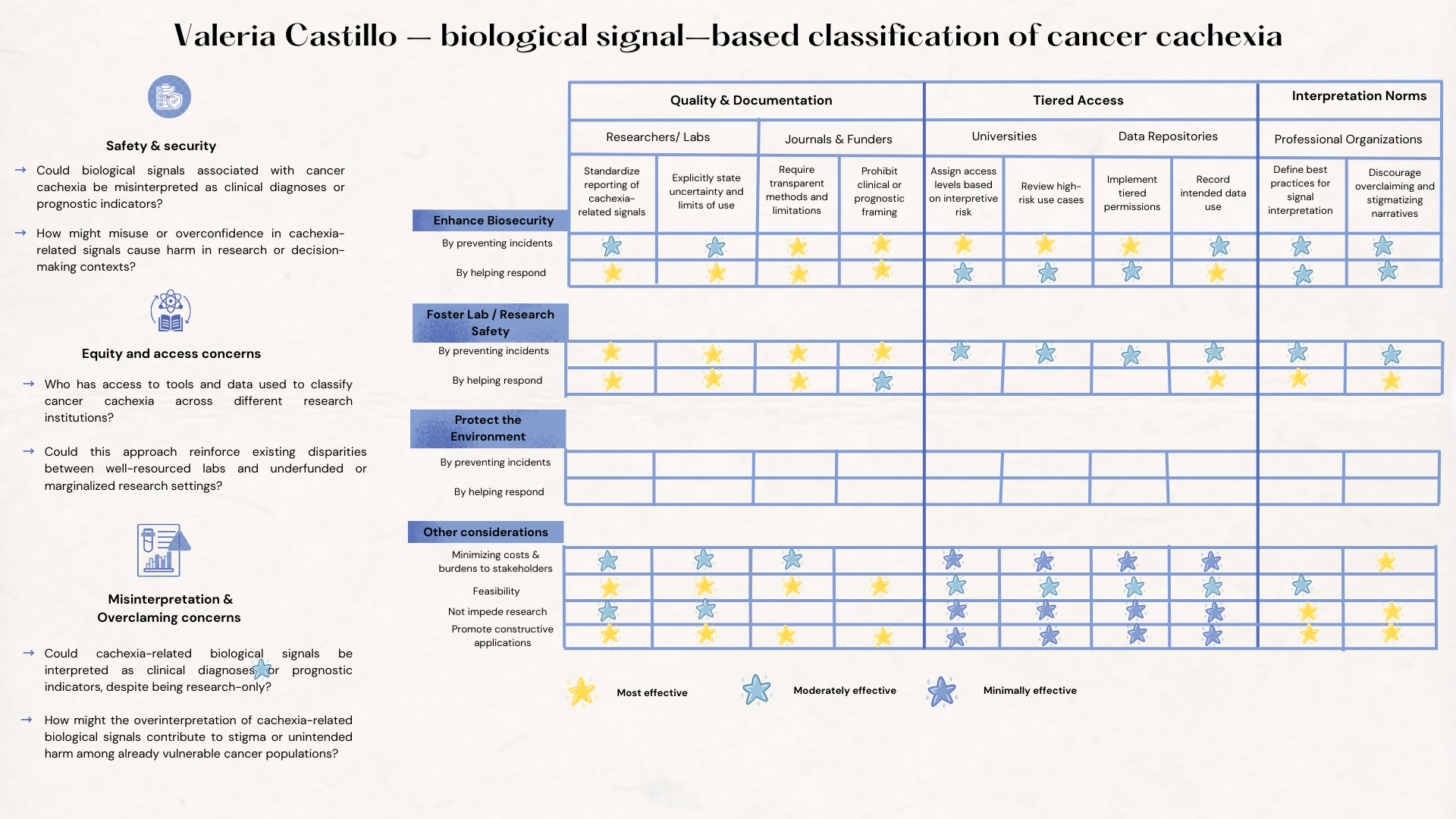
Biomedical Engineering student with experience in quantitative analysis, computational modeling, and technical documentation. Interested in research-oriented and interdisciplinary work, with a strong focus on applying engineering principles to biomedical and real-world challenges.
Homework Questions from Professor Jacobson: Nature’s machinery for copying DNA is called polymerase. What is the error rate of polymerase? How does this compare to the length of the human genome. How does biology deal with that discrepancy?
How many different ways are there to code (DNA nucleotide code) for an average human protein? In practice what are some of the reasons that all of these different codes don’t work to code for the protein of interest?
My homework Part 3:DNA Desing Challenge 3.1 Choose your protein Protein chosen: Human Interleukin-6 (IL-6)
Why I chose it: Because it is a clinically relevant inflammatory cytokine involved in immune signaling and cancer-associated systemic inflammation. As a biomedical engineering student, I am particularly interested in measurable biological signals that can be incorporated into predictive models and biomarker-based classification systems. IL-6 represents a translational protein that bridges molecular biology with clinical decision support and quantitative biomedical analysis.
Part A: Conceptual Questions How many molecules of amino acids do you take with a piece of 500 grams of meat? (on average an amino acid is ~100 Daltons)
Subsections of Homework
Week 1 HW: Principles and Practices
Homework Questions from Professor Jacobson:
Nature’s machinery for copying DNA is called polymerase. What is the error rate of polymerase? How does this compare to the length of the human genome. How does biology deal with that discrepancy?
How many different ways are there to code (DNA nucleotide code) for an average human protein? In practice what are some of the reasons that all of these different codes don’t work to code for the protein of interest?
Homework Questions from Dr. LeProust:
What’s the most commonly used method for oligo synthesis currently?
Why is it difficult to make oligos longer than 200nt via direct synthesis?
Why can’t you make a 2000bp gene via direct oligo synthesis?
Homework Question from George Church:
[Using Google & Prof. Church’s slide #4] What are the 10 essential amino acids in all animals and how does this affect your view of the “Lysine Contingency”?
[Given slides #2 & 4 (AA:NA and NA:NA codes)] What code would you suggest for AA:AA interactions?
Why I chose it:
Because it is a clinically relevant inflammatory cytokine involved in immune signaling and cancer-associated systemic inflammation. As a biomedical engineering student, I am particularly interested in measurable biological signals that can be incorporated into predictive models and biomarker-based classification systems. IL-6 represents a translational protein that bridges molecular biology with clinical decision support and quantitative biomedical analysis.
Protein sequence (FASTA format, obtained from UniProt):
Using the NCBI RefSeq database (NM_000600.5), the coding DNA sequence (CDS) corresponding to the human IL-6 protein was identified. The coding region spans nucleotides 64–702 of the IL6 transcript variant 1 and encodes the IL-6 precursor protein.
Codon optimization is necessary because different organisms prefer certain synonymous codons over others to encode the same amino acid. Adjusting codon usage improves translation efficiency and protein expression in the selected host organism without changing the amino acid sequence.
The IL-6 coding sequence was optimized for expression in Escherichia coli, a commonly used bacterial host for recombinant protein production due to its rapid growth and ease of genetic manipulation.
IL-6 DNA sequence with codon optimization (E. coli):
The optimized IL-6 coding sequence can be synthesized and cloned into an expression vector for recombinant protein production. One common approach is cell-dependent expression using Escherichia coli as a host organism. The DNA sequence would be inserted into a plasmid under the control of a bacterial promoter (such as T7). After transformation into E. coli, the DNA is transcribed into mRNA by bacterial RNA polymerase and then translated by ribosomes into the IL-6 protein.
During transcription, the DNA template strand is used to generate complementary mRNA, where thymine (T) is replaced by uracil (U). During translation, ribosomes read the mRNA in codons (sets of three nucleotides), each encoding one amino acid, resulting in synthesis of the IL-6 polypeptide chain.
Alternatively, a cell-free expression system could be used, where purified transcription and translation machinery produce the protein in vitro without living cells.
Part 4:Prepare a Twist DNA Synthesis Order
4.1
Part 5:DNA Read/Write/Edit
5.1 DNA Read
What DNA would you want to sequence and why?
I would want to sequence circulating tumor DNA (ctDNA) obtained from liquid biopsy samples for early cancer detection and monitoring of minimal residual disease (MRD).
Tumor cells continuously release small fragments of DNA into the bloodstream through apoptosis and necrosis. These circulating fragments contain tumor-specific genetic alterations, including point mutations, insertions, deletions, and copy number variations. By sequencing ctDNA, it is possible to detect these alterations at very low variant allele frequencies (VAF), enabling highly sensitive identification of residual disease or early relapse before clinical symptoms appear.
Sequencing ctDNA represents a powerful non-invasive approach to precision oncology, allowing real-time monitoring of tumor evolution, treatment response, and emerging resistance mutations. This strategy improves patient management by supporting earlier therapeutic interventions and more personalized treatment decisions.
In lecture, a variety of sequencing technologies were mentioned. What technology or technologies would you use to perform sequencing on your DNA and why?
I would use Next-Generation Sequencing (NGS) with hybrid-capture target enrichment to sequence circulating tumor DNA (ctDNA), because this method enables ultra-deep sequencing of specific cancer-associated genes. Since ctDNA is present at very low concentrations in blood, targeted enrichment increases sensitivity and allows detection of mutations at very low variant allele frequencies (VAF), which is essential for early cancer detection and minimal residual disease (MRD) monitoring.
Is your method first-, second- or third-generation or other? How so?
It is a second-generation sequencing technology because it uses massively parallel short-read sequencing with sequencing-by-synthesis and requires DNA amplification.
What is your input? How do you prepare your input (e.g. fragmentation, adapter ligation, PCR)? List the essential steps.
Cell-free DNA (cfDNA) extracted from plasma
Essential preparation steps:
Plasma separation and cfDNA extraction
Adapter ligation
PCR amplification
Hybrid-capture target enrichment
Final amplification and purification
What are the essential steps of your chosen sequencing technology, how does it decode the bases of your DNA sample (base calling)?
DNA fragments bind to a flow cell and are amplified. During sequencing-by-synthesis, fluorescently labeled nucleotides are incorporated one at a time. Each base emits a specific fluorescent signal, which is detected and converted into A, T, C, or G by software.
What is the output of your chosen sequencing technology?
The output consists of FASTQ files containing DNA sequence reads and quality scores, which are then aligned to a reference genome for mutation analysis.
5.2 DNA Write
What DNA would you want to synthesize and why?
I would synthesize a tumor-targeted therapeutic genetic construct, such as a gene encoding a pro-apoptotic protein under the control of a tumor-specific promoter.
This construct could selectively induce cell death in cancer cells while minimizing effects on healthy tissue. DNA synthesis enables precise design of therapeutic genes and regulatory elements for applications in oncology and personalized medicine.
What technology or technologies would you use to perform this DNA synthesis and why?
I would use phosphoramidite solid-phase DNA synthesis combined with gene assembly.
Short DNA oligonucleotides are chemically synthesized nucleotide by nucleotide. These oligos are then assembled into a full-length gene and cloned into a plasmid vector.
What are the essential steps of your chosen sequencing methods?
Chemical synthesis of oligonucleotides
Assembly of fragments into a full gene
Cloning into a plasmid
Sequence verification
What are the limitations of your sequencing method (if any) in terms of speed, accuracy, scalability?
Error rates increase with longer sequences
High GC content and repetitive regions can be challenging
Cost increases with gene length
5.3 DNA Edit
What DNA would you want to edit and why?
I would want to edit oncogenic mutations in human somatic cells, such as activating mutations in the KRAS gene. These mutations drive uncontrolled cell proliferation in many cancers. Editing these mutations could help restore normal cellular regulation and improve cancer treatment strategies.
What technology or technologies would you use to perform these DNA edits and why?
I would use CRISPR-Cas9 genome editing, because it allows precise and targeted modification of specific DNA sequences.
How does your technology of choice edit DNA? What are the essential steps?
How does CRISPR edit DNA?Essential steps:
Design a guide RNA (gRNA) complementary to the target mutation.
Deliver the gRNA and Cas9 enzyme into cells.
Cas9 creates a double-strand break at the target site.
The cell repairs the break through:
NHEJ (gene disruption)
HDR (precise correction using a donor template)
What preparation do you need to do (e.g. design steps) and what is the input (e.g. DNA template, enzymes, plasmids, primers, guides, cells) for the editing?
Guide RNA (gRNA)
Cas9 protein or plasmid
Donor DNA template (for precise edits)
Target Cells
What are the limitations of your editing methods (if any) in terms of efficiency or precision?
Off-target effects
Variable editing efficiency
Delivery challenges
Limited HDR efficiency in some cell types
Week 3 HW: HW Lab Automation
Week 4 HW:Protein Design Part I
Part A: Conceptual Questions
How many molecules of amino acids do you take with a piece of 500 grams of meat? (on average an amino acid is ~100 Daltons)