Week 5 HW: Protein design part II
Homework — DUE BY START OF MAR 10 LECTURE
Part A: SOD1 Binder Peptide Design (From Pranam)
Superoxide dismutase 1 (SOD1) is a cytosolic antioxidant enzyme that converts superoxide radicals into hydrogen peroxide and oxygen. In its native state, it forms a stable homodimer and binds copper and zinc.
Mutations in SOD1 cause familial Amyotrophic Lateral Sclerosis (ALS). Among them, the A4V mutation (Alanine → Valine at residue 4) leads to one of the most aggressive forms of the disease. The mutation subtly destabilizes the N-terminus, perturbs folding energetics, and promotes toxic aggregation.
Your challenge:
Design short peptides that bind mutant SOD1. Then decide which ones are worth advancing toward therapy. You will use three models developed in our lab:
PepMLM: target sequence-conditioned peptide generation via masked language modeling PeptiVerse: therapeutic property prediction moPPIt: motif-specific multi-objective peptide design using Multi-Objective Guided Discrete Flow Matching (MOG-DFM)
Part 1: Generate Binders with PepMLM
Begin by retrieving the human SOD1 sequence from UniProt (P00441) and introducing the A4V mutation. Using the PepMLM Colab linked from the HuggingFace PepMLM-650M model card: Generate four peptides of length 12 amino acids conditioned on the mutant SOD1 sequence. To your generated list, add the known SOD1-binding peptide FLYRWLPSRRGG for comparison. Record the perplexity scores that indicate PepMLM’s confidence in the binders.
sp|P00441|SODC_HUMAN Superoxide dismutase [Cu-Zn] OS=Homo sapiens OX=9606 GN=SOD1 PE=1 SV=2 MATKAVCVLKGDGPVQGIINFEQKESNGPVKVWGSIKGLTEGLHGFHVHEFGDNTAGCTS AGPHFNPLSRKHGGPKDEERHVGDLGNVTADKDGVADVSIEDSVISLSGDHCIIGRTLVV HEKADDLGKGGNEESTKTGNAGSRLACGVIGIAQ
- I generated these four peptides using PepMLM-650M.ipynb
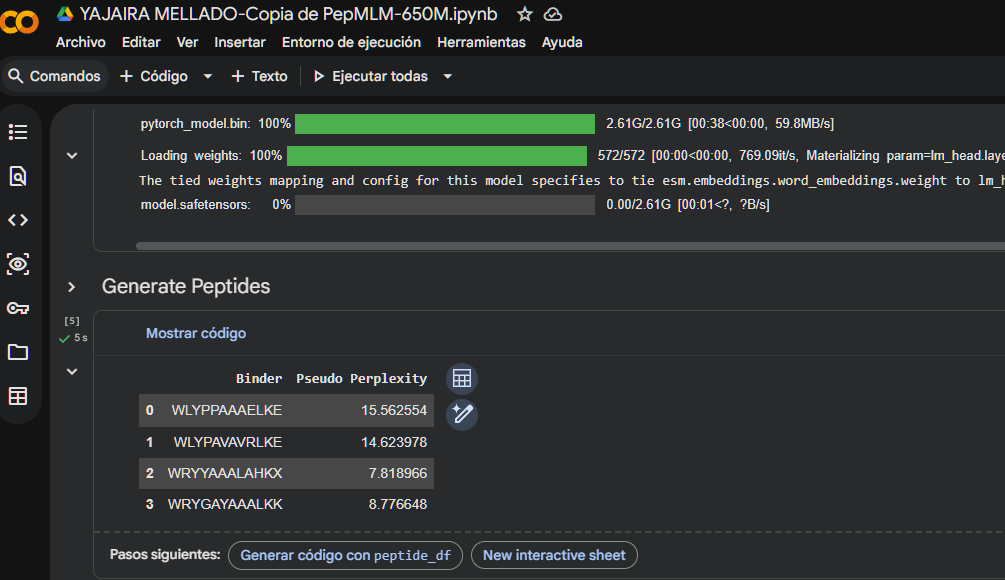
The perplexity scores were recorded to evaluate PepMLM’s confidence in the generated peptide binders. Lower perplexity values indicate higher confidence in the sequence. Among the designed peptides, P3 (7.82) showed the lowest perplexity score, followed by P4 (8.78), P2 (14.62), and P1 (15.56), suggesting that P3 and P4 are the most plausible sequences according to the model.
Part 2: Evaluate Binders with AlphaFold3
Navigate to the AlphaFold Server: alphafoldserver.com For each peptide, submit the mutant SOD1 sequence followed by the peptide sequence as separate chains to model the protein-peptide complex. Record the ipTM score and briefly describe where the peptide appears to bind. Does it localize near the N-terminus where A4V sits? Does it engage the β-barrel region or approach the dimer interface? Does it appear surface-bound or partially buried? In a short paragraph, describe the ipTM values you observe and whether any PepMLM-generated peptide matches or exceeds the known binder.
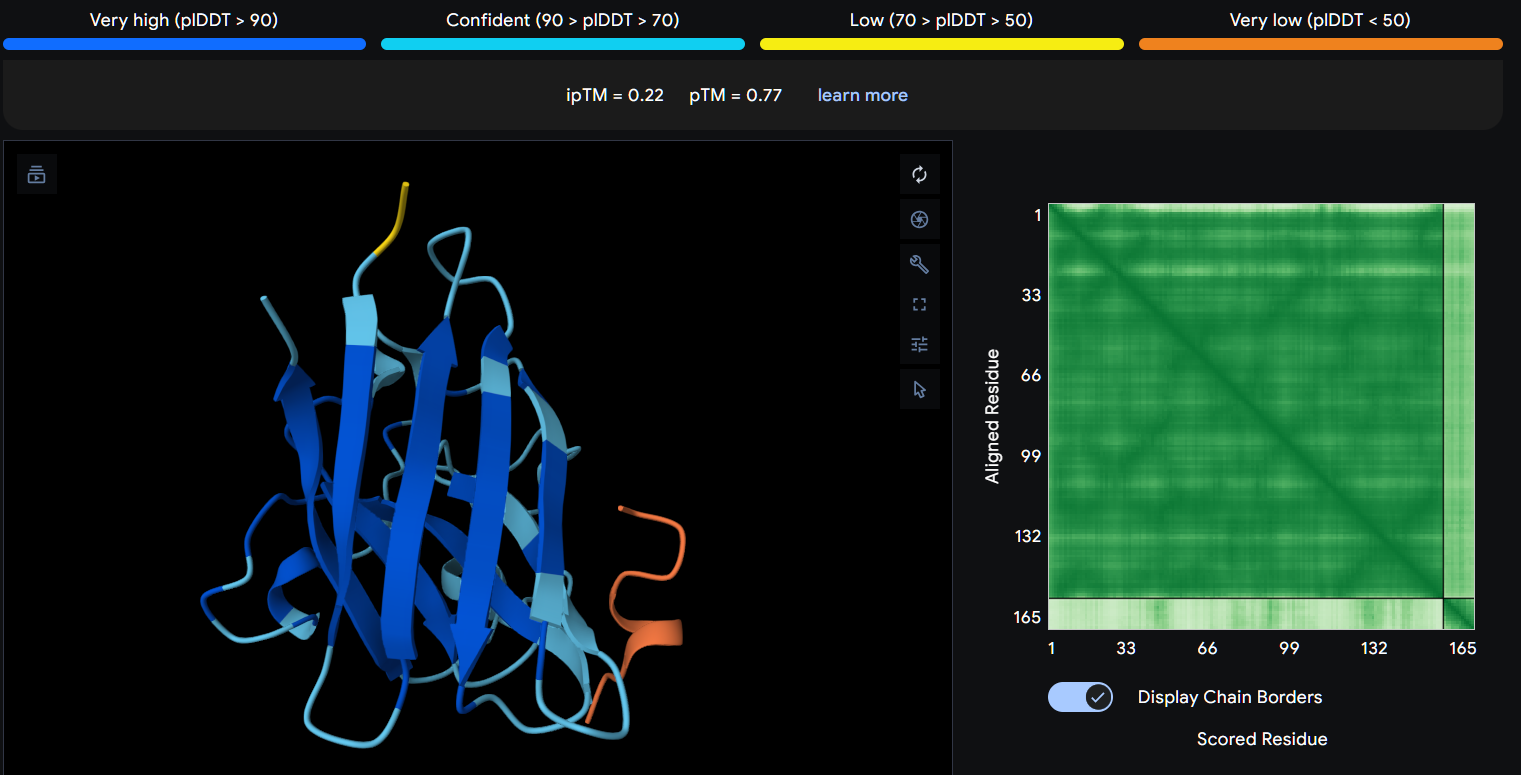
Peptide 1 (P1)
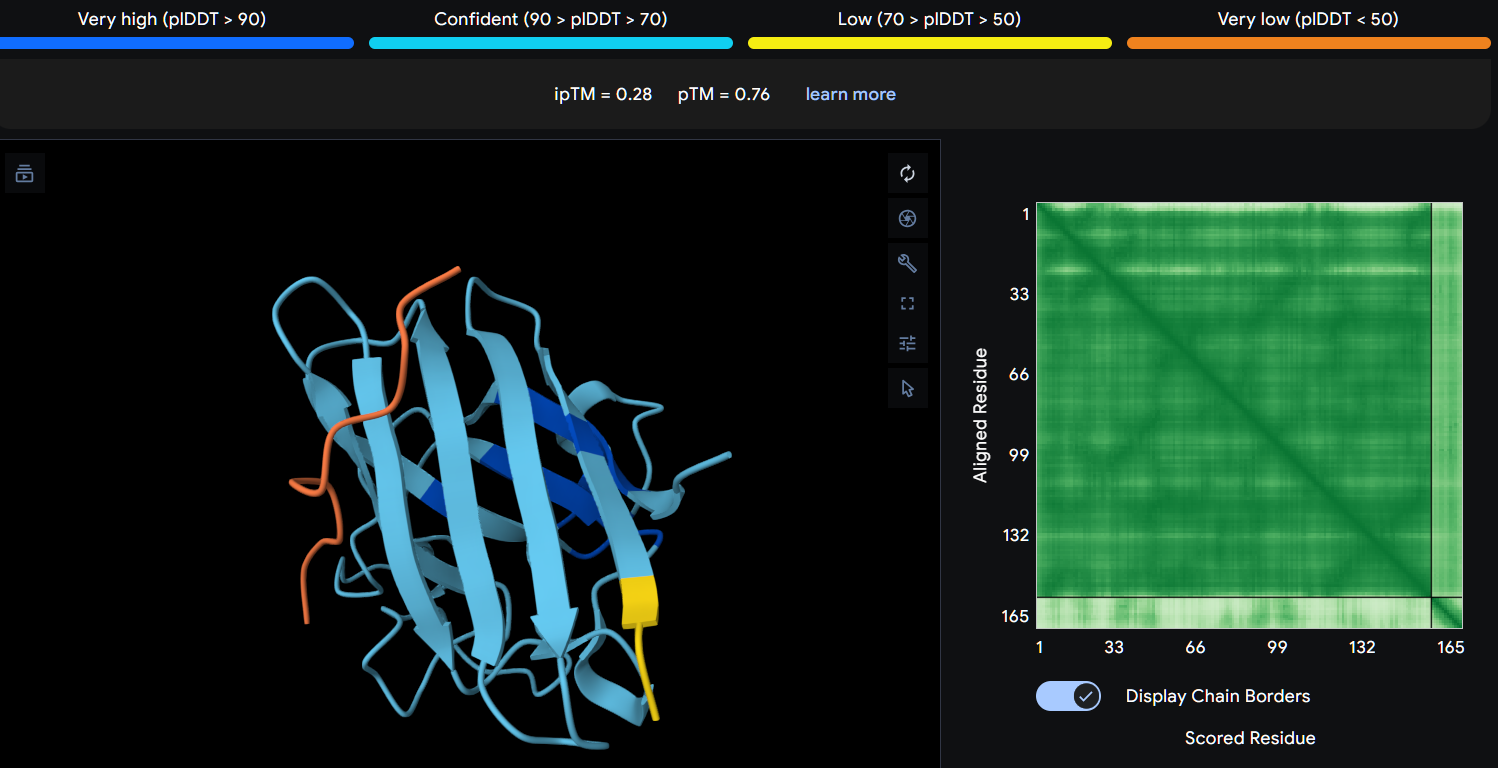
Peptide 2 (P2)
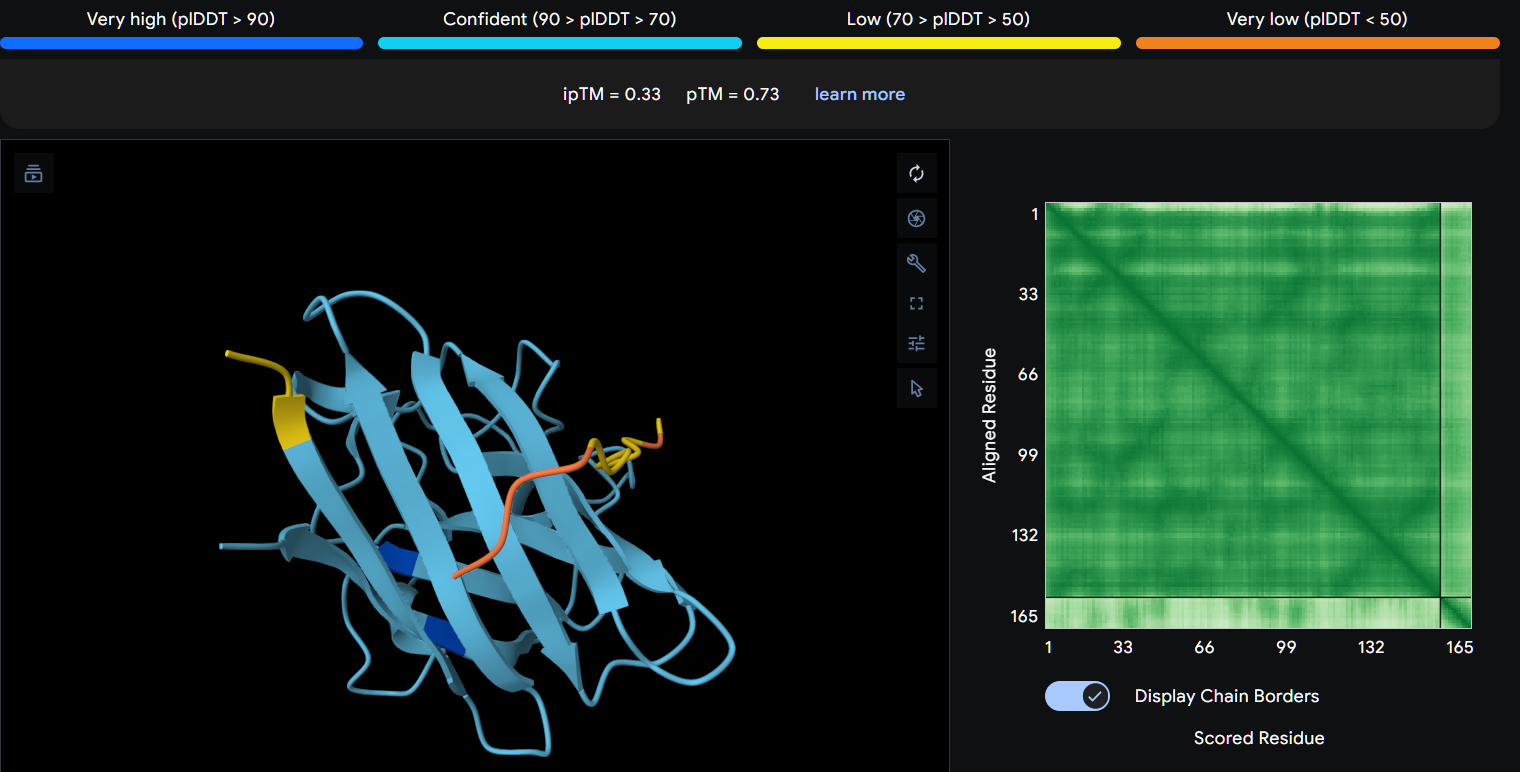
Peptide 3 (P3)
Peptide 4 (P4)
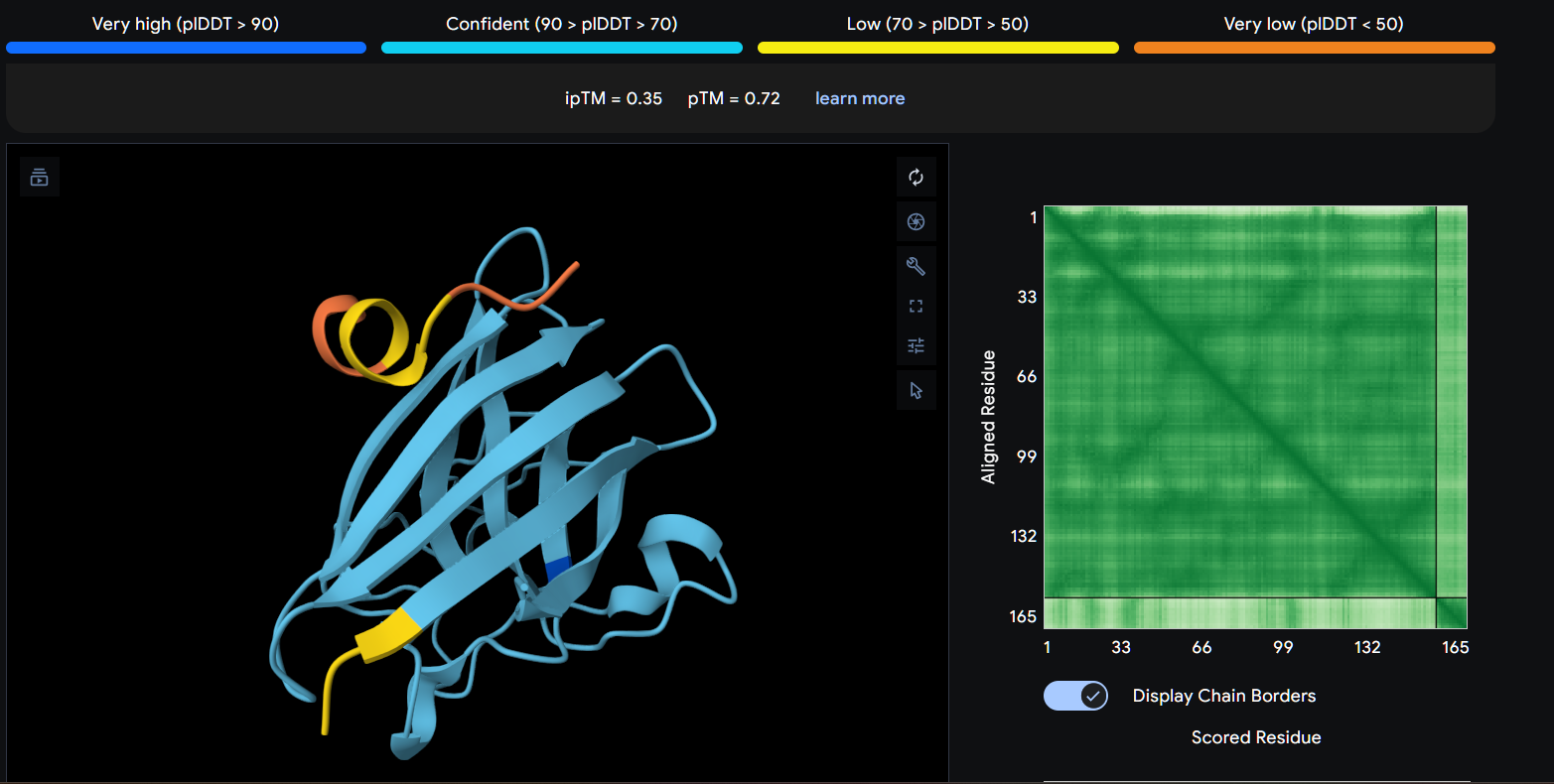
Using AlphaFold3, I determines that P2 and P1 appear to hav more stable structures, while P3 and P4 may exhibit greater interaction capability. Also AlphaFold3 analysis showed differences in structural confidence and interaction potential among the peptides. Based on the predicted TM-score (pTM), the ranking was P1 ≈ P2 > P3 > P4, indicating that P1 and P2 have the most reliable predicted structures. In contrast, the interface TM-score (ipTM) followed the order P4 > P3 > P2 > P1, suggesting that P4 has the highest potential for molecular interactions.
Part 3: Evaluate Properties of Generated Peptides in the PeptiVerse
Structural confidence alone is insufficient for therapeutic development. Using PeptiVerse, let’s evaluate the therapeutic properties of your peptide! For each PepMLM-generated peptide:
Paste the peptide sequence. Paste the A4V mutant SOD1 sequence in the target field. Check the boxes Predicted binding affinity Solubility Hemolysis probability Net charge (pH 7) Molecular weight Compare these predictions to what you observed structurally with AlphaFold3. In a short paragraph, describe what you see. Do peptides with higher ipTM also show stronger predicted affinity? Are any strong binders predicted to be hemolytic or poorly soluble? Which peptide best balances predicted binding and therapeutic properties?
Choose one peptide you would advance and justify your decision briefly.
Peptide 1 (P1)
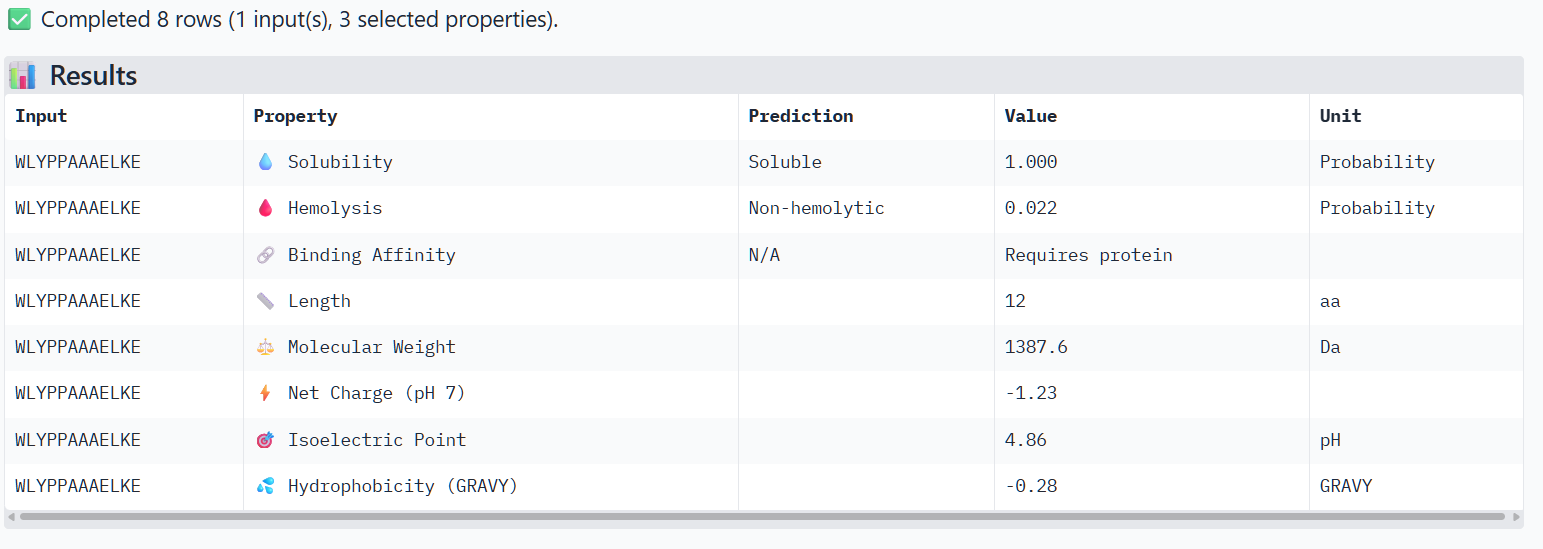
Peptide 2 (P2)
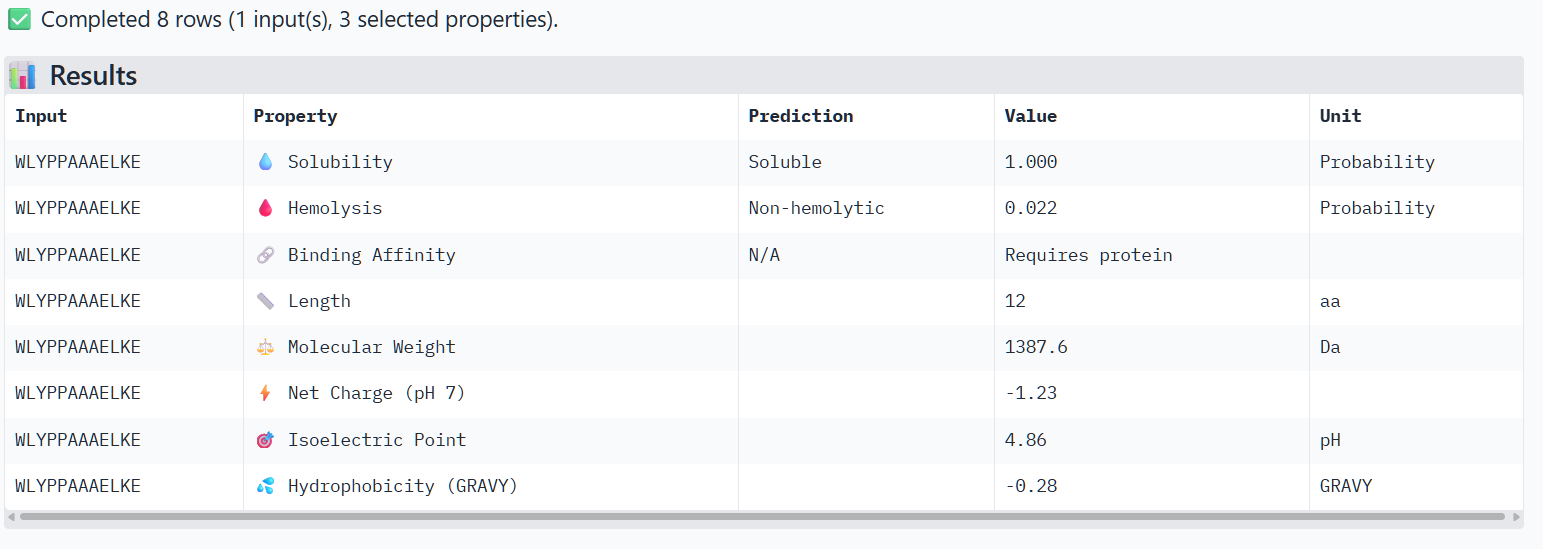
Peptide 3 (P3)
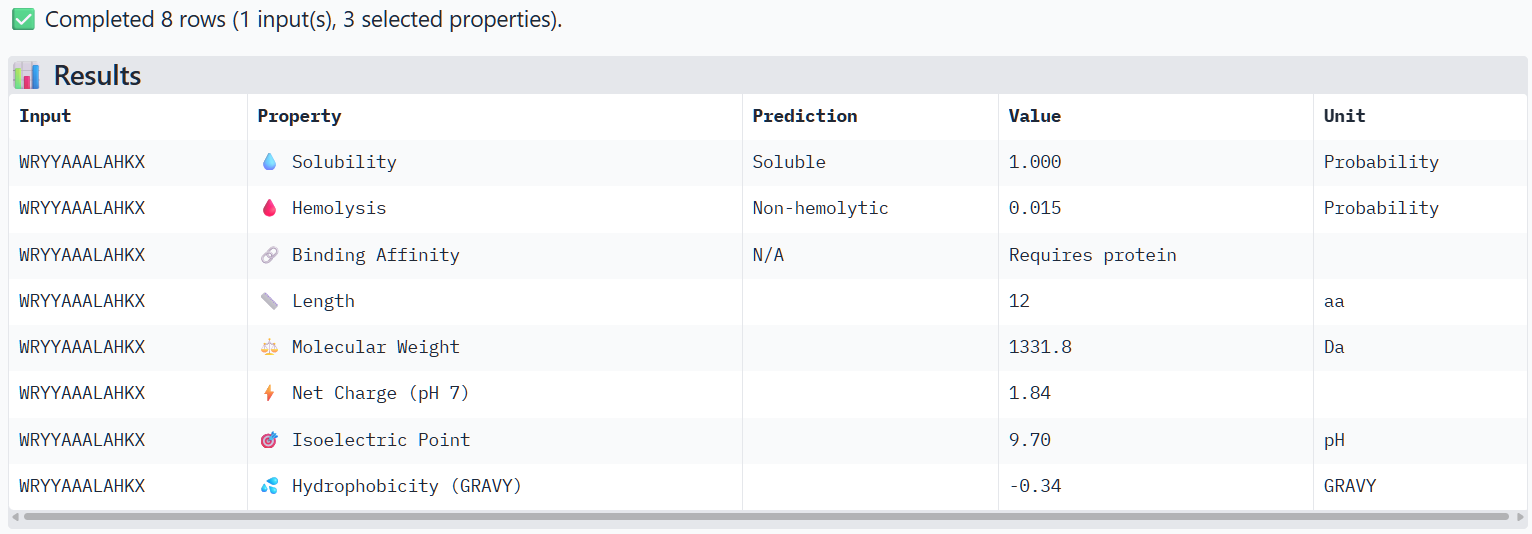
Peptide 4 (P3)
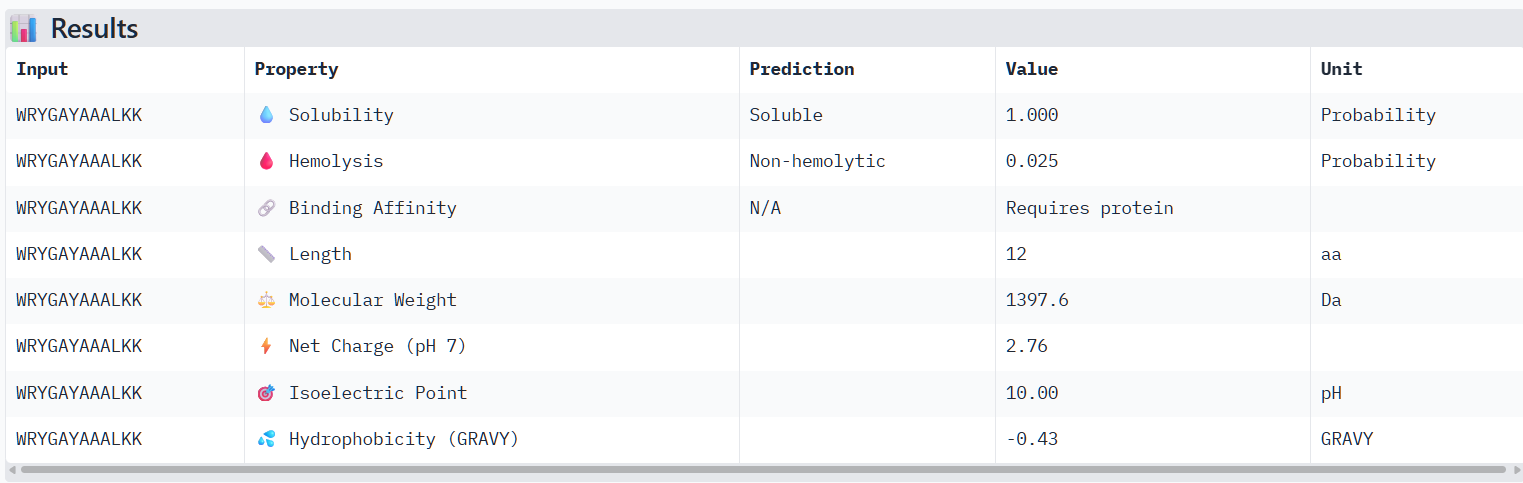
The structural predictions from AlphaFold3 were compared with the physicochemical properties predicted for the generated peptides. Peptides with higher ipTM scores, particularly P4 and P3, showed greater predicted interaction potential, suggesting stronger binding capability compared to P1 and P2. Importantly, all peptides were predicted to be non-hemolytic and soluble, indicating favorable therapeutic safety profiles. Considering both interaction potential and physicochemical properties, P3 appears to provide the best balance between predicted binding capability and therapeutic characteristics, while P4 also shows strong interaction potential but slightly lower structural confidence.
Part 4: Generate Optimized Peptides with moPPIt
Now, move from sampling to controlled design. moPPIt uses Multi-Objective Guided Discrete Flow Matching (MOG-DFM) to steer peptide generation toward specific residues and optimize binding and therapeutic properties simultaneously. Unlike PepMLM, which samples plausible binders conditioned on just the target sequence, moPPIt lets you choose where you want to bind and optimize multiple objectives at once.
Open the moPPit Colab linked from the HuggingFace moPPIt model card Make a copy and switch to a GPU runtime. In the notebook: Paste your A4V mutant SOD1 sequence. Choose specific residue indices on SOD1 that you want your peptide to bind (for example, residues near position 4, the dimer interface, or another surface patch). Set peptide length to 12 amino acids. Enable motif and affinity guidance (and solubility/hemolysis guidance if available). Generate peptides. After generation, briefly describe how these moPPit peptides differ from your PepMLM peptides. How would you evaluate these peptides before advancing them to clinical studies?
I couldn’t run the Colab notebook because I don’t have access to the required environment.
Part C: Final Project: L-Protein Mutants
L-Protein and DnaJ Sequence Lysis Protein Sequence (UniProtKB ID: https://www.uniprot.org/uniprotkb/P03609/entry)
METRFPQQSQQTPASTNRRRPFKHEDYPCRRQQRSSTLYVLIFLAIFLSKFTNQLLLSLLEAVIRTVTTLQQLLT
Note: Lysis protein contains a soluble N-terminal domain followed by a transmembrane protein (blue/last 35 residues). Transmembrane protein affects the lysis activity. The soluble domain (green) is the domain responsible for interaction with DnaJ.
DnaJ sequence (UniProtKB ID: https://www.uniprot.org/uniprotkb/P03609/entry)
MAKQDYYEILGVSKTAEEREIRKAYKRLAMKYHPDRNQGDKEAEAKFKEIKEAYEVLTDSQKRAAYDQYGHAAFEQGGMGGGGFGGGADFSDIFGDVFGDIFGGGRGRQRAARGADLRYNMELTLEEAVRGVTKEIRIPTLEECDVCHGSGAKPGTQPQTCPTCHGSGQVQMRQGFFAVQQTCPHCQGRGTLIKDPCNKCHGHGRVERSKTLSVKIPAGVDTGDRIRLAGEGEAGEHGAPAGDLYVQVQVKQHPIFEREGNNLYCEVPINFAMAALGGEIEVPTLDGRVKLKVPGETQTGKLFRMRGKGVKSVRGGAQGDLLCRVVVETPVGLNERQKQLLQELQESFGGPTGEHNSPRSKSFFDGVKKFFDDLTR
Additional Information
We can use pBLAST to find evolutionary sequences from other organisms and visualize it using ClustalOmega. BLAST results for L-protein are here - https://drive.google.com/drive/folders/1eQeuwL9WiO16bw6Lb8z-TVpbWIoAF4EH?usp=share_link You can upload it to ClustalOmega to get the alignments. It is usually a good idea not to make mutations in the conserved sites (the amino acid positions where you see no changes in the alignments) Additional Information about the sequence is linked here - https://www.notion.so/howtogrowalmostanything/L-Protein-Sequence-Information-7a29684affaa4e3b9adf070cbb7c9908?pvs=4 Using the mutational analysis of lysis protein from the attached source, https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5775895/ Here is a list of some mutations and their effect on lysis L-Protein Mutants [Three columns highlighted! Please copy the sheet before any edits).
L-Protein Engineering | Option 1: Mutagenesis
- Designing these mutants with good computational confidence is hard. It will show you limitations of some of the structure based models. Ultimately, you can pick various combinations of mutations and get lab results and then decide to pick the next round of mutations, but this assay will not be easy to run at scale in this class.
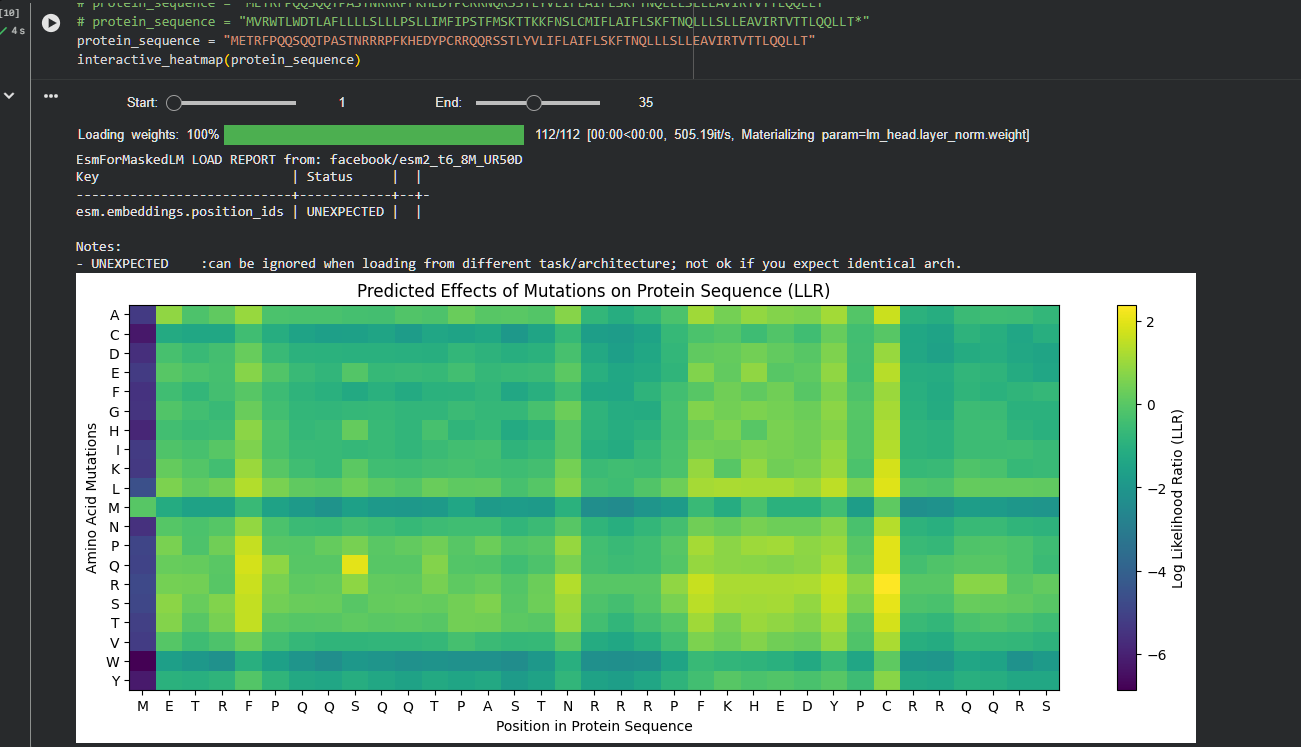
Run this notebook to generate for each position in the amino acid sequence, a “score” for what would happen to the protein if you mutated into another amino acid. It can be positive or negative for the protein. We want to identify possible mutations that are “positive” If you run this notebook - you will see a .csv file in the sidebar. You can download it and look at it in the google sheets if that’s easier
Use the experimental data here. This dataset contains information about mutants of the L-Protein and their effect on lysis in the lab - L-Protein Mutants
First check, does the experimental data correlate with the scores from the notebook in (b)? This should give you a clue on how well these language embeddings capture information about this protein sequence.
Using information about the effect of protein mutations at these sites - both the scores and the experimental data in the drive, come up with 5 mutations for each student along with how you came up with them and why you believe they would work. 2 of the variants you submit must have mutations in the transmembrane region (refer to notes above on what amino acid positions these are) and 2 of them must be in the soluble region . Remember that you can also use the pBLAST to see which residues are conserved and not mutate them if you want to.
One easy way to generate sequence mutations could be to look for residue positions and mutations that have a positive mutational effect either in the experimental or have a positive score from step 1. And pick a combination of those mutations. You can utilize Af2_Multimer to generate a Multimeric Assembly; you can do this by making your query sequence as. We want to do this because - A running hypothesis for how this protein functions is that it assembles to make a perforation in the bacterial membrane.
Figure generated using the following multimeric assembly (where each chain is separated from the other with a :):
METRFPQQSQQTPASTNRRRPFKHEDYPCRRQQRSSTLYVLIFLAIFLSKFTNQLLLSLLEAVIRTVTTLQQLLT:METRFPQQSQQTPASTNRRRPFKHEDYPCRRQQRSSTLYVLIFLAIFLSKFTNQLLLSLLEAVIRTVTTLQQLLT:METRFPQQSQQTPASTNRRRPFKHEDYPCRRQQRSSTLYVLIFLAIFLSKFTNQLLLSLLEAVIRTVTTLQQLLT:METRFPQQSQQTPASTNRRRPFKHEDYPCRRQQRSSTLYVLIFLAIFLSKFTNQLLLSLLEAVIRTVTTLQQLLT:METRFPQQSQQTPASTNRRRPFKHEDYPCRRQQRSSTLYVLIFLAIFLSKFTNQLLLSLLEAVIRTVTTLQQLLT:METRFPQQSQQTPASTNRRRPFKHEDYPCRRQQRSSTLYVLIFLAIFLSKFTNQLLLSLLEAVIRTVTTLQQLLT:METRFPQQSQQTPASTNRRRPFKHEDYPCRRQQRSSTLYVLIFLAIFLSKFTNQLLLSLLEAVIRTVTTLQQLLT:METRFPQQSQQTPASTNRRRPFKHEDYPCRRQQRSSTLYVLIFLAIFLSKFTNQLLLSLLEAVIRTVTTLQQLLT