Week 2: DNA Read, Write, & Edit
Homework
Part 0: Basics of Gel Electrophoresis
I have watched the Week 2 lecture and recitation on DNA read/write/edit, restriction digests, Benchling, Twist, and gel electrophoresis.
Part 1: Benchling & In-silico Gel Art
Opened Benchling and signed up. Found the Lambda sequence here and copied the sequence without the header. Pasted this sequence into Benchling through “Create” > “DNA / RNA Sequence” > “New DNA / RNA Sequence”. Then I just pasted the sequence in the “Bases” field, titled it “Lambda,” and selected the topology as “Linear.”
Clicked “Digest” (the scissors icon in the right menu), selected “All enzymes,” found all seven using the search tool, and clicked “Run Digest.”

This in-silico gel image uses simulated Lambda DNA restriction digest banding patterns from the required enzymes and arranges them as a visual composition inspired by Paul Vanouse’s Latent Figure Protocol.
Part 2: Gel Art - Restriction Digests and Gel Electrophoresis
I did not complete the wet-lab restriction digest and gel electrophoresis experiment. As a Committed Listener, I completed the required in-silico gel design in Benchling, but I did not have lab access for the optional wet-lab portion.
Part 3: DNA Design Challenge
3.1. Choose your protein: Poly(3-hydroxyalkanoate) polymerase subunit PhaC
I chose Polyhydroxyalkanoate synthase (PhaC) because it is involved in the catalysis of the reaction that polymerizes (R)-3-hydroxybutyryl-CoA to produce polyhydroxybutyrate (PHB), which is an important bioproduct of interest due to its plastic/polyethylene-like properties.
Biologically, PHB serves as an intracellular energy reserve material when cells grow under conditions of nutrient limitation.
Sequence of Polyhydroxyalkanoate Synthase (PhaC): MATGKGAAASTQEGKSQPFKVTPGPFDPATWLEWSRQWQGTEGNGHAAASGIPGLDALAGVKIAPAQLGDIQQRYMKDFSALWQAMAEGKAEATGPLHDRRFAGDAWRTNLPYRFAAAFYLLNARALTELADAVEADAKTRQRIRFAISQWVDAMSPANFLATNPEAQRLLIESGGESLRAGVRNMMEDLTRGKISQTDESAFEVGRNVAVTEGAVVFENEYFQLLQYKPLTDKVHARPLLMVPPCINKYYILDLQPESSLVRHVVEQGHTVFLVSWRNPDASMAGSTWDDYIEHAAIRAIEVARDISGQDKINVLGFCVGGTIVSTALAVLAARGEHPAASVTLLTTLLDFADTGILDVFVDEGHVQLREATLGGGAGAPCALLRGLELANTFSFLRPNDLVWNYVVDNYLKGNTPVPFDLLFWNGDATNLPGPWYCWYLRHTYLQNELKVPGKLTVCGVPVDLASIDVPTYIYGSREDHIVPWTAAYASTALLANKLRFVLGASGHIAGVINPPAKNKRSHWTNDALPESPQQWLAGAIEHHGSWWPDWTAWLAGQAGAKRAAPANYGNARYRAIEPAPGRYVKAKA Source: UniProt at https://www.uniprot.org/uniprotkb/P23608/entry#sequences
3.2. Reverse Translate: Protein (amino acid) sequence to DNA (nucleotide) sequence. reh:H16_A1437 K03821 poly(R)-3-hydroxyalkanoate polymerase subunit PhaC EC:2.3.1.304 | (GenBank) phaC1; Poly(3-hydroxybutyrate) polymerase (N) atggcgaccggcaaaggcgcggcagcttccacgcaggaaggcaagtcccaaccattcaaggtcacgccggggccattcgatccagccacatggctggaatggtcccgccagtggcagggcactgaaggcaacggccacgcggccgcgtccggcattccgggcctggatgcgctggcaggcgtcaagatcgcgccggcgcagctgggtgatatccagcagcgctacatgaaggacttctcagcgctgtggcaggccatggccgagggcaaggccgaggccaccggtccgctgcacgaccggcgcttcgccggcgacgcatggcgcaccaacctcccatatcgcttcgctgccgcgttctacctgctcaatgcgcgcgccttgaccgagctggccgatgccgtcgaggccgatgccaagacccgccagcgcatccgcttcgcgatctcgcaatgggtcgatgcgatgtcgcccgccaacttccttgccaccaatcccgaggcgcagcgcctgctgatcgagtcgggcggcgaatcgctgcgtgccggcgtgcgcaacatgatggaagacctgacacgcggcaagatctcgcagaccgacgagagcgcgtttgaggtcggccgcaatgtcgcggtgaccgaaggcgccgtggtcttcgagaacgagtacttccagctgttgcagtacaagccgctgaccgacaaggtgcacgcgcgcccgctgctgatggtgccgccgtgcatcaacaagtactacatcctggacctgcagccggagagctcgctggtgcgccatgtggtggagcagggacatacggtgtttctggtgtcgtggcgcaatccggacgccagcatggccggcagcacctgggacgactacatcgagcacgcggccatccgcgccatcgaagtcgcgcgcgacatcagcggccaggacaagatcaacgtgctcggcttctgcgtgggcggcaccattgtctcgaccgcgctggcggtgctggccgcgcgcggcgagcacccggccgccagcgtcacgctgctgaccacgctgctggactttgccgacacgggcatcctcgacgtctttgtcgacgagggccatgtgcagttgcgcgaggccacgctgggcggcggcgccggcgcgccgtgcgcgctgctgcgcggccttgagctggccaataccttctcgttcttgcgcccgaacgacctggtgtggaactacgtggtcgacaactacctgaagggcaacacgccggtgccgttcgacctgctgttctggaacggcgacgccaccaacctgccggggccgtggtactgctggtacctgcgccacacctacctgcagaacgagctcaaggtaccgggcaagctgaccgtgtgcggcgtgccggtggacctggccagcatcgacgtgccgacctatatctacggctcgcgcgaagaccatatcgtgccgtggaccgcggcctatgcctcgaccgcgctgctggcgaacaagctgcgcttcgtgctgggtgcgtcgggccatatcgccggtgtgatcaacccgccggccaagaacaagcgcagccactggactaacgatgcgctgccggagtcgccgcagcaatggctggccggcgccatcgagcatcacggcagctggtggccggactggaccgcatggctggccgggcaggccggcgcgaaacgcgccgcgcccgccaactatggcaatgcgcgctatcgcgcaatcgaacccgcgcctgggcgatacgtcaaagccaaggcatga Source: KEGG at https://www.genome.jp/dbget-bin/www_bget?reh:H16_A1437
3.3. Codon optimization. I optimized the phaC coding sequence for E. coli because it is a widely used chassis for recombinant protein expression and for rapid prototyping of metabolic engineering constructs.
I did this using the Benchling tool. I’ve selected the region of the AA sequence I wish to back translate and right clicked on the highlighted region. From the codon optimization tab:
- Host: E. coli K-12
- Method: Match codon usage
- GC content: Medium (0.33 to 0.66) because extreme GC content can create problems. High GC can create strong secondary structures and low GC can cause instability/repeats and can make synthesis harder.
- Uridine depletion: off (not relevant for bacterial expression)
- Hairpin parameters: Stem size: 8 and Window 50
- Restriction sites: avoid BsaI, BsmBI, BbsI (Type IIS enzymes for Golden Gate compatibility since I would have to clone phaA and phaB also, not phaC single gene in one vector)
- Patterns to reduce: AAAAAA and ATATATATA
I clicked on “Optimization preview” and got this result:
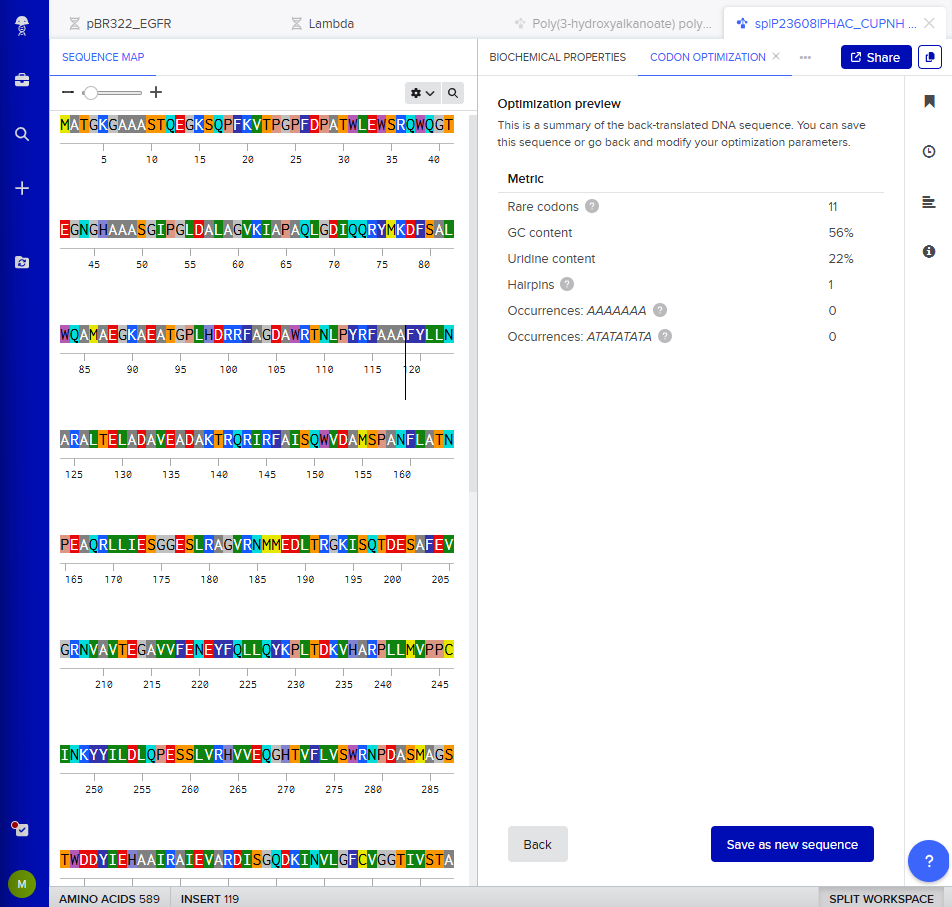
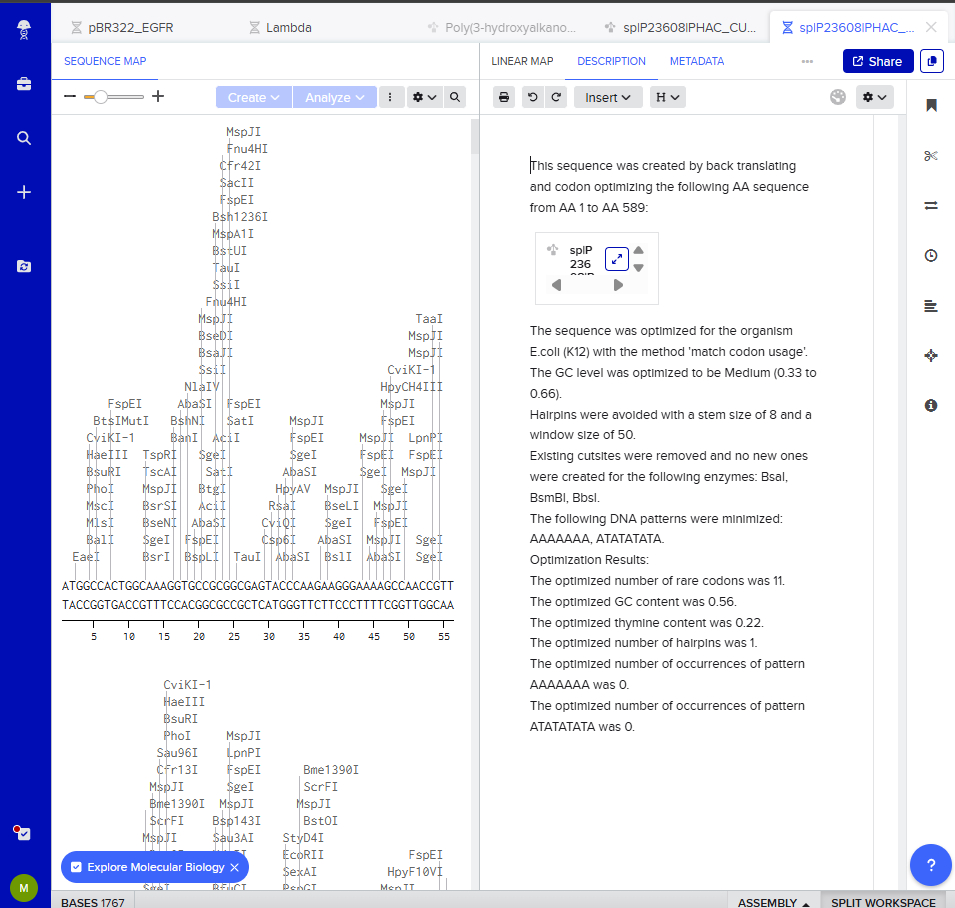
3.4. You have a sequence! Now what?
PhaC alone will not produce PHB. A minimal PHB pathway typically includes PhaA (β-ketothiolase) and PhaB (acetoacetyl-CoA reductase) in addition to PhaC (PHA synthase). PhaA and PhaB convert central metabolites (via acetyl-CoA) into (R)-3-hydroxybutyryl-CoA, which is the direct substrate that PhaC polymerizes into PHB. You will also need a host capable of supplying sufficient acetyl-CoA and NADPH.
Therefore, for PHB production in E. coli, phaA, phaB, and phaC are commonly co-expressed on the same plasmid (as a single operon with one promoter and RBSs for each gene) and grown under appropriate culture conditions (e.g., carbon excess and nutrient limitation) that favor polymer accumulation.
To produce the protein from DNA, the codon-optimized phaC sequence would be placed in an expression cassette with a promoter, RBS, start codon, coding sequence, stop codon, and terminator. In a cell-dependent system such as E. coli, RNA polymerase transcribes the DNA sequence into mRNA. The ribosome binds the RBS, reads the mRNA codons, and translates them into the PhaC amino-acid chain. For PHB production rather than PhaC expression alone, phaA, phaB, and phaC should be co-expressed so the host can convert acetyl-CoA into (R)-3-hydroxybutyryl-CoA and then polymerize it into PHB.
Part 4: Prepare a Twist DNA Synthesis Order
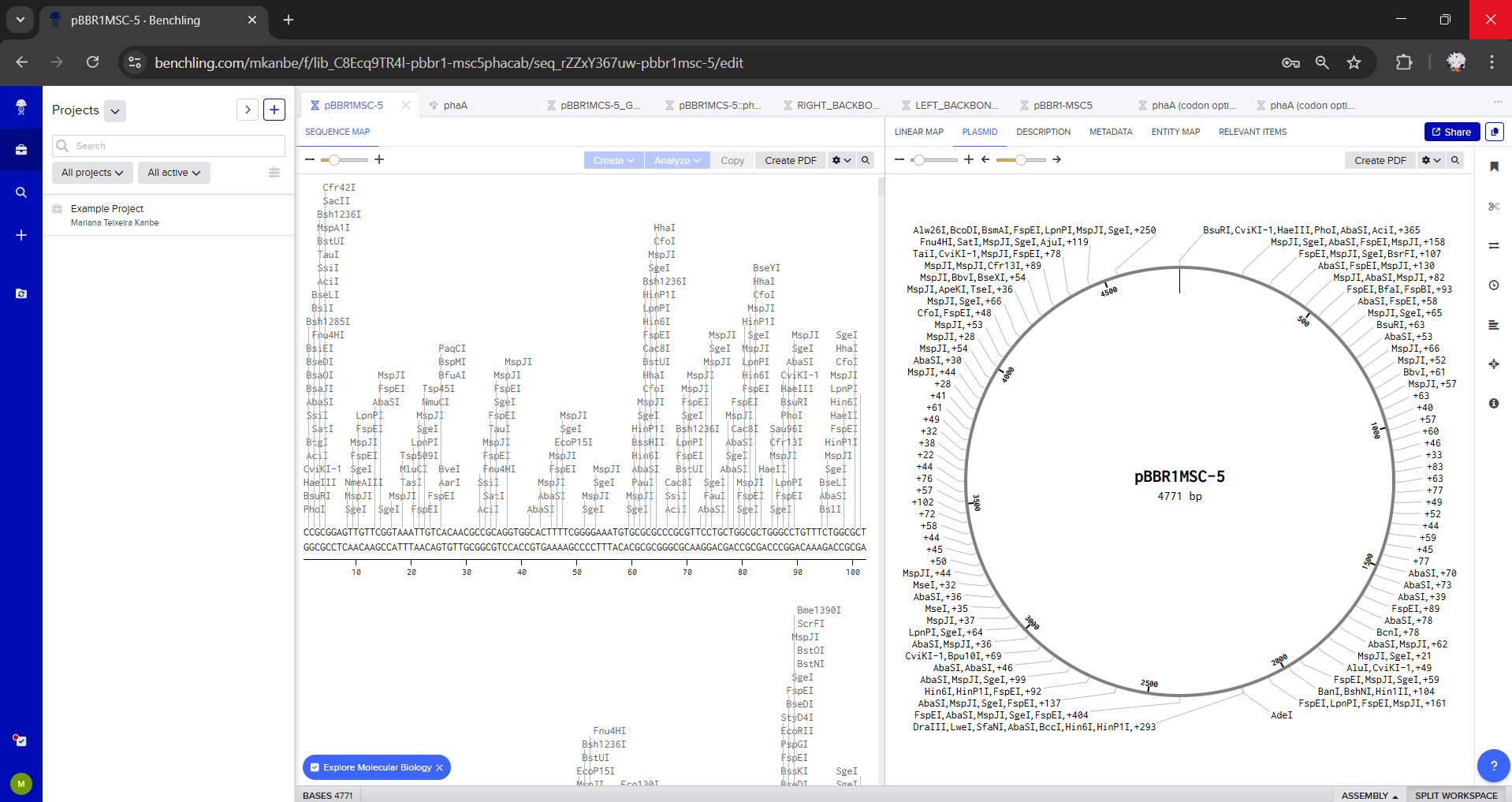
Project: pBBR1-MSC5::phaCAB Cell-dependent recombinant expression approach: cloning the codon-optimized phaA, phaB and phaC coding sequences into E. coli K12
Promoter - RBS - phaA - (RBS) - phaB - (RBS) - phaC - Terminator
phaA Sequence MTDVVIVSAARTAVGKFGGSLAKIPAPELGAVVIKAALERAGVKPEQVSEVIMGQVLTAGSGQNPARQAAIKAGLPAMVPAMTINKVCGSGLKAVMLAANAIMAGDAEIVVAGGQENMSAAPHVLPGSRDGFRMGDAKLVDTMIVDGLWDVYNQYHMGITAENVAKEYGITREAQDEFAVGSQNKAEAAQKAGKFDEEIVPVLIPQRKGDPVAFKTDEFVRQGATLDSMSGLKPAFDKAGTVTAANASGLNDGAAAVVVMSAAKAKELGLTPLATIKSYANAGVDPKVMGMGPVPASKRALSRAEWTPQDLDLMEINEAFAAQALAVHQQMGWDTSKVNVNGGAIAIGHPIGASGCRILVTLLHEMKRRDAKKGLASLCIGGGMGVALAVERK Source: UniProt at https://www.uniprot.org/uniprotkb/P14611/entry#sequences
phaB Sequence MTQRIAYVTGGMGGIGTAICQRLAKDGFRVVAGCGPNSPRREKWLEQQKALGFDFIASEGNVADWDSTKTAFDKVKSEVGEVDVLINNAGITRDVVFRKMTRADWDAVIDTNLTSLFNVTKQVIDGMADRGWGRIVNISSVNGQKGQFGQTNYSTAKAGLHGFTMALAQEVATKGVTVNTVSPGYIATDMVKAIRQDVLDKIVATIPVKRLGLPEEIASICAWLSSEESGFSTGADFSLNGGLHMG Source: UniProt at https://www.uniprot.org/uniprotkb/P14697/entry#sequences
phaC Sequence MATGKGAAASTQEGKSQPFKVTPGPFDPATWLEWSRQWQGTEGNGHAAASGIPGLDALAGVKIAPAQLGDIQQRYMKDFSALWQAMAEGKAEATGPLHDRRFAGDAWRTNLPYRFAAAFYLLNARALTELADAVEADAKTRQRIRFAISQWVDAMSPANFLATNPEAQRLLIESGGESLRAGVRNMMEDLTRGKISQTDESAFEVGRNVAVTEGAVVFENEYFQLLQYKPLTDKVHARPLLMVPPCINKYYILDLQPESSLVRHVVEQGHTVFLVSWRNPDASMAGSTWDDYIEHAAIRAIEVARDISGQDKINVLGFCVGGTIVSTALAVLAARGEHPAASVTLLTTLLDFADTGILDVFVDEGHVQLREATLGGGAGAPCALLRGLELANTFSFLRPNDLVWNYVVDNYLKGNTPVPFDLLFWNGDATNLPGPWYCWYLRHTYLQNELKVPGKLTVCGVPVDLASIDVPTYIYGSREDHIVPWTAAYASTALLANKLRFVLGASGHIAGVINPPAKNKRSHWTNDALPESPQQWLAGAIEHHGSWWPDWTAWLAGQAGAKRAAPANYGNARYRAIEPAPGRYVKAKA Source: UniProt at https://www.uniprot.org/uniprotkb/P23608/entry#sequences
For this exercise, I chose pBBR1MCS-5 as the plasmid backbone because it is a broad-host-range vector commonly used for cloning and expression of phaCAB. Source: https://www.teses.usp.br/teses/disponiveis/87/87131/tde-29042010-102817/publico/RogeriodeSousaGomes_Doutorado.pdf
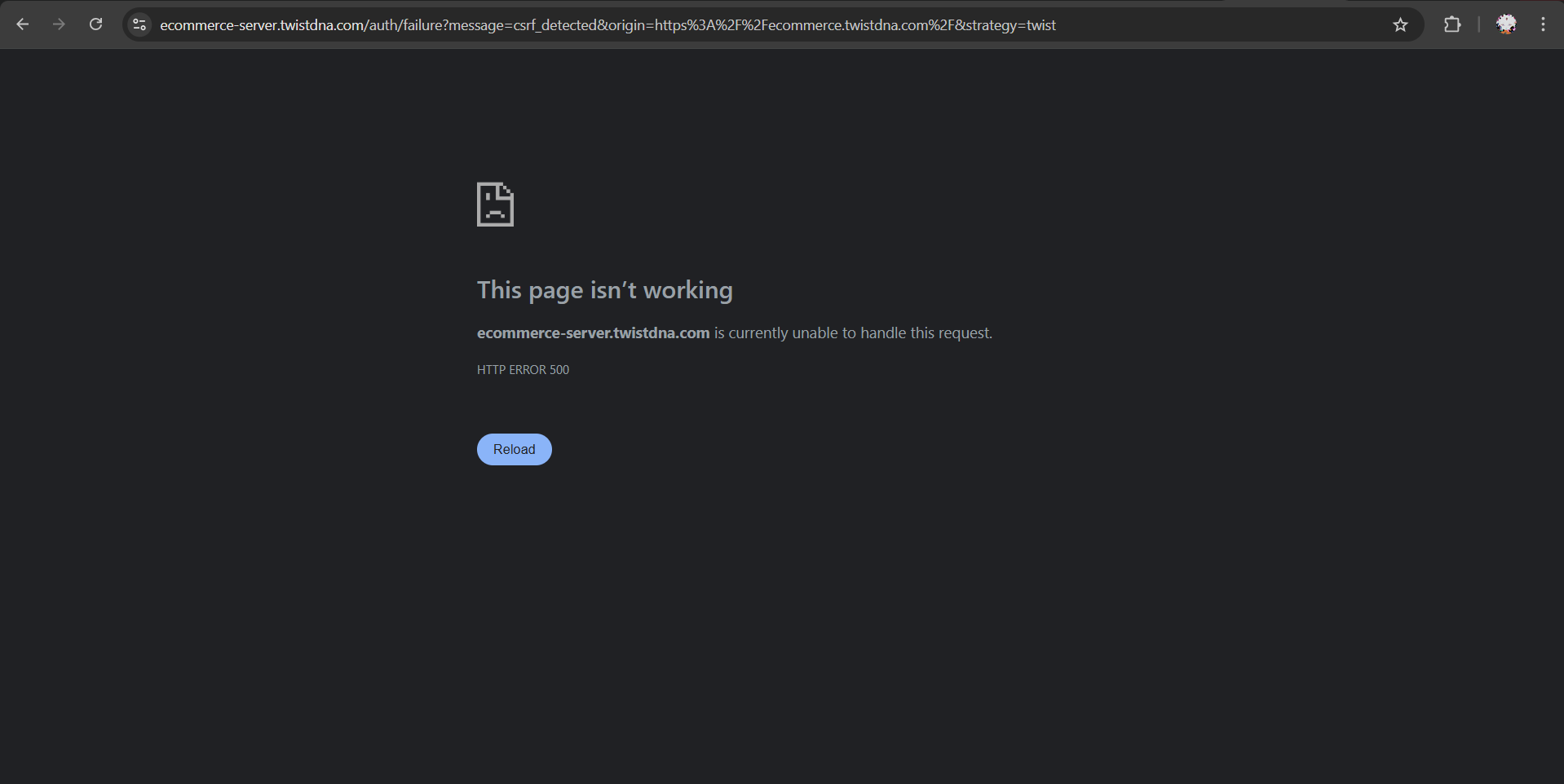
The screenshot shows that my Twist account was redirected to “Contact Your Distributor” for orders through Interprise USA Corp., and another page returned an HTTP 500 server error.
Part 5: DNA Read / Write / Edit
5.1 DNA Read
I would sequence DNA used for DNA-based digital data storage because I am interested in how biological molecules can encode digital information. It would be fascinating to recover stored information from DNA as if reading an archive.
I would use Illumina sequencing, a second-generation massively parallel short-read technology, for high-accuracy base calls and reliable decoding of short oligo pools. I would also consider Oxford Nanopore sequencing, a third-generation single-molecule long-read technology, to validate longer constructs and check sequence integrity.
For Illumina, the input would be a pool of synthetic DNA oligos encoding digital data. If the oligos are already short, fragmentation may not be necessary. Library preparation would involve adapter ligation or PCR addition of adapters/indexes, followed by sequencing-by-synthesis using fluorescent reversible terminators. The output would be millions to billions of short reads in FASTQ format with per-base quality scores. The stored data would then be decoded using alignment, consensus generation, and error correction.
5.2 DNA Write
I would synthesize a PHA production cassette for E. coli K-12 containing codon-optimized phaA, phaB, and phaC. The goal would be to rapidly test/study PHB production from a designed pathway rather than cloning each gene manually from genomic DNA.
I would use commercial gene synthesis, such as Twist, because it allows designed DNA sequences to be ordered directly with defined codon usage, avoided restriction sites, and synthesis constraints. The essential steps are: design the coding sequences, codon-optimize them for E. coli, add regulatory parts such as promoter/RBSs/terminator, screen for forbidden restriction sites and problematic repeats, synthesize short oligos, assemble them into longer fragments or a full insert, clone into a plasmid, and verify the final sequence.
The main limitations are length-dependent error accumulation, synthesis difficulty from repeats or extreme GC content, turnaround time, cost for long constructs, and the need for clonal verification before experimental use.
5.3 DNA Edit
Aiming for increased expression of phaCAB and improved PHA production, I would edit E. coli metabolic and stress-tolerance genes to increase PHB yield. For example, I would target pathways that improve acetyl-CoA/NADPH supply, reduce competing carbon sinks, and increase tolerance to intracellular polymer accumulation.
For precise point mutations, I would use CRISPR base editing or prime editing because these methods can introduce targeted sequence changes without relying on double-strand breaks. For larger edits or gene insertions, I would use Cas9-assisted homologous recombination with a donor DNA template.
The design steps would include selecting the target gene, designing guide RNAs, checking off-target risk, preparing the editor plasmid or Cas9/gRNA system, designing the donor template if needed, transforming E. coli, selecting edited colonies, and confirming edits by sequencing.
Limitations include editing efficiency, PAM constraints, off-target edits, toxicity from editor expression, and the increased screening burden when multiplexing several edits.