Week 2 HW: DNA Read, Write, and Edit
Homework
Part 0: Basics of Gel Electrophoresis
[This was a pure watch session. Thus there’s nothing to add here.]
Part 1: Benchling & In-silico Gel Art
Restriction Enzymes Simulated on Lambda_NEB: EcoRI, HindIII, BamHI, KpnI, EcoRV, SacI, and SalI
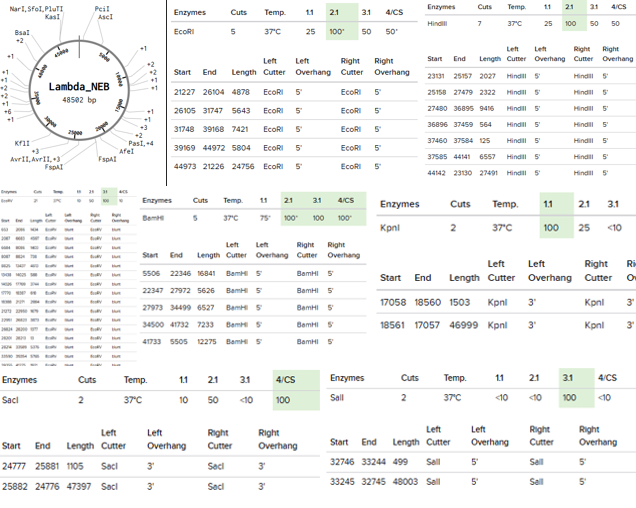
Simple Art produced by way of Paul Vanouse’s Latent Figure Protocol artworks through the use of RC Donovan’s Gel Art Iteration Tool (https://rcdonovan.com/gel-art):
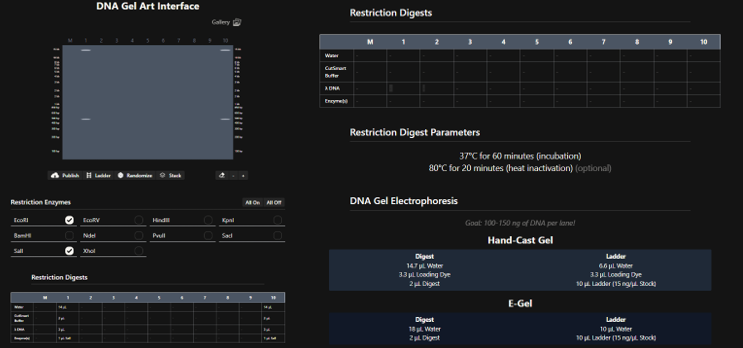
“4 corners”, using EcoRI and SalI in Lanes 1 and 10.
Part 2: Gel Art - Restriction Digests and Gel Electrophoresis
[This leaned on Wetlab Access. As a virtual student, this was not required.]
Part 3: DNA Design Challenge
3.1. Choose your protein.
Regarding proteins, I chose U-box domain-containing protein 12, also known as Plant U-box protein 12 or RING-type E3 ubiquitin transferase PUB12. I wanted to start with something and keep things relatively simple.
sp|Q9ZV31|PUB12_ARATH U-box domain-containing protein 12 OS=Arabidopsis thaliana OX=3702 GN=PUB12 PE=2 SV=1 MAKSEKHKLAQTLIDSINEIASISDSVTPMKKHCANLSRRLSLLLPMLEEIRDNQESSSE VVNALLSVKQSLLHAKDLLSFVSHVSKIYLVLERDQVMVKFQKVTSLLEQALSIIPYENL EISDELKEQVELVLVQLRRSLGKRGGDVYDDELYKDVLSLYSGRGSVMESDMVRRVAEKL QLMTITDLTQESLALLDMVSSSGGDDPGESFEKMSMVLKKIKDFVQTYNPNLDDAPLRLK SSLPKSRDDDRDMLIPPEEFRCPISLELMTDPVIVSSGQTYERECIKKWLEGGHLTCPKT QETLTSDIMTPNYVLRSLIAQWCESNGIEPPKRPNISQPSSKASSSSSAPDDEHNKIEEL LLKLTSQQPEDRRSAAGEIRLLAKQNNHNRVAIAASGAIPLLVNLLTISNDSRTQEHAVT SILNLSICQENKGKIVYSSGAVPGIVHVLQKGSMEARENAAATLFSLSVIDENKVTIGAA GAIPPLVTLLSEGSQRGKKDAATALFNLCIFQGNKGKAVRAGLVPVLMRLLTEPESGMVD ESLSILAILSSHPDGKSEVGAADAVPVLVDFIRSGSPRNKENSAAVLVHLCSWNQQHLIE AQKLGIMDLLIEMAENGTDRGKRKAAQLLNRFSRFNDQQKQHSGLGLEDQISLI Site: https://rest.uniprot.org/uniprotkb/Q9ZV31.fasta Base site: https://www.uniprot.org/uniprotkb/Q9ZV31/entry
3.2. Reverse Translate: Protein (amino acid) sequence to DNA (nucleotide) sequence.
Reverse Translation Tool – BCCM – GeneCorner (https://www.genecorner.ugent.be/rev_trans.html) PUB12, a plant U-box–type E3 ubiquitin ligase DNA sequence (1) >reverse translation of sp|Q9ZV31|PUB12_ARATH U-box domain-containing protein 12 OS=Arabidopsis thaliana OX=3702 GN=PUB12 PE=2 SV=1 to a 1962 base sequence of most likely codons. atggcgaaaagcgaaaaacataaactggcgcagaccctgattgatagcattaacgaaatt gcgagcattagcgatagcgtgaccccgatgaaaaaacattgcgcgaacctgagccgccgc ctgagcctgctgctgccgatgctggaagaaattcgcgataaccaggaaagcagcagcgaa gtggtgaacgcgctgctgagcgtgaaacagagcctgctgcatgcgaaagatctgctgagc tttgtgagccatgtgagcaaaatttatctggtgctggaacgcgatcaggtgatggtgaaa tttcagaaagtgaccagcctgctggaacaggcgctgagcattattccgtatgaaaacctg gaaattagcgatgaactgaaagaacaggtggaactggtgctggtgcagctgcgccgcagc ctgggcaaacgcggcggcgatgtgtatgatgatgaactgtataaagatgtgctgagcctg tatagcggccgcggcagcgtgatggaaagcgatatggtgcgccgcgtggcggaaaaactg cagctgatgaccattaccgatctgacccaggaaagcctggcgctgctggatatggtgagc agcagcggcggcgatgatccgggcgaaagctttgaaaaaatgagcatggtgctgaaaaaa attaaagattttgtgcagacctataacccgaacctggatgatgcgccgctgcgcctgaaa agcagcctgccgaaaagccgcgatgatgatcgcgatatgctgattccgccggaagaattt cgctgcccgattagcctggaactgatgaccgatccggtgattgtgagcagcggccagacc tatgaacgcgaatgcattaaaaaatggctggaaggcggccatctgacctgcccgaaaacc caggaaaccctgaccagcgatattatgaccccgaactatgtgctgcgcagcctgattgcg cagtggtgcgaaagcaacggcattgaaccgccgaaacgcccgaacattagccagccgagc agcaaagcgagcagcagcagcagcgcgccggatgatgaacataacaaaattgaagaactg ctgctgaaactgaccagccagcagccggaagatcgccgcagcgcggcgggcgaaattcgc ctgctggcgaaacagaacaaccataaccgcgtggcgattgcggcgagcggcgcgattccg ctgctggtgaacctgctgaccattagcaacgatagccgcacccaggaacatgcggtgacc agcattctgaacctgagcatttgccaggaaaacaaaggcaaaattgtgtatagcagcggc gcggtgccgggcattgtgcatgtgctgcagaaaggcagcatggaagcgcgcgaaaacgcg gcggcgaccctgtttagcctgagcgtgattgatgaaaacaaagtgaccattggcgcggcg ggcgcgattccgccgctggtgaccctgctgagcgaaggcagccagcgcggcaaaaaagat gcggcgaccgcgctgtttaacctgtgcatttttcagggcaacaaaggcaaagcggtgcgc gcgggcctggtgccggtgctgatgcgcctgctgaccgaaccggaaagcggcatggtggat gaaagcctgagcattctggcgattctgagcagccatccggatggcaaaagcgaagtgggc gcggcggatgcggtgccggtgctggtggattttattcgcagcggcagcccgcgcaacaaa gaaaacagcgcggcggtgctggtgcatctgtgcagctggaaccagcagcatctgattgaa gcgcagaaactgggcattatggatctgctgattgaaatggcggaaaacggcaccgatcgc ggcaaacgcaaagcggcgcagctgctgaaccgctttagccgctttaacgatcagcagaaa cagcatagcggcctgggcctggaagatcagattagcctgatt
(2) >reverse translation of sp|Q9ZV31|PUB12_ARATH U-box domain-containing protein 12 OS=Arabidopsis thaliana OX=3702 GN=PUB12 PE=2 SV=1 to a 1962 base sequence of consensus codons. atggcnaarwsngaraarcayaarytngcncaracnytnathgaywsnathaaygarath gcnwsnathwsngaywsngtnacnccnatgaaraarcaytgygcnaayytnwsnmgnmgn ytnwsnytnytnytnccnatgytngargarathmgngayaaycargarwsnwsnwsngar gtngtnaaygcnytnytnwsngtnaarcarwsnytnytncaygcnaargayytnytnwsn ttygtnwsncaygtnwsnaarathtayytngtnytngarmgngaycargtnatggtnaar ttycaraargtnacnwsnytnytngarcargcnytnwsnathathccntaygaraayytn garathwsngaygarytnaargarcargtngarytngtnytngtncarytnmgnmgnwsn ytnggnaarmgnggnggngaygtntaygaygaygarytntayaargaygtnytnwsnytn taywsnggnmgnggnwsngtnatggarwsngayatggtnmgnmgngtngcngaraarytn carytnatgacnathacngayytnacncargarwsnytngcnytnytngayatggtnwsn wsnwsnggnggngaygayccnggngarwsnttygaraaratgwsnatggtnytnaaraar athaargayttygtncaracntayaayccnaayytngaygaygcnccnytnmgnytnaar wsnwsnytnccnaarwsnmgngaygaygaymgngayatgytnathccnccngargartty mgntgyccnathwsnytngarytnatgacngayccngtnathgtnwsnwsnggncaracn taygarmgngartgyathaaraartggytngarggnggncayytnacntgyccnaaracn cargaracnytnacnwsngayathatgacnccnaaytaygtnytnmgnwsnytnathgcn cartggtgygarwsnaayggnathgarccnccnaarmgnccnaayathwsncarccnwsn wsnaargcnwsnwsnwsnwsnwsngcnccngaygaygarcayaayaarathgargarytn ytnytnaarytnacnwsncarcarccngargaymgnmgnwsngcngcnggngarathmgn ytnytngcnaarcaraayaaycayaaymgngtngcnathgcngcnwsnggngcnathccn ytnytngtnaayytnytnacnathwsnaaygaywsnmgnacncargarcaygcngtnacn wsnathytnaayytnwsnathtgycargaraayaarggnaarathgtntaywsnwsnggn gcngtnccnggnathgtncaygtnytncaraarggnwsnatggargcnmgngaraaygcn gcngcnacnytnttywsnytnwsngtnathgaygaraayaargtnacnathggngcngcn ggngcnathccnccnytngtnacnytnytnwsngarggnwsncarmgnggnaaraargay gcngcnacngcnytnttyaayytntgyathttycarggnaayaarggnaargcngtnmgn gcnggnytngtnccngtnytnatgmgnytnytnacngarccngarwsnggnatggtngay garwsnytnwsnathytngcnathytnwsnwsncayccngayggnaarwsngargtnggn gcngcngaygcngtnccngtnytngtngayttyathmgnwsnggnwsnccnmgnaayaar garaaywsngcngcngtnytngtncayytntgywsntggaaycarcarcayytnathgar gcncaraarytnggnathatggayytnytnathgaratggcngaraayggnacngaymgn ggnaarmgnaargcngcncarytnytnaaymgnttywsnmgnttyaaygaycarcaraar carcaywsnggnytnggnytngargaycarathwsnytnath
3.3. Codon optimization. Once a nucleotide sequence of your protein is determined, you need to codon optimize your sequence. You may, once again, utilize google for a “codon optimization tool”. In your own words, describe why you need to optimize codon usage.
- Optimizing codon usage can help account for host bias as well as reduce the pool of downstream errors to account for, as well as save materials and time.
Which organism have you chosen to optimize the codon sequence for and why?
Which: Arabidopsis thaliana
Why: I wanted to start somewhere, and this organism is familiar.
Optimization Tool Used: Vector Builder (https://en.vectorbuilder.com/tool/codon-optimization.html ) Chose to use the first sequence of the two. Enzyme recognition sites avoided included BsaI and BbsI.
Resulting Sequence is as follows: PUB12, a plant U-box–type E3 ubiquitin ligase DNA sequence ATGGCTAAATCTGAGAAGCATAAGTTGGCTCAGACTCTCATCGATTCTATAAATGAAATTGCTTCTATCTCAGATTCAGTTACTCCAATGAAGAAGCATTGTGCAAATTTGTCTAGGAGATTGTCACTTCTTCTTCCAATGTTGGAAGAGATTAGAGATAATCAAGAGTCTAGCTCTGAAGTCGTGAACGCTTTGCTCTCAGTTAAACAATCTTTATTACATGCTAAGGATCTCTTGTCTTTCGTCAGTCATGTGAGCAAGATATATCTTGTTCTTGAGAGAGATCAAGTGATGGTTAAGTTTCAAAAAGTTACTAGCCTTCTTGAGCAAGCTCTTTCTATAATCCCTTATGAGAATCTTGAAATTTCTGATGAATTGAAAGAACAAGTTGAATTGGTTCTTGTTCAACTTAGAAGATCTTTGGGTAAGAGAGGTGGTGATGTTTACGATGATGAACTTTATAAGGATGTTCTTTCACTTTACAGTGGAAGAGGATCAGTTATGGAGAGTGATATGGTTCGTCGAGTTGCCGAGAAATTGCAACTAATGACTATCACTGATTTGACACAAGAGTCTCTTGCTCTTCTTGATATGGTTTCTTCTAGTGGTGGAGATGATCCTGGAGAGTCATTCGAAAAGATGTCTATGGTTCTTAAGAAAATTAAGGATTTCGTTCAAACCTATAATCCTAACCTAGATGACGCTCCCCTTAGACTTAAATCATCATTGCCTAAATCGAGAGATGATGATCGTGATATGCTTATTCCACCTGAAGAATTCCGTTGTCCTATTTCGCTTGAGCTTATGACTGATCCTGTAATCGTTTCTTCAGGTCAAACCTATGAAAGAGAGTGTATTAAGAAGTGGCTTGAAGGAGGACATTTGACATGTCCTAAGACTCAAGAAACTTTGACATCTGATATCATGACCCCTAATTATGTTCTTAGATCTTTGATCGCTCAATGGTGTGAGTCGAATGGAATCGAGCCTCCAAAGAGGCCAAACATAAGTCAGCCTTCTAGTAAGGCTTCTTCATCATCTAGTGCTCCTGATGACGAACATAATAAGATCGAAGAATTGCTCTTGAAGTTGACTTCTCAGCAACCTGAAGATAGAAGATCCGCTGCTGGAGAGATCAGACTTTTGGCCAAACAAAACAACCATAACAGAGTTGCTATCGCTGCTTCAGGAGCTATTCCACTCTTGGTGAACCTTTTGACTATCTCAAACGATTCCAGAACACAAGAGCATGCTGTTACGTCTATCCTCAACCTTTCTATCTGCCAAGAAAATAAAGGTAAGATCGTTTATTCTAGTGGTGCAGTGCCTGGTATTGTTCATGTTTTGCAGAAGGGATCAATGGAGGCTAGAGAAAACGCTGCTGCTACTCTTTTCTCTCTTTCCGTTATAGATGAGAATAAGGTTACTATTGGAGCTGCTGGAGCAATTCCACCTTTGGTTACTCTCCTTTCTGAAGGATCACAGCGTGGAAAGAAGGATGCTGCTACTGCACTCTTCAACCTTTGTATCTTTCAGGGTAATAAAGGTAAGGCAGTTAGAGCAGGACTTGTGCCTGTGCTTATGAGGCTTTTGACTGAACCTGAATCTGGAATGGTTGATGAGAGCCTTTCTATTCTTGCTATTCTTTCTTCTCATCCAGACGGAAAGTCTGAAGTTGGAGCTGCTGATGCAGTTCCTGTTCTTGTTGATTTCATCAGATCTGGATCTCCTAGAAATAAGGAGAATTCTGCTGCAGTTCTTGTTCACTTGTGTTCATGGAATCAACAACATCTTATCGAAGCACAGAAGCTTGGAATCATGGATCTTCTCATCGAGATGGCTGAAAACGGAACTGATCGTGGTAAGAGAAAGGCCGCACAATTGCTTAATAGATTTTCTAGATTTAACGATCAGCAGAAGCAACACAGTGGTCTTGGTCTTGAAGATCAAATTTCATTGATT Below is a printout contrasting the two:
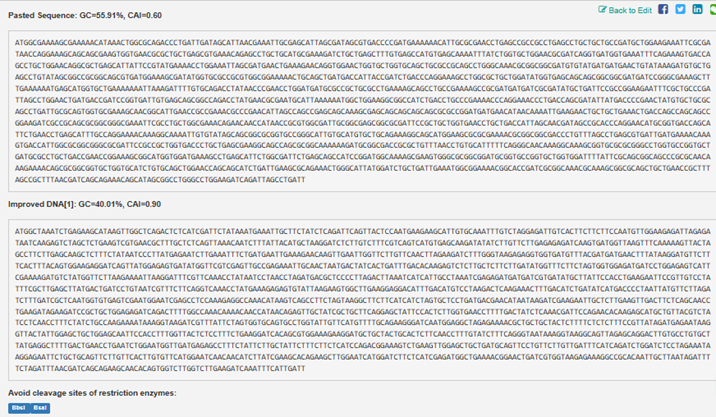
3.4. You have a sequence! Now what?
Recombinant DNA technologies could be utilized to make this protein from the DNA (Cell-free or Cell-dependent). Respectively they involve either special mix that can take place in a test tube or through using a live cell’s machinery to produce the protein.
Part 4: Prepare a Twist DNA Synthesis Order
Build Your DNA Insert Sequence
I prepared the above improved sequence as a test order. Below is the initial step through the creation of the DNA/RNA Sequence in Benchling with a Linear Topology.
It was annotated below as such within Benchling before a linear map and file was constructed that could be uploaded to Twist Bio.
Start Codon: ATG Coding Sequence: ATGGCTAAATCTGAGAAGCATAAGTTGGCTCAGACTCTCATCGATTCTATAAATGAAATTGCTTCTATCTCAGATTCAGTTACTCCAATGAAGAAGCATTGTGCAAATTTGTCTAGGAGATTGTCACTTCTTCTTCCAATGTTGGAAGAGATTAGAGATAATCAAGAGTCTAGCTCTGAAGTCGTGAACGCTTTGCTCTCAGTTAAACAATCTTTATTACATGCTAAGGATCTCTTGTCTTTCGTCAGTCATGTGAGCAAGATATATCTTGTTCTTGAGAGAGATCAAGTGATGGTTAAGTTTCAAAAAGTTACTAGCCTTCTTGAGCAAGCTCTTTCTATAATCCCTTATGAGAATCTTGAAATTTCTGATGAATTGAAAGAACAAGTTGAATTGGTTCTTGTTCAACTTAGAAGATCTTTGGGTAAGAGAGGTGGTGATGTTTACGATGATGAACTTTATAAGGATGTTCTTTCACTTTACAGTGGAAGAGGATCAGTTATGGAGAGTGATATGGTTCGTCGAGTTGCCGAGAAATTGCAACTAATGACTATCACTGATTTGACACAAGAGTCTCTTGCTCTTCTTGATATGGTTTCTTCTAGTGGTGGAGATGATCCTGGAGAGTCATTCGAAAAGATGTCTATGGTTCTTAAGAAAATTAAGGATTTCGTTCAAACCTATAATCCTAACCTAGATGACGCTCCCCTTAGACTTAAATCATCATTGCCTAAATCGAGAGATGATGATCGTGATATGCTTATTCCACCTGAAGAATTCCGTTGTCCTATTTCGCTTGAGCTTATGACTGATCCTGTAATCGTTTCTTCAGGTCAAACCTATGAAAGAGAGTGTATTAAGAAGTGGCTTGAAGGAGGACATTTGACATGTCCTAAGACTCAAGAAACTTTGACATCTGATATCATGACCCCTAATTATGTTCTTAGATCTTTGATCGCTCAATGGTGTGAGTCGAATGGAATCGAGCCTCCAAAGAGGCCAAACATAAGTCAGCCTTCTAGTAAGGCTTCTTCATCATCTAGTGCTCCTGATGACGAACATAATAAGATCGAAGAATTGCTCTTGAAGTTGACTTCTCAGCAACCTGAAGATAGAAGATCCGCTGCTGGAGAGATCAGACTTTTGGCCAAACAAAACAACCATAACAGAGTTGCTATCGCTGCTTCAGGAGCTATTCCACTCTTGGTGAACCTTTTGACTATCTCAAACGATTCCAGAACACAAGAGCATGCTGTTACGTCTATCCTCAACCTTTCTATCTGCCAAGAAAATAAAGGTAAGATCGTTTATTCTAGTGGTGCAGTGCCTGGTATTGTTCATGTTTTGCAGAAGGGATCAATGGAGGCTAGAGAAAACGCTGCTGCTACTCTTTTCTCTCTTTCCGTTATAGATGAGAATAAGGTTACTATTGGAGCTGCTGGAGCAATTCCACCTTTGGTTACTCTCCTTTCTGAAGGATCACAGCGTGGAAAGAAGGATGCTGCTACTGCACTCTTCAACCTTTGTATCTTTCAGGGTAATAAAGGTAAGGCAGTTAGAGCAGGACTTGTGCCTGTGCTTATGAGGCTTTTGACTGAACCTGAATCTGGAATGGTTGATGAGAGCCTTTCTATTCTTGCTATTCTTTCTTCTCATCCAGACGGAAAGTCTGAAGTTGGAGCTGCTGATGCAGTTCCTGTTCTTGTTGATTTCATCAGATCTGGATCTCCTAGAAATAAGGAGAATTCTGCTGCAGTTCTTGTTCACTTGTGTTCATGGAATCAACAACATCTTATCGAAGCACAGAAGCTTGGAATCATGGATCTTCTCATCGAGATGGCTGAAAACGGAACTGATCGTGGTAAGAGAAAGGCCGCACAATTGCTTAATAGATTTTCTAG Stop Codon: TAG
Linear Map:
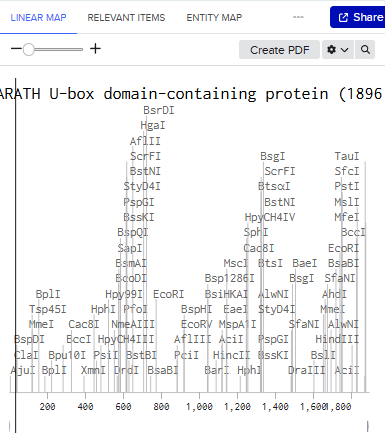
Here’s an example of what you just annotated in Benchling: Sequence Import and Quote Obtained
The pTwist Amp High Copy: pTwist Amp Vector was chosen after the Clonal Gene Choice was pursued. The quote is to the left.. The annotated sequence page from TwistBio from which a GenBank construct file was downloaded is to the right.
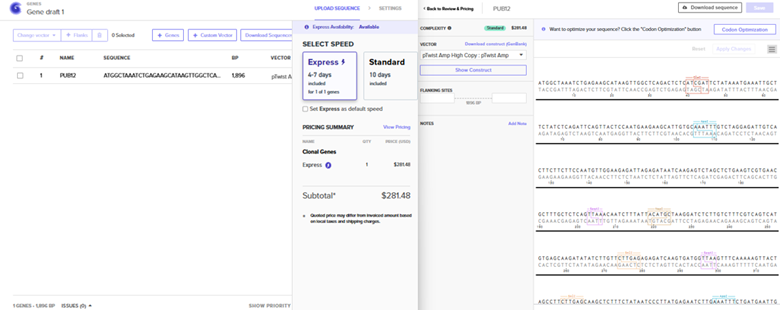
The construct was imported into Benchling to yield the plasmid below.

Part 5: DNA Read/Write/Edit
5.1 DNA Read
(i) What DNA would you want to sequence (e.g., read) and why?
- I might want to sequence large viruses, particularly out of sheer curiosity for the instructions that allow them to exist in their current forms.
Sources of interest:
Piacente, F., De Castro, C., Jeudy, S., Molinaro, A., Salis, A., Damonte, G., Bernardi, C., Abergel, C. and Tonetti, M.G., 2014. Giant virus Megavirus chilensis encodes the biosynthetic pathway for uncommon acetamido sugars. Journal of Biological Chemistry, 289(35), pp.24428-24439.
Legendre, M., Arslan, D., Abergel, C. and Claverie, J.M., 2012. Genomics of Megavirus and the elusive fourth domain of Life. Communicative & integrative biology, 5(1), pp.102-106.
Arslan, D., Legendre, M., Seltzer, V., Abergel, C. and Claverie, J.M., 2011. Distant Mimivirus relative with a larger genome highlights the fundamental features of Megaviridae. Proceedings of the National Academy of Sciences, 108(42), pp.17486-17491.
(ii) In lecture, a variety of sequencing technologies were mentioned. What technology or technologies would you use to perform sequencing on your DNA and why?
- I would borrow from the methods used in the aforementioned literature, particularly “454-titanium and Illumina HiSeq approaches”. These methods appear adequate. Lack of a priori knowledge of the genome or genomic features not being required is helpful, in addition to single-nucleotide resolution, higher dynamic range, and less DNA/RNA needed.
Also answer the following questions: Is your method first-, second- or third-generation or other? How so?
- Second-generation. They engage massively parallel sequencing.
What is your input? How do you prepare your input (e.g. fragmentation, adapter ligation, PCR)? List the essential steps.
- Library Preparation (fragmenting of DNA and adapters added to both ends of DNA for amplification)
- Sequencing
- Data Analysis and Cleanup
What are the essential steps of your chosen sequencing technology, how does it decode the bases of your DNA sample (base calling)?
Simplified:
- The DNA strand gets color coded with fluorescent terminators
- Images are taken of the flow cell after each letter is added
- Software determines the bases based on color intensities
- Calls are made, corrections are issued, and output is cleaned up
Source of interest: https://genohub.com/bioinformatics/10/base-calling
What is the output of your chosen sequencing technology?
- Numerous sequence reads
5.2 DNA Write (i) What DNA would you want to synthesize (e.g., write) and why?
I am not sure yet, but I am leaning towards DNA origami art to experiment with the medium and explore versatility of applications.
Sources of interest:
Bush, J., Singh, S., Vargas, M., Oktay, E., Hu, C.H. and Veneziano, R., 2020. Synthesis of DNA origami scaffolds: Current and emerging strategies. Molecules, 25(15), p.3386.
Weck, J.M. and Heuer-Jungemann, A., 2025. Fully addressable designer superstructures assembled from one single modular DNA origami. Nature communications, 16(1), p.1556.
DNA origami by Paul W. K. Rothemund, California Institute of Technology, 2004. 100 nanometers in diameter. (ii) What technology or technologies would you use to perform this DNA synthesis and why?
For validating the structures, if cost didn’t matter, I would consider using next generation sequencing (Illumina, for both sequences of the staples and scaffold) and Atomic Force Microscopy (Visual, especially confirming folds)
Also answer the following questions:
The essential steps of the chosen sequencing methods would be:
- Library Prep (DNA Fragmentation and Adapter ligation methods)
- Cluster Generation via amplification
- Sequencing and base calling
What are the limitations of your sequencing method (if any) in terms of speed, accuracy, scalability?
- The major limitations would be cost, error rates, and short read lengths. This would not be efficient to scale as is.
Improvements would involve: -Hand design of patterns (for ideating improvements) -Computer design and optimization of material usage -Production of material and strand-routing precision
5.3 DNA Edit (i) What DNA would you want to edit and why?
DNA edits that I would like to perform would be those that allow for the minimization and or elimination of metabolic disease states. The why comes down to the quality-of-life improvements for all involved.
(ii) What technology or technologies would you use to perform these DNA edits and why?
I can see myself engaging CRISPR-Cas9 and base editing for their precision. Of the two, especially the latter, in order to reduce off-target based effects.
Also answer the following questions:
How does your technology of choice edit DNA? What are the essential steps?
It uses guide RNA to direct modified Cas proteins to DNA sequences and convert nucleotides.
The major steps woud involve (i) Designing guide RNA that compliment the target gene(s); (ii) deliver said RNA and its editor protein to the cells of interest (iii) waiting as the guide RNA mediated editor binds to the target DNA site (iv) waiting as the deaminase converts targeted base paits (v) waiting as the edits are incoporated (vi) assaying for confirmation via suquencing and functional assay applications
Ethics meditations no doubt should accompany each step.
What preparation do you need to do (e.g. design steps) and what is the input (e.g. DNA template, enzymes, plasmids, primers, guides, cells) for the editing?
Preparation involves (i) identifying seuquences associated with disease states in select organisms, (ii) computationally designing guide RNAs to target them, (iii) computationally optimizing said guide RNAs and selecting a properly paired base editing system (iv) modeling the application of guide RNAs and base editor asystem applyed to DNA sequences highly associated with disease states in the bodies of select organisms (v) validating said results and modifying as needed (vi) developing in vitro cellular models capable of testing editing efficiency, safety, and functional outcomes (vii) Organoid and higher models may follow
What are the limitations of your editing methods (if any) in terms of efficiency or precision?
Avoiding off-target edits is not a given. Validation and optimization steps remain necessary.