Week 4 HW: Protein Design Part 1
PART A Conceptual Questions
How many molecules of amino acids do you take with a piece of 500 grams of meat? (on average an amino acid is ~100 Daltons)
Assuming ~20–25% protein in meat: 500 g meat → 100–125 g protein With average amino acid mass = 100 Da ≈ 100 g/mol: that protein corresponds to 1.0–1.25 moles of amino acids, i.e. (6.0–7.5) × 10²³ amino acid molecules.
Why do humans eat beef but do not become a cow, eat fish but do not become fish? Beef goes through the alimentary canal and is broken down to its smallest components before nutrients are absorbed into the person. The DNA is broken down in this process and does not enter the nuclei of the eater for them to take on new traits through the food they eat.
Why are there only 20 natural amino acids?
There are a combinination of reasons for this, including
- evolutionary history
- chemical functionality
- evolution of genetic code
a. Evolutionary Selection
Early life likely used a smaller set of amino acids that were easily formed through prebiotic chemistry. Experiments such as the Miller Urey experiment showed that several amino acids (e.g., glycine, alanine, and aspartate) can form under early Earth conditions. Over time, evolution gradually expanded the set until it stabilized around 20 amino acids, which provided sufficient chemical diversity for proteins to perform many biological functions.
Once the genetic code became fixed in early life, it became difficult for evolution to add many new amino acids because doing so would require major changes to tRNA molecules, aminoacyl-tRNA synthetases, and codon assignments.
b. Chemical Diversity Is Already Sufficient
The 20 amino acids provide a wide range of chemical properties, allowing proteins to perform diverse roles:
| Property | Example Amino Acids | Function |
|---|---|---|
| Nonpolar / hydrophobic | Valine, leucine | Protein core stability |
| Polar | Serine, threonine | Hydrogen bonding |
| Charged | Lysine, glutamate | Enzyme catalysis, ionic interactions |
| Aromatic | Phenylalanine, tryptophan | Stacking interactions, light absorption |
| Special structure | Proline, glycine | Structural flexibility |
This set already covers most chemical behaviors needed for enzyme catalysis, structural stability, and molecular recognition.
c. Genetic Code Constraints
The genetic code contains 64 codons:
61 codons encode amino acids
3 codons are stop signals
These codons map to the 20 amino acids, meaning multiple codons often code for the same amino acid (degeneracy). Expanding the number of amino acids significantly would require reorganizing this coding system, which evolution tends to avoid because it could disrupt many proteins at once.
d. Efficiency and Error Minimization
The standard 20 amino acids create a system that is robust to mutations. Many single-base changes in DNA produce amino acids with similar chemical properties, reducing harmful effects on proteins. This suggests the genetic code evolved to minimize translation errors.
- Can you make other non-natural amino acids? Go on. Design some new amino acids.
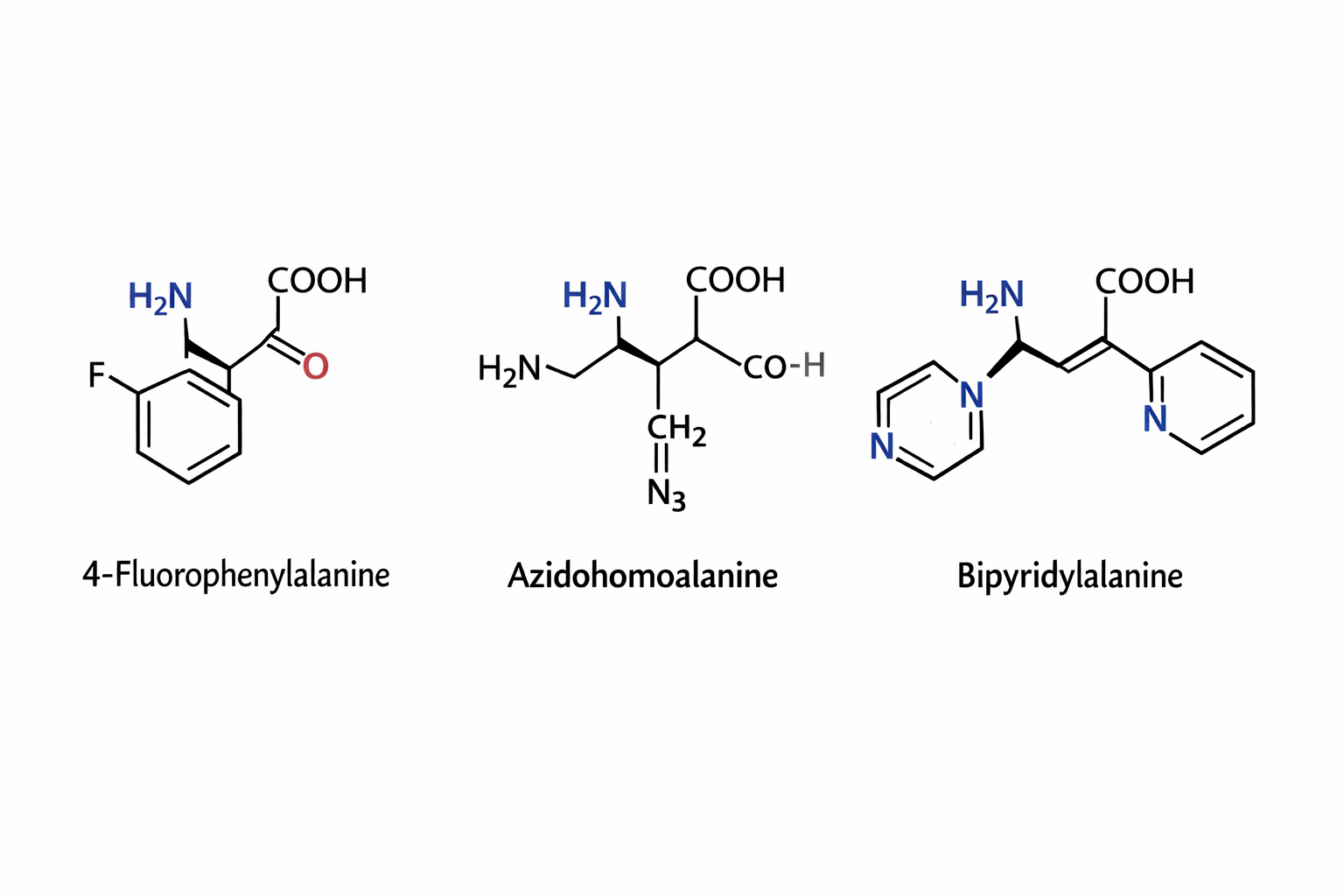
The three synthetic amino acids shown 4-fluorophenylalanine, azidohomoalanine, and bipyridylalanine are examples of noncanonical amino acids designed to extend the chemical capabilities of proteins beyond the twenty naturally occurring amino acids. By modifying the side chains while retaining the basic amino acid backbone, researchers can introduce new chemical properties into proteins for research, biotechnology, and biomedical applications.
4-Fluorophenylalanine is a modified analog of phenylalanine in which a fluorine atom replaces a hydrogen on the aromatic ring. The presence of fluorine alters the electronic properties and hydrophobicity of the side chain while maintaining a similar size to natural phenylalanine. This makes it useful in protein folding studies and structural biology, where it can act as a probe in spectroscopic techniques such as ¹⁹F NMR. Because fluorine is rarely found in natural proteins, its signal can be easily detected, allowing researchers to monitor conformational changes and interactions within proteins.
Azidohomoalanine contains an azide (-N₃) functional group, which is highly useful in bioorthogonal chemistry. This amino acid can be incorporated into newly synthesized proteins in place of methionine, allowing researchers to attach fluorescent dyes, affinity tags, or other molecules using “click chemistry” reactions. As a result, azidohomoalanine is widely used for protein labeling, tracking protein synthesis, imaging cellular processes, and studying protein turnover in living cells.
Bipyridylalanine includes a bipyridine moiety, a structure well known for its ability to bind metal ions such as iron, copper, or zinc. When incorporated into proteins, it can create artificial metal binding sites, enabling the design of engineered metalloenzymes, biosensors, or catalytic proteins. This amino acid can also be used to study metal protein interactions and to construct proteins with new catalytic or electronic properties.
Overall, synthetic amino acids like these expand the chemical diversity available to proteins. They allow scientists to probe protein structure, control biochemical reactions, introduce novel catalytic functions, and develop advanced tools for imaging and biotechnology, thereby playing an important role in modern protein engineering and synthetic biology.
Where did amino acids come from before enzymes that make them, and before life started? Amino acids can form in nature if the right chemical conditions exist. Amino acids have been detected in space rock and gases. This shows that they are a part of the universe’s natural building blocks, which can become more complex through further chemical reactions.
If you make an α-helix using D-amino acids, what handedness (right or left) would you expect? A standard α-helix made from D–amino acids will be left-handed because the chirality flips the preferred backbone geometry; therefore -L amino acids favour right-handed α-helices, while D amino acids favour the mirror-image left-handed form.
Can you discover additional helices in proteins? You can find additional helices if new conditions are used that improve resolution or biological context. The dynamics of the protein change depending on the conditions that were used to crystalise it and which is used to ellucidate the protein structure.
Why are most molecular helices right-handed? Most biological molecules are right-handed because Earth biology is built almost entirely from L-amino acids, and the stereochemistry of L-amino acids makes the right-handed α-helix the lowest-energy, most stable geometry.
Why do β-sheets tend to aggregate?
- What is the driving force for β-sheet aggregation?
Why do many amyloid diseases form β-sheets?
- Can you use amyloid β-sheets as materials? Amyloid diseases often form β-sheets because misfolded proteins can stack into a highly stable “cross-β” structure that hides exposed hydrophobic/backbone surfaces and then seeds more proteins to misfold the same way. These fibrils are hard for cells to get rid of, so they accumulate and disrupt cellular function. This may lead to disease. Yes, amyloid β-sheets can be used as materials because amyloid fibrils are strong, stiff, and chemically resistant nanofibers. They can be engineered into hydrogels, scaffolds, coatings, or templates for assembling other materials.
Design a β-sheet motif that forms a well-ordered structure.
Part B My Protein
I chose cycloviolacin cyclotide protein from Viola odorata
Sequence:
CAESCVYIPCTVTALLGCSCSNRVCYNGIP
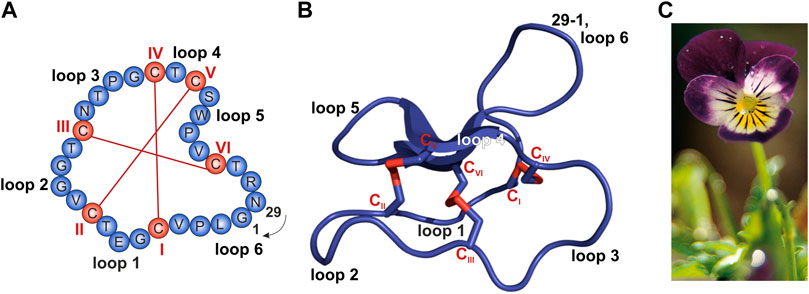
Sequence and structure of the prototypic cyclotide kalata B1 and photograph of Viola tricolor. (A,B) The cyclized peptide kalata B1 (C) Viola tricolor
From Conzelmann C, Muratspahić E, Tomašević N, Münch J and Gruber CW (2022) In vitro Inhibition of HIV-1 by Cyclotide-Enriched Extracts of Viola tricolor. Front. Pharmacol. 13:888961. doi: 10.3389/fphar.2022.888961
- Identify the amino acid sequence of your protein.
- How long is it? What is the most frequent amino acid? You can use this Colab notebook to count the frequency of amino acids. -Paste your amino acid sequence here my_sequence = “CAESCVYIPCTVTALLGCSCSNRVCYNGIP” Sequence Length: 30 Amino Acid Frequencies: C: 6 S: 3 V: 3 A: 2 Y: 2 I: 2 P: 2 T: 2 L: 2 G: 2 N: 2 E: 1 R: 1
- How many protein sequence homologs are there for your protein? Hint: Use Uniprot’s BLAST tool to search for homologs.
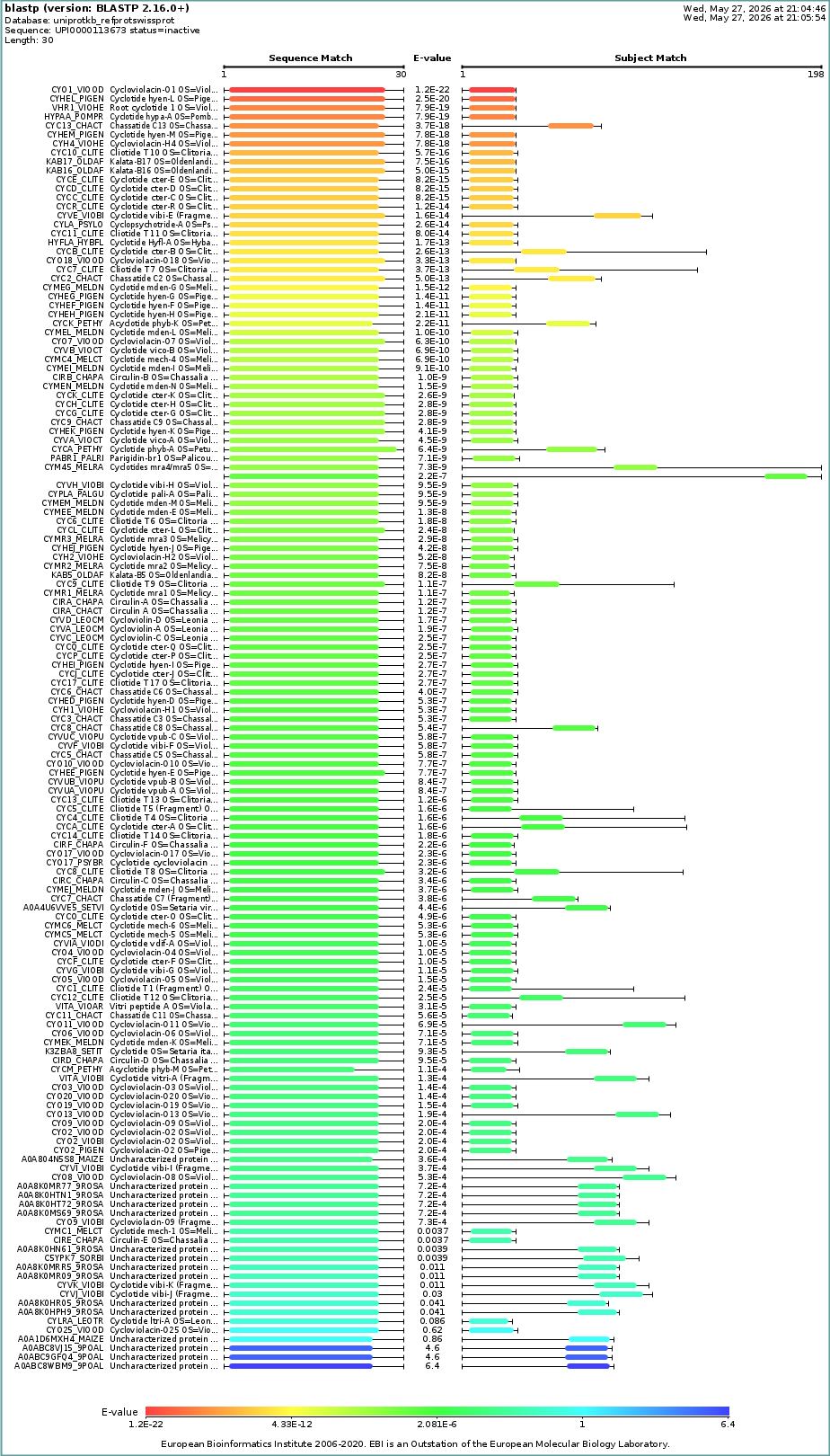
- Does your protein belong to any protein family?
- Identify the structure page of your protein in RCSB
Query (1,30) CAESCVYIPCTVTALLGCSCSNRVCYNGIP Subject: 1NBJ_1 (1,30) CAESCVYIPCTVTALLGCSCSNRVCYNGIP

When was the structure solved? Is it a good quality structure? Good quality structure is the one with good resolution. Smaller the better (Resolution: 2.70 Å)
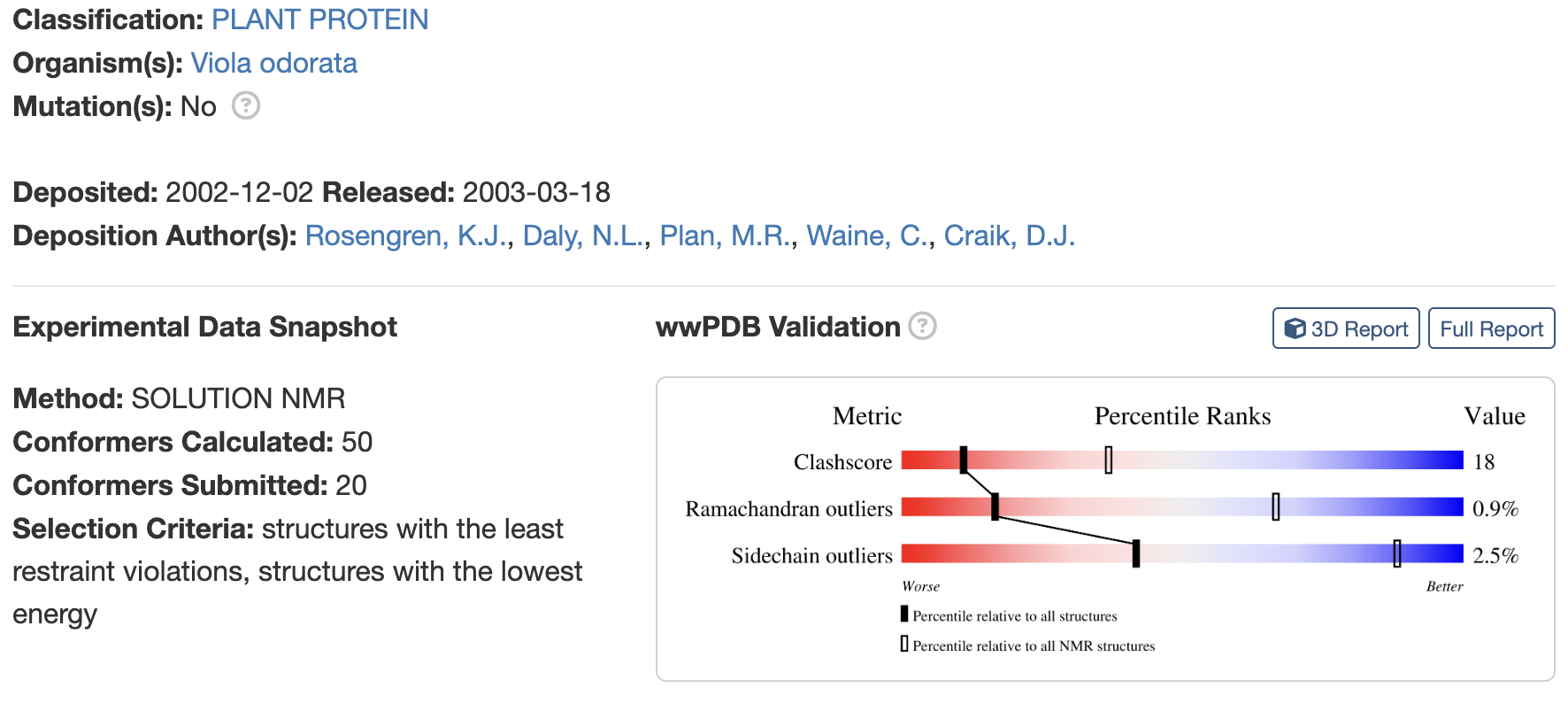
Are there any other molecules in the solved structure apart from protein? no
Does your protein belong to any [structure classification family]

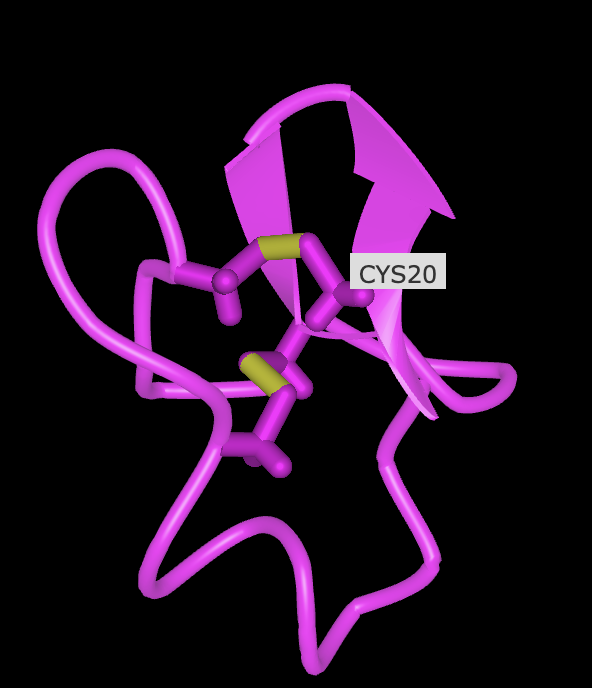
- Open the structure of your protein in any 3D molecule visualization software:
- PyMol Tutorial Here (hint: ChatGPT is good at PyMol commands)
- Visualize the protein as “cartoon”, “ribbon” and “ball and stick”.
- Color the protein by secondary structure. Does it have more helices or sheets?
- Color the protein by residue type. What can you tell about the distribution of hydrophobic vs hydrophilic residues? see below
- Visualize the surface of the protein. Does it have any “holes” (aka binding pockets)? No, it has binding domains though



 R
R
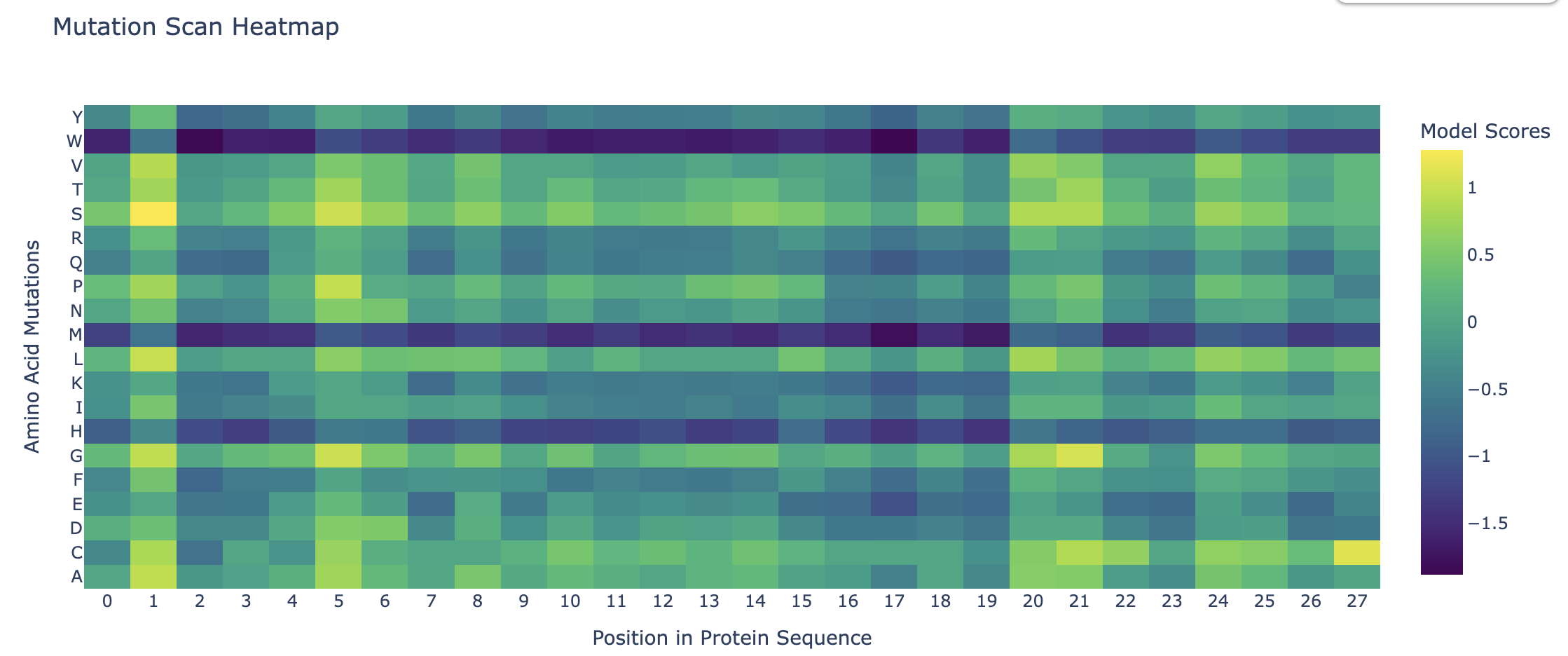
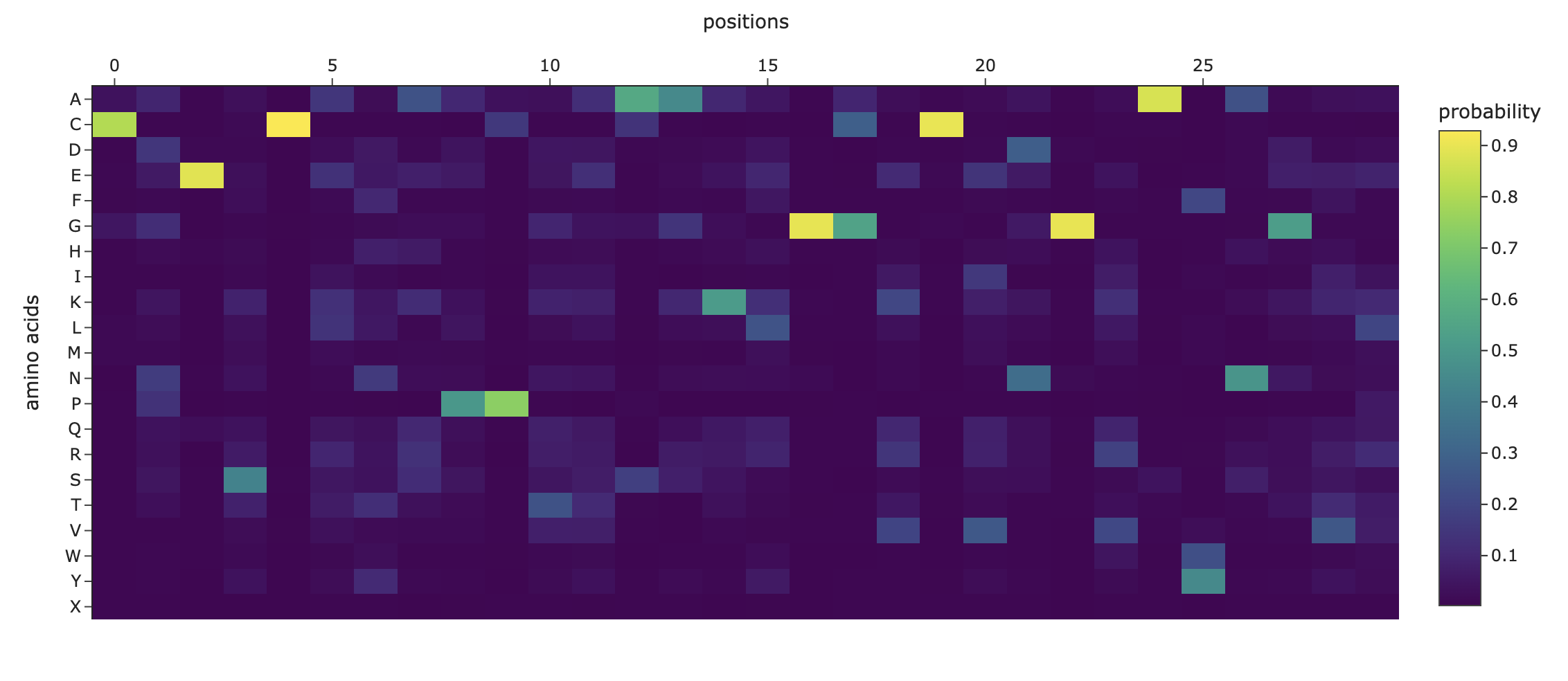
- Deep Mutational Scans Darker columns may indicate low likelihood of mutations at the residue, probably because it is structurally or functionally important.
Latent Space Analysis
ESMFOLD
1NBJ, score=2.0858, fixed_chains=[], designed_chains=[‘A’], model_name=v_48_020 CAESCVYIPCTVTALLGCSCSNRVCYNGIP >T=0.1, sample=0, score=0.9449, seq_recovery=0.4667 CNESCANAPPTEAAKLGGKCVNGRAWNGVP New Sequence:CNESCANAPPTEAAKLGGKCVNGRAWNGVP
Part D. Group Brainstorm on Bacteriophage Engineering
- I collaborated with Sami Tanveer (Islamabad, Pakistan), but we did not manage to finish the work.