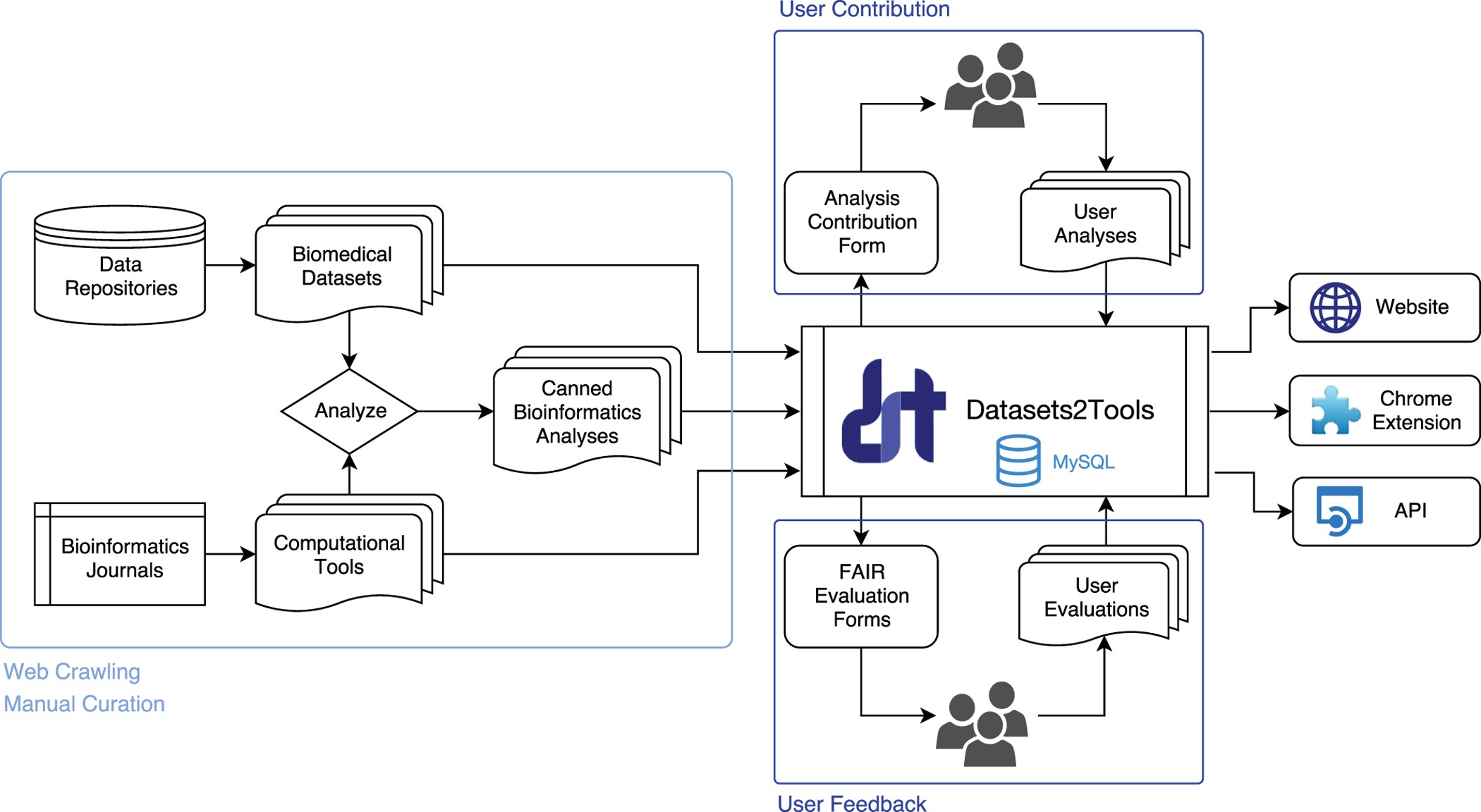
This week, I explored laboratory automation by writing and simulating a Python script for the Opentrons liquid handling robot using Google Colab. As a Committed Listener, I was not physically running the robot, but I focused on understanding the automation logic and API structure that controls robotic liquid handling.
I began by generating a coordinate-based design inspired by biological structures, particularly the DNA double helix, using the GUI at https://opentrons-art.rcdonovan.com/
Using mathematical functions in Python, I generated coordinate-based instructions that determine where liquid would be dispensed on a 96-well plate. I then structured the script using the Opentrons API format to simulate how the robot would execute these movements.
from opentrons import types
metadata = { # see https://docs.opentrons.com/v2/tutorial.html#tutorial-metadata
'author': 'Pascal Agbley',
'protocolName': 'DNA Double Helix Structure', # Give your protocol a name
'description': 'A custom design of a DNA Double Helix Structure.',
'source': 'HTGAA 2026 Opentrons Lab',
'apiLevel': '2.20'
}
TIP_RACK_DECK_SLOT = 9
COLORS_DECK_SLOT = 6
AGAR_DECK_SLOT = 5
PIPETTE_STARTING_TIP_WELL = 'A1'
well_colors = {
'A1' : 'Red',
'B1' : 'Green',
'C1' : 'Orange'
}
def run(protocol):
##############################################################################
### Load labware, modules and pipettes
##############################################################################
# Tips
tips_20ul = protocol.load_labware('opentrons_96_tiprack_20ul', TIP_RACK_DECK_SLOT, 'Opentrons 20uL Tips')
# Pipettes
pipette_20ul = protocol.load_instrument("p20_single_gen2", "right", [tips_20ul])
# Modules
temperature_module = protocol.load_module('temperature module gen2', COLORS_DECK_SLOT)
# Temperature Module Plate
temperature_plate = temperature_module.load_labware('opentrons_96_aluminumblock_generic_pcr_strip_200ul',
'Cold Plate')
color_plate = temperature_plate
# Agar Plate
agar_plate = protocol.load_labware('htgaa_agar_plate', AGAR_DECK_SLOT, 'Agar Plate') ## TA MUST CALIBRATE EACH PLATE!
# Get the top-center of the plate, make sure the plate was calibrated before running this
center_location = agar_plate['A1'].top()
pipette_20ul.starting_tip = tips_20ul.well(PIPETTE_STARTING_TIP_WELL)
##############################################################################
### Patterning
##############################################################################
###
### Helper functions for this lab
###
# pass this e.g. 'Red' and get back a Location which can be passed to aspirate()
def location_of_color(color_string):
for well,color in well_colors.items():
if color.lower() == color_string.lower():
return color_plate[well]
raise ValueError(f"No well found with color {color_string}")
# For this lab, instead of calling pipette.dispense(1, loc) use this: dispense_and_detach(pipette, 1, loc)
def dispense_and_detach(pipette, volume, location):
"""
Move laterally 5mm above the plate (to avoid smearing a drop); then drop down to the plate,
dispense, move back up 5mm to detach drop, and stay high to be ready for next lateral move.
5mm because a 4uL drop is 2mm diameter; and a 2deg tilt in the agar pour is >3mm difference across a plate.
"""
assert(isinstance(volume, (int, float)))
above_location = location.move(types.Point(z=location.point.z + 5)) # 5mm above
pipette.move_to(above_location) # Go to 5mm above the dispensing location
pipette.dispense(volume, location) # Go straight downwards and dispense
pipette.move_to(above_location) # Go straight up to detach drop and stay high
###
###
###
Red = [(-14.3, 34.1),(-12.1, 34.1),(12.1, 34.1),(-14.3, 31.9),(-12.1, 31.9),(12.1, 31.9),(14.3, 31.9),(-12.1, 29.7),(-9.9, 29.7),(-7.7, 29.7),(-5.5, 29.7),(-3.3, 29.7),(-1.1, 29.7),(3.3, 29.7),(5.5, 29.7),(7.7, 29.7),(9.9, 29.7),(12.1, 29.7),(14.3, 29.7),(-14.3, 27.5),(-12.1, 27.5),(12.1, 27.5),(-12.1, 25.3),(-9.9, 25.3),(9.9, 25.3),(-9.9, 23.1),(-7.7, 23.1),(-3.3, 23.1),(-1.1, 23.1),(1.1, 23.1),(3.3, 23.1),(5.5, 23.1),(7.7, 23.1),(9.9, 23.1),(-9.9, 20.9),(-5.5, 20.9),(5.5, 20.9),(7.7, 20.9),(9.9, 20.9),(-7.7, 18.7),(-5.5, 18.7),(-3.3, 18.7),(3.3, 18.7),(5.5, 18.7),(7.7, 18.7),(-5.5, 16.5),(-3.3, 16.5),(-1.1, 16.5),(1.1, 16.5),(5.5, 16.5),(-3.3, 14.3),(-1.1, 14.3),(1.1, 14.3),(3.3, 14.3),(-5.5, 12.1),(-3.3, 12.1),(1.1, 12.1),(3.3, 12.1),(5.5, 12.1),(-9.9, 9.9),(-7.7, 9.9),(-5.5, 9.9),(5.5, 9.9),(7.7, 9.9),(9.9, 9.9),(-12.1, 7.7),(-9.9, 7.7),(7.7, 7.7),(9.9, 7.7),(-12.1, 5.5),(-9.9, 5.5),(9.9, 5.5),(12.1, 5.5),(-12.1, 3.3),(-9.9, 3.3),(-7.7, 3.3),(-5.5, 3.3),(-3.3, 3.3),(-1.1, 3.3),(3.3, 3.3),(5.5, 3.3),(7.7, 3.3),(9.9, 3.3),(12.1, 3.3),(14.3, 3.3),(-14.3, 1.1),(-12.1, 1.1),(12.1, 1.1),(14.3, 1.1),(-14.3, -1.1),(-12.1, -1.1),(12.1, -1.1),(14.3, -1.1),(-14.3, -3.3),(-12.1, -3.3),(-9.9, -3.3),(-7.7, -3.3),(-5.5, -3.3),(-3.3, -3.3),(-1.1, -3.3),(1.1, -3.3),(3.3, -3.3),(5.5, -3.3),(7.7, -3.3),(9.9, -3.3),(12.1, -3.3),(14.3, -3.3),(-12.1, -5.5),(12.1, -5.5),(-9.9, -7.7),(7.7, -7.7),(9.9, -7.7),(-9.9, -9.9),(-7.7, -9.9),(5.5, -9.9),(7.7, -9.9),(9.9, -9.9),(-5.5, -12.1),(-3.3, -12.1),(-1.1, -12.1),(3.3, -12.1),(5.5, -12.1),(-1.1, -14.3),(1.1, -14.3),(-5.5, -16.5),(-1.1, -16.5),(1.1, -16.5),(3.3, -16.5),(5.5, -16.5),(-7.7, -18.7),(-5.5, -18.7),(-3.3, -18.7),(3.3, -18.7),(5.5, -18.7),(7.7, -18.7),(-9.9, -20.9),(-7.7, -20.9),(-5.5, -20.9),(5.5, -20.9),(7.7, -20.9),(9.9, -20.9),(-9.9, -23.1),(-7.7, -23.1),(-5.5, -23.1),(-3.3, -23.1),(-1.1, -23.1),(1.1, -23.1),(3.3, -23.1),(5.5, -23.1),(7.7, -23.1),(9.9, -23.1),(-12.1, -25.3),(9.9, -25.3),(-12.1, -27.5),(12.1, -27.5),(-14.3, -29.7),(-12.1, -29.7),(-9.9, -29.7),(-7.7, -29.7),(-5.5, -29.7),(-3.3, -29.7),(-1.1, -29.7),(3.3, -29.7),(5.5, -29.7),(7.7, -29.7),(9.9, -29.7),(12.1, -29.7),(-12.1, -31.9),(12.1, -31.9),(14.3, -31.9),(-14.3, -34.1),(-12.1, -34.1),(12.1, -34.1)]
Green = [(14.3, 34.1),(-14.3, 29.7),(1.1, 29.7),(12.1, 25.3),(-5.5, 23.1),(-7.7, 20.9),(3.3, 16.5),(-14.3, 3.3),(1.1, 3.3),(-9.9, -5.5),(9.9, -5.5),(-5.5, -9.9),(-3.3, -14.3),(3.3, -14.3),(-3.3, -16.5),(-9.9, -25.3),(12.1, -25.3),(1.1, -29.7),(14.3, -29.7),(-14.3, -31.9),(14.3, -34.1)]
def point_to_location(point):
x_offset, y_offset = point
return center_location.move(types.Point(x=x_offset, y=y_offset, z=0))
pipette_20ul.pick_up_tip()
# Pipette Red points
red_color_source = location_of_color('Red')
for i, point in enumerate(Red):
if i % 20 == 0: # Aspirate every 20uL to ensure enough liquid
pipette_20ul.aspirate(min(20, len(Red) - i), red_color_source)
target_location = point_to_location(point)
dispense_and_detach(pipette_20ul, 1, target_location)
pipette_20ul.drop_tip() # Drop tip after finishing Red points
pipette_20ul.pick_up_tip() # Pick up new tip for Green points
# Pipette Green points
green_color_source = location_of_color('Green')
for i, point in enumerate(Green):
if i % 20 == 0: # Aspirate every 20uL to ensure enough liquid
pipette_20ul.aspirate(min(20, len(Green) - i), green_color_source)
target_location = point_to_location(point)
dispense_and_detach(pipette_20ul, 1, target_location)
pipette_20ul.drop_tip()
A 2020 study demonstrated the use of Opentrons OT-2 robots for automated SARS-CoV-2 diagnostic workflows during the COVID-19 pandemic. Researchers used automated liquid handling to perform RNA extraction and PCR setup at scale, reducing manual error and increasing throughput. The Opentrons platform allowed laboratories to rapidly deploy affordable automation in response to urgent public health needs. This demonstrated how open-source robotics can accelerate diagnostics and improve reproducibility.
Reference: Implementation of an open-source robotic platform for SARS-CoV-2 testing by real-time RT-PCR (Villanueva-Cañas, J. L., Gonzalez-Roca, E., Gastaminza Unanue, A., Titos, E., Martínez Yoldi, M. J., Vergara Gómez, A., & Puig-Butillé, J. A. (2021). Implementation of an open-source robotic platform for SARS-CoV-2 testing by real-time RT-PCR. PloS one, 16(7), e0252509. https://doi.org/10.1371/journal.pone.0252509)
Automated Biosensor Screening Platform: I would automate the screening of environmental biosensor constructs using cell-free protein synthesis (CFPS).

:max_bytes(150000):strip_icc()/3-D_DNA-56a09ae45f9b58eba4b20266.jpg)