1.1 A Neighborly Bio-literacy Learning System for Non-Scientists, Living in a Disaster-Prone World Full disclosure: My house burned down in the Palisades, California fire last year with 5,000 other homes and it inspired me to see neighborhood disaster as a rich opportunity for study.
Rather than treating bio-literacy as isolated content mastery, this project frames bio-literacy as ethical sense-making within one’s own community and around community-based problems. Bio-literacy is understood as the ability to know ourselves and our world by asking questions, interpreting uncertainty, engaging responsibly, and building trust with biological systems. These capacities become more meaningful—and more powerful—when grounded in local concerns and lived experience. There is no shortage of biology-based shared community challenges: food security, extreme weather and fire, infectious disease, and environmental instability.
Part 1: Benchling & In-silico Gel Art Part 2: Gel Art - Restriction Digests and Gel Electrophoresis No lab access
Part 3: DNA Design Challenge 3.1. Choose your protein.
1/Create a Python file to run on an Opentrons liquid handling robot. This is what I want to do, but I am still working on it. Happy Late Valentines Day! 2/ Find and describe a published paper that utilizes the Opentrons or an automation tool to achieve novel biological applications. Bryant Jr. et al., 2023 — “AssemblyTron: Automated DNA Assembly Using the Opentrons OT-2.” Synthetic Biology (Oxford University Press). This paper describes an automated workflow that connects DNA design software to the Opentrons OT-2 liquid-handling robot. Rather than manual pipetting, the robot executes highly standardized molecular biology workflows.The innovation is novel because it is integration of design software and robotic execution. This reduces human error and makes it easier to reproduce experiements. Although this is challening information for me, I can see how it might lower the bar for entry into syn bio experiements and and speed up design cycles. If HTGAA’s mission is to democratize access to cutting-edge bioengineering and synthetic biology education and foster global “biological literacy” by equipping diverse, distributed participants with the skills and laboratory knowledge to design, experiment, and create with living organisms, then this Opentron is a gamechanger. 3/ Write a description about what you intend to do with automation tools for your final project. You may include example pseudocode, Python scripts, 3D printed holders, a plan for how to use Ginkgo Nebula, and more. You may reference this week’s recitation slide deck for lab automation details. In my wildfire soil project, automation might add rigor to the process of detecting subtle microbial differences in post-fire environments. My samples might be: Burned soil, Unburned soil, Sunflower rhizosphere soil, Adjacent burned soil away from roots. For each sample I will need to: Create standardized slurry. Perform serial dilutions. Plate onto defined media, Record colony morphology and counts, Measure pH 4/ Three Final Project Ideas What if post-fire soil holds a molecular archive of both hope + disturbance, and we could build biological instruments that translate that archive into visible signals — making ecological memory perceptible to communities rebuilding after disaster?
A protein created by RFdiffusion3, a newly released protein design tool from Nobel laureate David Baker’s lab, interacting with DNA. (UW Institute for Protein Design / Ian C. Haydon Image)
Protein Design I Objective:
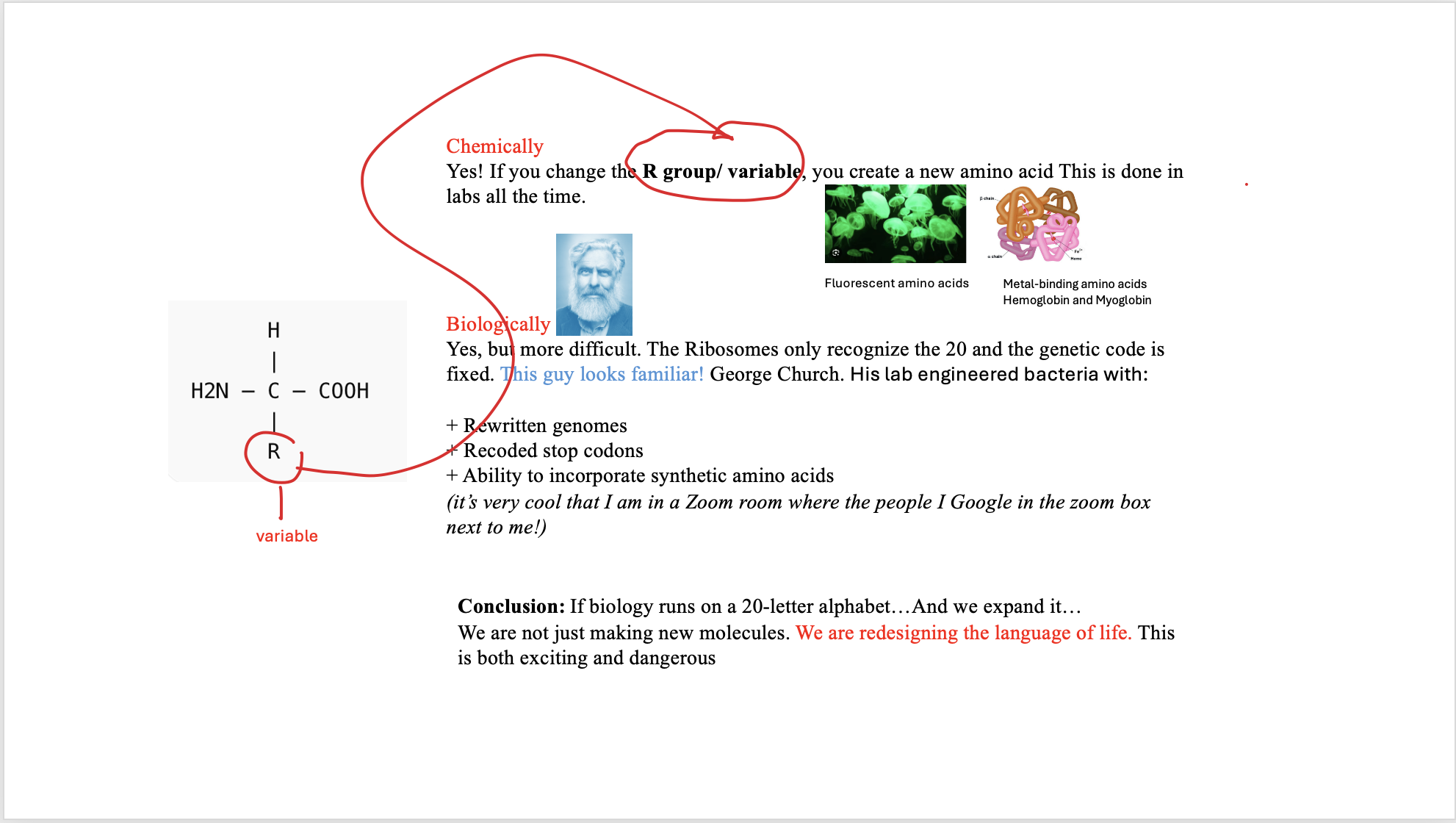
Learn basic concepts: amino acid structure 3D protein visualization the variety of ML-based design tools Part A. Conceptual Questions 1/ How many molecules of amino acids do you take with a piece of 500 grams of meat? 2/ Why do humans eat beef but do not become a cow, eat fish but do not become fish? 3/ Why are there only 20 natural amino acids? 4a/ Can you make other non-natural amino acids? Design some new amino acids. 4b/ Design some new amino acids. 5/ Where did amino acids come from before enzymes that make them, and before life started? Ran out of time. Will return!
Superoxide dismutase 1 (SOD1) is a cytosolic antioxidant enzyme that converts superoxide radicals into hydrogen peroxide and oxygen. In its native state, it forms a stable homodimer and binds copper and zinc.
Mutations in SOD1 cause familial Amyotrophic Lateral Sclerosis (ALS). Among them, the A4V mutation (Alanine → Valine at residue 4) leads to one of the most aggressive forms of the disease. The mutation subtly destabilizes the N-terminus, perturbs folding energetics, and promotes toxic aggregation.
https://kernel.asimov.com/hello@biopunklab.com Biopunk2026!
Part 1 — Concept Questions 1. Components of Phusion High-Fidelity PCR Master Mix
Phusion PCR master mix typically contains:
High-fidelity DNA polymerase • enzyme that synthesizes new DNA strands • has proofreading ability, reducing mutation errors
dNTPs (deoxynucleotide triphosphates) • building blocks used to create new DNA strands
Assignment Part 1: Intracellular Artificial Neural Networks (IANNs) What advantages do IANNs have over traditional genetic circuits, whose input/output behaviors are Boolean functions?
Traditional genetic circuits behave like Boolean logic gates (ON/OFF, 0/1), meaning they produce discrete outputs based on fixed thresholds. In contrast, Intracellular Artificial Neural Networks (IANNs) offer several advantages:
Prove lead-sensing logic Aim: I am designing a modular genetic cassette in which a heavy-metal sensing element, likely pbrR/pbr, controls either a standard reporter or a geosmin output module, with HSR considered as an auxiliary stress-sensitive element rather than the primary detector
Design intent: Detect bioavailable Pb(II) using a PbrR/pbr lead-responsive sensing module. Initial output will be a fluorescent reporter to validate sensing behavior. A later version may replace the reporter with a geosmin-associated output module for sensory repair signaling.
Subsections of Homework
Week 1 HW: Principles + Practices
1.1 A Neighborly Bio-literacy Learning System for Non-Scientists, Living in a Disaster-Prone World
Full disclosure: My house burned down in the Palisades, California fire last year with 5,000 other homes and it inspired me to see neighborhood disaster as a rich opportunity for study.
Rather than treating bio-literacy as isolated content mastery, this project frames bio-literacy as ethical sense-making within one’s own community and around community-based problems. Bio-literacy is understood as the ability to know ourselves and our world by asking questions, interpreting uncertainty, engaging responsibly, and building trust with biological systems. These capacities become more meaningful—and more powerful—when grounded in local concerns and lived experience. There is no shortage of biology-based shared community challenges: food security, extreme weather and fire, infectious disease, and environmental instability.
The project draws on local, embodied, and experimental pedagogies—such as role play, physical modeling, dialogue, and narrative—to make biological systems felt rather than merely understood abstractly. Participants develop bio-literacy in their “own backyard,” investigating biological questions that matter to them, their families, and their neighbors. In this way, Neighbor Gap Bridge (neighborgapbridge.com) reframes bio-literacy as a situated, relational practice rather than a distant technical competence.
Why this matters
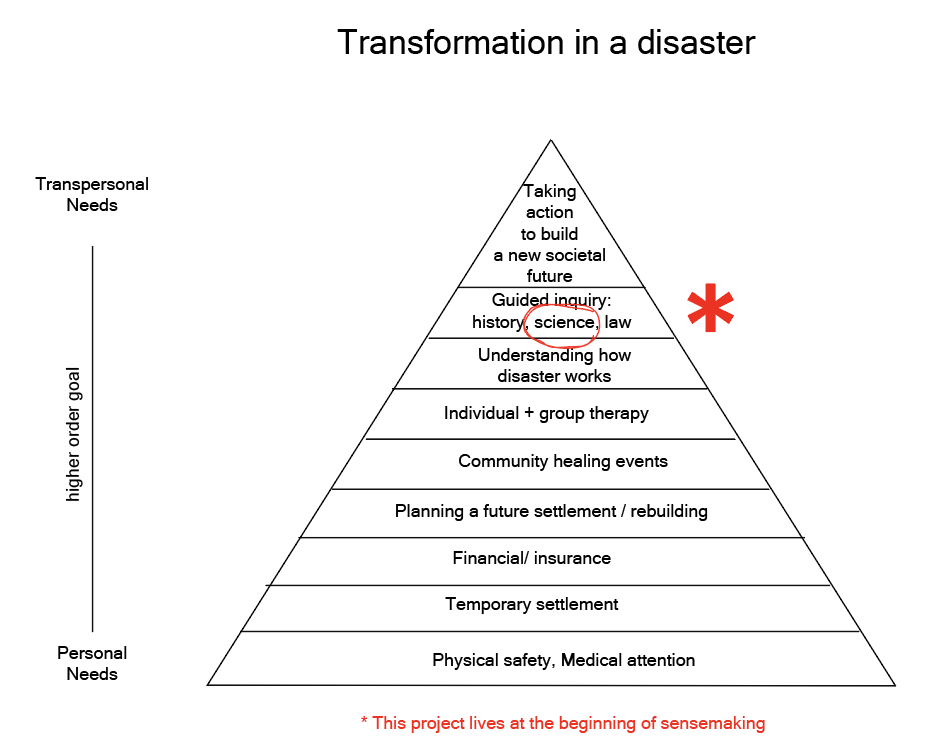
We are living in a world of disaster uncertainty in which consequential biological decisions—about health, environment, food systems, and governance—are increasingly made by non-biologists. Bio-literacy’s closest historical parallel is computer literacy: a decades-long project that succeeded in widespread participation, but not widespread understanding. This project reimagines the starting point of bio-literacy as the learner’s own backyard, privileging local problems as invitations into biological understanding, community participation, and compassion. This project is situated in the overall transformative experience of a disaster victim, creating opportunity for high level sensemaking and ability to know ourselves and our world by asking questions, and building trust with multiple systems including biological systems.
Existing bio- and AI-literacy efforts often optimize for scale, rigor, or engagement in isolation. This project instead optimizes for connection and meaning—situating learning within relationships, shared stakes, and ethical reflection.
Visionary (Infrastructure Design) What is missing is a governance-aligned learning infrastructure that treats ethical sense-making, uncertainty, pluralism, and participation as core learning outcomes rather than peripheral concerns. This project explores what such an infrastructure might look like, and what forms of governance, partnership, and institutional support would be required to sustain it.
Near-Future (Programmatic Pilot) Local, problem-based, intergenerational synthetic biology learning—using scaffolded play and embodied curriculum in partnership with LAUSD—focused on community-relevant biological questions.
Close-In (Rapid Prototyping / Extreme Events) Mobile syn-bio workshops and learning labs responding to “extreme events,” such as wildfire. For example, intergenerational workshops with residents affected by the Palisades fire to explore the biology of fire-resistant mycelium-based materials, alongside the design and fabrication of protective artifacts for future resilience.
1.2 Governance/Policy Goals for a Neighborly Bio-Literate Future
Governance Goal 1: Equitable Access Without Dilution
Open access (low or no cost)
Universal Design for Learning
Multi-generational participation
Not restricted to credentialed elites
Engage Creative athletics
Engages local biological problems
Governance Goal 2: Epistemic Pluralism
Interdisciplinary sources
Diverse instructors and perspectives
Recognition that different perspectives change what becomes knowable
Embodies Learning
Learning is felt
Governance Goal 3: Trustworthy Sense-Making
Transparency of sources
Open and updatable materials
Clear articulation of uncertainty
Avoidance of false certainty or hype
Care and Compassion based Learning
Feminine Technology of learning
Treat Error as opportunity
Governance Goal 4: Ethics as Infrastructure (Not Add-On)
Ethics embedded in delivery, not add-ons
Democratic dialogue and controversy included
Anticipation of ethical roadblocks
Delayed closure where appropriate
1.3 Potential Governance Actors + Actions
NSF-funded experimental bio literacy learning labs
Purpose
Bio-education funding prioritizes content mastery and workforce development. This action proposes NSF funding streams specifically for experimental, embodied bio literacy learning environments aimed at non-specialists.
Design
Competitive grants for interdisciplinary teams (science + education + design0
Competitive Grants for Neighorhood non scientists
Emphasis on process documentation, not standardized outcomes
Publicly available learning artifacts and reflections
Ethics embedded throughout the learning experience
Robust digital share community spaces
Assumptions
Embodied and experimental pedagogy improves ethical sense-making
Non-specialists can meaningfully engage without technical mastery
NSF will value exploratory education research
People actually want to work when they have been affected by trauma
Risks of Failure
Failure: Projects become performative or symbolic rather than substantive
Failure: Difficulty evaluating progress without traditional metrics
Say to day survival becomes more important
Department of Education Guidance on Bio-literacy + Trust
Purpose
Currently, bio education standards focus on factual knowledge. This action proposes non-binding federal guidance recognizing bio literacy as an ethical and civic competency.
Design
Advisory frameworks (not mandates)
Alignment with Universal Design for Learning
Encouragement of dialogue-based and participatory approaches
Recognition of uncertainty and ethical debate as learning outcomes
Assumptions
Federal guidance can shape discourse without enforcement
Educators want permission to teach uncertainty and ethics
Bio literacy can be framed as civic preparation
Bio Literacy can be framed astrauma informed
Risks of Failure
Failure: Guidance is ignored or politicized
Failure: Oversimplification for scale
Risk of “success”: Bio literacy reduced to compliance checklists
MIT Life-long Kindergarten as Model
Purpose
Traditional science education often prioritizes correctness, abstraction, and expert authority. This governance action supports play-based, experimental science literacy models that cultivate curiosity, agency, and ethical orientation before formal expertise. Rather than teaching biology directly, the approach develops habits of inquiry—iteration, questioning, and reflection—that are transferable to bio literacy contexts.
Design
Learning environments structured around play, making, and experimentation
Tools that lower barriers to participation (no prerequisite mastery)
Emphasis on remixing, peer learning, and public sharing
Ethics embedded implicitly through collaboration, attribution, and care
These workshops are part of a holistic plan for discovery and recovery
Assumptions
Play supports deeper engagement and long-term learning
Ethical orientation can emerge through participation, not instruction alone
Habits of inquiry transfer across domains (e.g., from computation to biology)
Framing can be sensitive enough to support engagement during or after a crisis
these Workshops are optional
Risks of Failure
Failure: Play is dismissed as insufficiently rigorous
Failure: Ethical dimensions remain implicit and unarticulated
Play becomes instrumentalized or gamified, losing its exploratory power and sensitivity
This becomes very Kumbaya and does not move our collective inderstanding forward
1.4 Scoring Table
–>
(1= lowest)
Does the option:
ED
NSF
MIT
Build Trust
• Uncertainty Embraced
3
2
1
• Care/ Compassion
3
2
1
Embed Ethics
• Democratic Dialog
3
2
1
• Delay closure
3
2
1
Interdis
• Perspectives
2
2
1
• Feminine Technology
3
3
1
Equitable
• Not just Elites
2
3
• Free/ low cost
1
3
2
-
Week 1 HW: Principles and Practices
Week 02 Homework: DNA Read, Write and Edit
Part 1: Benchling & In-silico Gel Art
Part 2: Gel Art - Restriction Digests and Gel Electrophoresis
No lab access
Part 3: DNA Design Challenge
3.1. Choose your protein.
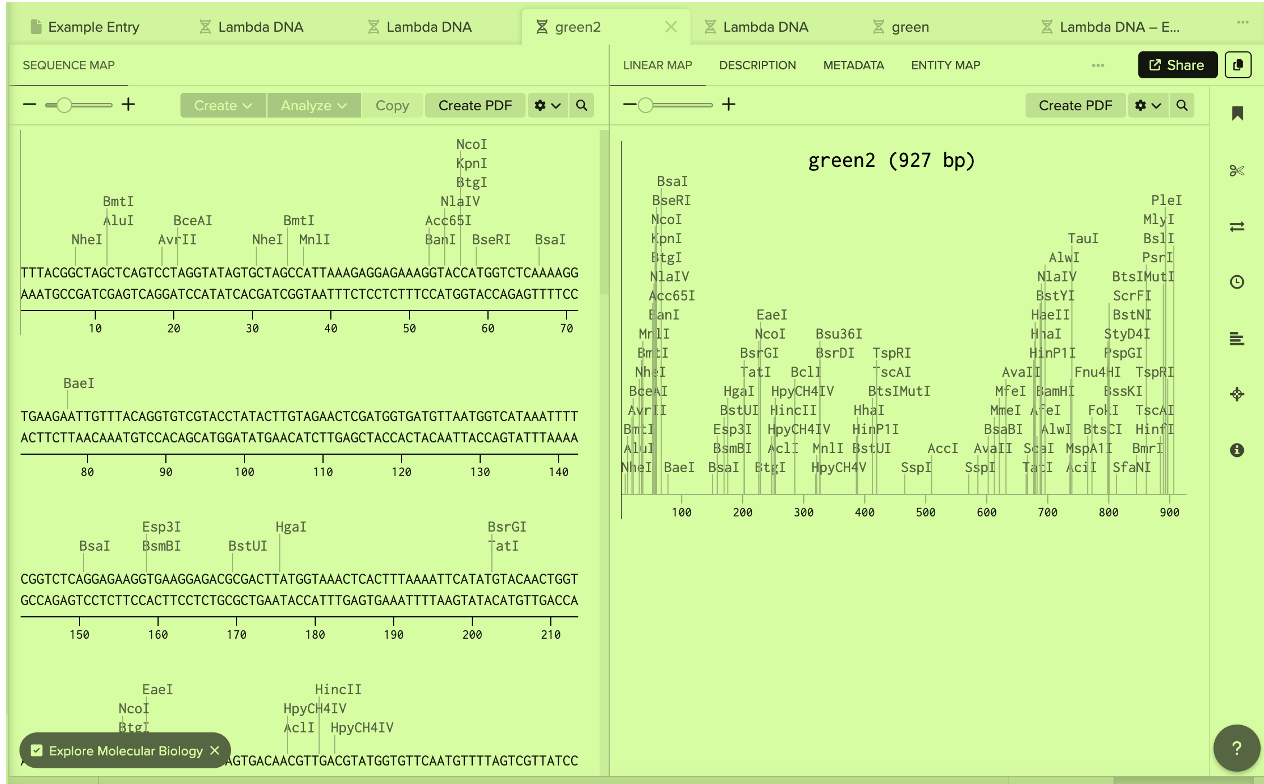
I chose Green Fluorescent Protein (GFP) because it is widely used in biotechnology as a visual reporter protein. Its ability to fluoresce green when exposed to blue light makes it an elegant example of how DNA sequences can encode observable biological functions. This is a random choice, I love green and this is HTGAA!
The 2008 Nobel Prize in Chemistry was awarded to Osamu Shimomura, Martin Chalfie, and Roger Y. Tsien for the discovery and development of Green Fluorescent Protein (GFP)
Protein Sequence:
P42212|GFP_AEQVI Green fluorescent protein OS=Aequorea victoria
MSKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDATYGKLTLKFICTTGKLPVPWPTLVTTLTYGVQCFSRYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYIMADKQKNGIKVNFKIRHNIEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGITHGMDELYK
3.4. You have a sequence! Now what? Describe in your words the DNA sequence can be transcribed and translated into your protein. You may describe either cell-dependent or cell-free methods, or both.
I read about how fluorescent green protein is used in molecular biology to identify and track protein movement and gene expression. I am not yet ready to describe how a DNA sequence can be transcribed and translated into this protein. The best I can do here “in my own words” is to go back to the central dogma / flow of genetic information: DNA >RNA> Protein This is what I think happened in this week’s HW
Part 4: Prepare a Twist DNA Synthesis Order: Design the full machine (Expression Cassette?) that makes bacteria glow.
4.1. Create a Twist account and a Benchling account
4.2. Build Your DNA Insert Sequence
Let’s make a sequence that will make E. coli glow fluorescent green under UV light by constitutively (always) expressing sfGFP (a green fluorescent protein):
Promoter TTTACGGCTAGCTCAGTCCTAGGTATAGTGCTAGC
RBS CATTAAAGAGGAGAAAGGTACC
Start Codon ATG
Coding Sequence GTCTCAAAAGGTGAAGAATTGTTTACAGGTGTCGTACCTATACTTGTAGAACTCGATGGTGATGTTAATGGTCATAAATTTTCGGTCTCAGGAGAAGGTGAAGGAGACGCGACTTATGGTAAACTCACTTTAAAATTCATATGTACAACTGGTAAATTACCTGTTCCATGGCCGACTTTAGTGACAACGTTGACGTATGGTGTTCAATGTTTTAGTCGTTATCCTGATCATATGAAACAACATGATTTCTTTAAAAGTGCAATGCCTGAGGGTTATGTTCAAGAACGGACGATTTTCTTTAAAGATGATGGGAATTACAAAACTCGCGCAGAAGTCAAATTTGAAGGAGACACACTGGTAAATCGTATAGAACTTAAAGGTATTGACTTTAAAGAAGATGGAAATATTTTAGGTCATAAACTTGAATACAATTTGAACTCCCATAATGTCTACATAATGGCAGACAAACAGAAGAATGGAATAAAAGTTAATTTTAAAATACGCCATAATATTGAAGATGGTTCGGTCCAACTGGCAGATCATTATCAACAGAATACTCCAATTGGAGATGGTCCAGTCTTGTTACCAGATAATCATTATCTCAGTACTCAATCAGCGCTCTCTAAGGATCCAAATGAAAAGCGTGACCATATGGTGTTGCTCGAATTTGTTACAGCGGCAGGCATTACATTAGGAATGGATGAATTATATAAA
7x His Tag CATCACCATCACCATCATCAC
Stop Codon TAA
Terminator CCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCTACTAGAGTCACACTGGCTCACCTTCGGGTGGGCCTTTCTGCGTTTATA
4.3. On Twist, Select The “Genes” Option4.4. Select “Clonal Genes” option4.5. Import your sequence
I had to stop here because Twist would not accept my .fasta file. When I loaded it kept adding.txt
4.6. Choose Your Vector
No can do
Part 5: DNA Read/Write/Edit
5.1 DNA Read
What DNA would you want to sequence (e.g., read) and why?
The Smell of Renewal: mapping post-fire soil chemistry + culture as a recovery marker
I would want to sequence DNA from soil bacteria called Streptomyces that produce geosmin, a key molecule behind petrichor (the earthy smell after rain). I’m interested in this because after a major fire, soil ecosystems change dramatically, and I want to understand what microbial communities survive, return, or disappear during recovery.
Why sequence it? The big “why” is that my home burned down in the Palisades fire last year.
As I recover from the trauma of the fire, I find myself deeply drawn to the repair and restoration of my neighborhood — both physically and emotionally. I am particularly interested in sequencing soil bacteria such as Streptomyces, which produce geosmin, a key molecule behind petrichor — the earthy smell after rain.
Sequencing would allow me to identify which Streptomyces species or strains are present in post-fire soil, compare them to soil from unaffected areas, and observe how the microbial “signature” of a burned landscape changes over time. This could support environmental monitoring by tracking soil recovery and ecosystem health after disaster.
Because petrichor is strongly tied to emotional memory and renewal, understanding the biology behind it could connect ecological recovery with human recovery after disaster.
(CHAT GPT: How would I do this?)To study these microbial communities, I would use 16S rRNA gene sequencing, a common method for identifying and comparing bacterial species in environmental samples. By extracting DNA from soil and sequencing this conserved bacterial marker gene, I could determine which Streptomyces strains are present and how their abundance changes over time following a fire.
What I learned this week
Understood the Central Dogma in a functional way.
Learned what promoters and RBS actually do.
Codon-optimized a gene.
Wrestled with file formats (real-world friction).
Designed a sequencing project grounded in lived experience.
Named 16S rRNA as a method.
Connected six diverse interdisciplinary areas of inquiry
Fire
Soil
Microbes
Memory
Recovery
Design
Biology
Week 03 Homework: Lab Automation
1/Create a Python file to run on an Opentrons liquid handling robot.
This is what I want to do, but I am still working on it. Happy Late Valentines Day!
2/ Find and describe a published paper that utilizes the Opentrons or an automation tool to achieve novel biological applications.
Bryant Jr. et al., 2023 — “AssemblyTron: Automated DNA Assembly Using the Opentrons OT-2.” Synthetic Biology (Oxford University Press).
This paper describes an automated workflow that connects DNA design software to the Opentrons OT-2 liquid-handling robot. Rather than manual pipetting, the robot executes highly standardized molecular biology workflows.The innovation is novel because it is integration of design software and robotic execution. This reduces human error and makes it easier to reproduce experiements. Although this is challening information for me, I can see how it might lower the bar for entry into syn bio experiements and and speed up design cycles. If HTGAA’s mission is to democratize access to cutting-edge bioengineering and synthetic biology education and foster global “biological literacy” by equipping diverse, distributed participants with the skills and laboratory knowledge to design, experiment, and create with living organisms, then this Opentron is a gamechanger.
3/ Write a description about what you intend to do with automation tools for your final project. You may include example pseudocode, Python scripts, 3D printed holders, a plan for how to use Ginkgo Nebula, and more. You may reference this week’s recitation slide deck for lab automation details.
In my wildfire soil project, automation might add rigor to the process of detecting subtle microbial differences in post-fire environments. My samples might be: Burned soil, Unburned soil, Sunflower rhizosphere soil, Adjacent burned soil away from roots. For each sample I will need to: Create standardized slurry. Perform serial dilutions. Plate onto defined media, Record colony morphology and counts, Measure pH
4/ Three Final Project Ideas
What if post-fire soil holds a molecular archive of both hope + disturbance, and we could build biological instruments that translate that archive into visible signals — making ecological memory perceptible to communities rebuilding after disaster?
Week 4 HW: Protein Design
A protein created by RFdiffusion3, a newly released protein design tool from Nobel laureate David Baker’s lab, interacting with DNA. (UW Institute for Protein Design / Ian C. Haydon Image)
Protein Design I
Objective:
Learn basic concepts:
amino acid structure
3D protein visualization
the variety of ML-based design tools
Part A. Conceptual Questions
1/ How many molecules of amino acids do you take with a piece of 500 grams of meat?
2/ Why do humans eat beef but do not become a cow, eat fish but do not become fish?
3/ Why are there only 20 natural amino acids?
4a/ Can you make other non-natural amino acids? Design some new amino acids.
4b/ Design some new amino acids.
5/ Where did amino acids come from before enzymes that make them, and before life started?
Ran out of time. Will return!
6/ If you make an α-helix using D-amino acids, what handedness (right or left) would you expect?
7/ Can you discover additional helices in proteins?
8/ Why are most molecular helices right-handed?
9/ Why do β-sheets tend to aggregate?
10/ What is the driving force for β-sheet aggregation?
11/ Why do many amyloid diseases form β-sheets?
12/ Can you use amyloid β-sheets as materials?
13/ Design a β-sheet motif that forms a well-ordered structure.
Part B: Protein Analysis and Visualization
In this part of the homework, you will be using online resources and 3D visualization software to answer questions about proteins. Pick any protein (from any organism) of your interest that has a 3D structure and answer the following questions:
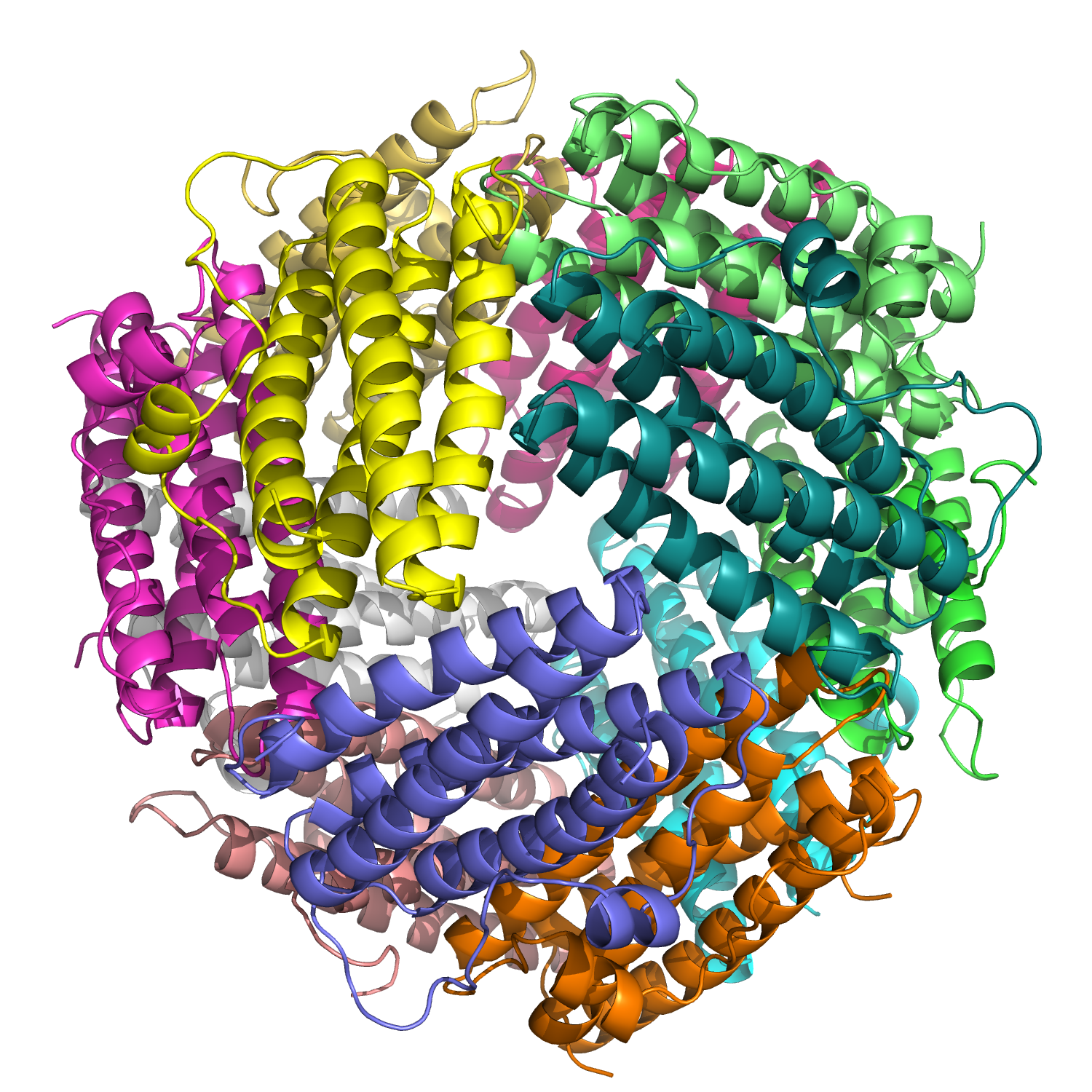
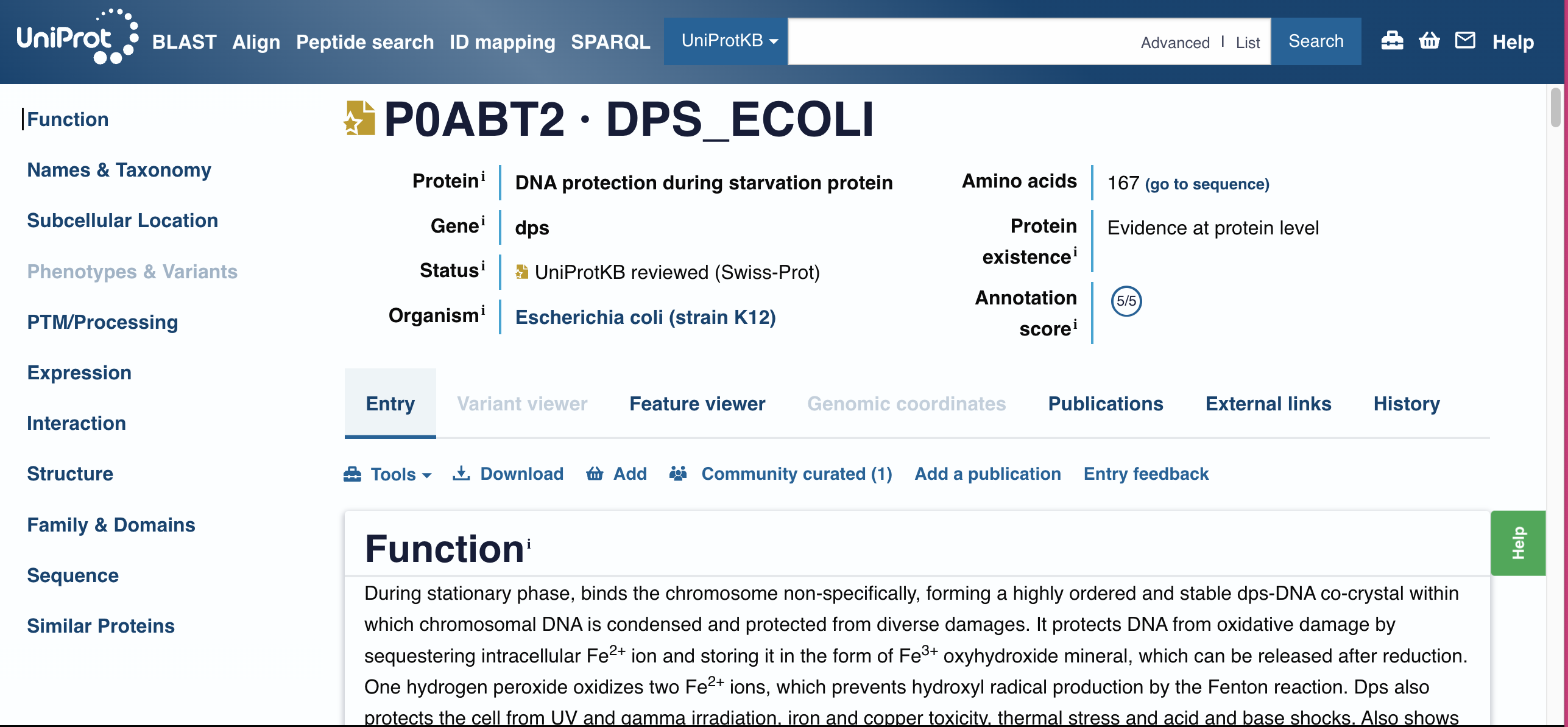
Dps (DNA-binding protein from starved cells)
I selected it because Dps is a bacterial stress protein that shows up strongly when cells are under starvation, oxidative stress, and other harsh conditions—exactly the kinds of conditions microbes face in disrupted environments (like post-fire soils). It binds and compacts DNA, helping preserve genetic information when conditions are bad. That’s very “molecular archive” which is something I proposed in mt final project. In addition, I became really interested in DNA storage after I went to the first BIOPUNK lab meeting. All 16 GB of English Wikipedia have been encoded into DNA? Dps is a natural DNA packaging and protection system. Dps is a gorgeous bridge between information and material protection before a fire.
715 amino acids
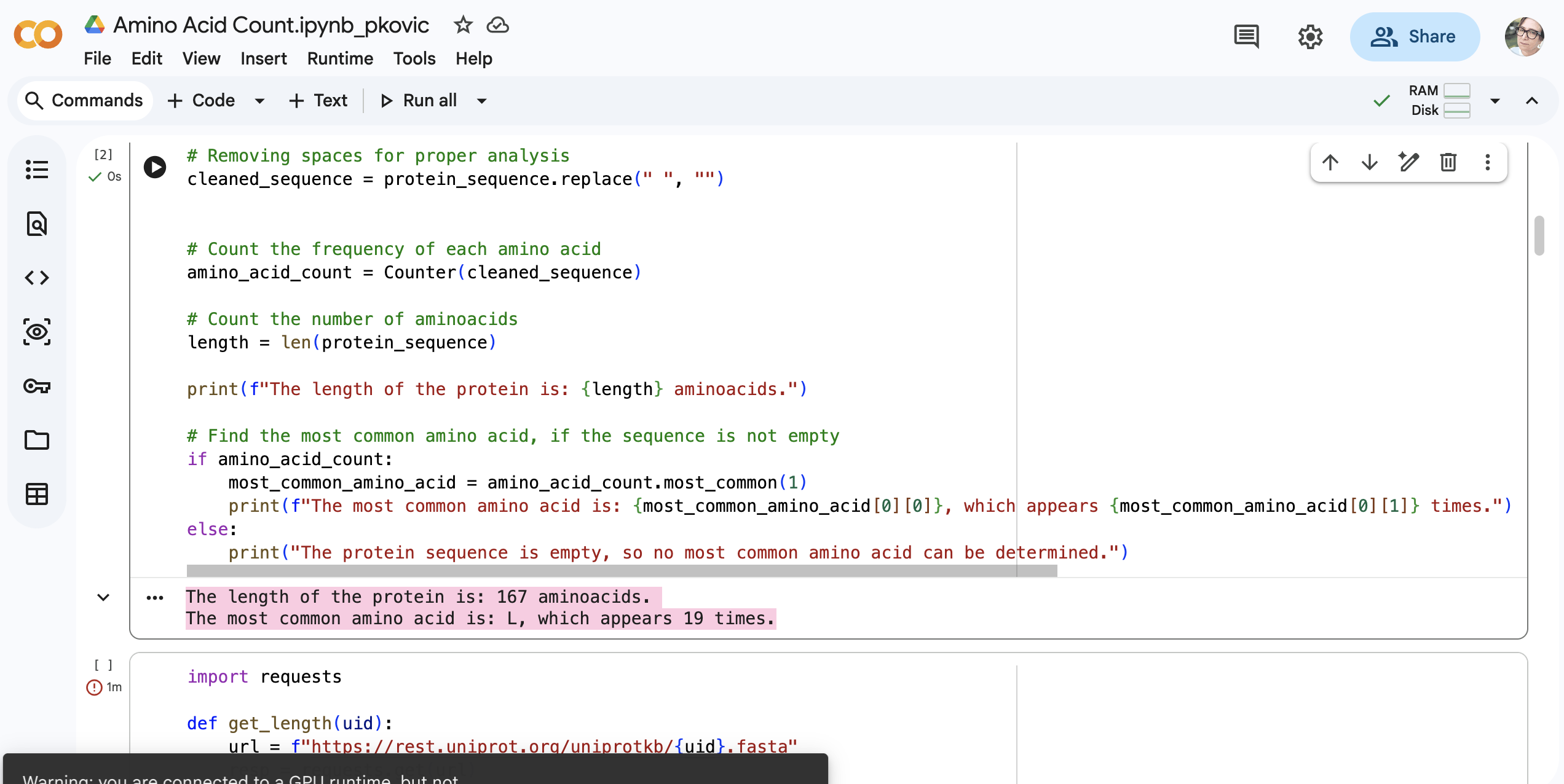
The length of the protein is: 167 aminoacids?
What is the most frequent amino acid? You can use this Colab notebook to count the frequency of amino acids.
The most common amino acid is: L, which appears 19 times.
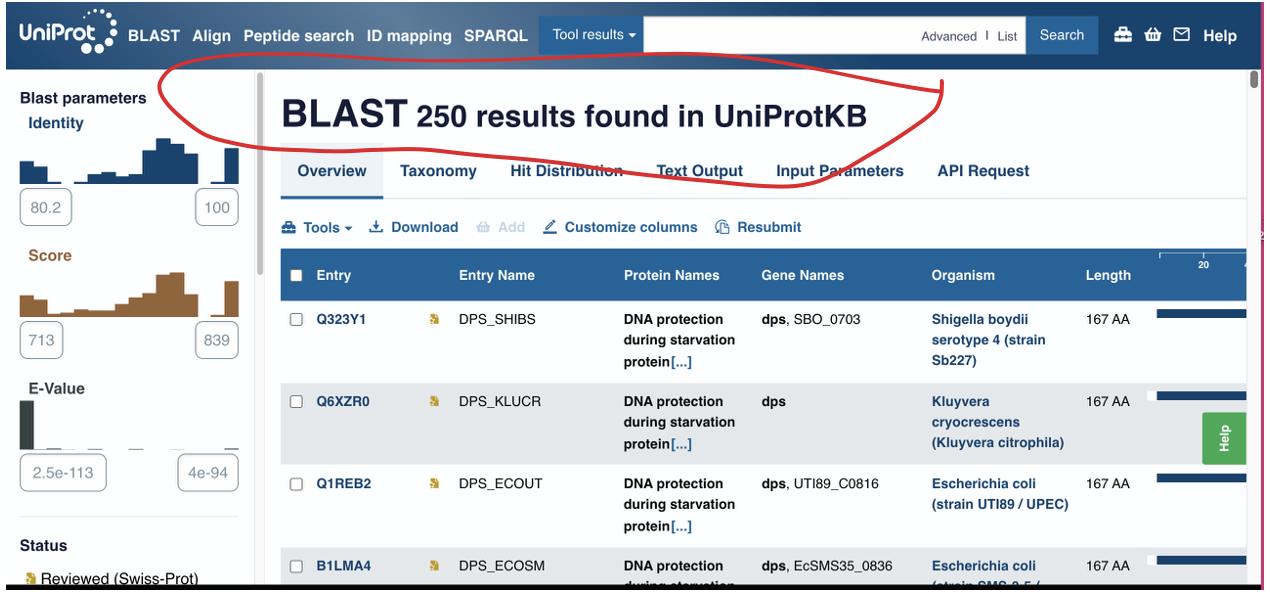
How many protein sequence homologs are there for your protein? Hint: Use Uniprot’s BLAST tool to search for homologs.
250
Does your protein belong to any protein family?
Dps / Ferritin-like superfamily
Dps family (DNA-binding proteins from starved cells)
Identify the structure page of your protein in RCSB
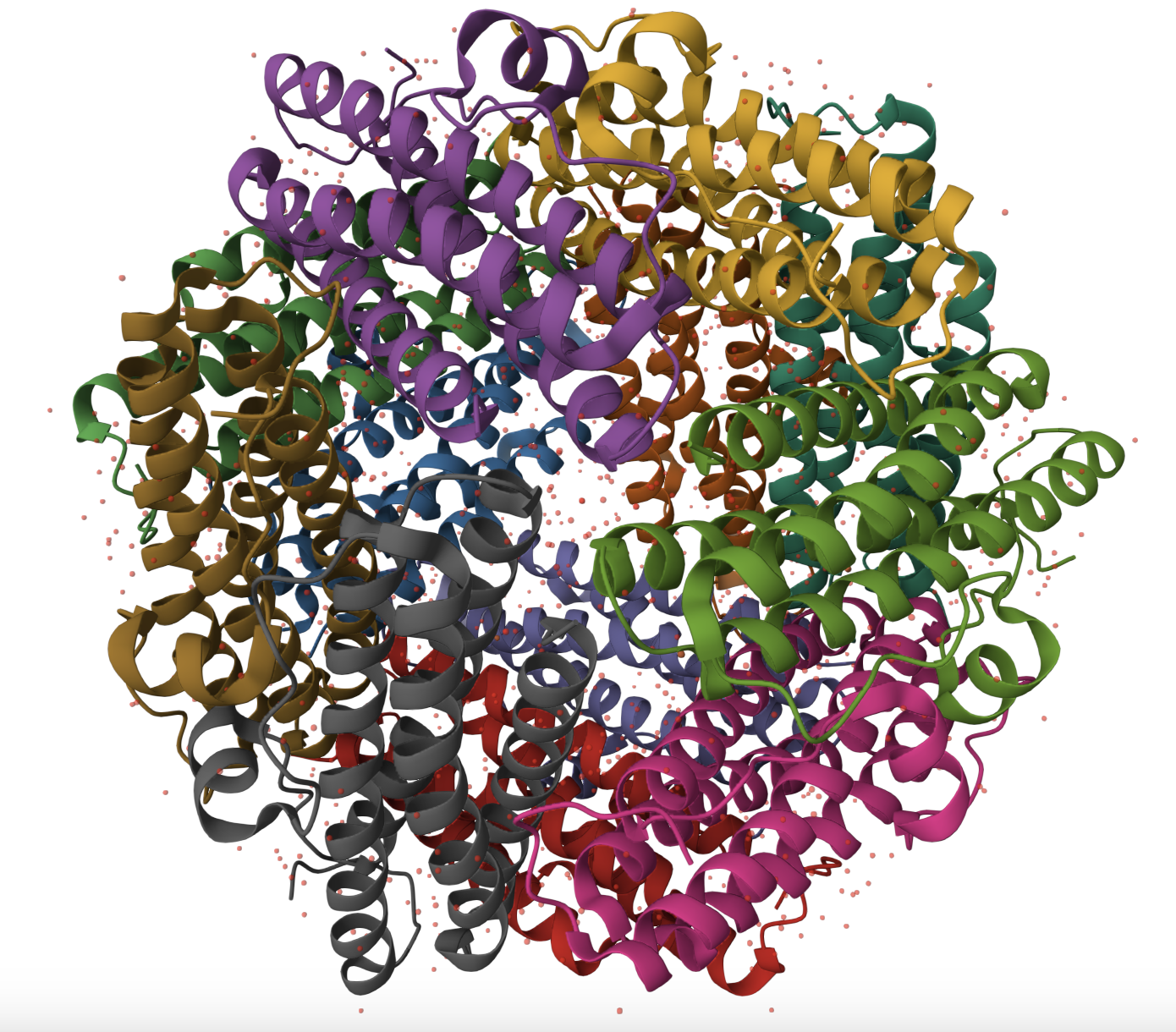
The structure of Dps from Escherichia coli can be found in the RCSB Protein Data Bank under PDB ID 9ZC2. The structure was determined using single-particle cryo-electron microscopy at 1.3 Å resolution, indicating excellent structural quality.
When was the structure solved? Is it a good quality structure? Good quality structure is the one with good resolution. Smaller the better (Resolution: 2.70 Å)
It is 1.3 Å resolution. That’s good@
Are there any other molecules in the solved structure apart from protein?
Ligand Interaction (FE)
Does your protein belong to any structure classification family?
Dps belongs to the ferritin-like structural fold and assembles into a homo-dodecamer (A12) with tetrahedral symmetry. The biological assembly consists of 12 identical alpha-helical subunits forming a hollow spherical cage, characteristic of the ferritin-like superfamily.The structure contains iron (Fe) ions in addition to the protein subunits, consistent with the iron-binding function of Dps.
Open the structure of your protein in any 3D molecule visualization software:
PyMol Tutorial Here (hint: ChatGPT is good at PyMol commands)
Visualize the protein as “cartoon”, “ribbon” and “ball and stick”.
Dps =
Mostly alpha helices
Connected by short loops
Assembled into a 12-subunit spherical cage
With metal ions inside
Color the protein by secondary structure. Does it have more helices or sheets?
Completely helices
Color the protein by residue type. What can you tell about the distribution of hydrophobic vs hydrophilic residues?
A moderate amount of evenly distributed tiny dots. Chat gPT says: Coloring the protein by residue type reveals that hydrophobic residues are predominantly buried within the interior of each helical subunit, stabilizing the protein core. Hydrophilic and charged residues are enriched on the outer surface and within the internal cavity. This distribution is consistent with Dps being a soluble cytoplasmic protein that binds DNA and coordinates iron, both of which require surface-exposed charged residues
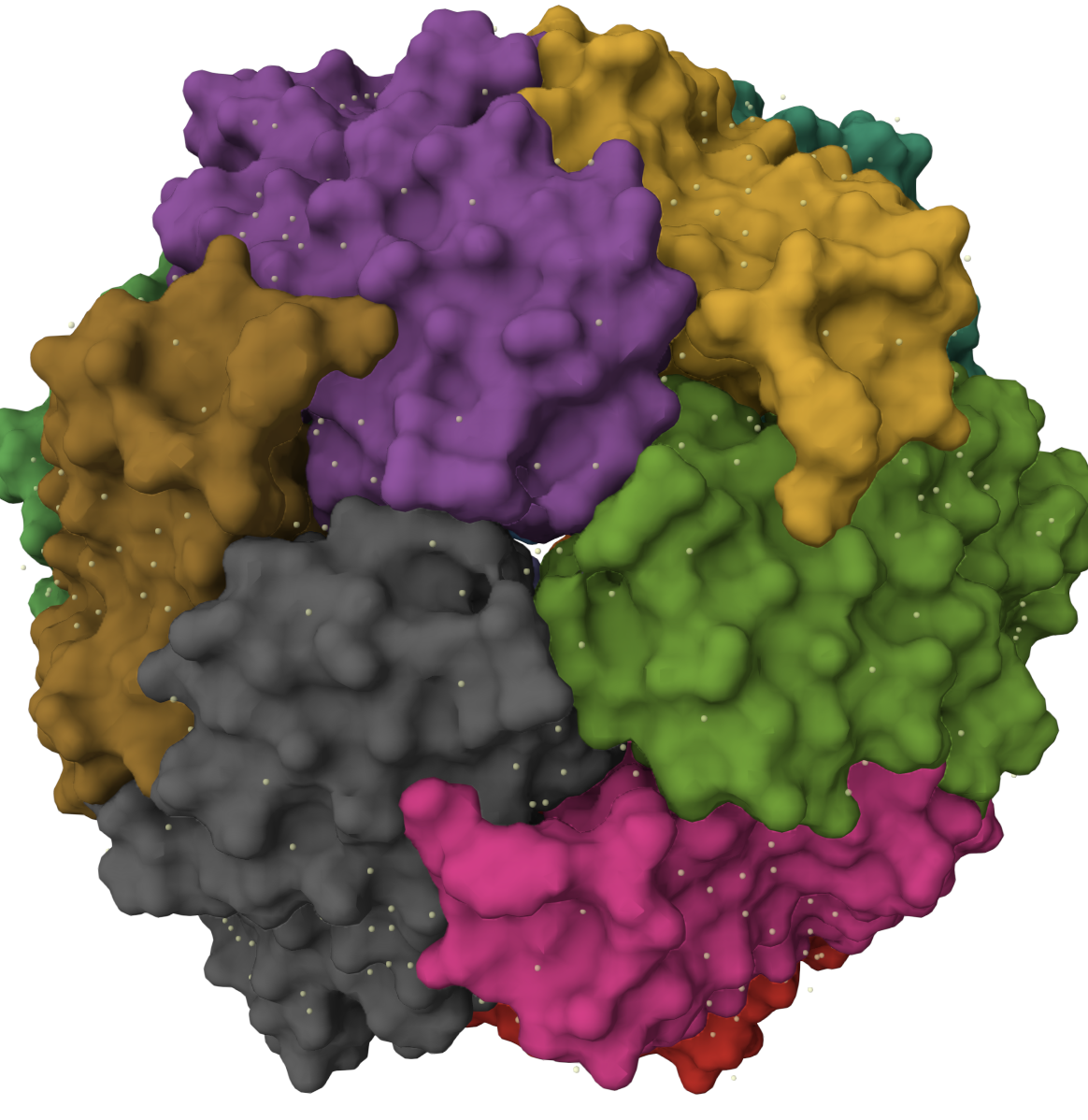
Visualize the surface of the protein. Does it have any “holes” (aka binding pockets)?
I see a center hole and small “insetion like shapes between the sub unites.Chat GPT says Surface visualization reveals that Dps forms a hollow spherical assembly with a large central cavity. Small pores and indentations are visible at the interfaces between subunits, particularly at symmetry axes. These openings likely facilitate iron transport into the internal cavity, consistent with the protein’s role in iron sequestration and stress protection.
Part C. Using ML-Based Protein Design Tools
Assignees for this section
MIT/Harvard students Required
Committed Listeners Required
In this section, we will learn about the capabilities of modern protein AI models and test some of them in your chosen protein.
Copy the HTGAA_ProteinDesign2026.ipynb notebook and set up a colab instance with GPU.
Choose your favorite protein from the PDB.
We will now try multiple things in the three sections below; report each of these results in your homework writeup on your HTGAA website:
C1. Protein Language Modeling
Picture Source: Bordin, Nicola et al (2023). Novel machine learning approaches revolutionize protein knowledge. Trends in Biochemical Sciences, Volume 48, Issue 4, 345 - 359
Picture Source: Bordin, Nicola et al (2023). Novel machine learning approaches revolutionize protein knowledge. Trends in Biochemical Sciences, Volume 48, Issue 4, 345 - 359
Deep Mutational Scans
Use ESM2 to generate an unsupervised deep mutational scan of your protein based on language model likelihoods.
Can you explain any particular pattern? (choose a residue and a mutation that stands out)
(Bonus) Find sequences for which we have experimental scans, and compare the prediction of the language model to experiment.
Latent Space Analysis
Use the provided sequence dataset to embed proteins in reduced dimensionality.
Analyze the different formed neighborhoods: do they approximate similar proteins?
Place your protein in the resulting map and explain its position and similarity to its neighbors.
C2. Protein Folding
Picture Source: Lin et al (2023). Evolutionary-scale prediction of atomic-level protein structure with a language model.
Picture Source: Lin et al (2023). Evolutionary-scale prediction of atomic-level protein structure with a language model.
Folding a protein
Fold your protein with ESMFold. Do the predicted coordinates match your original structure?
Try changing the sequence, first try some mutations, then large segments. Is your protein structure resilient to mutations?
C3. Protein Generation
Picture Source: 1. Post from Sergey Ovchinnikov 2. Roney, Ovchinnikov et al (2022). State-of-the-art estimation of protein model accuracy using AlphaFold. Phys. Rev. Lett. 129, 238101
Picture Source: 1. Post from Sergey Ovchinnikov 2. Roney, Ovchinnikov et al (2022). State-of-the-art estimation of protein model accuracy using AlphaFold. Phys. Rev. Lett. 129, 238101
Inverse-Folding a protein: Let’s now use the backbone of your chosen PDB to propose sequence candidates via ProteinMPNN
Analyze the predicted sequence probabilities and compare the predicted sequence vs the original one.
Input this sequence into ESMFold and compare the predicted structure to your original.
Part D. Group Brainstorm on Bacteriophage Engineering
Assignees for this section
MIT/Harvard students Optional
Committed Listeners Required
Find a group of ~3–4 students
Read through the Phage Reading material listed under “Reading & Resources” below.
Review the Bacteriophage Final Project Goals for engineering the L Protein:
Increased stability (easiest)
Higher titers (medium)
Higher toxicity of lysis protein (hard)
Brainstorm Session
Choose one or two main goals from the list that you think you can address computationally (e.g., “We’ll try to stabilize the lysis protein,” or “We’ll attempt to disrupt its interaction with E. coli DnaJ.”).
Write a 1-page proposal (bullet points or short paragraphs) describing:
Which tools/approaches from recitation you propose using (e.g., “Use Protein Language Models to do in silico mutagenesis, then AlphaFold-Multimer to check complexes.”).
Why do you think those tools might help solve your chosen sub-problem?
Name one or two potential pitfalls (e.g., “We lack enough training data on phage–bacteria interactions.”).
Include a schematic of your pipeline.
This resource may be useful: HTGAA Protein Engineering Tools
Each individually put your plan on your HTGAA website
Include your group’s short plan for engineering a bacteriophage
Week 5 HW: Protein Design Part Two
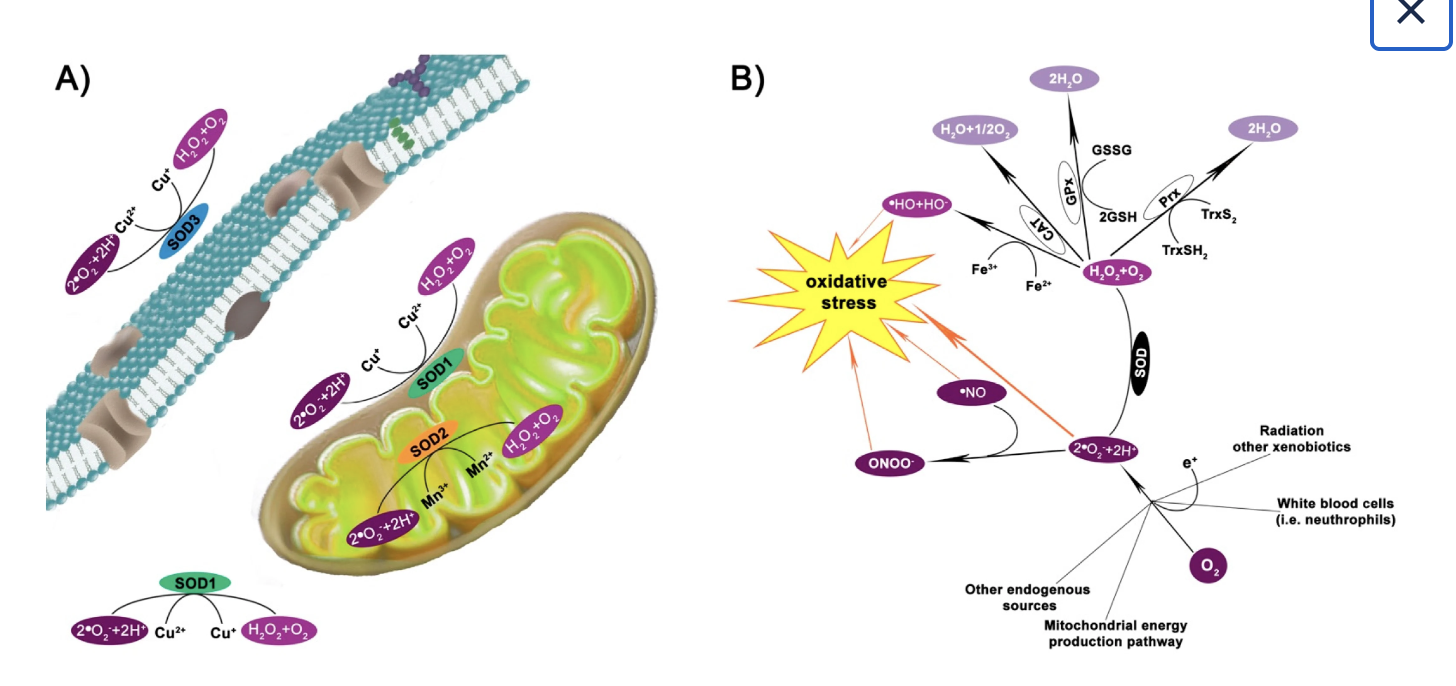
Superoxide dismutase 1 (SOD1) is a cytosolic antioxidant enzyme that converts superoxide radicals into hydrogen peroxide and oxygen. In its native state, it forms a stable homodimer and binds copper and zinc.
Mutations in SOD1 cause familial Amyotrophic Lateral Sclerosis (ALS). Among them, the A4V mutation (Alanine → Valine at residue 4) leads to one of the most aggressive forms of the disease. The mutation subtly destabilizes the N-terminus, perturbs folding energetics, and promotes toxic aggregation.
Your challenge:
Design short peptides that bind mutant SOD1.
Then decide which ones are worth advancing toward therapy.
PART 1
1/ The mutant SOD1 sequence
MATKVLCVLKGDGPVQGIINFEQKESNGPVKVWGSIKGLTEGLHGFHVHEFGDNTAGCTSAGPHFNPLSRKHGGPKDEERHVGDLGNVTADKDGVADVSIEDSVISLSGDHCIIGRTLVVHEKADDLGKGGNEESTKTGNAGSRLACGVIGIAQ
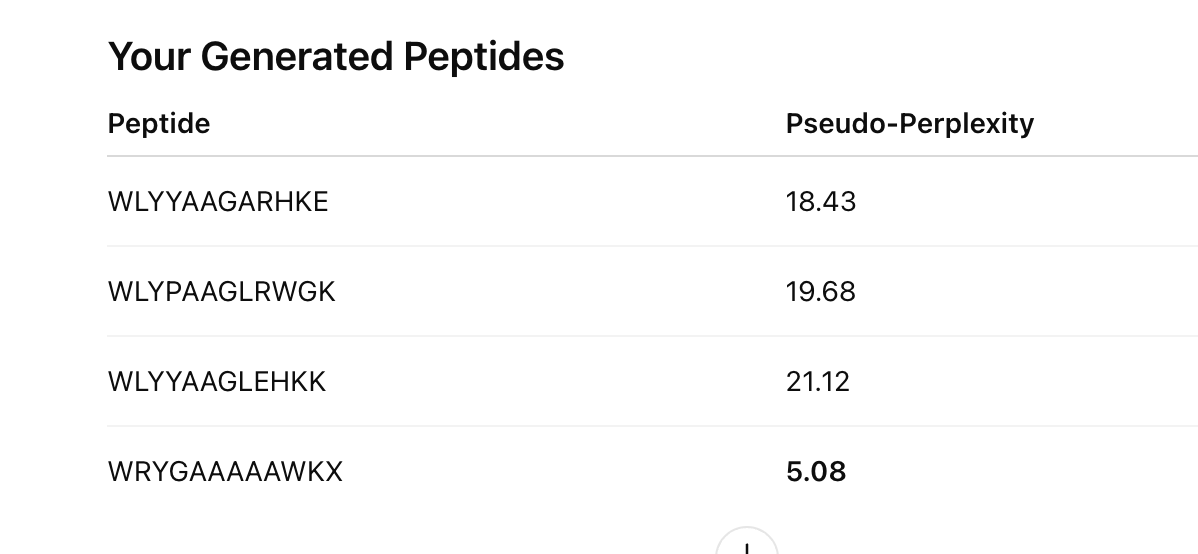
4 generated 12-aa peptides from PepMLM
the comparison peptide: FLYRWLPSRRGG
the perplexity score for each generated peptide, since the prompt says to record PepMLM confidence values
probably a small table you can later paste into your homework document
Part 2: Evaluate Binders with AlphaFold3
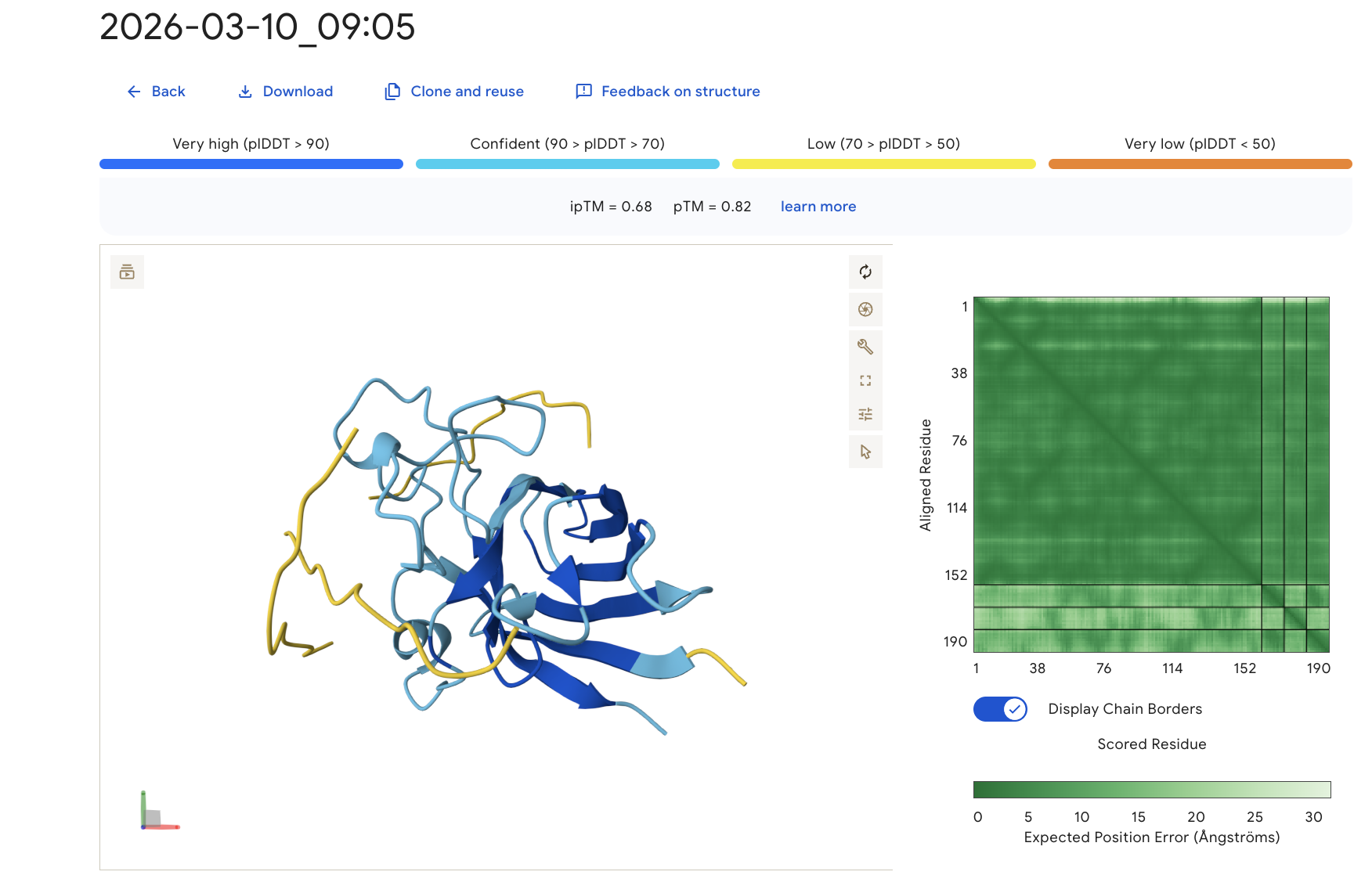
The predicted complex produced an ipTM score of 0.68, suggesting a moderately confident interaction between the peptide and mutant SOD1. The SOD1 β-barrel core is predicted with very high confidence (dark blue), while the peptide shows lower confidence values, which is typical for short flexible peptides. The peptide appears primarily surface-associated rather than deeply buried within the protein structure.
Part 3: Evaluate Properties of Generated Peptides in the PeptiVerse (in progress)
Structural confidence alone is insufficient for therapeutic development. Using PeptiVerse, let’s evaluate the therapeutic properties of your peptide! For each PepMLM-generated peptide:
Paste the peptide sequence.
Paste the A4V mutant SOD1 sequence in the target field.
Check the boxes
Predicted binding affinity
Solubility
Hemolysis probability
Net charge (pH 7)
Molecular weight
Compare these predictions to what you observed structurally with AlphaFold3. In a short paragraph, describe what you see. Do peptides with higher ipTM also show stronger predicted affinity? Are any strong binders predicted to be hemolytic or poorly soluble? Which peptide best balances predicted binding and therapeutic properties?
Choose one peptide you would advance and justify your decision briefly.
Part 4: Generate Optimized Peptides with moPPIt
Now, move from sampling to controlled design. moPPIt uses Multi-Objective Guided Discrete Flow Matching (MOG-DFM) to steer peptide generation toward specific residues and optimize binding and therapeutic properties simultaneously. Unlike PepMLM, which samples plausible binders conditioned on just the target sequence, moPPIt lets you choose where you want to bind and optimize multiple objectives at once.
Open the moPPit Colab linked from the HuggingFace moPPIt model card
Make a copy and switch to a GPU runtime.
In the notebook:
Paste your A4V mutant SOD1 sequence.
Choose specific residue indices on SOD1 that you want your peptide to bind (for example, residues near position 4, the dimer interface, or another surface patch).
Set peptide length to 12 amino acids.
Enable motif and affinity guidance (and solubility/hemolysis guidance if available). Generate peptides.
After generation, briefly describe how these moPPit peptides differ from your PepMLM peptides. How would you evaluate these peptides before advancing them to clinical studies?
1. Components of Phusion High-Fidelity PCR Master Mix
Phusion PCR master mix typically contains:
High-fidelity DNA polymerase
• enzyme that synthesizes new DNA strands
• has proofreading ability, reducing mutation errors
dNTPs (deoxynucleotide triphosphates)
• building blocks used to create new DNA strands
Reaction buffer
• maintains proper pH and salt conditions for enzyme activity
Mg²⁺ ions (magnesium)
• essential cofactor for polymerase activity
Stabilizers and enhancers
• improve enzyme stability and reaction efficiency
Purpose:
To allow accurate amplification of DNA during PCR.
2. Factors that determine primer annealing temperature
Primer annealing temperature depends mainly on:
Primer length
• longer primers bind more strongly
GC content
• G-C pairs have stronger hydrogen bonding
Primer sequence complementarity
• mismatches lower binding strength
Melting temperature (Tm)
• annealing temperature is typically 3–5°C below Tm
Salt concentration in buffer
• affects DNA duplex stability
3. PCR vs Restriction Enzyme Digests
Feature PCR Restriction Digest
Purpose Amplify DNA Cut DNA at specific sites
Enzyme DNA polymerase Restriction endonuclease
Output Many copies of a DNA fragment Linear fragments from cutting
Flexibility Primers allow custom fragments Limited to existing restriction sites
Use case Creating new DNA fragments Preparing plasmids or inserts
PCR is preferable when you need to generate or modify a DNA fragment.
Restriction digestion is useful when cutting DNA at known sequences for cloning.
4. Ensuring fragments work for Gibson Assembly
For Gibson assembly, DNA fragments must have:
overlapping homologous regions (20–40 bp)
so fragments can anneal to each other.
These overlaps can be created by:
• designing primers with overlap sequences
• cutting plasmids at appropriate sites
DNA fragments must also be:
• clean and correctly sized
• free of incompatible ends
5. How plasmid DNA enters E. coli during transformation
Plasmids enter bacteria through competent cell transformation.
Common methods:
Heat shock transformation
cold competent cells + plasmid DNA
↓
heat shock (~42°C)
↓
pores form in membrane
↓
DNA enters cell
or
Electroporation
electric pulse
↓
temporary membrane pores
↓
DNA enters cell
After transformation, cells replicate the plasmid.
6. Another Assembly Method: Golden Gate Assembly
Golden Gate Assembly is a cloning method that uses Type IIS restriction enzymes and DNA ligase in the same reaction.
Type IIS enzymes cut DNA outside their recognition site, creating custom overhangs. These overhangs allow multiple DNA fragments to assemble in a predefined order.
The process cycles between digestion and ligation, allowing fragments to be cut and joined repeatedly until the correct construct forms.
Golden Gate is highly efficient and allows the assembly of many DNA fragments in a single reaction. It is commonly used in synthetic biology to build complex genetic circuits.
Simple diagram
Fragment A Fragment B Fragment C
| | |
Type IIS enzyme cuts → custom overhangs
A – B – C
DNA ligase seals the backbone
PART 2 - Create a Repository for your work
Asimov Kernel is the computational synthetic biology environment.
1️ Create a repository
2️ Create a notebook entry
3️ Rebuild the Repressilator (The repressilator is a famous synthetic gene circuit.)
Repressilator idea:
Gene A represses Gene B
Gene B represses Gene C
Gene C represses Gene A
This results in an oscillating gene expression
A ─| B
B ─| C
C ─| A
Design three synthetic circuits
This assignment is teaching you how genetic circuits are engineered
This is basically electrical engineering for cells.
Promoters = switches
Genes = components
Repressors = logic gates
#1 TOGGLE SWITCH
Gene A represses Gene B
Gene B represses Gene A
Result: stable on/off state.
#2 Inducible gene
Promoter → gene expression when signal present
#3 Oscillator variant
Add feedback loops to control amplitude.
Week 7 HW: Genetic Circuits
Assignment Part 1: Intracellular Artificial Neural Networks (IANNs)
What advantages do IANNs have over traditional genetic circuits, whose input/output behaviors are Boolean functions?
Traditional genetic circuits behave like Boolean logic gates (ON/OFF, 0/1), meaning they produce discrete outputs based on fixed thresholds.
In contrast, Intracellular Artificial Neural Networks (IANNs) offer several advantages:
Continuous (analog) responses rather than binary outputs
Ability to integrate multiple inputs simultaneously with weighted influence
Support for more complex decision-making within cells
Greater flexibility in representing graded biological signals (e.g., concentration levels)
Potential to approximate nonlinear relationships, similar to machine learning models
In short, while Boolean circuits are rigid and rule-based, IANNs allow cells to behave more like adaptive information-processing systems.
Describe a useful application for an IANN; include a detailed description of input/output behavior, as well as any limitations an IANN might face to achieve your goal.
Example: Smart cellular sensor for inflammation
An IANN could be engineered to detect and respond to complex inflammatory environments in the body.
Inputs:
X₁: concentration of inflammatory cytokine A
X₂: concentration of inflammatory cytokine B
X₃: oxidative stress signal
Each input would be encoded as DNA constructs producing regulatory molecules (e.g., endoribonucleases or transcription factors).
Processing:
The IANN integrates these inputs using weighted interactions, allowing the cell to evaluate:
“Is this a mild, moderate, or severe inflammatory state?”
Instead of a simple ON/OFF response.
Output:
Low inflammation → no response
Moderate inflammation → mild reporter signal
High inflammation → strong expression of a therapeutic protein (or fluorescent output)
Why this is powerful
This allows context-sensitive decision-making, rather than triggering responses based on a single threshold.
Limitations:
Biological noise (gene expression variability)
Difficulty in precisely tuning weights and thresholds
Slow response times compared to electronic systems
Metabolic burden on the cell
Limited number of orthogonal (non-interfering) biological components
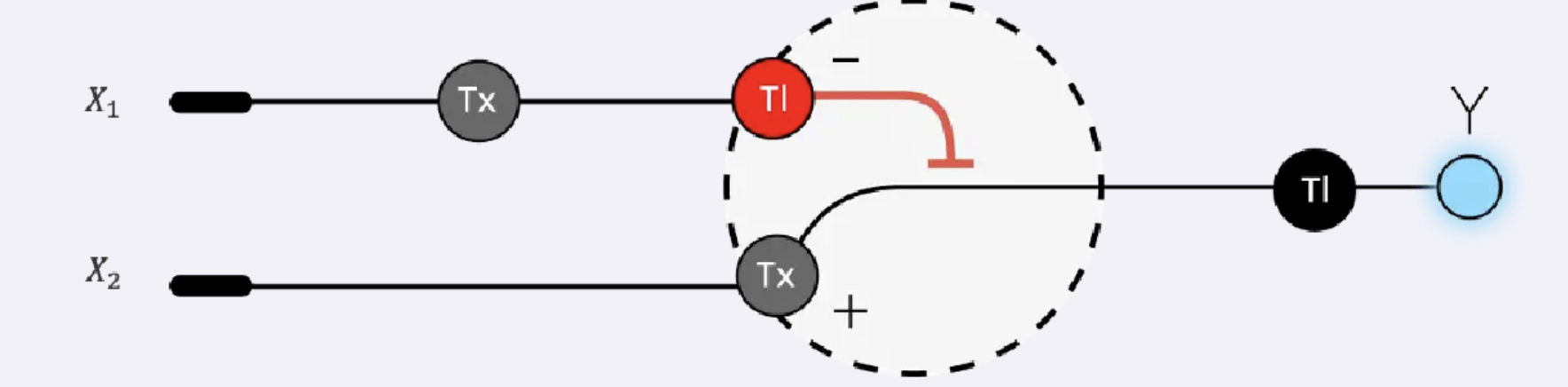
Below is a diagram depicting an intracellular single-layer perceptron where the X1 input is DNA encoding for the Csy4 endoribonuclease and the X2 input is DNA encoding for a fluorescent protein output whose mRNA is regulated by Csy4. Tx: transcription; Tl: translation.
Draw a diagram for an intracellular multilayer perceptron where layer 1 outputs an endoribonuclease that regulates a fluorescent protein output in layer 2.
This intracellular multilayer perceptron uses input DNA sequences to produce endoribonucleases in the first layer, which regulate mRNA stability in the second layer to produce a graded fluorescent output. This architecture enables analog signal integration rather than binary responses.
Assignment Part 1A ## Connecting This to MY Project
My emerging theme: Fire loss → soil → memory → sensing → regeneration
Concept: “Post-Fire Soil Intelligence Circuit”
Instead of abstract cytokines, my inputs become:
Inputs (Layer 0)
X₁ = heavy metal concentration (post-fire contamination)
X₂ = microbial recovery signal (soil health indicator)
X₃ = moisture / environmental recovery
These are real ecological signals.
Layer 1 (Processing layer)
Each input drives expression of:
different regulatory proteins (or endoribonucleases)
These act like weights in a neural network.
Layer 2 (Output)
Instead of just GFP, you could have:
fluorescence (for lab demonstration)
OR scent molecule (👀 geosmin/petrichor tie-in!)
OR pigment production
Conceptual diagram of MY system
POST-FIRE ENVIRONMENT
(low → damaged soil)
(high → recovered soil)
Project Reframe:
A living system that interprets ecological recovery as a continuous signal, rather than a binary “healthy/unhealthy” classification.
Just as human memory after fire is not binary but layered, partial, and evolving, an intracellular neural network allows biological systems to interpret environmental recovery as a gradient rather than a fixed state.
I’m interested in designing a system that brings together several biological sensing pathways that don’t عادة interact — like soil chemistry, microbial recovery, and environmental conditions — and integrating them using an intracellular neural network so the system can produce a graded signal of post-fire recovery rather than a simple on/off response.##
Optional poetic layer (if you want to go there)
You could even imagine:
low recovery → no scent
mid recovery → faint petrichor
high recovery → strong petrichor signal
So the system literally becomes:
soil health → smell of rain → memory of renewal
Assignment Part 2: Fungal Materials
What are some examples of existing fungal materials and what are they used for? What are their advantages and disadvantages over traditional counterparts?
What might you want to genetically engineer fungi to do and why? What are the advantages of doing synthetic biology in fungi as opposed to bacteria?
Assignment Part 3: First DNA Twist Order
Assignment Part 3
Review the Individual Final Project documentation guidelines.
Submit this Google Form with your draft Aim 1, final project summary, HTGAA industry council selections, and shared folder for DNA designs.
Review Part 3: DNA Design Challenge of the week 2 homework.
Design at least 1 insert sequence and place it into the Benchling/Kernel/Other folder you shared in the Google Form above. Document the backbone vector it will be synthesized in on your website.nv
Week 13 HW: Principles and Practices
1. Prove lead-sensing logic
Aim: I am designing a modular genetic cassette in which a heavy-metal sensing element, likely pbrR/pbr, controls either a standard reporter or a geosmin output module, with HSR considered as an auxiliary stress-sensitive element rather than the primary detector
Design intent: Detect bioavailable Pb(II) using a PbrR/pbr lead-responsive sensing module. Initial output will be a fluorescent reporter to validate sensing behavior. A later version may replace the reporter with a geosmin-associated output module for sensory repair signaling.
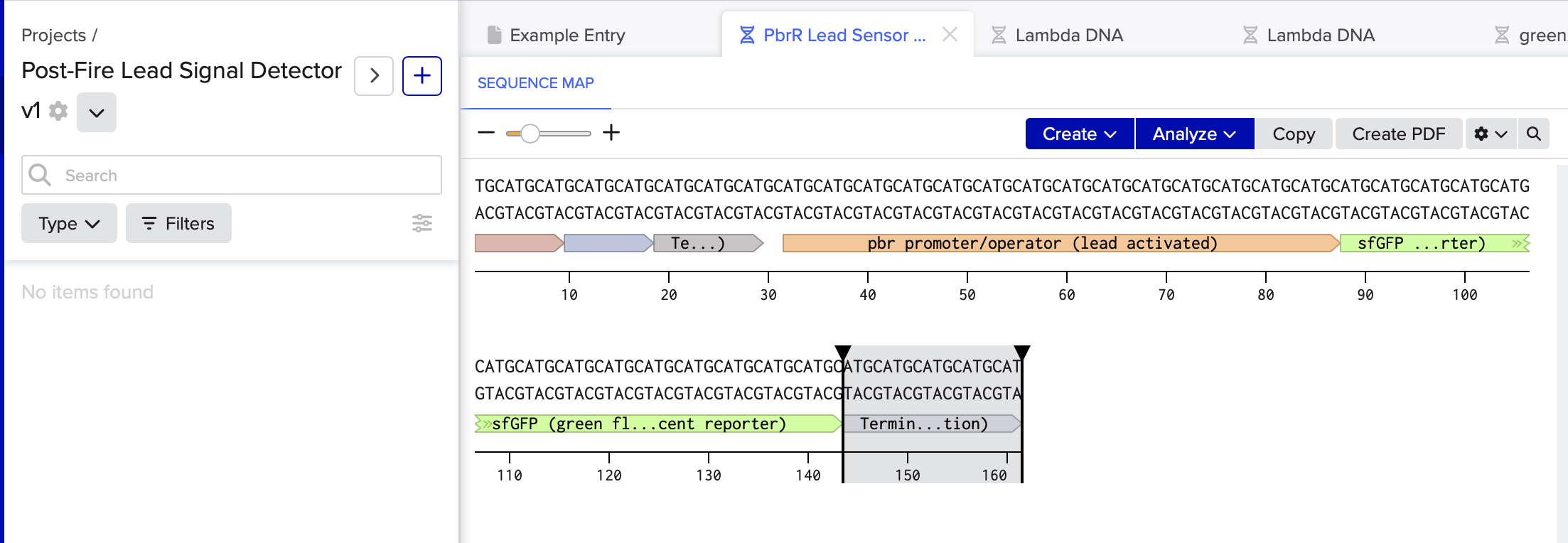
Cassette v1 should respond to bioavailable Pb(II) PbrR + pbr promoter/operator → reporter
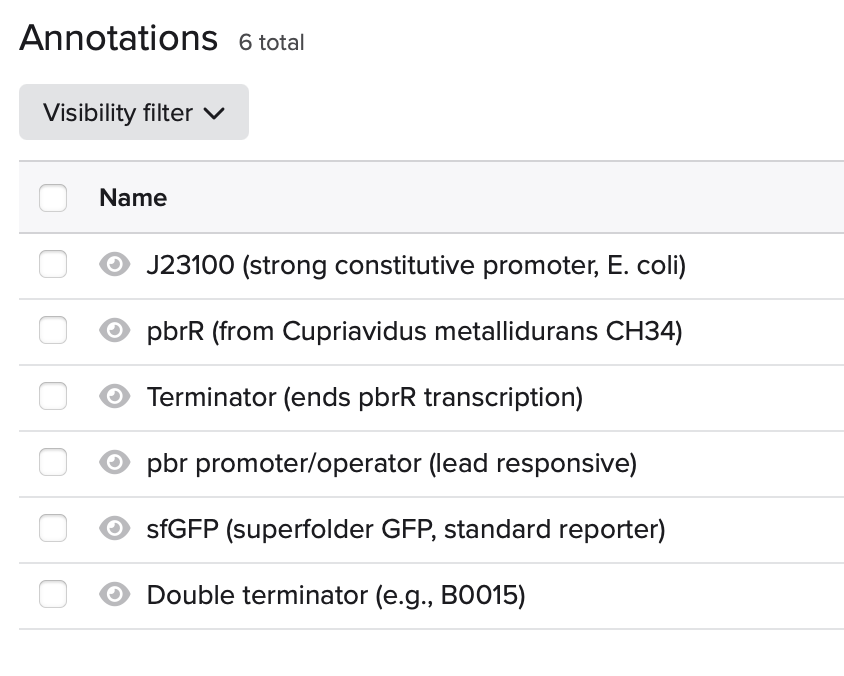
Building aa Benching Circuit Template Promoter → pbrR → Terminator → pbr promoter → sfGFP → Terminator benchling
Assuming E. coli as initial chassis for circuit implementation
2. Make this biologically plausible + lab-ready
I updated the annotiations
Design uses J23100 to constitutively express pbrR (from C. metallidurans). Lead-bound PbrR activates the pbr promoter controlling sfGFP.
Terminators used to isolate transcriptional units. Designed for E. coli chassis. ##
Questions for Elliot
I designed a lead-specific PbrR system. I’m wondering if you’d like me to instead—or additionally—explore an HSR-based stress-responsive promoter
Is PbrR/pbr a good system in your lab’s E. coli setup?
Would you recommend validating with GFP before attempting a geosmin output?
What are my next steps?
Anwers from Eliot
To validate put a small amoont of Lead nitrate ((\text{Pb(NO}{3}\text{)}{2})) or Lead acetate in an agar plate and grow ecoli in the presence of lead. Go to addgene. search PbrR and get the plasmid pjl74y. Regarding petrachor/ geosmin you need to add a that oroduces a similar smell. Use Goldergate to design DNA that emits geosmin smell.List all the supplies i need to conduct the basic experiment and email Elliot.