Governance as a Design Decision Tree This project treats governance not as an external constraint added after design, but as an integral part of the design process itself. Key technical uncertainties and scaling decisions are understood as ethical and governance decision points.
Decision Point 1: Living vs. Non-Living Pigment Systems At the current stage of the project, it is not yet determined whether pigments will be used through living bacterial systems (e.g., embedded or encapsulated) or extracted from non-living biomass after bacterial deactivation. This unresolved decision is treated as a critical ethical limitation.
Week 2 — DNA Read, Write & Edit This week focused on the fundamental processes of reading, writing, and editing DNA.
Using Benchling, restriction digest simulations, and sequence design tools, I explored how DNA can be interpreted not only as biological information but also as a visual and computational medium.
Part 1 — Benchling & In-silico Gel Art This exercise explores how restriction enzyme digestion can be simulated digitally and how gel electrophoresis patterns emerge from these cuts.
Co-Light Molecular Automation Study Concept Original visual identity
Code OT-2 Python protocol
Output Simulated agar deposition
Post-Lab Questions 1. Example of laboratory automation in biology One example of laboratory automation using the Opentrons platform is the paper:
Week 4 — Protein Design I Selected Protein For this assignment, I selected Calmodulin (CaM), a calcium-binding signaling protein found in many organisms, including humans.
Calmodulin plays an essential role in cellular signaling by detecting calcium ion (Ca²⁺) concentration changes and transmitting this information to other proteins.
Part 1: Generate Binders with PepMLM For this part, I retrieved the reviewed human SOD1 sequence from UniProt (P00441) and introduced the ALS-associated A4V mutation.
The mutant SOD1 sequence used for peptide generation was:
MATKAVCVLKGDGPVQGIINFEQKESNGPVKVWGSIKGLTEGLHGFHVHEFGDNTAGCTSAGPHFNPLSRKHGGPKDEERHVGDLGNVTADKDGVADVSIEDSVISLSGDHCIIGRTLVVHEKADDLGKGGNEESTKTGNAGSRLACGVIGIAQ Using the PepMLM Colab linked from the Hugging Face PepMLM-650M model card, I generated four peptides of length 12 amino acids conditioned on the mutant SOD1 sequence. PepMLM-generated peptides RTEDETPTEEPL — pseudo perplexity: 11.656761 RDGEGELLENRR — pseudo perplexity: 10.782790 DRTGETTVGEPE — pseudo perplexity: 16.547998 RTGGELELLGGR — pseudo perplexity: 12.788915 Known comparison peptide FLYRWLPSRRGG — known SOD1-binding peptide used for comparison Among the generated candidates, RDGEGELLENRR showed the lowest pseudo perplexity, suggesting the highest model confidence among the four PepMLM-generated peptides in this run. Overall, the generated peptides are enriched in charged and polar residues, which may be relevant for interactions with the exposed surface of mutant SOD1. Part 2: Evaluate Binders with AlphaFold3 To evaluate the binding potential of the generated peptides, I used the AlphaFold Server to model protein–peptide complexes.
Week 6 — DNA Assembly 1. Phusion High-Fidelity PCR Master Mix components The Phusion High-Fidelity PCR Master Mix contains several key components:
Phusion DNA Polymerase
A high-fidelity enzyme that synthesizes DNA with very low error rates.
dNTPs (deoxynucleotide triphosphates)
The building blocks used to construct new DNA strands.
Intracellular Artificial Neural Networks (IANNs) 1. Advantages of IANNs over Boolean Genetic Circuits Traditional genetic circuits operate based on Boolean logic, where outputs are typically binary (ON/OFF). While this approach is useful for simple decision-making, it is limited in representing complex and graded biological behaviors.
Week 9 — Biological Design Cycle Cell-Free Systems Material Integration Space Application Synthetic Cells Design
Logic A circular framework connecting cell-free systems, synthetic cells, material integration, and space applications into a continuous design cycle.
Week — Waters & Measurement (Conceptual Submission) Measurement Strategy for Final Project For my final project, which explores bio-responsive materials and spatial feedback systems, I approach measurement as a multi-layered process.
Rather than focusing on a single metric, I aim to evaluate:
Part A: The 1,536 Pixel Artwork Canvas | Collective Artwork Reflection on Collective Contribution
Interestingly, the pixels I initially contributed are no longer individually identifiable in the final composition.
Rather than seeing this as a loss, I interpret it as a key feature of the system. The artwork demonstrates how individual inputs dissolve into a collective output, similar to biological systems where single components rarely remain distinguishable but still contribute to the overall structure.
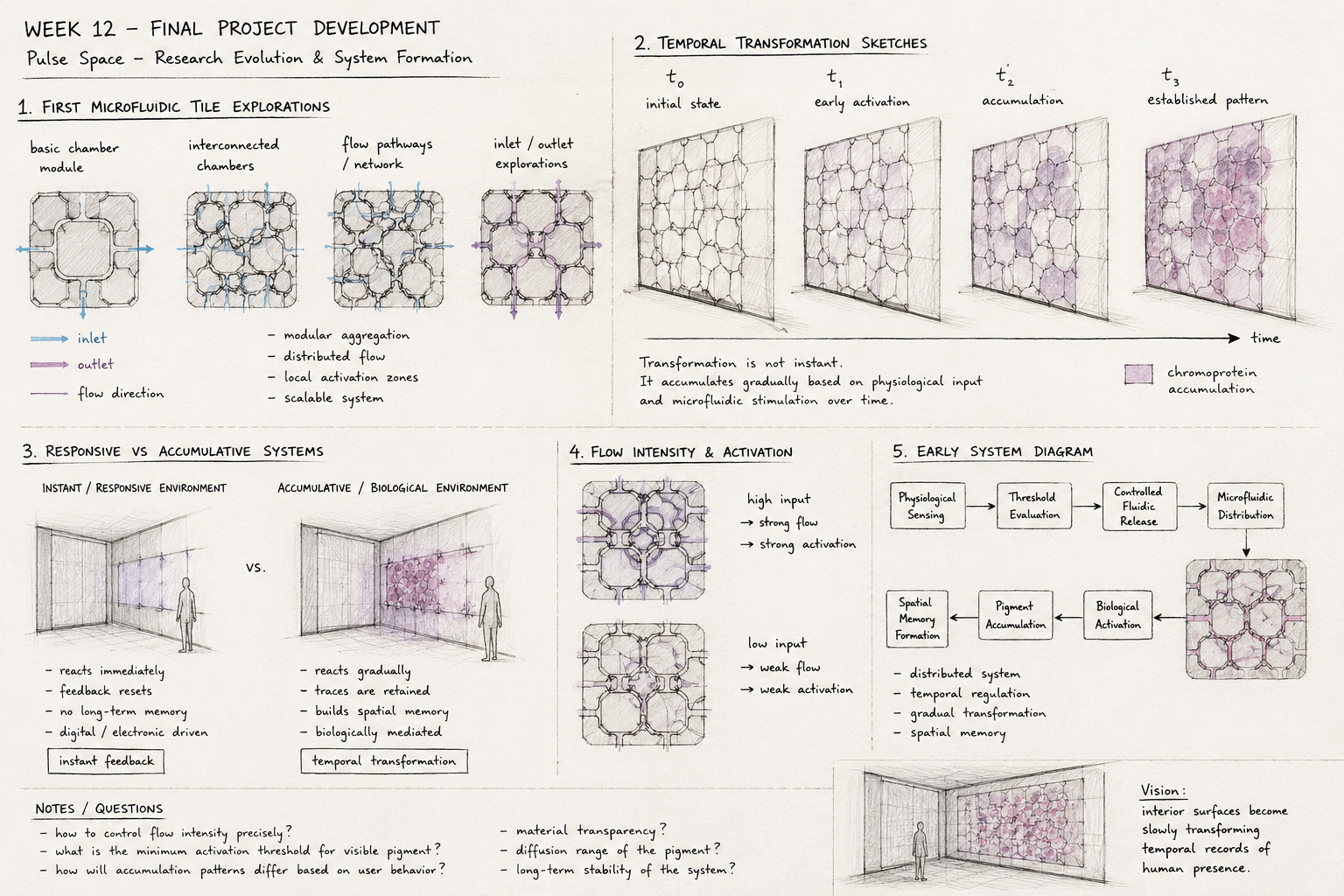
Pulse Space — Research Evolution & System Formation Final Project Development This week focused on transforming Pulse Space from a speculative responsive environment concept into a more structured biological-material system.
Rather than designing a conventional smart interior, the project began investigating how biological systems might operate as slow temporal infrastructures capable of accumulating physiological traces over time.
Pulse Space — Biological Direction & System Integration ## Biodesign & Biofabrication This week focused on strengthening the biological and fabrication framework of Pulse Space.
Earlier stages of the project primarily investigated conceptual questions around temporal interiors and spatial memory. This week, the research shifted toward developing a more grounded biological system architecture capable of supporting controlled material transformation.
Pulse Space — Final Reflection & Research Position Biodesign & Biofabrication This final stage of the project focused on consolidating Pulse Space as an experimental research framework situated between interior architecture, synthetic biology, responsive environments, and biofabrication.
Rather than presenting a finalized architectural product, the project evolved into an investigation of how biological systems may operate as temporal material infrastructures capable of gradual transformation over time.
Subsections of Homework
Week 1 HW: Principles and Practices
Governance as a Design Decision Tree
This project treats governance not as an external constraint added after design,
but as an integral part of the design process itself.
Key technical uncertainties and scaling decisions are understood as
ethical and governance decision points.
Decision Point 1: Living vs. Non-Living Pigment Systems
At the current stage of the project, it is not yet determined whether pigments
will be used through living bacterial systems (e.g., embedded or encapsulated)
or extracted from non-living biomass after bacterial deactivation.
This unresolved decision is treated as a critical ethical limitation.
If living systems are used:
Primary risk: Loss of control over engineered organisms beyond intended environments
Governance implication:
Phase-gated governance becomes essential
Reassessment required before any transition beyond the lab
Relevant governance actions:
Option 2 (Phase-Gated Governance for Scale-Up)
If pigments are extracted from non-living biomass:
Primary risk: Reduced biosecurity risk, but continued environmental impact
Governance implication:
Biosafety-by-design is largely sufficient at early stages
Relevant governance actions:
Option 1 (Biosafety-by-Design Requirement)
This decision point highlights that materialization choices directly shape ethical risk profiles.
Decision Point 2: Laboratory Scale vs. Industrial Scale
Ethical and safety risks change significantly as the system moves from
controlled laboratory conditions to pilot or industrial-scale production.
Laboratory-scale experimentation:
Primary concern: Lab safety and containment
Governance focus: Preventing incidents before they occur
Relevant governance actions:
Option 1 (Biosafety-by-Design)
Pilot and industrial-scale production:
Primary concern: Diminishing control, environmental exposure, and system persistence
This decision point reframes sustainability as a measured and governed outcome,
rather than an assumed property of “natural” systems.
Decision Point 4: Speed of Innovation vs. Depth of Oversight
Governance choices also affect the pace and openness of research.
If governance is too light:
Risk of irreversible harm emerging at scale
If governance is too heavy:
Risk of stalling exploratory research and creative experimentation
Design trade-off:
Early-stage flexibility supported by Option 1
Increased oversight introduced progressively through Option 2
Environmental accountability applied selectively through Option 3
This staged approach aims to preserve innovation while preventing loss of control.
Summary
By framing governance as a design decision tree, this project acknowledges that
ethical responsibility evolves alongside technical decisions.
Uncertainty—particularly around living systems and scale—is treated not as a failure,
but as a signal for adaptive and anticipatory governance.
Week 2 HW — DNA Read, Write & Edit
Week 2 — DNA Read, Write & Edit
This week focused on the fundamental processes of reading, writing, and editing DNA. Using Benchling, restriction digest simulations, and sequence design tools, I explored how DNA can be interpreted not only as biological information but also as a visual and computational medium.
Part 1 — Benchling & In-silico Gel Art
This exercise explores how restriction enzyme digestion can be simulated digitally and how gel electrophoresis patterns emerge from these cuts.
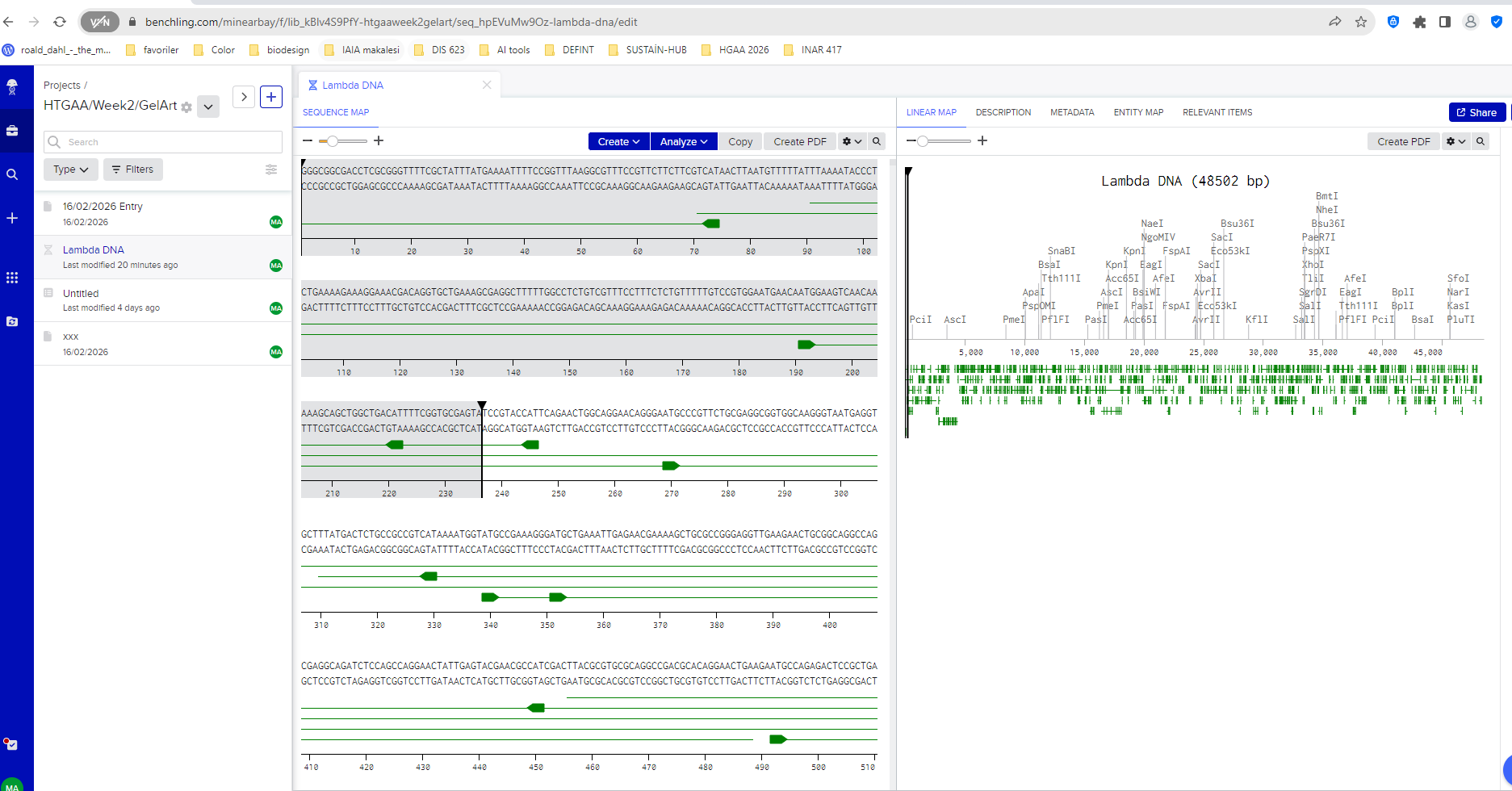
I began by creating a Benchling account and importing the Lambda DNA genome, which is commonly used as a reference molecule in molecular biology experiments. Once imported, Benchling allowed me to visualize the full DNA sequence and explore the locations where restriction enzymes cut the DNA.
Lambda DNA sequence imported into Benchling.
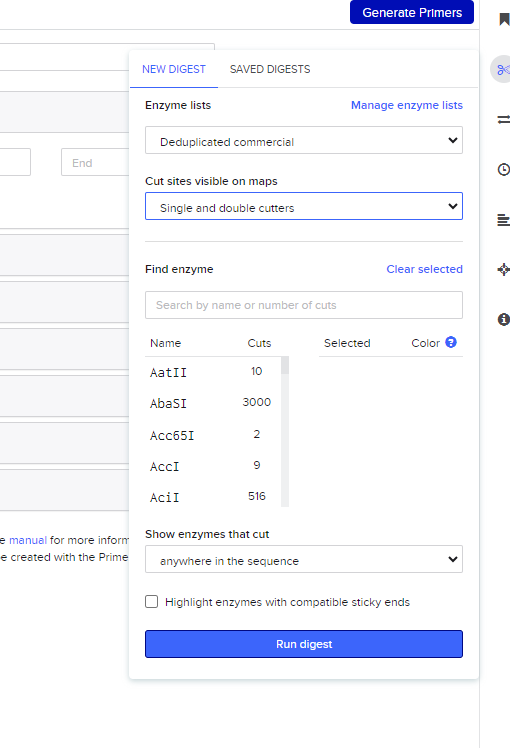
After importing the sequence, I opened the restriction digest tool. The interface lists many restriction enzymes, each recognizing a specific DNA sequence and cutting the DNA at that location.
Restriction enzyme selection interface in Benchling.
For this assignment I simulated restriction digests using enzymes discussed in the lab protocol:
EcoRI HindIII BamHI KpnI EcoRV SacI SalI
Each enzyme cuts the DNA at specific recognition sites, generating fragments of different sizes.
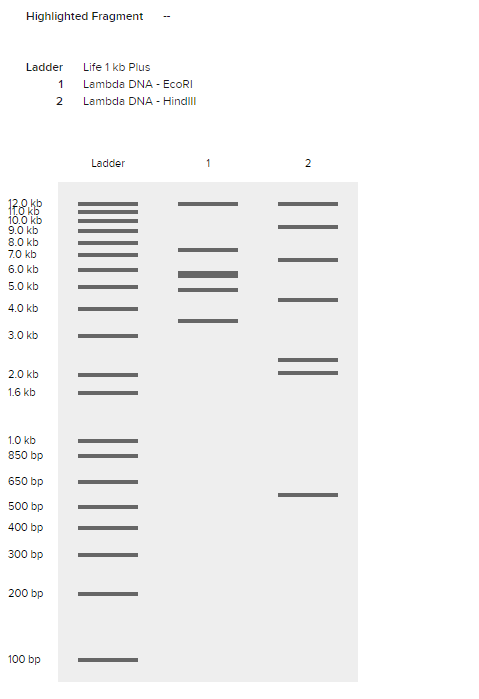
Benchling then generates a virtual gel electrophoresis result, where each band corresponds to a DNA fragment produced by the digestion. Larger fragments remain closer to the top of the gel, while smaller fragments travel further down.
EcoRI restriction digest simulation.
I then experimented with multiple enzyme combinations to observe how different fragment distributions create more complex gel patterns.
Multi-enzyme restriction digest simulation.
Comparing different enzymes also revealed how each enzyme produces a unique pattern of DNA fragments.
Comparison of EcoRI and HindIII digest patterns.
Inspired by Paul Vanouse’s Latent Figure Protocol, I began to interpret these gel patterns not only as analytical outputs but also as visual structures. Each gel lane behaves like a vertical column in a visual composition, where fragment size determines band position.
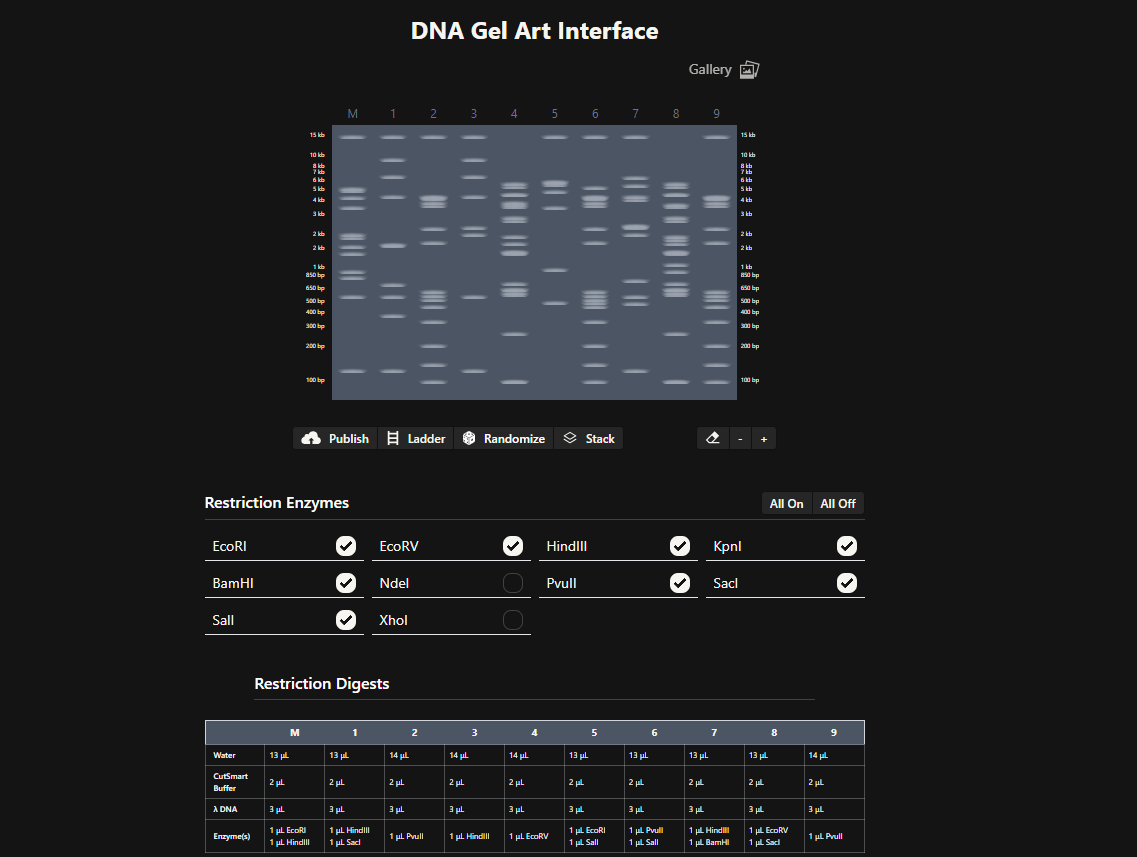
To experiment with pattern design more quickly, I also used Ronan Donovan’s Gel Art interface, which allows rapid testing of enzyme combinations and visualization of gel patterns.
Ronan Donovan's gel-art interface used for rapid pattern exploration.
Through this process I began to see gel electrophoresis not only as a scientific analysis method, but also as a generative visual system, where biological information becomes spatial patterns.
Part 3 — DNA Design Challenge
3.1 Chosen Protein
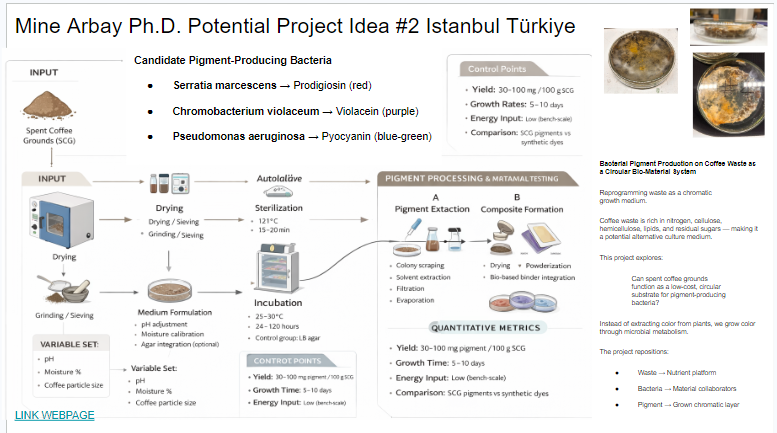
For this assignment, I chose VioA, the first enzyme in the violacein biosynthesis pathway.
I selected this protein because it connects directly to my broader research interest in producing biological color from waste-based substrates, especially coffee waste. Violacein is a naturally occurring purple pigment, and VioA is important because it catalyzes the first step of the pathway by oxidizing L-tryptophan, initiating the sequence of reactions that leads to pigment production.
This made VioA especially relevant for me: rather than choosing a generic reporter protein, I wanted to work with a protein that is conceptually close to my own research on sustainable pigment systems and microbial color production.
For the sequence source, I used UniProt, which provides a reviewed entry for VioA from Chromobacterium violaceum.
Protein source: UniProtKB: Q9S3V1 Entry name: VIOA_CHRVO Protein name: Flavin-dependent L-tryptophan oxidase VioA
To understand how proteins are encoded in DNA, I performed a reverse translation of the VioA protein sequence.
According to the Central Dogma of Molecular Biology, DNA is transcribed into RNA and then translated into protein. Reverse translation applies this process in the opposite direction by estimating the nucleotide sequence that could produce a given protein.
Because multiple codons can encode the same amino acid, reverse translation does not produce a single unique DNA sequence but rather a plausible coding sequence.
To perform this step, I used an online reverse translation tool:
Using the VioA amino acid sequence, I generated a nucleotide sequence that could encode the protein.
Example reverse-translated DNA sequence:
ATGAAGCACAGCAGCGACATCTGCATCGTCGGCGCCATCTCCGGCCTCACCTGCGCCTCGCATCTGCTCGACTCCCCGGCGTGCCGCGGCGGCTCTCTCCCGCATCTTCGACATGCAGCAGGAGGCGGCGGGGCGCATCCGCTCCAAGATGCTGGACGGCAAAGCCAGCATCGAGCTCGGCGCCGGCCGCTACAGCCCGCAGCTGCACCCGCACTTCCAGAGCGCCATGCAGCACTACAGCCAGAAGAGCGAGGTGTACCCCTTCACCCAGCTGAAGTTCAAGAGCCACGTGCAGCAGAAGCTGAAGCGCGCGATGAACGAGCTGAGCCCGCGCCTGAAGGAGCACGGCAAGGAGAGCTTCCTGCAGTTCGTGTCCCGCTACCAGGGCCACGACTCCGCCGTGGGCATGATCCGCTCCATGGGCTACGACGCCCTGTTCCTGCCCGACATCTCCGCCGAGATGGCGTACGACATCGTCGGCAAGCACCCCGAGATCCAGAGCGTGACCGACAACGACGCCAACCAGTGGTTCGCCGAGACCGGCTTCGCCGGGCTCATCCAGGGGATCAAGGCCAAGGTGAAGGCCGCCGGCGCCCGCTTCAGCCTGGGCTACCGCCTGCTGTCCGTGCGCACCGACGGCGACGGCTACCTGCTGCAGCTGGCCGGCGACGACGGCTGGAAGCTGGAGCACCGCACCCGCCACCTGATCCTGGCCATCCCCCCGAGCGCCATGGCCGGGCTGAACGTGGACTTCCCCGAGGCCTGGTCCGGCGCGCGCTACGGCAGCCTGCCGCTGTTCAGCGGCTTCCTGACCTACGGCGAGCCGTGGTGGCTGGACTACAAGCTGGACGACCAAGTGCTCATCGTGGACAACCCCCTGCGCAAGATCTACTTCAAGGGCGACAAGTACCTGTTCCTGTACACCGACAGCGAGATGGCCAATTACCGCTGGGGCTGCGTGGCCGAGGGCGAGGACGGCTACCTGGAGCAGATCCGCACCCACCTGGCGAGCGCCCTGGGCATCGTCCGCGAGCGCATCCCGCAGCCCCTGGCGCACGTGCACAAGTACTGGGCGCACGGCGTGGAGTTCGCCGACTCCGACATCGACCACCCGTCGGCGCTGTCCCACCGCGACAGCGGCATCATCGCCTGCAGCGACGCCTACACCGAGCACTGCGGCTGGATGGAGGGCGGCCTGCTGAGCGCGCGCGAGGCCAGCCGCCTGCTGCTGCAGCGCATCGCCGCC
3.3 Codon Optimization
Once the nucleotide sequence corresponding to the VioA protein was generated through reverse translation, the next step was codon optimization.
Although different organisms can produce the same protein, they often prefer different codons for the same amino acid. This phenomenon is known as codon bias. If a DNA sequence contains codons that are rarely used by the host organism, the translation machinery may work less efficiently, resulting in lower protein expression.
To improve protein production, the DNA sequence can be codon optimized for the organism in which the protein will be expressed.
For this project, I optimized the sequence for Escherichia coli (E. coli), since it is one of the most widely used host organisms for recombinant protein production in molecular biology and synthetic biology experiments.
I used the Twist Bioscience Codon Optimization Tool to generate an optimized sequence while avoiding problematic restriction sites.
The codon-optimized sequence maintains the same amino acid sequence of the VioA protein but replaces certain codons with those more frequently used in E. coli. This increases the likelihood that the protein can be efficiently produced in a bacterial expression system.
Example codon-optimized DNA sequence:
ATGAAGCACAGCAGCGACATCTGCATCGTCGGCGCCATCTCCGGCCTCACCTGCGCCTCGCATCTGCTCGACTCCCCGGCGTGCCGCGGCGGCTCTCTCCCGCATCTTCGACATGCAGCAGGAGGCGGCGGGGCGCATCCGCTCCAAGATGCTGGACGGCAAAGCCAGCATCGAGCTCGGCGCCGGCCGCTACAGCCCGCAGCTGCACCCGCACTTCCAGAGCGCCATGCAGCACTACAGCCAGAAGAGCGAGGTGTACCCCTTCACCCAGCTGAAGTTCAAGAGCCACGTGCAGCAGAAGCTGAAGCGCGCGATGAACGAGCTGAGCCCGCGCCTGAAGGAGCACGGCAAGGAGAGCTTCCTGCAGTTCGTGTCCCGCTACCAGGGCCACGACTCCGCCGTGGGCATGATCCGCTCCATGGGCTACGACGCCCTGTTCCTGCCCGACATCTCCGCCGAGATGGCGTACGACATCGTCGGCAAGCACCCCGAGATCCAGAGCGTGACCGACAACGACGCCAACCAGTGGTTCGCCGAGACCGGCTTCGCCGGGCTCATCCAGGGGATCAAGGCCAAGGTGAAGGCCGCCGGCGCCCGCTTCAGCCTGGGCTACCGCCTGCTGTCCGTGCGCACCGACGGCGACGGCTACCTGCTGCAGCTGGCCGGCGACGACGGCTGGAAGCTGGAGCACCGCACCCGCCACCTGATCCTGGCCATCCCCCCGAGCGCCATGGCCGGGCTGAACGTGGACTTCCCCGAGGCCTGGTCCGGCGCGCGCTACGGCAGCCTGCCGCTGTTCAGCGGCTTCCTGACCTACGGCGAGCCGTGGTGGCTGGACTACAAGCTGGACGACCAAGTGCTCATCGTGGACAACCCCCTGCGCAAGATCTACTTCAAGGGCGACAAGTACCTGTTCCTGTACACCGACAGCGAGATGGCCAATTACCGCTGGGGCTGCGTGGCCGAGGGCGAGGACGGCTACCTGGAGCAGATCCGCACCCACCTGGCGAGCGCCCTGGGCATCGTCCGCGAGCGCATCCCGCAGCCCCTGGCGCACGTGCACAAGTACTGGGCGCACGGCGTGGAGTTCGCCGACTCCGACATCGACCACCCGTCGGCGCTGTCCCACCGCGACAGCGGCATCATCGCCTGCAGCGACGCCTACACCGAGCACTGCGGCTGGATGGAGGGCGGCCTGCTGAGCGCGCGCGAGGCCAGCCGCCTGCTGCTGCAGCGCATCGCCGCC
3.4 Expression Explanation
After obtaining a codon-optimized DNA sequence, the next step is to understand how this sequence can actually produce the VioA protein inside a biological system.
In molecular biology this process follows the Central Dogma, which describes the flow of genetic information from DNA → RNA → Protein.
First, the DNA sequence is transcribed into messenger RNA (mRNA) by the host organism’s transcription machinery. This RNA molecule carries the genetic instructions encoded in the DNA sequence.
Next, the mRNA is translated by ribosomes. During translation, the ribosome reads the RNA sequence in groups of three nucleotides called codons. Each codon corresponds to a specific amino acid. These amino acids are then assembled sequentially to form the final protein structure.
In the context of this project, the codon-optimized VioA DNA sequence could be inserted into an expression vector and introduced into a host organism such as E. coli. Once inside the cell, the bacterial transcription and translation machinery would read the inserted DNA sequence and produce the VioA enzyme.
From my perspective as a designer working with biomaterials and color systems, this process can also be understood as a form of biological material programming. Instead of shaping materials directly, we design the genetic instructions that guide a living system to produce molecules with specific properties.
In the case of the violacein pathway, the VioA enzyme initiates the biochemical transformation of L-tryptophan, which ultimately leads to the production of the purple pigment violacein. If microorganisms capable of expressing this pathway grow on substrates such as coffee waste, the metabolic process could potentially convert organic waste into biologically produced color.
This perspective connects molecular biology with design research: DNA sequences function as programmable instructions that enable living systems to generate pigments and materials through metabolic processes.
Part 4 — Twist DNA Synthesis Practice
4.1 Creating Accounts
For this exercise I created accounts on both Benchling and Twist Bioscience, which are commonly used tools for designing and synthesizing DNA sequences.
Benchling was used to design and annotate the DNA sequence, while Twist provides services for synthesizing custom DNA constructs.
4.2 Building the DNA Insert Sequence
To express the VioA protein in a bacterial system, I designed a simple expression cassette. This cassette contains the genetic elements necessary for transcription and translation inside a host organism such as E. coli.
The structure of the insert sequence follows a common synthetic biology design:
Each part of the sequence has a specific function:
Promoter Initiates transcription and determines how strongly the gene is expressed.
Ribosome Binding Site (RBS) Allows ribosomes to recognize where translation should begin.
Start Codon (ATG) Signals the start of protein translation.
Coding Sequence The codon-optimized DNA sequence encoding the VioA protein.
His Tag A short peptide tag that allows the produced protein to be purified using affinity chromatography.
Stop Codon Signals the end of translation.
Terminator Stops transcription and stabilizes the mRNA transcript.
From a design perspective, this expression cassette can be understood as a programmable biological instruction set. Instead of directly shaping a material, we design the genetic instructions that guide a living system to produce a molecule—in this case, the VioA enzyme involved in pigment biosynthesis.
In principle, if such a construct were introduced into a bacterial host capable of metabolizing substrates from coffee waste, the expressed enzyme could contribute to a metabolic pathway producing colored biomolecules such as violacein.
4.3 Selecting the “Genes” Option in Twist
After preparing the insert sequence in Benchling, I navigated to the Genes section in the Twist Bioscience platform. This interface allows users to submit DNA sequences for synthesis.
Since the goal of this exercise is to simulate ordering a gene construct, the Clonal Genes option was selected. Clonal genes are delivered in a circular plasmid vector, which allows the DNA to be directly transformed into a host organism such as E. coli.
4.4 Clonal Gene Selection
Clonal genes are commonly used in synthetic biology experiments because they simplify the experimental workflow. Once the plasmid is received, it can be directly introduced into bacterial cells for protein expression.
This makes clonal genes particularly useful when testing metabolic pathways or producing proteins such as enzymes involved in pigment biosynthesis.
4.5 Importing the DNA Sequence
Next, the designed DNA insert sequence was uploaded to the Twist interface using the Upload Sequence File option.
The uploaded sequence contains the complete expression cassette:
This sequence encodes the VioA enzyme, which catalyzes the first step in the violacein pigment biosynthesis pathway.
From a design perspective, this step represents translating a conceptual biological function into a programmable genetic instruction that can be synthesized and tested experimentally.
4.6 Choosing a Vector
After uploading the sequence, a cloning vector was selected from the Twist vector catalog.
For this exercise, a standard bacterial expression vector such as pTwist Amp High Copy can be used. This vector provides:
an origin of replication allowing the plasmid to replicate inside E. coli
an antibiotic resistance marker (ampicillin) for selection
a stable backbone for the inserted gene construct
Once the construct is generated, the complete plasmid sequence can be downloaded as a GenBank file and re-imported into Benchling.
This plasmid represents the final synthetic construct containing the VioA gene expression system, which in principle could be used to express the enzyme in bacteria capable of metabolizing substrates such as coffee waste for pigment-related metabolic pathways.
Part 5 — DNA Read / Write / Edit
5.1 DNA Read
If I were to sequence DNA for my research, I would focus on microbial communities growing on organic waste substrates such as coffee waste.
Coffee waste contains a rich mixture of organic compounds that can support microbial growth. Sequencing the DNA of microorganisms that naturally colonize these environments could reveal bacteria capable of producing pigments or other useful biomolecules.
Understanding which microbial species are present and which metabolic pathways they contain would help identify organisms capable of transforming waste materials into valuable biological products such as color pigments.
To perform this sequencing, I would likely use Next Generation Sequencing (NGS) technologies such as Illumina sequencing.
Technology type: Second-generation sequencing
Input preparation steps
DNA extraction from microbial samples
DNA fragmentation
Adapter ligation
PCR amplification
Sequencing library preparation
How sequencing works
Illumina sequencing uses a method called sequencing by synthesis. DNA fragments are attached to a flow cell and amplified. Fluorescently labeled nucleotides are then incorporated during DNA synthesis, and the emitted fluorescence is detected to identify each base.
Output
The output is a large dataset of short DNA reads that can be assembled and analyzed to identify microbial species and genes involved in pigment biosynthesis.
5.2 DNA Write
If I were to synthesize DNA, I would design genetic constructs encoding pigment-producing metabolic pathways.
In particular, I am interested in pathways such as violacein biosynthesis, which converts the amino acid tryptophan into a purple pigment.
Designing such sequences could allow microorganisms to produce color directly from biological metabolism. This approach could potentially enable sustainable color production systems, where organic waste substrates serve as feedstock for microbial pigment synthesis.
Example design goal:
The DNA constructs for these enzymes could be synthesized using commercial DNA synthesis platforms such as Twist Bioscience.
Technology used
Modern DNA synthesis typically uses phosphoramidite chemical synthesis, where nucleotides are added sequentially to build a DNA strand.
Limitations
DNA synthesis technologies face challenges such as:
sequence length limitations
synthesis errors
high cost for very large constructs
However, these technologies continue to improve and enable increasingly complex genetic designs.
5.3 DNA Edit
DNA editing technologies allow scientists to modify genes inside living organisms.
For research related to biological pigments and biomaterials, DNA editing could be used to modify microorganisms so that they produce new colors, materials, or metabolic products.
One widely used technology is CRISPR-Cas9.
CRISPR works by using a guide RNA (gRNA) to direct the Cas9 enzyme to a specific location in the genome. The Cas9 enzyme then creates a cut in the DNA, allowing scientists to insert, delete, or modify genetic sequences.
Editing workflow
Design guide RNA targeting the gene of interest
Introduce Cas9 and gRNA into the cell
Cas9 cuts the DNA at the target location
DNA repair mechanisms insert or modify the sequence
Applications
DNA editing could be used to:
enhance pigment production
introduce new biosynthetic pathways
engineer microorganisms capable of converting waste into useful biomaterials
From a design perspective, these technologies transform DNA into a programmable material system. Instead of shaping materials directly, we design genetic instructions that allow living systems to generate color, structure, and material properties through biological processes.
Reflection
This week shifted my perspective on DNA. Before this exercise, I mostly understood DNA as a biological concept discussed in textbooks or laboratories. Through the assignments in this week, I started to see DNA as something closer to a design medium.
Coming from an interior architecture and design background, I am used to thinking about materials in terms of structure, transformation, and visual outcomes. Working with restriction digests, genetic sequences, and expression systems revealed that DNA can also function as a kind of instruction layer for material processes.
Instead of directly shaping matter, we design the genetic information that guides living systems to produce molecules, pigments, or structures.
For my own research, which explores biological color production from organic waste such as coffee grounds, this idea is particularly meaningful. The possibility that microorganisms could transform waste substrates into pigments suggests a different way of thinking about color production — one that is metabolic rather than industrial.
This week helped me see molecular biology not only as a scientific field, but also as a design space, where biological systems can be programmed to generate new materials, colors, and spatial possibilities.
Week 3 HW — Lab Automation
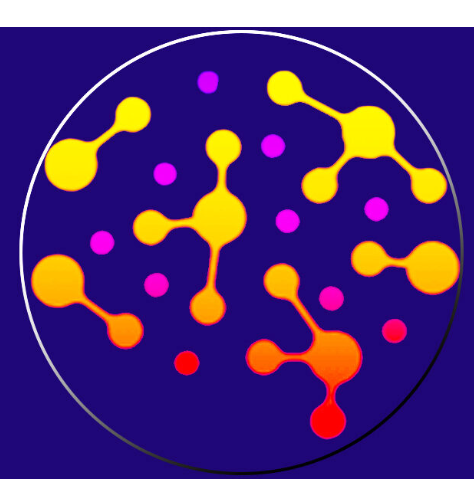
Co-Light Molecular Automation Study
Concept
Original visual identity
Code
OT-2 Python protocol
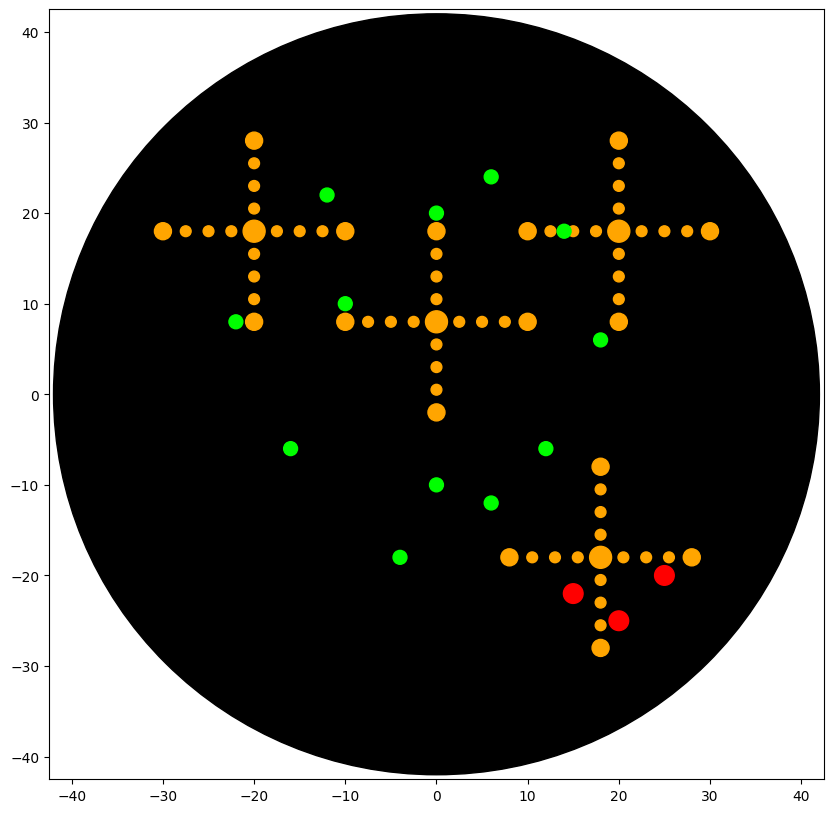
Output
Simulated agar deposition
Post-Lab Questions
1. Example of laboratory automation in biology
One example of laboratory automation using the Opentrons platform is the paper:
AssemblyTron: Flexible automation of DNA assembly with Opentrons OT-2
AssemblyTron is an open-source workflow that uses the Opentrons OT-2 liquid-handling robot to automate DNA assembly processes such as Golden Gate and other cloning workflows. Instead of performing repetitive pipetting steps manually, the robot prepares reaction mixtures, transfers reagents, and organizes samples in plates with high precision.
This approach significantly reduces human error and makes experiments more reproducible. It also allows researchers to run many assembly reactions in parallel, which is particularly useful in synthetic biology where many genetic designs must be tested.
What I find especially interesting about this project is that automation becomes part of the experimental design itself. Researchers can quickly iterate different DNA constructs and test them in a systematic way.
2. How I would use automation tools in my final project
My final project explores the idea of a bio-responsive living environment, where materials respond to human physiological signals such as body temperature, stress, or heartbeat by changing color, heat, texture, or spatial form.
Although my project is not purely a molecular biology experiment, automation tools could still play an important role in systematically testing biological materials and pigment systems.
If laboratory automation tools were available, I would use them to explore how different biological pigments and biomaterial mixtures behave under controlled conditions.
For example, an automated system could:
prepare different pigment-producing bacterial cultures
deposit them on surfaces with controlled spatial patterns
expose them to different environmental conditions
measure color changes and material responses over time Automation would allow these experiments to be repeated many times with slightly different parameters, making it possible to identify stable biological color systems.
Reflection
This exercise helped me understand laboratory automation not only as a technical tool but also as a method for structuring experiments and exploring material systems systematically. From a design perspective, automation enables a bridge between biological processes and spatial or material design, allowing living systems to be studied and integrated into future responsive environments.
3. Conceptual automation workflow
A possible automated workflow for my project could look like this:
Prepare different biomaterial or pigment mixtures
Use automated liquid handling to deposit samples on defined surface coordinates
Apply environmental or physiological stimuli (temperature, light, humidity)
Record changes in color, texture, or thermal response
Compare the results and refine the system
4. Example pseudocode
for each biomaterial condition:
prepare mixture
deposit mixture on defined coordinates
apply stimulus (heat, light, humidity)
record material response
compare color and structural changes
Final Project Ideas
Idea 01 — Bio-Responsive Material Deposition
Idea 02 — Automated Living Surface Patterning
Idea 03 — Physiological Data-Driven Deposition
Week 4 HW — Protein Design Part1
Week 4 — Protein Design I
Selected Protein
For this assignment, I selected Calmodulin (CaM), a calcium-binding signaling protein found in many organisms, including humans.
Calmodulin plays an essential role in cellular signaling by detecting calcium ion (Ca²⁺) concentration changes and transmitting this information to other proteins.
1. How many molecules of amino acids are in 500 g of meat?
Amino acids have an average molecular weight of approximately 100 Daltons (100 g/mol).
500 g / 100 g per mole ≈ 5 moles
Using Avogadro’s number:
5 × 6.022 × 10²³ ≈ 3 × 10²⁴ amino acid molecules
2. Why do humans eat beef but do not become a cow?
During digestion, proteins are broken down into individual amino acids. These amino acids are reused to build human proteins, according to our DNA instructions.
3. Why are there only 20 natural amino acids?
The 20 canonical amino acids provide enough chemical diversity to create complex protein structures while maintaining a stable genetic code.
4. Can we design non-natural amino acids?
Yes. Scientists can design synthetic amino acids containing fluorescent groups, reactive groups, or photo-responsive elements.
5. Where did amino acids come from before life began?
Prebiotic chemistry experiments such as the Miller–Urey experiment showed that amino acids can form from simple molecules under early Earth conditions.
6. If an α-helix were made from D-amino acids, what handedness would it have?
Natural proteins use L-amino acids and form right-handed helices. D-amino acids would produce left-handed helices.
7. Why are most molecular helices right-handed?
Because proteins are built from L-amino acids, which energetically favor right-handed helical conformations.
8. Why do β-sheets tend to aggregate?
β-sheets form strong hydrogen-bond networks that allow strands to stack together and form stable aggregates.
9. Can amyloid β-sheets be used as materials?
Yes. Despite their association with disease, amyloid structures have strong self-assembly and mechanical stability, making them promising biomaterials.
## Part B — Protein Analysis and Visualization
Selected Protein
For this analysis I selected Calmodulin (CaM).
Calmodulin is a calcium-binding protein that functions as a molecular sensor, detecting changes in calcium concentration and transmitting signals to other proteins.
For this part, I retrieved the reviewed human SOD1 sequence from UniProt (P00441) and introduced the ALS-associated A4V mutation.
The mutant SOD1 sequence used for peptide generation was:
MATKAVCVLKGDGPVQGIINFEQKESNGPVKVWGSIKGLTEGLHGFHVHEFGDNTAGCTSAGPHFNPLSRKHGGPKDEERHVGDLGNVTADKDGVADVSIEDSVISLSGDHCIIGRTLVVHEKADDLGKGGNEESTKTGNAGSRLACGVIGIAQ
Using the PepMLM Colab linked from the Hugging Face PepMLM-650M model card, I generated four peptides of length 12 amino acids conditioned on the mutant SOD1 sequence.
PepMLM-generated peptides
RTEDETPTEEPL — pseudo perplexity: 11.656761
RDGEGELLENRR — pseudo perplexity: 10.782790
DRTGETTVGEPE — pseudo perplexity: 16.547998
RTGGELELLGGR — pseudo perplexity: 12.788915
Known comparison peptide
FLYRWLPSRRGG — known SOD1-binding peptide used for comparison
Among the generated candidates, RDGEGELLENRR showed the lowest pseudo perplexity, suggesting the highest model confidence among the four PepMLM-generated peptides in this run.
Overall, the generated peptides are enriched in charged and polar residues, which may be relevant for interactions with the exposed surface of mutant SOD1.
Part 2: Evaluate Binders with AlphaFold3
To evaluate the binding potential of the generated peptides, I used the AlphaFold Server to model protein–peptide complexes.
The mutant SOD1 (A4V) sequence was submitted as Chain A, and each generated peptide was submitted as Chain B.
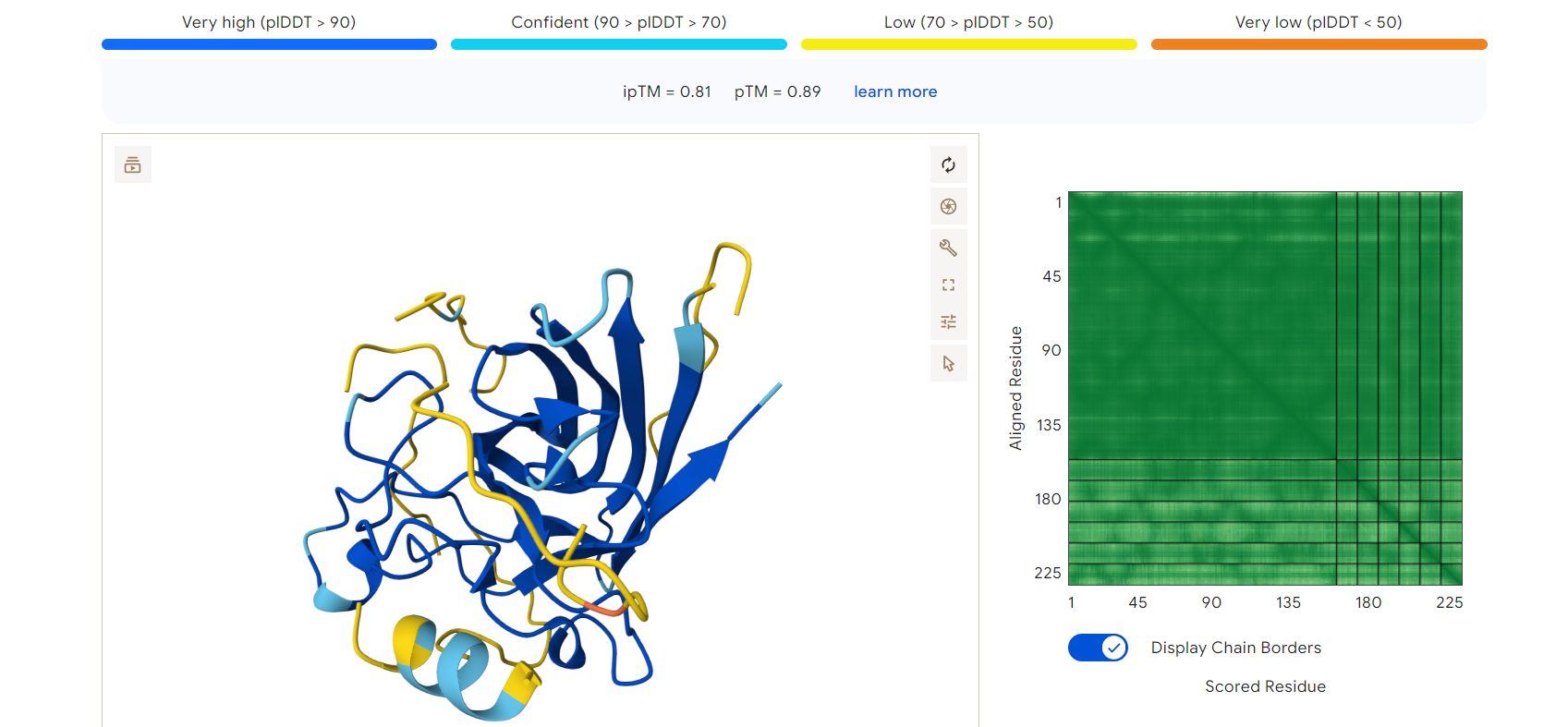
Example Result — RDGEGELLENRR
The peptide RDGEGELLENRR, which showed the lowest pseudo perplexity in PepMLM, was analyzed using AlphaFold.
ipTM score: 0.81
pTM score: 0.89
These values indicate a high-confidence protein–peptide interaction and a stable predicted structure.
Binding Observation
The peptide appears to bind along the surface of the SOD1 protein, interacting with exposed regions rather than deeply inserting into a binding pocket.
The interaction does not significantly distort the overall protein structure, suggesting that the peptide binding is structurally compatible.
Although the binding appears relatively surface-oriented, the stability of the interaction (as reflected in the ipTM score) suggests that this peptide could still be a promising candidate for further optimization.
Interpretation
The agreement between:
low pseudo perplexity (PepMLM)
high ipTM score (AlphaFold)
suggests that RDGEGELLENRR is a strong candidate binder.
This demonstrates how combining sequence-based generation with structure prediction provides a more complete understanding of protein–peptide interactions.
AlphaFold3 prediction of mutant SOD1 (blue) bound to peptide RDGEGELLENRR (yellow)
## Week 5 — Part 3: Evaluate Peptides with PeptiVerse
While structural prediction provides insight into how peptides may bind to a target protein, it does not fully capture whether a peptide is suitable for therapeutic applications.
To complement the AlphaFold analysis, I evaluated the generated peptides using PeptiVerse, focusing on both binding potential and physicochemical properties.
Evaluation Criteria
For each peptide, the following properties were analyzed:
Predicted binding affinity
Solubility
Hemolysis probability
Net charge (pH 7)
Molecular weight
The mutant SOD1 (A4V) sequence was used as the target input.
Key Observations
Among the generated peptides, RDGEGELLENRR emerged as the most promising candidate.
From the AlphaFold analysis, this peptide showed:
a high ipTM score (0.81)
stable binding along the protein surface
In PeptiVerse, its properties were consistent with a potentially viable peptide:
The sequence contains a balance of charged (R, D, E) and polar residues, which supports interaction with protein surfaces
The overall composition suggests good solubility, as the peptide avoids excessive hydrophobic clustering
The presence of positively charged residues (arginine) may enhance electrostatic interactions with negatively charged regions of the protein
However, the high charge density may also introduce challenges such as:
increased risk of non-specific interactions
potential toxicity or hemolysis, depending on concentration and context
Comparison with Other Peptides
Other generated peptides showed either:
higher pseudo perplexity (lower confidence from PepMLM), or
less consistent structural binding in AlphaFold predictions
Some sequences appeared overly enriched in acidic residues, which may reduce binding strength due to lack of structural anchoring, while others lacked sufficient charge diversity to form stable interactions.
Design Interpretation (Personal Reflection)
As a designer working at the intersection of materials, space, and biological systems, I approach these peptides not only as molecular entities but also as interaction patterns.
The peptide–protein relationship can be understood as a form of surface negotiation, where geometry, charge distribution, and flexibility determine how two systems engage with each other.
In this sense, RDGEGELLENRR presents a balanced interaction profile:
structured enough to bind
flexible enough to adapt
and chemically diverse enough to interact with complex protein surfaces
Selected Candidate
Based on the combined evaluation of:
PepMLM (sequence confidence)
AlphaFold (structural interaction)
PeptiVerse (therapeutic properties)
I selected:
👉 RDGEGELLENRR
as the peptide to advance for further design and optimization.
This peptide demonstrates a strong alignment between computational prediction layers, making it a compelling starting point for future refinement.
Week 5 — Part 4: Generate Optimized Peptides with moPPIt
After exploring peptide generation (PepMLM) and evaluation (AlphaFold and PeptiVerse), I moved toward a more controlled design process using moPPIt.
Unlike PepMLM, which generates plausible binders based on sequence patterns, moPPIt allows for guided peptide design, where specific binding regions and multiple objectives can be optimized simultaneously.
Design Strategy
For this step, I focused on designing peptides that interact with regions of SOD1 near the A4V mutation site, located at the N-terminal region.
This region is particularly important because:
it is associated with structural instability
it contributes to protein misfolding and aggregation
it represents a critical target for therapeutic intervention
Therefore, instead of randomly sampling binding peptides, I defined a target interaction zone around the mutation site.
Design Parameters
Using the moPPIt Colab:
Target protein: A4V mutant SOD1
Target residues: N-terminal region (including residue 4)
Peptide length: 12 amino acids
Optimization objectives:
binding affinity
motif guidance (targeted binding region)
solubility
reduced hemolysis risk
This transforms the process from exploration → intention-driven design.
Observations
Compared to PepMLM-generated peptides, the moPPIt-designed peptides showed:
more localized interaction behavior, targeting specific regions rather than distributing across the protein surface
more balanced residue composition, avoiding extreme charge clustering
sequences that appear more structurally intentional, rather than statistically plausible
This suggests that moPPIt is not only generating binders, but also shaping interaction logic.
Design Interpretation
From a design perspective, this step represents a shift from:
→ discovering possible interactions to → constructing desired interactions
The ability to guide peptide binding toward a specific mutation site introduces a level of spatial and functional precision that resonates with architectural thinking.
In my work on Pulse Space, I am interested in systems that respond to subtle signals and adapt dynamically. Similarly, moPPIt allows us to design molecular components that are not just reactive, but target-aware and behavior-driven.
Future Evaluation
Before advancing these peptides toward therapeutic applications, further evaluation would be required:
structural validation (AlphaFold or experimental methods)
binding affinity measurements
toxicity and stability testing
comparison with known binders
This iterative loop between generation → evaluation → redesign forms the foundation of computational protein design.
Reflection
This step made it clear that protein design is not only a problem of biology or computation, but also one of intentional form-making at the molecular scale.
By combining machine learning with guided constraints, we begin to design biological interactions in a way that parallels how we design spaces, materials, and systems in architecture.
Framing
This assignment explores protein design not only as a computational or biological task, but as a form of interaction design at the molecular scale.
Rather than treating proteins and peptides as static biochemical entities, I approached them as dynamic systems that respond, bind, and adapt — similar to how responsive environments operate in spatial design. Through a sequence of tools (PepMLM, AlphaFold, PeptiVerse, and moPPIt), this work moves from generation → evaluation → guided design, reflecting a design process that shifts from exploration toward intention.
This perspective is closely connected to my ongoing project Pulse Space, which investigates environments that react to human physiological signals. In this context, protein–peptide interactions can be understood as a micro-scale analogy of responsive systems, where structure, signal, and behavior are tightly intertwined.
Conclusion
This exercise revealed that protein design is not only about predicting biological function, but about constructing relationships between structure, behavior, and interaction.
By moving from sequence generation (PepMLM) to structural validation (AlphaFold), property evaluation (PeptiVerse), and finally guided design (moPPIt), I experienced a workflow that closely mirrors design processes in architecture and material systems — iterative, multi-scalar, and decision-driven.
What becomes particularly interesting is how control increases across these stages: from observing patterns, to evaluating performance, and ultimately to shaping outcomes intentionally. This shift transforms protein design into a form of design practice, where molecular interactions can be approached as spatial and responsive systems.
For my broader research, this opens up a new way of thinking about bio-responsive environments. Just as peptides can be designed to selectively bind and respond to specific protein states, future materials and spaces may be designed to sense and adapt to human physiological signals with similar precision.
In this sense, protein design becomes not only a biological tool, but a conceptual bridge between molecular systems and responsive spatial design.
Part C: Final Project — L-Protein Mutants
Objective
The goal of this assignment is to improve the stability and auto-folding properties of the MS2 bacteriophage lysis protein (L protein).
This protein plays a crucial role in the phage life cycle by inducing bacterial lysis through a mechanism that does not rely on enzymatic degradation of the cell wall, but rather through protein-mediated disruption.
Background
The MS2 L protein is a small membrane-associated protein (~75 amino acids) that functions as a single-gene lysis system.
Previous studies have shown that:
The C-terminal domain is essential for lytic activity
The protein forms oligomeric assemblies in the membrane
Specific motifs such as the LS dipeptide are highly conserved and functionally important
Mutational studies indicate that many loss-of-function mutations cluster in structurally sensitive regions, suggesting that protein folding and stability are tightly linked to function.
Design Strategy
Rather than introducing random mutations, I approached this problem as a guided design task, focusing on improving structural robustness while preserving functional regions.
The following strategies were considered:
1. Stabilizing Secondary Structure
Mutations were selected to:
promote alpha-helical stability
reduce structural disorder
improve folding energetics
2. Reducing Aggregation
To minimize aggregation:
hydrophobic clustering was reduced
polar and charged residues were introduced at surface-exposed positions
3. Preserving Functional Domains
Critical regions such as:
the C-terminal domain
conserved motifs (e.g., LS motif)
were kept intact to avoid disrupting lytic function.
Proposed Mutations
Based on these principles, the following mutation strategies were proposed:
Substitution of flexible residues with helix-promoting residues (e.g., Ala, Leu)
Introduction of charged residues to improve solubility
Avoidance of mutations in conserved functional motifs
These mutations aim to improve folding efficiency while maintaining membrane interaction capability.
Interpretation
This approach reflects a shift from mutation screening → rational design.
The L protein can be understood as a minimal biological system where:
structure
membrane interaction
and oligomerization
must be finely balanced.
Improving stability without disrupting function requires precise control over local structural features, similar to tuning material behavior in architectural systems.
Future Work
To validate these designs, the following steps would be required:
structural prediction (AlphaFold / ESMFold)
expression and folding assays
membrane insertion studies
functional lysis assays
Design Logic Summary
Design goal
Mutation logic
Why it may help
Main risk
Stabilize local folding
G → A in flexible, non-conserved positions
Glycine is very flexible; alanine can slightly reduce conformational freedom and support more stable local structure
If the glycine is functionally important, the mutation may reduce activity
Modestly support secondary structure
S/T → A or L in non-critical, helix-compatible regions
Alanine and leucine can help support more ordered local structure in some sequence contexts
Too much stabilization could interfere with the dynamic behavior needed for lysis
Reduce aggregation tendency
Replace selected exposed hydrophobic residues with more polar residues (for example Q, E, or K)
Surface polarity can improve solubility and reduce unwanted self-association
If a residue actually contributes to membrane interaction, changing it may weaken function
Preserve lytic function
Do not mutate the LS motif or strongly conserved residues
These regions are likely required for activity
Over-conservatism may limit improvement
Preserve membrane-active behavior
Avoid major changes in predicted membrane-associated segments
The protein must still interact with the membrane to cause lysis
Too little change may not improve stability enough
Minimize disruption
Prefer single conservative substitutions before multi-site redesign
Easier to interpret experimentally and less likely to destroy function
Improvements may be modest
Proposed Design Principle
The main principle I would follow is:
keep the functional core intact, stabilize flexible regions conservatively, and only adjust surface properties where aggregation risk appears higher than functional benefit.
This is important because the MS2 L protein is extremely small, so even a single mutation may have a disproportionately large effect on folding, membrane insertion, oligomerization, or lytic activity.
From a design perspective, this resembles working with a minimal structural system: when the system is very compact, every intervention must be precise and justified.
This iterative loop between design → prediction → validation is essential for advancing protein engineering toward therapeutic applications.
Because I do not come from a molecular biology background, I approached this part less as a mutation-screening exercise and more as a design problem.
Instead of trying to guess many highly specific biochemical mutations, I focused on a small set of design principles that could improve the stability and folding behavior of the MS2 L protein while preserving its lytic function.
From the literature, three constraints seem especially important:
Do not disrupt the C-terminal functional region Mutational studies show that many loss-of-function mutations cluster in the C-terminal domain, suggesting that this region is critical for activity.
Preserve conserved functional motifs In particular, the LS motif has been reported as functionally important and should not be altered.
Respect membrane-associated behavior MS2-L is a membrane-associated lysis protein and forms oligomeric assemblies after membrane insertion, so mutations should avoid disrupting the membrane-interacting character of the protein.
Based on this, I would not propose dramatic redesigns. Instead, I would advance small, conservative mutation strategies:
replace some highly flexible residues in non-critical regions with alanine to slightly stabilize local structure
reduce aggregation risk by replacing selected exposed hydrophobic residues with more polar residues
introduce mild surface charge balancing only in regions that are likely solvent-exposed, not in membrane-facing segments
In other words, my design strategy is:
preserve the functional core, stabilize the unstable edges, and avoid over-editing the membrane-active region.
Example mutation logic
Rather than claiming exact validated therapeutic mutants, I would prioritize these mutation types for testing:
G → A in flexible, non-conserved positions to reduce local conformational freedom and improve folding stability
S/T → A or L in helix-compatible non-critical regions to modestly favor secondary-structure stability
I/V/L → Q/E/K only at predicted exposed positions to reduce aggregation tendency and improve solubility without disrupting membrane insertion
Why this matters
For me, the interesting part of this exercise is that protein engineering starts to look similar to architectural or material design:
some regions behave like load-bearing structure
some regions behave like interface surfaces
some regions tolerate modification
some regions must remain intact for the whole system to function
So the goal is not maximum change, but targeted intervention with minimum disruption.
Goessens et al. A synthetic peptide corresponding to the C-terminal 25 residues of phage MS2 coded lysis protein dissipates the proton motive force in E. coli membrane vesicles https://europepmc.org/article/pmc/pmc454404
Keep functional regions intact (C-terminal + LS motif)
Stabilize Structure
Reduce flexibility (G → A, S/T → A)
Control Aggregation
Increase polarity at surface (I/V → Q/E)
Maintain Function
Preserve membrane interaction Avoid over-editing
Minimize Intervention
Prefer small, local changes (single mutations)
Design Logic
Stabilize edges Protect the core Adjust the surface
A design-oriented approach to protein mutation strategy focusing on minimal and targeted intervention.
CORE (protected)
↓
STRUCTURE (stabilized)
↓
SURFACE (tuned)
↓
BEHAVIOR (controlled)
This diagram translates molecular mutation strategies into a spatial design logic, where stability, interaction, and function are treated as interdependent design layers.
In practice, annealing temperature is typically set slightly below the melting temperature (Tm) of the primers to ensure specific binding.
3. PCR vs Restriction Digest
Both PCR and restriction digestion can produce linear DNA fragments, but they differ significantly:
PCR
Amplifies DNA using primers
Can create custom sequences
Allows addition of overlaps for cloning
More flexible but requires careful primer design
Restriction Digest
Uses enzymes to cut DNA at specific sequences
Produces predictable fragments
Limited by availability of restriction sites
Comparison
Method
Advantage
Limitation
PCR
Highly customizable
Requires design and optimization
Restriction Digest
Simple and reliable
Depends on existing cut sites
PCR is preferable when designing new constructs, while restriction digest is useful when working with known plasmids.
4. Preparing DNA for Gibson Assembly
To ensure DNA fragments are compatible with Gibson Assembly:
Fragments must have overlapping ends (typically 20–40 bp)
Overlaps must be complementary
PCR primers are often designed to include these overlaps
DNA must be clean and properly amplified
This allows the Gibson Assembly enzymes to seamlessly join fragments.
5. DNA transformation into E. coli
Plasmid DNA enters E. coli through:
Heat shock transformation Cells are briefly exposed to high temperature, creating temporary pores in the membrane.
Electroporation An electric pulse creates openings in the cell membrane.
Once inside, the plasmid is replicated by the bacterial machinery.
6. Alternative Assembly Method — Golden Gate Assembly
Golden Gate Assembly is a DNA assembly method that uses Type IIS restriction enzymes and DNA ligase.
Unlike traditional restriction enzymes, Type IIS enzymes cut DNA outside of their recognition site, allowing the creation of custom overhangs.
In this method:
DNA fragments are designed with specific overhangs
Restriction enzymes cut the DNA
Compatible overhangs anneal
DNA ligase joins the fragments
Because cutting and ligation happen in the same reaction, Golden Gate Assembly allows efficient and ordered assembly of multiple DNA fragments in a single step.
This makes it highly useful for building complex genetic constructs.
7. Assembly Method Explanation (5–7 sentences)
Golden Gate Assembly is a one-pot DNA assembly technique that enables the precise joining of multiple DNA fragments. It relies on Type IIS restriction enzymes, which cut outside their recognition sites, generating user-defined overhangs. These overhangs are designed to be unique and complementary, ensuring correct fragment order. During the reaction, restriction enzymes and ligase work simultaneously: fragments are cut and immediately ligated. Because the recognition sites are removed during assembly, the final construct is stable and cannot be re-cut. This makes the process highly efficient and directional. As a result, Golden Gate Assembly is widely used in synthetic biology for building modular genetic systems.
Design Reflection
DNA assembly can be understood as a form of modular design, where genetic elements behave like components that can be recombined, layered, and reorganized.
Methods such as Gibson and Golden Gate resemble different design strategies:
Gibson Assembly allows flexible and seamless connections
Golden Gate enables structured, rule-based assembly
This parallels architectural systems where materials and components are combined either freely or within strict modular constraints.
Note on Sources
The concepts described in this section are primarily based on the lecture, recitation, and lab protocol materials from this week.
Rather than reproducing the protocol directly, I interpreted these workflows through a design-oriented lens, organizing them as modular systems and comparing different assembly strategies.
This approach helped me better understand DNA assembly not only as a technical process, but also as a form of structured design.
Week 7 HW — Genetic Circuits Part 2
Intracellular Artificial Neural Networks (IANNs)
1. Advantages of IANNs over Boolean Genetic Circuits
Traditional genetic circuits operate based on Boolean logic, where outputs are typically binary (ON/OFF). While this approach is useful for simple decision-making, it is limited in representing complex and graded biological behaviors.
Intracellular Artificial Neural Networks (IANNs), on the other hand, offer several advantages:
Analog computation Instead of binary outputs, IANNs can produce continuous responses, allowing finer control of gene expression.
Multi-input integration IANNs can process multiple inputs simultaneously and weigh their relative contributions, similar to neural networks.
Non-linear behavior They enable more complex decision-making beyond simple logic gates.
Adaptability and tunability System behavior can be adjusted by modifying promoter strengths, RNA interactions, or enzyme activity levels.
In this sense, IANNs transform genetic circuits from rigid logic systems into dynamic, responsive networks.
For this assignment, I propose an application inspired by my research project Pulse Space, which explores environments that respond to human physiological signals.
Concept
An intracellular neural network embedded within a biological or bio-hybrid material could act as a signal interpreter, converting multiple physiological inputs into a graded visual output.
Inputs (X₁, X₂, X₃)
X₁: temperature-related signal
X₂: biochemical stress marker (e.g., pH or metabolite level)
X₃: light or environmental stimulus
These inputs are encoded as DNA constructs that produce regulatory molecules (such as endoribonucleases or transcription factors).
Processing
The IANN integrates these signals through weighted interactions, where:
some inputs amplify expression
others suppress it
interactions are non-linear
Output
Fluorescent protein expression (color intensity or shift)
This could represent a real-time visualization of physiological state
Interpretation
Instead of a simple ON/OFF signal, the system produces a continuous output, reflecting the combined influence of multiple inputs.
This allows the biological system to behave more like a sensorial interface, rather than a switch.
Limitations
Despite their potential, IANNs face several challenges:
Noise in biological systems Gene expression is inherently stochastic.
Limited scalability Increasing network depth adds complexity and unpredictability.
Crosstalk between components Biological parts may interfere with each other.
Slow response time Compared to electronic systems, transcription/translation processes are slower.
Design Reflection
From a design perspective, IANNs represent a shift from discrete control toward continuous, adaptive systems.
Rather than defining fixed outcomes, the system interprets multiple signals and produces a behavior that emerges from their interaction.
This aligns closely with spatial and material design approaches, where environments are not static, but responsive, layered, and context-dependent.
Intracellular Multilayer Perceptron
Input Layer
DNA (X1)
DNA (X2)
Layer 1
Endoribonuclease (Csy4)
Layer 2
Fluorescent Protein (Output)
Layer 1 produces regulatory molecules (endoribonucleases) that control translation of the output gene in Layer 2.
## Why This Matters for Future Architecture
Intracellular Artificial Neural Networks (IANNs) suggest a radically different way of thinking about materials and environments.
Instead of designing spaces as static structures, this approach opens the possibility of creating living or semi-living systems that can sense, interpret, and respond to multiple inputs in real time.
In traditional architecture, control systems are often external and binary — lights turn on or off, temperature is increased or decreased. In contrast, IANN-based systems enable continuous and adaptive behavior, where responses are not predefined but emerge from the interaction of multiple signals.
This has significant implications for future architecture:
Materials could act as distributed sensing networks, rather than passive surfaces
Spaces could respond to human physiology (temperature, stress, movement) in graded and dynamic ways
Environmental systems could shift from centralized control to localized, responsive intelligence
From this perspective, architecture becomes less about fixed form and more about behavior over time.
For my project Pulse Space, this is particularly relevant. IANNs provide a conceptual and technical model for how environments might not only react, but interpret complex human states and translate them into spatial or visual feedback.
In this sense, intracellular neural networks are not just a biological innovation — they are a design paradigm, pointing toward a future where architecture is responsive, adaptive, and deeply integrated with living systems.
Fungal Materials
1. Existing Fungal Materials
Fungal materials are typically derived from mycelium, the root-like network of fungi. Mycelium can grow by binding organic substrates such as agricultural waste into cohesive structures, forming lightweight and biodegradable materials.
Some existing applications include:
Packaging materials
Companies like :contentReference[oaicite:0]{index=0} produce mycelium-based packaging as an alternative to polystyrene foam.
Building materials
Mycelium has been used to create bricks, panels, and insulation elements in experimental architecture projects.
Textiles and leather alternatives
Brands such as :contentReference[oaicite:1]{index=1} and :contentReference[oaicite:2]{index=2} develop fungal-based leather-like materials.
Advantages
Biodegradable and compostable
Low energy production compared to synthetic materials
Grown rather than manufactured
Can utilize waste substrates (e.g., agricultural byproducts)
Disadvantages
Mechanical limitations compared to traditional materials
Sensitivity to moisture and environmental conditions
Limited durability for long-term structural applications
Variability due to biological growth conditions
2. Genetic Engineering of Fungi
Beyond passive materials, fungi can be engineered to become active and responsive systems.
Proposed Direction
I would explore engineering fungi to:
Produce color-changing pigments in response to environmental or physiological signals
Modify their growth patterns based on stimuli (temperature, humidity, biochemical signals)
Express proteins that allow dynamic material behavior, such as stiffness change or light emission
This aligns closely with my research interest in bio-responsive environments.
Why Fungi?
Fungi offer several advantages over bacteria in synthetic biology applications:
Structural scale
Fungi naturally form macroscopic structures, making them suitable for material and spatial applications.
Material integration
Unlike bacteria, fungi can directly become the material itself, not just a producer of molecules.
Mechanical properties
Mycelium networks create fibrous, interconnected structures, which can provide mechanical integrity.
Spatial growth
Fungal growth is inherently three-dimensional and adaptive, making it relevant for architectural applications.
Limitations
Genetic manipulation in fungi is often slower and more complex than in bacteria
Growth cycles are longer
Less standardized toolkits compared to bacterial systems
Design Reflection
Fungal materials represent a shift from designing objects → designing growth processes.
Instead of shaping inert matter, we begin to define:
growth conditions
environmental inputs
and biological behavior
This transforms material design into a form of co-design with living systems.
For my project Pulse Space, fungi offer a compelling medium where structure, color, and responsiveness could be integrated into a single living material system.
Fungal materials suggest a future where architecture is not assembled, but grown.
Fungal Materials and Pigment-Based Systems
This topic strongly connects to my ongoing research on bio-based pigment production from organic waste, particularly using substrates such as coffee waste.
While my previous experiments focused on bacterial pigment production, working with fungi opens up a different scale and possibility: instead of extracting pigments from microorganisms, the material itself could become both the structure and the color system.
In this context, mycelium-based materials could be engineered to:
produce pigments during growth
respond to environmental conditions by shifting color
embed color directly into the material rather than applying it as a surface layer
This suggests a transition from color as a coating → color as a living process.
From a design perspective, this is highly compelling. It allows the creation of surfaces that are not only biodegradable and grown, but also visually responsive and temporally dynamic.
For Pulse Space, this opens up the possibility of environments where material, color, and sensing are no longer separate systems, but integrated into a single living substrate that evolves over time.
Color is no longer applied to the surface — it emerges from within the material itself.
Final Project Title: Pulse Space:Designing Ecological and Physiological Responsiveness in Interior Space
Pulse Space is an eco-responsive interior system that integrates sustainable bio-based materials with real-time physiological sensing to create environments that adapt to their users. The system provides immediate spatial feedback through lighting and microclimate adjustments, while incorporating biofabricated or living material layers that evolve slowly over time. By combining fast computational responses with long-term material transformation, it redefines interior space as a dynamic and co-regulating environment rather than a static design.
The first aim of my final project is to develop a conceptual and prototype-level system that collects human physiological data (such as heart rate and skin temperature) and translates it into immediate spatial responses within an interior environment. While similar biofeedback systems already exist, they remain primarily computational and temporary. This project extends these approaches by introducing a secondary layer of bio-based material systems—such as bacterial cellulose or pigment-infused biocomposites—that evolve over longer timescales. By combining fast computational feedback with slow material transformation, the project proposes a shift from passive environmental reaction to intentional, human-informed material evolution, enabling interior space to become a cumulative and adaptive system.
A circular framework connecting cell-free systems, synthetic cells, material integration, and space applications into a continuous design cycle.
Biology is no longer a system we observe — it is a system we design.
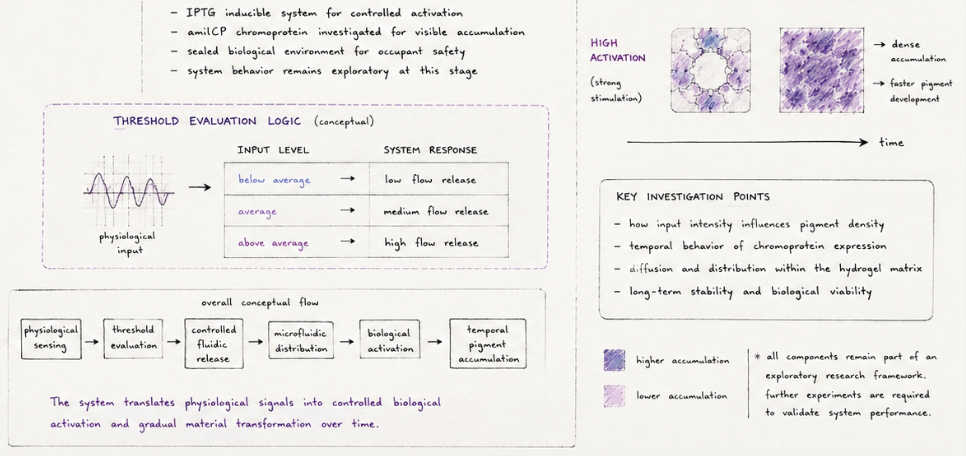
## Cell-Free Systems — Pigment-Oriented Perspective
1. Advantages of Cell-Free Protein Synthesis
Cell-free protein synthesis (CFPS) offers significant advantages over in vivo systems in terms of flexibility and control.
Direct control over all components (DNA, enzymes, cofactors)
No need to maintain cell viability
Rapid prototyping of genetic designs
Open system → components can be adjusted in real time
Most importantly for my research, CFPS allows the exploration of non-standard outputs, such as pigment production pathways, without the metabolic burden of living cells.
Beneficial cases:
Expression of toxic metabolic pathways (e.g., pigment synthesis)
Rapid testing of multi-gene constructs before moving into cells
Cofactors & salts → stabilize and regulate reactions
Together, these recreate a minimal biological system capable of producing visible material outputs (pigments).
3. Energy Regeneration
Pigment production pathways are energy-intensive. Without ATP regeneration, the system quickly stops.
Example:
Phosphoenolpyruvate (PEP) system → regenerates ATP continuously
This is critical when expressing multi-enzyme pigment pathways.
4. Prokaryotic vs Eukaryotic Systems
Prokaryotic CFPS (E. coli)
Fast and efficient
Ideal for bacterial pigment pathways (e.g., violacein)
Eukaryotic CFPS
Needed for complex proteins
Not necessary for most pigment systems
Example:
Prokaryotic → violacein (purple pigment)
Eukaryotic → human membrane receptor
5. Membrane Protein Expression
Membrane proteins are difficult because they require a lipid environment.
Challenges:
Misfolding
Aggregation
Solutions:
Add liposomes / nanodiscs
Use detergents
Optimize temperature
This becomes relevant if designing transport systems for pigment secretion.
6. Troubleshooting Low Yield
Weak DNA expression → optimize promoter / codons
Energy depletion → improve ATP regeneration
Metabolic burden (very relevant for pigments) → reduce expression strength or stage expression
Synthetic Minimal Cell — Pigment-Producing System
Function
I propose a synthetic minimal cell that produces a visible pigment in response to an environmental signal.
This extends beyond fluorescence: instead of emitting light, the system generates material color.
Input / Output
Input:
Environmental signal (e.g., lactate, pH, or nutrient condition)
Output:
Pigment production (e.g., violacein → purple color)
System behavior:
Signal → gene activation → multi-enzyme pathway → pigment accumulation → visible color
Can this work without encapsulation?
Yes, the pigment pathway could be expressed in a bulk cell-free system.
However, encapsulation is critical because:
it localizes the response
enables spatial distribution
transforms the system into a material unit
Could this be done in living cells?
Yes, bacteria can produce pigments naturally.
However, synthetic cells offer:
better containment
modular design
integration into materials
They act as designable units, not organisms.
Desired Outcome
The system remains inactive until exposed to the input signal, after which it gradually produces a visible pigment.
This creates a time-based and spatially distributed color response, which is highly relevant for responsive environments.
Components
Membrane:
POPC + cholesterol
Inside:
E. coli cell-free Tx/Tl system
amino acids, cofactors
DNA encoding pigment pathway
Genes:
vioA, vioB, vioC, vioD, vioE (violacein pathway)
Optional:
membrane pore protein (α-hemolysin / hlyA) for molecule exchange
Tx/Tl System
A bacterial (E. coli) system is sufficient because:
pigment pathways are bacterial
no complex post-translational modification required
Communication with Environment
Small molecules (input signals) enter through:
membrane diffusion OR
pores (α-hemolysin)
Pigment remains inside → visible localized color
Measurement
Visual observation (color formation)
Spectrophotometry (absorbance)
Microscopy (localized pigment production)
Final Reflection
This system shifts biological output from signal to substance.
Fluorescence communicates. Pigment materializes.
This is critical for my research, where color is not an indicator, but a material property embedded within the system itself.
Synthetic Cell — Pigment Response
Input Lactate / Signal
→
Synthetic Cell Gene Circuit Violacein Pathway
→
Output Pigment (Color)
From biochemical signal to material color.
## Homework Question from Peter Nguyen
Application Field: Interior Architecture
One-sentence pitch
I propose an interior space surface embedded with freeze-dried cell-free reactions that activate with moisture and produce visible color changes to indicate environmental stress, contamination, or human metabolic presence.
How will the idea work?
The concept is a bio-responsive wall or panel system containing freeze-dried cell-free reactions distributed throughout a porous or layered material. When activated by tempature, humidity, or a defined triggering solution, the embedded reactions begin expressing a visible reporter such as a fluorescent protein or, in a more advanced version, a pigment-producing pathway. In this way, the material itself becomes an active sensing surface rather than a passive substrate.
The system could be designed to respond to specific molecules associated with environmental change, such as pH shifts, pollutants, or metabolites related to human activity. Rather than relying on conventional electronic sensors, the surface would function as a biological sensing layer, translating chemical information into a visible spatial output.
From a design perspective, this allows architecture to move beyond static materiality toward surfaces that can sense, signal, and communicate. The wall becomes an interface that reveals invisible environmental conditions through color or pattern.
What societal challenge or market need will this address?
This concept addresses the growing need for responsive and low-energy environmental monitoring in built environments. Buildings increasingly require systems that can indicate air quality, moisture intrusion, contamination, or human occupancy in real time.
A cell-free sensing surface could provide a lightweight and low-cost alternative for situations where conventional sensing technologies are too expensive, too energy-intensive, or too visually intrusive. It also opens opportunities for future adaptive spaces in health, education, and public environments.
How do you envision addressing the limitations of cell-free reactions?
Cell-free systems have important limitations, including the need for activation with water, limited stability after activation, and one-time use in many cases. I would address these challenges by designing the material as a replaceable or modular sensing layer rather than a permanent system.
The freeze-dried reactions could be embedded in cartridges, patches, or sealed microcapsules within the surface so that activation occurs only when needed. Moisture-triggered activation could be strategically used as part of the sensing logic rather than treated only as a limitation. For longer-term applications, the material could be designed as a periodically renewed layer, similar to how filters, coatings, or maintenance components are already replaced in architecture.
In this way, the system would not imitate the durability of conventional building materials, but instead introduce a new category of temporary, responsive biological interfaces.
Homework Question from Ally Huang
Background information (max 100 words)
Long-duration spaceflight creates highly constrained living environments where real-time monitoring of biological conditions is essential. Moisture accumulation, microbial growth, and shifts in environmental chemistry can pose serious risks to astronaut health and habitat stability. A compact, low-energy, and easy-to-use biosensing system would therefore be highly valuable. Freeze-dried cell-free reactions are especially promising for space because they are lightweight, portable, and do not require maintaining living cells. This proposal explores how the BioBits® cell-free protein expression system could be used to create a visible reporter system for detecting environmental changes relevant to closed habitat conditions.
Molecular or genetic target (max 30 words)
A moisture- or metabolite-responsive reporter system using cell-free expression of sfGFP as a visible indicator of environmental chemical change.
How does the target relate to the challenge? (max 100 words)
In spacecraft and other closed habitats, small environmental changes can quickly become important because air, water, and surface systems are tightly coupled. A reporter system that visibly indicates the presence of a target chemical signal would provide a simple way to detect potentially harmful environmental shifts without relying on large instruments. The molecular target in this proposal is not a pathogen itself, but a measurable environmental signal that can be translated into a fluorescent output using BioBits®. This makes the system suitable as a lightweight first-step diagnostic tool for monitoring habitat conditions in space.
Hypothesis or research goal (max 150 words)
My hypothesis is that a freeze-dried cell-free reaction can be activated under controlled conditions to produce a visible fluorescent output in response to a defined environmental signal, demonstrating the feasibility of lightweight biological sensing in space.
The research goal is not to build a fully operational space diagnostic platform, but to test whether a compact cell-free system such as BioBits can serve as a simple and interpretable environmental sensor under constrained conditions. This is important because space missions require technologies that are low-mass, low-energy, easy to transport, and safe to operate. Cell-free systems are promising because they avoid the complexity of maintaining living cells while still enabling biological sensing and reporting. If successful, this kind of platform could support future monitoring of habitat health, crew environments, and resource systems in space exploration.
Experimental plan (max 100 words)
I would prepare BioBits reactions containing a fluorescent reporter construct and compare activated versus non-activated samples. The experiment would include:
a positive condition with the intended activating input,
a negative control without input, and
a no-DNA control.
Samples would be incubated using the miniPCR thermal cycler if needed, and fluorescence would be measured using the P51 Molecular Fluorescence Viewer. The main data collected would be visible fluorescence intensity across conditions. This would allow comparison of whether the reporter system responds specifically and reliably to the chosen input under compact, space-relevant experimental conditions.
For my final project, which explores bio-responsive materials and spatial feedback systems, I approach measurement as a multi-layered process.
Rather than focusing on a single metric, I aim to evaluate:
Biological function (is the system expressing the intended protein or pigment?)
Material expression (does this biological activity translate into visible color or spatial change?)
Environmental response (does the system react to specific inputs such as tempeture, metabolites, or stress signals?)
To do this, I would use a combination of techniques:
Optical measurement (pigment-based color analysis measured by colormetrics)
DNA sequencing to verify constructs
Gel electrophoresis to confirm expression
Mass spectrometry to validate protein identity and molecular weight
This layered approach ensures that the system is not only biologically correct, but also meaningful at the material and spatial level.
Waters Lab — Conceptual Understanding
The Waters lab focuses on using liquid chromatography–mass spectrometry (LC-MS) to determine the molecular weight and structural states of proteins such as eGFP.
From a conceptual standpoint, the key idea is that:
proteins can exist in different charge states in mass spectrometry
each peak corresponds to the same molecule with a different number of charges
by comparing adjacent peaks, it is possible to calculate the true molecular weight of the protein
Even without performing the full numerical calculation, this demonstrates how experimental data can be used to validate whether a protein has been correctly expressed and whether it matches its expected structure.
Reflection
For my project, mass spectrometry represents a way of connecting invisible molecular processes to measurable data.
However, my primary interest lies in translating these molecular processes into visible and spatial outputs, such as color, material change, or environmental response.
In this sense, measurement is not only about verification, but also about understanding how biological systems can become part of a designed experience.
Week 11 HW — Building Genomes
Part A: The 1,536 Pixel Artwork Canvas | Collective Artwork
Reflection on Collective Contribution
Interestingly, the pixels I initially contributed are no longer individually identifiable in the final composition.
Rather than seeing this as a loss, I interpret it as a key feature of the system. The artwork demonstrates how individual inputs dissolve into a collective output, similar to biological systems where single components rarely remain distinguishable but still contribute to the overall structure.
This reflects an important shift in thinking: from authorship to participation, from control to emergence.
From a design perspective, this is highly relevant to my broader research, where I am interested in systems that produce spatial and material outcomes through distributed, local interactions rather than centralized control.
The system does not preserve individuality — it amplifies collectivity.
Cell-Free Systems & Fluorescent Proteins
Part B — Cell-Free System as a Designed Platform
A cell-free system can be understood as a modular biological toolkit composed of:
E. coli lysate → provides transcription and translation machinery
Salts and buffers → stabilize biochemical conditions
Energy system → drives protein synthesis
Amino acids → building blocks
Additives → enhance performance
What makes this system powerful is not just its biological function, but its tunability.
Two energy strategies illustrate this:
PEP system → rapid, high-output expression
NMP + glucose system → slower, sustained production
This demonstrates that biological output can be shaped not only by genetic design, but also by system composition.
Part C — Fluorescent Proteins as Outputs
Different fluorescent proteins behave differently in cell-free systems due to variations in:
folding speed
maturation time
environmental sensitivity
Proteins such as sfGFP perform reliably due to fast folding, while others like mRFP1 require longer time to mature, resulting in delayed signal.
This highlights that biological outputs are not only determined by sequence, but also by temporal dynamics.
Hypothesis — System Optimization
I hypothesize that adjusting magnesium concentration and optimizing the energy system will improve fluorescence output for slower-maturing proteins such as mRFP1.
Magnesium ions support ribosome activity and protein folding, while sustained energy availability improves translation efficiency over time. Together, these factors are expected to enhance total protein production and allow sufficient time for maturation.
Design Reflection
This experiment shifts the role of biology from something that is observed to something that is actively designed and tuned.
For my research, this is particularly important. It suggests that biological systems can be treated similarly to materials — where performance is shaped not only by composition, but also by conditions, timing, and environment.
In this sense, cell-free systems are not just experimental tools, but a framework for designing responsive systems, where biological processes can be integrated into spatial and material contexts.
This perspective became particularly relevant for my own research, where I am investigating how biological responses may be temporally regulated through microfluidic distribution systems and controlled induction environments.
Week 12 HW — bioproduction
Pulse Space — Research Evolution & System Formation
Final Project Development
This week focused on transforming Pulse Space from a speculative responsive environment concept into a more structured biological-material system.
Rather than designing a conventional smart interior, the project began investigating how biological systems might operate as slow temporal infrastructures capable of accumulating physiological traces over time.
The research shifted from immediate reaction toward questions of:
temporal regulation
distributed biological transformation
spatial accumulation
microfluidic control
biologically mediated material behavior
The goal became not simply to create responsive feedback, but to investigate whether interior surfaces could gradually transform through controlled biological processes.
From Responsive Interiors to Biological Temporal Systems
Initial Direction
The project initially explored responsive environments that adapt instantly through lighting, HVAC systems, and digital feedback mechanisms.
However, these systems generally reset after each interaction and rarely preserve long-term traces of human presence.
Shift in Research Question
The project gradually shifted toward investigating whether interiors could accumulate biological traces over time rather than only reacting momentarily.
This introduced a new design question:
Could interior materials behave as slow spatial memory systems rather than instantaneous interfaces?
Emerging System Logic
To address this, the project began integrating:
physiological sensing
threshold-based data evaluation
microfluidic distribution systems
biological activation mechanisms
gradual chromoprotein accumulation
This transition reframed the project from “responsive architecture” toward biologically regulated material transformation.
Microfluidics as a Translation Layer
Why Microfluidics?
One of the key developments this week was identifying microfluidics as the missing translation layer between physiological data and biological transformation.
Rather than directly controlling color output, the system investigates how physiological conditions could regulate fluid distribution intensity across a sealed biological network.
Microfluidics became important because it allows:
controlled spatial distribution
temporal modulation
localized activation
scalable network behavior
delayed transformation patterns
The project therefore began treating the microfluidic layer not as a simple transport system, but as a temporal regulation infrastructure.
Pulse Space — Biological Direction & System Integration
## Biodesign & Biofabrication
This week focused on strengthening the biological and fabrication framework of Pulse Space.
Earlier stages of the project primarily investigated conceptual questions around temporal interiors and spatial memory. This week, the research shifted toward developing a more grounded biological system architecture capable of supporting controlled material transformation.
The project began exploring how synthetic biology, microfluidics, and hydrogel-supported systems could operate together as a distributed biological-material infrastructure.
Rather than treating biology as a decorative layer, the project investigates biology as a programmable and temporally regulated material system.
Current Biological Direction
The current biological direction investigates:
engineered non-pathogenic E. coli platform
inducible chromoprotein expression system
investigation of amilCP chromoprotein expression
hydrogel-supported bacterial chambers
sealed microfluidic activation environment
At this stage, the project remains exploratory and focuses on understanding how biological activation may be spatially and temporally regulated within interior material systems.
Biological Activation Logic
The project investigates how physiological conditions may be translated into biological transformation through a controlled activation workflow.
Pulse Space — Final Reflection & Research Position
Biodesign & Biofabrication
This final stage of the project focused on consolidating Pulse Space as an experimental research framework situated between interior architecture, synthetic biology, responsive environments, and biofabrication.
Rather than presenting a finalized architectural product, the project evolved into an investigation of how biological systems may operate as temporal material infrastructures capable of gradual transformation over time.
Throughout the semester, the project shifted from speculative responsive interiors toward questions of:
biological regulation
distributed activation
temporal material behavior
controlled transformation
spatial accumulation
programmable environmental systems
The project therefore became less about creating a “smart environment” and more about understanding how biological processes may become integrated into future spatial systems.