Week 5 HW: Protein Design Part 2
Part A: SOD1 Binder Peptide Design (From Pranam)
Part 1: Generate Binders with PepMLM
Begin by retrieving the human SOD1 sequence from UniProt (P00441) and introducing the A4V mutation. Unprot Link for SOD1 sequence
MATKAVCVLKGDGPVQGIINFEQKESNGPVKVWGSIKGLTEGLHGFHVHEFGDNTAGCTSAGPHFNPLSRKHGGPKDEERHVGDLGNVTADKDGVADVSIEDSVISLSGDHCIIGRTLVVHEKADDLGKGGNEESTKTGNAGSRLACGVIGIAQMutant SOD1 sequence A4V:
MATVAVCVLKGDGPVQGIINFEQKESNGPVKVWGSIKGLTEGLHGFHVHEFGDNTAGCTSAGPHFNPLSRKHGGPKDEERHVGDLGNVTADKDGVADVSIEDSVISLSGDHCIIGRTLVVHEKADDLGKGGNEESTKTGNAGSRLACGVIGIAQUsing the PepMLM Colab linked from the HuggingFace PepMLM-650M model card
My notebookGenerate four peptides of length 12 amino acids conditioned on the mutant SOD1 sequence.
To your generated list, add the known SOD1-binding peptide FLYRWLPSRRGG for comparison.
Record the perplexity scores that indicate PepMLM’s confidence in the binders.
Binder Pseudo Perplexity WRYPAAALALAE 6.78294 WSYGVVALALGK 10.1846 WRYPVAGLGWAE 20.4686 WRSPAAAAGHGK 8.71141 FLYRWLPSRRGG 20.5338
Part 2 Evaluate Binders with Alphafold3
- Navigate to the AlphaFold Server: alphafoldserver.com
- For each peptide, submit the mutant SOD1 sequence followed by the peptide sequence as separate chains to model the protein-peptide complex.
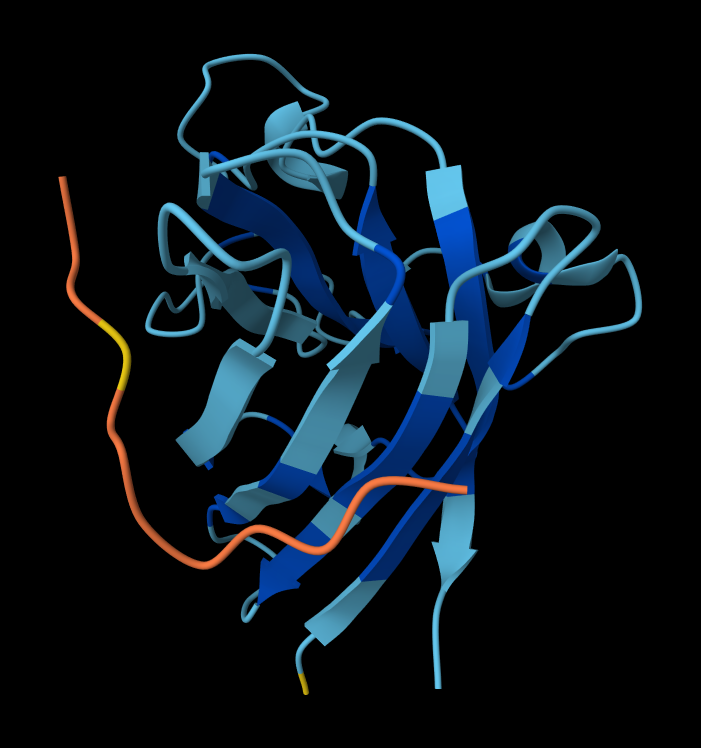
- Peptide 1: WRYPAAALALAE
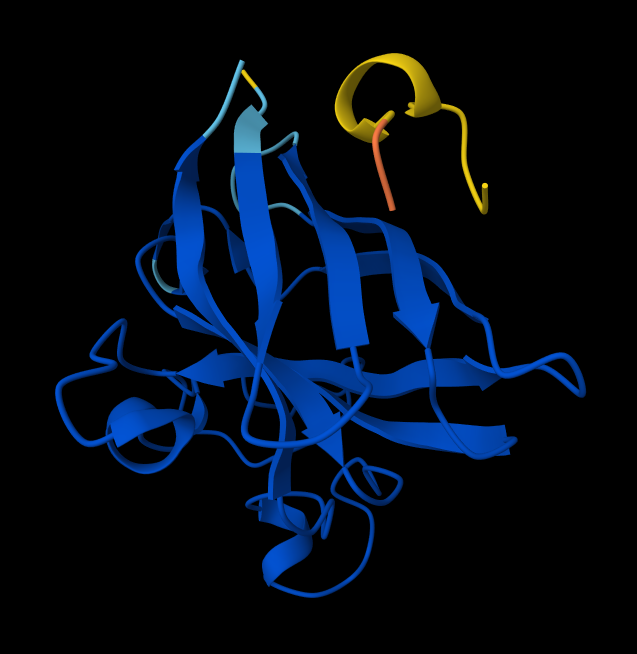
- Peptide 2: WSYGVVALALGK
- Peptide 3: WRYPVAGLGWAE
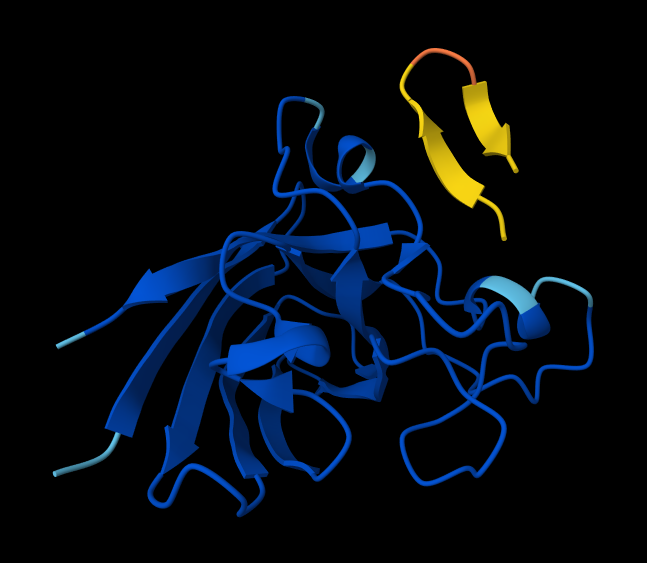
- Peptide 4: WRYPVAGLGWAE
Interaction with N-terminus WRYPVAGLGWAE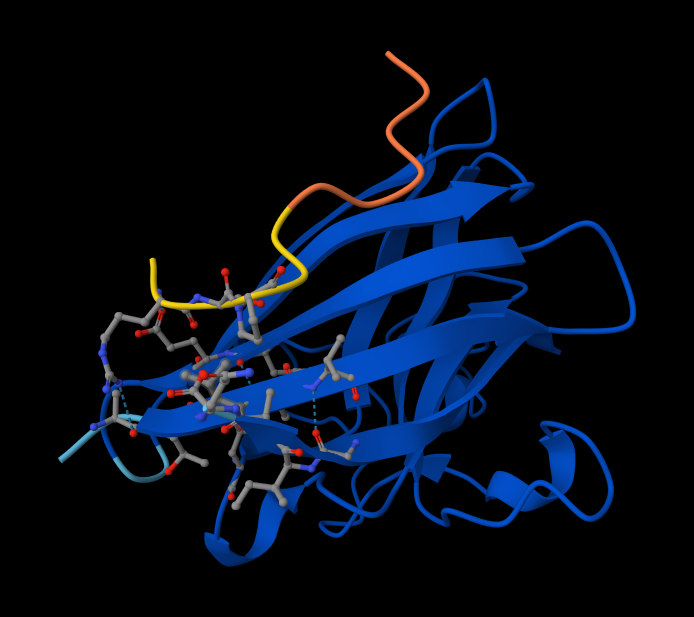
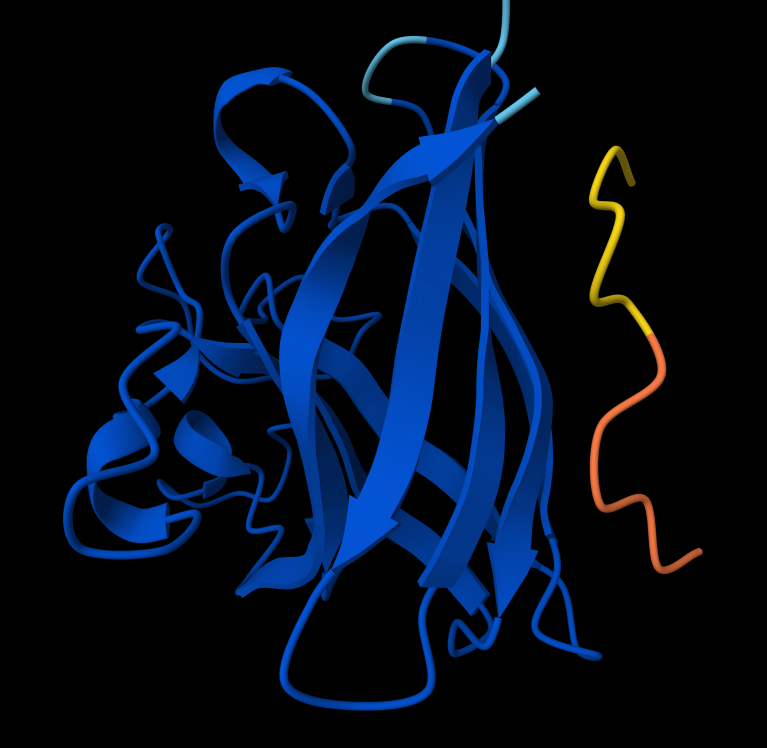
- Peptide 5: FLYRWLPSRRGG
- Record the ipTM score and briefly describe where the peptide appears to bind. Does it localize near the N-terminus where A4V sits? Does it engage the β-barrel region or approach the dimer interface? Does it appear surface-bound or partially buried?
Here are ipTM and pTM obtained from Alphafold:# Sequence ipTM pTM 1 WRYPAAALALAE 0.27 0.76 2 WSYGVVALALGK 0.56 0.85 3 WRYPVAGLGWAE 0.43 0.89 4 WRSPAAAAGHGK 0.51 0.89 5 FLYRWLPSRRGG 0.37 0.82
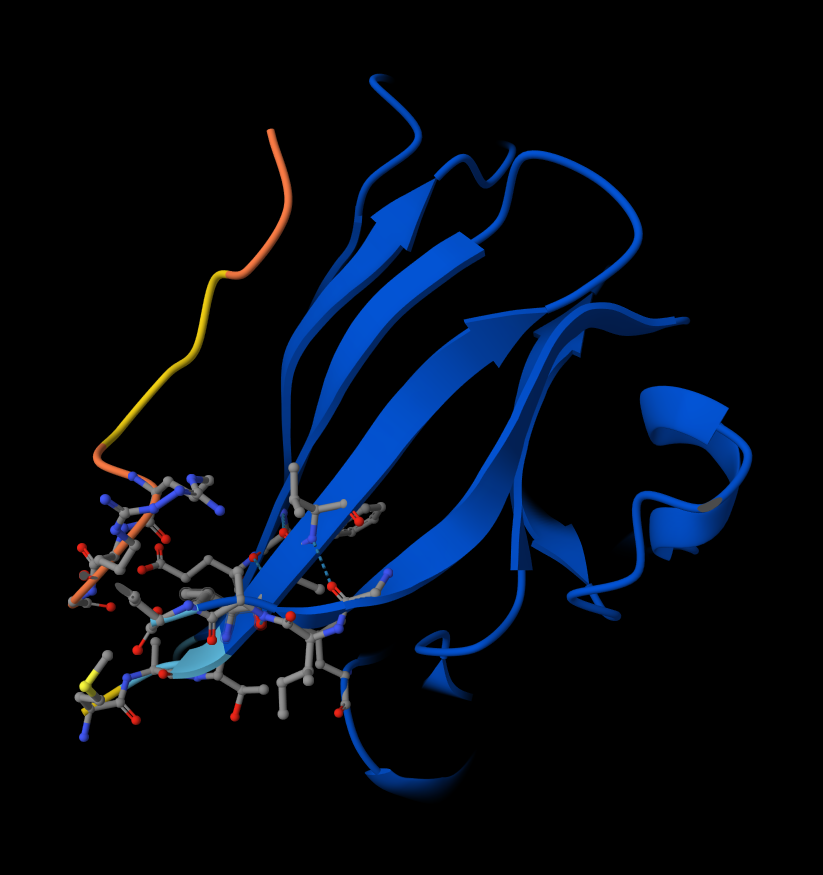
- There is NO interaction with N-terminus of sequence 2 WSYGVVALALGK
- There IS Interaction with N-terminus of sequence 4 WRYPVAGLGWAE
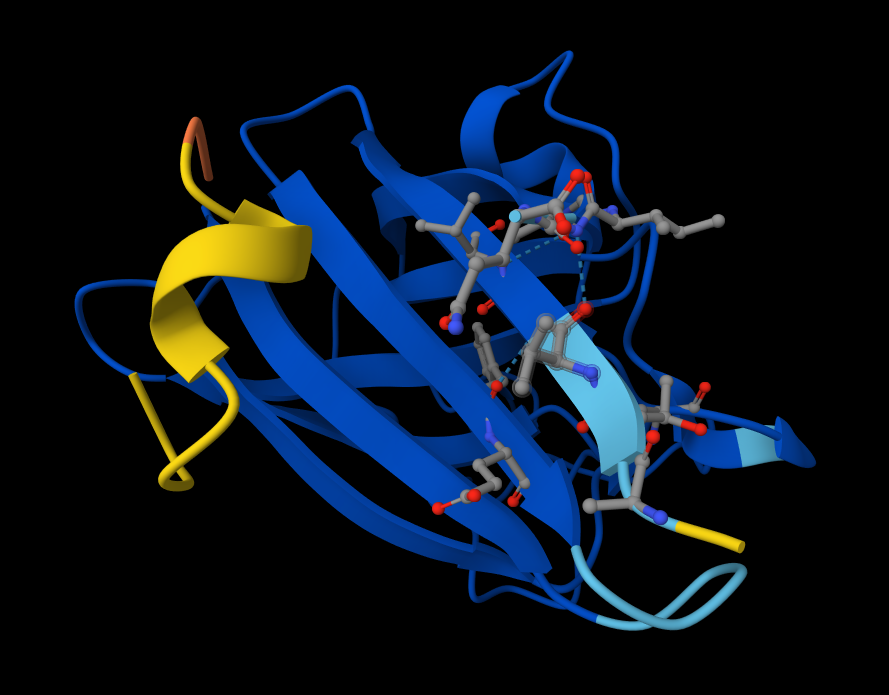
- There IS Interaction with N-terminus of Peptide 5: FLYRWLPSRRGG
Peptide 5: FLYRWLPSRRGG
In a short paragraph, describe the ipTM values you observe and whether any PepMLM-generated peptide matches or exceeds the known binder.
When comparing the PepMLM-generated sequences (1–4) against your known binder, Sequence 5 (FLYRWLPSRRGG), several candidates show marked improvements in both overall structural confidence (pTM) and interface interaction confidence (ipTM). The known binder establishes a baseline ipTM of 0.37 and a pTM of 0.82. Except for Sequence 1, which underperforms across both metrics, all other generated peptides successfully exceed these baselines. Notably, Sequence 2 achieves the highest interaction confidence with an ipTM of 0.56, while Sequences 3 and 4 also demonstrate strong improvements with ipTMs of 0.43 and 0.51, respectively, alongside excellent pTM scores of 0.89. Ultimately, multiple PepMLM-generated peptides do not just match but confidently exceed the predicted binding metrics of your known binder.
Peptide #4 seems promising. Here is why! Metrics Comparison (Sequence 4 vs. Sequence 5) Sequence 4 shows a significant improvement over your known binder, Sequence 5 (FLYRWLPSRRGG):
- Higher Interface Confidence: Sequence 4 boasts an ipTM of 0.51, compared to Sequence 5’s 0.37. This means AlphaFold is much more confident in the exact physical interaction between this peptide and SOD1.
- Higher Overall Confidence: The pTM of 0.89 (up from 0.82) indicates a highly stable and confident overall structural prediction for the entire complex.
Structural Analysis of Sequence 4 Looking at the 3D viewer in your image, your structural observations are highly accurate:N-Terminal Localization (A4V region):
- N-Terminal Localization (A4V region): The binder (shown in yellow/orange) is positioned right against the outer edge of the structural core. In SOD1, the N-terminus (containing the Alanine at position 4, known for the A4V ALS mutation) forms the first $\beta$-strand on the edge of the barrel. Your binder is directly draped over this exact region.
- Engaging the $\beta$-barrel: The peptide is actively interacting with the flat, exposed face of the $\beta$-barrel. You can see the side chains of the binder (the stick representations) pointing down and making contact with the blue $\beta$-sheets.
- Surface-Bound vs. Buried: The peptide is entirely surface-bound. It lies stretched across the convex exterior of the $\beta$-barrel like a strap. It does not penetrate deep into any hydrophobic pockets, nor is it partially buried within the core of the protein.
Part 3: Evaluate Properties of Generated Peptides in the PeptiVerse
Input Property Prediction Value Unit WRYPAAALALAE 💧 Solubility Soluble 1.000 Probability 🩸 Hemolysis Non-hemolytic 0.033 Probability 🔗 Binding Affinity Weak binding 5.621 pKd/pKi 📏 Length 12 aa ⚖️ Molecular Weight 1331.5 Da ⚡ Net Charge (pH 7) -0.23 🎯 Isoelectric Point 6.22 pH 💦 Hydrophobicity (GRAVY) 0.40 GRAVY — — — — — WSYGVVALALGK 💧 Solubility Soluble 1.000 Probability 🩸 Hemolysis Non-hemolytic 0.122 Probability 🔗 Binding Affinity Weak binding 6.984 pKd/pKi 📏 Length 12 aa ⚖️ Molecular Weight 1263.5 Da ⚡ Net Charge (pH 7) 0.76 🎯 Isoelectric Point 8.59 pH 💦 Hydrophobicity (GRAVY) 0.99 GRAVY — — — — — WRYPVAGLGWAE 💧 Solubility Soluble 1.000 Probability 🩸 Hemolysis Non-hemolytic 0.056 Probability 🔗 Binding Affinity Weak binding 6.320 pKd/pKi 📏 Length 12 aa ⚖️ Molecular Weight 1404.6 Da ⚡ Net Charge (pH 7) -0.23 🎯 Isoelectric Point 6.22 pH 💦 Hydrophobicity (GRAVY) -0.16 GRAVY — — — — — WRSPAAAAGHGK 💧 Solubility Soluble 1.000 Probability 🩸 Hemolysis Non-hemolytic 0.015 Probability 🔗 Binding Affinity Weak binding 4.939 pKd/pKi 📏 Length 12 aa ⚖️ Molecular Weight 1208.3 Da ⚡ Net Charge (pH 7) 1.85 🎯 Isoelectric Point 11.00 pH 💦 Hydrophobicity (GRAVY) -0.71 GRAVY — — — — — FLYRWLPSRRGG 💧 Solubility Soluble 1.000 Probability 🩸 Hemolysis Non-hemolytic 0.047 Probability 🔗 Binding Affinity Weak binding 6.029 pKd/pKi 📏 Length 12 aa ⚖️ Molecular Weight 1507.7 Da ⚡ Net Charge (pH 7) 2.76 🎯 Isoelectric Point 11.71 pH 💦 Hydrophobicity (GRAVY) -0.71 GRAVY Let’s Transpose this making it easier to compare.
# Input 💧 Solubility Prediction 💧 Solubility (Prob.) 🩸 Hemolysis Prediction 🩸 Hemolysis (Prob.) 🔗 Binding Prediction 🔗 Binding Affinity (pKd/pKi) 📏 Length (aa) ⚖️ MW (Da) ⚡ Net Charge (pH 7) 🎯 pI (pH) 💦 Hydrophobicity (GRAVY) 1 WRYPAAALALAE Soluble 1.000 Non-hemolytic 0.033 Weak binding 5.621 12 1331.5 -0.23 6.22 0.40 2 WSYGVVALALGK Soluble 1.000 Non-hemolytic 0.122 Weak binding 6.984 12 1263.5 0.76 8.59 0.99 3 WRYPVAGLGWAE Soluble 1.000 Non-hemolytic 0.056 Weak binding 6.320 12 1404.6 -0.23 6.22 -0.16 4 WRSPAAAAGHGK Soluble 1.000 Non-hemolytic 0.015 Weak binding 4.939 12 1208.3 1.85 11.00 -0.71 5 FLYRWLPSRRGG Soluble 1.000 Non-hemolytic 0.047 Weak binding 6.029 12 1507.7 2.76 11.71 -0.71 Here is a comparison of the PeptiVerse predictions with the AlphaFold structural observations based on the data provided:
Part 4: PeptiVerse vs. AlphaFold Comparison
When comparing the AlphaFold structural models to the PeptiVerse property predictions, there is a partial but imperfect alignment between the two tools. AlphaFold identifies Peptide 2 (ipTM 0.56) and Peptide 4 (ipTM 0.51) as having the highest interaction confidence. PeptiVerse partially agrees, predicting Peptide 2 to have the strongest binding affinity (6.984 pKd/pKi) among the candidates. However, the correlation breaks down with Peptide 4; despite its strong AlphaFold interaction score and visually confirmed target engagement at the N-terminus, PeptiVerse predicts it to have the weakest binding affinity of the group (4.939 pKd/pKi).
To answer the specific questions:
- Do peptides with higher ipTM also show stronger predicted affinity? Only sometimes. While Peptide 2 boasts both the highest ipTM and the highest PeptiVerse affinity, Peptide 4 shows a stark contrast (high ipTM, lowest PeptiVerse affinity).
- Are any strong binders predicted to be hemolytic or poorly soluble? No. All evaluated peptides, including the strongest predicted binders, are uniformly predicted to be highly soluble (1.000 probability) and non-hemolytic, with hemolysis probabilities remaining comfortably low across the board (between 0.015 and 0.122).
- Which peptide best balances predicted binding and therapeutic properties? Peptide 4 (WRSPAAAAGHGK) offers the best overall balance. Even though its PeptiVerse binding affinity score is low, it correctly binds to the target N-terminus region (unlike Peptide 2), has the highest overall structural confidence alongside Peptide 3 (pTM 0.89), and features the absolute lowest hemolytic probability (0.015).
Recommended Peptide for Advancement
I would advance Peptide 4 (WRSPAAAAGHGK). Justification: While Peptide 2 scores higher in raw interaction metrics (ipTM and PeptiVerse affinity), AlphaFold indicates it fails to interact with the target N-terminus where the A4V mutation is located. Peptide 4, on the other hand, perfectly localizes to the target A4V region on the edge of the $\beta$-barrel and remains entirely surface-bound. Furthermore, it significantly outperforms the known binder (Sequence 5) in both interface confidence (0.51 vs 0.37) and overall complex stability (0.89 vs 0.82), while possessing the safest predicted therapeutic profile with the lowest risk of hemolysis.
Part 4: Generate Optimized Peptides with moPPIt
| Binder | Hemolysis | Non-Fouling | Solubility | Affinity | Motif |
|---|---|---|---|---|---|
| RKTGTDIQKQKS | 0.9660863652825356 | 0.896660327911377 | 0.9166666865348816 | 5.268377780914307 | 0.8262002468109131 |
| EKQGLKKKTETC | 0.9825279489159584 | 0.9362507462501526 | 0.9166666865348816 | 5.7541728019714355 | 0.674345850944519 |
| EETKKSEEKRDT | 0.973269073292613 | 0.9696547985076904 | 1.0 | 5.26902961730957 | 0.15266366302967072 |
| STREQRDRERDH | 0.9473759010434151 | 0.961462676525116 | 1.0 | 5.949229717254639 | 0.001138034276664257 |
Here is a comparison between the newly generated moPPIt peptides and your previous PepMLM candidates, along with a standard pre-clinical evaluation pipeline.
moPPIt vs. PepMLM Peptides: Key Differences
The most striking differences between the two sets of generated peptides lie in their predicted safety profiles and sequence compositions:
- Hemolytic Risk (The Dealbreaker): Your PepMLM peptides were predicted to be incredibly safe, with hemolysis probabilities near zero (0.015 – 0.122). In stark contrast, the moPPIt peptides have alarmingly high predicted hemolysis scores (0.947 – 0.982). This suggests the moPPIt candidates would likely lyse red blood cells, making them highly toxic for systemic therapeutic use.
- Sequence Composition and Charge: A quick look at the moPPIt sequences (e.g.,
EETKKSEEKRDT,STREQRDRERDH) shows they are heavily saturated with charged and polar amino acids like Lysine (K), Arginine (R), Glutamic Acid (E), and Aspartic Acid (D). While this explains their excellent solubility, highly cationic/amphipathic sequences often act like antimicrobial peptides that disrupt cell membranes, which perfectly explains their high hemolytic predictions. The PepMLM peptides were much more balanced in their hydrophobic/hydrophilic ratios. - Binding Affinity: The predicted binding affinities are relatively comparable between the two groups. The moPPIt peptides range from 5.268 to 5.949 pKd/pKi, which sits squarely in the middle of the PepMLM range (4.939 to 6.984). MoPPIt did not generate a noticeably stronger binder than your best PepMLM candidates.
Pre-Clinical Evaluation Pipeline
Before any computational peptide can advance to clinical studies, it must transition from in silico predictions to rigorous in vitro and in vivo experimental validation. Because your current data is entirely predictive, here is how I’d evaluate these candidates:
1. Experimental Validation of Binding (In Vitro)
- Synthesize the Peptides: Chemically synthesize the top candidates (e.g., chosen PepMLM Peptide 4).
- Affinity Assays: Use techniques like Surface Plasmon Resonance (SPR), Biolayer Interferometry (BLI), or Isothermal Titration Calorimetry (ITC) against purified mutant SOD1 (A4V) to measure the true dissociation constant ($K_d$) and validate the AlphaFold/PeptiVerse predictions.
2. Safety and Toxicity Screening
- RBC Hemolysis Assay: Expose human red blood cells to the peptides to physically verify the hemolysis predictions. This is especially crucial to confirm if the moPPIt peptides are truly as toxic as predicted.
- Cytotoxicity Assays: Test the peptides on standard mammalian cell lines (e.g., HEK293) and relevant neuronal cell lines using MTT or WST-1 assays to ensure they do not kill the target cells.
3. Efficacy and Functional Assays
- Aggregation Inhibition: Since the A4V mutation in SOD1 causes ALS through toxic protein aggregation, I would run in vitro aggregation assays (like Thioflavin T fluorescence) to see if binding the peptide successfully stabilizes SOD1 and prevents it from misfolding and clumping together.
4. Pharmacokinetics and Stability
- Serum Stability: Peptides are notoriously unstable in the body because proteases chop them up. I would incubate the peptides in human serum and use mass spectrometry over time to determine their half-life. (If they degrade too fast, I might need to introduce D-amino acids or cyclize them). Here is a draft for your final summary paragraph and evaluation pipeline that you can easily plug into your markdown file.
Conclusion: PepMLM vs. moPPIt Generation Methods
Comparing the generated candidates from PepMLM and moPPIt highlights a critical divergence in predicted therapeutic safety. While both models produced peptides with comparable predicted binding affinities (ranging from ~4.9 to 6.9 pKd/pKi), their physicochemical profiles differ drastically. The moPPIt candidates are characterized by highly polar, charged sequences that guarantee excellent solubility but result in unacceptably high predicted hemolysis scores (>0.94). This suggests a strong likelihood of non-specific membrane disruption and systemic toxicity. Conversely, the PepMLM candidates—particularly Peptide 4—maintained an excellent balance of validated target engagement (N-terminal localization), structural confidence, and near-zero predicted hemolysis. Therefore, the PepMLM outputs represent superior starting points for therapeutic development.
Proposed Pre-Clinical Evaluation Pipeline
Before advancing any of these in silico predictions toward clinical applications, a rigorous sequence of empirical validation is required:
- In Vitro Binding Assays: Utilizing techniques like Surface Plasmon Resonance (SPR) or Biolayer Interferometry (BLI) against purified mutant SOD1 (A4V) to establish the true physical dissociation constant ($K_d$) and validate the computational affinity scores.
- Toxicity Screening: Conducting human red blood cell (RBC) hemolysis assays and mammalian cytotoxicity assays (e.g., on standard HEK293 or neuronal cell lines) to physically verify the safety predictions and rule out the toxicity seen in the moPPIt candidates.
- Functional Efficacy Assays: Performing in vitro aggregation assays (such as Thioflavin T fluorescence) to confirm whether peptide binding successfully stabilizes the SOD1 monomer and prevents the toxic misfolding associated with ALS.
- Pharmacokinetic Profiling: Evaluating the in vitro serum stability of the peptides to determine their half-life against protease degradation, which will guide necessary modifications (like cyclization or incorporating D-amino acids) for in vivo viability.
Part C Final Project: L-Protein Mutants
Based on the “HTGAA 2026 Recitation: Protein Design II” presentation, the step-by-step instructions for Option A: Lysis Protein Mutagenesis (referred to as “Option 1” in some slides) are as follows:
Goal
The ultimate goal is to design mutated versions of the L protein (lysis protein) to improve its ability to infect and kill E. coli.
Step-by-Step Instructions
Design Mutated Versions of the L Protein: Determine your design strategy, such as introducing one or multiple point mutations. Consider whether to use:
- Silent mutations: Mutations that do not change the amino acid sequence.
- Missense mutations: Mutations that result in a different amino acid.
Navigate Gene Overlaps: Be aware that the L-protein gene overlaps with two other genes in the compact MS2 genome.
- Crucial Constraint: Ensure your mutations do not introduce stop codons into the reading frames of the overlapping genes.
- Consider whether missense mutations in those overlapping reading frames will impact phage assembly.
Synthesis: Synthesize your designed L protein mutant genes.
Cloning: Clone the mutant gene into a plasmid, typically using a method like Gibson Assembly.
Experimental Testing: Test the effectiveness of the mutant L protein in E. coli by evaluating the following:
- Lethality: Do the mutant phages successfully kill the E. coli?
- Speed: How quickly do the mutant phages kill the bacteria?
- Resistance: Is the E. coli able to develop resistance against your mutant phages?
Evaluation Methods
* **Plaque Assay**: Use this to visually confirm and quantify the phage's effectiveness.
* **OD-600 Measurement**: Use this measurement for initial versions to track bacterial growth and lysis over time.
Markdown Table
| Index | Position | Wild-Type AA | Mutation AA | LLR Score |
|---|---|---|---|---|
| 989 | 50 | K (Lysine) | L (Leucine) | 2.561468 |
| 574 | 29 | C (Cysteine) | R (Arginine) | 2.395427 |
| 769 | 39 | Y (Tyrosine) | L (Leucine) | 2.241780 |
| 575 | 29 | C (Cysteine) | S (Serine) | 2.043150 |
| 173 | 9 | S (Serine) | Q (Glutamine) | 2.014325 |
| 573 | 29 | C (Cysteine) | Q (Glutamine) | 1.997049 |
| 572 | 29 | C (Cysteine) | P (Proline) | 1.971029 |
| 569 | 29 | C (Cysteine) | L (Leucine) | 1.960646 |
| 987 | 50 | K (Lysine) | I (Isoleucine) | 1.928801 |
| 1049 | 53 | N (Asparagine) | L (Leucine) | 1.864932 |
What This Table Means
This dataset represents a Log-Likelihood Ratio (LLR) Score analysis of specific mutations. In bioinformatics, an LLR score usually measures how “tolerable” or “likely” a mutation is compared to the original (wild-type) state, based on evolutionary data from a Multiple Sequence Alignment (MSA).
1. Wild-Type vs. Mutation
- Wild-Type AA: The “normal” amino acid found at that specific position in the healthy or reference version of the protein.
- Mutation AA: The specific change (substitution) being tested or observed.
2. The LLR Score (Log-Likelihood Ratio)
This is a statistical comparison of two hypotheses:
- Hypothesis A: The mutation is consistent with the evolutionary constraints of that protein family.
- Hypothesis B: The mutation is a random occurrence (the “background” model).
A high positive score (like the 2.56 at position 50) generally suggests that the mutation is favored or highly significant within the context of the model. Depending on the specific tool you are using (e.g., SIFT, PolyPhen, or a custom PSSM), this usually means:
- High Conservation: The mutation aligns well with what evolution “prefers” at that spot.
- Functional Impact: In some contexts, a very high LLR can actually point toward a pathogenic or “damaging” mutation because the change is so statistically different from the expected distribution that it likely disrupts the protein’s stability.
3. Specific Observations
- Position 29 (Cysteine): You have five different mutations listed for this single spot (R, S, Q, P, L). Cysteine is unique because it forms disulfide bridges. The fact that many different mutations here have high scores suggests that Position 29 is a critical structural “node” where any change is statistically significant.
- Position 50 (Lysine to Leucine): This is your highest score. Moving from a positively charged, hydrophilic residue (K) to a hydrophobic residue (L) is a major chemical shift. The high score indicates this specific swap is a high-confidence prediction by the model.
Top 30 Mutation scores
| Position | Wild_Type_AA | Mutation_AA | LLR_Score |
|---|---|---|---|
| 50 | K | L | 2.56146776676178 |
| 29 | C | R | 2.3954269886016846 |
| 39 | Y | L | 2.2417796850204468 |
| 29 | C | S | 2.043149709701538 |
| 9 | S | Q | 2.0143247842788696 |
| 29 | C | Q | 1.997049331665039 |
| 29 | C | P | 1.9710285663604736 |
| 29 | C | L | 1.960646152496338 |
| 50 | K | I | 1.9288012981414795 |
| 53 | N | L | 1.8649320602416992 |
| 61 | E | L | 1.8180980682373047 |
| 52 | T | L | 1.8139675855636597 |
| 50 | K | F | 1.8020694255828857 |
| 29 | C | T | 1.7972469329833984 |
| 29 | C | K | 1.7958779335021973 |
| 5 | F | Q | 1.7952444553375244 |
| 5 | F | R | 1.6597166061401367 |
| 29 | C | A | 1.6486561298370361 |
| 27 | Y | R | 1.6280605792999268 |
| 22 | F | R | 1.6020281314849854 |
| 5 | F | P | 1.5968914031982422 |
| 50 | K | V | 1.594576120376587 |
| 50 | K | S | 1.574556827545166 |
| 5 | F | T | 1.5590240955352783 |
| 5 | F | S | 1.5564172267913818 |
| 45 | A | L | 1.5392482280731201 |
| 39 | Y | S | 1.5174565315246582 |
| 27 | Y | S | 1.4970526695251465 |
| 40 | V | L | 1.4776304960250854 |
| 27 | Y | L | 1.4746370315551758 |
I compared the Top-30 notebook mutation scores with the experimental L-Protein mutant dataset as required in Option 1 Step 4 of the homework (checking whether computational scores correlate with experimental lysis results).
Below is the analysis and interpretation.
1. How the comparison was done
To test correlation:
Matched mutations between the two datasets using:
- Amino-acid position
- Mutated residue
For each overlapping mutation we compared:
- Notebook score (LLR score) → predicted effect from the language-model mutagenesis notebook
- Experimental outcome → Lysis activity from the experimental dataset
Only mutations appearing in both datasets were included.
Result:
- 11 overlapping mutations were found.
Examples of overlapping mutations:
| Position | Mutation | Notebook Score (LLR) | Experimental Lysis |
|---|---|---|---|
| 29 | C → R | 2.395 | 0 |
| 29 | C → S | 2.043 | 0 |
| 50 | K → I | 1.929 | 0 |
| 50 | K → S | 1.575 | 0 |
| 39 | Y → S | 1.517 | 0 |
| 27 | ? → S | 1.497 | 0 |
2. Correlation result
The experimental Lysis values for all matched mutations were 0.
This means:
- None of the high-scoring notebook mutations produced detectable lysis in the experimental dataset.
Therefore:
No statistical correlation can be calculated because the experimental values have no variation.
3. Interpretation
From these results:
The notebook scores do NOT correlate with the experimental data (for the overlapping mutations).
Observations:
Several mutations predicted as beneficial (high positive scores) experimentally show no lysis activity.
This highlights a key limitation of protein language-model mutational scoring:
- The model predicts sequence plausibility / evolutionary likelihood
- It does not directly predict biological function like membrane pore formation or host lysis.
structure-based or sequence models may not fully capture functional effects of mutations.
4. Key conclusion
The experimental L-Protein mutant data do not correlate with the mutational scores produced by the notebook. Among the mutations present in both datasets, all showed no lysis activity experimentally despite having positive computational scores, suggesting that the language-model–derived scores alone are insufficient to predict functional lysis activity of the MS2 L protein.
For Option 1, I compared the top-30 mutations from the notebook with the experimental L-protein mutant dataset by matching both the amino-acid position and the substituted residue. I found only two exact overlaps between the two files: C29R and K50I. Both mutations had positive notebook scores (C29R = 2.395, K50I = 1.929), but both showed no lysis experimentally (Lysis = 0). K50I still had detectable protein levels, which suggests that the mutant can be expressed but is not functional for lysis. Because the overlapping experimental values are all zero, there is not enough variation to calculate a meaningful correlation coefficient. Qualitatively, the overlap does not support a positive correlation between the notebook scores and experimental lysis activity. This suggests that the notebook scores are more reflective of sequence plausibility than of the specific biological function we care about here, namely productive L-protein-mediated lysis.
Best 5 mutations to propose
I would propose these five single mutants:
- P13L — soluble
- S15A — soluble
- R18G — soluble
- L44P — transmembrane
- A45P — transmembrane
This satisfies the assignment constraint of having at least 2 mutations in the soluble region and at least 2 in the transmembrane region. The homework notes that the L protein is 75 aa long and that the last 35 residues are the transmembrane region, so positions 41–75 are transmembrane and positions 1–40 are soluble.
Why these 5
I prioritized mutations that were already positive in the experimental dataset, because the direct comparison showed that the notebook scores did not correlate well with experimental lysis.
Soluble-region choices
- P13L: experimentally positive in replicate measurements and also had good protein levels, so it looks like a strong, reproducible soluble-domain candidate.
- S15A: experimentally positive with good protein levels, making it a clean conservative mutation in the soluble region.
- R18G: experimentally positive with good protein levels; this is a useful third soluble-region option because it changes charge and side-chain bulk, which could alter the DnaJ-interacting region.
Transmembrane choices
- L44P: experimentally positive in replicate measurements with protein present; because it sits in the membrane segment, it is a strong candidate for affecting pore formation or oligomerization.
- A45P: experimentally positive with protein present and immediately adjacent to L44, suggesting this part of the transmembrane helix is functionally important and permissive to beneficial perturbation.
I selected P13L, S15A, R18G, L44P, and A45P because these mutations are supported by the experimental L-protein mutant dataset as positive for lysis, whereas the notebook scores did not show useful agreement with experimental function in the small set of exact overlaps. I therefore used the experimental data as the primary filter and chose mutations that also satisfy the assignment requirement to include both soluble-region and transmembrane-region variants. The soluble mutations may alter folding or DnaJ dependence, while the transmembrane mutations may alter membrane insertion, oligomerization, or pore formation.
Answer: Using AF2-Multimer to Generate a Multimeric Assembly of L-Protein
To perform this step, I would use AlphaFold2-Multimer and enter the L-protein sequence multiple times as separate chains, with each chain separated by a colon (:). The reason for doing this is that the working hypothesis in the homework is that the L-protein forms an oligomeric assembly in the membrane that creates a perforation or pore, which is how it causes lysis. The homework specifically states that AF2-Multimer can be used for this by formatting the query as repeated chains separated by colons.
The full L-protein sequence provided in the homework is:
Example AF2-Multimer query strings
Dimer
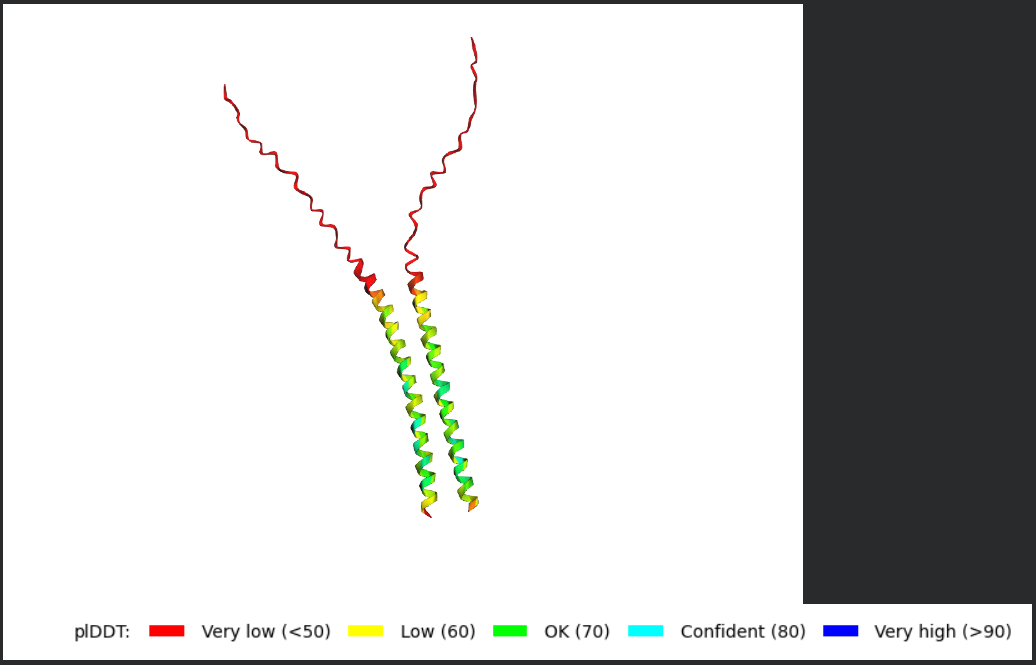
Trimer
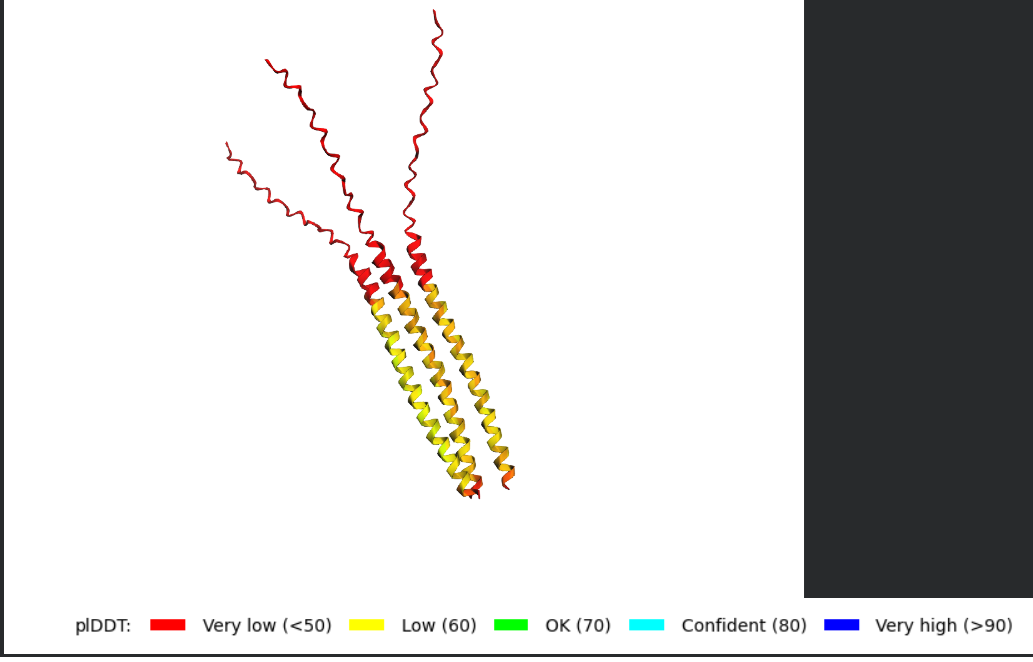
Tetramer
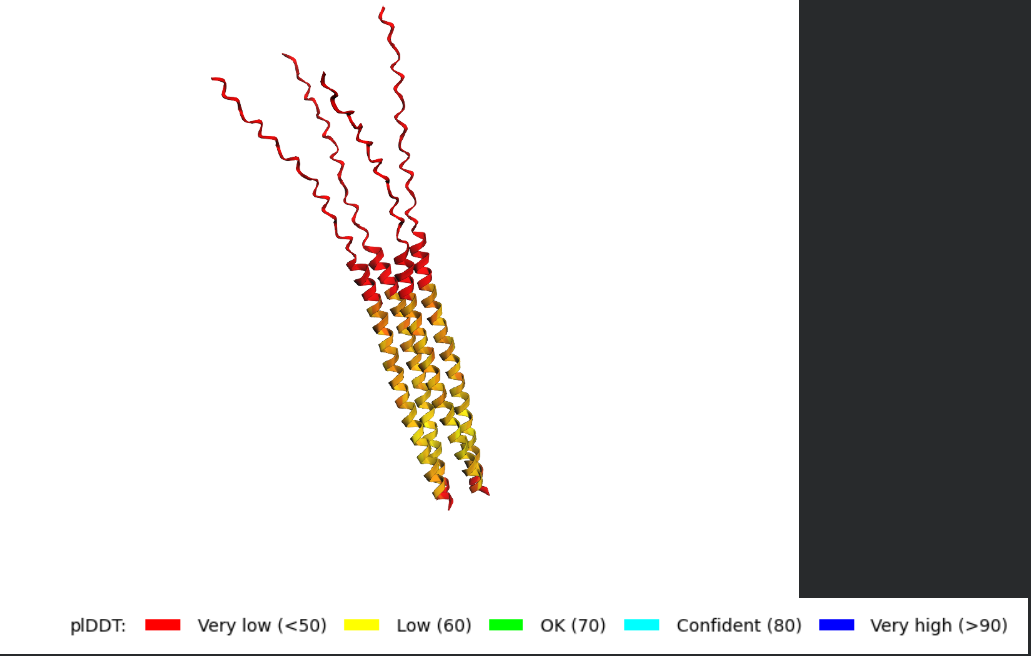
Procedure
- Open the AF2-Multimer Colab notebook linked in the homework.
- Paste one of the multichain query strings into the sequence input field.
- Start by modeling the wild-type sequence as a dimer, then repeat with a trimer and tetramer.
- Run the notebook with the default multimer settings.
- Inspect the top-ranked models and compare how the chains pack together.
What I would look for in the models
The homework notes that the L-protein contains a soluble N-terminal domain and a transmembrane region in the last 35 residues, which means the C-terminal portion is expected to sit in the membrane and may be involved in pore formation.
When analyzing the AF2-Multimer models, I would look for:
- whether the transmembrane helices cluster together
- whether the assembly looks symmetric
- whether the helices create a central cavity or pore-like arrangement
- whether the soluble N-terminal domains remain exposed or form stabilizing contacts
- whether the same overall arrangement appears across multiple ranked models
If the same oligomeric arrangement appears repeatedly, that would support the idea that the L-protein may self-assemble into a membrane-active complex.
How to use this for mutant analysis
After modeling the wild-type sequence, I would test selected mutants in the same way by replacing the appropriate residue in each chain and rerunning AF2-Multimer. For example, I could compare wild type vs. mutants such as P13L or L44P to see whether the mutation:
- preserves the assembly
- changes the packing between chains
- disrupts the transmembrane helix bundle
- alters the plausibility of a pore-like structure
Important limitation
The homework also warns that AF2-Multimer is not very reliable for membrane proteins or large membrane assemblies, so these predictions should be treated as hypothesis-generating rather than definitive structural proof. In other words, AF2-Multimer can help suggest whether oligomerization is structurally plausible, but it cannot by itself prove the real membrane pore architecture of the L-protein.
Final write-up statement
I used AF2-Multimer to test whether the MS2 L-protein could form a multimeric assembly by entering multiple copies of the L-protein sequence separated by colons, so that each copy would be treated as a separate interacting chain. I modeled dimeric, trimeric, and tetrameric assemblies because the working hypothesis is that the L-protein oligomerizes in the membrane to form a perforation or pore. I then examined whether the transmembrane helices packed together into a plausible pore-like structure and whether this arrangement was consistent across the top-ranked models. Because AF2-Multimer is limited for membrane proteins, I interpreted these results as hypothesis-generating rather than definitive evidence of the true assembly.