Week 2 HW: DNA Read, Write, & Edit

𓃠 Week 2 Homework 𓃠
Part 1: Benchling & In-silico Gel Art
Simulate Restriction Enzyme Digestion with the following Enzymes:
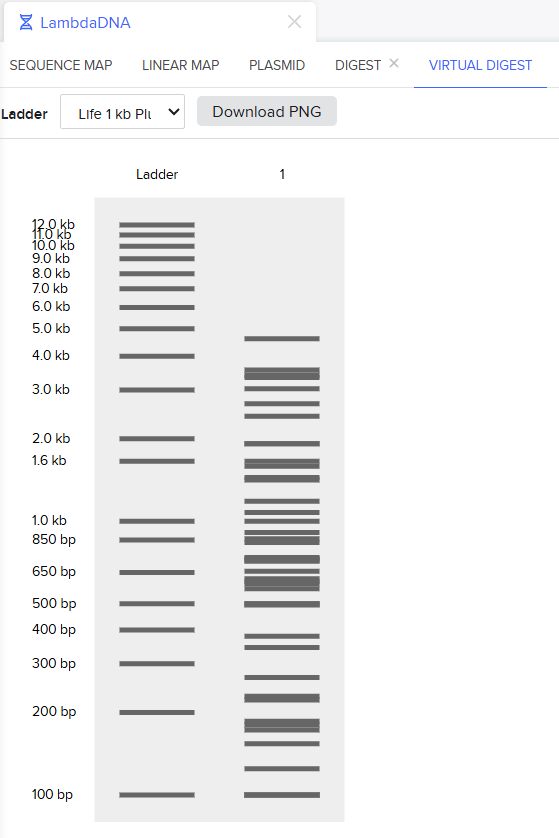
Create a pattern/image in the style of Paul Vanouse’s Latent Figure Protocol artworks.

- I tried to do a smiley face and it turned out so bad but i love it XD!
- Many thanks to Ronan for his Website, it really helped alot make this much faster!
Part 3: DNA Design Challenge
3.1. Choose your protein.
Hemocyanin. It is a giant, copper-based protein that functions as the respiratory pigment for many mollusks and arthropods, but the coolest thing is that when their blood is oxygenated it turns into Blue :D. Unlike our iron-based hemoglobin which is packed inside cells, hemocyanin floats freely in the hemolymph of animals like the Atlantic Horseshoe Crab and the Keyhole Limpet. It is a medical powerhouse for humans; its massive, alien structure provokes a strong immune response, making it an effective immunotherapy treatment for bladder cancer and a crucial carrier protein for vaccines (helping the body recognize small drug molecules) and more (1).

Here is a picture of the Horseshoe Crab (Limulus polyphemus) from the National Wildlife Federation (NWF)

Here is a picture of the Cayenne keyhole limpet (Diodora cayenensis) from the Bailey-Matthews National Shell Museum & Aquarium
Here is the Hemocyanin Protein Sequence
>sp|P04253|HCY2_LIMPO Hemocyanin II OS=Limulus polyphemus OX=6850 PE=1 SV=2 TLHDKQIRVCHLFEQLSSATVIGDGDKHKHSDRLKNVGKLQPGAIFSCFHPDHLEEARHLYEVFWEAGDFNDFIEIAKEARTFVNEGLFAFAAEVAVLHRDDCKGLYVPPVQEIFPDKFIPSAAINEAFKKAHVRPEFDESPILVDVQDTGNILDPEYRLAYYREDVGINAHHWHWHLVYPSTWNPKYFGKKKDRKGELFYYMHQQMCARYDCERLSNGMHRMLPFNNFDEPLAGYAPHLTHVASGKYYSPRPDGLKLRDLGDIEISEMVRMRERILDSIHLGYVISEDGSHKTLDELHGTDILGALVESSYESVNHEYYGNLHNWGHVTMARIHDPDGRFHEEPGVMSDTSTSLRDPIFYNWHRFIDNIFHEYKNTLKPYDHDVLNFPDIQVQDVTLHARVDNVVHFTMREQELELKHGINPGNARSIKARYYHLDHEPFSYAVNVQNNSASDKHATVRIFLAPKYDELGNEIKADELRRTAIELDKFKTDLHPGKNTVVRHSLDSSVTLSHQPTFEDLLHGVGLNEHKSEYCSCGWPSHLLVPKGNIKGMEYHLFVMLTDWDKDKVDGSESVACVDAVSYCGARDHKYPDKKPMGFPFDRPIHTEHISDFLTNNMFIKDIKIKFHE
3.2. Reverse Translate: Protein (amino acid) sequence to DNA (nucleotide) sequence.
accctgcatgataaacagattcgcgtgtgccatctgtttgaacagctgagcagcgcgaccgtgattggcgatggcgataaacataaacatagcgatcgcctgaaaaacgtgggcaaactgcagccgggcgcgatttttagctgctttcatccggatcatctggaagaagcgcgccatctgtatgaagtgttttgggaagcgggcgattttaacgattttattgaaattgcgaaagaagcgcgcacctttgtgaacgaaggcctgtttgcgtttgcggcggaagtggcggtgctgcatcgcgatgattgcaaaggcctgtatgtgccgccggtgcaggaaatttttccggataaatttattccgagcgcggcgattaacgaagcgtttaaaaaagcgcatgtgcgcccggaatttgatgaaagcccgattctggtggatgtgcaggataccggcaacattctggatccggaatatcgcctggcgtattatcgcgaagatgtgggcattaacgcgcatcattggcattggcatctggtgtatccgagcacctggaacccgaaatattttggcaaaaaaaaagatcgcaaaggcgaactgttttattatatgcatcagcagatgtgcgcgcgctatgattgcgaacgcctgagcaacggcatgcatcgcatgctgccgtttaacaactttgatgaaccgctggcgggctatgcgccgcatctgacccatgtggcgagcggcaaatattatagcccgcgcccggatggcctgaaactgcgcgatctgggcgatattgaaattagcgaaatggtgcgcatgcgcgaacgcattctggatagcattcatctgggctatgtgattagcgaagatggcagccataaaaccctggatgaactgcatggcaccgatattctgggcgcgctggtggaaagcagctatgaaagcgtgaaccatgaatattatggcaacctgcataactggggccatgtgaccatggcgcgcattcatgatccggatggccgctttcatgaagaaccgggcgtgatgagcgataccagcaccagcctgcgcgatccgattttttataactggcatcgctttattgataacatttttcatgaatataaaaacaccctgaaaccgtatgatcatgatgtgctgaactttccggatattcaggtgcaggatgtgaccctgcatgcgcgcgtggataacgtggtgcattttaccatgcgcgaacaggaactggaactgaaacatggcattaacccgggcaacgcgcgcagcattaaagcgcgctattatcatctggatcatgaaccgtttagctatgcggtgaacgtgcagaacaacagcgcgagcgataaacatgcgaccgtgcgcatttttctggcgccgaaatatgatgaactgggcaacgaaattaaagcggatgaactgcgccgcaccgcgattgaactggataaatttaaaaccgatctgcatccgggcaaaaacaccgtggtgcgccatagcctggatagcagcgtgaccctgagccatcagccgacctttgaagatctgctgcatggcgtgggcctgaacgaacataaaagcgaatattgcagctgcggctggccgagccatctgctggtgccgaaaggcaacattaaaggcatggaatatcatctgtttgtgatgctgaccgattgggataaagataaagtggatggcagcgaaagcgtggcgtgcgtggatgcggtgagctattgcggcgcgcgcgatcataaatatccggataaaaaaccgatgggctttccgtttgatcgcccgattcataccgaacatattagcgattttctgaccaacaacatgtttattaaagatattaaaattaaatttcatgaa
3.3. Codon optimization.
I decided to use Benchling’s Codon Optimization for E. Coli K-12. Codon Optimization is important because it uses the amino acids more native to the chosen organism which boosts speed and efficiency of translation and also if it is not done the organism might not have enough complementary tRNA anti codon molecules to synthesize this specific amino acid.
ACCCTGCATGATAAACAGATTCGCGTGTGCCATCTGTTTGAACAGCTGAGCAGCGCGACCGTGATTGGCGATGGCGATAAACATAAACATAGCGATCGCCTGAAAAACGTGGGCAAACTGCAGCCGGGCGCGATTTTTAGCTGCTTTCATCCGGATCATCTGGAAGAAGCGCGCCATCTGTATGAAGTGTTTTGGGAAGCGGGCGATTTTAACGATTTTATTGAAATTGCGAAAGAAGCGCGCACCTTTGTGAACGAAGGCCTGTTTGCGTTTGCGGCGGAAGTGGCGGTGCTGCATCGCGATGATTGCAAAGGCCTGTATGTGCCGCCGGTGCAGGAAATTTTTCCGGATAAATTTATTCCGAGCGCGGCGATTAACGAAGCGTTTAAAAAAGCGCATGTGCGCCCGGAATTTGATGAAAGCCCGATTCTGGTGGATGTGCAGGATACCGGCAACATTCTGGATCCGGAATATCGCCTGGCGTATTATCGCGAAGATGTGGGCATTAACGCGCATCATTGGCATTGGCATCTGGTGTATCCGAGCACCTGGAACCCGAAATATTTTGGCAAAAAAAAAGATCGCAAAGGCGAACTGTTTTATTATATGCATCAGCAGATGTGCGCGCGCTATGATTGCGAACGCCTGAGCAACGGCATGCATCGCATGCTGCCGTTTAACAACTTTGATGAACCGCTGGCGGGCTATGCGCCGCATCTGACCCATGTGGCGAGCGGCAAATATTATAGCCCGCGCCCGGATGGCCTGAAACTGCGCGATCTGGGCGATATTGAAATTAGCGAAATGGTGCGCATGCGCGAACGCATTCTGGATAGCATTCATCTGGGCTATGTGATTAGCGAAGATGGCAGCCATAAAACCCTGGATGAACTGCATGGCACCGATATTCTGGGCGCGCTGGTGGAAAGCAGCTATGAAAGCGTGAACCATGAATATTATGGCAACCTGCATAACTGGGGCCATGTGACCATGGCGCGCATTCATGATCCGGATGGCCGCTTTCATGAAGAACCGGGCGTGATGAGCGATACCAGCACCAGCCTGCGCGATCCGATTTTTTATAACTGGCATCGCTTTATTGATAACATTTTTCATGAATATAAAAACACCCTGAAACCGTATGATCATGATGTGCTGAACTTTCCGGATATTCAGGTGCAGGATGTGACCCTGCATGCGCGCGTGGATAACGTGGTGCATTTTACCATGCGCGAACAGGAACTGGAACTGAAACATGGCATTAACCCGGGCAACGCGCGCAGCATTAAAGCGCGCTATTATCATCTGGATCATGAACCGTTTAGCTATGCGGTGAACGTGCAGAACAACAGCGCGAGCGATAAACATGCGACCGTGCGCATTTTTCTGGCGCCGAAATATGATGAACTGGGCAACGAAATTAAAGCGGATGAACTGCGCCGCACCGCGATTGAACTGGATAAATTTAAAACCGATCTGCATCCGGGCAAAAACACCGTGGTGCGCCATAGCCTGGATAGCAGCGTGACCCTGAGCCATCAGCCGACCTTTGAAGATCTGCTGCATGGCGTGGGCCTGAACGAACATAAAAGCGAATATTGCAGCTGCGGCTGGCCGAGCCATCTGCTGGTGCCGAAAGGCAACATTAAAGGCATGGAATATCATCTGTTTGTGATGCTGACCGATTGGGATAAAGATAAAGTGGATGGCAGCGAAAGCGTGGCGTGCGTGGATGCGGTGAGCTATTGCGGCGCGCGCGATCATAAATATCCGGATAAAAAACCGATGGGCTTTCCGTTTGATCGCCCGATTCATACCGAACATATTAGCGATTTTCTGACCAACAACATGTTTATTAAAGATATTAAAATTAAATTTCATGAA
3.4. You have a sequence! Now what?
When this protein is introduced to the E. coli K-12, it can start transcribing this DNA into an mRNA then this mRNA can be translated into a protein so that the bacteria can use it, and since we have codon optimized it for the e coli, we should expect a smooth translation process without any stalling.
3.5. [Optional] How does it work in nature/biological systems?
1) Describe how a single gene codes for multiple proteins at the transcriptional level.
Alternative Splicing. A single Gene in Eukaryotes can code for multiple proteins through a process called Alternative Splicing, It takes on many forms, like Exon Skipping, where a certain exon might be skipped possibly altering the protein function, or Alternative 5’ or 3’ Splicing, where some exons can be longer or shorter hence affecting the number of produced amino acids altering the function too, another way is intron retention where some introns are not spliced out which can introduce a stop codon and can cause the protein to decay using the Nonsense mediated decay pathway.
2) Try aligning the DNA sequence, the transcribed RNA, and also the resulting translated Protein!!! See example below.
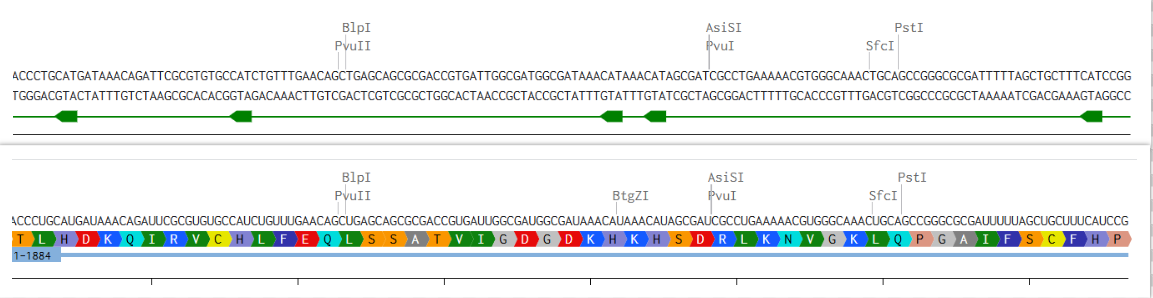
Here is a Picture of the very first few bases of Hemocyanin II DNA, RNA & Amino Acid
Part 4: Prepare a Twist DNA Synthesis Order
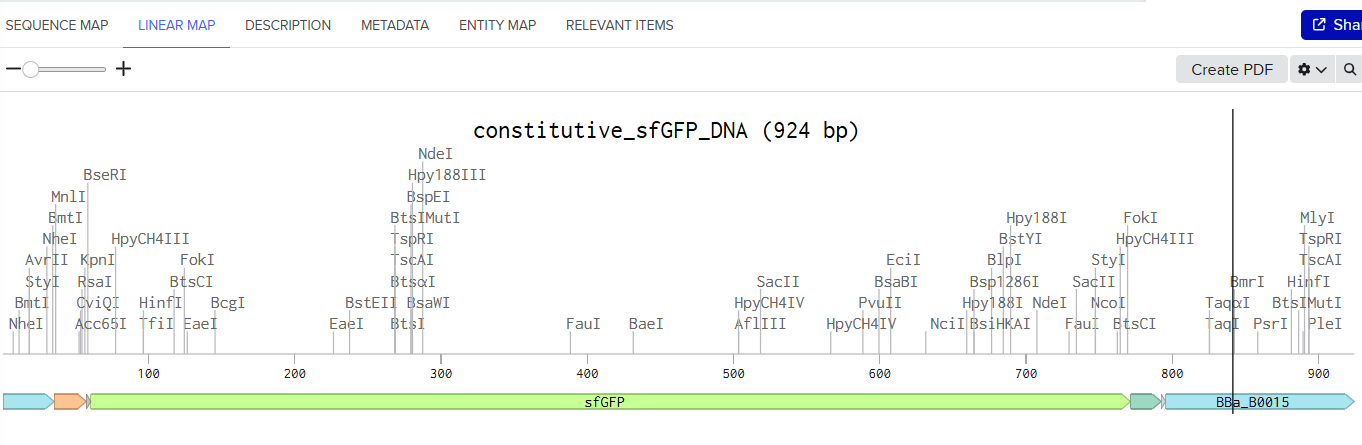
Here is a screenshot of my Linear map of Constitutive sfGFP DNA and here is the Benchling Link
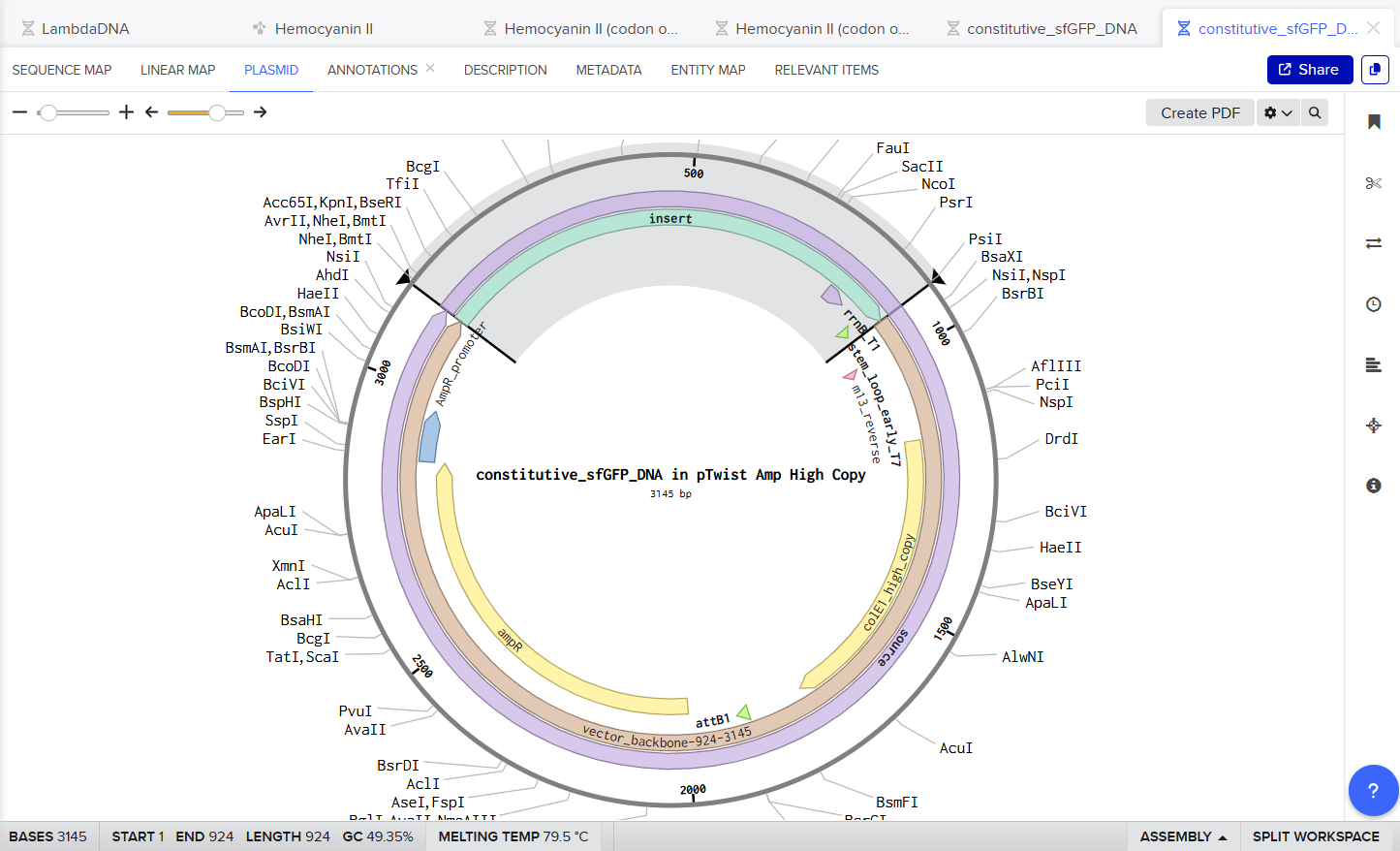
Here is a screenshot of my Twist Ready Plasmid :D
Part 5: DNA Read/Write/Edit
5.1 DNA Read
(i) What DNA would you want to sequence (e.g., read) and why?
I’d like to sequence and read the genome of the Axolotl (Ambystoma mexicanum) to learn more about the process of its limb regeneration and how it happens, and figure out if other species have these genes too whether Human, Marine or Plants.
(ii) In lecture, a variety of sequencing technologies were mentioned. What technology or technologies would you use to perform sequencing on your DNA and why?
I would use PacBio SMRT sequencing. This is a third-generation technology, which is perfect because the Axolotl genome is very huge (32 billion bases!) and full of repetitive parts that confuse older, short-read machines. Third-generation sequencing reads single molecules of DNA in real-time, giving us the long reads necessary to bridge those gaps and locate the regeneration genes i care about.
For the process, I’d follow the SMRTbells process where I’d start with really long strands of high-quality DNA and attach hairpin adapters to both ends, turning them into circular loops. These loops go into tiny wells where a polymerase enzyme runs around the circle, adding bases. As each base (A, C, T, G) is added, it gives off a specific colored flash of light. The machine records these flashes to decode the sequence. The final output is HiFi reads: extremely long, highly accurate digital sequences that we can assemble into a full map.
5.2 DNA Write
(i) What DNA would you want to synthesize (e.g., write) and why?
I want to synthesize the Dsup (Damage Suppressor) gene found in Tardigrades, Tardigrades are famous for surviving the vacuum of space and massive radiation because this specific protein wraps around their DNA like a physical shield to prevent damage. By synthesizing this gene and inserting it into human cells or gut bacteria or plants, I want to see if we can “borrow” this superpower to protect astronauts from lethal cosmic radiation on the long space journies, effectively genetically engineering a radiation protection.
(ii) What technology or technologies would you use to perform this DNA synthesis and why?
For the DNA synthesis technology, maybe i will rely either on the current common Phosphoramidite DNA synthesis or use an Enzymatic Synthesis using Terminal deoxynucleotidyl transferase (TdT), or maybe an even more easier and more quick method is to just use Twist Bioscience and order the gene right away :D
Basically the steps for phosphoramidite synthesis process would start first with deblocking of the nucleotide then it couples using phosphoramidite, after that we do Capping for the unreacted sites to prevent any faulty chains to continue growing, and then oxidation to seal and empower the bond of our newly added nucleotide, then the process is repeated until we get a chain of N bases, then these Oligos are stitched and assembled together using methods like Gibson Assembly, Golden Gate Assembly or the recently announced Sidewinder (2) way (which is pretty cool :D)
Phosphoramidite Synthesis currently faces the major issue of Exponentially Decaying Yield when the synthesized chain gets longer however Twist Bioscience seems to be doing a really great job regarding this especially for their achievement of direct synthesis of the first 700mer Oligo using “Enhanced Chemistry”. For DNA Assembly currenty Sidewinder (2) seems like a very promising tool that can achieve high accuracy and avoids many of the errors that can happen from long, repititve or high GC content Oligos that methods like Gibson Assembly or Golden Gate Assembly used to suffer from.
5.3 DNA Edit
(i) What DNA would you want to edit and why?
Quite a crazy idea but i would like to edit the DNA of the E. Coli K-12 and install regeneration genes from the Axolotl to allow the e coli to be able to regrow and detach vesicles containing molecules that it can produce or has been metabolically engineered to produce. this can allow it to match some Yeast ability for storing produced molecules especially hydrophobic molecules. These vesicles can be engineered to float to the top of flask or fermentation tanks which would allow easy extraction and purification.
(ii) What technology or technologies would you use to perform these DNA edits and why?
I would use CRISPR-Cas9 to edit the genome. The process starts with designing a Guide RNA (gRNA) that acts as a GPS coordinate for the specific location in the E. coli genome where I want to make the edit, then introduce a plasmid into the cells containing the Cas9 enzyme, the gRNA, and a Donor DNA template (which carries the Axolotl genes). The Cas9 enzyme cuts the bacterial DNA at the target site, and the cell repairs this cut using the Donor template, successfully “pasting” the new regeneration genes, this process is called Homology-Directed Repair.
However, this method has limitations, mainly of efficiency and payload size. Inserting large, complex gene pathways is much harder than making small mutations, the larger the DNA insert, the less likely the bacteria are to accept it. There is also the risk of off-target effects, where the enzyme cuts the wrong part of the genome, potentially killing the cell, Also sometimes the Homology-Directed Repair may not be efficient and may introduce mutations that can render the insert non functional
References
Keyhole limpet haemocyanin – a model antigen for human immunotoxicological studies
Construction of complex and diverse DNA sequences using DNA three-way junctions