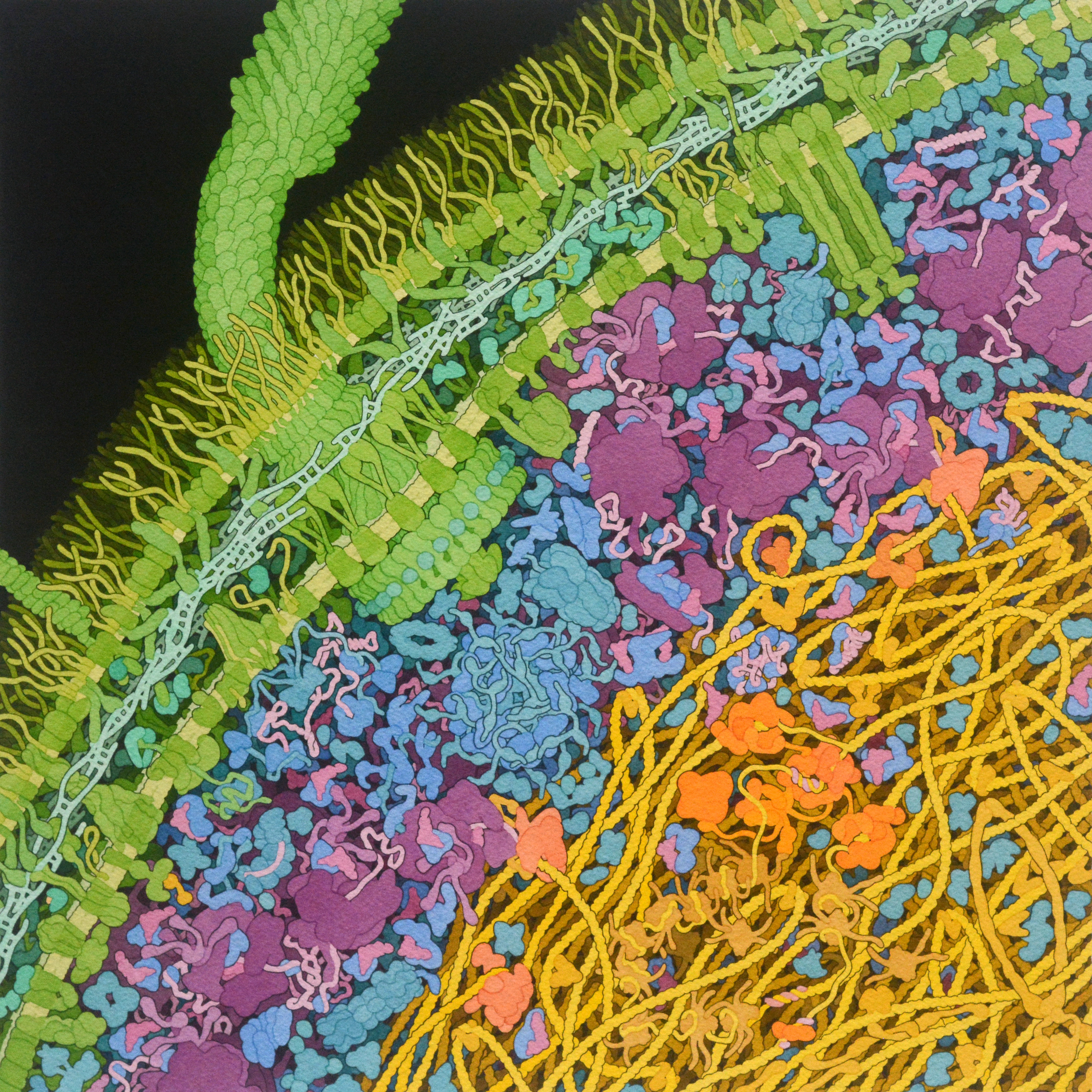
Proposed application (technical summary) What: An engineered endophytic bacterium intended to inoculate high-Andean tubers (e.g. Solanum tuberosum, Oxalis tuberosa, Tropaeolum tuberosum) that senses environmental signals inside plant tissue (temperature, water stress, osmotic status) and responds by producing protective factors.
While initially designed for high-Andean tuber crops, the same platform could be adapted to other frost- or stress-sensitive crops (e.g. Andean grains, legumes, or horticultural species) by modifying the endophytic chassis and/or the stress-response modules, without altering the core governance and biosafety framework.
My Homework DNA ;) HW1 — Part 0: Basics of Gel Electrophoresis Done (new account in Benchling: @Nicorriza)
Then imported Escherichia phage Lambda complete genome
GenBank: J02459.1 — from NCBI page to Benchling
Subsections of Homework
Week 1 HW: Principles and Practices
1) Proposed application (technical summary)
What: An engineered endophytic bacterium intended to inoculate high-Andean tubers (e.g. Solanum tuberosum, Oxalis tuberosa, Tropaeolum tuberosum) that senses environmental signals inside plant tissue (temperature, water stress, osmotic status) and responds by producing protective factors.
While initially designed for high-Andean tuber crops, the same platform could be adapted to other frost- or stress-sensitive crops (e.g. Andean grains, legumes, or horticultural species) by modifying the endophytic chassis and/or the stress-response modules, without altering the core governance and biosafety framework.
Possible protective outputs:
Antifreeze proteins (AFPs) and/or protective molecules (osmoprotectants), or
Functional RNAs (e.g. sRNA/siRNA or short mRNA) that modulate plant gene expression to induce protective mechanisms (increased compatible solutes, membrane modifications, protective enzymes).
How (practical routes):
Direct secretion: the bacterium synthesizes and secretes AFPs into the apoplast/tissues.
Cross-kingdom RNA delivery (cross-kingdom RNAi / mRNA): the bacterium produces sRNAs or packages mRNAs in vesicles that are transferred to plant cells and trigger protective pathways. This approach has conceptual precedent in literature on bacterium-mediated RNAi (see Goodfellow et al., 2019).
Non-living fallback: foliar formulation (permeable capsules containing proteins/RNA) for temporary application when frost is forecast — an alternative for contexts with restrictions on live organisms.
Why it may be valuable:
Enables localized, temporary protection without altering the plant genome (relevant where transgenic crops are restricted or socially contested).
Scalable solution appropriate for smallholder agriculture (low infrastructure investment) and adaptable to other crops.
Known technical limitations: transgenic plant studies with AFPs show modest improvements (~1–3 °C), so activity must be optimized and synergized with cellular solutes to achieve meaningful protection; AFP selection and tissue distribution must be studied. Scientific support for endophytes: endophytes show strong potential to modulate stress tolerance in crops.
Purpose: produce rigorous ecological and agronomic evidence before wide release. Design:
Phases: (i) controlled greenhouse, (ii) confined field plots (fencing, buffer zones), (iii) community pilots with explicit agreements.
Molecular monitoring (soil, root and water sampling; strain-specific genetic markers; periodic metagenomic sequencing).
Local biosafety committee with scientists, environmental authorities (e.g. Ministry/INIA), farmer organizations and NGOs. Actors: university researchers, INIA/Ministry of Environment, municipalities, farmer cooperatives. Assumptions: greenhouse results predict field behavior; resources exist for long-term monitoring. Failure risks: accidental escape without early detection; insufficient data quality/statistics; social rejection without participation. Success outcome: safe scale-up and community acceptance via participation and demonstrable benefits.
Background note: AFP research and plant applications typically rely on controlled trials; field improvements are hard to predict from greenhouse data.
Purpose: drastically reduce survival probability outside target environment using multiple genetic safety layers. Design (technical mix):
Synthetic auxotrophy for a compound absent in natural ecosystems (dependence on a supplied metabolite).
Inducible kill-switch that triggers lysis if the bacterium detects absence of a “permissive” signal (e.g. a co-applied chemical or specific temperature/ion).
Reduced genetic mobility: removal of mobile elements (plasmids, transposons); use of safe chromosomal loci.
Traceable genetic tags (neutral sequences) to detect the strain in the environment. Actors: R&D labs, regulators (requiring biocontainment tests), funders (condition funding on redundancy proofs). Assumptions: containment tech can be implemented without losing agronomic function; evolution will not defeat all safeguards simultaneously. Failure risks: escape via mutations restoring biosynthesis; horizontal transfer to native microbes; selection for compensatory variants. Success outcome: substantially lower establishment probability outside target; greater public and regulatory trust.
Background note: synthetic auxotrophy and CRISPR-based kill switches are documented strategies but require redundant design due to evolutionary risk.
Purpose: protect farmer rights, ensure equity, and define legal responsibilities and compensation mechanisms. Design:
National registry of releases and a public database (by crop, strain, location, dates).
Informed consent and use contracts with farmers (clauses on inoculant handling, obligations, and training).
Transparency requirements for companies: safety data, trial results, and access to strains for independent verification.
Benefit-sharing instruments (fair pricing, non-exclusive community licenses, contingency funds). Actors: legislators, Ministry of Environment/INIA, NGOs, farmer cooperatives, regulators/tribunals. Assumptions: political will exists to regulate (in moratoria contexts, policy may limit or condition trials); institutions can supervise. Failure risks: weak laws, regulatory capture by private interests, exclusion of smallholders. Success outcome: empowered end users and a clear legal framework enabling responsible trials and equitable scaling.
Practical note for Peru: Peru has a history of strict regulations and moratoria on some GMOs; any plan must map current laws and engage authorities early.
Purpose: detect unauthorized presence/establishment and trigger responses (material removal, kill-switch activation or targeted bactericide). Design:
qPCR/eDNA panel + periodic metagenomic surveillance in pilot sites and surroundings.
Predefined action thresholds and communication channels between extension agents, labs and regulators.
Mobile response teams (kits to activate kill-switch or apply specific bactericides in affected plots). Actors: national labs, seed/inoculant banks, municipalities, environmental NGOs. Assumptions: early detection enables effective mitigation; technical responses (kill-switch activation, bactericides) work in field conditions. Failure risks: late detection; ineffective action at scale; legal constraints to intervene on private plots. Success outcome: rapid containment of incidents and increased public confidence.
4) Brief technical & ethical considerations
AFP selection: highly active insect- or fish-derived AFPs might be needed, but their expression/stability in plant tissues/apoplast must be validated.
Physiological synergies: combining AFPs with controlled increases in compatible solutes (e.g. sugars) likely outperforms AFP alone; requires understanding tuber physiology.
Alternatives if GEMs are prohibited: non-living formulations (encapsulated proteins or RNA) or locally isolated, non-engineered bacteria enriched for beneficial traits (note: live isolates still require evaluation).
Indigenous participation & local rights: mandatory in Andean communities: Free, Prior and Informed Consent (FPIC) and benefit-sharing agreements are essential.
5) Suggested next roadmap (brief)
Review national regulations (map Peru / Cartagena Protocol requirements).
In vitro studies: select AFP candidate(s), test activity and stability in plant extracts.
Choose a native endophytic chassis (preferably isolated from Andean potatoes) to reduce incompatibility risks.
Design redundant biocontainment (auxotrophy + kill-switch + removal of mobile elements). Test in microcosms.
Implement phased trial protocol with local committees and molecular monitoring.
Selected key references
Duman, J. G., & Wisniewski, M. J. (2014). The use of antifreeze proteins for frost protection in sensitive crop plants (review on AFPs in plants and efficacy limitations).
White, J. F., et al. (2019). Endophytic microbes and their potential applications (review: endophyte potential in stress tolerance).
Goodfellow, S., Zhang, D., Wang, M. B., & Zhang, R. (2019). Bacterium-mediated RNA interference: potential application in plant protection.Plants, 8(12), 572.
Mandell, D. J., et al. (2015). Biocontainment by synthetic auxotrophy.
Rottinghaus, A. G., et al. (2022). Genetically stable CRISPR-based kill switches for… (examples of lysis/killswitch circuits).
Regulatory overview (Peru): reports on moratoria and legislation (e.g. USDA GAIN Report 2012 and later legal analyses).
Next, score (from 1–3 with 1 as the best, or n/a) each of your governance actions against your rubric of policy goals.
Does the option:
Option 1
Option 2
Option 3
Enhance Biosecurity
• By preventing incidents
X
• By helping respond
X
Foster Lab Safety
• By preventing incidents
X
• By helping respond
X
Protect the environment
• By preventing incidents
X
• By helping respond
X
Other considerations
• Minimizing costs and burdens to stakeholders
X
• Feasibility
X
• Not impede research
X
• Promote constructive applications
X
Justifications
Enhance Biosecurity
By preventing incidents (Option 1): Redundant genetic containment and phased trials reduce the probability of establishment and horizontal gene transfer (HGT).
By helping respond (Option 1): Genomic surveillance and a defined rapid-response network enable early detection and targeted mitigation.
Foster Lab Safety
By preventing incidents (Option 1): Clear lab standards, training, and built-in safeguards (e.g., kill-switches) lower accidental release risk during R&D.
By helping respond (Option 1): Incident protocols, recall/neutralization measures, and independent monitoring enable rapid corrective action.
Protect the Environment
By preventing incidents (Option 1): Use of native chassis, removal of mobile genetic elements, and non-cellular alternatives minimize ecological establishment and gene flow.
By helping respond (Option 1): Environmental monitoring plus field mitigation (selective removal, activation of kill-switches, or targeted treatments) limit impacts if escapes occur.
Other Considerations
Minimizing costs and burdens (Option 2): Non-cellular formulations (proteins/RNA) lower long-term surveillance and regulatory costs; therefore, Option 2 scores better.
Feasibility (Option 2): Regulatory and logistical hurdles are smaller for cell-free products, making short-term deployment in Peru more practical.
Not impede research (Option 1): The proposed safeguards allow continued R&D while managing risks.
Promote constructive applications (Option 1): FPIC, a public registry, and benefit-sharing provisions encourage equitable and responsible use.
Homework 1 (meta)
Title: Homework 1 Weight: 5
HW - Questions from Professor Jacobson1 (meta)
Title: HW - Questions from Professor Jacobson1 Weight: 2
1. Nature’s machinery for copying DNA is called polymerase. What is the error rate of polymerase? How does this compare to the length of the human genome. How does biology deal with that discrepancy?
Respuesta
DNA Replication and Error Rate
The natural mechanism for copying DNA is the DNA polymerase. The intrinsic error rate of a DNA polymerase during nucleotide incorporation is approximately 1 × 10⁻⁶ (one error per 10^6 bases) in the absence of proofreading, according to classic structural and biochemical studies (Beese et al., 1993).
The human genome has an approximate size of 3.2 × 10⁹ base pairs. If replication occurred only with that raw error rate, ~3,200 errors would be expected per genome replication, which would be incompatible with the observed genetic stability.
Biology resolves this discrepancy through multiple layers:
Proofreading: many DNA polymerases have 3′→5′ exonuclease activity that removes misincorporated nucleotides.
Mismatch repair (MMR): corrects errors left after replication.
Combined, these reduce the effective error rate to ~10⁻⁹ – 10⁻¹⁰ per base, yielding on the order of 1–3 mutations per diploid genome per replication (Kunkel & Erie, 2005).
Other buffering factors: redundancy of the genetic code, non-coding DNA, diploidy, and the fact that many mutations are neutral (Kimura, 1983).
Referencias
Beese, L. S., Derbyshire, V., & Steitz, T. A. (1993). Structure of DNA polymerase I Klenow fragment bound to duplex DNA. Science, 260(5106), 352–355.
Kunkel, T. A., & Erie, D. A. (2005). DNA mismatch repair. Annual Review of Biochemistry, 74, 681–710.
Alberts, B., et al. (2015). Molecular Biology of the Cell (6th ed.).
Kimura, M. (1983). The neutral theory of molecular evolution. Cambridge Univ. Press.
2. How many different ways are there to code (DNA nucleotide code) for an average human protein? In practice what are reasons that all of these different codes don’t work to code for the protein of interest?
Respuesta
Because of degeneracy of the genetic code, the same amino acid can be encoded by multiple synonymous codons. An average human protein contains ~300–350 amino acids; each amino acid can be encoded by 1–6 codons. Assuming an average of ~3 synonymous codons per amino acid, the number of possible coding sequences is on the order of (3^{300}) to (3^{350}) — astronomically large.
Why many synonymous sequences don’t work equally in practice:
Codon usage bias: organisms prefer certain codons; rare codons can reduce translation efficiency due to low tRNA abundance.
mRNA structure and stability: sequence affects secondary structure, stability, and interaction with RNA-binding proteins.
Cryptic signals: sequences can create unintended splice sites, premature polyadenylation, or regulatory motifs.
Translation kinetics and folding: synonymous changes alter ribosomal pausing and co-translational folding, affecting protein folding and function.
Referencias
Alberts, B., et al. (2015). Molecular Biology of the Cell.
Plotkin, J. B., & Kudla, G. (2011). Nat Rev Genet, 12, 32–42.
Ikemura, T. (1985). Mol Biol Evol, 2, 13–34.
Chamary, J. V., Parmley, J. L., & Hurst, L. D. (2006). Nat Rev Genet, 7, 98–110.
Komar, A. A. (2009). Trends Biochem Sci, 34, 16–24.
HW - Questions from Dr. LeProust (meta)
Title: HW - Questions from Dr. LeProust Weight: 2
1. What’s the most commonly used method for oligo synthesis currently?
Respuesta The most widely used method is phosphoramidite solid-phase chemical synthesis, consisting of cycles (deprotection → coupling → capping → oxidation) on a solid support (CPG). Industrial standard since the 1980s (Beaucage & Caruthers).
2. Why is it difficult to make oligos longer than 200 nt via direct synthesis?
Respuesta Because per-cycle efficiency <100% and failures accumulate multiplicatively. Example: if per-base efficiency = 99.5%, then yield for 200 nt ≈ 0.995^200 ≈ 36% full-length product. Beyond ~200 nt, correct product is overwhelmed by truncated sequences.
3. Why can’t you make a 2000 bp gene via direct oligo synthesis?
Respuesta Because yield becomes effectively zero: 0.995^2000 ≈ 0.00004 (0.004%). Additionally, cumulative chemical degradation and sequence errors make direct synthesis of very long sequences impractical; instead, assemble multiple oligos using PCR/Gibson assembly and correct errors.
Referencias
Beaucage, S. L., & Caruthers, M. H. (1981).
Kosuri, S., & Church, G. M. (2014).
Hughes, R. A., & Ellington, A. D. (2017).
Week 2 HW: DNA R/W/E
My Homework
DNA ;)
HW1 — Part 0: Basics of Gel Electrophoresis
Done (new account in Benchling: @Nicorriza)
Then imported Escherichia phage Lambda complete genome GenBank: J02459.1 — from NCBI page to Benchling
HW2 — Part 1: Benchling & In-silico Gel Art
Everything below is completed:
Created a free account at benchling.com
Imported the Lambda DNA
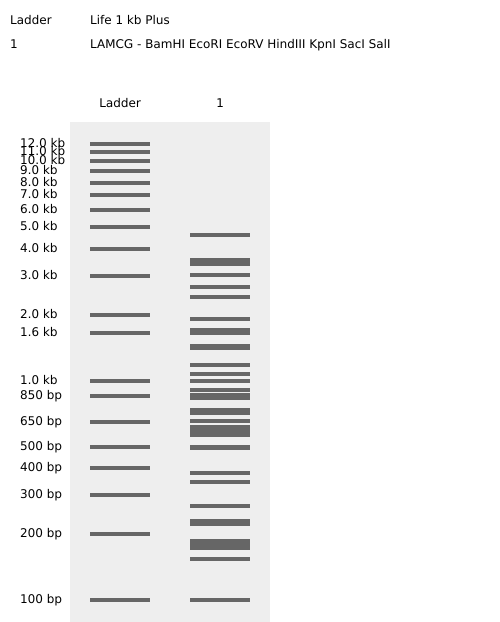
Simulated restriction enzyme digestion with the following enzymes:
EcoRI — GAATTC — G|AATTC
HindIII — AAGCTT — A|AGCTT
BamHI — GGATCC — G|GATCC
KpnI — GGTACC — GGTAC|C
EcoRV — GATATC — GAT|ATC (blunt)
SacI — GAGCTC — GAGCT|C
SalI — GTCGAC — G|TCGAC
Virtual digest result
Continuing with the work: (Create a pattern/image in the style of Paul Vanouse’s Latent Figure Protocol artworks. You might find Ronan’s website a helpful tool for quickly iterating on designs.)
I created a pareidolic face in an agarose gel pattern using the following restriction enzyme digests:
Ladder — Life 1 kb Plus
LAMCG — KpnI, PvuII
LAMCG — PvuII
LAMCG — PvuII, SacI
LAMCG — PvuII
LAMCG — PvuII, SacI
Resulting in:
The face appears in this region of the agarose gel between 2.0 kb and 1.0 kb.
Part 3: DNA Design Challenge
3.1. Choose Your Protein
Prompt
In recitation we discussed that you should choose a protein that seems interesting for your task. Which protein did you choose and why? Using one of the tools discussed in recitation (NCBI, UniProt, Google), obtain the sequence of the protein you chose.
Answer
During the course we were introduced to FPbase, a repository of fluorescent proteins that I found very interesting. I decided to explore proteins with blue fluorescence because that color is uncommon in nature and seemed intriguing for the project. The protein I selected was HcRed1-Blue for that reason.
Below is the amino-acid sequence I obtained for the selected protein:
Note: This sequence corresponds to the most likely codons according to the default table (E. coli).
3.3. Codon Optimization
Prompt
Explain why you need to optimize codon usage. For which organism did you choose to optimize the sequence and why?
Answer
Why Optimize Codons?
Although the genetic code is universal, codon usage frequencies differ between organisms. Codon optimization improves translation efficiency and protein expression in the chosen host. It also helps control:
Codon frequency (adaptation to the host)
GC content (affects stability and transcription)
Undesired mRNA secondary structures
Internal restriction sites
Repetitive sequences that complicate DNA synthesis
Organism Chosen for Optimization
For this exercise I used the default orientation toward E. coli (a practical choice for bacterial expression). Tools such as IDT provide organism-specific codon optimization options (e.g., E. coli, S. cerevisiae, Drosophila melanogaster, Mus musculus).
Example Optimized Sequence (Formatted in Codons)
Avoiding Specific Restriction Sites (IDT Optimization Settings)
Using the IDT Codon Optimization tool, it is also possible to exclude specific restriction enzyme recognition sites from the DNA sequence. This is particularly useful when designing constructs for cloning, since it prevents unwanted internal cutting within the gene of interest.
For this design, the following restriction sites were explicitly avoided:
EcoRI
BamHI
SacII
SalI
HindIII
EcoRV
By removing these internal restriction sites during optimization, the sequence becomes compatible with vectors that use these enzymes in their multiple cloning site (MCS), facilitating downstream cloning and assembly steps.
ATG GCA GGA TTG TTA AAA GAG TCA ATG CGT ATA AAA ATG TAT ATG GAA GGG
ACA GTC AAT GGT CAT TAT TTC AAA TGC GAA GGC GAA GGC GAT GGA AAC CCG
TTT GCG GGC ACC CAG TCC ATG CGT ATT CAT GTG ACC GAG GGC GCT CCC CTG
CCA TTT GCG TTT GAC ATC CTT GCG CCG TGT TGT CAT TAC GGT TCA AAG ACA
TTC GTC CAC CAT ACT GCA GAA ATT CCG GAT TTT TGG AAG CAG TCA TTT CCA
GAA GGT TTC ACG TGG GAA CGG ACA ACT ACT TAT GAA GAT GGC GGC ATT CTG
ACA GCC CAT CAA GAT ACA TCA TTA GAA GGC AAC TGT CTT ATA TAT AAG GTT
AAG GTC CAC GGG ACC AAT TTT CCT GCT GAC GGA CCA GTV ATG AAG AAT AAG
TCC GGC GGT TGG GAA CCT ATC ACC GAA GTC GTG TAC CCT GAA AAT GGA GTG
CTG TGT GGC CGC GCC GTT ATG GCT TTA AAA GTC GGG GAT CGT CAC CTT ATT
TGC CAT GCC TAC ACC AGC TAC CGC AGT AAA AAA GCG GTG CGT GCA TTA ACT
ATG CCT GGC TTT CAT TTC ACG GAC TAC CGT CTG CAA ATG CTG AGA AAA AAG
AAA GAT GAA TAC TTT GAA CTT TAC GAA GCC AGC GTA GCC AGA TAT TCA GAT
CTG CCT GAA AAG GCC AAC
Sequence Notes
Codon optimized for E. coli
GC content balanced : GC% = 47.09%
Restriction sites screened
Ready for plasmid cloning
---
Detected Restriction Sites (Examples to Avoid or Consider)
BglII — AGATCT
BspEI — TCCGGA
DraI — TTTAAA
MlyI — GAGTC
PmlI — CACGTG
PstI — CTGCAG
3.4. You Have a Sequence — Now What?
Prompt
Which technologies could be used to produce this protein from your DNA? Describe how the DNA sequence can be transcribed and translated into your protein (cell-dependent and/or cell-free methods).
Answer
Cell-Dependent Methods
Expression in Bacteria (e.g., E. coli)
Clone the optimized sequence into an expression plasmid (strong promoter, RBS, terminator).
Transform the plasmid into competent E. coli.
Induce expression (e.g., IPTG in lac-based systems).
The cell transcribes DNA → mRNA and translates mRNA → protein.
After expression, the protein can be purified (e.g., chromatography).
Other possible systems include yeast (S. cerevisiae) or mammalian cells if post-translational modifications are required.