part 3: First DNA Twist Order
I reviewed the Individual Final Project documentation guidelines, submitted the Google Form with my draft Aim 1, final project summary, HTGAA industry council selections, and shared DNA design folder, and completed Part 3 of the Week 2 DNA Design Challenge by designing and uploading at least one insert sequence. I also documented the backbone vector for synthesis on my website.
Week 9 HW: Cell Free Systems
Homework Part A: General and Lecturer-Specific Questions
General homework questions
Exercise 1
Explain the main advantages of cell-free protein synthesis over traditional in vivo methods, specifically in terms of flexibility and control over experimental variables. Name at least two cases where cell-free expression is more beneficial than cell production.
Cell-free systems allow full and direct control of reaction conditions and components, enabling rapid and flexible experimentation. Here’s a table with the main advantages of cell-free vs in vivo:
Aspect
Cell-free
In vivo
Environment control
Direct, tunable
Limited by cell physiology
Toxic proteins
Can express
Often lethal to host
Reaction conditions
Precisely adjustable
Fixed intracellular state
Speed
Minutes-hours
Hours-days
Component handling
Add/remove parts
Difficult
Cases where cell-free is more beneficial
Expression of toxic proteins (e.g., antimicrobial peptides)
Incorporation of non-natural amino acids
Expression of membrane proteins with detergents/liposomes
Rapid prototyping of genetic circuits
Exercise 2
Main components of a cell-free expression system and their role
Component
Role
Cell extract (lysate)
Provides ribosomes, enzymes, tRNAs
DNA/mRNA
Encodes target protein
Amino acids
Building blocks for protein
Energy system (ATP,GTP)
Drives transcription/translation
Cofactors (Mg²+, K+)
Maintain enzyme activity
Buffer
Stabilizes pH and environment
Exercise 3
Protein synthesis consumes large amounts of ATP and GTP. Because cell-free reactions lack the metabolic machinery of living cells, these energy molecules are rapidly depleted unless they are regenerated, which causes protein synthesis to stop and reduces yield.
A common way to maintain ATP supply is the phosphoenolpyruvate (PEP) system, in which PEP donates a phosphate group to ADP via pyruvate kinase to regenerate ATP: PEP + ADP → ATP (via pyruvate kinase). Other ATP regeneration strategies include creatine phosphate in which creatine phosphate transfers a phosphate to ADP via creatine kinase to rapidly regenerate ATP and glucose-based systems where Glucose is metabolized through enzymatic pathways to continuously produce ATP over longer reaction times.
PEP and creatine phosphate favor speed and simplicity, whereas glucose-based systems are better suited for longer and more sustainable reactions. Unless the process clearly requires extended reaction time, I would start with the PEP system because it typically delivers faster and higher ATP regeneration with a relatively simple setup.
Excercise 4: Compare prokaryotic versus eukaryotic cell-free expression systems. Choose a protein to produce in each system and explain why.
Prokaryotic vs eukaryotic cell-free systems
Prokaryotic
Eukaryotic
Speed
Fast
Slower
Cost
Lower
Higher
Protein folding
More limited
Better for complex proteins
Post-translational modifications
Minimal
Present or more compatible
Best suited for
Simple proteins
Complex eukaryotic proteins
Prokaryotic cell-free systems such as E. coli are faster and less expensive, making them suitable for producing simple proteins that do not require complex folding or post-translational modifications, such as GFP. In contrast, eukaryotic systems are slower and more costly but are better suited for proteins that require proper folding, disulfide bond formation, or eukaryotic processing, such as human antibody fragments.
Excercise 5
To optimize membrane protein expression in a cell-free system, I would design the reaction to include a membrane-like environment during synthesis, using detergents or liposomes to maintain solubility and support proper insertion. I would also optimize reaction conditions such as magnesium concentration and temperature, and add chaperones if necessary, to reduce misfolding and improve overall yield, because membrane proteins are especially prone to misfolding and insolubility in aqueous systems.
Challenge
Why it occurs
Experimental strategy
Expected benefit
Misfolding
Membrane proteins contain hydrophobic regions
Add chaperones; optimize temperature
Improves correct folding
Aggregation
Hydrophobic segments interact in solution
Add mild detergents (e.g., DDM)
Keeps protein soluble during synthesis
Insolubility
No native membrane is present
Add liposomes or nanodiscs
Provides membrane-like environment
Low insertion
Protein cannot embed properly in aqueous media
Include membrane mimics during expression
Supports insertion and stabilization
Poor yield
Reaction conditions may be suboptimal
Optimize Mg²⁺ and reaction conditions
Increases expression efficiency and stability
Excercise 6: Imagine you observe a low yield of your target protein in a cell-free system. Describe three possible reasons for this and suggest a troubleshooting strategy for each.
Low yield in a cell-free system can result from insufficient transcription, depletion of ATP, degradation of the expressed protein, or poor folding conditions. Troubleshooting should therefore target the limiting step directly: improve template quality if transcription is weak, reinforce energy regeneration if the reaction stalls, inhibit proteases if degradation is suspected, and optimize temperature or folding support if the protein is unstable or misfolded.
Homework question from Kate Adamala
I would design a phospholipid vesicle-based synthetic minimal cell that uses the blue-light regulator EL222 to activate expression of the tyrosinase gene melA, producing melanin as a visible record of cumulative light exposure.
Question 1
A light-exposure logging synthetic minimal cell for integration into a wearable or material patch.
a)
input:
the synthetic cell would detect blue/visible light and respond by producing melanin
a realistic light-sensing module is EL222, a one-component blue-light activated transcription factor from Erythrobacter litoralis that binds DNA upon illumination
output:
gradual, visible darkening that records cumulative exposure over time.
a realistic pigment-output gene is melA, a tyrosinase gene from Rhizobium etli that has been used to generate melanin in E. coli.
b) This function could be realized by cell-free Tx/Tl alone only partially. In bulk cell-free solution, the circuit could still produce melanin, but without encapsulation it would not behave as a discrete synthetic minimal cell and would be harder to localize, stabilize, or integrate into a material as a spatially resolved light-logging unit.
c) This function could also be realized by a genetically modified natural cell. For example, E. coli can be engineered to express melA and produce melanin. A synthetic minimal cell is preferable if the goal is a compartmentalized, material-compatible system rather than a living replicating microbe.
d) The desired outcome is that the synthetic cell becomes darker as cumulative light exposure increases. In a material, a population of these vesicles would function as a distributed exposure log: more illuminated regions would accumulate more melanin and therefore appear darker than shaded regions.
Question 2
a) The membrane would be a phospholipid vesicle, for example POPC + cholesterol, because that is a standard stable composition for synthetic cell vesicles and is also used in related artificial-cell communication systems.
b) Inside the vesicle, I would encapsulate an E. coli cell-free transcription/translation system, amino acids, NTPs, salts, and cofactors, an ATP regeneration system, such as PEP + pyruvate kinase, L-tyrosine as the melanin precursor
Cu²⁺ as a cofactor for tyrosinase, DNA encoding the light-response module and melanin-output module.
c) For the Tx/Tl source, a bacterial system is sufficient. The core regulator, EL222, is bacterial, and the output enzyme MelA tyrosinase does not require mammalian-specific post-translational processing to function as a pigment-producing enzyme.
d) The synthetic cell would communicate with the environment mainly through light, which crosses the membrane directly, so no membrane channel is required for the input. To simplify the system, I would preload tyrosine and copper inside the vesicle. If I later wanted continuous substrate exchange from the outside, I could add a pore such as α-hemolysin (Hla), which is commonly used in synthetic-cell communication designs.
Exercise 3 - Experimental details
a)
Lipids: POPC, cholesterol
Genes: EL222 from Erythrobacter litoralis as the light-activated transcription factor; melA from Rhizobium etli as the tyrosinase gene for melanin production
optional: hla for α-hemolysin if external substrate exchange is needed; Encapsulated reagents: E. coli cell-free lysate or PURE-like system, amino acids, NTPs, PEP, pyruvate kinase, tyrosine, Cu²⁺
b)
I would measure the function of the system by tracking darkening over time, using image analysis and bulk absorbance measurements. The most direct readout is the increase in visible pigmentation of illuminated vesicles relative to dark controls; microscopy could also be used to compare spatial patterns of melanin accumulation across the material.
Homework question from Peter Nguyen
Application field: Textiles / Fashion
One-sentence pitch
A textile integrated with freeze-dried cell-free melanin-producing modules that develops gradual, skin-adjacent tonal changes in response to light exposure, turning the garment into an exposure-recording surface.
How it works
The material would incorporate localized freeze-dried cell-free reaction zones containing the genetic and enzymatic components needed for melanin production, for example a light-responsive regulator such as EL222 coupled to a melanin-producing gene such as melA. When the textile is activated by hydration, these embedded reaction zones become functional and begin responding to light exposure by expressing tyrosinase and generating melanin from preloaded substrate. Over time, more exposed regions of the garment darken more than shaded or covered regions, creating gradients or “tan-line-like” traces directly in the material. Functionally, the textile behaves less like a conventional dyed fabric and more like a programmable, exposure-sensitive biological film.
Societal challenge or market need
This concept addresses the growing interest in responsive and personalized materials in fashion and design, especially materials that are not just decorative but capable of recording use, environment, or time. It also responds to demand for alternatives to static coloration and conventional dyeing by proposing a material whose visual output is generated biologically in place. Beyond fashion, the same platform could be relevant to design objects or artistic textiles that visibly register environmental exposure.
How to address limitations of cell-free reactions
Because freeze-dried cell-free systems require water for activation and are typically limited in duration, I would treat the material as an on-demand activation platform rather than a permanently active textile. The garment could be hydrated only when the user wants to generate a pattern or record a specific exposure event, which also helps manage stability and one-time use.
To improve shelf life, the cell-free modules would remain freeze-dried until use and be stored in sealed conditions;
To improve localization and handling, they could be embedded in discrete patches, printed zones, or replaceable inserts rather than distributed uniformly across the whole textile. This makes the limitation part of the design logic: the material is activated intentionally, records one event or interval, and then remains as the final artifact.
Background information (max 100 words)
Space radiation can damage DNA and reduce the reliability of biological systems used for diagnostics, manufacturing, and environmental sensing during long-duration missions. This is significant because future crews will likely depend on compact biotechnology tools rather than constant resupply from Earth. It is relevant for space exploration because cell-free systems are lightweight, storable, and already attractive for use in resource-limited environments. It is scientifically interesting because it links a basic biological question - how nucleic acid damage affects gene expression - to an applied engineering problem: how to maintain functional biotechnology in space.
Molecular or genetic target (max 30 words)
Integrity and expression efficiency of a PCR-amplified sfGFP DNA template after radiation-mimicking UV exposure.
How the target relates to the challenge (max 100 words)
The sfGFP DNA template serves as a simple reporter for whether a biologically useful DNA sequence remains functional after damage. If radiation-like exposure degrades the template, BioBits cell-free protein expression should produce less GFP signal. This makes the target directly relevant to the space biology challenge, because many space biotechnology applications depend on DNA templates remaining intact enough to be transcribed and translated. Measuring GFP output therefore provides a practical way to estimate how radiation damage could impair future cell-free diagnostics or production systems used in spacecraft or habitats.
Hypothesis or research goal (max 150 words)
My hypothesis is that increasing UV exposure, used here as a classroom-accessible proxy for radiation-induced nucleic acid damage, will reduce the ability of a PCR-amplified sfGFP DNA template to produce GFP in the BioBits cell-free expression system. I further expect that templates protected by a shielding condition, such as melanin-containing film or another UV-blocking barrier, will retain more expression than unprotected templates exposed to the same dose. The reasoning is that DNA damage should interfere with transcription and translation by reducing template integrity, while a protective barrier should lower that damage. The research goal is to test whether cell-free fluorescence output can function as a simple readout of DNA stability under space-relevant stress and whether a lightweight protective strategy improves performance.
Homework question from Ally Huang
Background information: Space radiation can damage DNA and reduce the reliability of biological systems used for diagnostics, manufacturing, and environmental sensing during long-duration missions. This is significant because future crews will likely depend on compact biotechnology tools rather than constant resupply from Earth. It is relevant for space exploration because cell-free systems are lightweight, storable, and already attractive for use in resource-limited environments. It is scientifically interesting because it links a basic biological question: how nucleic acid damage affects gene expression to an applied engineering problem: how to maintain functional biotechnology in space.
Molecular or genetic target: Integrity and expression efficiency of a PCR-amplified sfGFP DNA template after radiation-mimicking UV exposure.
How the target relates to the challenge: The sfGFP DNA template serves as a simple reporter for whether a biologically useful DNA sequence remains functional after damage. If radiation-like exposure degrades the template, BioBits cell-free protein expression should produce less GFP signal. This makes the target directly relevant to the space biology challenge, because many space biotechnology applications depend on DNA templates remaining intact enough to be transcribed and translated. Measuring GFP output therefore provides a practical way to estimate how radiation damage could impair future cell-free diagnostics or production systems used in spacecraft or habitats.
Hypothesis or research goal: My hypothesis is that increasing UV exposure, used here as a classroom-accessible proxy for radiation-induced nucleic acid damage, will reduce the ability of a PCR-amplified sfGFP DNA template to produce GFP in the BioBits cell-free expression system. I further expect that templates protected by a shielding condition, such as melanin-containing film or another UV-blocking barrier, will retain more expression than unprotected templates exposed to the same dose. The reasoning is that DNA damage should interfere with transcription and translation by reducing template integrity, while a protective barrier should lower that damage. The research goal is to test whether cell-free fluorescence output can function as a simple readout of DNA stability under space-relevant stress and whether a lightweight protective strategy improves performance.
Experimental plan:
I will amplify an sfGFP template with the miniPCR and divide it into groups:
no UV exposure
low UV
high UV, and
UV plus shielding
After treatment, each sample will be added to BioBits cell-free reactions. Negative controls will include reactions with no DNA template; positive controls will include unexposed template.
GFP fluorescence will be measured with the P51 Molecular Fluorescence Viewer and quantified by image intensity or relative brightness. The main data will be fluorescence level across conditions, which will indicate how template damage affects expression and whether the shielding condition preserves function.
Homework Part B: Individual Final Project
general info / link for my slide in the CT slide deck
Title: Engineering Tunable Skin Pigment Expression in Engineered Living Materials
Aim 1: Generate base data on melanogenesis by mapping key pathways and build an initial genetic circuit informed by this base data to produce tunable pigmentation (eumelanin-biased outputs for darker tones and pheomelanin-biased outputs for warmer tones).
Aim 2: Expand and refine the circuit aiming for selecting envisioned great candidates for wet-lab experimentation. Experiments planning.
Aim 3: Empirical essays to explore how variables such as pigment amount, distribution, and system conditions affect the final material output.
Companies: BioFabricate; Cultivarium
Industry Council Companies: BioFabricate and Cultivarium
I selected them because they each address a different core part of my project:
Biofabricate could potentially bring a strong expertise on how to translate embedding melanin-related genetic circuits into a desirable (aesthetic and functional) engineered living material, while Cultivarium is well aligned with the wet-lab side of the project, particularly chassis selection, non-model organism engineering, and the practical challenge of implementing and optimizing the circuit in a host such as Komagataeibacter rhaeticus.
Submit the Final Project selection form.
Started planning how I will write my final project documentation based on the guidelines
To be done by April 10 at 11PM ET.
Prepare your first DNA order and put it in the “Twist (MIT)” or “Twist (Nodes)” tab of the 2026 HTGAA Ordering: DNA, Reagents, Consumables spreadsheet, as appropriate.
I will measure visible melanin output in the material as the primary readout of the project.
I want to quantify:
Degree of darkening
Spatial distribution of pigmentation
Stability/Persistence of the pigmentation in the bacterial cellulose / after drying or storage
These measurements are directly relevant because they indicate whether the melanin-producing system is functioning and whether the output is compatible with the intended material application.
How to measure?
a) Initial measurements: Molecular biology
First, to validate the genetic component, I would measure the presence of the designed construct by PCR and confirm the DNA sequence by DNA sequencing. I would use agarose gel electrophoresis to confirm correct DNA assembly before testing expression.
To verify whether the melanin-producing pathway is being expressed in a cell-free or microbial test system before integration into the material, I could also use gel electrophoresis to confirm DNA assembly and cell-free assay readouts to test whether the construct produces the expected visible darkening before integrating it into bacterial cellulose.
b) Material measurements:
These are the most direct indicators of whether the melanin-producing system is working and whether the output is useful as a material feature rather than only a biochemical signal.
I would first document the material using standardized photography under controlled lighting and then quantify changes in tone by image analysis, comparing pixel intensity or color values across samples and conditions. I would also use absorbance or spectrophotometric measurements when possible to obtain a more objective estimate of pigment accumulation.
As a secondary measurement, I would use UV-Vis absorbance or reflectance spectroscopy, if available, to quantify pigment accumulation more objectively.
Homework: Waters Part 1 — Molecular Weight
Question 1
eGFP (native): ~26.9 kDa
eGFP + LEHHHHHH tag: ~27,875.41 Da
All spaces and line breaks were removed.
Question 2
To calculate the molecular weight of intact eGFP, I selected two adjacent peaks from the LC-MS spectrum at m/z 933.7349 and 965.9684.
Using the adjacent charge state equation, this gives a charge state of approximately 30 for the first peak, meaning the second adjacent peak corresponds to 29. I then used these charge states to calculate the molecular weight from each peak, using the relationship between m/z, charge, and proton mass. This gave values of 27,981.8 Da and 27,983.9 Da, respectively, with an average experimental molecular weight of 27,982.9 Da.
I then compared this experimental value with the theoretical molecular weight of the full eGFP construct, including the LE linker and His tag, which is 28,006.3 Da. The relative error was 0.084%, showing very good agreement between the experimental and predicted values. This indicates that the adjacent charge state method produced an accurate estimate of the intact protein mass.
For the zoomed-in peak near m/z 1474, the charge state can also be reasonably assigned. Based on the experimental molecular weight, a 19+ ion would appear at about m/z 1473.8, which closely matches the observed signal. So yes, the charge state of the zoomed-in peak can be observed, and it is most consistent with z = 19.
Homework: Waters Part II — Secondary/Tertiary structure
Question 1
This unfolding changes how the protein gets charged during electrospray ionization. In the native state, fewer sites are accessible for protonation, so the protein carries fewer charges and appears at higher m/z values. In the denatured state, more sites are exposed, so the protein can carry more charges, which shifts the signal to lower m/z values.
In the mass spectrum (Figure 2), this shows up clearly. The native protein has a tighter charge state distribution at higher m/z, while the denatured protein has a broader distribution shifted toward lower m/z. So basically, by looking at how the charge state envelope shifts, we can tell whether the protein is folded or unfolded.
Question 2
If we zoom into the peak around m/z ~2800 in the native spectrum, we can determine the charge state by looking at the spacing between the small peaks in the isotope pattern. At high resolution, these peaks are separated by approximately 1/z.
From the inset, the peaks are spaced by about ~0.05–0.06 m/z units. Since the spacing is equal to 1/z, this suggests:
z ≈ 1 / 0.05 ≈ 20
So the charge state is approximately 20+.
This also makes sense when compared to the protein’s mass (~28 kDa). A 20+ ion would appear around m/z ≈ 2800, which matches the observed peak. So both the isotope spacing and the overall m/z position are consistent with a charge state of 20+.
Homework: Waters Part III — Peptide Mapping - primary structure
Question 1
Lysine (K): 20
Arginine (R): 6
Total K + R: 26
Number of tryptic peptides generated: 27
To analyze the eGFP standard, I first reviewed the full amino acid sequence provided, including the LE linker and the C-terminal His-tag (HHHHHH). I then identified all lysine (K) and arginine (R) residues, since trypsin cleaves specifically after K and R residues unless the following amino acid is proline (P).
After counting the residues in the sequence using Benchlink, I found a total of 20 lysines (K) and 6 arginines (R), for a combined total of 26 potential trypsin cleavage residues.
Question 2
I also checked whether any of these K or R residues were followed by proline, which would block trypsin cleavage, and I found that none of them were followed by P. Therefore, all 26 sites are valid trypsin cleavage sites. Because each cleavage site divides the sequence into peptide fragments, the total number of peptides expected from complete tryptic digestion is the number of cleavage sites plus one. Based on this, the digest should generate 27 peptides in total.
To double check this, I have pasted the eGFP amino acid sequence into the ExPASy PeptideMass tool, selected trypsin as the digestion enzyme, and used the parameters shown in Figure 4, including 0 missed cleavages, monoisotopic mass, and no modifications. I then clicked “Perform the Cleavage” to generate the predicted list of tryptic peptides and determine the total number of peptides produced.
After manually counting 26 lysine and arginine residues, I expected a total of 27 tryptic peptides. When I ran the sequence in the ExPASy PeptideMass tool, the output showed fewer peptides than expected. However, this is because the tool was set to display only peptides with masses greater than 500 Da, which excludes smaller fragments.
Question 3
To analyze the peptide map, I examined the total ion chromatogram (TIC) in Figure 5a and focused on the retention time window between 0.5 and 6 minutes. I counted only peaks with a relative intensity greater than approximately 10% of the base peak, as specified. Based on this criterion, I observe approximately 18–20 chromatographic peaks between 0.5 and 6 minutes. The exact number depends slightly on how closely overlapping peaks are resolved, particularly in the region between ~2.5 and 3.5 minutes, where several peaks are closely spaced.
Question 4
The chromatogram shows fewer peaks than the number of peptides predicted from question 2. In question 2, the full tryptic digest was predicted to generate 27 peptides. In the chromatogram, counting only peaks above the 10% relative abundance threshold between 0.5 and 6 minutes gives roughly 20 peaks.So there are fewer peaks in the chromatogram than predicted peptides. This likely means that some peptides are either too low in abundance, too small, or co-elute with other peptides and therefore do not appear as separate visible chromatographic peaks.
Question 5
To analyze the peptide in Figure 5b, I first identified the most intense peak in the spectrum, which appears at m/z ≈ 525.77. I assumed this corresponds to the most abundant charge state of the peptide.
To determine the charge state, I examined the zoomed-in isotope pattern. The spacing between adjacent isotope peaks is about 0.5 m/z unit. Since isotope spacing is approximately equal to 1/z, a spacing of ~0.5 indicates that z ≈ 2. Based on this, I concluded that the most abundant charge state is z = 2+.
Next, I calculated the mass of the singly charged form of the peptide, M+H+, using the relationship:
M+H+ = z(m/z) − (z − 1)(1.0073)
Substituting the values:
M+H+ = 2(525.77) − 1.0073 ≈ 1050.53 Da
So, the peptide has:
m/z ≈ 525.77
charge state z = 2+
M+H+ ≈ 1050.53 Da
This result is consistent with the spectrum, since there is also a peak visible near m/z ≈ 1050.52, which corresponds to the singly charged form of the same peptide.
Question 6
From the previous step, I determined that the most abundant ion was at m/z 525.7671 with charge z = 2, which gives a singly charged mass of about M+H+ = 1050.53 Da. In the PeptideMass results, the closest expected peptide mass is 1050.5214 Da, which corresponds to the peptide FEGDTLVNR. Based on that match, I identified the peptide as FEGDTLVNR.
To evaluate the mass accuracy, I compared the experimental mass to the theoretical mass from PeptideMass. Using the exact value labeled in the spectrum, the experimental singly charged mass is 1050.52438 Da, and the theoretical mass is 1050.5214 Da. The mass difference is therefore:
I use the aid of chatgpt for comparing the theoretical and experimental subunits masses in the answering below.
To identify the Keyhole Limpet Hemocyanin (KLH)’s oligomeric states in the CDMS spectrum, I used the subunit masses given in Table 1 and multiplied them by the number of subunits expected in each assembly. I then compared those theoretical masses to the labeled peaks in Figure 7.
Here are the results summarized in a table:
Oligomeric species
Theoretical mass
Peak in the mass spectrum of Keyhole Limpet Hemocyanin (KLH) acquired on the CDMS
Interpretation
7FU Decamer
3.4 MDa
~3.4 MDa
This peak is consistent with the expected mass of a 10-subunit 7FU assembly.
8FU Didecamer
8.0 MDa
~8.33 MDa
This is the closest and most intense peak, so it is the strongest candidate for the 8FU didecamer.
8FU 3-Decamer
12.0 MDa
~12.67 MDa
This peak is reasonably close to the expected tridecamer mass and likely represents a higher-order 8FU assembly.
8FU 4-Decamer
16.0 MDa
~16-17 MDa
The weak signal in this region may correspond to the 8FU 4-decamer, although this assignment is more tentative.
Discussion
To interpret the CDMS spectrum, I compared the theoretical oligomer masses calculated from the known KLH subunit masses with the labeled peaks in Figure 7. Based on this comparison. The observed masses are not perfectly identical to the theoretical values, but they are close enough to support these assignments as working hypotheses.
Example proxy calculations:
For the 7FU decamer (10 units): 7FU subunit mass = 340 kDa
Since a decamer contains 10 subunits, the expected mass is: 10 × 340 = 3400 kDa = 3.4 MDa
In the spectrum, there is a labeled peak at about 3.4 MDa I would assign that peak to the 7FU decamer. This corresponds to a 4.5 mDa from the x axis analysis.
The slight offsets could reflect experimental uncertainty, heterogeneity in the sample, adducting, or the natural structural complexity of KLH. Overall, my interpretation is that the spectrum supports a mixture of KLH oligomeric states, with the 8FU didecamer appearing to be the predominant species and the larger 8FU assemblies likely representing less abundant higher-order associations.
The 8.33 MDa peak is by far the most intense feature in the spectrum. This suggests that the 8FU didecamer may be the dominant oligomeric state in this sample under the conditions used for CDMS.
In contrast, the peaks assigned to the 8FU 3-decamer and especially the 8FU 4-decamer are much less abundant, which may indicate that these larger assemblies are present only as minor populations or form less stably in solution.
Taking the absolute value, the mass error is approximately 836 ppm. The observed intact LC-MS mass is close to the theoretical eGFP construct mass, so the data supports that the sample is consistent with the expected GFP/eGFP construct.
I used ChatGPT as a writing and reasoning assistant to help review calculations, improve explanations, and check whether my answers addressed the homework prompts. All final interpretations, edits, and submitted content were reviewed by me.
Week 11 HW: Bioproduction & Cloud Labs
Part A: The 1,536 Pixel Artwork Canvas | Collective Artwork
I contributed 7 pixels to the global artwork experiment, helping extend a horizontal yellow line in the top-left area (see screenshot below).
At first, I was cautious and tried to understand the ongoing ideas for each section and whether there was a unifying concept. I considered introducing something new, but ultimately decided to stick with what seemed to be the area’s goal (a horizontal yellow line). For next year, it might be fun to have an in-app chat within the same domain to coordinate contributions more easily and check the current vibes.
Part B: Cell-Free Protein Synthesis | Cell-Free Reagents
Question 1
Component Category
Component
Corrected role in the cell-free reaction
Lysate
E. coli Lysate
Provides the endogenous transcription, translation, and metabolic machinery needed for in vitro gene expression.
BL21 (DE3) Star Lysate (includes T7 RNA Polymerase)
Provides the same core lysate machinery plus T7 RNA polymerase for strong transcription from T7 promoter templates.
Salts / Buffer
Potassium Glutamate
Helps set intracellular-like ionic conditions that support enzyme activity, ribosome function, and overall reaction performance.
HEPES-KOH pH 7.5
Maintains reaction pH in the range needed for stable transcription-translation activity.
Magnesium Glutamate
Supplies Mg2+, an essential cofactor for ribosomes, polymerases, and many ATP-dependent enzymes.
Potassium phosphate monobasic
Contributes phosphate and helps maintain buffer balance together with the dibasic form.
Potassium phosphate dibasic
Works with the monobasic form to maintain phosphate buffering and reaction stability.
Energy / Nucleotide System
Ribose
Supports nucleotide metabolism and regeneration pathways rather than serving as the main energy source.
Glucose
Serves as a metabolic energy substrate that helps regenerate ATP through endogenous lysate metabolism.
AMP
Acts as a nucleotide monophosphate precursor that can be phosphorylated into higher-energy adenine nucleotides.
CMP
Acts as a nucleotide precursor that can be converted into CTP for transcriptional needs.
GMP
Acts as a nucleotide precursor that can be converted into GTP for transcription and translation-related processes.
UMP
Acts as a nucleotide precursor that can be converted into UTP for transcriptional needs.
Guanine
Serves as a salvage precursor for guanine nucleotide synthesis.
Translation Mix (Amino Acids)
17 Amino Acid Mix
Provides most of the amino acid building blocks required for protein synthesis.
Tyrosine
Provides a required amino acid for translation and may also be supplied separately because of formulation or pathway-specific needs.
Cysteine
Provides a required amino acid for translation and is often added separately because of its chemical instability.
Additives
Nicotinamide
Serves as a precursor for NAD-related cofactors that support extract redox metabolism.
Backfill
Nuclease Free Water
Brings the reaction to the target volume without introducing nucleases or contaminants.
Question 2
The 1-hour PEP-NTP system supplies fully activated NTPs and high-energy phosphate (PEP) upfront, enabling fast, high-rate transcription and translation but with limited longevity due to rapid energy depletion.
In contrast, the 20-hour NMP-ribose-glucose system relies on metabolic regeneration, using NMPs and simple substrates (ribose, glucose) that are enzymatically converted into active nucleotides and ATP, trading peak speed for sustained, longer-duration protein production.
Part C: Planning the Global Experiment | Cell-Free Master Mix Design
Description: a basic (constitutively fluorescent) green fluorescent protein published in 2005, derived from Aequorea victoria. It is reported to be a very rapidly-maturing weak dimer.
sfGFP has very efficient folding and fast maturation (~13 min), allowing it to produce fluorescence quickly and reliably even under suboptimal cell-free conditions. This makes it ideal for early and robust readout.
b. Monomeric Red Fluorescent Protein 1 (mRFP1)
mRFP1: Derived from DsRed, mRFP1 has slow maturation and lower photostability, which delays fluorescence signal and reduces effective brightness in short or energy-limited cell-free reactions.
c. mKusabira-Orange2 (mKO2)
mKO2 has moderate maturation speed but higher sensitivity to photobleaching and environmental conditions, which can reduce signal stability during long incubations or repeated excitation. This protein is relatively acid-sensitive (higher pKa), so its fluorescence can decrease if the cell-free reaction acidifies over time, affecting signal stability.
d. mTurquoise2
This protein has an exceptionally high quantum yield and photostability, making it one of the brightest CFP variants and ideal for strong signal readout even at low expression levels.
e. mScarlet_I
mScarlet-I is optimized for high brightness and improved maturation efficiency among red FPs, enabling stronger signal compared to earlier RFPs, though maturation still limits very early readouts compared to GFP variants.
f. Electra2
As a newer engineered FP (likely optimized variant), its performance is typically influenced by trade-offs between brightness, folding efficiency, and maturation kinetics, meaning signal output depends strongly on how well it folds and matures in the cell-free environment.
Question 2
Hypothesis: For mKO2, increasing the HEPES-KOH buffer concentration and maintaining sufficient glucose in the cell-free mastermix will improve fluorescence over a 36-hour incubation by reducing pH drift and sustaining ATP regeneration.
Rationale: Because mKO2 is relatively acid-sensitive, stronger pH buffering should help preserve fluorescence, while sustained glucose-dependent energy regeneration should support continued protein expression and chromophore maturation, resulting in a higher final fluorescence signal.
Small caveat: glucose can also contribute to acidification depending on the metabolism of the lysate, so the strongest version is really HEPES-KOH + controlled glucose, not just “more glucose.”
Question 3
sfGFP → system calibration (TX-TL health)
Melanin has a broad absorbance spectrum, but it absorbs much more strongly at shorter wavelengths (blue/green) than at longer wavelengths (red). Melanin interferes with optical readout since we will be trying to measure fluorescence in a reaction that is simultaneously getting darker, which creates optical interference broadening the wavelengh espectrum of signal.
mScarlet-I → expression readout for melA tyrosinase especifically
fluorescence is less sensitive to melanin, so it better tracks expression alone (sfGFP → Ex ~488 nm / Em ~510 nm → high overlap with melanin absorbance; mTurquoise2 → even worse (blue region); mScarlet-I → Ex ~569 nm / Em ~594 nm → less overlap).
Question 4
For optimizing the Master Mix design for mScarlet-I in my melA tyrosinase cell-free system, I’d supplement CuSO4 since my analyte is a cooper dependent enzyme, HEPES-KOH pH 7.5 to have an additional buffer against acidification and magnesium glutamate to improve translation capacity.
At first I thought about adding glucose since it could extend energy regeneration, but then I wondered that it may also increase acidification. Since you’re worried about fluorescence readout in a pigment-producing system, I’d prioritize pH stability over extra glucose.
I’d actually supplement L-tyrosine that serve as a functional validation that my protein of interest MelA tyrosinase is being expressed and active.
Master Mix designs to be tested using mScarlet-I and sfGFP:
REACTION 1
My preparation before have received email (to your email address as registered here on the Forum) providing your personal link to participate in the Cell-Free Master Mix Cloud Lab Global Experiment:
my melA-tyrosine cell-free system
mScarlet-I
Supplement
Volume
Purpose
HEPES-KOH pH 7.5
1.0 µL
Buffer against pH drift over 36h, helping preserve mScarlet-I fluorescence and MelA activity.
L-tyrosine
0.75 µL
Provides additional substrate for MelA-driven melanin-like pigment production.
CuSO4, very low concentration
0.25 µL
Supports MelA tyrosinase activity as a copper-dependent enzyme while minimizing toxicity/inhibition.
Increasing buffering capacity with HEPES-KOH seems also a good idea because prolonged cell-free reactions coupled with melanin production lead to progressive acidification, which can reduce fluorescent protein signal, impair MelA activity, and shorten the productive lifetime of the TX-TL system.
REACTION 2
my melA-tyrosine cell-free system
sfGFP
Supplement
Volume
Purpose
HEPES-KOH pH 7.5
1.0 µL
Buffer against pH drift over 36h, helping preserve mScarlet-I fluorescence and MelA activity.
L-tyrosine**
0.75 µL
Provides additional substrate for MelA-driven melanin-like pigment production.
CuSO4, very low concentration
0.25 µL
Supports MelA tyrosinase activity as a copper-dependent enzyme while minimizing toxicity/inhibition.
Increasing buffering capacity with HEPES-KOH seems also a good idea because prolonged cell-free reactions coupled with melanin production lead to progressive acidification, which can reduce fluorescent protein signal, impair MelA activity, and shorten the productive lifetime of the TX-TL system.
REACTION 3
my melA-tyrosine cell-free system
mScarlet-I
Reagent
Volume
Purpose
L-tyrosine
0.8 µL
Direct substrate for MelA pigment production
HEPES-KOH pH 7.5
0.6 µL
Reduces pH drift over 36h
Magnesium glutamate
0.4 µL
Supports sustained transcription-translation
Low CuSO4
0.2 µL
Supports tyrosinase catalytic activity
As copper is required as a cofactor for MelA tyrosinase activity, but must be carefully controlled because excess Cu²⁺ can inhibit cell-free expression and promote nonspecific oxidative reactions I decided to test reducing it and supplement magnesium glutamate since it improves TX-TL capacity by supporting ribosomes, RNA polymerase, and Mg-ATP/GTP chemistry.
REACTION 4
my melA-tyrosine cell-free system
sfGFP
Reagent
Volume
Purpose
L-tyrosine
0.8 µL
Direct substrate for MelA pigment production
HEPES-KOH pH 7.5
0.6 µL
Reduces pH drift over 36h
Magnesium glutamate
0.4 µL
Supports sustained transcription-translation
Low CuSO4
0.2 µL
Supports tyrosinase catalytic activity
REACTION 5
my melA-tyrosine cell-free system
mScarlet-I
Reagent
Volume
Purpose
HEPES-KOH pH 7.5
1.25 µL
Stronger buffering against pH drift over 36h.
Low CuSO4
0.25 µL
Enables MelA tyrosinase activity as a copper-dependent enzyme.
Nuclease-free water
0.50 µL
Keeps total supplement volume at 2 µL without adding more substrate.
This reaction tests whether the main limitation is pH stability + copper availability, rather than additional tyrosine. It is useful because the base mastermix already contains tyrosine, so this condition asks whether MelA can produce pigment when copper is supplied and pH is stabilized without further increasing substrate concentration.
REACTION 6
my melA-tyrosine cell-free system
sfGFP
Reagent
Volume
Purpose
HEPES-KOH pH 7.5
1.25 µL
Stronger buffering against pH drift over 36h.
Low CuSO4
0.25 µL
Enables MelA tyrosinase activity as a copper-dependent enzyme.
Nuclease-free water
0.50 µL
Keeps total supplement volume at 2 µL without adding more substrate.
This reaction tests whether the main limitation is pH stability + copper availability, rather than additional tyrosine. It is useful because the base mastermix already contains tyrosine, so this condition asks whether MelA can produce pigment when copper is supplied and pH is stabilized without further increasing substrate concentration.
REACTION 7
my MelA-tyrosine cell-free system
sfGFP
Reagent
Volume
Purpose
L-tyrosine
1.50 µL
Pushes substrate availability to test whether pigment formation is substrate-limited.
CuSO4, very low concentration
0.25 µL
Enables MelA catalytic activity.
HEPES-KOH pH 7.5
0.25 µL
Minimal pH support.
This is the pigment-stress condition: it intentionally pushes melanin production to test whether sfGFP fluorescence collapses when the reaction darkens. If sfGFP drops while pigment rises, that supports using mScarlet-I as the better reporter.
REACTION 8
my MelA-tyrosine cell-free system
sfGFP or mScarlet-I
Reagent
Volume
Purpose
HEPES-KOH pH 7.5
1.50 µL
Strongly buffers against acidification over 36h.
CuSO4, very low concentration
0.25 µL
Enables MelA activity.
L-tyrosine
0.25 µL
Keeps substrate present but avoids overloading the system.
This is the long-incubation preservation condition: it tests whether the best 36h outcome comes not from maximizing substrate, but from preventing reaction decay. If fluorescence and pigment both remain stronger at 36h, pH stability is the key design variable.
My actual experiments submitted
Now that I’ve seen the inferface better, I got that the goal here is to focus on DNA construct performance, so I’ll treat this as an expression/readout experiment rather than enzyme validation.
Went too far into broader bioprocess hypotheses 😅 in my brainstorm composition hypothesis above.
Given the broader objective of optimizing the cell-free master mix for maximal fluorescence across six proteins, I will test the 2 reporters:
mScarlet-I = better reporter under melanin/dark pigment interference
sfGFP = system health / pigment-interference control
This 1st round I will test these 8 reactions - Table Followed by textual arguments
Same as Reaction 7, but tests sfGFP under melanin-producing conditions.
Reaction
Hypothesis
1
Low HEPES and low tyrosine will provide a baseline fluorescence condition for comparison across proteins.
2
The same low HEPES / low tyrosine condition will reveal whether sfGFP is more sensitive to pigment-related interference than mScarlet-I.
3
Increasing HEPES will improve fluorescence over 36h by reducing pH drift.
4
Increasing HEPES will help determine whether pH stabilization benefits sfGFP fluorescence under the same conditions.
5
Increasing tyrosine will test whether extra substrate/pigment formation reduces fluorescence through optical interference.
6
High tyrosine with sfGFP will test whether green fluorescence is especially affected by pigment accumulation.
7
Combining HEPES, tyrosine, and magnesium glutamate will improve fluorescence by supporting pH stability, substrate context, and TX-TL capacity.
8
The same combined condition with sfGFP will test whether translation support and buffering can preserve fluorescence despite stronger pigment-forming conditions.
Hypothesis: Under minimal buffering and substrate availability, both melanin production and mScarlet-I fluorescence will be limited, providing a baseline to compare improvements from other conditions.
Hypothesis: This condition mirrors Reaction 1 but uses sfGFP to evaluate baseline fluorescence without strong pigment production, serving as a reference for how each reporter behaves under minimal conditions.
Hypothesis: Increasing buffering capacity with HEPES-KOH will improve mScarlet-I fluorescence over 36 hours by reducing pH drift, even without increasing substrate availability.
Hypothesis: This condition mirrors Reaction 3 but uses sfGFP to test whether stronger buffering preserves green fluorescence, or if signal is still affected by pigment formation and optical interference.
Hypothesis: Increasing tyrosine concentration will enhance melanin-like pigment production, indicating that MelA activity may be limited by substrate availability under baseline conditions.
Hypothesis: This condition mirrors Reaction 5 but uses sfGFP to evaluate whether increased pigment formation interferes with green fluorescence, compared to the red-shifted mScarlet-I signal.
Testing: pH drift, substrate limitation, and TX-TL capacity
Hypothesis: Combining buffering (HEPES-KOH), substrate availability (tyrosine), and translation support (magnesium glutamate) will help sustain melanin production and mScarlet-I fluorescence over 36 hours by addressing the main system bottlenecks.
Hypothesis: This condition mirrors Reaction 7 but uses sfGFP to evaluate how green fluorescence behaves under melanin-producing conditions, serving as a control to assess pigment interference relative to mScarlet-I.