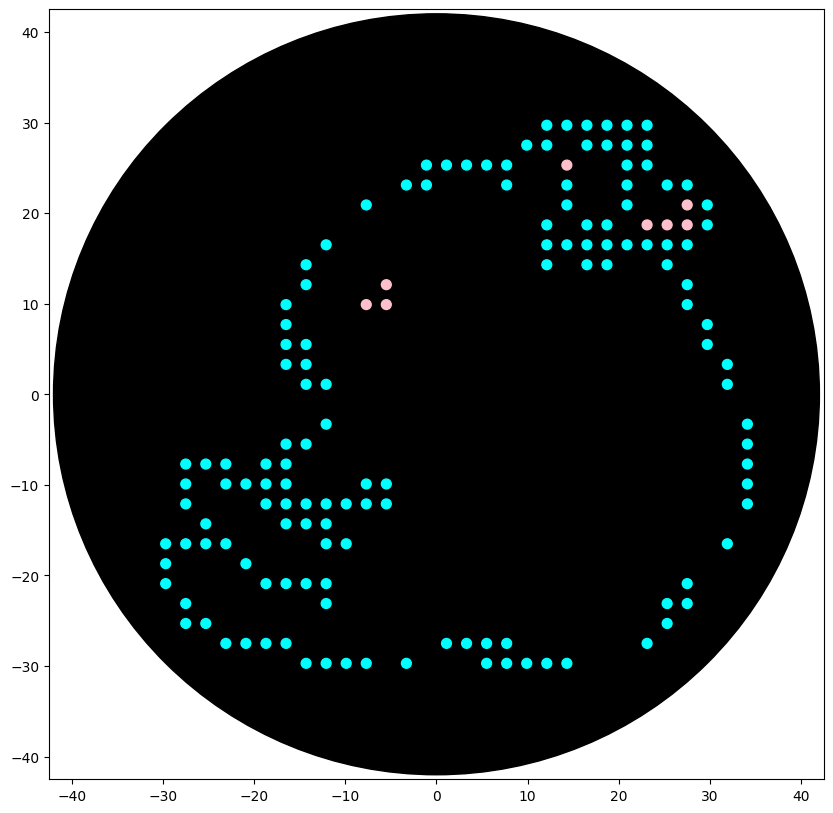
First, describe a biological engineering application or tool you want to develop and why. This could be inspired by an idea for your HTGAA class project and/or something for which you are already doing in your research, or something you are just curious about. I have worked with the concept of CA before within design and 3d space generative making through creating tools for generating patterns and environments, so it was really fascinating to see it being brought up during class. So, for my idea I’d like to merge my previous digital experience with CA and synthetic biology tooling in a form of a computer aided design tool for spatial synthetic biology
Part 1: Benchling & In-silico Gel Art Here’s my version of made in Benchling pattern/image in the style of Paul Vanouse’s Latent Figure Protocol artworks :)
.. It’s a frog!!!
https://benchling.com/s/seq-E1w2i5oXtxnqS8BWnwcZ?m=slm-mz29OlZAWUwDeJTn4nir
I also played around separately to that drawing with Ronan’s tool, and this is what I got ( I wanted to go for something more abstract this time)
Part A. Conceptual Questions 1.How many molecules of amino acids do you take with a piece of 500 grams of meat? (on average an amino acid is ~100 Daltons)
500g of meat = ~20% protein 100g ÷ 110 g/mol ≈ 0.91 mol 0.91 × 6.022 × 10²³ ≈ 5.5 × 10²³ molecules*
Why are there only 20 natural amino acids?
Assignment: DNA Assembly What are some components in the Phusion High-Fidelity PCR Master Mix and what is their purpose?
Based on Protocol for Phusion™ High-Fidelity PCR Master Mix with GC Buffer (https://www.neb.com/en-gb/protocols/protocol-for-phusion-high-fidelity-pcr-master-mix-with-gc-buffer-m0532)
Phusion DNA Polymerase - a high-fidelity enzyme that synthesises new DNA strands with 3’→5’ exonuclease activity for proofreading dNTPs - building blocks for DNA synthesis (200 µM each at 1X concentration) MgCl₂ - Cofactor required for polymerase activity (1.5 mM at 1X concentration) Possibly optional as the question doesn’t mention it (GC Buffer - optimised buffer for amplifying difficult templates with high GC content or secondary structure) DMSO (optional additive) - helps denature secondary structures in GC-rich or difficult templates (recommended at 3% final concentration)
Assignment Part 1: Intracellular Artificial Neural Networks (IANNs) What advantages do IANNs have over traditional genetic circuits, whose input/output behaviors are Boolean functions?
Analogue quality of computations (not just on and off, but rather treat them more like waves ->easier to work with) -> Thresholds finetuning works You can also work with more inputs simultaneously that will automatically become a weighted sum Which also means they can be trained like neural networks! whereas Boolean functions are just True/False with operators AND, OR, and NOT
Homework Part A: General and Lecturer-Specific Questions General homework questions
Explain the main advantages of cell-free protein synthesis over traditional in vivo methods, specifically in terms of flexibility and control over experimental variables. Name at least two cases where cell-free expression is more beneficial than cell production.
As the reaction happens outside living cells, you have much more flexibility and control over experimental variables!
Final Project Please identify at least one (ideally many) aspect(s) of your project that you will measure. It could be the mass or sequence of a protein, the presence, absence, or quantity of a biomarker, etc.
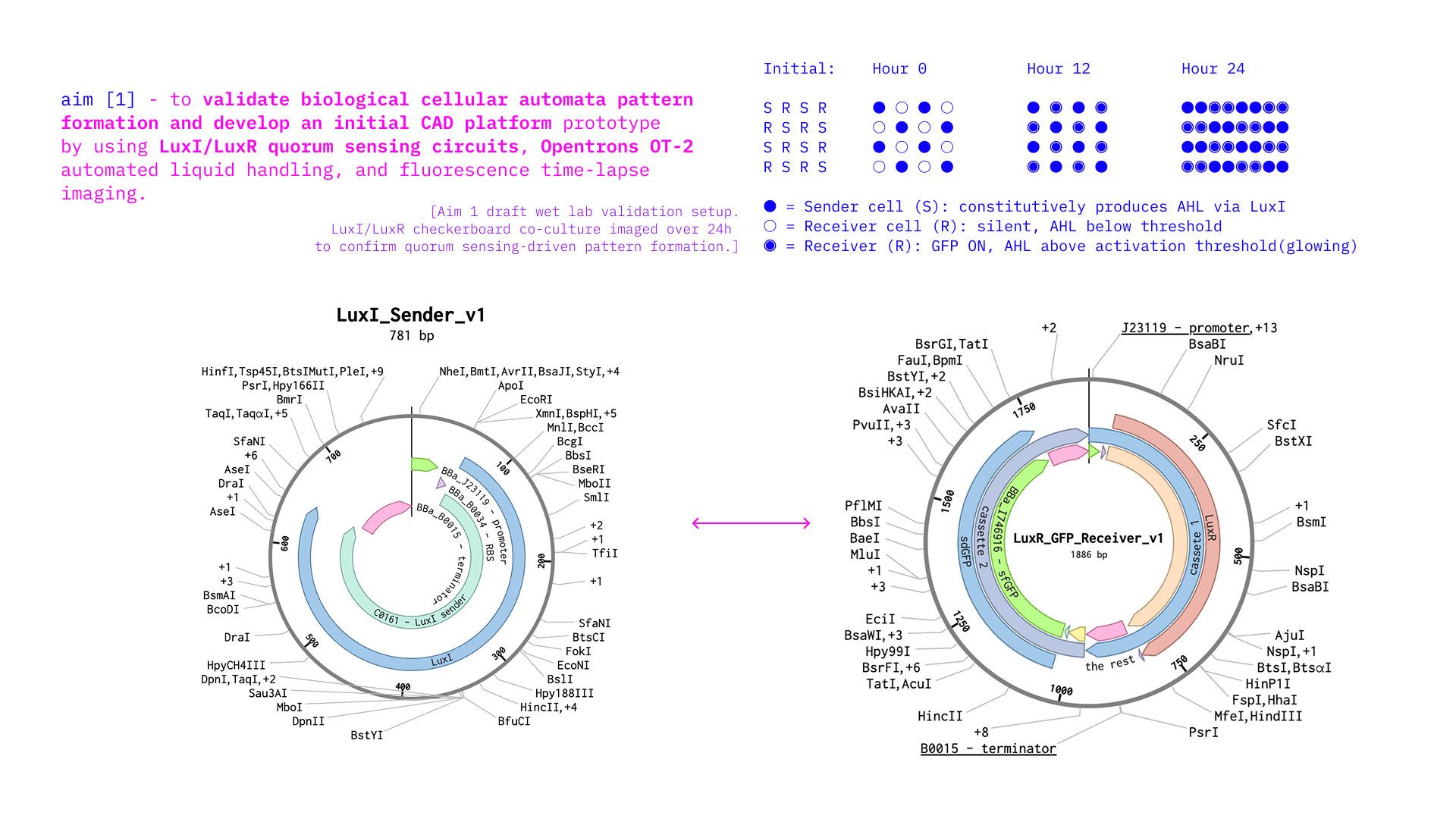
molecular validation (to confirm whether the Twist plasmids are correct and transformed properly) through the presence of the sender and receiver plasmid, correct insert size and sequence identity, then successful bacterial transformation functional signalling validation / AHL sensing ability through receiver activation threshold, GFP expression strength, dose-response curve, signal saturation spatial pattern formation to measure whether LuxI actually produces AHL through sender-generated AHL activity, effective AHL equivalent concentration, and hopefully signalling consistency between cultures ML/CAD dataset features through OT-2 plate maps, fluorescence reads and metadata logs Please describe all of the elements you would like to measure, and furthermore, describe how you will perform these measurements.
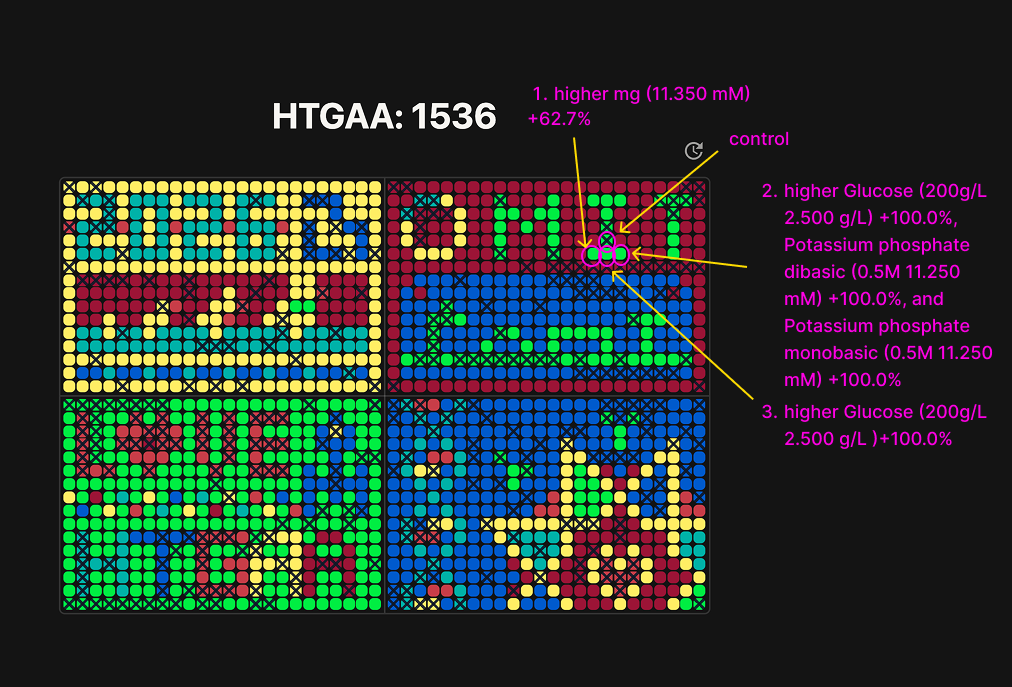
Part A: The 1,536 Pixel Artwork Canvas | Collective Artwork At this point, I’m not entirely sure what I’ve contributed to, as the artwork changed quite a lot. I’ve added a few yellow and green pixels when we first got access to the board, but as time went it changed so much that I don’t think any of them were left in the same spots. I did like the collaborative aspect of it, but going forward, I kind of wish everyone could contribute to just one/two pixels that couldn’t be overwritten. That would make the pointing-out aspect of it so much easier
First, describe a biological engineering application or tool you want to develop and why. This could be inspired by an idea for your HTGAA class project and/or something for which you are already doing in your research, or something you are just curious about.
I have worked with the concept of CA before within design and 3d space generative making through creating tools for generating patterns and environments, so it was really fascinating to see it being brought up during class. So, for my idea I’d like to merge my previous digital experience with CA and synthetic biology tooling in a form of a computer aided design tool for spatial synthetic biology
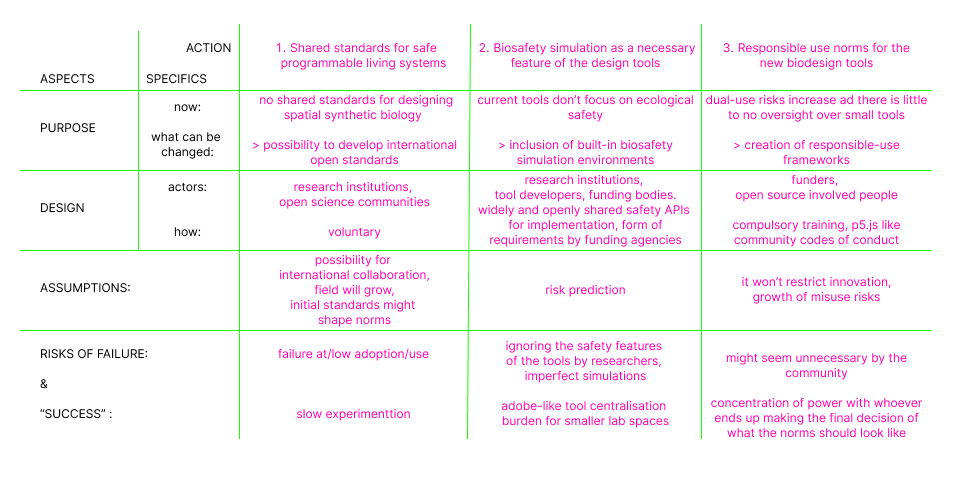
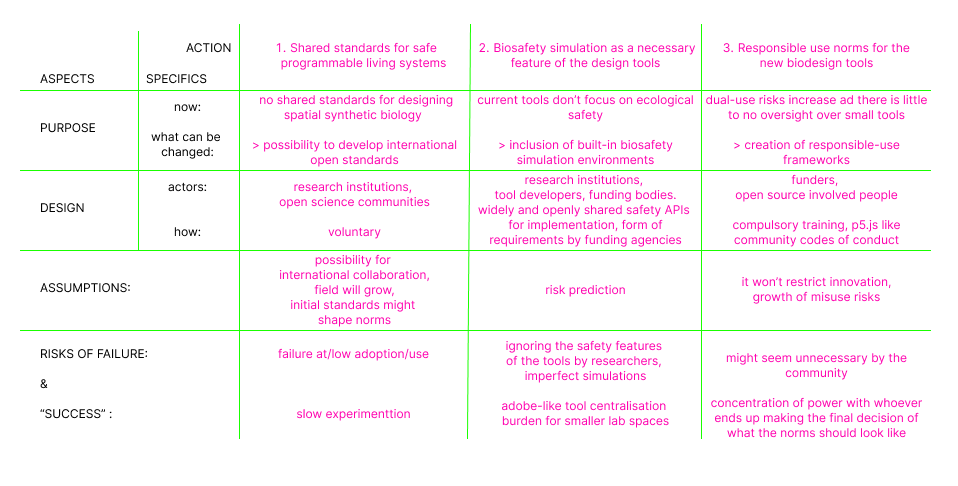
Next, describe one or more governance/policy goals related to ensuring that this application or tool contributes to an “ethical” future, like ensuring non-malfeasance (preventing harm). Break big goals down into two or more specific sub-goals.
Ensuring biosafety:
a) Possibility of the prediction of biological behaviour
b) Testable behaviour (not just false confidence in whatever is happening, both for a and b!)
c) safety protocols built in within the ux/ui of the software
d) training provided
Transparency whilst preventing harm:
a) Maintenance of accountability over the created projects (as in not fully automated)
b) Responsible use
c) (Ideally!) some sort of encouragement of socially beneficial applications
Next, describe at least three different potential governance “actions” by considering the four aspects below (Purpose, Design, Assumptions, Risks of Failure & “Success”). Try to outline a mix of actions (e.g. a new requirement/rule, incentive, or technical strategy) pursued by different “actors” (e.g. academic researchers, companies, federal regulators, law enforcement, etc). Draw upon your existing knowledge and a little additional digging, and feel free to use analogies to other domains (e.g. 3D printing, drones, financial systems, etc.).
Purpose: What is done now and what changes are you proposing?
Design: What is needed to make it “work”? (including the actor(s) involved - who must opt-in, fund, approve, or implement, etc)
Assumptions: What could you have wrong (incorrect assumptions, uncertainties)?
Risks of Failure & “Success”: How might this fail, including any unintended consequences of the “success” of your proposed actions?
Next, score (from 1-3 with, 1 as the best, or n/a) each of your governance actions against your rubric of policy goals. The following is one framework but feel free to make your own:
sp|P42212|GFP_AEQVI Green fluorescent protein OS=Aequorea victoria OX=6100 GN=GFP PE=1 SV=1
MSKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDATYGKLTLKFICTTGKLPVPWPT
LVTTFSYGVQCFSRYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGNYKTRAEVKFEGDT
LVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYIMADKQKNGIKVNFKIRHNIEDGSVQ
LADHYQQNTPIGDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGITHGMDELYK
3.2 Reverse Translate: Protein (amino acid) sequence to DNA (nucleotide) sequence.
reverse translation of sp|P42212|GFP_AEQVI Green fluorescent protein OS=Aequorea victoria OX=6100 GN=GFP PE=1 SV=1 to a 714 base sequence of consensus codons.
atgwsnaarggngargarytnttyacnggngtngtnccnathytngtngarytngayggn
gaygtnaayggncayaarttywsngtnwsnggngarggngarggngaygcnacntayggn
aarytnacnytnaarttyathtgyacnacnggnaarytnccngtnccntggccnacnytn
gtnacnacnttywsntayggngtncartgyttywsnmgntayccngaycayatgaarcar
caygayttyttyaarwsngcnatgccngarggntaygtncargarmgnacnathttytty
aargaygayggnaaytayaaracnmgngcngargtnaarttygarggngayacnytngtn
aaymgnathgarytnaarggnathgayttyaargargayggnaayathytnggncayaar
ytngartayaaytayaaywsncayaaygtntayathatggcngayaarcaraaraayggn
athaargtnaayttyaarathmgncayaayathgargayggnwsngtncarytngcngay
caytaycarcaraayacnccnathggngayggnccngtnytnytnccngayaaycaytay
ytnwsnacncarwsngcnytnwsnaargayccnaaygaraarmgngaycayatggtnytn
ytngarttygtnacngcngcnggnathacncayggnatggaygarytntayaar
ATGAGCAAAGGCGAAGAACTGTTTACCGGCGTGGTGCCGATTCTGGTGGAACTGGATGGCGATGTGAATGGCCATAAATTTAGCGTGAGCGGCGAAGGTGAAGGCGATGCGACCTATGGCAAACTGACCCTGAAATTTATCTGCACCACCGGTAAACTGCCGGTGCCGTGGCCGACCCTGGTGACCACCTTCAGCTACGGCGTGCAGTGTTTTAGCCGCTACCCGGATCATATGAAACAGCATGATTTTTTTAAAAGCGCGATGCCGGAAGGCTATGTGCAGGAACGCACCATTTTTTTCAAAGATGATGGCAATTACAAAACCCGTGCCGAAGTGAAATTCGAAGGCGATACCCTGGTGAATCGCATTGAACTGAAAGGCATTGATTTTAAAGAAGATGGTAACATTCTGGGCCACAAACTGGAATACAACTATAACAGCCATAACGTGTACATTATGGCGGATAAACAGAAAAATGGCATTAAAGTGAACTTTAAAATTCGCCATAACATTGAAGATGGCTCAGTGCAGCTGGCGGATCACTATCAGCAGAACACCCCGATTGGCGATGGCCCGGTTCTGCTGCCGGATAACCACTATCTGAGCACCCAGAGCGCGCTGTCGAAAGATCCGAACGAAAAACGCGATCACATGGTGCTGCTGGAATTTGTGACCGCCGCGGGCATCACCCATGGTATGGATGAACTGTATAAA
Avoid cleavage sites of restriction enzymes:
BbsI BsaI
It’s done to get a more reliable and consistent protein expression!
I chose Escherichia coli K-12 substr. MG1655 because it’s standard and saf to work with + GFP expression is well established within it
3.4
If it’s a cell-dependent method the DNA sequence can be transcribed and translated into my protein through these steps: 1. Transformation 2.Transcription 3.Translation 4.Protein Folding 5.Fluorescence
Afterwards in Twist I got a bunch of errors when importing as when I was making a sequence a copy pasted an article “a"into it as it was a part of it. It is also visible here as 931 is not divisible by 3
fixed version!>
how it works>
(i) What DNA would you want to sequence (e.g., read) and why?
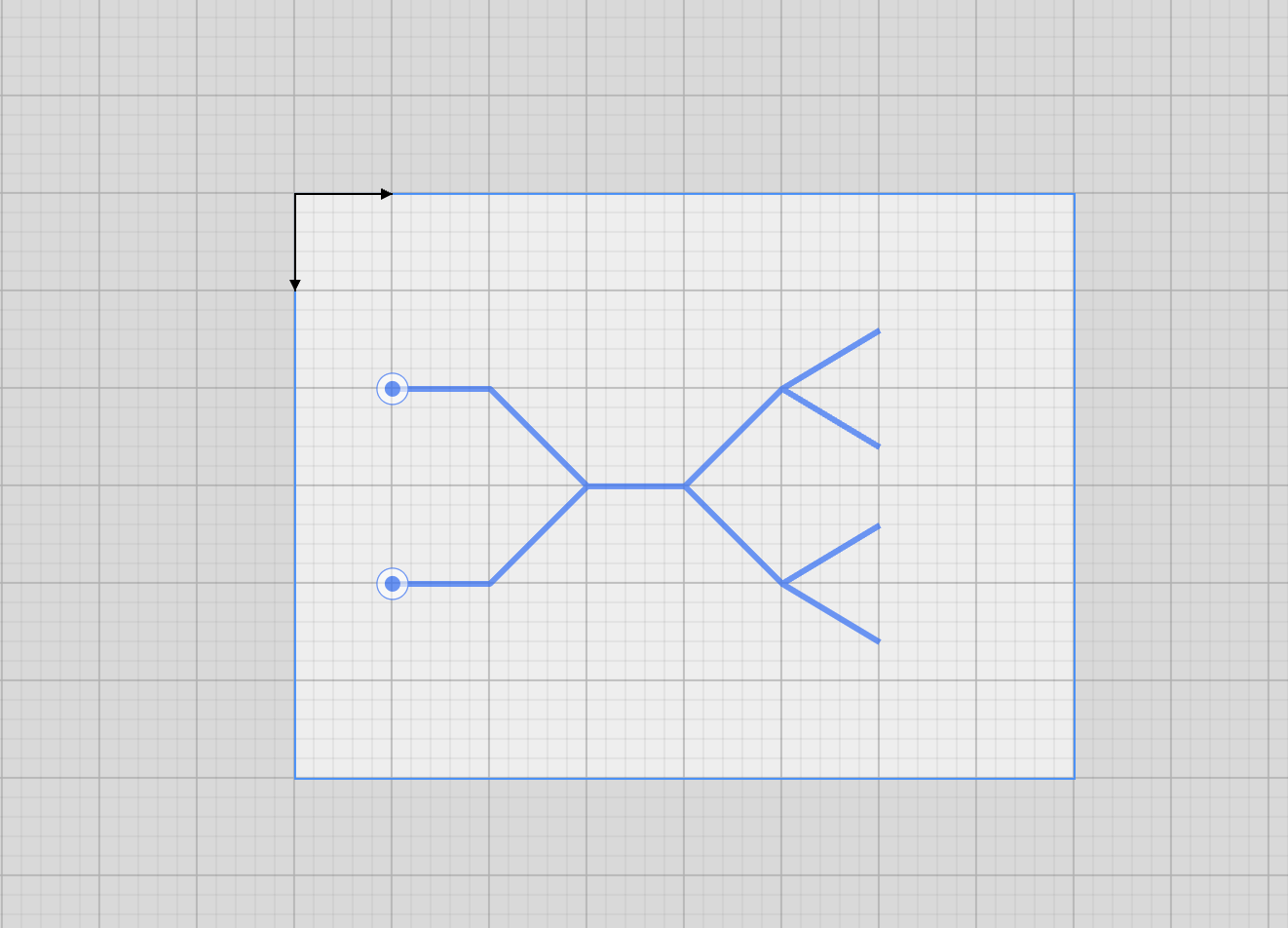
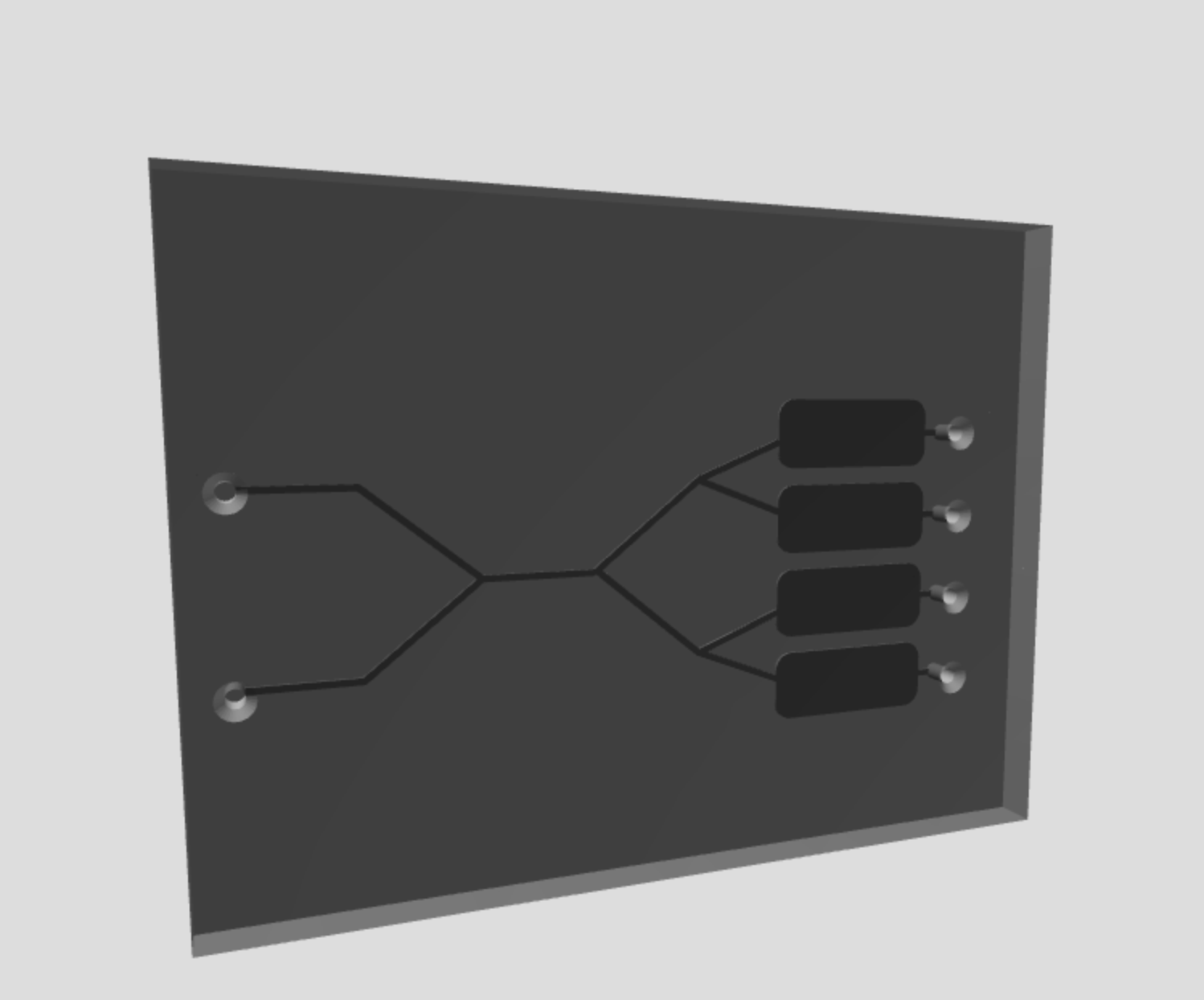
So far some sort of plasmids encoding CA-based pattern formation circuits in bacterial populations to be able to design patterns with them for the final project tool
(ii) In lecture, a variety of sequencing technologies were mentioned. What technology or technologies would you use to perform sequencing on your DNA and why?
Probably something like Illumina as it is pretty commonly used which means it will be easier to find
5.2 DNA Write
(i) What DNA would you want to synthesize (e.g., write) and why?
GFP-based circuits so I could prototype programmable living pattern systems
(ii) What technology or technologies would you use to perform this DNA synthesis and why?
PCR or Gibson assembly to do precise construction of my custom genetic circuit
And then in terms of computer based tech Benchling and Twist
5.3 DNA Edit
(i) What DNA would you want to edit and why?
So far based on my research for this project E. coli K-12 MG1655as it is safe, well-documented, accessible and also works amazing with my project
(ii) What technology or technologies would you use to perform these DNA edits and why?
I’m not fully sure what’s possible to use for the projects yet but if I can CRISPR-Cas9 as it can precisely edit genetic circuits
Week 3 HW: Principles and Practices
For this lab, I made a little bunny drawing! I used Ronan’s tool as a base and then fixed it to work with colab environment and colours that we have in our node.
This study by Norton-Baker et al. (2024) used an Opentrons OT-2 liquid-handling tool to efficiently characterise a large number of proteins. They also described a generalizable pipeline for high-throughput protein purification using small-scale expression in E. coli and an affordable liquid-handling robot. As a result, the automation significantly increased throughput, reduced manual labour, and improved consistency across samples, demonstrating how accessible robotics can accelerate biological research workflows. It also allowed to confirm the validity of previous findings.
On a separate note, I really enjoyed their explanation for using the tool :
“Therefore, we aimed to develop a protocol using the OT-2 to provide a low-cost option for the purification and analysis of enzymes, or other proteins, making high-throughput studies more accessible to a broader range of research laboratories. Beyond increasing efficiency, this automation-assisted approach reduces the labor burden on researchers and lowers the risk of repetitive use injuries.”"
Write a description about what you intend to do with automation tools for your final project. You may include example pseudocode, Python scripts, 3D printed holders, a plan for how to use Ginkgo Nebula, and more. You may reference this week’s recitation slide deck for lab automation details.
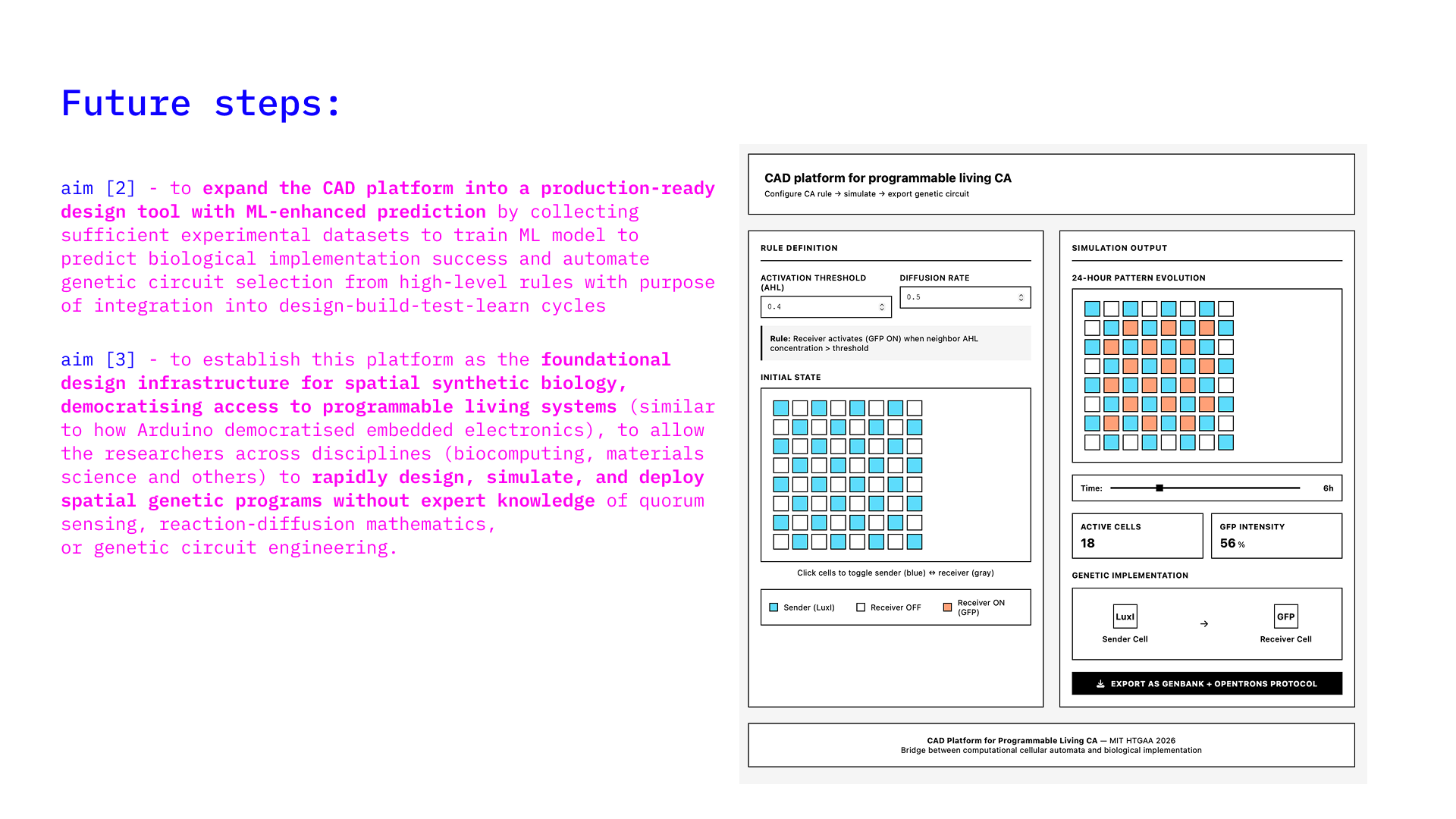
For my final project, I plan on using Opentrons to support a design, then build, test and learn pipeline for programmable living CA.
Things to do:
build libraries of sender receiver circuits with a range of parameters (I’ve done a similar thing with chi.bio before so should be straightforward). I’d also like to see how I can integrate it within the pre existing lab environment (Airtable) to get more transparent data for the future
Go through the process of general screening of spatial rule variants in plates to test pattern formation under different genetic and environmental conditions, depending on available options
In the later stages. use Cloud lab integration (e.g., Ginkgo Nebula) to scale, run large combinatorial libraries, and feed results back into the CA simulation engine for model fine tunning
All in all, this automation will increase reproducibility, enable systematic exploration of rule space, and accelerate the feedback loop between digital design and wet-lab experimentation.
I would also like to explore more of the idea using Ginkgo’s cloud lab (Nebula) to run large combinatorial libraries of CA rule variants. That would allow me to test hundreds of spatial rule configurations and feed experimental results back into the simulation engine!
Final Project Ideas:
Week 4 HW: Protein Design Part I
Part A. Conceptual Questions
1.How many molecules of amino acids do you take with a piece of 500 grams of meat? (on average an amino acid is ~100 Daltons)
Because of the frozen accident!! https://pubmed.ncbi.nlm.nih.gov/27926995/
Evolution has developed so, and it’s too late to change that also, they have the optimal protein structure
Why do β-sheets tend to aggregate?
their structure has edge strands with hydrogen-bonding capacity, making them thermodynamically prone to stacking through edge-to-edge or face-to-face interactions
What is the driving force for β-sheet aggregation?
It is determined by ATR-FTIR spectroscopy
Why do many amyloid diseases form β-sheets?
“Amyloid beta peptide (Aβ) is produced through the proteolytic processing of a transmembrane protein, amyloid precursor protein (APP), by β- and γ-secretases. Aβ accumulation in the brain is proposed to be an early toxic event”. https://www.nature.com/articles/aps201728
Can you use amyloid β-sheets as materials?
Design a β-sheet motif that forms a well-ordered structure.
Yes, they can be used as stable nano materials with applications in environmental sciences, material engineering, and translational medicines
https://pmc.ncbi.nlm.nih.gov/articles/PMC8508955/. Still unsure how to design it
Part B: Protein Analysis and Visualization
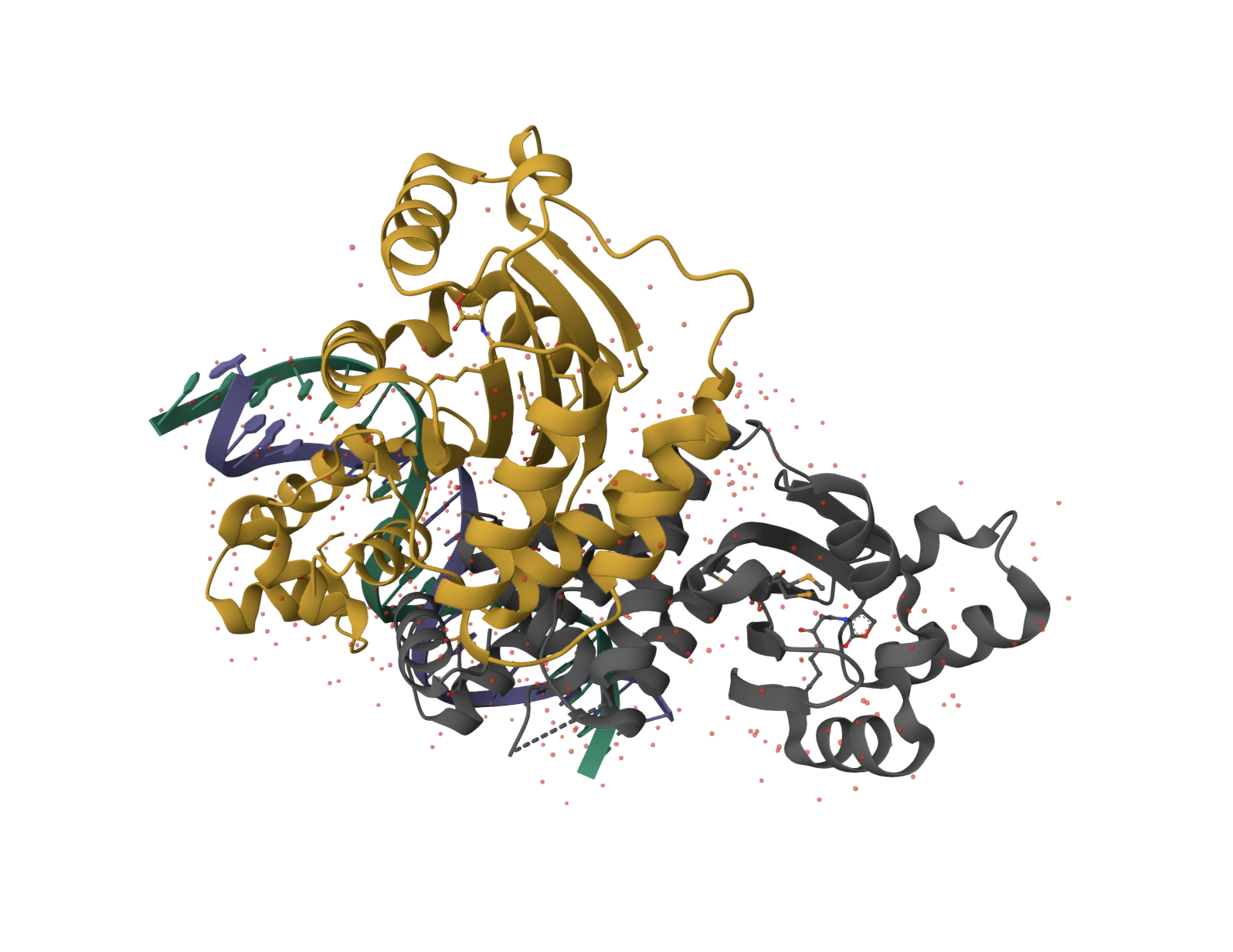
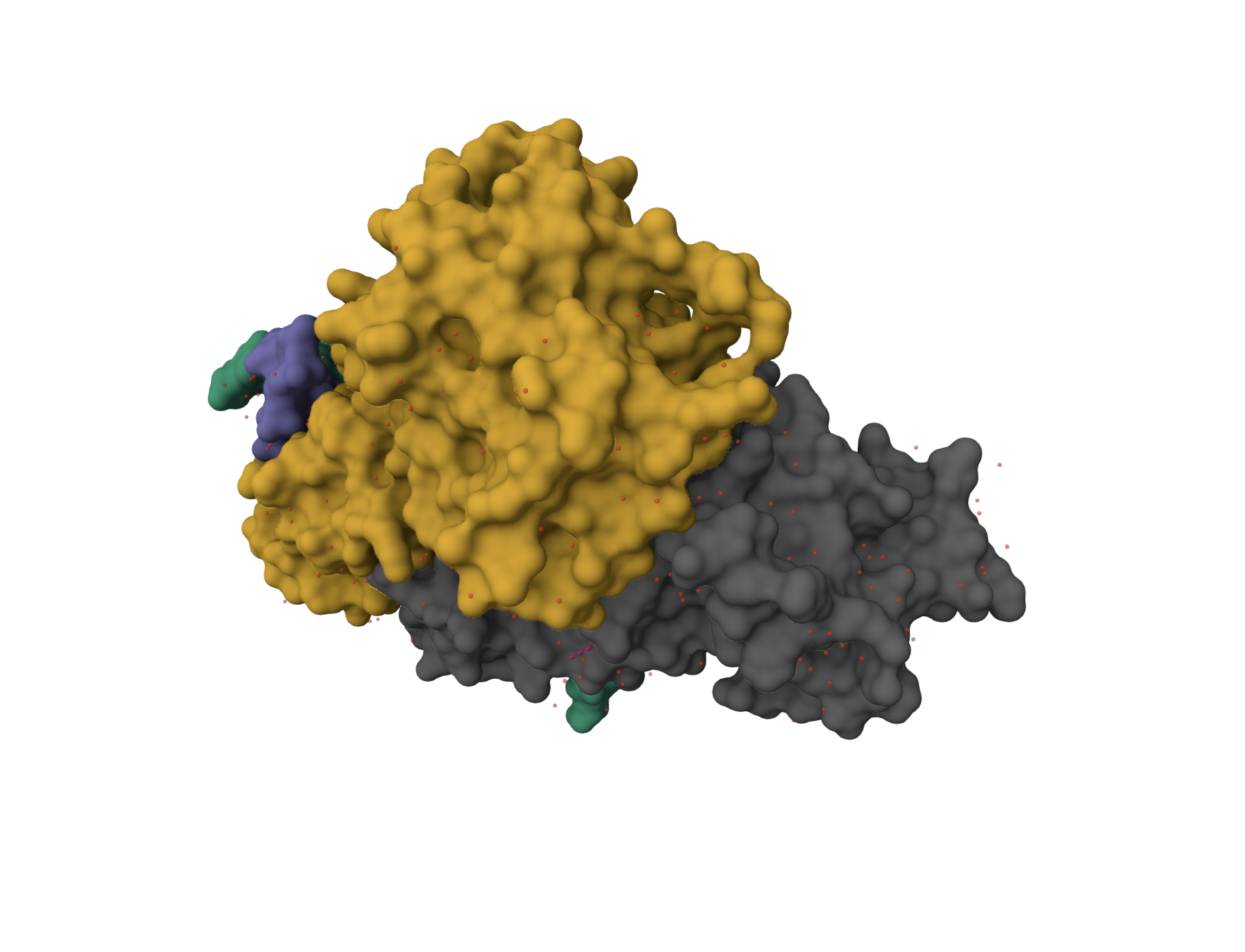
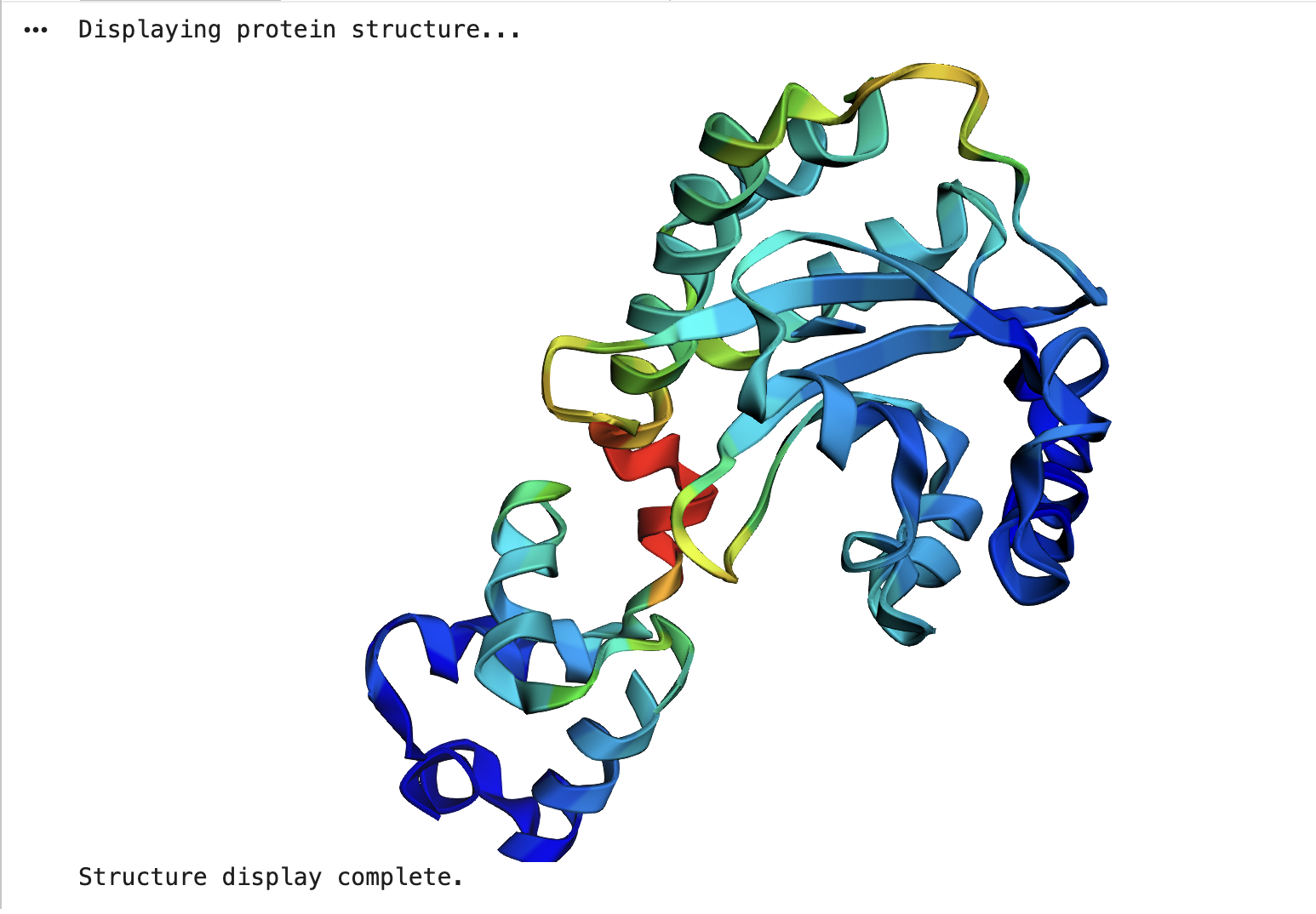
1. Briefly describe the protein you selected and why you selected it.
I’ve selected LuxR as it controls bioluminescence through quorum sensing which is a “is the regulation of gene expression in response to fluctuations in cell-population density”(https://pubmed.ncbi.nlm.nih.gov/11544353/). As I want to do project in connection to CA it seemed fitting. For structure visualizatio I will be using TraR (PDB: 1L3L)
2. Identify the amino acid sequence of your protein.
from collections import Counter:
Protein sequence provided by the user
protein_sequence = “MSSNIESLYRQMLNEIIEQMEKEGKISREEALAVLESKLKKSNVSRDIILSHGFNSGVTQSAQPSSFLNNMAAIAKQNLHFSDIFTDLENQFIAELEELEQSYKNLVTKLSQKLDLSSLTEQALVELRSYLNQIKQSGLLDSAQNIFNFSEQISALQEAIGQLSQSIANLELQSREISELNQRVQDLEQELSFLSQQLASAQTQASQLQAQINQLNHQLEALEKAHQEALSRAKQEIEKLRS”
The length of the protein is: 242 aminoacids.
The most common amino acid is: L, which appears 36 times.
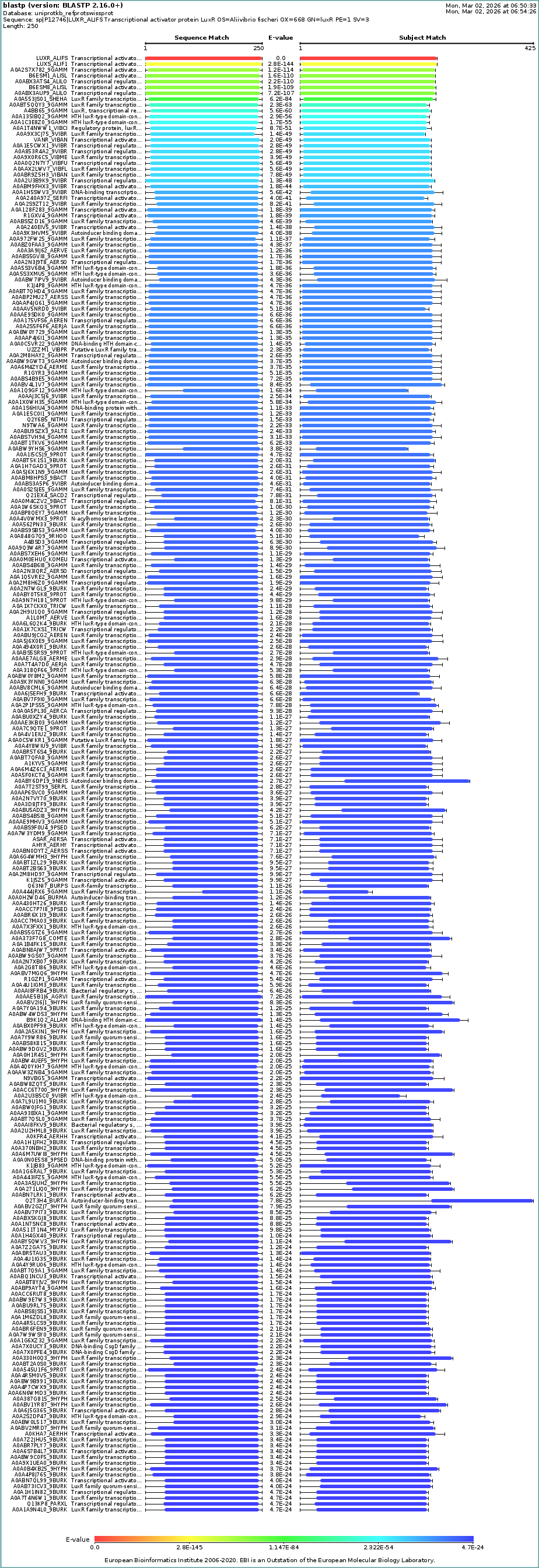
How many protein sequence homologs are there for your protein? Hint: Use Uniprot’s BLAST tool to search for homologs.
250!
*The UniProt BLAST search identified over 250 homologs with highly significant E-values (ranging from ~0 to 10⁻²⁴), indicating LuxR is part of a large, well-conserved protein family. LuxR belongs to the LuxR-FixJ superfamily and the LuxR family of transcriptional regulators, which are widespread across gram-negative bacteria and typically involved in quorum sensing and gene regulation.
LuxR belongs to the TetR family RCSB PDB of transcriptional regulators, specifically to Vibrio alginolyticus variant, and more broadly to LuxR-FixJ
3. Identify the structure page of your protein in RCSB
LuxR (TraR) belongs to the autoinducer-regulated transcriptional regulatory protein family. The 2 domains are an N-terminal autoinducer-binding domain (Pfam: Autoind_bind) that binds the AHL quorum sensing signal, and a C-terminal HTH LuxR-type DNA-binding domain (Pfam: GerE) that activates transcription. Also classified under the LuxR-FixJ superfamily (SUPFAM) and the Winged Helix DNA-binding superfamily for its C-terminal domain.
4.Open the structure of your protein in any 3D molecule visualization software:
:The structure is predominantly alpha-helical.
Hydrophobic residues are concentrated in the protein core, forming the structural interior and lining the AHL ligand-binding pocket.
It does have binding pockets
Part C. Using ML-Based Protein Design Tools
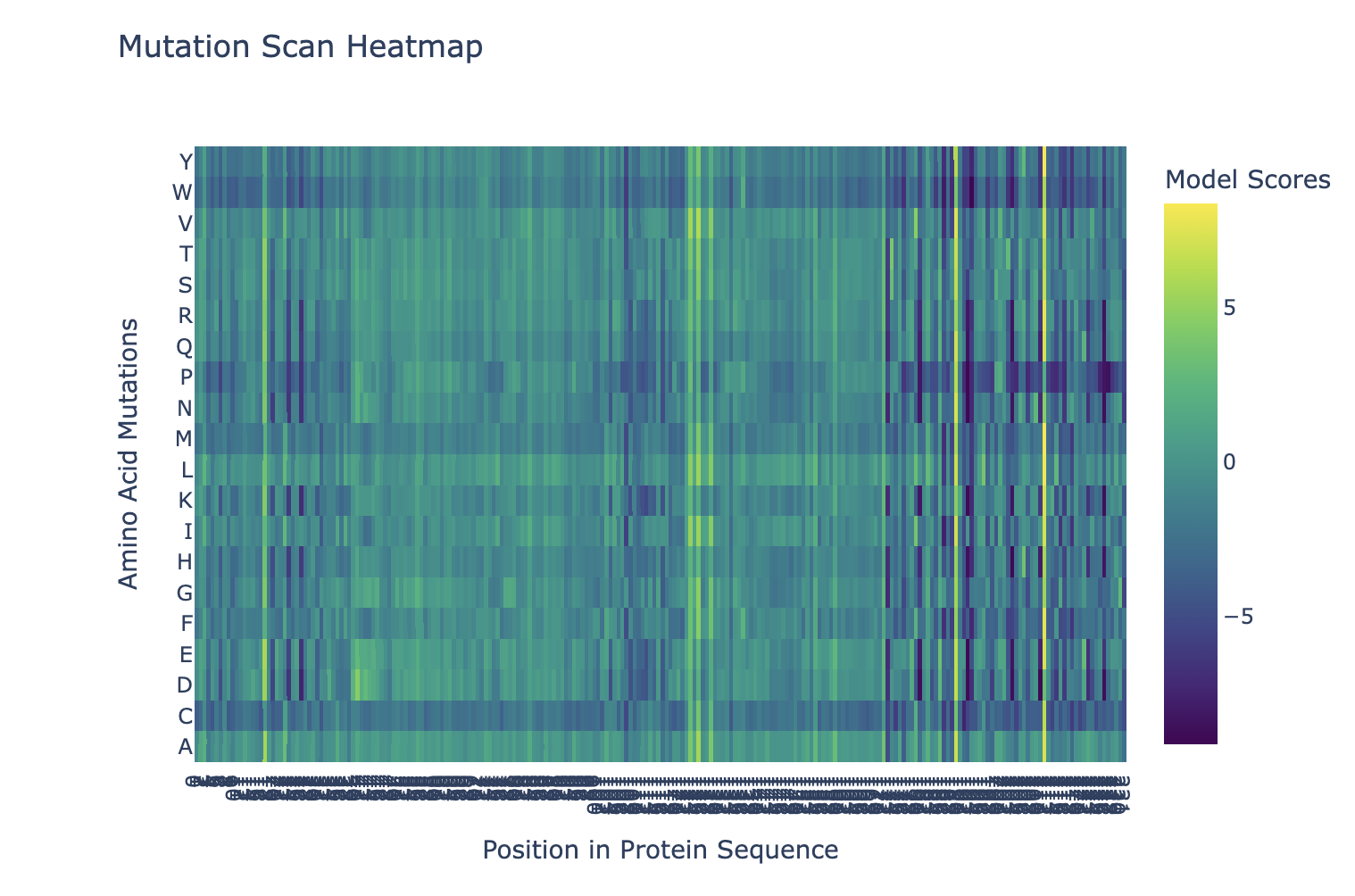
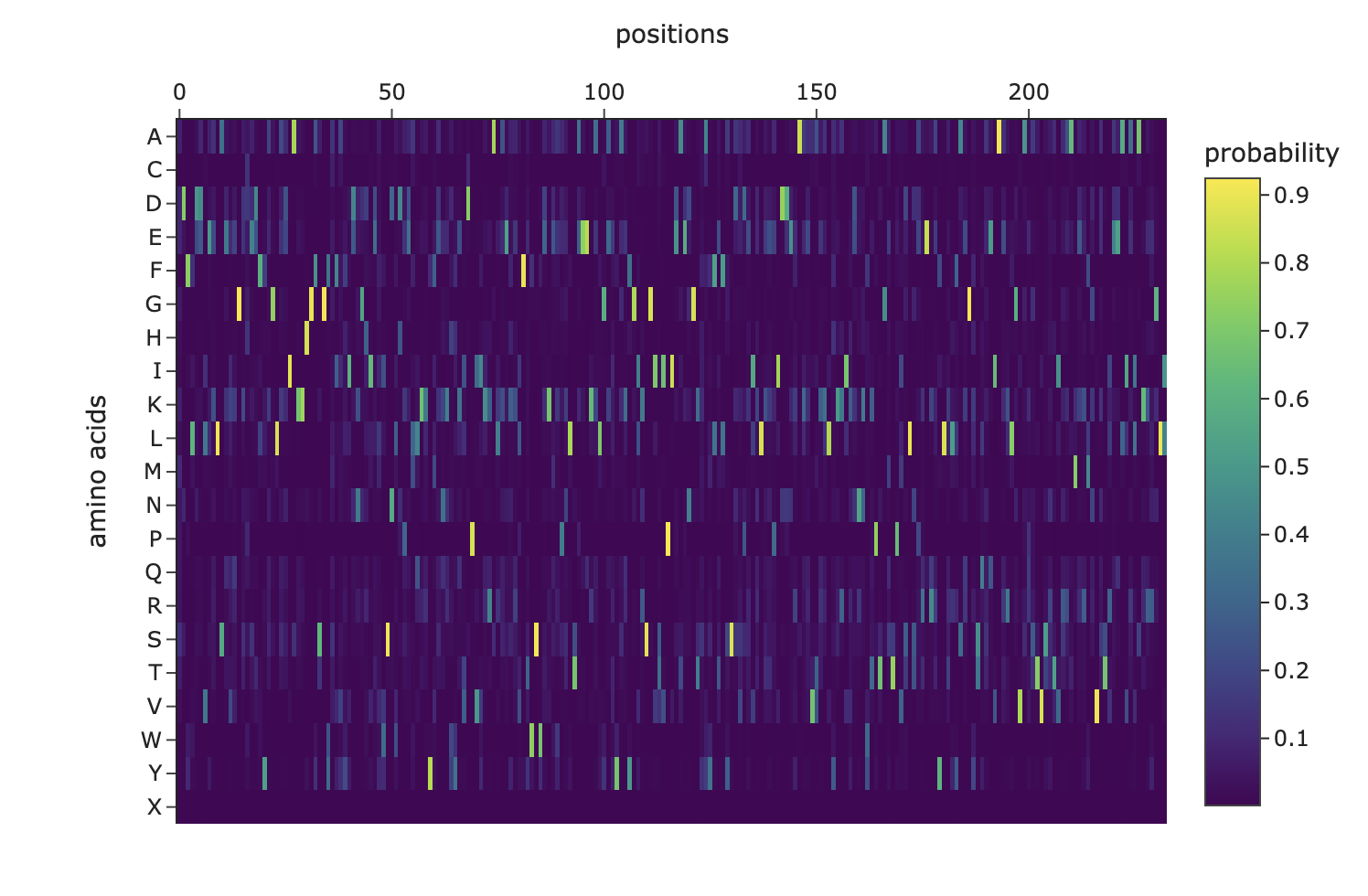
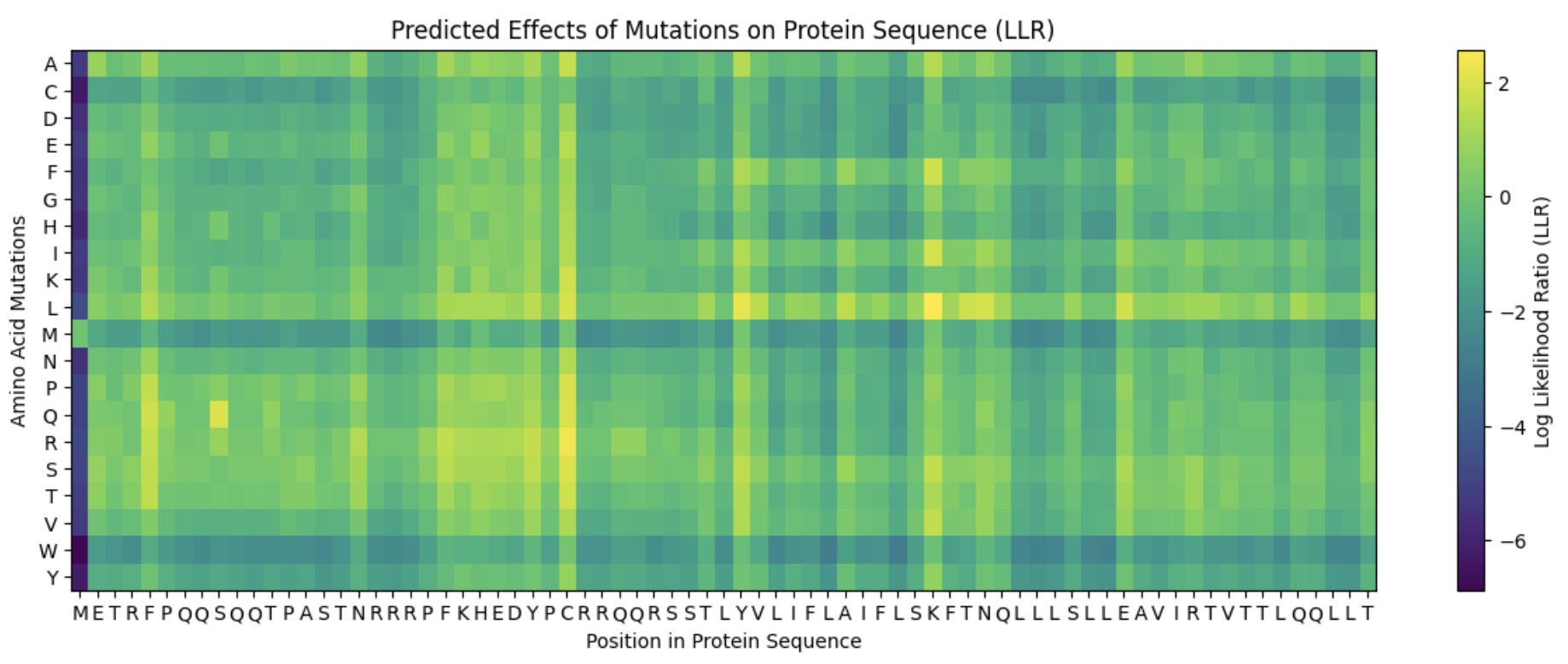
I also asked Gemini to identify mutation hotspots based on the compiled data in the heatmap:**
“Let’s analyze the mutation scan heatmap to identify potential mutation hotspots. I’ll write some code to scan through each position in the protein sequence and highlight those where several different amino acid substitutions are predicted to be favorable (meaning they have a high positive Log-Likelihood Ratio).
Here’s the analysis:
Mutation Hotspots Identified (positions with at least 3 mutations having LLR > 0.5):
Position 2 (Original: Q):
Mutate to M: LLR = 7.67
Mutate to A: LLR = 2.68
Mutate to L: LLR = 2.55
Mutate to V: LLR = 2.43
Mutate to R: LLR = 2.33
Mutate to E: LLR = 2.02
Mutate to I: LLR = 2.00
Mutate to T: LLR = 1.99
Mutate to S: LLR = 1.91
Mutate to K: LLR = 1.90
Mutate to Y: LLR = 1.89
Mutate to F: LLR = 1.69
Mutate to G: LLR = 1.59
Mutate to Q: LLR = 1.59
Mutate to H: LLR = 1.33
Mutate to D: LLR = 1.31
Mutate to N: LLR = 1.26
Mutate to P: LLR = 1.16
Position 4 (Original: W):
Mutate to A: LLR = 1.31
Mutate to E: LLR = 1.11
Mutate to T: LLR = 1.07
Mutate to S: LLR = 1.01
Mutate to R: LLR = 1.00
Mutate to Q: LLR = 0.96
Mutate to D: LLR = 0.95
Mutate to K: LLR = 0.80
Position 5 (Original: L):
Mutate to L: LLR = 2.45
Mutate to I: LLR = 1.99
Mutate to A: LLR = 1.96
Mutate to V: LLR = 1.77
Mutate to T: LLR = 1.17
Mutate to F: LLR = 1.07
Mutate to R: LLR = 0.80
Mutate to Y: LLR = 0.76
Mutate to E: LLR = 0.72
Mutate to S: LLR = 0.56
Position 15 (Original: E):
Mutate to A: LLR = 1.13
Mutate to S: LLR = 1.00
Mutate to T: LLR = 0.62
Mutate to R: LLR = 0.62
Mutate to L: LLR = 0.58
Position 20 (Original: I):
Mutate to E: LLR = 5.70
Mutate to A: LLR = 5.51
Mutate to D: LLR = 5.31
Mutate to T: LLR = 4.86
Mutate to Q: LLR = 4.72
Mutate to S: LLR = 4.71
Mutate to R: LLR = 4.31
Mutate to K: LLR = 4.31
Mutate to G: LLR = 4.15
Mutate to N: LLR = 4.03
Mutate to P: LLR = 3.68
Mutate to V: LLR = 3.55
Mutate to L: LLR = 3.52
Mutate to H: LLR = 3.47
Mutate to I: LLR = 2.68
Mutate to M: LLR = 2.11
Mutate to F: LLR = 2.08
Mutate to Y: LLR = 1.95
Mutate to W: LLR = 1.11
Position 25 (Original: L):
Mutate to A: LLR = 3.12
Mutate to V: LLR = 2.93
Mutate to L: LLR = 2.73
Mutate to I: LLR = 2.70
Mutate to T: LLR = 1.85
Mutate to M: LLR = 1.40
Mutate to F: LLR = 1.15
Mutate to C: LLR = 0.80
Position 28 (Original: I):
Mutate to E: LLR = 0.99
Mutate to A: LLR = 0.73
Mutate to L: LLR = 0.64
Position 38 (Original: A):
Mutate to V: LLR = 1.76
Mutate to A: LLR = 1.56
Mutate to I: LLR = 1.23
Mutate to S: LLR = 0.90
Mutate to L: LLR = 0.81
Mutate to G: LLR = 0.79
Mutate to T: LLR = 0.53
Position 40 (Original: L):
Mutate to I: LLR = 1.66
Mutate to L: LLR = 1.64
Mutate to V: LLR = 1.53
Mutate to F: LLR = 0.63
Position 42 (Original: I):
Mutate to D: LLR = 2.31
Mutate to E: LLR = 1.39
Mutate to L: LLR = 1.08
Mutate to S: LLR = 0.71
Mutate to G: LLR = 0.63
Mutate to N: LLR = 0.62
Mutate to V: LLR = 0.62
Mutate to T: LLR = 0.60
Position 43 (Original: Q):
Mutate to D: LLR = 4.50
Mutate to E: LLR = 2.76
Mutate to N: LLR = 2.38
Mutate to P: LLR = 2.35
Mutate to S: LLR = 2.06
Mutate to T: LLR = 1.76
Mutate to A: LLR = 1.44
Mutate to G: LLR = 1.35
Mutate to H: LLR = 1.29
Mutate to R: LLR = 1.26
Mutate to Q: LLR = 1.06
Mutate to K: LLR = 0.92
Mutate to L: LLR = 0.80
Mutate to V: LLR = 0.51
Position 44 (Original: H):
Mutate to D: LLR = 1.89
Mutate to E: LLR = 1.59
Mutate to P: LLR = 1.31
Mutate to G: LLR = 0.72
Mutate to A: LLR = 0.55
Position 45 (Original: R):
Mutate to D: LLR = 2.75
Mutate to N: LLR = 1.61
Mutate to E: LLR = 1.59
Mutate to G: LLR = 1.42
Mutate to S: LLR = 1.10
Mutate to T: LLR = 0.62
Position 46 (Original: H):
Mutate to D: LLR = 1.93
Mutate to G: LLR = 1.62
Mutate to E: LLR = 1.26
Mutate to N: LLR = 0.61
Position 47 (Original: I):
Mutate to E: LLR = 1.81
Mutate to D: LLR = 1.51
Mutate to R: LLR = 1.04
Mutate to T: LLR = 0.98
Mutate to S: LLR = 0.90
Mutate to G: LLR = 0.88
Mutate to Q: LLR = 0.77
Mutate to K: LLR = 0.74
Mutate to A: LLR = 0.60
Position 48 (Original: T):
Mutate to G: LLR = 1.72
Mutate to L: LLR = 1.12
Mutate to D: LLR = 0.98
Mutate to E: LLR = 0.85
Mutate to A: LLR = 0.75
Mutate to R: LLR = 0.50
Position 53 (Original: Y):
Mutate to G: LLR = 1.56
Mutate to E: LLR = 0.93
Mutate to A: LLR = 0.90
Mutate to D: LLR = 0.89
Mutate to S: LLR = 0.68
Position 55 (Original: R):
Mutate to G: LLR = 1.31
Mutate to S: LLR = 1.27
Mutate to D: LLR = 1.14
Mutate to T: LLR = 1.12
Mutate to P: LLR = 0.75
Mutate to A: LLR = 0.56
Position 56 (Original: Q):
Mutate to P: LLR = 1.07
Mutate to G: LLR = 0.79
Mutate to D: LLR = 0.77
Mutate to E: LLR = 0.59
Position 57 (Original: W):
Mutate to D: LLR = 1.10
Mutate to G: LLR = 0.99
Mutate to E: LLR = 0.93
Mutate to S: LLR = 0.56
Position 58 (Original: Q):
Mutate to G: LLR = 2.29
Mutate to D: LLR = 1.82
Mutate to E: LLR = 1.73
Mutate to P: LLR = 1.65
Mutate to A: LLR = 1.52
Mutate to S: LLR = 1.45
Mutate to T: LLR = 1.40
Mutate to L: LLR = 1.33
Mutate to R: LLR = 1.20
Mutate to N: LLR = 1.14
Mutate to Q: LLR = 1.01
Mutate to K: LLR = 0.96
Mutate to H: LLR = 0.91
Mutate to V: LLR = 0.90
Mutate to I: LLR = 0.84
Mutate to F: LLR = 0.60
Mutate to Y: LLR = 0.57
Position 59 (Original: S):
Mutate to G: LLR = 1.33
Mutate to L: LLR = 1.02
Mutate to A: LLR = 0.89
Mutate to D: LLR = 0.89
Mutate to S: LLR = 0.84
Mutate to P: LLR = 0.82
Mutate to T: LLR = 0.63
Mutate to E: LLR = 0.61
Mutate to I: LLR = 0.53
Position 61 (Original: Y):
Mutate to E: LLR = 0.68
Mutate to D: LLR = 0.61
Mutate to A: LLR = 0.60
Position 63 (Original: D):
Mutate to D: LLR = 1.12
Mutate to S: LLR = 0.94
Mutate to A: LLR = 0.84
Mutate to G: LLR = 0.75
Mutate to P: LLR = 0.74
Mutate to T: LLR = 0.67
Mutate to L: LLR = 0.59
Mutate to E: LLR = 0.56
Position 65 (Original: K):
Mutate to A: LLR = 0.89
Mutate to P: LLR = 0.88
Mutate to E: LLR = 0.87
Mutate to L: LLR = 0.85
Mutate to G: LLR = 0.80
Mutate to D: LLR = 0.67
Mutate to R: LLR = 0.65
Position 66 (Original: F):
Mutate to S: LLR = 1.46
Mutate to P: LLR = 1.41
Mutate to D: LLR = 1.29
Mutate to T: LLR = 1.27
Mutate to G: LLR = 0.86
Mutate to A: LLR = 0.79
Mutate to R: LLR = 0.78
Mutate to E: LLR = 0.75
Position 75 (Original: K):
Mutate to A: LLR = 1.30
Mutate to E: LLR = 1.23
Mutate to L: LLR = 1.01
Mutate to R: LLR = 0.86
Mutate to D: LLR = 0.65
Mutate to S: LLR = 0.59
Mutate to W: LLR = 0.52
Position 78 (Original: R):
Mutate to L: LLR = 2.00
Mutate to I: LLR = 1.32
Mutate to F: LLR = 0.60
Mutate to V: LLR = 0.56
Position 80 (Original: R):
Mutate to G: LLR = 1.42
Mutate to E: LLR = 0.95
Mutate to D: LLR = 0.84
Mutate to S: LLR = 0.69
Mutate to A: LLR = 0.64
Position 82 (Original: H):
Mutate to G: LLR = 1.36
Mutate to E: LLR = 1.11
Mutate to D: LLR = 1.00
Mutate to T: LLR = 0.96
Mutate to P: LLR = 0.96
Mutate to S: LLR = 0.92
Mutate to R: LLR = 0.89
Mutate to A: LLR = 0.87
Mutate to L: LLR = 0.55
Position 84 (Original: F):
Mutate to L: LLR = 1.07
Mutate to V: LLR = 1.05
Mutate to I: LLR = 0.99
Position 85 (Original: T):
Mutate to V: LLR = 0.84
Mutate to L: LLR = 0.65
Mutate to I: LLR = 0.54
Position 86 (Original: W):
Mutate to V: LLR = 2.01
Mutate to L: LLR = 1.91
Mutate to I: LLR = 1.90
Mutate to A: LLR = 1.64
Mutate to T: LLR = 1.52
Mutate to S: LLR = 1.39
Mutate to R: LLR = 1.12
Mutate to F: LLR = 1.10
Mutate to E: LLR = 0.90
Mutate to D: LLR = 0.82
Mutate to G: LLR = 0.71
Mutate to Y: LLR = 0.63
Mutate to K: LLR = 0.62
Mutate to H: LLR = 0.62
Mutate to P: LLR = 0.56
Mutate to N: LLR = 0.53
Position 90 (Original: H):
Mutate to L: LLR = 1.31
Mutate to I: LLR = 1.28
Mutate to V: LLR = 1.09
Mutate to A: LLR = 1.03
Mutate to T: LLR = 0.94
Mutate to P: LLR = 0.79
Mutate to S: LLR = 0.76
Mutate to G: LLR = 0.75
Mutate to D: LLR = 0.64
Mutate to E: LLR = 0.61
Position 92 (Original: R):
Mutate to L: LLR = 1.41
Mutate to I: LLR = 0.92
Mutate to D: LLR = 0.91
Mutate to V: LLR = 0.67
Position 93 (Original: P):
Mutate to L: LLR = 1.17
Mutate to I: LLR = 0.76
Mutate to V: LLR = 0.73
Position 97 (Original: K):
Mutate to A: LLR = 1.41
Mutate to P: LLR = 1.39
Mutate to E: LLR = 0.93
Mutate to D: LLR = 0.80
Position 105 (Original: H):
Mutate to L: LLR = 1.84
Mutate to A: LLR = 1.60
Mutate to I: LLR = 1.40
Mutate to F: LLR = 1.26
Mutate to V: LLR = 1.24
Mutate to E: LLR = 0.89
Mutate to Y: LLR = 0.75
Mutate to T: LLR = 0.72
Mutate to R: LLR = 0.71
Position 107 (Original: S):
Mutate to L: LLR = 1.67
Mutate to R: LLR = 1.33
Mutate to I: LLR = 1.30
Mutate to V: LLR = 1.14
Mutate to A: LLR = 0.70
Position 108 (Original: D):
Mutate to R: LLR = 1.01
Mutate to A: LLR = 0.62
Mutate to E: LLR = 0.57
Mutate to K: LLR = 0.51
Position 118 (Original: P):
Mutate to A: LLR = 0.97
Mutate to G: LLR = 0.81
Mutate to R: LLR = 0.67
Mutate to L: LLR = 0.50
Position 123 (Original: N):
Mutate to D: LLR = 1.15
Mutate to T: LLR = 0.76
Mutate to S: LLR = 0.58
Position 125 (Original: F):
Mutate to E: LLR = 1.39
Mutate to V: LLR = 1.08
Mutate to R: LLR = 1.00
Mutate to L: LLR = 0.98
Mutate to K: LLR = 0.93
Mutate to I: LLR = 0.87
Mutate to T: LLR = 0.87
Mutate to D: LLR = 0.72
Mutate to A: LLR = 0.64
Position 126 (Original: X):
Mutate to V: LLR = 5.51
Mutate to I: LLR = 5.07
Mutate to L: LLR = 4.74
Mutate to A: LLR = 4.02
Mutate to T: LLR = 3.96
Mutate to F: LLR = 3.36
Mutate to R: LLR = 3.28
Mutate to G: LLR = 3.26
Mutate to E: LLR = 3.18
Mutate to S: LLR = 3.08
Mutate to P: LLR = 3.07
Mutate to Y: LLR = 3.06
Mutate to C: LLR = 2.88
Mutate to M: LLR = 2.85
Mutate to K: LLR = 2.72
Mutate to D: LLR = 2.59
Mutate to W: LLR = 2.55
Mutate to Q: LLR = 2.46
Mutate to H: LLR = 2.39
Mutate to N: LLR = 1.89
Position 127 (Original: S):
Mutate to G: LLR = 1.53
Mutate to A: LLR = 1.52
Mutate to L: LLR = 1.44
Mutate to V: LLR = 1.37
Mutate to I: LLR = 1.23
Mutate to Y: LLR = 0.84
Mutate to F: LLR = 0.69
Mutate to T: LLR = 0.51
Position 128 (Original: X):
Mutate to V: LLR = 6.03
Mutate to A: LLR = 5.56
Mutate to L: LLR = 5.32
Mutate to I: LLR = 5.28
Mutate to T: LLR = 4.73
Mutate to G: LLR = 4.70
Mutate to F: LLR = 4.55
Mutate to S: LLR = 4.33
Mutate to M: LLR = 4.08
Mutate to Y: LLR = 3.94
Mutate to C: LLR = 3.80
Mutate to R: LLR = 2.84
Mutate to E: LLR = 2.66
Mutate to H: LLR = 2.64
Mutate to Q: LLR = 2.62
Mutate to W: LLR = 2.53
Mutate to N: LLR = 2.39
Mutate to D: LLR = 2.05
Mutate to P: LLR = 1.81
Mutate to K: LLR = 1.69
Position 129 (Original: F):
Mutate to L: LLR = 1.23
Mutate to I: LLR = 1.05
Mutate to V: LLR = 0.93
Position 130 (Original: T):
Mutate to L: LLR = 1.51
Mutate to I: LLR = 1.10
Mutate to V: LLR = 1.04
Position 131 (Original: X):
Mutate to V: LLR = 4.62
Mutate to I: LLR = 4.53
Mutate to L: LLR = 4.41
Mutate to A: LLR = 4.02
Mutate to G: LLR = 3.53
Mutate to F: LLR = 3.40
Mutate to S: LLR = 3.16
Mutate to M: LLR = 3.09
Mutate to T: LLR = 2.82
Mutate to C: LLR = 2.71
Mutate to Y: LLR = 1.81
Mutate to D: LLR = 1.67
Mutate to E: LLR = 1.65
Mutate to N: LLR = 1.64
Mutate to W: LLR = 1.44
Mutate to H: LLR = 1.37
Mutate to Q: LLR = 1.36
Mutate to R: LLR = 1.35
Mutate to P: LLR = 0.87
Position 137 (Original: V):
Mutate to R: LLR = 1.52
Mutate to G: LLR = 1.38
Mutate to S: LLR = 0.79
Mutate to A: LLR = 0.66
Mutate to D: LLR = 0.63
Position 138 (Original: I):
Mutate to A: LLR = 0.73
Mutate to S: LLR = 0.66
Mutate to L: LLR = 0.53
Position 139 (Original: D):
Mutate to F: LLR = 2.18
Mutate to W: LLR = 1.91
Mutate to P: LLR = 1.48
Mutate to L: LLR = 1.48
Mutate to Y: LLR = 1.07
Mutate to A: LLR = 0.53
Position 142 (Original: ):
Mutate to D: LLR = 0.74
Mutate to A: LLR = 0.69
Mutate to E: LLR = 0.59
Position 149 (Original: A):
Mutate to L: LLR = 1.31
Mutate to I: LLR = 0.67
Mutate to V: LLR = 0.53
Position 152 (Original: A):
Mutate to L: LLR = 1.36
Mutate to A: LLR = 1.14
Mutate to V: LLR = 0.83
Mutate to I: LLR = 0.71
Position 155 (Original: G):
Mutate to L: LLR = 1.54
Mutate to A: LLR = 1.41
Mutate to V: LLR = 0.68
Mutate to I: LLR = 0.65
Mutate to E: LLR = 0.63
Mutate to R: LLR = 0.61
Position 157 (Original: I):
Mutate to L: LLR = 2.75
Mutate to A: LLR = 2.72
Mutate to I: LLR = 1.95
Mutate to V: LLR = 1.88
Mutate to E: LLR = 1.73
Mutate to G: LLR = 1.66
Mutate to S: LLR = 1.64
Mutate to F: LLR = 1.55
Mutate to T: LLR = 1.35
Mutate to R: LLR = 1.11
Mutate to M: LLR = 1.03
Mutate to Q: LLR = 0.90
Mutate to D: LLR = 0.67
Mutate to K: LLR = 0.57
Position 161 (Original: I):
Mutate to E: LLR = 1.09
Mutate to A: LLR = 1.02
Mutate to D: LLR = 0.97
Position 162 (Original: S):
Mutate to A: LLR = 3.09
Mutate to E: LLR = 2.57
Mutate to R: LLR = 2.27
Mutate to S: LLR = 2.09
Mutate to T: LLR = 1.97
Mutate to D: LLR = 1.89
Mutate to K: LLR = 1.80
Mutate to Q: LLR = 1.79
Mutate to G: LLR = 1.70
Mutate to L: LLR = 1.47
Mutate to P: LLR = 1.05
Mutate to V: LLR = 1.02
Mutate to N: LLR = 0.98
Mutate to H: LLR = 0.90
Position 174 (Original: A):
Mutate to A: LLR = 3.50
Mutate to R: LLR = 3.12
Mutate to S: LLR = 3.01
Mutate to T: LLR = 2.99
Mutate to L: LLR = 2.88
Mutate to K: LLR = 2.82
Mutate to G: LLR = 2.71
Mutate to E: LLR = 2.64
Mutate to D: LLR = 2.51
Mutate to V: LLR = 2.51
Mutate to Q: LLR = 2.31
Mutate to N: LLR = 2.19
Mutate to I: LLR = 2.11
Mutate to P: LLR = 1.95
Mutate to H: LLR = 1.79
Mutate to M: LLR = 1.36
Mutate to F: LLR = 1.32
Mutate to Y: LLR = 0.83
Position 178 (Original: P):
Mutate to A: LLR = 1.11
Mutate to R: LLR = 0.96
Mutate to Q: LLR = 0.52
Position 181 (Original: A):
Mutate to E: LLR = 2.23
Mutate to D: LLR = 1.54
Mutate to R: LLR = 1.26
Mutate to Q: LLR = 0.98
Mutate to A: LLR = 0.85
Mutate to K: LLR = 0.67
Position 182 (Original: T):
Mutate to V: LLR = 4.57
Mutate to I: LLR = 3.69
Mutate to L: LLR = 3.16
Mutate to F: LLR = 2.15
Mutate to A: LLR = 2.15
Mutate to C: LLR = 1.91
Mutate to T: LLR = 1.13
Mutate to M: LLR = 0.77
Position 185 (Original: R):
Mutate to L: LLR = 2.84
Mutate to A: LLR = 1.98
Mutate to G: LLR = 1.76
Mutate to M: LLR = 1.67
Mutate to R: LLR = 1.53
Mutate to Q: LLR = 1.14
Mutate to S: LLR = 1.00
Mutate to E: LLR = 0.96
Mutate to H: LLR = 0.74
Mutate to T: LLR = 0.71
Mutate to D: LLR = 0.67
Mutate to F: LLR = 0.64
Mutate to K: LLR = 0.57
Mutate to Y: LLR = 0.56
Position 188 (Original: A):
Mutate to E: LLR = 3.31
Mutate to A: LLR = 2.80
Mutate to D: LLR = 2.68
Mutate to S: LLR = 2.50
Mutate to Q: LLR = 2.36
Mutate to T: LLR = 1.84
Mutate to N: LLR = 1.65
Mutate to G: LLR = 1.42
Mutate to L: LLR = 1.39
Mutate to R: LLR = 1.37
Mutate to K: LLR = 1.36
Mutate to H: LLR = 0.71
Position 192 (Original: T):
Mutate to V: LLR = 7.46
Mutate to N: LLR = 7.19
Mutate to Q: LLR = 6.97
Mutate to I: LLR = 6.92
Mutate to A: LLR = 6.88
Mutate to L: LLR = 6.77
Mutate to T: LLR = 6.67
Mutate to D: LLR = 6.52
Mutate to E: LLR = 6.46
Mutate to S: LLR = 6.35
Mutate to P: LLR = 6.23
Mutate to Y: LLR = 6.07
Mutate to M: LLR = 5.65
Mutate to G: LLR = 5.41
Mutate to R: LLR = 5.30
Mutate to H: LLR = 5.06
Mutate to F: LLR = 4.99
Mutate to K: LLR = 4.49
Mutate to W: LLR = 3.79
Mutate to C: LLR = 3.53
Position 198 (Original: D):
Mutate to A: LLR = 1.24
Mutate to E: LLR = 0.90
Mutate to L: LLR = 0.81
Mutate to I: LLR = 0.68
Position 199 (Original: V):
Mutate to L: LLR = 3.77
Mutate to M: LLR = 1.63
Mutate to V: LLR = 1.14
Mutate to I: LLR = 0.95
Mutate to F: LLR = 0.67
Mutate to T: LLR = 0.61
Position 202 (Original: V):
Mutate to S: LLR = 1.98
Mutate to P: LLR = 1.27
Mutate to A: LLR = 1.20
Position 203 (Original: K):
Mutate to V: LLR = 2.31
Mutate to P: LLR = 1.82
Mutate to I: LLR = 1.59
Mutate to L: LLR = 1.38
Mutate to E: LLR = 1.20
Mutate to A: LLR = 1.18
Mutate to R: LLR = 0.76
Mutate to T: LLR = 0.67
Position 208 (Original: R):
Mutate to T: LLR = 1.82
Mutate to N: LLR = 1.48
Mutate to S: LLR = 1.02
Position 209 (Original: V):
Mutate to H: LLR = 3.42
Mutate to Y: LLR = 2.66
Mutate to R: LLR = 1.62
Mutate to Q: LLR = 0.73
Mutate to L: LLR = 0.59
Position 212 (Original: R):
Mutate to N: LLR = 2.55
Mutate to S: LLR = 1.41
Mutate to R: LLR = 0.98
Mutate to A: LLR = 0.88
Position 214 (Original: E):
Mutate to M: LLR = 8.36
Mutate to Y: LLR = 8.16
Mutate to L: LLR = 8.13
Mutate to R: LLR = 7.78
Mutate to F: LLR = 7.65
Mutate to E: LLR = 7.36
Mutate to A: LLR = 7.24
Mutate to Q: LLR = 7.22
Mutate to K: LLR = 7.17
Mutate to I: LLR = 7.12
Mutate to V: LLR = 6.98
Mutate to S: LLR = 6.58
Mutate to C: LLR = 6.40
Mutate to T: LLR = 6.04
Mutate to W: LLR = 5.67
Mutate to H: LLR = 5.62
Mutate to G: LLR = 5.38
Mutate to N: LLR = 4.57
Mutate to D: LLR = 3.21
Mutate to P: LLR = 1.85
Position 224 (Original: K):
Mutate to E: LLR = 2.96
Mutate to Q: LLR = 2.18
Mutate to D: LLR = 1.11
Mutate to A: LLR = 0.56
Total hotspots found: 75”
These results seemed a bit too excessive so I changed the code around a little bit and got this
Mutation Hotspots Identified (positions with at least 3 mutations having LLR > 5):
Position 20 (Original: I):
Mutate to E: LLR = 5.70
Mutate to A: LLR = 5.51
Mutate to D: LLR = 5.31
Position 128 (Original: X):
Mutate to V: LLR = 6.03
Mutate to A: LLR = 5.56
Mutate to L: LLR = 5.32
Mutate to I: LLR = 5.28
Position 192 (Original: T):
Mutate to V: LLR = 7.46
Mutate to N: LLR = 7.19
Mutate to Q: LLR = 6.97
Mutate to I: LLR = 6.92
Mutate to A: LLR = 6.88
Mutate to L: LLR = 6.77
Mutate to T: LLR = 6.67
Mutate to D: LLR = 6.52
Mutate to E: LLR = 6.46
Mutate to S: LLR = 6.35
Mutate to P: LLR = 6.23
Mutate to Y: LLR = 6.07
Mutate to M: LLR = 5.65
Mutate to G: LLR = 5.41
Mutate to R: LLR = 5.30
Mutate to H: LLR = 5.06
Position 214 (Original: E):
Mutate to M: LLR = 8.36
Mutate to Y: LLR = 8.16
Mutate to L: LLR = 8.13
Mutate to R: LLR = 7.78
Mutate to F: LLR = 7.65
Mutate to E: LLR = 7.36
Mutate to A: LLR = 7.24
Mutate to Q: LLR = 7.22
Mutate to K: LLR = 7.17
Mutate to I: LLR = 7.12
Mutate to V: LLR = 6.98
Mutate to S: LLR = 6.58
Mutate to C: LLR = 6.40
Mutate to T: LLR = 6.04
Mutate to W: LLR = 5.67
Mutate to H: LLR = 5.62
Mutate to G: LLR = 5.38
Total hotspots found: 4
One thing I noticed whilst analysing the heatmap, the x spots around 16, 122 to 126, 189 and 211 appear brighter. That means that these are the areas where the protein’s sequence might be quite adaptable, making them interesting for further investigation into their role and potential for modification.
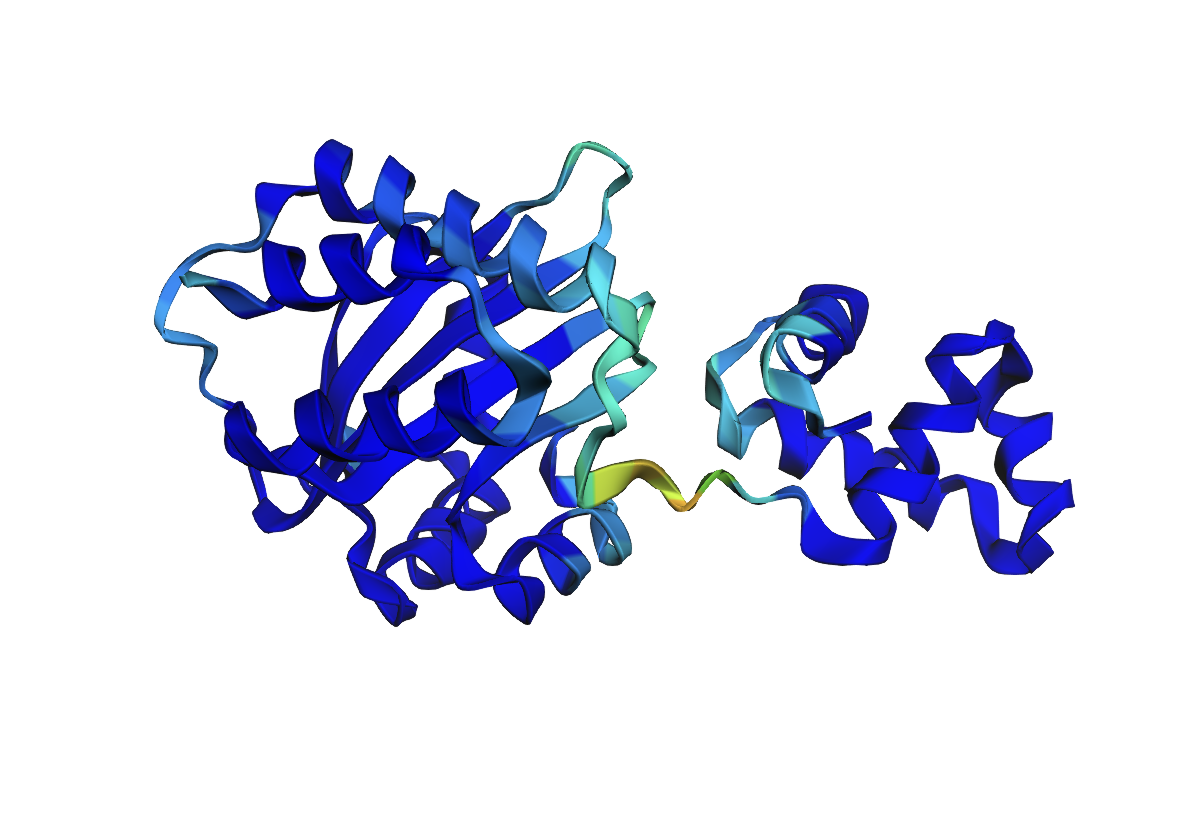
New sequence for folding: MNFLDDVEKLSKVKGDDETFKKGLEEIAKKHGFSGWNFVYDNNGHLKVWSNLDPALLKEYFEKNWYKVDPVIKKAREEEKLFTWSWDEEWPKLTEEEKALGEEYKKYGVKSGITIPIKAENGTRAYFTFYSKKDKIELKEPIDDEKAKKVTKLLYKKIVDNKWTPTGHTPMSLNEKERAYLKLRSKGYSQREIAEKLGVAQSTVSRTIRKAMEKFGVKTIEELIKIAKEMGLI
What it looks like -> somewhat similar to the original
Part D. Group Brainstorm on Bacteriophage Engineering
*Claude AI prompt: Can you please analyse the results of UniProtKB LuxR search
** Gemini built in to colab AI prompt “identify mutation hotspots based on the compiled data in the heatmap”
Week 5 HW: Protein Design Part II
Part A: SOD1 Binder Peptide Design (From Pranam)
Part 1: Generate Binders with PepMLM
sp|P00441|SODC_HUMAN Superoxide dismutase [Cu-Zn] OS=Homo sapiens OX=9606 GN=SOD1 PE=1 SV=2
MATKAVCVLKGDGPVQGIINFEQKESNGPVKVWGSIKGLTEGLHGFHVHEFGDNTAGCTS
AGPHFNPLSRKHGGPKDEERHVGDLGNVTADKDGVADVSIEDSVISLSGDHCIIGRTLVV
HEKADDLGKGGNEESTKTGNAGSRLACGVIGIAQ
(taken from https://rest.uniprot.org/uniprotkb/P00441.fasta )
-> muted form A-> V
MATKVVCVLKGDGPVQGIINFEQKESNGPVKVWGSIKGLTEGLHGFHVHEFGDNTAGCTS
AGPHFNPLSRKHGGPKDEERHVGDLGNVTADKDGVADVSIEDSVISLSGDHCIIGRTLVV
HEKADDLGKGGNEESTKTGNAGSRLACGVIGIAQ
(2-5)
#
Binder
Pseudo Perplexity
Notes
0
WHYGAAQAAHWX
7.60026377248636
High confidence
1
WLYGASAAAWKK
7.46473740432208
Highest confidence!!!
2
WLYGAAGVAWKE
10.9325804754158
Moderate confidence
3
WLYYPQAAKLKK
15.5499787120909
Lowest confidence
—
FLYRWLPSRRGG
20.9180890005569
Known binder (control)
Part 2: Evaluate Binders with AlphaFold3
So what I found out is that in WHYGAAQAAHWX X is an unknown amino acid and that AlphaFold3 is not going to work with it so I’m just skipping it for now.
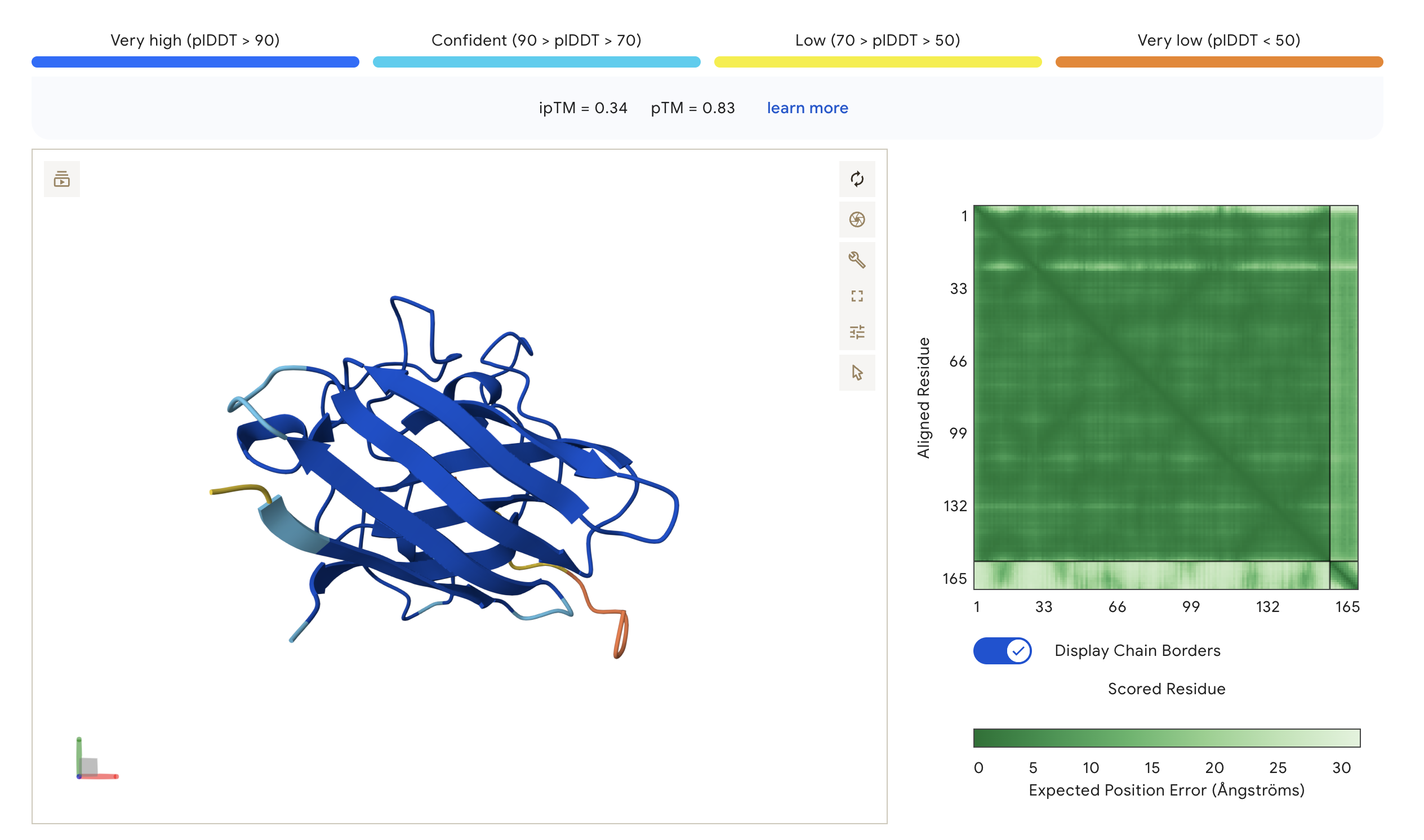
SOD1_A4V_WLYYPQAAKLKK
SOD1_A4V_WLYGASAAAWKK
SOD1_A4V_WLYGAAGVAWKE
SOD1_A4V_FLYRWLPSRRGG
Peptide
ipTM
pTM
Binding Location
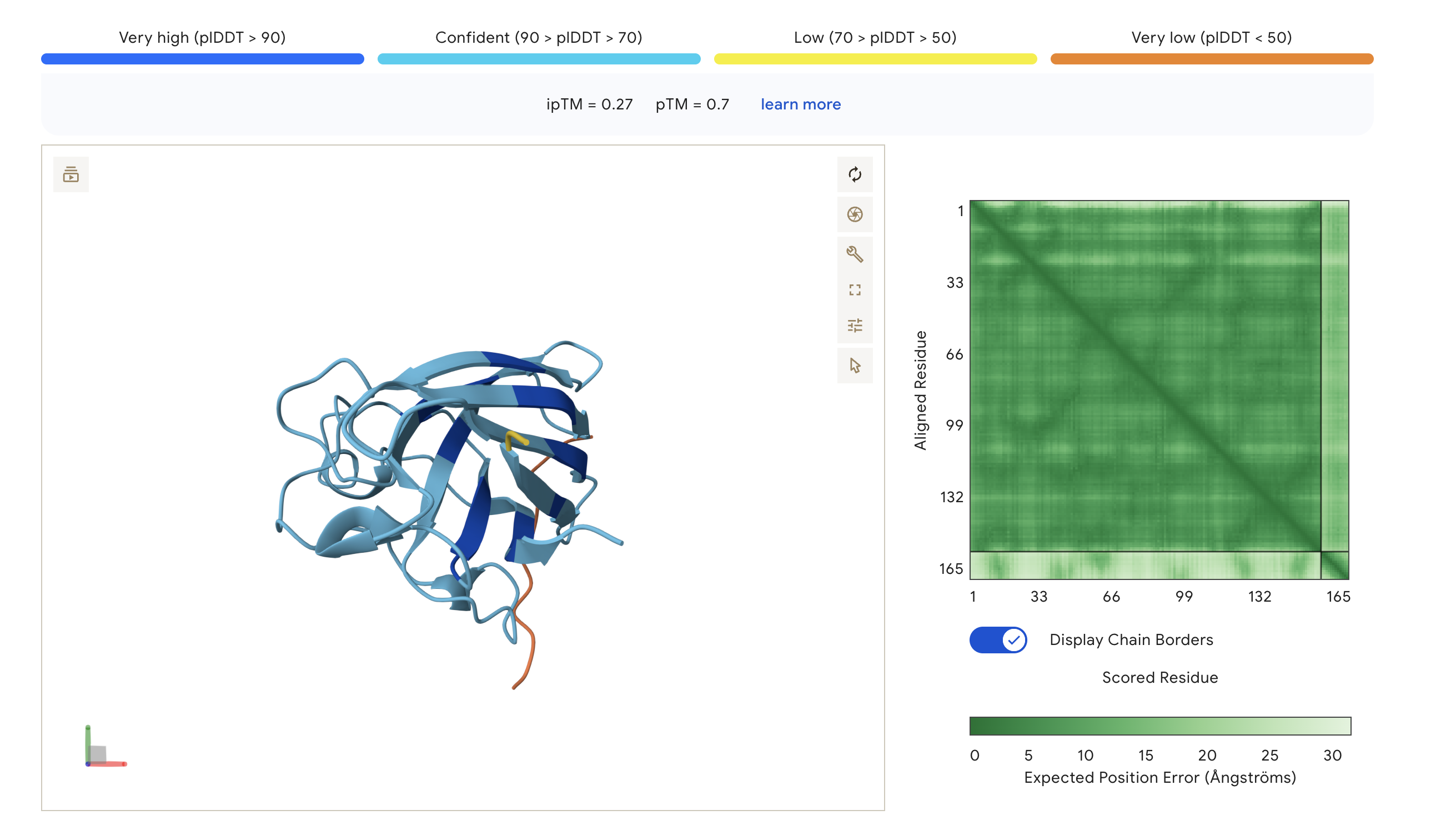
FLYRWLPSRRGG (known)
0.34
0.83
Surface-bound, near bottom/loop region
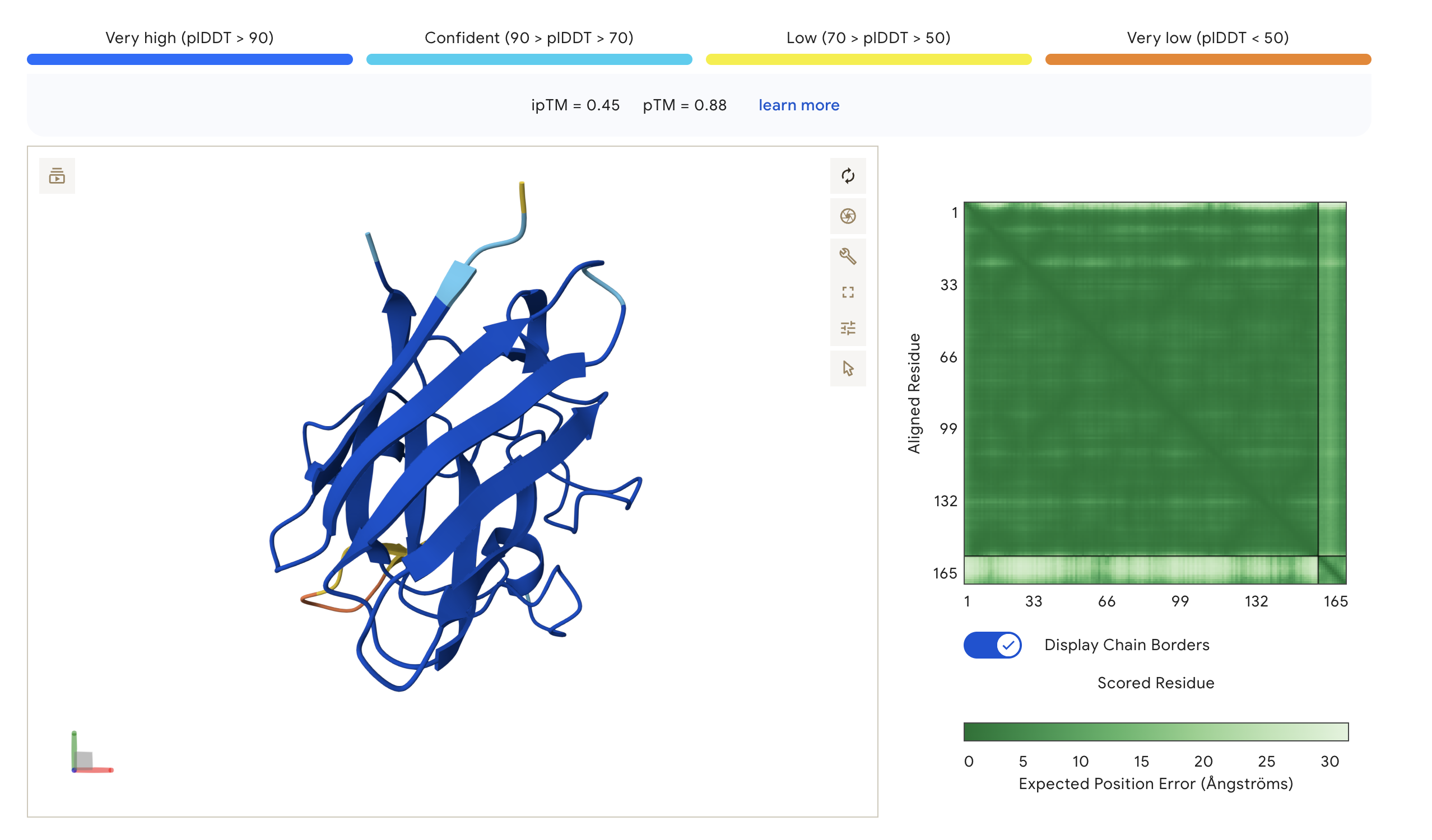
WLYGAAGVAWKE
0.45
0.88
Engages β-barrel, partially buried near core
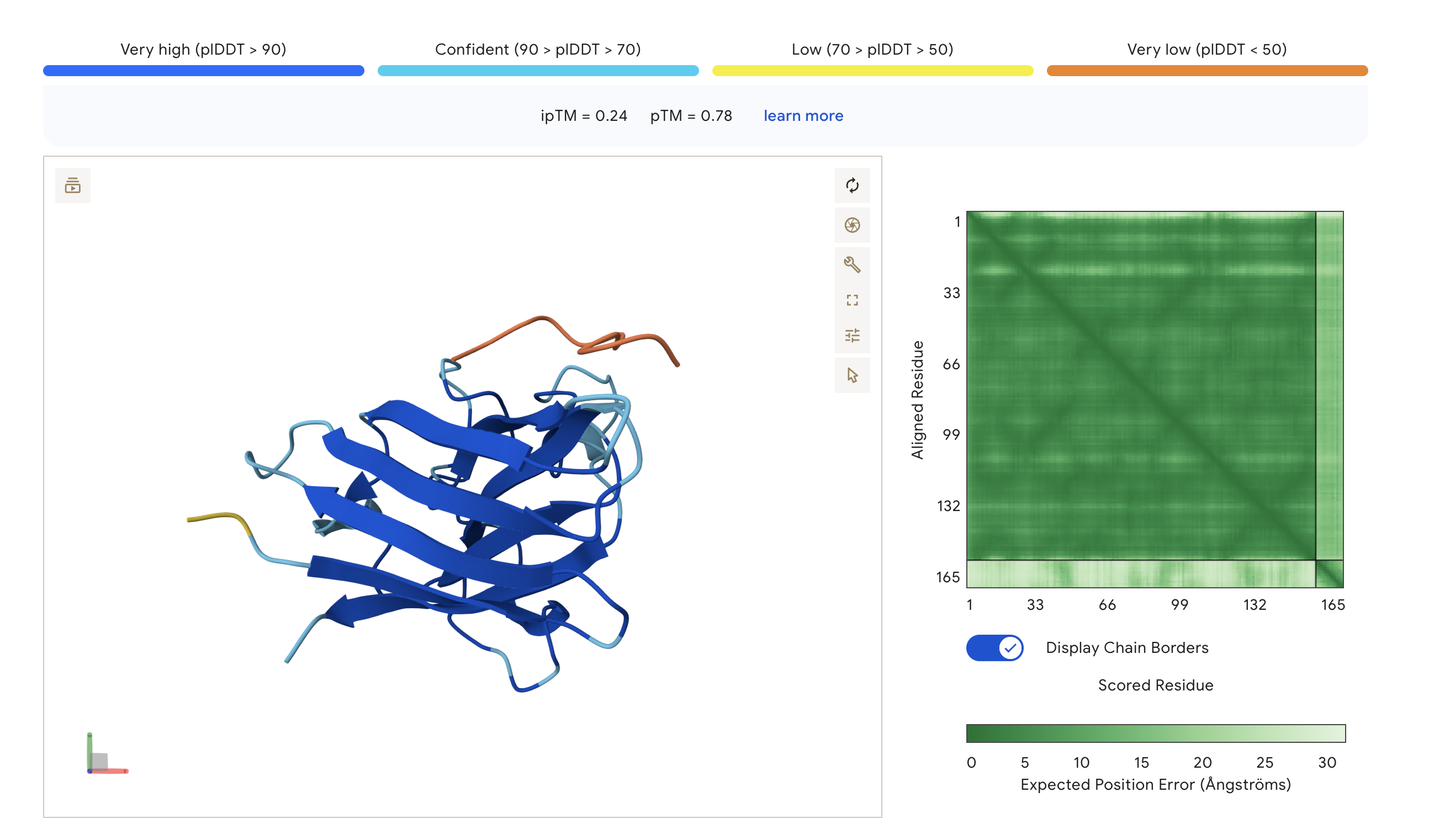
WLYGASAAAWKK
0.24
0.78
Surface-bound, near N-terminus/top loops
WLYYPQAAKLKK
0.27
0.70
Surface-bound, loose association near loops
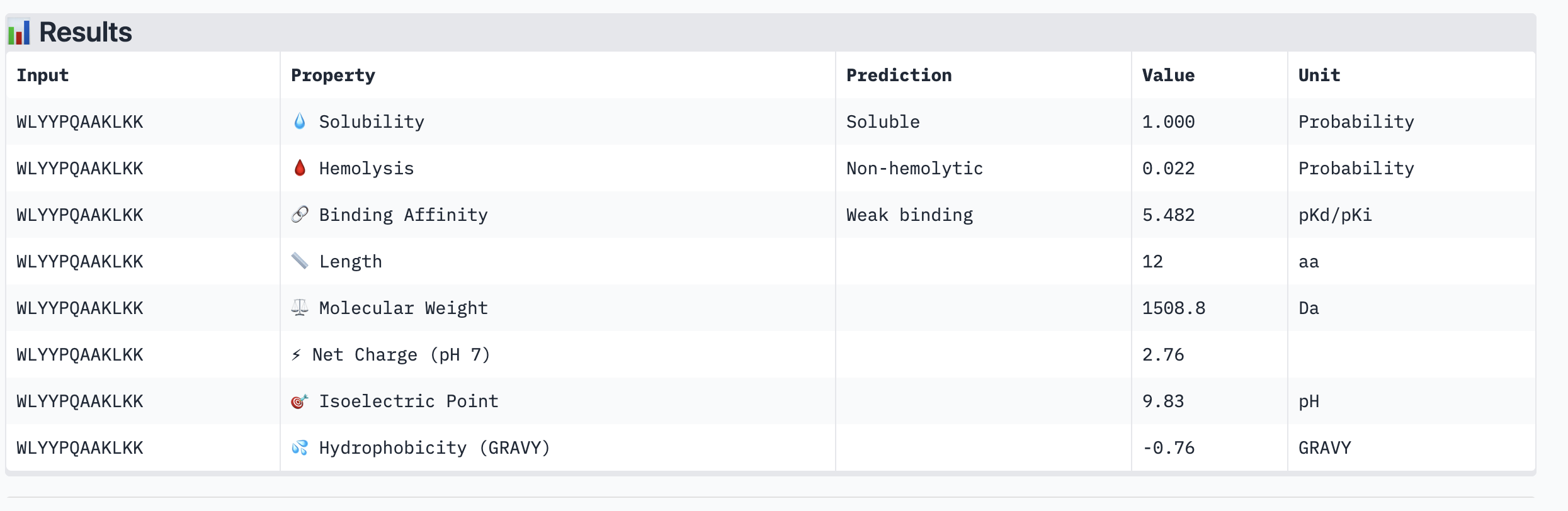
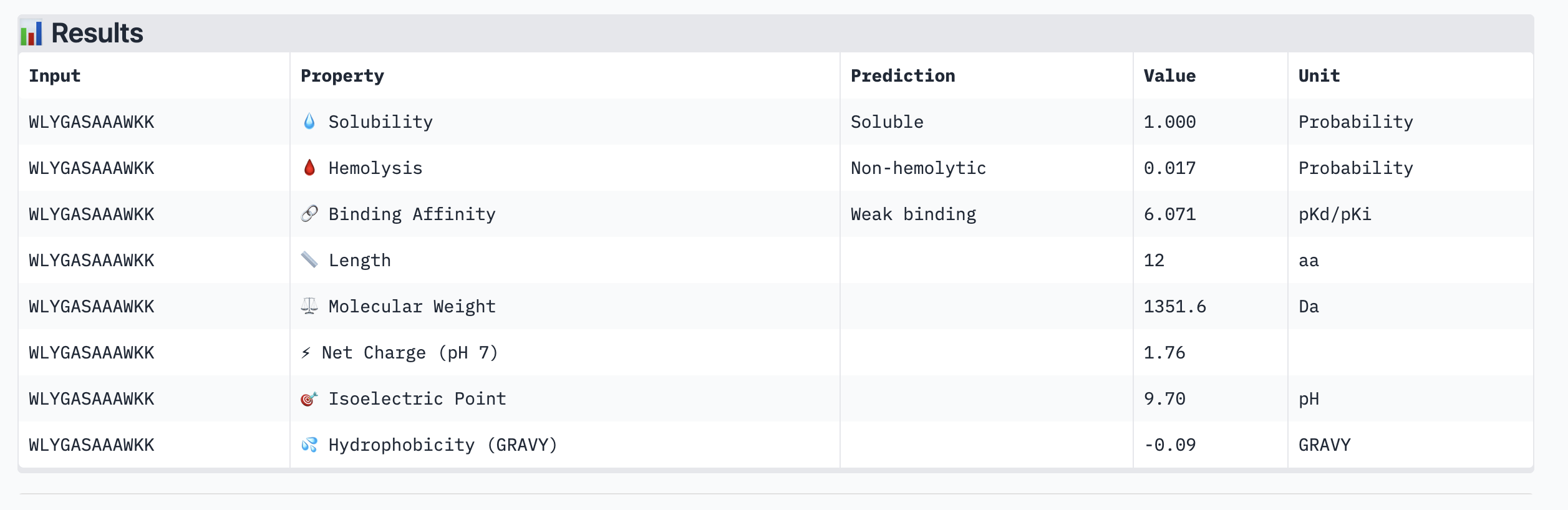
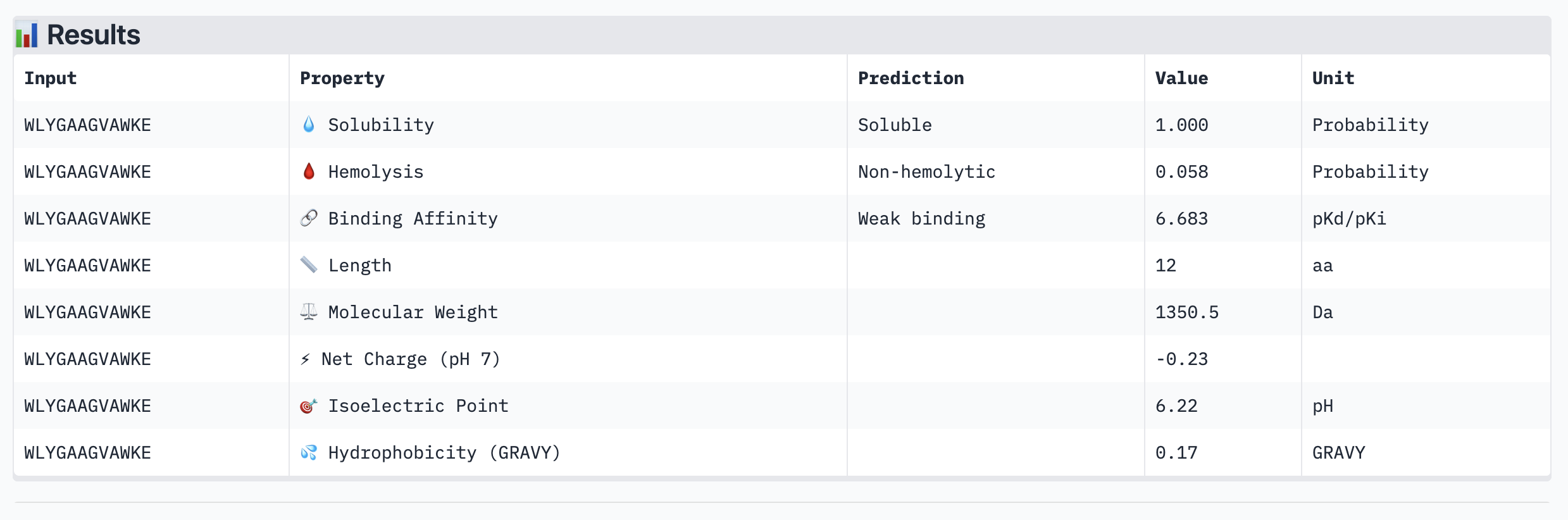
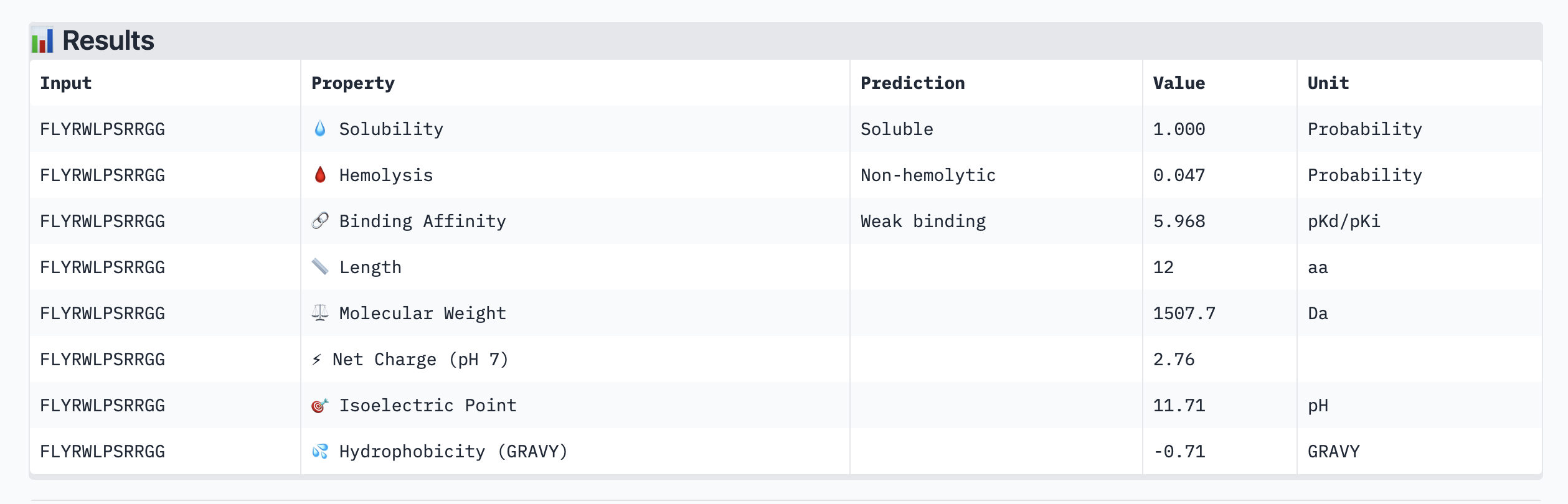
ipTM scores across all peptides ranged from 0.24 to 0.45 -> suggests weak-to-moderate predicted interface confidence. The PepMLM-generated peptide WLYGAAGVAWKE (ipTM = 0.45) outperformed the known binder FLYRWLPSRRGG (ipTM = 0.34), appearing more engaged with the β-barrel core of SOD1. The remaining two peptides WLYGASAAAWKK (ipTM = 0.24) and WLYYPQAAKLKK (ipTM = 0.27) scored below FLYRWLPSRRGG and appeared loosely surface-bound. None exceeded an ipTM of 0.5, which should be expected for short peptides against a structured target
Part 3: Evaluate Properties of Generated Peptides in the PeptiVerse
WLYYPQAAKLKK_pv
WLYGASAAAWKK_pv
WLYGAAGVAWKE_pv
FLYRWLPSRRGG_pv
Peptide
ipTM
Binding Affinity (pKd)
Solubility
Hemolysis
Net Charge
FLYRWLPSRRGG (known)
0.34
5.968
Soluble
Non-hemolytic
+2.76
WLYGAAGVAWKE
0.45
6.683
Soluble
Non-hemolytic
-0.23
WLYGASAAAWKK
0.24
6.071
Soluble
Non-hemolytic
+1.76
WLYYPQAAKLKK
0.27
5.482
Soluble
Non-hemolytic
+2.76
WLYGAAGVAWKE had both the highest ipTM (0.45) and the strongest predicted binding affinity (6.683 pKd), suggesting that structural confidence and binding prediction align for this peptide. All peptides were soluble and non-hemolytic, meaning none raised safety red flags. Notably, higher ipTM did loosely correlate with stronger affinity — WLYGAAGVAWKE topped both metrics while WLYYPQAAKLKK scored lowest on affinity and had a weak ipTM.
Peptide to Advance: WLYGAAGVAWKE!!!
WLYGAAGVAWKE has the best structural binding confidence (ipTM = 0.45), the strongest predicted affinity (6.683 pKd), is fully soluble, and
non-hemolytic. It outperforms the known binder FLYRWLPSRRGG on every key metric! Therefore, we should use this one
Part 4: Generate Optimized Peptides with moPPIt
I tried to run for Motif positions 1, 2, 3, 4, 5, 6, 7 but it’s just taking so long, so, I’m nit going to finosh running it but here’re some results that I got so far:
moPPIt Generated Peptides
#
Peptide
Target Residues
1
GKTEKTYTDCCD
1, 2, 3, 4, 5, 6, 7
2
EEQNTCIQTTKA
1, 2, 3, 4, 5, 6, 7
Comparison: moPPIt vs PepMLM Peptides:
moPPIt peptides differ notably from PepMLM-generated ones in both composition and
design intent. PepMLM peptides (e.g., WLYGAAGVAWKE, WLYGASAAAWKK) were dominated
by W at position 1 and showed a hydrophobic character, as the model
simply sampled sequences likely to bind SOD1 without any spatial constraints. In
contrast, moPPIt peptides (GKTEKTYTDCCD, EEQNTCIQTTKA) are more polar and charged while
balancing affinity, solubility and hemolysis objectives. moPPIt asks “what binds specifically near position 4, and is also
therapeutically viable?”
Before advancing the studies of moPPIt peptides, the following next steps/ evaluations needed:
SPR or ITC should be used to measure actual binding affinity
AlphaFold3 rystallography to
confirm binding near the target residues 1–7
To confirm non-toxic
Need to assess peptide half-life through test degradation in serum
Check for cell permeability
ALS mouse model
new!! TKCVATKKLQED
Part B: BRD4 Drug Discovery Platform Tutorial (Gabriele)
waiting to be accepted onto the platform
Part C: Final Project: L-Protein Mutants
I’ve also asked Claude* for help with the validation of computations, and this was the correlation assessment
STRONG CORRELATION between computational scores and experimental LLR values:
Computational Prediction
Experimental Validation
Agreement
K50L (Score: 2.56)
Bright yellow
Excellent
C29R (Score: 2.40)
Position 29 hotspot
Excellent
Y39L (Score: 2.24)
Bright at pos 39
Strong
N53L (Score: 1.87)
TM leucine pattern
Strong
S9Q (Score: 2.01)
Some positive signals
Good
Conclusion: The ESM2 language model predictions correlate well with experimental data, particularly for:
Identifying hotspot positions (29, 39, 50)
Predicting beneficial amino acid types (hydrophobic in TM, removing C29)
Overall mutation effects (positive vs negative)
This validates using computational approaches for rational protein design, though experimental validation remains essential.
Top 20 Mutations with Scores
Rank
Mutation
Original AA
New AA
Position
Score
Region
1
K50L
K
L
50
2.561
Transmembrane
2
C29R
C
R
29
2.395
Soluble
3
Y39L
Y
L
39
2.242
Soluble
4
C29S
C
S
29
2.043
Soluble
5
S9Q
S
Q
9
2.014
Soluble
6
C29Q
C
Q
29
1.997
Soluble
7
C29P
C
P
29
1.971
Soluble
8
C29L
C
L
29
1.961
Soluble
9
K50I
K
I
50
1.929
Transmembrane
10
N53L
N
L
53
1.865
Transmembrane
11
E61L
E
L
61
1.818
Transmembrane
12
T52L
T
L
52
1.814
Transmembrane
13
K50F
K
F
50
1.802
Transmembrane
14
C29T
C
T
29
1.797
Soluble
15
C29K
C
K
29
1.796
Soluble
16
F5Q
F
Q
5
1.795
Soluble
17
F5R
F
R
5
1.660
Soluble
18
C29A
C
A
29
1.649
Soluble
19
Y27R
Y
R
27
1.628
Soluble
20
F22R
F
R
22
1.602
Soluble
my final 5 mutations:
K50L (Transmembrane) 2.561
C29R (Soluble) 2.395
Y39L (Soluble) 2.242
N53L (Transmembrane) 1.865
S9Q (Soluble) 2.014
*prompt used with Claude find correlation between the experimental data L-Protein Mutants - Sheet1.csv and protein_mutations_scores.csv
Week 6 HW: Genetic Circuits Part I: Assembly Technologies
Assignment: DNA Assembly
What are some components in the Phusion High-Fidelity PCR Master Mix and what is their purpose?
Phusion DNA Polymerase - a high-fidelity enzyme that synthesises new DNA strands with 3’→5’ exonuclease activity for proofreading
dNTPs - building blocks for DNA synthesis (200 µM each at 1X concentration)
MgCl₂ - Cofactor required for polymerase activity (1.5 mM at 1X concentration)
Possibly optional as the question doesn’t mention it (GC Buffer - optimised buffer for amplifying difficult templates with high GC content or secondary structure)
DMSO (optional additive) - helps denature secondary structures in GC-rich or difficult templates (recommended at 3% final concentration)
What are some factors that determine primer annealing temperature during PCR?
Primer Tm as in melting temperature, primer length, GC content, primer pair Tm similarity
There are two methods from this class that create linear fragments of DNA: PCR, and restriction enzyme digests. Compare and contrast these two methods, both in terms of protocol as well as when one may be preferable to use over the other.
PCR vs. Restriction Enzyme Digests
Comparison Table
Aspect
PCR
Restriction Enzyme Digests
Mechanics
Amplifies specific DNA regions using primers
Cuts DNA at specific recognition sequences
Flexibility
More flexible; doesn’t require specific cut sites
Limited by existing restriction sites in sequence
Mutations
Can introduce mutations via primer design
Cannot introduce mutations
End Products
Variable ends based on primer design
Creates predictable, precise ends
Time needed
~90 minutes with thermal cycling
Faster (~1-2 hours incubation)
Template amount
Can work with small amounts of template
Requires sufficient DNA quantity
Sticky ends
Not applicable
Can create compatible sticky ends
When to use
When introducing mutations into sequences, no suitable restriction sites exist in the DNA, from small amounts of template DNA
When restriction sites are conveniently located in the sequence, Creating compatible sticky ends for cloning, Cutting plasmids for traditional cloning applications, Precise, predictable cuts are required
How can you ensure that the DNA sequences that you have digested and PCR-ed will be appropriate for Gibson cloning?
Ensure primers have 20-22 bp overhangs that are complementary between fragments
After PCR and DpnI digest, purify the DNA using the Zymo DNA Clean & Concentrator kit and measure concentration using Nanodrop/Qubit. The concentration should be above ~30 ng/µL.
Run the PCR products on an agarose gel to verify correct band sizes. Mix 3 µL of sample with 3.3 µL of 6x Loading Dye, run at ~100 mV for 15 min, and compare against a DNA ladder. Calculate your predicted digest on Benchling to verify the correct band size matches what you see on the gel
Ensure only unmethylated PCR products (not the original methylated template plasmid) are present through DpnI Treatment, reducing background colonies from unmutated template.
How does the plasmid DNA enter the E. coli cells during transformation?
By diffusion when the cells are shocked
Describe another assembly method in detail (such as Golden Gate Assembly)Explain the other method in 5 - 7 sentences plus diagrams (either handmade or online).
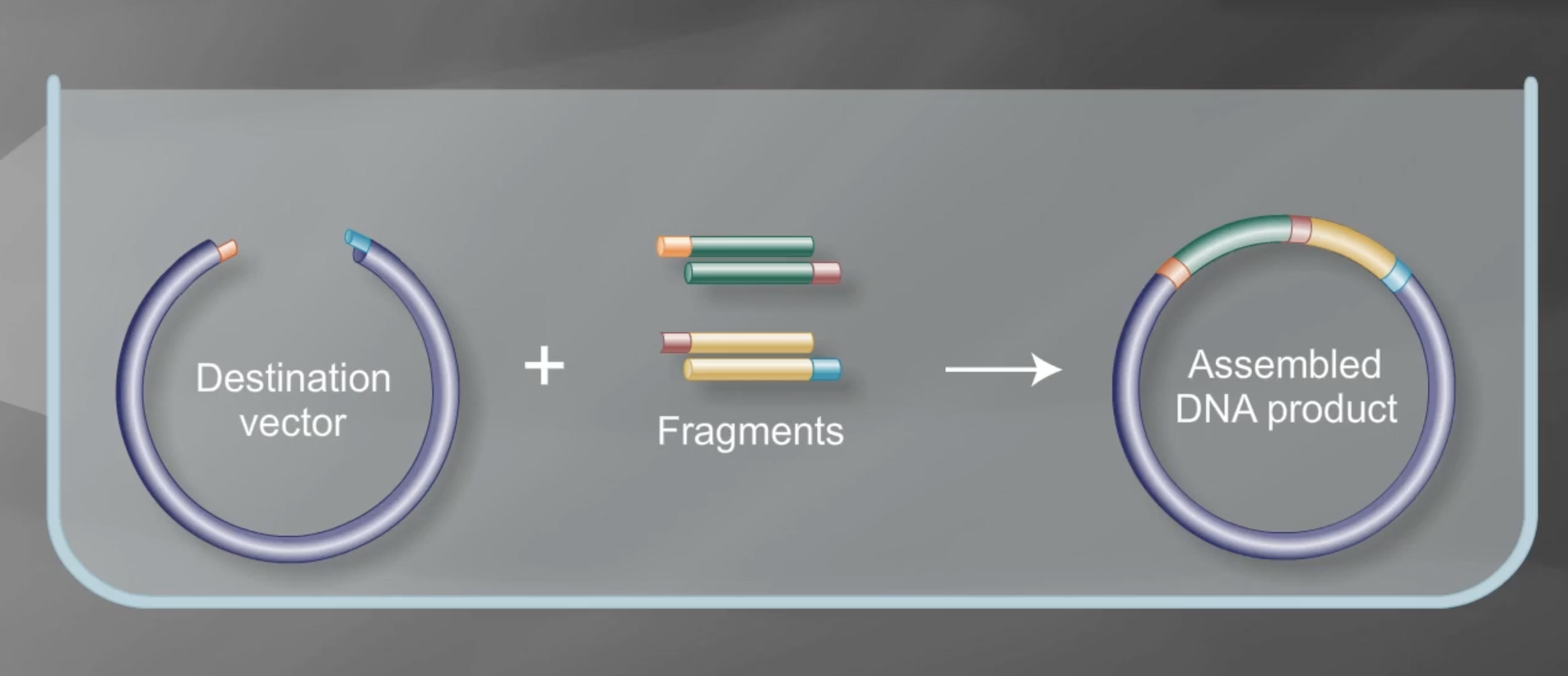
Golden Gate assembly is a molecular cloning technique used to join DNA fragments in a single reaction. Methods for golden gate include MoClo, GoldenBraid 2.0, Mobius assembly and EMMA. It’s an efficient and cost-effective means to generate construct variants. Type IIS restriction enzymes are used to assemble multiple fragments in a single reaction. It’s also important to make sure that the Type IIS included in the process is not present in the vector or insert sequences
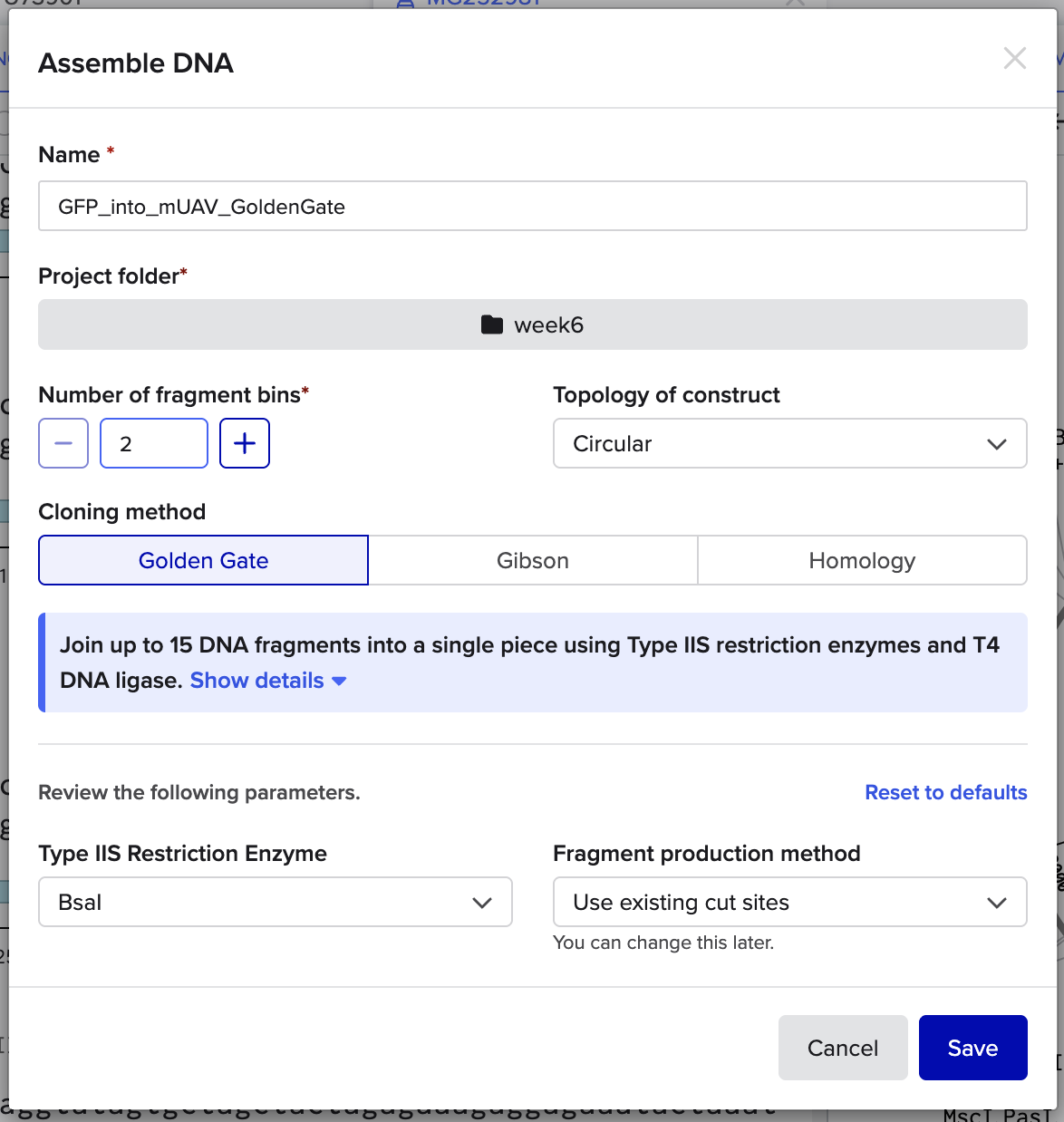
Model this assembly method with Benchling or Asimov Kernel!
As we don’t have access to Asimove I’ll be modelling this with Benchling
First, I added the DNA sequense of the well-known green fluorescent protein (GFP), which is native to the jellyfish Aequorea victoria
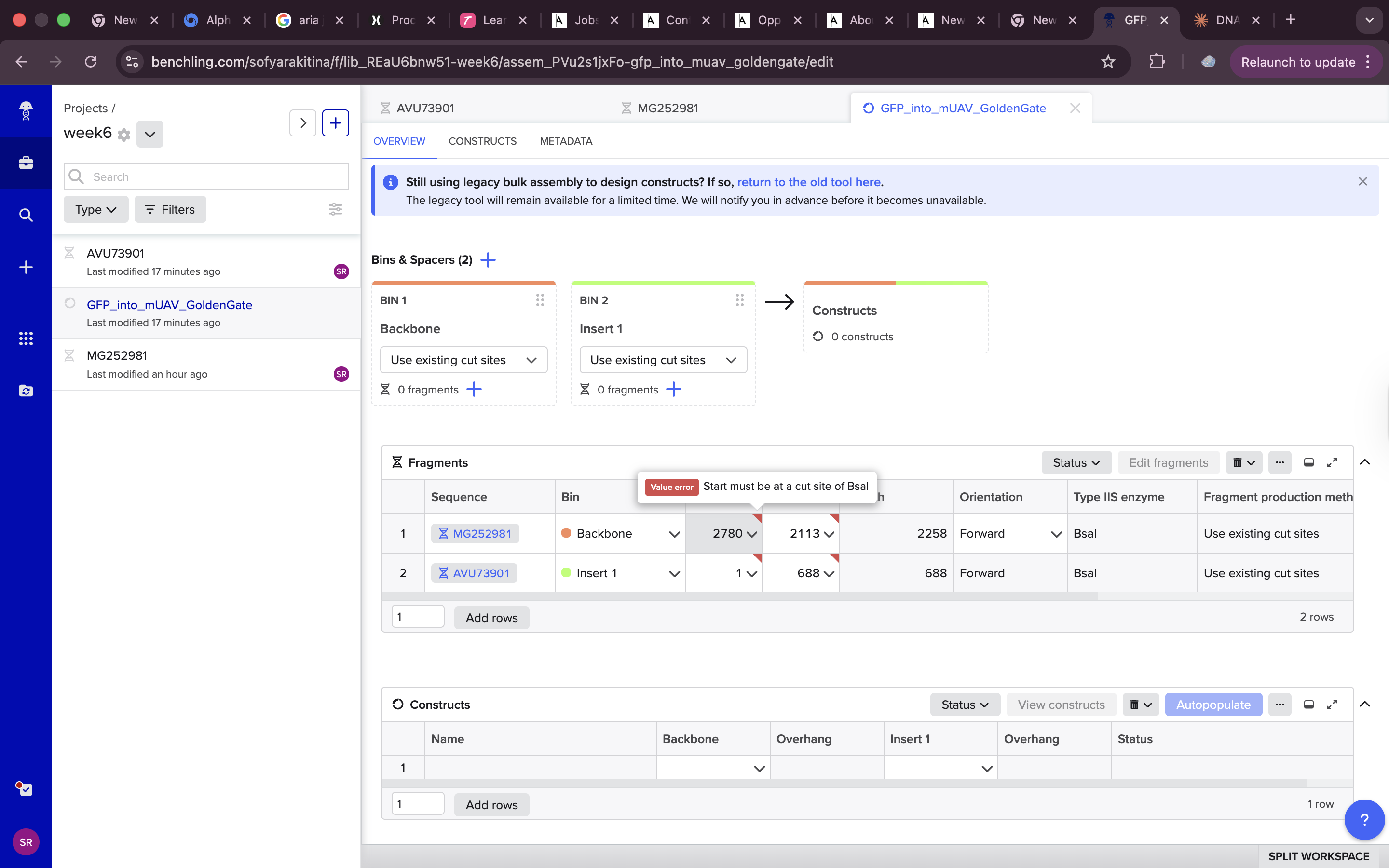
Changed the GGTCTC to GGTCTT to be able to work with the Golden Gate Assembly. Then I’ve added the plasmid to the project. I used the same one described in the lab. Then I checked for the presence of GGTCTC to use as the typeII enzyme.. there were 2 of those. Checked the other ones 2 of those again. Basically all three Type IIS enzymes (BsaI, BbsI, and Esp3I) have recognition sites in the mUAV plasmid
I ended up editing the GGTCTC ones as they were all in the base parts of the plasmid so they didn’t affect much. ( GGTCTC → GGTCTT )
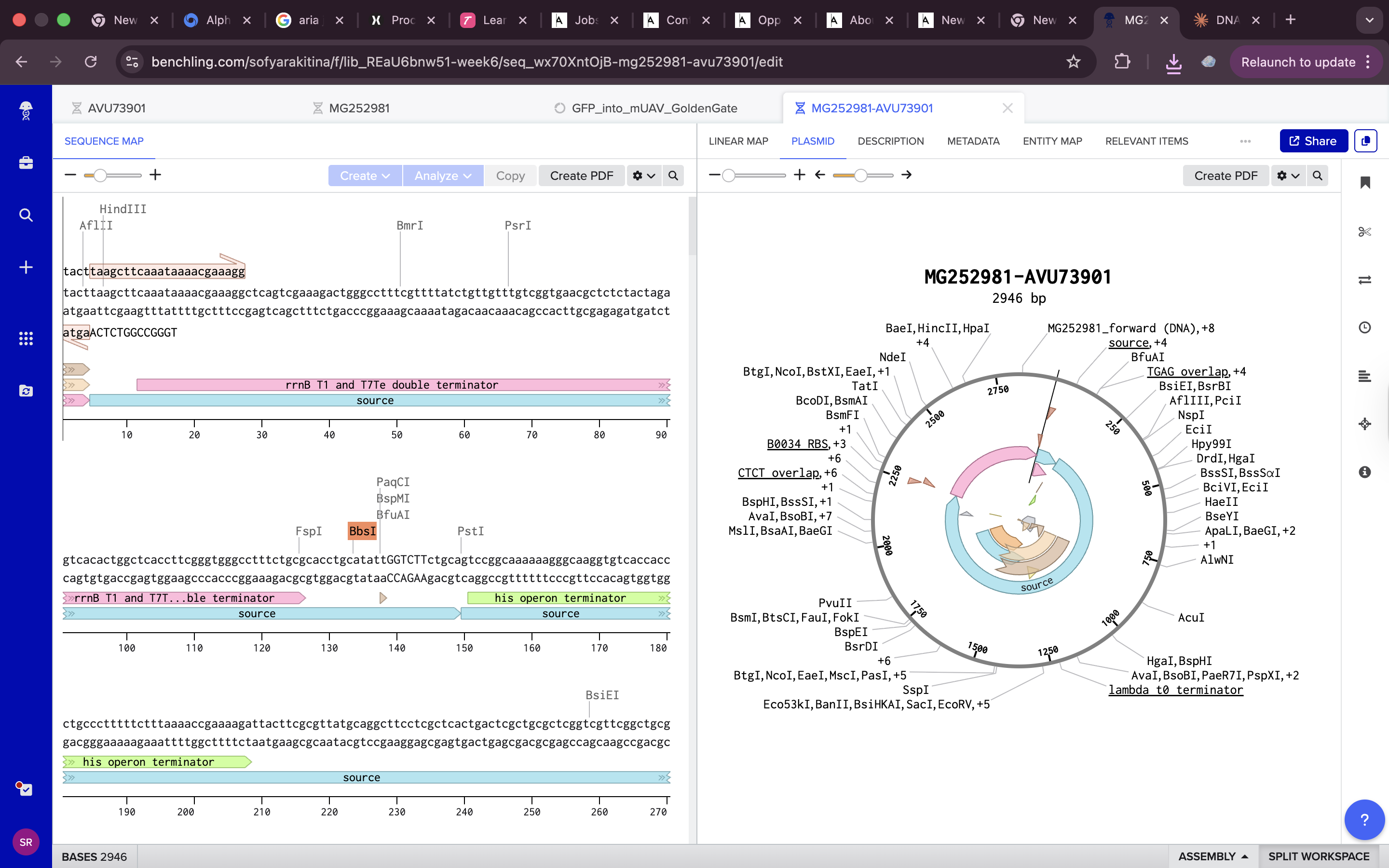
Then I figured out that amilCP gene starts at 2114 and ends at 2779
Complement: A↔T, G↔C
I then loooked for stop codons and found the TAA one. For the primer design i also needed the 20 protein sequence of the GFP which was atgtctaaaggtgaagaatt. Basically my primer components ended up being BsaI site: GGTCTC, Overhang A: AATG (includes the ATG start codon) and the binding region which is those first 20 bp of GFP = atgtctaaaggtgaagaatt. Then for the reverse binding region, the positions of 666 to 685 (20 before the TAA) are TGGTCTTGTTAGAATTTGTT therefore reverse complement ones are AACAAATTCTAACAAGACCA
End primers are GFP Forward 5’-GGTCTCAATGTCTAAAGGTGAAGAATT-3’ and GFP Reverse 5’-GAGACCAAGCAACAAATTCTAACAAGACCA-3'
Then as for the backbone forward primer 5’-GGTCTCGCTTAAGCTTCAAATAAAACGAA-3’ as it is (taagcttcaaataaaacgaa) where GGTCTC is a BsaI recognition site, G a spacer base, and CTTAAGCTTCAAATAAAACGAA a binding region.
Backbone Reverse ended up being 5’-GAGACCCATTTTAGTATTTCTCCTCTTTCT-3'
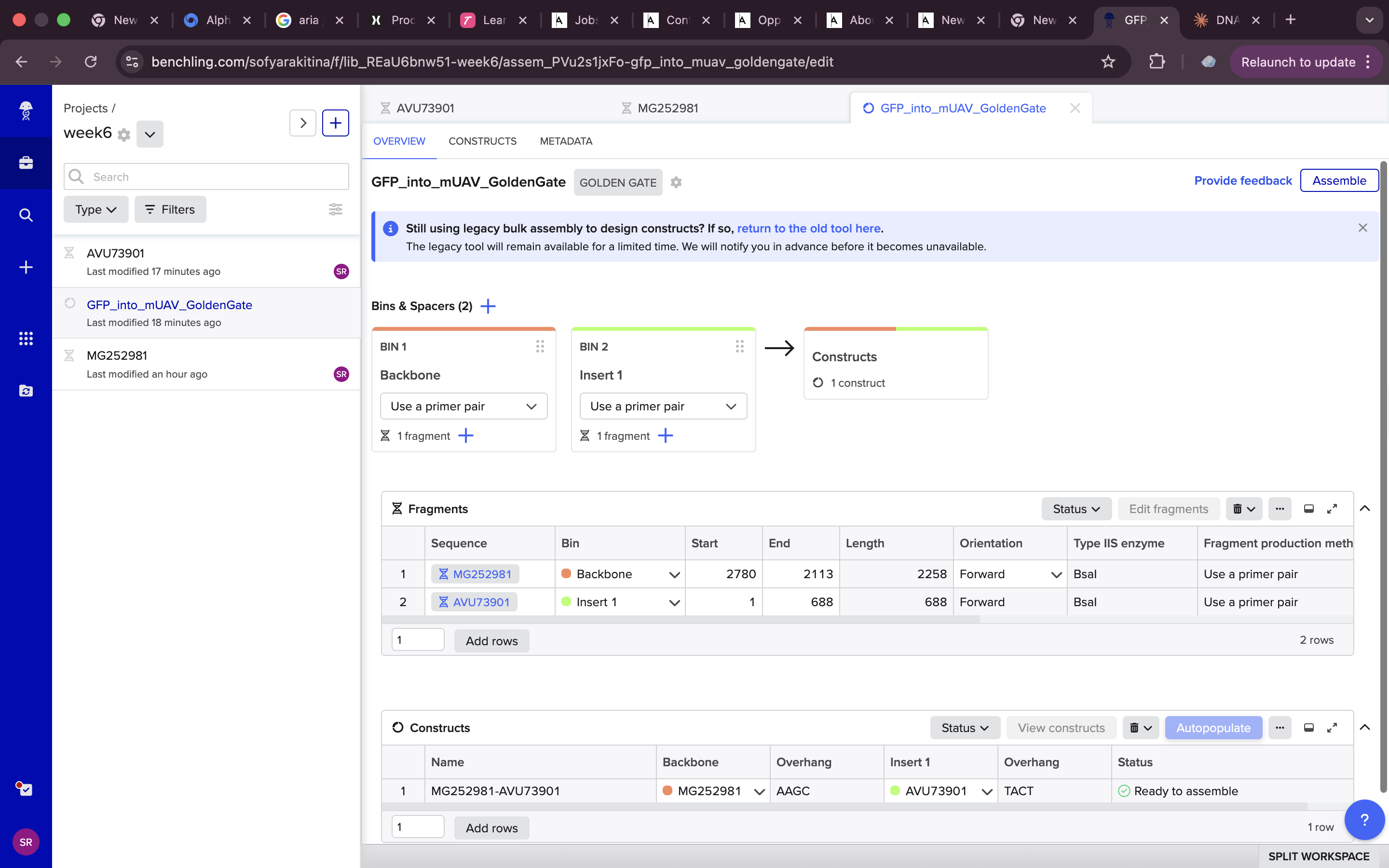
Then knowing all this it’s time to do the Golden Gate Assembly
Needed to change the setting from use cut lines otherwise i was getting an error
but other than that it was a pretty straightforward process
Week 7 HW: Genetic Circuits Part II: Neuromorphic Circuits
Assignment Part 1: Intracellular Artificial Neural Networks (IANNs)
What advantages do IANNs have over traditional genetic circuits, whose input/output behaviors are Boolean functions?
Analogue quality of computations (not just on and off, but rather treat them more like waves ->easier to work with)
-> Thresholds finetuning works
You can also work with more inputs simultaneously that will automatically become a weighted sum
Which also means they can be trained like neural networks!
whereas Boolean functions are just True/False with operators AND, OR, and NOT
Describe a useful application for an IANN; include a detailed description of input/output behavior, as well as any limitations an IANN might face to achieve your goal.
Actually, mycelium described in the later parts of the homework is a great application of IANN due to its non-uniform growth, which is basically a response to chemical gradients, nutrient availability, CO₂ levels, humidity, and light. That’s all analogue and continuous signals! Therefore, we could engineer a fungal cell to use an IANN to sense its local environment and decide how to grow, giving mycelium a programmable, environmentally-responsive architecture, which is basically a CA <3 where simple local rules produce complex emergent global patterns!!
So then, for input behaviour, we have
-Local nutrient and carbon concentration sensed via metabolite-responsive promoters
-CO₂ or O₂ levels
-Mechanical compression (fungi lowkey already have these)
-Neighbour cell density, which would act like quorum-sensing signalling molecules
Then, for output behaviour, we have
-Expression of growth-promoting genes
-Expression of growth-halting genes → denser, stiffer composite in that region
-Secretion of signalling molecules → coordinating behaviour with neighbouring cells
Limitations: intercellular signal noise (“local” signals may not stay local, warping and structural variability (Walter and Gürsoy (2022)), instability of speed as the IANN may lag behind rapidly changing environmental conditions
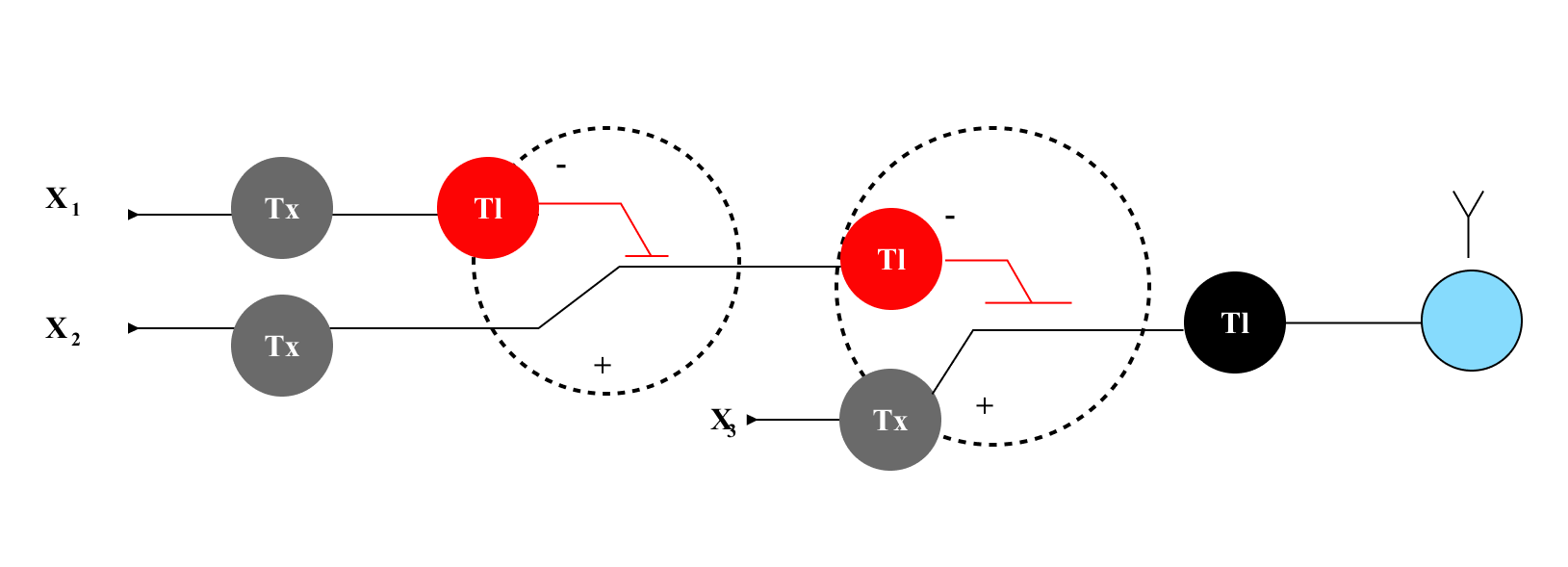
Draw a diagram for an intracellular multilayer perceptron where layer 1 outputs an endoribonuclease that regulates a fluorescent protein output in layer 2.
Here! A super quick sketch made in figma I tried to make it as close to the example as possible
Assignment Part 2: Fungal Materials
What are some examples of existing fungal materials and what are they used for? What are their advantages and disadvantages over traditional counterparts?
I ended up reading a lot about acoustic dampening and how fungal materials are used for it. So the most established fungal material is the mycelium-based composite. It is produced when the vegetative root network of fungi (mycelium), is grown on agricultural or waste plant substrates and then dried to stop growth. The resulting material has the potential to replace petrochemical-based materials within architectural systems and can serve as a biodegradable(!!!) alternative to synthetic sound-absorbing materials.
Based on this paper https://pmc.ncbi.nlm.nih.gov/articles/PMC9394424/ , the acoustic performance is genuinely competitive. Mycelium-based composites cultivated on shredded and fine cardboard can both be considered sound-absorbing materials and have the potential to compete with the performance of synthetic sound absorbers as both sample groups outperformed a polypropylene acoustic panel at low frequencies (125 Hz, 250 Hz, 500 Hz). An earlier study found that even the lowest-performing substrate, 100% cotton bur fibre, still yielded higher than 70% acoustic absorption at 1000 Hz.
Advantages over traditional counterparts like fibreglass or stone wool are primarily environmental. As for disadvantages, performance is variable and hard to control because mycelium growth is sensitive to humidity, temperature, and other things.
What might you want to genetically engineer fungi to do and why? What are the advantages of doing synthetic biology in fungi as opposed to bacteria?
I’d be so interested in researching further applications for acoustics. Making a speaker out of a part made out of fungi would be really interesting from a sound perspective. Like mycelium composites are already being used as acoustic panels because their fibrous, porous structure absorbs and diffuses sound well.
It’s so much easier to create a mater out of fungi. They are cheaper and easier to grow at scale. You can also also mold it, control its density, and at the end harvest a structured composite
Assignment Part 3: First DNA Twist Order
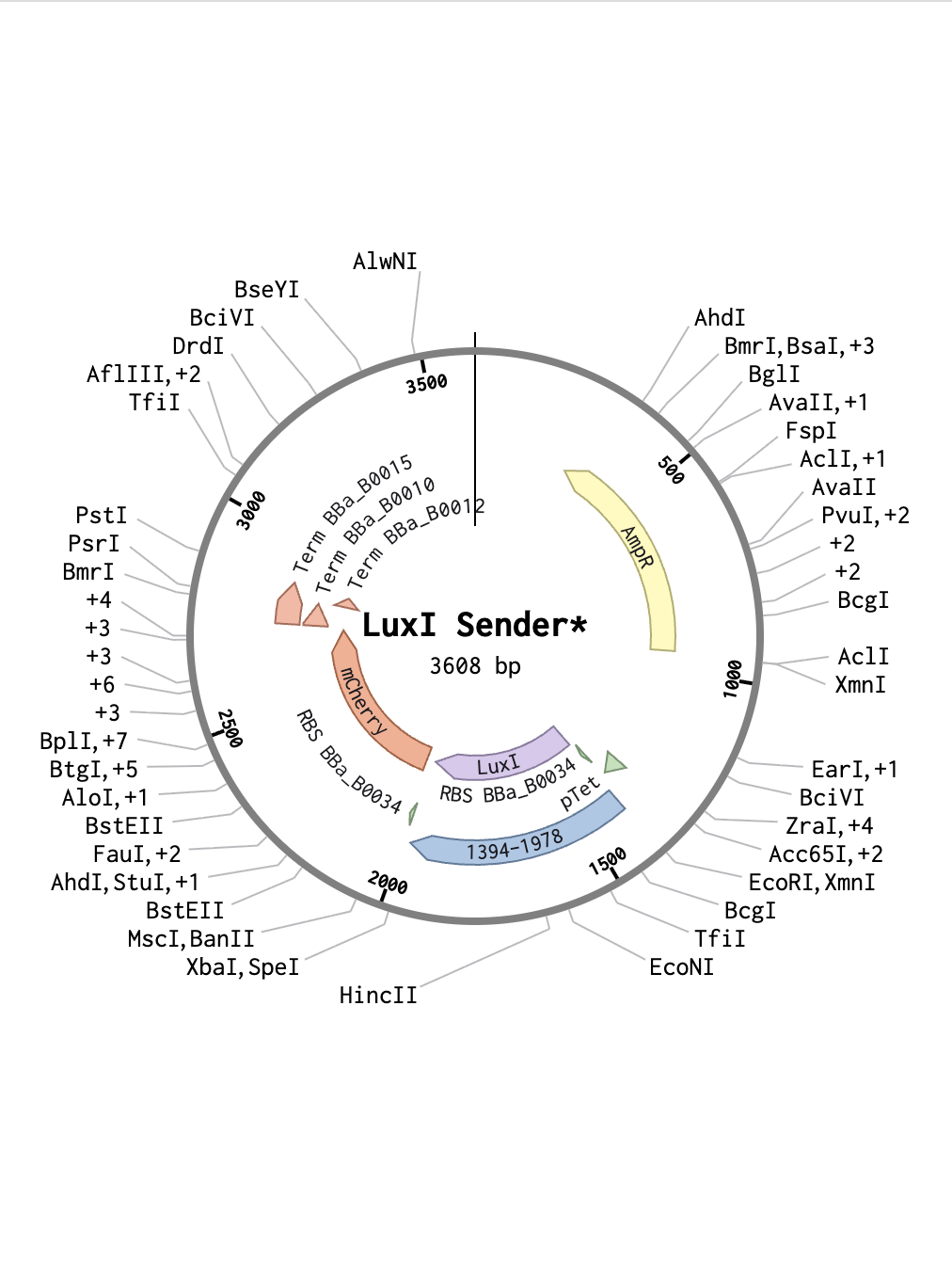
So, my order is the LuxI/LuxR sender-receiver circuit:
the LuxI expression cassette (constitutive promoter + LuxI + terminator) and the LuxR receiver cassette (LuxR + pLux promoter + GFP + terminator)
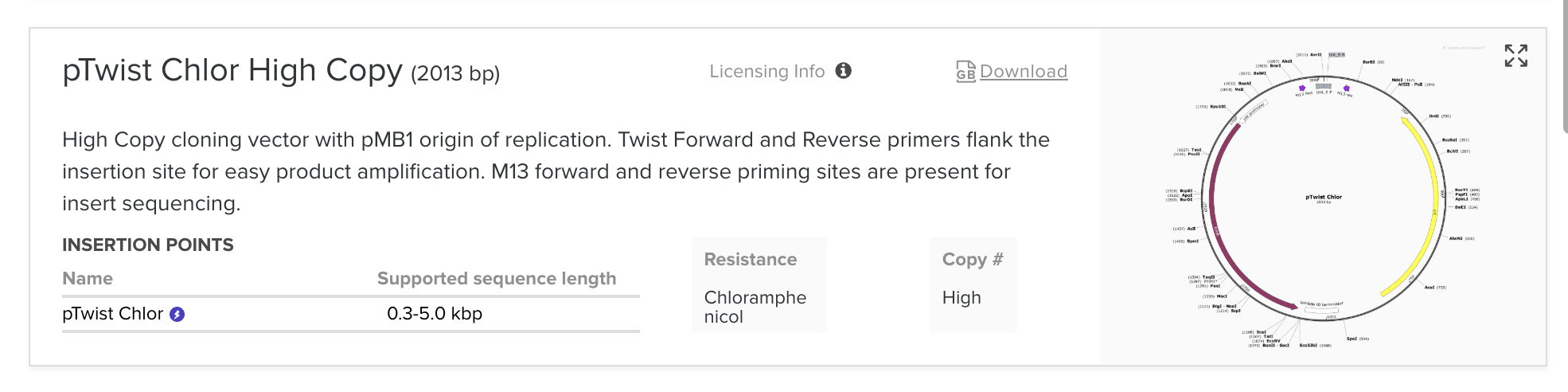
For a backbone vector, the construct will be synthesized in the pTwist Chlor High Copy backbone which is a high-copy pMB1-origin plasmid with chloramphenicol resistance
Homework Part A: General and Lecturer-Specific Questions
General homework questions
Explain the main advantages of cell-free protein synthesis over traditional in vivo methods, specifically in terms of flexibility and control over experimental variables. Name at least two cases where cell-free expression is more beneficial than cell production.
As the reaction happens outside living cells, you have much more flexibility and control over experimental variables!
To be more specific, the biggest difference is the promoter. In cell-free protein synthesis, a T7 promoter is often preferred because T7 RNA polymerase is readily added or already present in the extract, making transcription simple and highly controllable. And this is why we have a much more precise control over transcription This doesn’t happen with real bacteria, as gene expression is tied to cell growth phase, metabolism and others. That also means that prototyping is faster as you can propagate the plasmid in E. coli, then purify plasmid DNA, then add it to cell-free protein synthesis and be kinda done within so much faster
Two cases where cell-free expression is more beneficial than cell production:
unstable proteins degraded in vivo
toxic proteins, where something might kill bacteria before enough protein accumulates
or like if one needs to do any sort of rapid screening
Describe the main components of a cell-free expression system and explain the role of each component.
Cell Extract (Lysate). It provides the machinery for transcription/translation
Genetic Template (DNA or mRNA). Contains the gene encoding the target protein.
Energy Regeneration System. Sustain long-term protein synthesis through supplying ATP/GTP
Amino Acids and Building Blocks. Needed for polypeptide synthesis
Buffer and Salts. Stabilise the reaction environment and optimise enzyme function
and others
Why is energy provision regeneration critical in cell-free systems? Describe a method you could use to ensure continuous ATP supply in your cell-free experiment.
Transcription and translation consume ATP super fast -> ATP is quickly depleted. To avoid that a common method is adding PEP with pyruvate kinase (Calhoun and Swartz, 2007)
Compare prokaryotic versus eukaryotic cell-free expression systems. Choose a protein to produce in each system and explain why.
Prokaryotic cell-free systems - rapid, high-yield production of simple proteins
-> Green fluorescent protein (GFP) (small, soluble, no need for complicated glycosylation)
Eukaryotic systems - complex proteins requiring proper folding and post-translational modification
-> Erythropoietin (EPO) (requires specific disulfide bonds and glycosylation)
How would you design a cell-free experiment to optimize the expression of a membrane protein? Discuss the challenges and how you would address them in your setup.
To express a membrane protein, I would use a eukaryotic cell-free system with liposomes. Then I’d also include chaperones, and optimise reaction conditions to promote proper folding and membrane insertion while preventing aggregation.
Imagine you observe a low yield of your target protein in a cell-free system. Describe three possible reasons for this and suggest a troubleshooting strategy for each.
Low yield may result from ATP depletion (->add an energy regeneration system), protein misfolding (->include chaperones or membrane mimetics), or poor template quality(->would be solved by optimising template design and reaction conditions)
Homework question from Kate Adamala
Design an example of a useful synthetic minimal cell as follows:Pick a function and describe it.
For this mini project/ question, I’d like to explore how synthetic minimal cells for the wols of biocensors specifically, I’d like to look into the possibilities of heavy metal detection in water. It would be also interesting to explore what’s possible to be done after the detection as a form of capturing it
What would your synthetic cell do? What is the input and what is the output?
The synthetic cell would function as a heavy metal detector targeting mercury (Hg²⁺) contamination in water. It will first sense dissolved Hg²⁺ through a metal-responsive transcription factor, then synthesise both a fluorescent reporter (so you can see the signal) and a metal-binding protein to physically capture the mercury.
Input Hg²⁺ ions in the surrounding aqueous environment
Output GFP fluorescence, which would act as a quantitative detection signal
Could this function be realized by cell-free Tx/Tl alone, without encapsulation?
No, as it would be ineffective
Could this function be realized by genetically modified natural cell?
Yes, it’s possible to use E.coli but that wouldn’t be safe for the environment.
Describe the desired outcome of your synthetic cell operation.
The desired outcome would be a real-time fluorescent detection of mercury contamination (+passive remediation!)
Design all components that would need to be part of your synthetic cell.
PURE system - E. coli Tx/Tl machinery
MerR + PmerT-DNA - Hg²⁺ sensor + promoter
GFP - fluorescent reporter
Metallothionein - Hg²⁺ binding protein
ATP regen (creatine-P / CK) - energy source
What would be the membrane made of?
DPPC (structural bilayer backbone), cholesterol (reduced passive permeability), DSPE-PEG2000PE (for stability in water), DPhPC (help with protein reconstitution)
What would you encapsulate inside? Enzymes, small molecules.
Genetic material: A linear DNA expression cassette encoding gfp and MT1 (human metallothionein-1) under a single MerR-regulated PmerT promoter — both genes transcribed as a bicistronic message driven by the same mercury-sensing switch.
Tx/Tl machinery: PURE system (PUREfrex 2.0 or similar), providing all ribosomes, elongation factors, tRNAs, aminoacyl-tRNA synthetases, and RNA polymerase needed for in-vesicle protein synthesis.
Pre-loaded proteins/small molecules:
MerR transcription factor (pre-expressed and loaded — it is the sensor that detects Hg²⁺ and activates PmerT)
Creatine phosphate + creatine kinase (ATP regeneration system to power the PURE system)
All 20 amino acids and NTP mix
RNase inhibitor (to protect mRNA during synthesis)
Which organism your Tx/Tl system will come from? Is bacterial OK, or do you need a mammalian system for some reason? (hint: for example, if you want to use small molecule modulated promoters, like Tet-ON, you need mammalian)
A bacterial PURE system is the right choice here because all genes are prokaryotic (merR, merB, gfp, MT1 with bacterial codon optimization),
How will your synthetic cell communicate with the environment? (hint: are substrates permeable? or do you need to express the membrane channel?)
Through MerB and MscL
Experimental detailsList all lipids and genes. (bonus: find the specific genes; for example, instead of just saying “small molecule membrane channel” pick the actual gene.)
Then test the same synthetic cells against Pb, Cd, Cu, Zn, and Fe at equivalent concentrations
No-MerR negative control (cells assembled without the MerR protein but with the PmerT-gfp cassette should be no flouresebce)
Environmental validation through spiked water sample test
Homework question from Peter Nguyen
Freeze-dried cell-free systems can be incorporated into all kinds of materials as biological sensors or as inducible enzymes to modify the material itself or the surrounding environment. Choose one application field — Architecture, Textiles/Fashion, or Robotics — and propose an application using cell-free systems that are functionally integrated into the material. Answer each of these key questions for your proposal pitch:Write a one-sentence summary pitch sentence describing your concept.
I’m also really interested in how acoustics work and operate. I know there’s been a lot of recent development with mycelium-based material research for speakers, but for this project, I’d like to look into wall panels, which you can find a lot in music venues. In most cases, such venues require a specific setup for the type of music that’s going to be played, and this would solve this issue. I imagine them being updated with using freeze-dried cell-free enzymes to modify material porosity/stiffness in response to sound frequency and humidity, optimising acoustics in real-time for different performances.
How will the idea work, in more detail? Write 3-4 sentences or more.
The panels contain freeze-dried cell-free systems with mechanosensitive promoters and enzymes that degrade polymers in the material matrix. When sound waves vibrate the material and ambient humidity activates the system -> the enzymes modify the panel’s density and porosity. High-frequency performances trigger different enzymatic pathways than bass-heavy music, creating frequency-specific acoustic reflection. The material could shift from absorptive (for loud rock) to reflective (for classical) over the course of hours.
What societal challenge or market need will this address?
Live music venues struggle with “one-size-fits-all” acoustics; a room great for orchestras sounds terrible for others. Acoustic treatment is expensive and static. This addresses the massive live music industry with adaptive infrastructure that reduces the need for costly manual reconfiguration.
How do you envision addressing the limitation of cell-free reactions (e.g., activation with water, stability, one-time use)?
One could use multiple “generations” of enzymes with different activation thresholds. Early activators work on first moisture exposure, but reserve populations activate only after pH changes from initial reactions, creating extended activity. Incorporate hygroscopic materials that capture atmospheric moisture in humid London venues to enable repeated activation cycles.
Homework question from Ally Huang
Provide background information that describes the space biology question or challenge you propose to address. Explain why this topic is significant for humanity, relevant for space exploration, and scientifically interesting. (Maximum 100 words)
When in space, astronauts lose quite a bit of their bone density 1-2%, which is the same thing as having osteoporosis on Earth for a year. Therefore, it’s important to understand how bone-building and bone-resorbing cells operate for long missions in space. There is a chance that cellular automata could have an answer for that. With CA, we could simulate spatial-temporal patterns of bone remodelling to predict how mechanical unloading disrupts the delicate balance between mineralisation and resorption. This research could inform is of possible countermeasures
Name the molecular or genetic target that you propose to study. Examples of molecular targets include individual genes and proteins, DNA and RNA sequences, or broader -omics approaches. (Maximum 30 words)
The RANK/RANKL/OPG signalling pathway regulating osteoblast-osteoclast communication (RUNX2, osteocalcin, collagen type I).
Describe how your molecular or genetic target relates to the space biology question or challenge your proposal addresses. (Maximum 100 words)
The RANK/RANKL/OPG pathway controls bone remodelling balance. In microgravity, mechanical unloading downregulates osteoblast activity (reduced RUNX2 expression) while RANKL signalling increases osteoclast formation. Cellular automata can model how local cell-cell signalling rules—based on real gene expression data from spaceflight experiments—produce emergent bone microarchitecture patterns.
Clearly state your hypothesis or research goal and explain the reasoning behind it. (Maximum 150 words)
Altered RANK/RANKL/OPG expression ratios in microgravity create spatial signalling gradients that, when modelled using cellular automata rules, will reproduce bone loss patterns observed in astronaut imaging studies.
Traditional biomechanical models miss the discrete cellular interactions driving remodelling. Cellular automata excel at capturing emergent behaviour from simple local rules.
Outline your experimental plan - identify the sample(s) you will test in your experiment, including any necessary controls, the type of data or measurements that will be collected, etc. (Maximum 100 words)
Samples: Analyse existing NASA GeneLab datasets from microgravity analogue rodent hindlimb unloading experiments, measuring RANK/RANKL/OPG expression in bone tissue at multiple timepoints.
Controls: Earth-gravity parameter sets; randomised signalling gradients.
Data collected: Bone volume fraction, trabecular thickness, connectivity metrics from CA output; compare against μCT imaging data from actual experiments.
Calhoun, K.A. and Swartz, J.R. (2007). Energy Systems for ATP Regeneration in Cell-Free Protein Synthesis Reactions. In Vitro Transcription and Translation Protocols, pp.3–17. doi:https://doi.org/10.1007/978-1-59745-388-2_1.
Please identify at least one (ideally many) aspect(s) of your project that you will measure. It could be the mass or sequence of a protein, the presence, absence, or quantity of a biomarker, etc.
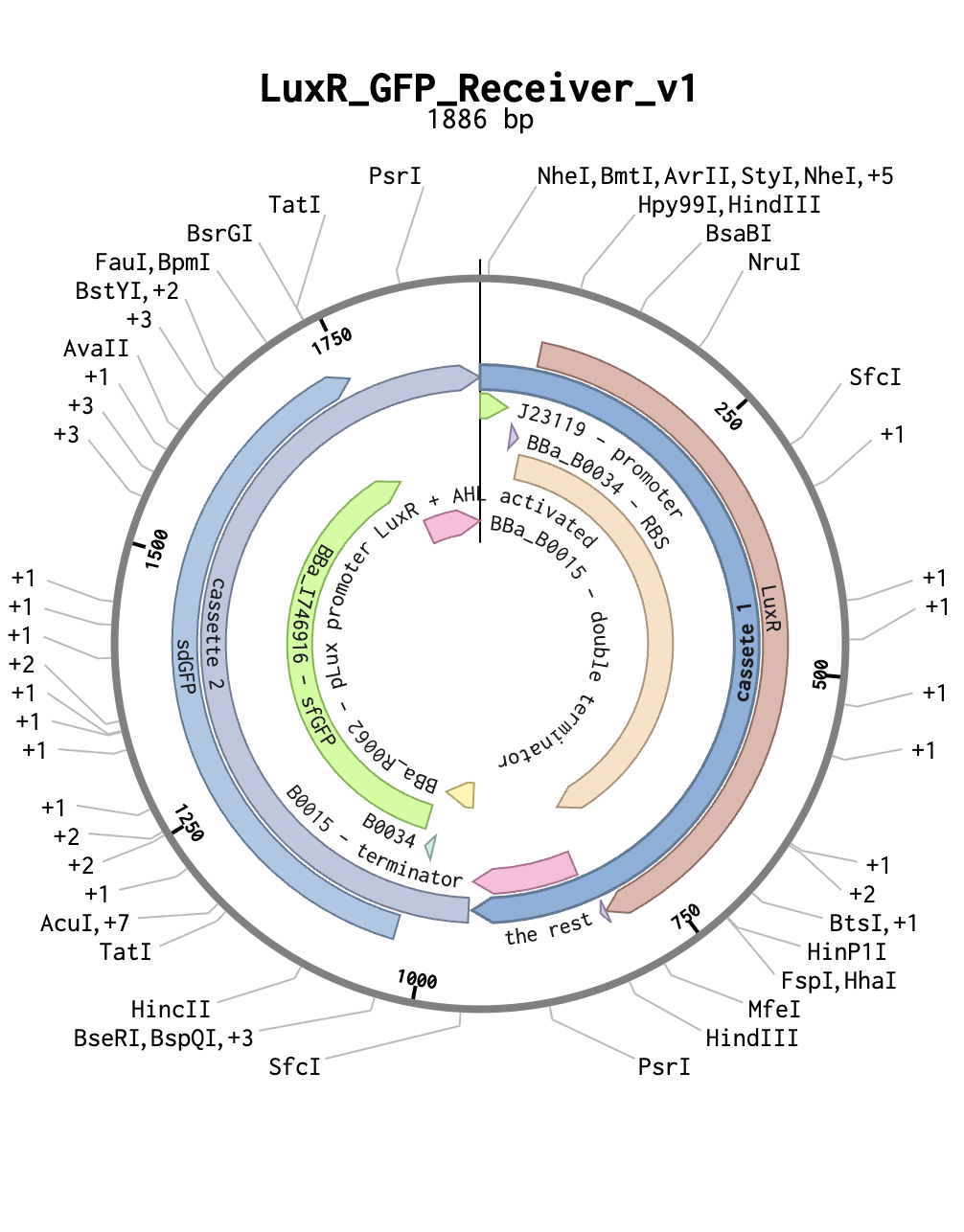
molecular validation (to confirm whether the Twist plasmids are correct and transformed properly) through the presence of the sender and receiver plasmid, correct insert size and sequence identity, then successful bacterial transformation
functional signalling validation / AHL sensing ability through receiver activation threshold, GFP expression strength, dose-response curve, signal saturation
spatial pattern formation to measure whether LuxI actually produces AHL through sender-generated AHL activity, effective AHL equivalent concentration, and hopefully signalling consistency between cultures
ML/CAD dataset features through OT-2 plate maps, fluorescence reads and metadata logs
Please describe all of the elements you would like to measure, and furthermore, describe how you will perform these measurements.
The project will measure genetic construct integrity, quorum-sensing response strength, sender-derived signalling output, and spatial cellular automata pattern formation
What are the technologies you will use (e.g., gel electrophoresis, DNA sequencing, mass spectrometry, etc.)? Describe in detail.
Plasmid integrity will be measured using agarose gel electrophoresis to confirm the expected insert sizes of the LuxI sender and LuxR-sfGFP receiver constructs.
Functional LuxR receiver performance will be quantified by exposing transformed receiver E. coli to a defined dilution series of 3-oxo-C6-HSL and measuring GFP fluorescence over time using a handmade(! to plan) fluorescence plate reader
LuxI sender activity will be measured indirectly by collecting cell-free sender supernatant and applying it to the receiver strain, using the previously generated AHL-GFP calibration curve to understand the effective signalling molecule concentration.
Spatial pattern formation relevant to biological cellular automata will be measured using Opentrons (OT-2) automated plate layouts combined with fluorescence time-lapse imaging. Metrics including activation radius, neighbourhood response, and endpoint fluorescence distribution will then be extracted and used as training data for ML-enhanced CAD prediction in Aim 2.
3. Based on the LC-MS data for the Peptide Map data generated in lab (please use Figure 5a as a reference) how many chromatographic peaks do you see in the eGFP peptide map between 0.5 and 6 minutes? You may count all peaks that are >10% relative abundance.
-5.
4. Assuming all the peaks are peptides, does the number of peaks match the number of peptides predicted from question 2 above? Are there more peaks in the chromatogram or fewer?
Observed LC peaks = ~19
Observed peaks are about the same as predicted
5. Identify the mass-to-charge of the peptide shown in Figure 5b. What is the charge of the most abundant charge state of the peptide (use the separation of the isotopes to determine the charge state). Calculate the mass of the singly charged form of the peptide based on its m/z and z
Main peptide peak = 525.76712
Spacing = 0.5 m/z, => most abundant charge state is 2+. The singly charged mass is 1050.52 Da
Charge = +2
[
M
+
H
]
+
[M+H]
+
= 1050.52145 Da
[
M
+
H
]
+
[M+H]
+
= 1050.52438 Da
Identified peptide: FEGDTLVNR
the error is about 2.8 ppm
6. Identify the peptide from PeptideMass
FEGDTLVNR has a theoretical monoisotopic mass of 1050.52143 Da
7. 88 is the percentage of the sequence that is confirmed by peptide mapping
Waters Part IV — Oligomers
7FU Decamer = 3.40 MDa
8FU Didecamer = 8 MDa
8FU 3-Decamer = 12 MDa
8FU 4-Decamer = 16 MDa
Waters Part V — Did I make GFP?
Yes!
Theoretical
Observed/Measured on Intact LC-MS
PPM Mass Error
comparing with
Molecular Weight (kDa)
26,905 Da
26,903 Da
0.7 ppm
26.90
Week 11 HW: Bioproduction & Cloud Labs
Part A: The 1,536 Pixel Artwork Canvas | Collective Artwork
At this point, I’m not entirely sure what I’ve contributed to, as the artwork changed quite a lot. I’ve added a few yellow and green pixels when we first got access to the board, but as time went it changed so much that I don’t think any of them were left in the same spots. I did like the collaborative aspect of it, but going forward, I kind of wish everyone could contribute to just one/two pixels that couldn’t be overwritten. That would make the pointing-out aspect of it so much easier
Part B: Cell-Free Protein Synthesis | Cell-Free Reagents
E. coli Lysate
Provides the cellular machinery for transcription and translation, including ribosomes, tRNAs, translation factors, and other essential proteins.
Salts/Buffer
Potassium Glutamate
Acts as the primary osmolyte to maintain ionic strength and pH stability in the reaction mixture.
HEPES-KOH pH 7.5
Maintains optimal pH for enzyme activity and protein synthesis throughout the reaction.
Magnesium Glutamate
Provides essential Mg²⁺ cofactor. Responsible for ribosome function, translation factors, and RNA stability.
Potassium phosphate monobasic & dibasic
Work together as a phosphate buffer system. Maintains pH stability and provide inorganic phosphate for nucleotide synthesis.
Energy/Nucleotide System
Ribose:
A pentose sugar that serves as the sugar backbone for nucleotide synthesis
Glucose:
Provides metabolic energy and carbon source
AMP, CMP, GMP, UMP
Nucleoside monophosphates serve as building blocks for RNA synthesis during transcription. They are recycled during the reaction
Guanine
A purine base that can be salvaged and converted into GMP. Gives an alternative route for guanine nucleotide synthesis when needed
Translation Mix (Amino Acids)
17 Amino Acid Mix
Provides the standard amino acids (minus Tyr and Cys, which are listed separately) needed for protein synthesis during translation(!)
Tyrosine & Cysteine
Amino acids requiring special handling (Tyr for fluorescent protein variants, Cys to prevent oxidation or for selenomethionine incorporation). They are also needed for protein synthesis during translation though
Additives
Nicotinamide: Acts as a precursor for NAD⁺/NADH. Needed for essential cofactors for energy metabolism within the cell-free system.
Backfill
Nuclease Free Water: Dissolves all components and serves as the reaction medium. The goal of nuclease-free formulation is to prevent degradation of RNA transcripts.
Main Differences:
1-hour PEP-NTP vs. 20-hour NMP-Ribose-Glucose Master Mixes
The 1-hour optimised PEP-NTP master mix uses PEP and NTPs, which provide rapid, readily available energy and nucleotides for quick transcription/translation reactions with high yields but shorter reaction windows.
In contrast, the 20-hour NMP-Ribose-Glucose master mix uses NMPs + glucose and ribose, for a more sustainable, self-regenerating system where nucleotides and energy are generated on-demand through metabolic pathways - > reaction continues for much longer periods BUT! longer reaction times to reach similar protein yields.
The longer format is designed for extended protein synthesis reactions, while the PEP-NTP system is optimised for speed
Part C: Planning the Global Experiment | Cell-Free Master Mix Design
Part 1: Biophysical/Functional Properties of Each Fluorescent Protein
sfGFP can fold in under 10 minutes, making it one of the fastest-maturing green fluorescent proteins.
mRFP1 is described as a somewhat slowly-maturing monomer with low acid sensitivity.
mKO2 is an orange fluorescent protein with moderate acid sensitivity
In mTurquoise2, the reaction with oxygen is a rate-determining step
mScarlet is a red fluorescent protein with moderate acid sensitivity, a fluorescence lifetime of 3.9 ns (which the highest value recorded to date for other red mRFPs) also generally highest calculated brightness in the mRFP spectral class.
Electra2 is a flavin-based fluorescent protein. fluorescence intensity is independent of molecular oxygen.
Part 2: Hypothesis for Optimization
So, for my hypothesis, I’d like to check whether fluorescence in sfGFP increases most when glucose and phosphate are added together, suggesting energy regeneration (not just translation) can be the limiting factor over long incubations. My guess here is that increasing magnesium concentration will enhance sfGFP fluorescence up to an optimal point (well 1), while simultaneous increases in glucose and phosphate (well 2) will further boost fluorescence over 36 hours through improving sustained energy regeneration. I also added just an increased glucose well (well 3) as another control to further support this hypothesis. This is based on research done for CFPS studies. Especially through Silverman et al. (2026) where they performed multi-dimensional optimization and emphasized Mg²⁺ and phosphate as key variables. They also showed that replacing GMP with guanine+ribose works (so transcription will succeed in all our conditions even though GMP is omitted). Then, Xu et al. (2026) found that single-component tweaks often had no effect, but certain pairs (e.g. sugar+phosphate) did, guiding us to test glucose+phosphate together
For this lab we first practised pouring the black agar plates and learnt about how to grow bacteria
then on a separate day we tested the automation on OT-2 and made our images
Process pictures from the microfluidics lab. I wanted to make something I could potentially use for my project, so in this, each chamber represents a controlled signalling condition that would allow parallel evaluation of threshold-based cellular responses. This is a strategy to enable experimental testing and evaluation of local interaction rules that underpin cellular automata behaviour in engineered biological systems, but in short, and more factually, it’s a 2-input microfluidic gradient generator with parallel observation chambers and controlled outflow
For this lab, we practised pipetting and also 3D printed our proteins of choice
pipetting
3D printing of our proteins of choice
Week 2 Lab: DNA Gel Art
DNA Gel Art process pictures
Week 3 Lab: Lab Automation
For this lab we first practised pouring the black agar plates and learnt about how to grow bacteria
then on a separate day we tested the automation on OT-2 and made our images
final result!! (see code in hw week 3)
Week 4 Lab: Protein Design Part I
Contained within the homework
Week 5 Lab: Protein Design Part II
Contained within the homework
Week 7 Lab: Microfluidics Lab
Process pictures from the microfluidics lab. I wanted to make something I could potentially use for my project, so in this, each chamber represents a controlled signalling condition that would allow parallel evaluation of threshold-based cellular responses. This is a strategy to enable experimental testing and evaluation of local interaction rules that underpin cellular automata behaviour in engineered biological systems, but in short, and more factually, it’s a 2-input microfluidic gradient generator with parallel observation chambers and controlled outflow
CAD platform for programmable living CA SECTION 1: ABSTRACT Biology is becoming programmable, but it lacks much of the design infrastructure for exploring spatial systems. So, I’d like to construct a spatial design tool for engineering microbial consortia that exhibit programmable cellular automata behaviour by building a simulation engine that translates CA rules into genetic circuit specification that would first be validated in a wet-lab environment via Opentrons. The central hypothesis is that bacterial LuxI/LuxR quorum-sensing circuits can implement the neighbour-counting and state-switching logic of classical cellular automata, and that this mapping is regular enough to be captured by a simulation engine and ultimately predicted by machine learning models.
Biology is becoming programmable, but it lacks much of the design infrastructure for exploring spatial systems. So, I’d like to construct a spatial design tool for engineering microbial consortia that exhibit programmable cellular automata behaviour by building a simulation engine that translates CA rules into genetic circuit specification that would first be validated in a wet-lab environment via Opentrons. The central hypothesis is that bacterial LuxI/LuxR quorum-sensing circuits can implement the neighbour-counting and state-switching logic of classical cellular automata, and that this mapping is regular enough to be captured by a simulation engine and ultimately predicted by machine learning models.
SECTION 2: PROJECT AIMS
Aim 1 — Build a single sender/receiver CA unit
To validate biological cellular automata pattern formation and develop an initial CAD platform prototype by using LuxI/LuxR quorum sensing circuits, Opentrons OT-2 automated liquid handling, and fluorescence time-lapse imaging.
Sender cells express LuxI → produce 3OC6-HSL (AHL signal)
Receiver cells express LuxR + GFP reporter → fluoresce above AHL threshold
Goal: demonstrate density-dependent state switching (the CA rule in biology)
Aim 2 - Build ML-enhanced CAD tool for circuit prediction
To expand the CAD platform into a production-ready design tool with ML-enhanced prediction by collecting sufficient experimental datasets to train ML model to predict biological implementation success and automate genetic circuit selection from high-level rules with purpose of integration into design-build-test-learn cycles
To establish this platform as the foundational design infrastructure for spatial synthetic biology, democratising access to programmable living systems (similar to how Arduino democratised embedded electronics), to allow the researchers across disciplines (biocomputing, materials science and others) to rapidly design, simulate, and deploy spatial genetic programs without expert knowledge of quorum sensing, reaction-diffusion mathematics, or genetic circuit engineering.
SECTION 3: BACKGROUND
1. Peer-reviewed research citations relevant to research
Synthetic biology has traditionally focused on engineering genetic circuits inside individual cells. However, there are still too few tools for designing multicellular spatial systems where cells interact through signalling. One important mechanism used in these systems is quorum sensing, which is where bacteria communicate by releasing and detecting small molecules called autoinducers (Windsor, 2020). This way, in the LuxI/LuxR quorum-sensing system, LuxI produces an AHL signalling molecule, while LuxR detects AHL and activates gene expression once a concentration threshold is reached. That creates a density-dependent state change that can be used to coordinate behaviour across populations of cells
Recent research has shown that quorum sensing can support collective spatial behaviour in bacterial populations. In “Quorum sensing as a mechanism to harness the wisdom of the crowds” (Moreno-Gámez, Hochberg and van Doorn, 2023), researchers demonstrated that quorum sensing allows populations to behave as distributed systems rather than isolated cells, particularly in spatially structured environments. Their work also used two-dimensional diffusion simulations, showing how neighbouring cells influence each other through signalling gradients. This is highly relevant to my project because it supports the idea that local bacterial interactions can approximate cellular automata-like behaviours.
Another relevant study called “Probing patterning in microbial consortia with a cellular automaton for spatial organisation”(Sankalpa Venkatraghavan, Sathvik Anantakrishnan and Raman, 2022). There, the researchers used computational cellular automata to simulate how local interaction rules produce larger emergent patterns across microbial populations. Their work highlights the usefulness of cellular automata as a framework for understanding multicellular biological pattern formation. BUT the study was primarily computational and never ended up connecting the simulations directly to experimentally deployable genetic circuits or automated wet-lab workflows.
Overall, these studies showcase a growing interest in spatial synthetic biology and microbial pattern formation, but there seems to remain a major gap between computational spatial models and experimentally validated biological design tools. My project addresses this by combining quorum-sensing genetic circuits, computational simulation, and automated experimental validation using Opentrons workflows
2. Innovation
This project is innovative because it applies concepts from cellular automata and computational design to spatial synthetic biology using quorum-sensing genetic circuits. While quorum sensing and microbial pattern formation have been studied before, most existing work focuses either on isolated biological experiments or purely computational simulations. My project combines these by proposing a CAD platform that translates high-level spatial behavioural rules into experimentally testable genetic circuit designs. The project also introduces and develops an innovative approach to an integrated workflow combining computational simulation, automated liquid handling with Opentrons, and fluorescence-based validation, helping bridge the gap between biological modelling and real-world experimental implementation.
Besides, it is also treating spatial synthetic biology as an engineering design problem rather than only a biological research problem. Current synthetic biology tools are largely designed for engineering single-cell circuits, but there is very limited infrastructure for designing multicellular spatial systems. By exploring whether quorum sensing can approximate cellular automata-like local state transitions, this project challenges the assumption that biological systems are too noisy or continuous for programmable spatial computation. The long-term vision expands the boundaries of synthetic biology by exploring how programmable living systems could eventually become more and more accessible through higher-level design tools and automation workflows.
3. Impact & significance
This project addresses the gaps in accessible design infrastructure for spatial synthetic biology. Synthetic biology is expensive, and there are currently very few tools that allow researchers to easily design, simulate, and experimentally test multicellular spatial behaviours accurately in vitro. This creates a major barrier for researchers outside of highly specialised synthetic biology laboratories. By developing a CAD-style workflow for spatial genetic systems, this project aims to make the design of programmable living systems more systematic and accessible by reducing experimental iteration costs and enabling virtual testing before wet-lab implementation.
For broader fields, the project is important because spatial biological computation could eventually contribute to many areas of science and engineering, including smart biomaterials, biosensing, biocomputing, tissue engineering, and environmental monitoring. Understanding how cells coordinate their behaviour across space could also improve our ability to engineer microbial consortia for medical or industrial applications.
If successful, this work could help shift synthetic biology toward more programmable, automated, and design-driven workflows. Similar to how AI-assisted tools have accelerated protein structure prediction and biological design, rather than manually engineering individual circuits, researchers could eventually specify desired behaviours at a higher level and allow software tools to generate, simulate, and optimise the underlying biological implementations, for example. The goal is to accelerate experimentation, improve reproducibility, and lower the barrier to entry for interdisciplinary researchers working with programmable biological systems.
4. Bioethical considerations
As programmable biological design tools become more accessible, it is important to ensure that they are developed responsibly and with biosafety in mind. One major governance goal of this project is ensuring biosafety and reducing the risk of harmful or poorly understood biological behaviour. This includes improving the prediction of biological system behaviour through computational simulation while also ensuring that simulations do not create false confidence in experimental outcomes. To support this, the platform should encourage experimental validation alongside computational modelling rather than relying solely on in silico predictions. Another important sub-goal is embedding biosafety directly into the software itself through built-in safety protocols, simulation warnings, and educational prompts within the user interface. Training and documentation should also be provided to help users understand both the capabilities and limitations of programmable biological systems.
A second governance goal is promoting transparency and responsible use while preventing misuse. Although automation and AI-assisted design can accelerate experimentation, the platform should maintain human accountability over final design decisions rather than becoming fully autonomous. Responsible-use guidelines and community standards could help reduce dual-use risks and encourage ethical applications of the technology.
Ideally, the platform would also encourage socially beneficial applications in areas such as environmental sensing, education, healthcare, and sustainable materials. Open scientific collaboration and shared biosafety standards may also help guide the development of spatial synthetic biology in a way that balances innovation with public responsibility.
One challenge is that overly restrictive governance could slow innovation or make the technology inaccessible to smaller research groups, while insufficient oversight could increase misuse risks. In addition, biosafety simulations may never perfectly predict real biological behaviour because living systems are inherently noisy and difficult to model. For this reason, the project should emphasize transparency about uncertainty, continuous experimental validation, and iterative safety review rather than assuming computational prediction alone guarantees safety.
SECTION 4: EXPERIMENTAL DESIGN/ PROTOCOL
1. Experimental plan
DAY 0 (Prep stocks + plates)
use:
LB broth: 100 mL
agar plates: 4
chloramphenicol: 100 µL stock used
DMSO: 100 µL
AHL: one aliquot
PBS: none yet
to do:
pour 4 LB chloramphenicol agar plates
make 100 mL LB + chloramphenicol
prepare 1 mL chloramphenicol stock
dissolve AHL to 10 mM in 100 µL DMSO
label OT-2 plates
DAY 1 — Transform sender + receiver
use
competent cells: 2 × 50 µL
LB recovery: 2 mL
plates: 2
chloramphenicol plates from Day 0
use
glycerol: 2 mL
black plate: 1
receiver culture: 10 mL
PBS: 10 mL
AHL stock: 10 µL
DMSO: already made stock
do
freezer stocks
500 µL culture + 500 µL 50% glycerol
sender + receiver
OT-2 AHL curve
Use 1 full 96-well plate
Receiver in all wells.
DAY 4 — Sender overnight culture
use
LB broth: 10 mL
chloramphenicol: 10 µL
do
Grow sender:
10 mL LB + chlor
for supernatant assay.
DAY 5 — Sender → receiver assay
use
black plate: 1
sender supernatant: 5 mL
receiver culture: 10 mL
PBS: 10 mL
do
Spin sender.
Collect supernatant.
OT-2:
sender supernatant dilution
receiver in all wells
GFP time-lapse
DAY 6 — Checkerboard CA pattern
use
sender culture: 5 mL
receiver culture: 5 mL
PBS: 10 mL
optional fresh plate
do
Build first:
sender / receiver checkerboard
Use same plate if signal stable, or a fresh one.
2. Techniques relevant to the project
✅ Pipetting
✅ Lab Safety
✅ Bioethical Considerations
✅ DNA Construct Design
✅ Databases (e.g., GenBank, NCBI, Ensembl, and UCSC Genome Browser)
✅ Opentrons
✅ Creating Code for Laboratory Automation
✅ Using Liquid Handling Robots (e.g., Opentrons)
✅ Chassis Selection (e.g., Dh5alpha)
✅ Registry of Standard Biological Parts
✅ Plasmid Preparation
✅ Bacterial Culturing
✅ Quality Control/Analysis
✅ Bacterial Processing (e.g., Centrifugation, Lysis, DNA Purification)
✅ Creating Twist Order
1. Utilizing these techniques in the final project
DNA construct design is really important to my project because the quorum-sensing system depends on the design of the sender and receiver plasmids with very specific genetic functions. For this, I constructed two plasmids in Benchling where the sender will produce AHL through LuxI and the receiver expresses LuxR and GFP under the lux promoter, activating fluorescence only above an AHL threshold. I pasted (import was not working) standard biological parts from the iGEM Registry into Benchling, assembled both expression cassettes, then also checked cloning compatibility and restriction sites, and finally exported the sequences for Twist ordering. They will experimentally test whether quorum sensing can support local state-switching behaviours similar to cellular automata(CA) rules.
Opentrons automation is used in this project to support experimental validation and improve reproducibility across spatial signalling, so I could use the data again and again to do the machine learning. I will use the OT-2 to automate the AHL dose-response curve and checkerboard co-culture plating patterns in well plates. The aim is to measure the activation threshold, GFP activation over time, and also how signalling spreads spatially across the grid over 24 hours. In the longer-term vision of the project, the CAD platform would enable defining a spatial rule digitally and exporting genetic circuit designs and Opentrons protocols for experimental validation in the wet lab.
2. How To Grow (Almost) Anything Industry Council companies which could be associated with the project
Opentrons: OT-2 automates the co-culture and imaging workflow (Aim 1 validation)
Ginkgo Bioworks: I’m building a tool that can accelerate DBTL cycles
Basecamp Research: Trillion Gene Atlas could provide foundation-model-scale sequence data to improve circuit outcome prediction beyond lab-generated datasets
Asimov (Kernel): genetic circuit design automation overlaps directly with the CA to circuit translation engine
Twist Biosciences: DNA synthesis for LuxI/LuxR constructs
New England Biolabs: cloning reagents for construct assembly
Addgene: source and deposition of validated QS plasmid parts
Nuclera: accessible benchtop biofoundry that aligns with Aim 3 democratisation goal
SecureDNA: Safety features integration for an open-access spatial circuit design platform
Transfyr.ai: overlaps with the ML prediction layer in Aim 2
SECTION 5: Results & Quantitative Expectations
1. First Aim Validation
Currently waiting for the Twist order
1. Validation Focus:
I was planning on going further with this and testing of the expression of the constructs, but we haven’t received our DNAs, so all my validation data stayed at the digital stage. So, instead, I stopped at completing the computational design of both expression cassettes, from part selection through submission-ready sequences. This constitutes a design validation confirming that the sequences are correctly assembled
Exported both sequences as FASTA. Verified final lengths: Sender = 781 Receiver = 1,886 bp
Submitted sequences to the SecureDNA screening tool (securedna.org) to verify no biosecurity-flagged sequences are present (both passed)
Uploaded FASTA files to Twist TwistGene ordering portal added all the details
3. Synthetic biology techniques utilized in validating this aspect of your final project
DNA construct design for assembling the sender and receiver quorum-sensing plasmids in Benchling using iGEM standardised biological parts from the iGEM Registry + Databases, such as the iGEM Registry and Benchling sequence libraries, were used to import promoters, ribosome binding sites, and terminators for construction.
The project also involved creating a Twist order for further experimental implementation. Although the validation bit had not yet started, the constructs were designed and prepared for purposes of bacterial transformation, Opentrons workflows, and spatial signalling experiments described in the experimental plan.
4. Related data
At the current stage, validation data consists of the completed sender and receiver construct designs, sequence verification results, no errors when checking through TWIST, and successful biosafety screening outputs.
The sender construct is at 781 bp, and the receiver construct is at 1886 bp prior to synthesising
The expected datasets from the experimental part include:
spatial fluorescence heatmaps showing signal diffusion across checkerboard co-cultures.
My expectation is that the receiver cells remain OFF below a found threshold AHL concentration and activate GFP expression once the local signalling concentrations become high enough
2. Challenges Encountered Whilst Validating
The main challenge is that the physical DNA constructs had not yet arrived from Twist Bioscience. That limits the possibility of validation and getting to the computational and sequence-design stages. As a result, experimental testing of GFP expression, quorum-sensing activation, and spatial signalling behaviour could not yet be performed.
Then the assembly itself proved to be quite tricky. As this was my first time making such designs from scratch scartch I had some troubles working with the spacers. This required additional sequence checking through a range of readings.
Moreno-Gámez, S., Hochberg, M.E. and van Doorn, G.S. (2023). Quorum sensing as a mechanism to harness the wisdom of the crowds. Nature Communications, [online] 14(1), p.3415. doi:https://doi.org/10.1038/s41467-023-37950-7.
Sankalpa Venkatraghavan, Sathvik Anantakrishnan and Raman, K. (2022). Probing patterning in microbial consortia with a cellular automaton for spatial organisation. Scientific Reports, 12(1), pp.17159–17159. doi:https://doi.org/10.1038/s41598-022-20705-7.