Affiliation: Committed Listener at BioClub Tokyo Node (HTGAA 2026)
“I used to be a computer person, but I’ve realized that the most interesting programming language is DNA. Biology is moving from a science to an engineering discipline.” — Jensen Huang, CEO of NVIDIA
🚀 My Mission: Scaling Cancer Research
As a student in Pakistan, I have witnessed the challenges of accessing high-end therapeutics. My research is focused on bridging the gap between advanced synthetic biology and affordable healthcare.
Core Interests:
Oncolytic Viral Therapy: Building on my experience from the iGEM Venture Creation Lab (2025).
Automated Biomanufacturing: Leveraging Cloud Labs to produce therapeutic peptides like BmK CT for Glioma research.
Genetic Diversity: My FYP on the genetic characterization of immune genes in domestic Yak from Northern Pakistan has given me a deep appreciation for local biological assets.
🛠 Skills & Toolbox
Wet Lab: PCR, DNA Assembly (Gibson), Bacterial Transformation.
In-Silico: DNA Design (Benchling), Protein Folding (AlphaFold), Metabolic Modeling.
Leadership: Outreach Team Lead at ISCB RSG-Pakistan.
🎯 HTGAA 2026 Goals
During this semester, I aim to:
Master Cloud-Lab protocols to decentralize drug production.
Design Neuromorphic genetic circuits for smarter therapeutics.
Advocate for Ethical Governance in biotech across developing nations.
Project: Recombinant production of BmK CT (Scorpion Peptide) via Cloud-Lab Automation.
Why: Venom-derived therapeutics are currently difficult to source sustainably. My goal is to engineer a microbial “cell factory” using E. coli to produce high-purity BmK CT for glioma (brain cancer) research, utilizing automated cloud-lab infrastructure for scalable access.
2. Governance/Policy Goals
My primary goal is to ensure Non-malfeasance (preventing harm) while promoting Constructive Use.
Sub-goal A (Biosecurity): Preventing the diversion of synthesized neurotoxin sequences for harmful, non-therapeutic purposes.
Sub-goal B (Equity): Ensuring that the digital blueprints and production protocols are accessible to researchers in developing regions like Pakistan to promote autonomy.
3. Governance Actions Matrix
Aspect
Action 1: Automated Screening
Action 2: User Verification
Action 3: Ethical Peer-Review
Actor
DNA Synthesis Companies
Cloud Lab Platforms
Academic Communities
Purpose
Flags regulated toxin sequences.
Mandatory ID for remote users.
Standardizing “Dual-Use” data sharing.
Assumptions
All toxins are indexed.
Affiliation equals ethics.
Users will follow protocols.
Risks
False positives slow research.
Excludes independent scientists.
Security breaches are possible.
4. Scoring Matrix
(1 = Best, 3 = Least)
Does the option:
Option 1
Option 2
Option 3
Enhance Biosecurity
1
1
2
Foster Lab Safety
2
1
3
Not Impede Research
2
3
1
Promote Constructive App
1
1
1
5. Prioritization & Recommendation
I prioritize a combination of Action 1 and Action 2. This recommendation is intended for International Regulatory Bodies. We must implement “Know Your Customer” (KYC) rigor for Cloud Labs, similar to financial institutions. While this adds a burden to remote researchers, it is a necessary trade-off for handling potent neurotoxins safely.
6. Ethical Reflection
The concept of an “Information Hazard” was a significant new concern for me. Even if my physical lab work is safe, publishing a “perfect roadmap” for toxin production could be misused. I propose “Ethical Red-Teaming” as a governance action where students peer-review project documentation for potential dual-use risks before publication.
Week 2 Pre-Lecture Preparation
In preparation for “DNA Read, Write, and Edit” lecture.
Part 1: Questions from Professor Jacobson
What is the error rate of polymerase? The error rate of DNA polymerase is approximately $10^{-7}$ to $10^{-8}$ per base pair.
How does this compare to the length of the human genome? The human genome is about 3 billion ($3 \times 10^9$) base pairs long, meaning mutations are inevitable without repair.
How does biology deal with that discrepancy? Biology utilizes Proofreading and Mismatch Repair (MMR) systems to reduce the final error rate to $10^{-9}$ or $10^{-10}$.
How many different ways are there to code for an average human protein? Due to Codon Degeneracy, there are millions of potential DNA sequences for a single protein.
Why don’t all of these different codes work? Factors like Codon Usage Bias, mRNA secondary structures, and cryptic splice sites can hinder protein expression.
Part 2: Questions from Dr. LeProust
Most common method for oligo synthesis: The Phosphoramidite method is the current standard.
Why is it difficult to make oligos > 200nt? Cumulative coupling inefficiencies lead to extremely low yields for long, pure sequences.
Why can’t you make a 2000bp gene via direct synthesis? The error rate and yield drop make direct synthesis of long genes unfeasible; they must be assembled from shorter oligos.
The “Lysine Contingency”: This is a Biocontainment strategy where organisms are engineered to depend on external amino acids to prevent survival outside the lab environment.
Week 2 HW: DNA Read, Write, and Edit
Part 1: Benchling & In-silico Gel Art
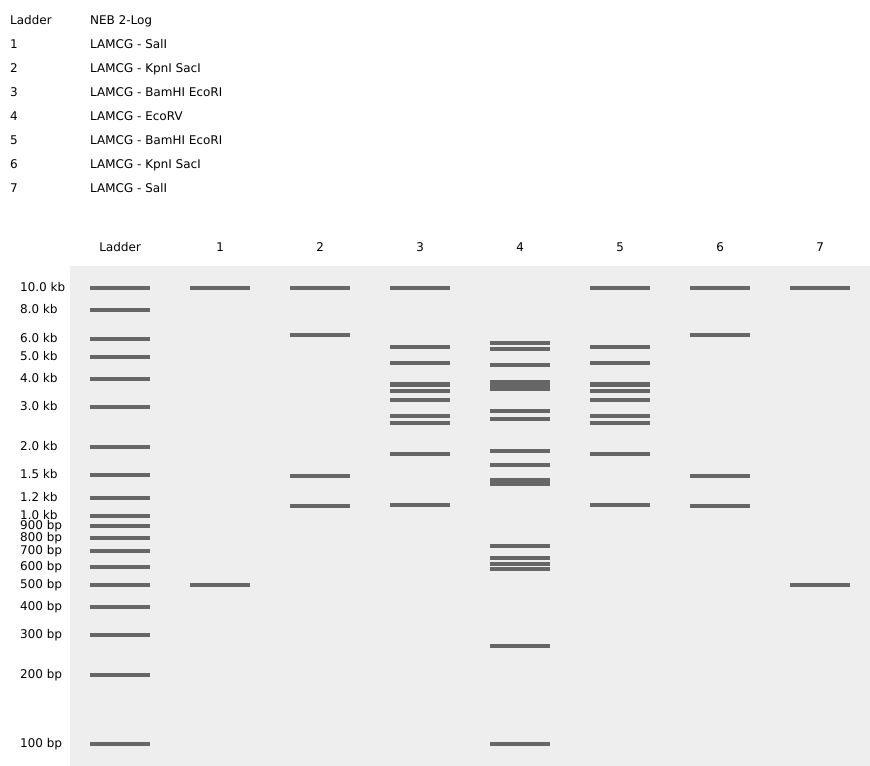
For this assignment, I performed a virtual restriction digest on Lambda DNA using Benchling. My creative goal was to produce a pattern that mirrors the anatomy of a scorpion, inspired by my final project on the BmK CT scorpion peptide.
Creative Vision: The Genetic Scorpion 🦂
To achieve this symmetrical design, I strategically assigned different enzymes and double-digests across 7 lanes:
Lanes 1 & 7 (The Pincers): I used SalI to create distinct high-molecular-weight bands.
Lanes 2 & 6 (The Legs): A double digest of KpnI and SacI created a wider spread of bands, mimicking the scorpion’s legs.
Lanes 3 & 5 (The Torso): Combining BamHI and EcoRI resulted in a dense cluster of bands to represent the main body segments.
Lane 4 (The Stinger): I used EcoRV, which produces 21 fragments, creating a solid vertical pillar in the center that represents the scorpion’s iconic stinger.
Methodology
Sequence: Imported the Lambda DNA (48,502 bp) sequence into Benchling.
Analysis: Used the Restriction Analysis tool to map sites for EcoRI, HindIII, BamHI, KpnI, EcoRV, SacI, and SalI.
Simulation: Conducted virtual gel electrophoresis using a NEB 2-Log Ladder as a size reference.
Result: The final digest achieved a balanced, symmetrical pattern that visually aligns with my biotech research interests.
Part 3: DNA Design Challenge
3.1. Choose your protein
The protein I chose for this assignment is BmK CT, a chlorotoxin-like peptide derived from the venom of the Chinese scorpion Olivierus martensii (previously called Mesobuthus martensii). It is a small bioactive peptide which functions primarily as a targeted anti-tumor agent against glioma cells, with key roles in inhibiting cell migration, invasion, and proliferation.
What makes BmK CT especially promising is that it can promote apoptosis and enhance the sensitivity of glioma cells to chemotherapeutic agents like temozolomide. Importantly, studies suggest that it exhibits minimal toxicity toward normal glial cells, highlighting its potential as a selective therapeutic candidate for high-grade gliomas.
The sequence was obtained from UniProt (Entry: Q9UAD0). I focused on the biologically active mature peptide consisting of 35 amino acids:
CGPCFTTDANMARKCRECCGGIGKCFGPQCLCNRI
This peptide is cysteine-rich, suggesting the formation of multiple disulfide bonds that stabilize its tertiary structure.
3.2. Reverse Translate
Using the Reverse Translate tool from the Sequence Manipulation Suite, the following 105 bp DNA sequence (35 × 3 nucleotides) was generated:
When expressing a foreign gene in a host organism, it’s important to consider codon usage bias. This refers to the preference of the host to translate certain synonymous codons more efficiently than others. Codon optimization replaces some codons in the sequence with those preferred by the host, without changing the amino acid sequence, to ensure efficient translation.
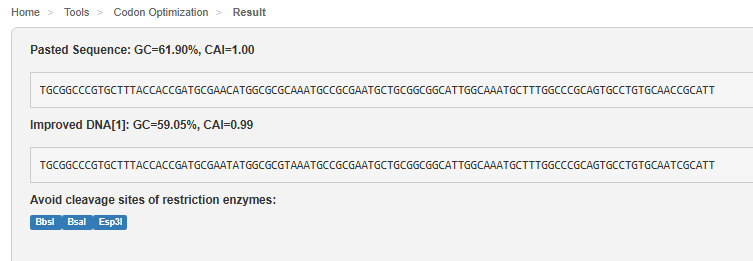
For BmK CT, I chose Escherichia coli (K-12 strain MG1655) as the host because it is a standard, well-characterized chassis in synthetic biology that grows rapidly and is easy to handle. Using the Codon Optimization Tool from VectorBuilder, I optimized the sequence while avoiding Type IIs restriction enzyme sites (BsaI, Esp3I, and BbsI) to make the sequence compatible with modular cloning workflows.
Once the optimized gene is synthesized, it can be produced using a hybrid approach that combines both cell-dependent and cell-free systems.
Cell-Dependent Recombinant Expression
In a traditional approach, the optimized gene is cloned into an expression vector (like pET-28a) under a strong promoter and transformed into E. coli.
Transcription: DNA is transcribed into mRNA by RNA polymerase.
Translation: mRNA is translated by ribosomes into the peptide.
Purification: The peptide is purified using chromatographic methods (e.g., IMAC via a His-tag).
Cell-Free Expression Systems
Alternatively, the optimized DNA can be directly introduced into a cell-free transcription–translation system. This offers:
Rapid prototyping and reduced toxicity constraints.
Precise control over reaction conditions.
Compatibility with high-throughput screening and automated cloud-lab paradigms.
This hybrid approach ensures the scalability of living cells while providing the flexibility needed to produce potentially toxic bioactive peptides like BmK CT.
Part 4: Prepare a Twist DNA Synthesis Order (Practice)
In this practice exercise, I simulated the workflow for ordering a synthetic gene, moving from a custom expression cassette design in Benchling to a clonal gene construct on the Twist Bioscience portal.
Step 1: Account Creation
I successfully set up accounts on Twist Bioscience and Benchling to facilitate DNA design and synthesis simulation. ✅
Step 2: Build Your DNA Insert Sequence
I designed a complete Expression Cassette for my codon-optimized BmK CT sequence, optimized for an E. coli expression system. Using Benchling, I sequentially assembled the following components into a single linear DNA sequence:
Promoter:TTTACGGCTAGCTCAGTCCTAGGTATAGTGCTAGC
RBS:CATTAAAGAGGAGAAAGGTACC
Start Codon:ATG
Coding Sequence (CDS): Codon-optimized BmK CT
7x His Tag:CATCACCATCACCATCATCAC (to enable protein purification)
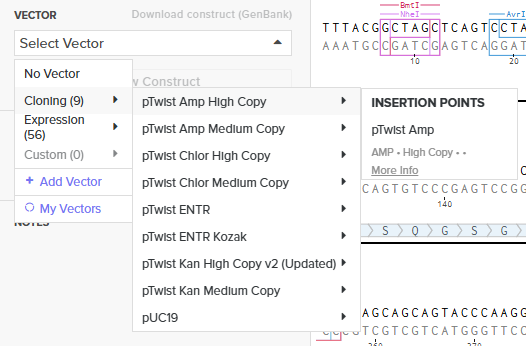
I simulated the ordering process by selecting the “Genes” category and choosing the “Clonal Genes” option. Unlike gene fragments, clonal genes arrive already inserted into a circular vector, which allows for direct transformation into E. coli.
Importing Sequence: I uploaded the FASTA file of the Benchling cassette.
Vector Selection: I chose the pTwist Amp High Copy cloning vector as the circular backbone.
Export: I downloaded the final construct as a GenBank (.gb) file for verification.
Recombinant Vector Overview:
Below is the visualization of the final construct as it appears in the Twist portal:
Step 4: Final Plasmid Verification in Benchling
After re-importing the Twist-generated GenBank file back into Benchling, I verified the final circular plasmid containing my custom expression cassette.
Part 5: DNA Read/Write/Edit
5.1 DNA Read
(i) Target for Sequencing
I want to sequence the metagenomic DNA from the venom glands of Northern Pakistani scorpions (specifically species related to Mesobuthus martensii).
Rationale: While BmK CT is documented, local Pakistani species might harbor unique genetic variants with higher therapeutic potency or different binding affinities for glioma cells. Sequencing this DNA helps explore local biodiversity and bioprospecting for novel drug precursors.
(ii) Sequencing Technology: Oxford Nanopore (ONT)
I have chosen Oxford Nanopore Technologies (ONT), a third-generation, single-molecule sequencing platform.
Input & Preparation:
Material: High Molecular Weight (HMW) genomic DNA from venom gland tissue.
Steps: 1. Optional fragmentation (kept long for ONT), 2. End-repair and A-tailing, 3. Adapter ligation with motor proteins, and 4. Tethering to the flow cell membrane.
Mechanism & Base Calling:
DNA strands pass through a protein nanopore, causing characteristic disruptions in the ionic current.
AI/ML algorithms decode these electrical signals into base sequences (A, T, G, C) in real-time.
Output:
FASTQ files containing long-read sequences, ideal for variant analysis and de novo assembly.
5.2 DNA Write
(i) Target for Synthesis
I want to synthesize a codon-optimized genetic construct for expressing the BmK CT peptide in E. coli.
Rationale: Synthesis allows the inclusion of a T7 promoter for high-level expression and a 6xHis-tag for streamlined purification. This is a direct therapeutic application for glioma drug discovery.
(ii) Synthesis Technology: Silicon-based Electrochemical Synthesis
I would utilize the technology implemented by Twist Bioscience.
Essential Steps:
Phosphoramidite chemistry performed on a high-density silicon chip.
Computer-controlled electrochemical activation of specific pixels to add nucleotides one at a time.
Short synthesized oligos are harvested and assembled into the full-length gene.
Limitations:
Error rates can increase with length, necessitating sequence verification.
Large constructs (>3 kb) are significantly more challenging to synthesize directly.
5.3 DNA Edit
(i) Target for Editing
I want to edit the genome of E. coli expression strains (e.g., BL21) to enhance the secretion of BmK CT.
Rationale: Normally, recombinant peptides accumulate in the periplasm; by editing secretion pathways or outer membrane proteins, the peptide could be secreted directly into the medium, simplifying downstream purification.
(ii) Editing Technology: CRISPR-Cas9
Mechanism & Essential Steps:
Recognition: A custom Guide RNA (gRNA) targets the specific genomic sequence.
Cleavage: The Cas9 enzyme generates a Double-Strand Break (DSB).
Repair: Homology-Directed Repair (HDR) inserts the desired mutation using a provided donor template.
Preparation & Input:
Design: Designing gRNA via Benchling to minimize off-target effects.
Inputs: Cas9 enzyme/plasmid, custom gRNA, donor DNA template, and competent cells.
Limitations:
Efficiency: HDR efficiency can be low in certain bacterial strains.
Precision: Potential for off-target effects requires careful validation.
Sources & Acknowledgments
I used a combination of published literature, AI tools (including ChatGPT and Google Gemini), and discussions with peers to compile and refine this assignment.
Week 3 HW: Lab Automation
Assignment: Python Script for Opentrons Artwork
This section documents my process of creating bio-art of the Markhor, Pakistan’s national animal, using the Opentrons OT-2 liquid handling robot.
1. Image Generation
I started by using Google Gemini to generate a high-quality image of a Markhor with a clean white background to serve as the reference for my design.
2. Pixel Art Conversion
I then requested the AI to convert the high-resolution image into pixel art, which is necessary for the robot to dispense discrete “dots” of bacteria.
3. Coordinate Generation via GUI
I uploaded the pixel art to the Opentrons Art GUI. The initial generation included many colors, so I tweaked the design to limit it to three primary fluorescent colors: Blue, Green, and Red. During this stage, I also manually added the Markhor’s ears, which were not correctly captured in the original AI image.
Using the Echo CSV coordinates from the GUI, I utilized Google Gemini (both the web interface and the integrated assistant in the HTGAA Colab) to write the final Python script.
The process involved significant debugging due to:
Color Swapping: Adjusting the mapping to ensure the robot pulled the correct color from the source wells (A1, B1, C1).
API Syntax: Fixing NameError and KeyError related to the labware setup and coordinate indexing in the simulator.
Finally, I successfully simulated the design, ensuring the Markhor pattern was centered and clearly defined.
Post-Lab Questions: Research & Automation Strategy
1. Published Research Paper Analysis
I have reviewed the following paper regarding advanced laboratory automation:
Paper Name: Automating life science labs at the single-cell level through precise ultrasonic liquid sample ejection: PULSE
The paper introduces PULSE (Precise Ultrasonic Liquid Sample Ejection), a novel laboratory automation platform designed for biological experiments at the single-cell level.
While current lab automation excels at bulk samples, it often lacks the precision and biocompatibility required for single-cell work, which can mask critical cellular heterogeneity.
PULSE overcomes these limitations by using focused acoustic waves to eject nanoliter-sized droplets containing reagents or individual cells from a compact, disposable chip.
This technology transforms standard titer plates into high-density microdroplet arrays, allowing researchers to programmably print “nanodrop pixels” with specific numbers of cells.
The platform integrates software that synchronizes over 100 parameters, enabling automated and scalable workflows.
Major Applications
The authors demonstrate the versatility of PULSE across three major areas:
Bio-fabrication: Precise deposition of different cell types to create 3D spheroids and patterned constructs.
Precision Gating: Isolating single cells in nanodrops to track behavior over time (e.g., response to drugs) and retrieving them for downstream analysis.
Deterministic Array Barcoding: Directly linking a single cell’s observable phenotype (via imaging) to its genotype (via sequencing) using pre-allocated, addressable primers.
Key Findings
High Precision: The platform can print single cells at speeds of 5-20 cells per second with an accuracy of 90.5-97.7%.
Biocompatibility: RNA sequencing revealed that the acoustic ejection process causes no significant differential gene regulation up to 24 hours post-treatment, outperforming FACS.
Accuracy: In deterministic barcoding experiments, the platform achieved a 95.6% accuracy in matching cell fluorescent phenotypes to genotypes.
2. Final Project Ideas
I am exploring three core directions for my final project, focusing on recombinant production, metabolic engineering, and industrial biocatalysis.
Idea 1: Recombinant Production of BmK CT Peptide for Glioma Therapy
The Concept: To engineer E. coli K-12 for the high-yield production of the 35-residue mature BmK CT scorpion peptide.
The Approach: Utilizing Twist Bioscience for codon-optimized gene synthesis and pET-series vectors for efficient recombinant expression.
Impact: Establishing a scalable bio-manufacturing pipeline for a peptide with high affinity for brain tumor cells to facilitate further oncological research.
Idea 2: CryoDesign Yak: AI-Engineered Cold-Active Enzymes
The Concept: Harnessing the unique metagenomic diversity of the Himalayan Yak microbiome to engineer psychrophilic enzymes for energy-efficient industrial bioprocessing.
The Approach: Utilizing ESM-2 Transformers for structural motif identification and ProteinMPNN for inverse folding to optimize catalytic loop flexibility.
Impact: Enabling room-temperature industrial catalysis (15°C–25°C) to slash heating energy demand, contributing to the EU Net Zero 2050 goal.
Idea 3: Automated Bio-manufacturing of Bryostatin-1 Precursors
The Concept: Engineering a microbial chassis for the sustainable production of Bryostatin-1, a potent marine-derived anti-cancer precursor.
The Approach: Implementing the biosynthetic gene cluster into a laboratory-friendly host and using Opentrons automation for screening optimal metabolic flux.
Impact: Transitioning from destructive marine harvesting to a sustainable, automated bio-manufacturing paradigm.
Lab Automation Strategies
Automation Strategy for Idea 2: CryoDesign Yak (Cold-Active Enzymes)
My automation strategy focuses on a Closed-Loop ‘Design-Build-Test’ cycle for validating AI-designed cold-adapted enzymes. Precision in thermal management is the primary constraint for this project.
Build (Ginkgo Nebula):
I will utilize the Echo Acoustic Liquid Handler to nanodisperse synthetic DNA variants into 384-well plates.
This will be coupled with the Bravo Automated Liquid Handling Platform to stamp in chilled cell-free protein synthesis (CFPS) reagents.
Test (Local Opentrons):
Since psychrophilic enzymes are heat-labile, I will use a 3D-printed chilled-block holder (maintained at 10°C) on the Opentrons deck.
Process Flow:
Opentrons P20 will perform high-accuracy dispensing of chromogenic substrates into the expressed enzyme variants.
The Inheco Thermoshaker module will be used for controlled incubation at ambient ‘cold-start’ temperatures (15°C).
Data will be captured via an integrated plate reader to measure the kinetic rate ($\Delta$ Abs / $\Delta$ time).
Automation Strategy for Idea 3: Bio-manufacturing of Bryostatin-1 Precursors
This strategy aims to automate the metabolic engineering and screening of Bryostatin-1 precursors in a laboratory-friendly microbial host. Since the biosynthetic gene cluster (BGC) is large and complex, automation is essential to find the optimal expression balance.
Design & Build (Ginkgo Nebula):
I will utilize the Echo Acoustic Liquid Handler to assemble combinatorial libraries of BGC components, including promoters, RBS, and biosynthetic modules.
The Bravo Automated Liquid Handling Platform will be used for rapid transformation and plating of the engineered chassis.
Test & Optimize (Local Opentrons):
I will use the Opentrons OT-2 to automate the metabolic screening of small-molecule precursors.
Process Flow:
Opentrons P300 will handle the precise serial dilution of feeding precursors (e.g., acetate/propionate units) into the culture media.
The Heater-Shaker Module will be programmed for automated induction and micro-fermentation at optimal temperatures.
Post-fermentation, the Opentrons will perform an automated extraction protocol (solvent addition and supernatant collection) for downstream analysis via an integrated HPLC or plate reader.
Week 4 HW: Protein Design Part I
Part A. Conceptual Questions
I have answered the following questions based on the concepts provided by Shuguang Zhang regarding protein structure and design.
1. How many molecules of amino acids do you take with a piece of 500 grams of meat?
To calculate the total molecules, we must first determine the actual protein content and molar mass:
Protein Content: 500g of meat is typically 20-25% protein, which is approximately 125g of protein. The remaining mass consists of water, fat, and minerals.
Molar Mass: The average mass of an amino acid is 100 Daltons, which is equivalent to 100 g/mol.
Moles Calculation: Using the formula n = m/M, we find 125g / (100 g/mol) = 1.25 moles of amino acids.
Total Molecules: Multiplying the moles by Avogadro’s constant (6.022 × 10²³): 1.25 × 6.022 × 10²³ = 7.53 × 10²³.
Result: Consuming a 500g piece of meat means taking in approximately 753 sextillion molecules of amino acids.
2. Why do humans eat beef but do not become a cow, eat fish but do not become fish?
The biological reason lies in the process of digestion and genetic reassembly:
Digestion: When we consume beef, our body does not recognize it as “cow protein"Instead, it sees a long chain of chemicals that must be broken down.
Enzymatic Breakdown: Our digestive system uses enzymes such as pepsin and trypsin to break the peptide bonds of bovine proteins. This reduces the meat to individual amino acids, which serve as “LEGO bricks”.
Identical Building Blocks: An amino acid like Leucine from a cow is chemically identical to one from a fish or a human.
Genetic Instructions: Our DNA contains the specific instructions for building human proteins. Ribosomes take these cow-derived “bricks” and reassemble them according to our own unique genetic code.
Analogy: If you take apart a LEGO castle (the cow) and have the instructions for a LEGO spaceship (the human), it doesn’t matter that the bricks were previously a castle; they will become a spaceship.
3. Why are there only 20 natural amino acids?
The selection of only 20 standard amino acids is a result of evolutionary optimization:
Frozen Accident: These 20 amino acids represent a “frozen accident” of early evolution, optimized nearly 4 billion years ago.
Chemical Diversity: They provide a balanced set of hydrophobic, polar, and charged side chains, which is sufficient for creating stable, soluble protein cores and specific binding pockets.
Metabolic Efficiency: Using 20 amino acids strikes an optimal balance between the metabolic cost of synthesis and the structural complexity required for life.
Folding Precision: This specific set allows for the precise and complex folding necessary for protein functionality.
Rarity of Others: While over 500 amino acids exist in nature, and others like selenocysteine are used rarely, the genetic code primarily selected these 20 to be incorporated directly by ribosomes.
4. Can you make other non-natural amino acids? Design some new amino acids.
It is entirely possible to design and synthesize non-natural (non-canonical) amino acids by manipulating the amino group, the carboxyl group, or the R-group (side chain). Below are three designed examples:
Boron-Phenylalanine (B-Phe): This amino acid is designed for Boron Neutron Capture Therapy (BNCT). By swapping a hydrogen atom on a Phenylalanine benzene ring for a boronic acid group, we create a tool for precision cancer treatment. When incorporated into a cancer-targeting antibody, it captures thermal neutrons and “explodes” on a microscopic scale, killing the cancer cell from the inside while sparing healthy tissue.
The “Magneto-Protein”: Ferro-Alanine (Fe-Ala): Inspired by magnetotactic bacteria, this design replaces the methyl group of Alanine with an organometallic complex containing an Iron (Fe) atom. This gives the protein paramagnetic properties. It could be used to create “magnetic enzymes” that can be easily pulled out of industrial bioreactors using magnets, significantly lowering production costs.
The “Light-Switch”: Azobenzene-Tyrosine (Azo-Tyr): This is a photo-switchable amino acid that allows for the control of biology with light. It uses an azobenzene group that “kinks” (cis-configuration) under UV light and “straightens” (trans-configuration) under visible light. This can be used to “cage” a drug, keeping it inactive until a specific wavelength of light is applied directly to a tumor site to activate it.
5. Where did amino acids come from before enzymes that make them, and before life started?
Amino acids likely originated through a process called abiotic synthesis:
Laboratory Evidence: Experiments such as the Miller-Urey experiment demonstrated that simple organic compounds can form from inorganic precursors like methane, ammonia, and water when exposed to energy sources like lightning or UV radiation.
Extraterrestrial Origins: Amino acids have also been discovered in meteorites, which suggests they may have arrived on Earth via extraterrestrial impacts before life began.
6. If you make an alpha-helix using D-amino acids, what handedness (right or left) would you expect?
An alpha-helix composed of D-amino acids will form a left-handed helix:
Mirror Images: Because D-amino acids are the mirror images of the L-amino acids used in natural proteins, they produce a mirror image of the standard right-handed helix.
Chirality: D-amino acids do not fit properly into a right-handed configuration due to chiral interactions; therefore, they naturally adopt the left-handed form.
7. Can you discover additional helices in proteins?
Yes, researchers have identified several helices beyond the common alpha-helix:
Identification: While alpha-helices are the most abundant, other types such as 3-10-helices, pi-helices, and polyproline helices exist.
Discovery Tools: These structures can be identified by searching database entries like the PDB or using visualization tools like PyMOL.
pi-helices: These occur in about 15% of known proteins and are often associated with functional sites, such as active sites.
3-10-helices: These are shorter and tighter than alpha-helices and are frequently found at the ends of standard alpha-helical structures.
Methodology: Discovering these involves analyzing the specific backbone hydrogen-bonding patterns.
8. Why are most molecular helices right-handed?
Right-handedness is the preferred orientation due to thermodynamic stability:
Energetic Stability: Most molecular helices, including DNA and protein alpha-helices, are right-handed because this configuration is more energetically stable.
Steric Hindrance: This arrangement reduces collisions (steric hindrance) between atoms compared to left-handed forms.
Optimal Bonding: In proteins, right-handed alpha-helices allow for the most favorable hydrogen bonding between amino acids.
9. Why do beta-sheets tend to aggregate?
beta-sheets have a natural tendency to clump together due to their structural chemistry:
Exposed Groups: beta-sheets possess exposed hydrogen-bonding groups (NH and C=O) along their edges.
Sticky Edges: Unlike alpha-helices, where hydrogen bonds are satisfied internally, beta-sheets have “sticky” edges.
Complex Formation: These edges can easily form new hydrogen bonds with the edges of other beta-sheets.
10. What is the driving force for beta-sheet aggregation?
The aggregation is driven by two primary physical forces:
Hydrogen Bonding: The main driving force is the formation of hydrogen bonds between the backbones of adjacent sheets.
Hydrophobic Effect: In many beta-sheets, hydrophobic side chains are exposed on the surface.
Energy Minimization: When these sheets aggregate, they bury these hydrophobic surfaces away from water.
Part B. Protein Analysis and Visualization
1. Protein Selection and Description
Protein Name: Green Fluorescent Protein (GFP)
Organism:Aequorea victoria
Why Selected: GFP is extensively used in cancer research, primarily as a molecular marker to track, visualize, and study tumor cells in real-time. It allows researchers to label cancer cells, enabling the study of tumor growth, metastasis, angiogenesis, and the effect of drugs on cancer in vivo.
Structure: It consists of a “β-can” motif, which is an 11-stranded β-sheet barrel with an α-helix running through the center.
Structure Solved: The structure was first solved and deposited on August 23, 1996.
Quality/Resolution: It has a resolution of 1.90 Å. Since this is significantly smaller than the 2.70 Å threshold, it is considered a high-quality structure.
Other Molecules: Apart from the protein chains, the structure contains water (HOH) molecules. The internal chromophore (CRO) is part of the protein sequence itself, formed by the cyclization of residues Ser65, Tyr66, and Gly67.
Structure Classification: According to CATH and SCOP, this protein belongs to the Beta Barrel architecture and the GFP-like fold family.
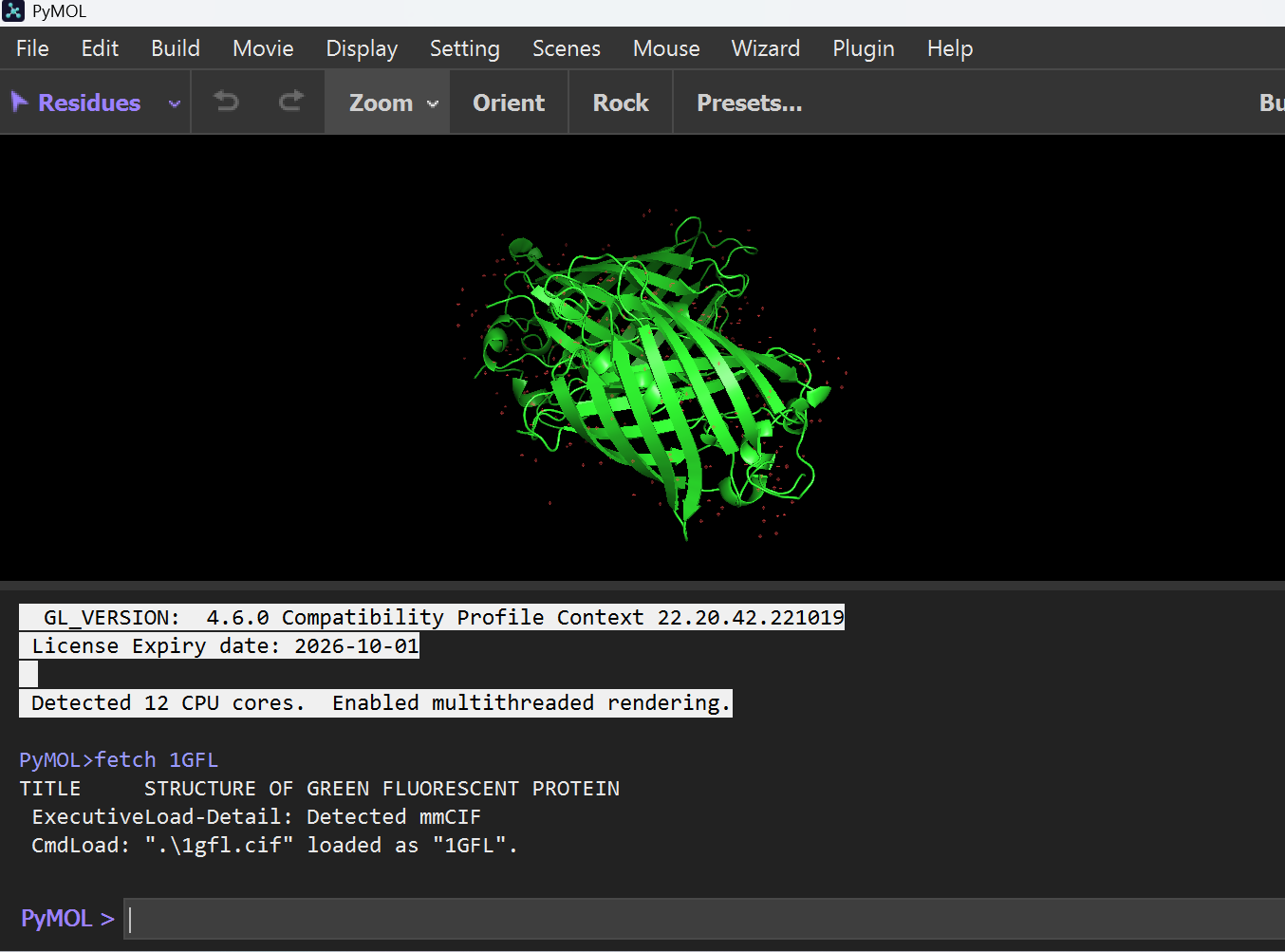
4. 3D Visualization and Structural Analysis (PyMOL)
I used PyMOL software to perform a detailed 3D visualization and analysis of the 1GFL (Green Fluorescent Protein) structure. Below are the steps and findings from this session:
A. Initial Loading
I started by fetching the 1GFL protein structure directly from the PDB database.
Command:fetch 1GFL
B. Visualization Formats
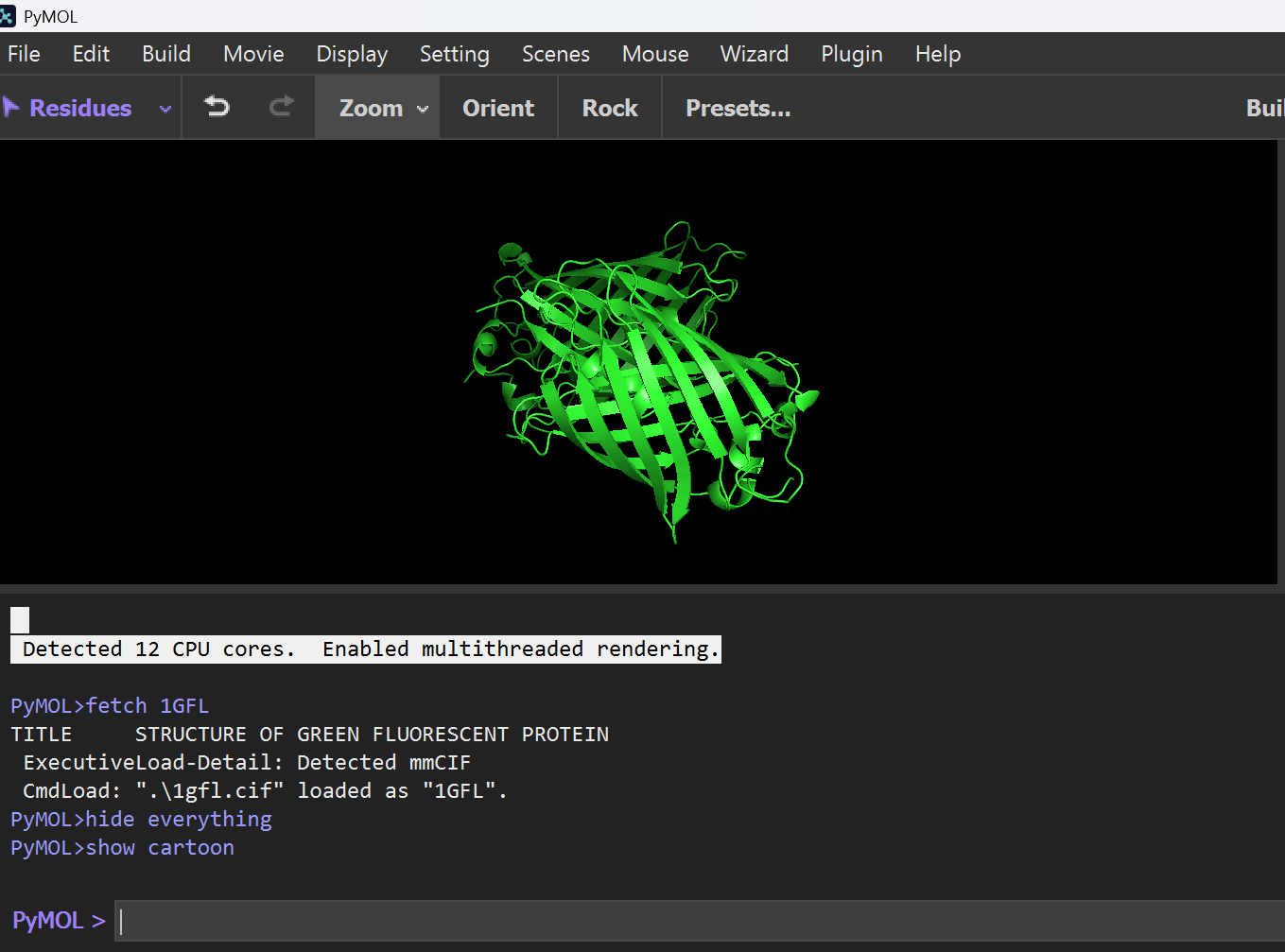
I explored different structural representations to understand the “Beta-can” architecture:
Cartoon Representation: Highlights the 11-stranded $\beta$-sheet barrel and the central $\alpha$-helix.
Command:hide everything; show cartoon
Ribbon Representation: Shows the smooth path of the polypeptide backbone.
Command:hide everything; show ribbon
Ball and Stick Representation: Used to visualize specific atomic interactions and side chains.
Command:hide everything; show sticks
C. Secondary Structure Analysis
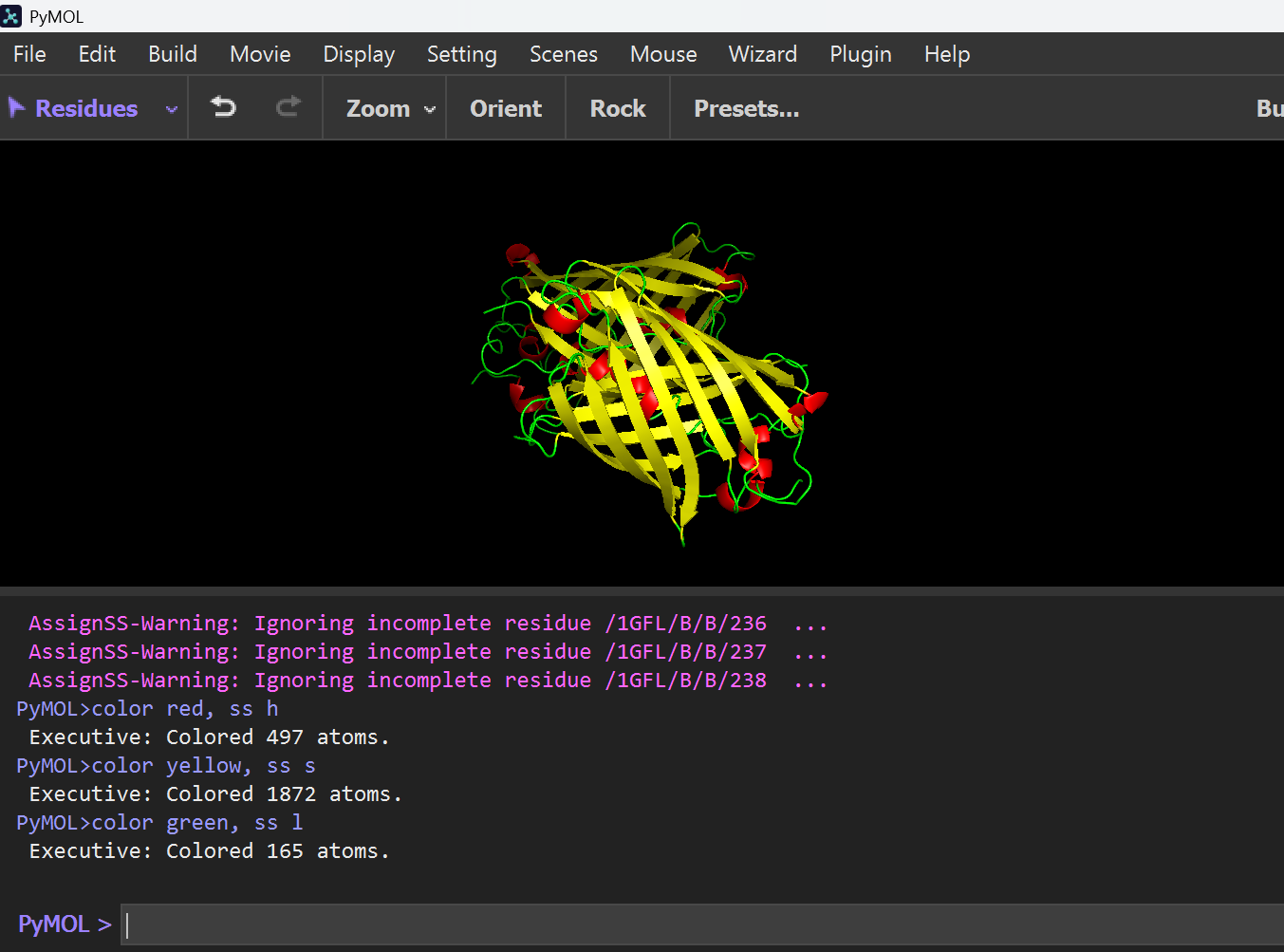
To determine the dominant structural elements, I assigned and colored the secondary structures.
Command:hide everything show cartoon dss color red, ss h color yellow, ss s color green, ss l
The image shows that the protein is predominantly composed of Beta-sheets (yellow) forming a cylindrical Beta-barrel structure, with very few Alpha-helices (red). Therefore, the structure is sheet-dominated.
D. Color by Residue Type
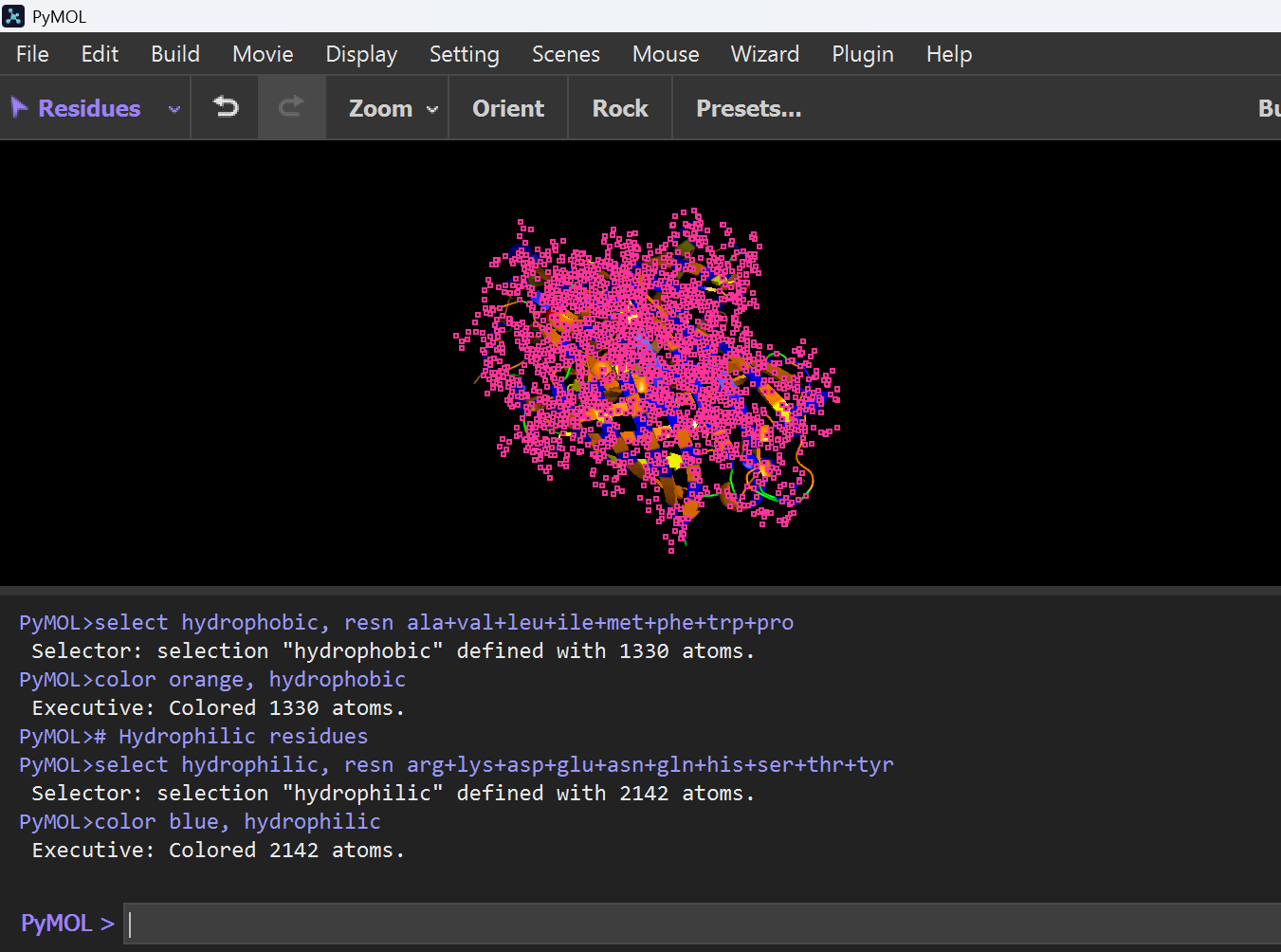
Then I typed this command to color by residue type (hydrophobic vs hydrophilic):
hide everything; show cartoon; # Hydrophobic residues; select hydrophobic, resn ala+val+leu+ile+met+phe+trp+pro; color orange, hydrophobic; # Hydrophilic residues; select hydrophilic, resn arg+lys+asp+glu+asn+gln+his+ser+thr+tyr; color blue, hydrophilic
Image shows that Hydrophobic residues (Orange) are primarily located in the interior of the protein, stabilizing the structure, while hydrophilic residues (blue) are exposed on the surface, allowing interaction with the aqueous environment.
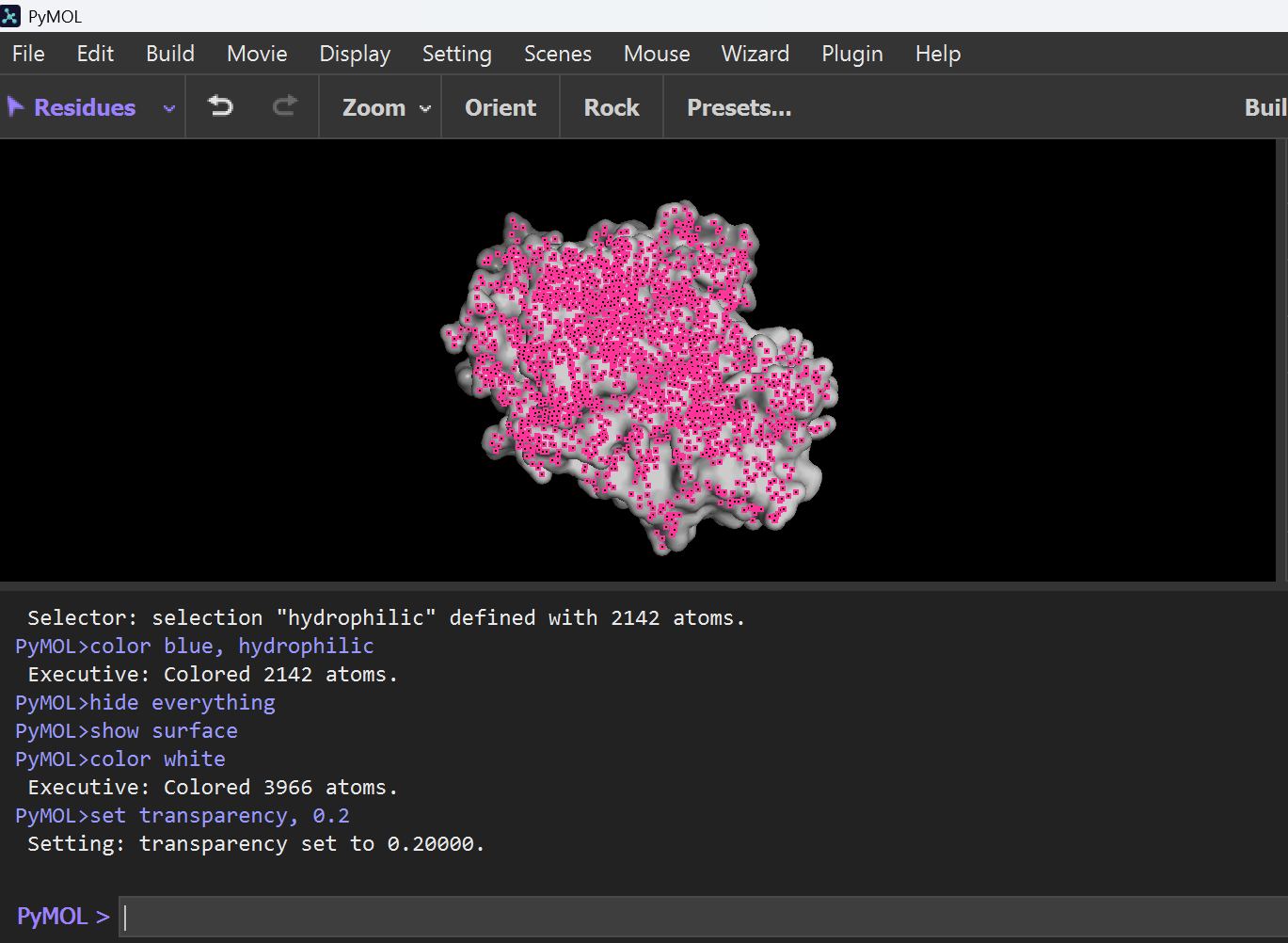
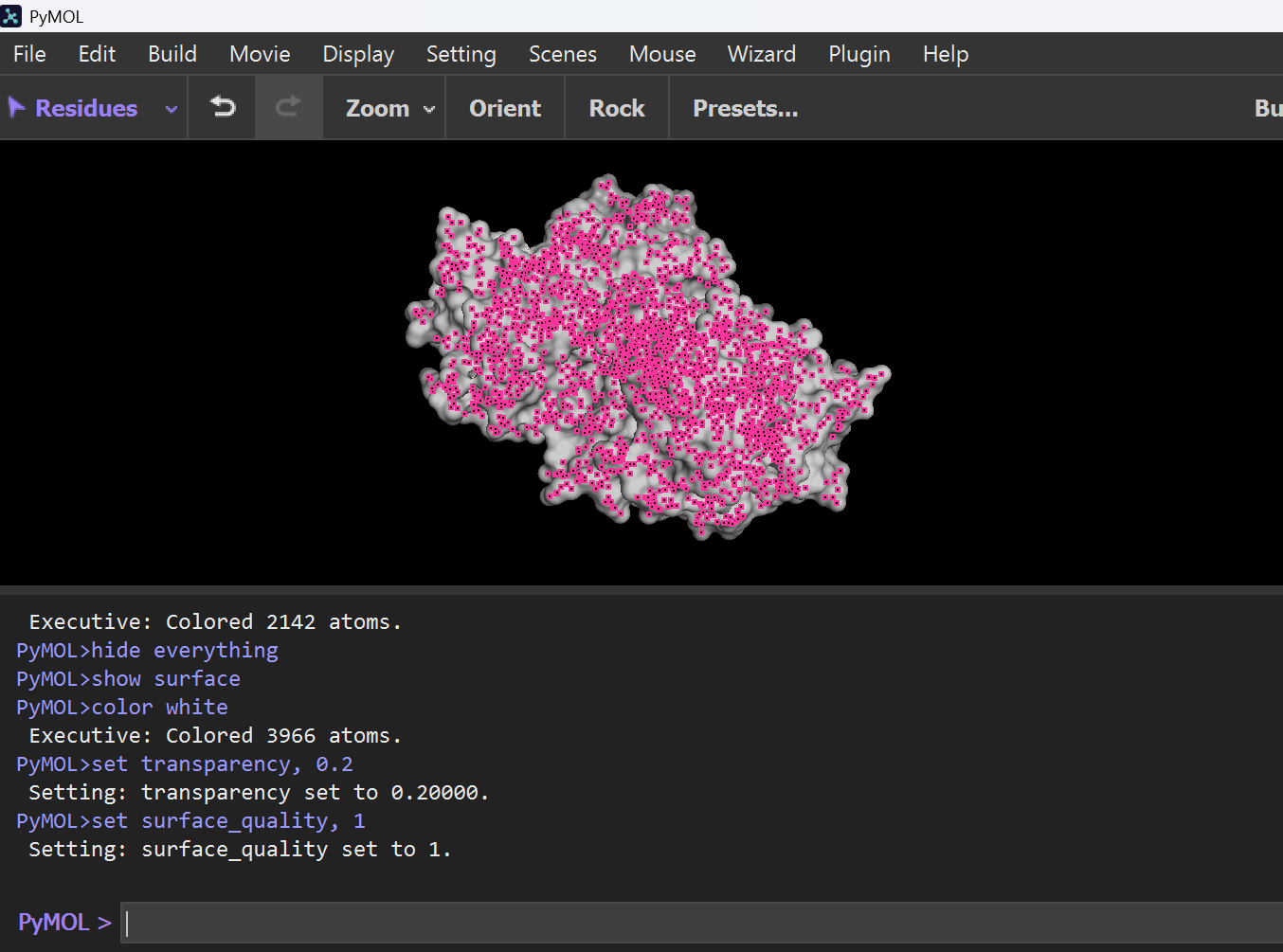
E. Binding Pocket
Then I typed this command to show surface visualization and binding pockets:
hide everything show surface color white set transparency, 0.2
To highlight pockets, I typed this this command:
set surface_quality, 1
Note: I got help from chatgpt for PyMol Portion
Part C. Using ML-Based Protein Design Tools
C1. Protein Language Modeling: Deep Mutational Scan
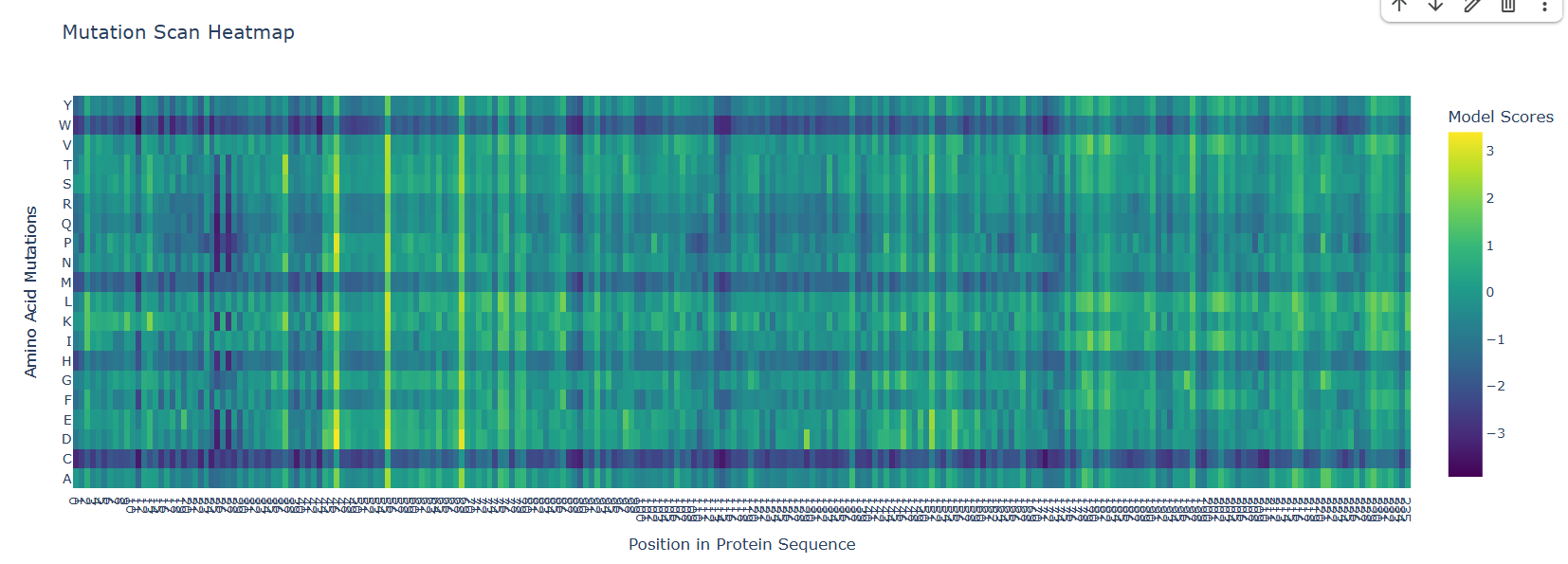
I used the ESM-2 (650M parameters) model in relative mode to generate an unsupervised deep mutational scan for the GFP (1GFL) sequence. The heatmap represents the log-likelihood of every possible single-point mutation across the 238 amino acids.
Pattern Analysis & Biological Interpretation:
Based on the heatmap results, I identified several distinct biological patterns that align with the structural functional requirements of GFP:
The “Kill Zone” (Chromophore: Positions 65–67):
Observation: A dense, dark vertical stripe is visible at positions Ser65, Tyr66, and Gly67.
Interpretation: These residues are essential for the spontaneous chemical reaction that forms the glowing fluorophore. The model correctly predicts that almost any mutation here is deleterious, as it would disrupt the electronic conjugation required for light emission.
The “Zebra Stripe” Pattern (Beta-Barrel: Residues 80–200):
Observation: There is a repeating pattern of low tolerance (dark) and high tolerance (light) spots.
Interpretation: This reflects the alternating nature of the β-barrel. Inward-facing residues are hydrophobic and hold the core together; the model punishes polar mutations here. Outward-facing residues interact with water and show high tolerance for mutations as they do not destabilize the primary fold.
Flexible Termini (N and C Tails):
Observation: Positions 1–10 and 230–238 show high tolerance (lighter colors).
Interpretation: These “floppy” ends do not contribute significantly to the structural stability of the barrel, allowing for mutations or the addition of affinity tags without breaking the protein’s function.
Specific Residue Highlight:
Residue:Glycine 67 (G67).
Mutation:G67A (Alanine).
Pattern: Even a small change to Alanine shows a high negative score (approx -3.0).
Explanation: G67 is structurally required because it is the only amino acid small enough to allow the protein backbone to “kink” into the specific shape needed for chromophore formation. Replacing it with Alanine introduces steric hindrance that prevents the cyclization reaction entirely.
Note: Google Cheat Sheet of GFP Protein for interpretation
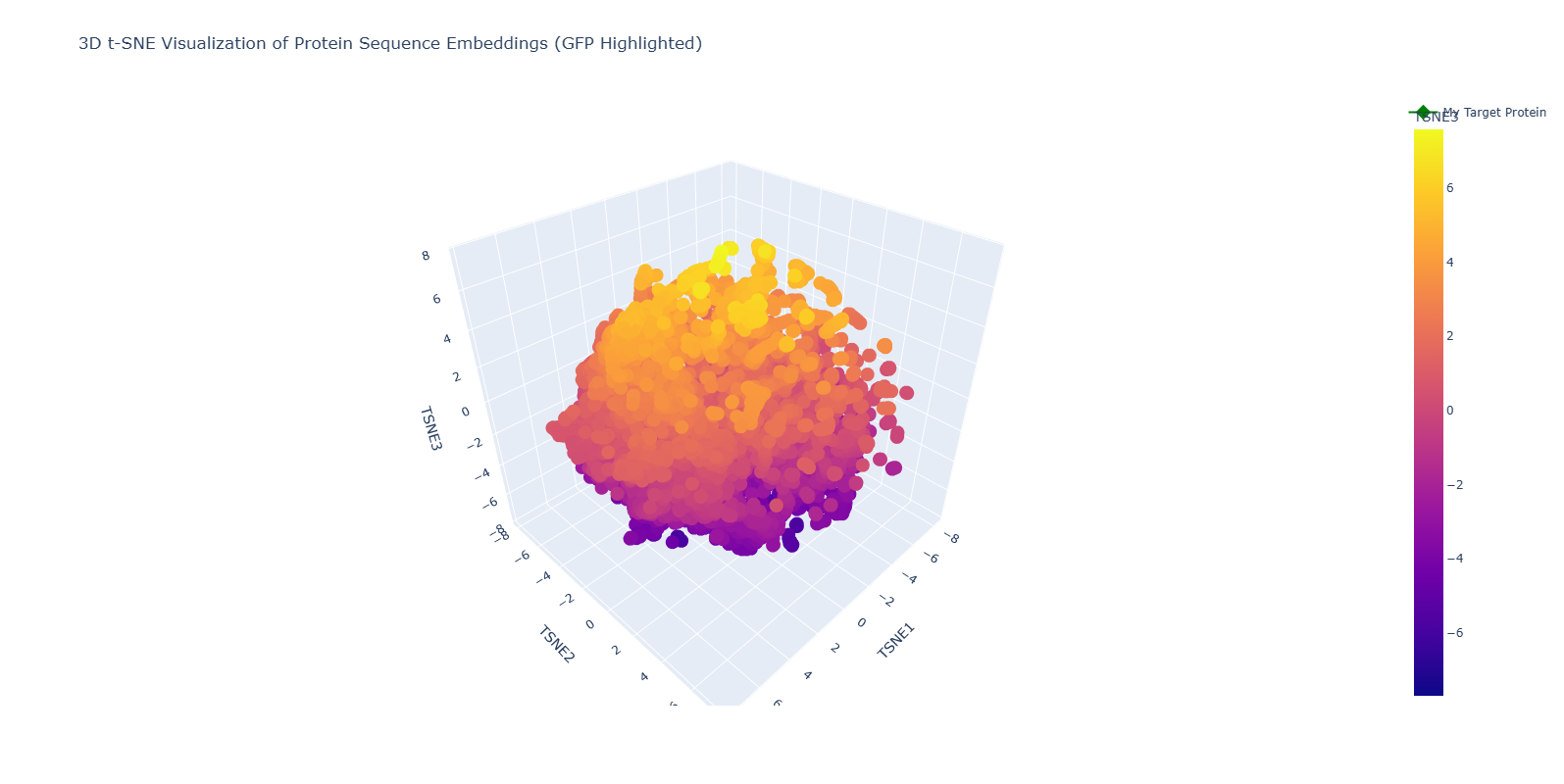
C1. Latent Space Analysis
I used the ESM-2 model to generate 320-dimensional embeddings for a dataset of protein sequences, to which I manually added my target protein GFP (1GFL). To visualize this high-dimensional data, I reduced it to 3 dimensions using t-SNE.
Observations: The resulting 3D map shows that the model effectively approximates similar proteins into “neighborhoods.” While exploring the interactive plot, I found clusters of specific families, such as interleukins, ribonuclear proteins, and globins from various species (Norway rat, mouse, etc.).
3D Perspective: Because this is a 3D visualization, the proximity of proteins changes depending on the orbital angle. This complexity reflects how the model evaluates multiple biochemical features (charge, hydrophobicity, length) simultaneously.
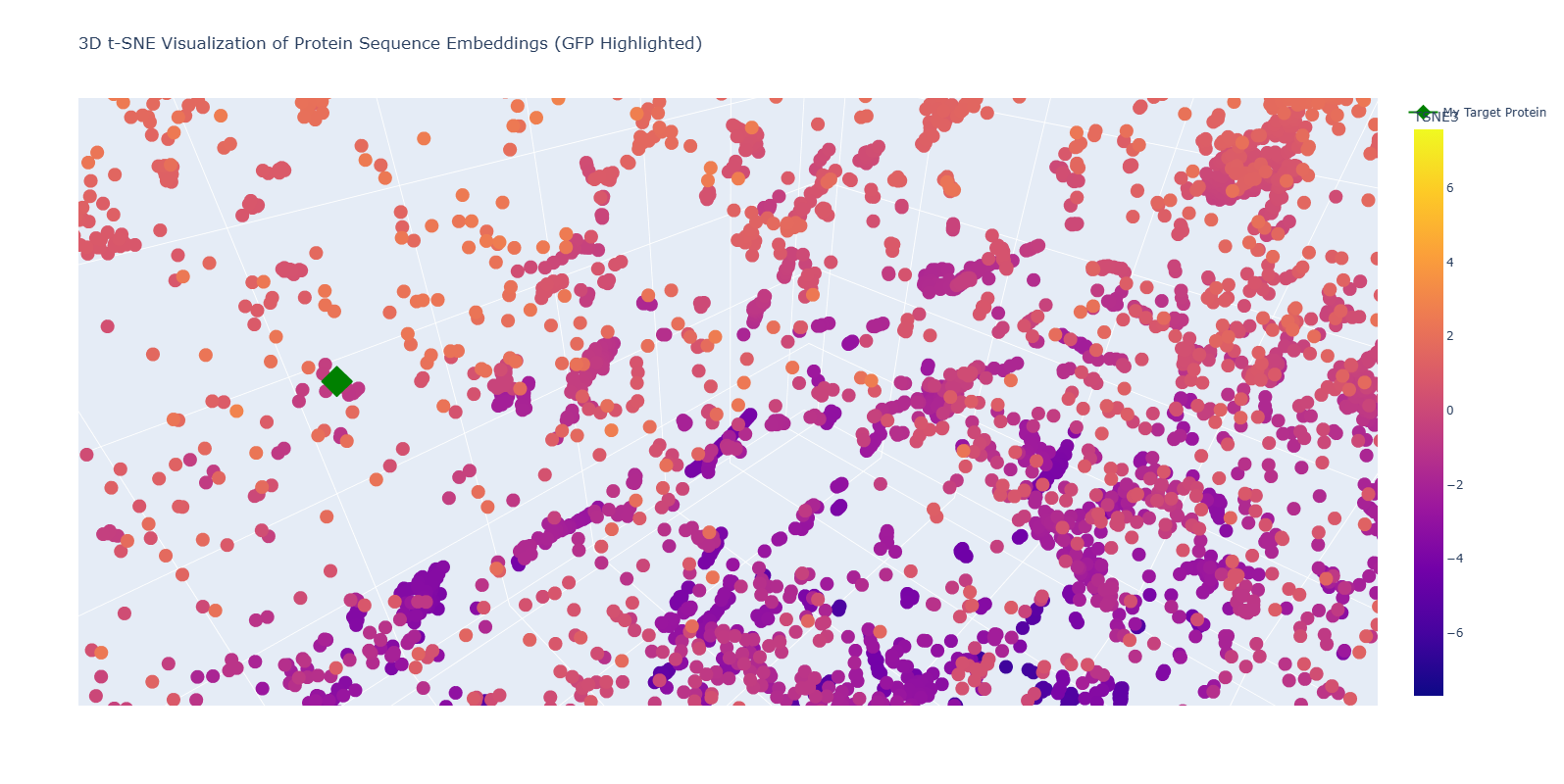
2. Positioning and Similarity of My Protein (GFP)
To easily identify my protein, I highlighted it as a Green Diamond in the plot.
The “Twin” Discovery: Upon zooming into the neighborhood of my highlighted point (1GFL), I discovered another protein entry: “d6l27a_ Green fluorescent protein, GFP {Jellyfish (Aequorea victoria)}”.
Biological Significance: This is a powerful validation of the ESM-2 model. Without being provided any structural data, the model recognized the unique amino acid patterns of the 11-stranded beta-barrel and placed my sequence directly next to its biological homolog (Jellyfish GFP).
Conclusion: The positioning confirms that the latent space of the language model successfully captures the “grammar” of protein folds. My protein is surrounded by other Beta-sheet dominated proteins, proving that the model can distinguish between different structural motifs (alpha vs. beta) based purely on the primary sequence.
How to visualize your protein in latent space
C2. Protein Folding (ESMFold Analysis)
I used ESMFold to predict the structure of GFP and tested its resilience by introducing specific mutations.
Version
Visual Description
Structural Analysis
Normal
Perfect 11-stranded $\beta$-barrel.
The model accurately predicts the native fold of 1GFL.
Mutation 1
Structure remains intact and stable.
Resilient: Changing Y66 to A66 does not disrupt the overall “beta-can” architecture.
Mutation 2
Significant structural collapse and loss of fold.
Not Resilient: Deleting a 20-residue segment from 100 to 120 amino acid breaks the hydrogen bond network, causing the barrel to unfold.
Normal GFP:
Mutation 1 (Point Mutation):
Mutation 2 (Large Deletion):
C3. Protein Generation (Inverse Folding)
In this final section, I explored Inverse Folding. While traditional protein folding (Forward) predicts a structure from a sequence, Inverse Folding uses a fixed 3D backbone to propose entirely new amino acid sequences that could stabilize that specific shape.
1. Sequence Proposal with ProteinMPNN
I used the 3D backbone of GFP (1GFL) as the input for ProteinMPNN. The model analyzed the geometric constraints of the 11-stranded $\beta$-barrel to suggest novel sequence candidates.
Probability Heatmap Analysis: The generated heatmap illustrates the likelihood of each amino acid at every position across the 238-residue sequence. Bright yellow regions indicate “fixed” residues that are structurally essential for the fold, while darker regions show areas where the model allows for more sequence diversity.
Sequence Recovery: My best-designed sequence achieved a Sequence Recovery of 66.38%. This indicates that while the AI-generated sequence is ~34% different from the natural one, it preserved the core chemical logic required to maintain the “beta-can” architecture.
2. Round-trip Validation with ESMFold
To verify if the AI-designed sequence (SYPGDELFEGVVPIKVNLKGDVNGEKFSVEGEGEGDAKKGEITLKFVCTTGKLPVPWPTLVDIFSGGIPCFTKYPEHMKHHDFFKSCMPEGYKQERTIYFEGDGKFETRATVKFEGDTLVNEIELKGSGFKKDGNILGHKLKFSYQSYKRYITADKAKNGIKATYTLEYPVEDGSVQKAKVEETYTPLGDGPVLLPEPHYLEVEVELSKDPNEKRDHVVLKAKMVAAGIE) actually folds into the intended shape, I performed a “round-trip” validation by folding the new sequence back into 3D space using ESMFold.
Observations: As shown in the predicted structure below, the new sequence successfully folded into a near-perfect $\beta$-barrel.
Structural Fidelity: The alignment of the $\beta$-strands and the overall topology remained consistent with the original 1GFL structure, despite the significant sequence divergence.
Conclusion
This experiment demonstrates the power of ProteinMPNN in de novo protein design. It proves that the model can “invent” new sequences that nature has not yet explored, which still satisfy the physical and geometric requirements of the GFP fold. The structural integrity remained robust, confirming that the “language” of proteins allows for multiple sequence solutions for a single structural fold.
For Part C: Extensive help was taken from Google Gemini to understand google collab notebook, methodology and results.
Part D. Group Brainstorm on Bacteriophage Engineering
By: Sami Ur Rehman (2026a-sami-ur-rehman) and Edna Wanjiru Macharia (2026a-ednah-wanjiru)
Goals and Strategy
Primary Goal: Increase the toxicity of the MS2 bacteriophage lysis protein (L) to achieve faster and more complete bacterial lysis, leading to higher phage titers for therapeutic applications.
Secondary Goal: Modulate the protein’s interaction with the host chaperone DnaJ by redesigning the N-terminal interface rather than simply deleting it. This allows for tunable control of lysis timing, not just complete bypass.
Design Focus: The strategy involves targeting the N-terminal regulatory domain (residues 1-36) while protecting essential functional elements: the C-terminal transmembrane domain (residues 46-75), the critical L48-S49 motif (which Chamakura, Edwards, et al. (2017) shows is essential for function), and the protein’s ability to form high-order oligomeric pores (>10 subunits) as demonstrated in Mezhyrova et al. (2023).
Computational Pipeline
The project utilizes a multi-step computational protein engineering pipeline to rationally design mutations:
Homolog Discovery (BLAST): Identifying related lysis proteins from related leviviruses to find evolutionarily conserved residues and natural sequence variations that inform design choices
Multiple Sequence Alignment (Clustal Omega): Mapping essential structural regions and differentiating between highly conserved zones (LS motif, pore-forming helix) that must be protected versus mutable sites (N-terminal domain) that can be engineered
In Silico Mutagenesis (Evo 2): Using phage-trained protein language models from King et al. (2025) to generate mutation heatmaps across the N-terminal domain and rationally select amino acid substitutions that improve protein fitness while maintaining “phage-like” sequence characteristics
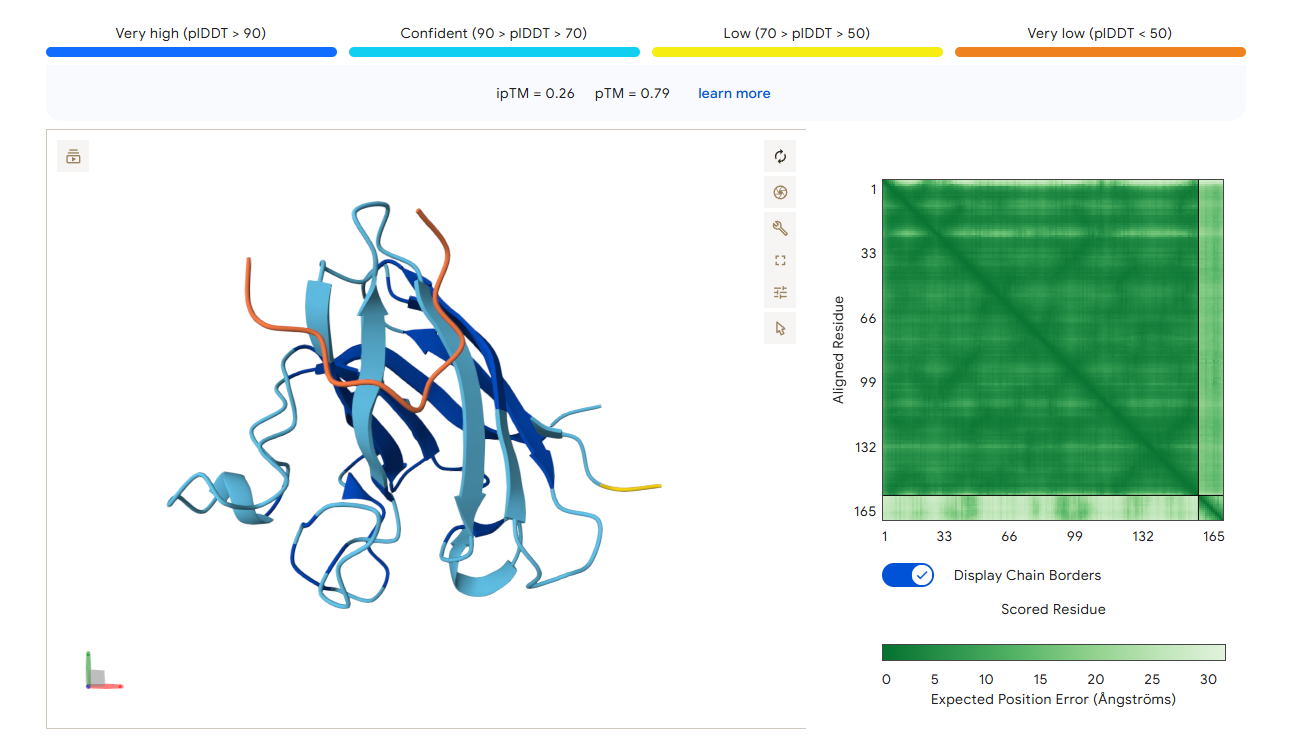
Structure Prediction (ESMFold): Modeling the 3D structures of promising mutants to ensure the essential transmembrane helix is not distorted and the LS motif remains intact (pLDDT >70)
Aggregation Screening (TANGO/AGGRESCAN): Filtering out mutants with high aggregation propensity that could impair membrane insertion
Complex Prediction (AlphaFold Multimer): Evaluating whether mutated proteins can successfully form the required oligomeric pore complex (>10 subunits) and assessing if N-terminal mutations successfully reduce interactions with DnaJ while preserving the core lytic domain
Overlapping Gene Check: Verifying that codon changes do not disrupt the overlapping Coat and Replicase reading frames essential for phage viability.
Expected Outcomes and Applications
The pipeline is expected to yield MS2 L variants with faster lysis kinetics, reduced DnaJ dependency, proper transmembrane insertion, and preserved pore-forming capability.
These optimized proteins have potential downstream applications in synthetic phage engineering for therapeutic cocktails, antimicrobial protein development, bacterial ghost cell production for vaccines, and tools to study lysis timing regulation in phage infection cycles.
Challenges and Future Validation
Key computational challenges include limited structural data for the L-DnaJ complex (no experimental structure exists), model bias toward globular proteins rather than small transmembrane toxins, poor database annotation of single-gene lysis proteins (amurins), and the risk of over-stabilization leading to rigid structures that fail to transition into the active pore-forming state.
Biological risks include mutations might inadvertently affect L’s interaction with its unknown lethal target, modified proteins may become vulnerable to host proteases, disruption of overlapping genes could break essential phage functions, and context-dependent interactions in the membrane environment are difficult to model computationally.
Future validation steps will involve experimentally expressing the computationally identified mutants in E. coli, measuring lysis kinetics (OD600), assessing protein stability via Western blot, testing DnaJ independence through pulldown assays in wild-type and DnaJ mutant backgrounds, and visualizing pore formation using cryo-EM in lipid nanodiscs (following Mezhyrova et al. (2023) protocols).
You can check out the fully detailed Project Proposalhere
Note: I acknowledge help from DeepSeek in understanding the complex research papers and computational tools. I also thank my batchmate 2026a-nourelden-rihan (BioClub Tokyo node) for sharing his approach, which helped clarify the project expectations. *
Week 5 HW: Protein Design Part II
Part A: SOD1 Binder Peptide Design (From Pranam)
Part 1: Generate Binders with PepMLM
Here is the Human SOD1 sequence from Uniprot (P00441)
2 of the generated peptides had X in their sequence and Alphafold was rejecting them so I replaced X with A or Alanine on the advice of Google Gemini.
AlphaFold3 Prediction Results
Peptide Sequence
ipTM Score
Binding Location & Characteristics
Screenshot
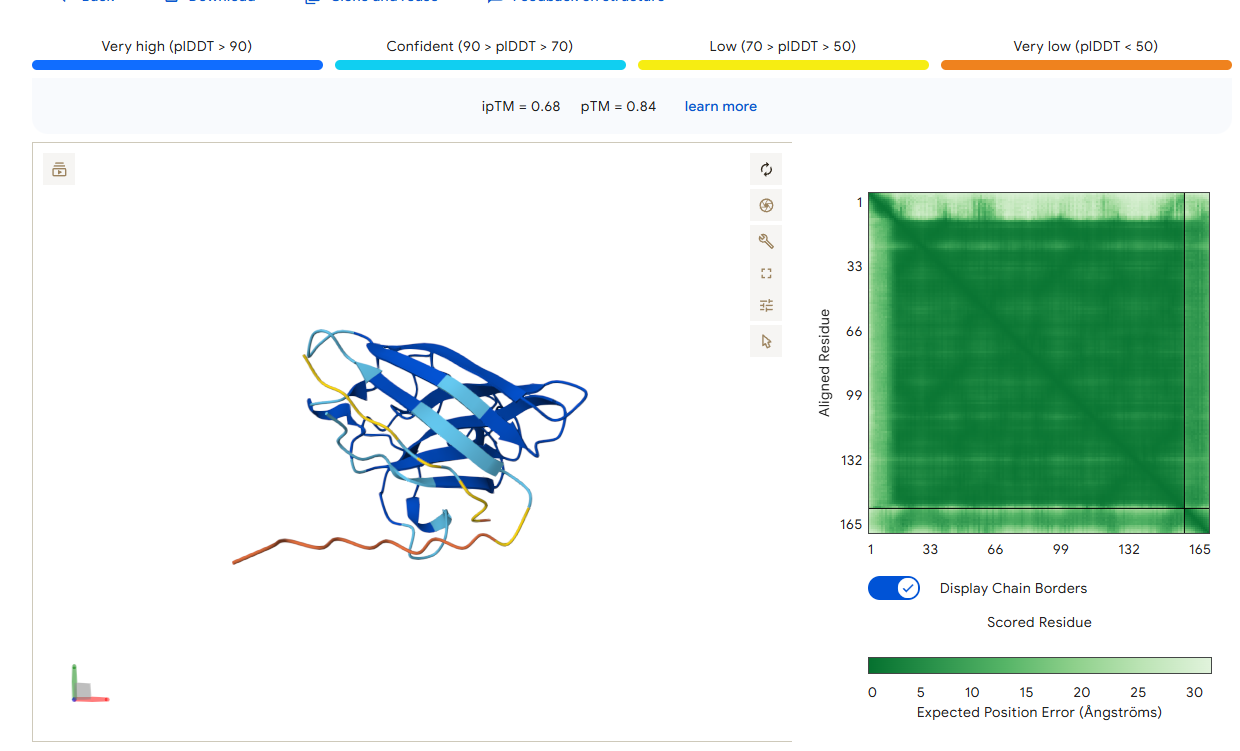
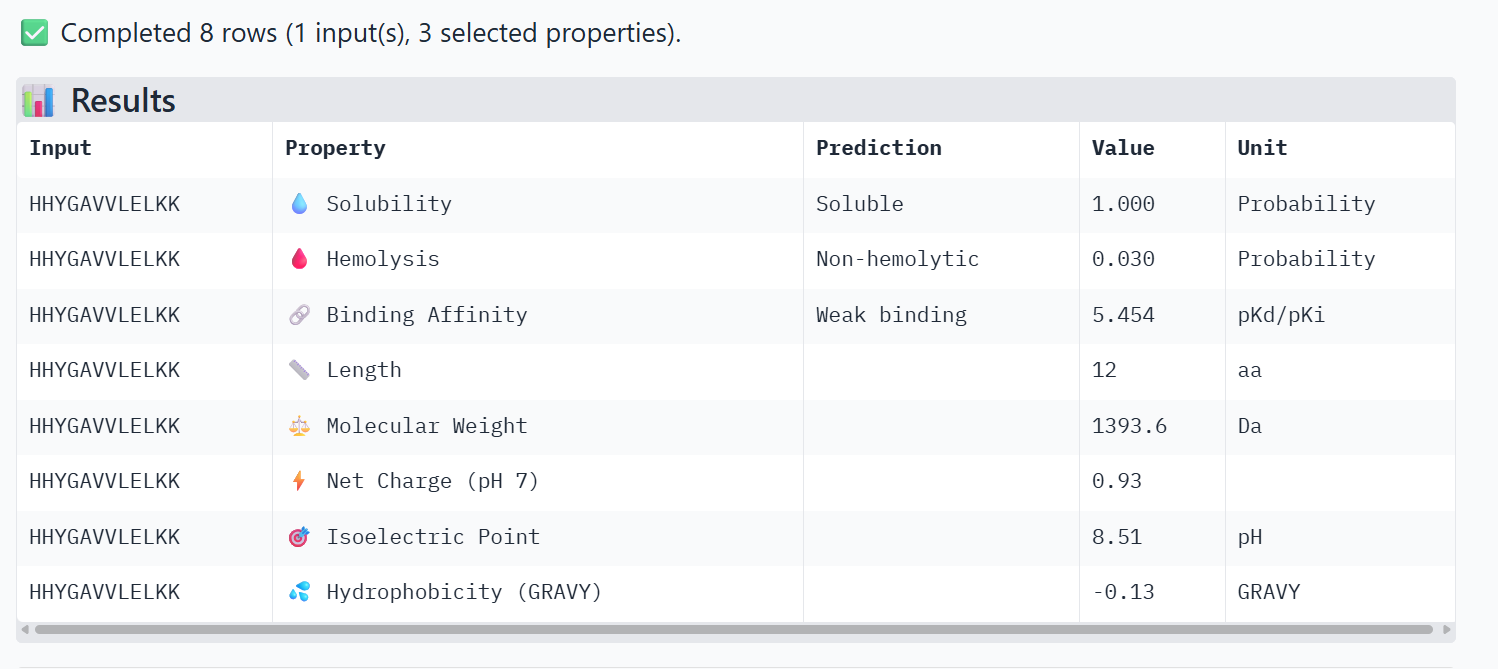
HHYGAVVLELKK
0.68
“Grey Zone” Candidate: This peptide is the most promising, as it is the only one to exceed the 0.6 failure threshold. It appears to engage more deeply with the protein structure, potentially approaching the dimer interface or the core Beta-barrel.
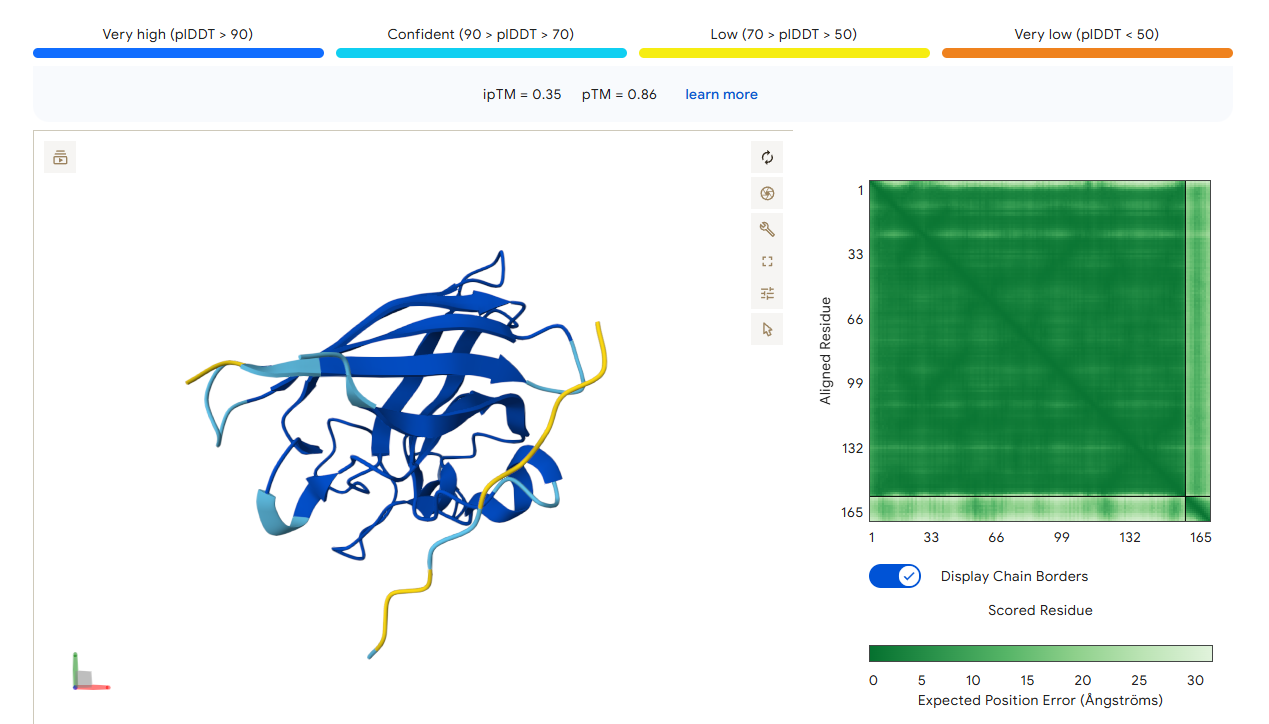
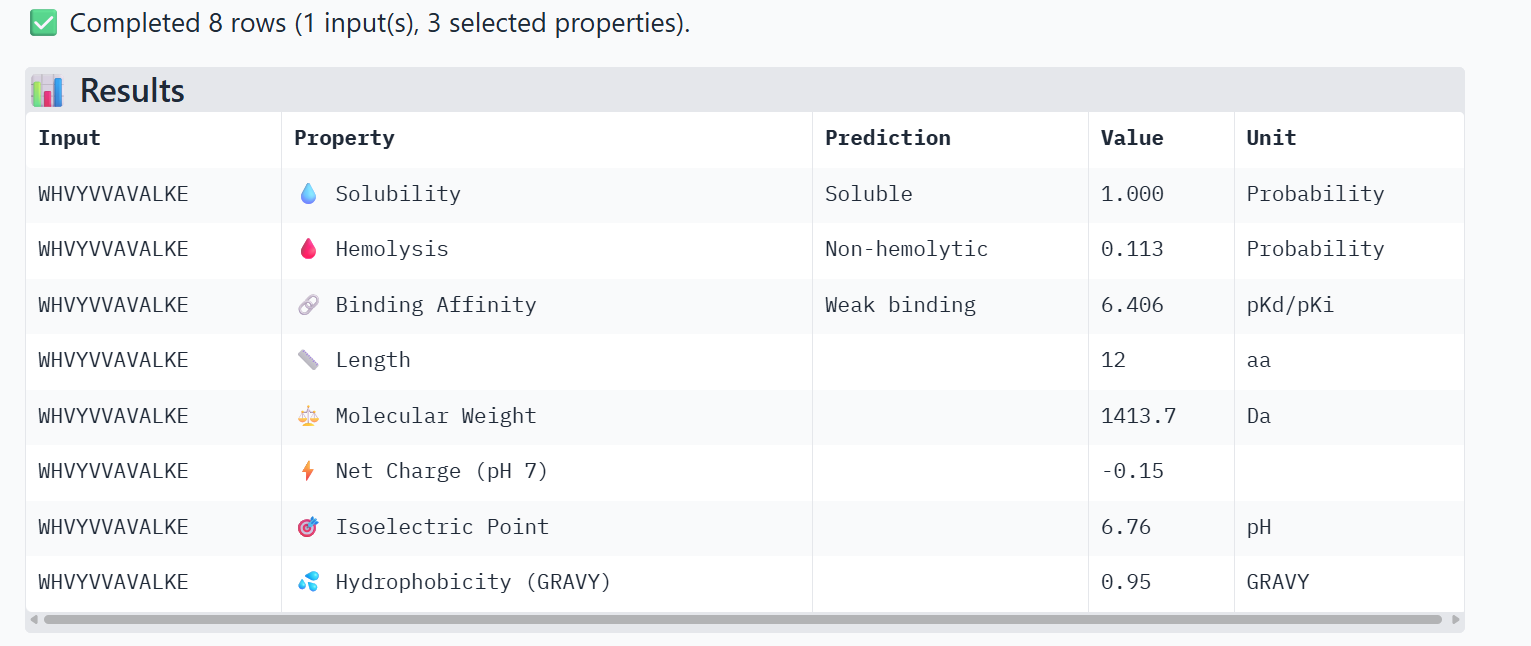
WHVYVVAVALKE
0.35
Failed Prediction: While it slightly exceeds the known binder’s score, it remains surface-bound on the Beta-sheet region with low confidence.
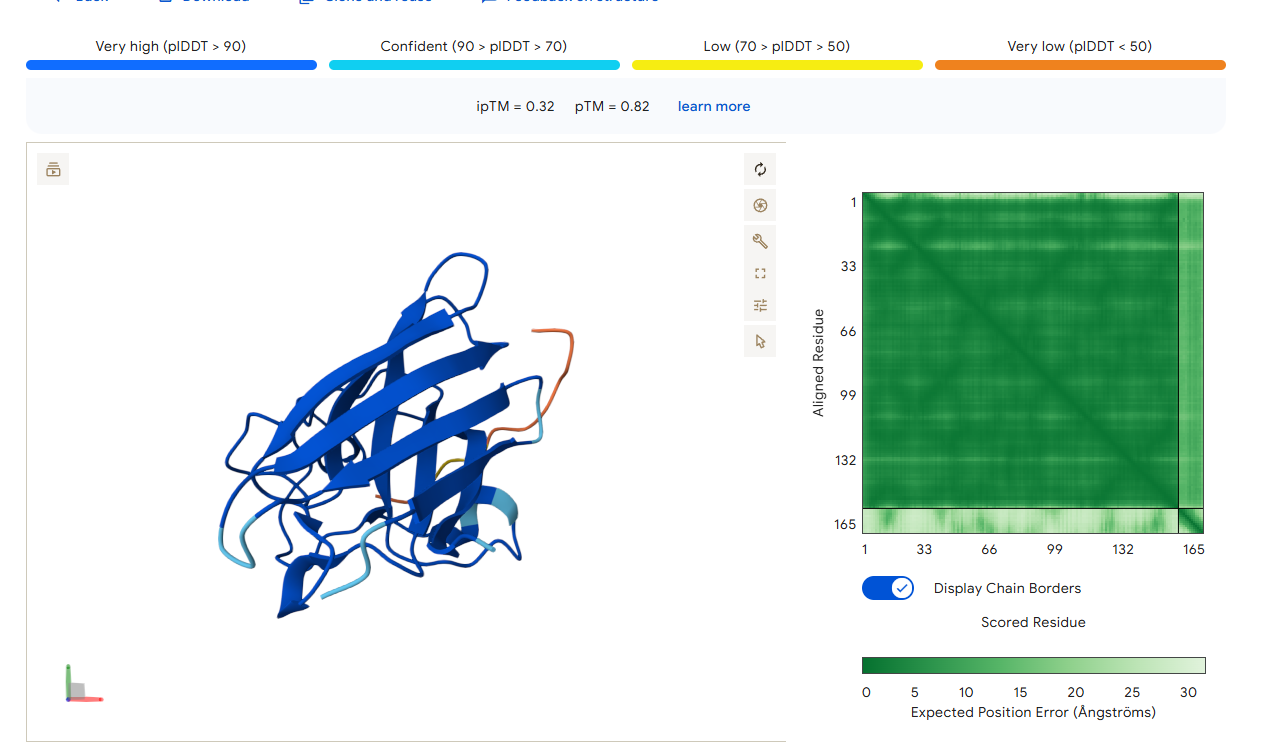
FLYRWLPSRRGG (Known)
0.32
Failed Prediction (Control): The baseline binder shows low confidence; it localizes on the protein surface but does not show specific engagement with the A4V site at the N-terminus.
KRYPVAAARWKX
0.30
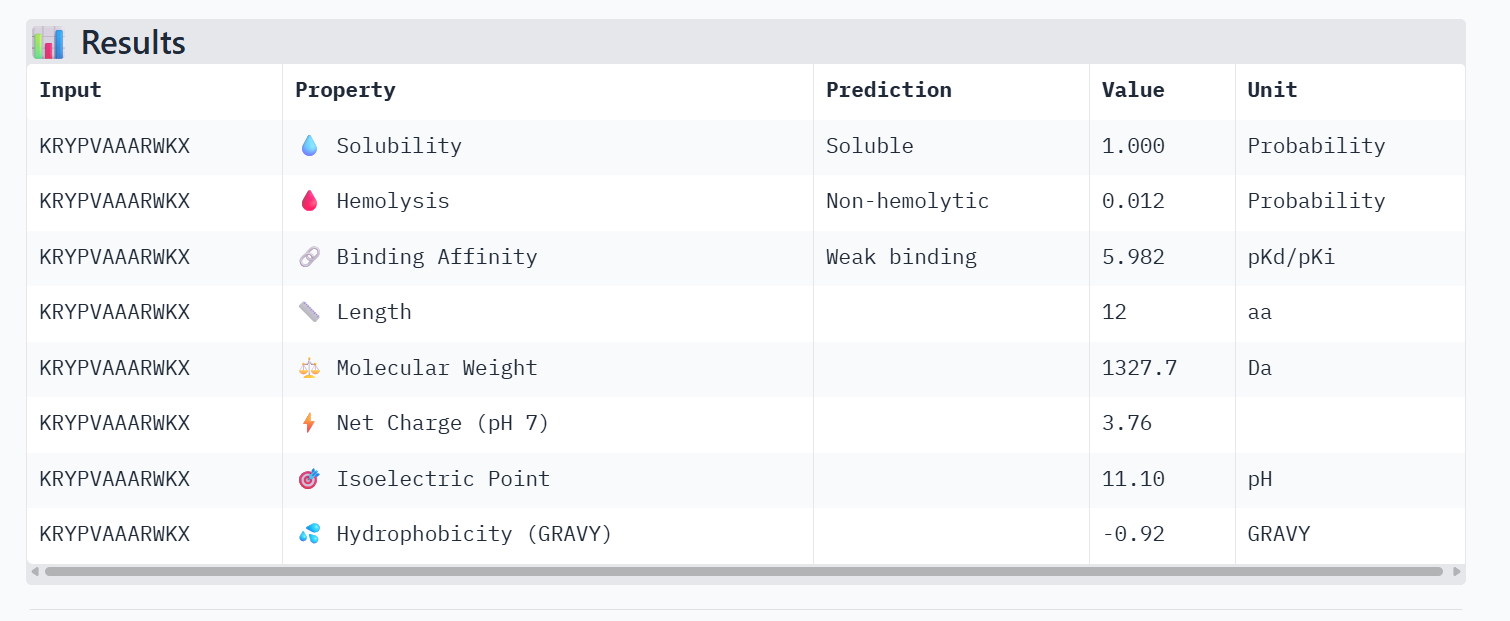
Failed Prediction: This peptide remains mostly surface-bound near flexible loops, showing low structural complementarity to the mutant SOD1.
WRYYPTGLRHKX
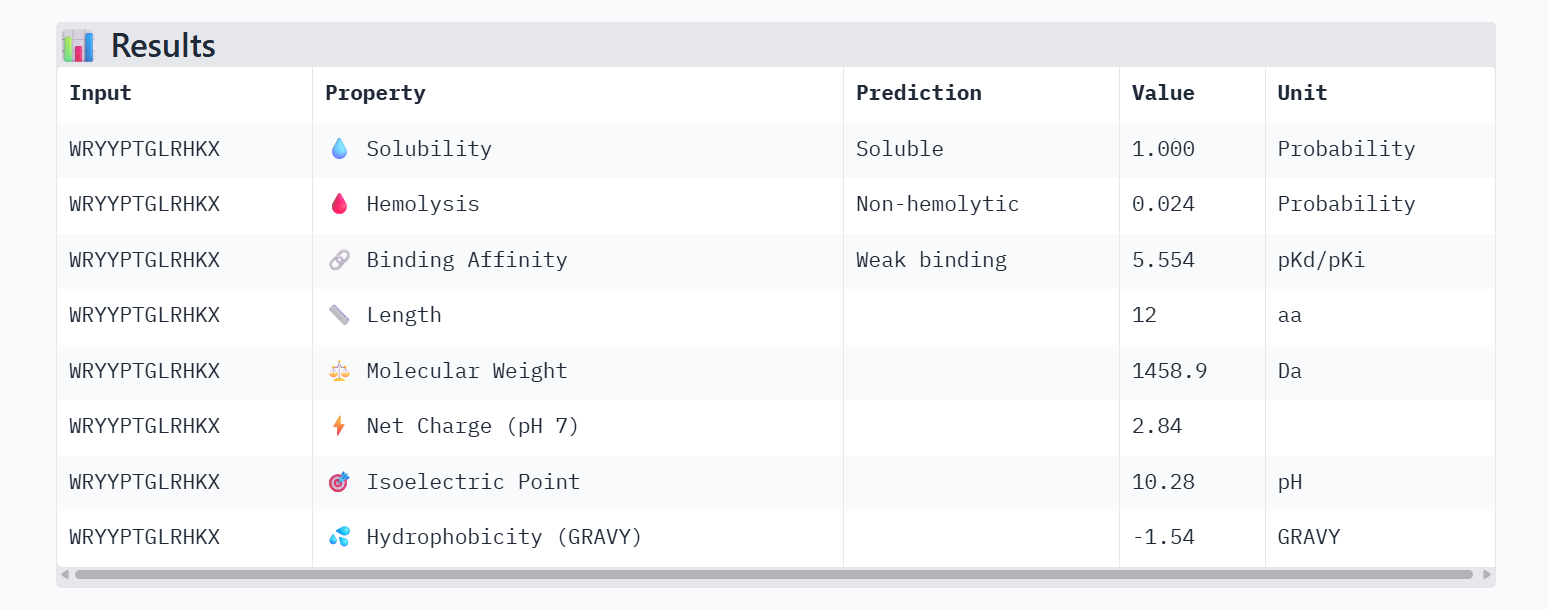
0.26
Failed Prediction: Despite a good PepMLM score, the structural model suggests this sequence is a poor fit, failing to localize near any specific functional region.
Summary Analysis
The ipTM scores for the PepMLM-generated peptides range from 0.26 to 0.68. According to AlphaFold standards, an ipTM score above 0.8 represents a high-quality prediction, while scores below 0.6 are generally considered failed predictions. Most candidates, including the known binder (0.32), fall into the failure category, indicating that these interactions are likely unstable or poorly modeled.
However, the peptide HHYGAVVLELKK achieved an ipTM of 0.68, placing it in the “grey zone” (0.6–0.8). This score indicates that the prediction could potentially be correct and represents a significant improvement over the control binder. While most peptides remain surface-bound, HHYGAVVLELKK shows the most potential to move beyond the surface and possibly engage with the dimer interface or the destabilized N-terminus where the A4V mutation sits.
Part 3: Evaluate Properties of Generated Peptides in the PeptiVerse
PeptiVerse Property Comparison
Peptide Sequence
ipTM Score
pKd/pKi (Affinity)
Solubility
Hemolysis Probability
Screenshot
HHYGAVVLELKK
0.68
5.454
1.000
0.030
WHVYVVAVALKE
0.35
6.406
1.000
0.113
FLYRWLPSRRGG (Known)
0.32
5.968
1.000
0.047
KRYPVAAARWKX
0.30
5.982
1.000
0.012
WRYYPTGLRHKX
0.26
5.554
1.000
0.024
Analysis Paragraph
Comparing the structural data from AlphaFold3 to the chemical properties from PeptiVerse reveals that higher structural confidence (ipTM) does not correlate with stronger predicted binding affinity in this dataset. For instance, HHYGAVVLELKK has the highest ipTM (0.68) but the lowest predicted affinity (5.454). Conversely, WHVYVVAVALKE shows the highest affinity (6.406) but is also the most hemolytic (0.113), which is a significant therapeutic drawback. Interestingly, all peptides are predicted to be highly soluble (1.000). While KRYPVAAARWKX stands out as the safest option with the lowest hemolysis probability (0.012), its structural confidence remains low.
Decision & Justification
Peptide to Advance:HHYGAVVLELKK
Justification: I would advance HHYGAVVLELKK because it is the only candidate that provides a credible structural binding mode, moving out of the “failure zone” and into the AlphaFold3 “grey zone” (0.68). While its predicted affinity is lower than others, structural stability is often a more reliable indicator of specific binding for complex targets like the SOD1 A4V mutation. Additionally, it remains highly soluble and has a low hemolysis probability, ensuring a safe therapeutic profile while potentially stabilizing the destabilized N-terminus better than the low-confidence surface binders.
Part 4: Generate Optimized Peptides with moPPIt
In this section, I moved from global sampling to controlled design. I used the moPPIt model to target specific residue indices (2, 3, 4, 5, 6) corresponding to the A4V mutation site at the N-terminus of SOD1.
Additionally, I selected all optimization properties in the notebook even though the computation was being performed on a T4 GPU in Google Colab, which has limited computational resources. It took 43 mins to implement the code.
Here are the moPPIt generated peptides:
Peptide Sequence
Hemolysis
Solubility
Affinity
Motif
KANYWTTWTSDS
0.93190462142229
0.75
5.74363183975219
0.78769564628601
KCETKFLQKREI
0.966306183487176
0.75
6.49503183364868
0.894703328609466
KRQSCQKTKPFV
0.938299626111984
0.75
6.26246261596679
0.869844377040863
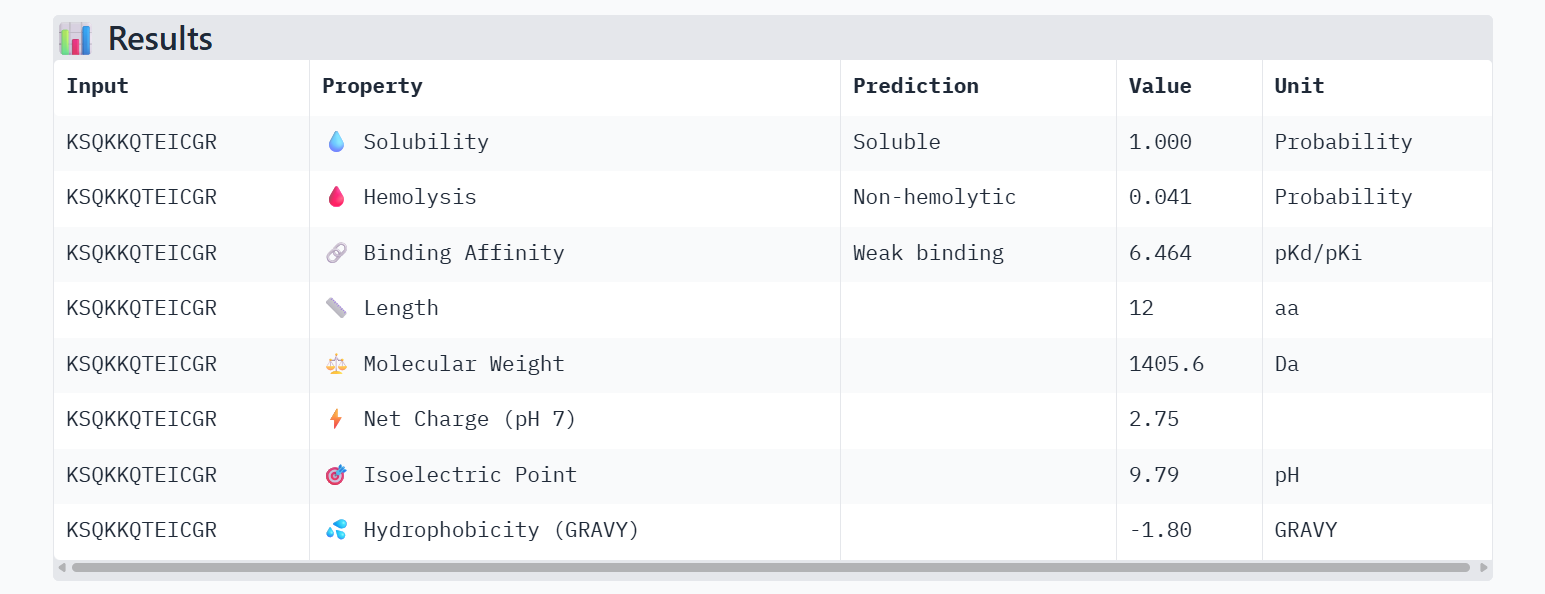
KSQKKQTEICGR
0.958696339279413
0.916666686534881
6.46437692642211
0.800572216510772
In next step, I have decided to take those Peptides, and run them through AlphaFold and PeptiVerse and compare them with the pepMLM ones.
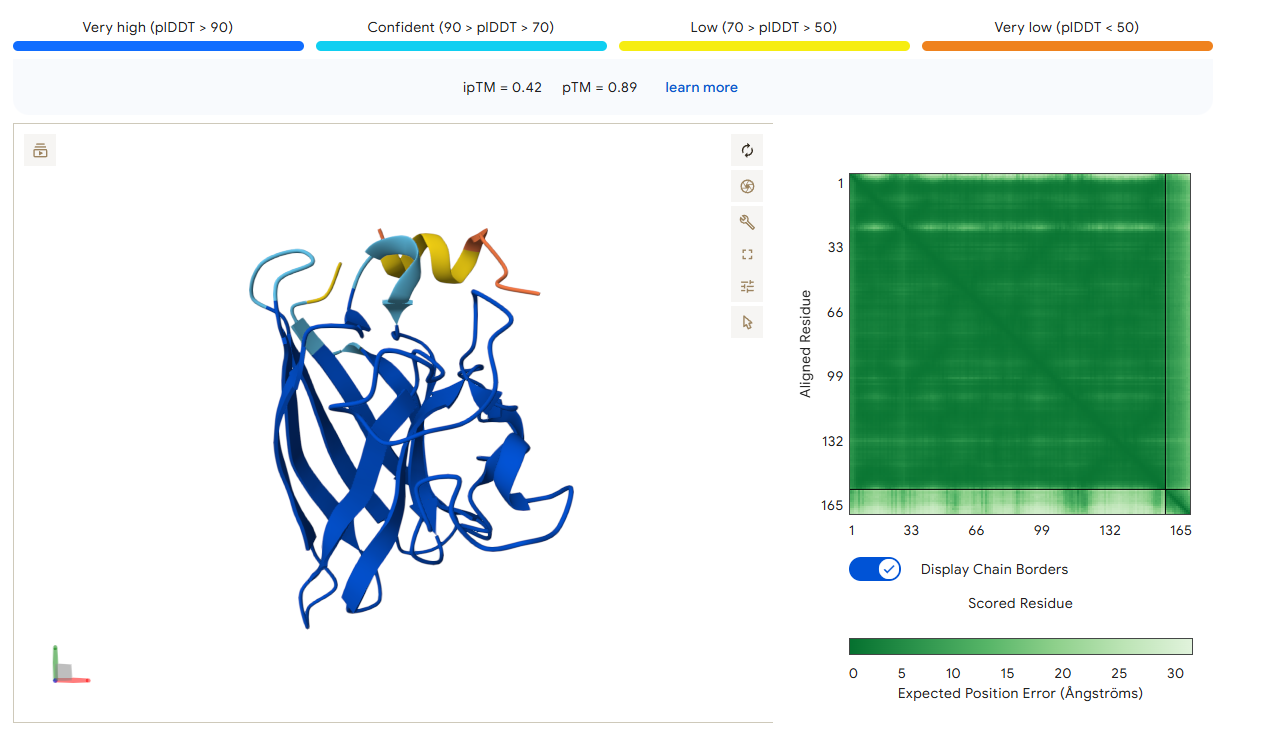
Candidate 1: KSQKKQTEICGR (Lead Candidate)
AlphaFold3 Validation:ipTM Score: 0.52 (The highest structural confidence among the optimized set).
Binding Analysis: This peptide shows the most promising localization. Unlike the PepMLM binders that were floating away, this sequence remains in close proximity to the N-terminal region. It appears to “hug” the site of the A4V mutation, suggesting it could potentially stabilize the destabilized fold.
PeptiVerse Property Profile:
Affinity: 6.464
Solubility: 1.000 (Perfectly soluble)
Hemolysis: 0.041 (Low toxicity)
Candidate 2: KCETKFLQKREI
AlphaFold3 Validation:ipTM Score: 0.42
Binding Analysis: While the confidence is slightly lower than Candidate 1, it remains docked near the beta-barrel region adjacent to the N-terminus. It is not “floating away” into the solvent, indicating a specific interaction with the protein surface.
PeptiVerse Property Profile:
Affinity: 6.495 (Highest Predicted Affinity)
Solubility: 1.000
Hemolysis: 0.074
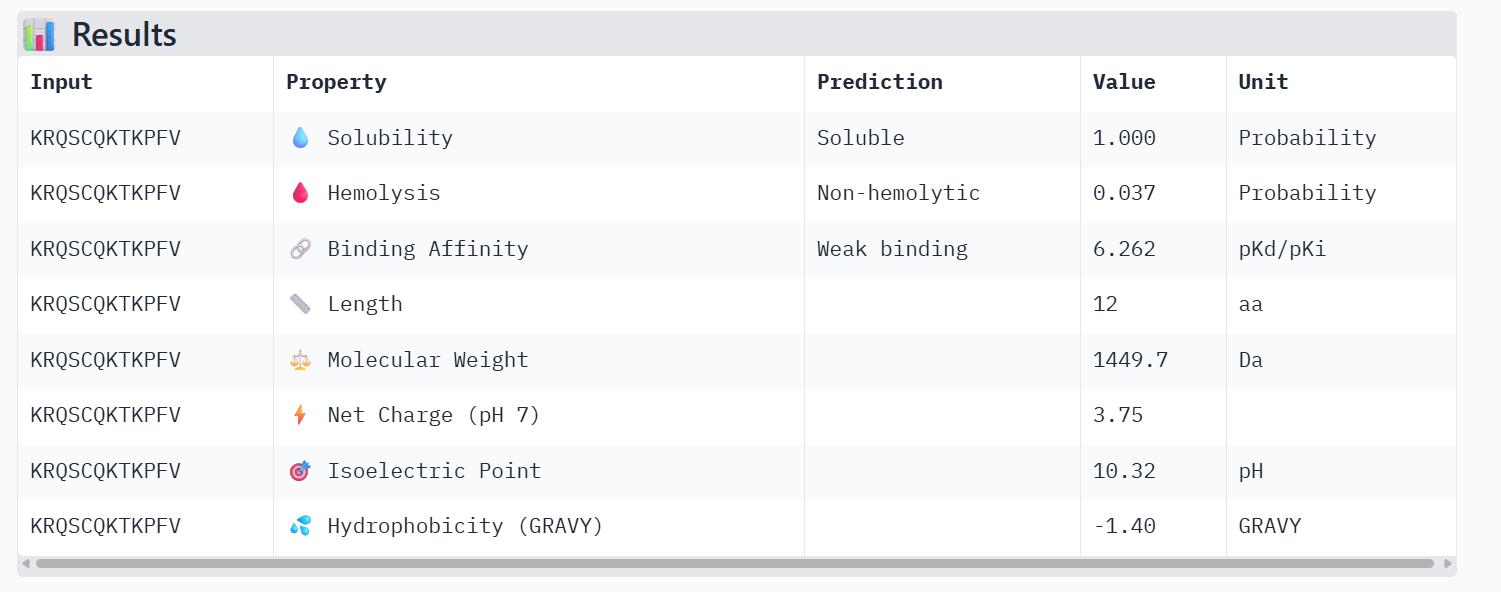
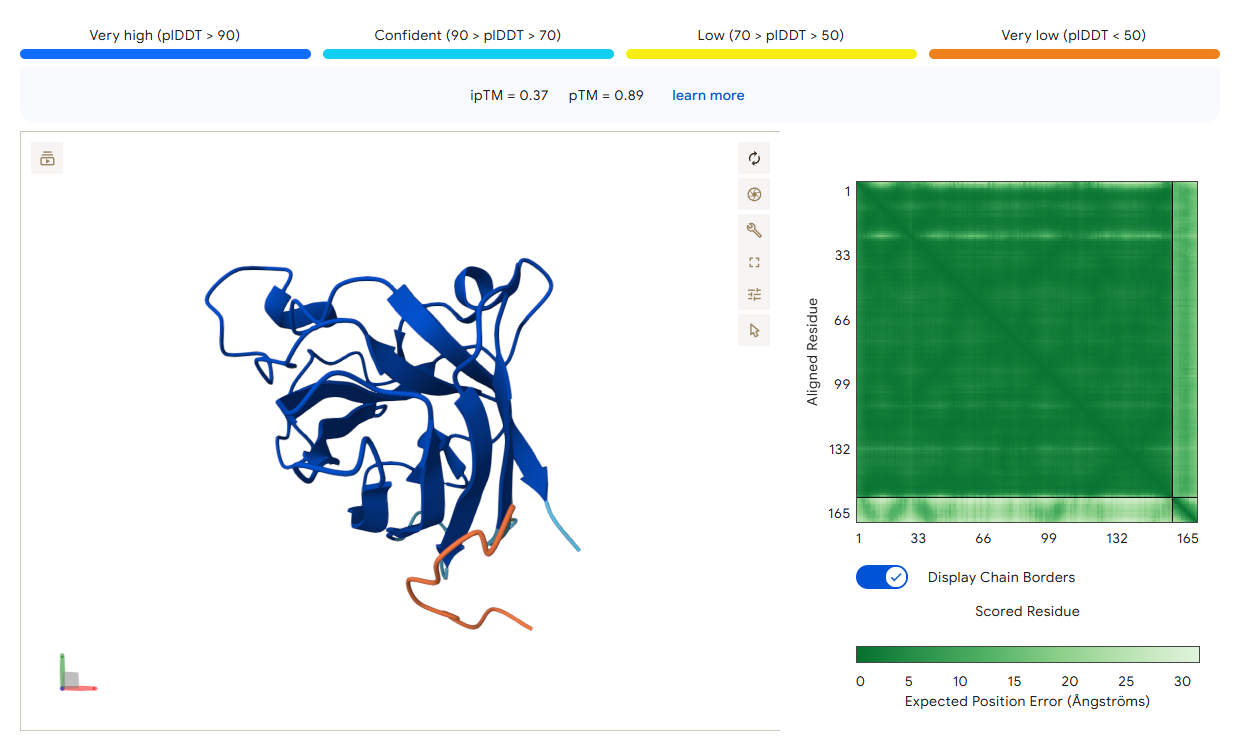
Candidate 3: KRQSCQKTKPFV
AlphaFold3 Validation:ipTM Score: 0.41
Binding Analysis: This candidate also shows proximity to the mutation site. While the ipTM is in the lower confidence range, the physical placement in the model remains focused on the targeted residue patch rather than random surface binding.
PeptiVerse Property Profile:
Affinity: 6.262
Solubility: 1.000
Hemolysis: 0.037
Candidate 3: KANYWTTWTSDS
AlphaFold3 Validation:ipTM Score: 0.37
Binding Analysis: This peptide localizes near the target but shows higher flexibility in the model, reflected in the lower ipTM score. It is close to the N-terminus but less “packed” than the lead candidate.
PeptiVerse Property Profile:
Affinity: 5.744
Solubility: 1.000
Hemolysis: 0.066
How moPPIt Peptides Differ from PepMLM Peptides
The moPPIt-designed peptides represent a significant improvement over the PepMLM set for several reasons:
Controlled Specificity: PepMLM performs “Global Sampling,” which often results in peptides that bind to random surface loops. moPPIt uses Multi-Objective Guided Discrete Flow Matching (MOG-DFM) to steer the peptide specifically toward residues 2-6 (the A4V site).
Property Reliability: moPPIt optimized for Affinity and Solubility during the generation phase itself. This resulted in a 100% success rate for solubility (1.000) and consistently high affinity scores (pKd/pKi > 6.2) across the lead candidates.
Targeting the “Toxic” Site: By forcing the model to bind near the N-terminus, moPPIt creates candidates more likely to stabilize the SOD1 dimer interface, which is the root cause of A4V-driven ALS.
Pre-Clinical Evaluation Strategy
To advance the lead candidate (KSQKKQTEICGR) toward clinical application, I would follow this validation pipeline:
Biophysical Assays (SPR/ITC): I would use Surface Plasmon Resonance (SPR) to confirm the pKd/pKi values. Computational predictions must be validated with physical measurements of binding kinetics to ensure high-affinity binding in the nanomolar range.
Aggregation Inhibition (ThT Assay): Since the A4V mutation causes toxic protein clumping, a Thioflavin T assay is essential to prove the peptide actually prevents SOD1 from aggregating.
Efficacy in Motor Neurons: Testing on ALS patient-derived motor neurons is required to see if the peptide reduces intracellular SOD1 aggregates without causing cellular toxicity.
Proteolytic Stability: I would evaluate the peptide’s half-life in human serum to ensure it isn’t degraded by proteases before it can reach the target neurons in the CNS.
Week 6 Genetic Circuits Part I: Assembly Technologies
Assignment: DNA Assembly
1. What are some components in the Phusion High-Fidelity PCR Master Mix and what is their purpose?
The Phusion High-Fidelity PCR Master Mix is a concentrated, 2X formulation designed for high-performance DNA amplification. Its primary components include:
Phusion DNA Polymerase: A recombinant enzyme consisting of a Pyrococcus-like proofreading polymerase fused to a dsDNA-binding domain (Sso7d). This fusion technology enhances processivity, allowing the enzyme to synthesize long fragments rapidly while maintaining a low error rate (50 × lower than Taq).
Deoxynucleotide Triphosphates (dNTPs): Equimolar concentrations of dATP, dCTP, dGTP, and dTTP serve as the chemical precursors for the nascent DNA strand.
Magnesium Chloride (MgCl2): A critical divalent cation cofactor. Mg2+ ions coordinate with the phosphate groups of the dNTPs and the enzyme’s active site, facilitating the nucleophilic attack of the 3’-OH primer end on the incoming nucleotide.
Reaction Buffers (HF or GC): These maintain optimal pH (8.8–9.3) and ionic strength. The HF (High-Fidelity) Buffer is the standard for most templates, while the GC Buffer contains additives (like DMSO) that lower the melting temperature of DNA to assist in the denaturation of templates with secondary structures or high GC content.
2. What are some factors that determine primer annealing temperature during PCR?
The optimal annealing temperature is vital for balancing primer specificity with yield. It is dictated by:
Melting Temperature (T_m): The temperature at which 50% of the primer-template duplex is dissociated. Annealing temperature is typically set 3–5 °C below melting temperature.
Base Composition (GC Content): Because Guanine-Cytosine pairs involve three hydrogen bonds compared to two for Adenine-Thymine, higher GC content increases the thermal stability of the primer.
Primer Length: Longer sequences possess higher cumulative hydrogen bonding, raising the energy required for dissociation.
Salt Concentration: Monovalent (K+) and divalent (Mg2+) cations neutralize the negatively charged phosphate backbone of DNA, reducing electrostatic repulsion and stabilizing the duplex, which effectively raises the melting temperature.
3. There are two methods from this class that create linear fragments of DNA: PCR, and restriction enzyme digests. Compare and contrast these two methods, both in terms of protocol as well as when one may be preferable to use over the other.
Both methods yield linear DNA fragments, but they differ fundamentally in mechanism and application:
Feature
PCR Amplification
Restriction Enzyme Digest
Mechanism
De novo enzymatic synthesis of specific DNA regions.
Hydrolysis of phosphodiester bonds at specific recognition sites.
Input Material
Requires only trace amounts of template DNA.
Requires a significant mass of pre-existing DNA (e.g., plasmid).
Product Ends
Typically blunt-ended (unless primers include overhangs).
Can produce sticky (overhanging) or blunt ends depending on the enzyme.
Precision
High flexibility; primers can be designed for any sequence.
Limited by the presence of specific palindromic recognition sites.
Primary Use
Scaling DNA quantity and adding functional “tails.”
Cloning into vectors or diagnostic mapping of DNA fragments.
4. How can you ensure that the DNA sequences that you have digested and PCR-ed will be appropriate for Gibson cloning?
To ensure compatibility with Gibson Assembly, fragments must satisfy the following criteria:
Overlapping Homology: Fragments must share 20–40 bp of identical sequence at their termini. For PCR products, these overlaps are engineered into the 5’ ends of the primers.
Sequence Purity: PCR products must be purified (via column or gel extraction) to remove residual primers and dNTPs, which could interfere with the Gibson Master Mix’s precise ratio of exonuclease and polymerase activity.
End Compatibility: While Gibson can join blunt or sticky ends, the presence of the correct homologous overlap is the only requirement for the 5’ → 3’ exonuclease to “chew back” the DNA and allow for annealing.
5. How does the plasmid DNA enter the E. coli cells during transformation?
Plasmid DNA enters E. coli cells through two primary laboratory methods:
Chemical Transformation (Heat Shock): Cells are treated with Calcium Chloride to coat the negatively charged cell membrane with Ca2+ ions, facilitating DNA adhesion. A rapid increase in temperature 42 °C creates a thermal imbalance that induces the formation of transient pores in the membrane, through which the DNA-calcium complex is internalized.
Electroporation: Cells are subjected to a high-voltage electric pulse (typically 1.8–2.5 kV). This causes dielectric breakdown of the cellular membrane, creating localized “nanopores” that allow the plasmid DNA to enter the cytoplasm via electrophoresis.
6. Describe another assembly method in detail (such as Golden Gate Assembly).
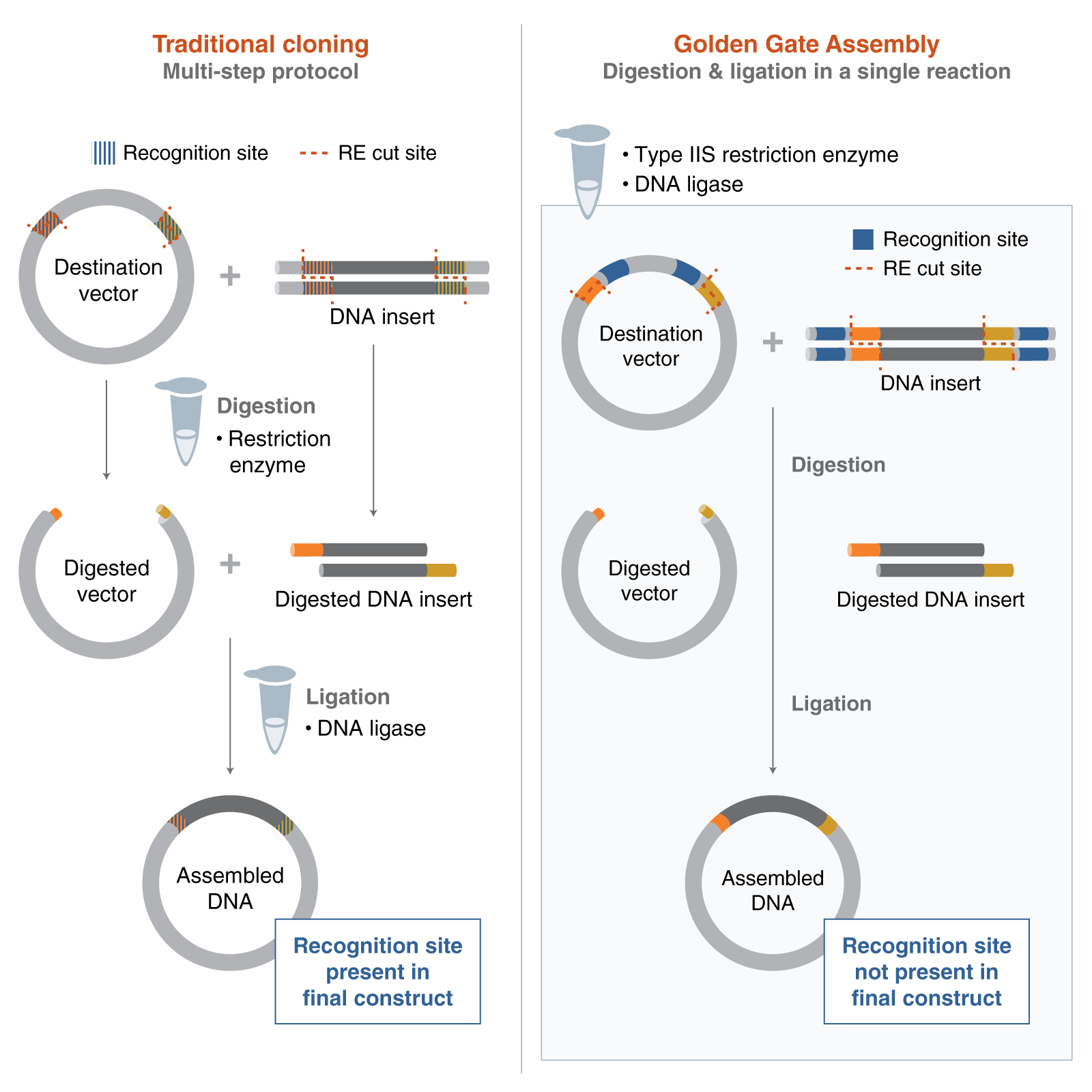
Golden Gate Assembly is a highly efficient molecular cloning technique that allows for the simultaneous, directional assembly of multiple DNA fragments into a single vector. This method relies on Type IIS restriction enzymes (such as BsaI or BpiI), which are unique because they cleave DNA at a specific distance outside of their non-palindromic recognition sequences. By strategically placing these recognition sites at the ends of DNA fragments, the enzyme generates unique, user-defined 4-base overhangs (sticky ends) that are eliminated from the final product during the reaction. Because the recognition sites are removed during cleavage, the desired assembly is “lossless” and cannot be re-cut by the enzyme, effectively driving the reaction toward the final circular product. The process occurs in a single-tube “one-pot” reaction where restriction digestion and T4 DNA ligation happen concurrently through biochemical cycling. This method is particularly favored for synthetic biology and modular cloning (MoClo) because it allows for the seamless “scarless” joining of many parts with nearly 100% efficiency.
The Mechanism of Type IIS Cleavage
The key to Golden Gate is that the enzyme binds to a recognition site but cuts a few nucleotides away. This allows you to design the “overhang” to be whatever sequence you need for perfect complementarity with the next fragment.
The “One-Pot” Reaction Cycle
Because the ligation of the correct fragments destroys the original restriction sites, the reaction is essentially a “one-way street.” If the enzyme cuts a fragment and it ligates back to its original orientation, the site is reformed and the enzyme will simply cut it again. Once the correct assembly is formed, the sites are gone, and the product remains stable.
Comparison: Golden Gate vs. Gibson Assembly
While Gibson Assembly uses overlaps and “chew-back” enzymes, Golden Gate uses specific 4-base sticky ends. This makes Golden Gate extremely reliable for assembling very small fragments or repetitive sequences that might confuse the Gibson exonuclease.
Week 7 HW: Genetic Circuits Part II: Neuromorphic Circuits
Assignment Part 1: Intracellular Artificial Neural Networks (IANNs)
1. What advantages do IANNs have over traditional genetic circuits, whose input/output behaviors are Boolean functions?
While traditional genetic circuits operate on binary logic (0 or 1), Intracellular Artificial Neural Networks (IANNs) utilize an analog approach that more accurately reflects biological reality. Their primary advantages include:
Realistic Analog Processing: Biology rarely exists in a strictly “on/off” state. IANNs can process continuous gradients of expression, allowing the cell to make decisions based on subtle shifts in concentration rather than waiting for a digital threshold.
Weighted Decision Boundaries: In a Boolean circuit, adding a new “condition” usually requires engineering entirely new genetic parts from scratch. In an IANN, you can adjust the “weight” of an input (e.g., by changing the binding affinity of a protein or the strength of a promoter), allowing for complex tuning without redesigning the whole system.
Advanced Logic (The “Dual Region” Zone): IANNs enable “non-monotonic” logic. For example, a cell can be programmed to activate only when an input is strictly below or strictly above a certain range, remaining inactive in the middle. This “band-pass” behavior is incredibly difficult to achieve with standard AND/OR gates.
Pattern Recognition: IANNs are superior at integrating multiple “weak” signals. Instead of requiring one signal to be 100% “on,” the network can sum several 20% signals to trigger a response, making them ideal for sensing complex environmental or disease signatures.
2. Describe a useful application for an IANN; include a detailed description of input/output behavior, as well as any limitations an IANN might face to achieve your goal.
Goal: A synthetic IANN designed for a bioremediation host (like P. putida) that triggers a cleanup response only when a specific ratio of heavy metals and organic pollutants is detected.
Input Behavior: The network senses three distinct analog inputs: Lead (Pb2+), Arsenic (As3+), and Toluene.
Output Behavior: The IANN calculates a weighted sum. If the “toxic signature” matches a specific profile (e.g., high Lead + moderate Toluene), it triggers the expression of degradative enzymes. If the inputs fall outside these specific “decision boundaries” (e.g., Lead is too low to be a threat, or so high it would kill the host), the output remains at 0 to conserve energy.
Limitations to Implementation
Metabolic Sequestration (The ERN Cost): Using Endoribonucleases (ERNs) to control the network is powerful but “expensive.” Because ERNs often bind to and hold RNA rather than instantly destroying it, they sequester cellular resources. A large IANN could potentially “clog” the cell’s translational machinery, leading to reduced fitness or growth arrest.
Orthogonality Scalability: As the circuit grows more complex to handle more inputs, you need an increasing number of unique ERNs. If these ERNs overlap in their target sequences, “cross-talk” occurs, where one branch of the neural network accidentally silences the wrong target, leading to a total failure of the logic.
Stochastic Noise: In an analog system, small random fluctuations in molecular counts (noise) can shift the decision boundary, potentially causing a “false fire” in a sensitive environment.
Assignment Part 2: Fungal Materials
1. What are some examples of existing fungal materials and what are they used for? What are their advantages and disadvantages over traditional counterparts?
Fungal materials, often referred to as mycomaterials, primarily utilize mycelium which is a vegetative, root-like network of a fungus.
Mycelium Composites (Bio-foams & Bricks)
How they’re made: Fungi are grown on agricultural waste (hemp, sawdust, rice hulls). The mycelium acts as a natural “glue,” binding the substrate into a solid form.
Applications:
Packaging: Companies like Ecovative produce biodegradable alternatives to Styrofoam.
Construction: Mycelium bricks and insulation panels. Notable projects like “Hy-Fi” (a 40-foot tower in NYC) have demonstrated their structural potential.
Acoustics: Sound-absorbing wall tiles for studios and offices.
Mycelium Leather (Myco-leather)
How it’s made: Pure mycelium is grown in mats, then tanned and processed like animal hide.
Applications: High-fashion items (e.g., Hermès and Adidas have explored mycelium leather), upholstery, and automotive interiors.
Fungal Textiles and Films
Applications: Biodegradable films for wound healing or flexible electronic substrates.
Advantages and Disadvantages vs. Traditional Counterparts
Feature
Fungal Materials
Traditional (Plastics/Leather/Concrete)
Environmental Impact
Carbon-negative/neutral. Uses waste and is biodegradable.
High carbon footprint; fossil-fuel based or methane-heavy (livestock).
Manufacturing
Grown in days; low energy/water requirements
Energy-intensive chemical synthesis or years of livestock raising.
Performance
Excellent thermal/acoustic insulation; natural fire resistance.
Variable; plastics are durable but toxic when burned.
Durability
Disadvantage: Sensitive to moisture and can biodegrade prematurely if not treated.
Extremely durable and weather-resistant.
Consistency
Disadvantage: Biological variability makes standardization difficult.
Highly predictable and standardized properties.
2. What might you want to genetically engineer fungi to do and why? What are the advantages of doing synthetic biology in fungi as opposed to bacteria?
Fungi offer a unique chassis for synthetic biology. I would love to use it to produce scorpion venom peptides but there are other appliations too.
Potential Engineering Goals
Material Customization: Engineering fungi to produce more chitin for stiffer bricks or more hydrophobins for water-resistant leather.
Self-Healing Materials: Designing fungi that remain “latent” in a material and reactivate to repair cracks when exposed to moisture or specific nutrients.
Biosensors: Programming mycelium to change color or produce a signal in the presence of environmental toxins or pathogens.
Biopharmaceuticals: Engineering filamentous fungi (like Aspergillus niger) to secrete complex human proteins or secondary metabolites for cancer therapy.
Advantages of Fungi vs. Bacteria in Synthetic Biology
Post-Translational Modifications (PTMs): As eukaryotes, fungi can perform complex PTMs (like glycosylation) that bacteria cannot. This is crucial for producing functional human-like proteins.
Secretion Powerhouses: Filamentous fungi are natural champions at secreting large amounts of enzymes and proteins directly into their environment, simplifying the “harvesting” process compared to lysing bacterial cells.
Complex Metabolism: Fungi possess vast biosynthetic gene clusters (BGCs) for secondary metabolites, making them superior for discovering and producing new antibiotics or anticancer drugs.
Structural Growth: Unlike bacteria (which grow as a “soup” or biofilm), fungi grow as a 3D physical network. This allows for the engineering of living materials with specific mechanical architectures.
Assignment Part 3: First DNA Twist Order
Week 9 HW: Cell-Free Systems
Part A: Conceptual Questions
1. Explain the main advantages of cell-free protein synthesis over traditional in vivo methods, specifically in terms of flexibility and control over experimental variables. Name at least two cases where cell free expression is more beneficial than cell production.
Cell-free protein synthesis (CFPS) has transitioned from a niche laboratory technique to a powerful platform for synthetic biology and biomanufacturing. By removing the constraints of maintaining cell viability, CFPS offers a level of engineering precision that traditional in vivo methods cannot match.
Advantages of CFPS: Flexibility and Control
In traditional in vivo expression, the cell’s “homeostasis” is the primary obstacle. The cell prioritizes its own survival over your recombinant protein. CFPS bypasses this by using only the necessary molecular machinery.
Direct Access: Since there is no cell membrane, you can directly manipulate the reaction environment. You can add non-natural amino acids, chaperones, or specific detergents without worrying about cellular toxicity.
Variable Control: You can precisely calibrate the concentrations of DNA templates, T7 polymerase, and energy substrates. In cells, these levels are dictated by the organism’s metabolic state.
Elimination of Toxicity: Many proteins (like antimicrobial peptides or certain enzymes) kill the host cell upon expression. In a cell-free system, the “host” is already dead, allowing for the synthesis of highly toxic molecules.
Two cases where CFPS is more beneficial
Rapid Prototyping (Design-Build-Test): Screening 100 variants of a protein takes days with CFPS (just add PCR products to the mix) compared to weeks for microbial transformation and cloning.
Incorporation of Non-Canonical Amino Acids (ncAAs): CFPS allows for the easy expansion of the genetic code to create “bio-orthogonal” proteins with unique chemical properties that might otherwise interfere with a living cell’s metabolism.
2. Describe the main components of a cell-free expression system and explain the role of each component.
A standard cell-free system consists of three functional groups:
Cell Extract (S30/S12): Provides the “hardware”: ribosomes, aminoacyl-tRNA synthetases, and initiation/elongation factors.
Energy Buffer: Contains ATP, GTP, and an energy regeneration substrate (e.g., phosphoenolpyruvate) to fuel the high-energy cost of translation.
Reaction Mix: Includes the DNA/mRNA template, salts (Mg2+, K+), amino acids, and often a T7 RNA polymerase for coupled transcription-translation.
3. Why is energy provision regeneration critical in cell-free systems? Describe a method you could use to ensure continuous ATP supply in your cell-free experiment.
Protein synthesis is energetically expensive; every peptide bond consumes multiple high-energy phosphates. In a batch CFPS reaction, endogenous ATP is depleted within minutes due to “side reactions” and phosphatase activity.
To maintain a steady-state concentration of ATP, we use secondary energy sources. A common method is the Creatine Phosphate/Creatine Kinase (CP/CK) system.
Method: We add Creatine Phosphate and the enzyme Creatine Kinase to the mix. The enzyme transfers a phosphate group from CP to ADP, constantly “recharging” the ATP pool as it is consumed. This prevents the accumulation of inorganic phosphate, which can eventually inhibit the reaction.
4. Compare prokaryotic versus eukaryotic cell-free expression systems. Choose a protein to produce in each system and explain why.
Feature
Prokaryotic (e.g., E. coli)
Eukaryotic (e.g., Wheat Germ/CHO)
Speed/Yield
Very high; fast turnaround.
Slower; lower yields.
Folding
Limited post-translational modifications.
Complex folding and glycosylation.
Prokaryotic Choice:T7 Polymerase. It is a simple, robust protein that doesn’t require complex folding or glycosylation, making E. coli extracts the most cost-effective choice.
Eukaryotic Choice:Human Erythropoietin (EPO). This requires specific glycosylation patterns to be biologically active. A CHO (Chinese Hamster Ovary) cell-free system would be used because it contains the microsomes/ER vesicles necessary for these modifications.
5. How would you design a cell-free experiment to optimize the expression of a membrane protein? Discuss the challenges and how you would address them in your setup.
Membrane proteins are notoriously difficult because they are hydrophobic and aggregate in aqueous buffers.
The Design:
To optimize expression, we must provide a “hydrophobic mimic” during synthesis. I would use Nanodiscs—small, discoidal bilayers held together by membrane scaffold proteins.
Challenge: Insoluble aggregation and misfolding.
Strategy: Perform a “co-translational” setup where Nanodiscs are added directly to the CFPS reaction. As the ribosome produces the hydrophobic transmembrane helices, they spontaneously insert into the Nanodisc bilayer, maintaining their native conformation and solubility.
6. Imagine you observe a low yield of your target protein in a cell-free system. Describe three possible reasons for this and suggest a troubleshooting strategy for each.
If I observe a low yield, I would consider these three potential points of failure:
Magnesium (Mg2+) Concentration:
Reason: Ribosome stability and polymerase activity are extremely sensitive to magnesium levels.
Strategy: Perform a magnesium titration. Run several small-scale reactions with Mg2+ concentrations ranging from 5mM to 20mM to find the “sweet spot.”
Template Degradation:
Reason: Endogenous nucleases in the cell extract may be chewing up your DNA or mRNA template.
Strategy: Use circular plasmid DNA instead of linear PCR products, or add RNase inhibitors to the reaction mix.
Codon Bias:
Reason: The tRNA pool in the extract (e.g., E. coli) might not match the codon usage of our target gene (e.g., a human gene).
Strategy: Supplement the reaction with extra tRNAs for rare codons or use a commercially available “Extra” extract enriched with rare tRNA species.