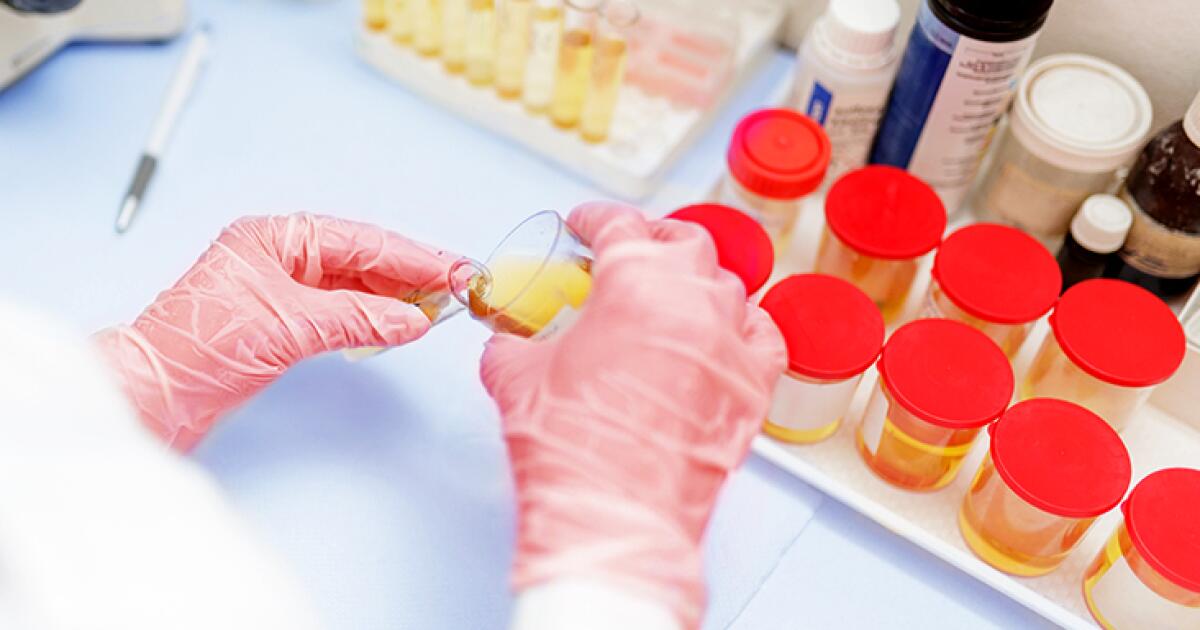
Biological Engineering tools: Rapid Urinary Heavy Metals Ion detection - Paper Based Lateral Flow Assay Heavy metal ions pose a serious threat to both the environment and human health due to their high toxicity and tendency to bioaccumulate in biological systems. Although conventional analytical techniques such as chromatography offer high sensitivity and accuracy, they are often expensive, and impractical for rapid, on-site detection. Therefore, I plan to develop a portable urinary test the detection of heavy metal ions using modified bioreceptors, such as aptamers, DNA probes, or DNAzymes, to enable selective and sensitive recognition. This approach is inspired by multi-parameter drug test assays, which can simultaneously detect multiple analytes (e.g., amphetamines, morphine, THC, benzodiazepines, and cocaine), using Lateral Flow Assay (LFA) principles.
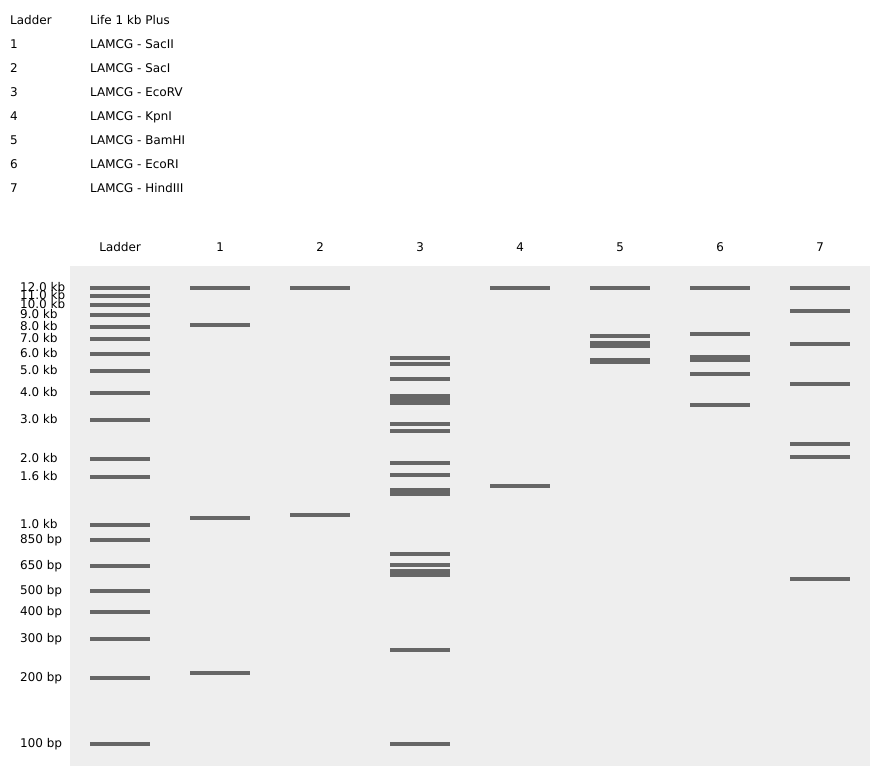
Part 1 Benchling & In-Silico Gel Art I simulated restriction enzyme digestion of Escherichia phage Lambda (complete genome) using the listed enzymes. Here are the results of the virtual digestion:
and I tried quick design using Ronan’s website:
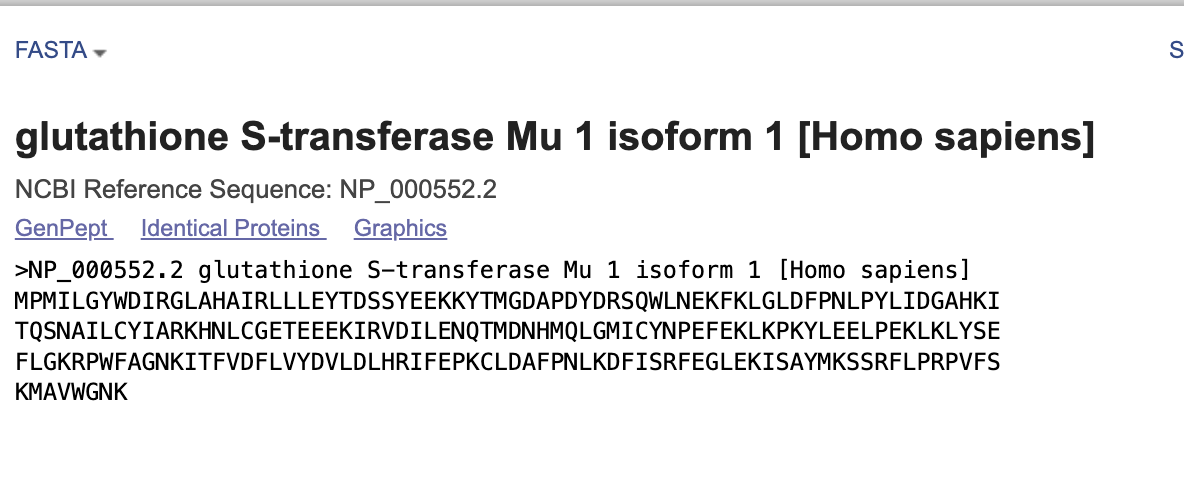
Part 3 DNA Design Challenge I choose Glutathione S-transferase Mu 1 (GSTM1). GSTM1 is a gene that encodes a Phase II detoxification enzyme, crucial for metabilizing xenobiotics, environmental toxins, and carcinogens by conjugating them with reduced glutathione. This gene located on chromosome 1p31 that protects cells from oxidative stress.
LAB Automation Post Lab Question Find and describe a published paper that utilizes the Opentrons Reference: Shaba, Chikondi, Decibel P. Elpa, and Pawel L. Urban. Automated and robotic sample delivery systems for mass spectrometry and ion-mobility spectrometry. Digital Discovery (2026).
Objectives: Integration of Mass Spectrometry (MS) and Ion Mobility Spectrometry (IMS) with an automated robotic sample delivery system. To reduce human labor in sample handling. Single-cell analysis is a key application area of automated MS methods.
Part A: Conceptual Questions How many molecules of amino acids do you take with a piece of 500 grams of meat? (on average an amino acid is ~100 Daltons)
Answer: 500 grams (raw ground beef) contains about 90-130 grams of protein. Let’s assume it contain 110 gram of protein. Proteins are chains of amino acids, with typically between 470 - 499 length amino acid. Average amino acid mass ~ 100 g/mol. If all protein were broken down into free amino acids, then:
Subsections of Homework
Week 1 HW: Principles and Practices
Biological Engineering tools:
Rapid Urinary Heavy Metals Ion detection - Paper Based Lateral Flow Assay
Heavy metal ions pose a serious threat to both the environment and human health due to their high toxicity and tendency to bioaccumulate in biological systems. Although conventional analytical techniques such as chromatography offer high sensitivity and accuracy, they are often expensive, and impractical for rapid, on-site detection. Therefore, I plan to develop a portable urinary test the detection of heavy metal ions using modified bioreceptors, such as aptamers, DNA probes, or DNAzymes, to enable selective and sensitive recognition. This approach is inspired by multi-parameter drug test assays, which can simultaneously detect multiple analytes (e.g., amphetamines, morphine, THC, benzodiazepines, and cocaine), using Lateral Flow Assay (LFA) principles.
Bioreceptor design (DNAzyme):
DNAzyme is a DNA molecule that has a specific metal ion-dependent enzymatic activity — that is, it will only perform a catalytic reaction (e.g., cleave a DNA substrate) when the target metal ion is present. DNAzymes have been selected through in vitro selection for their high specificity toward ions such as Pb²⁺, Cu²⁺, and Hg²⁺.
Design outline:
Selecting a suitable DNAzyme: Chose a DNAzyme that is specific to the target ion (e.g., Pb²⁺ 8–17 DNAzyme, Cu²⁺, Hg²⁺). The DNAzyme is selected by in vitro selection to achieve high affinity and specificity for a particular ion.
Design of cleavable DNA substrates: DNAzymes work by cleaving site-specific DNA/RNA substrates when the target ion is present. The substrates can be visually labeled so the resulting cleavage changes become measurable signals -> AuNP or fluorofor
Chemical Modification for integration with biocencor: Add functional groups (e.g., thiol, biotin) to the DNAzyme or substrate to allow it to bind to nanoparticles (AuNPs) or the strip surface. This allows integration with lateral flow system.
Governance/policy goals
Biosensing DNAzyme-based detection intersects with health monitoring, environmental justice, and personal data. Therefore, here is governance goals
Responsible & Safe Innovation
Transparent Safety validation: clear evaluation of safety, performance, and limitation before deployment
Adaptive Regulatory: Following latest monitoring and safety standard
Promote Trust, Transparency and Public accountability
Equitable distribution: Accessible to diverse populations without socioeconomics barriers
Monitor bias and performance: Regulary asssess test performance in different demographic groups, ensuring accuracy and precision
Ensure Privacy and Ethical use in implementation
Clear informed consent: Ensuring informed consent and secure data storage
Limit data use to purpose only: ensure health or exposure data collected by the device is used only for its intended purposes
Establish a risk-based approval path for Rapid Biosensors
P: Rapid biosensors often lack clear regulatory pathways, especially for diagnostics like DNAzyme metal sensor. Need to establish a specific risk-based regulation framework for novel biosensors, ensuring performance and validation data are required to clinical use
D: Select categories based on use cases (high, medium, low risk) through environmental monitoring. Establish validation standards for complex matrices such as urine. Ensure a review process.
A: All regulators have capacity and expertise to evaluate DNAzyme sensors and standarized set of perfomance metrics can be agreed across jurisdictions.
R: Failure: Overly stringent regulations, slow transition from research to implementation. If regulations are too strict, product performance quality declines.
Funding & Standard for Ethical Design
P: Introduce policy incentives and funding programs that require ethical, inclusive design and ongoing evaluation
D: Attach ethical & societal impact requirements to grants. Fund interdisciplinary teams (biologists, ethicists, community reps) working together. Develop standards for equitable access
A: Funding agencies and researchers value equity and community engagement.
R: Increasing project costs/time, disadvantaging smaller labs or startups that lack resources to meet expanded requirements.
Public engagement & Transparent report for community or stake holder
P: Formalize public and stakeholder engagement requirements during early design, deployment planning, and ongoing use
D: Host public consultations, workshops, and panels to integrate values and concern. Open reporting of performance, limitations, and real-world data in accessible formats.
A: Stakeholders will participate meaningfully
R: Broad public input may slow development cycles or push toward overly conservative use cases that limit innovation if dominant voices resist new tech.
Score (from 1-3 with, 1 as the best, or n/a) governance actions
Governance action
Regulatory
Monitoring
Environment
Responsible & Safe Innovation
• By preventing incidents
1
2
3
• By helping respond
2
1
3
Transparency and Public accountability
• By preventing incident
2
1
3
• By helping respond
3
1
2
Ethical use in implementation
• Minimizing costs and burdens to stakeholders
3
2
1
• Feasibility
2
1
3
• Not impede research
3
1
2
• Promote constructive applications
2
1
3
Governance Priority
Monitoring Governance: for preventing harm in performance data and helping respond to issues. For development of novel biosensor, ongoing surveillance of performance is critical. The action require ongoing performance report (post-market quality data)
Targeted Regulatory Standards: to ensure consistent quality before tools reach users. The developmental stage require evidence of safety in realistic biological samples (e.g., urine), and categorize the device based on intended use (environmental screening or clinical decision making)
Transparency & Accountability: Publish data of validation results, limitations, and uncertainties.
Resource
DNAzyme sensors for detection of metal ions in the environment and imaging them in living cells. DOI: 10.1016/j.copbio.2017.03.002
Assigment (Week 2 Lecture Prep) — DUE BY START OF FEB 10 LECTURE
Professor Jacobson
Nature’s machinery for copying DNA is called polymerase. What is the error rate of polymerase? How does this compare to the length of the human genome. How does biology deal with that discrepancy?
Answer:
Error rate of polymerase is 1 : 106 up to 108 if there is no correction. It occurs during replocation when DNA Polymerases add wrong nucleotides.
In compares to the human genome, 1 error per 10^7 nucleotides
Cell use multiple layers of fidelity mechanisms: Base selection, proofreading (3’–>5’ exonuclease), and mismatch repair.
How many different ways are there to code (DNA nucleotide code) for an average human protein? In practice what are some of the reasons that all of these different codes don’t work to code for the protein of interest?
Answer
DNA uses four nucleotides (A, T/U, G, C), with each set of three nucleotides (codon). There are 4^3 ways, resulting in around 64 possible codon, but there are only about 24 amino acids because some of the amino acids are coded by more than one codon. Most protein containing about 300 amino acids, which requires 300 codons including start and stop codon.
Not all sequences code for protein because there are possibilities where cells prefer certain codons, the variety of mRNA structure, and constraints that affect gene expression
What’s the most commonly used method for oligo synthesis currently?
Why is it difficult to make oligos longer than 200nt via direct synthesis?
Why can’t you make a 2000bp gene via direct oligo synthesis?
Answer:
Solid-phase Phosphoramidite chemistry method for oligo synthesis
Longer oligos increasing number of error rate which reducing the quality and purity
Increasing error and low yields, make it unreliable
George Church
What are the 10 essential amino acids in all animals and how does this affect your view of the “Lysine Contingency”?
(AA:NA and NA:NA codes)] What code would you suggest for AA:AA interactions?
[(Advanced students)] Given the one paragraph abstracts for these real 2026 grant programs sketch a response to one of them or devise one of your own:
Answer:
Histidine, Isoleucine, Leucine, Lysine, Methionine, Phenylalanine, Threonine, Tryptophan, Valine, Arginine. Lysine COntigency will make animals body depends on lysine being available in the right amount,when lysine is limiting the body can’t build protein effectively, slower growth, and weakening immune function.
Lys (K) - Arg (R), Asp (D) - Glu (E), Ser (S) - Thr (T) ???
HTGAA Website DONE ❤️
Week 2 HW: DNA read and Write
Part 1 Benchling & In-Silico Gel Art
I simulated restriction enzyme digestion of Escherichia phage Lambda (complete genome) using the listed enzymes. Here are the results of the virtual digestion:
and I tried quick design using Ronan’s website:
Part 3 DNA Design Challenge
I choose Glutathione S-transferase Mu 1 (GSTM1). GSTM1 is a gene that encodes a Phase II detoxification enzyme, crucial for metabilizing xenobiotics, environmental toxins, and carcinogens by conjugating them with reduced glutathione. This gene located on chromosome 1p31 that protects cells from oxidative stress.
Protein: GSTM1
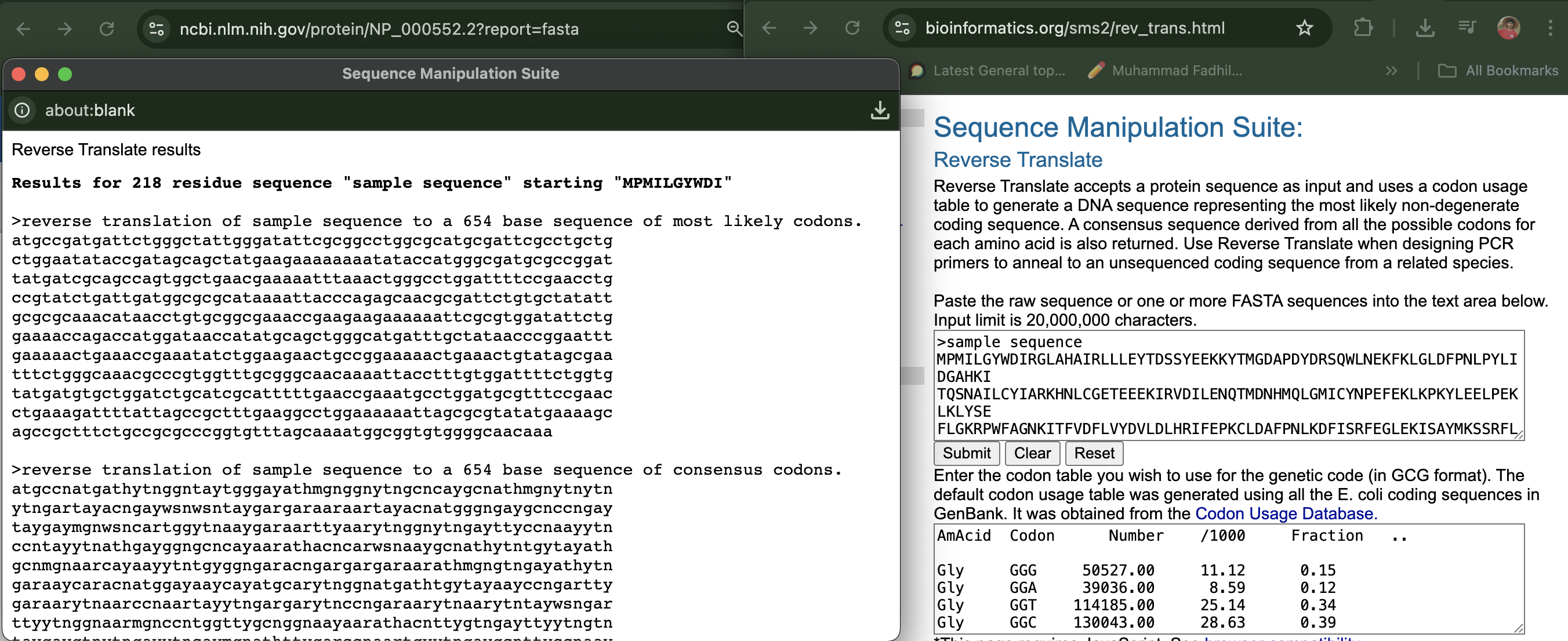
Reverse translate: Protein (amino acid) sequence to DNA (nucleotide) sequence.
Results for 218 residue sequence “sample sequence” starting “MPMILGYWDI”
reverse translation of sample sequence to a 654 base sequence of most likely codons.
atgccgatgattctgggctattgggatattcgcggcctggcgcatgcgattcgcctgctg
ctggaatataccgatagcagctatgaagaaaaaaaatataccatgggcgatgcgccggat
tatgatcgcagccagtggctgaacgaaaaatttaaactgggcctggattttccgaacctg
ccgtatctgattgatggcgcgcataaaattacccagagcaacgcgattctgtgctatatt
gcgcgcaaacataacctgtgcggcgaaaccgaagaagaaaaaattcgcgtggatattctg
gaaaaccagaccatggataaccatatgcagctgggcatgatttgctataacccggaattt
gaaaaactgaaaccgaaatatctggaagaactgccggaaaaactgaaactgtatagcgaa
tttctgggcaaacgcccgtggtttgcgggcaacaaaattacctttgtggattttctggtg
tatgatgtgctggatctgcatcgcatttttgaaccgaaatgcctggatgcgtttccgaac
ctgaaagattttattagccgctttgaaggcctggaaaaaattagcgcgtatatgaaaagc
agccgctttctgccgcgcccggtgtttagcaaaatggcggtgtggggcaacaaa
reverse translation of sample sequence to a 654 base sequence of consensus codons.
atgccnatgathytnggntaytgggayathmgnggnytngcncaygcnathmgnytnytn
ytngartayacngaywsnwsntaygargaraaraartayacnatgggngaygcnccngay
taygaymgnwsncartggytnaaygaraarttyaarytnggnytngayttyccnaayytn
ccntayytnathgayggngcncayaarathacncarwsnaaygcnathytntgytayath
gcnmgnaarcayaayytntgyggngaracngargargaraarathmgngtngayathytn
garaaycaracnatggayaaycayatgcarytnggnatgathtgytayaayccngartty
garaarytnaarccnaartayytngargarytnccngaraarytnaarytntaywsngar
ttyytnggnaarmgnccntggttygcnggnaayaarathacnttygtngayttyytngtn
taygaygtnytngayytncaymgnathttygarccnaartgyytngaygcnttyccnaay
ytnaargayttyathwsnmgnttygarggnytngaraarathwsngcntayatgaarwsn
wsnmgnttyytnccnmgnccngtnttywsnaaratggcngtntggggnaayaar
Codon optimization
Codon optimization is a way to ensure that the translation of our sequence’s codons is compatible with the host organism. If codon usage is incompatible with the host, protein expression will be inefficient. I try to optimized the GSTM1 coding sequence for expression in Escherichia coli, since it is widely used as a host organism.
Technology to produce this protein
I used cell-dependent system to optimized GSTM1 DNA. The gene is cloned into an expression plasmid using a T7 promoter, transformed into E.coli and induce the protein expression with IPTG (Isopropyl B-D-1-thiogalactopyranoside). The Recombinant GSTM1 protein would subsequently be purified using a His-tag through affinity chromatography.
How does it work in Biological System?
the GSTM1 coding DNA sequence ATG CCT ATG ATC CTG GGC is transcribed into mRNA as AUG CCU AUG AUC CUG GGC, which is translated into the amino acid sequence Met–Pro–Met–Ile–Leu–Gly.
Part 4 Twist DNA Synthesis (Order?)
I have a problem following the istruction, after I put my bases and create sequence. I don’t understand how to make annotation
Part 5 DNA Read/Write/Edit
What DNA would you want to sequence (e.g., read) and why?
I would like to sequence the GSTM1 coding region and promoter region from individuals exposed to lead to assess potential mutations, deletions, or regulatory changes associated with heavy metal exposure. Because lead is known to induce oxidative stress and genomic instability, sequencing detoxification genes may reveal genetic susceptibility factors contributing to impaired xenobiotic elimination.
The method I would use is PCR amplification followed by –> Sanger sequencing to analyze GSTM1 gene (1st generation).
The input would be genomic DNA extracted from blood samples of industrial workers exposed to lead. The GSTM1 gene region would be amplified using specific primers through PCR. The amplified product then undergo a sequencing reaction using fluorescently labeled ddNTPS.
During sequencing, incorporation of ddNTP terminates DNA synthesis. DNA fragments are separated by capillary electrophoresis. A laser detects fluorescent signals corresponding to each nucleotide, allowing base calling and reconstruction of the DNA sequence. The output consists of a chromatogram and a nucleotide sequence that can be compared with a reference sequence to identify mutations or variations.
What DNA would you want to synthesize and why?
I would like to make Synthetic Detoxification Gene Construct for Heavy metal response by optimizing GSTM1 gene under a strong inducible promoter in E.coli. This construct would include a strong T7 promoter, ribosome binding site, the GSTM1 coding sequence, a 6xHis purification tag, and a transcription terminator. The objectives of synthesizing this DNA is to study detoxification mechanisms under heavy metal exposure, particularly lead-induced oxidative stress. Since GSTM1 catalyzes glutathione conjugation reactions, overexpression of this enzyme may help investigate protective mechanisms against xenobiotic toxicity. The synthesized coding sequence begins with ATG (start codon) and encodes the GSTM1 amino acid sequence, followed by a His-tag (CATCACCATCACCATCAC) for affinity purification. This construct could be used for protein expression studies or detoxification research
What DNA would you want to edit and why?
I want to edit GSTM1 in human cells using CRISPR-Cas9 editing. The cell repairs the break either through non-homologous end joining (NHEJ) or homology-directed repair (HDR). For gene restoration, I would provide a donor DNA template to enable HDR-mediated insertion of a functional GSTM1 gene. The required inputs include guide RNA, Cas9 protein or plasmid, donor DNA template, and target cells. Although CRISPR is highly effective, limitations include off-target effects, low HDR efficiency, and delivery challenges in vivo.
Week 3 HW: Lab Automation
LAB Automation
Post Lab Question
Find and describe a published paper that utilizes the Opentrons
Reference:
Shaba, Chikondi, Decibel P. Elpa, and Pawel L. Urban. Automated and robotic sample delivery systems for mass spectrometry and ion-mobility spectrometry. Digital Discovery (2026).
Objectives:
Integration of Mass Spectrometry (MS) and Ion Mobility Spectrometry (IMS) with an automated robotic sample delivery system. To reduce human labor in sample handling. Single-cell analysis is a key application area of automated MS methods.
How Automation Tools (Opentrons) are used:
Automating routine, repetitive liquid handling (pipetting, reagent dispensing) to reduce human error and increase throughput
Enabling precise sample preparation steps for dilutions, aliquoting, plate setup for downstream analysis.
Using open-source protocols (Phyton API) to customize automation for specific biological or chemical assays.
Automation for Final Project
I would like to use Automation Tools Opentrons liquid-handling robot to design and develop a metal ion biosensor for detecting lead (Pb²⁺) in human urine samples. The automation platform would standardize sample preparation steps, including dilution, buffer addition, reagent mixing, and plate setup, thereby reducing variability and improving reproducibility.
By integrating automated liquid handling with a biosensing system (e.g., colorimetric, fluorescence-based, or aptamer-based detection), the workflow could enable high-throughput screening of urine samples for lead exposure. Automation would allow precise reaction timing, consistent reagent volumes, and scalable assay optimization, which are critical for developing a reliable and sensitive biomonitoring platform.
This automation approach builds upon my previous design of a lead biomarker detection biosensor integrated into a urine collection container. In that design, the biosensor system was embedded within the urine pot to enable immediate detection of Pb²⁺ exposure at the point of sampling. Incorporating an automation platform such as Opentrons, I aim to standardize and optimize the reagent preparation, calibration curves, and validation steps during assay development.
Automated liquid handling would improve reproducibility, sensitivity testing, and batch consistency of the biosensor components before integration into the urine pot system. This integration would strengthen the development of a scalable, reliable, and early-detection biomonitoring tool for lead exposure.
Week 4 HW: Protein Design 1
Part A: Conceptual Questions
How many molecules of amino acids do you take with a piece of 500 grams of meat? (on average an amino acid is ~100 Daltons)
Answer:
500 grams (raw ground beef) contains about 90-130 grams of protein. Let’s assume it contain 110 gram of protein. Proteins are chains of amino acids, with typically between 470 - 499 length amino acid. Average amino acid mass ~ 100 g/mol. If all protein were broken down into free amino acids, then:
Moles of amino acids = 110 g / 100 g/mol = 1.1 mol. mol —> molecules = 1.1 mol x 6.022 x10^23 ~~
Moles of amino acids = 6.6 x10^23.
Typical protein length: 470 - 499 amino acids.
Protein molecules = 1.1 mol / 480 amino acids per protein = 0.0023 mol proteins
Protein molecules = 0.0023 mol x 6.022 x10^23
Protein molecules = 1.4 x 10^21
Why do humans eat beef but do not become a cow, eat fish but do not become fish?
Answer:
When we eat, our digestive system breaks down proteins into amino acids (metabolism). Stomach acid and an enzyme (pepsin) break down proteins into smaller peptides. This is followed by a small intestinal enzyme (trypsin) that breaks down the peptides into individual amino acids. The amino acids are then absorbed into our bloodstream.
Amino acids are the building blocks of our bodies. We do not become what we eat because identity comes from genetic information, not protein fragments.
Why are there only 20 natural amino acids?
The 20 amino acids provide a wide enough range of properties based on its polarity, acidity, aromatic, and sulfur-contain to build all the proteins needed for life. Of the hundreds of amino acids that could possibly exist in nature, only 20 were selected early in evolution as being diverse enough to form all the necessary proteins.