1. How many molecules of amino acids do you take with a piece of 500 grams of meat? (on average an amino acid is ~100 Daltons)
To calculate this, we use a back-of-the-envelope estimation. Meat is not purely protein; it consists mostly of water and fat. Assuming meat contains about 20% protein by weight, 500 grams of meat yields roughly 100 grams of pure protein.
By definition, 1 gram is approximately equal to Avogadro’s number in Daltons (6.022 x 1023 Da). Therefore, 100 grams of protein equals 6.022 x 1025 Daltons. Dividing this total mass by the average mass of a single amino acid (100 Daltons) gives 6.022 x 10^23 molecules. Fascinatingly, eating 500 grams of meat equates to consuming almost exactly 1 mole of amino acids.
2. Why do humans eat beef but do not become a cow, eat fish but do not become fish?
The answer lies in the difference between “building blocks” and “blueprints.” When a human eats beef, the digestive system breaks down the cow’s complex proteins completely into individual amino acids. These amino acids are universal building blocks devoid of the cow’s genetic information. Once absorbed into the bloodstream, human cells use their own DNA blueprint and ribosomes to reassemble these generic amino acids into human-specific proteins.
3. Why are there only 20 natural amino acids?
This is an evolutionary compromise between chemical sufficiency and metabolic burden. These 20 amino acids provide a complete chemical toolkit (including polar, non-polar, acidic, basic, and aromatic side chains) sufficient to fold into complex 3D structures and catalyze almost any required biochemical reaction. Evolving to support more amino acids would require maintaining additional tRNAs and synthetases, increasing the metabolic cost. Furthermore, assigning 61 codons to just 20 amino acids creates a highly degenerate genetic code, making life significantly more robust against lethal DNA mutations.
4. Can you make other non-natural amino acids? Design some new amino acids.
Yes, through Genetic Code Expansion. By hijacking a stop codon (usually the Amber codon, UAG) and introducing an orthogonal tRNA/synthetase pair into the cell, we can incorporate unnatural amino acids (uAAs) into proteins.
Design 1: Click-Amino Acid. An amino acid carrying an Azide group (-N3) on its side chain. Since azides are biologically inert, we can use “Click Chemistry” to precisely attach fluorescent tags or drugs to this specific residue after the protein is translated.
Design 2: Photo-switchable Amino Acid. An amino acid featuring an Azobenzene group. Azobenzene undergoes a structural shift (from trans to cis) when exposed to UV light. Placing this in an enzyme’s active site would create a biological machine that can be turned on and off with light.
5. Where did amino acids come from before enzymes that make them, and before life started?
Amino acids are thermodynamically stable molecules that can synthesize spontaneously from simple chemical precursors without enzymes (abiogenesis). The famous 1953 Miller-Urey experiment demonstrated that applying electrical sparks (simulating lightning) to a mixture of early Earth gases (methane, ammonia, hydrogen, and water vapor) naturally produces amino acids like glycine and alanine. Additionally, astrobiology has shown that amino acids form in deep space via cosmic radiation; they have been abundantly found in carbonaceous meteorites, such as the Murchison meteorite.
6. If you make an α-helix using D-amino acids, what handedness (right or left) would you expect?
We would expect a left-handed helix. Natural proteins use L-amino acids, which fold into right-handed helices to minimize steric hindrance (physical clashing) between their side chains. Because D-amino acids are exact mirror images (enantiomers) of L-amino acids, the spatial forces are reversed. To achieve the lowest energy state and avoid steric clashes, a chain of D-amino acids must coil in the exact opposite direction, resulting in a left-handed helix.
7. Can you discover additional helices in proteins?
Yes, while the alpha-helix is the most common, other helical structures exist based on different hydrogen-bonding patterns:
3_10-helix: A tighter, more elongated helix where the hydrogen bond forms between residue i and i+3.
Pi-helix (π-helix): A wider, more compressed helix with hydrogen bonds between residue i and i+5. These are often found at enzyme active sites due to their functional flexibility.
Polyproline helix: Formed by consecutive proline residues, which act as “helix breakers” for standard alpha-helices. It lacks intra-chain hydrogen bonds and forms an extended, left-handed helix (Type II) critical for structural proteins like collagen.
8. Why are most molecular helices right-handed?
The preference for right-handed alpha-helices in nature is dictated by the chirality of L-amino acids and the rules of thermodynamics. When L-amino acids form a right-handed coil, their bulky side chains (R-groups) point outward and slightly downward. This orientation maximizes the distance between the side chains and the peptide backbone, minimizing steric hindrance. Forcing L-amino acids into a left-handed helix pushes the side chains too close to the backbone’s carbonyl oxygens, causing severe electron repulsion and energetic instability.
9. Why do β-sheets tend to aggregate? What is the driving force for β-sheet aggregation?
Unlike alpha-helices, which satisfy all their hydrogen-bonding requirements internally, beta-sheets have exposed, “sticky” edges. The outermost strands of a beta-sheet possess unsatisfied hydrogen bond donors (N-H) and acceptors (C=O) that readily bind to adjacent beta-strands.
The primary driving force is the hydrophobic effect; the hydrophobic faces of different beta-sheets come together to escape water. Once physically close, a massive intermolecular hydrogen-bonding network forms between the backbones. This cooperative bonding locks the sheets together in a deep global energy minimum, making the aggregate incredibly stable.
10. Why do many amyloid diseases form β-sheets? Can you use amyloid β-sheets as materials?
In amyloid diseases (like Alzheimer’s), misfolded proteins expose their hydrophobic cores. To escape the aqueous cellular environment, these proteins aggregate. Thermodynamics dictates that the most stable conformation for this aggregation is the “cross-beta spine”—a highly ordered stacking of beta-sheets. This structure is so tightly bonded that cellular proteases cannot degrade it, leading to toxic plaque accumulation.
Yes, we can use engineered (non-toxic) amyloids as biomaterials. Because of their extreme mechanical strength (comparable to steel or spider silk) and spontaneous self-assembly, scientists use amyloid fibrils to create highly durable hydrogels for tissue engineering, drug delivery systems, and biological nanowires.
11. Design a β-sheet motif that forms a well-ordered structure.
To create a self-assembling, well-ordered beta-sheet, we must design an alternating sequence of hydrophobic and hydrophilic/charged residues.
Motif Example:(AEAEAKAKAEAEAKAK)
(A = Alanine [hydrophobic], E = Glutamic acid [negative], K = Lysine [positive])
Mechanism: When this peptide folds into a beta-strand, all the hydrophobic Alanines face one side, while the charged E and K residues face the opposite side. The hydrophobic faces from different sheets pack tightly together to exclude water. On the hydrophilic side, the alternating positive (K) and negative (E) charges create precise ionic salt bridges with neighboring strands. This electrostatic “zipper” forces the beta-sheets to align with nanometer-level precision, forming a highly ordered and structurally rigid scaffold.
Subsections of Week 4: Protein Design
Week 1 HW: Principles and Practices
Project Proposal: “The Living Iris” - Smart Probiotic Contact Lenses
1. Application Description
I propose developing “The Living Iris,” a bio-integrated contact lens that functions as a non-invasive, continuous glucose monitor. This project leverages the ocular microbiome by encapsulating engineered probiotics, such as Staphylococcus epidermidis (a common ocular commensal), within a specialized annular hydrogel.
Using synthetic genetic circuits, these bacteria sense glucose levels in the tear film and respond via fluorescence (e.g., GFP or RFP). This transforms medical monitoring into a seamless “bio-wearable.”
Novelty and Justification
Why Living Cells? Unlike electronic smart lenses (e.g., Google’s project), living sensors require no external power source or battery, as they scavenge nutrients from tears.
Visual Feedback & Accessibility: The fluorescent output is detectable by a smartphone app or visible to caregivers in emergencies. This eliminates the need for painful daily finger-pricking for diabetic patients.
Aesthetic Integration: Merging health with fashion and cosmetics, the sensors are placed in the limbal ring (annular design) to ensure central vision remains unobstructed while providing a “glowing” aesthetic effect.
2. Governance Policy Goals
To ensure an ethical future, I aim for:
Ensuring Safety & Security: Preventing environmental leakage and horizontal gene transfer with the native eye microbiome.
Promoting Autonomy: Empowering patients with real-time, non-invasive data access.
Promoting Equity: Ensuring the “living” nature of the product keeps production costs low for global accessibility.
Design: A global database for users to report any changes in ocular health.
Risks: Data privacy concerns and administrative overhead.
4. Scoring Rubric (1 = Best, 3 = Least effective)
Does the option:
Option 1 (Kill-switch)
Option 2 (App)
Option 3 (Registry)
Enhance Biosecurity
• By preventing incidents
1
3
2
• By helping respond
3
1
2
Foster Lab Safety
• By preventing incident
1
2
3
• By helping respond
2
2
1
Protect the environment
• By preventing incidents
1
3
2
• By helping respond
3
2
1
Other considerations
• Minimizing costs and burdens
2
1
3
• Feasibility?
1
1
3
• Not impede research
2
1
3
• Promote constructive applications
1
1
2
5. Prioritization & Analysis
I prioritize Option 1 (Genetic Kill-switches) combined with Option 2 (Digital App). In bio-engineering, “safety-by-design” is non-negotiable. While the app ensures the tool is useful (Autonomy), the kill-switch ensures the technology does not harm the biosphere (Safety). The trade-off is a slightly higher technical complexity, but it provides the most robust ethical framework for “living medicine.”
7. Pre-lecture Questions (Week 2: DNA Read, Write, Edit)
1. How many base pairs (bp) are in the human genome?
There are approximately 3 billion (3 x 10^9) base pairs in a haploid human genome.
2. What is the current cost to “Read” (sequence) a human genome?
As of 2026, the cost has dropped significantly, approaching the $100 mark or even less for high-throughput sequencing.
3. What is the current cost to “Write” (synthesize) a human genome?
Writing DNA is still far more expensive, costing roughly $0.10 per base pair for standard synthesis. Synthesizing a full human genome would cost hundreds of millions of dollars, making it currently infeasible for individual projects.
4. What is the implication for the “Living Iris” project?
The vast gap between reading and writing costs means that for my project, it is much more feasible to “Read” and “Edit” existing microbial genomes (like S. epidermidis) using tools like CRISPR, rather than trying to “Write” a completely new synthetic genome from scratch.
8. AI Assistance & Documentation
In accordance with the course ethics policy, I acknowledge the use of **Gemini ** as an adaptive collaborator in the development of this assignment.
How AI was used:
Formatting: Helped structure the Policy Goals Rubric and troubleshoot Markdown rendering issues in the student template.
Prompts Used:
“How can I link synthetic biology to smart contact lenses for diabetic monitoring?”
“Explain the ‘mirror challenge’ for a color-changing lens and suggest technical mitigations for iris color interference.”
“Draft a Governance Policy Rubric comparing a genetic kill-switch, a digital app, and a regulatory registry.”
Week 2: Bioart & Genetics
Name: Negin Aghayan
Topic: From Reading DNA to Designing Antibiotic Resistance
Part 1 & 2: DNA Analysis and Gel Art
1.1. Virtual Digest of Lambda Phage DNA
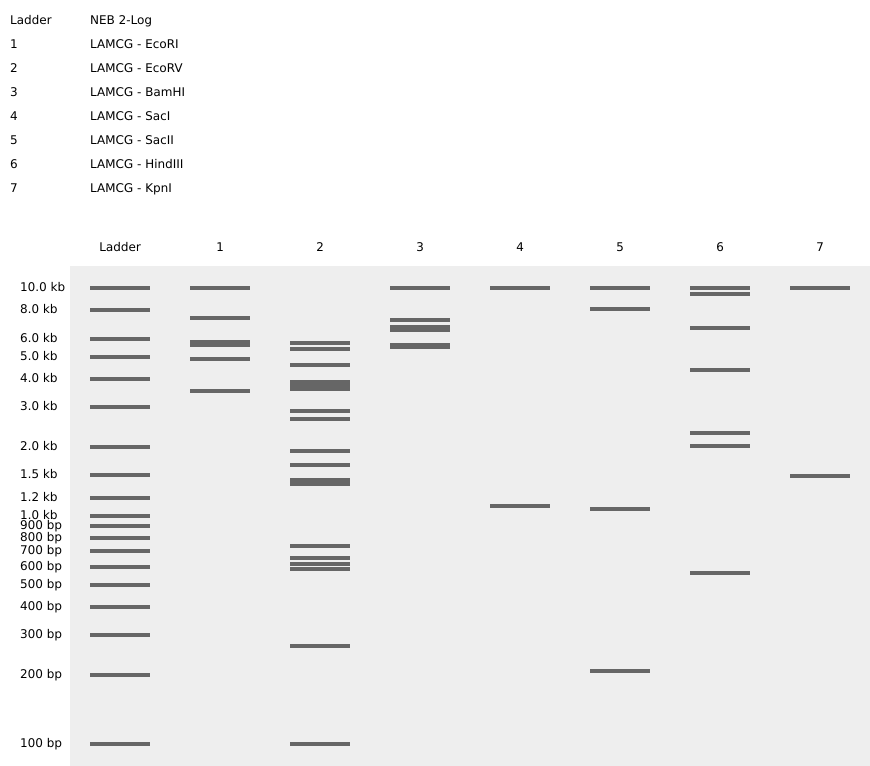
In this lab, I utilized Benchling to simulate a restriction digest of the Lambda DNA (48,502 bp). Lambda DNA is a classic substrate in molecular biology because its entire sequence is known, making it the perfect “map” for testing Type II restriction enzymes like EcoRI, HindIII, and BamHI. By simulating these digests, I visualized how specific palindromic sequences are recognized and cleaved, producing a unique “DNA fingerprint.”
1.2. Verification of Enzymatic Cleavage Patterns
Before proceeding to the creative design phase, I performed a standard benchmark digestion of the Lambda phage genome. This step is crucial to verify the specificity of Type II restriction enzymes and their respective recognition sites across the linear DNA molecule.
Establishing a reliable DNA ladder and reference digest is the foundation of any molecular cloning project, a practice consistent with rigorous laboratory standards.
Enzymes Characterized:
EcoRI, HindIII, BamHI: Standard enzymes used for mapping.
KpnI, EcoRV, SacI, SalI: Additional Type II enzymes to observe diverse fragment distributions.
Figure 1: Virtual electrophoresis showing individual digestion patterns for the seven required enzymes.
2.1. Gel Art: “The DNA Butterfly” - A 10-Lane Symmetrical Exploration
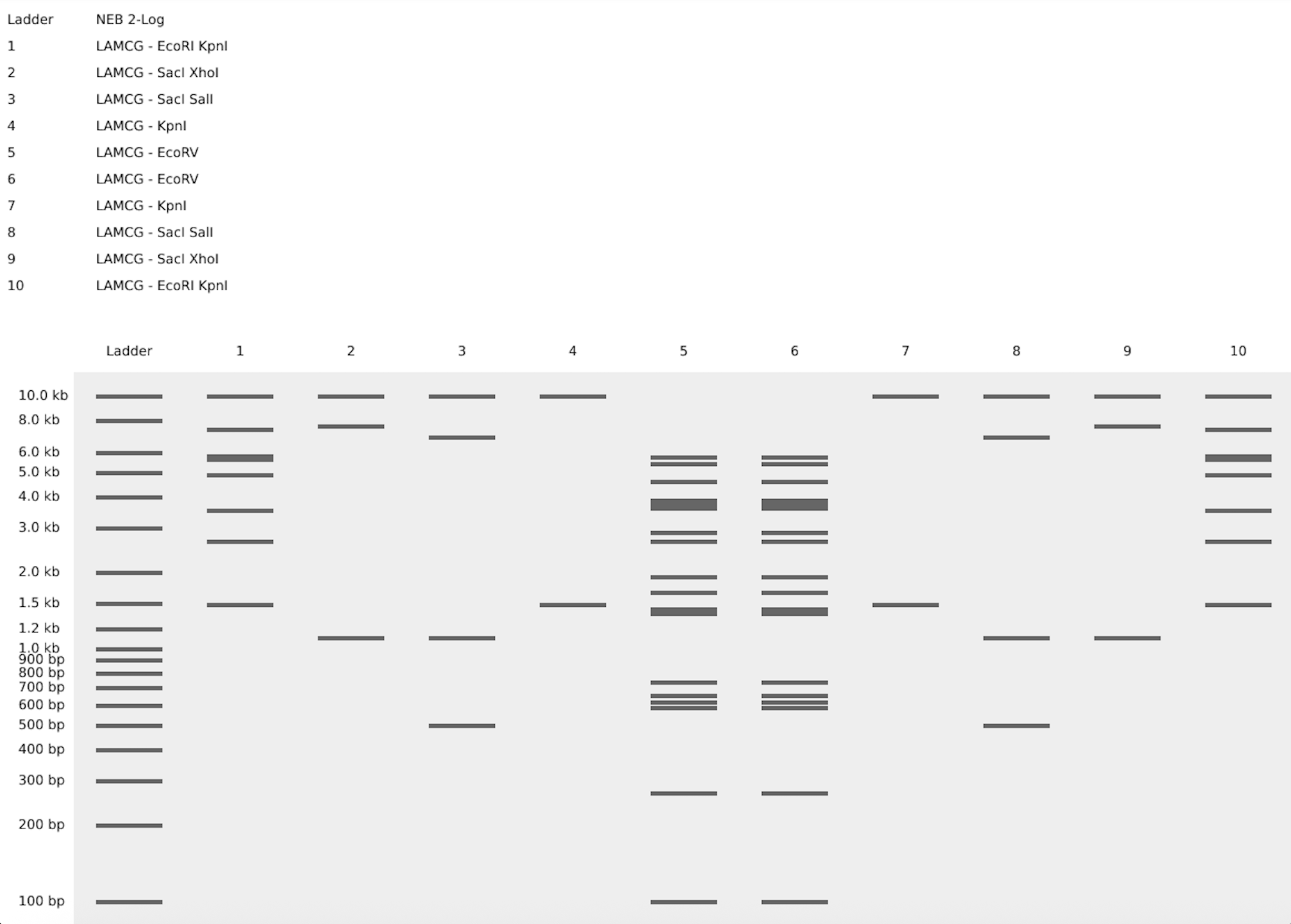
As a microbiology student with experience in molecular techniques, I aimed to bridge the gap between rigorous genomic analysis and aesthetic expression. The butterfly is more than just a visual choice; in the context of microbiology and biotechnology, it represents metamorphosis—the profound phenotypic transformation driven by underlying genetic information. This mirrors the Central Dogma, where static digital sequences are “transformed” into functional biological entities.For this assignment, I designed a 10-lane symmetrical pattern titled “The DNA Butterfly”, utilizing the 48.5 kb Lambda DNA as my molecular canvas.
The Design Protocol (10-Lane Symmetry):
To achieve a high-fidelity mirror image, I carefully selected Type II restriction enzymes based on their cleavage frequency to create a balanced visual weight across the gel:
Lanes 5 & 6 (The Axis of Symmetry): Digested with EcoRV. These lanes form the “body” of the butterfly. The high density of bands in the mid-range (approx. 3-6 kb) creates a solid central vertical axis.
Lanes 4 & 7 (Structural Framework): Digested with KpnI. These lanes provide the “scaffolding” for the wings, featuring a prominent high-molecular-weight band at ~17 kb, representing the strong upper edges of the butterfly’s wings.
Lanes 3/8 & 2/9 (Internal Wing Textures): Utilizing double digests (SacI + SalI and SacI + XhoI). By combining these enzymes, I generated specific low-molecular-weight fragments (1-3 kb) that simulate the intricate, delicate patterns found on the interior of a butterfly’s wing.
Lanes 1 & 10 (External Wing Margin): A double digest of EcoRI + KpnI. These lanes frame the entire artwork, providing a diverse range of band sizes that define the outer boundaries of the biological form.
This exercise demonstrates that DNA is not just a carrier of information but a medium for structural design. The precision of the band migration confirms the successful mapping of the Lambda genome through enzymatic “sculpting.”
For my protein design, I chose TEM-1 Beta-lactamase.
Reasoning: As a microbiology student, I am focused on the global crisis of Antibiotic Resistance. TEM-1 is the most common beta-lactamase found in Gram-negative bacteria (like E. coli). It provides resistance against Penicillin and early Cephalosporins by hydrolyzing the beta-lactam ring. Designing this protein from scratch allows me to study the fundamental “software” that enables bacterial survival against clinical interventions.
Protein Sequence (UniProt):
The following is the amino acid sequence for the TEM-1 Beta-lactamase (286 AA), which I will be using for the reverse translation and codon optimization phases:
3.2. Reverse Translation: Protein (amino acid) sequence to DNA (nucleotide) sequence
The Central Dogma of molecular biology serves as the fundamental framework for this process. In nature, information flows from DNA to RNA (transcription) and then to protein (translation). However, in Synthetic Biology, we often operate in reverse: we start with a functional protein—in this case, the TEM-1 Beta-lactamase—and work backward to determine the exact nucleotide sequence required to encode it.
I understand that while the genetic code is universal, it is also degenerate, meaning most amino acids are encoded by multiple codons. This reverse translation step is the first stage in “writing” biological software, allowing us to move from a structural protein sequence back to a digital DNA format ($A, T, C, G$). This process is critical for my future goals in biotechnology, as it enables the custom synthesis of genes for expression in various hosts.
Using Benchling’s reverse translation tool, I have derived the following 861 bp nucleotide sequence from the 286 amino acid sequence of TEM-1:
Once the nucleotide sequence of the protein is determined, it is essential to perform Codon Optimization before DNA synthesis.
describe why you need to optimize codon usage:
Although the genetic code is universal, it is also degenerate, meaning that most amino acids are encoded by multiple synonymous codons. However, different organisms do not use these codons with equal frequency, a phenomenon known as Codon Bias.
From my perspective as a microbiology student, optimization is necessary for the following reasons:
Translation Efficiency: Each organism has a specific pool of available transfer RNAs (tRNAs). By using codons that match the most abundant tRNAs in the host, we prevent “ribosomal stalling” and ensure rapid and efficient protein synthesis.
Maximizing Yield: For professional biotechnology applications, such as those performed at companies, achieving high-level protein expression is a primary goal for scalability and cost-effectiveness.
mRNA Stability and Folding: Optimization tools help eliminate unwanted secondary structures in the mRNA that could interfere with translation or lead to improper protein folding.
Sequence Sanitation: During this process, I ensured the removal of “forbidden” sequences, specifically Type IIs enzyme recognition sites such as BsaI, BsmBI, and BbsI. This makes the sequence compatible with modern assembly methods like Golden Gate Cloning and DNA synthesis requirements from providers like Twist Bioscience.
The Methodology: How was this achieved?
To perform this refinement, I utilized algorithmic tools (benchmarked against Codon Usage Tables like Kazusa) that analyze the frequency of codon usage in E. coli. The algorithm performs a synonymous substitution:
It identifies every amino acid in the TEM-1 sequence.
It replaces the existing codon with the one that has the highest frequency of use in the E. coli genome.
It performs Sequence Sanitation by screening the entire 861 bp sequence to eliminate Type IIs restriction sites—specifically BsaI, BsmBI, and BbsI. This step is vital for ensuring that the DNA is compatible with Golden Gate Assembly, a method I am familiar with through my research interests in biotechnology and synthetic biology.
Which organism have you chosen to optimize the codon sequence for and why?
I have chosen Escherichia coli as my expression host.
Reasoning:
Academic Background: Throughout my 7th-semester Microbiology curriculum, E. coli has been the primary model organism for studying microbial genetics and molecular biology.
Industry Standard: It remains the most widely used and well-characterized bacterial host for the commercial production of recombinant proteins in the biotechnology industry.
Practical Familiarity: My internship experience at the National Institute of Genetic Engineering and Biotechnology (NIGEB) and my lab work in microbial culturing and DNA extraction have provided me with the necessary hands-on skills to work with this specific host efficiently.
TEM-1 Beta-lactamase DNA sequence with Codon-Optimization (for E. coli):
Analysis of Modifications:
While it is impractical to list all 800+ nucleotide substitutions, I performed a comparative analysis between the original and optimized sequences.
Synonymous Changes: The majority of changes involved switching from rare codons (e.g., using AGA for Arginine) to the preferred E. coli codons (e.g., CGT or CGC).
Sequence Sanitation: I specifically verified the removal of internal BsaI (GGTCTC) and EcoRI (GAATTC) sites. In the original sequence, these might have interfered with downstream cloning protocols, but in this synthetic version, they have been successfully eliminated without altering the amino acid sequence of the Beta-lactamase.
3.4. Production Method: Transforming Digital Code into Matter
Having finalized the digitally optimized DNA sequence for TEM-1 Beta-lactamase, the challenge shifts from computational design to physical realization. To transform this 861 bp sequence into a functional enzyme, we must navigate through DNA synthesis, host selection, and the molecular execution of the Central Dogma.
1. DNA Synthesis: From Digital Information to Physical Matter
The first step is De Novo DNA Synthesis. Since this sequence is a synthetic product specifically optimized for E. coli, it cannot be extracted from a natural source; it must be chemically manufactured.
Synthesis Technology: Utilizing high-throughput silicon-based platforms, such as those provided by Twist Bioscience or IDT, the digital sequence is converted into physical DNA through phosphoramidite chemistry.
Verification: The resulting fragment is typically sequence-verified using Next-Generation Sequencing (NGS) to ensure 100% accuracy before being cloned into an expression vector (e.g., a pET-series plasmid) containing necessary regulatory elements like promoters.
2. Production Technologies: Choosing the Biological Factory
I have identified two primary technological routes for producing the protein from the synthetic DNA:
Cell-Dependent (In Vivo) Expression: This is the industry standard for large-scale production, widely utilized in biotechnology companies. The synthetic DNA is transformed into a specialized host, such as Escherichia coli (BL21 DE3). These bacteria serve as living bioreactors. Upon induction with a molecule like IPTG, the cellular machinery is “hijacked” to produce the Beta-lactamase. This method is highly scalable and benefits from the host’s natural chaperones that aid in proper protein folding.
Cell-Free Protein Synthesis (CFPS): This modern approach involves using cell lysates that contain all the necessary molecular components—ribosomes, RNA polymerase, and tRNAs—without the cell membrane. This allows for rapid “Transcription-Translation” (TX-TL) in a test tube. For research settings, such as those at institutes like NIGEB, this method is invaluable for quickly screening enzyme variants without the time-consuming steps of cell culture and transformation.
3. The Molecular Execution: Transcription and Translation
Regardless of the production method, the DNA sequence must be executed through the two-step process of the Central Dogma to become a protein:
Transcription (DNA → mRNA): The enzyme RNA Polymerase identifies the Promoter (the “start” signal) upstream of the Beta-lactamase gene. It reads the DNA template and assembles a complementary messenger RNA (mRNA) strand. This mRNA carries the genetic instructions from the stable DNA storage to the active protein-making machinery.
Translation (mRNA → Protein): The Ribosome identifies the Ribosome Binding Site (RBS) on the mRNA and initiates synthesis at the Start Codon (ATG). Guided by the optimized codons designed in the previous step, tRNAs deliver amino acids to the ribosome with high efficiency. Because the sequence was tailored to the host’s tRNA pool, the ribosome can move smoothly without stalling, linking amino acids into a polypeptide chain until it reaches a Stop Codon.
4. Achieving Functionality: Protein Folding
The final, crucial stage is Protein Folding. For TEM-1 Beta-lactamase, the polypeptide chain must fold into a precise three-dimensional conformation to form its active site. This folded structure is what enables the enzyme to bind to and hydrolyze the beta-lactam ring of antibiotics, providing the bacterial cell with the resistance mechanism that is a central focus of my current studies and research interests.
3.5. How does it work in nature/biological systems?
In classical genetics, we often think of “one gene, one protein.” However, natural systems—especially viruses and bacteria—are far more efficient. A single DNA locus can code for multiple proteins through several fascinating mechanisms:
1. Overlapping Genes (Frameshifting)
As seen in the Phage MS2 example provided in my research, biological systems can use Overlapping Reading Frames (ORFs). Because the genetic code is read in triplets, a single DNA sequence can encode different proteins depending on the “starting point” of the ribosome. By shifting the reading frame (e.g., a +1 or -1 shift), the same sequence of nucleotides is interpreted as a completely different set of codons, producing entirely distinct polypeptide chains.
2. Alternative Splicing (Eukaryotic Complexity)
In eukaryotic organisms, a single primary transcript (pre-mRNA) can undergo Alternative Splicing. By selectively joining different combinations of exons, a cell can generate multiple mRNA isoforms from a single gene. This allows for the production of protein variants with different functions or localizations within the cell.
3. Polycistronic mRNA (The Operon Model)
In many bacterial systems, multiple genes are grouped into a single Operon and transcribed into one long mRNA molecule. This polycistronic transcript contains multiple Ribosome Binding Sites (RBS), allowing ribosomes to initiate translation at several points and produce multiple independent proteins (like those in a metabolic pathway) simultaneously from a single transcriptional event.
Molecular Alignment: The Flow of Information (TEM-1 Case Study)
Following the example of the MS2 L-protein, I have aligned the first 30 nucleotides of my synthetic TEM-1 Beta-lactamase gene to demonstrate the molecular flow from DNA to Protein. Note that during transcription, Thymine (T) is replaced by Uracil (U), and during translation, each triplet (codon) is converted into a specific amino acid.
DNA (Coding Strand):5' - A T G A G C A T T C A A C A T T T C C G T G T C G C T - 3'
RNA (mRNA Transcript):5' - A U G A G C A U U C A A C A U U U C C G U G U C G C U - 3'
Protein (Amino Acid Sequence):M S I Q H F R V A L ...
Analysis:
This alignment illustrates the “digital-to-analog” conversion of life. A simple change in the DNA sequence—such as the codon optimization I performed in section 3.3—directly influences the efficiency of this flow without changing the final protein product. This dense packing of information is what allows a tiny phage or a complex bacterium to execute life-sustaining functions with such high precision.
Part 4: Building the Expression Cassette
4.2. Build Your DNA Insert Sequence
In this final design phase, I assembled a complete Expression Cassette for the TEM-1 Beta-lactamase gene. An expression cassette is a modular genetic unit consisting of a coding sequence and the necessary regulatory elements to direct the cell’s machinery to produce the desired protein.
Genetic Architecture and Components
The construct was assembled in Benchling using a linear topology. I manually integrated and annotated each component to ensure optimal expression in my target host, Escherichia coli.
Component
Sequence ID / Source
Function
Promoter
BBa_J23106
A strong constitutive promoter that ensures continuous transcription of the gene without the need for external induction.
RBS
BBa_B0034 (with spacers)
Optimized Ribosome Binding Site to ensure efficient translation initiation and prevent ribosomal stalling.
Start Codon
ATG
The universal initiation signal for protein synthesis.
Coding Sequence
Optimized TEM-1 (Section 3.3)
The core genetic instruction for Beta-lactamase, refined for E. coli codon bias to maximize yield.
7x His Tag
C-terminal extension
Added to enable downstream protein purification using Immobilized Metal Affinity Chromatography (IMAC), a standard technique I am familiar with through my laboratory experience.
Stop Codon
TAA
Signal to the ribosome to terminate translation and release the polypeptide chain.
Terminator
BBa_B0015
A robust double terminator that stops RNA polymerase to prevent transcriptional read-through into the vector backbone.
Design Rationale
The integration of a 7x His Tag is a strategic choice for my professional goals in biotechnology. In industrial settings, such as the production of recombinant enzymes, efficient purification is as critical as high expression. By placing the tag at the C-terminus (before the final stop codon), I ensure that the functional enzyme can be easily isolated from the E. coli lysate while maintaining its catalytic activity against beta-lactam antibiotics.
The final construct is verified to be compatible with Golden Gate Assembly as all internal BsaI, BsmBI, and BbsI sites were removed during the optimization phase in section 3.3.
4.6. Final Plasmid Construction and Verification
The final engineering step involved the successful integration of the synthetic expression cassette into a circular plasmid backbone.
Replication Origin: High-copy colE1, ensuring maximum yield.
By re-importing the GenBank file from Twist into Benchling, I have verified the structural integrity of the plasmid. The circular map clearly shows the seamless transition from the vector backbone to our custom-designed insert, confirming that the genetic tool is ready for transformation into E. coli BL21 (DE3) for protein production.
I would choose to sequence the whole-genome of a multi-drug resistant (MDR) clinical isolate of Escherichia coli.
Rationale:
Having designed a synthetic TEM-1 Beta-lactamase gene in the previous sections, it is scientifically valuable to observe how such genes exist and evolve in nature. Clinical isolates often carry resistance genes on complex mobile genetic elements. Sequencing the entire genome allows me to:
Identify the genomic context of resistance genes (e.g., chromosomal vs. plasmid-borne).
Discover co-existing resistance markers that contribute to a multi-drug resistant phenotype, which is a key area of interest in my microbiology studies.
Track the epidemiological spread of specific resistance alleles in hospital environments.
(ii) Selected Sequencing Technology
I would utilize Oxford Nanopore Technologies (ONT), specifically the MinION platform, to perform this sequencing.
Technology Breakdown:
Question
Analysis & Answer
Generation
Third-Generation. This technology performs single-molecule, real-time sequencing without the need for DNA synthesis or PCR amplification.
Input & Preparation
Input: High-molecular-weight (HMW) genomic DNA extracted from the E. coli isolate. Preparation Steps: 1. Extraction: Pure genomic DNA recovery. 2. End-repair & A-tailing: Preparing DNA ends for adapter attachment. 3. Adapter Ligation: Attaching motor proteins and sequencing adapters to the DNA library. 4. Clean-up: Using magnetic beads to remove reagents.
Decoding Mechanism
Ionic Current Disruption. As a single strand of DNA is pulled through a protein nanopore, each nucleotide ($A, T, C, G$) creates a unique disruption in the electrical current across the membrane.
Base Calling
The raw electrical signals (squiggles) are decoded using Neural Network-based algorithms that translate the specific current patterns into a nucleotide sequence in real-time.
Output
Raw Data: Fast5 files (containing signal data). Processed Data: FASTQ files (containing the sequence and quality scores), which can then be used for genome assembly and resistance gene mapping.
Why this technology?
the Long-Read capability of Nanopore is its greatest advantage for me as a microbiology researcher. It allows for the complete assembly of bacterial plasmids and the identification of large structural variations that short-read technologies (like Illumina) often miss. This is particularly relevant for the high-level genomic analysis performed at institutes like NIGEB.
5.2 DNA Write
(i) Target DNA for Synthesis
I want to synthesize the TEM-1 Beta-lactamase expression cassette (1,068 bp) that I’ve been meticulously designing and optimizing.
My Motivation:
There’s a special kind of satisfaction in seeing a digital design from Benchling turn into a physical piece of DNA. My goal here is to take what I’ve learned about antibiotic resistance and actually test it in the lab. Specifically, I want to:
Test the Optimization: See if the codon changes I made actually lead to the high protein levels I’m expecting in E. coli.
Study the Enzyme: Use the synthesized DNA to produce pure TEM-1 and analyze its kinetics against different antibiotics.
Create a Modular Tool: This isn’t just a homework assignment; it’s a standardized part that could be a building block for future biosensors or biotech projects I might work on.
The Sequence:```text
TTTACGGCTAGCTCAGTCCTAGGTATAGTGCTAGCCATTAAAGAGGAGAAAGGTACCAGCATTCAACATTTCCGTGTCGCTCTGATCCCGTTCTTCGCTGCCTTTTGCCTGCCGGTATTCGCTCACCCGGAAACCCTGGTTAAAGTTAAAGACGCCGAAGATCAGCTGGGTGCACGTGTTGGTTACATCGAACTGGATCTGAACAGCGGTAAAATCCTGGAAAGCTTCCGTCCGGAAGAACGTTTCCCGATGATGAGCACCTTTAAAGTTCTGCTGTGTGGTGCAGTTCTGAGCCGTATTGACGCAGGTCAAGAACAGCTGGGTCGTCGTATCCACTACAGCCAGAACGATCTGGTTGAATACAGCCCGGTTACCGAAAAACATCTGACCGACGGTATGACCGTTCGTGAACTGTGTAGCGCTGCTATCACCATGAGCGATAACACCGCTGCTAACCTGCTGCTGACCACCATTGGTGGCCCGAAAGAACTGACCGCCTTCCTGCACAACATGGGTGATCATGTTACCCGTCTGGATCGTTGGGAACCGGAACTGAACGAAGCTATCCCGAACGACGAACGTGATACCACCATGCCGGTTGCAATGGCTACCACCCTGCGTAAACTGCTGACCGGTGAACTGCTGACCCTGGCTAGCCGTCAGCAACTGATCGACTGGATGGAAGCTGATAAAGTTGCAGGTCCGCTGCTGCGTAGCGCTCTGCCGGCTGGTTGGTTCATTGCTGATAAAAGCGGTGCAGGTGAACGTGGTAGCCGTGGTATCATTGCTGCGCTGGGTCCGGATGGTAAACCGAGCCGTATTGTTGTTATCTACACCACCGGTAGCCAGGCTACCATGGATGAACGTAACCGTCAGATCGCTGAAATTGGTGCTAGCCTGATCAAACATTGGCATCACCATCACCATCATCACCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCTACTAGAGTCACACTGGCTCACCTTCGGGTGGGCCTTTCTGCGTTTATA
5.3 DNA Edit
(i) What DNA i would want to edit and why.
After designing and synthesizing the TEM-1 Beta-lactamase gene, the next logical step in my research is to explore how we can “undo” this resistance. I want to edit the chromosomal or plasmid-borne blaTEM-1 gene in clinical isolates of Escherichia coli.
The “Why” behind this:
While we spend a lot of time understanding how resistance works, the future of therapy might lie in reversing it. By editing this specific gene, I aim to:
Restore Antibiotic Sensitivity: If we can successfully disrupt the TEM-1 gene, we can make previously resistant bacteria susceptible to penicillin-group antibiotics again. This is a huge area of interest in the fight against “superbugs.”
Study Gene Function: By making precise edits (like single amino acid swaps) in the active site of the enzyme, I can study exactly which parts of the protein are responsible for its catalytic activity.
CRISPR-Antimicrobials: This serves as a proof-of-concept for using CRISPR as a sequence-specific antimicrobial, which is much more targeted than traditional broad-spectrum antibiotics.
(ii) Selected Editing Technology: CRISPR-Cas9
To perform these edits, I’ll use the CRISPR-Cas9 system. It’s currently the most versatile and precise tool we have for bacterial genome editing, and it’s something I’ve been keen to explore more in a lab setting like NIGEB.
Technical Breakdown:
Question
My Analysis & Answer
How does it edit DNA?
The system uses a Guide RNA (gRNA) to lead the Cas9 nuclease to a specific 20-bp sequence in the TEM-1 gene. Once there, Cas9 acts like “molecular scissors” and creates a Double-Strand Break (DSB). In bacteria, this break is often lethal or repaired by Non-Homologous End Joining (NHEJ), which introduces small errors (indels) that effectively break the gene’s function.
Essential Steps
1. Targeting: Identifying a unique sequence within the TEM-1 gene. 2. Binding: The Cas9-gRNA complex scans the DNA for a PAM sequence ($5’-NGG-3’$) and binds to the target. 3. Cleaving: Cas9 cuts both strands of the DNA. 4. Repair/Disruption: The cell attempts to fix the break, leading to mutations that “knock out” the resistance gene.
Preparation & Inputs
Design: Designing a 20-nucleotide gRNA that is specific to TEM-1 to avoid off-target effects. Inputs: 1. Cas9 Enzyme: Delivered via a plasmid. 2. sgRNA (single guide RNA): Designed to match the target gene. 3. Competent Cells:E. coli cells ready to take up the CRISPR plasmids. 4. Donor Template (optional): If I wanted to “swap” a base instead of just breaking it (Homology-Directed Repair).
Limitations: Precision
The main risk is Off-target effects, where Cas9 might cut a similar-looking sequence elsewhere in the genome. While rare in small bacterial genomes, it’s still a concern.
Limitations: Efficiency
Not every bacteria will take up the CRISPR system (low transformation efficiency). Also, since a DSB is often lethal for E. coli, the survival rate of the “edited” cells can be low unless a repair template is provided.
Conclusion of the Assignment
This assignment has been an incredible journey through the “Design-Build-Test-Learn” cycle of synthetic biology. From decoding the MS2 virus to optimizing an antibiotic resistance gene and finally learning how to read, write, and edit it, I feel much more equipped to handle complex genetic engineering tasks. It’s exciting to see how these digital tools can translate into real-world solutions for global health challenges.
Week 3: Lab Automation & Protest BioArt
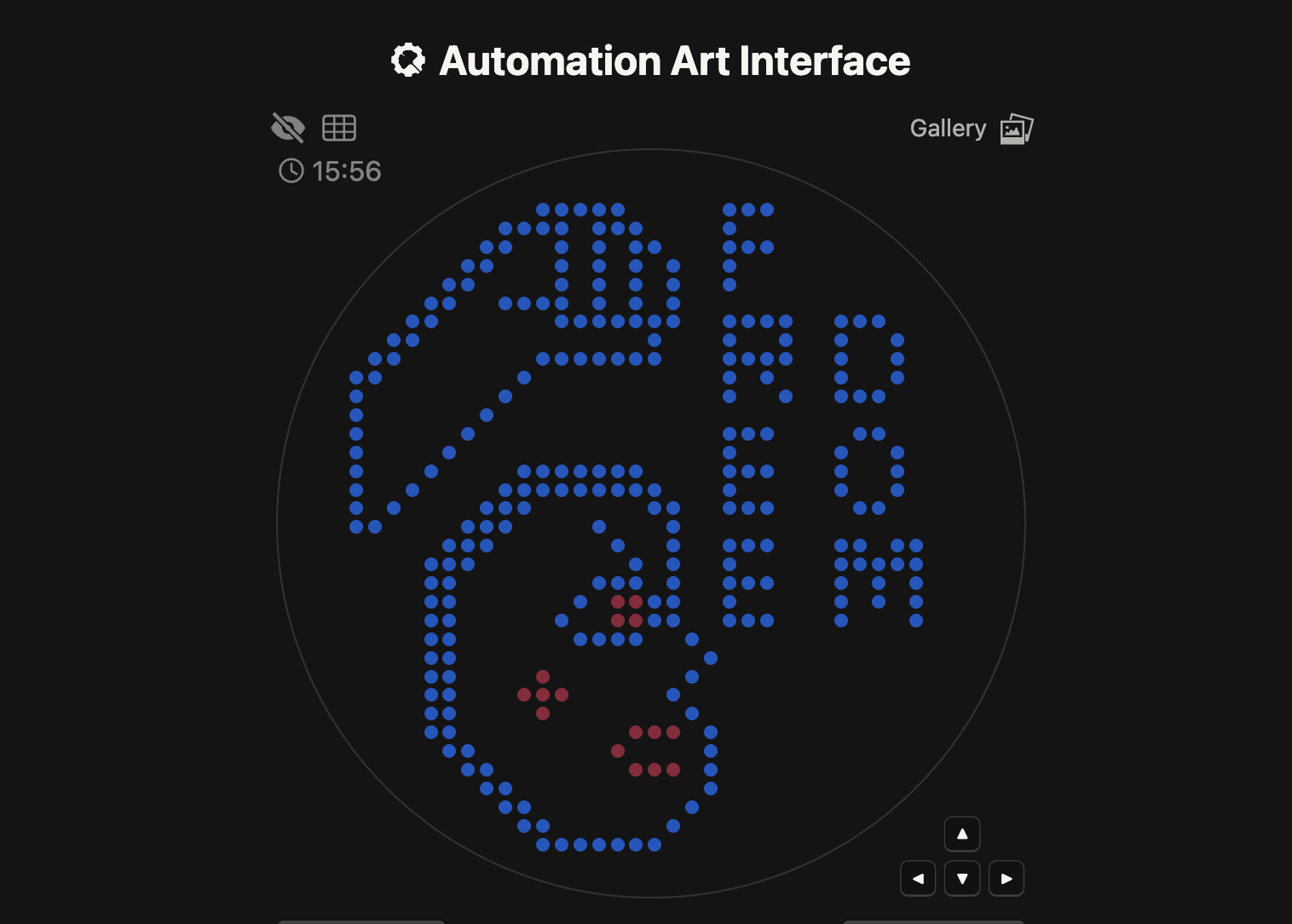
1. Artistic Concept: “Woman Life Freedom”
This project is more than a laboratory exercise; it is a piece of Protest Art. It is dedicated to the current situation in Iran, where thousands of people have been killed or continue to face violence in the streets while fighting for their fundamental freedoms.
The design features a raised fist—a universal symbol of resistance—accompanied by the slogan “Woman, Life, Freedom.” By using living, glowing bacteria to form this image, I aim to represent the resilience and the “living” spirit of the struggle for liberty in my country.
Color & Protein Mapping:
Blue (TagBFP): Used for the main outline, hair, and text to provide a strong, deep contrast.
Pink (mRFP1): Used for highlighting the eye and cheek details, representing vitality.
2. Technical Implementation
For this assignment, I utilized the Automation Art Interface (GUI) to map my design onto a 90mm circular Petri dish.
Code Source: As permitted by the assignment instructions for those focusing on the art concept, I have used the Full Python Script generated by the GUI website (opentrons-art.rcdonovan.com).
Labware Configuration: The script is configured for a 96-well PCR plate to hold the fluorescent bacterial strains.
Robotic Protocol: The Opentrons robot uses pick_up_tip(), aspirate(), and the specialized dispense_and_jog() function to deposit 0.75µL droplets without damaging the charcoal agar surface.
Spacing: A 2.2mm spacing was chosen for optimal resolution and clarity under UV light.
fromopentronsimporttypesimportstringmetadata={'protocolName':'Woman Life Freedom','author':'Negin Aghayan','source':'HTGAA 2026','apiLevel':'2.20'}Z_VALUE_AGAR=2.0POINT_SIZE=1# Robot deck setup constantsTIP_RACK_DECK_SLOT=9COLORS_DECK_SLOT=6AGAR_DECK_SLOT=5PIPETTE_STARTING_TIP_WELL='A1'# Well color mapping well_colors={'A1':'sfGFP','A2':'mRFP1','A3':'mKO2','A4':'Venus','A5':'mKate2_TF','A6':'Azurite','A7':'mCerulean3','A8':'mClover3','A9':'mJuniper','A10':'mTurquoise2','A11':'mBanana','A12':'mPlum','B1':'Electra2','B2':'mWasabi','B3':'mScarlet_I','B4':'mPapaya','B5':'eqFP578','B6':'tdTomato','B7':'DsRed','B8':'mKate2','B9':'EGFP','B10':'mRuby2','B11':'TagBFP','B12':'mChartreuse_TF'}volume_used={'TagBFP':0,'mRFP1':0}defupdate_volume_remaining(current_color,quantity_to_aspirate):rows=string.ascii_uppercaseforwell,colorinlist(well_colors.items()):ifcolor==current_color:if(volume_used[current_color]+quantity_to_aspirate)>250:row=well[0]col=well[1:]next_row=rows[rows.index(row)+1]next_well=f"{next_row}{col}"delwell_colors[well]well_colors[next_well]=current_colorvolume_used[current_color]=quantity_to_aspirateelse:volume_used[current_color]+=quantity_to_aspiratebreakdefrun(protocol):protocol.home()# Tips and Pipettestips_20ul=protocol.load_labware('opentrons_96_tiprack_20ul',TIP_RACK_DECK_SLOT,'Opentrons 20uL Tips')pipette_20ul=protocol.load_instrument("p20_single_gen2","right",[tips_20ul])# Reagent Plate (Aluminum block)temperature_plate=protocol.load_labware('opentrons_96_aluminumblock_generic_pcr_strip_200ul',COLORS_DECK_SLOT)# Agar Plateagar_plate=protocol.load_labware('htgaa_agar_plate',AGAR_DECK_SLOT,'Agar Plate')agar_plate.set_offset(x=0.00,y=0.00,z=Z_VALUE_AGAR)center_location=agar_plate['A1'].top()pipette_20ul.starting_tip=tips_20ul.well(PIPETTE_STARTING_TIP_WELL)# Helper functionsdefdispense_and_jog(pipette,volume,location):above_location=location.move(types.Point(z=2))pipette.move_to(above_location)pipette.dispense(volume,location)pipette.move_to(above_location)deflocation_of_color(color_string):forwell,colorinwell_colors.items():ifcolor.lower()==color_string.lower():returntemperature_plate[well]raiseValueError(f"No well found with color {color_string}")# Execution Loopforcurrent_color,point_listinpoint_name_pairing:ifnotpoint_list:continuepipette_20ul.pick_up_tip()max_aspirate=int(18//POINT_SIZE)*POINT_SIZEquantity_to_aspirate=min(len(point_list)*POINT_SIZE,max_aspirate)update_volume_remaining(current_color,quantity_to_aspirate)pipette_20ul.aspirate(quantity_to_aspirate,location_of_color(current_color))fori,(x,y)inenumerate(point_list):adjusted_location=center_location.move(types.Point(x,y))dispense_and_jog(pipette_20ul,POINT_SIZE,adjusted_location)ifpipette_20ul.current_volume==0andi<len(point_list)-1:quantity_to_aspirate=min(len(point_list[i+1:])*POINT_SIZE,max_aspirate)update_volume_remaining(current_color,quantity_to_aspirate)pipette_20ul.aspirate(quantity_to_aspirate,location_of_color(current_color))pipette_20ul.drop_tip()
Post Lab Question 1: Automation Strategy for Final Projects
1. Project Overview: Caff-Ink
For my final project, Caff-Ink, I am developing a silk-based bio-tattoo that monitors systemic caffeine levels using cell-free synthetic biology. The success of this project relies on the precise formulation of bio-inks and the high-definition printing of these inks onto thin silk membranes.
2. Intent for Automation
I intend to use the Opentrons OT-2 liquid handling robot to move beyond manual experimentation into a reproducible manufacturing process. Manual pipetting of cell-free reagents is often inconsistent and wasteful due to the high viscosity and low volumes involved.
Key Automation Goals:
High-Throughput Ink Screening: I will automate the mixing of various ratios of silk fibroin, cell-free extracts, and caffeine-responsive DNA riboswitches to identify the most stable “Bio-ink”.
Automated Bio-Printing: By utilizing the robot’s X-Y-Z precision, I will program the OT-2 to “draw” specific artistic patterns onto silk substrates, ensuring uniform thickness and chemical distribution.
3. Hardware and 3D Printed Components
To adapt the Opentrons deck for my specific needs, I will design and 3D print the following:
Silk Patch Stabilizer: A custom plate that holds multiple silk membranes under tension, preventing them from shifting during the dispensing process.
Micro-Reagent Rack: A specialized holder for 1.5ml tubes that minimizes dead volume, ensuring every microliter of expensive cell-free reagent is utilized.
4. Opentrons Python Protocol (Pseudocode)
The following script illustrates the logic for automated printing of a 10-point gradient tattoo pattern on a silk substrate:
fromopentronsimportprotocol_apimetadata={'protocolName':'Caff-Ink Precision Bio-Printing','author':'Negin - HTGAA 2026','description':'Automated deposition of caffeine-responsive ink onto silk membranes'}defrun(protocol:protocol_api.ProtocolContext):# Load Labwaretips=protocol.load_labware('opentrons_96_filtertiprack_20ul','1')ink_source=protocol.load_labware('opentrons_24_tuberack_eppendorf_1.5ml_safelock_snapcap','2')# Custom 3D printed silk holder in slot 3silk_patches=protocol.load_labware('custom_silk_holder_4_patches','3')# Load Pipettep20=protocol.load_instrument('p20_single_gen2','right',tip_racks=[tips])# Printing Procedurep20.pick_up_tip()# Logic: Printing a line of 10 dots to create an artistic patternforiinrange(10):p20.aspirate(2,ink_source['A1'])# Active Bio-Ink# Precision dispense at specific coordinates on the silk patchp20.dispense(2,silk_patches['A1'].top(z=-1).move(protocol_api.labware.Point(x=i*2)))p20.touch_tip()p20.drop_tip()
project 2
Automation Strategy for Project: Dia-Lens
** 1. Intent for Automation:**
For the Dia-Lens project, I will use the Opentrons OT-2 to automate the precise mixing of engineered S. epidermidis with the hydrogel matrix. Automation is essential to ensure a consistent microbial load across all lenses, which is critical for both lens transparency and accurate therapeutic dosing.
** 2. 3D Printed Components:**
Ocular Mold Rack: A custom 3D-printed holder designed to secure 12 contact lens molds on the Opentrons deck, ensuring the pipette can dispense the bio-ink into the center of each mold with sub-millimeter precision.
** 3. Python Pseudocode Logic:**
# Logic for filling lens molds with probiotic hydrogelp300.pick_up_tip()# Mix probiotics (A1) with hydrogel base (B1)p300.mix(5,100,hydrogel_base['B1'])# Fill each lens mold in the custom rackformoldinlens_molds.wells():p300.aspirate(80,hydrogel_base['B1'])# Slow dispense (rate=0.5) to prevent air bubblesp300.dispense(80,mold.bottom(z=2),rate=0.5)p300.drop_tip()
project 3
Automation Strategy for Project: The Living Glow
The Living Glow focuses on a personalized probiotic system using engineered Saccharomyces cerevisiae to address specific skin conditions via the gut-skin axis. Unlike “one-size-fits-all” supplements, this project aims to create custom yeast cocktails tailored to an individual’s skin profile—such as dehydration, acne-prone, or inflammatory conditions.
1. Intent for Automation: The “Digital Pharmacist”
I will use the Opentrons OT-2 as an automated formulation station to create personalized probiotic doses. Automation is the only way to achieve the precise mixing ratios required for multi-strain therapies.
Key Automation Goals:
Personalized Strain Blending: The robot will receive a digital “Skin Profile” and automatically mix different engineered yeast strains (e.g., Hyaluronic Acid producers for dry skin vs. Antimicrobial Peptide producers for acne) in specific ratios.
High-Precision Encapsulation: Automated dispensing of these custom ratios into capsule shells to ensure dose consistency and prevent cross-contamination between different patient formulations.
2. Hardware and 3D Printed Components
Dynamic Capsule Matrix: A 3D-printed rack designed to hold various capsule sizes, allowing the Opentrons to fill individual “personalized prescriptions” in a high-throughput manner.
Part 2: Summary of a Published Automation Paper
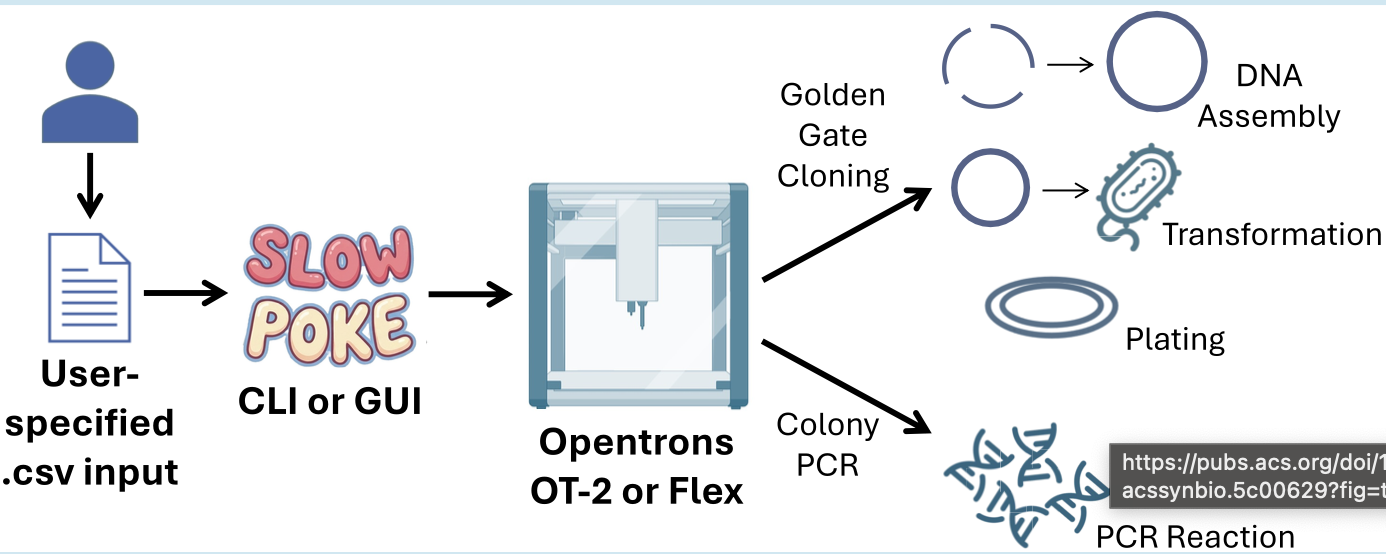
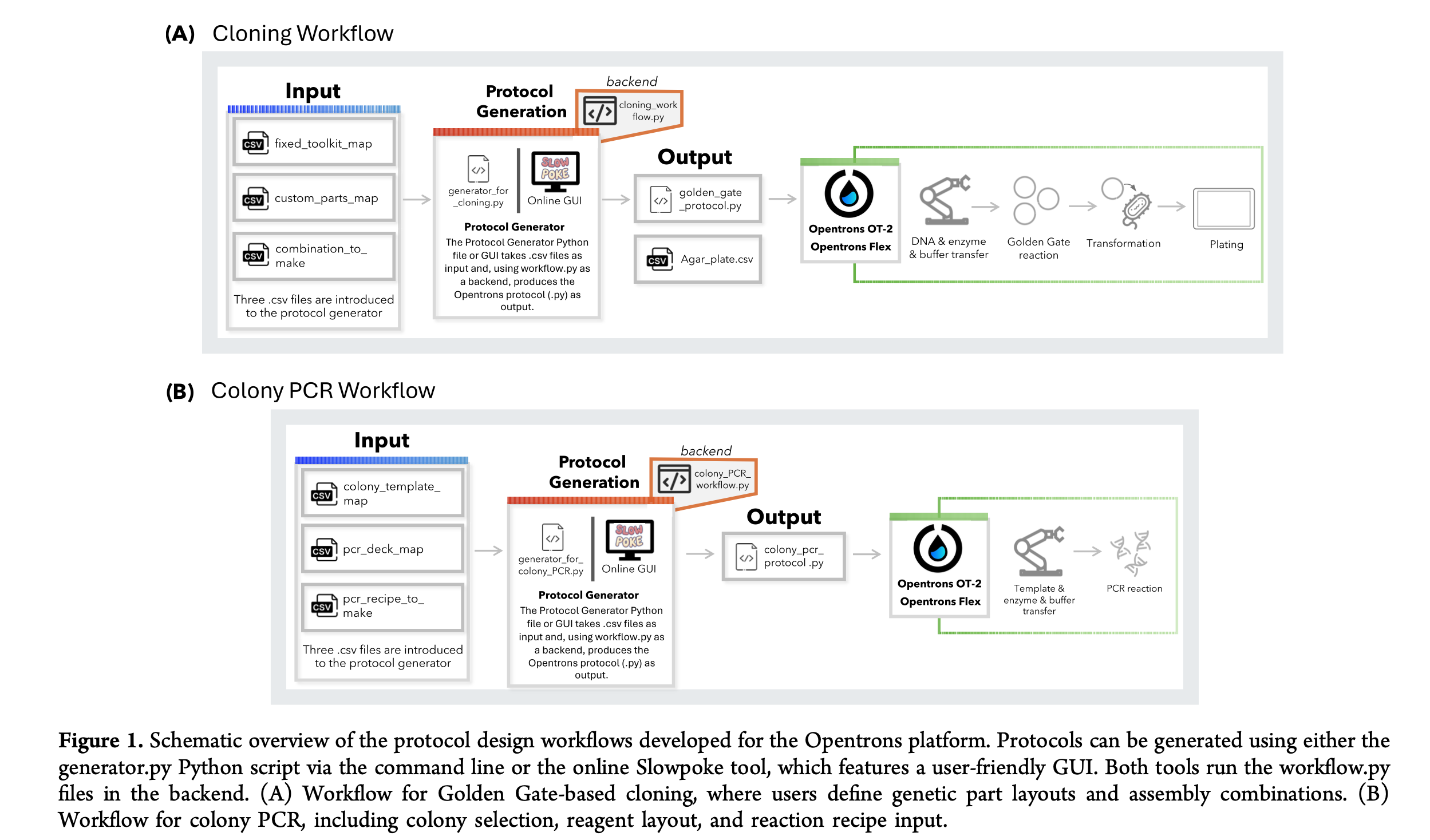
Paper Reference: Malcı, K., et al. (2026). Slowpoke: An Automated Golden Gate Cloning Workflow for Opentrons OT-2 and Flex. ACS Synthetic Biology.
General Overview
Synthetic biology relies heavily on DNA assembly, a routine but labor-intensive process that is often prone to human error when performed manually. To address these challenges, the authors developed Slowpoke, an open-source and modular automation workflow specifically designed for the accessible Opentrons OT-2 and Flex liquid-handling platforms. The system automates the most critical steps of the Golden Gate cloning cycle, including DNA assembly, Escherichia coli transformation, agar plating, and colony PCR.
A key innovation of this research is the introduction of a free Graphical User Interface (GUI) that allows researchers to generate complex Python protocols without any coding knowledge. By simply uploading a CSV file, the GUI converts biological parameters into instructions the robot can execute, requiring manual intervention only for colony picking and plate transfers. This significantly lowers the barrier to high-throughput genetic engineering for laboratories with limited programming expertise.
Findings
The validation of the Slowpoke workflow demonstrated its high reliability across different biological systems and automation hardware. Key results include:
Broad Compatibility: The effectiveness of the system was validated using established genetic toolkits for both yeast (S. cerevisiae) and bacteria (B. subtilis).
Assembly Precision: The Opentrons OT-2 platform achieved a 100% success rate (17/17 positive colonies) for basic transcription unit assemblies.
High-Throughput Scalability: In a complex assembly test involving six DNA parts and 57 different combinations, 55 out of 57 resulted in the correct genetic constructs.
System Robustness: These results confirm that Slowpoke provides a standardized and scalable solution, making it highly reliable for modern synthetic biology laboratories.